

1. 서 론
2. 대상유역과 자료
3. 연구방법
3.1 수문학적 가뭄지수
3.2 베이지안 네트워크
3.3 기상학적 가뭄에서 수문학적 가뭄으로의 가뭄전이
3.4 베이지안 네트워크 기반 가뭄 예측 모형
4. 연구결과
4.1 가뭄전이 관계를 고려한 확률론적 가뭄 예측
4.2 가뭄 예측 결과의 분석
5. 결 론
1. 서 론
우리나라에서는 2000년대 이후로 2001, 2008~2009, 2012, 2014~2015년에 가뭄이 발생되어, 1980~1990년대 보다 가뭄의 발생빈도가 증가하고 있다. 특히, 2014~2015년에는 경기도와 충청도를 중심으로 발생된 가뭄은 소양강댐에서는 주의 단계, 그리고 보령댐에서는 심각 단계까지 저수위가 낮아지는 심각한 물부족 위기를 초래하였다. 기후변화 시나리오를 활용한 미래의 가뭄 분석 결과에 의하면 우리나라는 건조기(10월에서 다음해 5월까지) 동안 가뭄의 발생빈도 및 심도가 현재보다 6% 정도 증가될 것으로 예상되었다(Lee et al., 2016). 이에 따라 가뭄에 대한 사전 대응의 필요성이 커지고 있으며, 이를 위해서는 신뢰성 있는 가뭄 예측이 필수적이다.
가뭄 예측기법은 과거의 자료를 활용하여 미래를 추정하는 통계학적 기법과 기후예측모형의 예측결과를 활용하는 역학적 기법으로 구분할 수 있다(Madadgar et al., 2016). 통계학적 가뭄 예측은 수문시계열 모형, 인공신경망 모형, 여러 가지 통계학적 모형을 결합한 하이브리드 모형 등을 활용한 다양한 연구가 진행되었다(Kim and Valdes, 2003; Mishra and Desai, 2005; Morid et al., 2007; Mishra et al., 2007; Mishra and Singh, 2011). 역학적 가뭄 예측은 기후예측모형인 Climate Forecast System (CFS), European Centre for Medium-Range Weather Forecasts (ECMWF), Multi-Model Ensemble (MME) 등의 예측결과인 강우량과 기온 등의 자료로 가뭄지수를 계산하는 연구가 수행되었다(Sohn et al., 2012; Yoon et al., 2012; Mwangi et al., 2014). 최근에는 통계학적 예측 결과와 역학적 가뭄 예측의 결과를 결합하여 가뭄 예측 정보를 생성하는 하이브리드 모형에 대한 연구도 수행되고 있다(Madadgar et al., 2016).
우리나라의 경우 30년 이상 장기간의 하천 유량과 지하수 등의 수문자료가 충분히 구축되어 있지 않기 때문에 통계적 기법을 활용하여 신뢰성 있는 수문학적 가뭄의 예측 결과를 얻기가 어려운 실정이다. 또한, 역학적 기후예측모형을 활용할 경우에는 기상인자의 예측 결과를 강우-유출 모형에 적용하여 예측 수문인자를 생성하고, 이를 활용하여 수문학적 가뭄지수를 산정하므로 기후모형과 강우-유출 모형의 매개변수를 추정할 때 불확실성이 커진다. 이처럼 수문학적 가뭄 예측에는 기상학적 가뭄보다 가뭄 판단에 활용되는 다양한 수문기상인자들의 불확실성이 높아지기 때문에 이를 정량적으로 표현 가능한 확률론적 가뭄 예측이 수행되어야 한다. 확률론적 가뭄 예측기법으로는 앙상블 기법이 널리 활용되고 있다. Hwang and Carbone (2009)는 과거 관측 자료와 Climate Prediction Center (CPC)에서 생산되는 예측 결과를 자기회귀모형에 적용한 뒤, 평균값에 대한 잔차를 리샘플링 방법으로 확률론적 예측 결과를 생성하였다. Kim et al. (2012)은 기상청에서 제공하는 강수량과 온도에 대한 과거 관측 및 미래 예측 자료를 abcd 모형에 적용하여 유출량과 지하수량을 추정하고, 이를 바탕으로 MSWSI (Modified Surface Water Supply Index)에 대한 앙상블 확률 예측을 수행한 바 있다.
본 연구에서는 수문학적 가뭄의 확률 예측과정에서 발생되는 불확실성을 고려하기 위하여 베이지안 네트워크 모형을 활용하였다. 베이지안 네트워크는 모형의 변수들 사이의 불확실성을 정량적으로 표현하는 것이 가능하기 때문에 의학, 경제학, 산업공학 등 다양한 분야에서 의사결정, 예측 및 추론을 수행하는데 활용되고 있다(Dey and Stori, 2005; Van Koten and Gray, 2006). 따라서 다양한 수문기상학적 변수들이 연계되어 있어 발생과정이 복잡한 수문학적 가뭄을 예측하는데 적용성이 높다. 본 연구에서 개발한 베이지안 네트워크 기반의 수문학적 가뭄 예측 모형은 Madadgar and Moradkhani (2014)에서 활용하였던 과거의 가뭄 정보, 현재의 가뭄 상태, 그리고 Shin et al. (2016)에서 활용한 MME 예측 정보 기반의 미래 가뭄 예측 결과를 바탕으로 구성되었다. 또한, 기상학적 가뭄에서 수문학적 가뭄으로 가뭄이 전이되는 관계를 추가적으로 고려함으로써, 수문학적 가뭄의 예측성을 높이고자 하였다. 최근에는 가뭄의 예측성 향상을 위하여 가뭄 유발인자(trigger)와 예측인자(predictor)를 활용한 연구와(Maity et al., 2013), 강수량, 온도, 그리고 기후지수(climate index)를 활용하는 연구가 수행된 바 있다(Cutore et al., 2009; Chen et al., 2013; Santos et al., 2014). 우리나라의 경우, 강수량은 가뭄 예측에 널리 활용되고 있으나, 기후지수와 가뭄과의 상관성 분석에 대한 연구가 많이 수행되었음에도 불구하고, 우리나라의 가뭄을 예측하는데 기후지수를 직접적으로 활용하기에는 효과적이지 않다(Lee, 1999). 따라서 본 연구에서는 기상학적 가뭄상태를 수문학적 가뭄의 유발인자로 가정하고, 수문학적 가뭄의 예측인자로 가뭄 전이 관계를 활용함으로써 Shin et al. (2016)에서 개발한 베이지안 네트워크 기반의 가뭄 예측 모형의 예측 정확성을 높이고자 하였다.
2. 대상유역과 자료
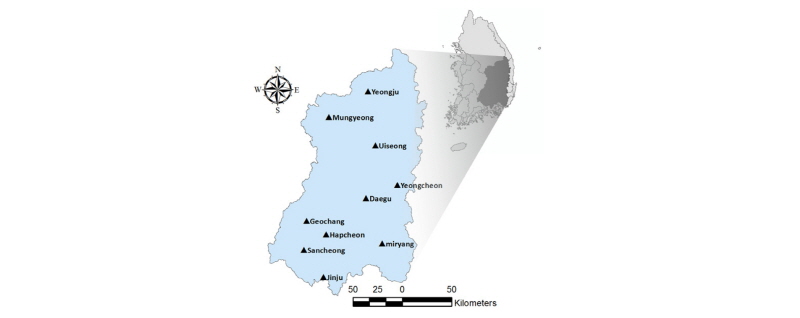
본 연구는 1973년부터 강우량과 온도 자료를 확보하고 있는 낙동강 유역의 10개 지점(Fig. 1)을 대상으로 Palmer Hydro-logical Drought Index (PHDI)를 산정하고, 이를 바탕으로 수문학적 가뭄 예측 모형을 개발하였다. 예측 모형에는 과거 관측 자료와 미래 예측 자료가 함께 활용되었다. 과거 관측 자료는 1973년부터 2016년까지 기상청에서 제공하는 강우량 및 온도 자료이며, 미래 예측 자료는 APCC (Asia-Pacific Economic Cooperation Climate Center)에서 제공하는 물리적 예측 모형 기반의 MME 예측 자료이다. MME 예측 자료는 강수량과 온도뿐만 아니라 고도를 포함한 8개 기상변수들에 대한 6개월까지의 예측정보이며, 2.5° × 2.5° 격자단위로 4가지의 결정론적 MME 예측(coupled pattern projection method, simple composite method, multiple-regression, synthetic super ensemble)과 1가지의 확률론적 예측방법으로 제공된다. 본 연구에서는 결정론적 MME 예측 자료 중 가장 널리 활용되는 SCM 예측 결과를 ADSS (APCC Data Service System, http://adss.apcc21.org)에서 제공받아 활용하였다. 우리나라의 경우, 공간적 규모가 작기 때문에 MME 예측 자료를 활용한 가뭄 예측을 위해서는 격자 공간 범위의 예측 결과는 다운스케일링 기법을 통하여 지점 단위로 변환되어야 한다. 하지만, 본 연구는 가뭄 예측 모형 개발이 주요 목적이기 때문에 특정 다운스케일링 기법을 적용하지 않고 지점에 해당되는 격자의 예측 아노말리(anomaly)를 과거의 평균값에 적용한 지점별 MME 예측 결과를 활용하였다.
3. 연구방법
3.1 수문학적 가뭄지수
우리나라의 경우, 수문학적 가뭄을 평가할 만큼의 장기적이고 신뢰성 있는 하천 유량 자료가 많지 않기 때문에 본 연구에서는 가뭄지수 산정을 위한 입력 자료(온도, 강수량)의 확보가 가능한 PHDI를 활용하였다. PHDI는 수자원시스템 내에서 장기간의 가뭄이 미치는 영향을 정량적으로 표현한 수문학적 가뭄지수로, 기상학적 가뭄지수인 PDSI (Palmer Drought Severity Index)와 산정과정이 유사하다. 물수지 방정식의 수요-공급 개념을 바탕으로 강수량과 기온 및 유효토양수분량을 입력 자료로 활용하여 증발산량, 함양량, 유출량 및 손실량, 그리고 잠재증발산량, 잠재함양량, 잠재유출량 및 잠재손실량 등 물수지방정식의 기본 항목들을 산정한다. 물수지 분석을 통해 기후적으로 필요한 강수량을 계산하고 실제 강수량과의 차인 수분편차(Zi)를 산정한 후, 다른 지역들과 다른 월들 간의 수분편차를 비교하여 동일한 기준이 되도록 수분편차를 보정하여 가뭄지수를 결정한다. PHDI와 PDSI는 Eq. (1)을 거쳐서 초기의 3가지(초기 습윤, 초기 건조, 습윤 혹은 건조 상태) 수분 상태에 따른 Xi를 산정한 뒤, 각각의 가뭄심도 판단기준을 통하여 가뭄지수 값을 산정한다(Guttman, 1991).
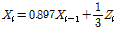 (1)
(1)
여기서, Xi는 3가지 수분 상태로 나뉘어 산정되며, 초기 습윤 상태는 X1,i≥0, 초기 건조 상태는 X2,i≤0, 습윤 혹은 건조 상태는 |X3,i|≥1과 같다. PHDI는 장기간의 수문인자들의 수분상태를 나타내는 X3,i 값을 기반으로, X3,i가 0일 경우에는 X1,i 혹은 X2,i으로 PHDI의 심도를 산정한다. PHDI는 PDSI의 값은 거의 유사하게 산정되나, PHDI는 가뭄의 종결을 수분 부족상태가 완전히 없어질 때까지로 판단하기 때문에 가뭄의 종료되는 시점이 PDSI보다 긴 편이며 가뭄심도의 변동성이 적다(Heim, 2000; Keyantash and Dracup, 2002). 본 연구에서 PHDI의 구체적인 산정과정은 Jacobi et al. (2013)을 참고하였다.
3.2 베이지안 네트워크
베이지안 네트워크는 베이즈 정리와 그래프 이론을 결합한 확률모형이다. 네트워크는 다양한 변수를 표현하는 노드(node)와 변수들 사이의 의존 관계를 표현하는 호(arc)로 구성되며(Fig. 2), 노드들 사이의 인과관계는 확률로 표현된다(Russell and Norvig, 1995). 베이지안 네트워크의 기본 이론인 베이즈 정리는 확률변수 θ와 y가 있을 때, 사전확률(prior probability, P(θ))과 사후확률(posterior probability, P(θ|y)) 사이의 관계를 Eq. (2)와 같이 나타낼 수 있다.
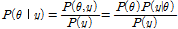 (2)
(2)
여기서, P(θ)는 θ의 사전확률이고, P(θ|y)는 사후확률로 y가 주어졌을 경우 θ의 조건부 확률이다. P(y|θ)는 θ가 주어질 경우 y의 조건부 확률이다. P(y)는 y의 사전확률 또는 경계확률이라 하며, 정규화 상수가 된다. 베이즈 정리에 의해 사후확률은 간단하게 사전확률과 우도함수(l(θ|y))의 곱에 비례한다.
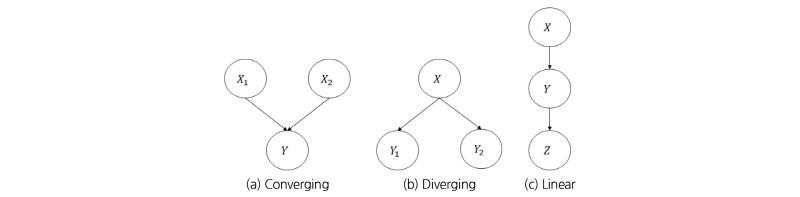
Fig. 2는 다양한 종류(수렴형, 분산형, 선형)의 베이지안 네트워크를 나타낸 것으로, 본 연구에서는 Fig. 2(a)의 수렴형 네트워크가 주로 활용되었다. Fig. 2(a)의 수렴형 베이지안 네트워크 모형은 총 3개의 확률변수 X1, X2, Y로 구성되어 있으며, X1과 X2는 독립변수이고, Y에 직접적인 영향을 준다는 사실, 즉, 변수 사이의 종속관계를 노드와 화살표를 활용하여 나타낼 수 있다. 여기서 X1과 X2는 Y의 부모 노드(parent node), Y는 X1과 X2의 자식 노드(child node)가 된다. 각각의 노드는 주어진 자료를 활용하여 그에 맞는 확률분포를 결정한다. Y에 대한 조건부 확률은 베이즈 정리를 이용하여 계산된다. 예를 들어, Fig. 2(a)의 수렴형 베이지안 네트워크는 Eq. (3)과 같이 표현될 수 있다.
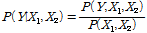 (3)
(3)
사후확률분포 P(Y|X1,X2)는 추론 알고리즘을 활용하여 추정하며, 추론 알고리즘으로는 likelihood weighting, rejection sampling, Gibbs sampling 방법 등이 있다. 본 연구에서는 적용 방법이 비교적 간단하며, 노드의 형태가 연속형 확률분포일 경우에도 사후확률분포의 추정이 가능한 우도 가중(likelihood weighting) 방법을 활용하여 사후확률분포를 추정하였다(Lee and Lee, 2006).
우도 가중 방법은 증거(evidence) 변수를 고정한 채로, 비증거(nonevidence) 변수의 샘플링을 수행한다(Russell and Norvig, 1995). 여기서 증거 변수는 베이지안 네트워크에서 알고 있는 값(대부분의 경우 관측값)으로, 만약 Fig. 2(a)에서 부모 노드(X1, X2,)를 활용하여 자식 노드(Y)를 추론하고자 한다면 X1과 X2의 값이 증거변수가 된다. 사후확률의 추정은 Eq. (4)의 경로 확률분포(path probability distribution, ρ(y,e))와 가중치 확률분포(weighting probability distribution, ω(y,e)), 그리고 이항 확률변수(binomial random variable, χ(y,e))를 활용하여 계산된다.
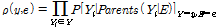 (4a)
(4a)
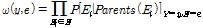 (4b)
(4b)
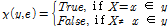 (4c)
(4c)
여기서, E는 관측 노드, Y는 E를 포함하지 않는 노드이다. Eq. (4)을 활용하여 Eqs. (5a) and (5b)를 산정하고, 이를 바탕으로 사후확률(Eq. (5c))을 추정한다.
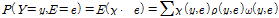 (5a)
(5a)
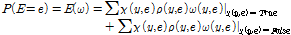 (5b)
(5b)
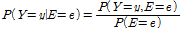 (5c)
(5c)
3.3 기상학적 가뭄에서 수문학적 가뭄으로의 가뭄전이
가뭄전이는 가뭄의 종류가 기상학적 가뭄에서 농업적 가뭄 혹은 수문학적 가뭄으로 발달되는 현상을 의미하며, Changnon Jr. (1987)과 Eltahir and Yeh (1999)가 다양한 수문변량의 평균에 대한 차이를 비교하면서 처음 제시되었다. 가뭄이 전이되면서, 4가지 특성(풀링, 감쇠, 지체, 연장)이 발생하게 된다(Van Loon, 2015). 본 연구에서는 기상학적 가뭄이 발생된 후 일정한 시간이 지난 뒤에 수문학적 가뭄이 발생되는 지체 현상을 가뭄 예측에 활용하였다.
일반적으로 가뭄 예측을 위한 인자로는 강수량이 가장 널리 활용되고 있지만, 최근 일부 지역에서는 기후지수인 NAO (North Atlantic Oscillation), PNA (Pacific North American index), AMO (Atlantic Multidecadal Oscillation), PDO (Pacific Decadal Oscillation)를 강수량의 장기 예측인자로 활용함으로써 가뭄 예측을 위한 인자로 쓰이고 있다(Chen et al., 2013, Maity et al., 2013; Santos et al., 2014). 또한, 가뭄지수와 기후지수의 상관관계를 고려하여 기후지수를 인공신경망 모형과 같은 통계학적 예측 모형의 입력 자료로 활용하여 가뭄 예측을 수행한 연구가 있다(Cutore et al., 2009; Santos et al., 2014; Bonaccorso et al., 2015). 우리나라의 경우, 기후인자와 가뭄지수와의 상관성이 통계학적으로 유의하지 않기 때문에 해외 연구사례와 같이 가뭄 예측에 직접적인 영향인자로 기후인자를 활용하기에는 한계가 있다(Lee, 1999). 예를 들어, Kim et al. (2017)은 가뭄과 여러 기후지수와의 상관성 분석을 수행하여 NAO가 우리나라 봄 가뭄과 상관성이 높다는 것을 제시하였으나, 상관계수가 -0.2~0.2로 가뭄 예측인자로 활용하기에는 상관성이 낮다.
본 연구의 대상 지점에 대해서 수행한 상관성 분석 결과, N번째 월의 기상학적 가뭄지수 SPI와 (N+1)번째 월의 수문학적 가뭄지수 PHDI 사이의 상관계수는 0.4~0.8이었다. 이는 Cutore et al. (2009)에서 제시한 NAO와 가뭄지수 사이의 상관계수(0.3~0.7)와 유사한 것이었다. 따라서 본 연구에서는 통계학적 예측 모형인 베이지안 네트워크에 이전 달의 SPI의 정보를 활용한 PHDI 값을 예측하기 위한 노드를 추가하였다.
3.4 베이지안 네트워크 기반 가뭄 예측 모형
본 연구에서는 확률론적 예측 모형인 베이지안 네트워크를 활용하여 수문학적 가뭄 예측 모형(PBNDF)을 구축하였다. 이 예측 모형은 Fig. 3에 나타낸 바와 같이, 이전 달의 가뭄 상황, 현재의 가뭄 상황과 물리적 예측 모형을 활용한 가뭄 예측 결과, 그리고 기상학적 가뭄지수 SPI와 수문학적 가뭄지수 PHDI 사이의 전이관계가 결합되어 미래 가뭄에 대한 새로운 확률 예측을 생성한다. PBNDF는 Shin et al. (2016)이 제시한 베이지안 가뭄 예측 모형(BNDF)에 가뭄전이 관계를 추가하고 다양한 예측 선행시간에 적용될 수 있도록 확장한 것이다. Fig. 3에 나타낸 바와 같이 PBNDF는 수문학적 가뭄지수 PHDI를 예측하기 위하여, HD (Hydrological Drought) 노드와 MHD (MME․Hydrological Drought) 노드를 구성하고, 가뭄전이 관계와 관련된 노드 DP (Drought Propagation)를 추가하였다. 예를 들어, 1개월 예측을 위해서 4개의 부모 노드(HDN-1, HDN, MHDN+1, DPN+1)와 1개의 자식 노드(HDN+1)로 네트워크를 구성하였으며, 2개월 가뭄 예측을 위해서는 3개의 부모 노드(HDn+1, MHDN+2, DPN+2)와 1개의 자식 노드(HDN+2)로 네트워크를 구성하였다. Shin et al. (2016)의 BNDF는 기본적으로 1개월 선행 SPI를 예측하는 것이기 때문에, 2개월 예측의 경우, Fig. 3에 나타낸 바와 같이, 이전 단계에서 예측된 HDN+1이 부모 노드가 된다. 이러한 과정이 6개월 예측까지 확장될 수 있다.
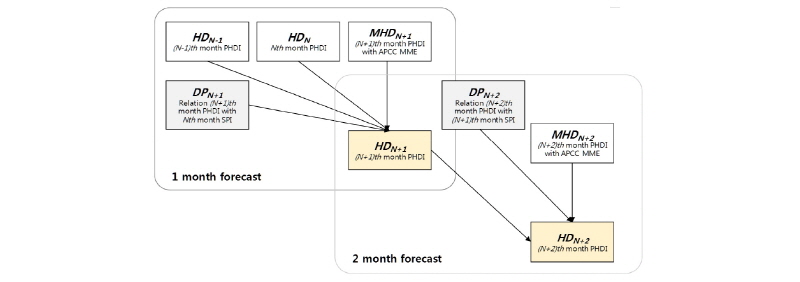
과거의 가뭄 상태(HDN-1)와 현재의 가뭄 상태(HDN)는 정규분포를 따른다는 가정 아래, 1973년부터 해당되는 기간까지의 PHDI를 산정하여 월별 PHDI의 확률밀도함수(PDF)를 산정하였다. MME 예측 정보가 반영된 미래의 가뭄 상태(MHDN+leadtime)는 1973년부터 MME 예측 정보를 포함한 기간까지의 PHDI를 산정한 뒤, 예측하고자 하는 월의 PHDI의 확률밀도함수를 산정하였다. 본 연구에서는 각각의 노드를 모두 정규분포를 따른다는 가정 아래 수행되었으며, 정규분포의 확률밀도함수는 Eq. (6)과 같다. Eq. (6)에서 μ는 평균, σ는 표준편차이며, HDt는 t월에 해당되는 수문학적 가뭄지수이다.
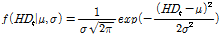 (6)
(6)
기상학적 가뭄에서 수문학적 가뭄의 전이 관계를 나타내는 노드 DPN+1은 앞에서 제시한 HDN-1, HDN, MHDN+1과 다른 방식으로 구성되었다. 현재의 기상학적 가뭄상황이 앞으로의 수문학적 가뭄으로 전이될 것이라는 가뭄전이 관계를 반영하기 위하여 예측하고자 하는 (N+1)번째 월의 수문학적 가뭄지수 PHDI와 현재 시점인 N번째 월의 기상학적 가뭄지수 SPI 사이의 회귀직선식과 해당 식에 대한 불확실성 구간을 활용하여 생산된다. Fig. 4는 1개월 PHDI 예측(예를 들어, 2014년 4월 PHDI)을 위하여 1973년부터 2013년까지 관측된 3월 PHDI와 이전 달인 2월 SPI의 자료를 도시화한 뒤, 두 변수들의 회귀식을 도출한 것이다. 회귀식은 Eq. (7)과 같이 표현이 간단한 회귀함수식을 활용하였다. Fig. 4에서 붉은 실선은 산정된 회귀식이며, 점선으로 표현된 선은 회귀식에 대한 90% 신뢰구간이다. 산정된 신뢰구간은 DPN+1 노드의 분산으로 활용된다.
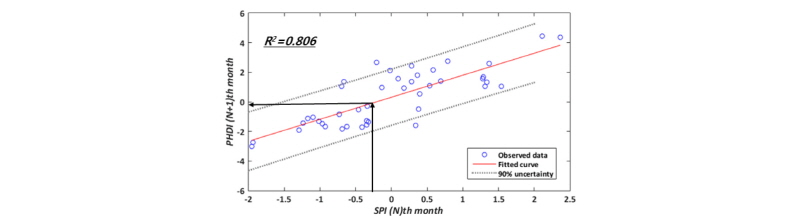
Fig. 4.
Relationship between Nth month SPI and (N+1)th month PHDI and the regression curve (the line is the regression fitted line about the observed data and the dashed line indicates the 90% uncertainty ranges of the regression, The black arrow means the (N+1)th month PHDI calculation procedure from Nth month SPI)
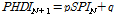 (7)
(7)
이어서, 예측하고자 하는 달의 이전 달 SPI를 산정(1개월 예측의 경우에는 현재의 SPI, 2개월 예측부터는 MME 예측 결과를 적용한 SPI)한 뒤, Eq. (7)을 활용하여 예측하고자 하는 달의 PHDI를 추정하였다. Fig. 4에서 1월 달의 SPI가 -0.2의 값으로 관측되었을 때, 화살표를 따라 회귀식을 거쳐서 2월 달의 PHDI가 약 -0.05의 값이 산정된다. 계산된 (N+1)번째 월의 PHDI는 노드 DPN+1의 평균값, 회귀식에서의 불확실성 범위는 분산이 되어, 노드 DPN+1의 확률분포 모형이 구성된다. 마지막으로, 1개월 이후의 가뭄 상황의 예측을 위하여 4개의 부모 노드(HDn-1, HDn, MHDn+1, DPn+1)를 활용하여 사후확률(Eq. (8a))로 표현된다. Eq. (8a)에 베이지안 이론과 연쇄법칙(chain rule)을 적용하면, Eq. (8b)와 같이 표현된다. 사후확률의 추정은 우도 가중 알고리즘을 활용하였다.
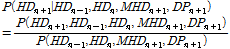 (8a)
(8a)
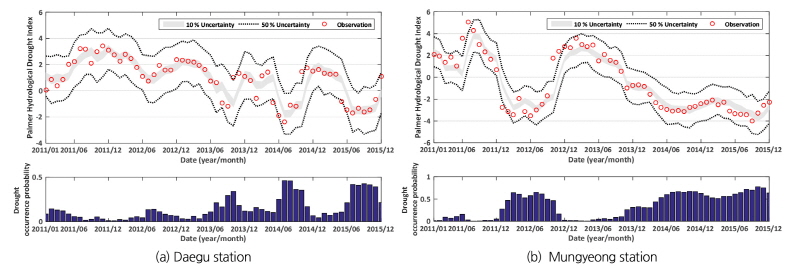
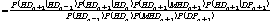 (8b)
(8b)
여기서, 부모 노드 HDN-1, HDN, MHDN+1, DPN+1은 증거 변수가 들어가야 되며, 본 연구에서 증거변수는 HDN-1는 (N-1)번째 월의 관측 PHDI,HDN은 N번째 월의 관측 PHDI, MHDN+1은 MME 강수 및 온도 자료를 활용하여 산정한 (N+1)번째 월의 PHDI 값이다.DPN+1은 Eq. (7)을 이용하여 산정된 (N+1)번째 월의 PHDI 확률분포이다.
4. 연구결과
4.1 가뭄전이 관계를 고려한 확률론적 가뭄 예측
본 연구에서는 2008년 1월부터 APCC에서 제공하는 MME 3개월 예측 결과와 2014년 1월부터의 MME 6개월 예측 결과를 베이지안 네트워크 가뭄 예측 모형에 적용하여 확률론적 수문학적 가뭄 예측 결과를 생산하였다. MME 3개월 예측 결과를 활용한 베이지안 네트워크 가뭄 예측 모형에서는 현재 시점을 기준으로 앞으로의 1, 2, 3개월의 예측 결과가 정규분포로 추정된다.
Fig. 5는 2014년 5월이 현재 시점일 때, 2014년 6월부터 8월까지의 예측된 월별 확률분포를 나타낸 것이다. Fig. 5(a)는 대구 지점, Fig. 5(b)는 문경 지점이다. 각각의 지점에서의 1~3개월 예측 결과를 살펴보면, Fig. 5(a)의 대구 지점과 Fig. 5(b)의 문경 지점에서 예측 PHDI 확률분포의 중앙값이 시간의 흐름에 따라 왼쪽으로 이동하는 것으로 가뭄이 심화되는 것으로 예측될 수 있다. 장기간(1~3개월)의 가뭄 예측 결과를 통하여 가뭄심도가 변화되는 양상을 파악 가능하며, 장기적인 가뭄 대책 마련으로 효율적인 가뭄 대응이 가능하다.
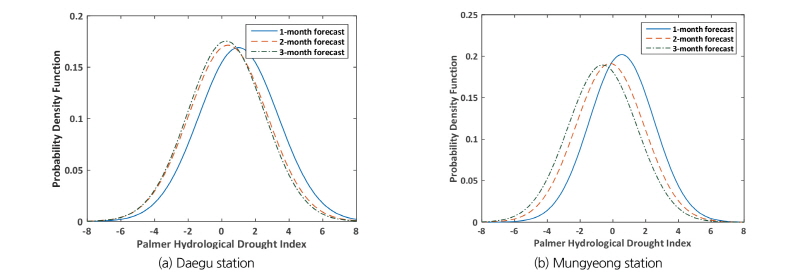
Fig. 6은 2011년부터 2014년까지의 1개월 예측 결과를 신뢰구간 10%와 50%로 표현하여 도시한 것이다. 관측된 강우와 온도 자료를 활용하여 산정된 관측 PHDI (‘o’)를 함께 표시하였다. 1개월 가뭄 예측 결과는 실제 관측 결과와 패턴이 유사하다는 것을 확인할 수 있으며, 10% 신뢰구간에 대해서는 관측값의 일부가 벗어나고 있으나, 50% 신뢰구간 내에 대부분 포함되고 있음을 확인할 수 있다. 또한, 예측된 PHDI의 확률분포를 활용하여 가뭄 발생 확률을 산정하여 Fig. 6에 도시하였다. 1개월 가뭄 발생 확률은 1개월 예측 PHDI의 누적확률분포에서 PHDI가 가뭄으로 판단되는 -2.0 이하의 누적 확률값을 계산 결과를 바탕으로 가뭄 발생 확률을 막대그림을 활용하여 제시하였다. Figs. 6(a) and 6(b)를 살펴보면, PHDI의 실제 관측값이 0 이하의 음의 값으로 관측된 기간에서 가뭄 발생 확률이 높게 나왔다는 것을 확인할 수 있다. 예측 기간의 가뭄 발생 확률은 가뭄 및 수자원 관리자에게 앞으로의 가뭄재해 발생 가능성을 정량적으로 파악할 수 있게 하고, 이는 가뭄의 사전 대응을 위한 정보를 활용 가능하다.
4.2 가뭄 예측 결과의 분석
본 연구에서 제안한 가뭄 예측 모형(PBNDF)의 예측성능을 정량적으로 평가하였다. 우선, 수신자 조작 특성(Receiver Operating Characteristics, ROC) 분석 기법을 활용하여 1~3개월 가뭄 예측 결과에 대하여 가뭄 발생 유무에 대한 예측성을 평가하였다. 6개월 가뭄 예측의 경우, MME 예측 결과의 자료 보유기간이 2년으로 짧기 때문에 가뭄의 발생 여부로 예측성을 평가하는 ROC 분석은 수행하지 않았다. PBNDF는 확률론적 예측 결과를 제공하므로, ROC 분석을 위하여 예측 확률분포의 50%에 해당되는 값인 평균 PHDI가 가뭄판단기준(-2.0) 이하인 경우 가뭄이 발생될 것으로 판단하였다. ROC 곡선은 Eq. (9)를 활용하여 적중률(hit rate)과 비적중률(false alarm rate)을 계산하여 표현되며, 두 값은 예측값과 관측값의 가뭄발생 유무를 판단하여 산정된다.
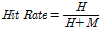 (9a)
(9a)
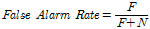 (9b)
(9b)
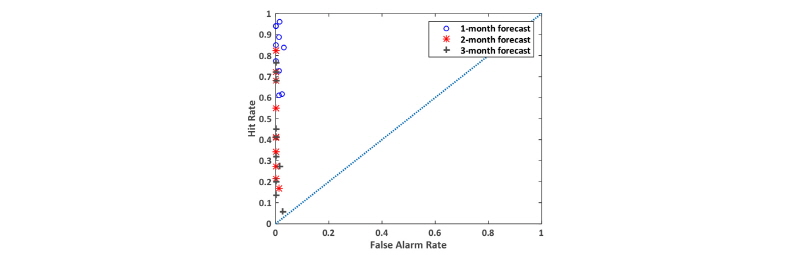
여기서, H는 관측값, 예측값 모두 가뭄인 경우, M은 관측값만 가뭄인 경우, F는 예측값만 가뭄인 경우, N은 관측값과 예측값 모두 가뭄이 아닌 경우의 갯수이다. 완벽한 예측이 수행되었을 경우에는 X축(비적중률)이 0, Y축(적중률)이 1이 되며, 해당값에 가까울수록 예측성이 좋다고 할 수 있다. 대상유역의 2008년부터 2015년까지의 1~3개월 예측 결과에 대한 ROC 분석결과를 Fig. 7에 도시하였다. 2, 3개월 예측의 경우 비적중률은 대부분 0이나 적중률은 1개월 예측보다 현저하게 낮았다. 즉, 1개월 예측이 2, 3개월 예측에 비하여 예측성이 우수한 것을 확인할 수 있다. ROC 분석에서 (0, 0), (FAR, HR), 그리고 (1, 1)을 연결한 곡선의 면적을 ROC 점수라고 하며, ROC 점수가 1.0이면 완벽한 예측, 0.5 이하일 경우에는 예측성이 낮다고 판단한다. Fig. 7에 도시된 결과들은 ROC 점수가 모두 0.5 이상으로 유의한 수준의 예측 결과인 것으로 판단되었다.
이어서, Ranked Probability Score (RPS)와 Ranked Prob-ability Skill Score (RPSS)를 활용하여 예측된 PHDI의 PDF의 불확실성을 평가하였다. RPS는 Epstein (1969)가 제시한 확률예측의 예측성을 검증하기 위한 기법으로, Eq. (10a)와 같이 관측값과 예측 확률분포의 누적밀도함수(CDF)의 비교를 통하여 계산된다.
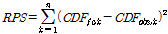 (10a)
(10a)
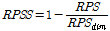 (10b)
(10b)
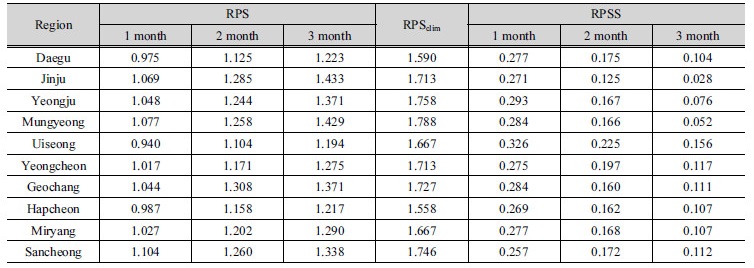
여기서, CDFfc,k는 예측값의 CDF, CDFobs,k는 관측값의 CDF이며, RPS의 값이 0에 가까울수록 예측성 좋은 모형이다. RPS의 Skill Score인 RPSS는 Eq. (9b)와 같이 산정되며, 본 연구에서 기후학적 모형의 RPS (RPSclim)을 판단 기준용 예측모형(reference forecasts)으로 활용하였다. RPSclim은 전체 연구기간 동안의 월별 관측 PHDI의 평균과 분산을 활용하여 산정된 정규분포를 따르는 예측 모형이다. PBNDF를 활용한 예측 결과의 RPS와 RPSclim을 Table 1에 제시하였다. 본 연구에서 제시한 모형의 RPS가 0에 더 가까운 값을 나타내어 예측성이 우수함을 확인할 수 있다. Table 1에 함께 나타낸 RPSS의 값이 모두 0 이상의 값으로 확률론적 예측 검정 결과에서도 PBNDF 모형의 예측 결과의 활용 가능성이 검증되었다.
PBNDF를 활용한 예측 결과를 다른 모형과의 비교를 통한 예측성 검토를 위하여 기존에 개발된 베이지안 네트워크 기반 예측 모형(BNDF) (Shin et al., 2016)을 활용한 예측 결과와 지속성(Persistence) 예측 결과와 비교하였다. 지속성 예측은 간단한 예측 방법으로, 현재의 관측값이 예측하고자 하는 기간의 예측값이 되도록 하는 예측 기법이다(Kim and Valdes, 2003). 기상 분야에서는 지속성 예측 모형의 예측결과는 다른 예측 모형의 성능평가의 기준으로 활용되고 있으며, 지속성 예측 모형보다 예측성이 떨어질 경우 해당 모형을 활용할 이유가 없는 것이다. BNDF 모형은 Shin et al. (2016)에서 베이지안 네트워크 모형을 활용하여 기상학적 가뭄지수 SPI 3개월 예측을 위하여 제시한 모형으로, Fig. 3에서 DPn+1노드가 제외된 것과 같다. 본 연구에서는 가뭄 전이 현상과 관련된 인자가 추가된 PBNDF 예측성능 검정을 위하여 BNDF 모형으로 수문학적 가뭄 예측을 수행하여 그 결과를 비교분석하였다.
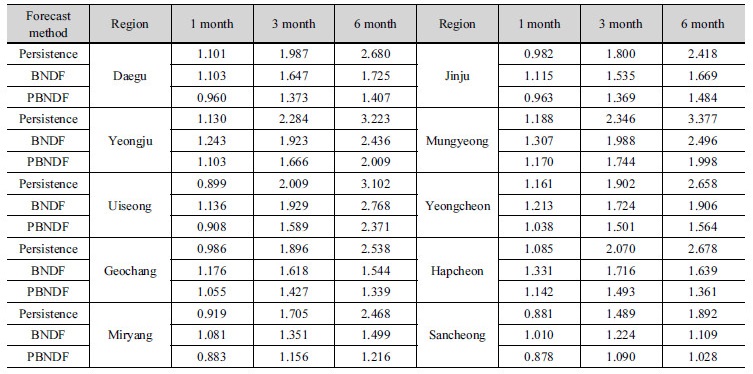
3가지 예측방법(PBNDF, BNDF, 지속성 예측)으로 수행된 가뭄 예측 결과를 비교하기 위하여 평균제곱오차의 제곱근(RMSE)를 활용하였다. RMSE는 오차 제곱값을 생성하여 예측의 정확성을 판단하며, 값이 0에 가까울수록 예측값이 관측값에 가까워진다. 지속성 예측은 결정론적 예측 결과를 제시하나, PBNDF과 BNDF 기법은 확률론적 예측 결과가 생산되어 단일 PHDI 값이 아닌 PHDI의 PDF가 결과로 산정되게 된다. 이 때문에 예측된 PHDI의 PDF에서의 중앙값을 활용하여 RMSE를 계산하여 비교하였다. 2014년도부터 2015년도까지의 1~6개월 예측을 수행하여 산정된 결과에 대한 RMSE를 Table 2에 제시하였다.
Table 2에 나타난 바와 같이 RMSE는 예측 기간이 1개월에서 6개월로 증가할수록 3가지 예측 모형 모두 RMSE가 증가하는 것을 확인할 수 있다. 또한, 본 연구에서 제시한 PBNDF의 RMSE가 전체 예측기간에서 가장 작은 값을 나타내어 세 모형 중에서 가장 예측성이 좋은 모형인 것을 확인할 수 있다. 이어서, 평균값에 대한 예측성 검토를 위하여 Eq. (11)과 같이 SS (Skill Score)를 산정하였다.
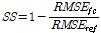 (11)
(11)
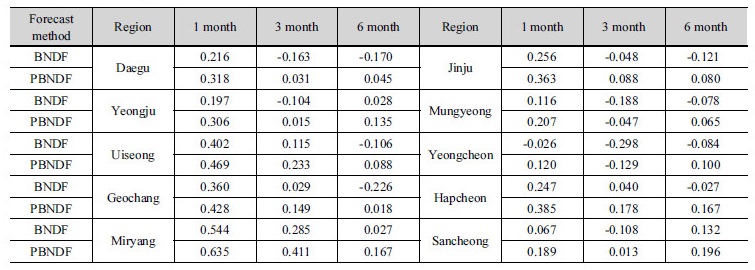
여기서, RMSEfc는 개발된 예측 모형의 RMSE, RMSEref는 기준 모형의 RMSE로, 본 연구에서는 기후학적 예측(climatology forecast) 결과의 RMSE를 활용하였다. SS는 1.0에 갈수록 예측성이 좋은 것을 의미하며, SS가 0인 경우 기후학적 예측모형보다 예측성이 개선되지 않은 상태를, SS가 음의 값이 나올 경우에는 기후학적 예측 결과보다 좋지 않은 것을 뜻한다. Table 2의 PBNDF와 BNDF의 RMSE와 기후학적 예측 모형 결과의 RMSE를 활용하여 SS를 산정된 결과는 Table 3에 제시하였다.
Table 3에서 대상유역 전체 예측 기간에 대하여 가뭄전이 관계를 추가적으로 고려한 PBNDF의 SS가 높아 예측성이 높은 것을 확인할 수 있다. 1개월 예측의 경우 약 0.104, 3개월 예측은 0.138, 6개월 예측은 0.169로 예측 기간이 증가될수록 BNDF 모형에 비하여 예측성이 높아지는 것을 확인할 수 있다.
5. 결 론
수문학적 가뭄 예측 과정에서 발생되는 불확실성을 고려하기 위하여 본 연구에서는 베이지안 네트워크 모형을 활용하여 확률론적 가뭄 예측 모형을 개발하였다. 베이지안 네트워크는 복잡한 관계를 지니고 있는 시스템을 변수들 간의 인과관계로 간단히 표현가능하며, 손쉽게 변수들을 추가하거나 제외할 수 있어 가뭄 예측과 연관된 다양한 인자들을 활용할 수 있는 예측 모형이다.
본 연구에서 제시한 베이지안 네트워크 가뭄 예측 모형은 통계학적 예측 기법을 기반으로 하고 있으나, 모형의 입력인자에 역학적 기후 모델 MME 예측 결과를 활용함으로써 통계학적 모형과 역학적 모형을 결합한 결과를 생산할 수 있었다. 이로써, 기존의 통계학적 모형을 활용했을 경우 생산되는 예측 결과는 과거의 자료에 의존된다는 한계를 벗어나고, 역학적 모형의 예측 결과의 불확실성을 반영한 예측 결과를 도출할 수 있었다. 또한, 기상학적 가뭄지수 SPI와 수문학적 가뭄지수 PHDI 사이의 관계식을 도출하여 가뭄전이 관계를 추가적으로 고려함으로써, Shin et al. (2016)에서 제시한 기존의 베이지안 네트워크 예측 모형(BNDF 모형)보다 예측성이 높아진 모형이 개발되었다.
PBNDF 모형은 과거 가뭄 정보에서 오는 불확실성과 역학적 기후 예측모형의 불확실성을 반영하여 가뭄 예측 결과를 생산하며, 예측된 확률분포를 분석하여 가뭄 발생확률을 가뭄심도에 따라 제시하는 것도 가능하다. 특정 값을 예측하는 결정론적 예측과 다르게 확률론적 예측은 발생할 수 있는 가능성이 높은 가뭄 심도부터 발생 확률이 낮은 가뭄심도의 값까지의 정보를 제공함으로써, 심도에 따른 다양한 가뭄 대응 시나리오가 만들어 질 수 있다. 이로써, 가뭄 재해 발생 이전부터 다양한 가뭄 대응 시나리오에 따라서 수자원 관리자들에게 탄력적인 가뭄 대응이 가능할 수 있는 정보를 제공 가능하여 효과적인 가뭄 대응의 도구로 활용가능 할 것으로 판단된다.
