

1. 서 론
2. 연구 방법
2.1 연구 지역
2.2 General Circulation Model
2.3 Quantile Mapping
2.4 평가지표
2.5 TOPSIS
2.6 Reliability Ensemble Averaging
3. 결 과
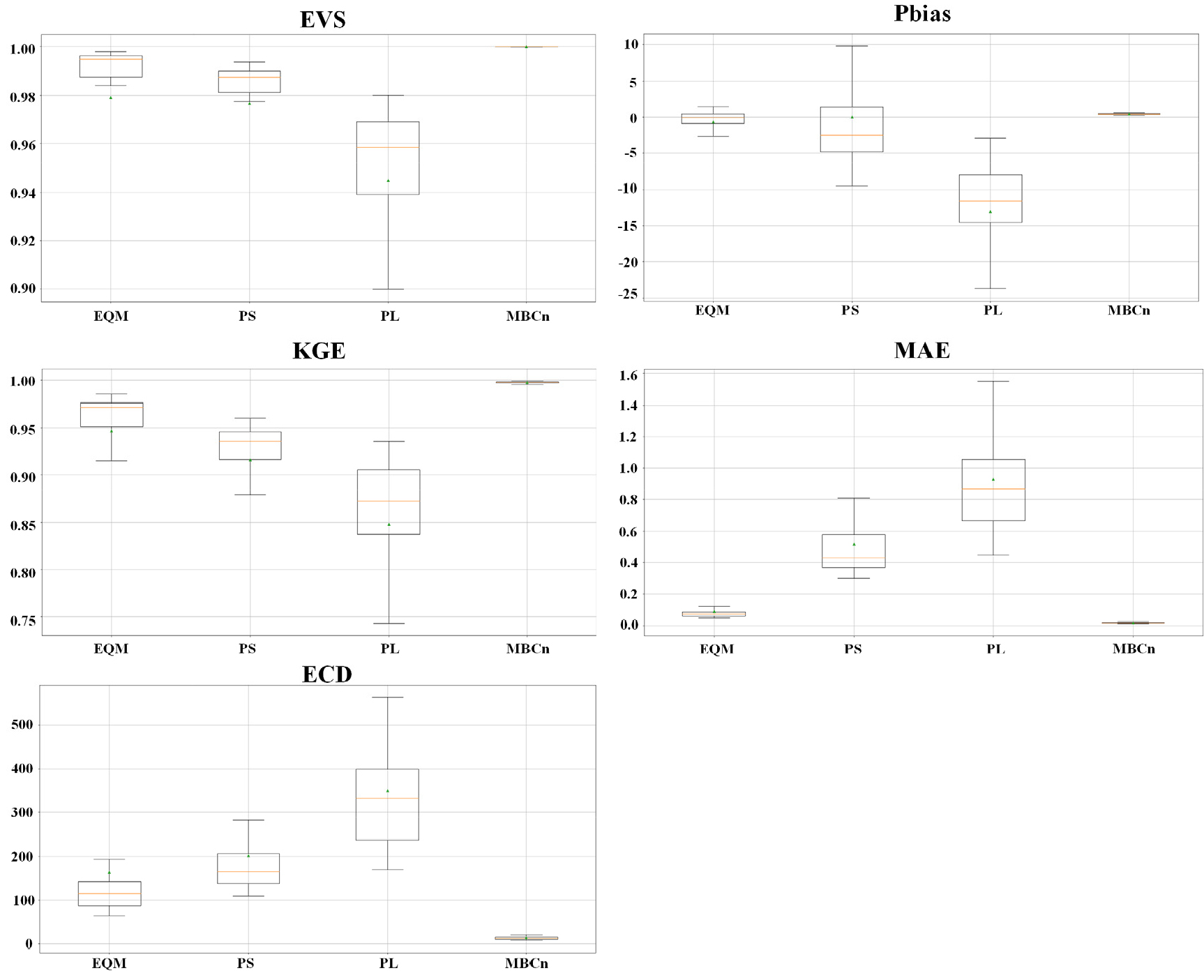
3.1 편의보정방법에 따른 일 강수량 재현성 비교
3.2 편의보정방법에 따른 일 강수량의 보정 성능 비교
3.3 GCM 우선순위 선정
3.4 편의보정방법에 따른 미래 강수량 예측
3.5 미래 강수량의 불확실성 정량화
4. 결 론
1. 서 론
Coupled Model Intercomparison Project (CMIP) General Circulation Model (GCM)은 다양한 분야에서 기후변화에 대한 과학적 증거를 제공하는 중요한 도구로 널리 사용되어 왔으며, 6차 평가보고서(6th Assessment Report)에서도 기후변화의 원인과 현상을 설명하는 데 큰 기여를 했다(IPCC, 2021; 2022). 그러나 GCM은 불완전한 모형 매개변수와 주요 물리적 프로세스에 대한 이해 부족으로 인해, 관측값과 비교했을 때 여전히 큰 오차가 존재한다(Woldemeskel et al., 2014; Song et al., 2022c). 이러한 문제를 해결하기 위해 사전 연구들은 다양한 편의 보정 방법을 제안하였으며, 이를 통해 원시 GCM 결과보다 신뢰도가 높은 기후 모의값을 여러 현상에 적용할 수 있게 되었다. 그러나 편의 보정 방법은 물리적 접근 방식에 따라 결과가 달라질 수 있으며, 특히 강수량의 경우 지역마다 상이한 강수 분포로 인해 극한 기후 현상을 충분히 반영하는 데 한계가 있다(Song et al., 2022b; Gudmundsson et al., 2012). 따라서, 편의 보정 방법의 선택은 미래 기후 예측에 직접적인 영향을 미치므로, 다양한 측면에서의 면밀한 평가가 필요하다.
수자원 관련 분야에서 GCM을 활용한 연구들은 관측값과의 오차를 줄이기 위해 다양한 편의보정방법을 사용해 왔으며, 그중 분위사상법(Quantile Mapping, QM)은 다양한 방법론을 쉽게 적용할 수 있고 접근이 쉬워 많은 연구에서 주로 채택되고 있다(Song et al., 2022a; Chae and Chung 2024; Kim et al., 2022). Teutschbein and Seibert (2012)는 Linear (PL)와 Scale (PS)을 사용하여 스웨덴의 다섯 개 유역에 대해 기후 모형의 기온과 강수량 자료를 보정하였으며, Enayati et al. (2021)은 경험적 QM방법(Empirical Quantile Mapping, EQM)을 사용하여 이란의 Karkheh 강 유역의 강수량과 기온 자료를 보정하였다. 그러나 기존의 일반적인 QM 방법은 정상성 강수량을 보정하는 데 뛰어난 성능이 보이지만 비정상성 강수량에 대해서는 보정 효율이 떨어진다는 한계가 있다(Song et al., 2022b). 이러한 한계를 극복하기 위해 많은 연구들은 강수량의 모든 분위수에 걸쳐 비정상성 강수량을 미래 예측에 반영할 수 있는 개선된 QM 방법을 제안해 왔다(Cannon et al., 2015; Cannon, 2018; Yang et al., 2010; Song et al., 2022b; Rajulapati and Papalexiou, 2023). 하지만, 기후 자료의 지역적 특성 및 강수 패턴의 공간적 불균질성에 의해 개선된 QM 방법이 모든 관측 지점에서 동일한 성능을 보장하지는 않는다(Song et al., 2022b, 2020; Ishizaki et al., 2022; Chua et al., 2022). 따라서, 보다 신뢰할 수 있는 미래 기후 예측을 위해 동일 가중치나 단순 평가지표를 사용하는 기존 접근법과 달리, 다기준의사결정기법과 같은 견고한 프레임워크를 기반으로 GCM의 우선순위를 선정할 필요가 있다.
다기준의사결정기법은 다양한 대안의 정보를 종합하여 우선순위를 선정하는 데 활용되며, 수자원 분야에서 기후변화 영향 평가에 적용되어 그 이론적 우수성과 적용의 안정성을 입증받았다(Chae et al., 2024; Chung and Kim, 2014; Song and Chung, 2016). Song et al. (2024)은 TOPSIS를 이용하여 전 지구 규모의 위도별 미래 강수량과 기온에 대해 GCM의 우선순위를 산정하고, 이를 바탕으로 MME를 구축하였다. 하지만, 다기준의사결정기법은 대안으로 사용되는 요소의 기준과 품질에 매우 민감하여, 정보가 부족하거나 특정 기준에 지나치게 집중될 경우 정확한 우선순위 산정이 어려워질 수 있다(Song and Chung, 2016; Song et al., 2024). 이러한 이유로 다기준의사결정기법을 기반으로 적절한 대안을 선정하기 위해서는 충분한 자료를 확보하는 것뿐만 아니라 다양한 측면에서의 평가지표를 활용하여 우선순위를 산정해야 한다. 또한, 일부 연구에서는 다기준의사결정기법을 적용할 때 평가지표에 동일한 가중치를 부여하였는데, 이는 각 지표의 중요도를 충분히 반영하지 못해 우선순위 산정에서 왜곡을 초래할 가능성이 있다(Zabihi and Ahmadi, 2024). 따라서, 가중치를 적절하게 산정하는 것은 정확하고 신뢰할 수 있는 결과를 도출하기 위해 필수적이다.
GCM은 모형의 구조, 경계 조건, 매개변수 등 다양한 요인으로 불확실성을 내포하고 있다(Pathak et al., 2023; Woldemeskel et al., 2014). 특히, 다양한 편의보정방법은 GCM 자체와 더불어 온실가스 배출 시나리오와 함께 불확실성의 주요 원인 중 하나로 꼽힌다(Jobst et al., 2018). GCM에서 발생하는 광범위한 불확실성은 기후변화에 대응하기 위한 적응 및 완화 정책을 수립하는 데 있어 효과적인 대책 마련을 어렵게 만든다. 기후의 예측 불가능한 특성으로 인해 이러한 불확실성을 큰 폭으로 줄이는 것은 불가능하지만, Multi-model ensemble (MME)와 같은 앙상블 접근법을 활용하면 이를 고려할 수 있다(Song et al., 2024). 그럼에도 불구하고, 지구의 순환 과정을 충분히 설명할 수 있는 방정식이 부족하기 때문에, 강수량을 정확하게 예측하는 것은 여전히 어려운 과제이다. 더욱이, QM (Quantile Mapping) 방법을 사용하여 보정된 강수량을 미래 예측에 적용하더라도, 물리적 한계로 인해 더 큰 불확실성이 발생할 수 있다(Lafferty and Sriver, 2023). 이러한 맥락에서 GCM 모의값의 불확실성을 고려하기 위한 다양한 방법들이 제안되었으며, 이를 통해 과거 및 미래 기후 변수에 대한 불확실성을 정량화하려는 연구가 활발히 진행되고 있다(Song et al., 2022a, 2022c; Giorgi and Mearns, 2002). 그러나 우리나라를 대상으로 한 연구에서는 편의보정방법에 따른 예측된 미래 강수량의 불확실성을 정량화한 연구가 부족한 실정이다. 따라서, 다양한 시나리오에서 예측된 미래 강수량의 불확실성을 정량화하는 작업은 정책 수립의 유연성을 높이고, 기후 모형의 한계를 보완하는 데 중요한 역할을 할 수 있다.
본 연구는 14개 CMIP6 GCM의 일 강수량을 활용하여, 우리나라 61개 관측소를 대상으로 4개의 편의 보정 방법의 성능을 비교하고 불확실성을 정량화하였다. 선정된 편의보정방법은 모수적 QM 방법인 PL 및 PS, EQM, 차원 확률밀도 함수 변환을 적용한 다변량 편의 보정 방법(Multivariate bias correction based on N-dimensional probability density function transform, MBCn)을 사용하였다. 편의보정된 일 강수량의 성능을 비교하기 위해 5개(Percent bias, Pbias; Mean absolute error, MAE; Kling-Gupta efficiency, KGE; Jensen-Shannon divergence, JSD; Euclidean Distance, ECD)의 평가지표를 사용하였으며, 이를 바탕으로 다기준의사결정기법 중 하나인 the Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS)를 사용하여 SSP5-8.5 시나리오에 대한 MME를 구축하였다. 또한, 미래에 예측된 강수량과 과거 강수량의 불확실성을 정량화하기 위해 reliability ensemble averaging (REA)를 사용하였다. 본 연구는 우리나라에 관측소별 적합한 편의보정방법을 제안하는 연구로써 기후변화에 대응하기 위한 정밀하고 신뢰성 있는 미래 강수량을 예측에 기여할 수 있을 것으로 기대된다.
2. 연구 방법
2.1 연구 지역
본 연구는 우리나라의 지역적 다양성을 충분히 고려하기 위해 미계측 자료 없이 가용 가능한 61개 관측소를 Fig. 1과 같이 선정하였다. Table 1은 선정된 61개 관측소에 대한 기본 정보를 나타낸다. 과거 강수량 자료는 CMIP6 GCM의 과거기간과의 비교를 위해 1980년부터 2014년까지의 일 단위 데이터를 사용하였으며, 기상청 기상자료개방포털(https://data. kma.go.kr/cmmn/main.do)에서 수집하였다. 선정된 관측소들은 해안과 내륙 지역에 고루 분포되어 있어, 홍수, 폭설, 가뭄 등 다양한 재해에 노출된 지역을 포함하고 있다. 이는 미래 기후변화로 인해 발생할 수 있는 재해를 보다 면밀하게 분석할 수 있는 기반을 제공하며, 지역별로 상이한 강수 분포로 인해 편의보정 성능을 다양한 관점에서 비교하고 해석하는 데 기여할 수 있다.
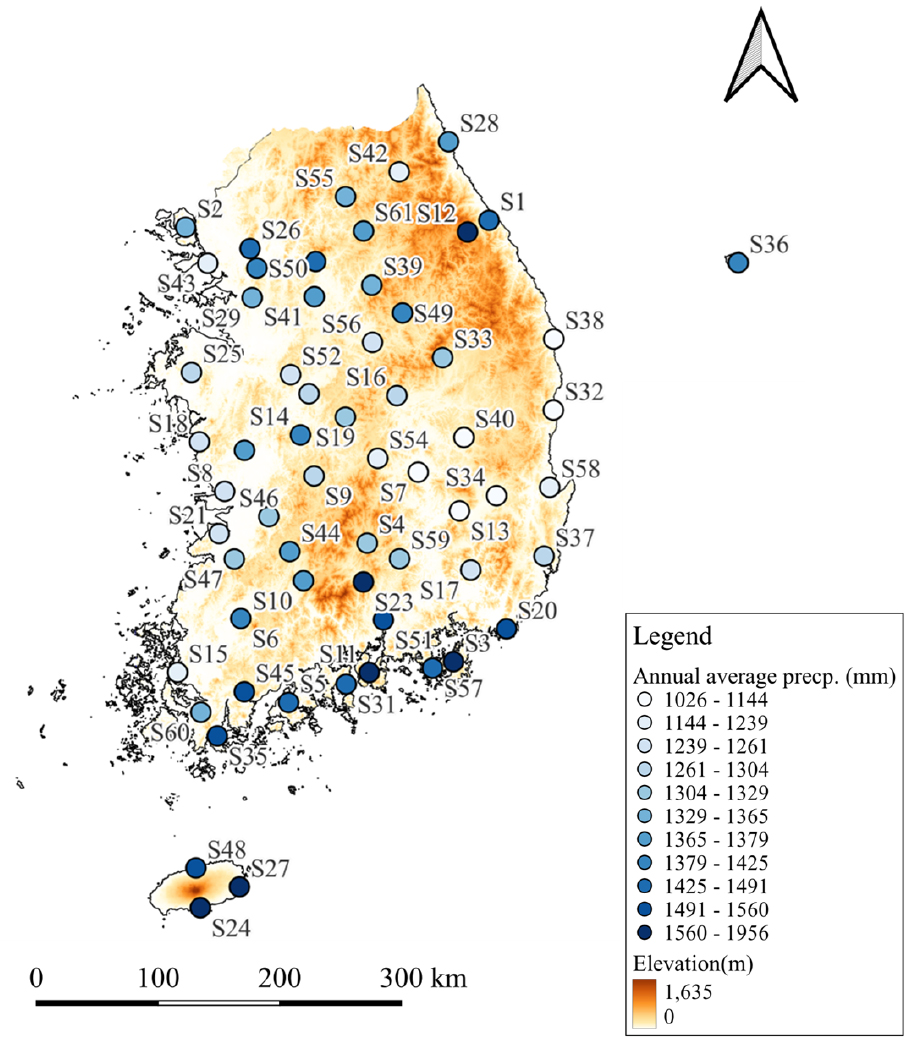
Table 1.
Information of observed stations, including symbols (sym), geographic coordinates (Lat and Lon), and ASOS Numbers (ASOS)
2.2 General Circulation Model
본 연구는 14개의 CMIP6 GCM에서 제공하는 일 단위 강수량 자료를 활용하였다. Table 2는 본 연구에서 선택된 14개의 CMIP6 GCM에 대한 기본 정보를 요약한 것이다. 선택된 GCM의 해상도는 0.9°에서 2.5° 사이이며, 과거 자료는 1980년부터 2014년까지의 기간을 사용하였다. 각 GCM은 첫 번째 앙상블 구성(realization r1)을 사용하였으며, 이는 모형의 대표성을 높이기 위한 표준적인 접근이다. 본 연구에서 선택된 GCM들은 우리나라의 기후변화를 다룬 수자원 관련 연구에서 유출량, 가뭄, 강수, 기온 등 다양한 기후변수의 과거 성능을 비교하고 미래 변화를 분석하는 데 빈번하게 활용되었다(Song et al., 2022a, 2022c; Chae et al., 2024; Kim et al., 2022). 또한, 본 연구에서는 가독성을 높이기 위해 각 GCM을 Table 2와 같이 심볼로 명명하여 결과 해석에 사용하였다.
Table 2.
Information about 14 CMIP GCM used in this study
본 연구는 극단적인 온실가스 배출 시나리오인 SSP5-8.5 기반으로 미래의 일 강수량을 예측하였다. SSP5-8.5는 빠른 경제 성장과 화석 연료 사용의 극대화로 인해 가장 높은 온실가스 배출을 보이는 시나리오로, 미래 강수 변화, 불확실성, 변동성을 면밀히 분석하기에 적합하다. 이를 통해 4개의 QM 방법을 사용하여 예측된 강수량의 차이뿐만 아니라 각 방법에서 나타나는 불확실성을 비교함으로써 극단적인 기후 시나리오 하에서 발생할 수 있는 강수의 패턴 변화를 심층적으로 평가할 수 있다.
2.3 Quantile Mapping
본 연구는 GCM의 일 강수량과 관측값 사이의 차이를 보정하기 위해 4개(PL, PS, EQM, MBCn)의 QM 방법을 사용하였다. QM은 Eq. (1)과 같이 변환 함수에 따라 보정법이 달라지며, 변환 함수 는 Eq. (1)와 같이 정의된다.
여기서, 는 편의보정된 일 강수량, 는 원시 GCM의 일 강수량을 의미한다. Eq. (2)에서 는 관측값의 분위수 함수를 의미하며, 는 의 누적 분포 함수를 의미한다.
2.3.1 Parametric Linear transformation
PL은 매개변수적 변환방법 중 하나로, Eq. (3)과 같이 선형 변환을 통해 편의보정을 수행한다(Piani et al. 2010).
여기서, 은 선형 변환된 GCM의 강수를 의미하며, 𝛼는 상수, 는 비율을 나타낸다.
2.3.2 Parametric Scaling transformation
PS는 Eq. (4)와 같이 scale 변환을 적용하여 보정하는 방법으로 단순 모형화된 값에 비율을 곱하는 방식이다.
여기서 은 scale 변환된 GCM의 강수를 나타내며, 는 scale 계수를 나타낸다.
2.3.3 Empirical Quantile Mapping
EQM은 경험적 누적 분포 함수를 Eq. 2에 적용하여 GCM과 관측값의 차이를 보정한다(Boé et al., 2007; Themeßl et al., 2012). 또한, 기후 예측 자료에서 경험적 누적 분포 추정보다 큰 값을 가질 경우, 가장 높은 백분위수를 대신해 사용한다.
2.3.4 Multivariate Bias Correction
MBCn은 Cannon (2018)에 의해 제안되었으며, 기존의 단변량 편의보정방법과 달리 여러 기후의 상관관계를 고려하여 다변량 확률 밀도 함수를 변환하는 방법이다. 이를 통해 모든 변수의 결합 분포를 관측된 분포와 일치시킨다. MBCn은 Eq. (5)와 같이 계산된다.
여기서는 각각 미래, 원시 GCM, 관측값의 강수량을 의미한다. 는 행렬로 개의 변수와 개의 자료가 포함되어 있으며, 는 직교 회전 행렬을 의미한다. 이 회전 행렬은 -차원 데이터 간의 상관관계를 선형 결합을 통해 새로운 축으로 변환하며, 각 축은 독립적인 변수로 변환되어 개별 변수를 독립적으로 보정할 수 있다. 각 변수는 Eq. (2)에 따른 단변량 보정을 통해 처리된다. Eq. (6)은 보정된 데이터를 원래의 좌표계로 변환하기 위해 반대 방향으로 회전을 수행하며, 해당 과정은 모든 변수에 대해 반복되고 모형의 다변량 데이터가 관측된 다변량 분포와 일치할 때까지 수행된다.
모든 과정은 여러번 반복되며, -번째 반복에서 원시 GCM은 점차 관측 데이터의 분포에 가까워지도록 보정된다. 본 연구는 MBCn을 적용하기 위해 최대 기온을 사용하여 GCM의 강수량에 대한 편의보정을 수행하였다.
2.4 평가지표
본 연구는 4개의 편의보정방법으로 보정된 일 강수량의 과거 기간 성능을 평가하기 위해 Percent bias (Pbias), Mean absolute error (MAE), Kling-Gupta efficiency (KGE)(Gupta et al., 2009), Explained variance score (EVS), Euclidean Distance (ECD)를 사용하였다. 각 평가지표는 Eqs. (7), (8), (9), (10), (11)과 같이 계산된다.
여기서 는 번째 시점의 관측 자료, 는 번째 시점의 보정된 GCM 자료, 는 관측 자료의 평균을 나타낸다. Eq. (5)의 은 GCM과 관측값 간의 상관계수, β는 GCM의 평균과 관측값의 평균 비율, 𝛼는 GCM의 변동성과 관측값의 변동성 비율을 나타낸다. 은 Kullback-Leibler divergence를 의미하며, 이는 을 기반으로 계산된다. Pbias, MAE, ECD는 값이 0에 가까울수록 좋은 성능을 나타내며, KGE와 EVS는 값이 1에 가까울수록 우수한 성능을 의미한다.
2.5 TOPSIS
본 연구는 다기준의사결정기법 중 하나인 Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS)를 활용하여 14개의 CMIP6 GCM에 대한 우선순위를 선정하였다. TOPSIS는 Hwang and Yoon (1981)에 의해 제안된 방법으로 수자원 및 기후 변화 분야에서 최적의 대안을 결정하는 데 자주 사용되고 있다(Song and Chung, 2016). TOPSIS는 Eqs. (12) and (13)과 같이 양의 이상해와 음의 이상해를 계산한 후 Eq. (14)를 통해 근접도 계수를 산정한다.
여기서 와 는 각 대안이 양과 음의 이상해와의 유클리드 거리를 나타내며, 모든 기준에 대한 합을 사용하여 계산된다. 는 대안의 정규화된 값, 는 기준 에 할당된 가중치를 의미한다.
본 연구는 Stillwell et al. (1981)이 제안한 순위합계법을 적용하여 Eq. (15)와 같이 근접도 계수에 따른 순위를 바탕으로 14개의 CMIP6 GCM에 대한 가중치를 계산하였다.
여기서 은 GCM의 총 개수, 은 근접도 계수에 따른 GCM의 순위를 나타낸다.
2.6 Reliability Ensemble Averaging
본 연구는 Reliability Ensemble Averaging (REA)를 적용하여 과거 및 미래 기간의 일 강수량에 대한 불확실성을 정량화하였다. 또한, 분석의 정확성을 높이기 위해 무강수일수를 제외하고 상위 70% 이상의 일 강수량을 기준으로 불확실성을 정량화하였다. REA는 Giorgi and Mearns (2002)에 의해 제안된 방법으로 GCM과 관측값을 비교하여 과거 기간의 유사성을 평가한 뒤 이를 바탕으로 미래 기간의 GCM 예측값과 예측값의 평균과의 차이를 계산한다. REA는 Eqs. (16) and (17)과 같이 계산되며 과거 및 미래 기간의 강수량을 모두 고려하여 신뢰도를 분석한다.
여기서 는 편의 보정된 GCM의 일 강수량에 신뢰도 기반 가중치를 의미하며, 는 과거 기간 동안 GCM과 관측값 간의 오차를 나타낸다. 는 미래 기간에 편의보정방법에 의해 예측된 강수량의 수렴도를 나타내며, 의 초기값은 에 의해 계산된다. 𝜖는 이동 평균의 최대값과 최소값의 차이를 나타내며, 과 은 각각 오차와 수렴 항에 대한 가중치를 나타낸다. Eq. (18)은 집합 모형의 신뢰도를 계산하는 과정을 나타낸다.
3. 결 과
3.1 편의보정방법에 따른 일 강수량 재현성 비교
본 연구는 4개의 QM 방법을 사용하여 과거 기간에 일 강수량에 대한 편의 보정을 수행하였다. Fig. 2는 Taylor diagram을 사용하여 61개 관측소에서 원시 GCM과 편의 보정된 GCM의 일 강수량을 비교한 결과를 나타낸다. 전반적으로, MBCn은 상관계수 평균값이 0.95 이상으로 가장 높았으며, 표준편차 역시 관측값과 가장 유사하였다. EQM은 상관계수 평균값이 0.91로 MBCn보다는 낮았으나, PS와 PL보다 우수한 성능을 보였다. PS는 상관계수 평균값이 0.84로 산정되었으며, PL은 0.67로 가장 낮았다. 또한, PS와 PL의 표준편차는 MBCn과 EQM에 비해 관측값과의 차이가 크게 나타났다.
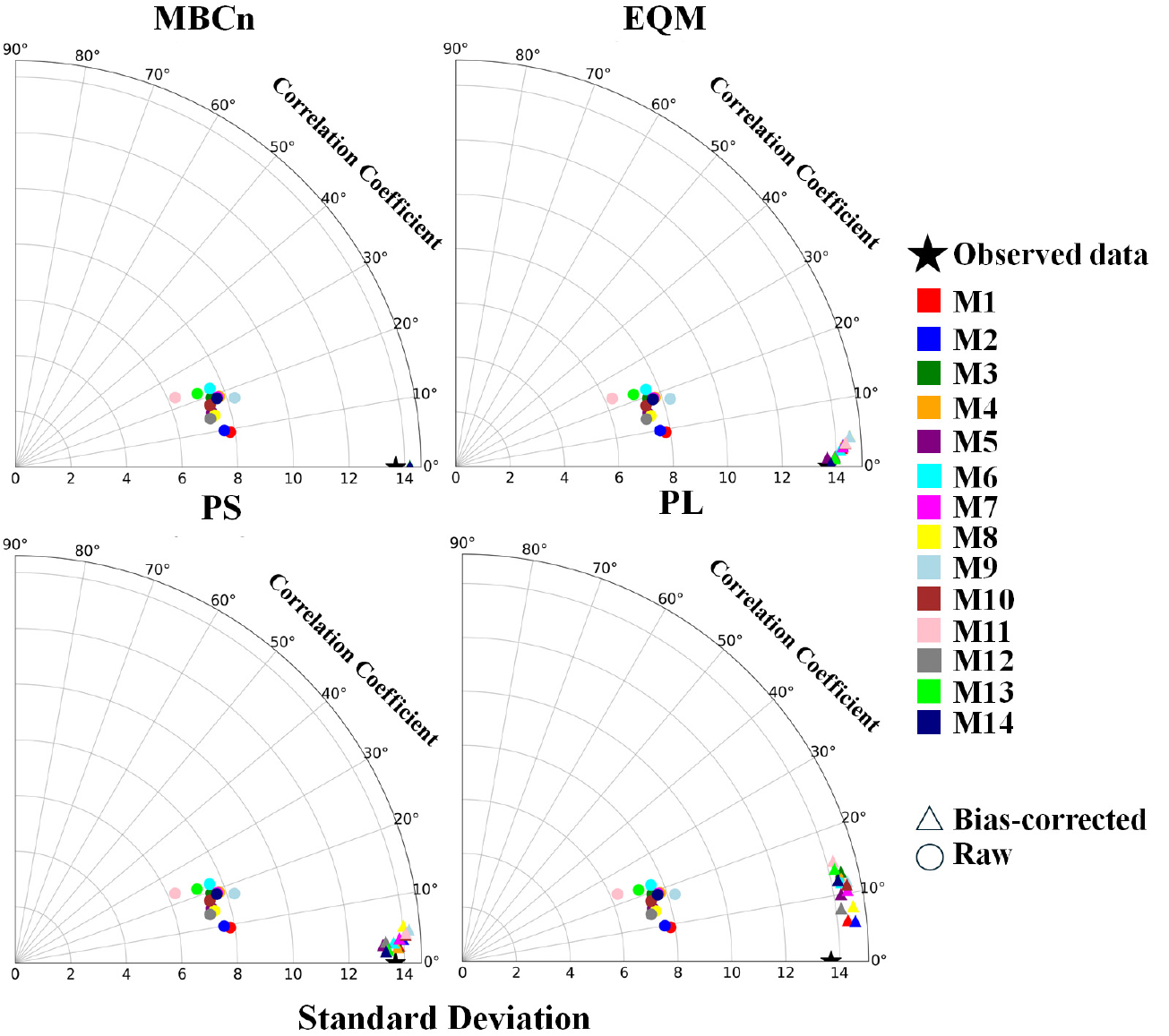
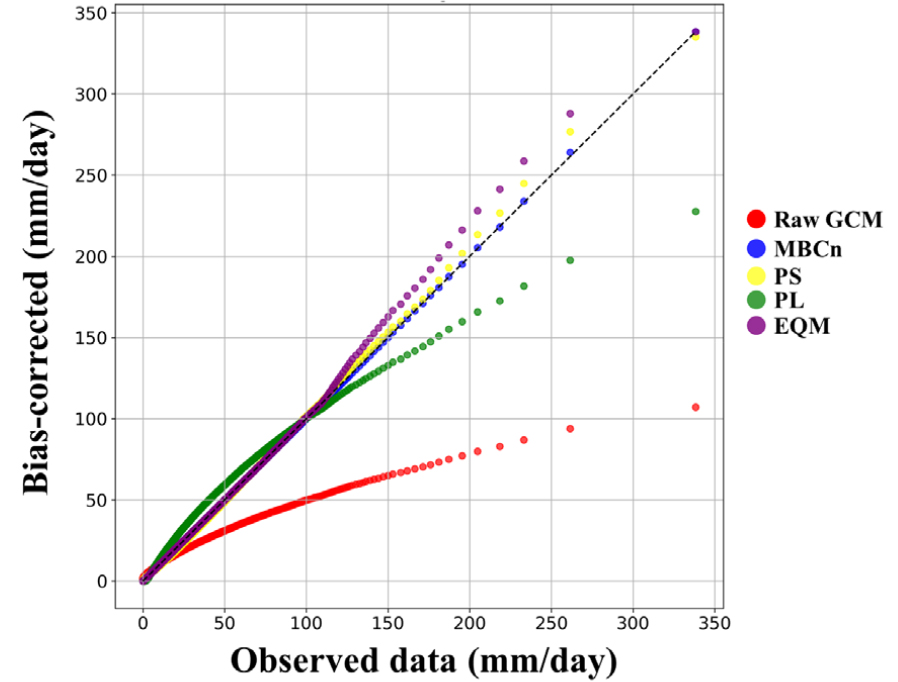
Fig. 3은 4개의 QM 방법을 사용하여 보정된 14개 GCM의 일 강수량을 61개 관측소에서 평균한 결과를 산점도로 나타냈다. MBCn에 의해 보정된 강수량은 전반적으로 관측값과 가장 유사하였으며, 특히 극한 강수량은 관측값과 거의 일치하였다. PS로 보정된 강수량은 중간 정도의 성능을 보였으나, 강수량이 많을수록 관측값보다 다소 과대평가 되었다. PL의 경우 다른 방법에 비해 전반적으로 성능이 낮았으며 특히 관측값에 비해 강수량이 과소평가 되었다. EQM은 낮은 강수량에서 관측값과 유사하였으나, 강수량이 많을수록 관측값보다 과대평가 되었다. 반면에, EQM으로 보정된 극한 강수량은 관측값과 유사하였다.
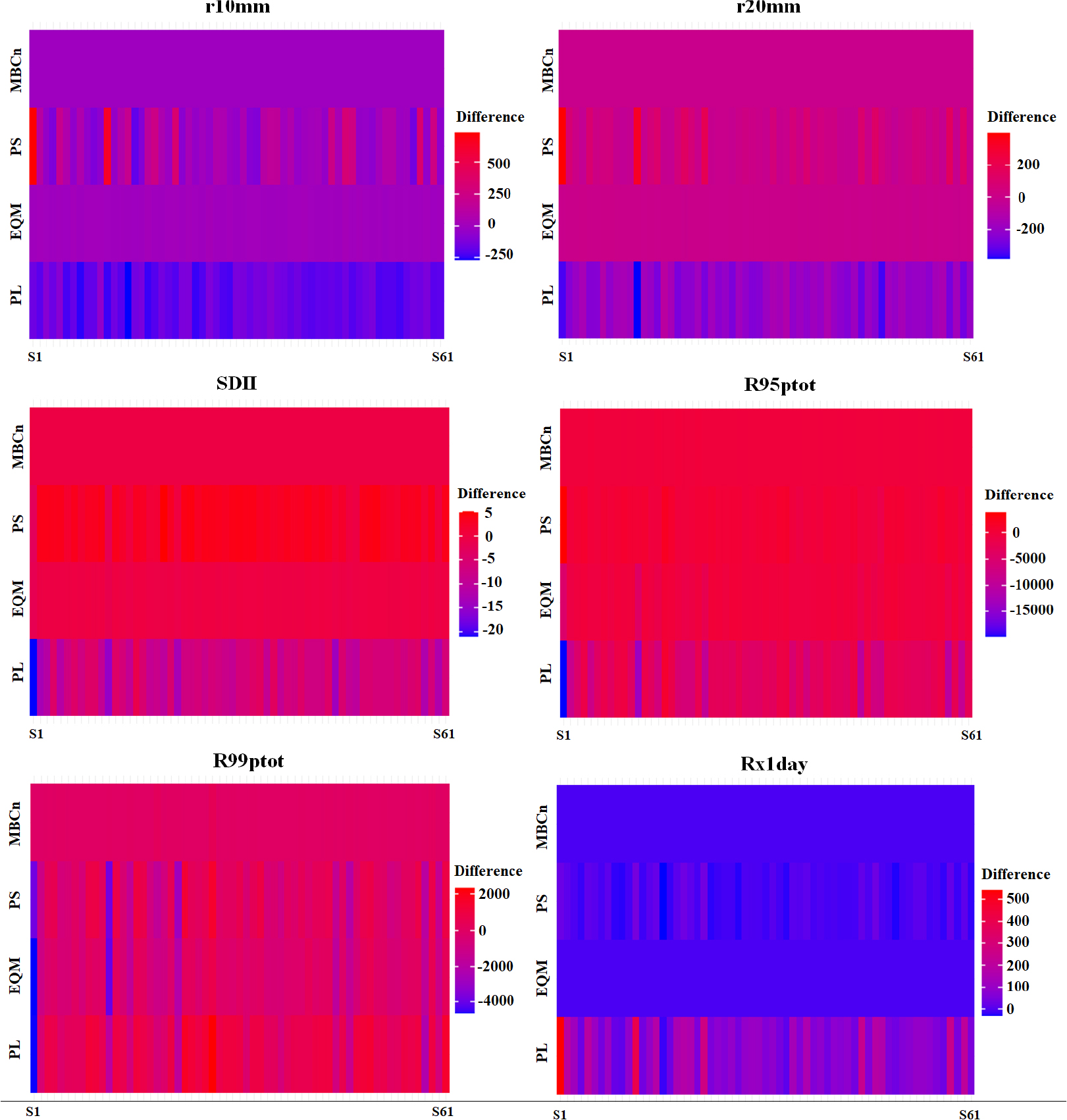
본 연구는 6개의 강수 지수에 대해 편의보정 방법별로 보정된 일 강수량과 관측값에서 산정된 지수의 차이를 Fig. 4와 같이 비교하였다. 전반적으로 MBCn은 모든 강수 지수에서 관측값과의 차이가 가장 작았으며, 특히 일 최대 강수량(Rx1day)은 관측값과 거의 일치하였다. 또한, 10 mm (r10 mm) 및 20 mm (r20 mm) 이상 강수일수에서도 최대 1일의 차이만을 보였고, 일일 강수 강도 지수(SDII)도 관측값과 매우 유사하였다. 반면에, PL로 보정된 강수량은 대부분 관측소에서 관측값보다 작았으며, 다른 방법에 비해 차이가 가장 컸다. EQM의 경우 Rx1day, r20 mm, r10 mm, SDII는 MBCn과 유사한 성능을 보였으나, 95 및 99번째 백분위수 이상의 강수량 총합(R95ptot, R99ptot)에서는 관측값보다 약간 작았다. 결론적으로 MBCn을 사용한 보정은 다른 방법들에 비해 강수 지수 측면에서 관측값과 가장 유사한 결과를 보였고, PL은 관측값과의 차이가 가장 컸다.
3.2 편의보정방법에 따른 일 강수량의 보정 성능 비교
본 연구는 4개의 QM 방법별 보정된 일 강수량 자료의 보정 성능을 5개의 평가지표를 사용하여 비교하였다. Fig. 5는 각 QM 방법으로 편의 보정된 14개 GCM의 일 강수량에 대한 평가지표 결과를 상자 그림으로 나타냈다. 전반적으로 MBCn은 모든 평가지표에서 가장 우수한 성능을 보였으며, EQM이 그 뒤를 이었다. 반면 PL은 모든 평가지표에서 성능이 가장 낮았으며, PS는 PL보다 성능이 높았으나 EQM과 MBCn에 비해 다소 낮은 성능을 보였다. MBCn의 Interquartile Range (IQR)은 다른 방법들에 비해 모든 지표에서 가장 작았으며, 이는 보정 결과의 일관성이 높음을 의미한다. 반면 PL은 IQR이 가장 컸으며, 이는 PL에 의해 보정된 강수량의 변동성이 크다는 것을 나타낸다. EQM의 IQR은 MBCn보다 컸으나 PL과 PS에 비해 작았다. 이러한 결과는 MBCn의 다변량 보정 방식이 다른 QM 방법에 비해 강수 보정에 더 효과적임을 나타낸다.
3.3 GCM 우선순위 선정
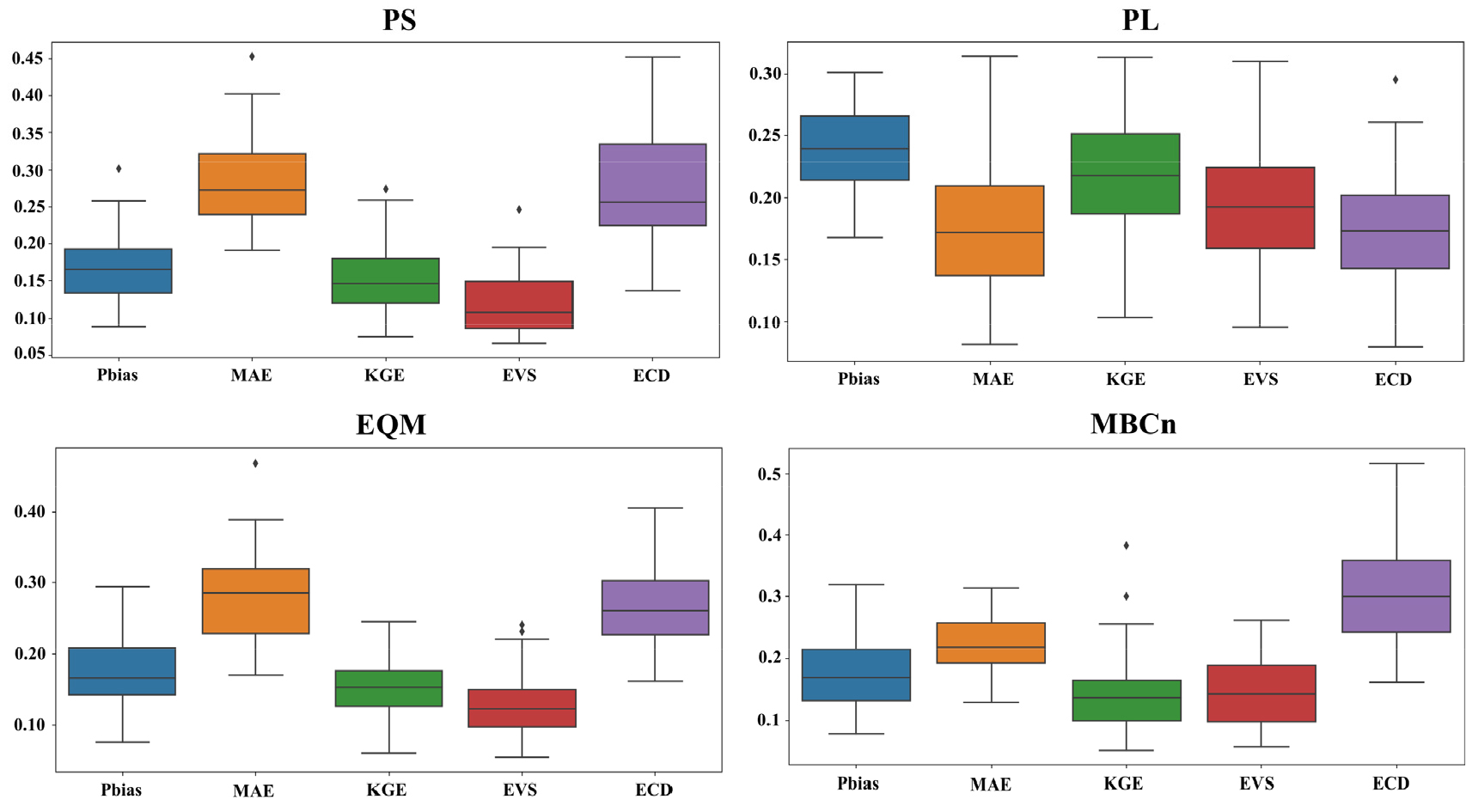
본 연구는 TOPSIS를 사용하여 성능 기반 GCM의 우선순위를 산정하였다. Fig. 6은 TOPSIS에서 사용된 평가지표에 대한 entropy 가중치를 상자 그림을 사용하여 나타냈다. 전반적으로 PS, EQM, MBCn에서 산정된 각 평가지표의 entropy 가중치는 서로 다른 양상을 보였다. MBCn의 경우, ECD의 가중치가 다른 평가지표에 비해 가장 컸으며, EVS는 가장 작았다. 반면 PL의 경우 Pbias의 가중치가 가장 크고, ECD가 가장 작았다. PS와 EQM의 경우, MAE의 가중치가 가장 컸다. 이러한 결과는 각 QM 방법의 적용 방식에 따라 특정 지표가 더 중요한 평가 기준으로 작용할 수 있음을 보여준다.
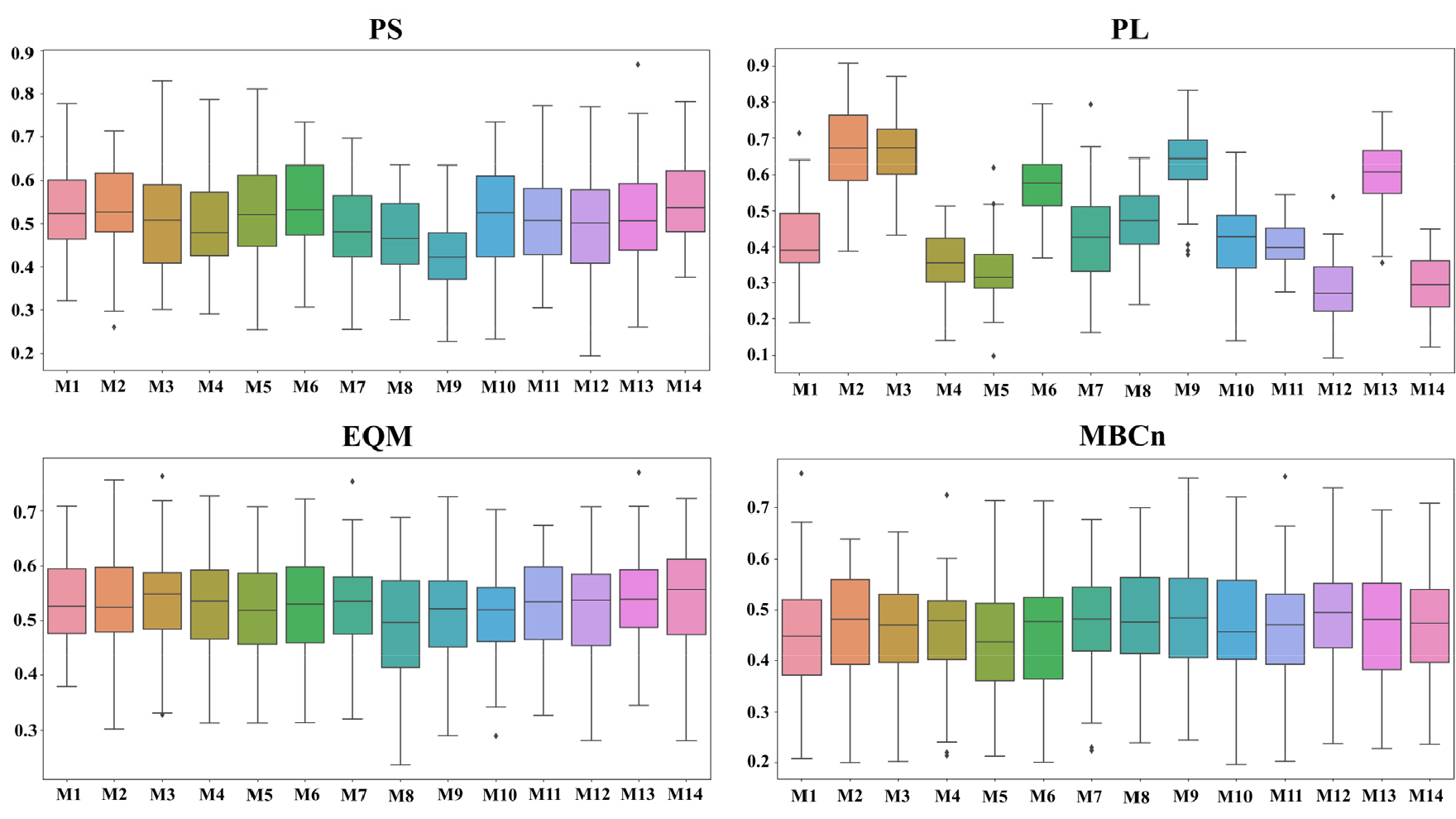
더 나아가, 본 연구는 entropy 가중치를 바탕으로 TOPSIS를 적용하여 GCM의 근접도 계수를 산정하고 Fig. 7과 같이 비교하였다. 전반적으로 EQM과 MBCn의 근접도 계수 중앙값은 모든 GCM에서 각각 0.5-0.6, 0.4-0.5 사이로 나타났으며, GCM들 간의 변동성이 적었다. 이는 두 QM 방법에 의해 보정된 일 강수량이 비교적 균일하게 분포되었음을 의미한다. PS의 근접도 계수는 EQM과 MBCn에 비해 GCM 간의 차이가 컸으며 중앙값은 0.3-0.6 범위로 산정되었다. PL의 경우 특정 GCM (M2, M3, M9, M13)이 근접도 계수가 높았으나, 이들을 제외한 나머지 GCM에서는 근접도 계수가 낮게 산정되었다. 이는 PL이 특정 강수 분포에 적합하다는 것을 시사한다.
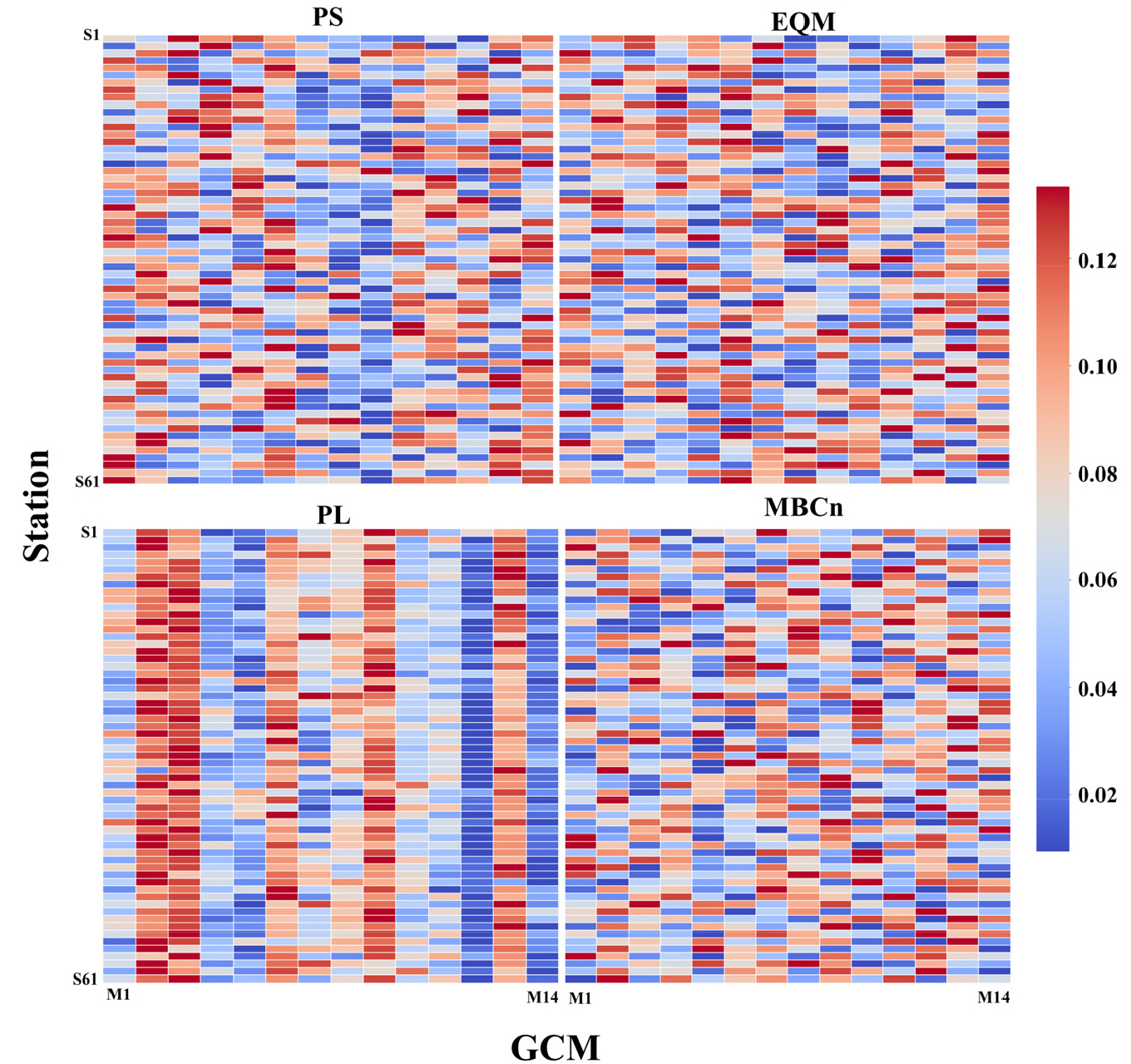
본 연구는 근접도 계수를 토대로 순위합계법을 사용하여 61개 관측소별 GCM에 대한 가중치를 산정하였으며, Fig. 8과 같이 비교하였다. 전반적으로 4개 QM 방법에 따른 14개 GCM의 가중치는 61개 관측소에서 모두 다르게 산정되었으나, 관측소에 따라 특정 GCM이 가중치가 높게 산정되었다. 예를 들어, PS는 M7과 M8이 일부 관측소에서 높은 가중치를 보였지만 대부분의 관측소에서 상대적으로 가중치가 낮았다. 특히 M9은 S3과 S18을 제외한 대부분의 관측소에서 가중치가 가장 낮았다. EQM은 GCM별 가중치가 관측소마다 다르게 산정되었으나, M14는 대부분 관측소에서 비교적 높았으며, M5와 M6도 비슷한 경향을 나타냈다. MBCn에 의해 보정된 GCM에서는 M2, M6, M7이 다른 모형에 비해 가중치가 높았으며, M3는 가중치가 가장 낮았다. 반면 PL은 61개 관측소에서 M2와 M3의 가중치가 가장 높았으며, M12와 M14의 가중치는 가장 낮았다. 이러한 결과들은 PL이 특정 GCM에만 적합할 수 있다는 가능성을 시사한다.
3.4 편의보정방법에 따른 미래 강수량 예측
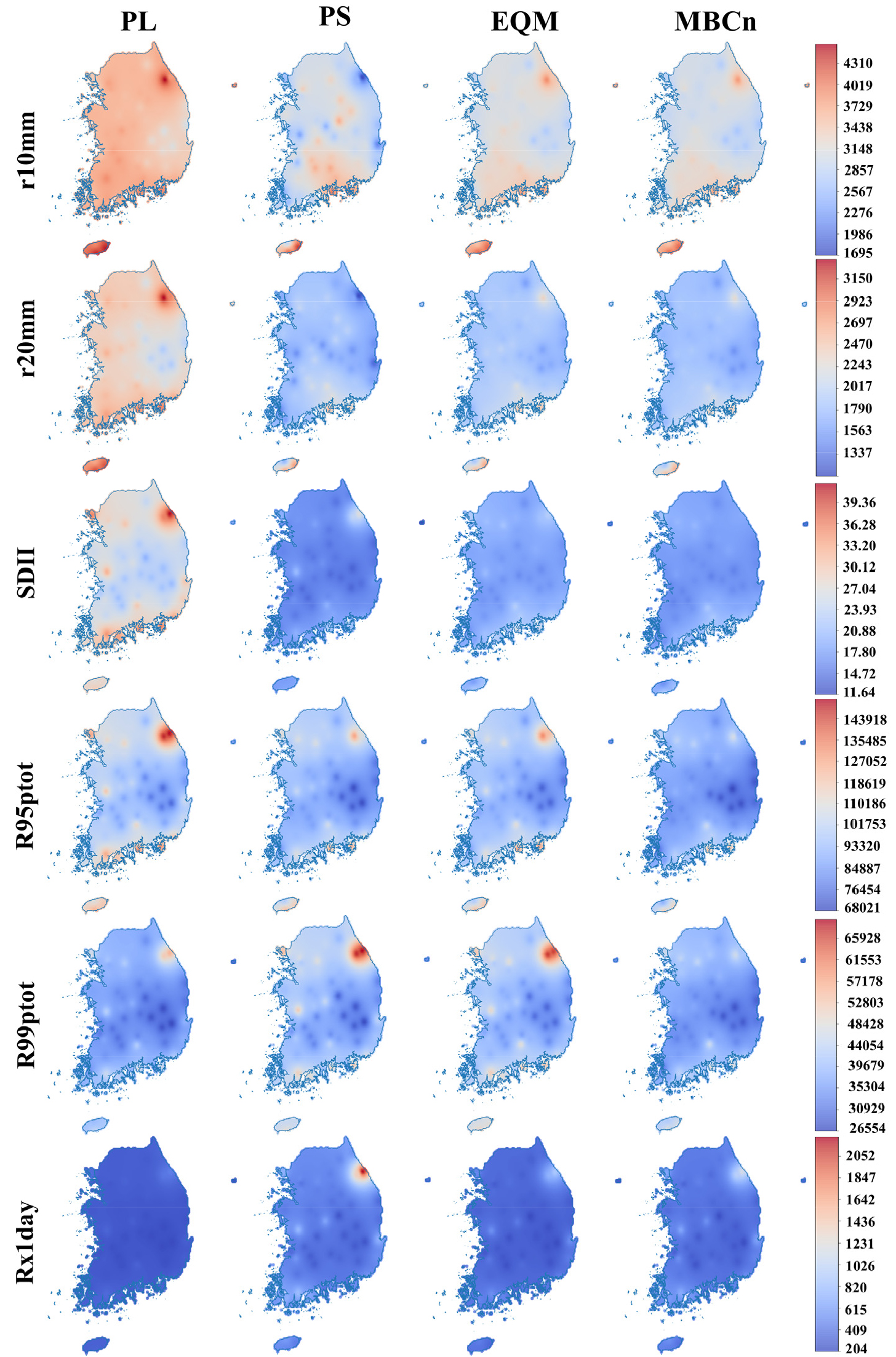
본 연구는 TOPSIS 가중치를 토대로 SSP5-8.5 하의 미래 기간(2015-2100) 강수량에 대한 MME를 구축하였다. Fig. 9는 4개의 QM 방법을 사용해 SSP5-8.5에서 예측된 일 강수량을 기반으로 계산된 6가지 강우 지수의 공간 분포를 나타낸다. 전반적으로, r10 mm와 r20 mm에서 PL은 다른 QM 방법보다 높은 값을 보였으며, 이를 통해 미래에 전국적으로 강수 발생 빈도가 높아질 것으로 예측되었다. PS에 의한 예측은 남부 및 제주지역에 강수일수가 많았으나, 동쪽의 일부 지역에서는 상대적으로 적은 강수일수가 예측되었다. EQM과 MBCn은 강수일수 측면에서 서로 유사하였으며, 동쪽과 남쪽에 더 많은 강수일수가 예상되었다. SDII에서는 PL이 가장 높은 값을 나타냈으며, MBCn이 가장 낮았다. 또한, SDII의 공간 분포는 강수일수 지수와 유사하게 나타났다. R95ptot에서는 PL이 다른 방법들보다 주로 동부에서 더 높은 값을 예측하였다. PL을 제외한 나머지 방법들은 공간 분포는 유사하였으며, PL보다 지수값이 더 작았다. 반면에, R99ptot에서는 PL이 PS와 EQM에 비해 더 낮은 강수량을 예측하였으며, PS가 가장 높았다. Rx1day의 경우, PL이 가장 낮은 값을, PS가 가장 높은 값을 보였다. 이러한 결과는 PL이 미래 강수량을 예측할 때 중간 분위수의 강수량은 상대적으로 크게 예측하는 반면, 극한 강수량은 가장 작게 예측한다는 것을 시사한다. 반면 PS는 극한 강수량에 대해 다른 방법들보다 더 크게 예측하였고, EQM과 MBCn은 비교적 작게 예측하였다.
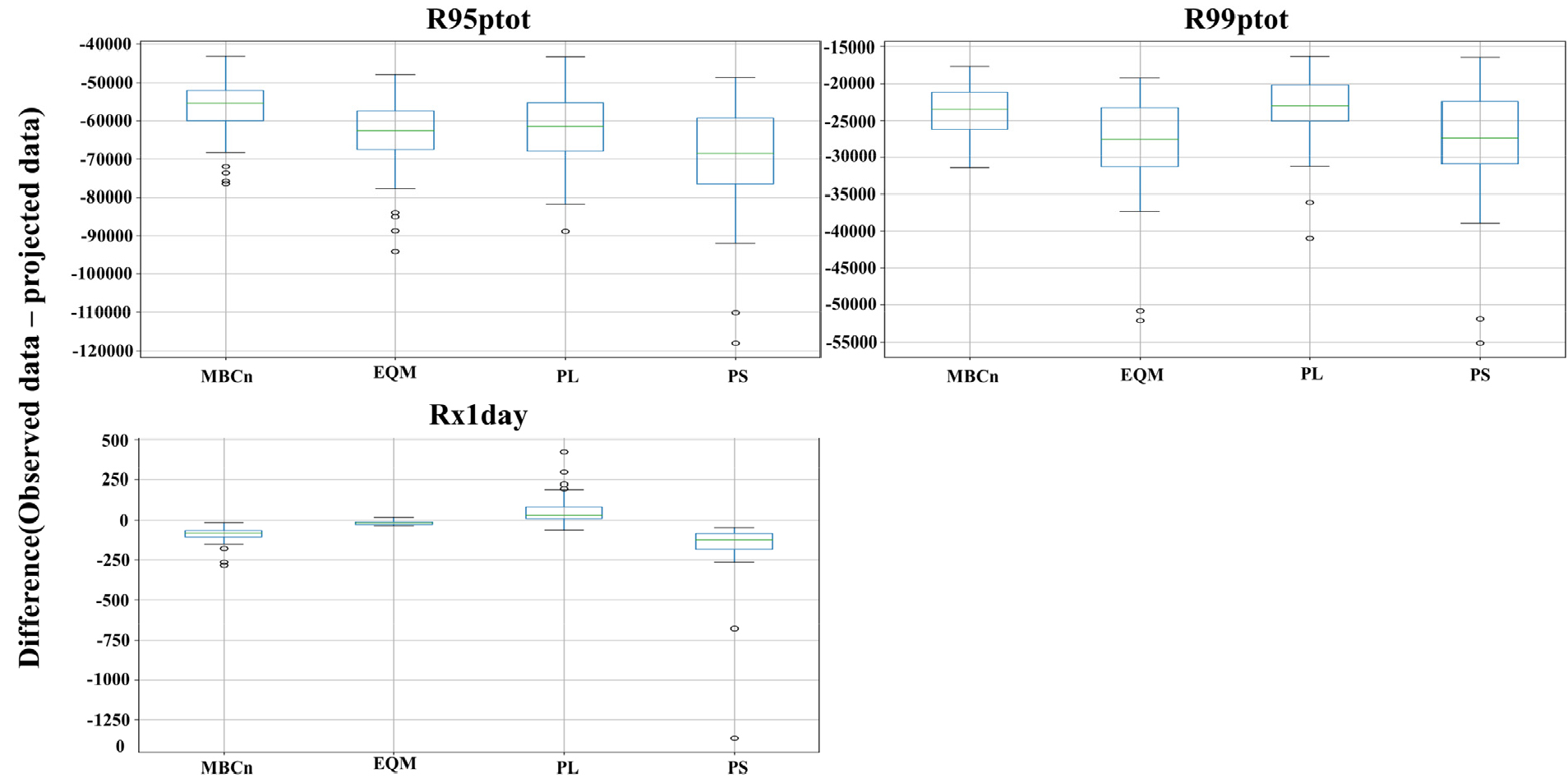
본 연구는 4개 QM 방법을 사용하여 예측된 미래 강수량에서 극한값을 나타내는 R95ptot. R99ptot, Rx1day 지수에 대해 관측값과의 차이를 Fig. 10과 같이 비교하였다. MBCn은 다른 방법에 비해 R95ptot에서 관측값과의 차이가 가장 작았으며, 반대로 PS는 차이가 가장 컸다. R99ptot의 경우, PL이 다른 방법에 비해가 관측값과의 차이가 가장 작았으나, PS와 EQM은 관측값과의 차이가 컸다. PL에 의해 예측된 Rx1day는 다른 방법에 비해 일부 관측소에서는 관측값보다 더 작았다. PS는 다른 방법들보다 Rx1day에서 관측값과의 차이가 가장 컸으며, MBCn도 일부 관측소에서 관측값과의 차이가 컸다. 반면에, EQM의 Rx1day는 관측값과 유사하였다.
3.5 미래 강수량의 불확실성 정량화
본 연구는 REA를 활용하여 예측된 미래 강수량에 대해 불확실성을 정량화하였으며, Fig. 11은 4개 QM 방법별로 REA를 통해 산출된 신뢰도의 공간적 분포를 보여준다. PL의 신뢰도는 다른 방법에 비해 가장 낮으며, 대부분의 관측소에서 0에 가까운 값을 산정하였다. PS는 북서쪽의 일부 지역에 중간 수준의 신뢰도를 보였으나, 동부와 남부 일부 지역에서는 신뢰도가 낮았다. 반면, EQM과 MBCn은 전국적으로 높은 신뢰도를 보였으며, MBCn이 EQM보다 신뢰도가 약간 더 높았다. 이러한 결과는 PL에 의해 산정된 과거 및 미래 강수량은 과거 재현성이 낮고 미래에 GCM들의 일관성이 떨어짐을 의미한다. 반대로 EQM과 MBCn은 과거 재현성이 뛰어나며, 미래 예측에서도 GCM 간 일관성이 높다는 점을 시사한다.
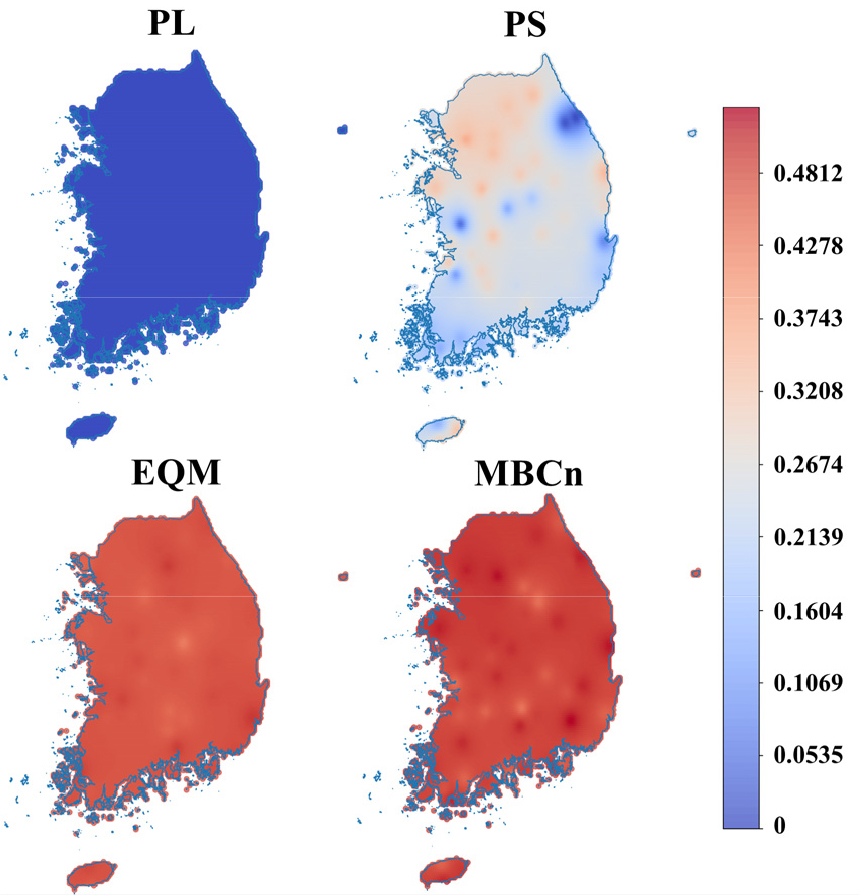
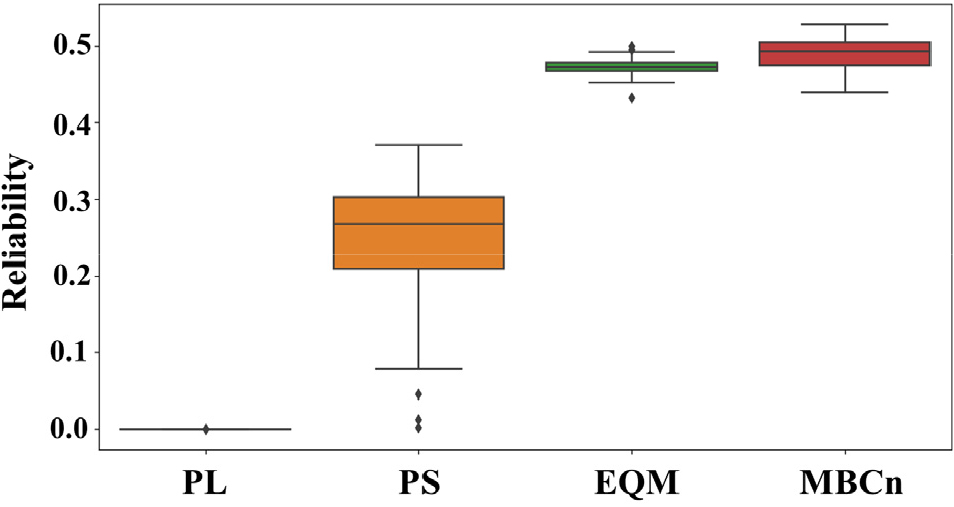
Fig. 12는 14개 GCM에서 각각 산정된 신뢰도를 61개 관측소별로 평균하여 상자 그림을 통해 비교한 결과를 보여준다. MBCn은 모든 관측소에서 신뢰도가 가장 높았으며, 신뢰도의 중앙값은 0.5에 근접하였다. EQM은 PS와 PL에 비해 신뢰도 중앙값은 높았으나 MBCn보다는 약간 낮았다. 특히 EQM의 1분위와 3분위 사이의 간격은 다른 방법들에 비해 좁았으며, 이는 모든 관측소에서 일관된 신뢰도를 나타낸다는 것을 의미한다. PS는 신뢰도의 중앙값이 0.2와 0.3 사이로 산정되었고, 1분위와 3분위의 간격은 비교적 크게 나타났다. PL의 경우, 모든 관측소에서 신뢰도가 0에 가까운 값으로 산정되었다.
4. 결 론
본 연구는 우리나라 61개 관측소의 일 강수량을 대상으로 4가지 QM 방법(PL, PS, EQM, MBCn)을 적용하여 편의보정을 수행하였으며, 6개의 강수 지수와 5개의 평가지표를 통해 과거 강수의 재현성을 평가하였다. 또한, 다기준의사결정기법 중 TOPSIS를 사용해 성능 기반 GCM의 우선순위를 선정하였으며, 평가 요소에 대한 가중치는 entropy 이론을 기반으로 합리적으로 부여하였다. 이후, SSP5-8.5를 적용하여 4개의 QM 방법을 통대 미래 강수량을 예측하였고 6개의 강수 지수를 이용하여 우리나라의 미래 강수 형태와 극한 강수 지수의 공간적 분포를 비교하였다. 더불어, REA를 활용해 4개의 QM 방법별 보정 및 예측된 일 강수량에 대한 불확실성을 정량화하였다. 본 연구의 주요 결론은 다음과 같다.
첫째, PL은 다른 방법에 비해 강수 지수 및 평가지표에서 과거 재현성이 매우 낮았다. 이러한 결과는 PL을 사용할 때 Gudmundsson et al. (2012)에서 주장과 같이 PL을 적용할 때 그 적합성을 충분히 검토해야 함을 시사한다. 반면에, MBCn과 EQM은 대부분의 관측소에서 과거 재현성이 우수하였으며, 다양한 강수 분포에 대해 적합한 편의보정 결과를 도출하였다.
둘째, PL의 Entropy 가중치는 다른 방법에 비해 고르게 분포되었으며, 이는 평가요소들의 변동성이 크고 관측소별 1분위와 3분위의 간격이 넓음을 의미한다. 반면에 다른 방법들은 ECD의 가중치가 상대적으로 높게 산정되었는데, 이는 각 관측소별 보정된 강수량의 실질적 차이가 크다는 점을 반영한다.
셋째, PL에 의해 예측된 미래 강수량은 극한 강수량이 관측값보다 낮게 산정된 반면, 95% 분위수 이상의 강수 수준에서는 관측값보다 크게 산정되었다. 이는 PL이 극한 강수량을 산정하는데 있어서 부적합하다는 것을 의미한다. MBCn은 극한 강수량을 더 크게 예측했으며, 이는 SSP5-8.5 시나리오에서 나타난 극단적인 기후 변화 추세를 잘 반영하는 것을 의미한다. 반면, PS에 의해 예측된 극한 강수량은 관측값보다 최대 1,250 mm 이상 더 크게 발생하였으며, 이는 PS를 사용할 때 극한 강수량의 과대평가에 주의가 필요함을 의미한다.
향후 연구에서는 추가적인 기후변화 시나리오를 적용하여 다양한 조건에서 QM 방법을 활용한 미래 기후변수를 예측하고, 편의보정된 기후변수를 바탕으로 홍수 및 가뭄과 같은 미래 수재해를 분석 및 예측하고자 한다.
