1. 서 론
2. 연구 방법
2.1 이론적 배경
2.2 연구 방법
3.M-RAT 모형 매개변수 최적화를 위한 데이터셋 구축 및 학습 방법
3.1 대상 유역 선정
3.2 대상 유역 현황 및 유역 특성 변수
3.3 M-RAT 모형 최적 매개변수
3.4 학습 및 검증 데이터셋 구축
3.5 머신러닝 모델 학습
4. M-RAT 매개변수 최적화 결과
4.1 정량적 검증 지표
4.2 모델별 매개변수 최적화 결과
4.3 M-RAT 모형 유출량 모의 결과
5. 결론 및 토의
부 록
1. 서 론
최근 기후변화로 인해 강수량, 유출량, 증발산량 등이 지역별로 변함에 따라 예상치 못한 홍수, 가뭄 등의 수재해의 발생 빈도와 강도가 증가되었다. 또한 급격한 도시화가 진행되며 콘크리트로 인한 불투수층 증가, 녹지 면적 감소 등에 따라 하천 유역내의 침투량이 감소되며 건천화 현상이 심각해지는 실정이다. 저수지, 소하천 등에서의 유량 감소는 하천의 생태계 파괴, 자정 기능 상실, 친수 기능 상실 등의 부작용 발생시킨다. 가뭄으로 인해 하천, 저수지 등에 저유량이 유지되는 유역은 유입량 및 유출량의 특성을 파악하는 것이 중요한 요소로 작용한다.
우리나라는 하천, 댐, 저수지 등의 유입량과 유출량을 관측 및 예측하여 유역을 대표하는 유량지속곡선 등을 생산하여 수재해를 대비하고 대응할 수 있는 지표로 활용중이다. 유량지속곡선은 장기간 관측된 자연유출량 자료를 활용하는데, 상시적으로 하천의 유속을 관측하는 것은 불가능하기 때문에 다양한 유량 추정 기법이 제안되었다(Choi et al., 2021). 보편적인 방법으로는 강우-유출 모형을 활용해 약 30년 이상의 일단위 유량 자료를 도출하여 유량지속곡선을 산정한다. 수문 자료 관측이 제한적인 미계측 유역의 경우, 유출량 산정을 위해 강우-유출모형의 지역화 모형을 개발하는 등의 기법을 사용한다(Choi and Lee, 2012).
유역을 대상으로 유출량을 모의하는 강우-유출 모형을 활용한 연구는 국내외 많은 유역에서 이루어졌다. 강우-유출 모형 중 하나인 SWAT (Soil Water Assessment Tool) 모형은 미국 농무성 농업연구소(USDA Agricultural Research Service, ARS)에서 개발된 장기 강우-유출 모형으로, 강우, 유출, 증발 등과 관련된 수문 요소를 조정하여 하천, 저수지 댐 운영을 고려하여 하천 유출량 및 유역의 수문순환을 모의할 수 있는 물리적인 모형이다(Arnold and Allen, 1996). SWAT 모형을 활용하여, 농촌의 소하천의 계절별 유출 특성을 파악하는 연구가 제안되었고(Kim and Jung, 2018), 남한강 유역을 대상으로 다목적 댐 및 다기능 보 운영을 고려한 신뢰도 높은 수문순환을 재현하고 모형의 보정능력을 증가시키는 연구가 수행되었다(Ahn et al., 2016).
M-RAT (Monthly Runoff Assessment Tools) 모형은 Temperature index function (Vandewiele et al., 1992)을 이용하여 강수의 양을 산정하고, 물수지 분석에 기초를 두며 월 유출량을 산정하는 강우-유출 모형이다. Jeung (2019)은 정치적 및 사회적 영향으로 인해 미계측 지역으로 분류된 북한을 대상으로 남한의 유역특성변수를 활용하여 M-RAT의 매개변수 추정식을 산정, 북한의 유역에 적용하여 추정식의 적용성을 검토하였다. 해당 기법을 통해 산정된 매개변수와 기후변화시나리오를 기반으로 북한의 압록강 유역에 적용하여 유역의 추후 특성 변화 동향을 파악하였다(Jeung et al., 2019b).
이러한 강우-유출 모형을 활용하여 장기간의 하천 유입량 및 유출량을 파악하여 수문순환 구조를 분석하기 위해서는 수문 모형이 정확하게 보정돼야 한다. 선행연구들은 모형에 영향을 미치는 매개변수를 고정하지 않고 유역의 특성인자를 기반으로 매개변수를 조정 및 산정하여 모형 결과의 오차를 줄이는 방법을 제안해왔다. Chang et al. (2019)은 수문자료가 제한적인 미계측 유역에 대해 태풍사상에 의한 피해를 대비하기 위한 강우-유출 모형의 지역화 모형을 개발하고 유역을 대표하는 모형 매개변수를 산정하는 연구를 수행하였고, 농업용 저수지 유입량 산정모형 중 하나인 DIROM의 매개변수를 유전자 알고리즘을 활용해 최적화하여 모의결과의 정확도를 향상시켰다(Hong et al., 2021).
유출 모의 시 모형의 매개변수 최적화 과정은 모의 결과의 정확도에 영향을 미치는 중요한 요소로 판단되나, 대부분의 강우-유출 모형을 사용하기 위해서는 다양한 지형, 수문 및 기상 인자들이 입력되어야 하므로 해당 데이터가 부재하는 미계측 지역의 경우 유출량 모의 시 한계가 있다. 앞서 언급한 M-RAT 모형은 월 물수지모형을 활용하여 다른 모델에 비해 입력자료의 구축이 간단하므로 모델 구축 및 적용에 필요한 시간과 비용을 절감할 수 있고, 지역화 기법으로 매개변수 추정이 용이하여 관측 자료가 부족한 유역 및 미계측 유역의 유출량을 계산할 수 있다. 또한, 다양한 기후변화 시나리오를 활용하여 미래 수문순환 변화를 평가할 수 있으며, 물수지 기반 접근법을 사용하는 월 단위 유출량 산정에 적합한 물수지 모델로, 비교적 획득이 쉬운 강수량과 증발산량 데이터를 효율적으로 활용하여 유출 특성을 모의할 수 있다는 장점이 있다.
최근에 하드웨어의 발전에 따라 기계학습 및 딥러닝을 활용하여 데이터의 특성을 학습하고 결과를 예측 및 분석하는 연구들이 활발히 진행되고 있다. 머신러닝 및 딥러닝에 관련된 오픈소스 라이브러리가 공개되며, 수자원 분야에서도 기존에 제안된 기법을 머신러닝으로 대체하여 보다 정확하고 높은 신뢰도의 결과를 도출하는 연구들이 진행되었다. Lee et al. (2020)은 기존에 설계강우-유출 관계 분석법으로 산정하던 설계홍수량을 보완하기 위해 선형 회귀모형과 머신러닝 기법을 활용하여 보다 높은 정확도의 확률 홍수량을 산정하였다. 해안가 지역을 대상으로, 물리모형을 적용하는 데 어려움이 있어 미계측 유역으로 지정하고 머신러닝 기법을 통해 한계강우량을 산정하고 강우-유출분석을 수행하였다(Choo, 2021). 도시지역을 대상으로, SWMM 모형을 강화학습(Reinforcement Learning)과 결합하여 SWMM 모델의 매개변수 자동보정 알고리즘인 SWMM-RL 모델을 개발한 연구가 제안되어 주기별 매개변수 보정을 통해 더욱 높은 정확도를 보임을 확인하였다(Yoon et al., 2022). 선행 연구 결과를 기반으로, 수자원 분야 및 강우-유출 모형에서 머신러닝 기법의 활용이 적합함을 확인하였고, 기존의 기법을 대체함으로써 개선된 결과를 도출함을 알 수 있다.
본 연구는 머신러닝 기법을 활용하여 강우-유출 모형 중 하나인 M-RAT의 매개변수를 최적화함으로써 보다 높은 신뢰도를 가진 매개변수를 도출하는 방법을 제안한다. 기 제안된 기법으로, Jeung et al. (2019a)은 다중회귀분석 기법을 활용하여 유역특성변수 간 상관관계를 분석하고 단계적 회귀분석을 통해 M-RAT 모형 매개변수 지역화식을 산정하는 방법을 제안하였다. 산정된 매개변수는 보정된 매개변수와 0.6이상의 Nash-Sutcliffe 계수(Nash and Sutcliffe, 1970)를 가지며 통계적으로 유의한 모형임을 보였으나, 유역특성변수 간 회귀식을 구성하고 변수를 제거하는 등의 부가적인 과정이 필수적이다. 또한, 지역회귀식의 주요변수가 변함에 따라 상관도가 달라져 모의 결과 또한 정확도가 낮아진다는 한계점이 있다. 따라서, 본 연구에서는 머신러닝 기법을 활용하여 보다 빠르고 높은 정확도를 보이는 M-RAT 매개변수 최적화 기법을 제안하고자 한다. 전처리, 변수 분석 등의 과정을 거치지 않고 머신러닝 모델을 사용하여 유역 변수 및 매개변수의 특징만을 통해 매개변수를 최적화하는 기법을 제안한다. 머신러닝 기법은 지도학습 알고리즘 중 일반적으로 사용되는 SVM (Support Vector Machine), Decision Tree, Random Forest, AdaBoost (AdaptiveBoost) 총 4가지를 활용하였으며, 실제 관측 자료로 보정한 M-RAT 모형의 매개변수(Jeung, 2019) 및 기 제안된 다중회귀식 분석 기법으로 최적화한 매개변수(Jeung et al., 2019a)와 비교를 통해 머신러닝 모델의 성능을 검증하였다. 또한, 최적화된 M-RAT 모형의 매개변수를 사용하여 유역의 유출량 모의에 대한 정확도 검증을 수행하였다.
본 논문의 구성은 다음과 같다. 1장에서는 현재 국내에서 사용되는 강우-유출 모형의 동향과 모형 내부의 매개변수 최적화 방법, 딥러닝의 발전에 따른 수자원 분야에 적용되는 사례를 설명하며 본 연구의 목적 및 필요성에 대해 기술하였다. 2장에서는 M-RAT 모형과 기 제안된 매개변수 최적화 기법인 다중회귀식 분석 기법 및 본 연구의 기술로 활용된 머신러닝 기법에 대해서 서술하였고, 3장에서는 매개변수 최적화를 위해 사용되는 데이터셋과 머신러닝 모델 학습 방법에 대해 서술하였다. 4장에서는 제안된 기법과 다중회귀식 분석 기법을 통해 최적화된 파라미터의 정량적 검증 결과와 M-RAT 모형을 통해 도출된 월 유출량 결과를 비교 및 평가하였다. 마지막으로, 5장에서는 본 연구로부터 도출된 결론 및 한계점과 향후 연구를 기술하였다.
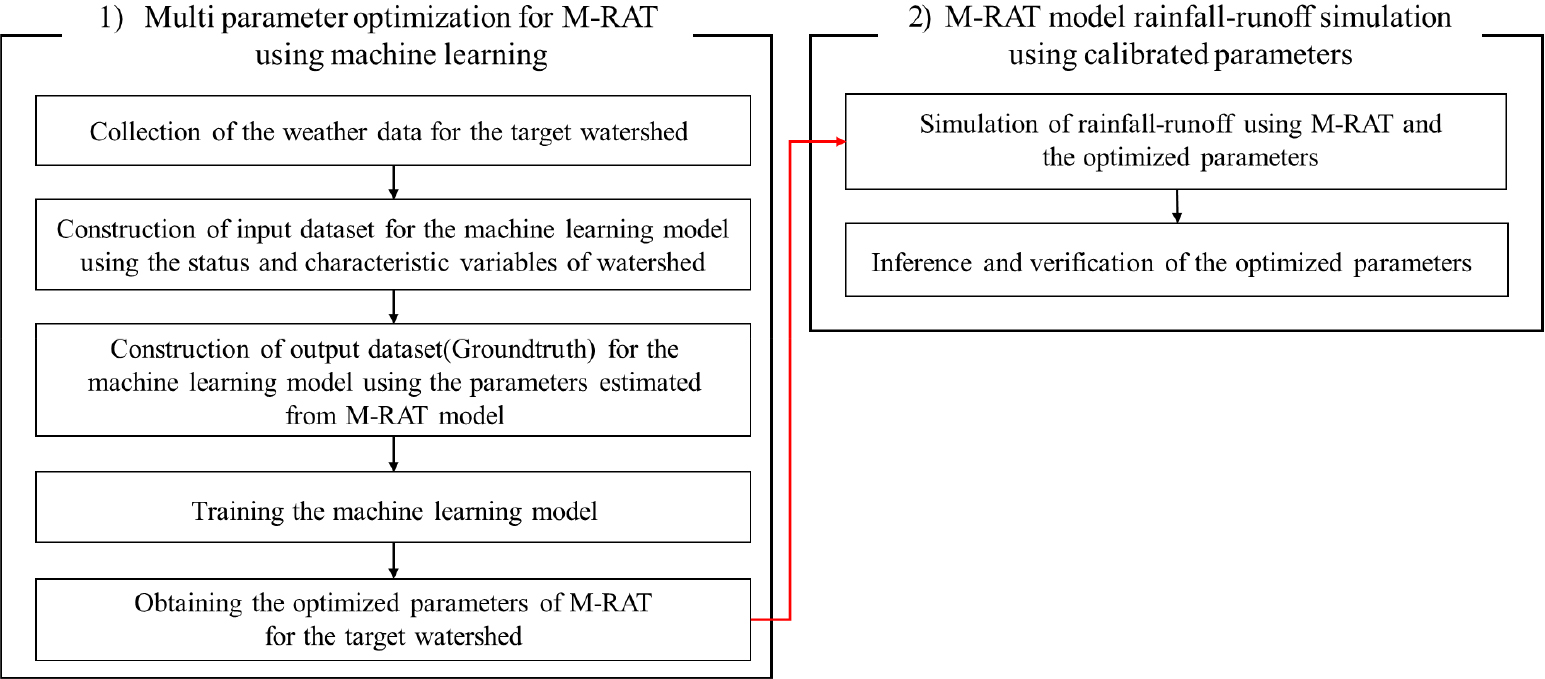
본 연구의 전체적인 흐름은 크게 2개의 과정으로 구분할 수 있으며, 첫 번째는 머신러닝 모델을 활용하여 M-RAT 모형 매개변수 최적화 과정, 두 번째는 최적화된 매개변수와 M-RAT 모형을 이용하여 강우-유출 모의 실행 과정이다. 전체적인 연구 흐름도는 Fig. 1과 같다.
2. 연구 방법
2.1 이론적 배경
2.1.1 M-RAT 모형
M-RAT 모형은 월 유출량을 모의할 수 있는 강우-유출 모형으로, 물수지 방정식을 기반으로 제안되었다(Jeung, 2019). M-RAT 모형에서 이전 달의 적설량은 강설량과 합쳐져 적설 저류량이 되고, 이 중 일부는 기온이 상승함에 따라 녹으며 토양수분 저류량에 기여한다. 강우 중 일부는 증발산에 의해 손실되며, 손실된 나머지 양을 실제 강우량으로 정의하여 실제 강우량이 토양수분 저류량에 기여한다.
유출은 기상 인자 및 지형 지질 인자 간의 특성에 영향을 받으나, 일반화하면 Eq. (1)과 같이 정의할 수 있다.
Eq. (1)에서, 는 강우량, 는 유출량, 는 증발산량, 는 차단량, 는 지표저류량, 는 유역저류수량, 는 침투량을 의미한다.
장기간을 고려하면 Eq. (1)에서 차단량 및 지표저류량은 증발산량 및 토양 수분변화량에 포함되기 때문에 물수지 방정식에서 생략이 가능하다. Eq. (1)을 적용하기 위해 단위시간에 대한 깊이단위로 표시함 변형하면 Eq. (2)와 같이 정의할 수 있다.
Eq. (2)에서, 는 단위시간을 의미한다. Eq. (2)에서 유출량 는 직접유출 성분과 기저유출 성분으로 나눠 고려할 수 있고, 토양수분 변화량은 이전 달의 토양저류수분과 해당 달의 토양저류수분 간의 차이로 고려할 수 있어, Eq. (3)과 같이 정의할 수 있다.
Eq. (3)에서, 는 직접유출, 는 기저유출, 은 이전 달의 유역저류수량, 는 해당 달의 유역저류수량을 의미한다. 우리나라는 강우가 대부분 여름에 집중되어 홍수로 직접 유출되는 수문학적 특성을 가져 해당 기간의 유출량에서 기저유출이 차지하는 비율은 크지않다. 그러나 그 외의 기간에서 기저유출은 유출량 추정에서 적지 않은 비중을 차지하기 때문에, 기저유출 및 이와 관계된 토양수분 변화량과 침투량은 물수지식에 포함돼야 하는 요소이다. 따라서 Eq. (3)은 월 유출량 추정을 위한 기본 수식이라고 볼 수 있다.
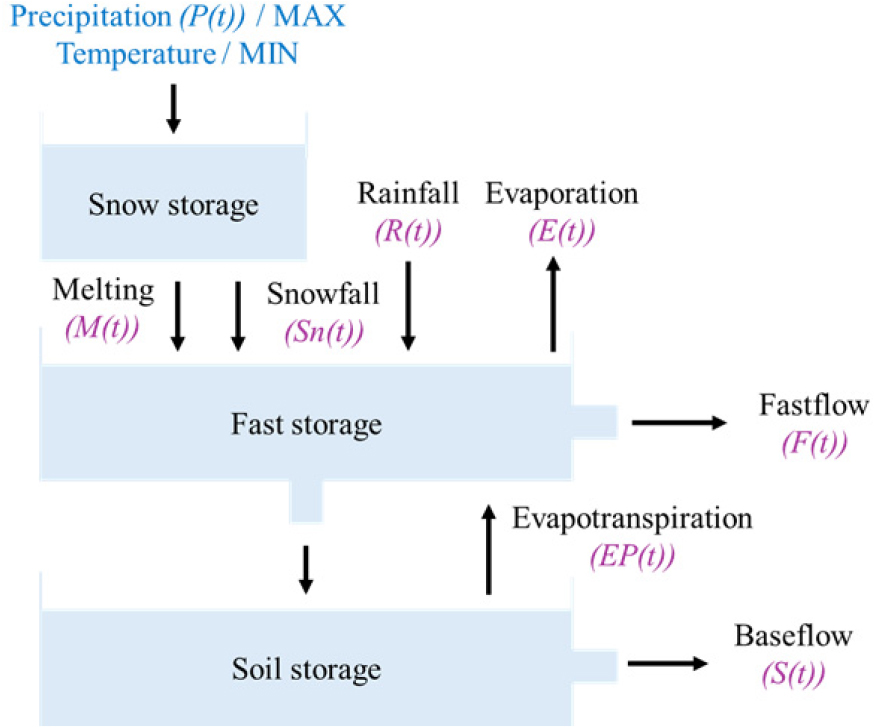
M-RAT의 유출량 추정은 강설량 및 융설량 산정 과정, 증발산량 산정 과정, 기저 및 지표 유출량 산정 과정으로 총 3개의 프로세스로 구분할 수 있다. 전체적인 M-RAT 모형의 동작 방식을 표현하는 개념도는 Fig. 2와 같으며, 자세한 M-RAT의 유출량 추정 방법은 참고문헌에서 설명한다(Jeung, 2019).
2.1.2 다중회귀식 분석 기법을 활용한 M-RAT 모형 매개변수 최적화
일반적으로 강우-유출 모형의 매개변수 검증 및 보정은 모의 자료와 관측 자료 간에 비교로 수행한다. 그러나 관측 자료를 획득하기 어려운 미계측 유역의 경우 통계적인 비교가 어렵다는 한계점이 있다. Jeung (2019)은 미계측 유역인 북한지역의 유출 모형 매개변수를 최적화하기 위해 남한의 계측 유역을 대상으로 매개변수를 검보정하고, 검보정한 매개변수와 유역 특성 변수간에 다중회귀식 분석 기법을 활용하여 미계측 유역에 적용할 수 있는 매개변수 추정식을 제시하였다.
M-RAT 모형의 매개변수들은 유역의 특성에 따라 다르기 때문에 유역 특성 변수와 모형의 매개변수 사이의 관계식을 통해 획득한다. 관계식은 수문모형의 매개변수를 종속변수로 설정하고 유역 특성변수를 독립변수로 하는 회귀식으로 구성된다. 각 유역별 유역 특성 변수가 다양하므로 하나의 종속변수에 두 개 이상의 독립변수가 대응되며, 선형적 관계가 기반이 되기 때문에 다중회귀분석을 주로 사용한다. 일반적으로 다중회귀식은 종속변수 와 독립변수 개로 구성 시 Eq. (4)와 같이 정의한다.
Eq. (4)에서, 자료의 수 의 크기가 보다 크다고 가정할 때, 는 종속변수인 수문모형의 매개변수, 는 절편, 𝛽는 독립변수의 계수, 는 유역의 특성변수, 𝜀은 오차항을 의미한다. 따라서, 수문 모형의 매개변수별로 회귀식이 생성되며, 오차는 서로 상관관계가 없는 , 를 따름을 가정한다.
회귀분석 시 독립변수 간에 상관관계가 높으면 다중공선성(Multi-collinearity)이 있다고 한다. 다중공선성이 생기면 각 변수들의 설명력이 저하되며, 통계적 유의성이 떨어지고, 입력 자료가 변함에 따라 모형의 변동성이 높아진다. 예시로, 두 개의 독립변수만을 갖는 회귀모형을 통한 다중공선성의 영향을 분석 식은 Eq. (5)와 같이 정의할 수 있다.
Eq. (5)에서, 는 과 간에 상관관계, 는 가 1, 2일 때 와 의 상관관계를 의미한다. 좌항의 의 역행렬은 Eq. (6)과 같이 구할 수 있다.
Eqs. (5) and (6)을 이용하여 최소 제곱 추정량을 구하는 식은 Eq. (7)과 같다.
과 간에 상관관계가 높다면 값이 커지고, 값이 1에 가까워지면 Eq. (8)은 +∞로, Eq. (9)는 ±∞로 발산한다.
그러므로 자료의 추가 및 변화에 따라 회귀모형이 쉽게 변동한다. 이는 독립변수가 추가되어도 동일하므로, 회귀분석 시 독립변수들 간의 상관관계를 전부 확인하여 높은 상관관계를 보이는 변수들은 분석 간에서 제거하여야 한다. 다중공선성 분석 방법은 상관관계 행렬(Correlation matrix), VIF (Variance Inflation Factors), Eigen system analysis 등이 있으며, 본 연구에서는 보편적으로 많이 사용되는 VIF를 이용하였다. VIF의 수식은 Eq. (10)과 같다.
Eq. (10)에서, 는 번째 독립변수 계수의 상관관계를 의미한다.
Jeung et al. (2019a)은 M-RAT 매개변수 최적화를 위해 유역 특성 변수 간에 상관관계를 분석했을 때 다중공선성이 존재하여 다중회귀식 분석 기법을 활용한 매개변수 회귀식을 산정하였다. 자세한 회귀식 산정 방법은 참고 문헌에서 설명하며(Jeung et al., 2019a), 각 매개변수(a1, a2, a3, a4, a5, a6, Snow, Soil Low-Water)별 산정된 회귀식은 아래와 같다.
Eq. (11)에서, 는 유역면적, 은 연최저기온을 의미한다.
Eq. (12)에서, 은 유역평균고도를 의미한다.
Eq. (13)에서, 는 유역면적을 의미한다.
Eq. (14)에서, 은 연최저기온, 은 연최고기온을 의미한다.
Eq. (15)에서, 은 연강수량을 의미한다.
Eq. (16)에서, 은 수자원부존량비율을 의미한다.
Eq. (17)에서, 은 연최저기온을 의미한다.
Eq. (18)에서, 은 수자원부존량, 은 유역평균고도를 의미한다.
2.2 연구 방법
2.2.1 서포트 벡터 머신(Support Vector Machine, SVM)
서포트 벡터 머신은 라벨 데이터를 활용하여 학습하는 지도 학습(Supervised Learning) 기반의 모델로, 구조적 위험 최소화(Structural Risk Minimization, SRM) 원리를 사용하는 커널(kernel) 함수 기반 알고리즘이다(Cortes and Vapnik, 1995). 서포트 벡터 머신은 회귀, 분류 및 이상치 탐지 등 다양한 태스크(task)에 모두 적용될 수 있는 강력한 기능을 가진 머신러닝 모델 중 하나이다. 일반적으로 복잡한 분류 문제에서 많이 사용되며, 선형 및 비선형 데이터에서 모두 사용될 수 있고 데이터의 양이 충분히 많지 않을 때에 적합한 모델이다. 해당 모델은 일반화 성능이 높아 과적합 위험이 적다는 장점이 있어, 학습 데이터셋이 많지 않은 본 연구에 적용하기 타당하다고 판단되어 활용하였다.
2.2.2 의사결정나무(Decision Tree)
의사결정나무는 데이터의 특징을 기반으로 데이터를 분류하거나 의사결정을 내리는 데 사용되는 알고리즘이다(Rokach and Maimon, 2005). 결정을 내리기 위해 적합한 분리 기준을 수립하고, 해당 기준으로부터 분리될 수 있는 기준을 또 다시 분리 및 수립하는 트리 구조를 형성하여 의사결정나무라는 이름을 가진다. 분류 및 예측이 모두 가능하며 비정규화 데이터를 처리할 수 있어 다양한 사용이 가능하다. 의사결정나무는 노드 내에 분리 기준이 직관적으로 명시되어 비전문가가 이해하기 쉽고 해석이 용이하다. 본 연구에 적용 시 매개변수를 최적화하는 과정을 직관적으로 살펴볼 수 있다는 장점이 있어 활용하였다.
2.2.3 랜덤 포레스트(Random Forest)
랜덤 포레스트는 배깅(Bagging) 앙상블 기법 중에 대표적인 모델로, 이름에서도 유추할 수 있듯 의사결정나무를 활용한 앙상블 기법 중에 하나이다(Ho, 1995). 의사결정나무를 여러 개 묶어 앙상블을 형성하고 Voting 및 Averaging 기법을 통해 결과를 예측 및 분류하는 모델이다. 복잡한 결정 경계를 고려할 수 있고, 많은 수의 의사결정나무를 기본 모형으로 구축하기 때문에 단일의 의사결정나무보다 더 우수한 성능을 보인다. 랜덤 포레스트는 결측치를 다루기 쉽고, 무작위로 표본을 추출하기 때문에 비교적 과적합이 될 가능성이 적으며, 앞서 언급한 Decision Tree를 활용하기에 두 모델 간 성능 비교 또한 가능하므로 본 연구에 활용하였다.
2.2.4 AdaBoost (Adaptive Boost)
에이다부스트는 앙상블 기법 중에 부스팅(Boosting) 기법을 활용한 대표적인 모델로, 여러 개의 약한 학습기를 결합하여 하나의 강한 결합기를 생성하는 알고리즘이다(Schapire, 2013). 에이다부스트는 약한 학습기로 하나의 노드와 두 개의 가지로 구성된 의사결정나무의 형태를 가진 스텀프(stump)를 개별 모델로 사용한다. 에이다부스트는 모든 스텀프의 예측값에 가중치를 곱하여 합하는 하드 보팅을 통해 예측값을 획득하며, 결과 예측 및 분류에 모두 사용될 수 있다. 에이다부스트는 이전 단계 스텀프의 오분류를 다음 스텀프에서 보완함으로써 데이터의 특징을 점진적으로 학습하는 순차적 학습을 한다는 특징을 가지며, 학습된 에이다부스트 모델은 각 스텀프별 가중치를 통해 결과를 해석할 수 있다. 에이다부스트는 랜덤포레스트와 같이 앙상블 기법 기반의 모델로 동일한 데이터를 활용한 성능 비교가 가능하여 본 연구에 활용하였다.
3.M-RAT 모형 매개변수 최적화를 위한 데이터셋 구축 및 학습 방법
3.1 대상 유역 선정
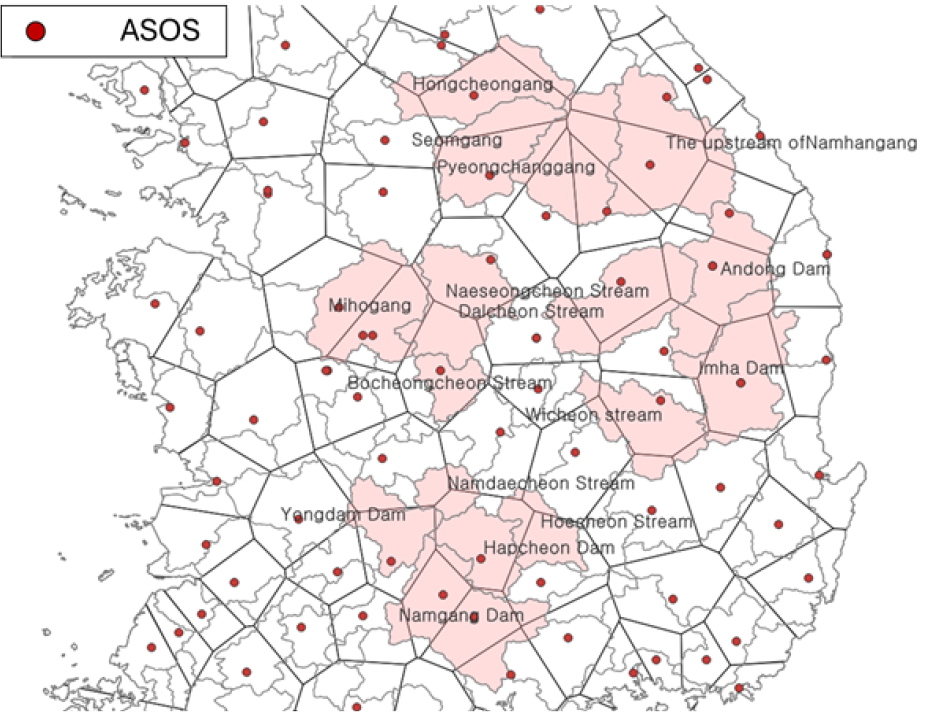
본 연구의 목적인 M-RAT 모형의 매개변수를 최적화하기 위해서 유출 특성을 일관성있게 반영하는 양질의 유량 자료가 있는 대상 유역을 선정해야 한다. 대상 유역 선정 조건은 인위적인 영향이 크지 않은 유량 흐름에서 수위, 강수량, 기온, 유량 등에 대한 신뢰성 있는 자료를 확보할 수 있어야하고, 수위-유량 관계곡선식이 존재하는 유역이어야 한다. 이와 같은 조건을 기반으로WAMIS (Water Resources Management Information System)에서 제공하고 있는 유역 중 해당 조건을 충족하는 16개의 유역을 선택하였다. 대상 유역은 Table 1과 Fig. 3과 같으며, Fig. 3은 대상유역의 기상청 ASOS (종관기상관측) 관측소 및 티센 면적망을 도시한 그림이다.
Table 1.
The selected watershed
3.2 대상 유역 현황 및 유역 특성 변수
선정된 대상 유역을 대상으로 각 유역 현황 및 유역 특성 변수를 수집하여 데이터를 구축하였다. 각 유역별 기상자료는 기상청에서 제공하는 기상관측소의 월 강수량 및 월 평균기온을 활용하여 적용하였으며, 유역 내에 기상 관측소가 없을 시 티센 면적망 방법을 통해 해당 유역 주변의 기상 관측소에서 측정된 값을 사용하였다.
유출량 산정을 위한 M-RAT모형의 입력 자료인 강수량, 잠재 증발산량, 평균 기온 자료는 대상 유역 내의 기상 관측소로부터 획득한 값을 사용하였다. 관측 수문 자료의 수집 기간은 수집 기간의 통일성을 위해 1976년부터 2020년까지 관측된 자료를 사용하였다. 대상 유역의 평균 강수량은 티센 면적망 방법을 이용하여 유역별로 평균 월강수량을 획득하였다. 잠재 증발산량은 Thornthwaite식을 사용하였다. 각 대상 유역별 월 유출량 자료는 환경부 한강홍수통제소 국가수자원관리종합정보시스템인 WAMIS에서 공식적으로 제공하는 장기 유출량 데이터를 획득하여 사용하였으며 유역단위의 유출량을 사용하였다. 해당 데이터는 환경부에서 수위-유량곡선 및 실측유량을 기반으로 하천별 하류 유역의 총유출량을 모형과 관측자료를 바탕으로 생산한 데이터로, 수문 전문가의 검토를 거치고 수자원통합모형의 결과를 보정한 후 공개된 신뢰성 높은 자료이다. 단순 모형 산정치가 아닌 국가단위 수자원 관리 계획 수립을 위해 검정을 거친 자료로 본 연구에 적용 가능하다고 판단되었다. 구축된 유역 현황 및 유역 특성 변수는 Table 2와 같다.
Table 2.
The watershed status and characteristic variables of watershed
3.3 M-RAT 모형 최적 매개변수
M-RAT 모형의 최적 매개변수를 결정하기 위해 1976년에서 2000년 까지를 대상으로 M-RAT 모형을 보정하였고, 2001년부터 2015년까지의 값을 대상으로 매개변수의 정확도를 검증하였다. 각 대상 유역별 최적화한 매개변수 값은 Table 3과 같다.
Table 3.
The Parameters estimation of M-RAT Model
a1과 a2는 강설 및 융설에 관련된 매개변수로, 기온이 a2 매개변수보다 높다면 융설이 발생, a1과 a2 사이의 값이라면 강설과 융설이 동시에 발생, a1 매개변수보다 높다면 강설이 중단된다. 매개변수 a3는 잠재증발산량에 관련된 변수, 매개변수 a4는 실제 증발산량에 관련된 변수, 매개변수 a5는 유역의 기저 유출량에 관련된 매개변수, 매개변수 a6는 지표 유출량에 관련된 매개변수이다. Snow와 토양저류수분(Soil Low- Water)은 각 모형의 초기값으로, 시계열 자료의 전반부 3년 동안의 자료를 활용하여 산정된다.
3.4 학습 및 검증 데이터셋 구축
머신러닝 모델 학습 및 검증을 위해 구축된 데이터셋을 학습 데이터셋과 검증 데이터셋으로 분할하였다. 학습 대상 유역은 총 13 지점(남강댐, 남한강 상류, 내성천, 달천, 남대천 보청천, 섬강, 안동댐, 용담댐, 위천, 임하댐, 평창강, 회천), 검증 대상 유역은 총 3 지점(미호강, 합천댐, 홍천강)으로 구분하였다. 검증 대상 유역은 총 3지점으로, 모두 다른 대권역에 위치하는 유역으로 검증을 수행하기 위해 한강의 홍천강, 낙동강의 합천댐, 금강의 미호강을 선택하였다. 데이터셋 수집 기간은 1976년에서 2020년까지이다.
머신러닝 모델의 입력값은 3.2에서 설명한 대상 유역 현황 및 유역 특성 변수로 총 12개의 변수로 구성된다. 출력값은 3.3에서 설명한 M-RAT 모형 최적 매개변수로 총 8개의 변수로 구성된다. 데이터 전처리는 수행하지 않았으며, 13개의 유역별 12개의 학습변수를 사용하여 총 13×12 크기의 입력 데이터셋이 구축되었다.
3.5 머신러닝 모델 학습
머신러닝 모델은 Python 기반의 라이브러리인 Scikit-learn (sklearn) 1.5.0 버전을 사용하여 구축하였다. 본 연구에서 사용된 모델별 학습 파라미터 및 값은 Table 4와 같다.
Table 4.
The Parameters of Machine Learning Models
머신러닝 모델은 각 매개변수별 모델을 사용하여 하나씩 학습 및 검증되었다. SVM으로 예를 들어, SVM 기반의 모델을 구축하여 a1, a2, a3, a4, a5, a6, snow, soil 매개변수를 사용해 총 8개의 알고리즘이 학습되었다. 다른 머신러닝 모델도 마찬가지로 학습 및 검증되었으며, 각 매개변수별로 총 4개의 알고리즘이 학습된 것이며, 결과적으로 4개의 머신러닝 모델을 사용한 알고리즘과 총 32개의 가중치가 도출되었다.
4. M-RAT 매개변수 최적화 결과
4.1 정량적 검증 지표
머신러닝 모델별 매개변수 최적화 성능을 검증하기 위한 정량적 검증 지표는 MAE (Mean Absolute Error)와 MAPE (Mean Absolute Percentage Error)를 사용하였다. MAE는 실제값과 예측값의 차이(Error)의 절대값의 평균값으로 머신러닝 모델로부터 생성된 매개변수와 최적 매개변수 간에 오차율을 계산하기 위해 사용하였다. MAPE는 MAE를 퍼센트로 변환한 값으로, 크기에 관계없이 절대적인 차이를 비교하여 모델 간 성능을 비교하기 위해 사용하였다.
M-RAT 유출량 모의의 정확도를 검증하기 위한 정량적 검증 지표는 R2 score를 사용하였다. R2 score는 선형 회귀 분석 시 회귀 모델의 적합도를 나타내는 지표 중 하나로, 획득된 매개변수를 활용하여 M-RAT 모형을 통한 대상 유역에 대한 모의 유출량의 정확도를 계산하기 위해 사용하였다.
4.2 모델별 매개변수 최적화 결과
모델별 M-RAT 모형 매개변수 최적화 결과는 Table 5와 같다. 모델을 통해 도출된 매개변수 중 최적 매개변수와 가장 가까운 값을 가진 매개변수는 SVM을 통해 가장 많이 획득되었다. a1의 경우, 모든 검증 유역에 대해 SVM을 통해 획득된 매개변수가 가장 최적 매개변수에 가까웠다. 이외에도 총 8개의 매개변수 중 미호강은 5개, 합천댐은 4개, 홍천강은 2개로 대부분의 매개변수와 모든 검증 유역에 대해 높은 정확도를 보였다.
Table 5.
Model Parameters and Predicted Parameters
Decision Tree와 AdaBoost는 기존의 다중회귀식 분석 기법과 동일한 개수인 3개의 매개변수에서 최고값을 보였다. 특히, Decision Tree는 홍천강에 대해 높은 정확도의 매개변수를 생성하였고, AdaBoost는 합천댐과 홍천강에 대한 높은 정확도의 매개변수를 생성하였다.
Tables 6 and 7은 모델별 각 매개변수의 MAE 및 MAPE값을 나타낸다. 오차율 비교 시 머신러닝 모델별 특성 및 매개변수별 특성 고려에 집중하기 위해, 검증유역 3곳별 MAE와 MAPE의 평균값으로 비교하였다. 먼저, 머신러닝 모델별 오차율을 비교한 결과, MAE를 확인했을 때 모델 중 Random Forest가 가장 낮은 오차율을 보임을 확인할 수 있었다. 이 외에 대부분의 유역에서 매개변수를 가장 높은 성능으로 최적화한 SVM 모델 또한 낮은 오차율을 보이는 경향이 있었다. MAPE를 확인했을 때, 최적화 결과 및 MAE 결과와 비슷하게 SVM이 가장 낮은 오차율을 보였다.
Table 6.
The Average of Mean Absolute Error of models for the validation watershed
Table 7.
The Average of Mean Absolute Percentage Error of models for the validation watershed
이러한 결과는 데이터의 분포 형태에 의해 도출되었다고 판단된다. 머신러닝 알고리즘 성능은 주로 데이터의 특성 및 분포에 따라 결정되는데, 입력되는 대상 유역 변수는 클래스 간 경계가 명확한 편이어서 선형적으로 분리가 잘 되며 학습 데이터셋의 크기가 크지 않다는 특징을 가진다. 이는 SVM이 결정 경계를 학습할 때 보다 안정적으로 경계를 생성할 수 있게끔 하며, 이로 인해 SVM 기반의 알고리즘이 가장 최적화된 매개변수를 생성하는 것으로 판단된다. SVM 다음으로 높은 성능을 보이는 Random Forest는 앙상블 기법을 활용한 모델로 여러 개의 약한 학습기를 활용하여 최적의 결과를 산정하기 때문에 비교적 낮은 오차율을 보이는 것으로 판단된다.
매개변수별 오차율을 확인한 결과, a3의 오차율은 전반적으로 낮고 a6는 높은 경향을 보인다. 이는 지도학습 기반 모델의 한계에 기인하는데, 지도학습은 학습 데이터셋의 특성 및 분포를 기반으로 데이터의 패턴을 학습하기 때문에 입력 변수의 값 범위, 출력값의 스케일, 노이즈 정도 등이 모델의 학습 결과와 일반화 성능에 직접적인 영향을 미친다. a3 매개변수의 경우, 학습 데이터 내 분산이 크지 않아 모델이 분포를 안정적으로 학습하였고 이에 따라 높은 일반화 성능을 보였다. 반면 a6 매개변수의 경우, 유역 간 값의 분산이 매우 커 모델이 분포 전반을 학습하기에 다른 매개변수에 비해 어려워 일반화 성능이 저하될 수 있다. 검증 유역의 라벨값인 실제 매개변수 값이 학습 데이터의 분포 범위를 벗어날 경우, 머신러닝 모델은 학습된 경향성을 기반으로 최적화를 수행하므로 상대적으로 큰 오차율이 발생하는 것으로 해석할 수 있다.
4.3 M-RAT 모형 유출량 모의 결과
모델별로 획득한 매개변수를 통해 M-RAT 모형을 활용하여 검증유역에 대해 유출량을 모의하였다. 각 모델별 검증 유역에 대한 R2 score는 Table 8과 같으며, 최적 매개변수를 활용한 유출량 모의 결과(Jeung, 2019)는 부록에 작성하였다. 모든 검증 유역에 모의 유출량은 다중회귀식 분석보다 머신러닝 모델로 획득한 매개변수를 활용했을 때 더 높은 정확도로 검증되었다. 특히, 다중회귀식 분석으로 모의한 홍천강과 합천댐의 유출량은 각각 0.39, 0.41의 R2 score를 달성했으나, 머신러닝 모델을 활용하여 획득한 매개변수를 사용했을 때는 각각 최대 0.77, 0.67의 R2 score를 달성하였다.
Table 8.
R2 score of models
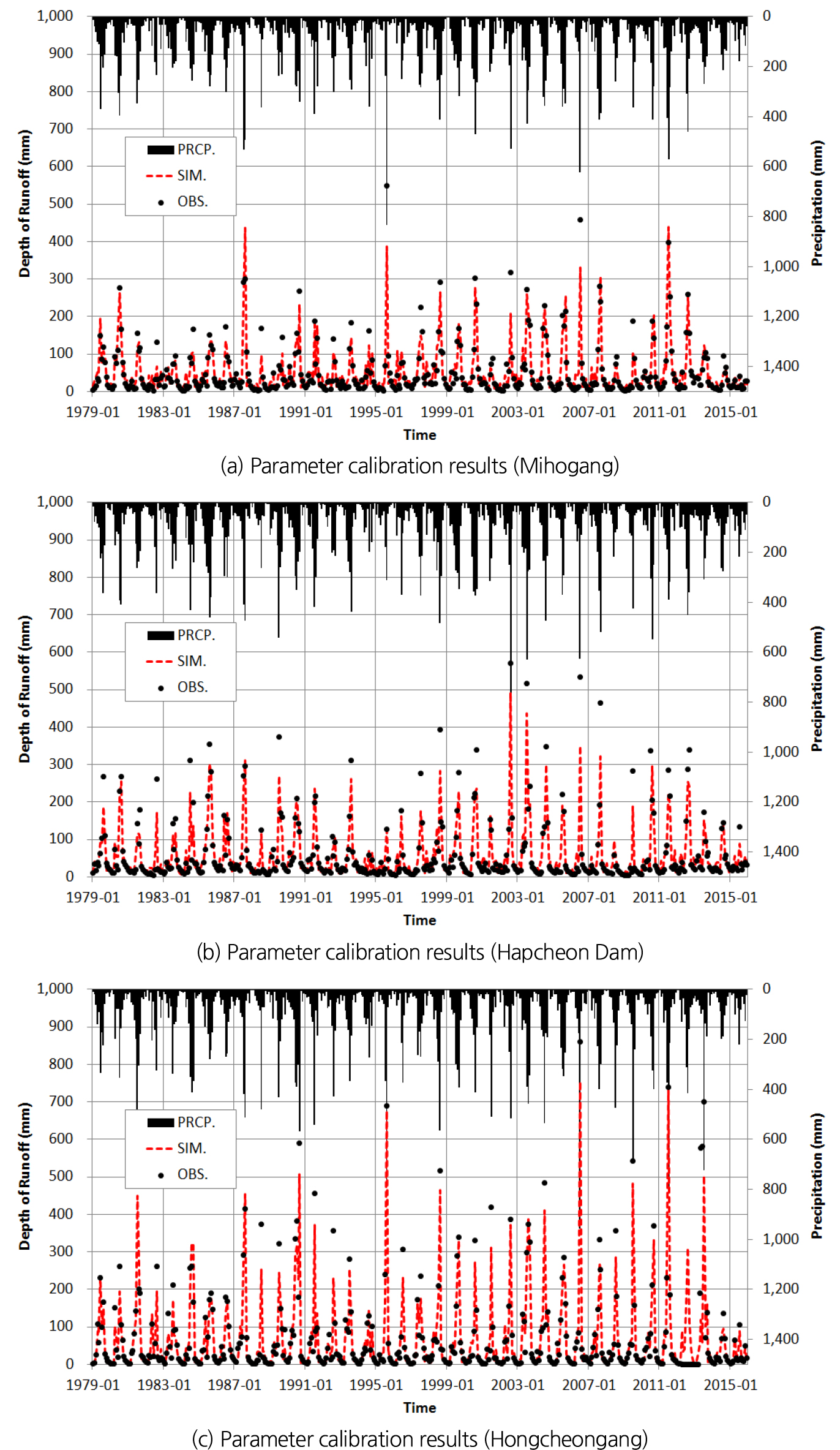
정성적 결과를 확인하기 위해 대상 유역별 유출량 모의 결과를 그래프로 살펴보았다. 다중회귀식 분석 기법으로 최적화한 매개변수를 활용한 유출 모의 결과와 머신러닝으로 최적화한 매개변수를 활용한 유출 모의 결과를 비교하였으며, 머신러닝을 활용한 결과의 경우 최고 성능을 보이는 모델의 그래프로 비교하였다. 만약 대상 유역에서 머신러닝별 정량적 성능이 동일하다면 하나의 모델을 임의로 선택하였으며, 모든 대상 유역에 대해 머신러닝 모델이 겹치지 않게끔 선택하였다. 따라서, 미호강은 Random Forest, 합천댐은 AdaBoost, 홍천강은 SVM을 활용한 유출량 그래프로 결과를 살펴보았다.
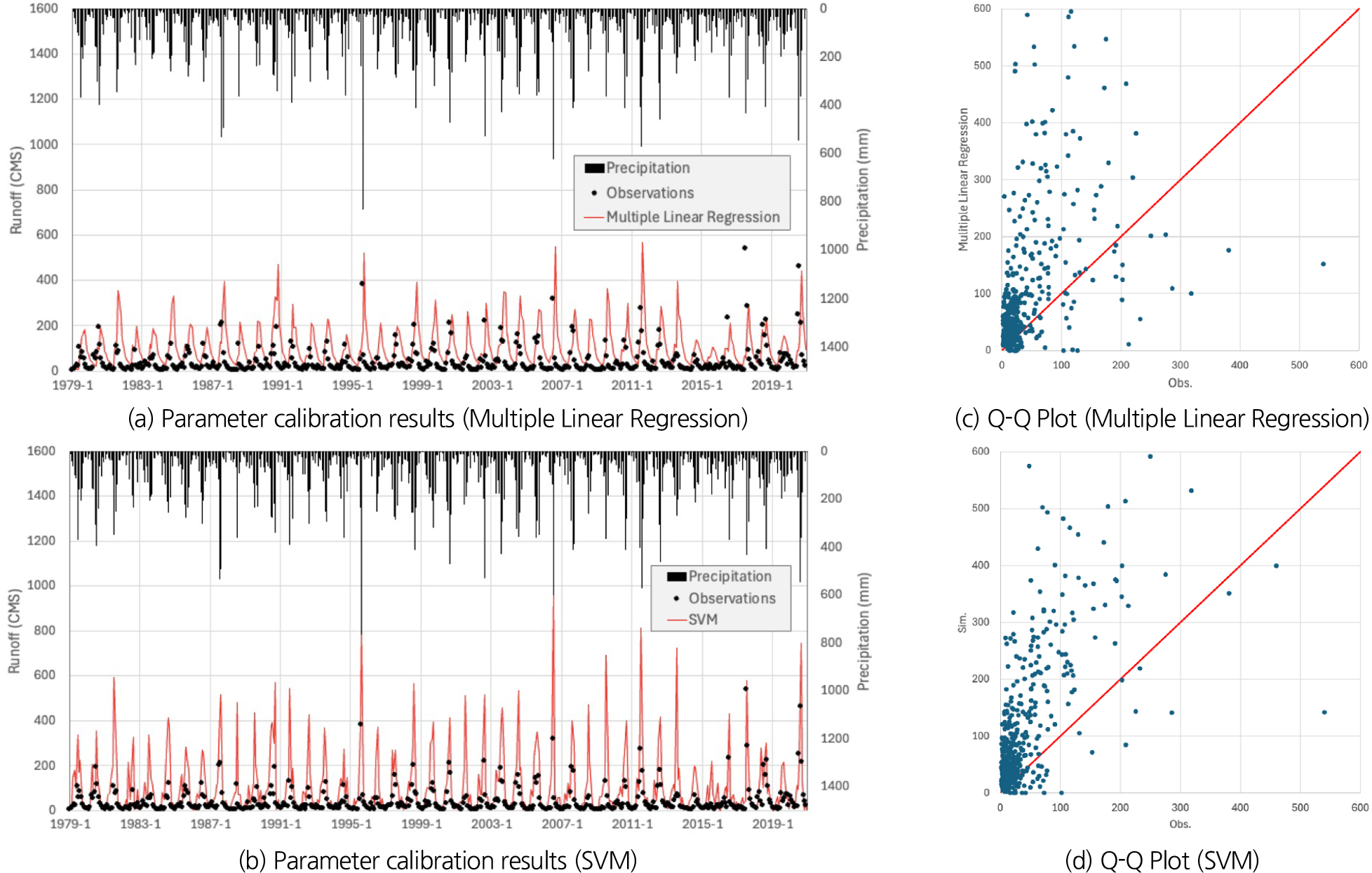
Fig. 4는 미호강의 유출량 모의 결과를 설명하는 그래프이다. Fig. 4(a)는 다중회귀식 분석으로, Fig. 4(b)는 Random Forest로 획득한 매개변수를 활용하여 유출량을 모의한 결과, Figs. 4(c) and 4(d)는 각 모델별 결과값을 분포시킨 Q-Q Plot 그림이다. 미호강을 대상으로 유출량 모의 결과의 정량적 정확도에는 큰 차이가 없었으나, 다중회귀식 분석으로 획득한 매개변수의 경우 첨두홍수량 값이 큰 차이를 보이나 장기유출에서 중요한 요소인 기저유출을 흡사하게 모사하였기 때문에 R2 score가 비교적 높게 계산된 것으로 판단된다. 미호강 유역은 실제 유출량보다 M-RAT 모형이 과대 산정을 하는 경향으로 모의되었는데, 유역 주변에 대청댐, 괴산댐 등이 있어 실제 관측값이 강우량에 비해 적게 관측되었다.
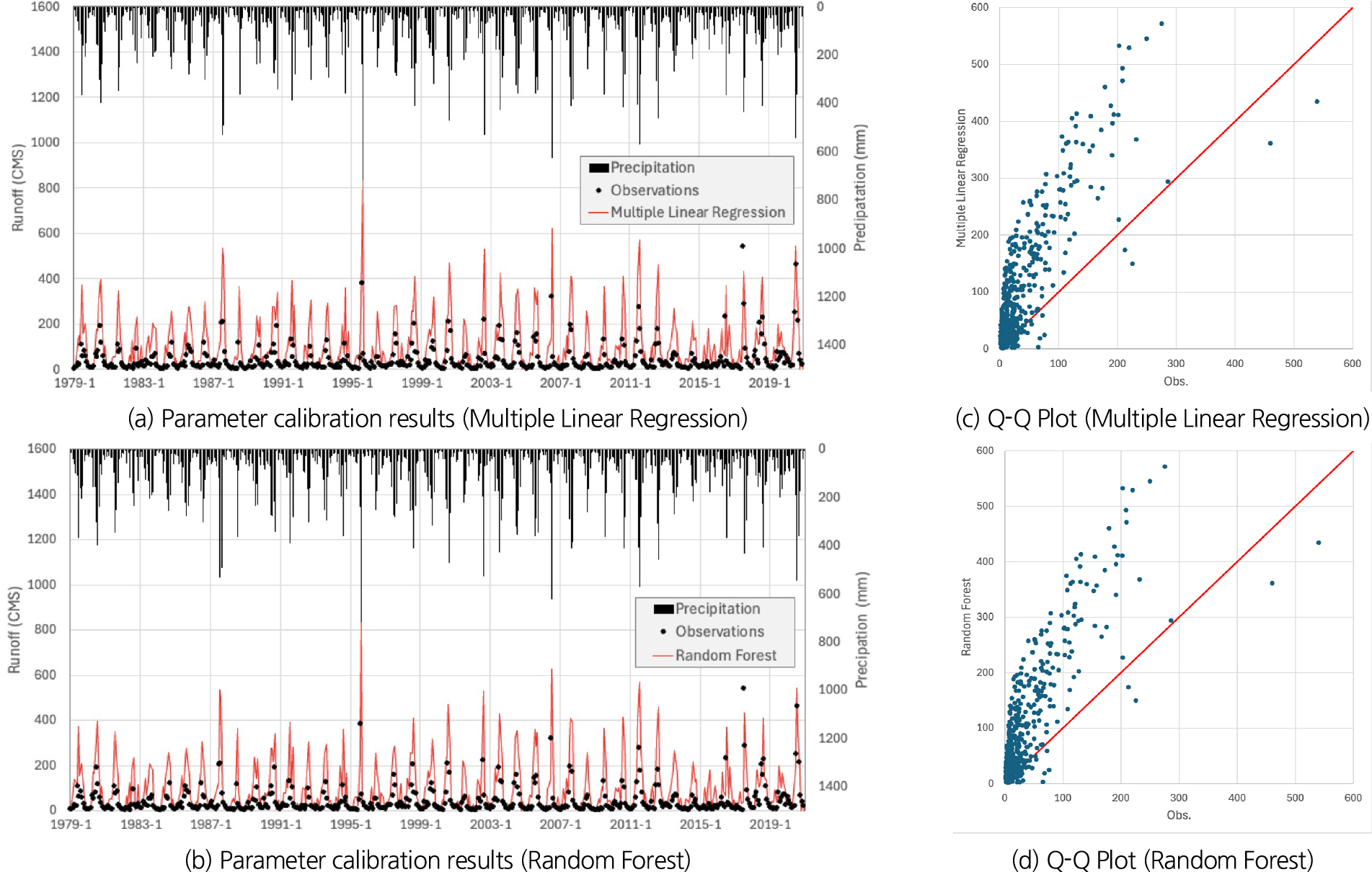
Fig. 5은 합천댐의 유출량 모의 결과를 설명하는 그래프이다. Fig. 5(a)는 다중회귀식 분석으로, Fig. 5(b)는 AdaBoost로 획득한 매개변수를 활용하여 유출량을 모의한 결과, Figs. 5(c) and 5(d)는 각 모델별 결과값을 분포시킨 Q-Q Plot 그림이다. 미호강에 비해 합천댐 검증 시, 머신러닝 모델들이 다중회귀식 분석 기법에 비해 전반적으로 우수한 성능을 보였으며 이로 인해 유출량 모의 정확도 또한 비교적 크게 높아진 것으로 판단된다. 특히, 많은 강우량으로 인해 관측 유출량이 늘어나는 시점에 비교적 높은 정확도를 보였다. 다중회귀식 분석은 저수위, 갈수위에 해당하는 유량 예측 시 낮은 정확도를 보였다.
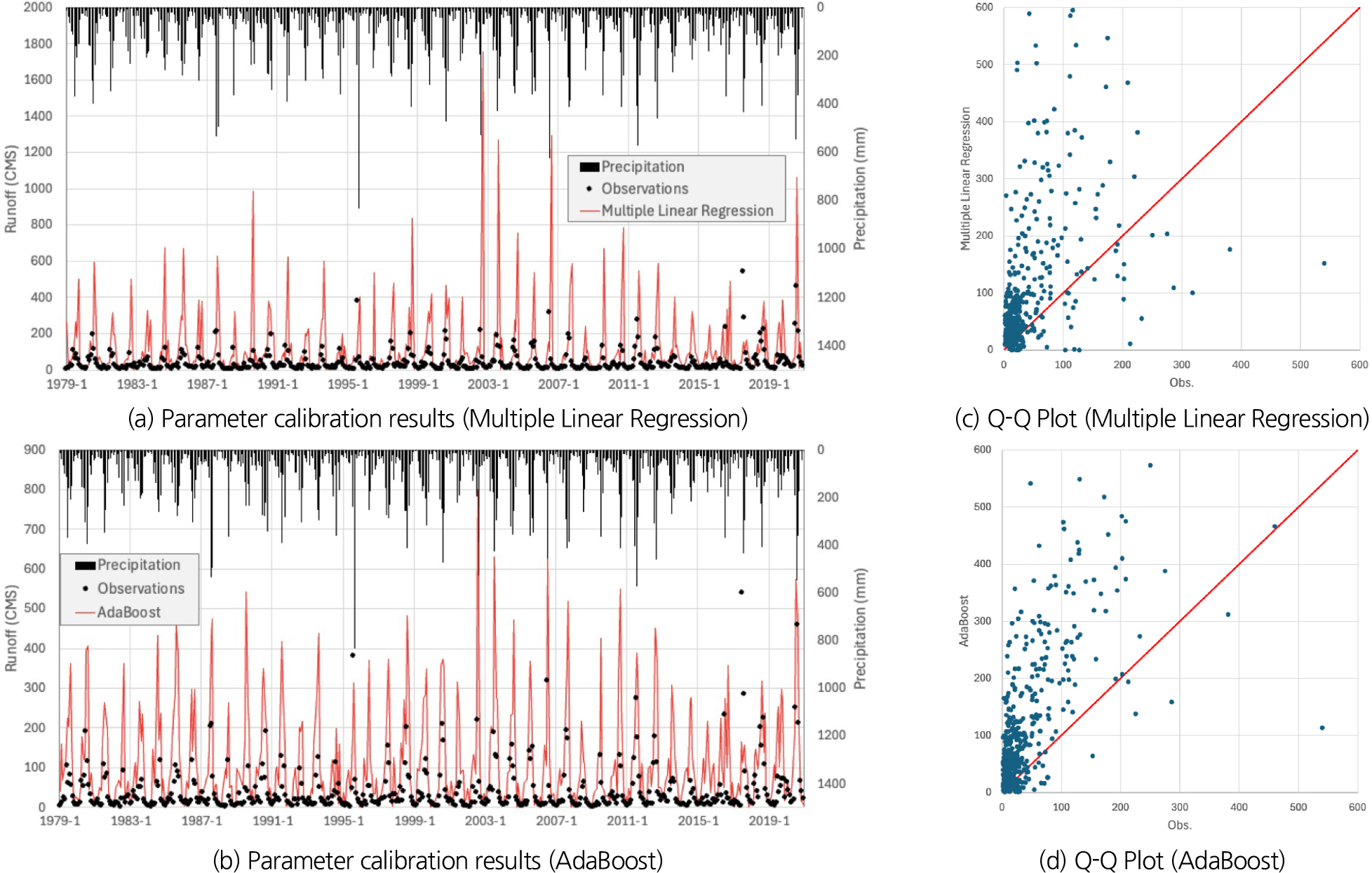
Fig. 6는 홍천강의 유출량 모의 결과를 설명하는 그래프이다. Fig. 6(a)는 다중회귀식 분석으로, Fig. 6(b)는 SVM으로 획득한 매개변수를 활용하여 유출량을 모의한 결과, Figs. 6(c) and 6(d)는 각 모델별 결과값을 분포시킨 Q-Q Plot 그림이다. 홍천강 유역 검증 결과를 살펴보면 다중회귀식 분석 기법의 정량적인 정확도는 비교적 낮게 측정되었다. 특히, 합천댐과 비슷하게 저수위 및 갈수위에 해당하는 유량의 예측 정확도가 떨어지는 경향을 보였다. 홍천강 유역은 주변 지역이 산악지형으로 하천의 굴곡이 심해 강우의 도달 시간이 길어 강우 유입에 시간이 지체되는 특성이 있으나, M-RAT 모형은 물수지 모형으로 지형적 유입 지연을 고려하지 못해 초기 유출량이 관측값에 비해 과대로 산정되는 경향이 나타났다.
검증 유역을 대상으로 유출량 모의 시 머신러닝 모델 기반 매개변수를 활용하였을 때 전반적으로 우수하게 모의됐으며, 이는 매개변수 최적화 시 머신러닝 모델의 정량적 성능이 다중회귀식 분석 기법보다 비교적 높은 점이 영향을 미친 것으로 판단된다.
5. 결론 및 토의
본 연구는 M-RAT 모형을 활용한 유역의 유출량 모의 시 필요한 매개변수 최적화를 위해 머신러닝 기법을 활용하여 모의의 정확도를 높이는 것을 목적으로 하였다. 대상 유역은 총 16개의 지점으로 머신러닝 모델 학습을 위해 데이터셋을 구축하였고, 13개는 학습용, 3개는 검증용으로 사용하였다. 입력 데이터셋은 1976년부터 2020년까지 총 12개의 각 유역별 유역 현황 및 유역 특성 변수를 활용하였다. 출력 데이터셋은 매개변수 보정을 통해 획득한 총 8개의 최적의 M-RAT 매개변수를 활용하였다.
M-RAT 매개변수 최적화를 위한 머신러닝 모델은 SVM, Decision Tree, Random Forest, AdaBoost 총 4개를 사용하였다. 검증 유역인 미호강, 합천댐, 홍천강 3곳 모두 머신러닝으로 최적화한 매개변수가 기 제안된 기법인 다중회귀식 분석으로 획득한 매개변수에 비해 높은 정확도로 최적화되었다. 최적화 결과의 정확도는 SVM이 가장 높았으며, Random Forest가 다음으로 높은 성능을 보였다. 다만, 매개변수별 오차율 차이가 큰 경향을 보였는데, 매개변수별로 데이터 분포가 달라 지도학습 시 일반화 성능이 떨어진다는 점을 고려하여 추후 매개변수별 적합한 전처리 기법을 적용하면 오차율을 감소시킬 수 있을 것으로 기대된다.
M-RAT 모형의 유출량 모의 또한 머신러닝 모델을 활용한 매개변수 활용 시 비교적 정확한 모의 결과를 도출하였다. 다중회귀식 분석으로 최적화한 매개변수를 활용한 모의 결과, 검증 지점 대상 전반적으로 저수위, 갈수위에 해당하는 유량의 예측율이 떨어지는 경향을 보였다. 머신러닝 모델로 최적화한 매개변수를 활용한 모의 결과가 다중회귀식 분석에 비해 평균적으로 약 19% 정량적 정확도가 높게 산정되었다.
매개변수 최적화 시, 머신러닝 모델은 구조적 차이는 존재하나 동일한 입력 데이터셋을 활용하므로 매개변수 최적화 시 더 많은 수의 특성을 고려하면 모델의 성능이 높아질 가능성이 있다. 향후 유역 현황 및 특성 변수 항목을 추가하여 입력 데이터셋 차원을 높이면 오차율을 보다 낮추며 매개변수의 최적화가 가능할 것으로 기대된다. 또한 M-RAT 매개변수별 특성을 분석하여 모델별 영향을 주는 특성을 고려한 모델 파라미터 튜닝을 통해 정확도 향상을 기대할 수 있다.
M-RAT 모형을 활용한 모의 유출량 분석 결과, 일부 유역에서는 모형 산정 유출량이 관측값보다 과대 또는 과소로 나타나는 구간이 확인되었다. 예를 들어, 1996년에서 1997년 사이 모형 결과에서 미호강 유역에서는 실제 관측 유량보다 과대 산정되었으며, 합천댐 유역에서는 과소 산정되었다. 이는 해당 시기의 단기 집중호우와 같은 순간 유출 증가가 월평균 단위로 환산된 유출량 데이터에 충분히 반영되지 못한 데 기인한 것으로 판단된다. 이는 M-RAT 모형이 월 단위 유출량을 입력자료로 사용하는 구조적 특성으로 인해, 일시적 유출 급증이나 국지적 강우에 민감하게 반응하지 못하는 시간 해상도의 한계를 내포하고 있기 때문이다. 향후 M-RAT 모형 개선을 통해 데이터의 시간적 및 공간적 단위를 세부적으로 고려한다면 머신러닝 모델을 활용하여 최적화된 매개변수를 통해 모의 유출량 분석 산정 결과의 정확도를 보다 향상시킬 수 있을 것으로 기대된다.