1. 서 론
2. 방법론
2.1 분석도구(머신러닝 및 딥러닝 모형)의 선정
2.2 입력자료의 구성
2.3 융설을 고려한 데이터 전처리 및 보정강우 산정
2.4 모델 최적 하이퍼파라미터 및 모델성능평가
3. 결과 및 분석
3.1 연구대상지역 및 자료수집
3.2 융적설 보정 전후에 따른 ML& DL 유입량 예측 성능 산정 결과
4. 결 론
1. 서 론
다목적댐의 정확한 강우유출 분석을 통한 댐 유입량의 예측은 매우 중요하다 . 2010년대말부터는 데이터 기반 머신러닝 분석도구들이 오픈소스 기반으로 공개되고, 다목적댐들의 유입량 데이터도 30년이상 축적되어 비교적 장기간의 자료를 활용할 수 있게 됨에 따라 강우유출 분석에서도 데이터 기반의 다양한 연구들이 활발히 진행되고 있다. 특히, 강우유출의 비선형성을 고려하기 위하여 인공신경망(Artificial Neural Network, ANN), SVM (Support Vector Machine), Random Forest (RF), Extreme Gradient Boosting (XGBoost) 등을 활용하기 위한 연구가 진행되었다(Cortes and Vapnik, 1995; Breiman, 2001; Ke et al., 2017; Chen and Guestrin, 2016). 또한 머신러닝 방법들의 한계를 극복하기 위하여 순환신경망(Recurrent Neural Network, RNN)계열의 LSTM (Long-Short Term Memory; Hochreiter and Schmidhuber, 1997) 과 같은 Deep Learning 방법(Fan et al., 2020; Hu et al., 2018; Kratzert et al., 2018; Xiang et al., 2020)과 합성곱신경망(Convolutional Neural Network, CNN)계열의 TCN (Temporal Convolutional Network; Bai et al., 2018)등이 적용되고 있으며 유량예측이 기존의 물리모델을 활용한 방법보다 성능이 더 우수함을 보여주고 있다(Kratzert et al., 2018). 그러나 이러한 데이터 모델은 복잡한 강우유출의 비선형관계를 설명하기에는 한계를 가진다(Janiesch et al., 2021). 이러한 한계를 극복하기 위하여 강우자료에 지체시간(Lag-time)이나 이동평균(Moving Average)을 적용하거나 예측 이전시간의 유입량자료를 입력자료(독립변수)로 활용한다든지 해서 독립변수인 입력데이터를 전처리함으로써 머신러닝과 딥러닝의 강우유출의 정확도를 향상시킨 연구도 진행되었다(Jo and Jung, 2023).
특히, 강우 유출해석에 있어서 융적설의 영향을 반영하는 것은 필수적이다. 융적설 영향은 PRMS (Precipitation Runoff Modular System; Leavesley, 1984), SWAT (Soil and Water Assessment Tool; Arnold et al., 1998), HSPF (Hydrological Simulation Prgram-Fortran; Bicknell et al., 2001)등과 같은 물리기반의 모델에서는 여러 가지 매개변수와 고도, 사면경사와 향, 태양복사에너지, 온도, 증발량 등 여러 입력 인자들과의 물리적 해석을 기반으로 한 융적설 성분의 모듈화를 통해 산정된다(Babur et al., 2016; Ghoraba, 2015).
최근 융적설을 반영한 머신러닝 및 딥러닝의 연구도 만년설 및 고지대 산악지대 유역에 대하여 수행되었는데 LSTM과 같은 딥러닝모델의 적용이 우수하다는 연구도 진행되었다(Thapa et al., 2020). 이 연구에서는 융적설이 지배적인 지역에서, 데이터 특성이 융적설의 현상을 주로 반영하는 경우에 있어서 유출량 예측성능이 우수한 것을 보여준다. 그러나 한국과 같은 기후 및 유역특성에서는 융적설이 지배적이지 않다. 데이터 모델에서는 이러한 융적설 현상이 강우(강설) 및 유출량의 값에 포함되어 데이터로서만의 의미를 가지면서 융적설이 일어나지 않는 기간의 강우유출 분석과 함께 포함되어 학습된다. 적설 및 융설의 메카니즘 관점에서 볼 때, 겨울철 영하 이하의 날씨에서는 강우량이 실제로 강설량일 가능성이 높다. 최근의 강우량 관측계기는 열선설비를 통하여 녹여 눈이 오더라도 비로 계측되기 때문에 강우량 데이터는 강우량으로 관측된다. 즉, 이때의 강우량은 눈으로 쌓여 Snow pack을 형성하고 온도가 높거나 태양복사에너지가 많아 융설(Snowmelt) 현상이 일어나 유출을 발생시키는 물리적 특성을 가진다. 그래서 봄이 되어 온도가 높을 때 강우량이 없거나 적음에도 불구하고 유출량이 많아지는 현상이 일어난다. 소양강댐 유역의 경우에도 이러한 현상이 일어나고 있다.
데이터 모델에서는 이러한 물리적 기작이 작동되는 것이 아니기 때문에 융설과 같은 조건을 기존의 입력자료로서는 충분히 모의하기 어렵다고 볼 수 있다. 왜냐하면 데이터 모델에서 학습한 강우와 유출과의 관계는 융설조건이 아닌 현상을 더 많이 학습하기 때문에, 시기와 상관없이 일단 강우가 발생하면 유출량이 발생하는 수문학적 응답을 데이터 값으로 보이고 있어 융적설 기간의 모의는 비융적설 기간의 데이터 학습과 구분되거나 융적설을 고려한 데이터의 합리적인 처리가 되어야 한다.
따라서 본 연구에서는 그동안 수자원분야 강우유출 해석분야에 활용되었던 대표적인 ML&DL 모델을 활용하여 모델의 하이퍼파라미터 튜닝뿐만 아니라, 융적설을 반영하는 강우데이터의 전처리를 수행하는 연구를 수행하였다. 이를 통하여 융적설이 영향을 미치는 유역에서의 데이터 모델 적용시에는 입력자료 구축시 적설 및 융설이 물리적으로 타당한 강우-유출 반응에 적합하도록 전처리과정이 중요함을 밝히고자 하였다.
2. 방법론
2.1 분석도구(머신러닝 및 딥러닝 모형)의 선정
본 연구에서는 소양강댐의 일유입량 예측을 위하여 머신러닝 분석 모형을 구축하였다. 분석을 위하여 머신러닝 회귀모형으로 1) 서포트벡터회귀모형(Support Vector Regression), 2) 랜덤 포레스트(Random Forest), 3) LightGBM (Light Gradient Boosting Model)을 적용하였고, 인공신경망 딥러닝 모형으로 4) LSTM (Long Short-Term Memory models), 5) TCN (Temporal Convolutional Network)을 적용하였다.
각 모형벌 설명과 적용 방법은 다음과 같다.
1) 서포트벡터 회귀모형: 분류를 위한 결정경계를 두는 SVM (서포트 벡터 머신)의 기법을 회귀에 적용한 SVR (Support vector Regression) 방법 (Scikit-learn의 라이브러리 적용)
2) 랜덤포레스트 모형: 트리형 구조로서 Decision Tree의 분류보다 정확도를 개선시키기 위해 여러개의 나무를 만들고 각 나무의 예측을 조합하는 RF (랜덤포레스트) 기법을 회귀에 적용한 방법(Scikit-learn ensemble의 RandomForest Regressor 라이브러리 적용)
3) LightGBM (Light Gradient Boosting Model) 모형: 여러개의 Tree를 만들되, 기존의 모델 tree를 조금씩 개선발전 시켜 이를 조합하는 방식(LGBM Regressor 라이브러리 적용)
4) 인공신경망 딥러닝(Deep Learning): 머신러닝 알고리즘 중에서 인공신경망을 기반으로 한 방법으로 시퀀셜한 데이터를 학습하고 예측하는데 유리한 순환신경망 RNN (Recurrent Neural Network)계열을 적용하되, RNN으로는 기존의 한계점인 기울기 소실문제와 오래된 정보 전달 문제를 해결하는 모형인 LSTM 적용(Keras Library)
5) TCN (Temporal Convolutional Network)은 최근 Sequence modeling에 RNN 계열과 더불어 성능이 우수하여 적용이 확대되고 있는 1D-CNN (Convolutional Neural Network) 구조 모델(Keras Conv1D 라이브러리 적용)
2.2 입력자료의 구성
입력데이터의 구축은 종속변수 댐유입량 Q(t)를 예측하기 위하여 다양한 독립변수인 강우, 유량, 기상(온도, 증발량)의 시나리오 조합으로 구성하였는데, 지체시간(Lag time)을 적용하여 전처리된 강우량, 유출성분분리를 통한 기저유출(Base flow, Bf)과 직접유출량(Surface flow, Sf)의 지체시간을 고려하여 전처리된 유입량을 독립변수로 구축하였다. 강우는 가장 민감도가 큰 인자로서 당일 예측강우 R(t)를 입력자료로 하여 당일 유입량 Q(t)을 예측하는 모델로 구성하되, 강우와 유출간의 물리적 상관관계가 나타날 수 있는 데이터의 규명을 위하여 Lag time이 적용된 전일 강우량 R(t-1), 전전일 강우량 R(t-2), 3일전 강우량 R(t-3), 5일전 강우량 R(t-5)를 구성하였고, 유량계열은 전일까지의 유입량 Q(t-1)까지의 자료를 입력으로 구축하되 유입량을 기저유출(Bf(t-n), Base flow)과 직접유출(Sf(t-n), Surface flow)로 Digital filtering에 의한 유출성분분리(El‐Nasr et al.. 2005)를 통하여 입력 데이터로 구축하였다.
2.3 융설을 고려한 데이터 전처리 및 보정강우 산정
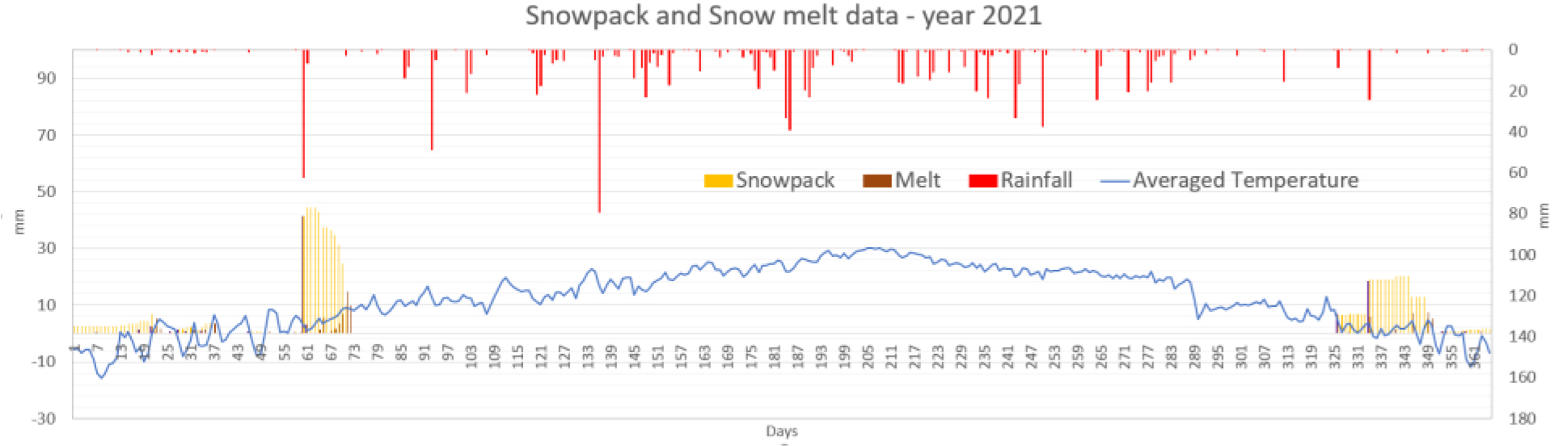
온도에 따라 기준온도 이하의 강우량은 적설량으로 보고 강우량은 없는 것으로 하고. 적설된 양은 적설(Snowpack)으로 산정하고 더해준다. 일단위로 기온에 따라 융설(Snowmelt)량을 계산해서 Snowpack의 증감량을 모의하고, Snowmelt량은 유출에 영향을 주는 값으로 판단하고 강우량 값에 더해 주었다. 이렇게 온도에 따라 적설과 융설을 고려한 보정된 강우량 계열 데이터를 산정하고 유입량과 학습시켜 예측모델을 구축하였다
2.3.1 적설량 산정 기준
입력자료중 강우량은 온도자료를 기준으로 적설량을 산정하였다. 물리기반 강우유출모형인 PRMS의 경우 강수형태를 구분할 때 강설조건, 강우조건, 혼합조건 3가지로 구분하였다. 강설조건은 기온이 0℃이하 일때, 강우조건은 기온이 4.5℃보다 클 때로 구분하였다. 이 사이의 있을 강우와 강설이 함께 존재하는 혼합조건으로 보았다(Leavesley, 1984). 따라서 본 연구에서는 같은 기작을 반영하여 최저기온과 평균기온이 0℃이하 일때는 강설, 최저기온이 0℃이상 평균기온이 4.5℃이상 일때는 강우로 구분하였고, 0℃에서 4.5℃이내 조건은 강설과 강우의 혼합조건으로 보고 온도 비율만큼 적설량으로 산정하였다. 산정 알고리즘은 다음 Table 1과 같다.
Table 1.
Calculation algorithm of adjusted rainfall by snow amount and snowmelt
2.3.2 융설량의 산정 기준
개념적 물리적 융설모형은 3가지 유형으로 나눌수 있는데, 첫째는 온도자료로부터 경험적으로 융설계수(melt factor)를 도출한 모형, 둘째는 열변환 관계를 표현하기 위한 지수(index)를 사용한 모형, 셋째는 열수지를 고려한 모형이다(Day, 1990). 본 연구에서 융설량은 데이터모델 입력자료의 한계를 고려하여 융설계수(melt factor)를 평균온도에 곱하여 산정하였다. 융설계수(mm/(day*℃))는 Lee et al. (2003)이 소양강댐 유역에 대해 제안한 1.655를 사용하였다. 산정 알고리즘은 다음 Table 1과 같다.
2.3.3 Snowpack 모의 및 보정강우 입력자료 산정
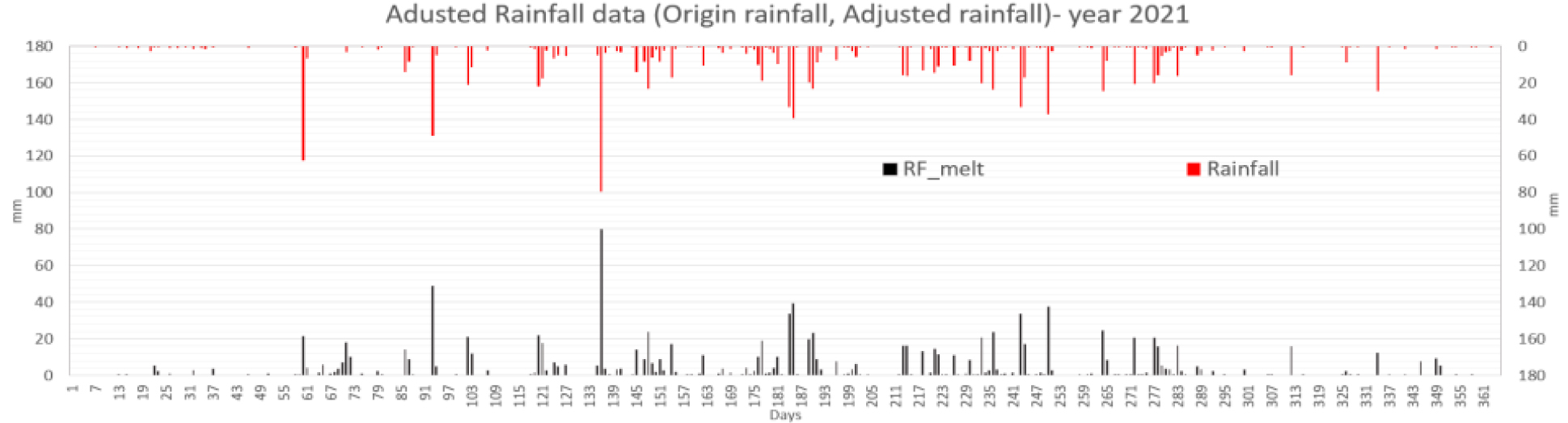
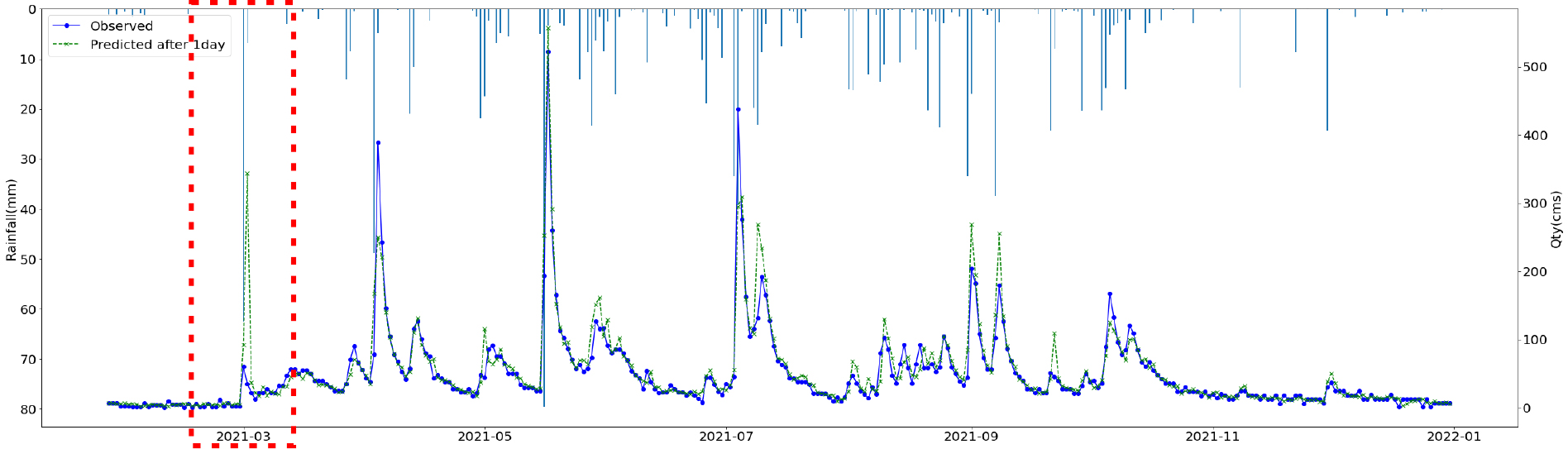
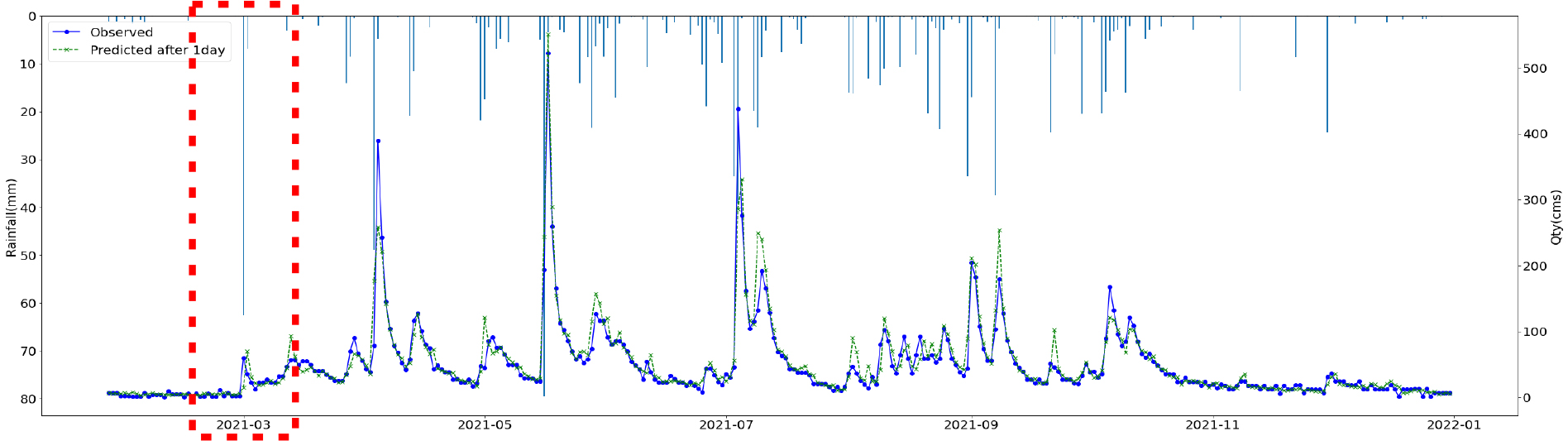
온도 조건에 따라 적설량을 산정하여 Snowpack에 쌓고 온도 조건에 따라 융설량을 산정하고 일단위로 가감하여 Snowpack을 모의하였다. 강우가 없더라도 온도조건이 맞으면 융설량이 발생하여 강우량 데이터에 포함시켰다. 조정된 강우량은 기온조건에 따라 적설, 융설 등의 기작을 통한 가감을 통하여 재산정한 후 입력자료로 활용하였다. 산정 방법은 다음 Table 1과 같으며, 융적설 모의 및 전처리를 통한 보정강우 산정후 융적설 모의를 Fig. 1에, 보정전 후 강우를 Fig. 2 나타내었다.
2.4 모델 최적 하이퍼파라미터 및 모델성능평가
각 모형의 적합한 수행을 위하여 직접 설정해야 하는 변수인 하이퍼파라메터의 최적값은 모델별로 최적의 튜닝을 한 기존연구(Jo and Jung, 2023)의 값을 Table 2와 같이 활용하였다. 모델 성능평가는 실제값과 모델에 의해 예측된 값을 비교하여 두값의 차이(오차)를 구하는 것으로, 과적합(Overfitting)을 방지하고 최적의 모델을 찾기 위함이며, 금번 연구에서는 NSE (Nash-Sutcliffe Efficiency; Nash and Sutcliffe, 1970)로 구성하여 각 데이터모델 및 데이터 시나리오별로 평가하고 예측력을 비교하였다.
Table 2.
Results of determining the optimal hyperparameters for ML&DL models
3. 결과 및 분석
3.1 연구대상지역 및 자료수집
본 연구의 대상지역은 소양강 다목적댐으로 선정하였다. 소양강 댐은 강원도 춘천시 신북읍과 동면 소양강에 위치한 다목적댐으로 4대강 유역종합개발사업의 일환으로 발전, 홍수조절 및 용수공급을 하기 위하여 1973년에 준공되었다. 소양강댐의 제원 및 수문현황은 다음 Table 3과 같으며 유역도는 Fig. 3과 같다
Table 3.
Status of Soyang River dam
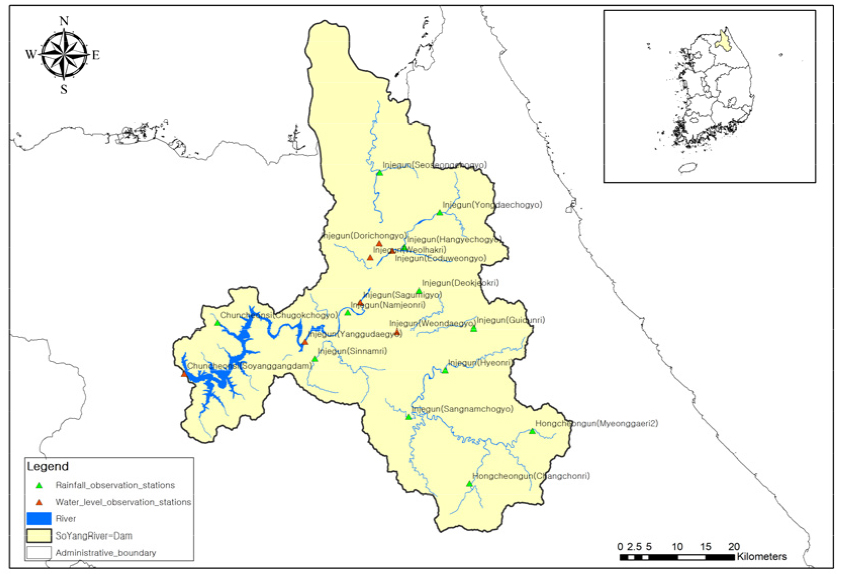
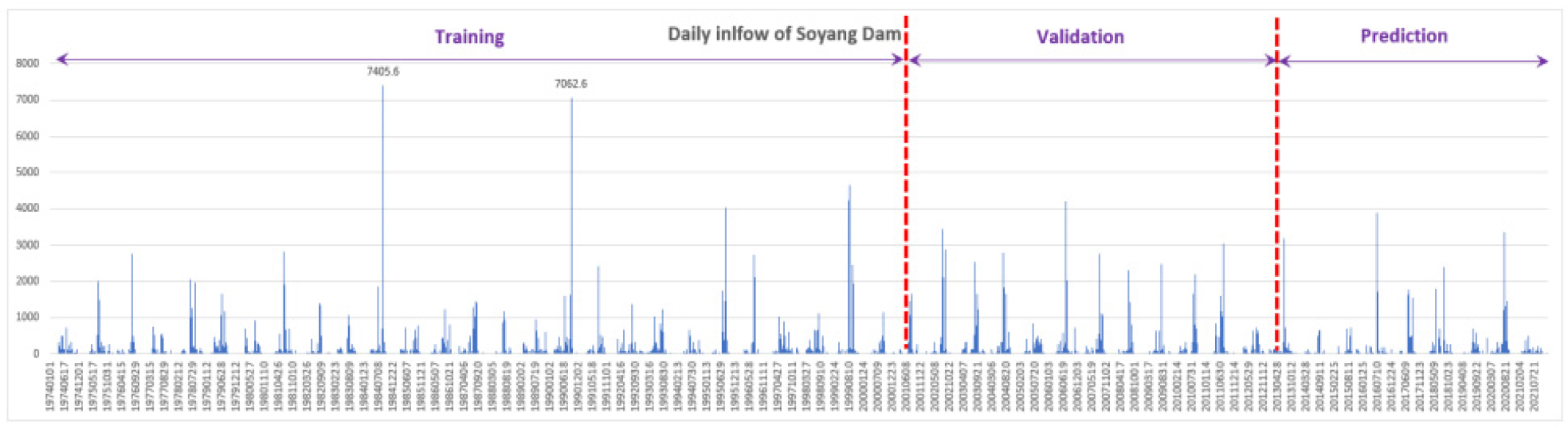
소양강댐유역 강우량 및 유입량자료는 K-water 댐 운영자료를 이용하였고, 1974년 준공이후부터 2021년 말까지의 평균강우량 및 일유입량 자료를 활용하였다(1974.1.1.~2021. 12.31., 17532일). 기상자료는 기상청에서 인제, 춘천관측소 자료를 수집하였다. 머신러닝 및 딥러닝을 위하여 데이터셋은 학습 구간내에 최대치, 최소치 값이 포함되도록 구성하였고 Table 4, Fig. 4와 같이 학습-검증-예측구간으로 구분하였다.
Table 4.
Splitting the dataset into training, validation, and test data
| Train | Validation | Test (Prediction) |
| day1~day10,000 | day10,001~day15,000 | day15,001~day17,532 |
3.2 융적설 보정 전후에 따른 ML& DL 유입량 예측 성능 산정 결과
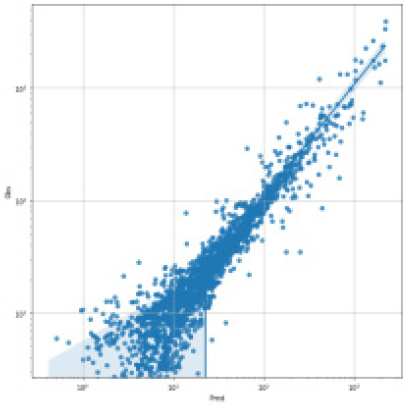
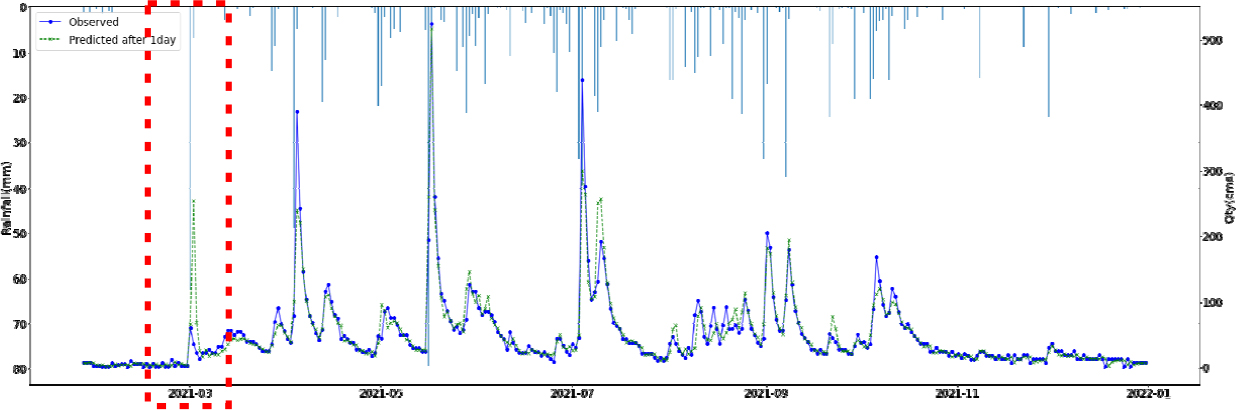
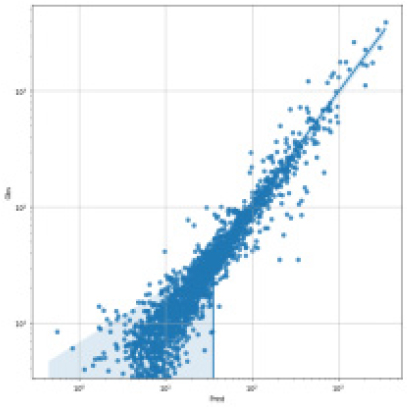
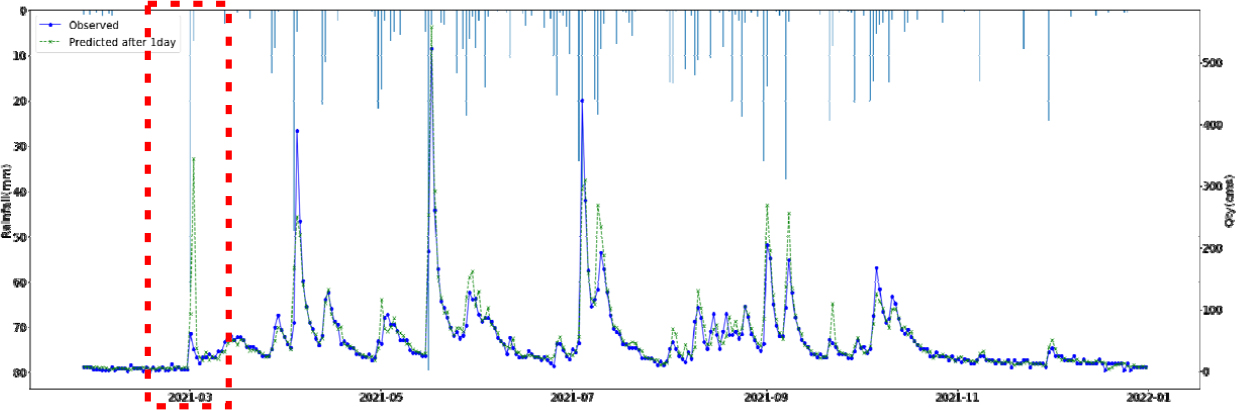
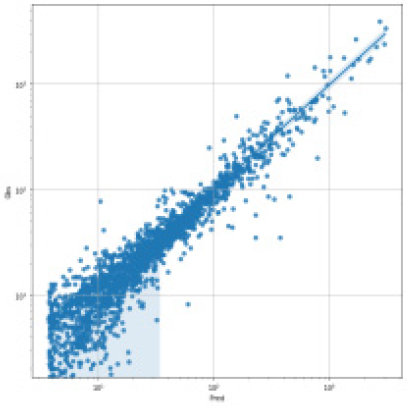
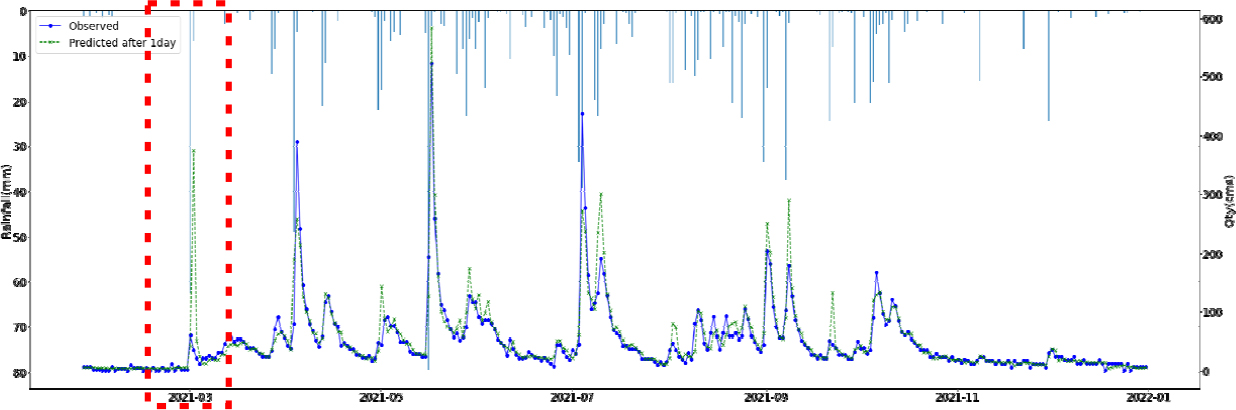
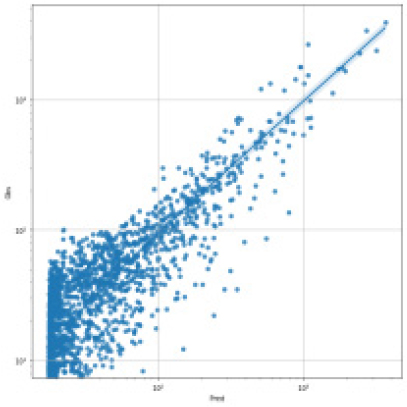
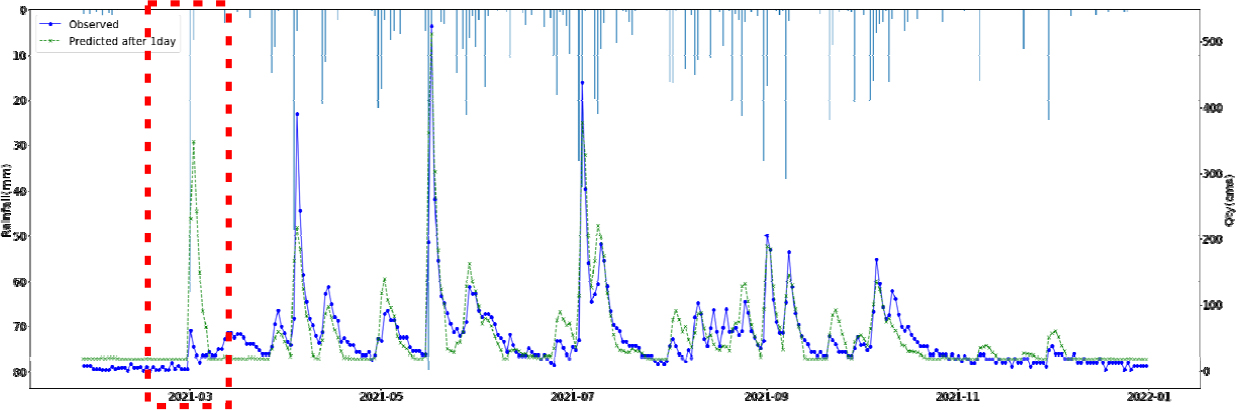
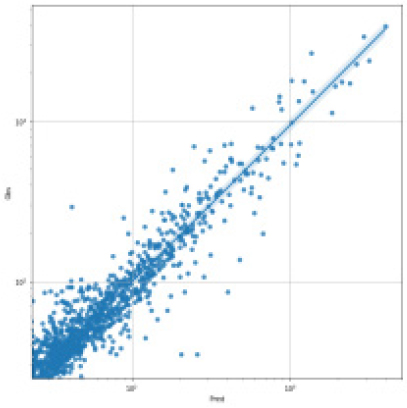
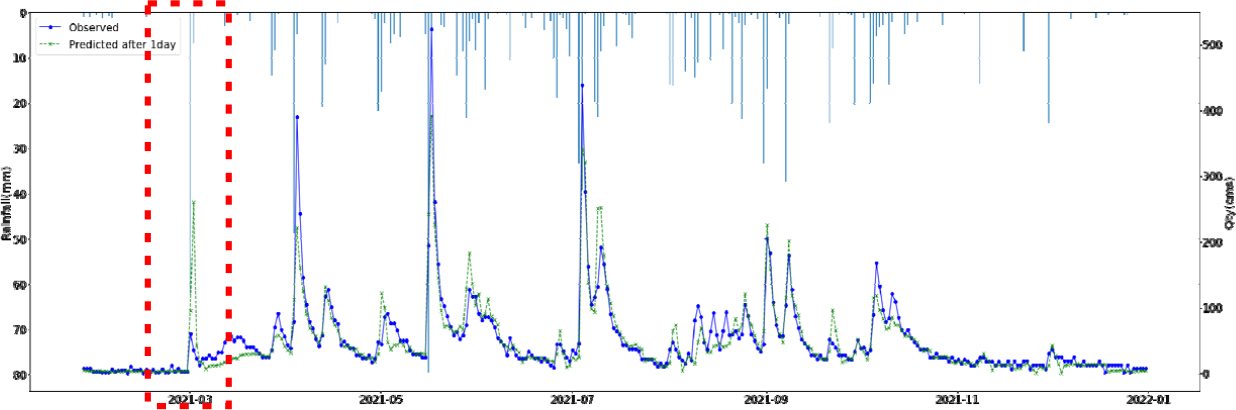
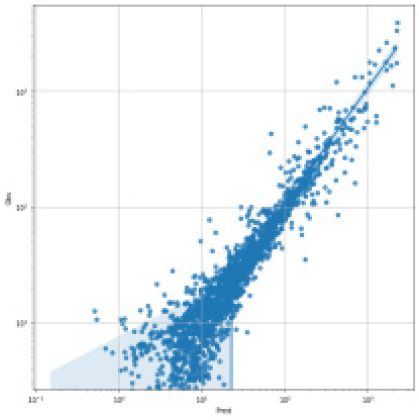
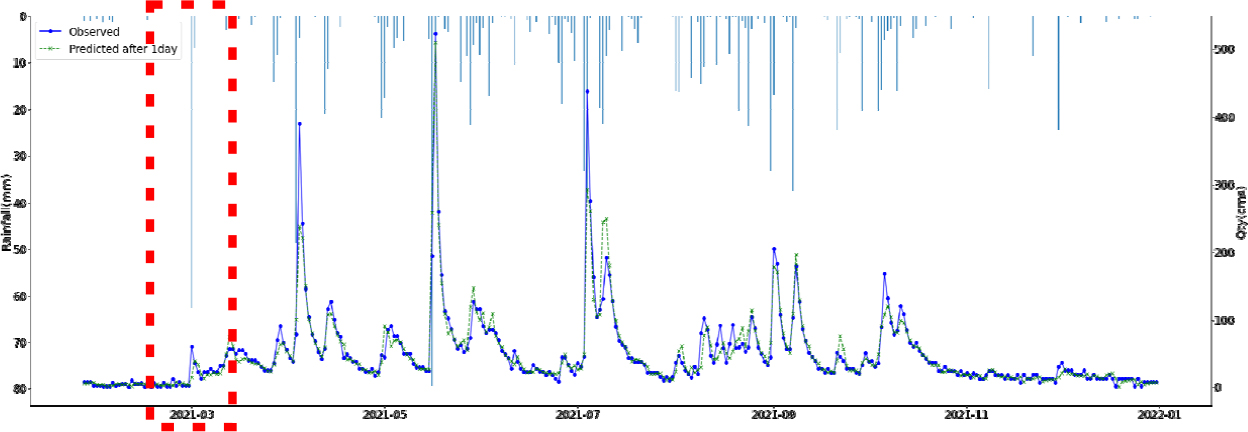
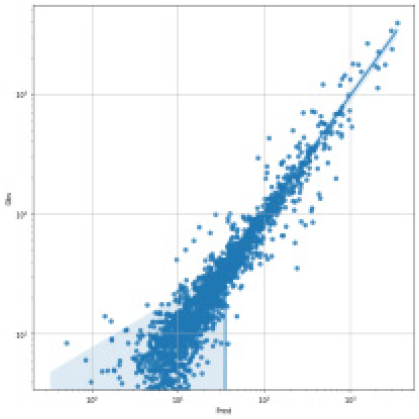
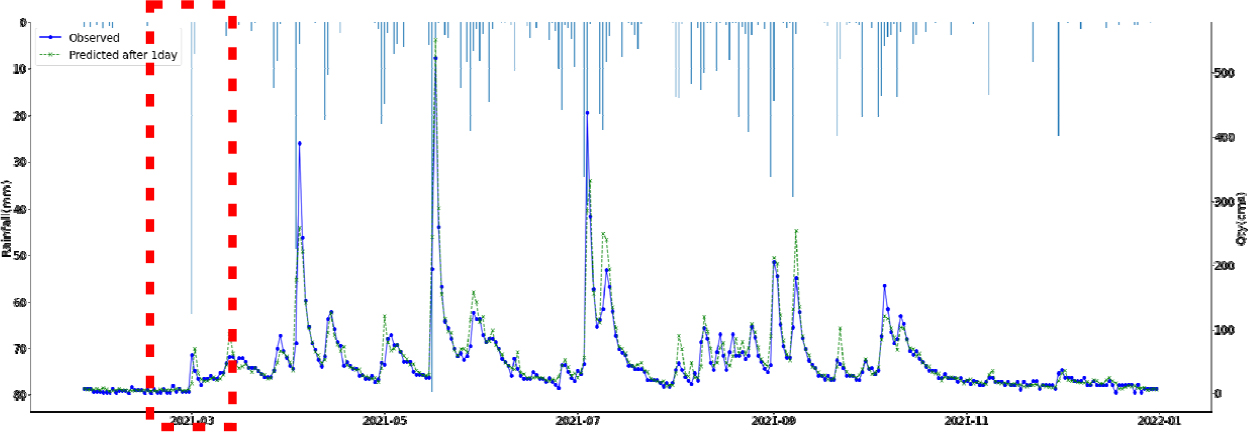
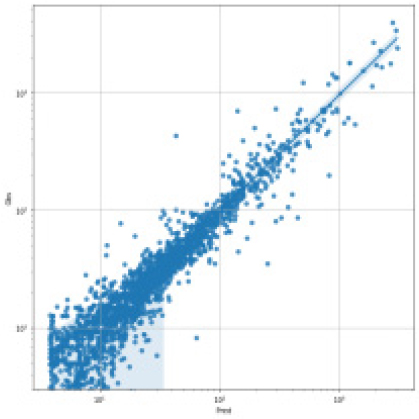
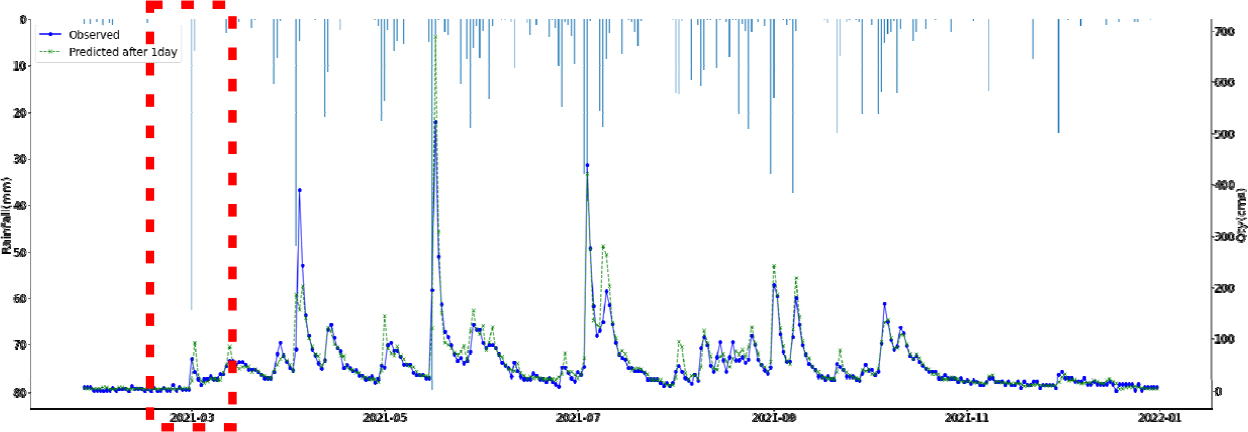
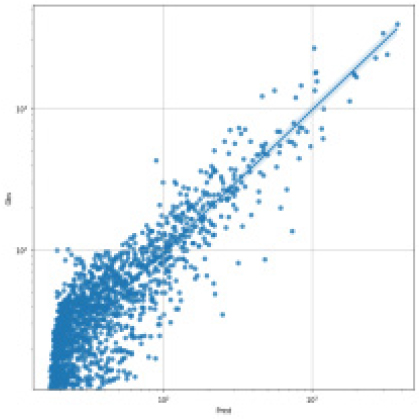
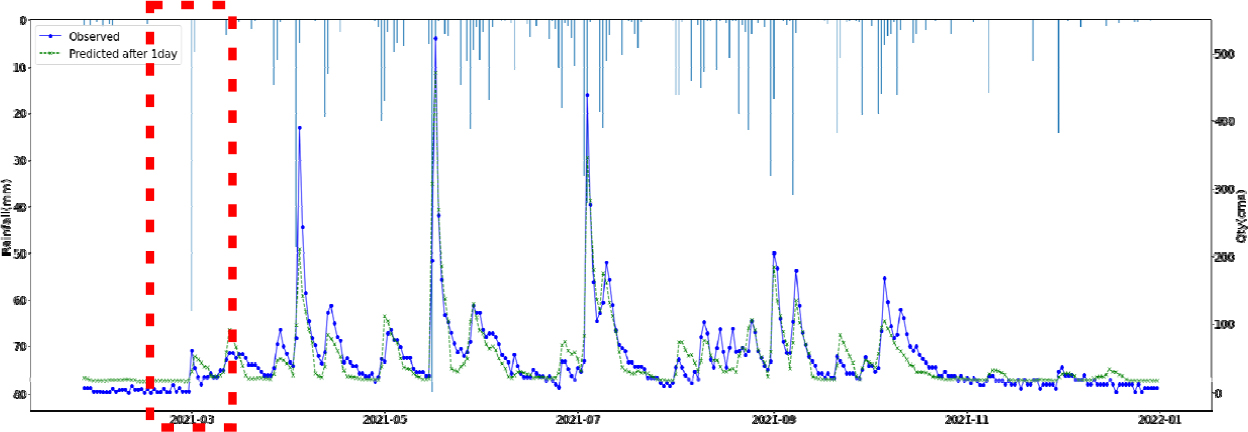
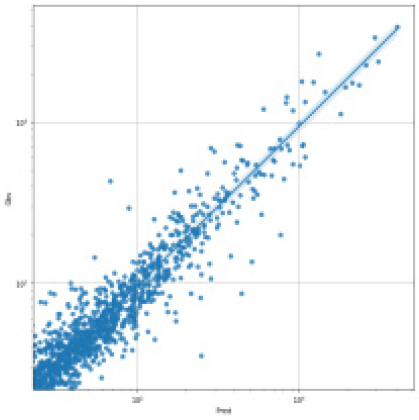
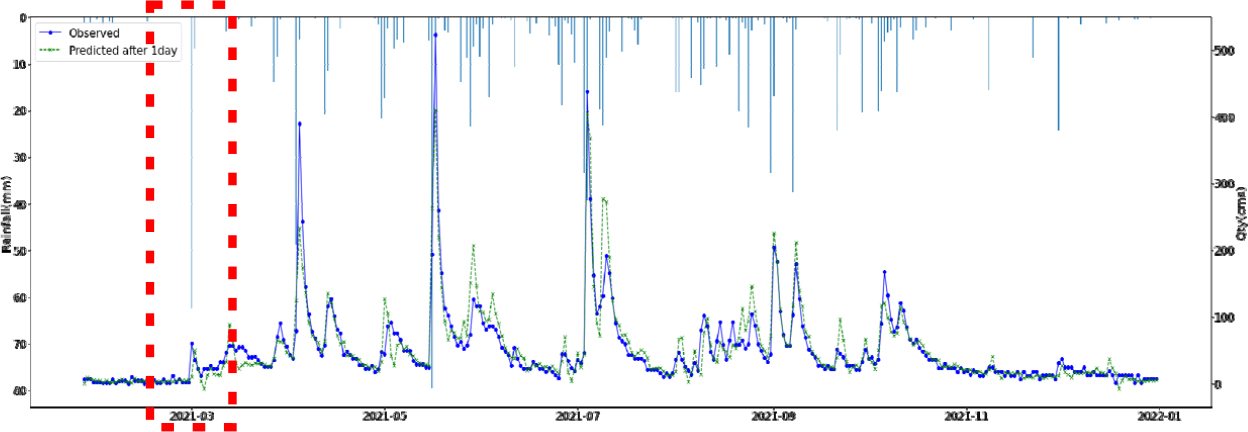
SVR, Random Forest, LGBM, LSTM, TCN 각각 모델에 대한 강설 보정 전후 강우자료를 적용하였을 때 결과는 Table 5와 Figs. 5 and 6과 같다. 각 모델별로 융설이 고려되지 않았을 때와 비슷한 NSE 성능이 나왔다. 이것은 강우와 유출을 학습하는 모든 기간내에 융적설 영향이 모델 전체 학습에는 큰 영향을 미치지 않기 때문으로 보인다. 그러나 융적설이 발생하는 기간에 대하여 세부적으로 살펴보면, Fig. 5에서 볼 수 있듯이 적설과 융설 영향이 반영된 보정된 강우의 적용으로 적설과 융설 현상이 나타난 기간의 실측 유입량에 가깝게 모의하는 것으로 나타났다. Fig. 5에서 원 강우가 많을 때 예측유출량은 많게 나타나는 것은 모델의 학습 때문에 강우의 크기에 따른 유출량 예측값을 보이지만, 실제 유출은 작게 나타난 것은 적설에 의한 효과 때문이다. 그러나 Fig. 6에서는 융적설을 고려한 데이터 전처리를 통하여 강우량이 보정되었고 이를 학습한 결과 유출량 예측이 실측에 가깝게 모의를 한 것으로 분석된다.
Table 5.
Result of Dam inflow prediction from ML& DL by considering snow effect
| NSE | SVR | RF | LGBM | LSTM | TCN |
| Dataset by Original Rainfall | 0.841 | 0.894 | 0.889 | 0.851 | 0.891 |
| Dataset by Adjusted Rainfall (Snowmelt) | 0.841 | 0.896 | 0.879 | 0.860 | 0.891 |
4. 결 론
소양강댐 댐유입량 예측에 대하여 강우계열, 유입량계열을 조합하여 3가지 머신러닝(SVM, RF, LGBM)과 2가지 딥러닝(LSTM, TCN) 모델을 구축하고, 최적 하이퍼파라메터 튜닝을 통하여 적합 모델을 적용한 결과, NSE 0.842~0.894로 높은 수준의 예측성능을 나타내었다.
소양강댐과 같이 융적설의 영향을 받는 댐유역에 대한 댐일유입량 예측시 겨울에 강설량이 적설이 되어 적게 유출되는 현상과, 봄에 융설로 인하여 무강우나 적은 비에도 많은 유출이 일어나는 물리적 현상을 머신러닝 회귀모형과 딥러닝 모델로 적용하기에는 한계가 있었다. 이는 머신러닝 회귀모델은 융적설이 발생하는 기간의 강설량도 강우량으로 학습되어, 해당 강우량에 맞는 유출량으로 학습한 결과에 맞는 유출량을 예측하기 때문이다. 따라서 융적설현상은 대부분의 강우유출을 학습하는 다른 기간의 학습패턴과 다르므로, 융적설의 유출 특성에 맞는 강우량으로 보정해주어야 한다.
융적설을 반영한 강우보정 데이터를 만들기 위하여 융적설 모의 알고리즘을 개발하고, 이를 통하여 보정강우를 산정하고 머신러닝 및 딥러닝 모델에 적용한 결과 NSE 0.841~0.896 으로 융적설 적용 전과 비슷한 수준의 예측 성능을 나타내었다. 그러나 Fig. 5에서 2021년 3월에 적설의 영향으로 실측유량에 비하여 모의 유량이 많이 산정되었으나, Fig. 6에서 비교하여 볼 수 있듯이 융적설 기간의 조정된 강우로 학습되어 예측되었을 때 실측유입량에 가깝게 적합한 모의를 하는 것으로 나타났다. 융적설의 영향을 받는 겨울과 초봄까지의 기간을 구분(12월~4월, 5월~11월)하여 평가를 하였으나, NSE가 유의미하게 개선되지는 않았으며 융적설이 명백하게 나타나는 시기만 구분하여 평가하는 방법의 추가연구가 필요하다.
융적설이 영향을 미치는 유역에서의 유출해석을 위한 데이터 모델 적용시에는 입력자료 구축시 분석시간 스케일에 따라 물리적으로 보다 타당한 강우-유출 반응에 적합하도록 융적설량을 조정하는 전처리 과정이 중요함을 확인하였다. 따라서 융적설과 같은 경우 강우량의 입력자료 구성시 모델 학습 왜곡을 최소화하기 위하여 강수량 자료를 타당하게 보완하는 것이 더 좋은 예측 성능을 가질 것으로 보인다