

1. 서 론
2. 적용 방법
2.1 역거리법
2.2 최적 거리 지수의 결정
2.2.1 최적 모형
2.2.2 모형 해법
3. 방법 적용 및 결과 분석
3.1 적용 대상
3.2 적용 및 결과 분석
4. 주요 결과 및 결론
1. 서 론
우기시 성공적인 수문 모델링이나 수질 모델링을 위해서 신뢰성 있는 강수 자료의 제공이 요구된다. 그러나 자료를 제공하는 강수 관측소는 설치하는데 공간적 한계가 있고 단전 사고, 기기 고장, 프로그램 오류 등으로 인하여 자료의 부족이나 단절이 다수 발생된다. 이 때문에 강수 자료의 보간이 필요하다. 강수 자료의 보간 방법은 많지만 모든 환경에 적합한 단일 방법은 없다(Nalder and Wein, 1998). 우수한 방법으로 알려진 크리킹 방법, 최적화 보간법, 인공신경망 또는 퍼지 이론에 의한 방법은 보간 하고자 하는 지역의 강수 자료의 통계적인 특성 값이나 복잡한 데이터를 필요로 한다. 따라서 이 방법들은 강수 관측 자료에 영향을 받기 때문에 관측 자료의 시공간적 한계나 오류가 있을 경우 방법의 신뢰성에 영향을 받는다. 이에 대한 대안적 방법으로 관측 자료나 통계치를 필요로 하지 않는 역거리법(inverse distance method)이 있다. 이 방법은 강수 관측소 간의 거리 요소만을 적용하기 때문에 간편하면서 강수 자료의 영향을 직접 받지 않는다.
이 방법에 대한 연구사례로, Wei and McGuinness (1973)는 강우량의 면적평균을 구하기 위한 전산기법으로 역거리제곱법(reciprocal distance squared method)을 도입하였고 Shearman and Salter (1975)는 강우 관측소로부터 일정한 격자 지점에 강우 자료를 보간하기 위해서 역거리제곱법을 적용하였고, Simanton and Osborn (1980)은 점 강우량 산출에 역거리법을 적용하였다. Tung (1983)은 산술평균법(arithmetic average method), 정상비법, 역거리법, 수정정상비법(modi-fied normal ratio method), 선형계획법(linear programming method) 등 강수 보완법 5가지를 비교하는 연구결과를 제시하였다. Tabios and Salas (1985)는 티센다각형법(thiessen polygon method), 다항식보간법(polynomial interpolation method), 역거리법, 다중제곱보간법(multiquadric interpo-lation method), 최적보간법(optimal interpolation method), 크리킹법(kriging method) 등 6가지 방법을 비교하여 크리킹법, 최적보간법 그리고 역거리법이 우수함을 입증하였다. Lo (1992)는 기존 역거리법에다가 고도차의 영향을 고려한 수정역거리법을 연구하였고 Bartier and Keller (1996)는 기존 역거리법 관계식에 추가적인 다변량의 가중치를 조합시키고 그 효과를 연구하였다. Kim et al. (1999)은 점 강우량을 보정하기 위해서 산술평균법, 정상비법, 역거리법, 선형계획법, 크리깅 법(kriging method) 등 7개 방법을 적용하여 상대적으로 쉽고 오차가 적은 역거리법을 권장하였고 Ahn et al. (2003)은 미계측 지점의 강수량을 산정하기 위해서 역거리법과 크리깅 법을 적용한 바 있다. 또한 Chang et al. (2005)은 관측소 간의 수평거리와 고도차의 조합 효과를 갖는 가중치를 설정하고 그 가중치를 퍼지 이론의 소속 함수(membership function)과 연결시켜 연구하였다. 그리고 Kim and Kim (2006)은 강우량의 이상치와 결측치를 보정하기 위해서 산술평균법, 역거리법, 수정역거리법, 인근관측소와의 관계식 법, 크리깅 법 등을 적용하였다. Han et al. (2009)은 한강권 실시간 우량자료의 결측치 보완에서 역거리법과 상관계수 가중법이 적용에 우수함을 보였다. Yoo (2010)은 한강유역의 강수 자료를 이용하여 산출평균법, 정상비법, 수정정상비법, 역거리법, 수정역거리법, 선형회귀분석법, 크리깅 법과 선형계획법을 비교하였다.
한편 현재 홍수예경보시스템이나 물관리정보유통시스템(WINS, 2017)에서 강수 자료의 보정에 역거리법을 이용하고 있다. 이 역거리법 또는 역거리제곱법(reciprocal distance squared method)에 포함된 거리의 지수 값은 제곱인 2를 적용해 왔다. 여기서, 역거리법의 거리 지수 값은 강우나 지형의 특성에 따라 결정될 수 있는 매개변수 값이다. 그런데 국내에서 적용 가능한 지수 값의 범위는 아직 정립되어 있지 않다. 이와 같은 지수 값에 관한 국외 산출 사례가 있지만 그 연구 성과로부터 국내에 적용 가능한 값을 구하기 어려운 실정이다. 따라서 역거리법은 국내 적용하는데 제한이 따른다.
이에 본 연구에서는 국내에서 역거리법의 거리 지수 값 또는 그 범위를 얻기 위한 방법론을 제시하고, 국내의 4개 지역의 강수 관측소의 13년(2004~2016년) 간의 시우량(hourly rainfall) 자료를 이용한 경우 분석(case study)을 통하여 최적의 매개변수를 결정하였다. 이 때 1차원적인 최적화 기법인 황금비 분할 조사법(golden section search method)을 적용하여 10년(2004~2013년) 간의 시우량 자료로부터 최적의 지수 값을 결정하였고 최근 3년(2014~2016년) 간의 자료를 통하여 검증하였다.
2. 적용 방법
본 연구에서 적용한 방법과 기존의 역거리법에 의해 계산한 결과를 함께 비교하였다. 일반적으로 보간이 필요한 기준 관측소의 강수량(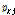 )은 기준 관측소(base station)의 주변에 위치한 주변 관측소(surrounding station)의 강수량(
)은 기준 관측소(base station)의 주변에 위치한 주변 관측소(surrounding station)의 강수량(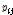 )에 의해서 Eq. (1)과 같이 나타낼 수 있다(Singh, 1989).
)에 의해서 Eq. (1)과 같이 나타낼 수 있다(Singh, 1989).
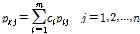 (1)
(1)
여기서, 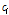 는
는 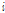 번째 주변 관측소의 강수가 기준 관측소의 강수에 기여하는 정도를 나타내는 가중치 계수를 의미한다. 그리고
번째 주변 관측소의 강수가 기준 관측소의 강수에 기여하는 정도를 나타내는 가중치 계수를 의미한다. 그리고 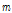 은 주변 강수 관측소의 개수이고
은 주변 강수 관측소의 개수이고 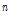 은 기준 관측소 강수량의 개수이고
은 기준 관측소 강수량의 개수이고 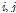 는 순서를 나타내는 기호이다.
는 순서를 나타내는 기호이다.
2.1 역거리법
본 연구에서는 역거리법에 포함된 거리의 지수 값을 제곱으로 고정하지 않았다. 이와 같은 역거리법에 의한 기준 관측소의 강수량(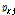 )은 Eq. (2)와 같이 계산된다.
)은 Eq. (2)와 같이 계산된다.
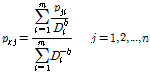 (2)
(2)
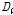 는 기준 관측소와
는 기준 관측소와 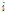 번째 주변 관측소 간 거리이다.
번째 주변 관측소 간 거리이다. 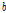 는 제곱에 의한 지수 값인 2가 아니고 매개변수(parameters)로 취급한다.
는 제곱에 의한 지수 값인 2가 아니고 매개변수(parameters)로 취급한다.
2.2 최적 거리 지수의 결정
역거리법의 거리 지수 값인 매개변수를 최적으로 결정하기 위해서 기준관측소의 관측치와 계산치의 오차의 제곱을 합계로 하는 최소화(minimization) 모형을 적용하였다.
2.2.1 최적 모형
최적화를 통하여 매개변수를 구하기 위해서는 목적함수 설정이 가장 중요하다. 수문학 분야에서 매개변수를 결정하기 위해서 다양한 목적함수(objective function)들이 이용되어 왔다(Diskin and Simon, 1977; Singh, 1988). 오차 없는 최적의 매개변수를 결정하기 위한 목적함수를 설계하는 것은 매우 힘들다. 하지만 적합한 목적함수를 설정하는 것은 최선의 매개변수를 결정하는데 매우 중요하다. 본 연구에서 거리 지수를 결정하기 위한 최적화 모형의 목적함수(objective function) 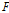 는 기준 강우 관측소의 관측치와 계산치의 오차를 제곱한 합계를 최소화 하도록 Eq. (3)과 같이 설계하였다.
는 기준 강우 관측소의 관측치와 계산치의 오차를 제곱한 합계를 최소화 하도록 Eq. (3)과 같이 설계하였다.
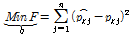 (3)
(3)
Subject to 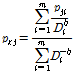 (4)
(4)
여기서, 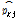 는 기준 강우 관측소의 관측치 이고
는 기준 강우 관측소의 관측치 이고 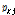 는 Eq. (4)와 같이 결정변수 b 가 포함된 역거리법에 의한 강우의 계산치 이다. 여기서, m은 주변 관측소의 개수를 나타내고, n 은 강우의 시간을 나타낸다.
는 Eq. (4)와 같이 결정변수 b 가 포함된 역거리법에 의한 강우의 계산치 이다. 여기서, m은 주변 관측소의 개수를 나타내고, n 은 강우의 시간을 나타낸다.
2.2.2 모형 해법
본 연구에서 Eqs. (3) and (4)와 같이 설계된 최적 모형은 제약 조건은 없고 1개의 결정변수 b를 갖는 목적함수 갖기 때문에 무제약의 1차원 비선형 최소화 모형(unconstrained one- dimensional minimization model)이다. 이와 같이 무제약의 1차원 최적화 해법은 여러 가지 있지만 가장 잘 알려져 선호되는 방법에는 피보나치와 황금비 분할 조사(fibonacci and golden section search) 방법이 있다(Gottfried and Weisman, 1973; Luenberger, 1984). 이 중 계산상에 강점을 갖는 황금비 분할 조사 기법을 본 연구에서 선택하였다. 즉 Eq. (3)이 최소화되는 최적 지수 b 값을 결정하기 위해서 황금비 분할 조사법을 적용하였다. 황금비 분할 조사법은 선 조사 방법(line search method)의 하나로서 최적 해가 존재하는 결정변수의 조사 구간(bracket interval for search)을 줄여 나가는 방법이라 할 수 있다. 최소화 문제의 경우 Fig. 1과 같이 첫 단계에서 해가 존재하는 구간 [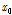 ,
, 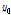 ]를 설정하고 다음 단계에서 구간의 내부에 두 점(
]를 설정하고 다음 단계에서 구간의 내부에 두 점(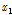 ,
, 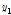 )을 Eqs. (5) and (6)과 같이 선택한다.
)을 Eqs. (5) and (6)과 같이 선택한다.
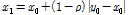 (5)
(5)
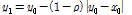 (6)
(6)
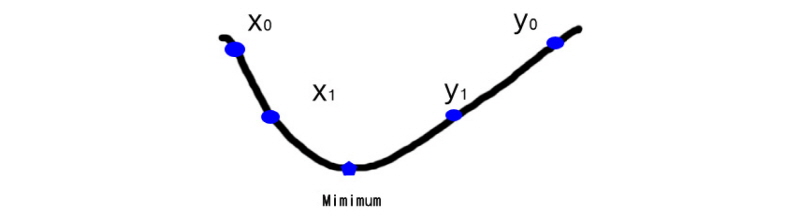
여기서, 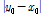 는
는 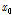 와
와 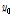 의 절대 차로서 구간 길이를 나타내고,
의 절대 차로서 구간 길이를 나타내고,  는 황금비(golden ratio ≒ 0.618034)를 나타낸다. 그리고
는 황금비(golden ratio ≒ 0.618034)를 나타낸다. 그리고 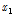 와
와 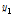 의 함수 값을 비교하여 둘 중 하나를 선택하면 다음 단계의 조사 구간은 [
의 함수 값을 비교하여 둘 중 하나를 선택하면 다음 단계의 조사 구간은 [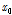 ,
, 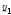 ] 또는 [
] 또는 [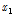 ,
, 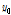 ]이 된다. 이와 같은 과정을 계속 반복하게 되면 최소 함수 값을 갖는 결정변수(minimum)를 찾게 된다.
]이 된다. 이와 같은 과정을 계속 반복하게 되면 최소 함수 값을 갖는 결정변수(minimum)를 찾게 된다.
황금비 분할 조사법의 알고리즘은 효율적인 알고리즘을 갖는 상용 패키지의 서브루틴(Press et al., 1996)을 이용하였다. 본 연구의 결정변수인 거리의 지수 b 값의 초기 입력치는 구간의 시작점, 중간점, 끝점에 각각 0.0, 2.0, 7.0을 적용하였고, 최적 수렴을 위한 허용치(tolerance, TOL in Table 3) 값은 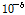 을 적용하였다.
을 적용하였다.
3. 방법 적용 및 결과 분석
3.1 적용 대상
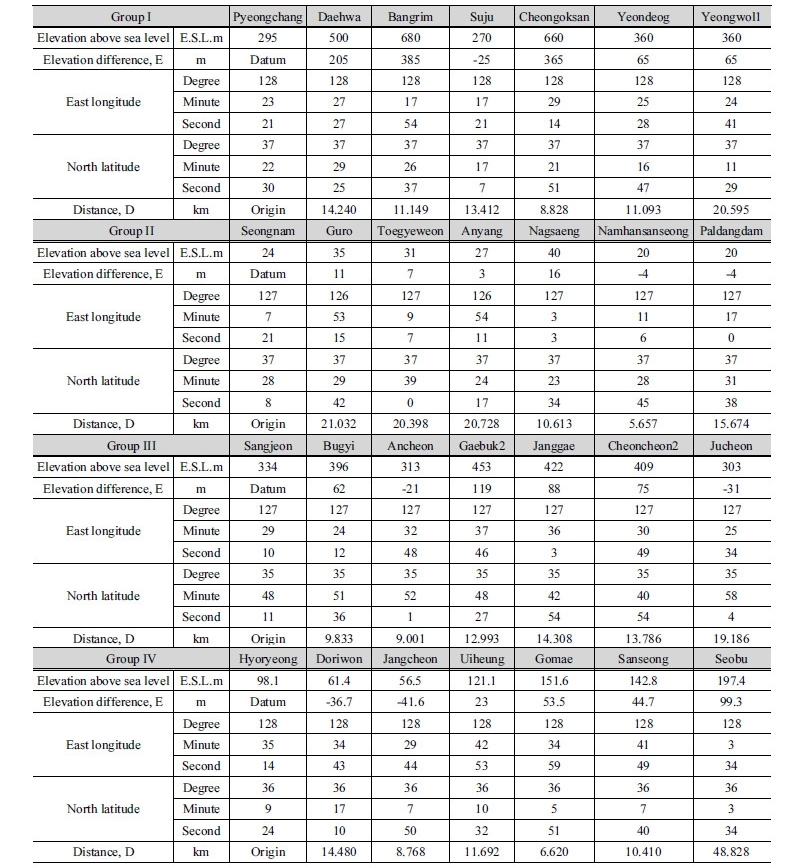
적용한 강수 자료는 Table 1과 같이 한강 상류, 한강 하류, 금강 상류, 낙동강 중류 등 4개 Group의 강우 관측소들을 선택하였다. 총 28개 관측소에서 최근 13년(2004~2016년) 간 발생한 5,417개의 시우량 자료(WAMIS, 2017)를 이용하였다. 여기서, 전반 10년간에 대하여 최적의 지수 값을 결정하였고 후반의 최근 3년간을 통하여 검증하였다. 그리고 4개 Group은 7개 관측소를 각각 포함하고 Group은 1개의 기준관측소와 6개 주변관측소로 구성된다. 그리고 한 Group은 10개 내외의 Case로 구성되어 전체는 52개의 Case로 이뤄진다. 여기서, Case는 최적의 거리 지수를 결정하기 위해서 설정한 관측 자료의 단위로서 1개의 기준관측소와 4개의 주변관측소의 자료로 구성된다.
Group I의 관측소는 평창을 기준 관측소로 하여 대화, 방림, 수주, 청옥산, 연덕, 영월1 관측소를 포함한다. Group II는 성남을 기준 관측소로 하고 구로, 퇴계원, 안양, 낙생, 남한산성, 팔당 관측소를 포함한다. Group III은 상전을 기준 관측소로 하고 부귀, 안천, 계북2, 장계, 천천2, 주천 관측소를 포함한다. Group IV는 효령을 기준으로 하고 도리원, 장천, 의흥, 고매, 산성, 서부 관측소를 포함한다. Group별 관측소 구성은 Fig. 2에서 보는 바와 같이 1개의 기준 관측소와 6개의 주변 관측소로 구성하였다. 그리고 최적치 매개변수 b 값을 결정하기 위해서 Case별 기준 관측소 1개는 중심부에 위치하고 주변 관측소 4개는 그 주변에 위치한다. 이와 같은 Case의 개수는 각 Group별로 각각 13, 15, 14, 10개 이다.
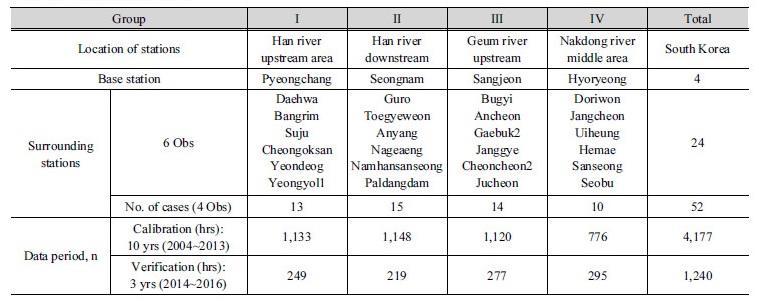
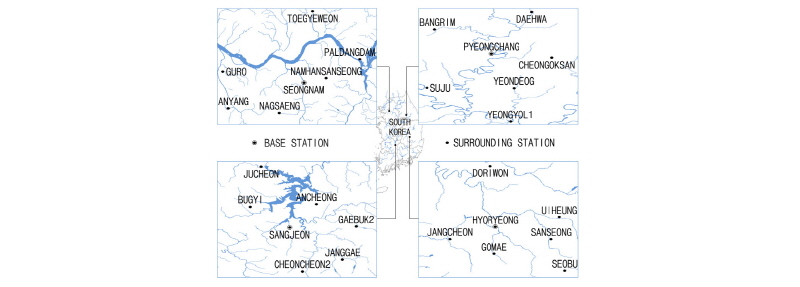
그리고 Table 2에서 보는 바와 같이 Group I의 기준 관측소는 동경 128도 23분 21초, 북위 37도 22분 30초에 위치한다. Group I의 주변 관측소는 수직적으로 가장 높은 경우 기준 관측소보다 385 m 만큼 더 높고 가장 낮은 경우 25 m 만큼 더 낮게 위치하고 수평적으로 기준 관측소로부터 9~21 km 정도 떨어져 위치한다. Group II의 기준 관측소는 동경 127도 7분 21초, 북위 37도 28분 8초에 위치한다. Group II의 주변 관측소는 수직적으로 가장 높은 경우 기준 관측소보다 16 m 만큼 더 높고 가장 낮은 경우 4 m 만큼 더 낮게 위치하고 수평적으로 기준 관측소로부터 6~21 km 정도 떨어져 위치한다. Group III의 기준 관측소는 동경 127도 29분 10초, 북위 35도 48분 11초에 위치한다. Group III의 주변 관측소는 수직적으로 가장 높은 경우 기준 관측소보다 119 m 만큼 더 높고 가장 낮은 경우 21 m 만큼 더 낮게 위치하고 수평적으로 기준 관측소로부터 9~19 km 정도 떨어져 위치한다. Group IV의 기준 관측소는 동경 128도 35분 14초, 북위 36도 9분 24초에 위치한다. Group IV의 주변 관측소는 수직적으로 가장 높은 경우 기준 관측소보다 99 m 만큼 더 높고 가장 낮은 경우 42 m 만큼 더 낮게 위치하고 수평적으로 기준 관측소로부터 7~49 km 정도 떨어져 위치한다.
3.2 적용 및 결과 분석
본 연구의 최적화 모형에 강우 관측소의 Group별, Case별로 10년(2004~2013년) 간의 시우량을 적용하여 Table 3과 같이 최적의 b 값을 결정(calibration) 하였고, 최근 3년(2014~ 2016년) 간의 시우량 자료에 대하여 검증(verification)을 수행하였다. Table 3 and Fig. 3은 황금비 분할 조사 방법에 의한 최적의 거리 지수인 b 값을 최적화 하는 자취(optimization history)를 보여 준다. 여기서, b_1과 b_2는 황금비 분할 조사 과정상에서 조사 구간의 양단 b 값이고 F(b_1)과 F(b_2)는 Eq. (3)에 의해서 계산되는 구간 양단의 목적함수 값이다. 여기서, ∣b_2 – b_1∣는 b_1과 b_2의 절대 차를 나타낸다. 이 절대 차가 수렴 허용치인 TOL = 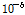 에 이르면 b 값이 최적화 되고 목적함수 F 값은 최소화 된다. 즉 기준 강우 관측소의 관측치와 최적 b 값을 적용한 역거리법에 의한 계산치의 오차를 제곱한 합계가 최소화 된 것이다.
에 이르면 b 값이 최적화 되고 목적함수 F 값은 최소화 된다. 즉 기준 강우 관측소의 관측치와 최적 b 값을 적용한 역거리법에 의한 계산치의 오차를 제곱한 합계가 최소화 된 것이다.
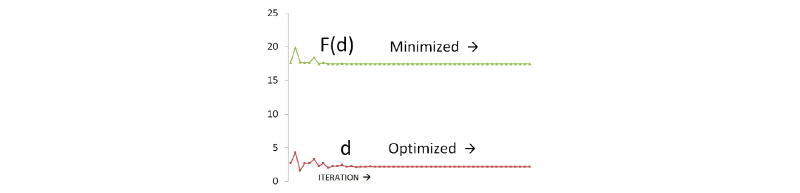
Table 3. Optimization of distance exponent, b with minimizing objective function, F(b) by golden section search method in Case 1 of Group II
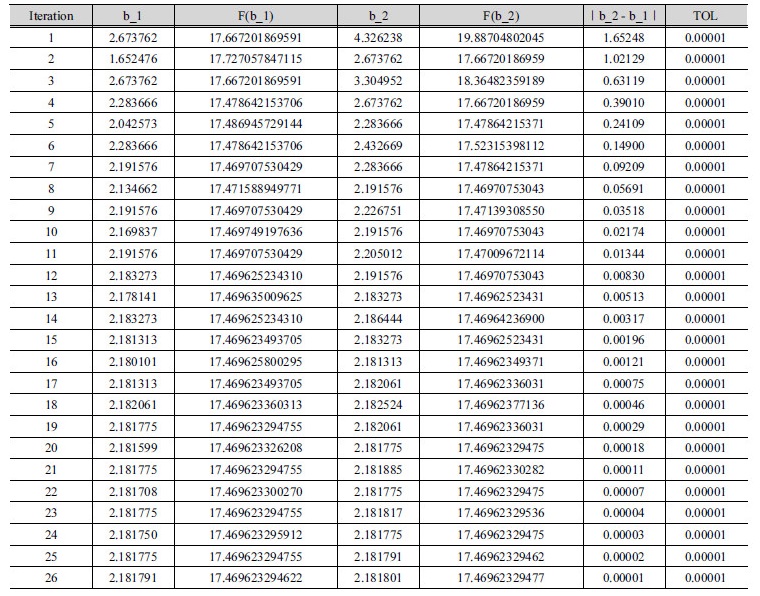 |
이와 같은 최적화 과정을 통하여 얻은 최적의 b 값은 Tables 3 and 5에서와 같이 2.1820이었다. 이로부터 계산된 역거리법의 가중치 계수(weighting factor) 값인 c 값(Eq. 1)은 Table 4와 같다. 이 경우(Group II, Case 1)에서 기준 관측소는 성남이고 주변 관측소 4개는 구로, 퇴계원, 안양, 낙생이다. Table 4에서 보는 바와 같이 성남 관측소와 가장 근접한 낙생 관측소의 가중치 계수가 가장 크게 나타난다. 이것은 강우에 있어서 주변 관측소 중에 낙생 관측소가 성남 관측소에 가장 영향을 주는 것을 의미한다.
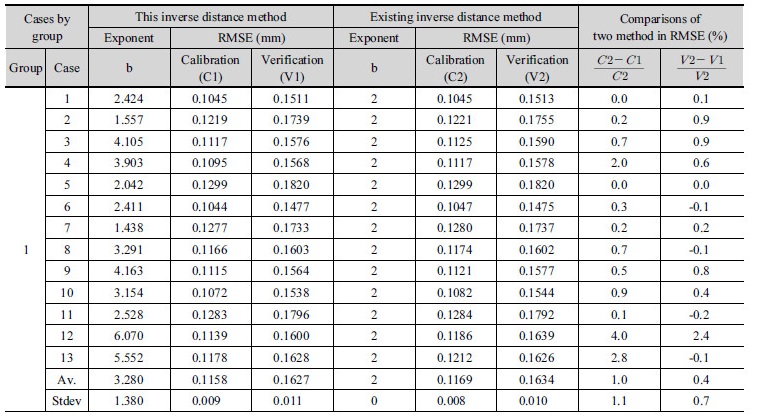
이와 같이 모든 Group별 Case별로 최적 거리 지수 값 b를 적용 한 본 연구의 방법과 b 값을 2로 하는 기존 역거리법을 동일한 자료 기간에 대하여 적용하였고 이를 Table 3과 같이 비교하였다. Table 5에서 평균 제곱근 오차(root mean squared error, RMSE)는 기준 강우 관측소의 관측치와 최적 b 값을 적용한 역거리법에 의한 계산치의 차이의 제곱한 합계를 평균하여 제곱근을 구한 값이다. 본 연구에서 평균 제곱근 오차(RMSE)와 목적함수 F와의 관계는 다음 Eq. (7)과 같다.
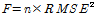 (7)
(7)

여기서, n은 자료의 수(data period in Table 1)를 나타낸다.
모든 Group과 Case에서 10년간 시우량 자료에 대하여 최적의 거리 지수 값을 적용한 평균 제곱근 오차는 지수 값 2를 적용한 것보다 Group별로 각각 1.0, 1.8, 0.3, 0.5% 만큼 작게 나타났고, 전체 Group을 평균하면 0.9% 만큼 작게 나타났다. 이와 같이 최적의 거리 지수를 적용한 본 연구의 역거리법이 지수 값 2를 적용한 기존 역거리법보다 평균 제곱근 오차가 작게 나타났기 때문에 본 연구의 역거리법이 기존 역거리법보다 우수함을 알 수 있다. 한편 최근 3년(2014~2016년) 간의 자료에 대하여 검증을 수행한 결과, Group I내의 경우 총 13개 Case 중의 9개 Case에서, Group II 내의 경우 총 15개 Case 중의 12개 Case에서, Group III 내의 경우 총 14개 Case 중의 11개 Case에서, Group IV 내의 경우 총 10개 Case 중의 7개의 Case에서 각각 기존 역거리법보다 평균 제곱근 오차가 적게 나타났다. 이와 같은 검증 과정에서는 기존 역거리법보다 본 연구 방법의 평균 제곱근 오차는 크게 나타나기도 하였으나 평균적으로 더 작게 나타났다.
이와 같이 최적화를 통하여 얻은 거리의 지수 값 b를 Group별로 살펴보면, Group I에서 b 값은 구간 [1.438, 6.070]에 나타났고 평균적으로 3.280이었다. 그리고 Group II에서는 b 값은 구간 [1.238, 5.388]에 나타났고 평균적으로 1.839이었다. Group III에서는 b 값은 구간 [1.162, 3.280]에 각각 나타났고 평균적으로 2.181이었다. Group IV에서는 b 값은 구간 [1.442, 3.934]에 나타났고 평균적으로 2.005이었다. 전체 Group을 평균한 b 값은 2.263이었다. 이 때 Group별 b 값의 표준편차(standard deviation, Stdev in Table 5)는 1.38, 1.02, 0.56, 0.95이었고 전체 표준편차는 0.98이었다. 이와 같이 Group I의 b 값에는 분산이 비교적 컸고 Group III에서는 상대적으로 작았고, Group II, IV에서는 평균적 수준이었다. Group별 b 값의 분산 정도는 Case별 주변 관측소의 기하학적 위치나 강우 특성 등에 의해서 좌우될 수 있다. 한강 하류부에 위치한 Group I은 지형적 기복이 상대적으로 적은 관측소 그룹이고 한강 상류부에 위치한 Group II, 금강 상류부에 위치한 Group III, 낙동강 중류부에 위치한 Group IV는 지형적 기복이 있는 관측소 그룹들이다. 관측소 그룹의 지형 특성과 지수 값의 뚜렷한 상관성을 찾기 어려웠으나 본 연구에서 구한 거리 지수 값은 기복이 적은 평지에서 더 작게 나타났다.
4. 주요 결과 및 결론
역거리법의 거리 지수를 최적 결정한 본 연구의 주요 결과와 결론은 다음과 같다.
1)본 연구에서 적용한 역거리법에 포함된 거리 지수를 제곱으로 고정하지 않고 변량으로 취급하였다.
2)거리 지수를 하나의 결정변수로 하고 기준 강우 관측소의 관측치와 계산치의 오차를 제곱한 합계를 목적함수로 한 비선형 최적화 모형을 설계하였고 황금비 분할 조사법을 적용하여 최적의 거리 지수를 결정하였다.
3)적용한 강수 자료는 한강 상류, 한강 하류, 금강 상류, 낙동강 중류 등 4개를 Group으로 하여 총 28개 관측소에서 최근 13년(2004~2016년) 간 발생한 5,417개의 시우량 자료를 이용하였고 4개 Group별로 기준 강우 관측소와 그 주변의 4개 관측소로 구성된 총 52개 Case를 선택하였다.
4)10년(2004~2013년) 간 시우량 자료로부터 구한 최적의 지수 값에 의한 평균 제곱근 오차는 모든 Case에서 기존 역거리법보다 평균 0.9% 만큼 작게 나타났다. 검증 과정에서는 기존 역거리법의 평균 제곱근 오차가 일부 크기도 하였으나 평균적으로 더 작게 나타났다.
5)52개의 경우 분석으로 최적화 한 지수 값의 평균은 Group별로 각각 3.280, 1.839, 2.181, 2.005이었고 전체 평균은 2.326이었다. 한강 상류에 위치한 Group I에서 지수 값의 표준편차가 1.38 로서 분산이 가장 컸고, 금강 상류인 Group III에서는 표준편차가 0.56 으로 분산이 가장 작았고 나머지 두 Group에서는 평균적 표준편차 0.98 정도의 분산이 나타났다.
6)본 연구에서 구한 지수 값들과 강우 관측소 위치의 지형적 특성과의 뚜렷한 상관관계를 도출하긴 힘들었지만 대체적으로 기복이 적은 평지에서 거리 지수 값이 상대적으로 적게 나타났다.
7)본 연구 분량의 한계로 인하여 물리적인 특성을 고려한 지수 값의 적용 범위는 보다 면밀한 연구가 필요하므로 후속의 연구 과제로 남긴다.
