

1. 서 론
2. TFN 모형 이론
3. 유량 예측 모형의 구축
3.1 대상 유역 및 자료구축
3.2 기존 모형 검토
3.3 TFN 모형 구축
3.3.1 입력 자료 변환
3.3.2 모형 선정 및 검증
4. 유량 예측 결과 및 검토
5. 결 론
1. 서 론
홍수예측 모형에는 개념적 또는 물리적 모형과 데이터 기반 모형을 활용한다(Wood and O’Connell, 1985). 홍수예측을 위해 개념적 또는 물리적 모형을 구축하는 경우는 기초 자료의 수집과 주기적인 자료 갱신이 필요하며, 실제 홍수사상을 모의하는 과정에서 숙련된 작업자가 매개변수를 조정하는 과정을 수행한다. 또한, 예측모형의 정확도를 확보하기 위해 매개변수의 개수가 많아지는 경우 매개변수 조정에 더 많은 시간이 소요되므로 선행시간 확보 측면에서는 불리하다(Kumar et al., 2005; Tokar et al., 1999; Tokar et al., 2000). 홍수통제소와 같이 홍수예보를 담당하는 국가기관은 대하천의 홍수예측에 개념적 모형과 물리적 모형을 활용해 왔으며(HRFCO, 2011), 관련 기관이 수해방지 업무에 홍수예측 결과를 활용할 수 있도록 기준 수위를 초과하기 3시간 전에는 예측 정보를 제공 하도록 하고 있다.
그러나 규모가 작아서 강수 발생부터 2~3시간 이내에 하천 수위가 급상승하는 하천의 경우에는 3시간의 예측 선행시간을 확보하기 어렵고 예측 모의 과정이 복잡할수록 효용성이 낮아진다. 국토교통부가 홍수특보를 발령하는 32개 하천 중 유역면적이 500 km2를 넘지 않는 하천은 한강의 지류인 탄천을 포함하여 한강권역에 총 4개소가 있다. 이런 하천의 경우 규모는 작지만 홍수관리 측면에서 중요도가 높기 때문에 충분한 관측 자료를 보유하고 있다면 시계열 데이터를 이용한 모형을 고려할 수 있다. 시계열 데이터를 활용한 하천의 유출량 예측의 경우 국외에서는 월 단위 또는 일 단위 자료를 활용하여 적용된 바 있으며(Lohani et al., 2011), 국내의 연구에서는 규모가 작은 하천을 대상으로 하는 다중 회귀 모형 적용 사례가 있다(Yoon and Kim, 2003; Jeong and Lee, 2010). Choi and Han (2011)은 한강의 지류하천인 중랑천을 대상으로 지점 강수량과 유역평균 강수량을 각각 입력 자료로 하는 회귀 모형을 적용하여 수위를 예측하였다.
시계열 모형인 전이함수잡음(Transfer function noise, TFN) 모형은 자기회귀분석을 통한 Autoregressive (AR), Autoregressive Moving Average (ARMA), Autoregressive Integrated Moving Average (ARIMA) 모형 등의 단변량 시계열 모형과 다르게 외생 변수를 고려할 수 있기 때문에 다양한 분야에서 실제 상황을 예측하는데 유리하다(Salas et al., 1980). 강수량을 외생변수로 하여 하천지점의 유출량 또는 수위를 예측할 수 있고 동적시스템을 활용하여 Autoregressive Moving Average Exogenous (ARMAX) 보다 일반적인 모형으로 평가된다(Young, 1984).
국외 적용 사례로 Anselmo et al. (1979)은 유역면적이 10 km2 및 800 km2 정도의 이탈리아의 소규모 하천에 TFN 기법을 적용하여 실시간 유량예측을 수행한 바 있고 Lees (2000)은 영국 Wales의 하천을 대상으로 홍수 예측을 위해 시간단위 자료를 활용한 TF 모형을 적용하였다. 국내에서는 일단위 또는 월단위 자료를 이용한 TFN의 적용이 주로 이루어졌는데 Kang and Heo (2006)은 한강수계의 월 유입량 모의에 TF, ARMA, ARIMA, TFN 모형을 적용하였고 Park et al. (2014)은 충주댐 유역의 유입량 모의를 위해 TFN 모형을 구축하고 GCM 불확실성을 고려하기 위한 앙상블 시나리오를 통해 유입량 변화 양상을 예측한 바 있다. 본 연구에서는 TFN 모형을 한강 지류하천인 탄천의 홍수예측 모형으로 적용하기 위해 강수량을 외생변수로 하여 홍수량 예측을 수행하였다. 또한 그 적용성을 평가하기 위해 국토교통부 홍수통제소가 홍수예보 실무에 활용중인 저류함수모형(Storage Function Model, Kimura, 1961)의 예측결과와 최소제곱오차(Root mean square error, RMSE)와 Nash-Sutcliffe 모형효율 계수(Nash-Sutcliffe Efficiency coefficient, NSE)를 통해 비교하였다.
2. TFN 모형 이론
TFN 모형은 시간에 따라 변하는 입출력 관계의 동적확률 구조를 이용하여 예측 오차를 적게 하는 효과를 갖는다(Box et al., 1976). 예측 대상 시계열의 과거시점부터 현재 시점의 값뿐만 아니라 그 시계열에 영향을 줄 수 있는 입력시계열을 예측에 이용한다. TFN 모형은 동적항(dynamic system)과 잡음항(noise term)으로 구성되어 있으며, 동적항은 Fig. 1과 같이 선형결합을 통해 출력시계열을 산정하고 나머지 부분은 잡음항으로 설정된다(Kang and Heo, 2006).
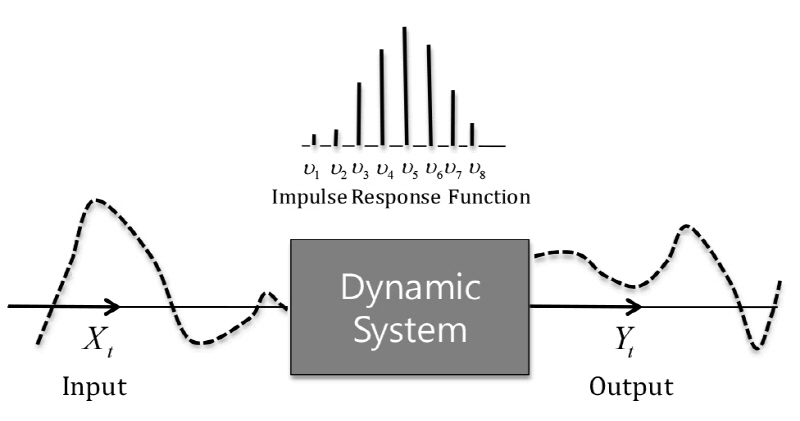
입력계열과 출력계열로 활용되는 두 시계열 사이의 관계에 대한 정보를 포함하는 동적시스템은 Eqs. (1) and (2)와 같이 나타낼 수 있다.
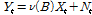 (1)
(1)
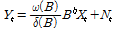 (2)
(2)
여기서, 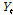 는 출력계열,
는 출력계열, 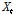 는 입력계열을 각각 나타내며,
는 입력계열을 각각 나타내며, 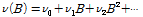 는 전이함수(transfer function), B는 후진 연산자(backward-shift operator;
는 전이함수(transfer function), B는 후진 연산자(backward-shift operator; 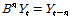 )이다. 또한,
)이다. 또한, 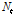 는 잡음과정(noise process)으로 입력계열
는 잡음과정(noise process)으로 입력계열 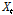 와는 독립임을 가정한다.
와는 독립임을 가정한다. 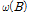 는
는 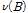 의 분자항으로 후진연산자 차수를 s로,
의 분자항으로 후진연산자 차수를 s로, 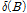 는
는 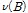 의 분모항으로 후진연산자 차수를
의 분모항으로 후진연산자 차수를 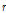 로 표현하여 각각의 매개변수는
로 표현하여 각각의 매개변수는 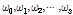 와
와 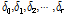 로 표현한다.
로 표현한다.
Eqs. (1) and (2)의 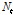 는 Eq. (3)와 같은 ARMA 모형으로 가정한다.
는 Eq. (3)와 같은 ARMA 모형으로 가정한다.
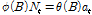 or
or 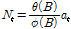 (3)
(3)
여기서, 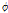 는 자귀회귀과정 계수,
는 자귀회귀과정 계수,  는 이동평균 과정의 계수, 그리고
는 이동평균 과정의 계수, 그리고 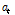 는 백색잡음항이다.
는 백색잡음항이다.
TFN 모형은 앞서 언급한 매개변수를 이용하여 Eq. (4)와 같이 다시 표현 할 수 있다. 이때, 지체시간 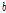 는 출력시계열에 최초로 영향을 주는 입력시계열
는 출력시계열에 최초로 영향을 주는 입력시계열 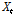 의 시점을 나타내며,
의 시점을 나타내며,  는
는 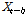 에서 시작하여 지속적으로
에서 시작하여 지속적으로 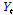 에 영향을 주는 독립변수의 항의 개수,
에 영향을 주는 독립변수의 항의 개수, 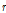 은
은 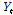 와 선형관계를 갖는 자기 과거의 항의 개수를 고려하여 결정한다.
와 선형관계를 갖는 자기 과거의 항의 개수를 고려하여 결정한다.
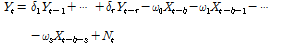 (4)
(4)
3. 유량 예측 모형의 구축
3.1 대상 유역 및 자료구축
TFN 모형을 이용한 홍수량 예측을 위해 한강의 지류인 탄천 유역을 대상 유역으로 선정하였다. 탄천 유역은 면적 303.07 km2, 유로연장 32.55 km, 평균 경사는 7.68 %이며, 행정구역으로는 성남시와 용인시 및 서울특별시에 걸쳐 있다. 유역의 동쪽과 서쪽은 산악지형이고, 중앙부는 시가지 지형으로 구릉지이다. Fig. 2와 같이 유역 내에 국토교통부가 운영하는 수위관측소 2개소와 강수량 관측소 5개소가 있으며, 유역 평균 강수량 산정을 위한 티센망 구성에는 탄천 유역 내에 위치한 5개의 강수량 관측소와 인근 1개소를 포함하여 총 6개의 관측소를 활용하였다. 수위관측소 2개소 중 서울시(대곡교) 지점은 2007년부터 홍수예보지점으로 고시되었으며, 홍수예보 실무에서는 저류함수 모형을 예측모형으로 활용하고 있다.
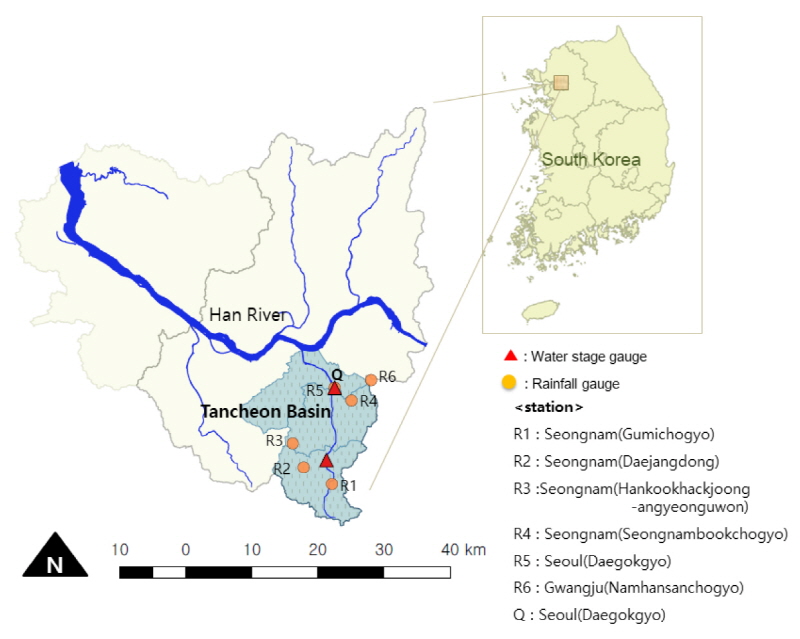
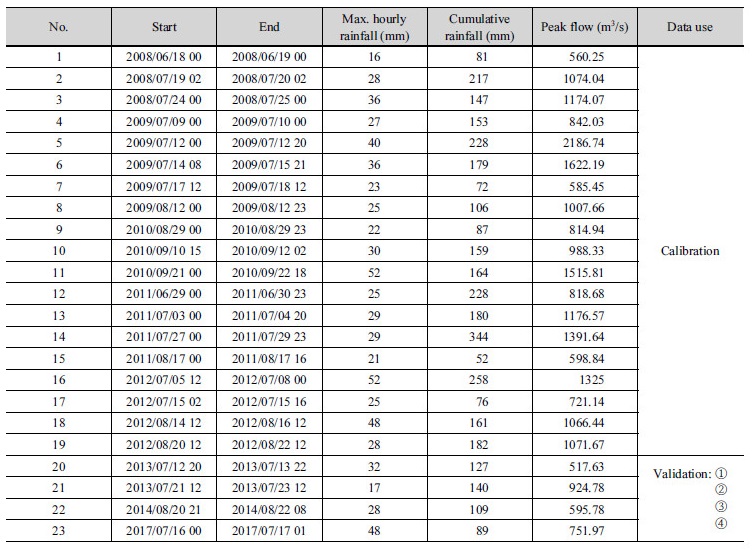
본 연구에서는 홍수예측 모의를 위해 최근 10년간(2008~ 2017년) 탄천 유역의 평균 강수량과 서울시(대곡교) 지점의 유량 자료를 이용하였으며(http://www.hrfco.go.kr), 500 m3/s 이상의 유량을 기록한 23개 홍수사상을 Table 1과 같이 선정하였다. 이 중 과거 19개 홍수사상을 TFN 모형과 저류함수모형 매개변수 검정에 이용하였으며, 그 결과를 최근에 발생한 4개의 홍수사상에 적용하여 결과를 비교하였다. 이때, TFN 모형은 19개 홍수사상 전체를 입력자료로 하여 하나의 매개변수를 선정하였으며, 저류함수 모형은 사상별로 모의하기 때문에 전역 최적화 기법인 SEC-UA 방법(Chung et al., 2012)을 이용해 각 사상별로 최적화된 매개변수를 구한 후 산술평균한 값을 이용하였다.
3.2 기존 모형 검토
저류함수모형은 단위도법 등 다른 방법에 비해 매개변수의 개수가 많고 실무자가 매개변수 조정을 통해 실제의 홍수사상에 가깝게 모의할 수 있다는 장점이 있는 반면, 적용된 매개변수가 유역의 물리적인 특성을 반영하지 못하는 경우에도 실제 사상과 유사한 모의결과를 만들어낼 수 있기 때문에 개연성이 부족하다는 평가를 받고 있다(Chung et al., 2012). 홍수예측 실무에서는 실제 홍수사상을 적용하여 갱신한 매개변수를 상황발생시 업무담당자가 시행착오법으로 조정하여 활용하고 있다. 저류함수모형에서는 우선 유역 전반에 걸쳐 일정한 강우강도로 호우가 내릴 때, 초기유출률을 나타내는 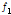 와 포화우량
와 포화우량 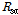 , 유역의 포화유출률
, 유역의 포화유출률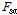 을 이용하여 유효강수량을 산정한다. 이 과정에서 강수 관측 과정에서 발생하는 손실을 고려하기 위해 강수량 확대계수
을 이용하여 유효강수량을 산정한다. 이 과정에서 강수 관측 과정에서 발생하는 손실을 고려하기 위해 강수량 확대계수 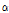 를 사용한다. 또한 직접유출고
를 사용한다. 또한 직접유출고 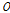 와 유역 내 저류고
와 유역 내 저류고 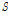 사이의 관계를 비선형으로 가정하여 유역 내 저류고가 증가함에 따라 유출속도가 증가하여 직접유출량이 증가하는 현상을 모의한다. 이 과정에서 유역과 하도의 지체시간
사이의 관계를 비선형으로 가정하여 유역 내 저류고가 증가함에 따라 유출속도가 증가하여 직접유출량이 증가하는 현상을 모의한다. 이 과정에서 유역과 하도의 지체시간 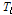 , 저류상수
, 저류상수 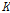 ,
, 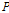 를 결정하여 적용한다.
를 결정하여 적용한다.
저류함수 모형은 Eqs. (5)~(7)를 기본식으로 이용한다.
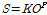 (5)
(5)
여기서, K, P는 유역 혹은 하도구간에 대한 상수이다.
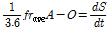 (6)
(6)
여기서, 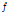 는 평균유입계수이며,
는 평균유입계수이며,  는 단위시간당 유역평균 강수량(mm/hr),
는 단위시간당 유역평균 강수량(mm/hr), 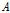 는 유역면적(km2),
는 유역면적(km2), 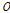 는 유역지체시간
는 유역지체시간 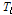 을 고려한 유역으로부터의 직접유출량(m3/s),
을 고려한 유역으로부터의 직접유출량(m3/s), 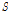 는 유역 내의 실제 저류량(m3) 이다.
는 유역 내의 실제 저류량(m3) 이다.
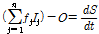 (7)
(7)
여기서, 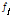 는 평균유입계수이며,
는 평균유입계수이며, 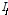 는 유역 및 하도로의 유입량 혹은 하도구간의 상류 유입량(m3/s)이고,
는 유역 및 하도로의 유입량 혹은 하도구간의 상류 유입량(m3/s)이고, 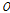 는 지체시간
는 지체시간 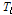 을 고려한 하도구간의 하류 유출량(m3/s),
을 고려한 하도구간의 하류 유출량(m3/s), 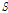 는 하도구간 저류량(m3)이다.
는 하도구간 저류량(m3)이다.
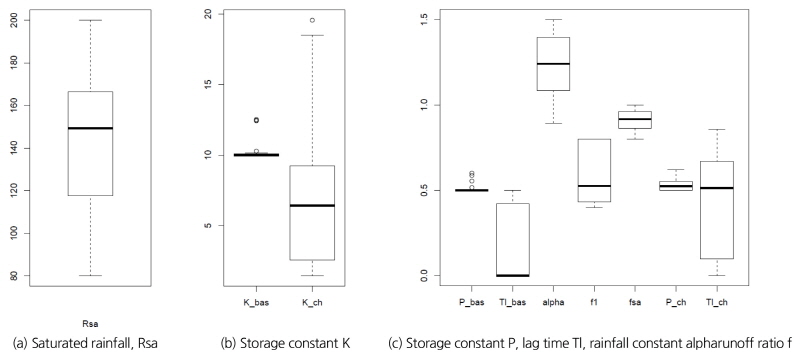
본 연구에서는 매개변수 조정과정의 주관성을 배제하기 위해 전역 최적화 기법인 SCE-UA (Shuffled Complex Evolution) 방식을 적용(Chung et al., 2012)하였으며, 그 결과는 Fig. 3과 같이 박스플롯(Box plot)으로 나타낼 수 있었다. 여기서 포화우량 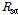 , 하도의 저류상수
, 하도의 저류상수 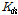 , 유역 및 하도의 지체시간
, 유역 및 하도의 지체시간 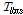 ,
, 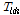 , 초기 유출율
, 초기 유출율 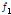 은 실무자가 매개변수를 조정할 때에도 고려할 수 있는 폭이 클 것으로 판단된다.
은 실무자가 매개변수를 조정할 때에도 고려할 수 있는 폭이 클 것으로 판단된다.
3.3 TFN 모형 구축
TFN 모형 구축을 위한 입력자료는 서울시(대곡교) 지점의 시간단위 유량자료와 티센망을 이용한 유역평균 자료를 사용하였다. 상류의 성남시(궁내교) 지점은 국토교통부가 2003년, 2004년, 2008년 그리고 2014년 등 총 4회의 유량측정을 실시하였으며, 예보지점인 서울시(대곡교)에 대한 유량측정이 매년 이루어지고 있는 것과 비교하여 유량자료의 신뢰도를 확보하기에 충분하지 않다고 판단하였으며, 입력자료 에서 제외하였다. 본 연구에서는 1시간 이후 유량 예측에 1시간 단위 자료를, 2시간 이후 유량 예측에는 2시간 단위 유량 자료를 이용하여 각각 모형을 구축하여 실측값과 비교하였다.
3.3.1 입력 자료 변환
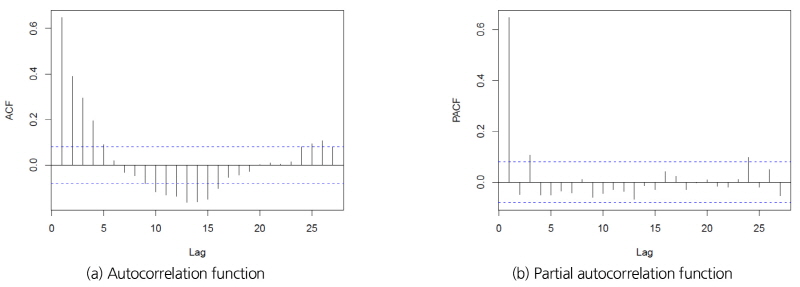
입력자료인 강수량 자료와 출력자료인 유량 자료는 표준정규화한 후 사용하였다. 또한, 입력시계열이 출력시계열에 영향을 주는 시차(lag)를 확인하기 위해서 교차상관 함수를 사용하는데 이 때, 두 가지 계열 중 하나에 자기상관이 포함되어 있는 경우 그 영향 관계를 확인하기 어렵다. 따라서 자기 상관 추세를 제거하기 위한 사전백색화를 수행하여 문제를 해결한다. 본 연구에서는 Box-Jenkins의 근사적 방법을 이용하여 사전백색화를 수행하였다. 입력계열 강수량자료의 표본 자기상관함수와 표본 편자기상관함수는 Fig. 4와 같았다.
모형의 차수를 판단하기 위해 간결성 검토(test of Parsimony)를 수행하였으며, Eq. (8)에 의한 AIC (Akaike Information Criterion)을 적용한 결과는 Table 2와 같았으며, 이를 바탕으로 입력계열은 AIC 값이 가장 작은 ARMA(1,0) 과정을 따르는 것으로 판단하였다.
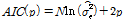 (8)
(8)
여기서, 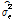 는 분산의 최우도 추정량이며, p는 매개변수의 개수이다.
는 분산의 최우도 추정량이며, p는 매개변수의 개수이다.
따라서 입력 및 출력계열은 Eqs. (9a) and (9b)와 같이 사전백색화하여 사용하였다. 이때, 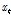 ,
, 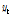 는 표준정규화한 입력 및 출력계열이며,
는 표준정규화한 입력 및 출력계열이며, 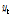 계열은
계열은 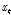 계열과 같이 백색잡음계열은 아니다. 또한,
계열과 같이 백색잡음계열은 아니다. 또한, 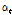 와
와 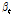 는 각각 사전백색화된 입력계열과 출력계열을 나타낸다.
는 각각 사전백색화된 입력계열과 출력계열을 나타낸다.
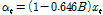 (9a)
(9a)
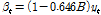 (9b)
(9b)

3.3.2 모형 선정 및 검증
TFN 모형 선정을 위해서 경험적인 방법, Box와 Jenkins방법 그리고 Haugh와 Box 판별 방법 등을 사용한다(Hipel, 1994). 본 연구에서는 Box와 Jenkins 방법에 의해 다항식 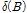 및
및 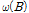 의 최적 차수
의 최적 차수 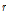 과
과  , 지체시간
, 지체시간 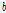 를 결정하고 매개변수들을 추정하였다. 변환된 입력 및 출력 시계열 자료에 대한 충격반응함수(Impulse Response Function)를 구하기 위해 충격반응함수
를 결정하고 매개변수들을 추정하였다. 변환된 입력 및 출력 시계열 자료에 대한 충격반응함수(Impulse Response Function)를 구하기 위해 충격반응함수 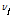 와 동적항의 매개변수
와 동적항의 매개변수 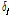 및
및 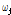 의 관계는 Eq. (10)을 활용하였다.
의 관계는 Eq. (10)을 활용하였다.
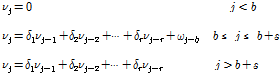 (10)
(10)
이때, 사전백색화된 입력 및 출력 계열 사이의 시차 j에 대한 교차공분산 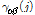 또는 교차상관함수
또는 교차상관함수 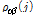 에 의하여 Eq. (11)과 같이
에 의하여 Eq. (11)과 같이 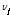 를 구하였다.
를 구하였다.
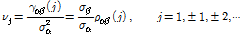 (11)
(11)
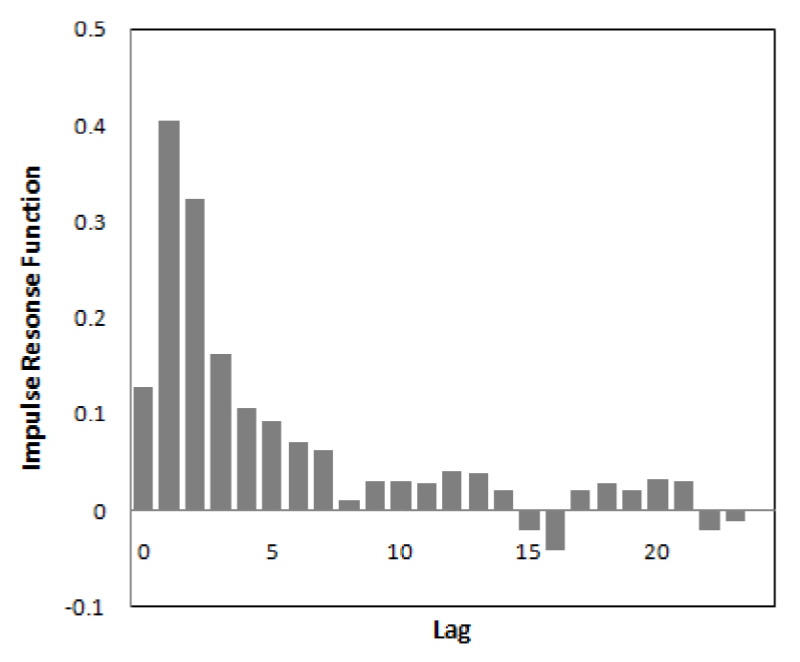
Fig. 5는 본 연구에서 검토한 강수량과 유출량간의 충격반응함수 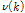 를 나타낸 것으로 이를 바탕으로 전이함수 모형의 차수(
를 나타낸 것으로 이를 바탕으로 전이함수 모형의 차수( ,
, 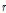 ,
, 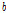 )를 (1, 1, 1)로 결정하였으며, 결정된 모형 차수에 따라 TF 모형을 Eq. (12)의 형태로 구축하고 그 매개변수를 추정하였다.
)를 (1, 1, 1)로 결정하였으며, 결정된 모형 차수에 따라 TF 모형을 Eq. (12)의 형태로 구축하고 그 매개변수를 추정하였다.
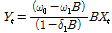 (12)
(12)
매개변수 추정에는 최우도추정법(Maximum Likelihood Estimation) 등을 이용하나, 실제 홍수사상의 시계열 자료는 서로 독립이 아닌 것이 특징이며, 확률표본을 기초로 하는 기존의 추정이론을 그대로 사용하는데 한계가 있다. 본 연구에서는 최소제곱법(Least Squares)을 적용하여 Eq. (2)의 동적항의 매개변수를 추정하였으며, 추정된 매개변수를 반영한 식은 Eq. (13)과 같았다.
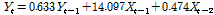 (13)
(13)
구축된 모형 오차항의 표본자기상관계수를 기초로 Eq. (2)의 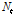 항이 ARMA 과정을 따르는지 검토한 결과
항이 ARMA 과정을 따르는지 검토한 결과 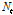 는 MA(2) 과정을 따르는 것으로 나타났다. 이를 반영하여 구축된
는 MA(2) 과정을 따르는 것으로 나타났다. 이를 반영하여 구축된 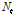 항을 TF 모형과 결합한 결과는 Eq. (14)와 같다.
항을 TF 모형과 결합한 결과는 Eq. (14)와 같다.
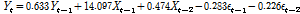 (14)
(14)
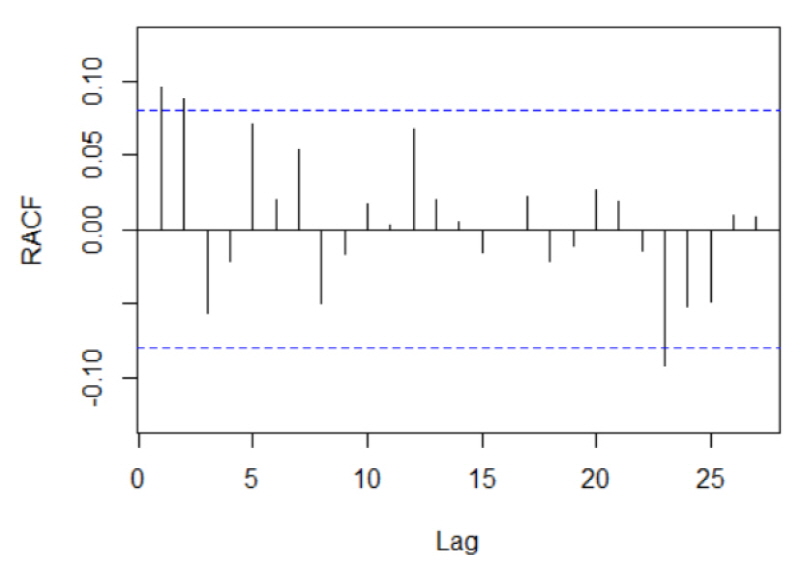
구축된 모형의 적합성 판별은 잔차 분석(Residual analysis)을 통해 할 수 있으며, 추정된 잔차 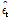 가 백색잡음계열을 만족하는지를 검토한다. 이를 위해 잔차항의 ACF (Autocorrelation Function)인 RACF를 구한 결과는 Fig. 6과 같으며, 잔차가 백색잡음계열을 만족하는 것을 확인하였다. 따라서, 구축된 TFN 모형은 타당한 것으로 판단하였다.
가 백색잡음계열을 만족하는지를 검토한다. 이를 위해 잔차항의 ACF (Autocorrelation Function)인 RACF를 구한 결과는 Fig. 6과 같으며, 잔차가 백색잡음계열을 만족하는 것을 확인하였다. 따라서, 구축된 TFN 모형은 타당한 것으로 판단하였다.
4. 유량 예측 결과 및 검토
TFN 모형을 통해 모의한 1시간과 2시간 예측 유량과 저류함수모형을 통해 모의한 예측 유량을 각각 관측 유량과 비교하였다. 여기서 TFN 모형의 2시간 예측 유량은 1시간 예측 유량 산정 시와 동일한 절차를 거쳐 산정하였다. 탄천의 서울시(대곡교) 지점의 최근 4개의 홍수사상에 적용한 유량 예측 결과는 Fig. 7과 같았다. 본 연구에서는 모형 성능을 평가하기 위해서 Eqs. (15a) and (15b)의 평균제곱근오차(Root Mean Square Error, RMSE)와 Nash-Sutcliffe 효율계수(Nash- Sutcliffe Efficiency coefficient, NSE)를 사용하였으며, 홍수시 유량 예측에 활용하는 경우에 초점을 두어 사상별 첨두 홍수량과 첨두 홍수발생 시각을 실측값과 비교하였다. 이때, RMSE는 관측값과 예측값의 차이를 다룰 때 흔히 사용되는 통계지표로 정밀도(precision)를 표현하는데 적합하며, NSE는 모의된 홍수사상과 실측 사상의 일치 여부를 판단하기 위해 사용하는 무차원 계수로, 1에 가까운 값을 가질수록 모의된 사상이 실측 사상과 잘 일치한다고 판단한다(Song et al., 2013; Song et al., 2015).
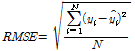 (15a)
(15a)
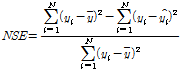 (15b)
(15b)
여기서, 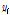 는 관측유량,
는 관측유량, 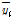 는 관측유량의 평균값,
는 관측유량의 평균값, 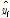 는 예측유량, N은 데이터 개수를 말한다.
는 예측유량, N은 데이터 개수를 말한다.
Table 3에서 1시간과 2시간 단위 입력자료를 이용해 각각 모의한 TFN 모형 예측 결과의 경우 1시간 단위 자료를 이용했을 때, RMSE와 NSE 값이 실제 홍수사상을 잘 반영하고 있는 것으로 나타난 반면 2시간 단위자료를 이용한 경우 1시간의 경우에 비해 RMSE가 큰 값을 나타냈다. 또한 NSE가 0.25~ 0.6로 실측 사상과 유사한 모의결과를 얻는데 부적합한 것으로 나타났다. Figs. 7(a)~7(b)에서 2시간 단위자료를 이용한 경우는 실측 홍수사상 보다 1시간의 지체가 발생하는 것으로 나타났는데 모형 검증에 이용한 4개의 홍수사상은 지속시간이 6시간에서 12시간 이내로 짧기 때문에 TFN 모형 구축에 1시간 단위 이상의 입력자료를 활용하는 경우 유의미한 자료로 활용하기 어려운 것으로 판단된다.
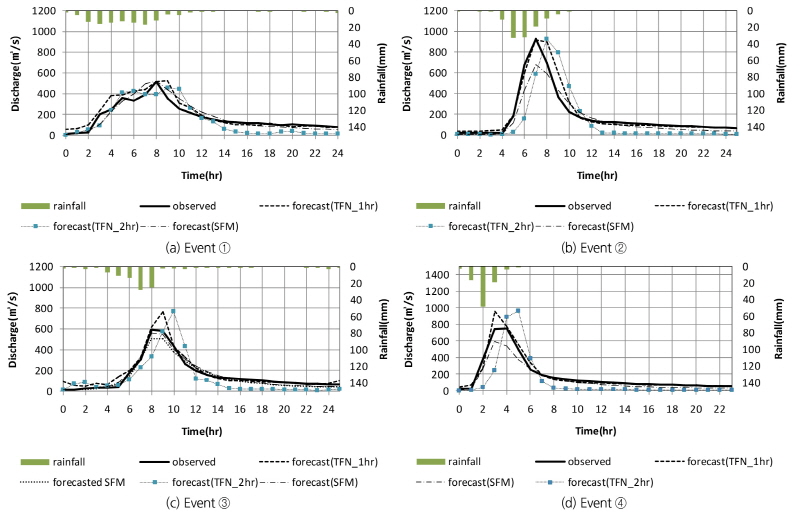
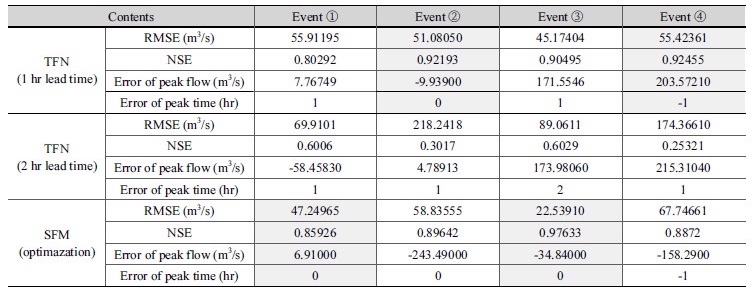
1시간 단위 입력자료를 이용한 TFN 모형을 저류함수 모형과 비교하여 모의 성능을 비교한 결과 두 모형의 NSE 값은 모두 0.8~1.0 사이의 값으로 실제에 가깝게 홍수사상을 모의한 것으로 나타났다. 또한 event ①과 event ②의 경우 저류함수 모형이 더 좋은 RMSE와 NSE 값을 나타냈고, 첨두유량도 TFN에 비해 실측값과 가깝게 모의한 것으로 나타났다. 반면에 event ②와 event ④는 TFN 모형이 RMSE, NSE와 첨두유량 값에서 더 나은 예측 결과를 보인 것으로 나타났다. 첨두유량의 발생 시각은 저류함수 모형이 event ④의 경우에만 1시간 앞서 모의하고 다른 사상에서는 실제 첨두 발생 시각과 일치한 것으로 나타나 더 좋은 결과를 보였다.
5. 결 론
본 연구에서는 하천의 홍수예측을 위해 시계열 데이터를 이용하는 TFN 모형을 적용하여 활용성을 검토하였다. TFN 모형 구축에 한강의 지류하천인 탄천의 홍수예보지점 서울시(대곡교) 지점 유량과 탄천의 유역평균 강수량을 입력자료로 활용하였으며, 예측 결과는 기존 홍수예측 업무에 활용 중인 저류함수 모형의 예측 결과와 비교하여 다음과 같은 결론을 도출하였다.
1)TFN 모형의 차수를 결정하기 위해 자료의 표준정규화 및 사전백색화를 수행하고 충격반응 함수를 구한 결과 강수량은 1~2시간까지 유출량에 영향이 큰 것으로 판단할 수 있었다. 따라서 입력자료 시간단위를 3시간 이상으로 할 경우 강수량과 유량의 영향관계를 규명하기 어려울 것으로 판단하여 1시간과 2시간 간격의 예측 모형을 각각 구축하였다.
2)2013년부터 2017년까지의 4개 홍수사상에 대한 유량예측을 실시하고 RMSE, NSE, 첨두유량과 첨두유량 발생시각에 대해 검토한 결과 1시간 단위 입력자료를 이용한 경우는 NSE가 0.8~1.0 내외로 실제 홍수사상과 유사한 예측 모의를 수행한 것으로 판단하였다.
3)그러나 2시간 간격 자료를 예측에 이용한 결과에서 실측과 비교하여 1시간의 지체가 발생하는 것을 확인하였는데 이는 홍수사상의 지속시간이 6~12시간인 점과 유량에 1시간 강수량의 영향이 큰 점을 고려할 때 강우-유출 관계를 모의하기에 2시간 간격의 입력자료를 이용하는 것은 부적절한 것으로 나타났다.
4)또한, 기존에 활용중인 저류함수모형의 각 홍수사상별 매개변수를 SCE-UA 기법으로 최적화하여 산술평균한 값을 사용한 예측 결과와 1시간 단위 입력자료를 이용한 TFN 모형의 예측 결과를 RMSE, NSE, 첨두유량과 첨두유량 발생시각에 대해 검토한 결과 홍수 사상별로 예측 결과가 더 양호한 모형은 다르게 나타났으나 두 모형 모두 실제 유량 예측에 유의미한 것으로 판단되었다.
5)본 연구에서 검토한 TFN 모형은 기존에 활용중인 저류함수 모형에 비해 모형 구축 및 모의 과정이 간단하여 실무 활용성이 큰 것으로 판단되며, 향후 TFN 모형 구축을 위한 데이터 선정 방법에 대한 심도 있는 연구가 진행된다면 모형 성능을 더욱 향상 시킬 수 있을 것으로 판단된다.
