

1. 서 론
2. L-comoment
3. 수문학적 동질지역 구분
3.1 지역구분 방법
3.2 불일치 척도
3.3 이질성 척도
4. 적 용
5. 결과 및 토의
5.1 지역구분 결과
5.2 불일치 척도 결과
5.3 동질성 검토 결과
6. 결 론
1. 서 론
수공구조물의 설계 및 운영에서 관측된 수문자료의 정확한 빈도해석은 매우 중요하다. 국내의 극한 강우, 홍수, 가뭄 등과 같은 다양한 수문인자에 대하여 단변량 지점빈도해석이 수행되었으며, 최근에는 기후변화를 고려한 수문인자에 대한 비정상성 단변량 지점빈도해석에 대한 연구가 진행되고 있다. 단변량 지점빈도해석에서 다양한 특성을 분석하고자 많은 경우 단변량 지점빈도해석 결과를 모아 다변량 자료에 대한 빈도해석 결과로 사용한다. 하지만 단변량 자료를 이용하여 단변량 지점빈도해석을 실시하는 것보다 다변량 자료를 이용하여 다변량 지점빈도해석을 실시할 경우 단변량 지점빈도해석보다 많은 정보를 빈도해석에 사용하기 때문에 단변량 지점빈도해석에서는 분석할 수 없는 자료의 특징들을 분석 할 수 있다. Joo et al. (2012)는 copula 모형을 이용하여 국내의 극한 강우사상에 대한 이변량 빈도해석을 수행하였다. 이변량 자료로는 연별 최대강우량-지속기간을 사용하였고 copula 모형으로는 archimedean copula를 사용하였다. 적용된 copula 모형에 따른 확률강수량의 변화를 분석하였다. Kim et al. (2016)은 copula 모형을 이용하여 국내 가뭄자료에 대하여 삼변량 가뭄빈도해석을 실시하였으며 사용된 삼변량 자료로는 가뭄 지속기간-심도-강도를 이용하였다. 삼변량 copula 모형을 구축하기 위해서 Archimedean copula와 Meta-elliptical copula를 적용하였으며 삼변량 자료에 대한 빈도해석 시 copula 모형의 선택이 정확한 빈도해석을 위해 중요하다는 것을 밝혀내었다.
위에서 언급한 빈도해석의 경우 빈도해석 시 한 지점의 자료만 이용하는 지점빈도해석들이다. 정확한 빈도해석을 위해서는 많은 자료의 수를 확보하는 것이 중요한데, 수문분야에서 사용하는 대부분의 자료들이 짧은 자료연수를 가지고 있다. 또한 수문인자의 관측소가 존재하지 않은 지점의 경우 관측자료가 존재하지 않아 빈도해석이 불가능하다. 이러한 문제점들을 극복하고자 지역빈도해석이 제안되었다. 국내에서는 극한 강우 및 홍수 자료의 빈도해석을 위한 지역빈도해석 연구가 활발히 진행되었다. Heo et al. (2007a, 2007b)은 지수홍수법과 지역형상추정법을 이용하여 국내 강우자료에 대한 지역빈도해석의 적용성을 평가하였다. 적용된 지역빈도해석 기법들의 성능을 평가하기 위해서 모의실험을 수행하였으며 지역빈도해석이 지점빈도해석보다 정확한 확률강수량을 추정하는 것을 확인하였고, 지역빈도해석간의 성능 비교에서는 지역형상추정법이 지수홍수법보다 정확한 확률강수량을 추정하는 것을 확인하였다. Nam et al. (2008)은 다변량 분석 기법을 활용하여 강우 지역빈도해석에 사용되는 수문학적 동질지역을 선정하는 연구를 진행하였으며 연구 결과 남한의 강우지점은 총 6개의 구역으로 구분이 가능한 것으로 나타났다. Lee et al. (2016)은 지수홍수법을 이용하여 금강유역 내 미계측 유역의 설계홍수량을 산정하는 연구를 진행하였다. 위 연구에서 금강유역의 지역홍수빈도 관계식을 제안하였다.
지역빈도해석의 장점과 다변량 빈도해석의 장점을 동시에 만족시키고자 다변량 지역빈도해석이 제안되었다. Chebana and Ouarda (2007)는 수문학적 동질지역을 판정하는 불일치 척도와 이질성 척도를 이변량 지역빈도해석에 맞게 수정 제안하였으며 Chebana and Ouarda (2009)은 이변량 자료에 대하여 copula 모형을 이용한 이변량 지역빈도해석 방법을 제안하였다. 이 연구에서는 단변량 자료에서 사용되는 지수홍수법(index flood)을 이변량자료에 적용할 수 있도록 수정하였다. 제안된 모형의 성능을 확인하고자 모의실험을 실시한 결과 이변량 지역빈도해석이 단변량 지역빈도해석과 정확도 상으로는 큰 차이를 보이지 않는 것으로 나타났다. 또한 단변량 지역빈도해석의 경우 다양한 사상들을 고려할 수 없기에 다변량 지역빈도해석이 수문빈도해석에 적절하다고 분석하였다. Ben Aissia et al. (2015)는 캐나다 연최대 수위-홍수량 자료를 이변량 지역빈도해석을 이용하여 홍수자료를 모의하였으며 빈도해석결과 이변량 지역빈도해석은 주변분포의 적절한 선택이 매우 중요하다는 것을 찾아냈다. Requena et al. (2016)은 기존에 적용되었던 다변량 지역빈도해석 기법의 자세한 적용 방법들을 제안하였다. 제안한 방법론의 적절성을 평가하기 위해서 스페인 각 홍수사상의 최고수위-홍수량 자료를 사용하였으며 이변량 지역빈도해석을 통하여 수문자료에 대한 이변량 확률분포형을 얻을 수 있고, 이변량 확률분포형을 통하여 수공구조물의 설계기준을 정하는 것이 가능하다고 분석하였다.
다변량 지역빈도해석은 기존에 사용되어 온 다변량 빈도해석과 지역빈도해석의 장점을 모두 가지고 있는 방법으로 다양한 변수를 고려함으로써 수문현상에 대한 빈도해석을 통하여 다른 빈도해석 기법보다 많은 정보를 얻어낼 수 있다. 현재까지는 우리나라의 수문자료를 이용하여 다변량 지역빈도해석이 실시된 적이 없기 때문에 국내의 수문자료를 대상으로 다변량 지역빈도해석의 적용성을 검토할 필요가 있다. 지역빈도해석은 크게 두 단계로 나누어져 있다. 첫 번째 단계는 수문학적 동질지역을 설정하는 것이고, 두 번째 단계는 지역매개변수를 산정하여 확률수문량을 추정하는 것이다. 본 연구에서는 지역빈도해석의 두 단계 중 첫 번째인 수문학적 동질지역을 설정하는 단계에 집중하여 이변량 수문자료인 연최대 강우량-지속기간 자료에 대하여 수문학적 동질지역을 설정하였다. 한국의 연최대 강우량-지속기간 자료에 대한 이변량 지역빈도해석에서 사용되는 지역구분의 적용성을 평가하였고 그 특성을 분석하였다.
2. L-comoment
L-모멘트(moment)는 지역빈도해석에서 수문학적 동질지역을 평가하거나, 확률분포형의 매개변수를 추정할 때 널리 쓰이고 있다. 일반모멘트 방법으로 산정된 변동계수, 왜도, 첨도계수는 표본크기가 작은 경우 크게 편의되는데 비하여 L-모멘트의 표본추정량은 순차로 정리된 관측치의 선형조합으로 산정되어 무차원화된 변동계수나 왜도의 추정치가 거의 편의되어 있지 않고 정규분포에 가까운 특징이 있다(Lee and Heo, 2001). 기존에 사용되어온 L-moment의 경우 단변량 자료에 대한 것으로 다변량 자료를 위해서는 L-comoment를 사용해야 한다. Serfling and Xiao (2007)는 다변량 자료에 대한 L-comoment를 유도하였다. 이변량 자료의 L-comoment는 Eq. (1)을 이용하여 산정 할 수 있다.
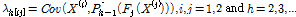 (1)
(1)
여기서, h는 L-comoment의 차수, X는 확률변수, F는 X의 누가분포함수, P는 이동된 Legendre 다항식을 의미한다. i는 대상이 되는 확률변수를 지칭하는 숫자이며, j는 i와 상관관계가 있는 확률변수를 지칭하는 숫자이다. Eq. (1)로부터 계산된 L-comoment를 이용하여 L-comoment 계수는 아래 Eq. (2)를 통하여 산정된다.
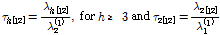 (2)
(2)
L-comoment는 일반적으로 사용되는 모멘트와 공분산과 비슷한 개념으로 하나의 계수가 아닌 행렬 형태로 표현된다. h차 L-comoment 행렬은 다음과 같이 정의된다.
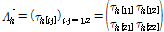 (3)
(3)
표본자료를 이용하여 k차 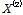 에 대한
에 대한 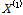 의 L-comment의 경우 Eq. (4)를 이용하여 산정하게 된다.
의 L-comment의 경우 Eq. (4)를 이용하여 산정하게 된다.
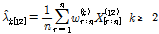 (4)
(4)
여기서, n은 표본자료의 수를 나타내고, 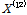 는
는 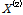 의 오름차순으로 정리된
의 오름차순으로 정리된 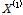 를 나타낸다.
를 나타낸다. 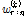 는 가중치로서 Eq. (5)를 이용하여 계산된다.
는 가중치로서 Eq. (5)를 이용하여 계산된다.
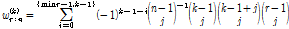 (5)
(5)
3. 수문학적 동질지역 구분
3.1 지역구분 방법
수문학적인 동질지역을 구분하기 위해서는 우선적으로 지역구분을 실시하여야 한다. 지점의 수문학적 특징을 나타내는 인자들을 선택하고, 선택된 인자들에 군집화 기법(clustering method)을 이용하여 1차적인 지역구분을 실시한다. 본 연구에서는 군집화 기법으로 K-medoids 방법을 적용하였다. 군집화 기법 내에서 적용 지점들이 같은 군집인지 아닌지를 평가하는 기준으로는 유클리드 거리(Euclidean distance)가 사용되었다. K-medoids 방법 중 Kaufman and Rousseeuw (1990)가 제안한 K-medoids clustering partitioning around medoids (PAM) 방법을 이용하였으며 절차는 아래와 같다.
1. 전체 N개의 자료 중 임의의 k개의 자료를 선택하여 medoid로 설정한다.
2. 선택된 medoid들이 바뀌지 않을 때 까지 다음의 단계를 반복한다.
2-1. 선택되지 않은 자료들을 유클리드 거리를 기준으로 가장 가까운 medoid와 묶는다.
2-2. 선택되지 않은 각 자료들에 대해, 해당 자료를 자신이 포함된 집합의 새로운 medoid로 가정하여 거리 비용을 계산한다. 선택된 거리 비용은 선택된 medoid로부터 포함된 집합 안에 있는 자료까지의 유클리드 거리의 총합을 이용한다.
2-3. 기존의 medoid들에 대한 거리 비용과 새로 제안된 medoid들에 대한 거리 비용을 비교하여, 비용이 낮아질 경우 medoid를 교체한다.
K-medoid 방법은 K-mean 방법보다 이상치가 있는 자료군이나 잡음이 심한 자료에서 보다 안정적이고 정확한 결과를 도출하는 특징이 있다(Park and Jun, 2009). 본 연구에서는 최적 군집수를 선택하기 위해서 실루엣 지수(Silhouette index)를 사용하였다. 실루엣 지수는 군집에 대한 군집 내의 자료간의 거리와 군집 간 거리의 정도를 의미하며 군집해석에서 최적 군집수를 결정하는 지표로 쓰이고 있다. 실루엣 지수는 Eq. (6)를 이용하여 산정된 각 자료의 실루엣 폭의 평균값이다.
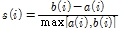 (6)
(6)
여기서, 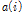 는 정해진 군집 내에서 i번째 자료와 다른 자료들이 얼마나 다른가는 나타내는 지표로 일반적으로 i번째 자료와 다른 자료들 간의 유클리드 거리로 나타낸다.
는 정해진 군집 내에서 i번째 자료와 다른 자료들이 얼마나 다른가는 나타내는 지표로 일반적으로 i번째 자료와 다른 자료들 간의 유클리드 거리로 나타낸다. 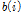 는 군집내의 i번째 개체와 제일 가까운 군집 내의 개체들 간의 평균거리이다. 실루엣 폭은 -1 부터 1 사이의 값을 가지며 1에 가까울수록 군집화가 잘 이루어 진 것이며 -1에 가까울수록 군집화가 잘 이루어지지 못한 것이다.
는 군집내의 i번째 개체와 제일 가까운 군집 내의 개체들 간의 평균거리이다. 실루엣 폭은 -1 부터 1 사이의 값을 가지며 1에 가까울수록 군집화가 잘 이루어 진 것이며 -1에 가까울수록 군집화가 잘 이루어지지 못한 것이다.
3.2 불일치 척도
불일치 척도는 가정된 동질지역 내에 자료집합과 동질하지 않은 지점을 찾을 때 사용하는 척도이다. 본 연구에서는 Chebana and Ouarda (2007)이 제안한 불일치 척도를 사용하여 K-medoid 방법으로 구분된 지역 안에 있는 지역의 불일치 척도를 산정하였다. 이변량 자료에 대한 불일치 척도(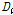 ) 산정 방법은 Eqs. (7)~(10)과 같다.
) 산정 방법은 Eqs. (7)~(10)과 같다.
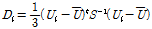 (7)
(7)
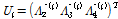 (8)
(8)
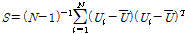 (9)
(9)
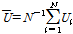 (10)
(10)
여기서, 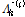 는 i번째 지점의 h차 L-comoment 행렬이다.
는 i번째 지점의 h차 L-comoment 행렬이다.  값은 행렬로써 하나의 값으로 변환을 해줄 필요가 있다. 본 연구에서는 Chebana and Ouarda (2007)가 최종적으로 적용했던 spectral norm을 적용하였다. 또한 위 연구에서 동질유역의 불일치 척도의 한계값으로는 2.6을 제안하였으며, 지점의 불일치 척도가 2.6 이상을 가지면 구분된 지역 내의 자료들과 불일치 한 것으로 판정하였다.
값은 행렬로써 하나의 값으로 변환을 해줄 필요가 있다. 본 연구에서는 Chebana and Ouarda (2007)가 최종적으로 적용했던 spectral norm을 적용하였다. 또한 위 연구에서 동질유역의 불일치 척도의 한계값으로는 2.6을 제안하였으며, 지점의 불일치 척도가 2.6 이상을 가지면 구분된 지역 내의 자료들과 불일치 한 것으로 판정하였다.
3.3 이질성 척도
지역빈도해석에서 수문학적으로 동일한 지역을 선정하는데 있어서의 기본 가정은 동질 지역 내 각 지점들의 자료가 동일한 확률분포를 따른다는 것이다. 따라서 구분된 지역의 자료계열이 수문학적인 동질성을 가지는지 평가하기 위한 기준이 필요하다. 이질성 척도(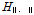 )는 지역 내 자료들이 얼마나 동일한지를 평가하는 지표이다. 동질성을 가진 지역에서의 모든 지점의 자료는 같은 모집단 L-모멘트를 가진다고 가정한다. 하지만 표본 L-모멘트는 서로 다를 가능성이 높으므로 그러므로 동질성을 가진 지역에서 산정되는 이산도를 해당 지역의 표본 L-모멘트가 가지고 있는지 확인해야 한다. 표본자료의 이산도 산정 및 가정된 모집단 이산도 산정을 하고 산정된 이산도들을 기준으로 이질성 척도를 산정해야 한다. Hosking and Wallis (2005)은 지역의 이산도(
)는 지역 내 자료들이 얼마나 동일한지를 평가하는 지표이다. 동질성을 가진 지역에서의 모든 지점의 자료는 같은 모집단 L-모멘트를 가진다고 가정한다. 하지만 표본 L-모멘트는 서로 다를 가능성이 높으므로 그러므로 동질성을 가진 지역에서 산정되는 이산도를 해당 지역의 표본 L-모멘트가 가지고 있는지 확인해야 한다. 표본자료의 이산도 산정 및 가정된 모집단 이산도 산정을 하고 산정된 이산도들을 기준으로 이질성 척도를 산정해야 한다. Hosking and Wallis (2005)은 지역의 이산도(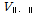 )로 지역 내 지점 자료기간의 비율로 가중된 표준편차를 제안하였으며, 이질성 척도는 자료의 이산도를 모의발생시킨 이산도들의 평균과 차, 그리고 모의발생시킨 이산도들의 표준편차의 비로 정의하였다. Chebana and Ouarda (2007)는 이변량 자료의 대한 이산도를 Eq. (11)과 같이 제안하였다.
)로 지역 내 지점 자료기간의 비율로 가중된 표준편차를 제안하였으며, 이질성 척도는 자료의 이산도를 모의발생시킨 이산도들의 평균과 차, 그리고 모의발생시킨 이산도들의 표준편차의 비로 정의하였다. Chebana and Ouarda (2007)는 이변량 자료의 대한 이산도를 Eq. (11)과 같이 제안하였다.
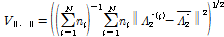 (11)
(11)
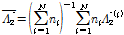 (12)
(12)
여기서, 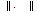 은 spectral norm을 의미한다. 위에서 언급되었듯이 이질성 척도를 산정하기 위해서는 대상 지역의 관측자료를 이용한 이산도와 모의실험을 통한 가정된 모집단에서의 이산도를 추정해야 한다. 각 지점의 자료를 몬테카를로(Monte- Carlo) 방법을 이용하여 모의실험을 수행한다. 몬테카를로 모의실험을 위해서는 모집단의 확률분포모형을 알고 있어야 한다. 하지만 각 지점의 모집단의 확률분포모형을 확인하는 것은 매우 어렵기 때문에 Kappa 분포형(Kappa distribution)을 이용하여 몬테카를로 모의실험을 수행하였다. Kappa 분포형은 다양한 극치 확률분포모형을 재현해 낼 수 있기에 모의실험을 수행하기에 적절한 것으로 판단되어 이질성 척도를 산정하는 모의실험에 널리 사용되고 있다(Hosking and Wallis, 2005).
은 spectral norm을 의미한다. 위에서 언급되었듯이 이질성 척도를 산정하기 위해서는 대상 지역의 관측자료를 이용한 이산도와 모의실험을 통한 가정된 모집단에서의 이산도를 추정해야 한다. 각 지점의 자료를 몬테카를로(Monte- Carlo) 방법을 이용하여 모의실험을 수행한다. 몬테카를로 모의실험을 위해서는 모집단의 확률분포모형을 알고 있어야 한다. 하지만 각 지점의 모집단의 확률분포모형을 확인하는 것은 매우 어렵기 때문에 Kappa 분포형(Kappa distribution)을 이용하여 몬테카를로 모의실험을 수행하였다. Kappa 분포형은 다양한 극치 확률분포모형을 재현해 낼 수 있기에 모의실험을 수행하기에 적절한 것으로 판단되어 이질성 척도를 산정하는 모의실험에 널리 사용되고 있다(Hosking and Wallis, 2005).
본 연구에서는 이변량 자료를 사용하기 때문에 Kappa 분포형만으로는 모의실험이 불가능하다. 이변량 자료를 몬테카를로 방법으로 발생시키기 위해서는 이변량 분포형을 이용해야 한다. 따라서 본 연구에서는 copula 모형을 이용하여 이변량 자료를 발생시켰다. copula 모형은 두 개 이상의 주변분포들을 묶어서 다변량 확률분포형을 만드는 모형이며 두 개의 단변량 분포형을 묶어서 이변량 분포형을 만들었다. 주변분포로는 Kappa 분포형을 사용하였고 copula 모형으로는 Gumbel 모형을 사용하였다. Chebana and Ouarda (2007)과 Abdi et al. (2017)은 극치 copula모형인 Gumbel 모형이 이질성 척도 산정을 위한 모의실험에서 각 자료간의 상관도를 적절히 모의하는 것으로 나타났다. Eq. (13)은 Kappa 분포형의 누가분포함수을 나타낸다.
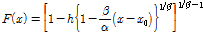 (13)
(13)
여기서, 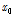 는 위치매개변수,
는 위치매개변수, 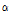 는 규모매개변수,
는 규모매개변수, 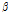 와
와 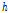 는 형상매개변수이다. Eq. (14)은 Gumbel logistic copula모형을 나타낸다.
는 형상매개변수이다. Eq. (14)은 Gumbel logistic copula모형을 나타낸다.
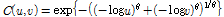 (14)
(14)
여기서, 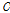 는 copula 함수,
는 copula 함수, 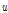 와
와  는 확률변수,
는 확률변수,  는 매개변수를 나타낸다. Eq. (15)를 이용하여 이질성 척도를 산정한다.
는 매개변수를 나타낸다. Eq. (15)를 이용하여 이질성 척도를 산정한다.
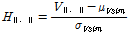 (15)
(15)
여기서, 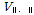 은 관측자료의 이산도,
은 관측자료의 이산도, 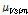 은 모의실험된 이산도의 평균,
은 모의실험된 이산도의 평균, 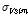 은 모의실험된 이산도의 표준편차를 나타낸다. 간소한 이질성 척도 산정 과정은 아래에 정리되어 있다.
은 모의실험된 이산도의 표준편차를 나타낸다. 간소한 이질성 척도 산정 과정은 아래에 정리되어 있다.
1. 선택된 지역의 이산도(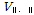 )를 산정한다.
)를 산정한다.
2. 각 지점 자료를 이용하여 Kappa 분포형의 매개변수를 추정한다.
3. 각 지점 자료를 이용하여 Gumbel copula 모형의 매개변수를 추정한다.
4. 2번과 3번에서 추정된 매개변수를 이용하여 각 지점의 이변량 자료를 500번(N = 500) 발생시키고, 발생된 자료의 이산도를 산정한다. 산정된 이산도의 평균과 표준편차를 계산한다.
5. 이질성 척도(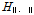 )를 산정한다.
)를 산정한다.
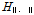 이 2보다 큰 값을 가지는 경우 대상 지역은 이질한 것으로 판단하며,
이 2보다 큰 값을 가지는 경우 대상 지역은 이질한 것으로 판단하며,  이 1과 2 사이일 때에는 비교적 동질한 지역으로 판단하고,
이 1과 2 사이일 때에는 비교적 동질한 지역으로 판단하고,  이 1보다 작을 경우 동질한 지역으로 판단한다(Chebana and Ouarda, 2007; Hosking and Wallis, 2005).
이 1보다 작을 경우 동질한 지역으로 판단한다(Chebana and Ouarda, 2007; Hosking and Wallis, 2005).
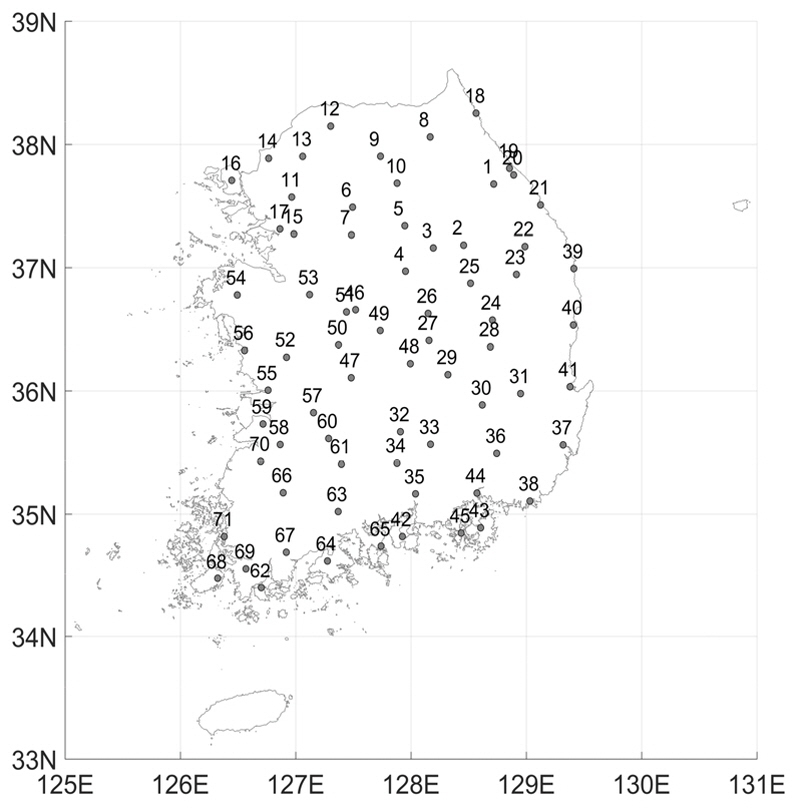
4. 적 용
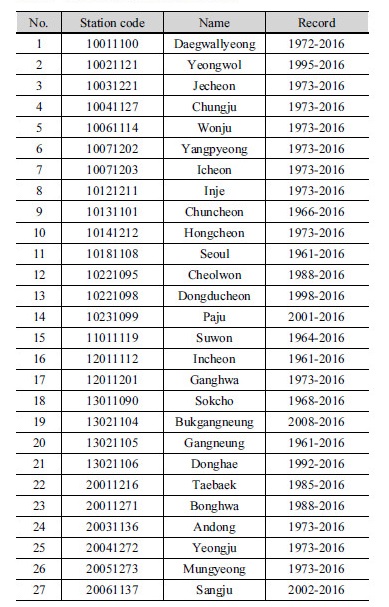
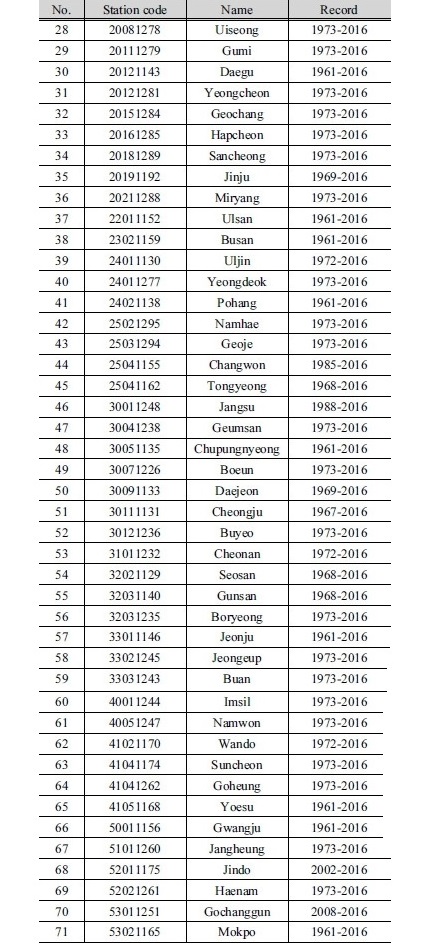
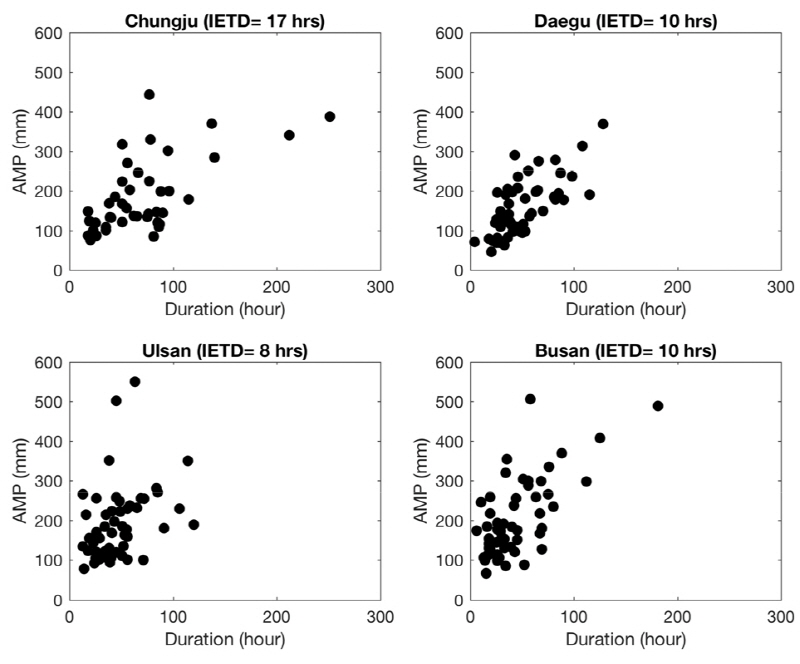
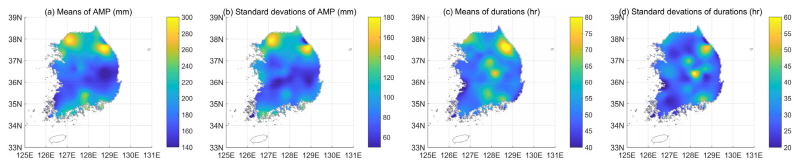
본 연구에서는 기상청 71개 지점 자료를 이용하여 연구를 수행하였으며 제주도, 울릉도, 백령도에 위치한 기상청 지점의 경우, 내륙에 위치한 지점들과 다른 특성을 보이기에 본 연구에서는 섬 지역의 자료는 사용하지 않았다. 사용된 기상청 지점의 이름과 자료 기간은 Table 1에 표시되어 있으며 위치는 Fig. 1에 표시되어 있다. 이변량 자료를 만들기 위해서 각 지점의 사상간 무강수 시간(Inter event distance time, IETD)을 산정하여야 하며 본 연구에서는 Song et al. (2016)이 제안한 무강수 시간을 사용하여 강우사상을 구분하였다. 무강수시간을 이용하여 추출된 강우사상 중 연최대강우량을 기준으로 강우사상을 선택하였다. Fig. 2는 충주지점, 대구지점, 울산지점, 부산지점의 선택된 연최대강우량과 연최대강우량 발생 사상의 지속기간을 나타낸 그림이다. IETD가 증가할수록 지속기간이 증가하는 것을 확인할 수 있었다. 연최대강우사상의 통계적 특성을 보고자 연최대강우량과 지속기간의 평균과 표준편차를 Fig. 3에 도시 하였다.
5. 결과 및 토의
5.1 지역구분 결과
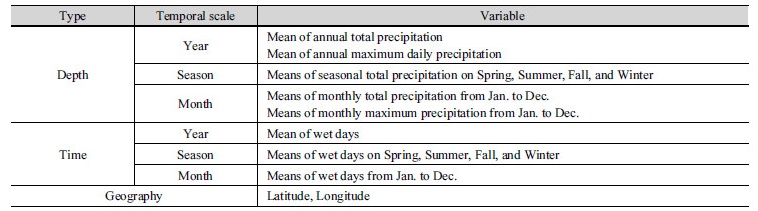
강수량과 관련된 49개 인자를 선택하여 군집해석의 인자로 사용했으며 사용된 인자로는 사용 지점의 위치, 월 별 강수량 평균, 월 별 최대 강수량, 월 별 평균 강수일수, 연평균 강수일수, 연최대 강수량, 계절별 강수량 평균, 계절별 평균 강수일수가 있다. 군집해석에 사용된 49개의 인자는 Table 2에 나타냈다. 군집해석을 실시하기 전에 각 인자를 표준화하여 각 자료간의 축척차이를 제거 하였으며 최적 군집수를 찾기 위해서 본 연구에서는 실루엣 지수가 사용되었다. Hosking and Wallis (2005)는 각 군집마다 20개 정도의 지점이 들어가는 것을 추천하였다. 본 연구에서 사용된 지점수는 총 72개로 20개 내외의 자료가 들어가기 위해서는 군집수가 4~8개로 되는 것이 적절한 것으로 판단되어 4~8개의 군집수에 대하여 최적 군집수 검사를 진행하였다. 군집해석 방법의 초기값 문제를 해결하고자 군집수마다 같은 자료를 사용하여 100회의 군집해석을 실시하였고 100회의 군집해석 결과에 대한 실루엣 지수를 산정하였다. 군집수에 따라서 산정된 100개의 실루엣 지수 중 최댓값을 찾았고 찾은 실루엣 지수의 최댓값은 Fig. 4에 도시되어 있다.
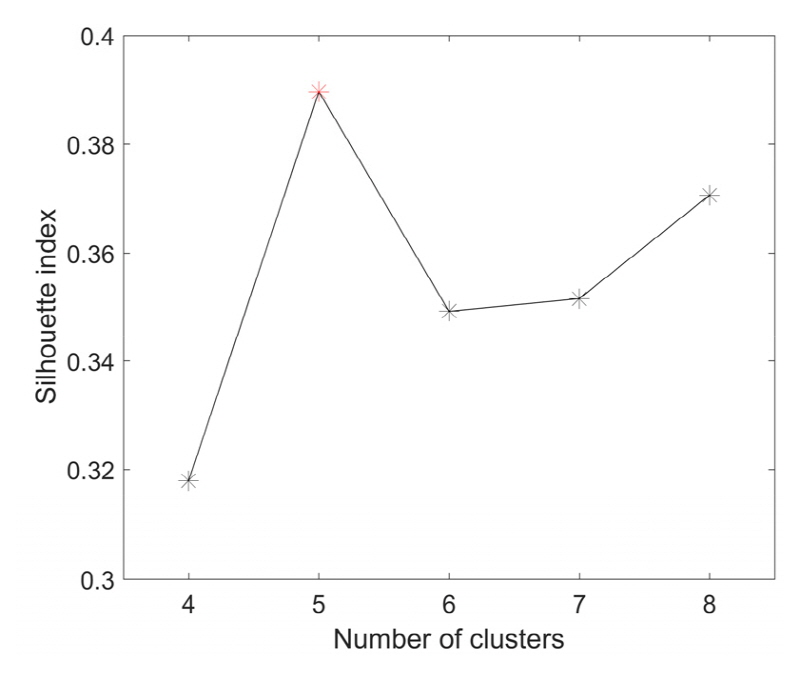
실험한 군집수내에서 실루엣 지수는 군집수가 4개일 때 최솟값을 가졌고 군집수가 5개일 때 최댓값을 가지는 것으로 나타났다. 군집수가 6개 이후로 군집수가 증가할수록 실루엣 지수가 증가하는 것을 확인 할 수 있었다. Kim et al. (2012)의 연구에서도 설명되었듯이 실루엣 지수의 경우 군집의 수가 증가할수록 증가하는 특성이 있다. 군집수가 9개 이상일 경우 각 군집 안에 있는 지점의 개수는 평균 8개 이하로 지역빈도해석을 실시하기에 군집 안의 지점수가 부족하므로 많은 군집수에서 높은 실루엣 지수가 예상되더라도 지역빈도해석 측면으로 보았을 때는 부적절한 군집수라고 판단할 수 있다.
기존에 널리 쓰인 K-mean 방법을 적용해서도 지역구분을 실시하였을 경우 기초값에 따라서 지역구분결과가 많이 달라지는 것을 확인할 수 있었습니다. 이와 비교하여 K-medoid 방법은 기초값의 영향이 작은 것을 확인 할 수 있었고, K-mean 방법과 비교하여 보다 안정적인 결과를 얻을 수 있는 것을 확인하였습니다. 이러한 이유로 본 연구에서는 K-medoid 방법을 적용하였습니다. 최적 군집수인 5개의 군집수를 이용하여 K-medoid로 군집분석을 실시하였다. 본 연구에서 군집해석에 사용되는 인자는 총 49개로 불필요한 잡음이 분석에 사용될 가능성이 매우 높을 수 있기 때문에 주성분 분석을 통하여 인자의 분산도를 99%까지 사용한 군집분석과 표준화된 인자를 사용하여 군집분석을 실시하였다. 다른 인자 선처리 방법을 사용하였을 시에도 군집분석 결과는 큰 차이가 없는 것으로 나타났다. Fig. 5는 최종적으로 구분된 지역구분을 나타낸 그림이다. Nam et al. (2008)에서는 한국의 강우지점을 총 6개의 지역으로 구분하였는데 위 연구에서는 5개의 지역은 내륙에 있고 1개의 지역이 제주도에 위치하였다. Nam et al. (2008)의 연구에서 제주도 지역을 제외하면 본 연구의 결과와 매우 흡사한 결과가 된다. 하지만 사용된 지점수와 자료수가 다르기 때문에 본 연구에서의 결과와 Nam et al. (2008)의 결과가 완전히 같지는 않는 것으로 판단된다.
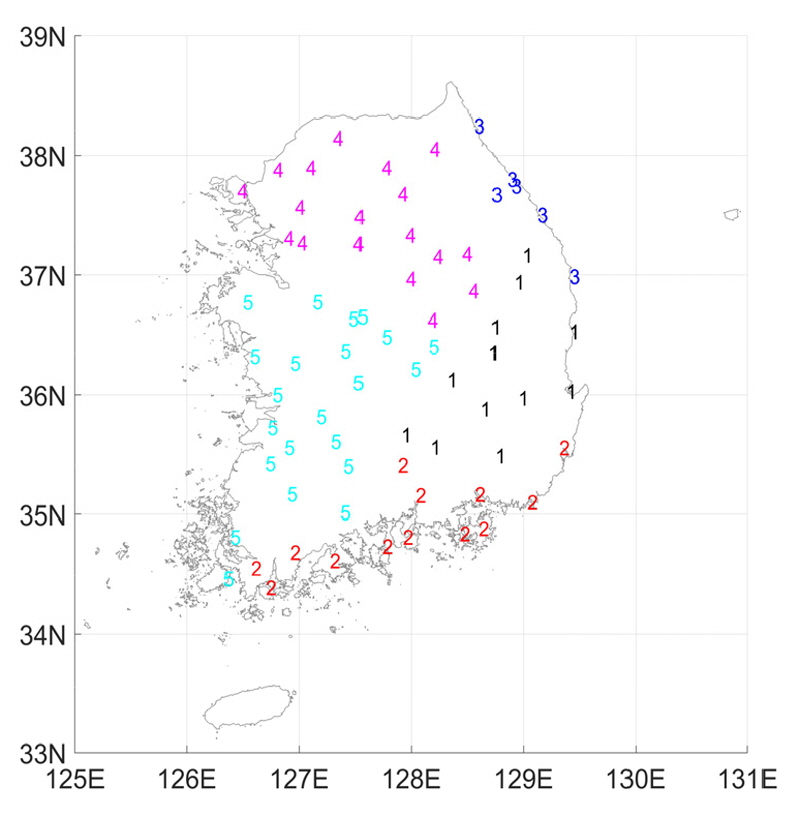
5.2 불일치 척도 결과
구분된 5개의 군집 안의 각 강우자료의 불일치 척도를 산정하였으며 불일치 산정 결과는 Fig. 6에 나타나 있다. 1번, 2번 3번 지역(Region 1, Region 2, Region 3)에서는 지역 내 모든 지점의 강우 자료에서 불일치 척도가 2.6보다 낮은 것으로 확인되었다. 4번째 지역과 5번째 지역에서는 불일치 척도가 2.6 이상인 지점이 발견되었다. 4번 지점에서는 동두천지점(10221098)의 불일치 척도가 2.6보다 큰 것으로 나타났다. 동두천 지점의 강우기록 연수가 짧아서 지역 내 다른 지점들과 상이한 L-모멘트 값을 보이는 것으로 여겨지는데 4번 지역 내에서 기록연수가 가장 짧은 지역인 파주지점의 불일치 척도도 2.6보다는 작으나 상대적으로 큰 값을 가지는 것을 확인 할 수 있다.
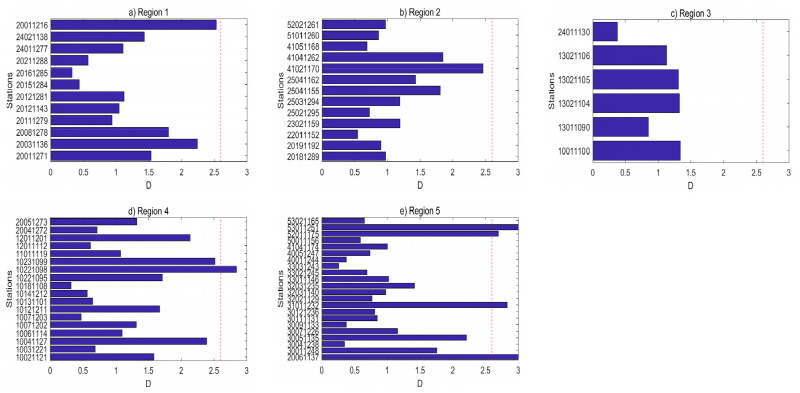
5번 지역에서는 상주지점(20061137), 천안지점(31011232), 진도지점(52011175), 고창군지점(53011252)의 불일치 척도가 2.6 보다 큰 값을 가지는 것으로 나타났다. 상주, 진도, 고창군 지점들의 경우 기록연수가 다른 지점보다 짧은 것을 확인할 수 있다. 4번과 5번 지역에서 높은 불일치 척도를 보인 지점들의 큰 특징 중 하나가 짧은 기록연수 인 것으로 나타났다. 안정적인 L-comoment 값을 얻기 위해서는 다소 많은 수의 자료가 필요한 것으로 판단된다. 일반적으로 불일치 척도가 2.6 이상인 지점은 다른 지역으로 이동시킨 후 다시 불일치 척도를 재산정해서 불일치 정도를 검사해야 하나, 불일치 척도가 높게 나온 지점이 자료연수가 짧아서 발생하는 것으로 판단되어 추가로 지역구분 결과를 수정하지는 않았다.
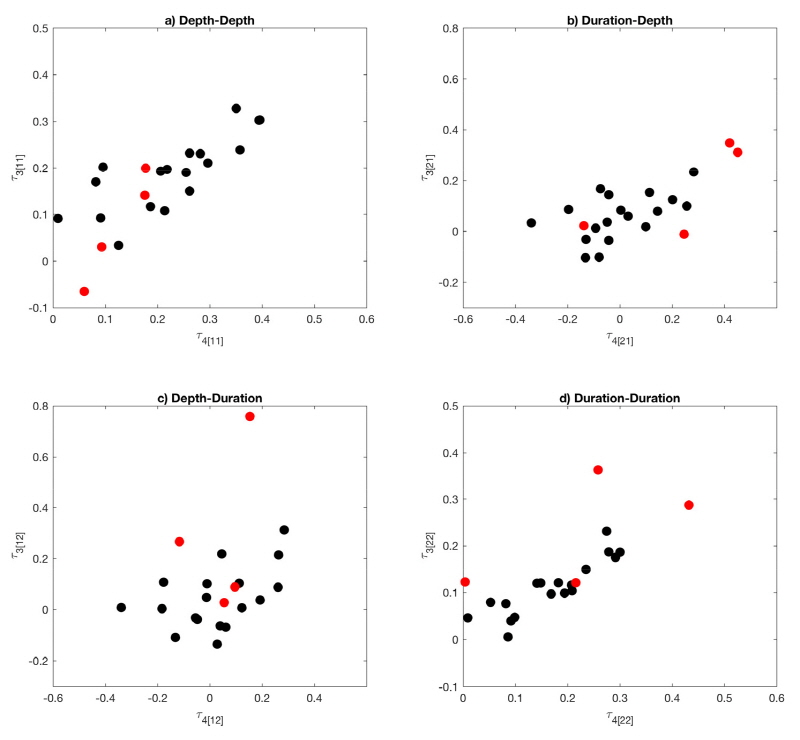
천안지점의 경우 기록연수는 짧지 않으나 높은 불일치 척도를 보이는 것으로 나타났다. 불일치 척도의 경우 자료의 개수나 지점의 변화에 따라 변동이 크기 때문에 사용되는 지점과 자료에 따라서 그 결과가 크게 변할 수 있다. 불일치 척도가 높게 나온 지점들의 L-comoment 특성을 분석하고자, 4번과 5번 지역의 각 지점들의 3차와 4차 L-comoment 지수를 도시하여 비교하였다. Fig. 7은 4번 지역 안에 있는 지점들의 3차 4차 L-comoment 지수를 나타낸 그림이다. 적색점이 불일치 척도가 2.6 이상이 나온 동두천지점을 의미한다. L-comoment 지수를 보면 강우자료에 대해서는 동두천지점의 자료가 다른 지점과 상이한 것을 확인할 수 있다. 또한 상관성을 의미하는 Depth-Duration과 Duration-Depth의 경우에서도 동두천지점이 다른 지점들 보다 지점들의 군집에서 떨어져 있는 것을 확인할 수 있다. L-comoment의 경우 일반적으로 사용하는 공분산과는 달리 선형가중치와 순위 자료를 이용하여 산정된다. 두 변수 중 한 변수를 오름차순으로 정리하고 각 자료의 순위를 정한 다음 정해진 순위에 짝이 되는 다른 변수에 선형가중치를 이용하여 L-comoment를 산정한다. 동일한 변수 조합을 이용하여도 기준이 되는 변수에 따라서 산정된 L-comoment값이 다르다. 이러한 이유로 두 변수의 상관성을 의미하는 Depth-Duration과 Duration-Depth의 L-comoment의 산도가 다르게 나타난다.
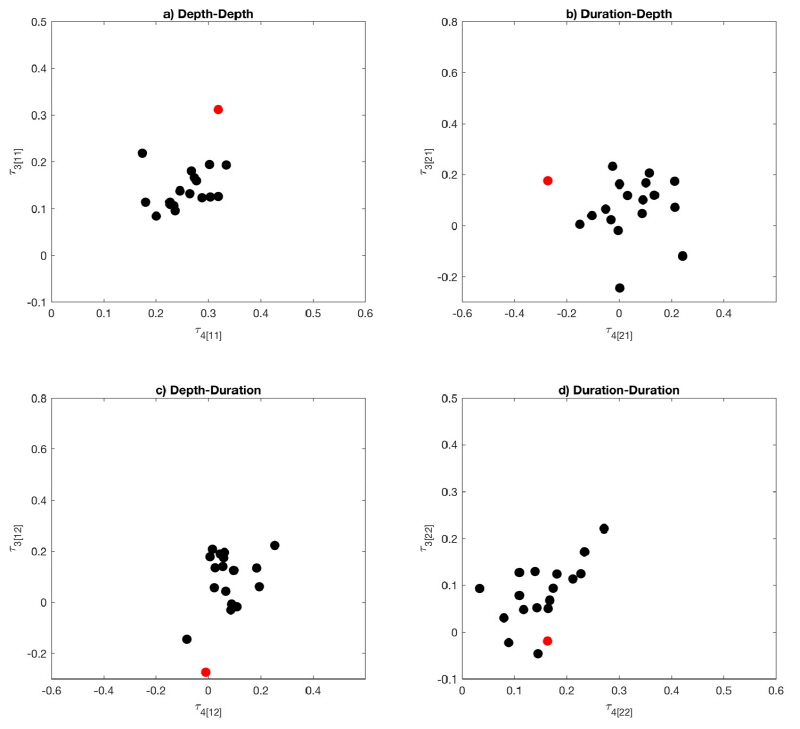
Fig. 8은 5번 지역 안에 있는 지점들의 3차 4차 L-comoment 지수를 나타낸 그림이다. 적색점들은 불일치 척도가 2.6 이상이 나온 상주, 천안, 진도, 고창군지점들을 의미한다. 불일치 척도의 계산에는 2차, 3차, 4차 L-comoment가 사용이 되고 각 L-comoment는 2방 행렬로 총 4개의 값을 가지므로 지점당 총 12개의 값을 이용하여 지점의 불일치 척도를 산정한다. 각 지점의 L-comoment를 보면 Figs. 6(a)~6(d)에 표현되어 있는 L-comoment중에서 하나라도 지역 내 지점들의 L-comoment들과 상이한 값을 보이면 불일치 척도 값이 2.6 이상인 것을 확인 할 수 있다. 이런 결과로 미루어 보아 불일치 척도는 전체적인 차이보다는 하나의 값에서 큰 차이를 보일 경우 보다 민감하게 반응하는 것으로 유추할 수 있다.
5.3 동질성 검토 결과
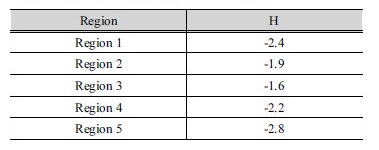
각 지역의 동질성 검토를 위하여 이질성 척도(Heterogeneity measure)를 산정하였다. 산정된 이질성 척도는 Table 3에 도시되어 있는 모든 지역의 이질성 척도가 음수 값을 보여, 구분된 지역이 모두 동질한 것으로 나타났다. 산정된 지역들의 이질성 척도가 매우 낮은 것을 확인 할 수 있는데 낮은 값이 나올수록 지역 내 지점들의 동질성이 높은 것을 나타낸다. 이질성 척도가 너무 낮은 값을 보이는 경우, 예를 들어 음수 값이 나왔을 때는 지역 내 지점들간의 상관성이 매우 높은 것을 의미한다. 기존의 단변량 지역빈도해석의 위한 지역구분에서 이질성 척도 산정 연구들의 결과를 보면 이질성척도가 -3에서 1사이의 값을 가지는 것을 확인 할 수 있다. 단변량자료와 이변량자료의 이질성척도 차이는 적용된 강우자료의 기록연수와 지점수에 따라서 달라 질 수 있을 것으로 판단됩니다. 사용된 자료의 기록연수나 지점수보다는 이변량자료와 단변량자료의 특성 때문에 이런 문제가 발생하는 것으로 판단됩니다. 이변량 강우-지속기간 자료의 경우 지속기간을 고정하지 않기 때문에 매우 큰 강우량이 발생하는 사상이 많은 지점에서 동시 연최대강우사상으로 선택된다. 이러한 이유로 단변량자료를 사용한 강우지역빈도해석에서는 크게 나타나지 않는 지역 내 지점간의 상관성이 매우 크게 나타나는 것으로 판단된다. 이러한 경우 분석 시 지점간의 상관성을 고려해 줄 경우 보다 정확한 지역빈도해석이 가능할 것으로 판단된다.
6. 결 론
본 연구에서는 연최대 강우량-지속기간 이변량 자료에 대한 수문학적 동질지역 선정기법의 적용성을 평가하였다. 기상청 71개 지점의 강우자료를 이용하여 연최대 강우량-지속기간 자료를 산정하였고, 산정된 연최대 강우량-지속기간 자료들에 대한 수문학적 동질지역을 구분하였다. 본 연구를 통하여 아래와 같은 결과를 얻을 수 있었다.
k-medoid 방법을 이용하여 수문학적으로 동질한 지역구분이 가능한 것으로 나타났으며, 한국은 5개 지역으로 구분될 때 실루엣 지수를 기준으로 최적화된 군집화 결과를 얻을 수 있는 것으로 나타났다.
5개로 구분된 지역 중 3개 지역에서는 지역 내 모든 지점에서 불일치 척도가 기준값보다 낮을 것을 확인할 수 있었고, 2개 지역에서는 각각 1개, 4개의 지점의 불일치 척도가 기준값보다 높은 것을 확인하였다. 불일치 척도가 높은 지역들은 대부분 기록연수가 짧은 지점들이며, 향후 각 지점의 자료수가 많아질 경우 불일치 척도가 감소할 것으로 예상된다.
불일치 척도는 대상지점의 L-comoment와 동질지역 내 다른 지점들과의 L-comoment의 전체적인 차이보다는 하나 또는 두 개의 L-moment에서 다른 지점들과의 차이가 클 때 높아지는 것을 확인할 수 있었다.
구분된 모든 지점이 이질성 척도 기준으로 동질한 것으로 나타났다. 모든 지역에서 이질성 척도는 음수로 매우 동질한 것으로 나타났다. 이질성 척도의 음수값은 지역 내 지점들간의 상관성이 매우 높다는 것을 의미하므로, 연최대 강우량-지속기간 자료의 경우 동일 지역 내에서 매우 높은 상관성을 가지는 것으로 판단된다.
본 연구의 지역구분 결과를 이용한 지역빈도해석을 실시하여 한국의 연최대 강수량-지속기간 자료에 대한 지점빈도해석과 지역빈도해석의 모의 정확도를 비교하는 연구가 향후에 진행되어야 할 것으로 판단되며, 지점간 상관성이 동질성 검토나 빈도해석 결과에 미치는 영향에 대한 연구가 필요한 것으로 판단된다.
