

1. 서 론
2. 대상유역 및 물부족량 예측 방법
2.1 대상유역
2.2 RCP 시나리오 분석
2.3 물수지 분석 모형 적용
2.4 다층신경망 모형 구성
3. 물부족량 예측 결과
3.1 다층신경망 모형 훈련 및 검증
3.2 최적의 다층신경망 모형 선정 및 물부족량 예측
4. 결론 및 향후 연구
1. 서 론
가뭄은 예년에 비해 부족한 강우량으로 인해 발생하는 재해로 그 영향범위가 광범위한 특징을 가지고 있다. 또한 다른 재해와 다르게 그 발생과 종료시점을 명확하게 정의하기 어렵기 때문에 가뭄으로 인한 영향 또는 피해를 평가하는 것도 굉장히 복잡한 문제이다(Wilhite, 1993). 그렇기 때문에 과거의 연구에서는 가뭄의 형태(기상학적, 수문학적, 농업적, 사회경제적)와 특성(지속기간, 심각도, 공간적인 분포, 재현기간 등)을 정의하고, 이를 통해 가뭄 발생을 조기에 경보하는 것이 가뭄으로 인한 피해를 줄이는 중요한 요소로 고려되었다(Kogan, 2000). 가뭄지수는 가뭄의 발생과 그 특성을 정량적으로 측정하기 위해 등장한 것으로서, 강수량, 증발산량 등 여러 가지 관측 데이터를 하나의 값으로 합성하여 표현이 가능하다는 편의성 때문에, 현재까지 전 세계적으로 약 150여 개의 가뭄지수가 개발되어 적용되고 있다(Zargar et al., 2011). 이러한 가뭄지수들은 의사결정자(decision maker)나 지역주민들(stakeholders)에게 현재 발생한 가뭄의 심각도, 공간적인 분포 등에 대해서는 효과적인 정보전달이 가능하지만, 미래에 발생할 가뭄에 대한 예측과 그에 대한 대책수립에는 그 기능이 부족하다는 단점이 있다.
이러한 단점을 극복하기 위해 도입된 것이 Risk 기반의 가뭄관리기법으로 정책결정자에게 필요한 의사결정체계를 Monitoring & Early Warning - Risk Assessment - Mitigation & Response의 3단계로 제안하였다(Wilhite and Svoboda, 2000). 하지만 이는 현재 발생한 가뭄에 대한 평가를 통해 대응수준을 결정하는 정도라는 한계성이 있다. 그래서 과거 발생한 가뭄의 사례 또는 기상예측을 기반으로 미래 발생할 가뭄 시나리오를 예측(forecast & outlook)하고, 결정된 시나리오 발생 시 예상 물부족 지역과 물부족량에 따른 대책마련(countermeasure), 그리고 결정된 대책 수행에 따른 사후평가를 관리(records management)하는 의사결정 체계를 제안한 사례도 있다(Nam et al., 2012). 여기에서 효과적인 가뭄관리를 위해 가장 중요한 요소는 미래 발생할 가뭄의 심각도 예측인데, 주로 물리적/개념적(physical/conceptual) 모형이나 데이터 기반(data driven) 모형이 적용된다.
먼저 물리적/개념적 모형을 적용하여 가뭄의 심각도를 예측한 선행연구로 물수지 분석을 통해 예상되는 물부족량과 SPI (Standardized Precipitation Index; McKee et al,. 1993), SRI (Standardized Runoff Index; Shukla and Wood, 2008), SSVI (Standardized Storage Volume Index; Gusyev et al., 2015) 가뭄지수를 Bayesian Networks 모형에 적용하여 빈도별 예상 물부족량을 산출한 사례가 있다(Kim et al., 2018). 또한 중국에서는 밀 생산량을 예측할 수 있는 EPIC모형과 가뭄위험지수의 상관관계 도출을 통해 미래 기후변화로 인해 예상되는 밀 생산 감소량을 모의하였다(Yue et al., 2018). 유럽에서는 21개국을 대상으로 강수 부족으로 인해 예상되는 곡물 생산 감소와 발전량 감소에 대한 개념적 모형을 도출하여 각 국가별로 가뭄에 대한 취약도를 분석하였다(Naumann et al., 2015). 이러한 물리적/개념적 모형은 전체 대상유역에서 예상되는 가뭄의 직접적 피해(물부족량, 농업생산량 감소, 발전량 감소)를 공간적, 시간적으로 확인할 수 있다는 장점이 있으나, 시뮬레이션을 위해 많은 종류의 데이터가 요구되고, 모형 구축에 많은 시간과 노력이 투입된다는 단점이 있다.
다음으로 데이터 기반 모형을 이용하여 가뭄의 심각도를 예측한 선행연구로 과거에는 ARIMA (Auto-Regressive Integrated Moving Average)나 SVMs (Support Vector Machines), ANNs (Artificial Neural Networks) 등의 Machine Learning 기법을 단순히 적용한 사례가 많았으나, 그 이후에는 선행 관측 시계열 자료를 Wavelet 변환 후 SVMs에 적용하여 SPI 예측의 정확도를 향상 시킨 사례가 있다(Belayneh et al. 2013). 또한 ANNs의 심층학습 기법인 Long Short Term Memory (LSTM)을 이용하여 지하수위 예측 모형을 만들고, 이로부터 SGI (Standardized Groundwater level Index; Bloomfield and Marchant, 2013)를 산정하여 미래 가뭄 발생 가능성을 모의한 경우도 있다(Lim and Yang, 2020). 이렇게 데이터 기반 가뭄 예측방법은 물리적/개념적 모형보다 상대적으로 요구되는 데이터의 종류가 적고, 빠른 분석이 가능하다는 장점이 있다. 그러나 물리적 모형에 기반하지 않기 때문에 가뭄 심각도 예측 결과가 주로 SPI, SPEI (Standardized Precipitation Evapotranspiration Index; Vicente-Serrano et al., 2010)와 같은 가뭄지수로 나타나게 된다. 이러한 가뭄지수를 통해서는 의사결정자 또는 지역 주민들이 직접적으로 가뭄의 심각도를 체감하거나, 가뭄 대책의 실효성 등을 확인하기 어렵다는 단점이 있다.
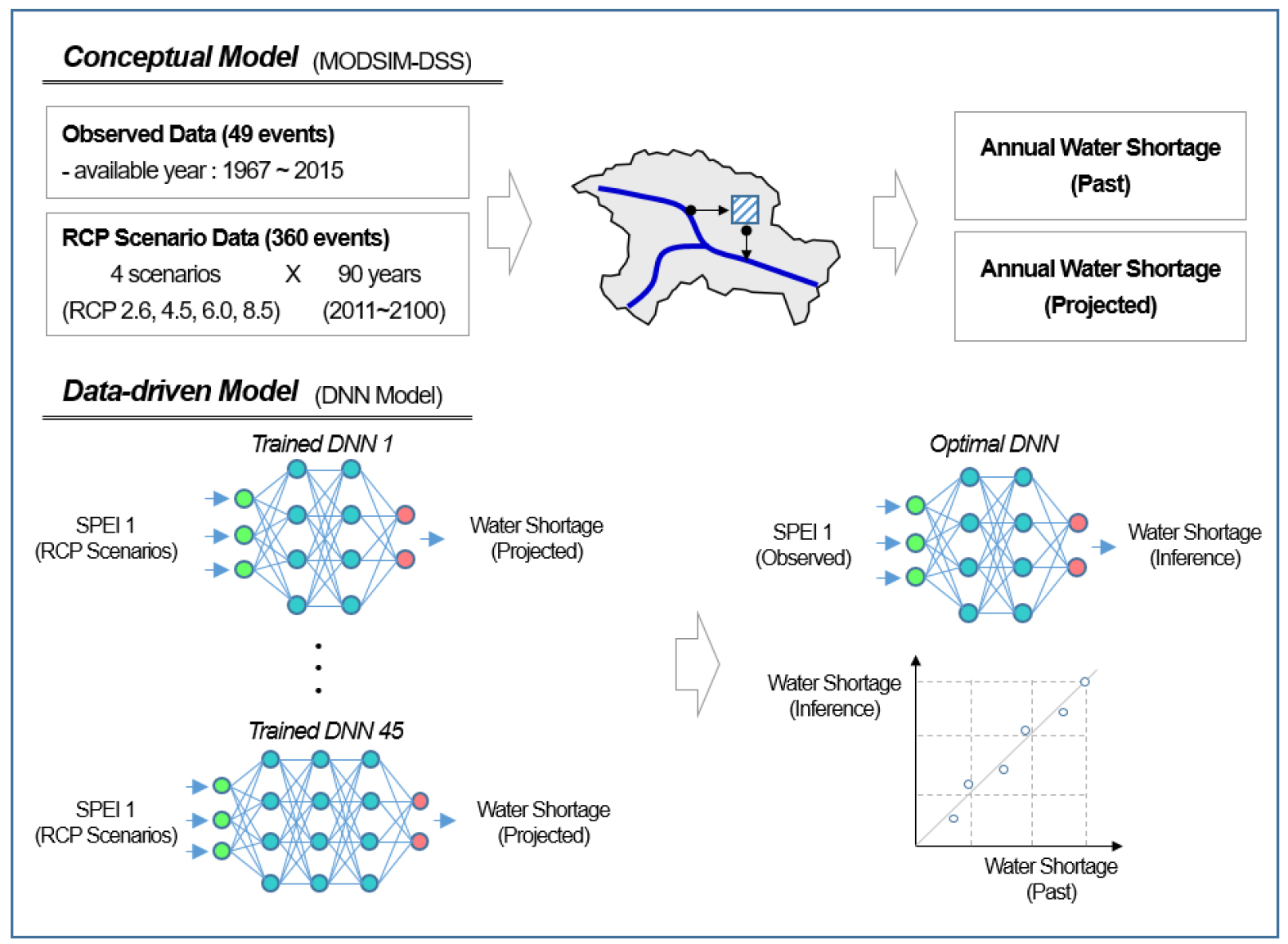
본 연구에서는 의사결정자나 지역 주민들이 가뭄의 심각도를 쉽고, 신속하게 파악할 수 있도록 하기 위해, 개념적 모형을 통해 산출된 결과를 기반으로 다층신경망(Deep Neural Network, DNN) 모형을 구축하여 연간 물부족량을 예측할 수 있는 방안을 Fig. 1과 같이 제시 하였다. 먼저, 개념적 모형으로 대표적인 물수지 분석 모형인 MODSIM-DSS을 적용하여 대상유역에서 가뭄발생시 예상되는 연간 물부족량을 모의하였다. 그러나 현재 국내에서 수행되는 수자원장기종합계획(MOLIT, 2016)의 경우 그 분석기간이 1967년부터 2015년까지 총 49년에 불과하기 때문에 과거 자료만을 적용하여 다층신경망 모형을 구축하는데 한계가 있다. 특히 과거 자료의 범위를 벗어나는 경우가 발생하게 되면 그 예측의 신뢰도가 떨어진다는 문제가 발생한다. 그러므로 본 연구에서는 기상청(KMA, 2020)에서 제공하는 기후변화 예측시나리오(RCP 2.6, 4.5, 6.0, 8.5)를 대상 유역의 물수지 분석 모형에 적용하였다. 이로써 총 360개년의 데이터(4개 시나리오 × 분석기간 90년 (2011-2100년))를 추가 확보함으로써 과거 자료의 관측범위를 벗어나는 경우에 대한 물수지 분석 결과도 확보할 수 있었다. 다음으로 미래 RCP 시나리오 자료에서 획득된 SPEI 가뭄지수를 설명변수로 그리고, 연간 물부족량을 목적변수로 하는 dataset을 다층신경망 모형의 학습에 적용하였다. 모형의 학습은 은닉층의 수와 학습 횟수를 증가시키면서 수행하였으며, 이를 통해 여러 개의 학습된 모형(trained DNN)을 구축할 수 있었다. 그 후 학습에 적용되지 않은 과거 관측자료를 학습된 모형 별로 적용하여 물부족량을 추정하고, 추정된 물부족량과 물수지 분석을 통해 산출된 물부족량이 가장 일치하는 모형을 중권역 별로 최적의 DNN 모형으로 선정하였다. 이를 향후에 가뭄 피해 예측에 적용한다면, 특정 시점까지의 가뭄 상황과 향후에 예상되는 기상 상황을 SPEI 지수 형태로 최적의 DNN 모형에 입력함으로써 예상 물부족량을 신속하고, 신뢰성 있게 산출할 수 있을 것으로 판단된다.
2. 대상유역 및 물부족량 예측 방법
2.1 대상유역
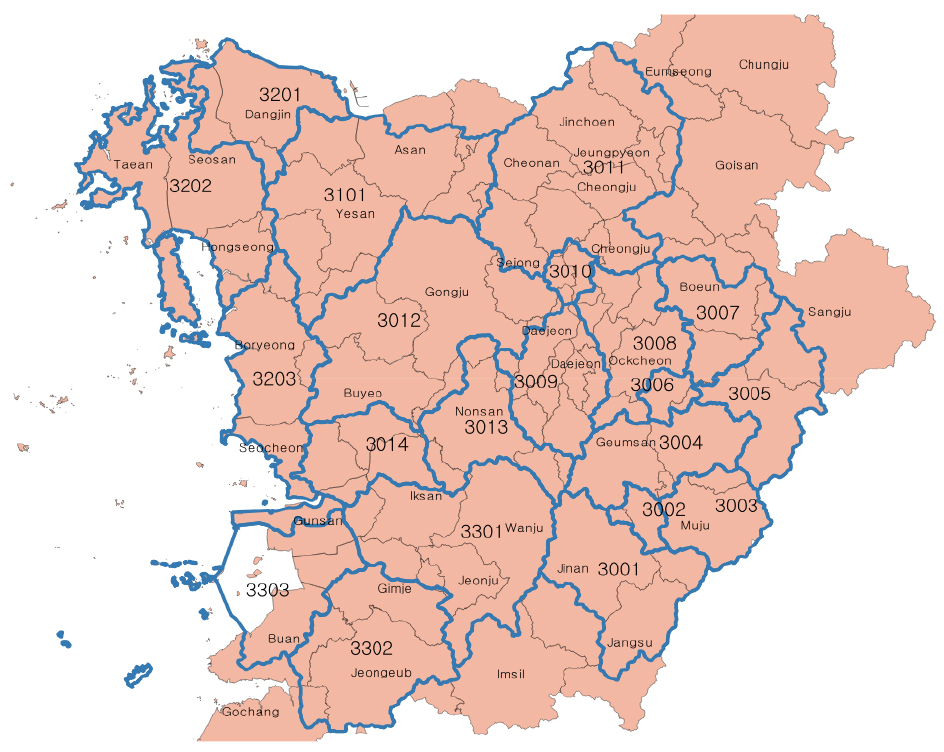
본 연구의 대상유역은 금강권역(Fig. 2)으로 유역면적은 17,924.8 km2이며 하천의 총 길이는 36,142.3 km이다(WAMIS, 2020). 대상 유역은 4개의 대권역(금강, 삽교천, 금강서해, 만경·동진강) 내에 21개 중권역으로 구성되어져 있다. 수자원 공급 측면에서는 4개의 다목적댐 (용담댐, 대청댐, 보령댐, 부안댐)이 위치하고 있고, 유효저수량 5백만 m3 이상의 대규모 저수지가 27개소, 4개의 담수호(대호호, 간월호, 보령호, 석문호), 2개의 하구둑 및 방조제(금강하구둑, 삽교천 방조제)가 위치하고 있다. 수자원 수요 측면에서는 생활용수 수요가 많은 대전, 청주, 전주, 천안, 아산 등 대도시가 포함되어 있으며, 군산, 아산, 서산·당진 등의 산업단지에서 공업용수 수요가 많다. 또한 예산군, 당진시 등 충남 서북부 일대의 예당평야, 논산시, 부여군 등 충남 남부 일대의 논산평야, 만경강과 동진강 일대의 호남평야에서 농업용수 수요가 많다. 이렇듯 국내 5대 하천(한강, 낙동강, 금강, 섬진강, 영산강) 중 유역면적으로는 3번째에 해당하지만, 대도시와 농업지역의 특성을 동시에 고려할 수 있으며, 다양한 수자원 공급시설을 포함한 모의가 가능하기 때문에 금강권역을 대상유역으로 선정하였다.
2.2 RCP 시나리오 분석
본 연구에서는 기상청(KMA, 2020)에서 제공하는 RCP (Representative Concentration Pathways; 대표농도경로) 기후변화 시나리오를 적용하였다. 인간 활동이 대기에 미치는 복사강제력만큼을 온실가스 농도로 표현한 이 시나리오(RCP 2.6, 4.5, 6.0, 8.5)는 영국기상청 해들리센터의 지역기후모형(HadGEM2-RA)을 사용하여 한반도 영역에 위도, 경도 0.125° 단위의 공간해상도로 2006년부터 2100년까지 미래 기후변화 전망자료(강수량, 평균기온, 최고기온, 최저기온, 상대습도, 풍속)를 제공하고 있다.
해당 자료 적용을 위해 먼저 한반도 전체에서 대상유역의 공간적 범위 35.5°-37.125° N, 126.0°-128.0° E에 해당하는 224개 격자자료를 추출하였다. 다음으로 Fig. 2에 나타난 중권역 별 자료를 산출하기 위해 224개 격자지점의 Thiessen polygon을 구축하여 중권역 별로 격자의 가중치를 산정하였다. 물수지 분석을 위해서 필요한 자료는 중권역의 일 강수량과 증발산량 자료로 강수량은 격자별 기후변화 전망자료와 Thiessen polygon의 합성을 통해 산정이 가능하지만, 증발산량 자료는 태양복사에너지 또는 일조시간 등의 자료가 부족한 상황에서 나머지 기상 자료들을 통해 추정해야 한다. 이를 위해 일최고기온과 일최저기온, 대기권 밖의 복사에너지로 순복사량을 추정한 결과를 FAO Penman-Monteith 방법에 적용하여 증발산량 산출하는 방법(Allen et al., 1998; Kim et al. 2017)을 본 연구에 적용하였다.
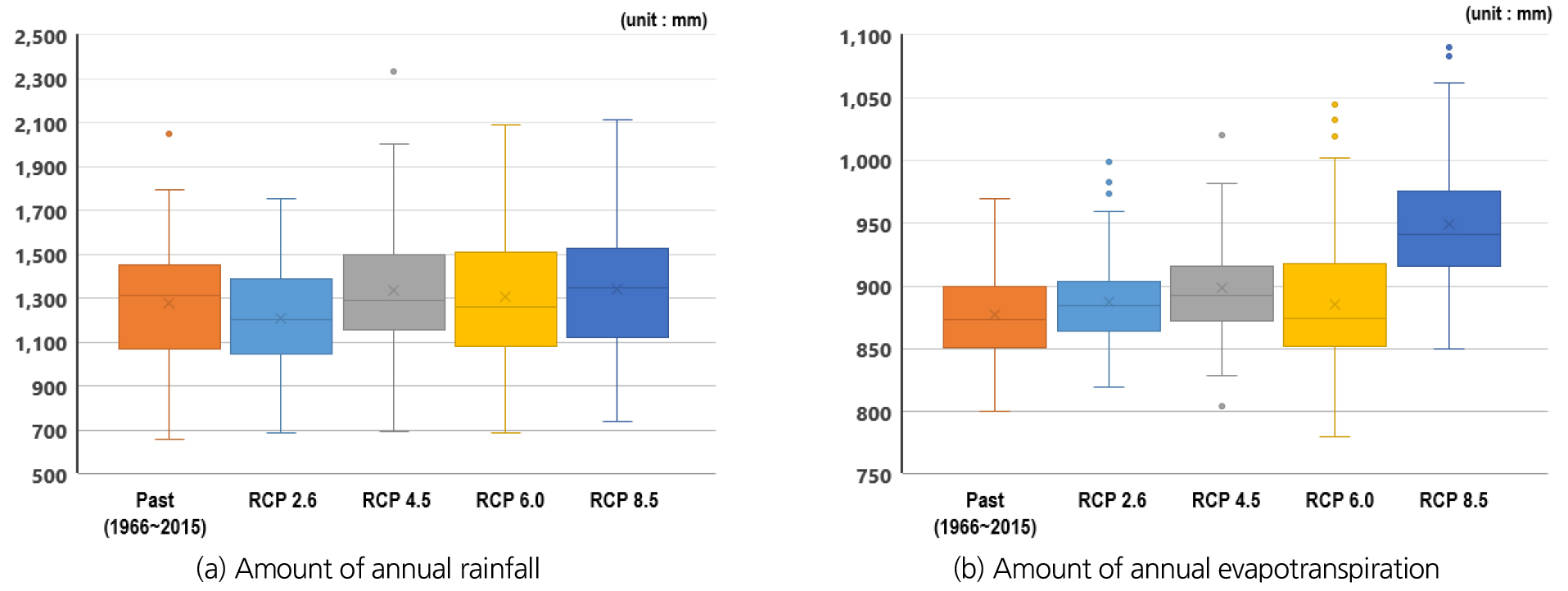
대상유역에 대해 연간 강수량과 증발산량을 산출한 결과를 과거 1966년부터 2015년까지 관측된 자료와 2011년부터 2100년까지 각 RCP 기후변화 시나리오를 적용하여 예측한 값을 비교한 결과는 Fig. 3과 같다. 먼저 강수량의 경우 과거 관측자료와 미래 예측자료의 평균치는 RCP 시나리오에 관계없이 비슷한 범위 안에 있는 것으로 보이나, 온실가스 농도가 증가할수록 연최소 강수량과 연최대 강수량의 변동 범위는 넓어지는 경향이 있는 것을 알 수 있었다. 또한 증발산량의 경우, 온실가스 저감정책이 상당히 실현된 시나리오(RCP 2.6, RCP 4.5)의 경우에는 과거와 유의미한 차이가 없었으나, 현재 추세대로 온실가스가 배출되는 RCP 8.5 시나리오의 경우 미래 90년의 평균치가 과거 50년의 평균치보다 약 8.4% 증가하는 것으로 나타났다. 그리고 4개의 RCP 시나리오를 중첩하게 되면, 과거 관측자료의 범위를 포괄하기 때문에 기존보다 더 다양한 가뭄상황에 대한 검토가 가능하다는 것을 간접적으로 확인 할 수 있었다.
본 연구에서는 이와 같은 과정을 거쳐 다음 절에서 설명할 물수지 분석 모형의 입력값으로 과거 관측자료와 RCP 시나리오 별로 반순(5일) 단위 강수량과 증발산량 데이터를 산출하였다. 또한 다층신경망 모형의 입력값으로 적용될 SPEI 지수 산정을 위해 먼저 과거 관측자료와 RCP 시나리오 자료를 통합하여 전체 데이터를 구성하였다. 다음으로 Eqs. (1) and (2)와 같이 1개월 단위로 합산된 강수량과 증발산량의 차이를 3-변량 Log-logistic 분포에 적합시키고, 그 결과를 표준정규분포로 변환하여 SPEI지수를 산정하였다.
여기서 Pi는 i월의 강수량 합계(mm), PETi는 i월의 증발산량 합계(mm)이고, Di는 i월의 강수량과 증발산량의 차이이다. 또한, 는 특정 j월부터 선행하는 k개월의 Di를 합산한 값이다.
2.3 물수지 분석 모형 적용
대상유역에 가뭄으로 인해 발생할 수 있는 피해를 가장 직접적으로 확인할 수 있는 방법은 각 유역 또는 행정구역별로 예상되는 물부족량과 발생 시기를 확인하고, 그로 인해 발생할 수 있는 농작물 생산량 감소, 공장의 제품 생산량 감소, 대체 수자원 공급에 투입된 비용 등을 추산하는 것이다. 이를 위해서는 기존의 용수공급시설(댐, 농업용 저수지, 상수도 등) 외에 인위적인 요소 없이 발생할 수 있는 물부족량을 산정하는 것이 우선적으로 필요하다. 즉, 현실에서 댐과 저수지의 공급능력, 그리고 상수도 공급시설의 시설용량 등과 각 지역별 시기별 용수 수요를 가장 잘 반영한 물수지 분석 모형의 구축이 선행되어야 한다.
본 연구에서는 미국 텍사스의 수자원 개발부가 개발했던 네트워크 모형인 SIMYLD를 미국 Colorado State University의 Labadie 교수가 수정하여 개발한 MODSIM-DSS (MODified SIMyld-Decision Support System)모형(K-water, 2007)을 적용하였다. 모형의 구성에 있어서는 기존 수자원장기종합계획(MOLIT, 2016)을 Fig. 4와 Table 1과 같이 용수의 수요량 산정과 용수 공급측면에서 개선한 선행 연구결과를 적용하였다(Jang et al., 2021).
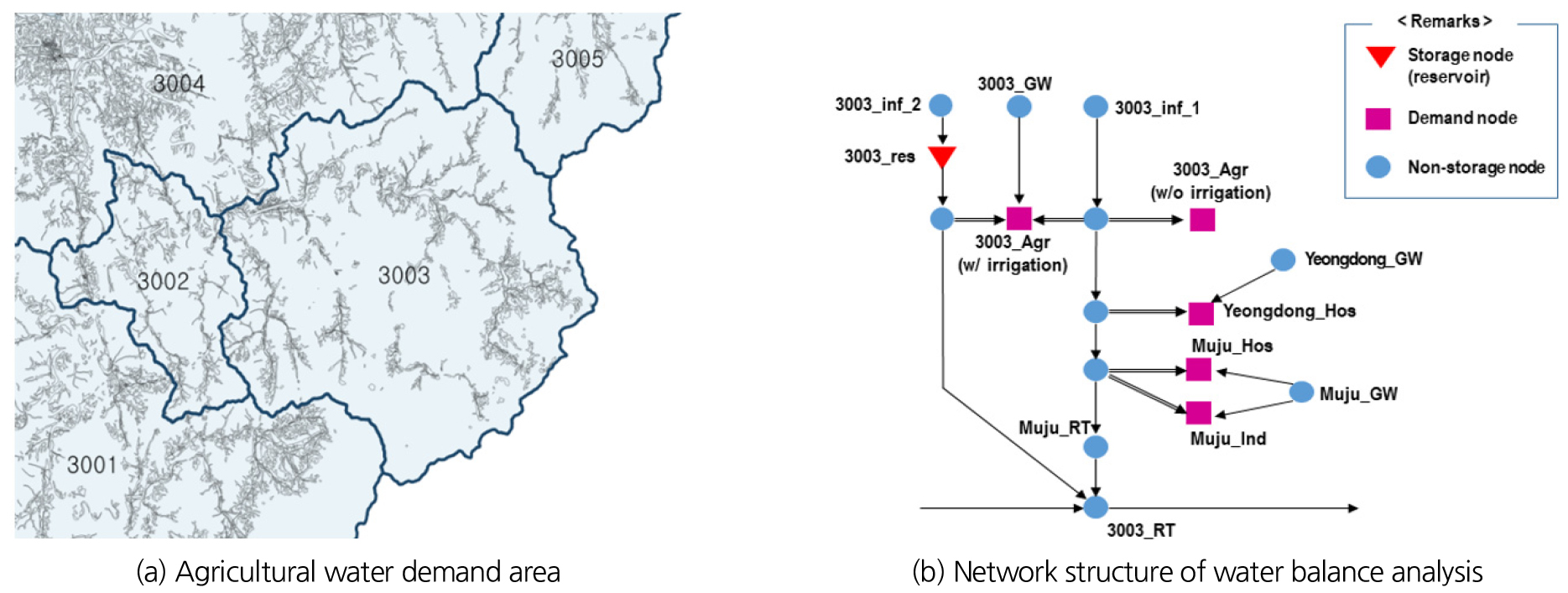
Table 1.
Water balance analysis comparison between MOLIT (2016) and improved method
| National Water Resources Plan (MOLIT, 2016) | Improved Method (Jang et al., 2021) | |
|
Network Components |
‧ Household & industrial demand : one node in each sub-basin ‧ Agricultural demand : one node in each sub-basin |
‧ Household & industrial demand : one node in each administrative district ‧ Agricultural demand : one node in each sub-basin |
|
Water Demand |
‧ Calculated based on each administrative district's area in the sub-basin |
‧ Calculated based on the number of population and the water demand area in the sub-basin |
|
Water Supply |
‧ Underground water and reservoirs : The supply capacity is considered after the simulation |
‧ Underground water and reservoirs : Included in the simulation |
|
‧ Local water supply and treatment system : Not included in the simulation |
‧ Local water supply and treatment system : Included in the simulation |
기존 방법 대비 개선점을 간단하게 소개하면, 먼저 물수지 분석 네트워크 구성에 있어서 기존에는 중권역 별로 생공용수와 농업용수 노드 각각 하나씩만을 포함하던 것을 생공용수는 행정구역 별로 노드를 추가함으로써 행정구역 별 물공급(지방상수도)과 처리체계(하수처리장)를 반영할 수 있게 하였다. 수요량 산정은 기존에 중권역 별로 포함되는 행정구역의 면적비를 적용하여 생활용수, 공업용수, 농업용수 수요량을 산정하던 것을 중권역에 포함되는 인구수, 그리고 농업지역과 공업지역의 GIS 면적을 적용하여 좀 더 현실적으로 산정하였다. 용수 공급은 기존에 지하수와 농업용 저수지는 시뮬레이션에 포함하지 않고, 시뮬레이션 수행 이후 물부족량에서 감해 주던 것을 시뮬레이션에 포함시켜 검토함으로써 물부족량 뿐만 아니라 물부족 발생시기를 검토할 수 있게 하였다.
물수지 분석은 1966년부터 2015년까지 관측자료를 기반으로 한 분석과 2006년부터 2100년까지 RCP 시나리오를 기반한 분석으로 나누어서 수행하였다. 먼저 두 자료에서 산출된 강수량과 증발산량 자료를 강우-유출모형인 저류구조 4단 탱크모형에 입력하여 중권역 별 자연유출량을 산출하였고, 2025년 기준수요를 기반으로 MODSIM-DSS 모형을 구성하였다. 물수지 분석의 단위는 전년도 10월부터 금년도 9월까지를 동일한 수년으로 간주하여 연단위로 물부족량을 산출하였다. 과거 관측자료의 경우 1966년부터 1967년까지는 분석모형의 안정화 단계로 보고, 1968년부터 물부족량을 산정하였고, RCP 시나리오를 적용한 경우에는 2011년부터 물부족량을 산출하였다.
RCP 시나리오를 적용한 물부족량 산출결과, Fig. 3과 같이 강수량의 변동폭이 커지고, 증발산량이 증가했음에도, 금강 대권역에 위치한 중권역에서는 물부족이 10-20년에 한 번으로 드물게 나타났고, 발생량도 1-10백만 m3의 수준으로 적었다. 이는 금강 대권역에 위치한 2개의 다목적댐과 하구둑, 농업용 저수지 등이 미래 가뭄에도 어느 정도 대응이 가능한 공급능력을 갖추고 있다는 것을 나타낸다. 그러나 중권역 3101(삽교천), 3201(대호방조제), 3202(부남방조제), 3203(금강서해), 3302(동진강)과 같이 서해와 가까운 곳에 위치하여 자연하천 발달이 취약한 곳에서는 지속적인 가뭄발생이 예상되었다. 이들 지역의 물수지 분석 결과를 정리한 Table 2를 살펴보면, RCP 시나리오를 적용했을 때 연간 최대물부족량이 과거 관측자료를 적용했을 때보다 대부분 증가하는 것을 볼 수 있다. 이는 현재보다 증가하는 온실가스 농도에 의한 영향도 있겠지만, 과거 데이터가 50여년의 제한적인 경우의 수를 검토한 것보다 다양한 가뭄상황에 대한 검토가 가능해진 요인도 있다고 판단된다. 또한 과거 자료에서 발생한 연간 최대갈수량보다 더 큰 물부족이 발생하는 경우를 각 중권역 별로 3-26개 데이터를 확보함으로써 과거에 발생한 가뭄을 초과하는 이상가뭄으로 인한 물부족 상황도 예측이 가능하게 되었다. 이는 홍수빈도분석에서 극치값(extreme values)를 추가적으로 확보한 것과 동일한 효과라고 할 수 있다.
Table 2.
Water balance analysis result in case of the past data and RCP scenarios
물수지 분석 모형을 적용하여 산정된 물부족량은 과거 실제 발생한 가뭄피해 자료와 비교하여 모형의 신뢰성을 검증하는 과정이 필요하고, 이를 위해 여러 방면으로 과거 국내에서 발생한 가뭄의 피해 상황을 조사하여 발간한 자료들을 확인해 보았다. 하지만, 현재까지 국내에서 발간되고 있는 자료들은 모형을 보정할 수 있는 만큼 자세한 자료가 조사되고 있지 않은 것이 현실이다. 행정안전부 주도로 조사한 ‘2018년 국가가뭄정보통계집(MOIS, 2018)’이 가장 상세하게 조사된 자료이다. 그런데 이 자료에도 각 행정구역별 논과 밭의 물마름이 발생한 면적과 기간을 명시하고 있을 뿐 그 밭이 관개전인지 비관개전인지 가뭄의 원인은 무엇인지 명시하고 있지 않다. 그 이전에 발간된 가뭄조사보고서에는 이러한 행정구역 별 자료도 포함되어 있지 않은 것이 현실이다. 그렇기 때문에 현재로서는 기존 연구보다 물공급과 수요측면에서 현실의 여건을 좀 더 충실히 반영하여 산정된 결과가 과거와 미래 기상상황으로 인해 발생될 수 있는 가뭄피해를 가장 잘 표현할 수 있다고 가정하고, 본 연구를 수행하였다.
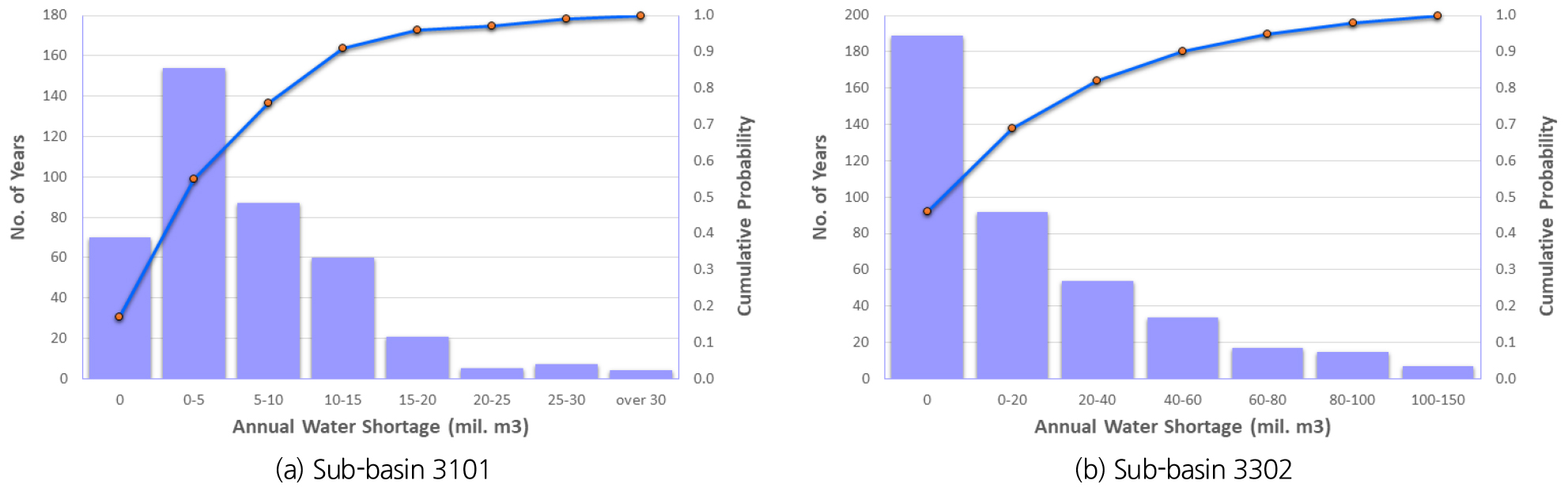
과거 관측자료와 RCP 시나리오를 적용하였을 때 중권역 3101(삽교천)과 3302(동진강)에서 발생한 연간 물부족량의 발생빈도는 Fig. 5와 같다. 두 중권역 모두 물부족이 발생하지 않는 경우를 포함하여 데이터의 분포가 좌측으로 치우쳐지고, 분포의 꼬리가 우측으로 길게 늘어진 양의 왜곡(positively skewed)된 상태인 것을 알 수 있다. 이러한 데이터 분포에 적합한 확률분포형을 검정과 PPCC (Probability Plot Correlation Coefficient) test를 통해 확인한 결과 다음 Eq. (3)와 같이 GEV (Generalized Extreme Value) 분포가 적합한 것으로 나타났다. 다층신경망 모형에서는 scale이 큰 특정 변수의 영향이 커지는 것을 제한하고, 학습시 지역 최소값(local minima)에 빠지는 것을 방지하기 위해, 설명변수와 목적변수 모두를 표준화 또는 정규화 하는 전처리과정을 수행한다. 표준화는 변수의 최대값과 최소값의 범위 내에서 각 변수의 상대적 위치를 나타내는 것이고, 정규화는 변수가 정규분포를 따른다는 가정 하에 평균과 표준편차를 적용하여, 각 변수의 비초과확률을 산정하는 것이다. 두 방법 모두 결과는 0과 1사이의 값으로 표현되지만, Fig. 5에 나타난 것과 같이 실제 변수의 분포와 일치하지 않는 분포를 적용하기 때문에 특정 구간에 변수가 몰리는 경향을 나타내었다. 따라서 본 연구에서는 Eq. (3)과 같이 물부족량의 발생빈도에 적합한 것으로 확인된 GEV 분포의 누적 분포 함수(cumulative distribution function)에 특정 물부족량을 적용하여 산출되는 비초과확률()을 가뭄 심각도(0-1)로 표현하였으며, 이 값은 뒤에서 다층신경망 모형의 목적변수로 적용하였다.
여기서, x는 연간 물부족량(천 m3), k는 형상 매개변수, 는 축척 매개변수, u는 위치 매개변수이다.
2.4 다층신경망 모형 구성
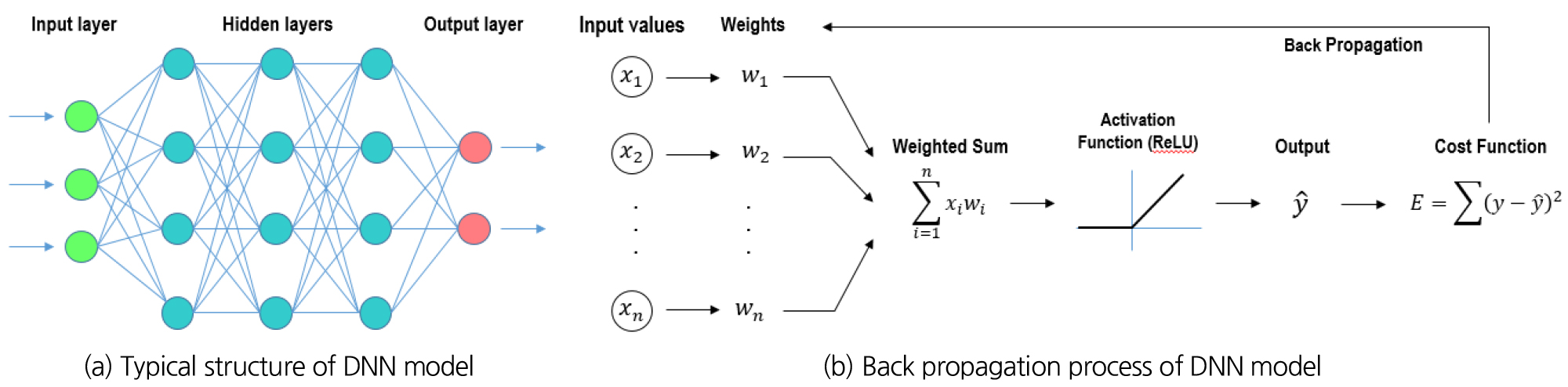
다층신경망 모형은 일반적으로 입력층(input layer), 은닉층(hidden layer), 그리고 출력층(output layer)으로 구성되어 진다. Fig. 6(a)에 나타내고 있는 것과 같이 각 층은 다음 층의 모든 node와 다중으로 연결된 node들로 구성된다. 입력층은 단일층으로 구성되어져 있으며 여기로 데이터가 입력되면, 2개 이상의 layer로 구성된 은닉층에서 처리를 통해 결정된 예측결과가 출력층에 나타나게 된다. Fig. 6(b)는 다층신경망에서 출력값 예측과 역전파알고리즘(back propagation algorithm)을 통한 모형 학습과정을 설명하고 있다(Raschka and Mirjalili, 2019; Nielsen, 2020). 먼저 각 node의 입력값()에 가중치()를 곱한 값의 합계, 즉 입력값들의 가중합계(weighted sum)가 은닉층의 입력값이 되며, 은닉층에서는 활성화 함수(activation function)을 통해 입력값을 출력값으로 변환하게 된다. 본 연구에서는 그래디언 소실(gradient vanishing)문제를 방지하고자 활성화 함수로 ReLU함수를 적용하였다. 이 함수는 입력값이 양수이면, 입력에 대한 도함수가 항상 1이기 때문에 복잡한 신경망에서 학습시간을 줄이는 효과가 있다. 학습단계에서 여러 은닉층을 통해 출력층에서 예측된 값()과 관측값()의 오차 제곱의 합계를 비용함수(cost function)라고 하며, 이 비용함수가 최소가 되도록 가중치를 조정하는 과정을 반복적으로 수행하게 된다. 비용함수와 가중치는 Eqs. (4) and (5)와 같다.
여기서 과 는 출력층의 k번째 노드에서 관측값과 예측값을 나타내며, 는 t번째 모형 학습에서 이전 층의 i번째 노드와 다음 층의 j번째 노드 사이에 가중치를 의미하고, 는 학습률(learning rate)를 나타낸다.
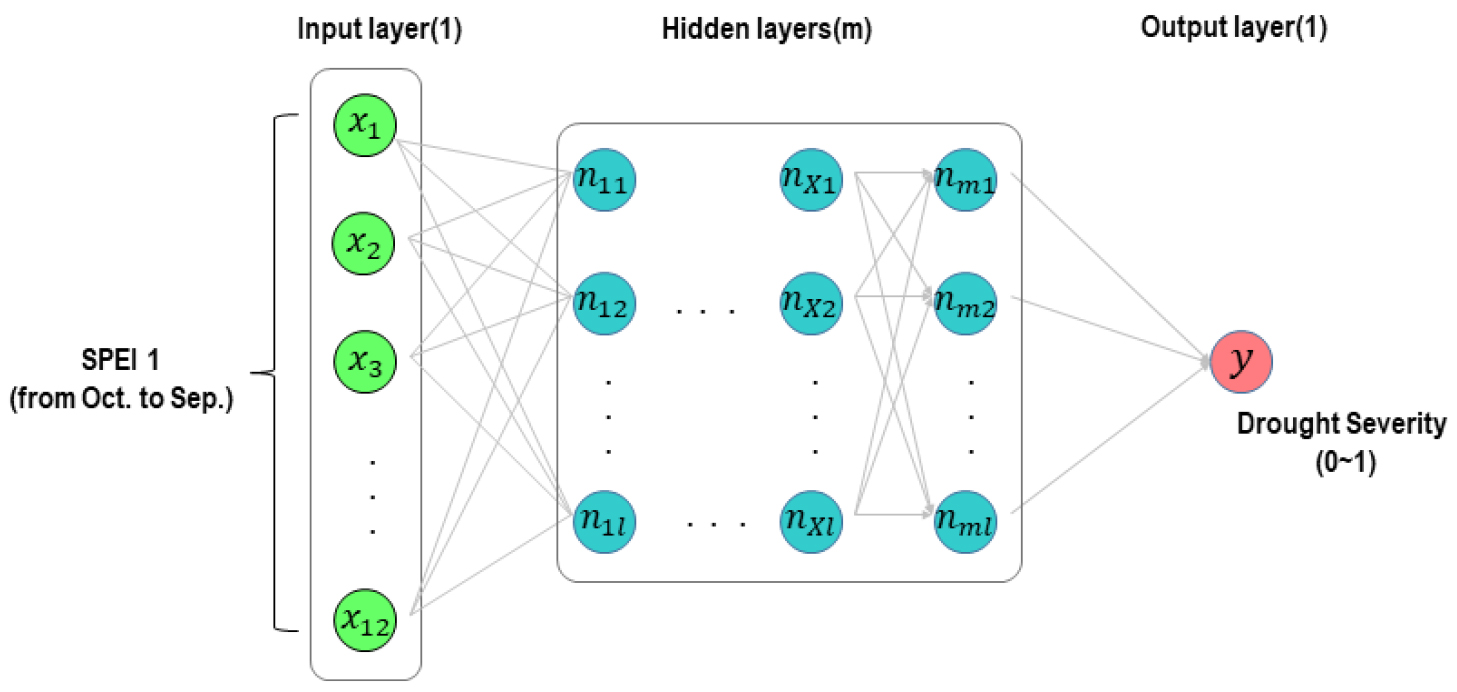
본 연구에서 적용한 다층신경망 모형의 출력층에서 예측하고자 하는 것은 Fig. 7과 같이 가뭄 심각도로서, 앞서 설명한 것과 같이 미래에 발생 가능한 연차별 물 부족량을 Eq. (3)의 GEV 분포에 적용하여 산정된 비초과확률(0-1)을 모형의 목적변수로 적용하였다. 다음으로 설명변수에는 전년도 10월부터 금년 9월까지의 월단위 SPEI지수 12개를 적용하였다. 설명변수 역시, SPEI지수를 표준정규분포에 적용하여 산정된 비초과확률(0-1)을 적용함으로써, 동일한 scale의 값이 모형 입력과 출력에 적용되었다. 가뭄대응가이드북(NDIC, 2016)에서는 기상가뭄의 예·경보 발령을 6개월 누적 강우량을 기반으로 한 SPI지수(SPI 6)를 적용하고 있지만, 가뭄에 있어서는 증발산량을 같이 보는 것이 필요한 것으로 판단되어 SPEI지수를 적용하였다. 또한 벼농사의 모내기와 작물의 생육에 필요한 농업용수 공급으로 인해 대부분의 물부족이 5월에서 9월 사이 기간에 발생한다는 것을 고려할 때 본 연구에서 적용한 매월의 SPEI지수는 6개월 이상의 누적 강우량을 분석에 포함하고 있다고 볼 수 있다.
다층신경망 모형 구축을 위해선 모형 학습과 검증과정이 필요하다. 통상적으로 70-80%의 데이터를 무작위로 선정하여 모형 학습에 적용하고, 나머지 20-30% 데이터를 검증에 적용하는 교차검증을 통해 모형을 구축한다. 본 연구에서는 RCP 시나리오(RCP 2.6, 4.5, 6.0, 8.5) 별로 2011년에서 2100년까지 물수지 분석에 적용하여 구축된 총 360개년의 자료를 모형의 학습과 검증과정에 적용하였다. 모형의 학습과 검증은 은닉층의 층수와 은닉층별 노드의 수, 학습횟수(epoch 수) 등 하이퍼파라메타(hyperparameter)를 조정시키며 진행되었고, 검증시의 비용함수 평균제곱오차가 최소가 되도록 가중치를 조정하였다. RCP 시나리오를 적용하여 구축된 모형은 학습과 검증과정에는 투입되지 않은 과거 49년의 관측자료(1967-2015년)에 적용하여 물수지 분석 모형을 통해 산정된 물부족량과 다층신경망을 통해 산정된 물부족량이 가장 유사한 모형을 중권역별로 최적의 다층신경망 모형으로 선정하였다.
3. 물부족량 예측 결과
3.1 다층신경망 모형 훈련 및 검증
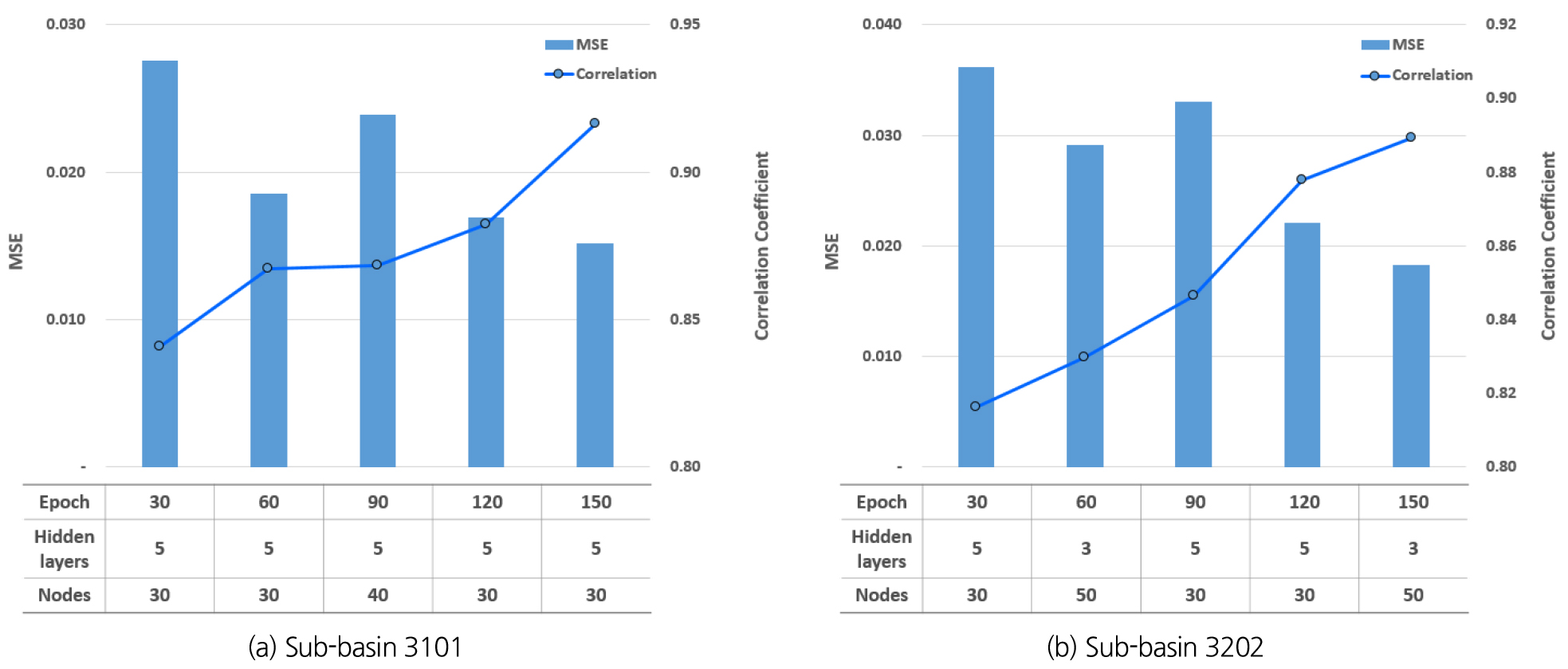
각 중권역별 다층신경망 모형의 최적 하이퍼파라메타 결정을 위해 은닉층의 수와 은닉층 노드의 개수, 그리고 학습횟수(epochs)를 조정하며 Table 3과 같이 총 45회의 시뮬레이션을 수행하였다. 학습횟수의 경우 그 수를 500회까지 증가시키며 학습(training)과정과 상호교차검증(cross validation)과정에서 발생한 MSE (Mean Squared Error)를 검토한 결과 학습횟수 30번에서 validation error의 최솟값이 발생하였다. 그 이후에는 training error는 감소하는 반면, validation error는 변화가 거의 없거나 오히려 증가하는 과적합의 양상을 보였다. 그렇기 때문에 학습횟수는 30회부터 150회까지 5가지 case에 대해 수행하였다.
RCP 시나리오를 적용하여 구축된 총 360개의 학습데이터에서 80%는 학습에 그리고 나머지 20%는 검증에 적용하여, 각 중권역별로 45회의 시뮬레이션을 수행하였다. 매번 학습 종료 후에는 검증데이터를 적용하여 가중치를 수정하였고, 학습이 모두 끝났을 때 검증 데이터를 적용한 예측값과 목표값의 오차와 두 값의 상관관계를 검토하였다. 각 학습횟수(epoch = 30, 60, 90, 120, 150) 별로 예측값과 목표값의 오차(MSE)를 가장 작게 하고, 상관계수를 가장 크게 하는 case (은닉층의 수, 노드의 개수)를 Fig. 8과 같이 나타내었다. 모든 학습횟수에서 상관관계가 0.8이상을 나타내어 학습의 결과로 도출된 모형이 각 중권역 별로 가뭄 상황을 잘 반영하고 있는 것으로 판단되었다.
Table 3.
Simulation cases of DNN model training and cross validation
| No. of hidden layers | No. of nodes in each hidden layer | No. of epochs | Simulation cases |
| 3 to 5 layers (3 cases) | 30, 40, 50 nodes (3 cases) | 30, 60, 90, 120, 150 (5 cases) | 45 cases |
3.2 최적의 다층신경망 모형 선정 및 물부족량 예측
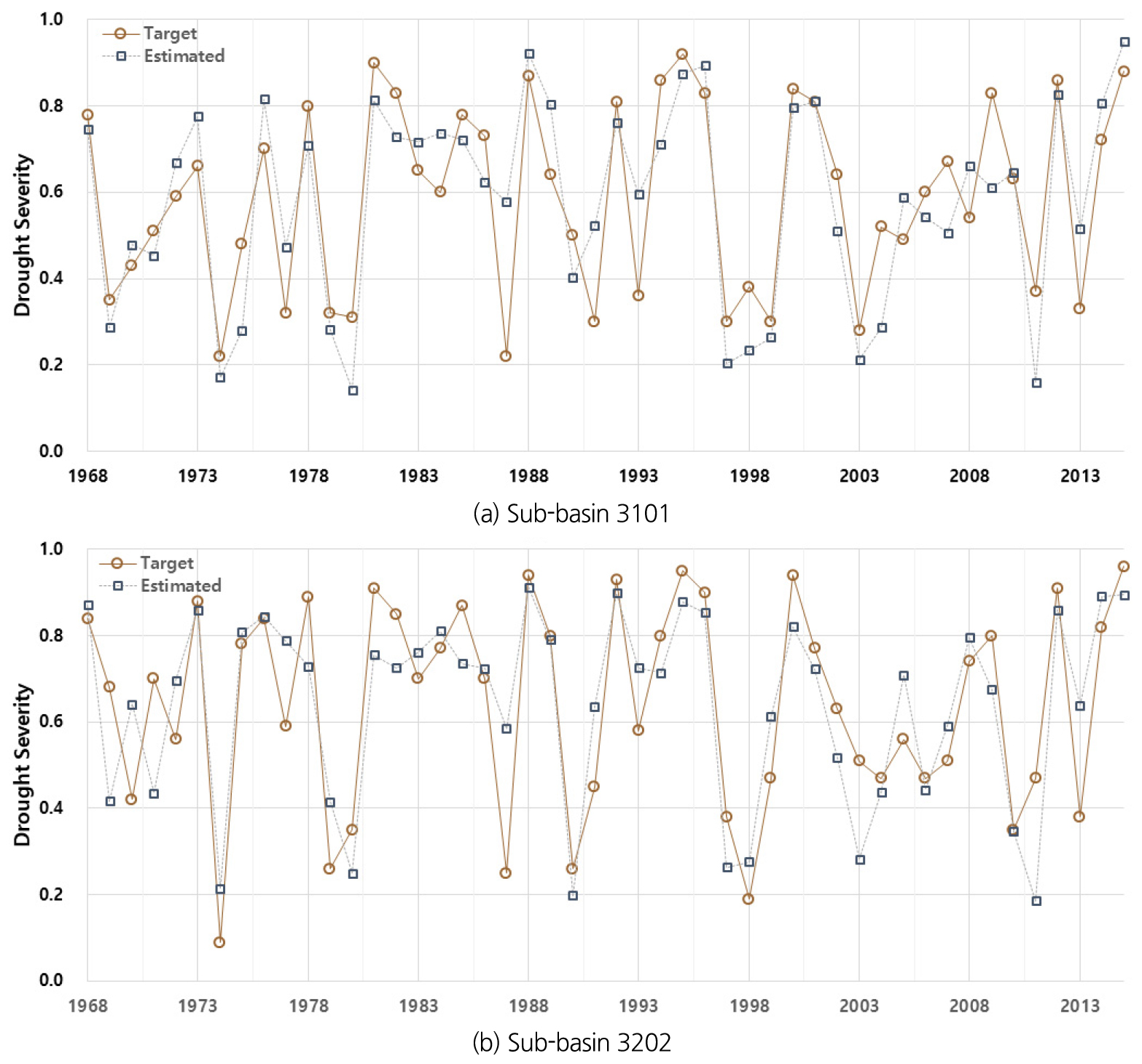
각 중권역 별로 훈련된 45개의 다층신경망 모형 중 최적의 다층신경망 모형(optimal DNN model)을 선정하기 위해 학습단계에서는 적용하지 않은 과거의 관측자료를 모형에 적용하여 가뭄의 심각도를 추정(inference)하였다. 대상유역에서 5개의 중권역 별로 학습된 45개의 다층신경망 모형에 과거 관측자료를 입력하고, 예측되는 가뭄의 심각도와 물수지 분석 모형의 결과값을 비교하여 최적의 다층신경망 모형을 선정하였다. 학습에 적용되지 않은 자료를 중권역 3101에 적용하여 목표로 하는 가뭄 심각도와 다층신경망으로부터 예측된 가뭄 심각도를 비교한 결과는 Table 4와 같다. 학습횟수가 150회이고, 은닉층이 4개 그리고, 각 층의 노드 개수가 40개일 때 목적변수와의 오차가 가장 작고, 상관계수도 0.8 이상으로 높게 나타났기 때문에 해당 모형을 최적의 다층신경망 모형으로 선정하였다. 이와 같은 과정을 통해 각 중권역 별로 선정된 최적의 모형을 과거 관측자료에 적용하여 가뭄의 심각도를 시계열로 나타낸 결과는 Fig. 9와 같다. 물수지 분석 모형으로부터 산출된 목표값(target drought severity)과 최적의 다층신경망 모형으로부터 산출된 예측값(estimated drought severity)을 비교해 보면 이전년도와 올해 그리고 올해와 내년의 가뭄 심각도 변화 추세는 거의 일치하는 것을 알 수 있었다. 또한 1981년, 1995년, 그리고 2015년에 중권역 3101에서 발생한 가뭄 심각도 0.9 이상의 가뭄에 대해서도 다층신경망 모형이 잘 예측하고 있는 것을 볼 수 있다.
Table 4.
Optimal DNN model selection using inference results (sub-basin 3101, epoch = 150)
위와 같이 RCP 시나리오를 적용하여 모형을 구축한 경우(Case 2)와 과거 관측자료를 적용하여 모형을 구축한 경우(Case 1)를 비교하여 어느 정도 모형의 신뢰도가 향상되었는지 비교한 결과는 Table 5와 같다. 먼저 과거 관측자료를 적용한 경우는 1967년부터 2005년까지 39년의 자료를 적용하여 모형의 훈련과 검증을 반복하여 다층신경망 모형을 도출하였으며, RCP 시나리오를 적용한 경우는 지금까지 중권역 별로 도출된 최적의 다층신경망 모형을 적용하였다. 훈련에 사용한 데이터의 개수가 다를 뿐 과거 관측자료를 적용하여 모형을 훈련한 경우에도 앞에서 설명한 것과 같이, 여러 모형을 훈련시키고, 그 중 최적 모형을 선정하는 것은 동일한 절차를 수행하였다. 그리고, 그 훈련과 검증 성과를 동일한 기준으로 비교하기 위해, 2006년부터 2015년까지 과거 관측자료를 두 모형에 적용하여 가뭄 심각도를 산출하고, 그 결과를 물수지 분석에 적용하여 도출된 가뭄 심각도와 비교하였다. Table 5를 살펴보면, 훈련과 검증 과정의 결과는 과거 관측자료를 적용한 case와 RCP 시나리오를 적용한 case에서 큰 차이를 나타내지 않았다. 그러나 훈련에 적용되지 않은 경우에 대한 추정에 있어서, RCP 시나리오를 적용한 모형은 훈련과정과 추정과정의 결과에 큰 차이가 없었던 반면에 과거 관측자료로 훈련한 모형은 MSE가 증가하거나, 결정계수가 감소하는 것을 알 수 있었다. 그 만큼 많은 데이터를 가지고 모형을 구축한 경우가 그렇지 못한 경우보다 미래 발생할 수 있는 가뭄 심각도 추정에 있어 신뢰성 있는 결과를 나타낸다고 볼 수 있다.
Table 5.
Inference results comparison between the models trained by the past data and RCP scenarios
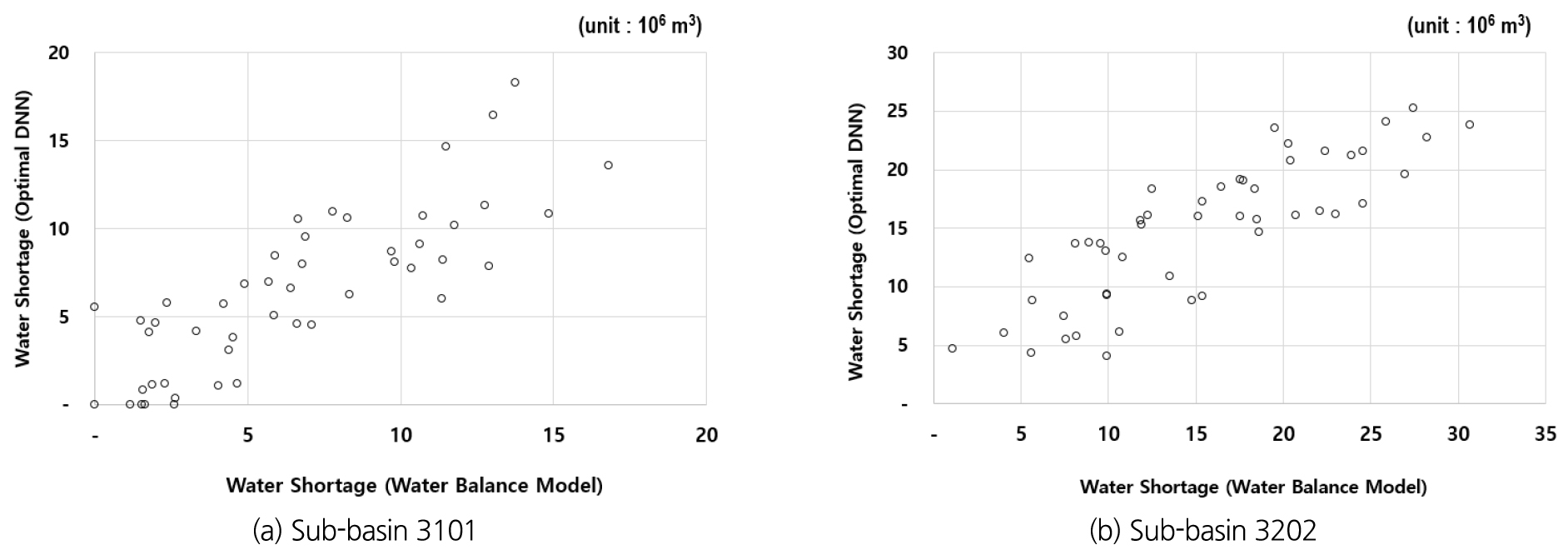
가뭄시 물부족량 산출을 위한 마지막 단계로 Fig. 9에 나타난 중권역 3101과 3202의 가뭄심각도를 Eq. (3)에 적용하여 역으로 연간 물부족량을 산출하고, 이를 물수지 분석 모형인 MODSIM-DSS에서 산출된 물부족량과 비교한 결과는 Fig. 10과 같다. Fig. 10의 점들이 크게 분산되지 않고, 우상향하는 것으로 나타내고 있어서 가뭄 발생 이전에 충분하게 예상되는 가뭄을 정량적으로 제시할 수 있는 신뢰성은 확보하고 있다고 판단된다.
이와 같이 각 중권역 별로 신뢰성 있는 다층신경망 모형을 RCP 시나리오와 물수지 분석 모형 기반으로 구축을 해 놓을 경우 연중 특정시점에 올해 예상되는 물부족량과 가뭄 해갈을 위해 필요한 강수량 등을 산정할 수 있다. 예를 들면, 특정연도에 봄 가뭄이 발생한 경우 전년도 10월부터 해당 월까지 관측된 월별 SPEI를 입력하고, 해당 월부터 금년의 9월까지 기상예측 등을 통해 예상되는 SPEI값을 입력하면 여러 가지 case에 대한 물부족량 또는 가뭄 해갈을 위해 필요 강수량 등을 산정할 수 있다. 이러한 과정은 물리적/개념적 모형만을 적용하여 강우량 예측, 강우-유출분석, 물수지 분석을 차례로 수행하는 것보다 간단하면서 신뢰성 있는 결과 도출이 가능하다고 판단된다.
4. 결론 및 향후 연구
본 연구에서는 의사결정자로 하여금 가뭄재해 관리에 있어 효율적이고, 신속한 의사결정을 위해 미래 발생할 가뭄의 물부족량을 신속하고, 신뢰성 있게 예측할 수 있는 방안을 제시하고자 하였다. 이를 위해 먼저, 개념적 모형으로 물수지 분석 모형을 적용하여 연간 물부족량을 산출하였고, 이를 GEV분포에 적용하여 가뭄 심각도 지수로 변환하였다. 또한 물수지 분석의 입력자료인 강우량과 증발산량을 기초로 SPEI 지수를 산정하였다. 다음으로는 산출된 SPEI지수를 데이터 기반의 다층신경망 모형의 입력값으로 적용하고, 가뭄 심각도를 추정할 수 있도록 모형을 학습시켰다. 여기서 중요한 부분은 여러 RCP 시나리오를 발생 가능한 기상현상으로 가정하고, 이를 다층신경망 모형 학습과 검증에 투입함으로써 신뢰성 있는 모형을 구축하였다는 점이다. 이를 통해 과거 관측된 기상자료만으로 다층신경망 모형을 구축하기에는 자료 길이가 약 50여년의 데이터로 제한된다는 한계와 그리고, 과거에 발생했던 가뭄재해 이상의 극한 가뭄이 발생하는 경우 그 피해를 예측하기 어렵다는 문제를 해결할 수 있었다. 또한, 개념적 모형과 데이터 기반 모형을 동시에 적용함으로써 두 모형의 장점을 모두 활용 가능하게 되었다. 즉, 복잡한 일별 예상 강수량 예측, 강우-유출분석과 물수지 분석 없이 신속하게 물부족량 추정이 가능하며 그 추정 결과도 의사결정자나 지역 주민이 알기 어려운 가뭄지수로 표현되는 것이 아니고, 실질적인 물부족량 또는 가뭄 해갈을 위해 필요한 강우량 등으로 표현이 가능한 것이다.
향후 연구에서는 최적 다층신경망 모형을 통해 예측된 값과 물수지 분석을 통해 산출된 값의 일치도를 더 향상시키고, 다양한 경우에 대한 예측의 신뢰성을 높이기 위해서는 본 연구에서 적용한 기상청 RCP 시나리오 이외에 타 기관에서 제공하는 기후변화 자료를 추가적으로 확보하여 발생 가능한 이벤트의 수를 늘리는 것이 필요한 것으로 판단된다. 또한, 다층신경망 모형의 입력값에 현재 적용된 SPEI지수 이외에 다른 변수를 추가하는 것도 검토해 볼 필요가 있다. 예를 들면, 강우가 월 중 여러 날 고르게 내리는 경우와 특정 며칠 동안 발생한 경우는 다른 물부족 양상을 나타낼 것이기 때문에 월 중 강우발생 일수나 평균 강우강도 등을 입력값을 넣는 것도 검토해 볼 필요가 있다고 판단된다. 추가적으로 본 연구에서는 전년도 10월부터 금년 9월까지 매월의 SPEI지수를 모형의 입력값으로 적용하였으나, 향후 연구에서는 이 대신 SPEI3 또는 SPEI6 등 다양한 변수를 적용하여 모형의 신뢰성을 높이는 것이 필요하다고 판단된다. 그리고, 다층신경망 모형의 예측된 결과에 대한 발생 원인을 파악하기 어렵다는 단점을 극복하기 위해, 다른 machine learning 기법을 적용하여, 각 중권역별 가뭄 발생 양상을 사전에 분석해 놓을 필요가 있다. 예를 들면, Jang et al. (2021)이 수행한 것과 같이 현재 모형의 학습에 적용된 가뭄지수와 물부족량을 decision tree을 적용하여, 중권역 별로 가뭄을 발생시킬 수 있는 가뭄지수의 임계치를 분석해 놓는다면, 물부족을 발생시킨 시기와 원인을 개략 추정할 수 있을 것으로 판단된다.
