

1. 서 론
1.1 연구 배경과 중요성
1.2 기존 연구의 한계
1.3 연구 목적 및 기여
2. 문헌 고찰 및 이론적 배경
2.1 하구둑 관련 성능평가 현황
2.2 베이지안 네트워크 이론적 배경
2.3 관련 선행연구 검토
3. 연구 방법론
3.1 연구 절차 및 데이터
3.2 변수 도출 및 선정 근거
3.3 DAG 구조 설정 및 CPT 구축
4. 연구 결과
4.1 모델 학습 및 검증 결과
4.2 혼동행렬 및 성능지표 제시
5. 요약 및 결론
1. 서 론
1.1 연구 배경과 중요성
하구둑은 하천 상류의 유입수와 해수 조위의 상호 영향을 조절함으로써 배수, 수질 관리, 해수 역류 방지 등 다양한 기능을 동시에 수행하는 복합 수자원시설이다. 특히 도심지 하구부에 설치된 하구둑은 홍수기에는 상류 유입 하중, 평수기에는 조위 역류 및 해수 염분 침투에 동시에 노출되는 구조적 특성을 가지므로, 사고 발생 시 광범위한 침수 및 사회·경제적 기능 마비로 이어질 가능성이 높다. 이에 따라 하구둑에 대해서는 지속적이고 정량적인 성능평가 및 유지관리 체계 구축이 필수적이다. 국내에서는 2018년 「시설물의 안전 및 유지관리 관련 특별법」 개정을 계기로 하구둑을 포함한 수자원시설에 대한 정기적인 성능평가 제도가 본격 도입되었으며, 이에 따라 구조 안정성뿐만 아니라 갑문·배수 설비의 작동성, 조위 영향에 대한 대응성, 유지관리 체계 등 다양한 측면을 종합적으로 평가하도록 하고 있다.
그러나 기존 종합성능평가 방식은 평가 항목이 많고 절차가 복잡하여 실제 현장에서 신속한 판단에 활용하기 어렵다는 한계가 있다. 이에 본 연구는 주요 성능 요인만을 활용해 하구둑의 종합성능등급을 간편하게 예측할 수 있는 베이지안 네트워크 기반 확률모델을 개발하고자 하였다. 또한 본 논문은 기존 종합성능평가의 복잡한 절차를 단순화하면서도 주요 요인을 바탕으로 등급을 신속히 예측할 수 있는 방법을 제시하고 그 적용 가능성을 검증하였다. 이를 통해 학문적으로는 성능평가 기법의 실용적 확장 가능성을 탐색하였으며, 정책적으로는 수자원시설 유지관리 효율화를 위한 기초 연구로서의 방향성을 제시한다.
1.2 기존 연구의 한계
현재 적용되고 있는 종합성능등급은 항목별 평가점수를 가중 평균하여 산출하는 단일 시점의 진단 결과에 불과하므로, 시간의 경과에 따른 성능 저하 예측, 향후 유지보수 시점 판단, 예산의 우선순위 설정 등과 같은 실제 의사결정 지원에는 한계가 있다(MOLIT, 2017; 2021). 이와 유사한 문제의식은 해외 기반시설 연구에서도 제기되어 왔는데, 예를 들어 교량(Kamariotis et al., 2022)과 댐(Li and Ji, 2023) 관리 분야에서는 베이지안 네트워크를 활용해 불확실성을 반영하고 성능 저하를 예측하는 시도가 이루어지고 있다. 이러한 해외 사례는 하구둑 분야에서도 확률적 예측모델 도입의 필요성과 학문적·실무적 의의를 뒷받침한다. 또한 기후변화, 사고 이력 등 다양한 요인이 복합적으로 작용하여 성능이 변동되는 하구둑의 특성을 충분히 반영하지 못한다는 한계도 존재한다.
이러한 문제를 보완하기 위해, 최근에는 댐(Kim et al., 2017), 하굿둑(Kim and Ahn, 2017; Sim et al., 2023), 교량(Kamariotis et al., 2022), 도로(Chen and Wang, 2017) 등 기반시설의 변수 간 인과 관계와 불확실성을 동시에 고려할 수 있는 통계적 모델 기반의 성능평가 기법의 적용 필요성이 강조되고 있으며, 특히 조건부 확률을 활용한 인과 추론 기법인 베이지안 네트워크(Bayesian Network)는 시설물 유지관리 계획의 수립 및 의사결정 과정에 효과적인 도구로 주목받고 있다.
1.3 연구 목적 및 기여
본 연구는 하구둑의 종합성능평가에서 기존의 단순 점수 합산 방식이 갖는 한계를 보완하고자 베이지안 네트워크 기반의 평가모델을 적용하였다. 이를 위해 성능등급뿐만 아니라 구조결함지수, 관리 주기 적정성, 사고 이력 등 주요 요인을 핵심 변수로 설정하였으며, 이를 기반으로 하구둑 성능 저하의 발생확률을 정량적으로 추정할 수 있는 베이지안 네트워크 모델을 구축하였다. 특히 본 연구에서는 각 상태변수 간의 인과 관계 및 내재된 불확실성(조건부 확률)을 모델에 통합함으로써, 보다 신뢰성 있는 종합성능등급 예측체계를 마련하는 것을 목표로 하였다.
2. 문헌 고찰 및 이론적 배경
2.1 하구둑 관련 성능평가 현황
현재 하구둑은 58개소가 운영 중이며, 제1종 시설물은 19개소, 제2종 시설물은 39개소로 관리되고 있다. 종합성능평가란 하구둑을 구성하는 주요 요소의 상태와 기능성을 종합적으로 진단하여 최종 성능등급을 부여하는 제도로, 평가 항목은 일반적으로 구조적 요소, 설비의 기능성, 환경조건 및 운영관리 수준 등의 영역으로 구분된다. 평가 결과는 A(우수)~E(위험)까지 5단계 등급으로 제시되며, 각 세부 항목의 평가점수에 가중치를 적용한 총점을 기반으로 정해진 기준구간에 따라 최종 등급이 결정된다.
24년 기준(KALIS, 2021; 2025)으로 하구둑의 74.1%가 C등급이며, 제1종 및 제2종 시설물의 사용 연수는 모두 30년 이상에서 가장 높게 조사(Table 1)되었다. 제1종보다는 제2종에서 C등급의 비율이 높았으며, 사용 연수도 제2종 시설물은 대부분 30년 이상으로 분석(Table 2)되었다.
Table 1.
Distribution of comprehensive performance grades by service life (As of December 31, 2024, unit: number of locations)
Table 2.
Analysis of safety grades and service life by facility type (As of December 31, 2024, unit: number of locations)
현행 종합성능평가는 정량화된 점수에 기반하고 있으며, 일정 주기(약 1~6년)의 단발성 점검 결과에 머문다는 한계가 있다. 또한 기후, 사고 이력 등 다양한 변수 간의 인과 관계가 평가 결과에 충분히 반영되지 못하고 있다는 문제점도 존재한다. 따라서 종합성능평가 결과를 통계 기반 모델과 연결하여 성능 저하를 예측하고, 유지관리 의사결정에 활용할 수 있는 기반자료로 확장하려는 연구의 필요성이 제기되고 있다.
2.2 베이지안 네트워크 이론적 배경
베이지안 네트워크는 확률적인 인과 관계를 방향성이 있는 비순환 그래프(Directed Acyclic Graph, DAG)의 형태로 표현하는 확률기반 그래픽 모델이며, 변수 간 조건부 의존성을 기반으로 불확실한 상황에서 합리적인 추론과 의사결정을 가능하게 해주는 기법이다. 베이지안 네트워크는 일반적으로 노드(node), 간선(edge), 그리고 조건부 확률 테이블(Conditional Probability Table, CPT)로 구성되며(Table 3), 각 노드는 변수, 각 간선은 변수 간 인과 관계를 나타내고, CPT는 이러한 관계를 수치적으로 정의한다(Needham et al., 2007).
Table 3.
Major components of a bayesian network
베이지안 네트워크는 베이즈 정리를 기반으로 확률 추론을 수행한다.
여기서, H는 가설(예: 성능 저하 발생 여부), E는 증거(예: 균열, 침수, 감시설비 고장 등), P (H∣E)는 증거 E가 주어졌을 때의 H의 사후확률을 의미한다. Eq. (1)은 다변량의 인과 관계로 확장되며, 네트워크 구조를 통해 복잡한 변수들 간의 연쇄적인 조건부 확률 추론이 가능하다(Chan and Darwiche, 2003).
2.3 관련 선행연구 검토
베이지안 네트워크는 최근 인프라 및 시설물 유지관리 분야에서 데이터 기반의 의사결정 모델로 주목받고 있으며, 기반시설, 교량, 터널, 도로 등 다양한 인프라 관리 분야에서 활용(Table 4)되고 있다.
Table 4.
Applications of bayesian models in infrastructure maintenance and management
| Field | Application Description | Reference |
| Infrastructure | A Bayesian updating-based prediction model was used to evaluate recovery progress after disasters (e.g., roads, bridges) under uncertainty. | Li and Ji, 2023 |
| Infrastructure | Comprehensive review of Bayesian Network-based approaches for damage prediction, data fusion, uncertainty modeling, and decision support in SHM for various infrastructure (bridges, roads, tunnels). | Wang et al., 2025 |
| Bridge | Damage diagnosis and reliability assessment using Bayesian model updating based on accelerometer- based vibration data; also quantified the value of information for improving structural safety. | Kamariotis et al., 2022 |
| Bridge | Fault Tree for fall hazards in bridge construction was converted into a Bayesian Network to perform a stable safety evaluation. | Chen and Wang, 2017 |
| Tunnel | Multi-state Dynamic Bayesian Network (DBN) and parameter learning were applied for modeling collapse risks in highway tunnels. | Ou et al., 2022 |
| Road | Ground displacement monitoring data from inclinometers (e.g., road shoulder) were analyzed using a Bayesian filter for anomaly detection and prediction. | Green and Jaspan, 2023 |
현재 하구둑을 대상으로 한 베이지안 네트워크 기반 연구는 매우 제한적이며, 종합성능등급과 연계하여 위험도를 정량적으로 예측할 수 있는 모델은 거의 제시되지 않은 실정이다. 국내외에서는 수자원 또는 주요 기반시설을 대상으로 종합성능평가 및 유지관리 전략을 수립하려는 연구들이 일부 수행되어 왔으나(Kim et al., 2017; Li and Ji, 2023), 그 대부분은 마코프 체인(Markov Chain)이나 와이블 분포(Weibull) 등 수리적 열화 모델 또는 전문가 판단에 기반한 다기준 의사결정 기법에 의존하고 있어, 인과 관계 기반의 확률 추론 모델링에 대한 적용은 미흡한 것이 현실이다.
본 연구는 이러한 문제의식을 바탕으로 하구둑 특성에 적합한 베이지안 네트워크 기반 예측 모델을 제안하였다. 기존 종합성능평가 결과를 입력 변수로 직접 활용함과 동시에, 구조결함, 사고 이력 등 주요 변수 간의 인과 관계를 모델에 반영하여 조건부 확률 기반의 추론을 통해 종합성능등급을 정량적으로 예측할 수 있는 분석 프레임 워크를 구축하였다. 또한 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1 Score 등 대표적인 성능지표를 활용하여 모델의 예측성능을 검증하고 실무 적용 가능성을 평가하였다. 특히 종합성능등급을 베이지안 네트워크 입력 변수와 직접 연결한 사례는 국내에서 거의 제시된 바 없으며, 이는 본 연구의 차별적 의의라 할 수 있다.
3. 연구 방법론
3.1 연구 절차 및 데이터
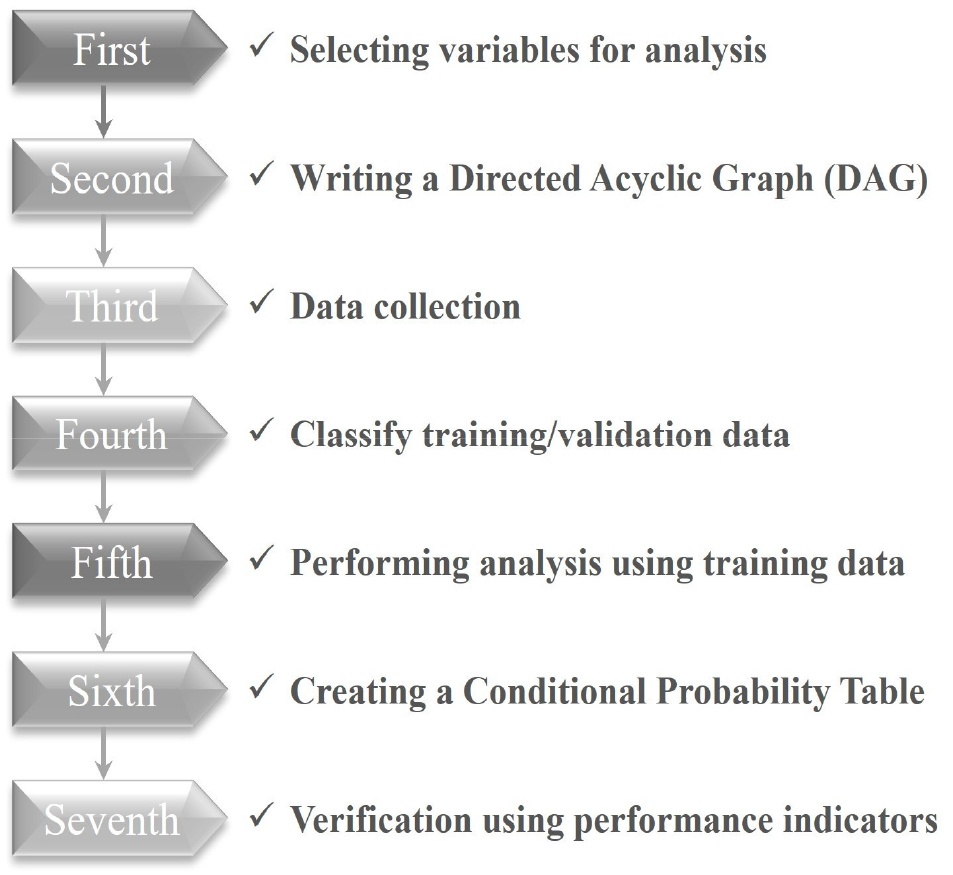
본 연구는 하구둑의 종합성능평가 데이터를 기반으로 베이지안 네트워크 모델 도출 후 검증하고자 하며, 이를 위해 아래와 같이 연구 절차(Fig. 1)를 수행하였다. 모델에 사용할 변수 선정 후 DAG 작성을 수행하며, 모델 수립을 위한 자료 수집 후 학습/검증 데이터로 분류한다. 그리고, 학습 데이터를 활용하여 조건부 확률 테이블 작성 후 검증을 수행하여 모델의 정확도를 평가하도록 하였다.
3.2 변수 도출 및 선정 근거
분석에 사용할 변수들을 도출하기 위해, 하구둑의 운영 현황, 설계 기준, 유지관리 지침 및 관련 선행연구 등을 종합적으로 조사하였으며, 이를 바탕으로 카테고리별로 후보 변수를 정리하였다. 이후 베이지안 네트워크를 구성하는 과정에서 각 변수 간 중복 여부와 인과적 관련성을 검토하였고, 데이터 확보 가능성, 측정 가능성 및 인과 구조 내 중요도를 고려하여 최종 입력 변수를 선정하였다. 최종적으로 선정된 변수들에 대해서는 변수의 역할(입력 노드 등), 세부 정의, 상태 구분 기준을 체계적으로 정리(Table 5)하였다.
Table 5.
Procedure for deriving input variables
하구둑의 성능에 영향을 미칠 수 있는 요인을 파악하기 위해, 기존 연구 및 관련 문헌들을 분석한 결과 성능 저하에 영향을 주는 요인을 크게 5개의 범주로 분류하였다. 해당 분류체계는 ① 구조적 조건, ② 운영 및 유지관리 현황, ③ ICT와 스마트 요소, ④ 사고 및 이상 이력, ⑤ 기후/수문/수리학적 조건으로 구성하였으며, 이는 하구둑의 리스크 특성을 포괄적으로 반영할 수 있도록 설정된 것이다. 범주별로 총 17개의 후보 변수를 도출한 후, 데이터 확보 여부 및 변수 간 상관성, 인과적 중요도 등을 평가하여 최종적으로 6개의 핵심 변수를 기존 문헌, 정책적 기준, 데이터 가용성을 종합적으로 고려한 객관적이고 합리적인 기준에 근거하여 선별하였다. 스마트센서 설치 여부는 단순한 이분법적 변수처럼 보일 수 있으나, 실제로는 SHM (Structural Health Monitoring) 체계의 도입 여부를 대변하는 지표로서 베이지안 네트워크와의 융합을 통해 센서 기반 데이터가 성능예측에 기여할 수 있음을 이론적으로 정리(Wang et al., 2025)하였고, 인클리노미터 계측치를 활용해 이상 탐지 및 예측 성능을 입증(Green and Jaspan, 2023)하였다. 따라서 본 연구에서는 스마트센서 설치 여부를 예측 가능성 강화 및 운영 신뢰성 확보를 반영하는 핵심변수로 정의하였다(Table 6).
Table 6.
Categories and candidate variables with final selection rationale
| Category | Candidate Variables | Final Variable | Selection Rationale (References) |
| Structural Condition |
·Slope stability factor ·Degree of foundation scour ·Change in impermeable layer permeability | ·Structural defect index | ·Structural defect is a key indicator explaining performance degradation and accident risk (Chan and Darwiche, 2003; Kamariotis et al., 2022) |
| Operation and Maintenance status |
·Compliance rate of regular and detailed inspections ·Inspection results of major equipment (gates, pumps, etc.) ·Maintenance/repair performance relative to budget | ·Management cycle appropriateness | ·Maintenance cycle reflects adequacy of inspection/repair intervals and investment priorities (MOLIT, 2017) |
| ICT and smart elements |
·Real-time alarm system (emergency response capability) ·Digitalized inspection and maintenance history ·Monitoring data (settlement, crack length/ depth, strain, etc.) ·Instrument health status | ·Whether or not a smart sensor is installed | ·Smart sensor installation represents digital infrastructure management and anomaly detection capability (Wang et al., 2025; Green and Jaspan, 2023) |
| Accident and abnormal history |
·Number of past failures (collapse, malfunction, flooding) ·Emergency discharge events ·Number of functional failures during the past 10 years | ·Accident history | ·Accident history reflects direct link to structural failure and safety risk (Chan and Darwiche, 2003; Kamariotis et al., 2022) |
| Climatic, hydrological, and hydraulic conditions |
·Frequency of maximum reservoir level exceedance ·Changes in rainfall intensity / flood frequency ·Gate inspection status ·Frequency of overtopping |
·Sluice Gate operation reliability ·Inflow ratio to design flood volume | ·Gate operation reliability and inflow ratio reflect climate/hydrological risks and operational stability (Needham et al., 2007; Li and Ji, 2023; Ou et al., 2022) |
본 연구의 결과변수는 종합성능등급이며, 이는 입력 변수들의 조건부 확률 조합을 기반으로 베이지안 네트워크에서 추론되는 값이다. 하구둑의 종합성능등급을 예측하기 위해 총 7개의 변수(입력 6개, 출력 1개)를 이용한 베이지안 네트워크 모델을 구성하였으며(Table 7), 입력 변수로는 구조결함지수, 관리 주기 적정성, 스마트센서 설치 유무, 사고 이력, 갑문 운영신뢰도, 설계홍수량 대비 유입량 비율을 설정하였다. 각 입력 변수는 베이지안 네트워크 내에서 상호 조건부 의존관계를 가지며, 이들 조합을 기반으로 종합성능등급을 확률적으로 도출하도록 모델을 설계하였다. 이때 종합성능등급은 출력(목표) 노드이며, 나머지 6개 변수는 입력 노드로서 인과 관계를 반영하여 연결된다.
Table 7.
Types and definitions of variables
본 연구에서는 6개의 입력 변수를 기반으로 하구둑의 종합성능등급을 예측하기 위한 베이지안 네트워크를 구축하였으며, 각 입력 변수(노드)는 2~3단계의 상태로 구분하였다. 이러한 설정에 따라 전체 조건부 확률 테이블(CPT)은 144개(3×2×2×3×2×2)의 상태 조합으로 구성되며, 각 입력 변수 간 조건부 의존관계를 통해 종합성능등급이 확률적으로 추론되도록 설계하였다(Table 8).
Table 8.
Variable definitions and characteristics of the model
3.3 DAG 구조 설정 및 CPT 구축
본 연구에서 설계한 베이지안 네트워크는 하구둑의 종합성능등급을 예측하기 위한 인과 관계 구조로, 총 7개 주요 변수(노드)로 구성(Fig. 2)된다. 이 인과관계 구조에서 ‘사고이력’은 ‘구조결함지수’와 연결되어 과거 사고 발생이 구조적 건전성 저하에 영향을 미칠 수 있음을 보여준다. 또한 ‘관리주기 적정성’은 ‘갑문 운영 신뢰도’와 연결되어 유지관리 체계가 운영 성능에 직접적으로 작용함을 나타낸다. 이러한 대표적 인과관계 외에도 변수 간 다양한 연결 관계를 DAG에 시각화하였다. 본 연구에서는 기존 연구와 정책 자료를 근거로 DAG 구조를 정의하였으며, 이는 데이터 기반 구조학습을 적용하기 위한 기초 모형으로 설정되었다. 노드의 목록은 확률 변수, 노드 간 방향성 있는 연결은 조건부 인과 관계를 나타낸다. 즉, 입력 노드 6개가 출력 노드 1개로만 연결되는 단일 방향 인과 구조라면, 해당 네트워크의 구조는 바뀌지 않는다(Koski and Noble, 2012; Deleu et al., 2022).
스마트센서 설치 여부는 관리주기 및 갑문 신뢰도에 긍정적 영향을 주며, 구조결함과 유입 비율은 사고 및 운영신뢰도 경로를 통해 성능등급에 영향을 미치는 구조를 갖는다. 이러한 인과 관계 구조는 DAG 형태로 시각화하여 Fig. 2에 제시하였으며, 모든 화살표는 입력 변수에서 출력 변수(종합성능등급)로 향하는 단방향 흐름으로 구성된다.
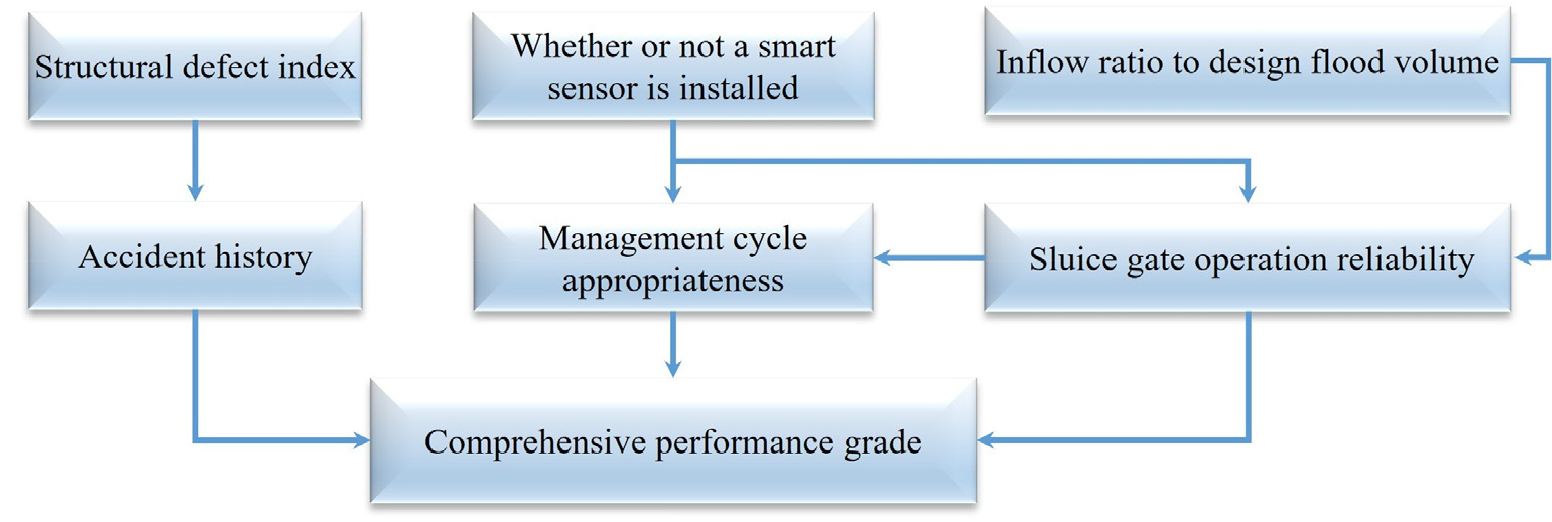
Table 9는 각 노드 간 연결 방향과 그 인과 관계 설정에 대한 세부 사항이다. 구조결함지수가 높으면 사고 이력이 누적되고, 이는 직접적으로 종합성능등급을 낮추며, 스마트센서 설치 유무는 두 경로로 영향을 미친다. 관리주기 적정성 향상은 종합성능등급 개선과 관련 있으며, 갑문 운영신뢰도는 성능개선 및 관리주기 개선과 관련이 있다. 설계홍수량 대비 유입 비율은 갑문 운영신뢰도를 저하시켜 성능등급에 부정적 영향을 준다. 또한, 갑문 운영신뢰도는 직접적으로 성능등급을 높이고, 동시에 관리주기 이행 가능성을 높여 간접적으로도 성능등급을 향상시킨다.
Table 9.
Causal relationships and influence logic between variables
학습 데이터는 기반시설 관련 시스템의 기본정보와 상세정보, 그리고 정밀안전점검·진단 보고서 등 실제 유지관리 자료를 활용하여 전처리한 후 분석에 적용하였다. 자료의 수집은 시설물통합정보관리시스템(FMS, 2025), 점검진단평가관리시스템(IREMS, 2025), 기반시설관리시스템(IMS, 2025), 국가건설기준센터(KCSC, 2025), 지자체 정보공개포털(Open Government Portal, 2025) 등을 통해 수행하였으며, 데이터의 기간은 2010년부터 2024년까지, 대상은 총 58개 하구둑(148건의 평가 사례)이다. 전처리 과정에서는 결측값 보정, 범주형 데이터의 정규화 및 상태 값 통일 작업을 수행하였다. 총 148건의 데이터를 대상으로 베이지안 네트워크 학습 및 검증을 수행하기 위해 전체 데이터를 학습용과 검증용으로 8:2 비율로 분할 하였다. 그 결과 118건의 학습 데이터(Table 10)는 조건부 확률 추정 및 구조 학습에, 30건의 검증 데이터는 종합성능등급 예측 정확도 및 정밀도 평가에 활용하였다.
Table 10.
Case data for training (118 cases)
조건부 확률 테이블(CPT)은 베이지안 네트워크의 핵심 구성 요소 중 하나로, 노드 간 인과 관계를 수치적으로 표현하는 역할을 수행한다. CPT 설정의 논리적 근거는 일반적으로 ① 전문가 추정(Expert Elicitation), ② 시나리오 기반 시뮬레이션(Scenario-based Simulation), ③ 과거 사례 및 문헌 기반 통계 추정(Empirical Estimation)의 세 가지 방법으로 정당화될 수 있다. 본 연구에서는 과거 유지관리 사례 및 관련 보고서 등에 기반한 통계적 추정 방법을 적용하여 CPT를 구성하였으며, 이러한 CPT를 바탕으로 베이지안 네트워크 모델의 학습 및 추론을 수행하였다.
과거 사례 및 문헌 기반의 통계적 CPT 설정(즉, 데이터 기반 학습 방식)은 실제 수집된 이력 데이터에 대해 각 입력조건 조합별 사례 수를 집계한 후, 해당 조합에 나타난 등급 빈도를 상대적인 비율로 환산하여 사후확률로 적용하는 방식이다. 동일한 입력조건을 가진 사례 그룹 내에서 특정 등급이 얼마나 자주 발생했는지를 확률적으로 반영하는 것이다. 다만, 입력 변수가 다차원으로 구성될 경우 빈도 테이블이 희소(Sparse)해지는 문제가 발생할 수 있으며, 이를 완화하기 위해 본 연구에서는 다차원 빈도 테이블 구성 후 라플라스 스무딩(Laplace Smoothing)을 적용하고, 관측된 조합에 대해서는 경험적 비율을 그대로 사용하는 반면, 관측되지 않은 조합에 대해서는 균등분포 기반의 초깃값을 부여하였다(Bonafede and Giudici, 2007). 이와 같은 방식은 베이지안 네트워크 기반 시설물 위험평가 및 성능 관련 선행연구에서 사용되었던 절충형 접근에 해당한다.
본 연구의 CPT 구축을 위한 학습 방식, 알고리즘 및 도구는 Table 11에 정리하였다. 조건부 확률 테이블은 사전에 정의된 DAG 구조와 수집된 학습 데이터를 기반으로 도출하였으며, 조건부 확률 계산 및 최대우도추정(MLE)을 활용하여 각 상태 조합의 확률값을 산정하였다. 최종 CPT 구축은 Excel과 Python 기반의 분석 및 계산 스크립트를 통해 수행하였다(Ji et al., 2015).
Table 11.
Learning method and tools for CPT construction
Table 12는 Table 10의 학습 데이터를 기반으로 산정된 데이터 기반 CPT 결과를 나타낸 것이다. 총 144개의 입력조건 조합에 대해 등급별 확률값을 계산하였으며, 각 조합에서 확률이 가장 높은 등급을 최종 등급으로 판단하였다. 그 결과, 전체 조합 중 B등급으로 분류된 경우는 27개, C등급은 112개, D등급은 5개로 나타나 입력 변수 조합에 따라 등급 분포가 달라지는 것을 확인할 수 있었다.
Table 12.
CPT results derived from data-driven estimation
학습 데이터를 기반으로 산정한 CPT에 대한 모델 검증은 제4절 ‘실증 적용 및 결과 분석’에서 수행할 예정이며, 본 절에서는 해당 모델을 검증하기 위한 구체적인 방법과 절차에 관해 기술하고자 한다.
본 연구는 정확도와 정밀도를 기반으로 예측 모델 성능을 평가하였으며, 더불어 클래스 간 분포 불균형에 따른 왜곡을 방지하고자 재현율과 F1 Score 지표를 함께 분석하였다. 이는 종합적인 성능 진단 및 실무 적용 시 오 분류 리스크를 최소화하기 위함이다. 정밀도는 모델의 양성 예측 신뢰도(예측된 등급 중에서 실제로 해당 등급인 경우의 비율)를 보여주며, 재현율은 실제 양성을 얼마나 포착했는지(실제 해당 등급인 항목을 얼마나 잘 찾아냈는지를 나타냄)를 나타낸다. 이 두 지표는 서로 다른 오류 유형을 반영하므로, 서로 대체하거나 유도할 수 없는 별개의 평가지표이다. 따라서 F1 Score는 이 둘의 조화평균으로, 모델의 균형적 성능을 평가하는 데 유용하기 때문에 병행하여 분석함으로써 모델의 성능을 보다 균형 있게 평가할 수 있다(Powers, 2011). 또한, 다등급 분류 문제의 특성을 고려하여, 종합성능등급(A~E)에 대해 각각의 정밀도, 재현율, F1 Score를 클래스별로 산출하였다. 이 지표들은 클래스마다 서로 다른 예측성능을 반영하기 때문에, 단일 지표인 정확도만으로는 성능을 충분히 평가할 수 없으며, 클래스 수준에서의 정밀 분석이 필요하다.
F1 Score는 정밀도와 재현율의 조화평균(Harmonic Mean)으로 정의되며, 두 지표의 균형을 동시에 고려할 수 있는 종합적인 성능지표이다. 특히 Precision 또는 Recall 중 어느 하나라도 값이 낮으면 F1 Score 역시 크게 감소하게 되므로, 불균형한 클래스 분포 문제에서 모델의 실제 성능을 평가할 때 유용하게 사용(Eq. (2))된다. F1 Score는 정밀도와 재현율의 조화평균으로 정의되며, 본 연구에서는 다등급 분류 상황에서 등급 간 균형성과 예측성능을 종합적으로 확인하기 위해 Macro F1 Score와 Weighted F1 Score를 병행하여 분석하였다(Harbecke et al., 2022).
여기서, Precision은 예측이 “맞다”라고 한 것 중 실제로 맞은 비율 = TP / (TP + FP), Recall은 실제 “맞는 것” 중 예측이 맞은 비율 = TP / (TP + FN), F1 Score는 두 값의 조화평균 → Precision과 Recall이 모두 높아야 F1이 높음을 의미한다.
F1 Score 분석 결과와 관련하여, F1 해석 가이드(Futurense, 2025) 에서는 F1 값이 0.8 이상일 경우 “균형 잡힌 성능을 가진 강력한 모델(strong and well-balanced model)”로 평가하고 있으며, Crudu and MoldStud 또한 F1 점수가 0.75 이상이면 일반적으로 신뢰 가능한 수준으로 간주한다고 언급하였다(Moldstud Research Team, 2025). 또한 Encord 에서는 F1이 0.8~0.9 범위일 경우 “Good” 수준, 0.9 이상일 경우 “Very Good” 수준으로 분류하고 있다(Encord, 2023). 기존 문헌에서 범위가 상이하여 기존 문헌을 바탕으로 F1 Score의 범위 및 평가 정도를 재구성(Table 13) 하였다.
Table 13.
A Guide to interpreting F1 score ranges for performance
학습 데이터(118건)에 대해서도 동일한 검증 방법을 적용하여 정확도 및 정밀도 지표를 산정하였으나, 이는 모델이 이미 학습한 데이터를 대상으로 계산된 값이기 때문에 과적합 가능성을 내포하고 있다. 따라서 본 연구에서는 모델의 일반화 성능을 보다 객관적으로 평가하기 위해, 별도로 분리된 검증 데이터(30건)를 사용하여 성능지표를 산정하고 그 결과를 제시하였다.
4. 연구 결과
4.1 모델 학습 및 검증 결과
3.4.1절의 학습 데이터 구성에서 전체 148건의 사례 중 118건(80%)을 확률 모델 학습에 사용하였으며, 나머지 30건(20%)은 모델 검증을 위해 별도로 분리하여 활용하였다(Table 14). 자료의 출처, 기간 및 전처리 절차는 앞선 학습 데이터 구성과 동일하므로 본 절에서는 반복 서술을 생략하였다.
Table 14.
Case data for validation (30 cases)
4.2 혼동행렬 및 성능지표 제시
검증 데이터(30건)에 대한 혼동행렬 분석 결과, B등급과 C등급 사례가 대부분을 차지했으며, A 및 E등급은 나타나지 않았다(Fig. 3). B등급은 총 7건 중 6건이 정확히 B로 예측되었으며, 1건은 C로 오 분류되었다. C등급은 총 23건 중 20건이 C로 정확히 예측되었고, 나머지는 1건이 B, 2건이 D로 오 분류되었다. 전반적으로 모델은 B등급과 D등급에 대해 높은 예측 정확도를 보였으며, 오 분류 역시 인접한 등급 간에서 제한적으로 발생한 것으로 확인되었다. 이는 등급 간 경계가 모델에 의해 비교적 명확하게 학습되었음을 의미한다.
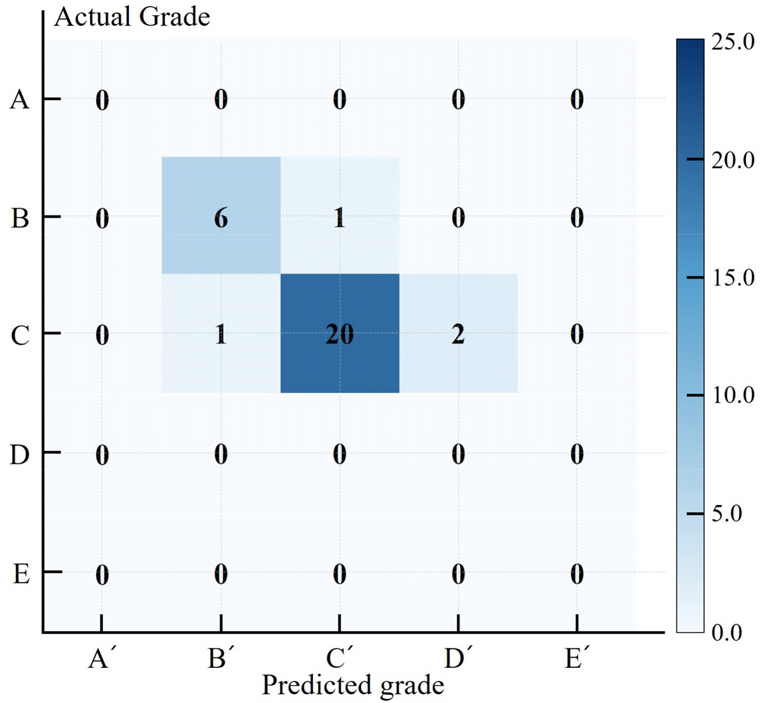
결론적으로, 본 모델은 B 및 C 등급에 대해서는 우수한 예측성능을 보였으나, 전체 등급 범위에 대한 일반화 성능을 확보하기 위해서는 추가적인 보완이 필요한 것으로 판단된다. 이는 현재 하구둑 58개 중 D등급 사례가 1건에 불과하고, A 및 E등급 사례가 존재하지 않는 데이터 특성으로 인해 다등급 분류 모델로서의 일반화 성능을 충분히 확보하기 어려웠던 데에서 기인한다.
Fig. 3은 제안된 베이지안 네트워크 모델에 대한 혼동행렬 결과를 제시하고 있으며, Table 15에는 혼동행렬을 기반으로 계산된 정밀도, 재현율, F1 Score를 요약하였다. 그 결과 C등급이 B등급보다 모든 지표(정밀도, 재현율, F1 Score)에서 우수한 값을 나타냈으며, 모델 전체 성능은 Accuracy = 0.867, Macro F1 = 0.883, Weighted F1 = 0.897로 확인되었다.
Table 15.
Results of prediction performance metrics by grade
| Grade | Precision | Recall | F1 Score |
| A | - | - | - |
| B | 0.857 | 0.857 | 0.857 |
| C | 0.952 | 0.870 | 0.909 |
| D | - | - | - |
| E | - | - | - |
| Macro F1 | - | - | 0.883 |
| Weighted F1 | - | - | 0.897 |
본 모델의 F1 Score는 0.883으로, 일반적인 분류 모델 평가 기준에 비추어 볼 때 실무 적용에 충분한 수준의 성능을 보인 것으로 판단된다. 또한 정밀도(0.905)와 재현율(0.863) 사이에 큰 편차가 없으며, 두 지표 간 균형을 유지한 결과 F1 Score 역시 안정적으로 나타난 것으로 확인되었다. 즉, 특정 등급에 편중되지 않고 전체 클래스에 대해 균형 있는 예측력을 발휘하고 있음을 의미한다.
5. 요약 및 결론
본 연구에서는 하구둑을 대상으로 종합성능등급을 예측할 수 있는 베이지안 네트워크 기반 통계 모델을 제안하였다. 우선 기존 점수기반 평가방식의 한계를 보완하기 위해, 구조결함지수, 사고 이력, 스마트센서 설치 여부, 관리주기 적정성, 수문·갑문 운영신뢰도, 설계홍수 대비 유입 비율 등 총 6개의 핵심 변수를 선정하였으며, 이들 간의 인과 관계를 반영하여 베이지안 네트워크 구조(DAG)를 구성하였다. 수집된 148건의 하구둑 성능평가 데이터를 기반으로 학습(118건)과 검증(30건)을 분리하였고, 조건부 확률 테이블(CPT)을 구축한 후 모델 학습 및 추론을 수행하였다. 이는 교량·댐 등 개별 요소 시설을 대상으로 한 기존 연구와 달리, 국내 하구둑의 종합성능등급 체계와 직접 연계한 첫 시도로서 차별성을 가진다. 검증 데이터의 성능평가 결과, 제안된 모델은 Accuracy 0.867, Macro F1 0.883, Weighted F1 0.897의 우수한 예측성능을 보였다. 특히 정밀도(0.905)와 재현율(0.863)의 균형이 유지되면서 B·C 등급에 대하여 안정적인 예측력을 나타내었다.
혼동행렬 분석 결과에서도 오 분류가 대부분 인접 등급 간에서 제한적으로 발생하는 것으로 확인되었다. 다만 A, E등급 사례가 존재하지 않고 D등급 사례 또한 매우 적고, 다등급 분류 모델로서의 일반화 성능을 충분히 확보하기에는 한계가 있었다. 따라서 향후에는 다양한 등급 사례를 확보하고 불균형 데이터를 보정할 수 있는 통계적·기계학습적 기법을 적용함으로써 모델의 신뢰성과 일반화 가능성을 강화할 필요가 있다. 본 연구의 DAG 구조는 현재 연구자 정의 방식으로 구성되었으나, 향후에는 데이터 축적과 불균형 보정 기법을 적용하고, 데이터 기반 구조학습을 통해 변수 간 인과관계를 검증함으로써 모델의 일반화 성능을 강화할 예정이다. 또한 예측 결과가 실제 안전점검 주기 조정이나 예산 배분 등 유지관리 의사결정에 어떻게 기여할 수 있는지에 대한 공학적 의미를 보다 구체적으로 도출할 계획이다.
본 연구에서 제안한 베이지안 네트워크 모델은 단순한 예측 도구를 넘어, 실제 유지관리 및 정책 의사결정 단계에서의 활용 가능성을 가진다. 우선, 예측 결과를 통해 하구둑의 성능저하 위험도를 사전에 파악함으로써 시설별 보수·보강의 우선순위를 정량적으로 산정할 수 있으며, 이는 예산 배분의 합리화와 점검·정비 주기의 최적화에 기여할 수 있다. 또한 성능등급 예측값을 활용하여 사전점검 및 예방보수 계획의 대상 선정, 관리주기 적정성 검토, 장기 유지관리 전략 수립 등 현장 중심의 관리 효율화에도 직접적으로 적용될 수 있다. 나아가 이러한 예측 결과는 향후 성능 기반의 투자계획 수립 및 위험도 관리체계 고도화의 기초자료로 활용될 수 있을 것이다.
학문적으로 본 연구는 기존 점수 합산 방식이 가지는 정적 평가의 한계를 보완하고, 조건부 확률과 인과 구조를 반영한 베이지안 네트워크를 하구둑 종합성능등급 예측에 적용함으로써 성능평가 방법론으로 활용될 가능성이 있다. 또한 기존 연구가 전문가 판단이나 단순 가중치 산정에 의존한 것과 달리, 실제 성능평가 자료를 확률모형 학습에 반영함으로써 데이터 기반 추론의 가능성을 제시하였다. 실무적으로는 본 연구에서 제안한 모델이 하구둑의 종합성능등급을 해석하고 유지관리 방향을 설정하는 데 참고할 수 있는 기초적 분석 틀을 제시한다.
