

1. 서 론
2. 재료 및 방법
2.1 대상유역
2.2 분석방법
2.3 Multi-model Ensemble 모델 개발
3. 결과 및 고찰
3.1 입력자료 구축 결과 및 HSIC-Lasso 모형에 의한 입력변수 추출
3.2 알고리즘 결과
3.3 공간분포 결과
4. 요약 및 결론
1. 서 론
담수호는 간척지 내 수자원 개발과 토지이용률의 증대를 위해 인공적으로 조성된 저수지를 말하며, 유역의 하류라는 지리적 특성으로 모든 오염물질이 재유입되는 특성이 있어 환경오염이 발생하기 쉬운 조건을 가지고 있다(Kim et al., 2002). 특히 최근에는 유역 토지에서 유출되는 비점오염, 생활오염원 및 축산오염원의 증가로 인해 난분해성 유기물질 유입이 증가하고 있다(Jung et al., 2021). 환경부에서는 다양한 오염원과 비점오염원으로부터 유입되는 난분해성 유기물질을 반영하기 위해 2013년부터 총유기탄소(Total Organic Carbon, TOC)를 호소의 수질 및 수생태계 환경기준의 수질지표 항목으로 도입하여 관리하고 있다(Jeong et al., 2018). 물에 포함된 유기탄소의 총량을 나타내는 TOC는 수질오염을 나타내는 정량 지표 중 하나이며, 외부에서 유입된 유기물뿐만 아니라 호소 내부의 생물 활동 및 유기물 분해 과정을 통해 형성되기 때문에, 호소의 생태학적 상태 및 오염원 관리의 중요한 지표가 된다(Kim et al., 2007; Kim and Lee, 2019). 따라서 TOC 모니터링은 호소의 생태적 상태를 이해하고 관리하기 위해 필수적이다.
최근에는 원격감지 기술을 통해 수질 매개변수를 효율적으로 모니터링하는 연구가 활발히 진행되고 있다. 광학적 활성 성분(Optical Active Components, OAC)에 해당하는 물질에는 Chlorophyll-a, 유색용존유기물질(Colored Dissolved Organic Matter, CDOM), 총부유물질(Total Suspended Solids, TSS) 등이 포함되며 이러한 물질들은 물속에서 빛을 흡수하거나 산란하는 수중 성분을 말한다(IOCCG, 2018). 위성영상을 활용해 단일 OAC 성분을 추정하는 연구가 많이 진행된 바 있다. Shin et al. (2020)은 Landsat-8을 활용하여 대청호, 용담호, 옥정호에 대한 Chlorophyll-a를 산정하여 평가한 바 있으며, Park et al. (2018)은 Sentinel-2와 RapidEye 위성을 통해 4대강 유역에 설치된 보 부근을 분석 대상으로 하여 Chlorophyll-a를 산정하였으며 5mg/m3 내외의 차이를 확인한 바 있다. non-OAC에 해당하는 TOC의 경우 OAC 물질을 활용하여 간접 추정할 수 있다. Chang et al. (2014)는 Landsat 이미지와 MODIS 이미지를 활용하여 CDOM 기반 용존성유기탄소(Dissolved Organic Carbon, DOC)과 Chlorophyll-a 기반 입자성유기탄소(Particulate Organic Carbon, POC)을 활용하여 IDFM (Integrated data fusion and mining) 기법을 통한 TOC 예측을 진행하였으며, 검증에서 0.8745의 R2으로 높은 정확도를 보인 바 있다. Kutser et al. (2015)는 MERIS 위성에서 생산되는 CDOM 흡수계수, Chl-a, TSS 및 탁도 등의 프로세서를 활용하여 DOC 및 TOC에 대한 R2를 각각 0.71, 0.74의 정확도로 산정한 바 있으나 아직 국내를 대상으로 한 연구는 미비한 실정이다.
원격감지를 통해 수질매개변수를 추정하는 방법은 경험적 방법과 반분석적 방법 등을 통해 추정되며, 최근 머신러닝에 기반한 방법으로 높은 정확도로 수질매개변수를 추정하는 문헌이 제시되고 있다. 머신러닝 기법은 환경변수 간 복잡한 비선형 관계를 정확하게 평가하고 해결할 수 있어 Extreme Gradient Boosting (XGB), Support Vector Regression (SVR), Artificial Neural Network (ANN) 등 다양한 머신러닝 기법을 통해 수질 변수 평가에 적용되었다(Tian et al., 2024). 머신러닝은 수질오염을 예측하는데 상당한 이점을 제공하지만, 개별 머신러닝 모델의 사용은 일반적으로 과적합 되는 경향을 보인다(Satish et al., 2024). 이러한 문제를 해결하기 위해 다중모델 앙상블(Multi-model ensemble) 기법을 통해 두 개 이상 모델의 장점을 결합하여 예측 성능을 최적화하고자 하는 연구가 진행되고 있다(Ahmed et al., 2020; Kim et al., 2022). Panahi et al. (2022)는 SVM 모델과 결합한 앙상블 Bagging 기술을 기반으로 한 데이터 전처리 방법을 통해 하천 유량과 수질을 예측하였으며, Chen et al. (2020)은 중국의 주요 강, 호수에 대해 7개 머신러닝 모델과 3개의 앙상블 모델을 활용하여 수질 예측 능력을 비교하여 앙상블 모델의 유효성을 입증한 바 있다. 또한, Kim et al. (2022)는 남한지역 1.5 km 공간해상도의 시간별 오존 농도를 산출하기 위해 Stacking 앙상블 모델을 개발하였으며, 전반적인 모델 성능향상 결과를 확인하였으나 TOC를 예측하기 위한 앙상블 모델의 개발 연구는 부족하다.
따라서 본 연구에서는 담수호 모니터링을 위해 위성영상을 활용하여 TOC를 간접 추정할 수 있는 반사도를 확인하고, 머신러닝 기반 Multi-model Ensemble을 통해 담수호 TOC를 산정하여 평가하고자 한다.
2. 재료 및 방법
2.1 대상유역
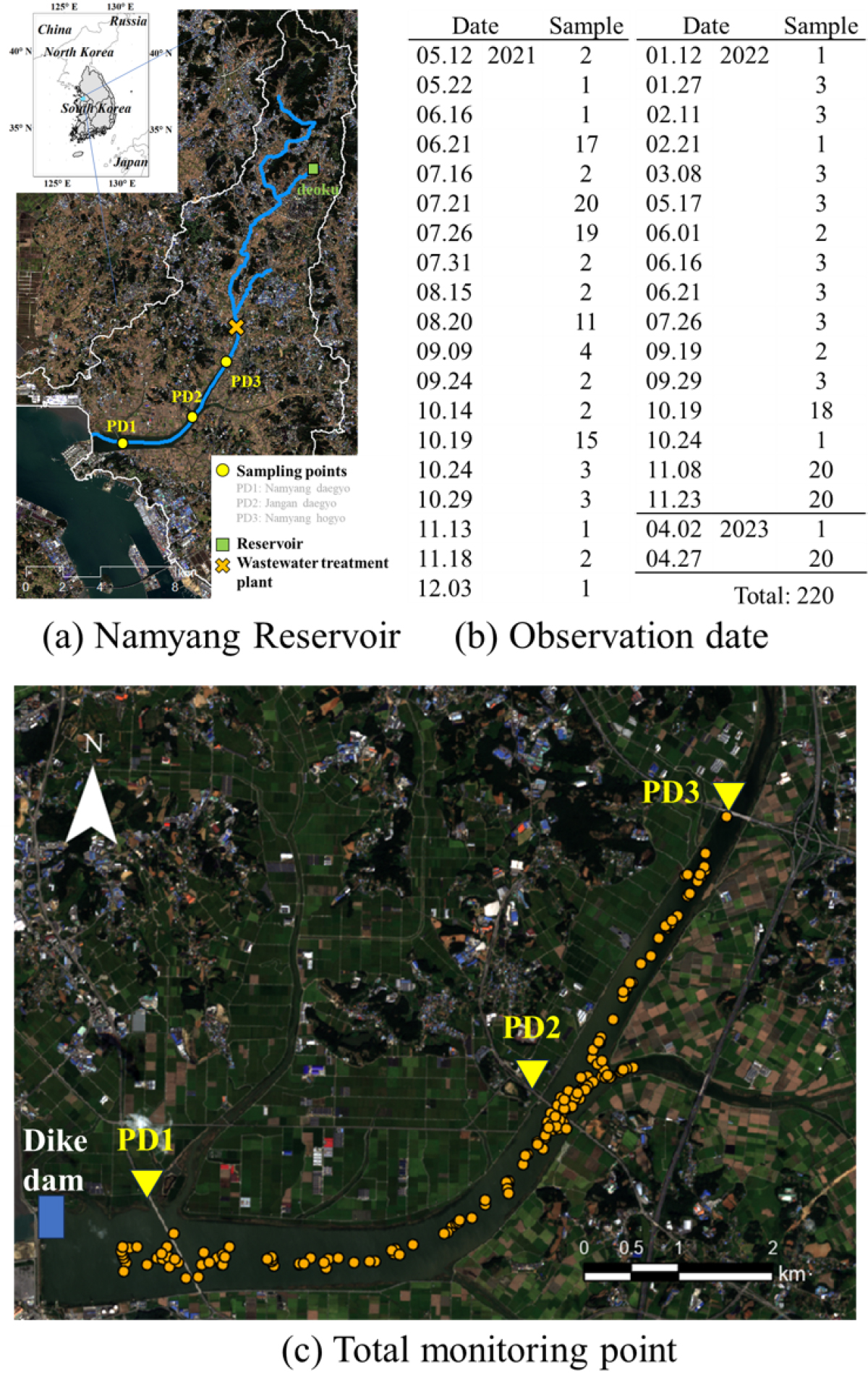
본 연구의 대상유역은 서해 중부지역 경기도 화성시에 위치한 인공 담수호인 남양호 상류 유역이다(Fig. 1). 남양호는 유역크기가 209 km2, 하천 폭은 900 m, 수혜면적은 3,449 ha, 유효저수량은 20,407×103m3이다. 남양호는 유역의 28.3%가 논이며, 12.2%가 밭으로 농업지역이 차지하는 비율이 큰 유역이다(Kim et al., 2021). Kim et al. (2021)에서 조사된 남양호의 5년(2018~2022) 평균 TOC 농도는 6.5 mg/L로 이는 환경정책기본법 제2조 호소생활수질환경 기준 중 TOC를 기준으로 구분한 수질 등급에서 5등급에 해당하는 농도로 남양호의 수질이 열악한 상태로 나타났다. 이에 따라 2022년에 경기도에서 지정한 중점 관리 저수지 수질개선 대책 수립에 해당하는 저수지로 선정된 바 있다.
2.2 분석방법
2.2.1 위성자료
Sentinel-2는 유럽우주국(European Space Agency, ESA)의 GMES (Global Monitoring for Environment and Security) program으로 발사된 MSI (MultiSpectral Instrument)를 탑재한 위성군이다. Sentinel-2는 가시광선, 근적외선, 및 단파적외선 범위를 13개 대역에서 관측하며, 공간해상도는 밴드별로 10, 20, 60 m의 고해상도를 290 km의 광역 영상으로 제공한다. Sentinel-2는 2015년 6월에 발사된 2A와 2017년 3월에 발사된 2B의 쌍둥이 위성이 각각 10일 주기로 지구를 관측해 5일 간격의 높은 재방문 주기를 가지고 있어 지속적인 수질 모니터링이 가능하다.
Sentinel-2 위성군의 자료는 ESA Copernicus Open Access Hub (https://scihub.copernicus.eu/)에서 Level-1C TOA (Top- of-Atmosphere)과 Sentinel Application Platform (SNAP v 6.0)의 Sen2Cor 프로세서를 사용하여 방사, 기하 및 대기보정이 진행된 Level-2 BOA (Bottom-of-Atmosphere) 반사율 자료를 제공한다. Level-1C의 대기보정은 같은 영상에서 얻어진 에어로졸 광학두께(Aerosol Optical Depth, AOD)와 대기 중 수증기(Water Vapor, WV)를 이용하여 보정된다(Chung et al., 2023). Sentinel-2 Level-2 영상과 같이 제공하는 SLC (Scene Classification Map) 영상은 각 pixel을 물, 그림자, 권운, 구름 및 눈 등의 클래스로 분류하며(Raiyani et al., 2021), 이 중 물 pixel에 해당하는 point 값만 추출하여 활용하였다. 모든 영상은 Band2, Band3, 및 Band4에서 제공되는 공간해상도 10m에 맞춰 resampling 하였으며, 각 point의 3×3 pixel 창으로 평균하여 반사도 값을 추출하였다.
본 연구에서는 2021년 5월 12일부터 2023년 4월 27일까지의 기간 중 Senitnel-2A/B 위성이 연구지역을 통과하는 날짜에 맞춰 총 37회 샘플링을 진행하였다. 남양호 전반에 걸친 수질을 파악하기 위해 샘플링 총 기간 중 9번의 샘플링(2021; 6/21, 7/21, 7/26, 8/20, 10/19, 2022; 10/19, 11/08, 11/23, 2023; 4/27)은 배를 이용하여 남양호 전역에 대한 20개의 수질 샘플링을 수행하였으며, 그 외 일자는 남양대교(PD1), 장안대교(PD2), 남양호교(PD3)에서 3개의 수질 샘플링을 진행하였다. 20개의 샘플은 표층에서 채수되었으며, 대교에서 샘플링을 진행할 때는 반사도 값의 왜곡을 최소화하기 위해 하천 중앙부에서 샘플을 채취하였다(USGS, 2023). Fig. 1(b)와 같이 총 샘플링 기간(37회) 동안 샘플링된 point 데이터는 264개이며 이 중 SLC 분류에서 구름 및 기타 간섭 요소로 분류된 44개의 데이터를 제거하고 총 220개의 데이터를 분석에 활용하였다.
2.2.2 수질자료
수질자료 중 Chlorophyll-a, CDOM, TSS, 및 TOC는 실험을 통해 측정되었다. Chlorophyll-a는 Carry 5000 UV-vis-NIR Spectrophotometer에서 흡광도를 측정하고 고유 흡광특성을 이용한 식으로 산정하였으며 TOC는 총유기탄소 분석기(TOC-VCPH, Shimadzu, Kyoto, Japan)을 활용하여 측정하였다. TOC 분석을 위해 물샘플은 0.7 µm의 유리 섬유 필터(GF/F; Whatman, Clifton, NJ, USA)로 여과하여 4°C로 보관 후 측정하였다. CDOM은 0.2 µm NucleporeTM polycarbonate 멤브레인 필터(Whatman, Buckinghamshire, UK)로 여과 후 분광광도계(UV-1280, Shimadzu, Kyoto, Japan)를 사용하여 용존유기물의 흡광도(350-800 nm)를 측정하였으며, 기준파장 355 nm에서의 흡수계수인 를 산정하였다.
2.3 Multi-model Ensemble 모델 개발
2.3.1 입력자료 구축 및 선별
Multi-model Ensemble 모델 구축을 위해 측정된 수질 인자 중 OAC 성분을 가진 매개변수와 TOC 간 상관성을 분석하였다. 상관성이 가장 높은 OAC 성분을 대상으로 TOC를 예측하기 위해 Sentinel-2A/B의 Band1~Band12까지 파장 중 가시광선부터 근적외선 범위에 해당하는 Band1~Band8 파장을 활용하여 총 56개의 밴드비를 입력자료로 구축하였다. 모든 밴드비를 고려할 경우 적은 양의 데이터에서는 오히려 모델 성능을 감소시킬 수 있으며, Band selection을 통해 상관성이 높다고 판단되는 밴드비를 추출하여 알고리즘의 정확도를 개선하고자 하였다(Sun and Du, 2019).
Band selection 기법에는 HSIC-Lasso (Hibert-Schmidt Independence Criterion-Lasso) 모형이 적용되었다(Yamada et al., 2014). HSIC-Lasso 모형은 비선형 종속성이 있는 데이터에서 중요한 변수를 선택하는데 효과적인 모형으로, Frobenius 노름 기반의 회귀 계수 추정을 포함한다(Eq. (1)).
여기서, 는 Frobenius 표준으로 행렬의 각 원소의 제곱합의 제곱근을 나타내며, 이는 중심화 Gram 행렬을 통해 입력변수 와 출력변수 의 커널함수로 정의한다. 또한, 𝛼는 회귀 계수 벡터, 𝜆는 정규화 매개변수를 나타낸다. HSIC- Lasso 모형은 Ren et al. (2018)에서 월별 유량을 예측하기 위한 입력변수 선별에 사용되었으며, Amri and Marrel (2021)는 입력변수의 민감도 분석을 위해 최적화 HSIC-Lasso 모형을 활용하여 수행하였다. 본 연구에서는 각 위성영상의 밴드비와 TOC 간 상관성을 도출하고 입력변수를 선별하기 위해 HSIC-Lasso 모형을 활용하였다.
2.3.2 Machine Learning
각 밴드 별 입력변수가 결정되면 기존에 많이 사용되었던 머신러닝 모델을 구축하여 TOC를 예측하는 알고리즘을 구축하였다. 머신러닝에 선정된 모델은 Support Vector Machine (SVR), Random Forest (RFR), eXtreme Gradient Boost (XGB), Multi Layer Perceptron (MLP)를 활용하였다. SVR은 Vapnik et al. (1996)에 의해 개발된 모델로 데이터를 분리할 수 있는 최적의 결정 경계를 결정하는 알고리즘이다. 회귀문제에 적용될 경우 가우시안 커널과 같은 비선형 커널을 사용하여 예측값과 관측값의 오차가 최소화되는 초평면을 찾는 방식으로 적용된다. RFR은 Breiman (2001)에 의해 개발된 모델로 여러 개의 bootstrap 샘플을 추출하여 의사결정 트리 모델링을 한 후 여러 의사결정 트리를 병합하여 예측을 수행하고, 최종적으로 투표를 통해 예측 결과를 도출하는 모형이다. XGB는 Chen and Guestrin (2016)에 의해 개발된 모형으로 기울기 부스팅 기법을 적용하여 예측 정확도를 높인다. MLP는 Rumelhart et al. (1986)에 의해 제안된 모델로, 다층의 은닉층을 통해 비선형 관계를 학습하며, 특히 복잡한 패턴 인식과 예측 문제에 효과적이다. MLP는 역전파 알고리즘을 활용하여 학습하며, 다양한 회귀 및 분류 문제에서 좋은 성능을 보이는 모델로 평가된다.
2.3.3 Multi-model Ensemble
본 연구에서는 과적합을 줄이고 모델의 안정성을 높이기 위해 Multi-model Ensemble의 일종인 Stacking 모형을 활용하여 TOC를 예측하였다(Wolpert, 1992). Stacking 모델은 훈련 데이터가 첫 번째 계층(Base Model)에서 처리된 후, 해당 예측값이 두 번째 계층(Meta Model)의 입력으로 사용되는 앙상블 모델로, 단일 모델보다 높은 정확도를 입증하고 있어 다양한 환경 분야에서 활용되고 있다(Zhai and Chen, 2018; Cho et al., 2020). 본 연구에서 적용한 Stacking 모델의 흐름은 Fig. 2에 나타나 있다.
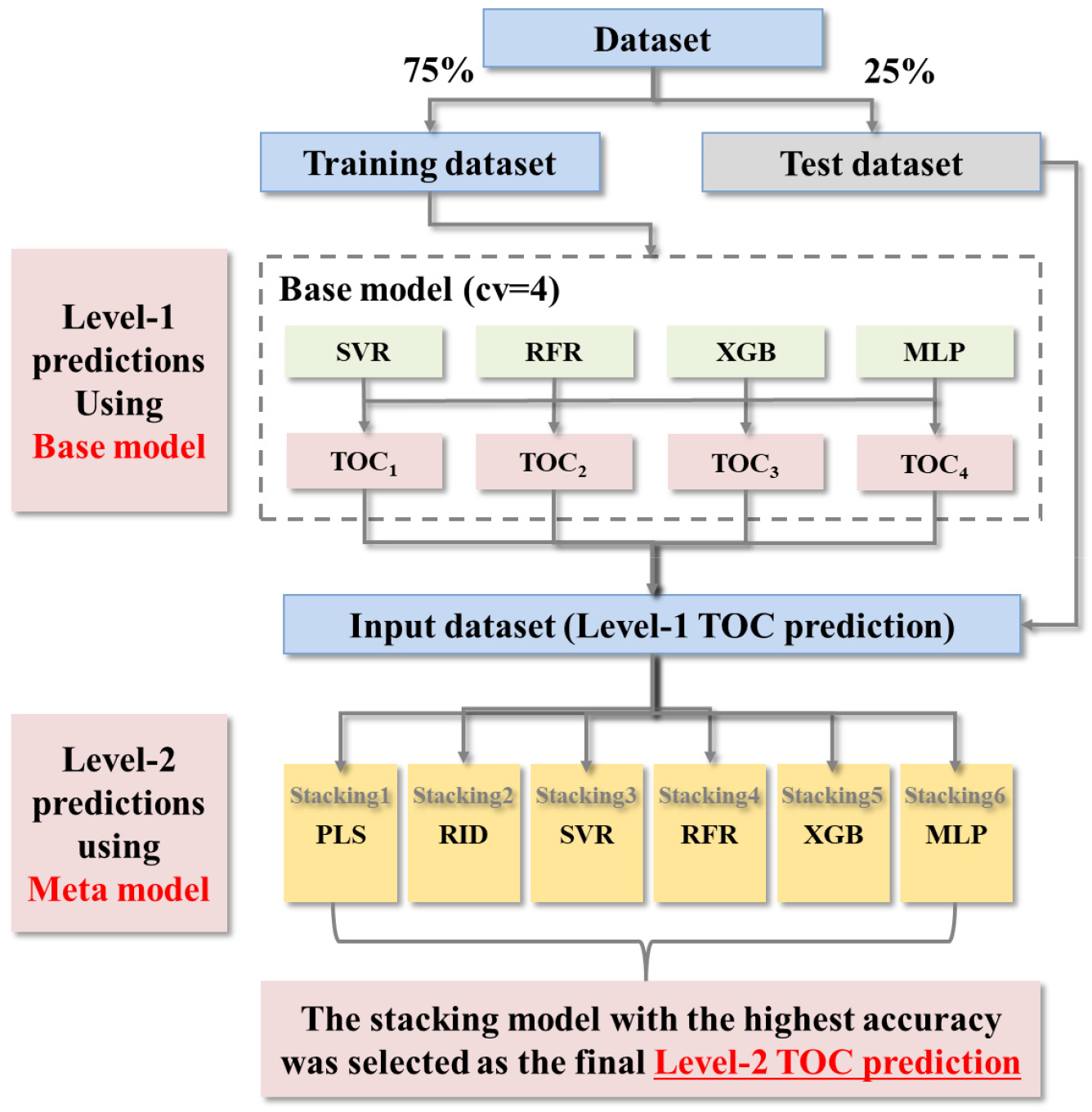
먼저, HSIC-Lasso 모형을 이용하여 도출된 밴드 비율을 Stacking 모델의 입력변수로 설정한 후, 전체 데이터를 75%의 훈련 데이터(train)와 25%의 테스트 데이터(test)로 분리하였다. 훈련 데이터에 대해서는 4-fold 교차검증을 수행하였으며, 베이스모델(Base Model)로는 Support Vector Regression (SVR), Random Forest Regression (RFR), eXtreme Gradient Boosting (XGB), Multi-Layer Perceptron (MLP)을 사용하였다.
각 베이스모델은 개별적으로 TOC를 예측하며, 생성된 예측값들은 새로운 입력변수로 활용되어 메타모델(Meta Model)로 전달된다. 메타모델은 개별 베이스 모델의 결과를 종합하여 최종 TOC 값을 산출하는 역할을 수행한다. Kim et al. (2024) 등에서는 메타모델을 모델의 편향성을 줄이기 위해 선형 기반 모델인 Partial Least Square Regression (PLS) 혹은 Ridge Regression (RID)를 활용하였으며, Kwak et al. (2023) 등에서는 Nonlinear Regression analysis (NR), Artificial Neural Network (ANN), Gaussian Process Regression (GPR), SVM을 베이스모델로, ANN을 메타모델로 활용하여 예측 성능을 향상시켰다. 본 연구에서는 다양한 메타모델을 적용했을 때의 결과를 비교하기 위해 6개(PLS, RID, SVR, RFR, XGB, MLP)의 알고리즘을 사용하였다. Level-1에서 베이스모델이 되는 SVR, RFR, XGB, 및 MLP의 단일 모델과 Level- 1 결과를 입력변수로 하여 예측하는 메타모델의 하이퍼파라미터 튜닝은 Random Search를 이용하여 최적화하였다. test 데이터는 Stacking 모델의 훈련 과정에 참여하지 않고 Level- 2의 최종 메타모델을 선정하기 위한 TOC 예측 결과를 평가하는데 사용되어 모델의 성능을 객관적으로 검증하고 과적합을 방지하였다.
2.3.4 모델 성능평가
각 밴드비와 수질 매개변수에 대한 모델 성능은 결정계수(Coefficient of determination, R2), 평균제곱근오차(Root Mean Sqaure error, RMSE) 및 상대 평균 제곱근 오차(Relative RMSE, RRMSE)를 통해 평가하였다(Eqs. (2), (3), (4)).
여기서, 는 관측값, 는 관측값의 평균, 는 추정값, 는 추정값의 평균이다. 0~1 범위의 값을 가지는 R2는 1에 가까울수록 모델의 결과가 관측값을 잘 모의하는 것을 의미한다. 또한 RMSE 및 RRMSE는 머신러닝의 모델 정확도를 측정할 때 사용되는 지표로 0에 가까울수록 오차가 적어 모델의 정확도가 높음을 의미한다.
3. 결과 및 고찰
3.1 입력자료 구축 결과 및 HSIC-Lasso 모형에 의한 입력변수 추출
남양호 대상 샘플링 일자별 Chlorophyll-a, CDOM, TSS, 및 TOC의 농도는 Table 1과 같다. Sentinel-2A/B 영상을 확인하여 구름이 없는 point를 추출하고, 해당 point 시료의 평균 및 표준편차를 표시하였다. 전체 조사 기간동안 측정된 TOC의 평균 값은 6.76 mg/L로 나타났으며 최소와 최대 값이 각각 2.56 mg/L, 32.83 mg/L로 변동이 큰 것으로 나타났다. 특히 2022년 2월에 약 4.54~4.87 mg/L에서 6월 장마기 전까지 5.49~9.37 mg/L로 지속해서 상승하는 경향을 보였다. 한편, Chlorophyll-a는 평균이 64.22 mg/m3, 표준편차가 57.09 mg/ m3으로 수질 인자 중 가장 큰 변동성을 보였고 Chlorophyll-a의 농도가 높게 나타났던 2022년 6월 및 11월에서 TOC 농도도 마찬가지로 8.7~15.7 mg/L로 높게 나타났다. TSS는 평균이 18.39 mg/L, CDOM은 평균이 4.28 m-1으로 나타났으며, 2022년 5월 12일~9월 29일까지 농번기에 TOC와의 경향이 비슷하게 나타났다. 그러나 TOC의 농도가 11.72 mg/L, 15.71 mg/L로 가장 높은 2022년 11월의 경우 TSS 및 CDOM의 농도는 각각 15.14 mg/L, 16.00 mg/L와 3.06 m-1, 3.38 m-1로 상대적으로 낮게 나타났다. 이는 TOC의 농도가 계절적 요인, 특히 농번기 및 장마기의 영향을 받을 수 있으며 외부 유기물 공급원, 조류 활동 및 강우로 인한 퇴적물 유입과 침강으로 인한 복합적인 요인에 의해 변화되기 때문으로 판단된다(Lee and Kam, 2024). Table 2는 계절별로 TOC와 주요 수질인자(Chlorophyll-a, a355, TSS) 간의 상관관계를 나타낸다. Chlorophyll- a는 봄과 겨울철에 각각 0.442, 0.481로 상대적으로 높은 상관성을 보였으며, a355는 겨을철을 제외한 모든 계절에서 높은 상관관계를 나타냈다. TSS는 봄과 겨울철에 상관성이 각각 0.447, 0.767로 높았다. 이러한 결과는 동일지역 수질인자간 상관관계를 확인한 Jang et al. (2024)의 연구 결과와 유사한 경향을 보인다.
Table 1.
Descriptive statistics of water quality in the Namyang Reservoir. (Chl-a: Chlorophyll-a, TSS: Total Suspended Solid, a355: , TOC: Total Organic Carbon).
Table 2.
Correlation analysis between TOC and other water quality parameters
| Season | Chlorophyll-a (mg/m3) | TSS (mg/L) | |
| Spring (3~5) | 0.442* (p<0.01) | 0.441* (p<0.01) | 0.447* (p<0.01) |
| Summer (6~8) | 0.167 (p=0.13) | 0.379* (p<0.01) | 0.042 (p=0.71) |
| Autumn (9~11) | 0.041 (p=0.69) | 0.337* (p<0.01) | 0.187 (p=0.07) |
| Winter (12~2) | 0.481* (p<0.01) | 0.075 (p=0.85) | 0.767* (p<0.01) |
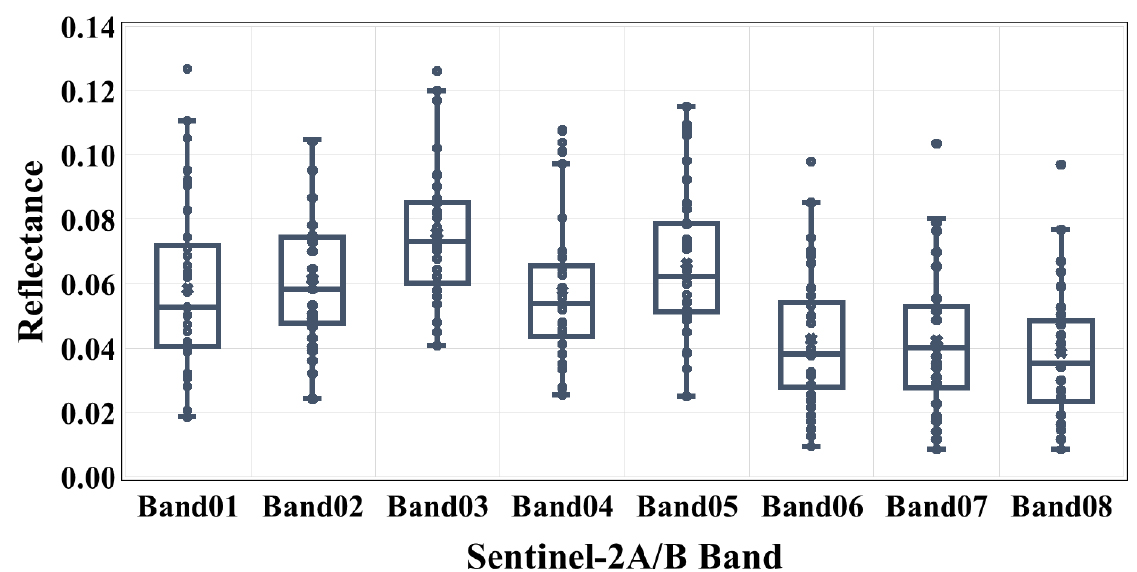
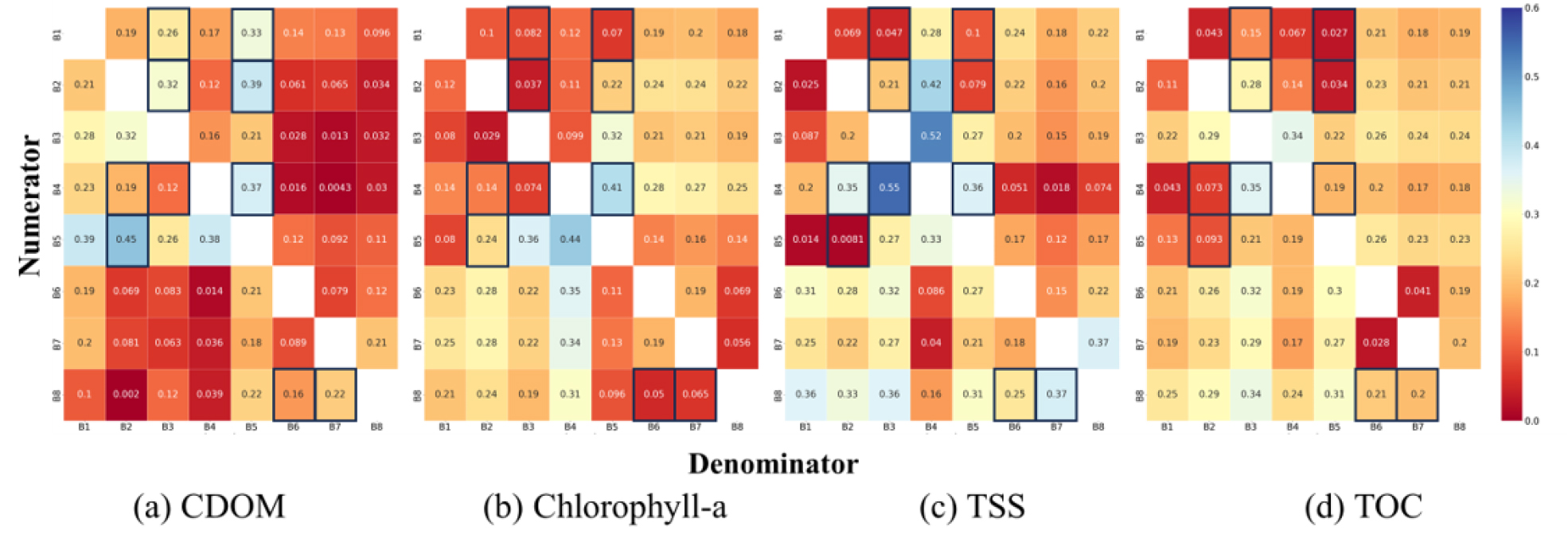
연구 대상 지역인 남양호에 대해 2021년 5월 12일부터 2023년 4월 27일까지의 Sentinel-2A/B 자료를 취합한 후 QC를 통해 추출된 point의 밴드값을 산정하였으며, Fig. 3과 같이 나타냈다. 각 밴드 별 비율 및 TOC 자료를 구축하여 HSIC- Lasso 모형을 통해 입력변수를 선별하였다. HSIC-Lasso 모형은 반사도와 TOC간 비선형 독립성을 고려하여 예측을 위한 그룹을 설정하며, 입력변수를 선별한 결과 B4/B3, B4/B5, B2/B3, B8/B7, B4/B2, B1/B3, B1/B5, B8/B6, B5/B2, B2/B5로 총 10개의 입력변수가 선별되었다. 선별된 밴드의 정량적 기준을 확인하기 위해 Fig. 4와 같이 모든 밴드비율과 TOC간 상관성을 정리하였으며 추가적으로 조사된 CDOM, Chlorophyll-a, 및 TSS와 상관성도 나타내었다. TOC와의 상관성이 낮게 나타나는 B4/B2, B5/B2와 B1/B5, B2/B5의 경우 CDOM과의 상관성이 매우 높게 나타나며 B4/B3은 CDOM, Chlorophyll-a, 및 TSS 모두 0.37, 0.41, 및 0.36으로 높게 나타났다. Bonelli et al. (2022)는 Chlorophyll-a, CDOM 및 TSS가 TOC 예측에서 상관성 있는 변수로 작용하였다고 보고하였다. Kahru and Mitchell (1998)는 Chlorophyll-a와 관련한 입력변수로 B1/B3, B2/B3를 사용한 바 있으며, 최근 Latwal et al. (2023) 연구에는 Sentinel-2 위성에서 중심파장 665 nm, 705 nm, 740 nm를 기반한 B4, B5, B6 중심의 2~3Band 알고리즘에 활용되었다. CDOM은 B4/B2, B4/B3, B5/B2 등과 상관성이 높으며 TSS 추정을 위해 B2, B3, B4, B6의 밴드가 고려된 바 있다(Shang et al., 2021; Jiang et al., 2023).
3.2 알고리즘 결과
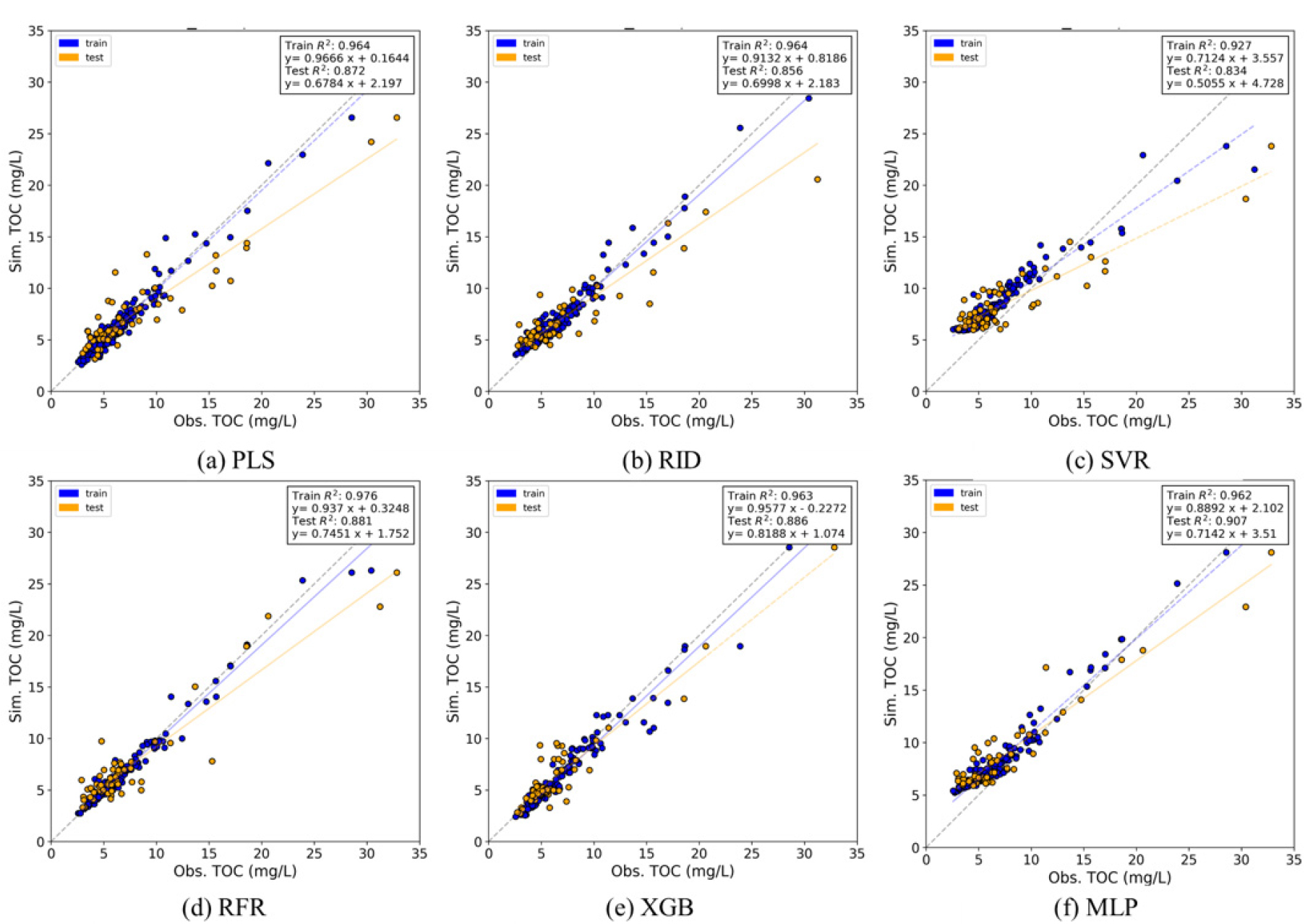
Table 3은 앞서 HSIC-Lasso를 통해 선별된 10개의 입력변수를 이용하여 구축된 Stacking 모델의 train, test 성능 지표별 평균 및 best case에 대한 결과를 나타낸다. 메타모델별 Overall 성능 결과는 train에서 case별 R2가 최소 0.905에서 최대 0.976로 모두 높게 나타났으나 RMSE와 RRMSE에서는 SVR과 MLP의 성능이 각각 2.110 mg/L과 0.310, 1.916 mg/L와 0.282 mg/L로 다른 모형에 낮게 나타나며 표준편차 또한 0.687 mg/L와 0.102, 0.855 mg/L와 0.126 mg/L로 상대적으로 더 크게 나타났다. test의 overall 성능은 R2, RMSE, 및 RRMSE가 PLS에서 각각 0.689, 2.507 mg/L, 및 0.365로 RFR에서 각각 0.680, 2.489 mg/L, 및 0.362로 가장 높게 나타나 TOC 예측에서 신뢰도가 높게 나타났다. Best case에서는 test R2는 MLP에서 0.970으로 가장 높게 나타났으나, RMSE와 RRMSE 성능이 각각 2.487 mg/L, 0.341로 낮게 나타났다. 반면 XGB의 test R2는 0.886으로 MLP보다는 낮으나 RMSE와 RRMSE에서 각각 1.556 mg/L, 0.241로 가장 낮게 나타났다. 선형 기반의 PLS 및 RID에서의 R2는 0.872, 0.856으로 나타났으며, RMSE와 RRMSE 또한 XGB, RFR보다 낮은 2.408 mg/L, 0.308, 2.327 mg/L, 0.314로 산정되었다. 이를 통해 Stacking 모델의 베이스모델뿐 아니라 메타모델에 대해서도 다양한 모델의 최적화를 같이 진행한다면 더 좋은 결과를 확인할 수 있을 것으로 판단된다.
Table 3.
Staking model average and best case result
Best case에 대한 실제 TOC 값과 예측 TOC에 대한 scatter plot으로 정리하였으며 train dataset의 결과를 파란 점으로, test dataset의 결과를 주황 점으로 하여 Fig. 5와 같이 나타내었다. MLP Best case에서의 Fig. 5(f)를 확인하면 고농도에서의 예측 정확도는 상대적으로 높으나, 저농도에서 상대적으로 TOC를 과대평가하며 RMSE 및 RRMSE가 높아진 것을 확인할 수 있다. 반면 XGB의 Fig. 5(e)에서는 고농도 및 저농도의 예측 정확도가 상대적으로 높은 것으로 나타났다.
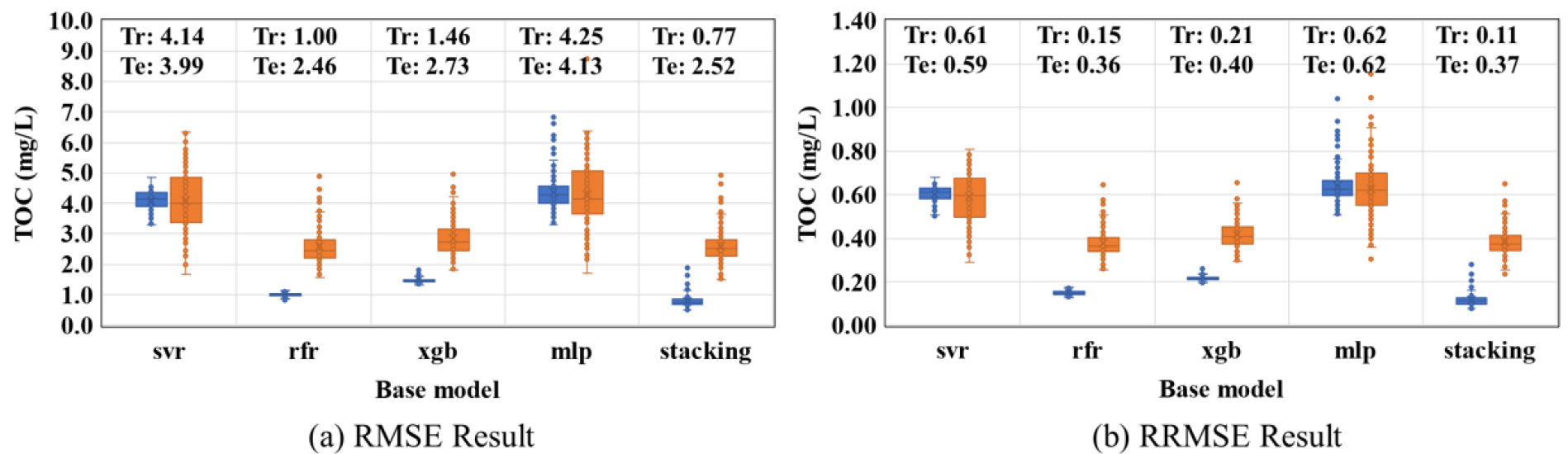
Stacking 모형의 결과가 기존 모델의 정확도보다 향상되었는지 검증하기 위해 가장 성능이 좋다고 판단되는 메타모델을 XGB로 하는 Stacking 모형과 Level-1 베이스모델의 RMSE 및 RRMSE 분포는 Fig. 6와 같이 나타났다. RMSE 및 RRMSE에서 Stacking 모형이 다른 모형에 비해 Train 중앙값이 각각 0.44, 1.67 및 0.77, 2.52로 가장 낮게 나타난 것을 알 수 있다. 이는 Stacking 모형이 다른 머신러닝 모델의 여러 단점을 상호보완해줄 수 있을 것으로 판단된다.
3.3 공간분포 결과
메타모델을 XGB로 선정하였으며 2021년 5월 12일부터 2023년 4월 27일까지 일별 강수량 및 최고기온과 함께 PD1(남양대교), PD2(장안대교), 및 PD3(남양호교)의 지점별 관측 TOC와 Stacking 모형에 따른 예측 TOC 값을 나타냈다(Fig. 7). 남양호 유역의 TOC는 강수량이 큰 장마기 전까지 지속적으로 상승하다가 비가 온 순간 감소하게 되며, 가을철부터 겨울철까지 지속적으로 상승하는 패턴을 가진 것으로 파악되었다. 이는 일반적으로 한국의 호수에서 봄철 플랑크톤 성장과 유기물 용출로 인해 TOC 농도가 증가하는 경향 및 9월 초 폭우 이후 유기물 농도가 증가하는 패턴과 일치하는 결과이다(Lee et al., 2014).
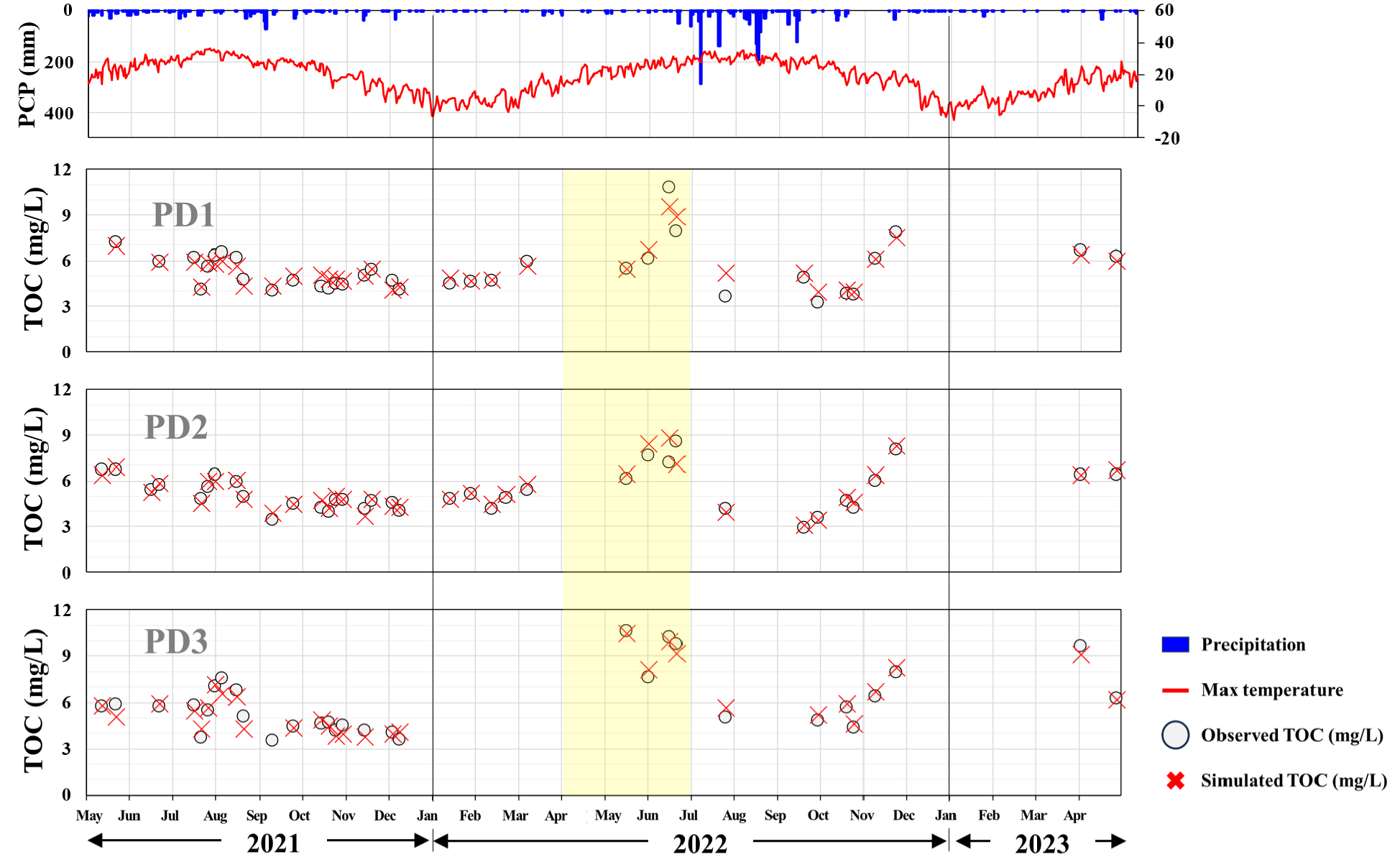
관측된 TOC와 예측된 TOC를 비교하였을 때 2021년 6월을 중심으로 12월까지, 2022년 9월부터 11월까지 관측된 TOC와 예측된 TOC의 경향성이 비슷하게 나타나 Multi-model Ensemble을 통한 TOC 예측의 적절함을 확인할 수 있다. 그러나, Fig. 7에서 노랗게 표시된 2022년 4월~6월 기간에는 TOC 농도가 전반적으로 높은 것을 확인할 수 있다. 이를 바탕으로 가뭄 발생으로 인해 TOC 농도가 크게 나타난 2022년 5~7월을 중심으로 예측된 TOC 공간분포를 Fig. 8과 같이 표현하였을 때, 봄철 높은 값을 유지하다가, 7월 16일과 9월 19일에 낮은 TOC 농도 값을 나타냈으며 다시 서서히 높아지는 결과를 확인할 수 있다. 이는 Lee and Kam (2024)의 연구에서도 2021년부터 2022년까지 지속된 가뭄이 TOC 농도에 미친 영향을 PCA 분석을 통해 평가한 결과, 본 연구 지역이 속한 PC2에서 계절별 TOC 농도 평균이 3.35~5.25 mg/L로 나타났다. 특히, 2022년 4~6월 TOC 농도가 5.25 mg/L로 해당 범위에서 가장 높았으며, 이는 가뭄의 영향이 반영된 결과로 해석된다. 이러한 경향은 본 연구에서 2022년 6월 16일 TOC 농도가 9.30 mg/L까지 상승한 결과와도 부합한다.
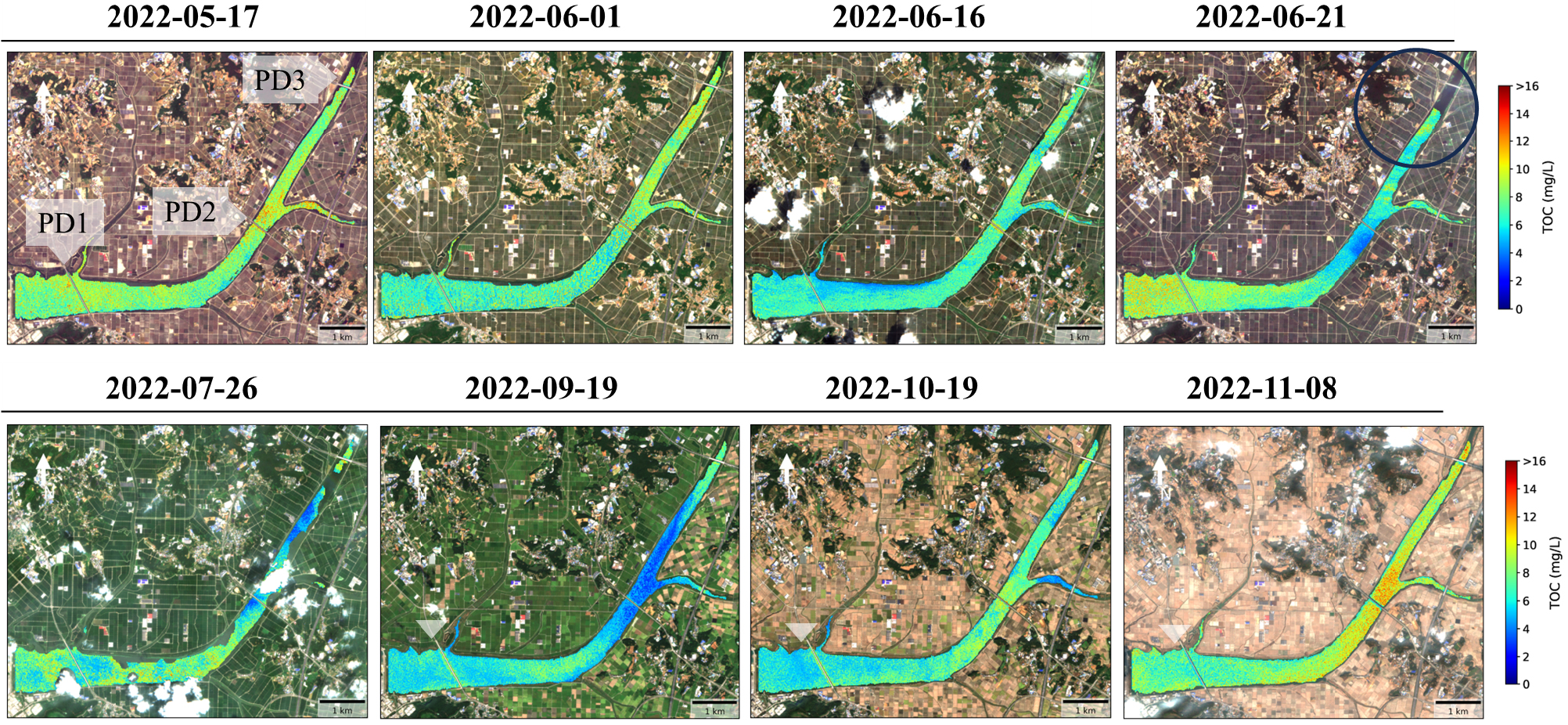
또한 이 시기는 다른 시기보다 예측값의 편차가 상대적으로 크게 나타난 구간이며, 포인트와 예측치 및 공간분포 전체적인 경향과는 다소 상이하다. 특히, Fig. 8의 2022-06-21에서 나타난 부분과 같이 SLC 분류에서 안개로 분류되어 도출되지 않는 부분이 발생하였으며, 이보다 낮은 수준의 안개 발생으로 인해 예측 모델의 반사율 왜곡이 포함될 가능성이 있다. 이는 위성 이미지에서의 대기 산란과 안개의 영향으로 인해 데이터 품질이 저하되는 현상과 유사하며(Gascon et al., 2017), 추후 반사도 품질 저하를 확인하고 보정한다면 위성 데이터 기반 수질 예측 모델의 신뢰도를 높이고, 특정 기상 조건에서의 예측 성능 저하를 개선할 수 있을 것이다.
4. 요약 및 결론
본 연구는 남양호 유역을 대상으로 위성 원격탐사와 머신러닝 기반 Multi-Ensemble 모델을 결합하여 총유기탄소(Total Organic Carbon, TOC)를 간접적으로 추정하고자 하였다. 연구의 주요 결과는 다음과 같다:
(1) Sentinel-2A/B 위성자료를 활용하여 남양호 유역의 반사도 데이터를 구축하였으며, HSIC-Lasso 모형을 통해 TOC와 높은 상관성을 가지는 10개의 입력변수(B4/B3, B4/B5, B2/B3, B8/B7, B4/B2, B1/B3, B1/B5, B8/B6, B5/B2, B2/B5)를 도출하였다.
(2) TOC 예측을 위해 Support Vector Regression (SVR), Random Forest Regression (RFR), eXtreme Gradient Boosting (XGB), Multi-Layer Perceptron (MLP)을 베이스모델로, Partial Least Squares (PLS), Ridge Regression (RID) 등을 포함해 SVR, RFR, XGB, MLP의 총 6개 메타모델을 활용하여 Stacking 앙상블 모델을 개발하였다. Stacking 모델은 train 및 test 데이터셋에서 각각 R2 0.963, 0.886 및 MAE 0.697 mg/L, RMSE 1.556 mg/L로 가장 높은 성능을 보였으며, 베이스모델 대비 예측 정확도가 향상되었다.
(3) 2021년 5월부터 2023년 4월까지의 TOC 시계열 분석 결과, 장마철 전후로 TOC 농도가 뚜렷하게 변화하며 계절적 영향을 크게 받는 것으로 나타났다. 공간분포 분석에서는 TOC가 여름철 장마기 이후부터 가을, 겨울철에 걸쳐 증가하는 패턴을 보였으며, PD1(남양대교) 지점에서 장마철 TOC 감소 폭이 더 크게 나타났다.
Stacking 모델을 활용한 TOC 예측은 기존 단일 머신러닝 모델 대비 우수한 성능을 보였으며, 베이스모델과 메타모델의 조합이 예측 정확도 향상에 기여하였다. 본 연구 결과는 위성 데이터와 머신러닝 모델을 통합하여 TOC를 비용 효율적이고 지속 가능한 방식으로 모니터링할 수 있는 기반을 제시하며, 추후 장기간의 TOC 데이터 축적을 통해 수질 관리 및 정책 개발을 위한 실용적인 도구로 활용될 수 있을 것으로 기대된다.
