1. 서 론
물은 인류에게 중요한 자원으로 평가되나 다른 자원들에 비해 강우와 눈을 통해 간헐적으로 얻어지는 물의 안정적인 이용은 제한적이다. 때문에 인류는 댐 혹은 저수지와 같은 시설물을 설계하고 물을 저장함으로써 물의 안정적인 이용을 지향해왔다. 하지만 전 세계적으로 이상기후가 고조됨에 따라 물의 안정적인 이용뿐만 아니라 효율적인 이용이 요구되고 있으며, 이를 위해 유역면적, 연평균 강수량, 유입량, 필요수량 그리고 방류량 등을 계측하여 효율적인 이용 계획에 이용되어야 한다. 효율적인 농업용 저수지 관리를 위해서는 지속적인 모니터링과 과학적 근거에 의한 운영이 되어야 하지만 현장에서는 경험적 관리에 의해 운영되고 있다는 것이 현실이다. 또한 국내 농업용 저수지 17,000여 개 중 농어촌공사 관할 저수지와 일부 지자체가 관할하는 저수지만이 모니터링하고 있으며, 실시간으로 계측되고 있는 저수지도 공사관할 일부에 불과한 것이 현 실정이다(Kang et al., 2019). 또한 대부분 농업용 저수지의 상류는 미계측 유역으로 저수지의 계획, 설계 및 운영을 위한 올바른 유입량 계측이 어렵다. 이에 시설물의 효율적인 설계 및 운용을 위해서는 지형적 특성을 고려하여 유입량 예측의 정확성을 높일 수 있는 모형이 선정되어야 한다. 이에 대부분 미계측 유역인 농업용 저수지의 상류를 추정하기 위해 유역내 물리적인 특성(지형학적 및 토지이용 특성)을 활용하여 개발된 강우-유출 모형으로 유입량 및 공급량을 추정하고 있다. 또한 강우-유출 모형을 미계측 유역에 적용하기 위해서는 계측자료가 충분히 확보된 지역의 자료를 통해 모형의 매개변수를 추정하고, 미계측 유역에 추정된 매개변수를 전이하여 이용한다. 하지만 이렇게 매개변수를 전이하여 사용할 경우 유역의 물리적 특성이 동일해야 한다는 한계가 발생한다(Lee et al., 2008). 이에 유역의 물리적인 특성과 매개변수와의 관계를 분석하여 효율적인 미계측 유역 적용을 위한 연구가 진행되어 왔다(Bae et al., 2003; Lim et al., 2001; Kim, 2001; Noh, 2003; Koo et al., 2007; Kang et al., 2013).
현재 국내에서 미계측 유역의 효과적인 적용을 위해 많은 모형이 활용되고 있으며, 그 중 Tank 모형은 미계측 유역의 공급량 및 유입량 추정에 가장 널리 활용되고 있다, 해당 모형은 10개 이상의 많은 매개변수를 기반으로 구동되는 개념적인 모형이다. Tank 모형에 활용되는 매개변수들은 유역의 물리적인 특성을 반영하고, 해당 모형의 매개변수를 효과적으로 추정하기 위해 국내에서는 대상유역들에 대해 최적화를 수행한 후 매개변수들과 유역인자들 간의 관계를 회귀식 형태로 만들어 미계측 유역에 적용하는 연구도 진행되어 왔다(Kim and Park, 1986, 1988; Yoo and Park, 2006; Lee and Kang, 2007). Kim and Park (1988)은 6개 유역에 대하여 4가지 유역인자를 사용하여 회귀식을 유도하였고, Huh et al. (1993)은 6종류의 유역인자를 사용하여 회귀식을 유도한 바 있으며, Kim et al. (2000)은 26개의 하천유역에 대해 7개의 유역인자를 사용하여 회귀식 유도를 시도하였고, An et al. (2015)은 30개의 유역을 대상으로 6종류의 유역인자를 사용하여 회귀식을 유도하였다.
하지만 앞선 연구들에서 제안된 회귀식은 적은 표본을 기반으로 구축되었기 때문에 해당 회귀식의 성능과 범용성에 대한 검증 차원에서의 추가적인 연구가 필요한 실정이다. 또한 앞선 연구들의 회귀식에 사용된 몇몇 물리적인 매개변수의 경우 시설물을 관리하고 있는 기관에서 공개하고 있지 않은 자료를 활용하고 있기 때문에 이러한 회귀식을 활용하기 위해선 추가적인 계측이 필요하다는 단점이 존재한다. 이에 Noh et al. (2017a)은 Tank 모형의 단점을 개선한 ONE 모형을 개발한 바 있으며, 해당 모형의 경우 하나의 매개변수를 활용하여 댐과 저수지의 유입량과 방류량을 분석할 수 있어 미계측 유역의 적용과 보정이 유리하다는 장점이 존재한다(Lee and Noh, 2015). 하지만 ONE 모형의 경우 Tank 모형에 비해 비교적 적용성과 성능에 대한 검증이 미비한 실정이기에 다양한 유역에 대한 적용성 검토가 필요한 실정이다.
따라서 본 연구에선 Tank 모형과 ONE 모형을 관측자료를 충분히 확보하고 있는 15개의 댐 상류 유역에 대해 유출량을 계산하였으며, 각 모형을 정량적으로 비교 분석하고자 수문 모델링 분야에서 널리 활용되고 있는 Nash Sutcliffe Efficiency (NSE)와 회귀식 결정 계수인 R2을 계산하여 Tank 모형과 ONE 모형의 성능을 검토하고 국내 유역에 대한 ONE 모형의 적용성을 분석하였다.
2.모의 모형의 선정
2.1 Tank 모형의 개요
유역의 정확한 유입량과 유출량 모의를 위해선 모형에 필요한 입력 자료, 매개변수를 고려하여 모형을 선정해야 한다 (Kang et al., 2013). Tank 모형은 모형의 구조가 다른 모형보다 단순하고 미계측 유역에 적용할 수 있는 알고리즘을 갖고 있으며, 국내 유역 유출 해석에 있어서 좋은 결과를 제시한 바가 있다. 또한 국내의 농업용 저수지 특성상 중, 소규모 유역 저수지가 대다수이므로, 본 연구에서는 매개변수의 최소화에 따른 모형 적용의 편리성을 위하여 Sugawara의 4번째 Tank 수를 3개로 줄인 수정 3단 Tank 모형을 선정하였다. 수정 3단 Tank 모형은 Sugawara의 Tank 모형을 국내 유역에 맞게 유역 특성인자를 조정하고 Tank의 수를 줄여 모형의 단순화를 통해 기존 모형보다 미계측 유역에 대한 적용이 유리한 모형으로 Kim and Park (1988)에 개발되었으며, 이에 대한 모식도는 Fig. 1에 제시하였다. Kim and Park (1988)의 수정 Tank 모형에 의한 유출량은 다음 Eq. (1)에 의하여 계산된다.
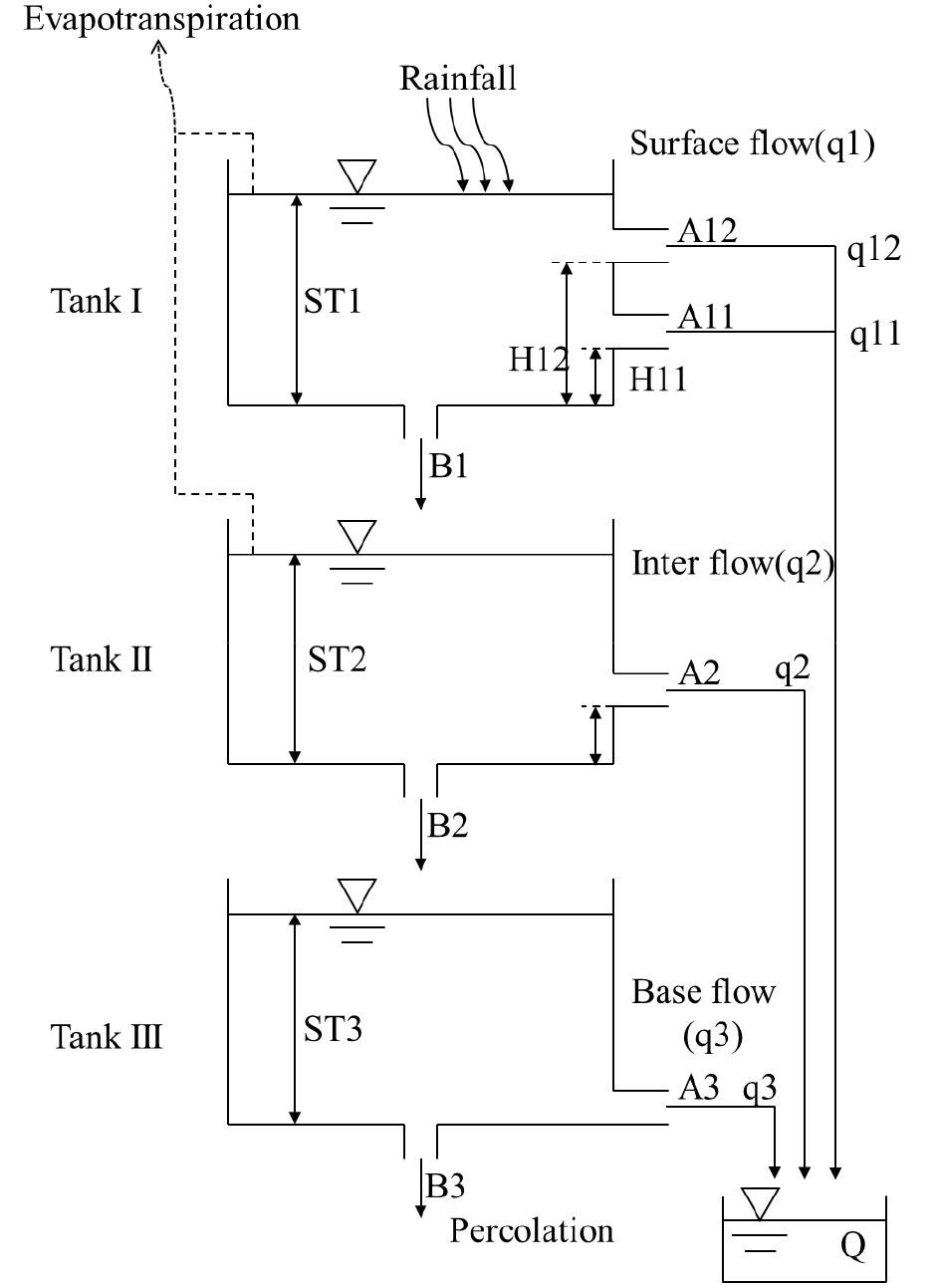
Fig. 1.
Schematic diagram of the Tank model
각 탱크는 지표유출, 중간유출, 기저유출을 의미하며 i는 각 탱크를 의미한다. 본 식에서 는 유역 내 t일의 총유출량(mm), j는 유출공의 수 는 i 번째 Tank의 저류량, 는 i번째 탱크의 j번째 유출공의 높이(mm), 는 유출공의 계수(무차원)를 의미한다. 는 단위시간 t에 따른 저류수심으로 Eq. (2)에 의해 계산된다.
Eq. (2)에서 은 t-1에서의 i번째 Tank의 수심(mm)을 의미한다. 기본적으로 의 값은 물수지 방정식에 따라 계산된다. 이에 는 t일의 강우량(mm), 는 t일에서의 증발산량(mm), 은 i번째 Tank의 t-1일의 유출량, 는 침투량 (mm)로 Eq. (3)으로 계산한다.
Eq. (3)에서 는 i번째 Tank의 침투계수를 의미하며 무차원이다.
2.2 ONE 모형의 개요
본 연구에서 사용된 ONE 모형의 모식도는 Fig. 2에 제시하였으며, 식의 기본 설계 방식은 다음과 같다. ONE 모형은 기본적으로 일 단위 유출계산을 위해 설계되었다. 또한 유역의 물수지를 강수량과 증발산량 유출성분을 기본으로 식을 구성했으며, Monte Calro 기법을 통해 매개변수를 하나만 남겨놓고 다른 매개변수를 상수화한 강우 유출 모형이다(Noh et al., 2017a). 다른 매개변수를 상수화하는 자세한 방법은 Noh et al. (2017b)와 Lee and Noh (2023)을 참고하기 바란다.
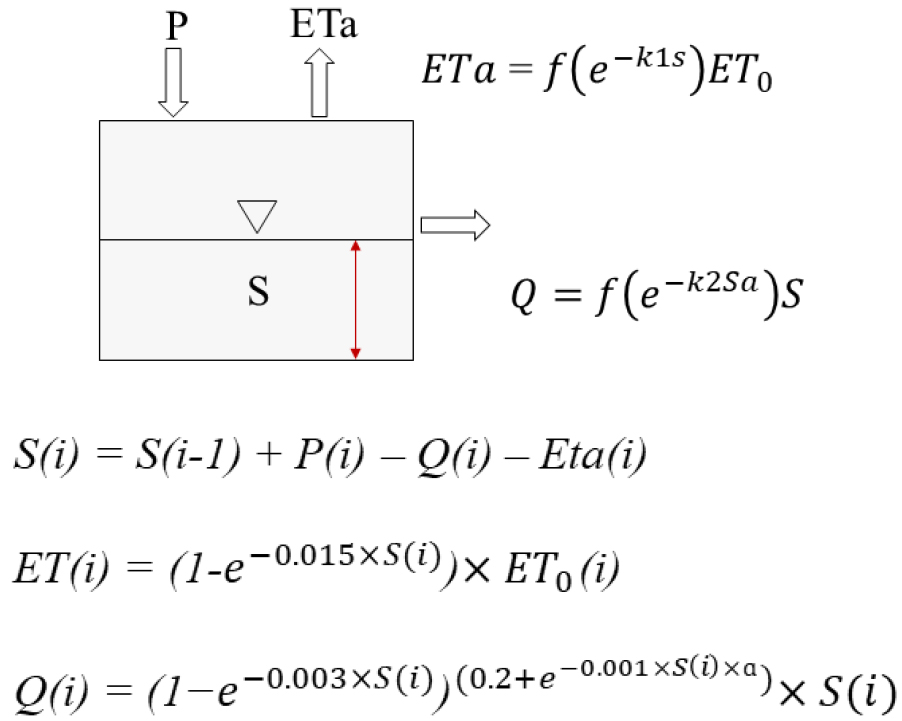
Fig. 2.
Schematic diagram of the ONE model
기본적인 ONE모형의 식은 Eq. (4)와 같으며, 는 유출량(mm), 는 저류량(mm), 𝛼는 유출반응을 고려한 매개변수(무차원)를 의미한다. 저류량 를 구하기 위한 식은 Eq. (6)과 같다. 본 연구에서는 Eq. (4)의 매개변수를 Eq. (5)와 같이 조정하였다.
기본적으로, Eq. (4)과 식의 구성은 같으며, 본 연구에서는 𝛼와 마찬가지로 유출반응을 고려한 Eq. (5)의 매개변수 β를 단 하나의 매개변수로 보고 Noh et al. (2017a)을 참고하여 Monte Calro 기법 적용 결과 최적의 매개변수로 판단하여 𝛼의 값을 2로 고정하고 모의를 진행했다. 또한 매개변수 β를 Noh et al. (2017b)에서 제시한 연간 유출률에 근접하도록 이분법(Bisection method) 기법을 통해 최적의 매개변수를 각 유역에 맞게 적용하여 모의를 진행하였다.
는 저류량 는 강우량(mm) 는 유출량(mm) 는 실제증발산량(mm)을 나타내며 첨자 는 일을 나타내며 -1은 -1일을 나타낸다. 실제증발산량을 구하기 위한식은 Eq. (7)과 같다.
는 실제 증발산량이며 는 잠재증발산량(mm)을 의미한다.
3. 모형의 적용
3.1 미계측 유역 적용을 위한 알고리즘의 선정 및 최적화 기법
강우 유출 모형은 매개변수에 많은 영향을 받기 때문에 모형에 알맞은 매개변수의 선정이 필요하다. 모형의 매개변수는 유역의 지형적 특성 및 수문학적 특성에 따라 결정되므로 매개변수의 최적화를 위해선 이러한 특성들이 고려되어야 한다. 하지만, 다목적 댐과 달리 소규모 저수지와 같은 미계측 유역은 수문자료가 부족하다. 이에 미계측 유역에 대한 모형의 매개변수 추정은 유역특성인자만을 활용한 회귀식으로 추정할 수 있다. 따라서 본 연구에서는 수정 Tank 모형에 대한 미계측 유역 알고리즘으로 Kim and Park (1988)이 개발한 회귀식을 기존 Tank 모형의 검증을 위해 선정하였으며, 회귀식은 Table 1에 제시하였다. 또한 유전자 알고리즘을 활용하여 수정한 An et al. (2015)의 회귀식을 Tank 모형의 비교 검증을 위한 알고리즘으로 선정하였으며 Table 2에 제시하였다. 또한 Table 1과 Table 2에서 제시하고 있는 회귀식을 계산하기 위한 유역면적 (Area), 논비율 (Paddy), 밭비율 (Upland), 산림비율 (Forest), 유로연장 (Length), 유역평균경사 (Slope)와 같은 유역특성 인자는 Table 3에 제시하였다. 마지막으로, 본 연구에서는 각 모형의 최적화 시 성능을 비교하고자 개미군집 알고리즘을 활용하여 Tank 모형에 대해서 최적화를 진행했으며 유출율을 활용하여 ONE 모형에 대해 최적화를 진행하였다. 본 연구에서 사용한 Tank 모형의 최적화 방법인 개미군집 알고리즘(Ant Colony Optimization, ACO)은 다음과 같다. 개미군집 알고리즘은 개미의 집단행동에서 착안한 알고리즘으로, 개미가 개미집에서 먹이를 따라 경로를 찾을 때 먹이를 찾은 첫 개미는 집으로 돌아오며 페로몬을 남긴다. 다음 개미는 앞선 개미와 같이 페로몬을 뿌리며 이전 개미가 남긴 페로몬을 따라 먹이를 찾게 되지만, 중간중간 경로를 바꾸며 여러 가지 경로를 찾게 된다. 개미들의 이러한 행동이 반복되고 이후에는 오래된 페로몬이 사라지면서 최적의 경로를 찾게 되는데, 이러한 최적의 경로를 찾는 원리에 의한 방법이 개미군집 알고리즘이다. 또한 ONE 모형에 대한 최적화 기법은 다음과 같다. 우선 최적화가 종료되는 허용오차를 설정하고, 현재 매개변수 β에서 NSE를 계산한다. 이후 최적화가 종료되는 조건인 허용오차까지 β의 값을 조금 더 증가시켜 반복함으로써 새로운 NSE를 계산하고 β의 변화에 따른 NSE의 변화율과 학습률을 통해 NSE가 최대가 될 수 있는 매개변수 β를 찾는 방식으로 최적화를 진행하였다. 이에 본 연구에서는 기존 모형들로 15개의 댐 유역에 대한 성능을 비교하고 각 모형에 대한 최적화를 통해 국내 유역에 대한 적용성을 검증하였다.
Table 1.
|
Regression equations
|
Correlation
|
F-values
|
Remarks
|
|
H12=16.68(lnA)+24.20
|
0.9998
|
34408.00
|
P : Paddy(%)
F : Forest(%)
U : Upland(%)
A : Watershed (㎢)
|
|
B1=-0.070(lnA)+0.470
|
-0.969
|
138.37
|
|
B3=.0.00618(lnA)+0.0351
|
-0.931
|
58.89
|
|
ST3=43.686(lnA)+37.159
|
0.9998
|
29674.00
|
|
A12=-0.00175F+0.333
|
-0.996
|
1312.50
|
|
A11=-0.00414P+0.160
|
0.996
|
1302.10
|
|
B2 = 0.00998P+0.111
|
0.998
|
4177.50
|
|
A2=0.00657U+0.163
|
0.985
|
303.20
|
|
A3=-0.000267U+0.00912
|
-0.972
|
155.70
|
|
*lnH2=-0.0934U+2.0904
|
-0.688
|
8.10
|
Table 2.
|
Parameters
|
Regression equation
|
R
|
R2 |
|
A11
|
-0.0003Slope-0.017ln(Area)-0.067ln(Upland)+0.398
|
0.60
|
0.36
|
|
A12
|
-0.004Paddy+0.001Forest+0.163ln(Slope)-0.27
|
0.56
|
0.31
|
|
A2
|
9.897×10-5Paddy+0.028ln(Forest)+0.0003ln(Slope)-0.03
|
0.60
|
0.36
|
|
A3
|
-0.0002Upland+4.092×10-5ln(Area)+0.001ln(Length)+0.006
|
0.58
|
0.34
|
|
B1
|
0.003Slope-0.101ln(Upland)+0.262
|
0.59
|
0.35
|
|
B2
|
-0.01ln(Area)+0.1
|
0.64
|
0.41
|
|
B3
|
7.086×10-6Paddy+7.754×10-5Forest+0.001
|
0.55
|
0.31
|
|
H11
|
0.318Forest-0.543Slope+22.018
|
0.79
|
0.63
|
|
H12
|
-0.004Area+0.333Slope+44.939
|
0.69
|
0.48
|
|
H2
|
0.421Forest+15.412(Upland)-22.099
|
0.65
|
0.42
|
|
ST3
|
1.147Forest-49.086
43.013
|
0.40
|
0.16
|
|
-
|
-
|
|
|
Parameters
|
Symbols
|
|
Storage of 1st Tank
|
ST1
|
|
Storage of 2nd Tank
|
ST2
|
|
Storage of 3rd Tank
|
ST3
|
|
Area of upper side outlet in 1st Tank
|
A11
|
|
Area of lower side outlet in 1st Tank
|
A12
|
|
Area of bottom outlet in 1st Tank
|
B1
|
|
Area of side outlet in 2nd Tank
|
A2
|
|
Area of bottom outlet in 2nd Tank
|
B2
|
|
Area of side outlet in 3rd Tank
|
A3
|
|
Area of bottom outlet in 3rd Tank
|
B3
|
|
Height of upper side outlet in 1st Tank
|
H11
|
|
Height of lower side outlet in 1st Tank
|
H12
|
|
Height of upper side outlet in 2nd Tank
|
H2
|
|
Height of lower side outlet in 2nd Tank
|
H3
|
Table 3.
Landuse and characteristics of the study watersheds
|
Watershed
|
Area (km2)
|
Paddy (%)
|
Upland (%)
|
Forest (%)
|
Length (km)
|
Slope (%)
|
|
1-group
|
Soyangang
|
2694.36
|
1.20
|
4.50
|
87.40
|
136.98
|
37.87
|
|
Chungju
|
6661.58
|
2.00
|
8.20
|
82.80
|
274.04
|
24.89
|
|
Andong
|
1590.72
|
2.60
|
7.30
|
81.90
|
166.41
|
30.19
|
|
Imha
|
1367.74
|
3.30
|
7.60
|
82.00
|
122.75
|
30.25
|
|
Namgang
|
2293.42
|
11.20
|
4.80
|
74.60
|
12.52
|
28.94
|
|
Daecheong
|
4134.00
|
8.70
|
8.30
|
72.50
|
253.27
|
25.74
|
|
Juam
|
1010.00
|
11.10
|
5.70
|
73.20
|
90.50
|
25.10
|
|
Hoengseong
|
207.88
|
4.00
|
7.40
|
81.50
|
28.71
|
30.69
|
|
2-group
|
Hapcheon
|
928.94
|
9.90
|
5.30
|
75.40
|
63.00
|
24.87
|
|
Milyang
|
103.47
|
6.00
|
3.50
|
83.70
|
28.06
|
41.65
|
|
Yongdam
|
930.43
|
8.10
|
6.40
|
78.10
|
62.60
|
27.52
|
|
Boryung
|
162.29
|
6.30
|
4.00
|
80.70
|
22.30
|
30.05
|
|
Buan
|
59.00
|
9.50
|
8.80
|
72.50
|
18.90
|
35.86
|
|
Sumjingang
|
763.47
|
8.50
|
6.60
|
74.40
|
82.40
|
22.78
|
|
Tamjin
|
192.34
|
7.92
|
3.44
|
86.59
|
27.67
|
27.94
|
4. 대상유역 선정 및 모의
기존 모형인 Tank 모형과 ONE 모형의 유출량 비교를 통해 국내 유역에 대한 ONE 모형의 적용성을 검토하기 위해 계측자료가 있는 15개의 다목적 댐 상류 유역 (소양강, 횡성, 청주, 안동, 임하, 합천, 남강, 밀양, 대청, 용담, 보령, 부안, 섬진강, 주안, 탐진)을 대상유역으로 선정하였으며 Fig. 3에 도시하였다. 본 연구에서는 유역의 크기에 따른 모형의 결과를 비교하기 위해 15개의 댐을 유역면적 1,000km2를 기준으로 2그룹으로 구분 하였다. 대규모 유역은 면적이 250km2 이상인 유역을 기준으로 대규모 유역으로 분류하지만, 면적이 1,000km2 이상인 유역을 중규모 유역의 경계로 분류하기 때문에 본 연구에서는 1,000km2 이상인 유역을 1그룹(소양강, 청주, 안동, 임하, 남강, 대청, 주암) 이하인 유역을 2그룹으로 (횡성, 합천, 밀양, 용담, 보령, 부안, 섬진강, 탐진) 분류하였다. 대상유역의 유입량, 강수량의 자료는 국가수자원관리종합정보시스템(WAMIS)에서 제공하는 자료를 활용하였으며, 증발산 자료는 유역 내 인접 유역의 기상관측 자료를 활용하였으며 각 유역별 수문자료의 가용기간과 기상관측 지점은 Table 4에 제시하였다. 이에 본 자료를 활용하여 3단 Tank 모형에 대한 2가지 알고리즘에 대한 검증과 ONE 모형에 대한 적용성을 평가하고자 수문모델링 분야에서 많이 이용되는 지표인 NSE를 활용하였으며, 모의 결과를 분석하기 위해 회귀분석에 사용되는 결정 계수인 R2를 사용하여 각 모형을 비교하였으며, 각 모형을 통해 계산한 유출량과 실제 유출량 간의 비교를 통해 모형의 적합성을 평가하였다.
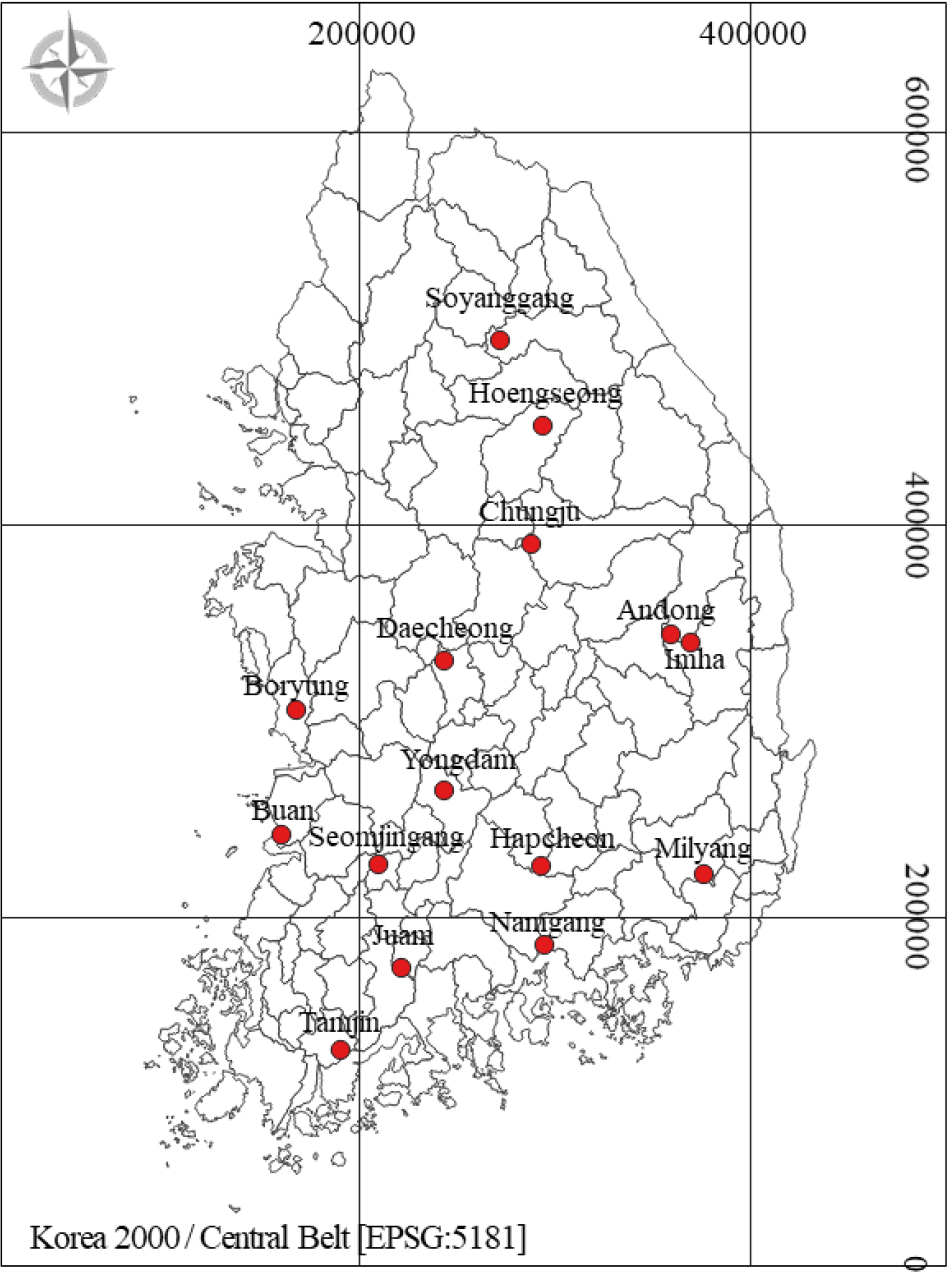
Fig. 3.
Study area
Table 4.
Watershed characteristics and data period
|
Watershed
|
Area (km2)
|
Weather station
|
Data Period
|
|
1-group
|
Soyangang
|
2694.36
|
Chuncheon
|
1990.01.01.-2019.12.31
|
|
Chungju
|
6661.58
|
Chungju
|
1990.01.01.-2016.12.31
|
|
Andong
|
1590.72
|
Andong
|
1990.01.01.-2016.12.31
|
|
Imha
|
1367.74
|
Andong
|
1998.01.01.-2020.12.31
|
|
Namgang
|
2293.42
|
Jinju
|
2000.01.01.-2019.12.31
|
|
Daecheong
|
4134.00
|
Daejeon
|
2000.01.01.-2019.12.31
|
|
Juam
|
1010.00
|
Suncheon
|
1997.01.01.-2019.12.31
|
|
2-group
|
Hoengseong
|
207.88
|
Hongcheon
|
2000.01.01.-2016.12.31
|
|
Hapcheon
|
928.94
|
Hapcheon
|
2000.01.01.-2016.12.31
|
|
Milyang
|
103.47
|
Milyang
|
2001.01.01.-2016.12.31
|
|
Yongdam
|
930.43
|
Geumsan
|
2001.01.01.-2016.12.31
|
|
Boryung
|
162.29
|
Boryung
|
2022.01.01.-2020.12.31
|
|
Buan
|
59.00
|
Buan
|
1997.01.01.-2016.12.31
|
|
Sumjingang
|
763.47
|
Imsil
|
1988.01.01.-2016.12.31
|
|
Tamjin
|
192.34
|
Jangheung
|
2005.01.01.-2019.12.31
|
5. 모의 결과
본 연구에서는 국내 유역에 대한 유출량을 정확히 모의하고 효율적인 저수지 운영을 위해 2가지 강우 유출 모형에 대한 성능을 비교하고 적용성을 검토하고자 하였다. 이에 실무에서 활용되고 있는 모형인 Tank 모형에 대한 검증을 위해 Kim and Park (1988)의 수정 Tank 모형과 An et al. (2015)의 유전자 알고리즘을 활용하여 유출량을 산정하였다. 또한 국내 유역에 대한 ONE 모형의 적용성을 평가하고자 ONE 모형을 활용하여 Tank 모형과 같이 동일한 유역에 대한 유출량을 산정하였다. 본 연구에서는 두 모형에 대한 정확한 지표를 확인하고자 15개 유역을 2개의 그룹으로 나누어 NSE와 R2를 계산하였다. 기본적으로 두 가지 지표에 대해서 홍수기를 위한 1일 단위 유출량을 기반으로 계산했으며, 농업용 저수지 조작을 위해 10일 단위와 갈수기를 위한 연간 물수지를 보기 위해 1년 단위로 나누어 계산하였다. 두 모형의 단위별 NSE와 R2의 정확한 수치는 Table 5와 Table 6에 정리했으며, 효율적인 비교를 위해 Fig. 4와 Fig. 5에 각 모형의 NSE와 R2의 그래프를 정리하였으며 음수로 나타난 부분은 -로 대체하였다. 여기서 Kim and Park (1988)의 Tank 모형은 Tank, An et al. (2015)의 Tank 모형을 Tank_A로 나타냈고, ONE모형은 ONE으로 표기하였으며, 두가지 모형에 대한 최적화 결과는 Tank_opt와 ONE_opt로 표기하였다. 또한, 본 연구에서는 각 모형의 연 유출량을 효율적으로 비교하기 위해 실제 관측값과 각 모형들의 모의 결과를 Fig. 6에 도시하였다.
Table 5.
NSE and R2 of group 1
Model Watershed |
Tank
|
Tank_A
|
Tank_opt
|
ONE
|
ONE_opt
|
Daily
Data
|
Andong
|
NSE
|
-
|
0.68
|
0.76
|
0.79
|
0.81
|
|
R2 |
-
|
0.69
|
0.77
|
0.80
|
0.81
|
|
Daecheong
|
NSE
|
-
|
0.63
|
0.75
|
0.74
|
0.74
|
|
R2 |
-
|
0.68
|
0.75
|
0.74
|
0.75
|
|
Chungju
|
NSE
|
-
|
0.64
|
0.75
|
0.80
|
0.81
|
|
R2 |
-
|
0.65
|
0.76
|
0.82
|
0.82
|
|
Imha
|
NSE
|
-
|
0.71
|
0.73
|
-
|
0.66
|
|
R2 |
-
|
0.72
|
0.74
|
0.39
|
0.72
|
|
Namgang
|
NSE
|
-
|
0.75
|
0.80
|
0.77
|
0.83
|
|
R2 |
-
|
0.81
|
0.81
|
0.81
|
0.83
|
|
Juam
|
NSE
|
0.19
|
0.78
|
0.81
|
0.79
|
0.79
|
|
R2 |
0.67
|
0.78
|
0.81
|
0.81
|
0.80
|
|
Soyangang
|
NSE
|
-
|
0.82
|
0.86
|
0.81
|
0.89
|
|
R2 |
-
|
0.82
|
0.86
|
0.84
|
0.89
|
10
days
data
|
Andong
|
NSE
|
-
|
0.90
|
0.90
|
0.95
|
0.94
|
|
R2 |
-
|
0.93
|
0.93
|
0.95
|
0.95
|
|
Daecheong
|
NSE
|
-
|
0.88
|
0.88
|
0.88
|
0.87
|
|
R2 |
-
|
0.89
|
0.89
|
0.91
|
0.91
|
|
Chungju
|
NSE
|
-
|
0.86
|
0.86
|
0.94
|
0.94
|
|
R2 |
-
|
0.92
|
0.92
|
0.95
|
0.95
|
|
Imha
|
NSE
|
-
|
0.82
|
0.82
|
0.26
|
0.60
|
|
R2 |
-
|
0.85
|
0.85
|
0.73
|
0.84
|
|
Namgang
|
NSE
|
-
|
0.90
|
0.90
|
0.93
|
0.94
|
|
R2 |
-
|
0.94
|
0.94
|
0.94
|
0.94
|
|
Juam
|
NSE
|
-
|
0.92
|
0.92
|
0.84
|
0.86
|
|
R2 |
0.85
|
0.92
|
0.92
|
0.90
|
0.91
|
|
Soyangang
|
NSE
|
-
|
0.94
|
0.94
|
0.95
|
0.97
|
|
R2 |
-
|
0.95
|
0.95
|
0.95
|
0.97
|
Yearly
data
|
Andong
|
NSE
|
-
|
0.50
|
0.50
|
0.96
|
0.91
|
|
R2 |
0.05
|
0.94
|
0.94
|
0.96
|
0.96
|
|
Daecheong
|
NSE
|
-
|
0.92
|
0.92
|
0.89
|
0.85
|
|
R2 |
0.04
|
0.94
|
0.94
|
0.95
|
0.95
|
|
Chungju
|
NSE
|
-
|
0.30
|
0.30
|
0.82
|
0.88
|
|
R2 |
0.05
|
0.91
|
0.91
|
0.92
|
0.92
|
|
Imha
|
NSE
|
-
|
0.71
|
0.73
|
-
|
0.66
|
|
R2 |
-
|
0.72
|
0.74
|
0.39
|
0.72
|
|
Namgang
|
NSE
|
-
|
0.61
|
0.61
|
0.79
|
0.75
|
|
R2 |
-
|
0.85
|
0.85
|
0.80
|
0.83
|
|
Juam
|
NSE
|
-
|
0.87
|
0.87
|
0.34
|
0.49
|
|
R2 |
0.54
|
0.88
|
0.88
|
0.89
|
0.89
|
|
Soyangang
|
NSE
|
-
|
0.66
|
0.66
|
0.84
|
0.96
|
|
R2 |
0.07
|
0.97
|
0.97
|
0.97
|
0.97
|
Table 6.
NSE and R2 of group 2
Model Watershed |
Tank
|
Tank_A
|
Tank_opt
|
ONE
|
ONE_opt
|
Daily
Data
|
Hoengseong
|
NSE
|
0.81
|
0.83
|
0.89
|
0.89
|
0.92
|
|
R2 |
0.83
|
0.84
|
0.89
|
0.90
|
0.93
|
|
Hapcheon
|
NSE
|
0.68
|
0.80
|
0.87
|
0.82
|
0.85
|
|
R2 |
0.71
|
0.82
|
0.87
|
0.82
|
0.86
|
|
Milyang
|
NSE
|
0.68
|
0.88
|
0.91
|
0.84
|
0.91
|
|
R2 |
0.75
|
0.89
|
0.91
|
0.86
|
0.92
|
|
Yongdam
|
NSE
|
0.64
|
0.79
|
0.83
|
0.76
|
0.85
|
|
R2 |
0.69
|
0.82
|
0.83
|
0.78
|
0.85
|
|
Boryung
|
NSE
|
0.65
|
0.72
|
0.79
|
0.72
|
0.80
|
|
R2 |
0.70
|
0.76
|
0.79
|
0.75
|
0.81
|
|
Buan
|
NSE
|
0.55
|
0.77
|
0.79
|
0.57
|
0.79
|
|
R2 |
0.61
|
0.77
|
0.79
|
0.60
|
0.79
|
|
Sumjingang
|
NSE
|
0.59
|
0.67
|
0.70
|
0.65
|
0.72
|
|
R2 |
0.61
|
0.68
|
0.71
|
0.67
|
0.72
|
|
Tamjin
|
NSE
|
0.63
|
0.76
|
0.84
|
0.74
|
0.82
|
|
R2 |
0.66
|
0.78
|
0.84
|
0.75
|
0.84
|
10
days
data
|
Hoengseong
|
NSE
|
0.94
|
0.96
|
0.96
|
0.97
|
0.96
|
|
R2 |
0.95
|
0.96
|
0.96
|
0.97
|
0.97
|
|
Hapcheon
|
NSE
|
0.72
|
0.95
|
0.95
|
0.92
|
0.90
|
|
R2 |
0.87
|
0.95
|
0.95
|
0.94
|
0.95
|
|
Milyang
|
NSE
|
0.85
|
0.93
|
0.93
|
0.92
|
0.93
|
|
R2 |
0.85
|
0.94
|
0.94
|
0.92
|
0.96
|
|
Yongdam
|
NSE
|
0.76
|
0.90
|
0.90
|
0.93
|
0.93
|
|
R2 |
0.89
|
0.94
|
0.94
|
0.93
|
0.94
|
|
Boryung
|
NSE
|
0.85
|
0.80
|
0.80
|
0.89
|
0.88
|
|
R2 |
0.86
|
0.88
|
0.88
|
0.89
|
0.90
|
|
Buan
|
NSE
|
0.85
|
0.90
|
0.90
|
0.86
|
0.89
|
|
R2 |
0.88
|
0.91
|
0.91
|
0.86
|
0.92
|
|
Sumjingang
|
NSE
|
0.82
|
0.84
|
0.84
|
0.87
|
0.89
|
|
R2 |
0.84
|
0.87
|
0.87
|
0.87
|
0.90
|
|
Tamjin
|
NSE
|
0.90
|
0.86
|
0.86
|
0.91
|
0.86
|
|
R2 |
0.91
|
0.91
|
0.91
|
0.93
|
0.93
|
Yearly
data
|
Hoengseong
|
NSE
|
0.75
|
0.90
|
0.90
|
0.90
|
0.79
|
|
R2 |
0.88
|
0.91
|
0.91
|
0.92
|
0.92
|
|
Hapcheon
|
NSE
|
-
|
0.92
|
0.92
|
0.93
|
0.77
|
|
R2 |
0.56
|
0.96
|
0.96
|
0.96
|
0.96
|
|
Milyang
|
NSE
|
0.96
|
0.86
|
0.86
|
0.98
|
0.80
|
|
R2 |
0.98
|
0.98
|
0.98
|
0.99
|
0.99
|
|
Yongdam
|
NSE
|
-
|
0.45
|
0.45
|
0.89
|
0.78
|
|
R2 |
0.83
|
0.91
|
0.91
|
0.92
|
0.92
|
|
Boryung
|
NSE
|
0.82
|
0.40
|
0.40
|
0.88
|
0.69
|
|
R2 |
0.87
|
0.91
|
0.91
|
0.9
|
0.89
|
|
Buan
|
NSE
|
0.78
|
0.71
|
0.71
|
0.84
|
0.32
|
|
R2 |
0.88
|
0.88
|
0.88
|
0.86
|
0.84
|
|
Sumjingang
|
NSE
|
0.15
|
0.50
|
0.50
|
0.88
|
0.77
|
|
R2 |
0.69
|
0.87
|
0.87
|
0.89
|
0.89
|
|
Tamjin
|
NSE
|
0.59
|
0.34
|
0.34
|
0.68
|
-
|
|
R2 |
0.9
|
0.88
|
0.88
|
0.92
|
0.92
|

Fig. 4.
NSE and R2 square of group 1

Fig. 5.
NSE and R2 square of group 2
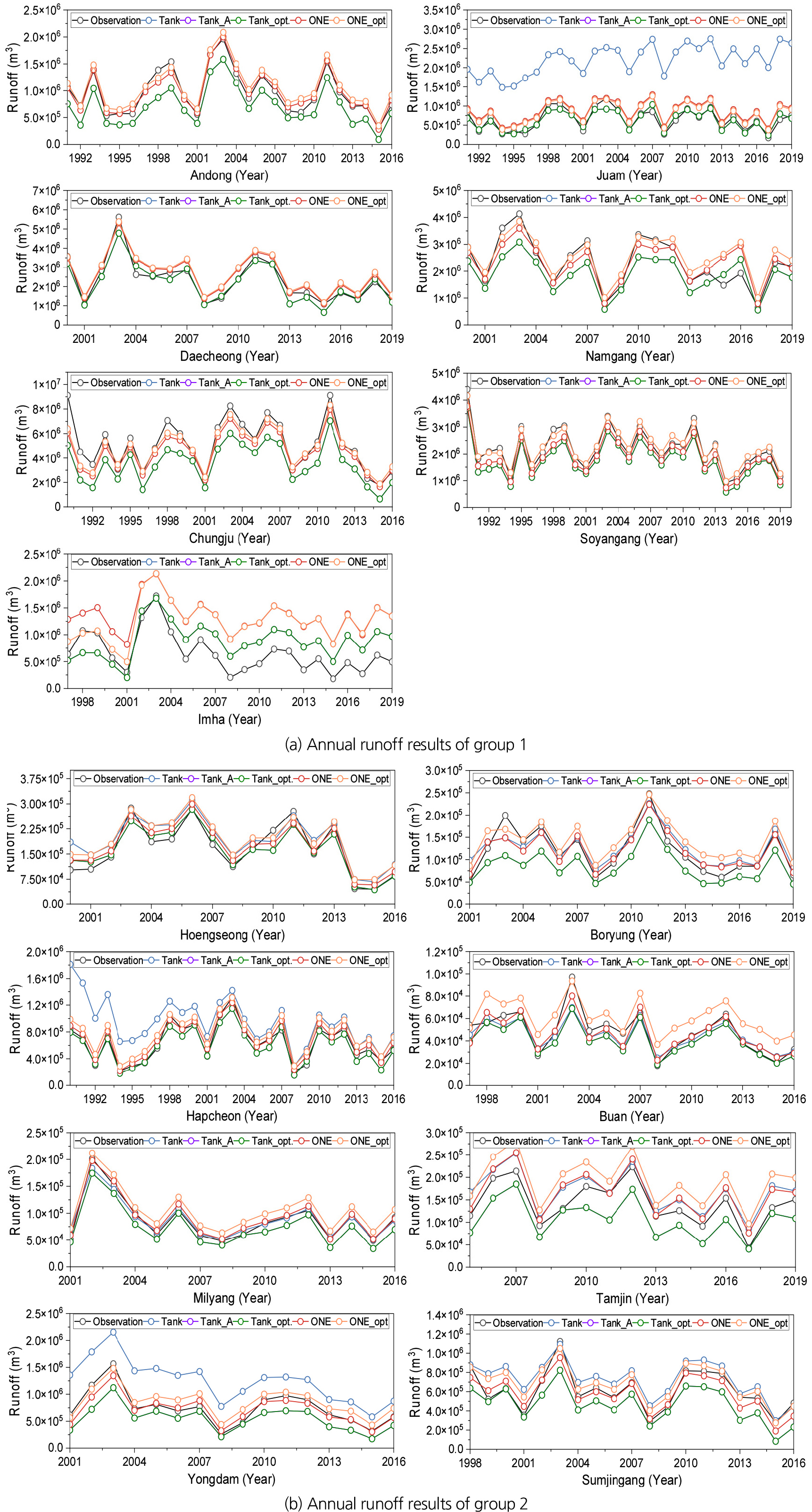
Fig. 6.
The results of annual runoff of group 1 and group 2
1그룹의 일 단위별 모의 결과를 분석한 결과 임하댐을 제외한 6개의 유역에 대해 ONE 모형의 NSE와 R2가 Tank와 Tank_A보다 우수하게 나타났으며, 각 모형의 최적화시 NSE와 R2값 또한 ONE_opt의 결과가 Tank_opt의 결과보다 우수하거나 비슷하게 나타났다. 또한 1그룹의 10일 단위 모의 결과를 분석한 결과 일 단위별 모의 결과와 마찬가지로 임하댐을 제외한 유역에 대해 ONE 모형의 모의 결과가 Tank 및 Tank_ A보다 우수하게 나타났으며, 최적화 결과 또한 ONE_opt가 다소 비슷하거나 우수하게 나타났다. 마지막으로 1그룹의 연 단위별 모의 결과를 분석한 결과 이전과 마찬가지로 ONE 모형이 임하댐을 제외한 유역에 대해 Tank, Tank_opt의 NSE와 R2보다 우수하거나 비슷한 결과를 보였으며 최적화시 모의 결과 또한 앞선 결과와 같은 결과를 나타냈다.
1그룹과 마찬가지로 2그룹의 모의 결과를 분석한 결과는 다음과 같다. 우선 일 단위 2그룹의 모의 결과를 분석한 결과 ONE 모형의 NSE와 R2값이 Tank 모형보다 우수하게 나타났으며, Tank_A와는 다소 비슷하거나 우수하게 나타났다. 또한 2그룹의 각 모형에 대한 최적화 결과를 분석한 결과 ONE_ opt의 결과가 Tank_opt의 결과보다 우수하거나 비슷하게 나타났다. 2그룹의 10일 단위별 분석 결과는 ONE 모형과 Tank, Tank_A의 결과와 비교 시 전체적으로 다소 비슷하거나 우수한 결과를 나타냈으며 ONE_opt 또한 Tank_opt와 비슷하거나 우수한 것으로 나타났다. 마지막으로, 연 단위별 2그룹의 분석 결과는 ONE 모형의 결과가 Tank 및 Tank_opt의 결과와 다소 비슷하거나 우수한 것으로 나타났으며, ONE_opt와 Tank_opt 역시 같은 결과를 나타냈다. 또한 각 그룹의 최적화 결과를 비교한 결과 Tank 모형의 경우 전체적으로 Tank_opt의 결과가 우수한 것으로 나타났으며, 또한 10일 및 연 단위 모의 결과를 비교한 결과 Tank_A와 Tank_opt의 결과가 동일한 것으로 나타났다. 이는 An et al. (2015)가 적용한 15개 유역에 대한 유전자 알고리즘을 활용한 최적화가 개미군집 알고리즘을 활용하여 진행한 최적화의 결과가 동일하게 나타난 것으로 보인다. 반면, ONE 모형의 경우 두 그룹 모두 일 단위를 제외한 10일 단위와 연 단위에서 ONE 모형의 모의 결과와 ONE_opt의 모의 결과가 다소 비슷하거나 ONE 모형이 우수하게 나타나는 경향을 보였다. 이는 미계측 유역에 대한 ONE 모형의 적용이 가능할 것으로 판단된다.
6. 결 론
본 연구에서는 계절과 기후의 변화의 민감한 농업용 저수지의 효과적인 운용을 위해서 강우 유출 모형의 적용성을 검토하였다. 국내에 널리 활용되고 있는 모형인 Tank 모형과 매개변수의 수가 적은 ONE 모형을 선정하였으며, 대상 지역은 계측자료를 확보하기 쉬운 15개의 댐 유역에 대해 유역 면적을 기준으로 두 그룹으로 분류하였다. 모의에 사용되는 강우 자료 및 유입량 자료는 국가수자원관리종합정보시스템(WAMIS)와 기상청 자료를 활용하였다. 이에 본 연구에서는 15개의 댐 유역에 대해 각 모형들의 정확성과 적용성을 검토하였으며, 그 결과를 요약하면 다음과 같다.
1) 15개의 댐 유역에 대해 두 모형의 적용성을 검토한 결과, 전반적으로 1그룹과 2그룹 모두 ONE 모형의 NSE와 R2값이 Tank 모형보다 우수하게 나타났다. 이는 국내 유역에 대해 매개변수의 수가 월등히 적은 ONE 모형의 적용을 통한 유출량 계산이 Tank 모형보다 우수할 것으로 판단된다.
2) 본 연구에서는 ONE 모형의 매개변수 α의 값을 2.0, β의 매개변수를 이분법 기법으로 찾아가는 방식으로 모의를 진행하였다. 임하댐의 경우에는 모의 결과가 제대로 나오지 않았으며, 이는 유출률을 기반으로 한 β의 값이 임하댐에 알맞은 값을 재현하기에는 한계가 있었던 것으로 판단된다.
3) 저수지 운용을 위한 이수관리 측면에서는 연 유출량이 매우 중요하다. 이에 유출률 만으로 최적화 가능한 ONE 모형이 매우 유리할 것으로 판단되며, 광범위한 관계식(유출률 = 연 강우량, 국내 모든지역 적용)이 아니라 국소적인 관계식 (지역별, 특정 유역) 또는 회귀식 개발보다 뛰어난 성능을 보일 가능성이 있고 ONE 모형의 연 유출량 기반 최적화 가능성이 보인다.
본 연구와 같은 강우 유출 모형을 통한 유출량 예측은 효과적인 저수지 운영을 위해 적용되어 댐 유역의 정확한 유입량과 유출량 예측을 하는데 도움을 줄 수 있을 것으로 기대된다. 본 연구에서는 계측자료가 많은 15개의 댐 상류 지역에 대해 진행하여 모의를 진행하였으며, 추후 연구에는 계측자료가 부족한 미계측 유역에 올바른 적용이 가능한지 검토를 하고자 한다. 또한 ONE 모형의 경우 임하댐 유역에 대한 매개변수의 적용이 미흡한 것으로 판단되었으나, 추후 연구에서는 임하댐 유역과 같은 유역에 대한 매개변수의 조정을 위한 유출률의 국소적인 관계식 개발이 필요할 것으로 보인다.
Acknowledgements
This work was supported by Korea Institute of Planning and Evaluation for Technology in Food, Agriculture and Forestry (IPET) through Agricultural Foundation and Disaster Response Technology Development Program (or Project), funded by Ministry of Agriculture, Food and Rural Affairs (MAFRA) (321071-3)
Conflicts of Interest
The authors declare no conflict of interest.
References
An, J.H., Song, J.H., Kang, M.S., Song, I., Jun, S.M., and Park, J. (2015). "Regression equations for estimating the TANK model parameters."
Journal of the Korean Society of Agricultural Engineers, Vol. 57, No. 4, pp. 121-133.
10.5389/KSAE.2015.57.4.121Bae, D.H., Jeong, I.W., Kang, T.H., and Noh, J.W. (2003). "Automatic parameter estimation considering runoff components on Tank model."
Journal of Korea Water Resources Association, Vol. 36, No. 3, pp. 423-436.
10.3741/JKWRA.2003.36.3.423Huh, Y.M., Park, S.W., and Im, S.J. (1993). "A streamflow network model for daily water supply and demands on small watershed (I): Simulating daily streamflow from small watersheds."
Journal of the Korean Society of Agricultural Engineers, KSAE, Vol. 35, No. 1. pp. 40-49.
Kang, H., An, H., Nam, W., and Lee, K. (2019). "Estimation of agricultural reservoir water storage based on empirical method."
Journal of the Korean Society of Agricultural Engineers, Vol. 61, No. 5, pp. 1-10.
Kang, M.G., Lee, J.H., and Park, K.W. (2013). "Parameter regionalization of a Tank model for simulating runoffs from ungauged watersheds."
Journal of Korea Water Resources Association, Vol. 46, No. 5, pp. 519-530.
10.3741/JKWRA.2013.46.5.519Kim, H.J. (2001).
Development of two-parametric hyperbolic model for daily streamflow simulation. Ph. D. Dissertation, Seoul National University.
Kim, H.Y., and Park, S.W. (1986). "An evaluation of parameter variations for a linear reservoir (TANK) model with watershed characteristics."
Journal of the Korean Society of Agricultural Engineers, Vol. 28, No. 2, pp. 45-45. (in Korean)
Kim, H.Y., and Park, S.W. (1988). "Simulating daily inflow and release rates for irrigation reservoirs: Modeling inflow rates by linear reservoir model."
Journal of the Korean Society of Agricultural Engineers, KSAE, Vol. 30, No. 1, pp. 50-62.
Kim, S.J., Kim, P.S., and Yoon, C.Y. (2000). "A regression equation of Tank model parameters for daily runoff estimation in a region with insufficient hydrological data."
Journal of Korea Society of Agricultural Engineers Symposium, pp. 412-418.
Koo, B.Y., Kim, T.S., Jung, I.W., and Bae, D.H. (2007). "Optimization of TANK model parameters using multi-objective genetic algorithm (II): Application of preference ordering."
Journal of Korea Water Resources Association, Vol. 40, No. 9, pp. 687-696.
10.3741/JKWRA.2007.40.9.687Lee, D.R., and Moon, J.W. and Kim, J.H. (2008) "Analysis of relationship between physical characteristics in watershed and Tank model parameters."
Journal of Civil and Environmental Engineering Research, KSCE, pp. 3536-3539.
Lee, J., and Noh, J. (2015). "Evaluating water supply capacity of embankment raised reservoir on climate change."
Journal of the Korean Society of Agricultural Engineers, Vol. 57, No. 4, pp. 73-84.
10.5389/KSAE.2015.57.4.073Lee, J.N., and Noh, J. (2023). "Development of a One-Parameter New Exponential (ONE) model for simulating rainfall-runoff and comparison with data-driven LSTM model."
Water, Vol. 15, No. 6, 1036.
10.3390/w15061036Lee, S.H., and Kang, S.U. (2007). "A parameter regionalization study of a modified Tank model using characteristic factors of watersheds."
Journal of Civil and Environmental Engineering Research, KSCE , Vol. 27, No. 4B, pp. 379-385.
Lim, D.S., Kim, H.S., and Seoh, B.H. (2001). "A study on computation methods of monthly runoff by water balance method."
Journal of Korea Water Resources Association, KWRA, Vol. 34, No. 6, pp. 713-724.
Noh, J., An, H., and Lee, J. (2017a). "Is that possible to simulate daily runoff with one parameter?."
In Proceedings of the Korea Water Resources Association Conference, pp. 29-29.
Noh, J., An, H., Shinogi, Y., Oh, T., and Lee, J. (2017b). "Comparing water quality between Korean and Japanese river."
Journal of the Faculty of Agriculture, Kyushu University, Vol. 62, No. 2, pp. 493-502
10.5109/1854025Noh, J.K. (2003). "Applicability of the DAWAST model considered return flows."
Journal of Korea Water Resources Association, KWRA, Vol. 36, No. 6, pp. 1097-1107.
10.3741/JKWRA.2003.36.6.1097Yoo, C.S., and Park, Y.H. (2006). "A study of the IHACRES model's parameters regionalization for discharge computation on ungaged catchment."
Proceedings of the 2006 Korea Water Resources Assoꠓciation Conference, KWRA, pp. 1792-1796.


