

1. 서 론
2. 이론적 배경
2.1 데이터 불균형 완화
2.2 학습력 강화 효과 분석 모델
2.3 성능 평가 지표
3. 모델 구축
3.1 대상 지점 개요
3.2 데이터 수집
3.3 데이터 전처리
3.4 모델 설정
4. 결과 및 고찰
4.1 오버샘플링
4.2 예측성능 개선 효과
4.3 모델의 일반화 성능 검증
5. 결 론
1. 서 론
남조류 급증으로 인한 유해 조류 대발생(CyanoHAB)은 인간 활동에 의한 담수 생태계의 부영양화가 직접적인 원인으로 알려져 있으며(Backer et al., 2015; Chorus and Welker, 2021), 기후변화 영향으로 인해 점점 심각해지는 기온상승은 이를 더 심화시키고 있다. 남조류 대발생은 댐과 호소, 하천에서 수자원의 안정적 관리에 중대한 위협이 되고 있으며, 남조류 중 일부 속은 독소를 생성해 생태계와 인간의 건강에까지 직접적인 영향을 미칠 수 있다(Briand et al., 2003; Carmichael and Boyer, 2016; Haffar et al., 2024). 따라서 유해남조류가 확산할 때에는 경보발령 및 물 공급 시설에서의 신속한 대처가 필요하나, 더욱 효과적인 대응을 위해서는 남조류 증식에 영향을 미치는 다양한 인자들의 관계 파악을 통해 사전 예측력을 높여야 한다(Jeong et al., 2022; Ahn et al., 2023).
일반적으로 남조류의 증식은 영양염 증가에 의한 부영양화 및 여름철 수온 상승이 직접적인 원인이라는 점에는 이견이 없으나(Rastogi et al., 2015), 이 외에도 다양한 환경 인자들의 복합적인 영향과 상호작용이 남조류 생장에 관여한다(Reichwaldt and Ghadouani, 2012). 그러나 비슷한 수질, 수문기상 조건에서도 해마다 다른 속의 남조류가 우점하거나, 발생 시점과 심도 또한 제각각인 등 명확한 인과관계는 밝히지 못하고 있다(Cascallares and Gleiser, 2015; Shan et al., 2019; Rousso et al., 2022). 최근에 수문・기후 채찍(hydroclimate whiplash)으로 지칭되는 건조와 습윤 상태의 급격한 전환이 남조류 증식의 역학적 메커니즘에 변화를 유발하며, 대부분은 증식을 심화시킨다는 연구 결과도 다수 발표되었다(Larsen et al., 2020; Yuan et al., 2024; Preece et al., 2025; USGS, 2025).
이처럼 다양한 인자가 상호 작용하여 물리적 기작이 불분명하거나 수치모형의 매개변수 등이 확립되지 않은 경우, 변수 간 관계를 추론하는 머신러닝 기반 모델 적용이 활발하게 이루어지고 있다. 특히 저해상도, 소표본, 불균형이 특징인 수질 및 남조류 데이터를 활용한 예측에서는 이상치 및 결측치와 불규칙한 간격에 대한 민감도가 낮고, 작은 표본 크기에도 안정적인 성능을 보이며, 비선형 관계나 변수 간 상호작용을 자동으로 포착할 수 있는 트리 기반 모델이 딥러닝 모델보다 실용성과 예측 안정성 측면에서 우수하다는 보고가 다수 제시되고 있다(Prokhorenkova et al., 2018; Derot et al. 2020; Jeong et al., 2022; Rousso et al., 2022; Ahn et al., 2023; McElfresh et al., 2023; Sun et al., 2025).
그러나 기존 연구의 상당수는 남조류 발생 여부 또는 위험등급과 같은 분류형(classification) 문제로 단순화하여 모델링 하는 경향이 있었다. 이러한 접근은 관리단계와 직접 연계된다는 장점이 있으나, 생태계 반응의 연속성을 충분히 반영하지 못하고, 정량적 특성을 단순화시키며, 경계값 인근의 오차에 따른 왜곡 등의 한계가 지적되고 있다(Cruz et al., 2021; Busari et al., 2023). 따라서 최근에는 남조류 세포수를 연속값으로 다루는 회귀형(regression) 예측이 학술적으로 더욱 의미 있는 접근으로 평가받고 있다(Park et al., 2024).
한편, 남조류 세포수 데이터셋은 연중 대부분이 저농도 구간으로 고농도 구간의 샘플 비중이 매우 낮은 극단적 불균형 분포를 나타낸다. 일반적인 분류 및 회귀 기반 지도학습 알고리즘은 전체 손실(loss)을 최소화하는 방식으로 학습되므로 불균형한 데이터에서는 다수 구간(majority region)인 저농도 자료의 오차를 줄이는 방향으로 학습하게 되고, 결과적으로 수원 관리상 중요성이 높은 고농도 시점에 대한 예측성능이 낮아지게 된다. 이러한 데이터 불균형(data imbalance)을 완화하기 위해서는 고농도 구간의 샘플 밀도를 보강하는 오버샘플링(oversampling) 기법을 적용하여 모델 학습 시 해당 구간의 기여도를 높이는 접근이 필요하다. 분류형 모델에서는 SMOTE (Synthetic Minority Oversampling Technique), ADASYN (Adaptive Synthetic Sampling)과 같은 오버샘플링 기법이 많이 활용되며, 영상자료 합성에 널리 사용되는 GAN (Generative Adversarial Networks)도 활용되고 있다. 일례로 Jeong et al. (2022)은 XGBoost 모델에 SMOTE를 적용한 오버샘플링을 통해 저수지 남조류 발생 여부를 예측하였으며, Kim et al. (2021)은 ANN 및 SVM 모델에 ADASYN을 적용해 조류 대발생 경보 수준을 예측한 바 있다.
본 연구의 목적은 회귀 기반 머신러닝 모델을 활용하여 남조류 세포수 예측의 연속적, 정량적 변동 특성을 고려하고, 오버샘플링을 통해 고농도 희소 구간의 샘플을 보강하는 것이 예측성능 개선에 효과적인지를 정량적으로 분석하는 데 있다. 이를 위해 환경부의 대청호 조류경보지점 남조류 세포수 데이터에 SMOGN (SMOT for regression using Gaussian Noise), GAN 및 TimeGAN (Time-series GAN) 등 회귀형 오버샘플링 기법들을 적용해 불균형을 완화하고, 오버샘플링 전후 모델 예측성능이 개선된 결과를 비교하였다. 모델 입력 데이터셋은 남조류 세포수와 주요 영향 인자들에 대해 최대 3주의 지연시간(lag time) 변수를 도입함으로써 녹조 증식 시퀀스가 하나의 데이터 샘플이 되도록 하고, 이를 통해 희소데이터를 합성할 때 시간 의존적 특성을 일부 반영하였다. 오버샘플링에 따른 남조류 세포수 예측모델의 학습력 강화 효과 분석은 트리 기반 앙상블 학습 모델로 대표적인 랜덤포레스트(Random Forest) 모델을 활용하였다.
2. 이론적 배경
2.1 데이터 불균형 완화
오버샘플링은 구간별 샘플 수가 불균형한 데이터셋에서 소수 구간(minority region)의 샘플 수를 인위적으로 증가시켜 데이터 분포를 균형 있게 맞추는 통계적 기법이다. 가장 단순한 형태인 무작위 오버샘플링(random oversampling)은 소수 구간 샘플들을 단순 복제하여 그 수를 늘리는 방법으로 구현이 간단하다는 장점이 있지만, 모델이 특정 샘플에 과적합 되기 쉬운 한계가 있다. 이러한 한계를 극복하기 위해 단순 복제 대신 합성 데이터(Synthetic Data)를 생성하는 혁신적인 접근법들이 다수 등장했다(Chawla et al., 2002).
2.1.1 SMOGN
대부분의 오버샘플링 기법이 불균형 분류 문제를 다루지만, SMOTE-R (SMOTE for Regression)은 불균형 회귀 문제에 특화된 오버샘플링 기법이다. 분류 문제의 불균형이 불연속적인 클래스 간의 샘플 수 차이를 의미한다면, 회귀 문제의 불균형은 연속적인 목표변수(Y)의 값 분포가 특정 희소 구간(rare region)에 치우쳐져 있는 상태를 의미한다. 희소하지만 예측이 매우 중요한 의미가 있는 문제에서 SMOTE-R과 같이 불균형 회귀 문제에 특화된 방법론의 효용성은 매우 높다.
SMOGN (SMOTE for regression with Gaussian Noise)은 SMOTE-R에 가우시안 노이즈를 결합한 하이브리드 알고리즘이다(Branco et al., 2017). 이 기법은 원본 데이터에서 선택된 두 샘플 간의 거리를 기준으로 데이터 합성 방식을 결정한다. 만약 두 샘플 간의 거리가 가까워 보간이 적절하다고 판단되면 SMOTE-R을 사용하여 선형 보간을 수행한다. 반면, 거리가 멀어 단순 보간이 부적절하다고 판단되면 가우시안 노이즈를 추가하여 새로운 샘플을 생성한다. 이는 단순히 보간하는 것을 넘어 데이터 분포의 희소 구간을 효과적으로 채우려는 시도로, 회귀 문제의 연속적인 특성을 고려한 독창적인 접근법이다(Branco et al., 2017).
2.1.2 GAN
GAN은 생성자(generator)와 판별자(discriminator)라는 두 개의 신경망이 서로 경쟁하며 학습하는 적대적 학습 체계를 갖추고 있다(Goodfellow et al., 2020). 생성자는 무작위 노이즈 벡터를 입력받아 실제 데이터와 구별할 수 없을 만큼 현실적인 가짜 데이터를 생성하려고 시도하며, 판별자는 실제 데이터와 생성자가 만든 가짜 데이터를 입력받아 어떤 것이 진짜인지 판별한다.
이 경쟁적인 학습 과정에서 생성자는 판별자를 속이려 하고, 판별자는 속지 않으려 하는 상호작용이 반복된다. 이러한 적대적 관계를 통해 두 신경망은 점진적으로 발전한다. 생성자는 실제 데이터의 복잡한 분포를 충실히 모방하는 데이터를 만들어내고, 판별자는 가짜와 진짜를 더욱 정교하게 식별하는 능력을 갖추게 된다. 이러한 분석체계는 고품질의 현실적인 데이터를 대량 생성할 수 있어, 데이터 희소성 및 불균형 문제 완화 등 강력한 데이터 증강(Data Augmentation) 도구로 활용되고 있다.
2.1.3 TimeGAN
시계열 데이터는 이미지 같은 정적 데이터와 달리 시간 의존성(temporal dependency)과 동역학(dynamics)이라는 고유한 특성이 있다. 단순히 통계적 특성만 유사하게 만드는 것을 넘어, 시간 흐름에 따른 데이터의 인과관계와 패턴을 보존하는 것이 시계열 데이터 오버샘플링의 핵심 과제이다. 기존의 GAN은 합성 데이터를 생성할 때 이러한 시간적 동역학을 고려하지 않는 문제가 있었다. 이러한 문제를 해결하기 위해 TimeGAN (Time series GAN)은 지도 학습 손실(Supervised Loss)과 비지도 학습 손실(Unsupervised Loss)을 결합한 분석체계를 제안했다(Yoon et al., 2019).
TimeGAN은 GAN과 마찬가지로 비지도 학습 손실을 통해 잠재공간 상에서 실제 데이터 분포의 유사성을 보존함으로써 합성된 시퀀스와 실제 시퀀스를 구별할 수 없도록 만들지만, 지도 학습 손실까지 포함해 시계열의 시간 의존성과 동역학적 구조를 보존한다. 즉, 생성자는 모델이 각 시간 단계에서 다음 단계의 조건부 분포(conditional distribution)를 명시적으로 학습하도록 지도한다. 이는 단순히 ‘진짜처럼 보이는’ 시퀀스를 만드는 것을 넘어 현실의 데이터가 시간에 따라 변화하는 규칙을 내재화해, 단순히 노이즈 주입이나 시간 축 이동(time shift) 같은 기법으로는 불가능한 복잡한 시계열 데이터도 합성할 수 있도록 훈련하는 것이다.
2.2 학습력 강화 효과 분석 모델
오버샘플링에 따른 머신러닝 모델의 학습력 강화 효과 분석을 위해서는 다양한 분류 및 회귀 문제에서 널리 활용되는 랜덤포레스트 모델을 선정하였다. 대표적 트리 기반 모델인 랜덤포레스트는 강건성(robustness)이 높아 안정적인 예측 성능을 발휘하는 것으로 알려져 있으며(Sun et al., 2025), 변수 중요도(feature importance)를 통해 결과에 대한 설명력을 제공한다. 특히, 변수 간 상호작용이 복잡하고 비선형성이 강한 녹조 발생 특성을 고려하면 랜덤포레스트는 부트스트랩(Bootstrap) 샘플링과 무작위 변수 선택을 통해 트리 간 상관성을 낮추므로(Breiman, 2001) 트리 기반 앙상블 모델 중에서도 과적합 위험이 적은 장점이 있다. 랜덤포레스트 모델의 회귀 문제 예측은 Eq. (1)과 같이 주어진다.
여기서, 는 트리 개수, 는 서로 다른 부트스트랩 표본과 무작위 변수 선택으로 학습된 트리이다. 또한, 는 녹조 발생에 영향을 미치는 환경요인으로 구성된 입력 벡터를 의미하며, 는 해당 입력 조건에 대해 모델이 최종적으로 예측한 남조류 세포수를 의미한다.
2.3 성능 평가 지표
본 연구에서는 오버샘플링에 따른 랜덤포레스트 모델의 성능 개선을 다각적으로 평가하기 위해 Eqs. (2), (3), (4), (5)와 같이 수문·수질 분야에서 널리 사용하는 네 개의 성능 지표를 병행 산정하였다. 여기서, 은 전체 샘플의 수를 의미한다. 각 지표는 예측 정확도 및 모형 특성을 다른 관점에서 설명하므로, 단일 지표로만 평가할 때 나타날 수 있는 편향적인 해석을 방지할 수 있다.
RMSE (Root Mean Squared Error)는 관측값과 예측값의 절대적 오차의 크기를 원자료와 동일한 단위로 나타내므로 모델의 평균적 오차 규모를 설명할 수 있으나, 제곱을 취함에 따라 오차의 크기에 민감하고, 값 자체만으로는 단위가 다른 데이터 간 비교에 한계가 있다. 이에 반해 NSE (Nash-Sutcliffe Efficiency)는 관측값의 변동성을 기준으로 모델의 설명력을 비율 형태로 제시함으로써 단순히 평균값으로 예측하는 것보다 어느 정도 효율적인지를 정량적으로 판단할 수 있게 한다(Moriasi et al., 2007). NSE 값이 크면 모형이 시간적 변동 패턴을 적절히 재현하고 있음을 의미하므로, 시계열적 구조를 갖는 수문·수질 예측에서 특히 중요한 평가 기준이다.
한편, PBIAS (Percent Bias)는 관측값과 예측값의 오차의 합을 관측값의 합에 대한 백분율로 나타낸 것으로 부호에 따라 전반적 과대(+) 또는 과소(-) 추정도 알 수 있어 모델의 전반적인 편향성을 파악하기 쉽다. MAPE (Mean Absolute Percentage Error)는 PBIAS와 비슷해 보이지만, PBIAS가 오차 합의 백분율을 계산해 과대/과소가 상쇄되어 개별 샘플의 변동성을 설명하지 못하는 데 반해 각 샘플별 오차 백분율의 절댓값을 평균하므로 샘플별 예측 정확도 자체를 평가할 수 있는 장점이 있다. 그러나 관측값이 0에 근접할 정도로 작은 경우 비율이 무한대로 폭증하는 단점이 있다(Hyndman and Athanasopoulos, 2018). PBIAS도 겨울철 남조류 또는 갈수기 강우량과 같이 관측값 전체 수준이 매우 작다면 비슷한 문제가 나타날 수 있으나, MAPE처럼 단일 샘플 만으로 문제가 발생하지는 않는다.
3. 모델 구축
3.1 대상 지점 개요
본 연구는 남조류 세포수 예측을 위한 머신러닝 모델 구축 및 오버샘플링 효과 분석을 위해 환경부 조류경보제 지점 중 하나인 대청호를 선정하였다(Fig. 1). 금강 유역의 대표적 취수원인 대청호는 길고 구불구불한 사행천과 만입부 형태를 가지고 있어 평균 체류시간이 199일이나 되는 등 지형적으로 조류 발생에 취약하고, 강우 시 유역 내 농・축산 오염물질이 다량 유입되어 여름철 호 내에 장기간 체류하며 조류 발생 요인으로 작용하고 있다.
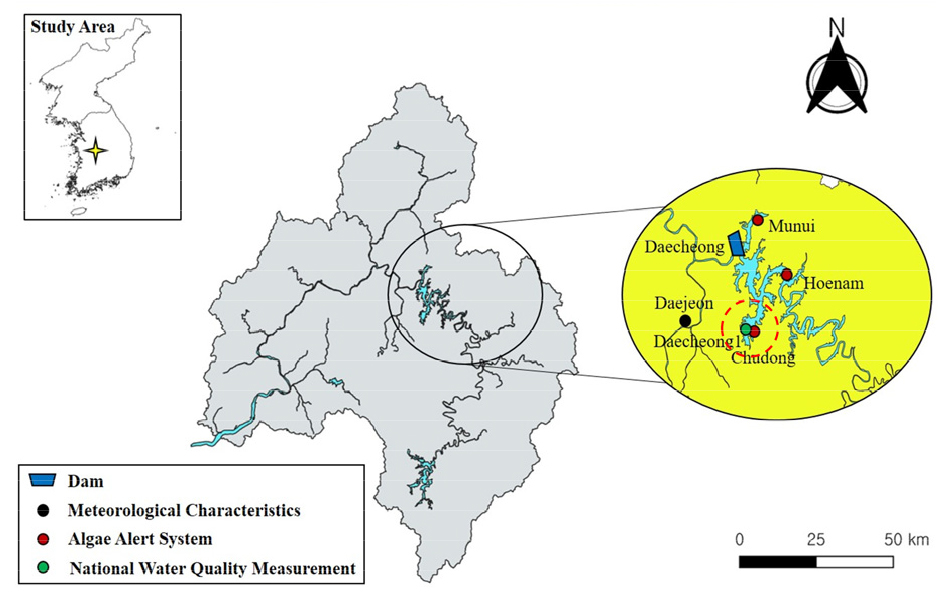
대청호는 1998년 조류경보제를 시행한 이후 현재까지 1999년과 2014년을 제외하고 매년 조류경보가 발령되고 있다(ME, 2024). 대청호 조류경보제는 회남, 추동, 문의 등 3개 지점이 운영 중인데, 본 연구는 취수장 상류 1 km에 위치하고, 인근에 국가수질관측망 지점(대청댐1)이 있어 상관성 높은 일반수질 자료 취득이 용이한 추동 지점을 연구 대상으로 선정하였다.
3.2 데이터 수집
머신러닝 모델 구축을 위한 데이터셋은 남조류, 일반수질, 수리・수문, 기상 데이터를 각각 수집하여 관측일 기준으로 결합하였다. 대청호의 추동 조류경보 지점은 2003년부터 주 1~2회 간격으로 남조류 세포수를 측정(12~3월 제외)하고 있으며, 일반수질의 경우 2016년부터 클로로필-a (Chl-a), 수온, 수소이온농도(pH), 용존산소(DO) 등을 측정하고 있다. 다만, 일반수질의 경우 남조류 세포수에 비해 자료 연한이 매우 짧은 문제로 국가수질측정망인 대청댐1 지점의 측정값으로 대신하였다.
대청댐1 지점은 1997년부터 주 1회 간격으로 일반수질 항목을 측정하고 있으며, 2004년부터는 상층, 중층, 하층 3개 수심별 측정값을 제공하고 있어 이를 별도로 정리했다. 관련 자료들은 환경부 물환경정보시스템을 통해 수집하였다. 수질・녹조 자료 외 수리・수문 특성 반영을 위해서는 대청댐 유입량 및 방류량 등 K-water의 댐 운영 자료를 수집했으며, 기온, 강우량, 일사량 등 기상자료는 기상청 기상자료개방포털의 종간기상관측(ASOS) 자료 일 단위로 수집하였다.
수집된 자료 중 남조류 및 일반수질은 주 단위, 댐 운영 및 기상자료는 일 단위인 등 자료 분류별로 시간 해상도가 다르고, 주 자료의 경우 관측일도 규칙적이지 않았다. 따라서 기본 데이터셋은 일 단위를 기준으로 미측정 데이터를 결측 처리하는 방식으로 구축해 데이터 손실을 방지하였다. 수집한 데이터셋의 세부 내용은 Table 1과 같다.
Table 1.
Summary of observational data in the study area
3.3 데이터 전처리
데이터 전처리는 머신러닝 모델의 성능을 극대화하기 위한 필수 과정으로, 불완전하거나 부정확한 데이터를 정제해 모델이 효과적으로 학습할 수 있도록 변환하는 역할을 한다. 본 연구에서는 2005년부터 2024년까지 20년간 수집한 총 7,305개 일 단위 샘플에 대한 전처리 첫 단계로 이상값 탐지(anomaly detection)를 수행하였고, 다음으로 자료별로 다른 시간 해상도를 일치시키기 위해 일 단위로 구축된 원시 데이터셋을 주 단위로 재표집(resampling) 하여 1045개의 주 단위 샘플로 줄였으며, 마지막으로 결측값 대체(missing value imputation)를 수행하였다.
이상값 탐지를 위해 Z-score, 사분위범위법(IQR)과 같은 단순 통계 기반 기법과, 지수평활(Exponential Smoothing), STL (Seasonal-Trend decomposition using Loess) 등 평활 기반 시계열 기법을 변수별로 비교·평가하였다. 평가 결과, 계절성, 추세, 단기 변동성을 함께 반영하여 국소적 시계열 맥락을 기준으로 이상 여부를 판단할 수 있는 평활 기반 기법이 녹조 특성에서 자주 나타나는 급격한 고농도 증가 구간에서 안정적인 탐지 성능을 보였다. 반면, 단순 통계 기반 기법은 전역 통계량을 기준으로 임계값을 설정하여 점 이상값(point anomaly)을 탐지하는 특성이 있어, 생태계 반응의 연속적 증가 과정에서 발생하는 희소하지만, 정상적인 고농도 값을 이상값으로 오탐지할 가능성이 상대적으로 높게 나타났다. 이에 본 연구에서는 시계열적 문맥을 고려한 평활 기반 이상값 탐지기법을 최종적으로 적용하였다.
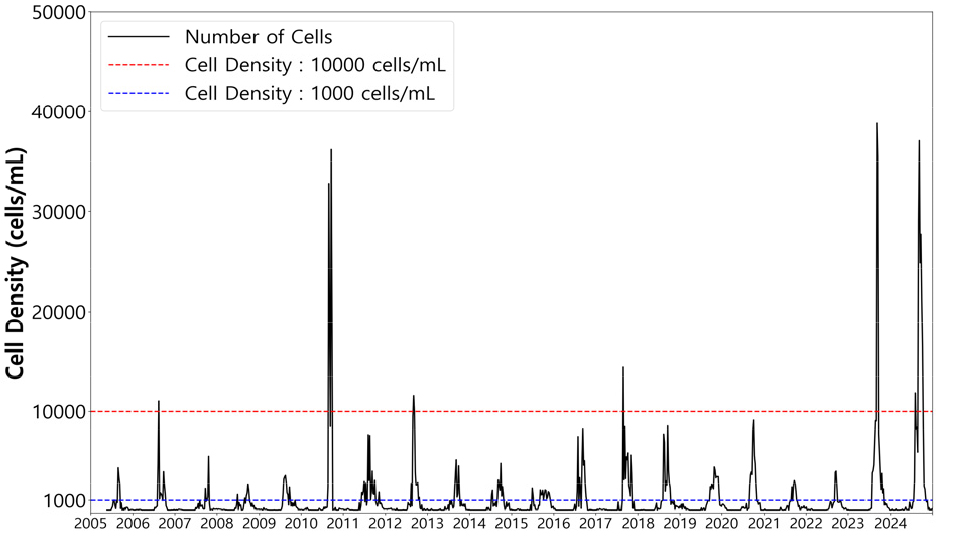
시간 해상도 일치를 위한 재표집 시 일주일 내 2개 이상의 측정값이 있으면 변수의 특성을 고려해 평균, 합계, 최댓값, 최솟값 등의 대푯값으로 대체하였다(Fig. 2). 시간 해상도를 주 단위로 일치시킨 후 남아있는 결측값은 거리 기반 알고리즘인 k-NN을 활용하여 대체하였다. k-NN은 결측 시점과 유사한 이웃 관측치의 값을 가중 평균하는 방식으로 보간하므로, 원자료에 존재하지 않는 급격한 변동이나 인위적인 피크를 새로 생성하지 않는다는 방법론적 특성을 가진다. Fig. 3은 전처리 후 남조류 세포수 시계열을 나타내고 있다.
3.4 모델 설정
본 연구에서는 수집된 총 84개의 녹조, 일반수질, 댐 운영, 기상 관련 변수를 대상으로 종속변수 및 다른 설명변수와의 상관성, 녹조발생 특성에 대한 도메인 지식을 종합적으로 고려하여 최종적으로 40개의 설명변수를 선정하였다. 또한, 남조류 세포수의 시간적 의존성과 계절적 변화 양상을 반영하기 위하여 각 변수에 대해 현재 시점()을 포함하여 최대 3주 전 시점(-3)까지의 시차 변수(lag variable)를 추가하였다.
아울러, 단기 예측과 중기 예측의 성능 차이를 비교·분석하기 위해 리드타임(lead time), 즉 예측 선행시간을 1주(+1)에서 최대 3주(+3)까지 설정하였다. 이에 따라 모델 입력 데이터셋은 리드타임별로 개별 구축되었으며, 데이터 불균형 문제가 모델 학습에 영향을 미치는 것을 최소화하기 위해 오버샘플링 절차 또한 리드타임별로 독립적으로 수행하였다. 동일한 방식으로 모델 학습 및 검증 역시 리드타임별로 분리하여 수행함으로써, 리드타임 증가에 따른 예측 정확도 변화 및 민감도를 체계적으로 평가할 수 있도록 하였다. Eq. (6)은 모델 입력 데이터셋의 구성을 나타낸 것이다.
오버샘플링 적용을 위해 Eq. (6)의 입력 데이터셋은 훈련/시험용으로 먼저 분할하였으며, 오버샘플링은 훈련용(training set)에 대해서만 수행하고, 생성된 합성 샘플 역시 훈련 데이터에만 추가하였다. 이는 오버샘플링 과정에서 시험 데이터셋의 정보가 모델 학습에 유입되어 발생할 수 있는 데이터 누수(data leakage)에 따른 과적합을 방지하기 위함이다. 데이터 분할 기준은 녹조 시계열의 시간 연속성과 계절성, 그리고 고농도 희소 구간인 경계단계(≥10,000 cells/mL)의 샘플 확보 등을 고려하여 연도 단위로 설정하였다. 구체적으로 2005~2023년 자료를 훈련용으로, 2024년 자료를 시험용(test set)으로 구성하였다. 또한, 녹조가 거의 발생하지 않는 기간의 저농도 패턴을 제거함으로써 오버샘플링의 실효성을 높이기 위해 실제 대청댐에서 조류 증식이 집중적으로 나타나는 7~10월까지의 시계열만을 훈련용 데이터셋에 포함하였다.
Table 2는 각 오버샘플링 기법들의 하이퍼파라미터 설정값을 정리한 것이다. SMOGN의 오버샘플링은 반응변수 (남조류 세포수)에서 “희소하지만 중요한 구간”을 relevance function 𝜙로 정의한 뒤, 가 임계값 이상인 관측치를 희소(rare) 사례로 간주하여 해당 구간을 중심으로 합성 데이터를 생성하는 방식이다. 구체적으로 는 목표변수 값을 0~1의 중요도(relevance)로 설정하며, 이면 희소·관심 구간, 이면 일반(다수) 구간으로 분리한다. 본 연구는 관련 하이퍼파라미터를 rel_method=auto, rel_ xtrm_type=high로 설정하였다. 일반적으로 목표변수의 표본분포로부터 를 추정하기 위해 rel_method= auto로 설정하는데, IQR (Inter Quantile Range)을 이용해 극단 구간을 희소구간(el_xtrm_type=high로 상위 꼬리로 한정)으로 간주한다(Branco et al., 2017). rel_method를 수동(manual)으로 설정하면 중요도 함수의 구간 분할을 사용자가 이산적으로 입력해야 한다.
Table 2.
Hyperparameter settings for each oversampling model
희소 구간의 threshold ()는 rel_thres를 이용해 중요도 함수 𝜙의 0~1 값 범위에서 설정 하거나, IQR 기반 희소구간 경계인 rel_coef로 설정할 수 있는데, 본 연구는 rel_coef=4로 설정하여 해당 구간의 샘플 밀도를 집중적으로 보강하였다. 실제 합성샘플은 근접 이웃 방식인 k-NN 기반으로 생성(k=4)하게 되며, 전반적인 오버샘플링 분포는 samp_method='extreme'을 적용해 희소 구간에서 상대적으로 더 높은 오버샘플링이 이루어지도록 설정하였다. 또한 다수 구간의 정보 손실을 최소화하기 위해 under_samp=False로 언더샘플링은 수행하지 않았다.
GAN과 TimeGAN의 경우 오버샘플링으로 합성하는 데이터의 스케일 일관성과 수치적 안정성을 확보하기 위해 입력변수에 대해 Min-Max 정규화를 적용하였다. 이는 변수 간 범위를 통일함으로써 생성자가 상대적 분포 구조를 안정적으로 학습하고, 학습 초기에 특정 변수 스케일이 기울기 업데이트를 지배하는 현상을 완화하기 위한 전처리 전략이다. 생성자와 판별자의 네트워크 구조는 Radford et al. (2015)이 제시한 안정적 GAN 학습 설계 원칙을 참고하여, 생성자는 저차원 특징 벡터를 점진적으로 확장(64-128-256)해 다변량 분포를 복원하고, 판별자는 반대로 축소(256-128-64)하여 진위 판별에 유효한 핵심 특징을 추출하도록 구성하였다. 활성 함수는 은닉층에 ReLU를 적용해 비선형 표현력을 확보하였으며, 판별출력층에는 시그모이드를 배치해 입력 샘플의 진위 여부를 확률값으로 산출하도록 하였다. 또한 학습 과정의 불안정성을 완화하기 위해 Radford et al. (2015)에서 경험적으로 안정성이 보고된 Adam 설정(learning rate=0.0002, 𝛽=0.5)을 채택하여, 진동 및 발산 가능성을 낮추는 방향으로 훈련 파라미터를 선택하였다.
기본 GAN 구조를 기준선으로 선택한 이유는 그 구현의 단순성과 검증된 안정성 때문이다. GAN의 대표적인 구조로, 비교적 적은 파라미터 튜닝만으로도 확실한 학습 과정을 거칠 수 있으며, 이는 다양한 변형 모델들이나 대체 구조들의 성능을 검증하기 위한 출발점으로서 유용하다. 다만 본 연구에서 채택한 GAN 학습은 판별기가 상대적으로 빠르게 최적화될 경우 생성자로 전달되는 유효 기울기가 약화하여 학습이 정체될 수 있으며, 특히 데이터가 여러 개의 떨어진 값 범위에 나뉘어 분포하는 경우 이러한 문제가 두드러질 수 있다(Arjovsky and Bottou, 2017). 따라서 향후 연구에서는 Wasserstein 거리를 도입한 WGAN 또는 기울기 페널티를 추가한 WGAN-GP와 같은 대안적 손실/구조를 적용함으로써, 희소구간에서의 분포 보존 성능과 수렴 안정성을 개선할 가능성을 추가 검토할 필요가 있다(Arjovsky and Bottou, 2017).
4. 결과 및 고찰
4.1 오버샘플링
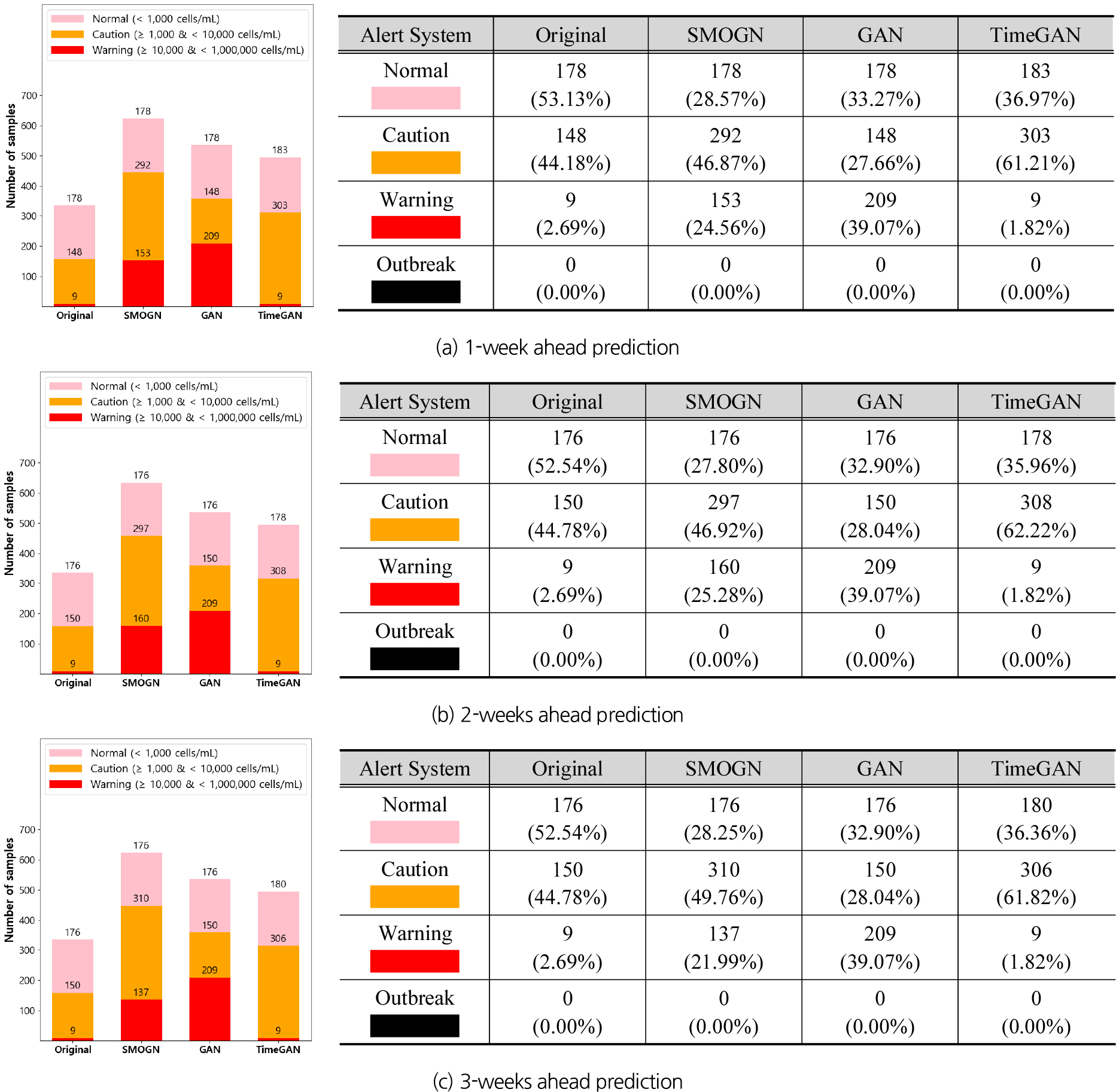
본 연구는 데이터 불균형을 완화해 모델의 예측성능을 개선하기 위하여 SMOGN, GAN, TimeGAN 등 다양한 오버샘플링 기법을 적용하였으며, Fig. 4는 오버샘플링 전・후의 구간분포 변화를 조류경보제 등급으로 재분류해 나타낸 것이다. 리드타임별로 구축된 원본 훈련 데이터셋은 정상(1,000셀 미만)과 관심(1,000셀 이상) 등급 샘플이 각각 180여 개, 150여 개로 상대적으로 많고, 경계(10,000셀 이상) 등급은 9개에 불과한 전형적인 불균형 구조를 보였다. 오버샘플링 적용 결과 모든 기법에서 소수 구간의 샘플 비중이 증가하였지만, 등급별 재분류 기준으로 살펴보면 기법 간 결과 차이가 컸다.
SMOGN은 관심등급과 경계등급에 해당하는 합성 샘플을 유사한 수로 생성하였는데, 희소성이 클수록 중요도를 더 높게 설정해 집중적으로 오버샘플링 하였음을 나타내는 것이다. 이는 SMOGN이 다수 구간과 소수 구간의 국소적 밀도(local density) 차이를 보정(balancing)하는 방식으로 구간 간 비율을 중요도 기반(relevance-aware) 으로 균형 있게 조정하기 때문이다. 즉, 다수와 소수 구간을 강제로 균등화하는 것이 아니라, 목표변수의 연속형 분포를 유지하면서 소수 구간의 밀도만 강화하는 방식이다. 결국 SMOGN은 중·고농도 구간의 샘플 수를 전반적으로 강화하는 데 유리한 것으로 볼 수 있다.
반면, GAN은 학습 과정에서 원본 데이터의 분포를 최대한 모사하도록 설계되어 희소 구간의 비중을 의도적으로 조정하지 않으므로, SMOGN과 달리 생성된 데이터에서도 고농도 샘플의 희소성은 그대로이다. 따라서 본 연구는 경계등급을 조건부 희소 구간으로 지정해 합성 샘플을 생성한 후, 이를 원본 데이터와 결합하는 conditional GAN (cGAN) 방식으로 오버샘플링을 수행하였다. 결과적으로 GAN은 원본 데이터의 통계적 특성을 충실히 재현하면서도 데이터의 다양성 확보 및 일반성을 강화하므로 과적합 가능성을 줄이면서 새로운 데이터셋을 생성하는 데에는 효과적이나, 구간 간 분포를 자연스럽게 재조정하는 데에는 한계가 있는 것으로 판단된다.
TimeGAN은 설계상 시간 의존성 보존에 특화되어 시간적 구조를 가진 시퀀스를 통합된 형태로 재현하는 데 초점을 두고 있다. 따라서 각 샘플을 시계열적 맥락 없이 독립적으로 생성하는 일반 GAN처럼 희소 구간에 대한 명시적 조건을 통해 원하는 고농도 샘플만 증강하는 방식을 적용하기는 어렵다. 결과적으로 Fig. 4에서 나타나듯이 극도로 희소한 경계등급 샘플의 밀도는 전혀 개선하지 못하고 오히려 샘플이 풍부한 관심등급만 추가로 증강하는 현상이 나타났다. 이러한 점을 종합하면, TimeGAN은 시계열 구조 보존과 분포 재현 측면에서는 유용하지만, 본 연구와 같이 원자료에서 극히 일부만 존재하는 고농도 경계등급을 선택적으로 강화해야 하는 오버샘플링 목적에는 적합하지 않은 방법으로 판단된다.
4.2 예측성능 개선 효과
오버샘플링 기법별로 증강된 훈련용 데이터는 랜덤포레스트 모델로 학습시킨 후, 사전 분할된 2024년 관측치로 이루어진 시험 데이터셋에 적용하여 원본 데이터셋 대비 오버샘플링의 예측성능 개선 효과를 분석하였다. Fig. 5는 오버샘플링 기법별 남조류 세포수 예측 결과를 리드타임에 따라 나타낸 것이다. 전반적으로 오버샘플링을 적용했을 때의 결과가 적용하지 않은 원본 데이터(original data)의 결과보다 상대적으로 관측 데이터의 고농도 구간 주변 패턴을 유사하게 재현하는 경향을 보였다. 특히, SMOGN이 다른 기법보다 남조류 세포수가 급증하는 첨두 구간에서 관측 데이터의 형태와 높이를 가장 근접하게 예측한 것으로 나타났다.
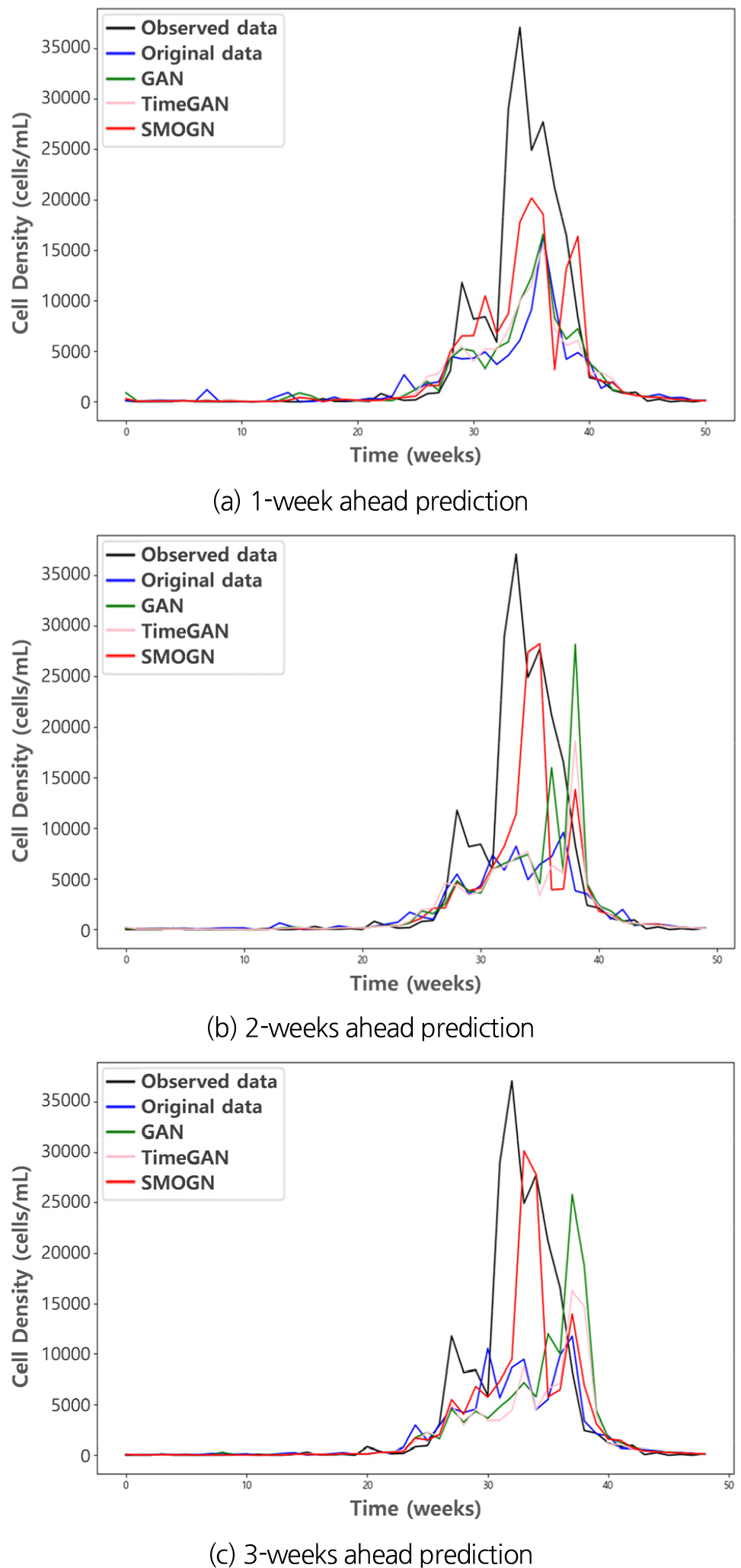
한편, 모델의 리드타임이 길어질수록 예측성능은 불안정해지고 관측값과의 오차가 커지는 것이 일반적이나, SMOGN은 전반적인 성능이 안정적으로 유지되는 것을 확인할 수 있다. 반면 GAN은 첨두의 크기는 SMOGN과 비슷한 수준이었으나, 리드타임이 길어짐에 따라 발생 시점의 정확도가 크게 낮아졌다. TimeGAN의 예측성능은 전반적으로 원본 데이터셋에 비해 개선된 점이 없었으며, 이는 희소 구간에서 오버샘플링이 전혀 이루어지지 않았기 때문으로 판단된다.
예측성능 개선 효과를 더욱 엄밀하게 분석하기 위해 성능 평가 지표를 산정하였다. Table 3은 시험 데이터셋에 대한 랜덤포레스트 모델의 성능 평가 지표 값을 오버샘플링 기법과 리드타임별로 나타낸 것이고, Fig. 6은 이를 리드타임에 따른 성능 변화 양상으로 나타낸 것이다. 전체적으로 오버샘플링을 적용한 모든 경우가 원본 데이터 대비 일정 수준의 개선을 보이는 가운데, 그 정도와 양상은 오버샘플링 기법과 리드타임에 따라 뚜렷한 차이가 있음을 알 수 있다.
Table 3.
Comparison of predictive performance metrics by oversampling methods
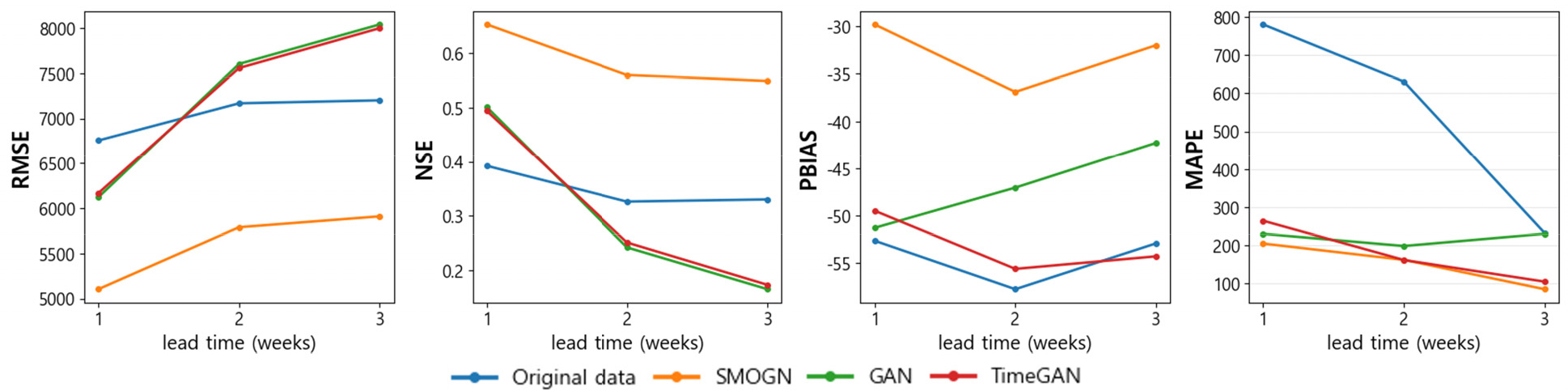
RMSE는 모든 리드타임에서 SMOGN이 가장 낮은 값을 보여 모델의 평균 오차 규모 측면에서 가장 일관된 개선 효과를 나타냈다. 특히 1주 예측에서는 원본보다 약 20% 이상 감소하였고(6756→5104), 2·3주 예측에서도 약 18-20% 수준의 감소가 유지되어 첨두 시점이나 고농도 구간의 오차를 효과적으로 억제한 것으로 해석된다. 반면 GAN과 TimeGAN은 1주 예측에서는 원본보다 다소 작지만, 2·3주 예측에서는 오히려 오차가 커진 것을 알 수 있다. 이는 중·고농도 구간의 샘플 수를 균형 있게 조정한 SMOGN에 비해 GAN과 TimeGAN 처럼 특정 구간의 샘플만 중점 생성해 학습함으로써, 전체 평균 오차 구조를 악화시켰기 때문으로 판단된다.
NSE는 모델이 관측값의 변동성을 얼마나 잘 설명하는지를 비율로 나타내는 지표로, 시계열 구조 재현 성능을 평가하는 데 핵심적이다. SMOGN은 1주 예측에서 0.65, 2·3주 예측에서 각각 0.56, 0.55로 원본의 성능을 효과적으로 개선한 것으로 나타났다. GAN과 TimeGAN도 1주 예측에서는 NSE 0.50, 0.49로 원본보다 개선되지만, 리드타임이 길어질수록 0.25 이하로 급격히 저하되어 변동성 재현 능력이 크게 떨어지는 것으로 나타났다.
PBIAS는 모형의 전반적 편향성을 진단하는 지표로, 부호와 크기를 통해 과대(+)·과소(-) 추정을 구분할 수 있다. 전체적으로 원본을 포함 네 가지 데이터셋 모두 음(-)의 PBIAS를 보여 남조류 세포수를 전반적으로 과소 추정하는 경향이 유지되고 있으나, SMOGN은 모든 리드타임에서 PBIAS의 절댓값이 뚜렷이 감소하여 전반적인 편향 규모가 유의미하게 완화된 것으로 해석된다. GAN의 경우도 원본 대비 과소추정 완화 효과를 보이지만, 그 개선 폭은 SMOGN에 비해서는 매우 제한적이며, TimeGAN은 PBIAS 절댓값이 거의 감소하지 않거나 오히려 커지는 구간도 나타나 비효율적인 것으로 나타났다.
MAPE는 각 관측치별 상대 오차의 절댓값을 평균한 지표로, 개별 샘플 수준의 예측 정확도를 평가하는 데 유용하다. 오버샘플링을 적용한 세 가지 데이터셋의 MAPE는 동일 리드타임에서 원본에 비해 매우 감소하여, 상대오차 관점에서의 예측 안정성이 크게 향상된 것을 확인할 수 있다. 오버샘플링 기법 간 비교에서는 SMOGN이 가장 낮은 오차를 나타냈다.
Fig. 6에서 리드타임에 따른 성능 변화를 살펴보면, 모든 데이터셋에서 리드타임이 길어질수록 RMSE 증가와 NSE 감소가 나타나 남조류 세포수 예측의 불확실성이 예측시간 선행이 길어질수록 커지는 일반적 경향을 확인할 수 있다. 반면 PBIAS와 MAPE는 리드타임 증가에 따른 단조적 경향을 보이지 않았는데, 이는 RMSE와 NSE와 같이 오차 분산의 크기에만 반응하는 것이 아니라 과대・ 과소추정의 상쇄 효과, 관측값의 크기, 구간별 샘플 분포 등 데이터셋의 구조 변화에 더욱 민감하게 반응하기 때문으로 판단된다.
4.3 모델의 일반화 성능 검증
본 연구는 오버샘플링 기법을 적용한 녹조예측 모델의 일반화 성능을 검증하기 위해, 앞서 예측성능 개선 효과가 가장 큰 것으로 나타난 SMOGN에 대해 연도 기반 Rolling Cross-Validation을 수행하였다. 실험은 20개년(2005-2024년)의 데이터셋을 순차적으로 과거 5년 데이터로 훈련하고, 미래 1년 데이터에 검증하는 방식으로 전진시켜 총 15개 rolling 분할(splits)로 이루어졌다. Table 4는 오버샘플링 수행 유/무에 따른 Original 모델과 SMOGN 수행 모델의 연도별 RMSE 기준 성능 변동성을 나타내고 있으며, 95% 신뢰구간은 15개 rolling 분할 결과를 표본 단위로 하여 부트스트랩(percentile, 반복횟수=2000) 방법을 적용해 산출하였다. 그 결과, Original 모델의 평균 RMSE는 3581.35(95% CI: 2736.91-4542.76)이며, SMOGN의 평균 RMSE는 3273.00(95% CI: 2603.07-4069.07)으로 나타났다. 이는 SMOGN으로 오버샘플링을 수행하는 것이 수행하지 않는 것에 비해 평균적으로 낮은 오차를 발생시키고 있음을 확인하는 결과이나, 두 방법 모두 신뢰구간의 폭이 크게 나타나고 상당부분 중첩되는 등 변동성이 커서 평균적 성능 차이가 통계적으로 유의하다고 단정 짓기는 어려움을 의미한다.
Table 4.
Results of rolling cross-validation
이러한 결과의 근본적 원인은 SMOGN과 같은 오버샘플링 기법들이 모델이라기보다 데이터 변환 연산자에 가깝기 때문이다. 즉, 모델 파라미터보다 훈련 데이터의 분포(불균형 정도)에 민감하게 반응하기 때문에 각 분할의 데이터 불균형 정도가 다를 경우 CV 평균 성능이 SMOGN의 본질적 효과를 대표하지 못할 수 있다. Table 4에서 방법 간 성능 차이인 ()의 결과를 살펴보면 이러한 점이 명확해진다. 가 음수이면 성능 개선, 양수인 경우 성능 악화를 나타내는데, 15개 분할 중 9개 연도에서 SMOGN 수행이 모델 성능을 개선하였으나, 6개 연도에서는 오히려 성능을 악화시킨 것으로 나타났다. Fig. 7에서는 더욱 직관적인 해석이 가능한데, 분할 6(2010-2014년 훈련, 2015년 검증)이 매우 큰 음의 를 나타낸 것은 훈련 데이터의 데이터 불균형이 심각해 SMOGN 오버샘플링 후 극단적 개선이 이루어진 것으로 추정할 수 있으며, >0인 분할들은 훈련 데이터의 분포가 비교적 안정적이어서(극단값 비중 낮음) SMOGN 합성 샘플들이 오히려 노이즈를 증가시키거나 원본 분포를 왜곡했을 가능성이 있다.
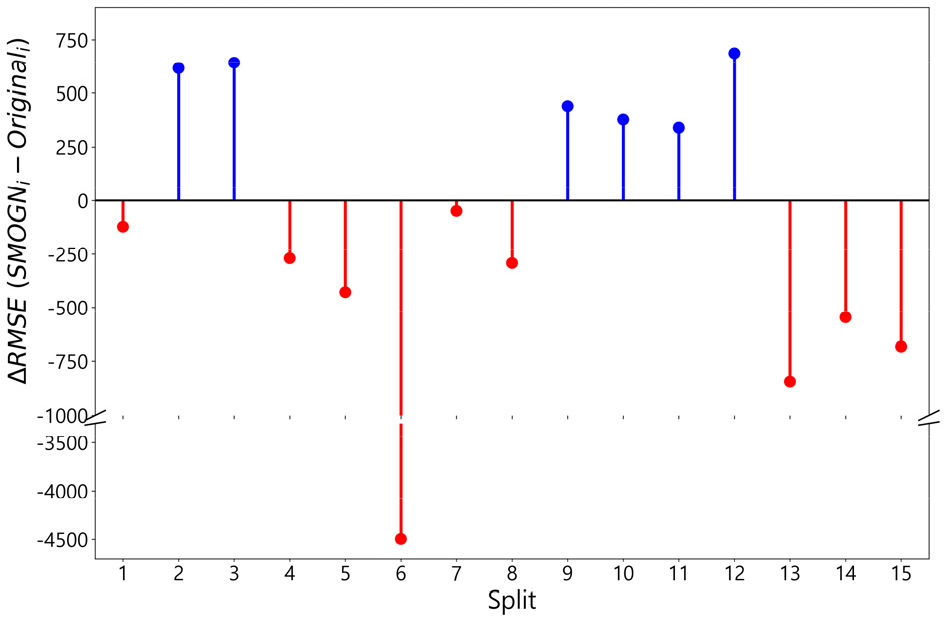
결론적으로 연도 기반 Rolling CV에서 분할마다 불균형 구조가 다를 경우, 동일 파라미터의 SMOGN 적용이 항상 성능 향상으로 이어지지 않을 수 있다. 따라서 오버샘플링 기법이 적용된 모델의 교차검증은 평균 성능 우위 증명을 목표로 하기보다 원본 자료 대비 성능 민감도를 확인하여 파라미터의 강건성을 평가하는데 맞춰져야 할 것이다.
5. 결 론
본 연구는 고농도 남조류 세포수 데이터의 희소성으로 인한 녹조 데이터셋의 불균형 문제를 오버샘플링을 통해 완화하면 고농도 희소 구간에 대한 모델 예측성능이 개선되는지를 정량적으로 분석하는 것을 목표로 하였다. 이를 위해 SMOGN, GAN, TimeGAN 등 세 가지 오버샘플링 기법을 적용하여 훈련 데이터셋에서 희소한 고농도 구간 샘플을 증강하고, 작은 표본 크기에도 안정적인 성능을 보이는 랜덤포레스트 모델을 활용하여 남조류 세포수의 1~3주 후 예측성능을 비교 분석하였다.
연구 결과, SMOGN 기반 오버샘플링으로 구축한 훈련 데이터셋으로 학습한 모델이 원본 데이터 및 GAN, TimeGAN 적용 모델에 비해 우수한 예측성능 개선 효과를 나타냈다. SMOGN은 원본 데이터 대비 평균 오차 규모(RMSE) 감소, 시간적 변동성 재현(NSE) 증가를 동시에 달성하면서, 전반적 편향(PBIAS)을 축소하고, 개별 샘플 정확도(MAPE)를 개선하여 다양한 평가 관점에서 우수한 예측성능 개선 효과를 보였다.
원본 데이터와 다른 기법에 비교해 SMOGN이 고농도 구간의 오차를 유의미하게 줄이면서도 전반적인 예측성능 개선 폭이 가장 크게 나타난 이유는 목표변수의 연속형 분포를 유지한 채 국소적 밀도(local density)에 따라 다수/소수 구간의 중요도를 균형 있게 조정하는 중요도 기반 오버샘플링 전략에 있다. 이를 통해 중·고농도 구간의 샘플 밀도를 효과적으로 보강하면서 회귀형 불균형 문제를 완화할 수 있었다. 반면 GAN은 원본 분포 재현을 우선하는 구조적 특성으로 인해 극히 희소한 경계등급의 비중을 충분히 조정하지 못하였고, TimeGAN 역시 시계열의 시간적 의존성 보존에 초점을 둔 설계로 인해 희소 구간을 조건적으로 확대하는 기능이 제한되었다. 이러한 결과는 시계열 기반 예측에서 극히 희소한 고농도 구간을 다룰 때 합성 데이터의 ‘질적 유사성’과 ‘양적 확보 전략’이 동시에 충족될 때에만 예측성능 향상이 실질적으로 나타날 수 있음을 시사한다.
더 나아가 본 연구의 결과는 남조류 세포수 예측에 국한되지 않고, 극단값이 드물고 불균형이 심한 연속형 수문·환경 시계열 전반에 적용 가능한 시사점을 제공한다. 특히 시계열적 연속성을 지닌 회귀 문제에서는 분포를 보존하면서 국소 밀도에 따라 희소 구간을 선택적으로 증강하는 오버샘플링 전략이 모델의 안정성과 일반화 성능을 높이는 데 유효한 대안이 될 수 있음을 보여준다.
다만 본 연구는 특정 수역의 장기 시계열과 랜덤포레스트 중심의 단일 모델링에 기반하고 있어, 기상·수문 조건이 다른 수계나 딥러닝 기반 예측모형으로의 확장 가능성은 추가 검증이 필요하다. 그럼에도 불구하고, 본 연구는 비정상(non-stationary)성과 극단값 특성이 강한 수문·환경 시계열에서 오버샘플링에 의한 예측모형 성능 향상을 모색하는 데 참고할 수 있는 기초적 근거로 활용될 것으로 기대된다.
