

1. 서 론
2. 연구방법
2.1 Vision Correction Algorithm (VCA)
2.2 Modified Hybrid Vision Correction Algorithm (MHVCA)
3. 연구결과
3.1 2변수 수학문제(Three hump camel back function)의 적용
3.2 30변수 수학문제(Sphere function)의 적용
3.3 제약조건이 있는 문제의 적용
3.4 상수관망 최적설계 문제의 적용
4. 결 론
1. 서 론
상수관망은 중요 사회기반시설물 중 하나이다. 상수관망은 재질과 직경 등이 다양한 관으로 구성되어 물이 필요한 지점으로 물을 공급하는 역할을 한다. 일상생활에 필요한 용수 이외에도 화재 등을 위한 비상용수도 상수관망을 통해 공급받는다. 다양한 관의 배치로 인해 상수관망 설계안의 경우의 수는 기하급수적으로 증가한다. 많은 설계안의 수, 절점의 최소 요구 수압 만족 및 비용의 최소화문제 등으로 인해 상수관망 최적설계에 최적화 기법을 적용하는 연구가 진행되었다(Choi et al., 2015; Lee et al., 2015a, 2015b).
과거에는 상수관망 최적설계를 위해 수학적 방법을 통한 최적화를 적용하였다. 그러나 수학적 방법은 실제 상수관망의 비선형적인 요소들로 인해 최적설계의 한계를 보였다. 수학적 방법의 한계를 극복하기 위해 발견적 탐색법이 이용되었다.
개발된 발견적 탐색법은 기반이 된 부류에 따라 군집지능기반 알고리즘(Swarm intelligence-based algorithm, SIA), 자연모방알고리즘(Bio-inspired algorithm, BIA), 물리화학기반 알고리즘(Physics and Chemistry based algorithm, PCA) 및 기타 알고리즘으로 분류할 수 있다(Fister Jr et al., 2013). SIA는 개미군집최적화(Ant Colony Optimization, ACO) 및 입자군집최적화(Particle Swarm Optimization, PSO) 등이 있다(Dorigo and Di Caro, 1999; Kennedy and Eberhart, 1995). BIA는 유전알고리즘(Genetic Algorithm, GA) 및 Human-Inspired Algorithm 등이 있다(Goldberg and Holland, 1988; Zhang et al., 2009). BIA는 SIA보다 더 넓은 범주의 알고리즘이다. SIA는 군집을 이루고 있는 집단에서 영감을 받았으나, BIA는 군집뿐만이 아닌 자연에서 영감을 받아 개발된 알고리즘이다. PCA는 화음탐색법(Harmony Search, HS) 및 Vision Correction Algorithm (VCA) 등이 있다(Geem et al., 2001; Lee et al., 2017).
SIA를 개량한 알고리즘은 Improved Ant System Algorithm 및 Improved PSO 등이 있다(Bullnheimer et al., 1999; Yiqing et al., 2007). BIA를 개량한 알고리즘은 Improved Genetic Algorithm 등이 있다(Dandy et al., 1996). PCA를 개량한 알고리즘은 Improved Harmony Search (IHS), Exponential Bandwidth Harmony Search with Centralized Global Search (EBHS-CGS) 및 Hybrid Vision Correction Algorithm (HVCA) 등이 있다(Mahdavi et al., 2007; Kim and Lee, 2020; Ryu and Lee, 2021).
다양한 알고리즘들 중 Lee et al. (2017)이 제안한 VCA는 시력교정과정에서 고안된 최적화 알고리즘이다. VCA는 시력검사와 시력교정을 통해 검안하는 과정을 최적해 탐색에 적용하였다. VCA는 시력검사와 시력교정과정을 반복수행하면서 나온 렌즈 중 최적의 조합을 최적해로 한다. VCA의 매개변수는 Division Rate1 (DR1), Division Rate2 (DR2), Astigmatic Rate (AR), Modulation Transfer Function Rate (MR), Compression Factor (CF) 및 Astigmatic Factor (AF)이다. VCA 내 6개의 매개변수는 사용자가 직접 설정하기 때문에 사용성이 떨어진다는 단점이 있다. 또한 VCA 내 매개변수의 설정값에 따라 최적값을 다르게 찾는다는 단점이 있다.
Ryu and Lee (2021)는 VCA의 단점을 보완하고 성능의 개선을 위해 VCA를 기반으로 한 HVCA를 제안하였다. HVCA는 기존 VCA의 매개변수인 AR과 MR를 자가적응형 매개변수로 개선하였다. 자가적응형 매개변수(Hybrid Rate, HR)로 개선하기 위해 Mahdavi et al. (2007)이 제안한 IHS 내 Pitch Adjusting Rate (PAR)의 개념을 적용하였다. IHS의 PAR은 반복시산횟수가 증가함에 따라 PAR의 최솟값(MinPAR)에서 PAR의 최댓값(MaxPAR)까지 증가하게 된다. HVCA는 PAR의 개념을 HR에 적용하였다. HR은 AR과 MR을 통합한 매개변수로 현재시산횟수가 증가함에 따라 0부터 값이 증가하게 되는 자가적응형 매개변수이다. HVCA는 기존 VCA의 단점을 개선과 함께 전역탐색을 강화하기 위해 Kim and Lee (2020)가 제안한 알고리즘인 EBHS-CGS의 CGS를 추가했다. CGS의 추가로 인해 HVCA의 탐색방법은 기존 VCA와 CGS로 구성된다. HVCA는 두 가지 탐색방법을 유동적으로 사용하기 위해 반복시산이 진행되면서 최적해를 찾은 탐색방법의 선택확률을 증가시키는 방법을 적용하였다.
Ryu and Lee (2021)가 제안한 HVCA의 HR은 선형적으로 증가하는 형태이다. 따라서 반복시산 후반부에는 전역탐색의 확률이 낮아지는 단점이 있다. HVCA의 단점을 개선하기 위해 HR의 형태를 개선한 MHVCA를 제안하였다. 자가적응형 매개변수 개선이 적용된 MHVCA의 성능을 확인하기 위해 결정변수가 2개 및 30개로 구성된 수학문제와 제약조건이 있는 수학문제에 적용하였다. MHVCA의 적용결과를 HS, IHS, VCA 및 HVCA와 비교하였다. MHVCA를 수학문제 뿐만 아니라 수자원공학 문제 중 상수관망 최적설계 문제에 적용하여 결과를 다른 최적화 알고리즘들과 비교하였다.
2. 연구방법
2.1 Vision Correction Algorithm (VCA)
VCA는 시력교정과정에서 고안된 최적화 알고리즘이다. VCA의 특징 중 하나는 유동적인 전역탐색과 지역탐색을 실행하기 위한 Division Rate (DR)를 적용하였다는 점이다. DR은 반복시산이 진행되면서 최적값을 찾아낸 탐색방법의 선택확률을 증가시키는 매개변수이다. VCA의 DR은 DR1 및 DR2로 구성되어 있다. DR1은 현재시산에서 전역탐색과 지역탐색 중 탐색방법을 정하는 매개변수이다. DR2는 전역탐색을 실행하게 되는 경우 전역탐색의 탐색방향을 정하는 매개변수이다. 탐색방향은 최적결정변수 기준으로 양(+)의 방향과 음(-)의 방향 중 한 가지로 실행된다. 기존 VCA 내에서 각 결정변수의 미세조정은 지역탐색에서 이루어지며 Modulation Transfer Function (MTF), CF 및 AF를 통해 실행된다. 미세조정 중 MTF는 MR의 확률을 바탕으로 적용되며, AF는 AR의 확률을 따른다.
2.2 Modified Hybrid Vision Correction Algorithm (MHVCA)
Ryu and Lee (2021)가 제안한 HVCA는 기존 VCA에 자가적응형 매개변수인 HR의 적용과 Kim and Lee (2020)가 제안한 EBHS-CGS 내 CGS의 추가로 사용성과 성능을 개선한 알고리즘이다. HVCA는 반복시산 초기에 CGS를 통한 전역탐색을 실행한다. CGS는 탐색범위의 중간값과 현재시산의 최적값을 이용해 새로운 탐색범위를 설정하여 전역탐색을 진행한다. 탐색범위의 중간값과 최적값이 근접한 경우 CGS를 통한 최적값 탐색이 빠르게 실행된다. CGS의 특징으로 인해 HVCA는 반복시산 초기에 오차가 빠르게 줄어든다. VCA를 통한 지역탐색이 진행될수록 CGS의 선택확률이 줄어들며, VCA의 선택확률이 증가하게 된다. HVCA는 증가하는 VCA의 선택확률과 HR로 인해 미세조정을 실행하여 빠르게 최적값을 찾을 수 있다.
Ryu and Lee (2021)가 제안한 HVCA의 자가적응형 매개변수인 HR은 반복시산이 진행됨에 따라 현재시산횟수를 설정된 전체 반복시산횟수로 나눈 값으로 선형으로 증가하게 된다. Eq. (1)은 기존 HR의 형태이다.
여기서, Total iteration은 설정한 전체 반복시산횟수이며, Current iteration은 현재시산의 횟수이다.
기존 HR은 증가하는 지역탐색 확률로 인해 반복시산 후반부에는 전역탐색을 통한 최적해 탐색이 이루어지지 않는다는 단점이 있다.
본 연구에서는 이러한 단점을 극복하기 위해 새로운 HR이 적용된 MHVCA를 제안하였다. 새로운 HR은 반복시산이 진행됨에 따라 비선형적으로 증가한다. Eq. (2)는 MHVCA에 적용된 새로운 HR의 형태이다.
여기서, Total iteration은 설정한 전체 반복시산횟수이며, Current iteration은 현재시산의 횟수이다.
Fig. 1은 반복시산횟수에 따른 기존 HR과 새로운 HR의 변화를 보여주고 있다.
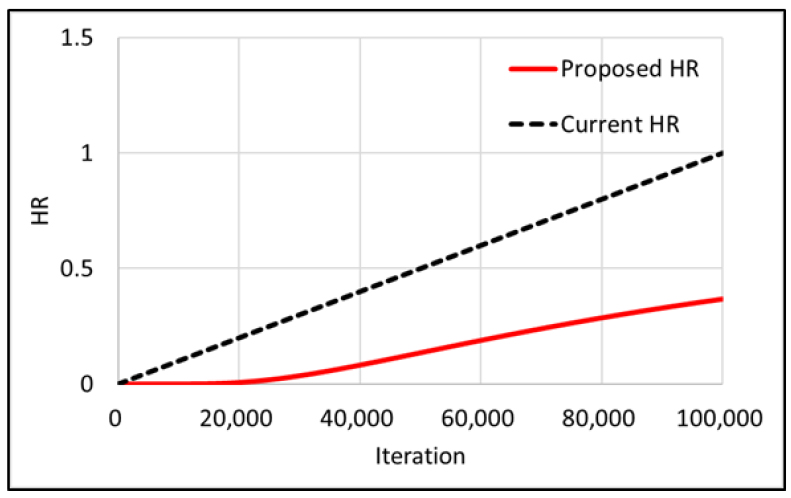
기존 AR 및 MR 대신 HR의 확률에 따라 MTF, AF 및 CF를 통해 실행한다. MHVCA의 매개변수는 Centralized Global Search Rate (CGSR), HR, DR1, DR2, AF 및 CF로 구성되어 있다. CGSR은 CGS를 실행하기 위한 확률을 나타내는 매개변수이다. CGSR, DR1 및 DR2는 반복시산이 진행되면서 최적해를 찾은 탐색방법의 선택확률을 증가시킨다.
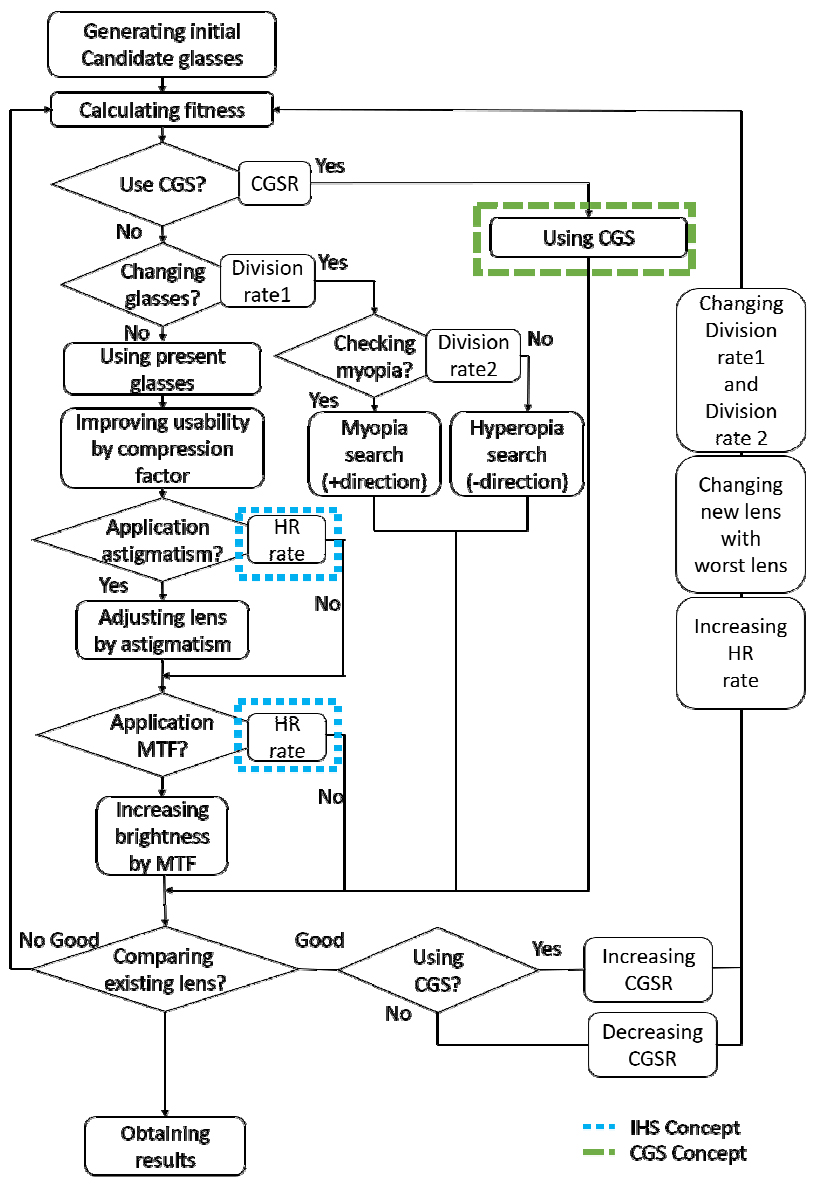
MHVCA는 세 가지 방법으로 최적해 탐색을 진행한다. VCA의 지역탐색을 통한 최적해 탐색, VCA의 전역탐색을 통한 최적해 탐색 및 CGS의 전역탐색을 통한 최적해 탐색으로 최적해를 찾는다. VCA를 통한 탐색방법은 IHS의 PAR개념을 적용한 HR을 통해 최적해 탐색이 실행된다. Table 1은 MHVCA의 의사코드이며, Fig. 2는 MHVCA의 탐색 과정을 보여주고 있다.
Fig. 2에 따르면 MHVCA는 초기 결정변수들의 집합을 생성한다. MHVCA는 생성된 결정변수들의 집합을 통해 목적함수에 대한 값을 계산한다. MHVCA는 생성된 결정변수의 집합들을 기반으로 CGSR을 통해 CGS를 통한 탐색과 VCA를 통한 탐색 중 탐색방법에 대한 결정을 하게 된다. VCA를 통한 탐색을 실행하게 되는 경우 DR1을 통해 전역탐색과 지역탐색 중 탐색방법에 대한 결정을 하게 된다. 전역탐색을 실행하게 되는 경우 DR2를 통해 탐색방향을 결정하게 되고, 지역탐색을 실행하게 되는 경우 HR을 통해 미세조정에 대한 결정을 하게 된다. MHVCA는 매개변수에 따라 결정된 탐색방법을 기반으로 탐색된 결정변수를 기존의 결정변수와 비교한다. 기존의 결정변수보다 좋은 결과를 가진 결정변수를 탐색한 경우 좋은 결과를 가진 결정변수를 탐색한 과정의 선택확률을 증가시키는 구조로 되어있다.

3. 연구결과
제안된 MHVCA의 성능을 비교하기 위해 최적화문제에 적용하였다. 최적화 알고리즘을 적용한 문제는 결정변수가 2개로 구성된 수학문제(Three hump camel back function), 결정변수가 30개로 구성된 수학문제(Sphere function), 결정변수 7개로 구성되어 있으며, 제약조건이 있는 수학문제(Constrained problem) 및 상수관망 최적설계 문제(Water distribution problem)이다. 결정변수가 2개 및 30개로 구성된 수학문제는 최적값이 존재하기 때문에 알고리즘을 적용한 결과와 최적값을 비교하여 오차(Error)로 제시하였다. 제약조건이 있는 수학문제와 상수관망 최적설계 문제는 최적값이 존재하지 않기 때문에 알고리즘을 사용하여 구한 결과(Result)를 비교하였다. 각 문제의 최적값과 결정변수의 수는 Table 2와 같다.
Table 2.
Specification of benchmark function
| Benchmark problem | Optimal value | Number of decision variables |
| Three hump camel function | 0 | 2 |
| Sphere function | 0 | 30 |
| Constrained problem | N/A | 7 |
|
Water distribution problem (Balerma Network) | N/A | 454 |
각 알고리즘의 적용결과와 성능을 비교하기 위해 Mean Number of Function Evaluations (MeanNFEs), Success Rate (SR) 및 소요시간(Time)을 이용하였다. Number of Function Evaluations (NFEs)는 목적함수에 의해 생성되는 새로운 해의 개수와 설정된 전체 반복시산횟수를 곱하여 나타내는 값이다. MenaNFEs는 각 알고리즘의 반복실행 적용결과에 대해 최적값에 수렴한 최초의 NFEs의 평균값이다. MeanNFEs은 알고리즘이 최적해를 얼마나 빨리 찾아내는지를 알 수 있는 정량적 지표이다. SR은 알고리즘이 구한 결과가 얼마나 정확하게 찾았는지 알 수 있는 최적해 탐색 성공에 대한 지표이다. SR은 100번의 반복실행 중 알고리즘의 적용결과와 최적화 문제에 대한 답의 오차가 1.0E-10 이하인 경우에 대한 총합을 나타내었다. Time은 설정된 반복실행동안 알고리즘이 구동되는 시간을 나타낸 값으로 실제 걸리는 시간을 측정하였다. 최적화 알고리즘을 수학문제에 적용하기 위해 동일한 컴퓨터환경에서 Visual Basic 6.0 프로그램을 사용하였다. 프로그램 내 각 결정변수의 형태는 Double로 4.94065645841246544E-324부터 -4.94065645841246544 E-324까지의 값을 나타낸다.
최적화 알고리즘들을 문제에 적용하기 위해 각 알고리즘의 매개변수를 설정하였다. Table 3은 수학문제를 위해 적용한 HS와 IHS의 매개변수이다. MaxPAR, MinPAR, Maxbw 및 Minbw는 IHS에서 사용되는 매개변수이다. IHS의 PAR은 현재시산횟수가 증가함에 따라 MinPAR부터 MaxPAR까지 증가하고, bw는 현재시산횟수가 증가함에 따라 Maxbw부터 Minbw까지 감소한다.
Table 3.
Parameter setting of HS and IHS for the application of benchmark function
| HS | IHS | |
| HMS | 10 | 10 |
| HMCR | 0.9 | 0.9 |
| PAR | 0.5 | - |
| MaxPAR | - | 0.99 |
| MinPAR | - | 0.35 |
| Maxbw | - | 0.05 |
| Minbw | - | 0.00001 |
HS의 매개변수 중 PAR은 설정에 따라 최적값의 차이가 발생한다. Table 4는 HS의 PAR에 따른 수학문제 적용결과이다.
Table 4에 따르면 HS는 PAR이 0.5일 때 각 문제의 평균값이 최소를 나타내었다. Three hump camel back function의 경우 PAR이 0.5일 때 평균오차(Mean Error), 최소오차(Best Error), 최대오차(Worst Error) 및 표준편차(SD)가 가장 낮게 나왔다. Sphere function의 경우 PAR이 0.2인 경우와 0.5인 경우의 평균오차는 동일하였으며, 최소오차는 PAR이 0.2일 때 더 낮은 값을 나타내었다. 그러나 PAR이 0.5일 경우 최대오차와 표준편차가 더 낮은 값을 나타내었다. 따라서 PAR이 0.2인 경우보다 0.5인 경우가 더 좋은 값을 나타내었다. Constrained problem의 경우 PAR이 0.5인 경우가 모든 결과에 대해 낮은 값을 나타내었다. 수학문제 적용결과에 따라 HS의 PAR을 0.5로 설정하였다. IHS의 MaxPAR, MinPAR, Maxbw 및 Minbw는 Mahdavi et al. (2007)이 제안한 IHS의 매개변수를 사용하였다.
Table 4.
Comparison of error (result) for application of benchmark function using HS along with PAR
Table 5는 수학문제를 위해 적용한 VCA와 MHVCA의 매개변수이다. VCA의 매개변수 중 Candidate Glasses (CG)는 알고리즘 내 저장공간으로 HS와 IHS의 매개변수 중 Harmony Memory Size (HMS)와 같은 역할을 하는 매개변수이다. CG와 HMS는 같은 역할을 하는 매개변수이기 때문에 같은 값으로 설정하였다.
Table 5에 따르면 VCA의 매개변수 중 MR 및 AR은 Lee et al. (2017)이 제안한 VCA의 General value인 0.1을 적용하였다. VCA, HVCA 및 MHVCA의 정확한 비교를 위해 공통된 매개변수는 같은 값으로 적용하였다.
Table 5.
Parameter setting of VCA, HVCA and MHVCA for the application of benchmark function
| VCA | HVCA | MHVCA | |
| CG | 10 | 10 | 10 |
| CGSR | - | 0.1 | 0.1 |
| DR1 | 0.1 | 0.1 | 0.1 |
| DR2 | 0.5 | 0.5 | 0.5 |
| MR | 0.1 | - | - |
| CF | 20 | 20 | 20 |
| AR | 0.1 | - | - |
| AF | 45 | 45 | 45 |
3.1 2변수 수학문제(Three hump camel back function)의 적용
결정변수가 2개인 수학문제(Three hump camel back function)에 대해 HS, IHS, VCA, HVCA 및 MHVCA를 적용하였다. 아래의 Eq. (3)은 Three hump camel back function의 식이다. Three hump camel back function에서 NFEs는 50,000으로 설정하였으며, 총 100회 반복실행하였다.
여기서, , 는 Three hump camel back function의 결정변수이다.
Table 6은 Three hump camel back function을 HS, IHS, VCA, HVCA 및 MHVCA에 적용한 결과를 비교한 표이다.
Table 6에 따르면 VCA, HVCA 및 MHVCA가 가장 좋은 최적값을 찾아냈다. HVCA 및 MHVCA는 최대 오차(Worst Error), 최소 오차(Best Error), 평균 오차(Mean Error) 및 표준편차(Standard Deviation, SD)가 모두 0으로 나왔으며, SR이 100이다. 따라서 VCA, HVCA 및 MHVCA는 100회의 반복실행에서 모두 최적값을 찾았다. HS 및 IHS의 표준편차는 각각 4.35E-08, 2.80E-09 및 1.07E-77로 100회의 반복실행동안 모두 해를 찾지 못했다. HS, IHS의 MeanNFEs는 50,000번에 가깝게 나왔다. HS, IHS는 설정한 50,000번의 NFEs에서 최적값을 찾기 위해 연산이 진행되고 있다. MHVCA는 다른 알고리즘에 비해 매우 낮은 3,073의 NFEs에서 최적값에 수렴했다. 그러나 MHVCA는 반복실행동안 소요된 시간이 962초로 다른 알고리즘에 비해 가장 많은 시간이 소요되었다. HR로 인해 반복시산이 증가할수록 MHVCA의 미세조정이 실행되는 확률이 증가하기 때문이다.
Table 6.
Comparison of error for application of Three hump camel back function
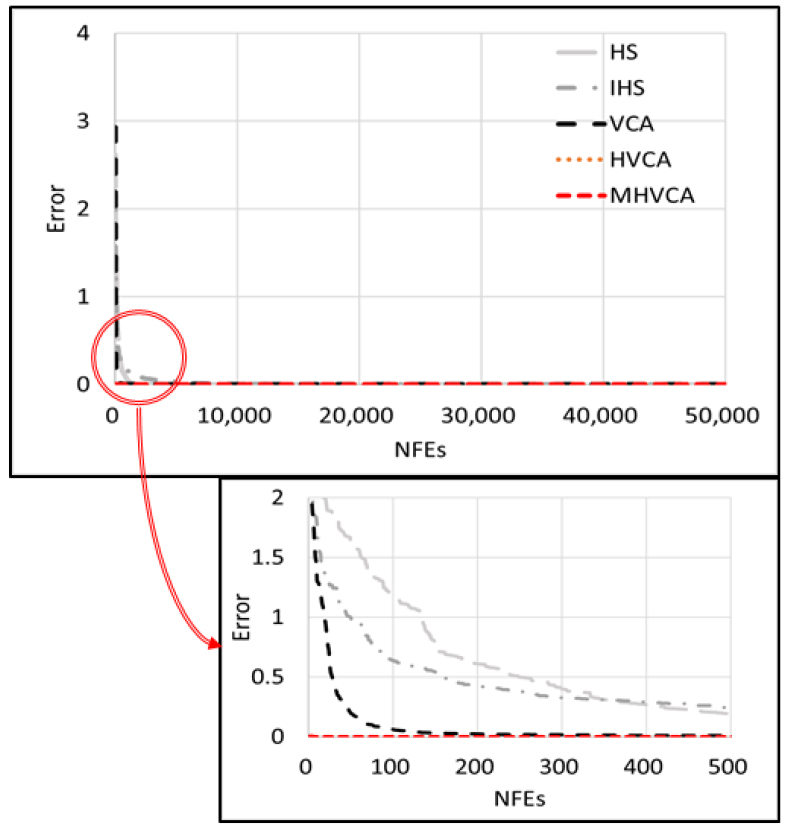
Fig. 3은 Three hump camel back function에 대해 각 알고리즘별 수렴곡선을 나타낸 것이다. 수렴곡선은 100회의 반복실행결과의 평균값으로 나타내었다.
Fig. 3에 따르면 반복시산의 초기에 모든 알고리즘의 오차가 빠르게 감소되었다. HS와 IHS는 약 500의 NFEs까지 감소하다가 수렴하는 모습을 보였다. VCA는 약 50의 NFEs까지 오차가 빠르게 감소하였으며, HVCA 및 MHVCA는 반복시산의 시작과 동시에 오차가 빠르게 감소하였다. VCA와 달리 HVCA 및 MHVCA는 CGS를 이용한 전역탐색을 실행하여 빠르게 오차가 줄어든다. 오차가 줄어든 이후 HVCA 및 MHVCA는 지역탐색 확률이 증가하면서 최적값을 찾는다. 2변수 수학문제에서 HVCA 및 MHVCA는 HS, IHS 및 VCA보다 낮은 MeanNFEs를 보여주며, 안정적으로 최적값을 찾을 수 있다는 것을 보여준다.
3.2 30변수 수학문제(Sphere function)의 적용
결정변수가 30개인 수학문제(Sphere function)에 대해 HS, IHS, VCA, HVCA 및 MHVCA를 적용하였다. 아래의 Eq. (4)는 Sphere function의 식을 나타낸 것이다. Sphere function을 해결하기 위해 NFEs를 100,000으로 설정하였으며, 100회 반복실행하였다.
여기서 는 결정변수의 수이고, 은 Sphere function의 결정변수이다.
Table 7은 Sphere 문제를 HS, IHS, VCA, HVCA 및 MHVCA에 적용한 결과를 비교한 표이다.
Table 7에 따르면 VCA, HVCA 및 MHVCA가 가장 좋은 최적값을 찾아냈다. VCA, HVCA 및 MHVCA는 최대 오차, 최소 오차, 평균 오차 및 SD가 0으로 100회의 반복실행에서 모두 최적값을 찾았다. HS는 평균 오차가 약 2.66E-05 및 IHS는 평균오차가 약 8.07E+01로 100회의 반복실행동안 모두 해를 찾지 못했다. HS 및 IHS의 MeanNFEs는 100,000번에 가깝게 나왔다. HS는 설정한 100,000번의 NFEs에서 최적값을 찾기 위해 연산이 진행되고 있다. HVCA는 CGS로 인해 VCA에 비해 매우 낮은 1,129의 MeanNFEs를 나타냈다. MHVCA는 연산과정의 추가로 인해 반복실행동안 소요된 시간이 8,050초로 기반이 된 VCA에 비해 많은 시간이 소요되었으며, VCA보다 약 2배의 시간이 소요되었다. HVCA의 경우 소요된 시간이 오래 걸렸다. HVCA는 HR의 구조상 미세조정을 하는 확률이 급격하게 증가한다. HR로 인해 HVCA는 미세조정을 다른 알고리즘보다 많이 실행하게 되며, 결정변수가 30개이기 때문에 VCA 및 MHVCA보다 많은 시간이 소요된다.
Table 7.
Comparison of error for application of Sphere function
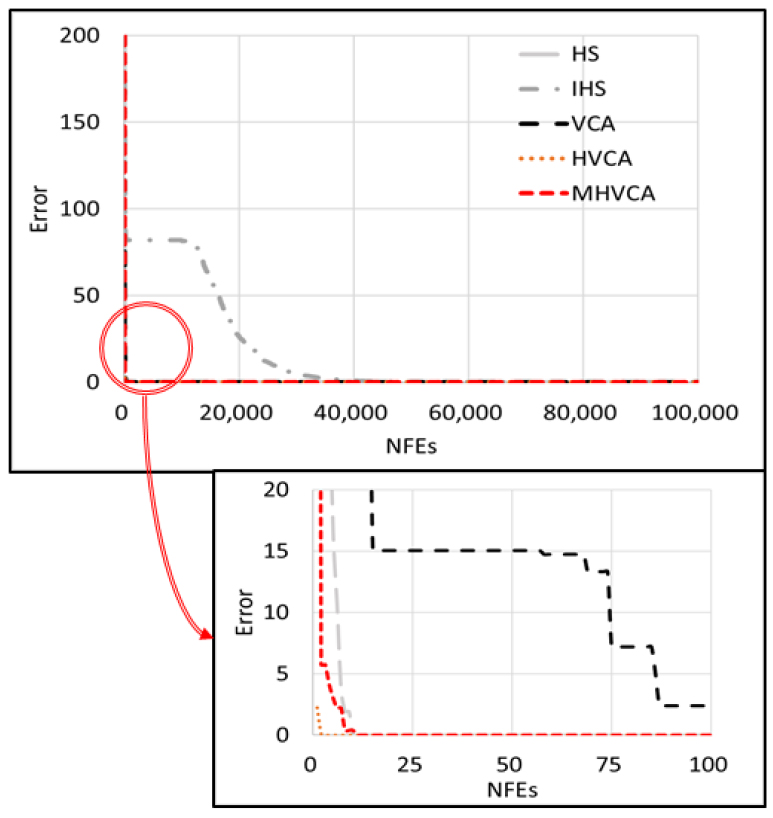
Fig. 4는 Sphere function에 대해 각 알고리즘의 수렴곡선을 나타낸 것이다. 수렴곡선은 100회의 반복실행결과의 평균값으로 나타내었다.
Fig. 4에 따르면 IHS의 경우 약 15,000의 NFEs까지 오차가 일정하게 유지되다가 오차가 감소하는 것을 볼 수 있다. HS는 초반부의 NFEs에서 수렴을 하였으나 HS와 IHS 모두 최적값을 찾지 못하였다. VCA의 경우 반복시산이 시작한 이후 매우 빠르게 오차가 감소하였다. HVCA는 반복시산이 시작함과 동시에 낮은 결정변수의 값을 찾아 다른 알고리즘에 비해 낮은 오차값을 보였다. 그러나 반복시산의 초반 NFEs에서 MHVCA가 VCA 및 HVCA보다 더 작은 오차로 수렴했다. 30변수 수학문제에서 MHVCA는 HS, IHS, VCA 및 MHVCA보다 낮은 MeanNFEs 및 낮은 오차를 보여주었다.
3.3 제약조건이 있는 문제의 적용
제약조건이 있는 문제는 제약조건을 만족하면서 최적값을 찾는 문제이다. 문제에 대한 정답이 존재하지 않는 문제이기 때문에 각 알고리즘의 적용결과를 비교하였다. 결정변수가 7개로 구성된 제약조건이 있는 문제에 대해 HS, IHS, VCA, HVCA 및 MHVCA를 적용하였다.
아래의 Eq. (5)는 제약조건이 있는 문제의 식을 나타낸 것이다. 제약조건이 있는 문제를 해결하기 위해 NFEs를 100,000으로 설정하였으며, 100회 반복실행하였다.
여기서 은 제약조건이 있는 문제의 결정변수이다.
Table 8은 제약조건이 있는 문제를 HS, IHS, VCA, HVCA 및 MHVCA에 적용한 결과를 비교한 표이다.
Table 8에 따르면 VCA와 MHVCA가 평균 결과(Mean Result)가 680.648로 동일하게 나왔다. HS, IHS 및 HVCA는 평균 결과가 각각 681.661, 680.723 및 680.659로 VCA와 MHVCA보다 큰 값으로 나왔다. 최솟값(Best Result)이 나온 알고리즘은 MHVCA로 680.631이 나왔다. IHS와 HS의 경우 각각 680.645 및 680.735로 나왔다. 최댓값(Worst Result)은 MHVCA가 680.710으로 가장 낮았으며, HVCA가 680.920, VCA가 680.748, IHS가 681.308, HS가 682.043으로 결과가 나왔다. MHVCA는 표준편차가 0.014로 알고리즘 중 가장 낮은 결과를 보여주었다. 반복실행동안 소요된 시간은 IHS가 2919초로 가장 높았으며, VCA (2,513초), MHVCA (2,374초), HVCA (2,369초), HS (1,146) 순으로 높은 시간을 나타내었다. MHVCA는 제약조건이 있는 문제에서 안정적으로 좋은 결과를 보여주었으나, 실제로 소요되는 시간은 HVCA보다 느린 결과를 보여주었다. 이를 통해 MHVCA와 HVCA는 결정변수가 적은 문제에 대해 미세조정 과정에서 소요되는 시간이 큰 차이가 나지 않는다는 것을 알 수 있다.
Table 8.
Comparison of error for application of constrained problem
Fig. 5는 제약조건이 있는 문제에 대해 각 알고리즘의 수렴곡선을 나타낸 것이다. 수렴곡선은 100회의 반복실행결과의 평균값으로 나타내었다.
Fig. 5에 따르면 반복시산 동안 VCA, HVCA 및 MHVCA의 수렴하는 속도가 빠르게 나타났다. HS와 IHS는 약 30,000의 NFEs에서 수렴을 시작하는 모습을 보였으나 낮은 값에 수렴하지 못하였다. 제약조건이 있는 문제에서 VCA 및 MHVCA가 HS 및 IHS보다 좋은 성능을 보여준다는 것을 알 수 있다.
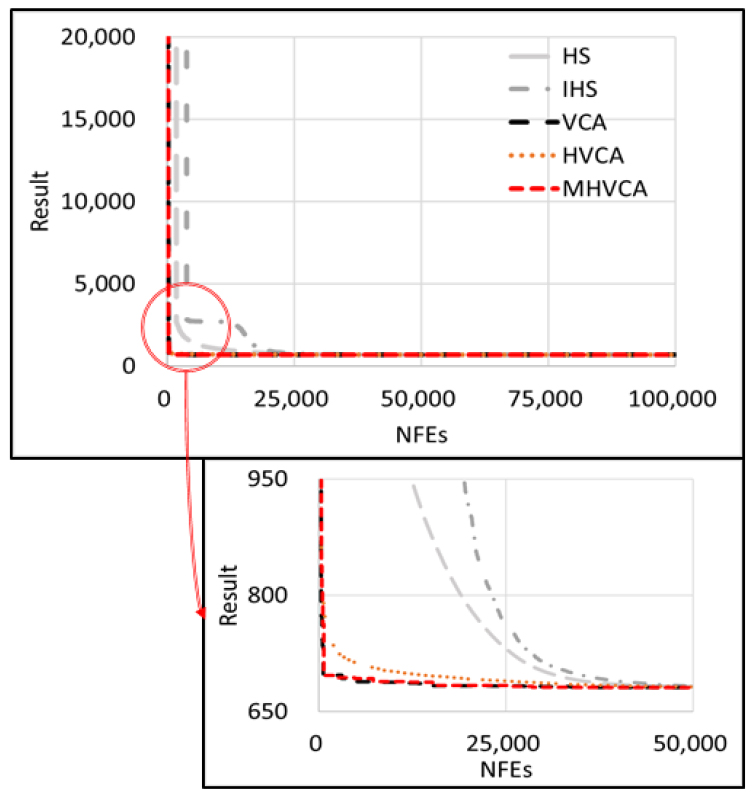
3.4 상수관망 최적설계 문제의 적용
결정변수가 2개 및 30개로 구성된 수학문제와 제약조건이 있는 수학문제를 통해 MHVCA의 성능을 검토하였다. 적용한 모든 문제에서 MHVCA는 좋은 성능을 보여주었다. 실제 수자원공학 문제에 적용하기 위해 MHVCA를 상수관망 최적설계 문제에 적용하여 다른 최적화 알고리즘들과 비교하였다. 상수관망 최적설계 문제에 적용하기 위해 MHVCA를 미국 환경보호국이 개발한 EPANET과 연동하여 수리해석을 진행하였다. MHVCA의 적용결과를 HS, Multi-Layerd Harmony Search (MLHSA), VCA 및 HVCA의 결과와 비교하였다(Lee et al., 2016, 2017; US EPA, 2000). Fig. 6은 MHVCA를 상수관망 최적설계 문제에 적용하기 위해 선택한 스페인의 Balerma 관망이다.
Balerma 관망은 443개의 절점, 454개의 관 및 4개의 저류시설로 구성되어 있다. Balerma 관망은 자연유하식이며, 8개의 폐합형으로 되어있다. Balerma 관망에 대한 손실 수두는 Darcy-Weisbach 공식을 통해 구하였으며, 각 관의 계수 k는 0.0025 mm로 설정하였다. Table 9는 상수관망 최적설계 문제에 사용되는 관의 직경당 가격이다.
Table 9.
Pipe cost per diameter
| Diameter (mm) | Cost (€/m) |
| 113.0 | 7.22 |
| 126.6 | 9.10 |
| 144.6 | 11.92 |
| 162.8 | 14.84 |
| 180.8 | 18.38 |
| 226.2 | 28.60 |
| 285.0 | 45.39 |
| 361.8 | 76.32 |
| 452.2 | 124.64 |
| 581.8 | 215.85 |
아래의 Eq. (6)은 Balerma 관망의 최적설계를 위한 비용함수와 만족해야 하는 최소 수압이며, 최소 수압을 만족하지 못할 경우의 페널티를 부여하는 함수이다.
여기서 는 단위 길이(mm)당 비용, 는 관의 길이(m), 는 관의 직경(mm)이다. 은 관의 수, 은 절점의 수이다. 제약조건 및 페널티 함수에서 는 절점 의 수압이며, 은 절점의 최소 요구 수압이다. Balerma 관망에서 최소수압은 20 m이다. 는 최소 요구 수압을 만족하지 않는 경우 부여하는 패널티이며, ,는 부여하는 패널티의 값이다. 패널티 는 1020이며, 패널티 는 107이다.
Table 10은 상수관망 최적설계 문제에 대해 MHVCA를 적용한 결과이다. MHVCA의 설정한 매개변수는 CF와 AF로 각각 10 및 1로 상수관망 최적설계 문제에 대해 가장 좋은 값을 나타내는 변수로 설정하였다. MHVCA의 결과를 비교하기 위해 설정한 HVCA의 매개변수는 CF와 AF로 각각 10 및 45로 상수관망 최적설계 문제에 대해 가장 좋은 값을 나타내는 변수로 설정하였다. 기존에 연구된 알고리즘들과 결과를 비교하기 위해 HVCA 및 MHVCA의 NFEs를 45,400으로 설정한 후 실행하였다. Table 11은 HS, MLHSA, VCA 및 HVCA를 상수관망 최적설계 문제에 적용한 결과이다(Lee et al., 2016, 2017).
Table 11에 따르면 HS의 최소 비용은 2.60E+06€으로 다른 알고리즘에 비해 많은 비용이 발생하였다. Table 10과 Table 11에 따르면 제안된 MHVCA는 MLHSA보다 최소 비용이 약 0.01E+0.6 낮게 나왔으며, 최대 비용이 MHVCA가 MLHSA보다 0.16E+06 낮게 나왔으며, 평균 비용이 MHVCA가 MLHSA보다 0.15E+06 낮게 나왔다. MHVCA는 VCA보다 평균 비용, 최대 비용 및 최소 비용이 낮게 나왔다. 평균 비용은 MHVCA가 VCA보다 약 0.06E+06€ 만큼 낮게 나왔으며, 최소 비용은 MHVCA가 VCA보다 약 0.05E+06€ 만큼 낮게 나왔다. 최대 비용은 MHVCA가 VCA보다 약 0.067+06€ 만큼 낮게 나왔다. MHVCA는 VCA보다 평균 비용이 약 2.67% 감소하였으며, 최소 비용은 약 2.29% 감소하였으며, 최대 비용은 약 3.03% 감소하였다. MHVCA는 HVCA보다 평균비용이 약 0.01E+06€ 만큼 낮게 나왔으며, 최소비용이 약 0.02E+06€ 만큼 낮게 나왔으며, 최대비용이 약 0.04E+06€ 만큼 낮게 나왔다. MHVCA는 HVCA와 비슷한 결과를 보였으나, 다른 알고리즘에 비해 좋은 결과를 많이 보여준다. 이를 통해 MHVCA가 수자원공학문제에 대해 좋은 결과를 보여준다는 것을 알 수 있다.
4. 결 론
본 연구는 상수관망 최적설계를 위해 새로운 형태의 HR을 적용한 MHVCA를 제안하였다. MHVCA는 HVCA의 단점을 보완하기 위해 새로운 형태의 HR을 적용하였다. HVCA의 기존 HR은 선형적으로 증가하기 때문에 지역해에 빠지는 문제가 발생하였다. HVCA가 지역해에 빠지는 문제를 해결하기 위해 새로운 형태의 HR을 적용하였다.
새로운 형태의 HR이 적용된 MHVCA의 성능을 비교하기 위해 HS, IHS, VCA 및 HVCA의 적용결과와 비교하였다. 적용결과를 비교하기 위해 최적값을 찾아내는 횟수, 오차(제약조건이 있는 문제의 경우 최적값) 및 MeanNFEs를 제시하였다. 최적값을 찾아내는 횟수는 적용한 알고리즘이 얼마나 안정적으로 최적값을 찾아내는지 보여주는 것이다. 결과 중 오차는 알고리즘을 적용하여 나온 결과와 최적값과의 차이를 보여주는 것이다. MeanNFEs는 적용한 문제에 대해 적용한 알고리즘이 최적값을 찾아내는 속도를 확인할 수 있다. 최적값을 찾아내는 횟수, 오차(제약조건이 있는 문제의 경우 최적값) 및 MeanNFEs를 통해 적용한 알고리즘의 성능을 검토할 수 있었다.
MHVCA의 성능을 검토하기 위해 결정변수가 2개로 구성된 수학문제, 결정변수가 30개로 구성된 수학문제 및 결정변수가 7개로 구성된 제약조건이 있는 수학문제에 적용하였다. 모든 수학문제에서 MHVCA는 HS, IHS, VCA 및 HVCA보다 최적값을 안정적으로 찾았으며, 낮은 MeanNFEs를 통해 다른 알고리즘보다 빠르게 최적해를 찾는다는 것을 확인할 수 있었다. 그러나 반복실행에 실제로 소요되는 시간은 증가하였다.
실제 수자원공학 문제 적용하여 MHVCA의 성능을 검토하기 위해 상수관망 최적설계 문제에 적용하였다. MHVCA의 적용결과를 HS, MLHSA, VCA 및 HVCA와 비교하였다. 상수관망 최적설계 문제를 적용하기 위해 기존에 연구된 45,400의 NFEs를 사용하였으며, 적용결과 MHVCA가 HS, MLHSA, VCA 및 HVCA보다 낮은 비용을 나타낸다는 것을 확인할 수 있었다. MHVCA는 기존 VCA보다 평균 비용과 최소 비용 및 최대 비용이 낮았다. 평균 비용은 약 2.67% 감소하였으며, 최소 비용은 약 2.29%, 최대 비용은 약 3.03% 감소하였다. MHVCA는 HVCA보다 평균 비용이 0.45% 감소하였으며, 최소 비용은 약 0.39%, 최대 비용은 약 1.75% 감소하였다. 개선된 HR을 통해 MHVCA가 HVCA보다 좋은 결과를 나타냈다.
수학문제 적용결과와 상수관망 최적설계 문제적용결과를 통해 MHVCA가 기존 HVCA보다 상수관망 최적설계 뿐만 아니라 수자원공학 문제에 대해서 좋은 성능을 보여줄 수 있을 것으로 기대된다. MHVCA는 기존 VCA에 CGS를 추가하며 알고리즘의 연산과정이 추가되었기 때문에 코드가 복잡해져 반복실행에 소요되는 실제 시간이 길어졌다. 향후 추가적인 연구를 통해 MHVCA의 구조 단순화 및 연산의 단순화가 이루어진다면 MHVCA는 사용자가 쉽게 사용 가능한 알고리즘이 될 것이다.
