

1. 서 론
2. 기본이론
2.1 인공지능 기반 독립적 자체 경보 관측소의 컨셉
2.2 기계학습 알고리즘
2.3 예측 정확도 검증
3. 모형구축
3.1 대상유역
3.2 입력자료
3.3 학습 파라메터
4. 연구결과
4.1 학습결과
4.2 예측 결과
4.3 홍수예측모형의 예측 정확도 분석
5. 결 론
1. 서 론
최근 전 세계적으로 기후변화의 영향으로 강우량이 집중되고 강우강도가 커지면서 홍수피해의 규모를 증가시키고 있다. 기존에는 관측되지 않았던 규모의 강우가 내리는가 하면 기록적으로 장기간동안 장마가 지속되기도 한다. 특히, 이러한 피해들은 아세안 국가들에 집중되고 있으며, 최근 해수면 상승, 태풍 및 집중호우로 인해 침수가 빈번히 빌생하는 등 아세안 국가 국민들 중 최소 2,000만 명이 영향을 받고 있다. 우리나라도 2020년에 54일간의 최장기간 장마 기록이 경신되기도 했으며, 중국과 유럽도 해마다 홍수피해 기록을 갈아치우고 있다.
홍수피해를 방지하는 방법에는 구조적인 방법과 비구조적인 방법이 있는데 구조적인 방법의 대표적인 것은 제방의 축조이다. 이는 단기간에 완료하기 어려우며 많은 비용이 발생한다. 비구조적인 방법의 대표적인 것은 홍수예경보이다. 미리 피해를 알려 인명피해를 줄이고자 하는데에 목적이 있다. 우리나라는 1974년 한강홍수통제소 설립 이후에 각 유역별 홍수통제소에서 중앙제어형으로 홍수예경보를 수행하고 있다. 각종 ODA사업을 통해 국내의 홍수예경보시스템을 아세안 국가에 지원하고 있으며, 매년 지원국가를 늘려가는 실정이다. 하지만, 통신시설이 불안정하여 수문자료가 중앙의 통제센터에 전송되지 않는 경우가 빈번하게 발생하여 홍수예경보에 어려움을 겪는 경우가 많다. 이렇게 통신네트워크가 불안정한 경우에는 중앙제어방식만으로는 한계가 있다. 기존의 중앙제어방식은 물리적 모형에 기반하는 강우-유출모형을 사용하므로 모형의 입력자료가 많은데다가 통신장애로 인해 한 곳의 관측소의 값만 누락이 되어도 정확한 유출계산을 수행하기 어려우며, 계산의 오류는 하류로 전달되어 전체적인 예측 정확도를 저하시키는 원인이 된다. 따라서 본 연구에서는 단일 관측소의 관측값 만으로도 홍수위 예측이 가능한 인공지능 기반의 예측모형을 개발하였다. 자료에 기반한 인공지능 모형으로 계산의 속도가 빨라 관측소 자체적인 계산이 가능하다.
인공지능을 활용한 홍수예측 연구는 국내외에 아주 활발하게 진행되고 있다. Fang et al. (2021)은 홍수민감도를 예측하기 위해 LSTM 기법을 활용하여 홍수취약성 지도를 작성하여 의사결정지원모델을 제안하였다. Le et al. (2019)은 일별 유출량과 강우량을 입력데이터로 하여 LSTM으로 하천의 유량을 예측하는 모델을 제시하였다. Tran and Song (2017)은 텍사스 트리니티강의 침수 수위를 예측하기 위해 표준 순환신경망(Recurrent Neural Network, RNN), RNN-BPTT, LSTM의 세 가지 모형으로 예측하였고, 가장 우수한 성능의 모형을 제시하였다. 국내에서는 Kim et al. (2020)이 강우-월류량-침수 관계를 도시유출모형인 SWMM을 이용하여 구축하고 과거 홍수발생자료를 활용하여 LSTM 및 로지스틱 회귀를 통해 도시침수예측을 수행하였다. Yoo et al. (2019)은 시간적 매개변수(Time delay = 2시간)를 고려한 NARX 신경망 모형을 사용하여 한강대교의 수위를 예측하는 연구를 수행하였다. Park and Kim (2020)은 LSTM으로 2개의 상류지점 수위를 이용하여 수위를 예측하는 하드웨어 및 소프트웨어를 개발하여 검증하였다.
본 연구에서는 시계열 예측에 주로 활용이 되는 LSTM을 활용하여 동일지점의 수위와 강우자료를 활용하여 수위를 예측하는 모형을 개발하였으며, 소유역의 산지하천에 대한 최적 선행예보시간을 제안하였다.
2. 기본이론
본 연구에서 자체경보가 가능한 인공지능기반의 독립적 자체 경보 관측소를 제안하였으며 이를 위해 필요한 인공지능 기반의 홍수예측모형을 개발하였다. 또한, 다양한 방법으로 예측의 정확도를 분석하여 홍수예측 모형의 신뢰성을 향상시켰다.
2.1 인공지능 기반 독립적 자체 경보 관측소의 컨셉
독립적 자체경보가 가능한 인공지능기반 하천홍수예측 모형의 컨셉은 동남아시아 등지에 설치된 홍수예측모형의 운영을 통해 도출된 개선사항으로부터 시작되었다. 필리핀이나 인도네시아에 우리나라의 ODA 사업을 통해 운영 중인 홍수예경보시스템은 중앙제어형으로 모든데이터가 중앙에 수집되고 수집된 자료로부터 유출모의를 수행하여 각 관측소별 예측수위를 계산하고 주의보나 경보 수위를 넘을 경우 경보를 발령한다. 그러나, 통신네트워크가 국내에 비해 열악한 동남아시아에서는 통신문제로 경보를 발령하지 못하는 경우가 빈번하게 발생하였다. 본 연구에서는 중앙제어형을 보완하기위해 통신이 단절된 상황에서도 관측소 자체적으로 관측자료를 활용하여 홍수를 예측하는 시스템을 구상하고 컨셉을 제시하였다. 관측소 자체에서 홍수예측을 하기위해서는 자료기반의 홍수예측이 필요하며 이를 위해 인공지능 알고리즘을 적용하였다. 상세한 독립적 자체경보 관측소의 컨셉은 Fig. 1에 도시하였다.
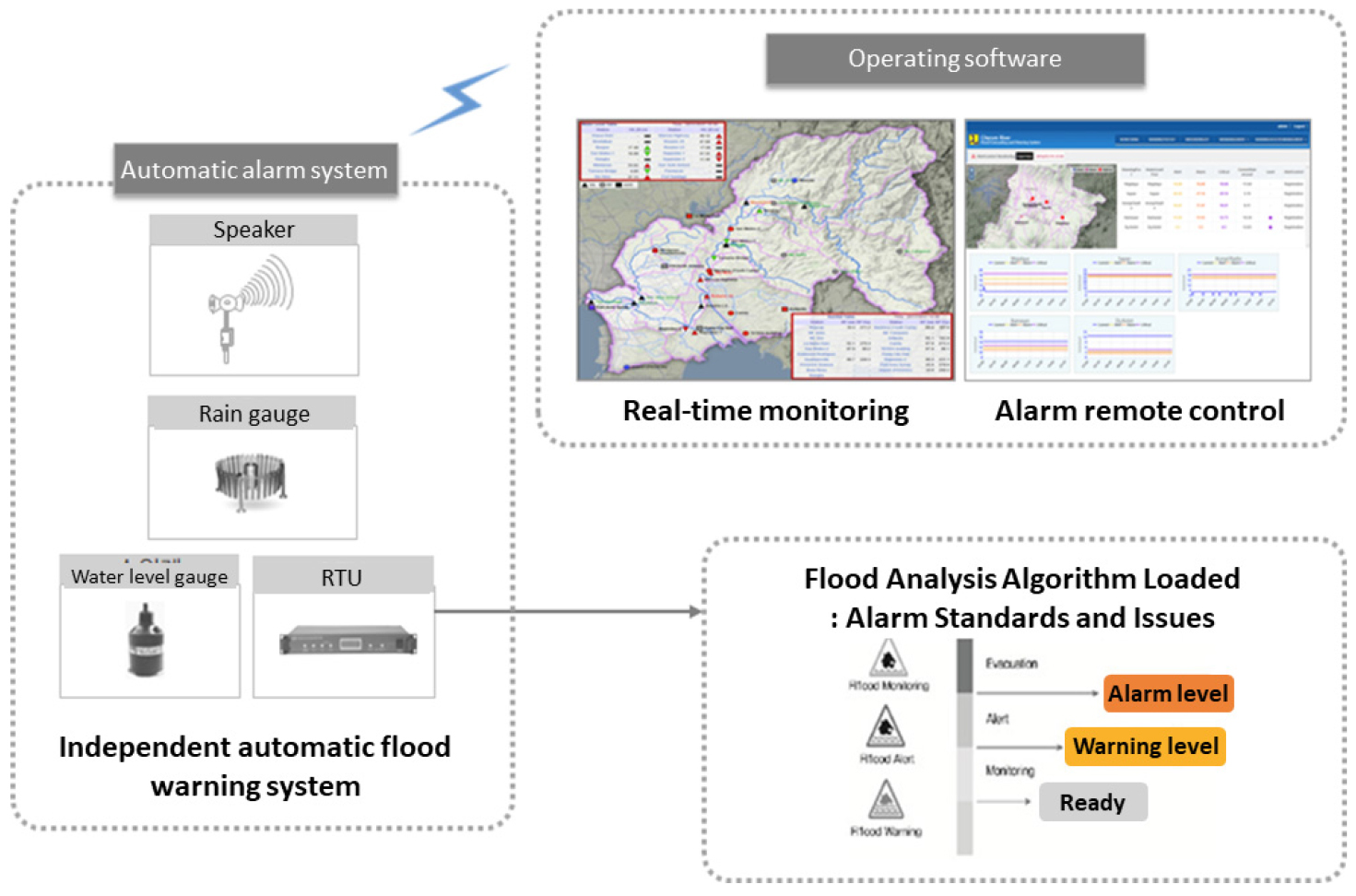
2.2 기계학습 알고리즘
본 연구에서는 기존의 관측값을 학습하여 선행예보시간 후의 수위를 예측하는 모형을 구축하고자 한다. 관측값은 10분단위 시계열 자료의 형태를 가지고 있어 시계열 머신러닝에 적합한 RNN (Recurrent Neural Network)을 적용하는 것이 타당하다. RNN 모형은 일반적인 딥러닝 모형과 달리, 선행시간에 도출된 예측결과를 다시 입력 값으로 활용하여 학습 및 예측을 수행, 시계열이 갖는 연속성에 대한 높은 정확도를 확보할 수 있는 장점이 있다. 최근에는 초기의 RNN에 비해 발전된 형태인 LSTM (Long Short-Term Memory)이 광범위하게 적용중이다. LSTM은 기본적인 RNN의 단점인 시점이 길어질수록 앞의 정보가 뒤로 충분히 전달되지 못하는 장기의존성 문제(the problem of Long-Term Dependencies)를 해결한 모형으로 기존 RNN이 은닉층 내에 1개의 tanh layer를 두고 있는데 반해 4개의 layer가 특별한 방식으로 정보를 주고받도록 되어있다(Olah, 2015)(Fig. 2). 따라서, 본 연구에서는 LSTM을 활용하여 홍수예측 모형을 구축하였다.
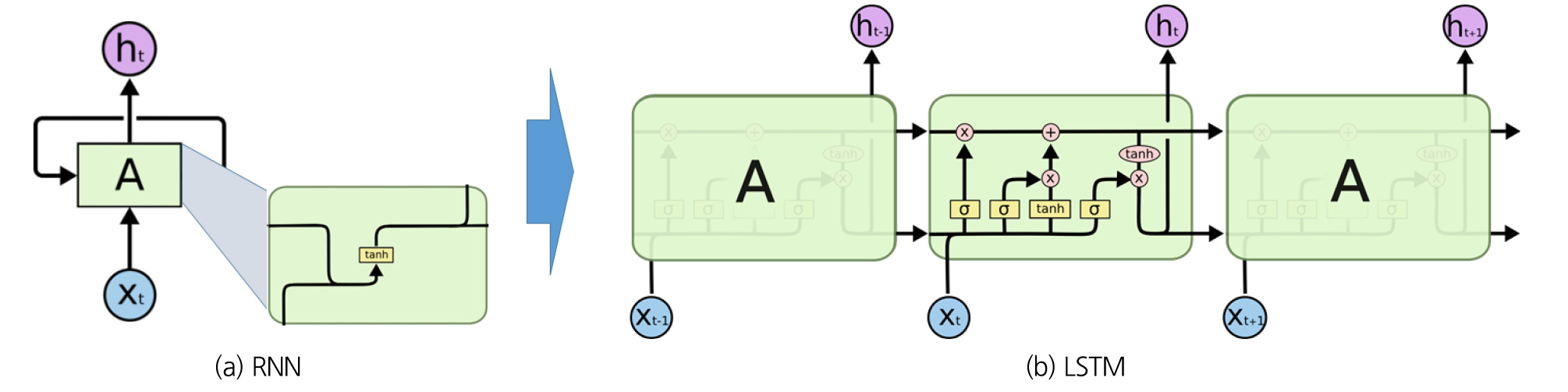
2.3 예측 정확도 검증
예측모형의 정확도 검증은 크게 두가지 항목으로 구분하여 진행하였다. 하나는 예측값과 실측값의 적합도 검증이고 하나는 오차검증이다. 홍수의 예측은 예측값과 관측값의 상관성이나 모형의 적합도에 대한 정확도도 중요한 지표이나, 첨두 홍수량의 오차도 중요한 검증항목으로 홍수가 발생하는 최대값의 오차가 적게 발생하는 것이 중요하다.
적합도 검증의 지표로는 수문모형의 예측기술을 평가하는데 가장 광범위하게 사용되는 NSE (Nash-Sutcliffe model efficiency coefficient)와 회귀모형의 변동성에 대한 상관성을 보여주는 R2 (Coefficient of determination)을 적용하였다(Krause et al., 2005). 오차에 대한 분석으로는 RMSE (Root Mean Square Error), 최대오차(Maximun error, Emax), 첨두오차(Error of peak value, EPeak), MAPE (Mean Absolute Percentage Error)으로 일반적인 오차를 정량화 하는 방법을 다양하게 적용하였다. 각 지표별 산정식과 범위는 Table 1에 나타냈다.
Table 1.
Fit Indicators and equations for validating prediction accuracy
3. 모형구축
본 연구에서는 강우와 수위를 동시에 관측이 가능한 설마천 유역의 전적비교 관측소에 대해서 자체 관측 자료를 바탕으로 홍수를 예측하는 인공지능 기반의 예측모형을 개발하고자 한다. 이어 관측소에서 관측된 강우와 수위를 활용하여 학습, 검증, 시험 자료를 구축하였으며, LSTM 알고리즘을 바탕으로 모형을 구축하였다. 검증을 통해 학습이 과대적합이나 과소적합되지 않았는지 확인하였으며, 선행예보시간(lead time)별로 예측의 정확도를 비교하였다.
3.1 대상유역
본 연구의 대상유역인 설마천 시험유역은 1995년부터 한국건설기술연구원에서 신뢰성 있는 수문자료를 지속적으로 수집하고, 물 순환과정을 파악하기 위한 기초 연구자료로 활용하기 위해 운영하고 있다.
설마천은 임진강의 지류로써 시험유역은 설마천의 상류에 위치한다. 시험유역의 유역면적은 8.48 km2, 유로연장은 5.59 km이며, 유역 평균 경사는 31.84°로 산지소하천으로 분류가 가능한 유역이다(KICT, 2015). 시험유역 내에는 11종의 유량관측시설과 8종의 하천수위 관측장비, 13항목의 기상관측 시설이 설치되어 있다(Fig. 3). 이 중 수위와 강우관측이 동시에 가능한 관측소는 전적비교 관측소가 유일하다. 따라서 본 연구의 대상 관측소로 전적비교 관측소를 선정하였다.
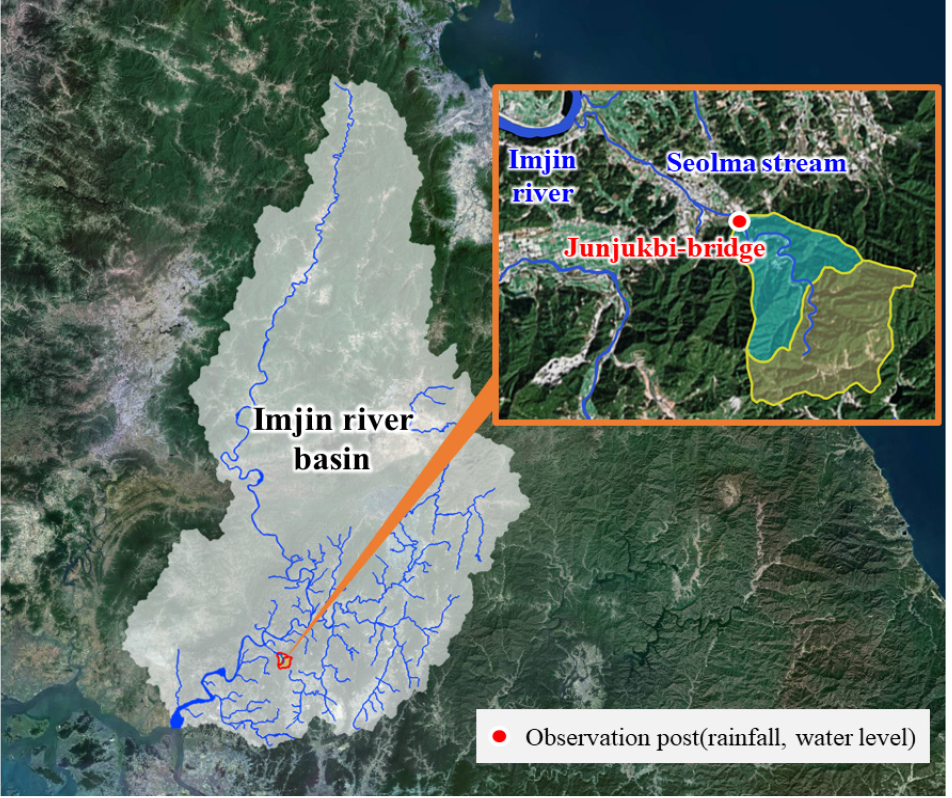
3.2 입력자료
설마천 시험유역의 전적비교 관측소는 10분단위의 강우와 수위 관측이 가능하다. 2009년부터 2020년 까지의 강우와 수위자료를 확보하였으며 총 데이터의 개수는 각각 약 63만개에 달한다. 강우와 수위 모두 계절적인 영향이 크고 홍수기에 집중되는 만큼 무강우 기간에 대해서는 학습자료로써 효과가 없다. 따라서 63만개에 달하는 자료중 무강우가 8시간이상 지속되는 경우는 입력자료에서 제외하는 전처리를 수행하였으며 전처리후 자료는 약12만개로 20%로 감소하여 학습의 효율성을 향상시켰다(Table 2).
Table 2.
Period of flood and simulation conditions for original and preprocessed data
| Original data | Preprocessed data | |
| Period of flood | 2009-01-01 00:10~2020-12-31 24:00 | 2009-01-15 18:00~2020-12-28 08:20 |
| Number of data | 631,152 | 124,613 |
전처리후 강우 및 수위자료는 Fig. 4에 나타냈다. 2009년~2018년 자료는 학습자료로 활용되며, 이 중 후반부 20%는 검증에 활용되고 모델에서 자동으로 추출된다. 2019~2020년 자료는 시험에 활용된다. 각각의 기간 및 자료의 수는 Table 3에 나타냈다.
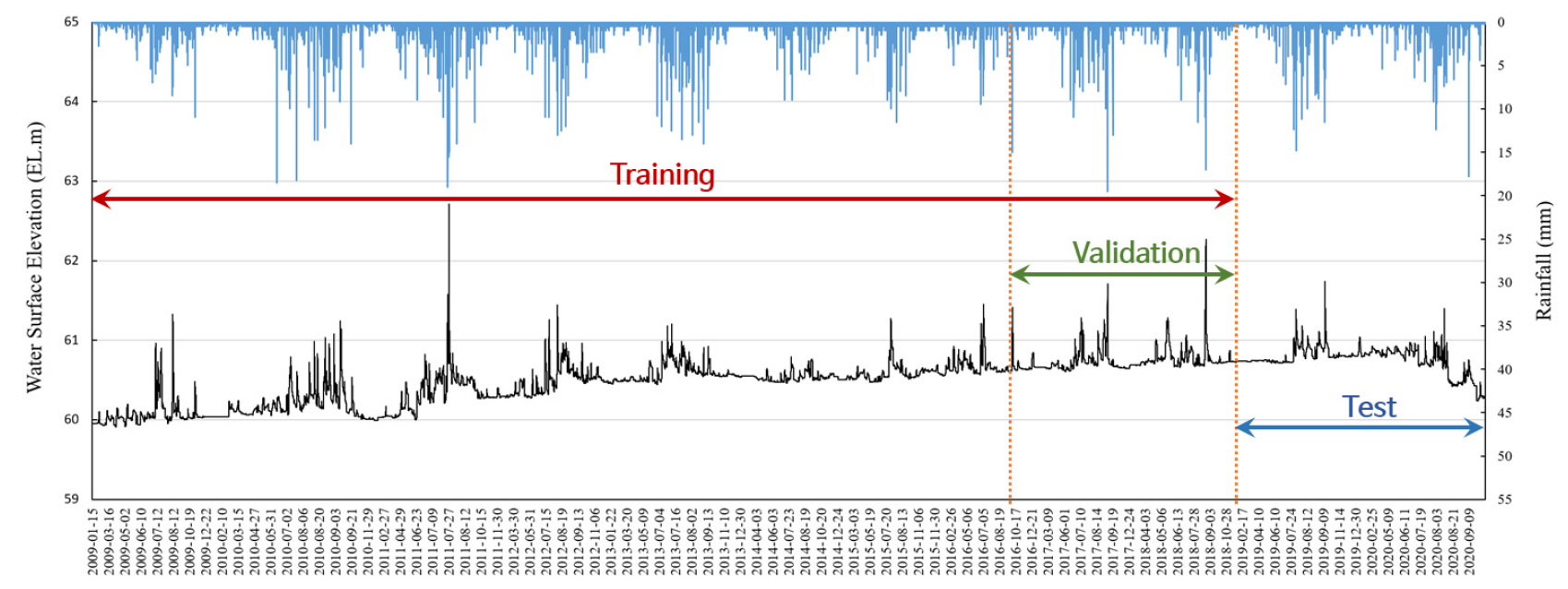
Table 3.
Data information for training, validation and test
| Type | Training | Validation | Test |
| Period of data | 2009~2018 | 2016.10~2018 | 2019~2020 |
| Number of data | 102,374 | 20% of training data (auto-selected in model) | 22,239 |
전적비교의 수위와 강우자료를 활용하여 선행예보시간(현재시점 기준으로 0.5, 1, 2, 3, 6시간 후)의 수위예측이 가능하도록 인공지능모델 구축을 위한 입력자료를 생성하였다. 학습자료에 해당하는 X는 현재시점의 강우와 수위자료이며, 예측값에 해당하는 Y는 0.5, 1, 2, 3, 6시간후의 수위로 설정하였다. 선행예보시간 별로 학습을 개별로 진행하나 입력자료는 한번에 구축하였다. 입력자료의 구조는 Table 4에 나타냈다.
Table 4.
Structure of input dataset
| Date_time | Rainfall | WL* | WL_after 0.5 h | WL_after 1 h | WL_after 2 h | WL_after 3 h | WL_after 6 h |
| - | X | Y | |||||
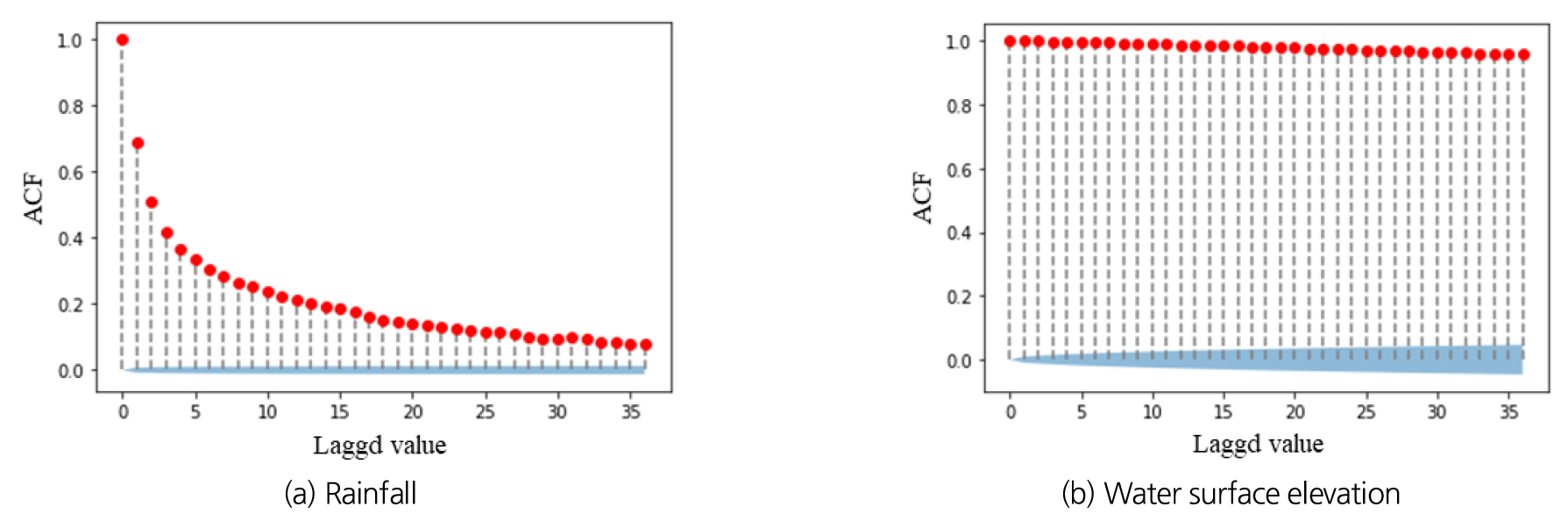
입력자료인 강우량과 수위는 모두 시계열 자료로써 과거의 시계열 자료를 통해 미래를 예측하는 경우 자료의 정상성(Stationarity) 을 만족하는지 평가해야 한다. 자료의 정상성은 자료 또는 그 통계적 특성이 시간에 따라 변하지 않는 것을 의미한다. 자료의 정상성은 자기상관함수(Autocorrelation function, ACF)를 통해 확인이 가능하다. 자기 상관계수가 높은 값을 유지하는 경우는 해당 시계열 자료가 시간에 따라 일정한 정상성을 갖는다고 판단할 수 있다. 또한, ACF가 신뢰구간 내에 분포하는 시점 이전 까지는 관측값이 임의시간 관측값과 상관이 있음을 의미한다(Yoo et al., 2020). Fig. 5에 강우량과 수위에 대한 ACF 값을 도시하였으며, 두 값 모두 시차(Lagged value) 36(6시간)에 대해서 정상성을 만족하고 있는 것으로 나타났다. 따라서, 본 연구에서 입력자료로 사용되는 강우량과 수위는 6시간 이후에 대한 예측모형을 만드는데 적합한 입력자료임을 확인하였다.
3.3 학습 파라메터
인공지능을 활용하는 모형의 구축에는 학습을 위한 파라메터를 선정하는 것이 무엇보다 중요하다. 파라메터의 설정을 통해 학습의 효율성과 정확성이 결정되며, 적절한 형태의 학습에 맞는 파라메터를 설정하는 것이 중요하다. 본 연구에서 적용하는 LSTM의 경우 Activation function으로 비선형 함수인 ReLU를 적용하였다. Optimizer 로는Adam, Loss Function은 Mean squared error로 설정하였다. 딥러닝 인공신경망 구조를 갖도록 Hidden layer는 총 5개 층으로 구성하였고, 일반적으로 홍수예보에서 적용하는 하천의 도달시간은 3~4시간이므로 강우 발생이 수위변화에 충분히 반영되도록 Sequence length는 24로 설정하여 입력자료가 직전 4시간의 자료를 참조할 수 있도록 하였다. 기타 모델에 사용된 학습 파라메터는 Table 5에 나타냈다.
4. 연구결과
4.1 학습결과
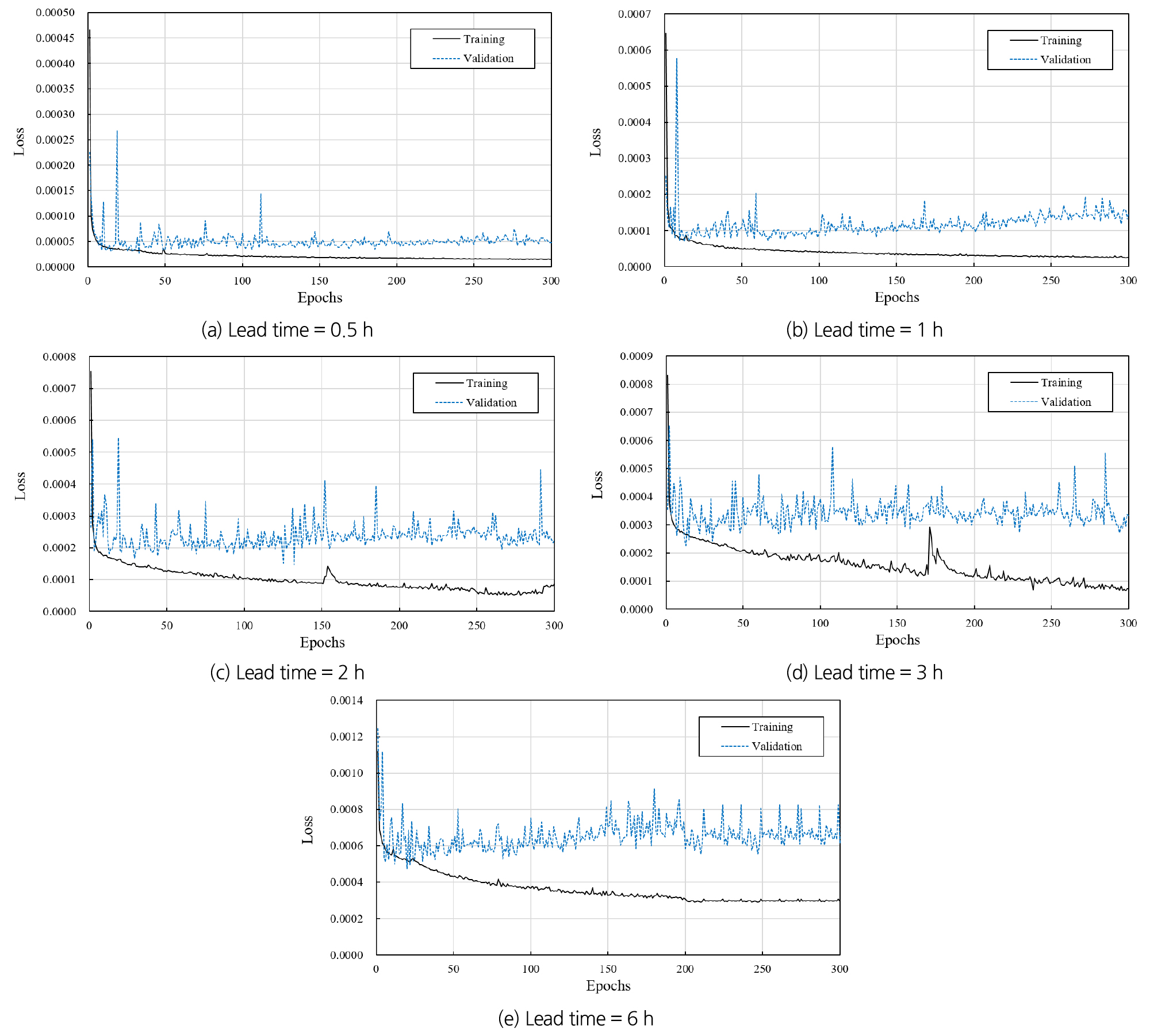
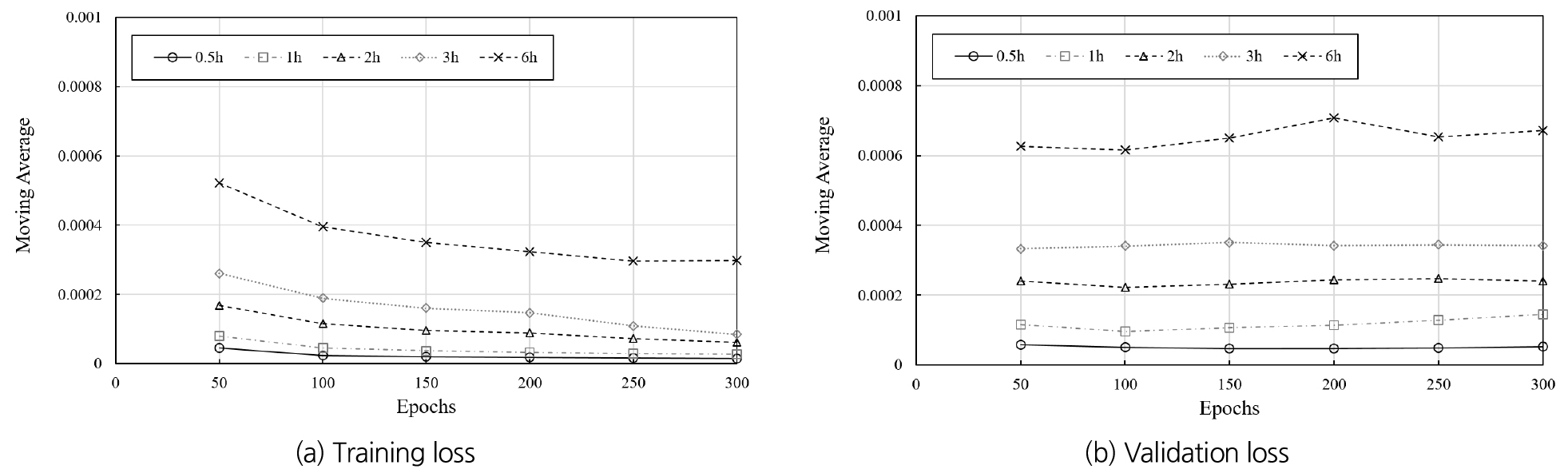
선행예보시간별로 홍수예측모형을 학습한 결과 모든 케이스에 대해서 Training loss 값이 지속적으로 감소하고 일정 값에 수렴하는 결과를 나타내면서 학습이 완료되었다. Validation loss 값 또한 일정 값에 수렴하는 형태를 나타냈으며 학습이 경과함에 따른 loss 값의 변화는 Fig. 6에 도시하였다. 각 loss 값은 기계 학습의 과대적합 또는 과소적합을 판단하는 기준으로써 Training loss와 Validation loss가 일정하게 유지되면서 수렴할 때 적절하게 학습이 된 것으로 판단이 가능하다(Jabbar and Khan, 2015). Training loss와 Validation loss는 진동하는 값이므로 수렴판단을 위해 이동평균 값을 산정하였으며 Fig. 7에 50 epochs 단위의 이동평균을 도시하였다. 그 결과 모든 케이스에 대해서 일정한 값으로 수렴하는 결과를 나타냈다. 따라서, 본 연구에서 진행된 학습은 모두 적절하게 진행이 되었다고 판단하였다.
4.2 예측 결과
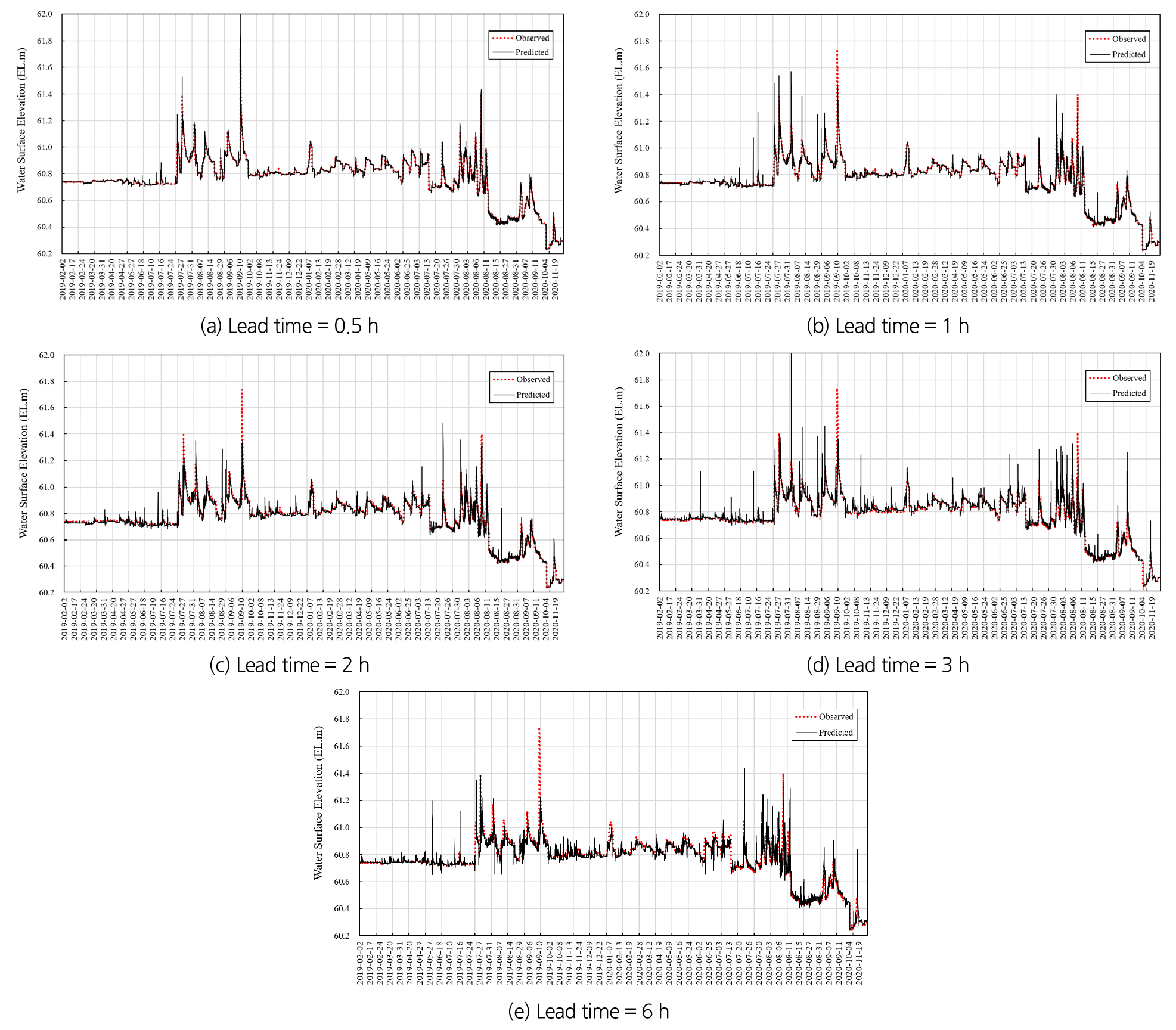
학습이 완료된 모형을 활용하여 시험단계를 수행하여 예측의 정확도를 분석하였다. 시험에 사용된 자료는 총 22,239개로 2019~2020년 자료이다. 전체적으로 예측값이 관측값의 수위를 잘 따라가면서 예측이 수행되고 있음을 확인하였다. 각 선행예보시간 별 예측결과는 Fig. 8에 도시하였다.
4.3 홍수예측모형의 예측 정확도 분석
각 선행예보시간 별 예측결과를 바탕으로 예측정확도 분석을 수행하였다. 먼저 모형적합도 분석을 위해 NSE와 R2값을 산정했고, 오차 분석으로는 RMSE, 최대오차, 첨두오차, MAPE를 산정하였다. 각각의 산정결과는 Table 6에 나타냈다.
Table 6.
Analysis of prediction results for each lead times
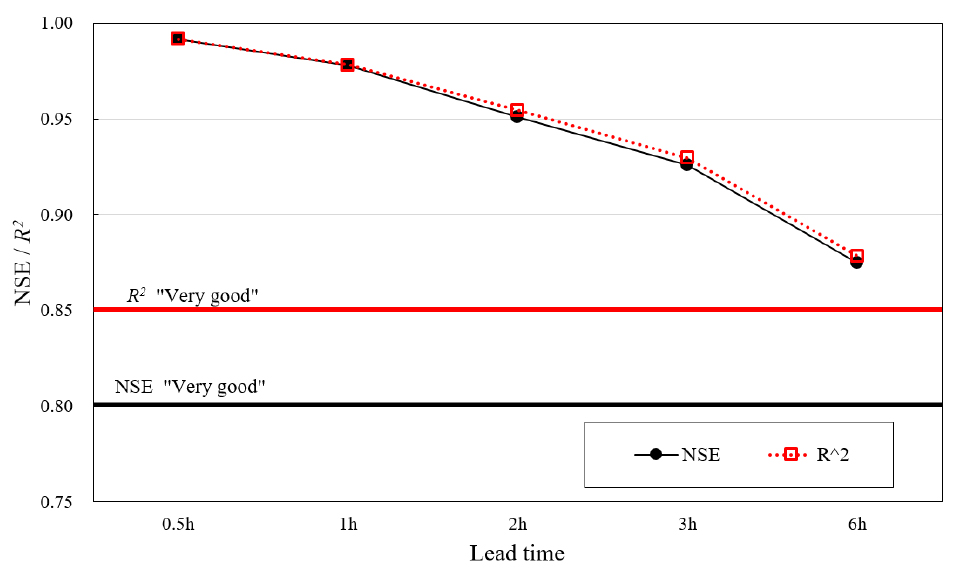
Moriasi et al. (2015)은 수문모형의 적합도를 판정하는 기준으로 NSE와 R2에 대해서 제시하였다(Table 7). NSE의 경우 0.8이상인 경우 최고 등급인 Very good 등급, R2의 경우 0.85이상 일 때 최고 등급인 Very good 등급으로 판단한다. 본 연구의 예측결과는 모든 선행예보시간에 대해서 NSE는 0.87이상으로 나타났고, R2도 모든 선행예보시간에 대해서 0.87이상으로 나타나 NSE, R2모두 Very good등급의 높은 적합도를 나타냈다(Fig. 9). 따라서, 본 연구에서 제시한 홍수예측 모형이 관측값과 예측값이 높은 적합도를 나타내고 있어 정확도 높은 홍수예측이 가능함을 확인하였다.
Table 7.
Grading Criteria of Model fit Indicators (Moriasi et al., 2015)
| Grade | Very good | Good | Satisfactory | Not satisfactory |
| NSE | NSE ≥ 0.80 | 0.80 > NSE ≥ 0.70 | 0.70 > NSE ≥ 0.50 | 0.50 > NSE |
| R2 | R2 ≥ 0.85 | 0.85 > R2 ≥ 0.75 | 0.75 > R2 ≥ 0.60 | 0.60 > R2 |
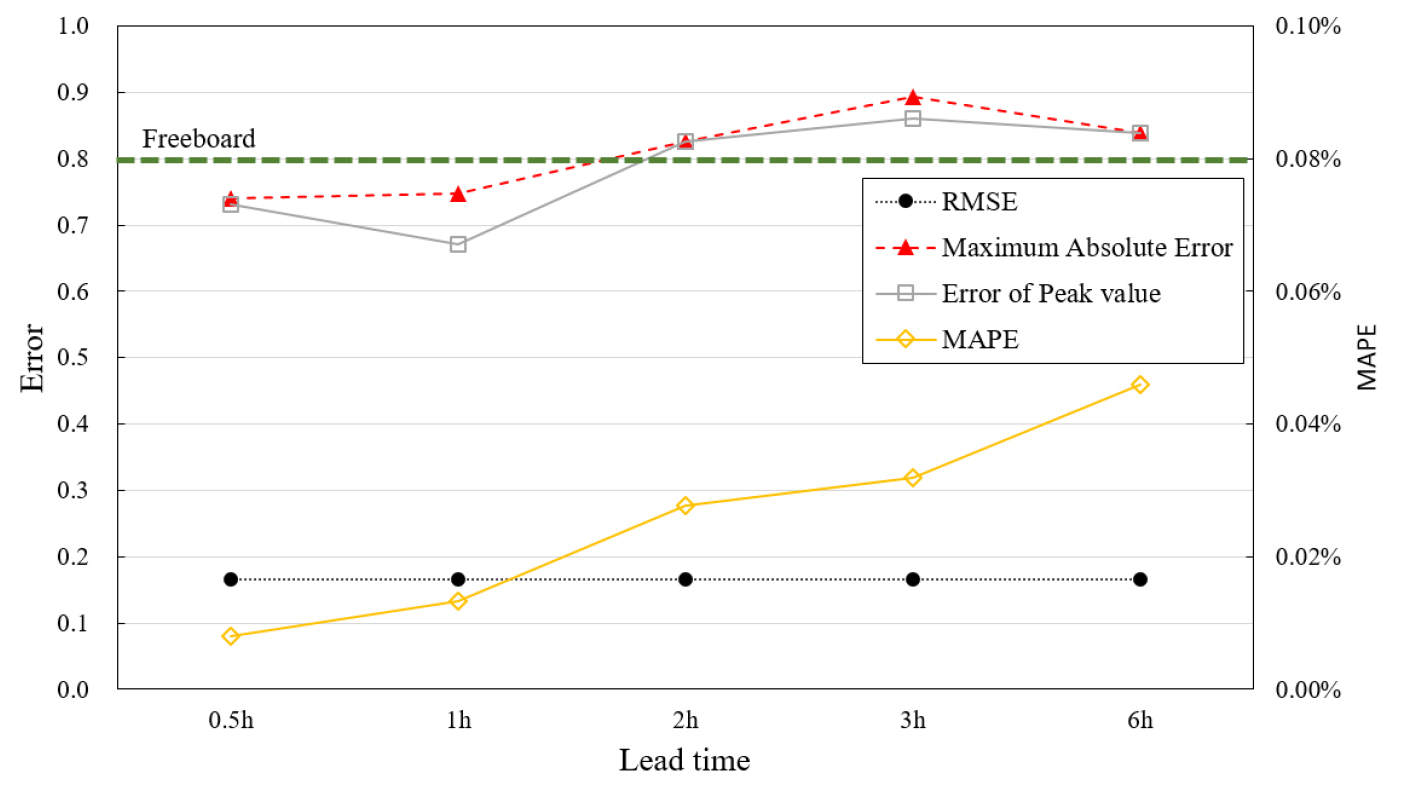
홍수예측모형의 수위예측정확도는 높은 정확도를 요구하나 실질적으로 정확한 값을 추정하기는 거의 불가능하다. 따라서 하천의 제방을 축조하는 경우에도 여유고를 두어 수위예측의 불확실성을 보완한다. 하천제방의 여유고는 하천설계기준(KWRA, 2019)에서 제시하고 있으며, Table 8에 나타냈다. 설마천의 50년 빈도 계획홍수량은 225 m3/s로 여유고는 0.8 m 이다(Kim et al., 2011). 실제 계획홍수량 규모의 홍수에 대해서 인공지능 기반의 예측모형이 홍수위를 예측했을 때 여유고 보다 작은 오차가 발생한다면 하천이 제방을 월류하는 피해는 발생하지 않을 것이다. 따라서, 본 연구에서는 이 여유고 0.8 m를 기준으로 오차분석을 수행하였다.
Table 8.
freeboard according to planned flood (KWRA, 2019)
모든 케이스에 대해서 선행예보시간이 증가하면서 오차값도 증가하는 경향을 나타냈으며, RMSE는 그 변화가 확연히 나타나진 않았다. 최대오차와 첨두오차의 경우 선행예보시간 0.5, 1시간인 경우에 0.8 보다 작은 값을 나타내 정확도를 만족하였다. 또한, MAPE의 경우 모든 케이스에 대해서 0.05% 이내의 높은 정확도를 나타냈다(Fig. 10).
5. 결 론
본 연구에서는 독립적 자체경보가 가능한 인공지능기반 하천홍수예측 모형을 개발하기위해 관측소 자체적으로 홍수예측이 가능하도록 인공지능기반의 예측모형을 개발하였다. 동일 지점의 강우와 수위 관측값을 활요하여 홍수예측이 가능한 모형을 개발하였으며 다양한 방법을 통해 모형을 검증하였다. 학습단계에서는 모형의 과대적합, 과소적합을 방지하기 위해 학습의 loss값과 검증의 loss값을 비교하여 격차가 벌어지지 않고 수렴하는 지를 확인하였으며, 시험단계에서는 관측값과 예측값의 적합도를 검토하였고, 오차에 대한 검증도 수행하였다.
모형의 적합도는 NSE, R2값 모두 0.87 이상으로 최고등급(Very good)의 적합도 등급을 나타냈다. 오차분석에서는 RMSE 값은 0.16으로 모든 선행예보시간에 대해서 유사하게 나타났으며, 최대오차와 첨두오차는 여유고 0.8 m 이내는 선행예보시간 0.5, 1시간에 대해서만 만족하였다. 그러나 2, 3, 6시간에 대해서도 오차는 0.9를 초과하지는 않았으며 예측모형의 보완을 통해 개선될 수 있을 것으로 판단된다. MAPE값도 선행예보시간이 증가하면서 증가하기는 했지만 전체적으로 0.05%이내의 높은 정확도로 나타났다. 전체적인 모형의 적합도는 높은 수준을 유지하였으나 최대오차 및 첨두오차 등은 제방의 여유고를 상회하는 결과가 나오는 등 극한 홍수사상이 발생 할 경우에 대한 예측에는 미흡한 것으로 나타났다. 이는 크게 학습에 활용된 관측자료의 품질에 따라 발생할 가능성도 있으며 학습알고리즘의 한계로 인한 것일 수도 있을 것이다. 이에 대한 분석은 향후 연구를 통해 다양한 알고리즘 적용과 민감도 분석을 통해 원인을 파악하고 정확도를 개선해야 할 과제이다.
본 연구에서는 임진강의 지류인 설마천에 위치한 시험유역에 대해서 독립적 자체경보가 가능한 인공지능기반의 하천홍수예측 모형을 개발하였다. 개발된 기술은 통신상태가 불확실한 경우에도 중앙에서의 통제 없이 자체적으로 판단하여 홍수경보를 발령하는 기술로 동남아시아 등의 개발도상국이나 북한 등에도 적용이 가능 할 것으로 판단된다. 다만 하천의 유역이 작아서 하나의 관측소가 유역을 대표하는 경우에는 단일 관측소 만으로도 홍수위 예측이 가능할 것으로 판단되나 유역의 규모가 증가하면 단일관측소 만으로는 만족할 만한 결과를 도출하기 어려울 것으로 예상된다. 따라서 단일관측소에 의한 독립적 하천홍수위 예측은 산지의 소하천에만 적용이 가능할 것이며 중규모 이상의 하천 유역에서는 근접 강우관측소의 관측값을 직접통신을 통해 수집하여 예측에 활용하는 방안에 대해서 향후 연구에서 적용 가능성을 검토하여 활용성을 향상시킬 예정이다. 또한, 중앙제어 홍수예측을 실시하는 시스템에도 적용하여 모델기반의 홍수예측 모형을 보완하여 홍수 예경보 담당자의 의사결정을 지원하는 역할도 할 수 있을 것으로 판단된다.
