

1. 서 론
2. 연구 방법 및 모델 개요
2.1 연구 방법
2.2 모델 개요
3. 모형의 적용
3.1 대상유역 및 자료수집
3.2 기상 및 유출량 자료 구축
3.3 LSTM 및 LSTM-MLP 모델 학습결과
4. 결 론
1. 서 론
지구온난화로 인해 발생한 기후변화는 지역별 강수량, 유출량 및 증발산량을 변화시켜 예외적이던 홍수 및 가뭄 등의 발생빈도 및 강도를 증가시켰다. 이에 우리나라는 기후변화로 인한 수재해 대응을 위하여 국가하천 및 다목적 댐 등의 유출량과 유입량을 관측하고 유황곡선(Flow-Duration-Curve)등을 만들어 평상시의 수자원 관리 및 가뭄 시 하천수 사용 조정 등에 활용하고 있다(MOLIT, 2000). 일반적으로 강우-유출 모형으로부터 도출된 30년 이상의 일 유량 자료를 이용하여 유량지속곡선을 산정하고 있으며, 미계측 유역의 경우 비유량법 및 강우-유출 모델 매개변수의 지역화 등의 방법론을 사용하여 추정한다(KRIHS, 2020; Choi et al., 2021b).
유역 기반의 강우-유출 모델으로는 대표적으로 Soil and Water Assessment Tool (SWAT), Tank, Hydrological Simulation Program-FORTRAN (HSPF)등이 있으며(Han et al., 2016) 최근에는 기존의 강우-유출 모델 이외에 시계열 데이터의 특성을 학습하여 예측하는 딥러닝 오픈소스 라이브러리가 공개됨에 따라 수자원 분야에서도 이를 이용한 시계열 예측 연구가 활발히 진행되고 있다(Lee and Jung, 2018; Lee et al., 2020). 딥러닝 알고리즘의 하나인 LSTM (Long Short-Term Memory)은 기존의 RNN (Recurrent Neural Network)의 시간 의존성 문제를 개선한 모형으로 구글의 텐서플로우와 결합하여 수문 분야에서 많이 사용되고 있다(Mok et al., 2020).
국내에서 Han et al. (2021)과 Mok et al. (2020)은 각각 소양강댐과 용담댐을 대상으로 댐 유입량을 예측했다. Choi et al. (2021a)은 SWAT 물리모델의 매개변수 보정 결과 중 일 최고기온과 강수량을 LSTM 모델에 이용해 유출모의를 진행 했다. 해외에서는 Xu et al. (2020)이 기상자료를 LSTM 모델에 학습하여 Hun강과 Yangtze강의 유출량을 예측했으며 Sahoo et al. (2019)은 LSTM을 이용하여 인도 Mahanadi 강 유역의 저유량 기간 동안 일 유출량을 예측하여 LSTM의 높은 신뢰도를 검증하였다. Jiang et al. (2021)은 LSTM과 MLP를 결합한 HAL (Hybrid ANN-LSTM)을 개발하여 실내온도를 예측한 결과 LSTM으로 온도 패턴을 모델링하고 MLP로 변수와의 관계를 동시에 학습할 수 있음을 확인했다.
본 연구에서는 강원도 삼척시 오십천을 대상유역으로 하였으며 입력자료 구축의 한계점을 극복하고자 LSTM 인공신경망에 관측자료만을 사용하여 유출모의를 수행했다. 또한 강수량 외 요소들이 결과에 어떻게 영향을 미치는지 확인하고자 3개의 입력자료군(기상관측요소, 일 강수량 및 잠재증발산량, 일 강수량 - 잠재증발산량)을 구성해 LSTM (Long Short-term Memory)모델에 각각 학습한 후 비교하여 최적 모형을 선정했다. LSTM 모델에 MLP (Multi Layer Perceptron) 모델을 병렬로 결합하면 LSTM에서 파악하지 못하는 특징들을 학습해 성능이 향상 될 수 있고 구축이 용이한 장점이 있어(Jiang et al., 2021) 선정된 최적 LSTM 모델에 MLP신경망을 결합한 6개의 LSTM-MLP 앙상블 모델을 구축하고 실측값과 비교하여 수자원 분야에서 LSTM-MLP 모델의 가능성을 평가했다.
2. 연구 방법 및 모델 개요
2.1 연구 방법
삼척 오십천 유역의 일 유출량을 모의하는데 있어서 5개 기상관측소의 일 단위의 기상자료를 이용해 Hargreaves & Angstrom 공식으로 잠재증발산량을 산정한 후 티센 면적비를 적용했으며 이를 이용해 3개의 자료군을 구성한 뒤 2011년부터 2018년 까지를 Training 기간으로, 2019년부터 2020년까지를 Test 기간으로 사용하여 각각 3개의 LSTM 모델에 학습시켜 최적 모형을 선정했다. 이후 입력데이터의 구성이 자유롭고 데이터가 여러 레이어를 거치면서 발생하는 정보의 손실이 없으며 LSTM 모델에 병렬로 결합했을 때 LSTM 모델에서 파악하지 못하는 특징들을 학습하여 성능이 향상 될 수 있는 장점을 가진 MLP 모델을 결합하여 6개의 LSTM-MLP 앙상블모델(평균값 이용)을 구축 및 학습한 뒤 전체기간(2011년~2020년)의 일 유출량을 모의한 결과를 분석했다(Fig. 1).
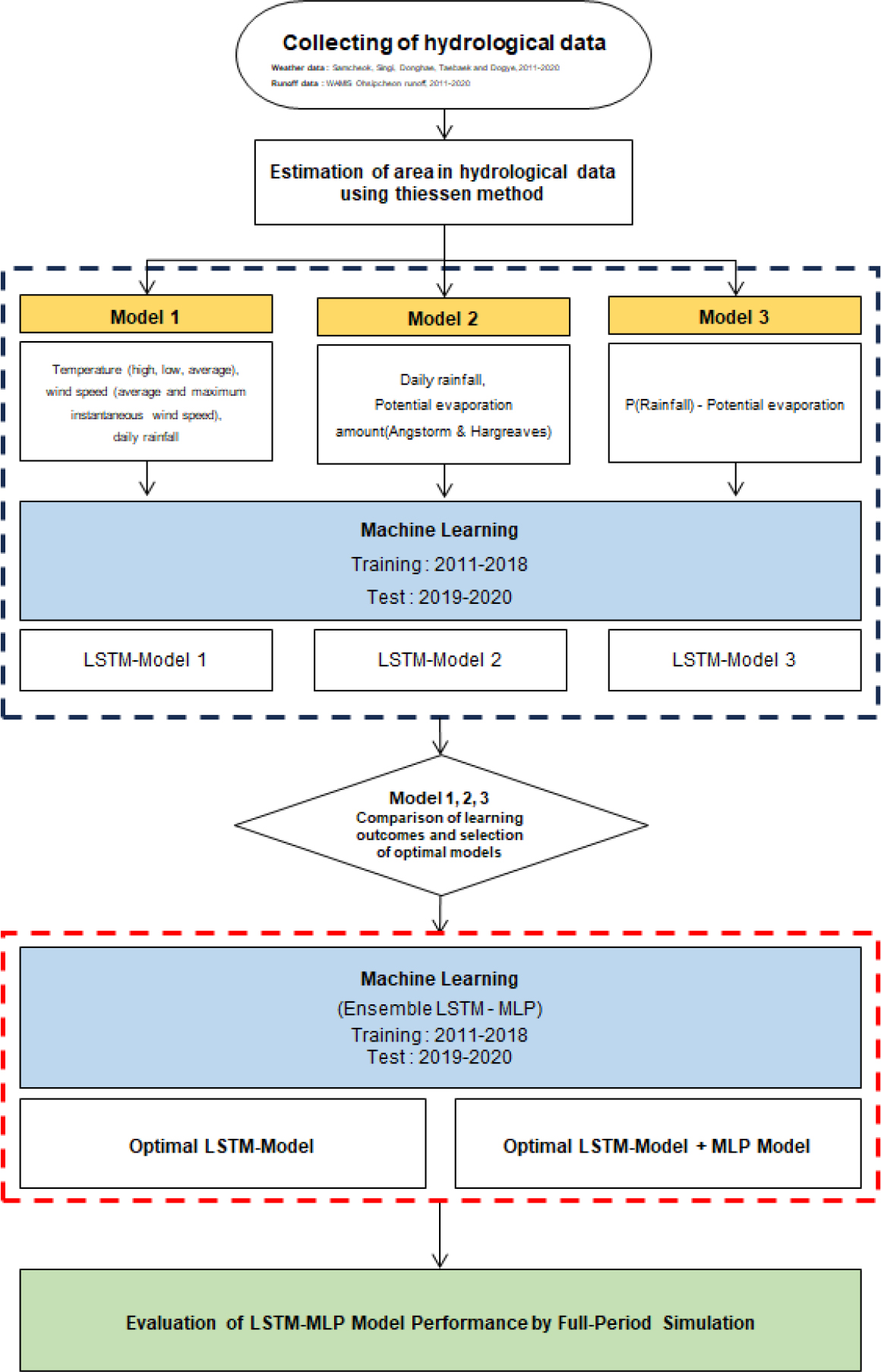
2.2 모델 개요
2.2.1 LSTM 기반 딥러닝 기법
LSTM은 시계열 데이터 처리에 효과적인 딥러닝(Deep Learning) 기법인 순환신경망(Recurrent Neural Network, RNN)이 가지고 있는 기울기 소실과 폭주(Vanishing and Exploding gradient)의 문제를 해결하기 위해 Hochreiter and Schmidhuber (1997)가 제안하였다. LSTM은 여러개의 셀(cell)로 구성되어 있으며, 각 셀에는 데이터 흐름을 조절하기 위한 입력 게이트(Input Gate, ), 망각 게이트(Forget Gate, ) 및 출력 게이트(Output Gate, )로 구성된다(Fig. 2).
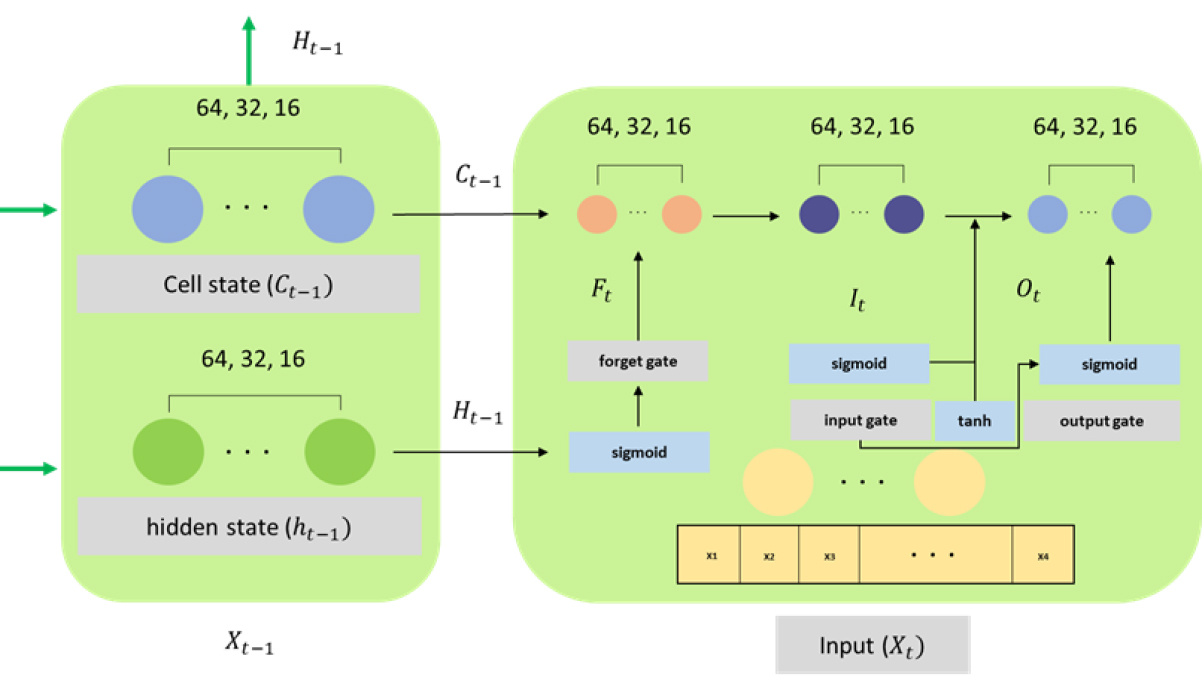
망각 게이트()는 이전 셀()에서 들어온 정보를 매개변수와 시그모이드 함수(Sigmoid Function, 𝜎)를 이용해 얼마나 잊을지 결정하게 된다(Eq. (1)).
여기서, 는 (0, 1) 범위의 값을 가진 결과 벡터, 𝜎는 Sigmoid 활성 함수, 는 망각 게이트에 대한 매개변수 집합, 는 현재 입력, 는 이전 스텝의 상태이다. 입력 게이트()에서는 하이퍼볼릭 탄젠트(Hyperbolic Tangent, tanh)를 이용하여 새로운 셀의 업데이트시 사용되는 후보 셀()을 생성하고(Eq. (2)), 시그모이드 함수(𝜎)를 이용해 어떤 정보를 업데이트 할지 결정하여(Eq. (3)), 최종적으로 현재의 셀 상태()를 업데이트 한다(Eq. (4)).
여기서, 는 범위(-1, 1)의 값을 가진 벡터, 와 는 각각 와 이전 스텝의 가중치, 는 학습 가능한 매개변수 집합이다. 또한, 는 범위 (0, 1)의 값을 가진 벡터, 는 입력게이트에 대해 정의된 학습 가능한 파라미터 집합이며, ⊙는 요소 곱 이다. 마지막으로 출력 게이트()의 시그모이드 함수(𝜎)를 거쳐 출력하고(Eq. (5)), 하이퍼볼릭 탄젠트(Hyperbolic Tangent, )를 이용하여 특정 시점의 상태()를 업데이트하게 되어 기울기의 소실과 폭주 문제를 해결할 수 있다(Eq. (6)).
여기서, 는 범위(0, 1)의 값을 가진 벡터이며, 및 는 출력 게이트에 대해 정의된 학습 가능한 파라미터의 집합이다(Hochreiter and Schmidhuber, 1997).
2.2.2 모형의 평가 방법
본 연구에서는 실측값과 모델 예측값의 오차범위 확인에 있어서 MAE (Mean Absolute Error)와 RMSE (Root Mean Square Error)를 사용했으며, PBIAS (Percent Bias)와 VE (Volume Efficiency)를 이용해 모형에서 도출된 총합 값의 범위를 확인했고, NSE (Nash-Sutcliffe Efficiency)와 결정계수 (Coefficient of Determination)를 이용해 모델의 적합도를 확인했다. 평균절대오차(MAE)와 평균제곱근오차(RMSE)는 수문 모형의 예측값과 실측값 간의 오차를 비교하는 지표로 각각 Eqs. (7) and (8)와 같으며, 0에 근접할수록 실측값과의 오차가 적어 최적값을 보인다. PBIAS와 체적효율(VE)은 수문 모형의 참값과 예측값 간의 총합의 크기를 비교하는 지표로 각각 Eqs. (9) and (10)과 같이 계산되며, 0%의 값에 가까울수록 최적값을 보인다. NSE와 결정계수()는 각각 모형의 경향성 및 적합도를 비교하는 지표로 Eqs. (11) and (12)과 같이 계산되며, 1에 가까울수록 최적의 값을 보인다(Choi et al., 2021b).
3. 모형의 적용
3.1 대상유역 및 자료수집
본 연구에서는 한강권역 삼척오십천수계에 속하는 강원도 삼척시의 오십천을 대상유역으로 선정했으며 인근의 삼척, 동해, 신기, 도계, 태백 ASOS 및 AWS 기상자료와 오십천 유량자료를 활용해 오십천 유출모의 및 분석을 수행했다. 삼척 오십천 유역면적은 394.20 km2이며 유출모의 지점으로 선정한 삼척오십천 하구의 설계빈도와 계획홍수량은 100년, 2,764 m3/s이다. 대상 유역 및 관측소 현황을 Fig. 3과 Table 1과 같이 나타냈다.

Table 1.
Weather and flow station
3.2 기상 및 유출량 자료 구축
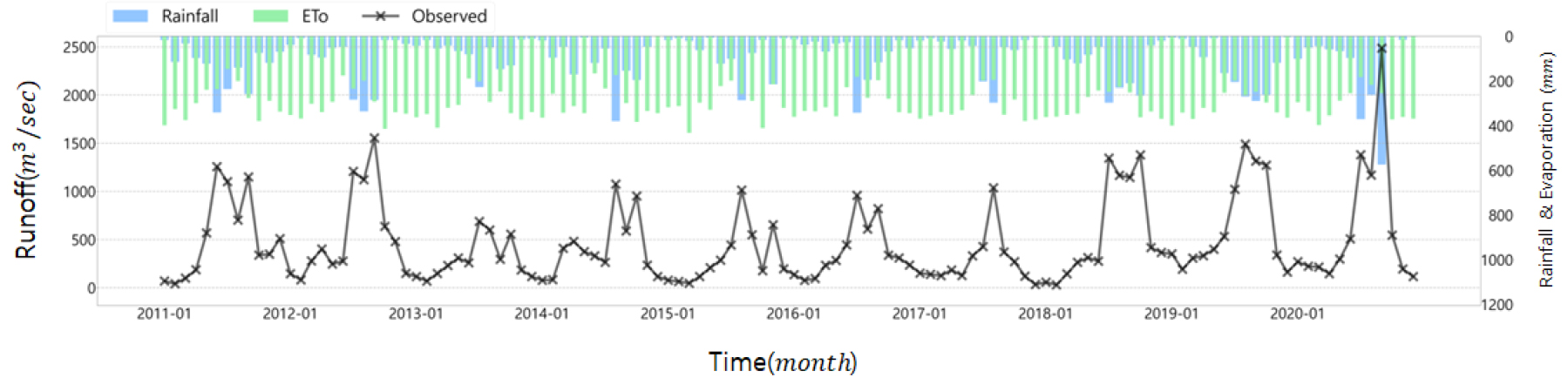
본 연구에서는 인공신경망을 이용한 삼척 오십천 유역의 장기유출모의 입력자료로 일 단위 유출량과 기상자료를 활용했다. WAMIS에서 2011년~2020년 까지의 강원도 삼척 오십천 유역의 일 유출량 자료를, 기상청에서 같은 기간의 AWS (삼척, 신기, 도계) 및 ASOS (동해, 태백) 일 기상자료(강수량, 최고 및 최저기온, 평균기온, 최대 순간 풍속, 평균풍속, 일조시간)를 수집한 후 Hargreaves & Angstorm 공식을 이용해 잠재증발산량을 산정하여 Table 2와 같이 3개의 입력자료군을 구성했다. 2011년~2020년 삼척 오십천 유역의 연 평균 유량은 5,539.68 m3이며 강수량과 증발산량은 각각 1,239.96 mm, 3,652.04 mm이고 Fig. 4와 같이 그래프로 나타냈다.
Table 2.
LSTM model input data
본 연구에서는 LSTM 인공신경망에 대상 유역의 기상자료를 학습하여 유출모의를 진행했을때 강수량 외 요소들이 결과에 어떻게 영향을 미치는지 확인하고자 3개의 입력자료군을 Table 1과 같이 구성하여 각각 LSTM-Model 1에는 6개의 기상요소, LSTM-Model 2에는 일 강수량과 잠재증발산량 2개의 요소, LSTM-Model 3에는 일 강수량에서 잠재증발산량을 뺀 1개의 요소로 입력자료를 구성하여 학습했다. 세 LSTM 모델의 입력자료 모두 유역면적평균을 반영하기 위해 5개의 기상관측소(삼척, 도계, 신기, 동해, 태백)를 기준으로 하여 티센 면적비를 적용하였다. 그 후 3개의 LSTM 모델 학습결과 중 가장 높은 성능을 보인 모델을 선정한 후 MLP 신경망을 더해 LSTM-MLP 앙상블 모델을 구축하여 2011년부터 2020년 까지의 삼척 오십천의 유출 모의 및 분석을 수행했다.
3.3 LSTM 및 LSTM-MLP 모델 학습결과
3.3.1 모델 구축
앞서 기술한 Table 1과 같이 총 3개의 LSTM 모델을 학습함에 있어 총 자료 기간 중 2011년부터 2018년 까지를 Training 기간으로, 2019년부터 2020년 까지를 Test 기간으로 정하여 학습한 후 최적 모델을 선정했다(Table 2, Fig. 5(a)). 모델의 학습횟수는 2000번의 학습 중 Training Loss와 Validation Loss가 최소가 되는 시기를 선정했으며(Table 3) 모델 학습에 12분 27초가 소요되었다. Hidden Layer는 모델 은닉층을 의미하며 Optimizer는 모델 학습 중 오차에 대한 최적화 알고리즘, Sequence Length는 입력자료 길이, Epoch는 학습횟수 이다.

Table 3.
Model parameter setting of LSTM and LSTM-MLP
3.3.2 LSTM 및 LSTM-MLP 모델 학습결과(Test)
3개의 LSTM 모델 학습 결과는 Fig. 6, Table 4와 같으며 모두 예측모형의 정확도를 정량적으로 평가할 수 있는 지표인 NSE가 0.7 이상으로 준수한 성능(Very good: NSE ≥ 0.7, Good: 0.5 ≤ NSE < 0.7, Satisfactory: 0.3 ≤ NSE < 0.5, and Unsatisfactory: NSE < 0.3)임을 알 수 있다(Kalin et al., 2010).
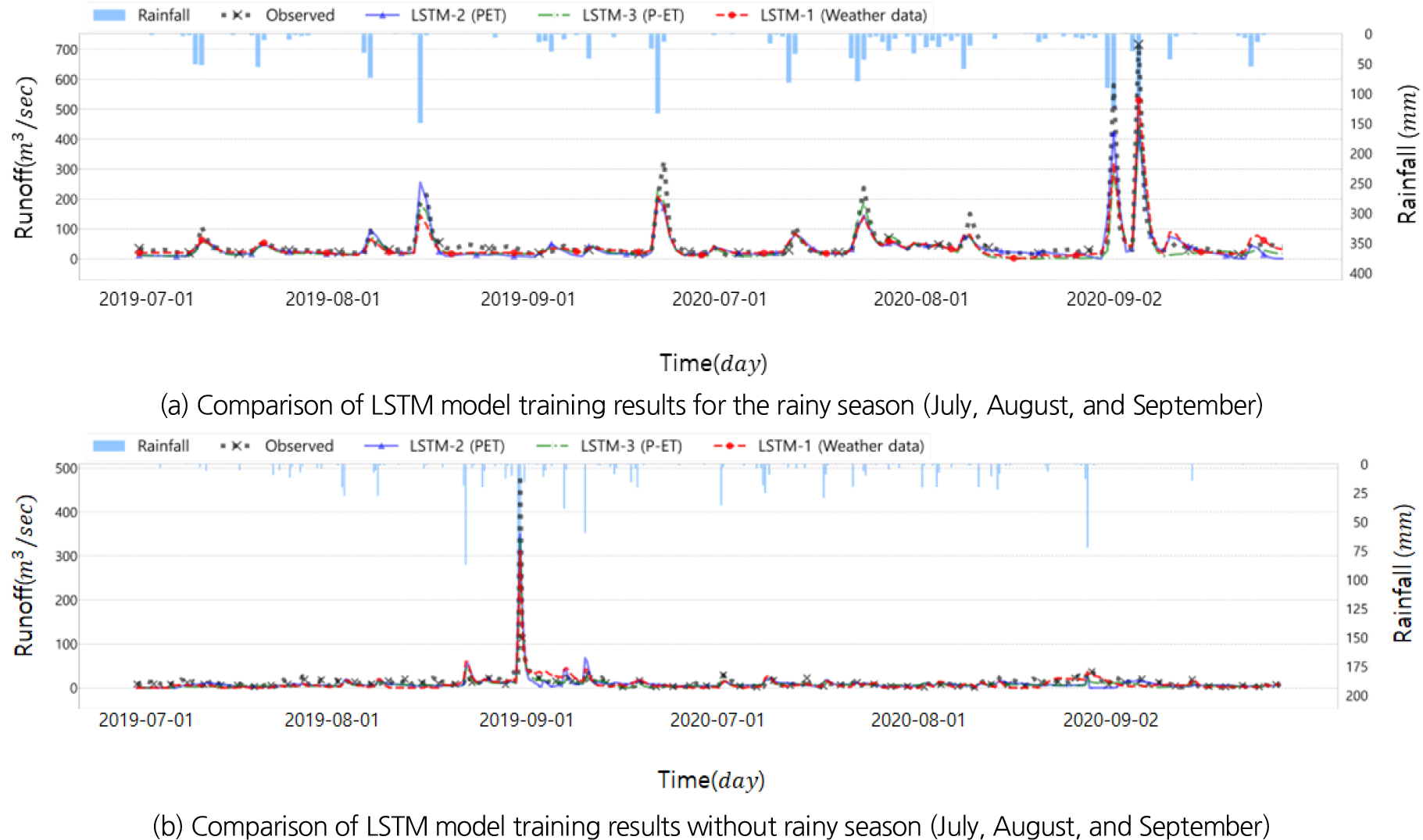
Table 4.
LSTM model training results metrics (Test)
강우가 많은 여름철(7월, 8월, 9월)과 여름철을 제외한 기간으로 나누어 세 LSTM 모델을 비교했을때 여름철기간의 결과에서는 Model 1의 PBIAS가 가장 낮았고, 여름철기간을 제외했을때는 Model 2가 가장 낮았다(Table 5). 여름철 기간을 제외했을때 Model 3의 NSE가 가장 높았고 오차를 나타내는 RMSE가 가장 낮게 나타났다. 세 LSTM 모델이 유사한 결과를 보여 예측에 있어 편향의 정도를 나타내는 PBIAS가 가장 낮은 Model 1을 최적 모델로 선정했고(Table 4), LSTM-Model 1을 이용해 Fig. 5(b)와 같이 총 6개의 LSTM-MLP을 구축하여 학습한 후 평균값을 사용하여 전체기간(2011년~2020년)에 대한 유출량을 모의했다.
Table 5.
LSTM model training results metrics for the rainy season
3.3.3 LSTM 및 LSTM-MLP 모의결과 비교(Simulation)
LSTM 및 LSTM-MLP 모델을 이용해 전체기간(2011년~2020년)에 대해 삼척 오십천의 유출량을 모의한 결과는 Fig. 7과 같다.

LSTM-Model 1과 비교했을때 LSTM-MLP 모델의 정확도 측면에서 여름철 및 여름철 제외기간에서는 각각 NSE 0.76, 0.72로 약간 감소했으며, PBIAS는 각각 -12.6, -8.5로 개선됐음을 알 수 있다(Table 6). 특히 전체기간(2011년~2020년)에 대한 통계비교를 했을때(Table 7) 25%에 해당하는 저유량 부분이 개선되어 이는 LSTM-MLP 앙상블 모델을 이용해 유출량을 모의했을 때 더 높은 성능을 보였다고 판단된다.
Table 6.
LSTM and LSTM-MLP models results metrics
Table 7.
Results of comparing observed vs. predicted (2011~2020)
LSTM-MLP 모델의 모의 결과에 대해 고유량과 저유량에 대한 비교를 위해 Fig. 8과 같이 월별 시계열로 나타내었다. 관측 유출량과 비교시 저유량 부분과 고유량 부분에서 과대 및 과소추정하는 경향을 보였는데, 여러 선행연구에서 정확도 개선을 위한 방법으로 입력데이터의 특징 파악에 강점을 가지고 있는 CNN (Convolution Neural Network)을 LSTM에 결합한 ConvolutionLSTM 등 다양한 모델이 제안되고 있다. 이에 향후 연구에서 ConvolutionLSTM 등 다양한 모델을 이용한다면 보다 관측값에 유사한 결과를 도출 할 수 있을 것으로 기대된다.

4. 결 론
기후변화로 인한 수재해 대비 및 대응을 위해 일반적으로 사용되는 물리적 기반의 강우-유출 모형의 입력자료 구축 및 구동에 시간이 오래 걸리며 모형의 매개변수 검·보정에 사용자의 높은 이해도가 요구되는 등 한계가 있다. 반면 자료기반 모델의 경우 입력자료가 간단하며, 모델 구동 시간이 비교적 짧은데 비해 예측력이 높은 장점이 있다. 본 연구에서는 LSTM (Long Short-Term Memory) 신경망과 MLP (Multi Layer Perceptron) 신경망을 활용해 유출량을 모의했으며 연구의 결과 및 시사점은 다음과 같다.
(1) 기존 물리적 강우-유출 모형의 구동에 있어서 모형의 입력자료와 매개번수 검·보정에 대한 사용자의 높은 이해도가 필요하며 모형의 구동시간이 오래 걸리지만 데이터 기반의 딥 러닝 기법은 손쉽게 입력자료 구축을 할 수 있으며 물리적 강우-유출 모형에 비해 구동시간이 짧다.
(2) 강원도 삼척 오십천 유역을 대상으로 2011년부터 2020년 까지 총 10년의 일단위 유출량과 기상자료(삼척, 동해, 태백, 신기, 도계)를 수집했고, Hargreaves & Angstorm 공식을 이용해 잠재증발산량을 산정한 후 티센 면적비를 적용해 3개의 입력자료군(6개 기상관측요소, 일 강수량 및 잠재증발산량, 일 강수량 - 잠재증발산량)을 구축해 각각 LSTM 모델에 학습시켰다.
(3) 3개의 LSTM 모델 중 6개의 기상관측요소(일 강수량, 최고 및 최저기온, 평균기온, 평균 풍속, 최대 순간 풍속)를 이용해 학습한 LSTM-Model 1을 최적 모델로 선정했으며, LSTM-Model 1에 MLP를 더한 LSTM-MLP 모델 6개를 구축하고 학습하여 각 모델의 평균값을 이용해 전체기간(2011-2020)까지의 유출량을 모의했다.
(4) LSTM-MLP 모델을 이용해 유출량을 모의한 결과 LSTM 모델의 결과와 대체적으로 비슷했으나 LSTM 모델에 비해 LSTM-MLP 모델이 약간의 오차가 감소했으며 특히 저유량 부분의 분산이 개선되었음을 확인했다.
(5) 본 연구에서는 관측자료만을 이용하여 삼척 오십천 유역의 장기유출 모의를 진행했으며 ConvolutionLSTM 등으로 저유량 부분의 정확도를 개선하여 지형자료 수집이 어려운 미계측 유역등에 활용성이 높을 것으로 기대된다.
