

1. 서 론
2. 연구지역 및 분석자료
2.1 연구지역
2.2 분석자료
3. 연구방법
3.1 XGBoost
3.2 DNN
3.3 LSTM
3.4 LOOCV
3.5 성능 평가 지수
4. 결 과
4.1 최적 모델 선정
4.2 생활용수 수요량 예측 결과
5. 결 론
1. 서 론
기후변화로 인해 지구온난화가 극심해지면서 기후 취약성이 증가하고 있다. 특히 기후변화로 인한 가뭄의 발생빈도 증가는 사회, 경제, 환경에 연쇄적인 위험으로 작용할 것이다(IPCC, 2023). 과거에는 수자원이 무한할 것이라는 전제하에 공급 위주의 기후대응 정책이 추진되었다. 하지만, 최근에는 수자원의 유한성을 인식하고 수자원의 수요 측면에서 기후대응 정책을 수립하고 있다(Molle, 2010). 우리나라의 경우 급수인구의 증가로 생활용수 이용량이 1965년 51억m3 대비 2018년 244억m3으로 4.8배 증가하였다(ME, 2020). 제1차 국가물관리기본계획에서는 2020년 대비 2030년의 생활용수 및 공업용수 수요량이 4.4억m3 증가할 것으로 전망하였다(ME, 2020). 전 세계적으로 1900년부터 2000년대까지 물 소비량은 4배 증가했고, 물 부족 인구는 세계 인구의 14%에서 58%로 증가하였다(Kummu et al., 2016). 인구 증가와 산업화로 인해 용수 사용량이 증가하지만, 수원의 고갈이 심화되면서 안정적인 생활용수 확보에 어려움이 커지고 있다. 국가물관리기본계획에서는 미래 용수 수요 전망을 위해 장래 추계 인구와 시군별 1인 1일당 급수량을 활용하였다. 하지만 이는 미래 인구가 현재까지의 경향을 지속한다는 가정으로 예측된 것이며, 변동요인을 고려하지 않았다. 따라서 사회, 경제, 기상학적 변동요인을 고려한 수요량 예측 결과를 수자원 정책에 반영할 필요가 있다.
용수 수요량 예측 방법은 전통적인 시계열 모델부터 머신러닝까지 다양하다. 과거에는 회귀모형과 ARIMA (Autoregressive Integrated Moving Average), SARIMA (Seasonal ARIMA)와 같은 시계열 모형이 적용되었으며, 인공신경망(Artificial Neural Network, ANN) 모형이 개발되면서 2000년 이후 여러 분야에 적용되었다. 수요량 전망 관련 연구 결과를 살펴보면, ANN 기반 기법이 단기 예측에서는 높은 정확도를 보였지만, 중장기 예측에서는 정확도가 낮게 나타났다(Ghalehkhondabi et al., 2017). 또한 단기 예측에서는 사회 및 경제적 변수를 활용했지만, 장기 예측 모델에서는 이러한 변수를 활용한 사례는 적었다. 2010년 이후로는 Random Forest (RF), Support Vector Regression (SVR), Extreme Gradient Boosting (XGBoost) 같은 머신러닝 모델이 전통적 모델을 대체하기 시작하였다. 최근에는 Deep Neural Network (DNN), Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU) 같은 딥러닝 모델이 사용되고 있다. Said et al. (2021)은 물 소비량 단기 예측을 위해 Deep Learning in Neural Network (DLNN)을 기반으로 생성된 DLNN - Multilayer Perceptron (DLNN-MLP), DLNN - Convolutional Neural Network (DLNN-CNN), DLNN-LSTM 모델을 비교하였다. 그 결과 DLNN-LSTM의 성능이 가장 안정되고 일관되었다. Liu et al. (2023)은 ARMA로 사회경제적 입력지표의 미래값을 예측하였고, DNN으로 중국 Minjiang 유역의 2021년 농업용수, 산업용수, 생활용수, 환경용수 수요량을 예측하였다. Mu et al. (2020)은 LSTM과 ARIMA, SVR, RF 모델 비교를 통해 LSTM이 15분과 1시간 단위 물 수요량 예측에서 가장 높은 정확도를 보이며, 고해상도 데이터를 다루는데 적합하다는 것을 보여주었다. 이러한 연구사례는 LSTM이 과거 데이터를 현재 예측에 반영하여 다른 모델보다 물 수요의 시계열적 패턴을 효과적으로 처리한다는 것을 보여준다.
예측모형과 관련된 연구에서 학습 자료가 충분하지 않을 경우 교차검증을 통한 모형의 정확도 평가와 과적합 방지가 필요하다. 최근 수자원 분야에서 Leave-One-Out Cross-Validation (LOOCV) 방법이 교차검증으로 많이 활용되고 있다(Fleming and Garen, 2022; Arsenault et al., 2023; Shrestha et al., 2025). LOOCV는 대부분의 데이터를 학습에 사용하기 때문에 데이터 수가 적을 때 유용하며, 과적합 방지에 효과적이다. Arsenault et al. (2023)은 미계측 유역에서 유량을 예측하기 위해 LSTM 모델을 사용했으며, LOOCV 방법으로 예측 성능을 평가하였다.
우리나라의 경우 수자원장기종합계획에서 제시한 1인 1일 급수량을 추정하여 목표연도의 수요량을 계산하는 것이 대표적인 방법이지만(MLTM, 2011), 인구, 기후, 사회경제적 요인 등 다양한 변동요인은 물 수요량에 영향을 미치므로 이를 배제할 수 없다(Haque et al., 2015). 따라서 체계적인 물 수요-공급 관리를 위해 변동요인을 고려한 생활용수 수요량 예측이 필요하다. 본 연구에서는 기후변화 시나리오에서 제공하는 사회·경제·기상 예측 자료를 활용하여 XGBoost, DNN, LSTM 모델의 생활용수 수요량 예측 성능을 비교·분석하고, 최적의 모델을 선정하여 미래 생활용수 수요량을 예측하였다.
2. 연구지역 및 분석자료
2.1 연구지역
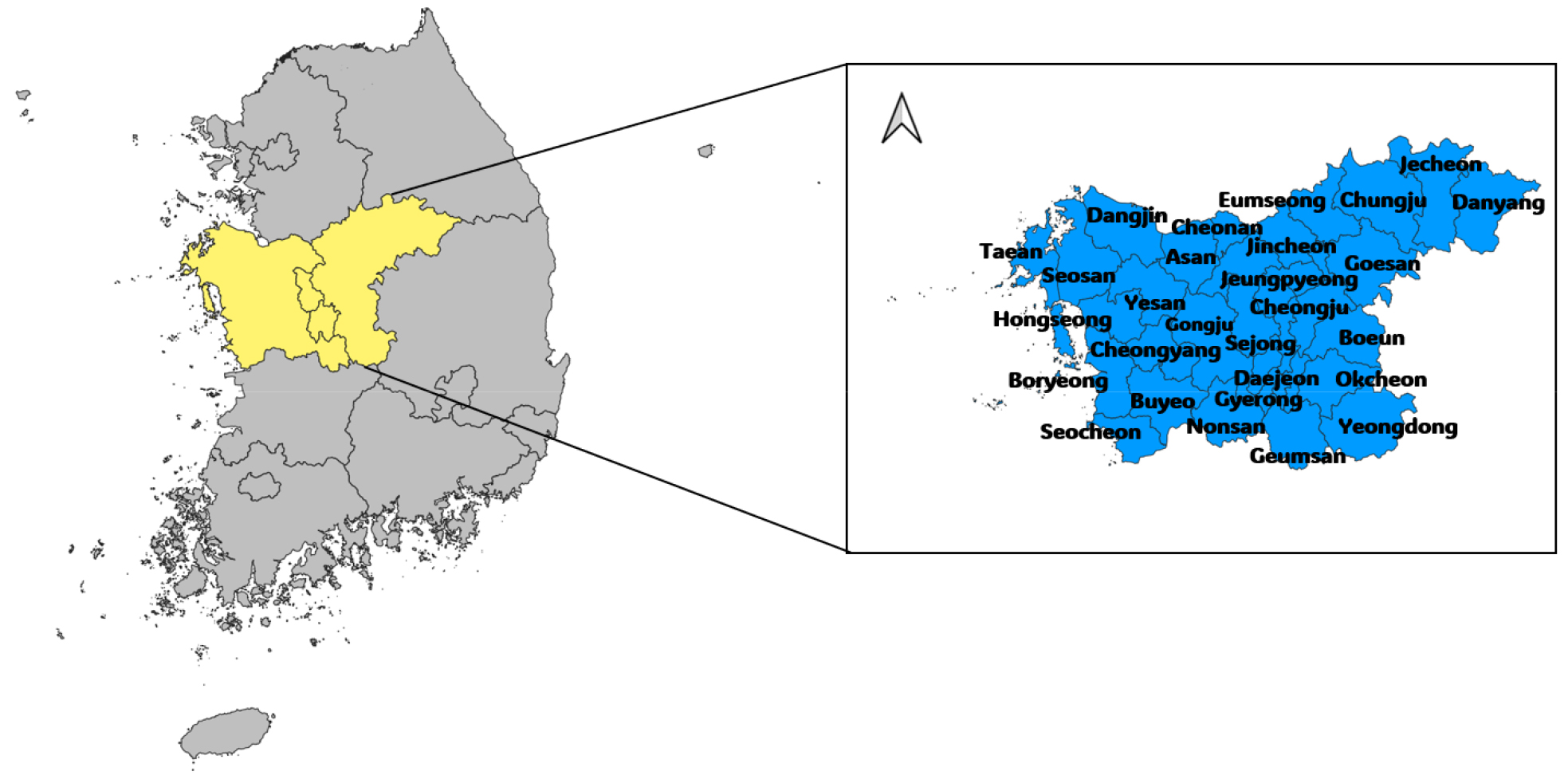
충청권역은 대전광역시, 세종특별자치시, 충청남도, 충청북도로 구성되며, 28개의 시군을 포함한 대한민국 중부 지역이다(Fig. 1). 행정안전부 보도자료(2024년 12월 18일)에 따르면, 2024년 12월 충청권역 4개의 시·도로 구성된 충청광역연합이 출범하였다. 충청광역연합은 시·도의 경계를 넘어선 광역 교통 인프라 구축, 산업 및 환경 개선과 같은 부문별 정책 과제를 통해 사회경제적으로 큰 발전을 목표로 하고 있다. 한편, 충청권역은 가뭄으로 인해 용수 공급 피해가 자주 발생한다. 2015년 충청남도 보령댐은 가뭄으로 인해 역대 최저 저수율인 18.9%를 기록하며, 제한급수가 시행되었다. 이로 인해 6월부터 12월까지 충청권역의 총 896명이 생활용수 사용에 어려움을 겪었다(ME and K-water, 2015). 또한 충북의 기상가뭄 발생일수는 42.7일, 충남은 51.3일로 전국평균인 31.4일보다 매우 높다(KMA, 2024). 충청광역연합의 출범에 따라 안정적인 용수 이용을 위한 통합 물관리 사업의 필요성이 제기되고 있다(Oh et al., 2021). 사회경제적 발전에 따라 용수 수요량에 있어 지역적 차이가 나타날 것이고, 통합 물관리를 위해 이를 고려한 정확한 지역별 용수 수요량 예측이 필요하다.
2.2 분석자료
본 연구에서는 공통사회경제경로(Shared Socioeconomic Pathways, SSP) 시나리오를 기반으로 기후변화에 따른 사회·경제·기상 자료를 구축하였다. IPCC 6차 평가보고서에서 제시한 SSP 시나리오는 인구, 경제 발전, 사회 인자, 정책 등을 고려하여 미래 기후변화로 인한 영향을 나타낸다. KEI (2022)에서는 사회, 경제, 기상 측면에서 미래 시나리오에 따른 자료 생산 방법을 제시하고 있다. 먼저 사회 및 경제 부문에서 SSP1은 지속가능 고위성장 시나리오, SSP2는 현재 추세를 유지하는 시나리오, SSP5는 지속가능하지 않은 저위성장 시나리오이다. 사회측면에서 SSP1 시나리오는 효율적인 인구정책으로 출산율 및 기대수명이 증가하며, SSP2는 기존의 인구정책을 유지함에 따라 인구가 유지되고, SSP5에서는 비효율적인 인구정책으로 출산율 및 기대수명이 감소한다. 경제 측면에서 SSP1은 지속가능 경제성장 체계를 통해 지역 간 경제 격차가 감소하여 3차 산업 비중이 증가하고 2차 산업의 비중은 감소하는 시나리오이다. SSP2는 현재의 경제 추세를 유지하는 것이며, SSP5는 지속가능하지 않은 경제성장으로 지역간 경제 격차가 커지는 시나리오이다. 기상 측면에서 SSP1-2.6은 기술 발달로 지속가능 경제성장을 이루는 저탄소 시나리오이며, SSP2-4.5는 기후변화가 완화되고 사회경제 발전이 중도 성장하는 시나리오이고, SSP5-8.5는 기후변화 완화능력이 낮은 사회의 고탄소 시나리오이다. 시나리오의 첫 번째 숫자는 사회, 경제적 상황이며, 두 번째 숫자는 2100년 복사강제력을 나타낸다.
Table 1은 본 연구에서 머신러닝 모형의 학습과 검증에 활용된 자료이다. 입력자료 중, 사회 영향인자에는 총인구(Total Population), 남성인구(Male Population), 여성인구(Female Population), 유소년인구(Youth Population, 14세 이하), 생산연령인구(Economically Active Population, 15~64세), 고령인구(Elderly Population, 65세 이상)와 같은 성별 및 연령 계층별 인구 자료가 활용되었다. 경제 영향인자는 충청권역의 지역내총생산(Gross Regional Domestic Product, GRDP)을 활용하였다. GRDP는 농림어업 및 광업의 경우 1차, 제조업은 2차, 서비스업은 3차로 분류한다. 총 GRDP (Total GRDP), 1차 GRDP (Primary Sector GRDP), 2차 GRDP (Secondary Sector GRDP), 3차 GRDP (Tertiary Sector GRDP) 자료가 분석에 사용되었다. 기후 영향인자는 강수량(Precipitation), 평균기온(Average Temperature), 상대습도(Relative humidity), 풍속(Wind Velocity) 등이다. 상수도 통계의 부과량을 바탕으로 생활용수 수요량(w1) 자료를 구축하였다. 이는 계측 수도 요금에 기반한 자료이다. 자료 보유 기간은 사회 영향인자의 경우 1930년~2023년, 경제 영향인자는 2000년~2021년, 기후 영향인자는 1973년~2025년, 생활용수 수요량은 2000년~2023년까지 수집하였다. 가장 짧은 기간인 경제 영향인자를 기준으로 2000년부터 2021년까지 수요량 예측 모델의 학습 자료를 연단위로 구축하였다.
Table 1.
Data used in training and validating prediction models
미래 수요량 예측을 위한 입력자료는 Table 1의 입력변수(Input)에 대한 SSP 시나리오 추정량(2022~2050)을 사용하였다(KEI, 2022). 사회 영향인자 자료는 통계청 장래인구추계 방법론을 기반으로 인구변동요인(출생, 사망 및 국제이동)에 따라 산정하였다. 경제 영향인자 자료는 2050 탄소중립시나리오의 경제 성장률, 국회예산정책처의 장기재정전망, IIASA의 GDP성장률 전망 데이터를 활용하여 산정되었고, GRDP의 경우 시도별 인구 비중 변화와 비례하여 조정되는 변화율을 도출하였다. 기상 영향인자 자료는 전지구기후모형(Global Climate Model, GCM) 18개 중 3개의 GCM (GFDL-ESM4, ACCESS-ESM1-5, CanESM5)과 기상청 기후정보포털(http://www.climate.go.kr/home/)에서 제공하고 있는 앙상블 모델인 5ENSNM을 조합하여 구축하였다.
3. 연구방법
3.1 XGBoost
XGBoost 약한 예측 모델의 학습 오차에 가중치를 두고, 순차적으로 다음 학습 모델에 반영하여 강한 예측 모델을 생성하는 부스팅 기법이다. 약한 모델은 학습오차에 가중치를 적용하기 전 모델이며, 강한 모델은 적용 후 모델이다. XGBoost은 기존 Gradient Boosting Machine 보다 연산 속도 향상, 병렬 처리 지원, 과적합 방지, 희소 데이터 처리 능력이 강화되었다(Chen and Guestrin, 2016). Fig. 2는 XGBoost의 작동 원리를 도식화한 그림이다.
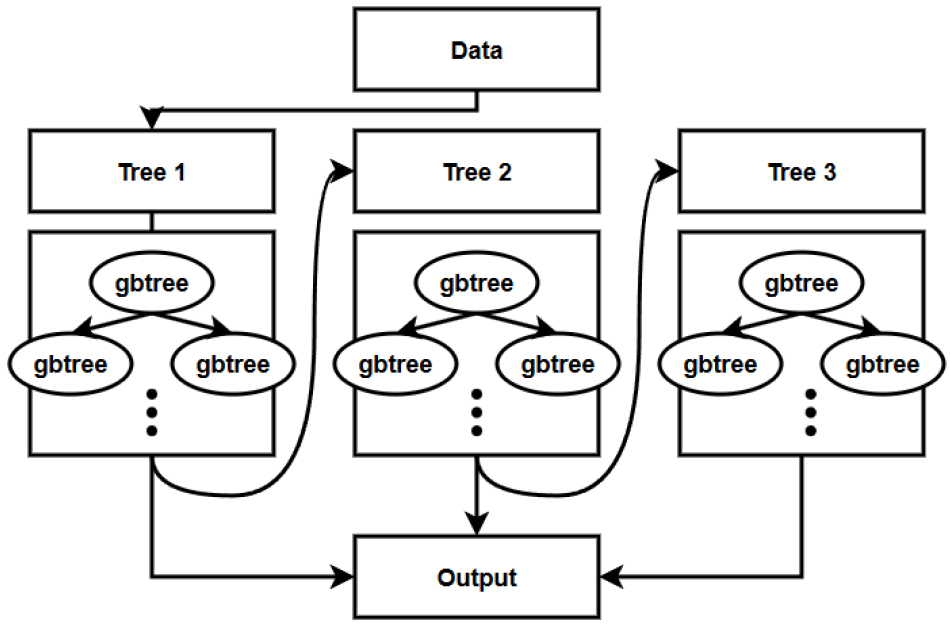
본 연구에서 XGBoost 모델의 예측값()은 생활용수 수요량이며, 계산과정은 Eqs. (1), (2), (3)과 같다.
여기서, 는 입력값으로 Table 1의 사회, 경제, 환경 영향인자이다. K는 의사결정나무 모형의 개수, 는 k번째 의사결정나무 모형을 나타낸다. Eq. (2)의 L은 목적함수이며, 첫 번째 항은 손실함수로서 본 연구에서 은 평균제곱오차(Mean Squared Error, MSE)를 사용하였다. 두 번째 항은 정규화 항으로서 는 회귀나무 함수에 페널티를 부여하여 가중치를 매끄럽게 한다. Eq. (3)의 𝛾는 정규화 계수, T는 나무의 리프 개수, 𝜆는 가중치 벡터에 대한 정규화 계수, 𝜔는 리프 노드의 가중치 벡터이다.
하이퍼파라미터는 모델 성능을 향상시키고, 과적합을 방지하기 위해 모델 실행 전 설정하는 값으로 일반 파라미터, 부스터 파라미터, 학습 파라미터로 나뉜다. 예측 성능을 높이기 위해 Bayesian Optimization 기반 Optuna 프레임워크를 사용하여 최적의 하이퍼파라미터를 찾았다. Bayesian Optimization은 목적함수를 최소화하기 위한 파라미터 조합을 찾는 과정이다. 목적함수는 MSE로 설정하였고, 학습 중 MSE가 최소화하려는 방향으로 구성하였다. Learning rate는 예측값에 가중치로 부여되며, Max depth는 T에 영향을 주는 하이퍼파라미터이다. Subsample은 Eq. (3)의 손실함수 부분에 데이터 비율을 결정할 때 사용된다.
3.2 DNN
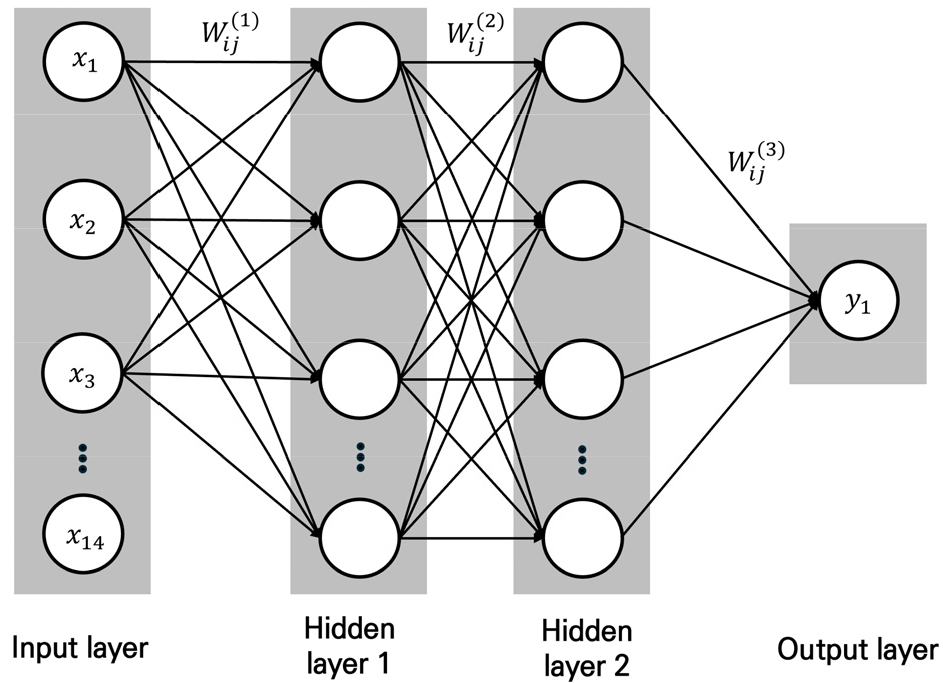
DNN은 ANN의 한 종류로 은닉층이 여러 개인 신경망이다. DNN은 입력층, 은닉층, 출력층으로 구성되고, 얕은 구조인 ANN과 달리 3개 이상의 층을 가지고 있다. 각 층의 뉴런은 이전 층의 출력에 가중치를 곱하고, 비선형 함수를 적용하여 다음 층으로 전달한다. 따라서 복잡하고 추상적인 특징을 학습할 수 있으며, 음성인식, 이미지 분류, 자연어 처리 등 다양한 분야에 응용되고 있다(Sze et al., 2017). Fig. 3은 DNN의 모형구조를 나타낸 것이다.
은닉층은 2개이며, 은닉층에 따른 뉴런의 개수는 베이지안 최적화를 통해 결정된다. Fig. 3에서 , , 은 입력값이며, Eq. (4)에 나타난 바와 같이 는 연결된 노드 간 가중치, b는 편향이다. j는 이전 계층의 노드 수, i는 다음 계층의 노드 수를 뜻한다. 입력값에 가중치를 곱해 다음 노드로 전달한 뒤, 가중치가 곱해진 모든 값들을 합산한다. 결과적으로 f인 비선형 활성화 함수를 통해 출력값을 다음 계층으로 전파하는 연산 과정이다. 대표적인 활성화 함수는 Sigmoid, Hyperbolic Tangent, ReLU (Rectified Linear Unint) 등이 있다. 과거 가장 많이 사용되는 Sigmoid 함수의 경우 가중치 소실 및 발산 문제가 발생하기에, 본 연구에서는 빠른 학습이 가능한 ReLU 함수(Eq. (5))를 사용하였다.
3.3 LSTM
LSTM 모형은 딥러닝 모형 중 하나로 Recurrent Neural Network (RNN) 모형과 유사하게 시간에 따른 종속적인 특성을 학습하여 반영하는 구조적 형태를 가진다. RNN 모형의 경우 시퀀스가 길어지는 경우 정보가 제대로 저장되지 못하는 장기 의존성 문제가 있다. 그러나 LSTM은 RNN 모형에서 고려하는 장기적인 변동 특성에 추가로 단기적인 변동 특성을 반영할 수 있다. 시간에 따른 장기간 변동 특성을 고려함에 따라 주기성, 경향성 등을 갖는 시계열 자료의 추정에 효과적이다(Hochreiter et al., 1997). Fig. 4는 LSTM의 모형 구조를 나타낸 것이다. 3개의 주요 연산 과정과 1개의 업데이트 과정으로 구성되며, 각각 Forget gate, Input gate, Output gate, Cell candidate로 정의된다.
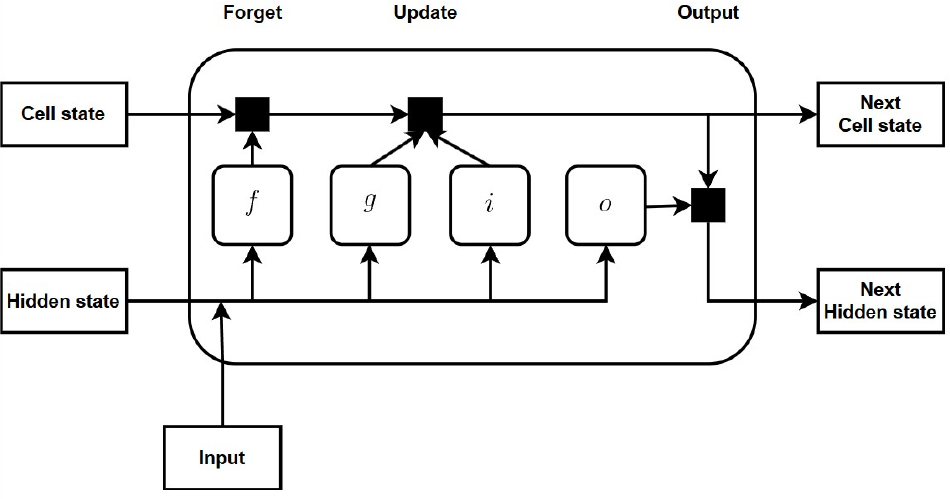
Forget gate (f)는 전달받은 장단기 정보를 계속 유지할 것인지 하지 않을 것인지를 결정한다. Input gate (i)는 새로운 입력자료에 대한 중요성을 정량화하여 전달한다. Cell candidate (g)는 새로운 장단기 특성을 생성한다. Output gate (o)는 장기특성 정보를 단기정보에 전달하는 역할을 한다. Eqs. (6), (7), (8), (9), (10)은 LSTM 실행에 따른 연산 과정이다.
여기서 는 Forget gate의 출력, 는 시그모이드 함수,는 입력 가중치, 는 t 시점의 입력 벡터, 는 은닉 가중치 는 t-1 시점의 은닉 상태, 는 편향이다. 는 하이퍼볼릭 탄젠트 함수, 는 cell state이다.
3.4 LOOCV
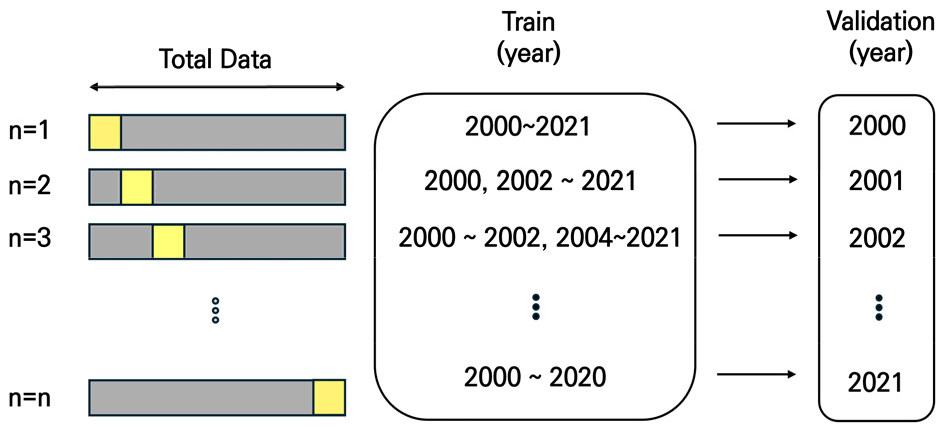
LOOCV는 모형의 성능 검토를 위한 교차 검증 기법으로 K-folds Cross Validation의 일부분이다. 머신러닝에서 과적합을 줄이고, 예측 정확도를 높이기 위해 LOOCV와 같은 교차 검증 기법이 자주 사용된다(Lumumba et al., 2024). n개의 데이터 중 1개를 비교 데이터로 남기고 n-1개의 데이터로 학습한 뒤, 남겨 둔 비교 데이터로 예측 오차를 계산하는 것을 n번 반복하는 교차검증 방법이다. 데이터를 K개로 나누어 K번만 교차검증하는 K-folds Cross Validation과 달리, LOOCV는 Fig. 5와 같이 모든 샘플이 자기 자신을 제외한 모든 세트에 포함되어 검증하기에 데이터의 개수가 적은 모델에 효과적이다.
3.5 성능 평가 지수
본 연구에서는 실제값과 예측값 간의 정확도를 평가하기 위한 성능 평가 지수로 R2(Coefficient of determination), RMSE (Root Mean Squared Error), MAE (Mean Absolute Error)를 사용하였다(Eqs. (11), (12), (13)).
여기서 는 i번째 실제값, 는 입력 자료의 평균, 는 예측값, n은 예측값의 개수이다.
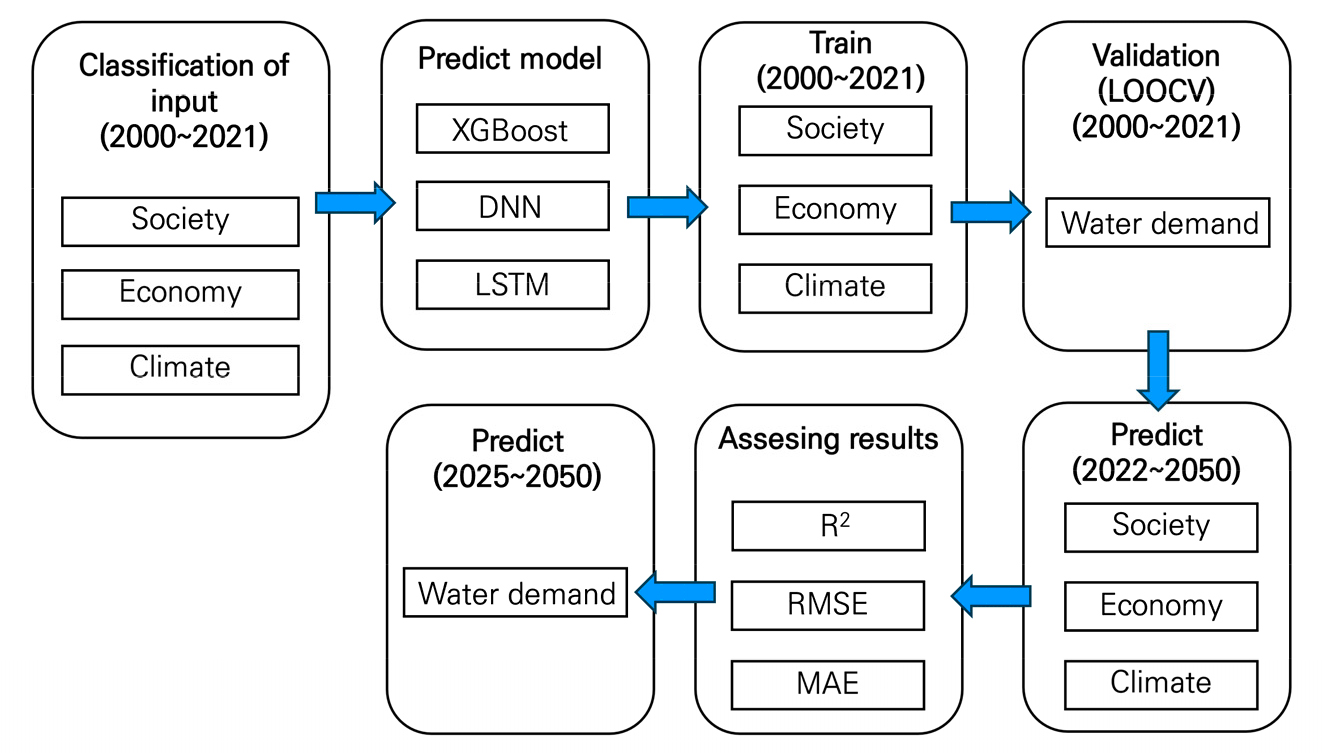
본 연구에서는 충청권역의 28개 시군을 대상으로 XGBoost, DNN, LSTM 모델로 2000년부터 2021년까지 영향인자들을 학습시켜 2025년부터 2050년까지의 생활용수 수요량 예측 결과를 분석하였다. 2000년부터 2021년까지 과거 생활용수 수요량 데이터로 검증하였고, 미래 수요량을 예측하기 위해 2022년부터 2050년까지의 미래 SSP 시나리오에 따른 영향인자를 활용하였다. Fig. 6은 예측 과정에 대한 흐름도이다.
4. 결 과
4.1 최적 모델 선정
XGBoost, DNN 그리고 LSTM의 정보를 활용하여 미래기간에 대한 예측을 수행하기 위해, 선형이동방식을 기반으로 Min-max 정규화 및 역정규화를 통해 과거자료와 예측치의 편차를 보정하였다. Table 2는 대표지역(계룡시, 아산시, 증평군)의 모델에 따른 하이퍼파라미터 값이다.
Table 2.
Hyperparameters of machine learning models for representative regions
XGBoost, DNN, LSTM의 하이퍼파라미터는 베이지안 최적화를 활용하여 가장 성능이 좋은 조합을 찾아내는 방식으로 결정하였다. 대표지역은 수요량 예측 결과에 대한 뚜렷한 패턴을 가진 지점으로 선정하였다. Table 3는 대표지역의 모델에 따른 성능 평가 결과이다.
Table 3.
Performance results of machine learning models for representative regions
XGBoost의 충청권역 평균 R2는 학습 구간(Train)과 검증 구간(Validation)에서 각각 0.99, 0.94로 학습 대비 검증에서 모델의 오차가 커졌다. RMSE와 MAE의 단위는 106 m3이다. 학습과 검증에서 RMSE는 0.42, 0.97이고, MAE는 0.11, 0.78로 학습 대비 검증에서 모델의 오차가 커졌다. DNN의 R2는 학습과 검증에서 각각 0.998(≒1.00), 0.90으로 학습보다 검증의 예측력은 떨어진다. RMSE는 학습과 검증에서 각각 0.08, 1.32이고, MAE는 0.06, 0.99로 학습 대비 검증에서 모델의 오차가 커졌다. 두 모델 모두 학습보다 검증에서 성능이 떨어지며, 과도하게 학습 성능이 좋기 때문에 과적합 가능성이 있다. LSTM의 R2는 학습과 검증에서 각각 0.98 0.94이고, RMSE는 0.49, 0.98, MAE는 0.37, 0.73이다. 세 모델 중 학습과 검정에서 오차 차이가 크지 않아 과적합 가능성이 낮다. Fig. 7은 세 모델의 지역별 성능평가지수를 나타낸 상자그림이다. 막대 그래프는 각 모델의 평균 성능 값이며, 점은 지역별 개별 성능 값, 에러 바는 표준편차를 뜻한다. Fig. 7(a)에서 막대 그래프가 높고 점이 밀집될수록 안정적인 모델이다. Figs. 7(b) and 7(c)에서 LSTM과 같이 에러 바가 짧고 점이 아래쪽에 분포될수록 이상치가 적고, 대부분의 지역에서 오차가 적은 것이다. 따라서 세 모델 중 LSTM 모델이 가장 예측력이 뛰어난 모델이다.
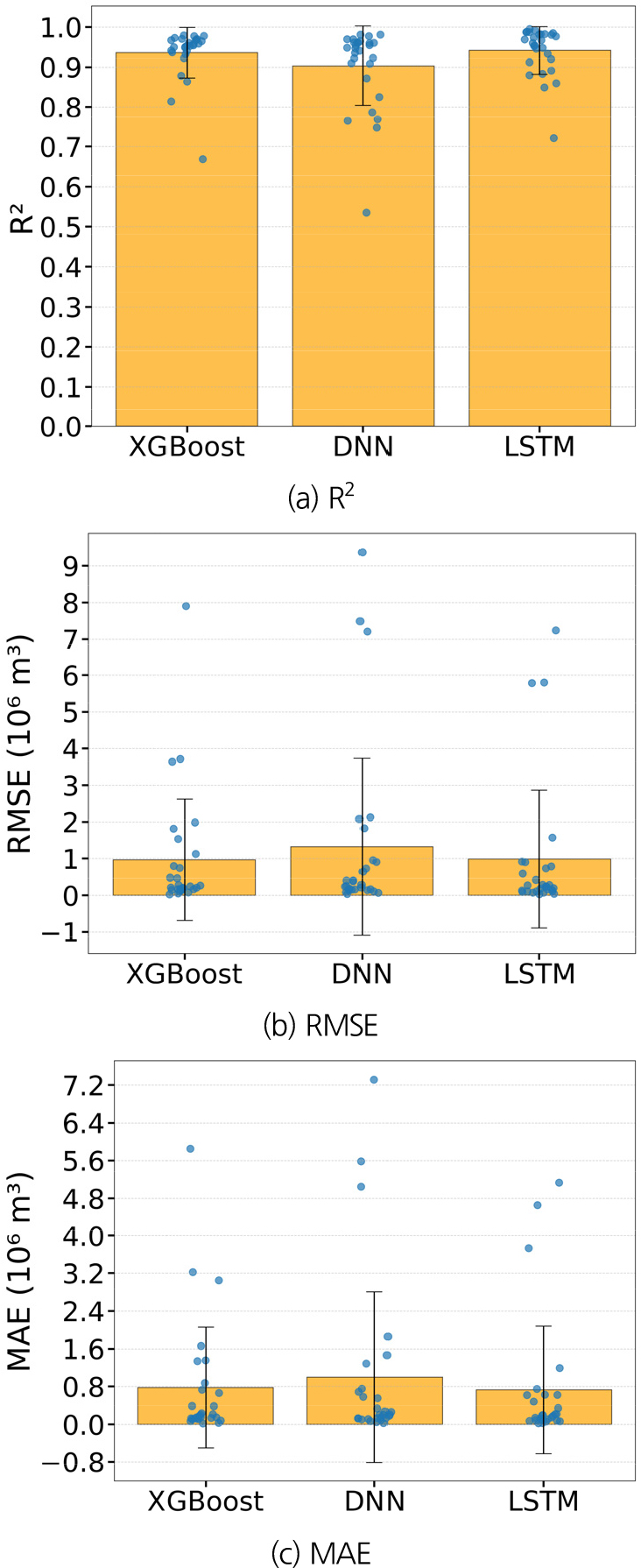
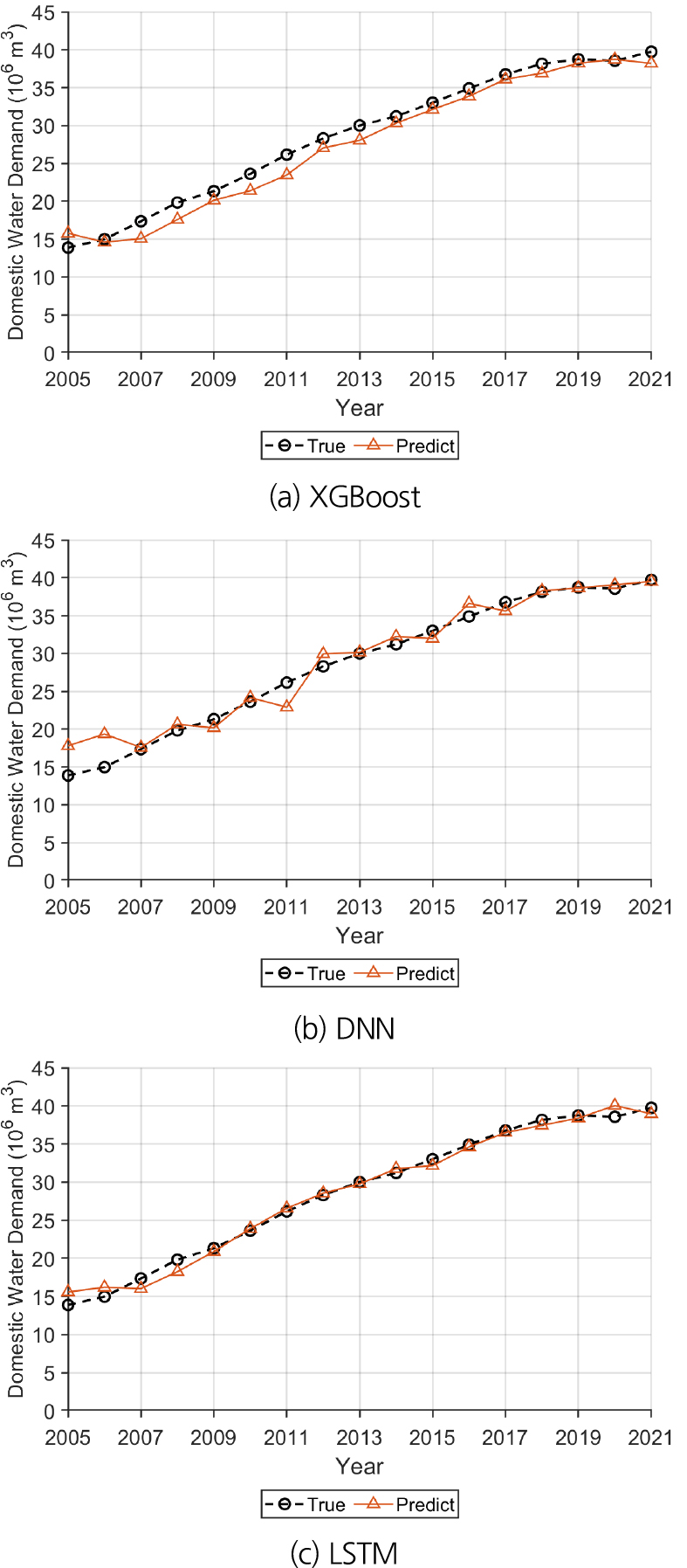
Fig. 8은 아산시의 모델별 실제값과 예측값을 비교한 결과이다. XGboost은 LSTM에 비해 낮게, DNN은 변동성이 크게 예측되었다. 이는 예측 모델의 특징에 따른 결과이다. XGBoost는 시계열 특성을 고려하지 않기에, 시간에 따라 영향인자가 증가하거나 감소하는 SSP 시나리오의 특성을 반영하지 못했다. DNN은 복잡한 특성을 반영하기에 기상인자와 같은 변동성이 큰 인자를 과도하게 반영했을 가능성이 있다. 따라서 본 연구에서는 LSTM을 최적의 모델로 선정하였다.
4.2 생활용수 수요량 예측 결과
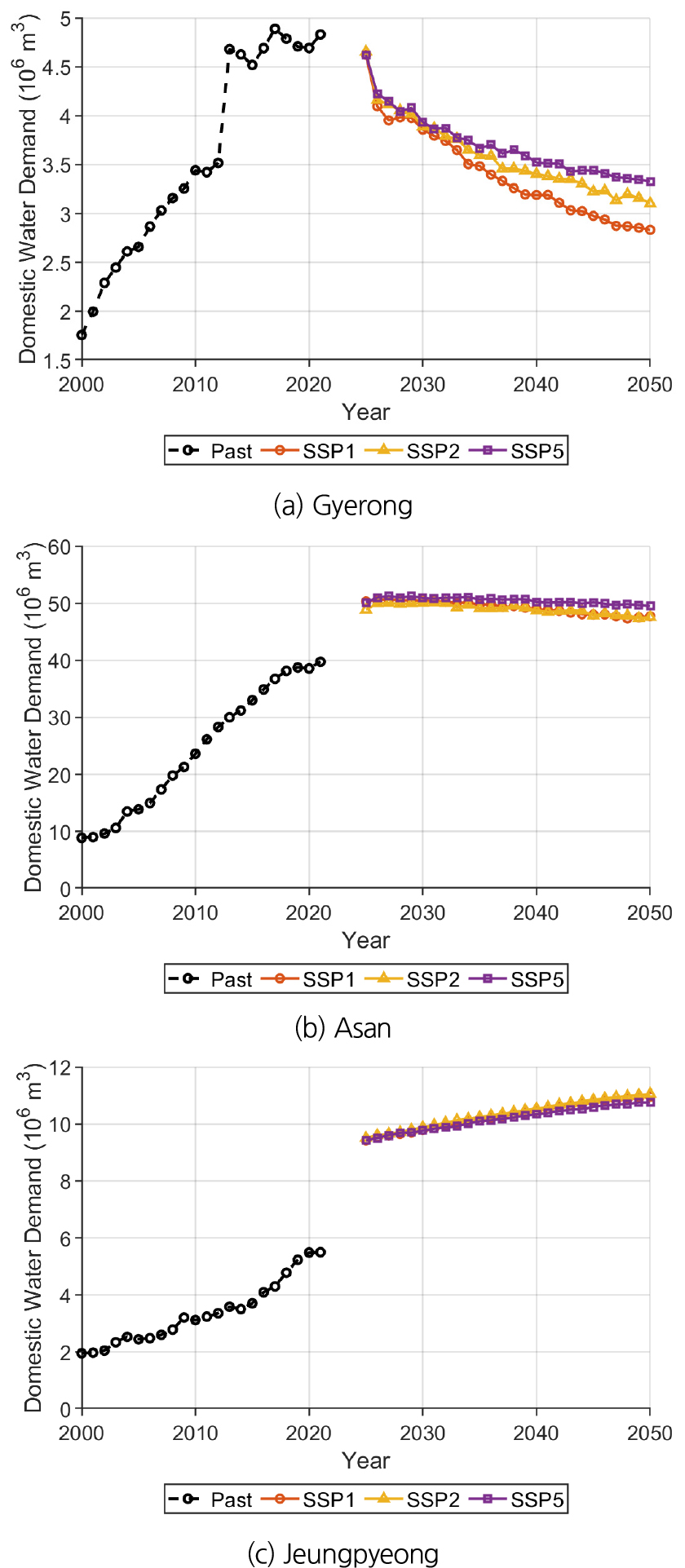
2025년부터 2050년까지 미래 생활용수 수요량을 예측한 LSTM 결과, 충청권역의 생활용수 수요량은 감소, 유지, 증가와 같이 지역 간 영향인자에 따라 상이한 추세를 보인다. 대표지역으로 Fig. 9와 같이 생활용수 수요량이 감소하는 계룡시, 유지하는 아산시, 증가하는 추세인 증평군을 선택하였다. 계룡시의 결과, 생활용수 수요량이 감소하며, SSP1, SSP2, SSP5 순으로 감소하였다(Fig. 9(a)). 영향인자 중 특히 생산인구를 제외한 모든 인구 인자에서 큰 감소 추세를 보였다. 아산시(Fig. 9(b))에서는 총 인구, GRDP, 남성인구, 여성인구, 생산인구는 증가하고, 노인인구, 유소년인구가 감소했지만, 서로 상쇄되어 유지 추세를 보였다. 증평군은 생활용수 수요량이 증가하며, 영향인자 중 모든 GRDP 인자에서 증가 추세였다(Fig. 9(c)).
제1차 국가물관리기본계획은 2020년부터 2035년까지 5년 단위의 고수요, 기준수요, 저수요 시나리오를 제시하였다. LSTM 예측 결과의 타당성을 위해 Fig. 10과 같이 제1차 국가물관리기본계획의 생활용수 수요량 시나리오와 비교하였다. 국가물관리기본계획에서 산정한 장래 생활용수 수요량 중 개발 계획, 기타용수 등을 제외한 충청권역의 총 급수량만을 합하여 그래프에 제시하였다.
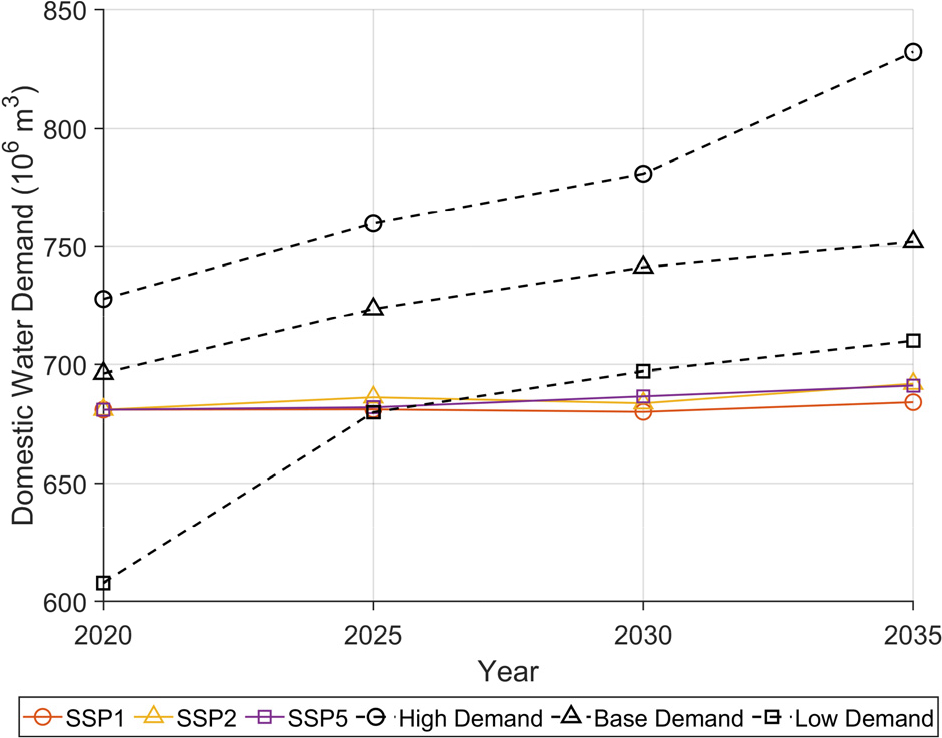
Table 4는 LSTM으로 예측한 충청권역의 생활용수 수요량 값이다. SSP1, SSP2, SSP5 간 충청권역 생활용수 수요량 예측값은 국가물관리기본계획의 저수요보다 작지만 추세가 상승세로 유사하다. SSP1에서 2025년 대비 2035년의 증가율은 0.44% 증가하였고, SSP2에서 0.87%, SSP5에서는 1.32% 증가하였다. 이는 기후변화에 취약하고, 사회 및 경제 부문에서 저위 성장하는 SSP5 시나리오와 부합되는 결과이다.
5. 결 론
본 연구에서는 생활용수 수요량에 영향을 미치는 사회, 경제, 기상 영향인자를 고려하여 2025년부터 2050년까지 연 단위 충청권역 생활용수 수요량을 예측하였다. 머신러닝 모델 중 XGBoost, DNN, LSTM 모델에 LOOCV를 적용하여 과적합을 방지하고 비교적 평균화된 예측값을 산출했으며, R2, RMSE, MAE를 이용한 성능 평가를 통해 최적의 모델을 선정하였다. XGBoost는 시계열 특성을 반영하는 데 한계가 있고, DNN은 예측에서 정확도가 LSTM보다 낮게 나타났다. LSTM의 경우 미래의 생활용수 수요량의 변동성을 광범위하게 고려할 수 있어 최적 모형으로 선정되었다. LSTM 예측 결과를 제1차 국가물관리기본계획에서 제시한 수요 시나리오와 비교했을 때, 생활용수 수요량이 증가하는 유사한 추세를 보였다. 제1차 국가물관리기본계획은 인구만을 변동요인으로 고려하였고, 생활용수 수요량을 실측자료가 아닌 1인 1일 평균 사용량을 바탕으로 산정했다. 이에 반해 본 연구에서는 기존 생활용수 수요량 예측의 한계였던 변동요인을 고려하였고, 예측 주기를 5년 단위에서 1년으로 단축하였다.
SSP 시나리오의 정의에 따르면 SSP1에서 인구와 GRDP의 증가가 예상되기에 인자의 영향으로 생활용수 수요량이 가장 높게, SSP5에서 가장 낮게 나타나야 했다. 하지만 본 연구에서는 SSP 시나리오별 생활용수 수요량의 특징이 두드러지지 않는다. 이는 첫째, SSP 시나리오의 정의에 따른 자료는 2100년까지인데, 예측에 활용될 영향인자를 2050년까지만 사용했기 때문이다. 2100년까지의 특징이 모두 반영되도록 영향인자의 기간을 늘릴 수 있지만, 자료의 불확실성이 커서 유의미한 생활용수 수요량 예측을 하기 어렵고 예측 성능이 떨어진다. 둘째, 사회, 경제, 기상 영향인자끼리 증감이 상반되게 나타나 상쇄되기 때문이다. 저출산 및 인구 고령화, 경제 성장과 같이 뚜렷한 증감의 인자가 지배적이지 않는 이상 SSP 시나리오에 따른 차이가 크게 나타나지 않는다.
본 연구를 통해 사회, 경제. 기상 영향인자에 따라 지역별 생활용수 수요량의 상승, 유지, 감소 추세를 예측할 수 있었다. 비슷한 추세를 보이더라도 변동 폭의 차이, 실제적인 수요량 값이 다르게 나타났다. 지역 간 수요량의 편차가 나타나기에 추후 생활용수 수요량 예측에서 사회, 경제, 기상과 같은 다양한 영향인자를 고려하며 지역 맞춤 수요 및 공급 정책을 추진해야 한다.
