

1. 서 론
2. 방법론
2.1 관측 및 Glosea5-GC2 장기예보 자료
2.2 Copula 모형
2.3 Multisite Non-stationary Hidden Markov 모형
3. 분석 결과
3.1 조건부 Copula 모형을 통한 편의 보정
3.2 MNHMM 모형 기반 통계적 상세화 결과
4. 결 론
1. 서 론
기후변화의 영향으로 이상기후에 대한 발생빈도가 증가하고 있으며, 이러한 현상은 우리나라를 포함하여 국제사회 경제에 막대한 피해를 발생시키고 있다. 수문·기상학적 변동성은 다양한 시공간적 규모에서 서로 연계되어 있으며, 시공간적 규모별 기상예측정보의 정확성도 서로 상이하게 나타난다. 특히, 우리나라와 같이 중위도 지역의 주기적 몬순의 영향을 받는 지역의 경우에는 짧은 지속시간에서의 예측력이 현저하게 낮게 나타나는 것으로 평가되고 있으며, 이에 관한 많은 연구가 이루어지고 있다. 2020년 발생한 집중호우로 인명피해뿐만 아니라 사회·경제적 피해가 매우 크게 나타났다(Kim et al., 2020). 응급재해데이터베이스(EM-DAT)에 등록된 1900~2019년의 전 세계 자연재해추세에 따르면, 산업화 이후 가뭄 및 홍수 등의 발생빈도가 다른 재해에 비교하여 상대적으로 증가 폭이 상대적으로 큰 것으로 나타나고 있다.
이러한 점에서 미래 기상 및 기후 예측을 위해서 연구에서 다양한 시간 규모에 대한 연구의 중요성이 사회적으로 대두되고 있다. 특히, 기후 변동성 증가로 신뢰할 수 있는 기상정보에 대한 수요가 증가하고 있다. 현재 기상관측장비 및 컴퓨터 성능의 발달로 인하여 양적으로나 질적으로 과거에 비하여 개선된 기상 예측 정보 취득이 가능하다. 우리나라에서는 중단기에 대한 기상 예측 정보 생산을 위하여 영국 기상청(Met Office)과 협정을 통해 전지구기후모델 HadGEM (Hadley Center Global Environmental Model) 기반의 계절예측시스템(Global Seasonal Forecasting System, GloSea)을 현업에 활용되고 있다. Jung et al. (2015)은 GloSea5의 과거 6개월 기후 Hindcast 자료를 기반으로 예측력 평가하였으며, 앙상블 멤버 생산 방법 개선, 해상도 및 물리과정 수정 등의 모형 개선이 필요한 것으로 평가하였다. MacLachlan et al. (2015)은 계절단위에서 El Niño Southern Oscillation (ENSO) 패턴 검증 및 북서태평양 아열대 고기압을 기반으로 동아시아 여름강수 예측성을 검증하여 통계적으로 유의한 결과를 확인하였다. Camp et al. (2015)은 계절적 주기성 및 ENSO에 따른 카리브해 열대성 저기압의 공간적 변화 및 특성 예측 성능을 검증한 연구에서 기존 GloSea4보다 GloSea5에서 우수성을 확인하였으며, 유의한 검증 결과를 나타냈다.
과거부터 기후변화 양상은 대기순환모형(General Circulation Model, GCM)을 통하여 짧은 지속시간에서 강우강도의 증가가 전망되고 있으며(Mearns et al., 1990; Lim et al., 2010; Kumar et al., 2014; Noor et al., 2018; Qiu et al., 2021), 이러한 점에서 신뢰성 있는 단기 예측 정보 생산의 필요성이 대두되고 있다. 특히, 유량 예측 등 수자원 분야의 적용성을 높이기 위해서는 월 및 계절 단위의 예측 및 전망자료를 시간 및 일단위 시계열로 상세화하는 연구가 필수적이다. 이러한 기상정보의 시간적·공간적 상세화 기법 관련 연구는 국내·외적으로 활발히 진행되고 있다.
Wilby et al. (2000)는 미국 일부 유역을 대상으로 수행한 통계학적 상세화 결과에서 관측 자료를 기반으로 산출한 선형 회귀분석 결과 및 상세화 결과가 재해석 자료보다 더 우수한 모의 성능을 나타내는 것으로 평가하였다. 최근에는 1차적 분석으로 생산된 자료를 통계적으로 보정하여 기존 모형에 내재된 편의를 상당 부분 감소할 수 있다는 결과가 제시되기도 하였다. Willems and Vrac (2011)은 예측 강우량자료를 기반으로 분위섭동법(quantile perturbations)과 Weather Typing 기법을 이용하여 일단위 이하의 강우량 모의를 수행한 바 있다. 일강수량 자료계열은 수문학적인 지속성이 크지 않지만, 유출량 자료와 다르게 유연성이 크고 Markov Chain Model을 적용하면 그 특성이 잘 묘사될 수 있다(Nord, 1975). 우리나라에서는 관측 일강우량의 통계치를 효과적으로 반영하기 위하여 특정 확률분포형을 가정하는 일강우량 모의 방법과 특정 분포형 가정 없이 일강우량 모의가 가능한 비매개변수적 방법이 활용되고 있다(Kwon and Kim, 2009; Choi et al., 2008). So et al. (2015)은 기존 Markov Chain 모형에 불연속 Kernel-Pareto 분포 기반의 모의기법을 적용하여 일강수량의 평균적 특성과 극치 특성을 동시에 모의할 수 있는 모형을 제시하였으며, 특정 유역에 적용하여 적합성을 확인하였다. Shin et al. (2009)는 우리나라의 지형 및 계절 온도의 특성뿐만 아니라 상세화 이전의 광역 규모 온도 자료의 기후적 특성을 반영한 상세화를 수행한 바 있다. Kim et al. (2018)은 Bayesian Four Parameter Beta 모형을 기반으로 일 극치강우량을 24시간 이하의 지속시간에 대한 값으로 상세화하는 연구를 수행하였으며, 원자료 특성으로 인하여 지속시간이 24시간에 가까울수록 높은 신뢰성을 보였다. 위와 같이 국내외적으로 통계학적 모형 기반의 일단위 기상자료 상세화 연구가 활발하게 수행되고 있지만, 수치모델의 예측 강수량을 직접적으로 연계한 상세화 연구는 상대적으로 미진하다.
따라서, 본 연구에서는 중단기 일단위 강우량 예측 시나리오를 생산하기 위하여 기상청 GloSea5-GC2(Global Coupled modeling configuration 2.0) 모델의 월단위 과거 재현자료(Hindcast)와 예측자료(Forecast) 기반의 상세화 기법을 제시하고자 한다. 예측자료 생산에 앞서, 서로 다른 분포 특성을 갖는 변량들의 의존관계를 정의할 수 있는 Copula 함수 기반의 조건부 모형을 통하여 관측자료와 Hindcast 강우량의 최적 확률분포에 따른 결합분포 관계를 구축하였으며, 구축된 결합분포를 전이함수(transfer function)로 이용하여 GloSea5로부터 도출된 월단위 예측 강수량을 보정하였다. 이후 보정된 월강수량 자료를 입력 자료로 하여 직접적으로 일단위 시계열로 상세화 시킬 수 있도록 Multivariate-Non-stationary Hidden Markov Model (MNHMM)을 연계할 수 있는 방법을 제시하는 것이 주요 연구 목적이다. Fig. 1은 연구 흐름도를 나타낸다.
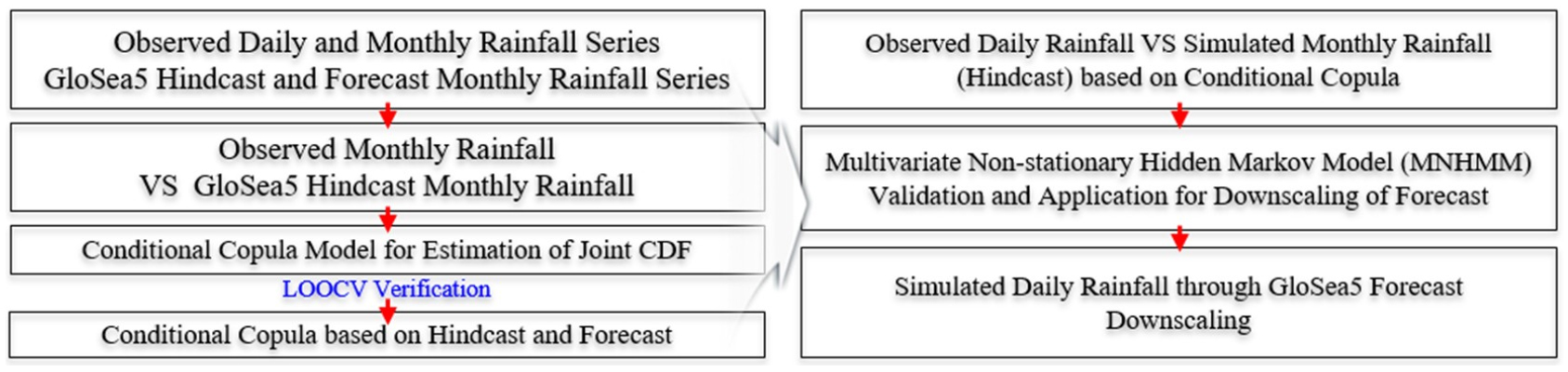
2. 방법론
2.1 관측 및 Glosea5-GC2 장기예보 자료
기상청(Korea meteorological Administration, KMA)은 2010년에 장기예보시스템 구축을 위하여 영국기상청(Met Office)과 공동계절예측시스템 운영 협정서를 체결하고, GloSea를 현업에 도입하였다. 우리나라의 기후예측시스템(GloSea5-GC2)은 대기, 해양, 해빙 및 지표면 모델이 결합된 시스템으로 대기는 중단기 기상예보에 사용되고 있는 통합모델(Unified Model, UM, 버전8.6), 해양은 프랑스 라플라스 연구소에서 개발된 NEMO (Nucleus for European Modelling of the Ocean, 버전3.4), 해빙은 미국 Los Alamos National Laboratory에서 개발한 CICE (community Ice CodE, 버전4.1)가 적용되었으며, 지표면은 영국 기상청 JULES (Joint UK Land Environment Simulator, 버전8.6)를 기반으로 하고 있다.
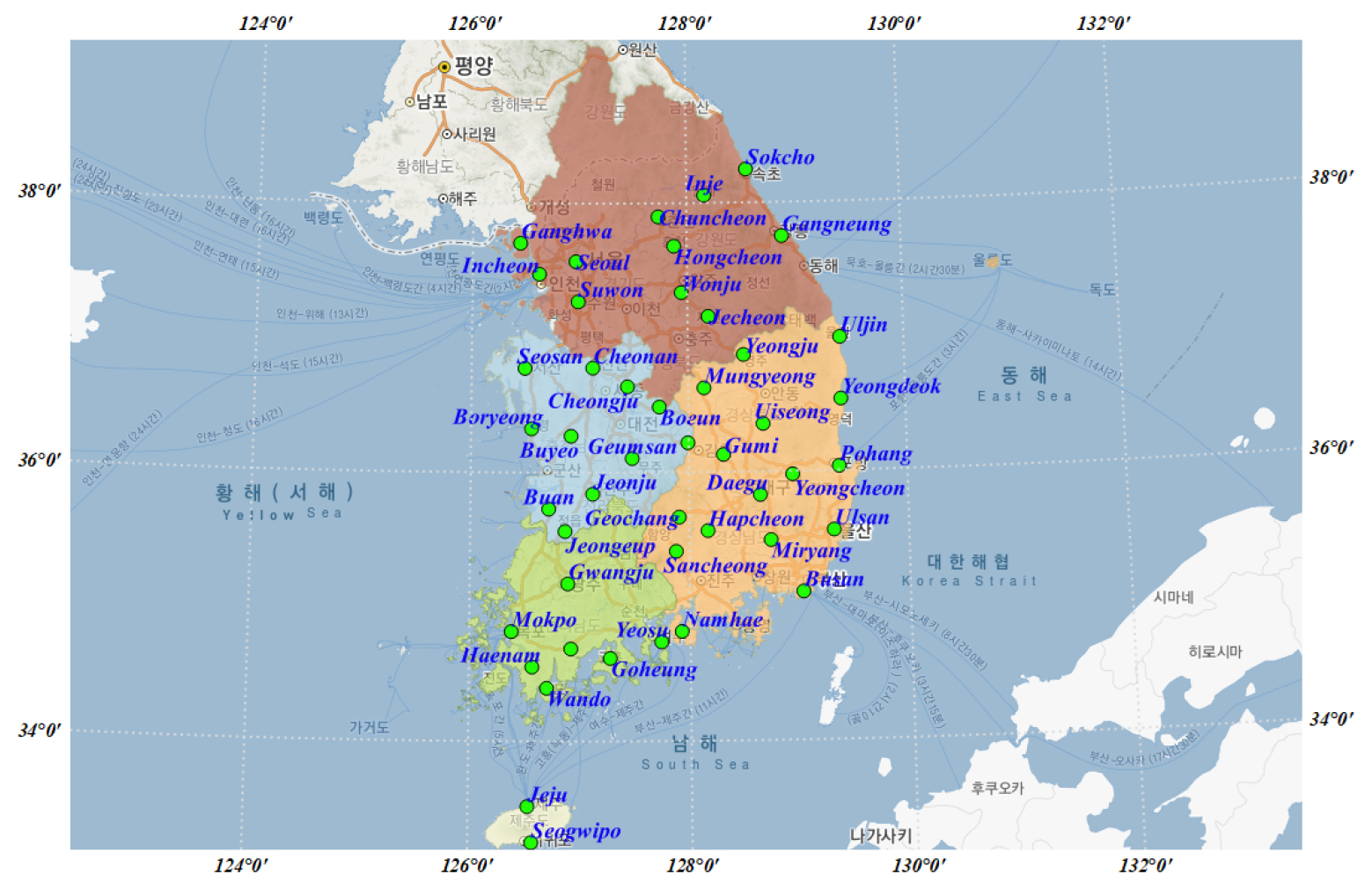
본 연구에서는 GloSea5-GC2 자료의 통계적 상세화를 수행하기 위하여 기상청(http://www.kma.go.kr/) 산하 종관기상관측장비(automated synoptic observing system, ASOS) 관측소 중 기상청에서 선정한 대표지점 47개를(과거부터 관측 위치가 변경되지 않았으며, 자료기간이 상대적으로 긴 지점) 적용하였으며, 대기모델의 활용성 측면에서 정확성이 비교적 높은 시간규모인 월단위 시계열 강우량을 입력자료로 유역별 일단위 시계열 강우량을 생산하였다. 본문에는 한강유역을 대표 유역으로 선정하여 분석 수행하였다. Fig. 2는 선정된 47개 지점에 대한 위치를 나타낸다.
2.2 Copula 모형
다변량 자료 상호간의 의존관계를 규명하기 위해서는 개별 변량간의 주변분포함수(marginal distribution)의 결정이 필요하며, 이들 주변분포함수를 기준으로 결합분포를 추정하는 과정이 필요하다. Copula 함수는 변량간의 결합확률을 정의하는 경우 주변분포함수에 제약없이 활용이 가능한 장점으로 인해 기상, 수문 및 수자원 분야에서 수문기상변량간의 관계를 규명하는데 활발히 적용되고 있다(Favre et al., 2004; Chen et al., 2013). 본 연구에서는 조건부 Copula 함수를 통해 월단위의 Hindcast와 관측값 사이의 결합분포 관계를 이용하여 전이함수를 구축하였으며, 이를 예측 정보인 Forecast 강수량의 편의를 보정하는데 활용하였다.
2.2.1 Copula 함수의 종류
Copula 함수는 모집단 분포에 대한 정보의 유무에 따라서 매개변수적 및 비매개변수적으로 구분된다. 매개변수적 Copula는 Gaussian copula, Student’s t-Copula와 Archimedean Copula (Clayton Copula, Gumbel Copula, Frank Copula 등)가 있으며, 비매개변수적 Copula는 Empirical Copula, Kernel Copula 등이 존재한다.
Gaussian Copula는 상대적으로 이해가 쉽고 계산이 편리하여 많이 적용되고 있는 Copula 함수이다. Gaussian Copula는 자료 사이의 상관관계가 매개변수를 의미하며, 상관관계에만 의존하는 함수이다. n개의 정규 확률변수와 상관관계 행렬을 통해 산정되는 Gaussian Copula 함수는 Eqs. (1) and (2)와 같이 표현된다.
여기서, Gaussian Copula를 추정하는 Eq. (1)은 Eq. (2)와 같은 관계를 통해 나타낸다. Eq. (1)에서 은 다변량 정규분포의 결합누가분포 함수이며, 은 역함수이다. Eq. (2)에서 는 단위행렬(identity matrix)을 의미한다.
다양한 Copula 함수 중 Archimedean Copula는 매개변수 추정이 용이하고 함수식이 비교적 간단하여 활용도가 높다. 일반적인 시계열 자료에 Copula 함수를 적용하는 경우 Gumbel Copula는 자료의 극치 부분을 잘 표현하며, Clayton Copula는 양의 상관관계를 가지고 있는 변량들에 대한 적용이 적합하고 자료의 극소값을 잘 반영한다. Frank Copula는 극대 ‧ 극소값에 대하여 상단부와 하단부 모두 유사한 수준으로 모의하는 특징을 가지고 있다(Kwak et al., 2012).
Gumbel Copula는 Gumbel-Hougaard Copula로 불리기도 하며, 매개변수 가 을 만족하는 에 대해 Eq. (3)과 같이 나타낼 수 있다.
Clayton Copula 함수는 을 만족하는 매개변수인 에 대하여 다음 Eq. (4)와 같이 정의할 수 있다.
Frank Copula는 변량간의 양(+)과 음(-) 상관계수를 모두 추정할 수 있는 Copula 함수 중 하나로, 왼쪽과 오른쪽 꼬리 부분을 모두 유의하게 반영하는 것으로 알려져 있다. Frank Copula 함수는 Eq. (5)와 같이 나타낼 수 있다.
2.2.2 조건부 Copula 모형을 이용한 편의보정
본 연구에서는 GloSea5 상세화를 수행하기 위하여 Hindcast 기간(1991~2010년)과 동기간의 관측자료를 기반으로 중단기 자료를 구축하여 자료간 결합분포 관계를 Copula 함수를 통해 구축하였다. 이후, GloSea5의 Forecast를 활용하여 구축된 결합분포로부터 해당 중단기 강수량을 조건부 Copula 모형을 통해 편의 보정하였다. 조건부 Copula는 특정 변량 에 따른 를 도출하고자 할 때 사용되는 기법으로 이에 대한 유도과정은 Eq. (6)과 같으며, 는 Copula 함수의 기본 가정에 근거한 누적확률분포 값을 나타낸다.
Archimedean Copula의 경우 조건부 Copula를 얻기 위해선 다음과 같이 주어진 Eq. (7)이 공통적으로 요구된다.
Eq. (7)의 는 Archimedean Copula 함수의 Generator를 의미하며 각 Generator는 Table 1과 같다. Archimedean Copula는 각 함수별 를 계산하면 보다 쉽게 Copula 함수를 추정할 수 있으며, 본 연구에서는 원하는 변량 를 얻기 위해서는 Eq. (7)을 에 대해 편미분 하여 조건부 Archimedean Copula 식으로 유도한 함수(Eq. (8))가 요구된다.
최종적으로 조건부 Copula 함수를 통해 원하는 변량 ()값은 Eq. (9)와 같이 함수의 역함수를 통해 산정이 가능하다.
2.3 Multisite Non-stationary Hidden Markov 모형
2.3.1 마코프 체인 모델(Markov Chain Model)
관측된 자료들이 순차적으로 나열되어 있는 시변성(time-varying) 특성을 통한 자료에 내재된 특성을 기반으로 추계학적 모형을 구축하고 미래값을 예측하는 다양한 연구가 수행되었다. 이중 마코프 모델(Markov model)은 현재와 과거가 미래에 영향을 주지 않고 바로 이전의 상태에만 영향을 받는다. 일반적으로 무작위 시계열간의 계열 상관성과 미래 상태를 현재와 과거의 상관관계 분석만으로 추계학적으로 추출하는 과정을 마코프 과정(Markov process)이라고 하며, 마코프 연쇄(Markov chain)는 주어진 조건이나 상태에 따라 발생확률 값이 어떻게 변화하는지를 분석하는 것을 의미한다. 본 연구에서 적용한 자료는 유연성이 크고 자기상관성이 크지 않은 자료로서 마코프 체인을 적용하면 그 특성을 우수하게 반영할 것으로 판단된다(Nord, 1975).
마코프 체인 모델은 먼저 강수의 발생(rainfall occurrence)을 결정하고 이후에 강수 발생 시점에 대해서 강수량(rainfall amount)을 결정하는 과정으로 구분된다. 마코프 체인은 미래상태의 확률이 과거에 의존하므로 Eq. (10)과 같이 조건부 확률(conditional probability)을 나타낼 수 있다(Haan et al., 1976).
여기서, 은 현재 상태를 나타내고, 은 과거의 상태를 나타낸다. 미래는 과거와 독립이며, 가장 근접한 현재 상태에만 영향을 받는다고 가정하면 Eq. (10)를 통하여 마코프 모델의 성질을 Eq. (11)과 같이 조건부 확률로 표현할 수 있다.
2.3.2 다지점 비정상성 은닉 마코프 모델(Multisite Non-stationary Hidden Markov Model, MNHMM)
은닉 마코프 모델(Hidden Markov Model, HMM)은 통계적 마코프 모델의 하나로, 주어진 다지점(multisite) 시계열을 가장 잘 반영한 모델이다. HMM은 관측이 불가능한 은닉상태(hidden state)의 추계학적 과정(stochastic process)을 관측이 가능하도록 다른 추계학적 과정을 통하여 모형화하는 이중의 과정이다. 강수 및 무강수 상태가 전이되는 과정은 관측되지 않은 은닉상태에 따라 진행되며, 이러한 은닉상태를 규정하는 과정은 자료들의 범주화(classification) 문제로서 규정할 수 있다. 각 은닉상태들은 마코프 연쇄과정을 갖는다고 가정하며, 은닉상태별로 강우량을 추정하기 위한 확률분포가 정의된다. 이러한 확률분포는 대부분 혼합분포(mixture distribution) 형태를 활용한다.
일반적으로 시계열 자료에서 시간에 대한 의존성을 반영하기 위해서는 전이확률(transition probability)뿐만 아니라 출력확률(emission probability)을 동시에 고려하는 것이 유리하다. 시간적 의존성을 고려하지 않는 정상성 HMM의 경우에는 발생 사상을 나타내는 전이확률은 시간에 따라 동일한 값을 갖게 되며, 예측보다는 자료를 확장하는데 주로 활용된다. 반면 다지점 비정상성 MNHMM (Multisite Non-stationary HMM)은 전이확률 결정에 예측인자를 사용함으로써 시간에 따라 전이확률이 다르게 계산되며 예측모형으로 활용될 수 있다.
은닉상태의 전이확률을 추정하는 일반적 방법은 로지스틱 회귀모델(logistic regression model)을 활용하는 것이다. 즉, 예측인자와 이전의 상태()는 현재의 상태()의 발생 확률을 조정하므로 예측인자의 시간에 따른 변화가 각 상태 전이확률의 변화를 발생시킨다. 은닉상태 는 구성요소를 포함한 비정상성 전이행렬 의 마코프 모델을 나타낸다. 본 연구에서는 시간 에서 은닉상태의 전이확률을 추정하기 위해 일반적으로 독립변수의 선형결합을 통하여 수문·기상사상의 발생확률을 예측하는데 적용되고 있는 다항(multinomial) 로지스틱 회귀모형을 적용하였다(Holsclaw et al., 2017).
여기서, 는 -차원의 공통 은닉인자의 시계열 을 의미하며, 는 의 성분에 대응하는 계수의 D-차원 벡터를 나타낸다. MNHMM의 다른 주요 구성요소는 상태별로 정의되는 출력분포(emission distribution) , 이다. 각 지점()과 상태()에 해당하는 출력분포가 정의되며, 일반적으로 이러한 분포는 시간에 따라 변화하는 예측인자(e.g. 예측 월강수량)에 의존하여 가중치 와 출력분포 함수 산출함으로써 예측강수시계열을 생성할 수 있다. 여기서, 는 출력분포의 전체 매개변수를 의미한다. 은닉상태()의 값을 알고 있는 경우 Eq. (12)에 대한 조건부 우도 값은 Eq. (13)과 같이 나타낼 수 있다.
여기서, 에 대한 는 초기 상태분포 에 의하여 나타낼 수 있으며, 전이확률 은 Eq. (13)을 통하여 정의된다. 우도함수 는 MNHMM에 대하여 일반적 순환방식으로 알 수 없는 값을 소거하여 산정할 수 있다(Scott, 2002).
Fig. 3에서 은 관측값을 나타내며, 는 출력분포, 는 전이확률, 은닉상태이다. 는 외부인자()와 은닉상태의 마코프 속성으로부터 발생하는 전이확률을 포함하는 행렬 집합을 나타낸다.
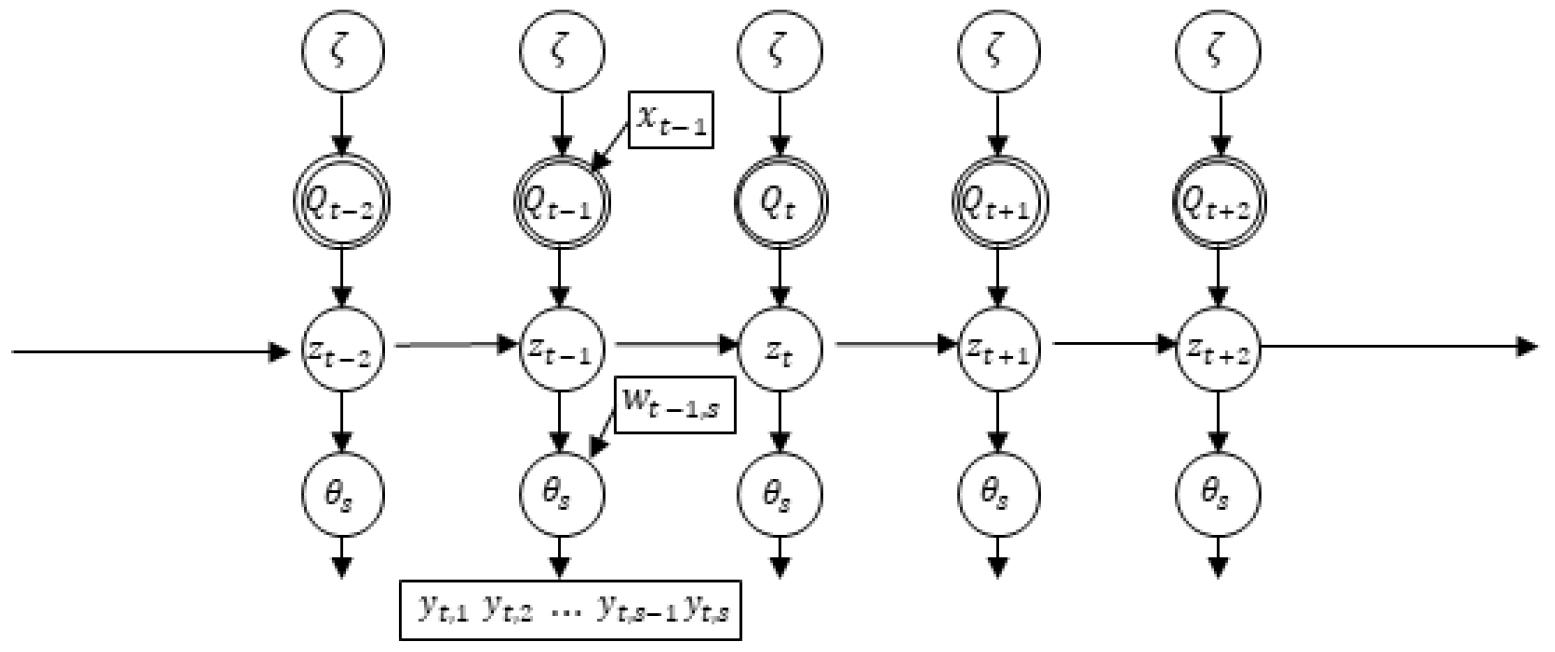
3. 분석 결과
3.1 조건부 Copula 모형을 통한 편의 보정
조건부 Copula 모형의 검증을 위하여 관측값과 Hindcast를 입력값으로 교차검증을 수행하였다. 다양한 교차검증(Gyalistras, 2003; Willmott and Matsuura, 1995) 방법 중 Leave-One-Out Cross Validation (LOOCV)을 통한 검증을 수행하였으며, LOOCV 방법은 교차검증 방법 중 전체 자료 기반의 분석으로 무작위성이 존재하지 않고 안정된 결과가 산정되어 다양한 분야에 적용되고 있는 검증 방법이다.
교차검증 시 Hindcast의 20년(1991~2010년) 자료를 통하여 매년, 매월 기반의 분석을 수행하여 지점별 240번(20년 × 12개월)의 모의를 수행하였다. 교차검증 결과 모의된 1월 평균 값과 1월 평균 관측값은 0.01 mm로 가장 작은 오차가 산정되었으며, 상대적으로 9월에는 4.71 mm로 관측값과 모의값의 차이가 발생하였다. Hindcast의 원자료(Fig. 4(b) 빨간색)는 관측값을 크게 상회하는 값이 있으며, 조건부 Copula 방법을 통하여 보정된 결과(Fig. 4(a) 파란색)에서는 관측값에 유사하게 보정되었다. 모의된 결과의 불확실성 구간(Fig. 4(c) 회색 음영)에 관측값이 포함되어 신뢰성 있는 결과가 산정된 것으로 판단된다. Table 2는 교차검증을 통하여 모의된 결과와 관측 및 Hindcast 원자료의 월별 평균값을 나타낸다.
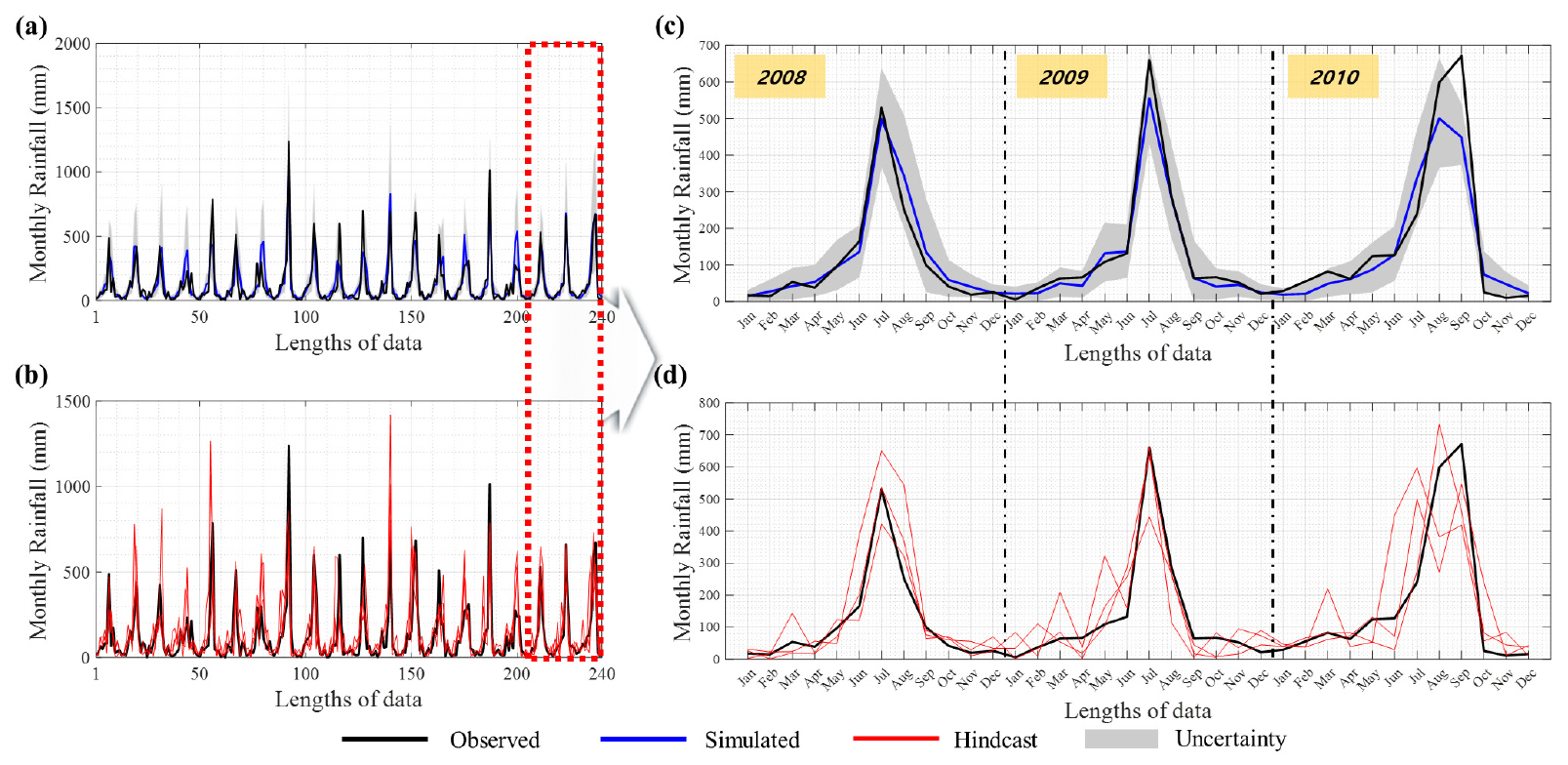
Table 2.
Cross-validated results of conditional Copula model (1991~2010, Seoul (No.108))
본 연구에서 적용한 조건부 Copula 모형은 앞서 언급한 것과 같이 주변확률분포가 서로 상이한 변량간의 결합확률분포를 보다 효율적으로 구축이 가능한 모형이다. 본 연구에서는 조건부 Copula 모형을 이용하여 관측값과 Hindcast의 관계를 규정하고 이를 기반으로 예측치(forecast)를 편의보정 수행하였다. Fig. 5의 회색은 예측강수량의 원자료를 나타내며, 매주 약 4개월의 자료가 Member별(42개)로 생산되기 때문에 동일 연도의 매월 자료가 약 160개 이상 구축된다. 생산된 예측강수 자료의 정확도 및 정밀도는 계절별로 다르게 나타나며, 특히 여름철에는 최대, 최소의 차이가 1,000 mm 이상인 나타나는 경우도 확인되었다.
제안된 편의 보정 방법을 적용한 경우, 2018년부터 2020까지의 예측된 원자료를 기반으로 조건부 이변량 편의보정을 수행한 결과(Fig. 5), 6월과 12월에는 관측값과 가장 유사한 월강우량이 산정된 반면 여름의 경우에는 비교적 오차가 큰 것을 확인할 수 있다. 한편 편의과정을 통해 예측범위를 동시에 제공함으로써 향후 앙상블 정보로서 활용성도 가능할 것으로 판단된다. Fig. 5에서 검은선은 관측값을 나타내며, 파란선은 결과의 중앙값, 파란색 범위는 모의결과의 불확실성, 회색구간은 GloSea5-Forecast 원자료 불확실성 구간을 나타낸다. Table 3은 Fig. 5의 모의값과 관측값을 나타낸다.
산정된 결과에서 알 수 있듯이 편의 보정 후 관측값과의 편의가 상당히 줄어들었지만, 편의보정에 활용된 전이함수(transfer function) 구축 시 Hindcast를 기준으로 구성된 결합확률분포를 활용하기 떄문에 모형 구축 시 나타난 편의보정 특성과 유사한 결과를 보정된 예측결과에서도 확인할 수 있었다.
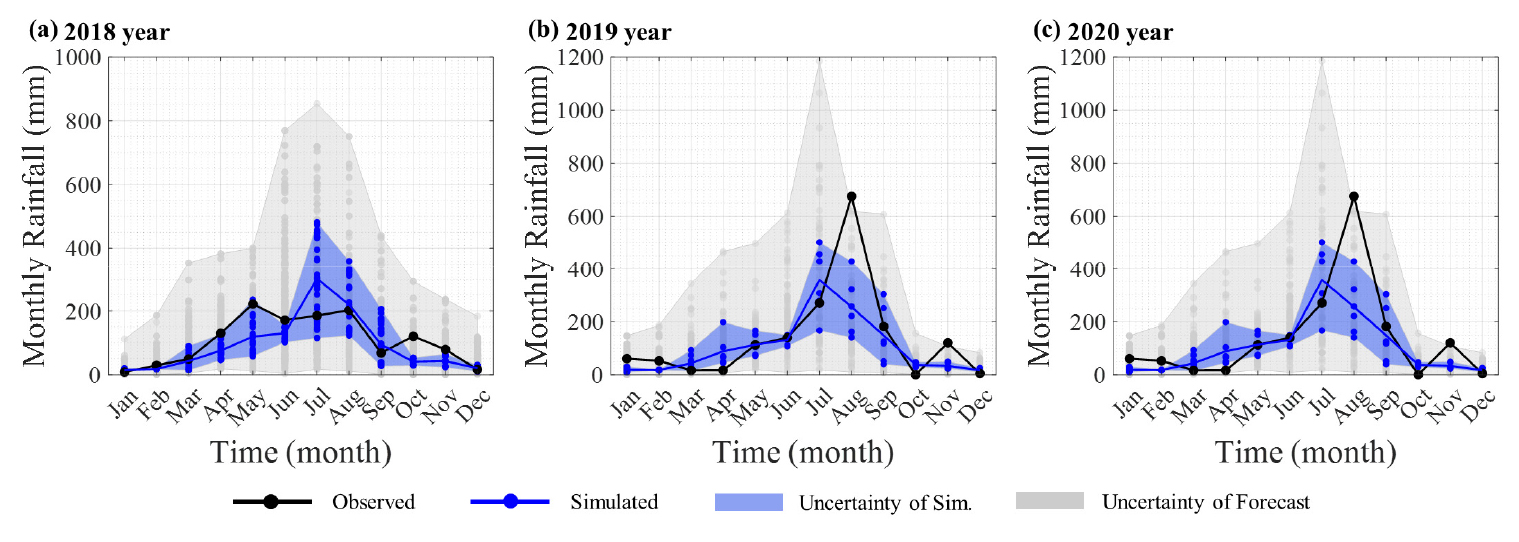
Table 3.
Comparison of observation and bias-corrected forecast through conditional Copula model (2018~2020, Seoul (No.108))
3.2 MNHMM 모형 기반 통계적 상세화 결과
MNHMM 모형은 단기간의 자기상관성이 큰 일단위 시계열 자료에 대한 적용 시 그 특성을 효과적으로 반영한다. MNHMM을 통한 상세화는 유역별 공간 상관성을 고려하기 위하여 한강, 금강, 낙동강, 영산강 및 섬진강 유역으로 지점을 구분하여 수행하였으며, 본 연구에서는 한강유역을 대표 유역으로 선정하여 관측 일강수량과 모의 Hindcast (월강수량)의 관계를 기반으로 Forecast (월강수량)를 일단위 시계열의 강수량으로 상세화 수행하였다.
유역의 은닉상태 수(state)는 은닉상태 수가 무한히 증가시 발생하는 과적합(overfitting) 문제를 피하기 위해서 log-likelihood (LLH), AIC (Akaike Information Criterion) 및 BIC (Bayesian Information Criterion) 값을 기준으로 최적 은닉상태 수를 7로 결정하였다. 모형에 대한 검증은 강우량, 연속강우발생확률, 연속무강우발생확률 및 강우발생일을 기준으로 수행하였으며, 한강 유역에 대한 분석 시 월별 강우량은 -5.69 mm~0.74 mm의 차이를 나타냈으며, 상대적으로 강수량 변동성이 큰 여름철의 오차가 크게 산정되었다. 연속강우 발생확률은 0.00~0.02, 연속무강우 발생확률 0.00~0.04 및 강우발생일 -0.42~-0.04의 관측 및 모의값의 오차를 나타내어 모형의 일강수량 모의능력을 확인하였다. Fig. 6에는 모의값(파란색 실선), 관측값(빨간색 실선) 및 모의값의 불확구간을 나타내며, Fig. 7에는 한강유역에 적용된 지점에 대한 강우량, 연속강우확률, 연속무강우확률 및 강우일수를 관측값(초록색원)과 비교한 결과를 나타낸다. Table 4는 MNHMM 모형의 검증 결과를 나타낸다.
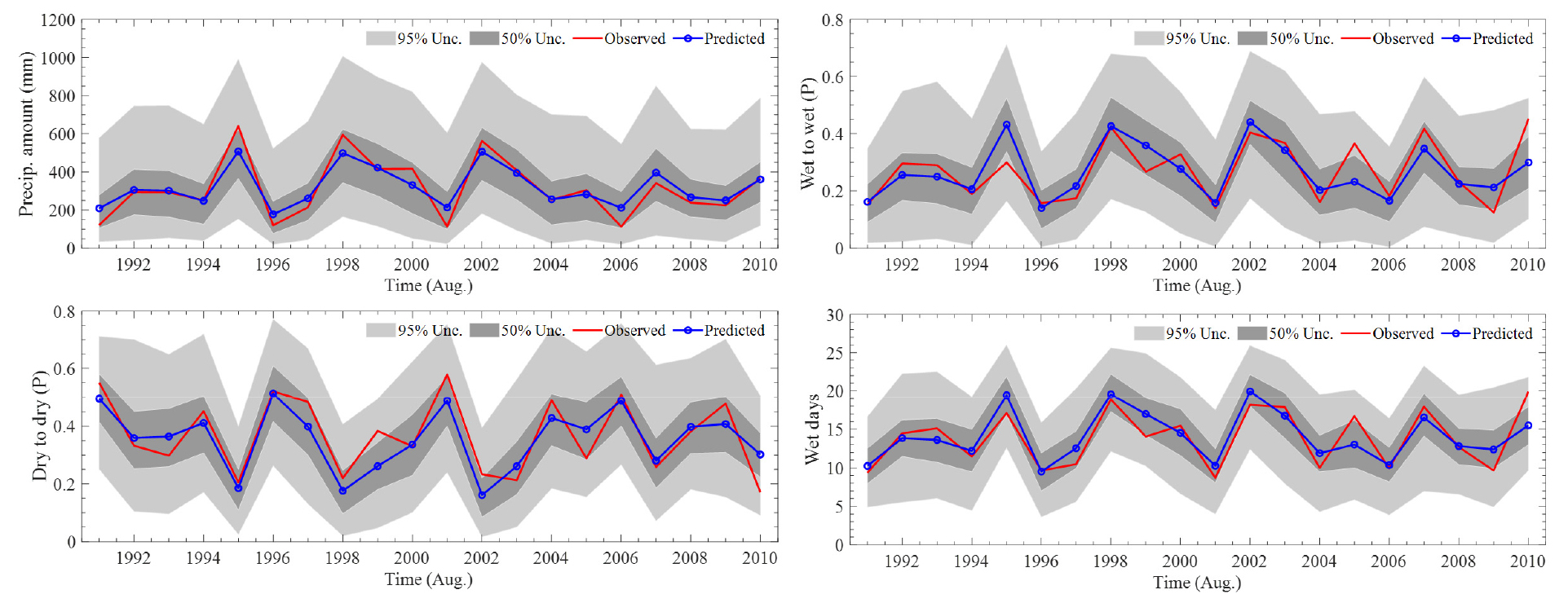
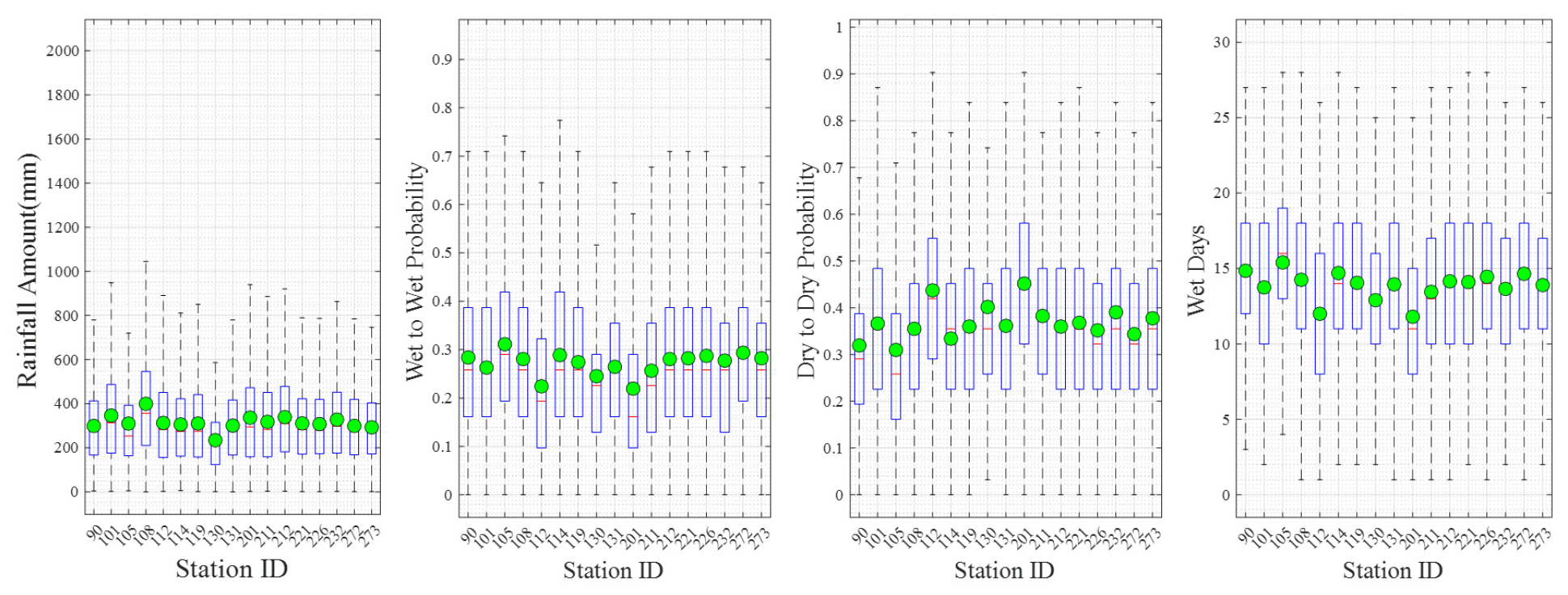
Table 4.
Validation result of MNHMM model (1991~2010, Han-river basin)
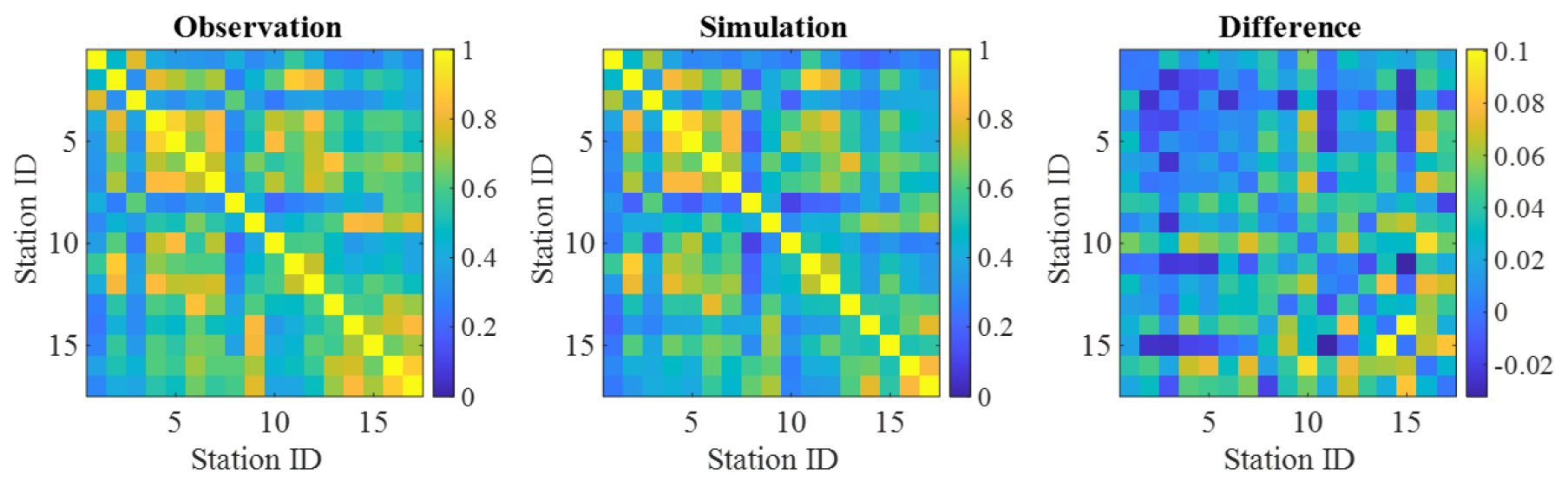
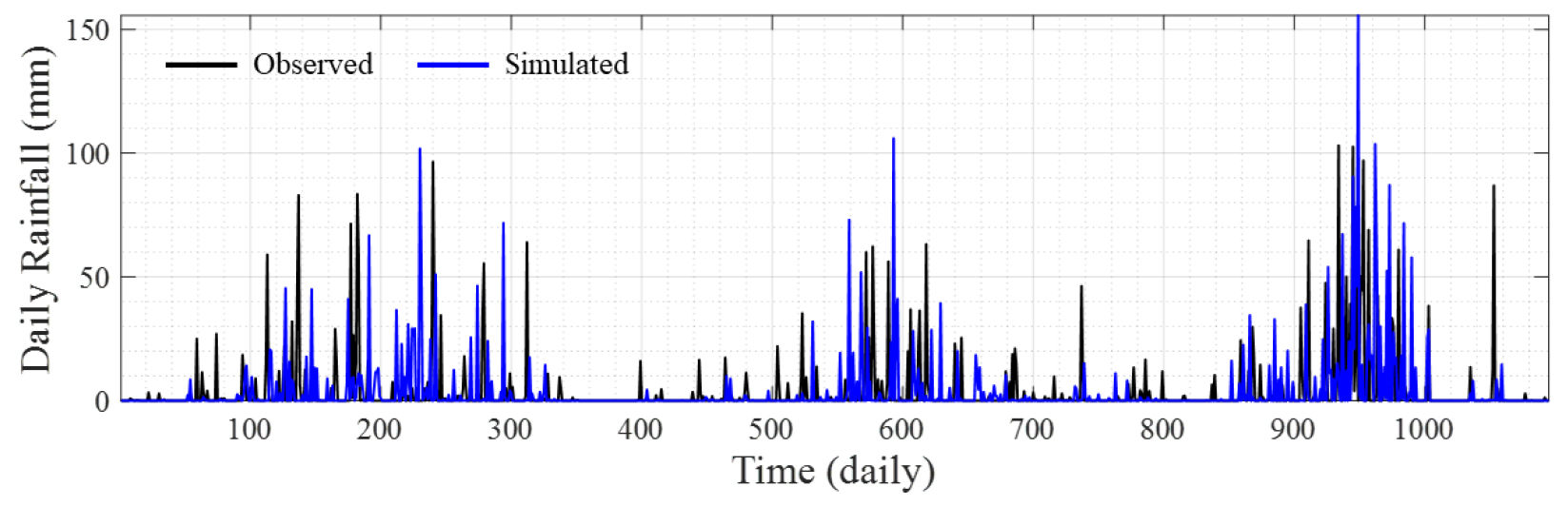
적용 모형의 유역단위 상관성 복원여부의 적합성을 평가하기 위해서 한강유역 총 17개의 관측지점간의 상관행렬(correlation matrix)을 계산하여 지점간의 상관계수를 비교·분석한 결과, 최소 -0.02에서 최대 0.10의 차이로 강우관측소간의 상호종속성을 효과적으로 고려한 것으로 판단되었다. Fig. 8은 관측과 모의 강우량의 상관행렬 및 차이를 나타내며, Fig. 9는 2018~2020년에 대한 모의 결과와 관측 일강우량 시계열을 나타낸다.
4. 결 론
우리나라는 기후변화에 따른 이상기후로 인해 극치강수량의 빈도 및 양적 증가가 나타나고 있는 등 강수의 변동성이 크게 증가하고 있다. 특히, 2020년 8월 대홍수 이후, 강우변동성 증가로 인한 수자원 관리의 어려움을 개선하기 위해서 정확한 수문기상 정보에 대한 필요성 및 중요성이 대두되고 있다. 국내에서는 기후예측 모델인 GloSea5 기반의 편의보정 및 상세화를 통한 중단기 자료 모의 등의 다양한 연구가 수행되고 있지만, 댐운영, 가뭄예측 등을 위한 유역단위 상세화된 강우자료에 대한 연구는 상대적으로 미진한 실정이다. 본 연구에서는 GloSea5를 입력자료로 조건부 Copula와 MNHMM 모형을 적용하여 일단위 시계열 강우량 예측정보를 생산할 수 있는 모델링 체계를 제시하였다. 본 연구 결과를 통한 주요 결과는 다음과 같다.
1)GloSea5 앙상블 기반의 기상예측자료 개선을 위하여 지상관측소에 대해 조건부 Copula 모형을 통한 월단위 예측값의 편의보정 기법을 적용하였다. 전처리과정으로 관측값과 Hindcast간의 관계를 정의하고 후처리과정으로 구축된 전이함수를 통해 예측강수량에 대해서 편의보정을 수행하였으며, LOOCV 기법을 적용하여 1991년부터 2010년 기간 동안의 모형 검증을 수행하였다. GloSea5 예측 강수량은 매주 동일한 요일에 반복적으로 월강수량을 생산한다. 그러나 매주 생산되는 월 단위 예측 결과의 경우에도 큰 차이를 나타내고 있었으며, 본 연구에서 제안된 모형을 적용하는 경우 매주 생산되는 30일 예측정보를 효과적으로 갱신할 수 있는 것을 확인할 수 있었다.
2)본 연구에서 적용된 MNHMM은 복잡한 강우의 발생 기작을 효과적으로 고려할 수 있는 일기상태 기반의 강우량 상세화 기법으로서 강우의 발생 및 강우의 양적특성을 효과적으로 분석하였다. 모형 검증에서 모의된 일강수량, 연속강우확률, 연속무강우확률 및 강우일수가 관측자료와 유사한 값으로 모의되는 등 수문모형의 입력자료로써 활용성이 클 것으로 판단된다.
3)유역 단위에서의 모의된 강수량 계열간의 상관성 차이가 최소 -0.02에서 최대 0.10로 유역의 강우관측소간 상호종속성을 효과적으로 복원되는 등 수문모형의 입력자료로 활용 시 유역의 수문기상학적 반응을 보다 현실적으로 모의가 가능할 것으로 기대된다.
본 연구에서는 GloSea5 자료 기반의 상세화 기법을 제안하였으며 월강우 예측정보로부터 연속된 일강우량 모의를 목적으로 진행되었다. 본 연구를 통하여 제시된 상세화 체계는 기후정보의 수문학적 활용측면에서 다양한 가능성을 제공한다 할 수 있으며, 향후 댐운영 모의시나리오, 가뭄전망 등 이수체계 전반의 위험도 관리에 활용이 가능할 것으로 기대된다.
