

1. 서 론
2. 방법론
2.1 인공신경망(Artificial Neural Network, ANN)
2.2 인공신경망의 처리 과정
2.3 연구지역
2.4 연구 자료
3. 네트워크 구조 선정
3.1 입력자료 선정
3.2 은닉층의 노드 수 결정
3.3 데이터 수 설정
4. 결 과
4.1 입력자료가 측정값인 경우
4.1.1 단순공간보간기법(Kriging)과 인공신경망의 성능 비교
4.1.2 적설량 크기별 분석 결과
4.1.3 관측소별 인공지능 성능 평가
4.2 입력 데이터를 추정한 경우
5. 결 론
1. 서 론
2014년 2월 17일 경주에 위치한 마우나오션리조트 체육관의 지붕이 폭설의 무게를 이기지 못하고 무너져내려 10명의 사망자와, 103명의 부상자가 발생하였다. 사고의 주요원인은 부실공사였지만(Yoo and Jung, 2015), 단기간에 걸쳐 이 지역에 국한되어 발생한 폭설량을 알 수 있었다면 사고의 예방이 가능했을 것이다. 사고 지점으로부터 불과 14 km 떨어진 가장 가까운 울산 관측소에서 사고 당일 기록된 적설량은 16 cm였지만 사고 지점에서는 50 cm를 초과하는 적설량이 관측되었는데, 이러한 차이의 주 원인은 Fig. 1에 보였듯이 사고 위치의 고도(400 m)와 관측지점의 고도(35 m)의 차이가 컸기 때문인 것으로 분석되었다(Lee et al., 2015). 이와 같이 적설량은 고도에 많은 영향을 받는 강수량, 기온 등의 기상인자에 대하여 매우 민감하기 때문에 공간적 변동성이 매우 커 정확한 추정이 힘들며, 이로 인한 인명과 산업 피해를 예견하기도 어렵다.

적설 피해를 예방하기 위해 일반적으로 적설량은 강수량과 적설량의 비율이 10대1인 환산법칙(ten-to-one)을 사용하여 구한다(Arthur et al., 2000). 하지만 적설량(cm)과 강수량(mm)의 비율은 2:1부터 45:1까지 폭넓게 변화한다(Kim et al., 2013). 이 현상의 원인은 주변 기온에 따라 적설이 건설과 습설로 나뉘는 특징에 있다. 기온이 증가하면서 건설 입자 크기가 작아지고 작아진 입자는 입자 사이의 빈 공간을 채우고 단위밀도가 증가한 습설로 된다. 적설이 함유한 물의 양이 같더라도 기온에 따라 눈의 높이는 달라진다. 이러한 적설의 메커니즘을 물리적으로 해석(Dingman, 2002)하면 비교적 정확하게 적설량을 추정할 수 있으나, 이러한 해석방법에 필요한 변수의 수가 매우 많아 실용성의 관점에서 한계를 갖는다.
적설량은 지상관측자료를 활용하여 구할 수도 있고, 인공위성 기반의 관측자료를 활용하여 구할 수도 있다. 지상관측자료를 활용하는 방법은 물리기반의 방정식을 활용하는 기법(Junsei and Takeshi, 1990; E. Brun et al., 1992)과 적설에 영향을 미치는 다양한 기상인자들과 적설량의 상관관계를 활용하는 통계기반의 기법(Lee et al., 2007; Vivian et al., 2007)이 주를 이룬다. 지상관측자료에 기반한 이러한 방법들은 평균 기온, 하루 기온의 분포, 증기압 외의 관측자료의 공간적인 변동성을 정확히 예측하기 어려워 미계측 지역에서의 정확도가 지역마다 다양하게 분포하는 단점이 있다(Mark et al., 1999). 또한 지역마다 공간 규모의 크기를 어떻게 설정하느냐에 따라서 접근 방법도 달라진다(Christopher, 2006). 원격탐사자료를 활용한 기법은 넓은 지역에 걸쳐 촬영한 영상을 활용하므로 이러한 단점을 보완할 수 있으며, 크게 두 가지로 분류할 수 있다. 첫 번째 기법은 위성 자료로부터 얻은 변수 값을 물리기반의 방정식에 대입하는 방법(Jouni et al., 1999; Vincent at el., 2004)과, 또 다른 하나는 다양한 위성자료와 관측 적설량 사이의 회귀 방정식을 활용하는 통계기반의 방법이다(Cao et al., 2008; Chang et al., 1987; Kunzi et al., 1982; Edward and Nelly, 2002). 인공위성에서 측정한 지표면의 밝기온도(Brightness Temperature)가 주로 회귀 방정식의 독립변수로 사용된다. 하지만 인공 위성 자료는 촬영주기가 2회/월 내외로 길며, 촬영한 자료를 즉각적으로 구하기 힘들기 때문에 장기간에 걸쳐 발생하는 점진적인 적설량변화 관측 분야로 활용이 제한된다.
최근에는 적설량을 추정하기 위해 인공지능의 도입이 시도되고 있다. 인공지능의 가장 큰 장점은 적설 현상에 대한 물리적 이해를 필요로 하지 않는다는 점이다. Daniel et al. (1993)은 서로 다른 5개의 밝기 온도로부터 인공신경망을 활용하여 평균 적설 입자 크기, 적설의 밀도, 적설의 온도, 적설의 깊이를 산출하였다. Thian et al. (2009)는 인공지능 알고리즘 중 하나인 인공 신경망(Artificial Neural Network)를 이용하여 미국 중부에 있는 Rid River 부근을 대상으로 적설량을 산출한 결과 0.71 이상의 높은 검증상관계수를 얻었다. 또한 Samaneh et al. (2016)는 인공지능 알고리즘의 일종인 M5 Decision Tree algorithm을 이용하여 이란에 있는 반 건조 지역의 적설량을 산정하였다. 타 지역에 비해 적설 관측이 어려운 지역이므로 Channel network, Stream power와 같이 지역의 특성을 반영하는 변수들을 인공지능의 입력자료로 활용하였다. M. Tedesco et al. (2004)는 강설이 발생한 지역의 SSM/I (Special Sensor Microwave Imager) 자료를 인공신경망을 활용하여 관계식을 사용하지 않고 한 자료로부터 적설량과 SWE (Snow Water Equivalent)를 함께 산출하였다. Changyi et al. (2015)도 또한 SSM/자료로부터 적설 인자와 지표면의 밝기온도 관계를 인공지능으로 해석하고 이를 복잡한 지형인 산악지역에 적용하였다. Dobreva and Klein (2011)는 MODIS (Moderate Resolution Imaging Spectroradiometer) 영상 자료를 활용하여 인공신경망 기법으로 적설 분포도를 산출하였다. Jiayong et al. (2015)는 SSM/I 자료와 가시광선/적외선 표면 반사율 자료를 합성하여 SVM (Support vector machine) 알고리즘으로 적설량을 추정하였다. Elzbieta et al. (2014)은 IKONOS 위성이 제공하는 이미지를 해석하여 접근하기 어려운 알프스 산맥지역의 적설량을 산출하였다. Park et al. (2014)은 기온과 강수량 데이터로 강설이 발생하였는지 여부를 판단하는 인공신경망 모형을 구축하였다. 또한 Kim et al. (2014)은 기온과 강수량으로 적설량을 산정하는 인공신경망을 구축한 후 기후 시나리오를 적용하여 미래 확률 적설량을 산정하였다. Paul et al. (2006)은 인공신경망 기반의 적설량 추정기법과 지표온도기반방법(Surface Temperature Based Lookup Table Method) 및 기후학적 적설비 기법(Climatological Snow Ratio)을 비교하였다.
본 연구는 인공신경망 기법을 활용하여 지상 관측소의 기상 자료로부터 미계측 지역의 적설량을 파악하고자 하였다. 이를 위하여 시행 착오 법을 통해 최적의 인공신경망 네트워크 구조를 설계하고, 이를 사용하여 적설량을 산출한 후 관측적설량과 교차검증을 실시하였다. 또한, 제시된 기법의 비교 평가하기 위하여 지상에서 관측된 적설량을 Ordinary Kriging 방법을 사용하여 공간보간한 경우의 결과와 비교하였다. 본 연구는 특히 결과의 재난분야의 활용성에 초점을 맞추었다. 앞서 언급하였듯이 인공위성에 기반한 적설량 산출방법들은 자료의 수득이 쉽지 않아 장기간에 걸쳐 발생하는 점진적인 적설량변화관측 분야로 활용이 제한된다. 또한, 인공지능을 활용한 선행연구들을 살펴보면 우리나라와 같이 지형의 공간적 변동성이 큰 지역에서 인공지능기반 적설량산출 기법의 적용성을 검증한 사례가 없으며, 연구지역의 방법론이 유사한 Kim et al. (2014)의 경우 본 연구의 주요 목표인 미계측 지역의 적설량 산출에 초점을 두기 보다는 관측자료가 존재하는 지점에서의 미래확률적설량의 산정에 초점을 두고 있다. 본 연구는 관련 선행연구의 이러한 한계점을 극복하여 우리나라 전역에 대한 적설량의 즉각적인 산출을 가능케 하는 방법론을 제시하고자 하였다.
2. 방법론
2.1 인공신경망(Artificial Neural Network, ANN)
Fig. 2는 본 연구에서 사용한 최적의 인공신경망 구조로써 기본적으로 입력층, 은닉층, 출력층으로 구성되어 있다. 층 안에 있는 각 노드는 다음 층에 있는 노드와 가중치로 서로 연결되어 있다. 이와 같은 구조는 뉴런의 정보 처리 과정을 모방하여 만들어졌다. 인체의 뉴런은 수상돌기로 자극을 받아들인 후 축색으로 다른 뉴런에게 정보를 전달한다. 뉴런과 뉴런 사이는 시냅스로 연결되어 있듯이 마찬가지로 인공신경망은 노드와 노드 사이가 가중치로 서로 연결되어 있다. 가중치로 연결된 인공 신경망은 기존의 순차적인 처리 방식이 아니라 병렬 구조로 명령을 처리한다. 병렬 처리 방식으로 인해 인공신경망은 다소 복잡한 문제에서도 일반화가 가능하다. 최종 설계된 인공 신경망은 아직 접하지 못한 데이터를 올바르게 출력하는 것을 목표로 갖는다.
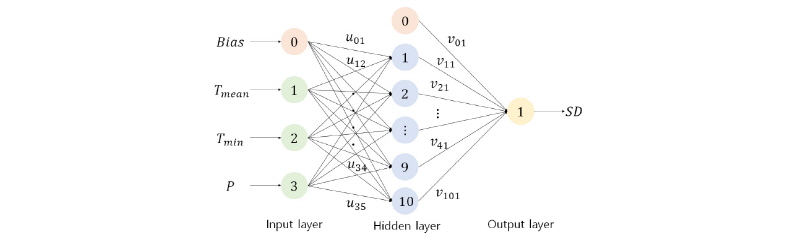
2.2 인공신경망의 처리 과정
Fig. 3에 나와 있듯이 각 노드는 Eq. (1)처럼 입력 값에 가중치만큼 곱한 후 활성화 함수를 통해 출력된 값을 다음 노드로 전달한다. Eq. (1)에서 가중치와 바이어스는 입력의 크기를 조절하는데 1차 방정식의 예로 각각의 역할을 이해할 수 있다. 가중치는 기울기 역할로 출력 값의 범위를 조절하고 바이어스는 상수 역할로 출력 범위를 이동시키는 역할을 한다. 바이어스는 필요에 따라서 변화를 줄 수 있지만 보통 1로 값을 설정한다. 가중치와 바이어스에 의해 조절된 입력값은 활성화 함수에 의해 출력의 발생여부가 결정된다. 이는 인체의 뉴런에서 자극의 세기가 특정 값 이상이 되어야 반응을 보이는 과정을 모방한 것이다(Tariq, 2016).

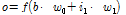 (1)
(1)
o : Output
f : Activation function
b : Bias
w: Weight
i : Input
가중치를 결정하는 과정을 학습과정이라 부르며, 각 가중치는 관측값과 추정값 사이의 오차가 최소화되도록 결정된다(Oh, 2008; Cho et al., 2008). 매번 학습할 때마다 오차를 계산하여 전 학습의 오차보다 큰 경우 학습을 종료한다. 이 과정을 여러 번 반복하여 오차가 가장 작을 때의 가중치를 최종 인공신경망의 가중치로 선택한다(Oh, 2008; Tom M. Mitchell, 1997).
학습을 진행하기 전에 신경망의 네트워크 구조를 먼저 설정해야 한다. 같은 자료를 사용하더라도 어떻게 구조를 설정했느냐에 따라서 인공 신경망의 성능이 달라지기 때문이다. 이를 조정(Regularization)이라 부른다. 조정은 아직까지 일반화된 방법은 나와있지 않기 때문에 시행 착오 법을 주로 사용한다. 조정과정에는 입력자료의 종류; 은닉 층의 개수; 각 은닉 층에 속해 있는 노드의 수; 활성화 함수의 종류 등을 정해야 한다. 복잡한 네트워크의 구조와 고급 알고리즘 기법이 항상 높은 성능을 가진 모델로 이어지지 않는다(Oh, 2008). 가령 네트워크 구조를 결정하는 매개변수의 수가 많을수록 학습은 잘 되나 일반화 성능이 떨어지고 반대로 매개변수의 수가 적을수록 적합한 학습이 진행되지 않는다(Richard et al., 2001). 이러한 조정과정은 앞서 언급된 다양한 변수들의 조합을 반복 시도하여 가장 정확한 출력값을 산출하는 모형을 정하는 것으로 마무리된다.
2.3 연구지역
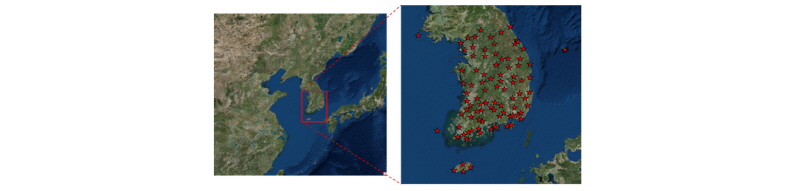
Fig. 4에 보인 연구 지역은 제주도를 포함한 남한 전체로 대상 지역 내에 있는 관측소의 고도는 가장 낮은 2.3 m부터 842.52 m까지 분포하였고 평균적으로 106.18 m에 위치하였다. 2017년 현재 94개의 관측소가 운영되고 있으며 폐쇄한 관측소까지 포함하면 총 123개의 관측소의 자료가 있다. 가장 오래된 관측소는 부산과 목포 관측소로 1904년 04월부터 시작하여 지속적으로 관측하고 있다. 관측소는 종관규모의 날씨를 파악하기 위해 모든 관측소에서 같은 시각에 자동관측하거나 목측한 기상관측자료를 제공한다.
2.4 연구 자료
연구에 사용된 데이터는 1960년부터 2016년까지 폐쇄되거나 신설된 곳을 모두 포함한 총 90개 관측소에서 신적설이 기록된 32,855일치의 자료이다. 기상청으로부터 자료를 제공받았다(https://data.kma.go.kr/cmmn/main.do). 제공되는 서비스 중 종관기상관측 자료에 평균 기온, 강수량, 최대 풍속, 최심신적설 등 총 59개의 특성이 일별로 기록되어 있다. 이 자료 중에서 인공지능을 통해 추정할 적설량은 특정일의 00시에 0 cm부터 시작하여 24시까지 가장 많이 쌓였을 때 기록된 적설량을 의미하는 일최심신적설로 선택하였다.
3. 네트워크 구조 선정
3.1 입력자료 선정
일강수량(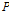 )과 일최심신적설 사이의 상관계수는 0.65 내외의 높은 값을 가지는 것으로 조사되었다. 따라서, 일강수량을 인공신경망 모형의 후보입력자료로 항상 고려하고 적설에 영향을 미치는 것으로 알려진 기온 자료(Kenneth F. Dewey, 1977; Rafael L. Bras., 1990) 중 일최대기온(
)과 일최심신적설 사이의 상관계수는 0.65 내외의 높은 값을 가지는 것으로 조사되었다. 따라서, 일강수량을 인공신경망 모형의 후보입력자료로 항상 고려하고 적설에 영향을 미치는 것으로 알려진 기온 자료(Kenneth F. Dewey, 1977; Rafael L. Bras., 1990) 중 일최대기온(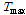 ), 일최저기온(
), 일최저기온(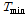 ), 일평균기온(
), 일평균기온(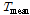 )을 인공신경망의 후보 입력자료로 추가 선정하였다. 일 강수량을 제외한 3개의 기온 변수를 7가지의 경우로 나누었다. 검증은 교차 검증(Cross Validation) 방법을 사용하였고 다음과 같은 순서로 진행하였다.
)을 인공신경망의 후보 입력자료로 추가 선정하였다. 일 강수량을 제외한 3개의 기온 변수를 7가지의 경우로 나누었다. 검증은 교차 검증(Cross Validation) 방법을 사용하였고 다음과 같은 순서로 진행하였다.
①하나의 관측소를 지정하고, 이 관측소에서 제외한 모든 관측소에서 관측된 자료를 인공신경망의 학습자료로 선정.
②하나의 은닉 층을 가진 인공신경망을 구성하고(Oh, 2008), 목표 교차 검증 상관 계수는 0.9로 은닉층의 노드는 5개로 설정.
③②에서 구성한 인공신경망을 ①의 자료를 활용하여 학습시킴.
④③에서 학습이 종료된 인공신경망을 활용하여 ①에서 지정된 관측소의 모든 일 최심신적설을 추정.
⑤②-④ 과정 모든 관측소에 대하여 반복하여 모든 관측소의 적설이 관측된 날의 일 최심신적설을 구한 후 추정 값과 측정 값 사이의 상관계수를 계산.
⑥산정한 상관계수가 목표 상관계수보다 클 경우 기록, 목표 상관계수 보다 작은 경우 노드의 수를 1개 추가하여 과정 ③부터 다시 시작.
⑦노드의 수가 20개까지 설정했음에도 불구하고 목표 상관계수를 넘지 못하는 경우, 목표 상관계수를 0.01 감소시키고 은닉층의 노드는 5개로 설정한 후 과정 ③부터 다시 시작.
⑧①-⑤ 과정을 20회 반복한 후 기록한 상관계수의 평균 값을 구함.
Fig. 5에 나와있는 그래프는 ①-⑧번 과정을 50회 반복하여 기록한 결과이다.
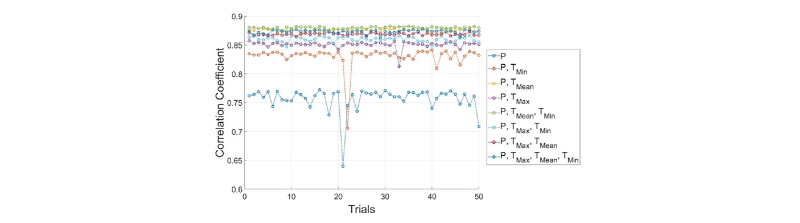
Fig. 5은 목표 검증 상관계수를 넘었을 때 상관계수를 기록한 결과이다. 그래프의 x축은 반복 시행 번호이고 y축은 교차검증 상관계수이다. 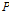 만 입력자료로 사용했을 때의 상관계수가 0.64~0.77사이로 가장 낮았고,
만 입력자료로 사용했을 때의 상관계수가 0.64~0.77사이로 가장 낮았고, 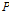 ,
, 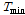 ,
, 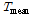 을 입력자료로 사용했을 때 상관계수가 0.87~0.88로 가장 높았다. 이러한 결과로부터 기온은 강수량과의 직접적인 상관관계는 매우 낮지만 보조 자료로서의 활용가치가 높다는 것을 알 수 있다. 또한 상관계수가 높은 입력자료를 사용할수록 산출되는 상관계수의 범위가 감소하는 추세를 확인할 수 있다.
을 입력자료로 사용했을 때 상관계수가 0.87~0.88로 가장 높았다. 이러한 결과로부터 기온은 강수량과의 직접적인 상관관계는 매우 낮지만 보조 자료로서의 활용가치가 높다는 것을 알 수 있다. 또한 상관계수가 높은 입력자료를 사용할수록 산출되는 상관계수의 범위가 감소하는 추세를 확인할 수 있다.
3.2 은닉층의 노드 수 결정
은닉층에 있는 적절한 노드의 수를 찾기 위해 입력자료를 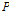 ,
, 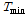 ,
, 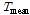 으로 고정시킨 후 은닉층에 있는 노드의 수를 1개부터 1개씩 추가하여 20개까지 각각 인공신경망을 실행하며 위에서 언급한 과정으로 상관계수를 확인하였다. 그 결과를 Fig. 6에 보였다.
으로 고정시킨 후 은닉층에 있는 노드의 수를 1개부터 1개씩 추가하여 20개까지 각각 인공신경망을 실행하며 위에서 언급한 과정으로 상관계수를 확인하였다. 그 결과를 Fig. 6에 보였다.
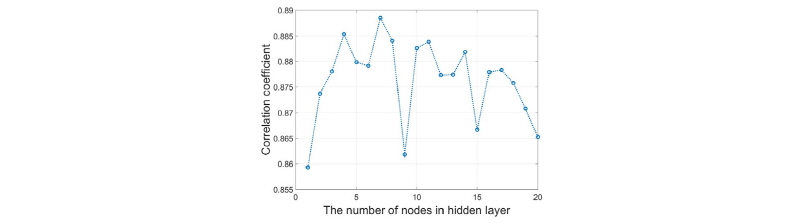
Fig. 6에서 x축은 은닉층에 있는 노드의 수이고 y축은 교차 검증 상관계수이다. 학습을 시작할 때마다 가중치를 새로 설정하기 때문에 실행할 때마다 교차 검증 상관계수는 매번 달랐지만 Fig. 5의 결과와 같이 상관계수가 높기 때문에 0.85~ 0.89사이의 일정한 범위를 가졌다. 노드수가 교차 검증 상관계수가 큰 영향을 주지 않는다고 판단하였다.
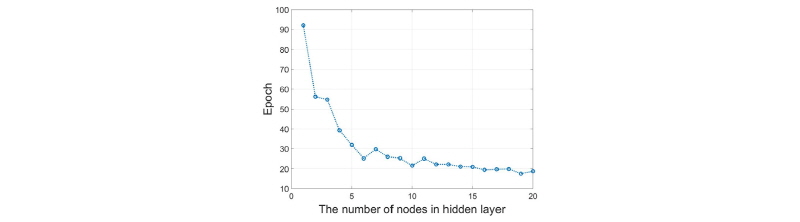
다른 요인인 에포크(Epoch)으로부터 노드의 수를 결정하였다. 학습 자료 전부를 학습에 사용한 횟수을 에포크라고 부른다. 예를 들어 데이터 베이스에 100개의 학습 자료가 있다면 학습하는 동안 가중치가 100회 갱신된다. 그 다음 다시 처음부터 100회 추가적으로 갱신되는데 이때를 2에포크라고 하며 처음 학습을 시작했을 때를 1에포크라 한다. 2에포크 후 성능을 평가하여 오차가 전 에포크보다 크면 학습을 종료하고 전 에포크의 가중치를 사용한다. 은닉층에 있는 노드수와 에포크 사이의 관계를 알기 위해 Fig. 6의 시뮬레이션을 할 때 함께 에포크를 기록하였고 그 결과는 Fig. 7과 같다.
Fig. 7에서 x축은 은닉층의 노드수이고 y축은 한 관측소에서 일최심신적설을 예측할 때 소요되는 에포크이다. 노드수가 많을수록 학습시간은 감소하였고 노드수가 10개 이상부터는 에포크가 20으로 수렴하였다. 자료의 양과 특성에 따라 1에포크당 걸리는 시간은 다르지만 본 연구에서는 100에포크당 약 1분의 시간이 소요되었다. 적설량을 산정할 때 큰 제약을 받는 것은 아니지만 본 연구의 특성상 모든 관측소를 여러 번 시행착오로 검증해야하기 때문에 에포크가 수렴하기 시작한 10개를 최적의 노드수로 설정하였다. 만약 분 단위의 예측일 경우 반드시 에포크를 고려하여 노드의 수를 결정해야 한다.
3.3 데이터 수 설정
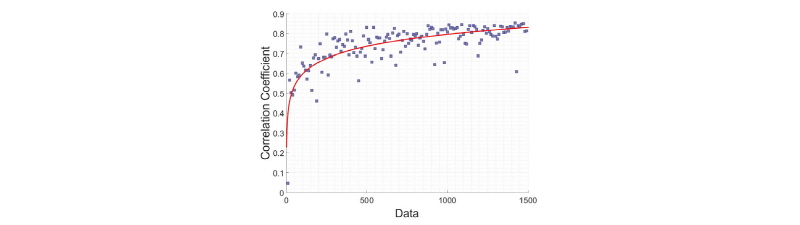
데이터의 비효율성을 감소시키기 위해 학습 데이터 수와 검증 상관계수의 관계를 알아보았다. 과도하게 많은 학습 데이터는 지나친 학습으로 하나의 추세로 편향시켜 일반화 성능을 감소시킨다(Ian et al., 2011). 예를 들어 5~10 cm의 적설량이 다른 구간에 비해 데이터의 양이 지나치게 많다면 예측 정확도가 5~10 cm 구간에서는 증가하나 그 외의 구간에서는 감소하여 전반적으로 성능을 감소시킨다. 학습 데이터 수와 검증 상관계수의 관계를 확인하기 위해 데이터 수를 설정하여 5회 학습 후 평균 검증 상관계수를 기록하였다. 데이터 수는 10개부터 시작하여 10개씩 추가하였고 그 결과는 Fig. 8과 같다.
Fig. 8의 그래프에서 x축은 학습 데이터 수이고 y축은 5회 시뮬레이션의 평균 검증 상관계수이다. 학습 데이터수가 20개일 때부터 평균 검증 상관계수는 급격히 상승하고 학습 데이터 수가 더 많아질수록 평균 검증 상관계수의 변화 폭은 감소되었다. Fig. 8에 빨간색 실선으로 보인 두 변수 사이의 회귀식은 학습할 수 있는 Data 수가 1000개 이상일 때 0.8 내외의 안정적인 상관계수를 갖는 것을 보여준다. 따라서 본 연구에서는 총 32,855개의 자료 중 가장 최근 날짜순으로 1,040개의 데이터를 무작위로 선별하여 인공지능의 학습을 시행하였다. 위 결과들로부터 최적의 네트워크 구조를 앞서 나타낸 Fig. 2와 같이 설정하였다.
4. 결 과
4.1 입력자료가 측정값인 경우
4.1.1 단순공간보간기법(Kriging)과 인공신경망의 성능 비교
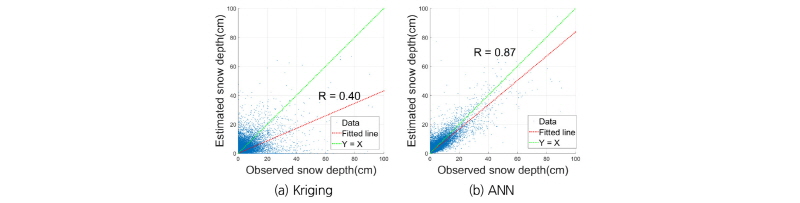
Fig. 9는 한 관측소를 제외한 나머지 관측 자료로부터 인공신경망을 학습시킨 후 지정한 관측소의 입력 값을 토대로 일 최심신적설을 추정한 경우와 Kriging 기법을 통해 일최심신적설을 보간하여 추정한 경우의 결과를 보인다.
Fig. 9에서 x축은 관측된 일최심신적설이고 y축은 (a) Kriging, (b) 인공신경망을 이용하여 추정한 일최심신적설이다. 모든 90개 관측소에서 모든 일자에 대하여 관측된 결과를 함께 보였다. 그 결과 Kriging과 인공신경망의 교차 검증 상관계수는 각각 0.40과 0.87이 나왔다. Fig. 9(a)와 같이 공간보간을 통한 일최심신적설 추정의 정확도가 낮은 이유는 일최심신적설의 공간적인 상관도가 강수량에 비하여 현저히 낮기 때문이다. 이는 일최심신적설이 강수 뿐 만이 아니라 기온, 고도 등 기상학적/지형학적 조건에 의하여 큰 영향을 받는다는 사실에 기인한다(Broxton et al., 2016). 상관계수가 2배 이상 차이가 발생하게 된 배경은 예측하는 조건이 서로 다르기 때문이다. Kriging의 경우, 날짜가 기준이 되어 해당 날에 적설이 기록된 관측소가 5개 이상인 경우에만 추정이 가능했다. 반면 인공신경망은 날짜에 제약을 받지 않기 때문에 입력자료만 주어진다면 추정이 가능했다. 가령 의령의 경우 약 3년의 기간 동안 일 최심신적설이 기록된 날은 8일에 불과하다. 근처 지역인 부산의 경우도 마찬가지로 최근 약 50년 기간 동안 일 최심신적설이 기록된 날은 55일로 다른 지역에 비해 기록된 자료의 수가 작다. 반면 인공신경망의 경우 지역 구분 없이 전국을 대상으로 모델링이 가능하며 강설이 발생한 날의 여부와 상관없이 일괄적으로 학습할 수 있다. 부산의 경우 인공신경망으로 예측하여 실제 적설량과 분석한 결과 상관계수가 0.77로 지역의 한계를 줄일 수 있었다.
4.1.2 적설량 크기별 분석 결과
Fig. 9(b)의 결과를 적설량 10 cm 구간으로 나눠 상관계수를 비교해보았다. 그 결과는 Fig. 10과 같다.
Fig. 10은 Fig. 9와 마찬가지로 x축은 관측된 일최심신적설이고 y축은 인공신경망을 이용하여 추정한 일최심신적설이다. 10 cm 간격으로 구간을 나눠 각 구간에 해당되는 일최심신적설의 상관계수를 기록하였다. 30~40 cm를 제외한 나머지 구간에서는 적설량이 클수록 상관계수가 감소하였다. 상관계수가 0~10 cm으로 편향된 원인을 조사하기 위해 아래 Table 1과 같이 구간별로 정보를 정리하였다.
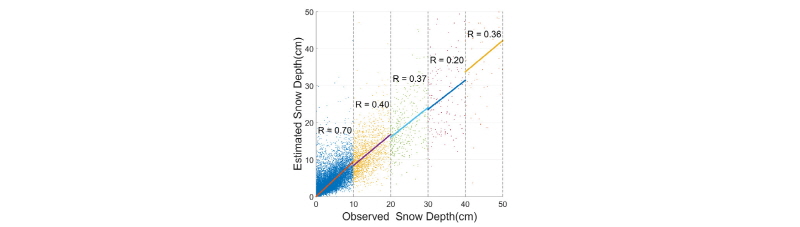
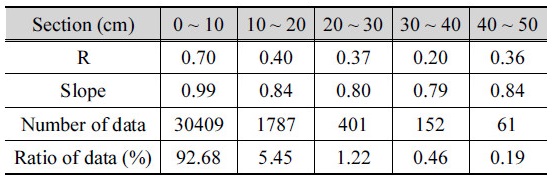
Table 1은 각 구간의 상관계수, 추세선의 기울기, 데이터 수를 보여준다. 0~10 cm을 제외한 나머지 구간에서 기울기는 평균 0.8175로 큰 변화가 없었다. 이에 반해 0~10 cm에서 상관계수와 기울기가 각각 0.70, 0.99로 가장 높게 나타났다. 편향된 결과의 원인은 데이터 수에 있다. 총 32,810개 중에서 0~10 cm에 해당되는 데이터 수는 30.409개로 전체 중 92.682%에 해당된다. 학습 데이터를 무작위로 추출할 때 주로 일최심신적설이 0~10 cm의 데이터가 선택되어 편향된 학습 결과로 이어졌다. 따라서 편향된 학습 효과를 방지하기 위해서는 데이터를 추출할 때 고르게 선별해야 한다.
4.1.3 관측소별 인공지능 성능 평가
Fig. 11은 교차 검증상관계수를 각 관측소에 대하여 구하고 이를 Ordinary Kriging 기법을 이용하여 지도로 표현한 결과이다.
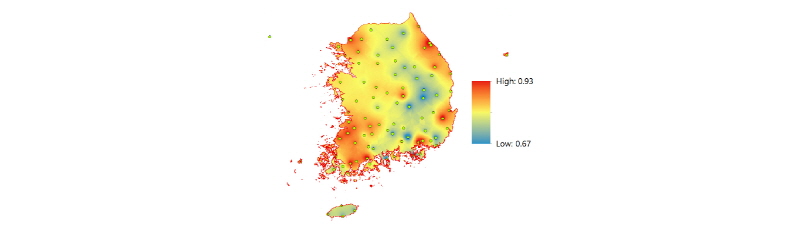
상관계수가 높은 지역은 주로 해안에 위치하였고 상관계수가 낮은 지역은 대부분 내륙에 위치하였다. 0.82~0.84의 상관계수를 갖는 지역이 가장 많았고 산맥을 중심으로 하여 해안으로 갈수록 상관계수가 증가하는 양상을 보였다. 정밀한 분석을 위해 DEM (Digital Elevation Model)을 이용하여 고도와 상관계수의 관계를 Histogram으로 표현하였다. 그 결과는 Fig. 12와 같다. Fig. 12의 x축은 교차검증 상관계수, y축은 각 교차검증 상관계수에 해당되는 빈도수로 고도 200 m를 기준으로 구분하여 나타냈다.
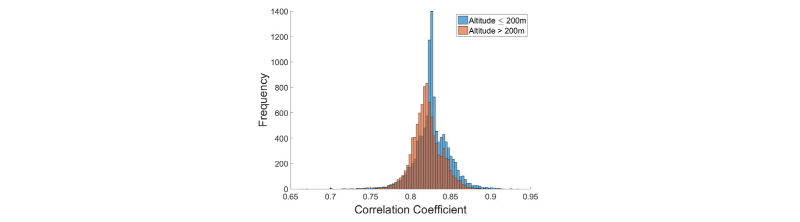
산맥을 따라 높은 고도에 위치한 지역은 고도가 낮은 지역에 비해 상관계수가 낮았다. 고도가 200 m 이상인 지역은 200 m 미만인 지역보다 낮은 상관계수에 분포하였다. 고도가 200 m 이상인 경우와 200 m 미만의 경우로 추출된 데이터 수는 각각 10,735개와 9,216개로 1,519개 차이가 있었다. 고도가 200 m 미만인 경우 1399개의 데이터가 교차 검증 상관계수 0.83으로 집중되었다. 하지만 고도가 200 m 이상인 지역은 최대로 많은 집중된 데이터 수는 833로 교차 검증 상관계수는 0.81였다. 고도가 200 m 이상인 경우 200 m 미만인 경우에 비해 상대적으로 고르게 분포하였고 교차 검증 상관계수의 범위는 0.72~ 0.90였다. 이에 비해 200 m 미만인 지역의 교차 검증 상관계수의 범위는 0.66~0.94로 고도가 200 m 이상인 경우보다 상관계수의 범위가 증가하였다. Fig. 12의 결과로부터 데이터 추출할 때 관측소의 고도도 함께 고려해야 하는 것을 알 수 있다. 본 연구에서 사용한 전체 관측소 90개 중 고도가 200 m 이상 위치한 관측소는 총 18개로 전체에서 20%를 차지한다. 앞서 2.4 연구지역에서 서술했던 평균 관측소의 고도가 106.18 m인 것을 감안한다면 4.1.2 적설량 크기별 분석 결과와 마찬가지로 편향된 학습을 방지하기 위해서는 관측소의 고도도 함께 고려하여 데이터를 추출해야 한다.
4.2 입력 데이터를 추정한 경우
미계측지역은 인공신경망 모형에 입력자료로 사용할 관측 자료가 존재하지 않는다. 적설량을 추정해도 검증하는 데 한계가 있기 때문에 마찬가지로 교차 검증 방법을 이용하였다. Fig. 5에서 입력자료로 최종 선정한 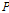 ,
, 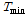 ,
, 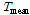 를 Kriging 공간보간 기법을 사용하여 추정한 결과를 보였다.
를 Kriging 공간보간 기법을 사용하여 추정한 결과를 보였다.
Fig. 13은 입력자료로 사용할 일 평균 기온, 일 최저 기온, 강수량을 Kriging 보간 기법으로 추정한 후 실제 관측값과 비교한 결과이다. 실제 관측값은 x축으로 추정값은 y축으로 설정하였고 모든 자료의 총 상관계수를 계산하였다. 보조 입력자료인 일 최저 기온과, 일 평균 기온은 상관계수가 0.70임에 비해 기준 입력자료인 강수량은 상관계수가 0.58로 정확도가 감소하였다. 모든 관측소가 기온 자료를 날마다 보유하고 있지만 강수량은 기록된 관측소에만 있기 때문에 상대적으로 정확도가 다른 입력자료에 비해 더 감소되었다. 검증할 관측소를 제외한 나머지 관측소의 관측값으로 인공 신경망을 설계한 후 추정한 입력자료로 적설량을 산출하였다. 같은 방법으로 모든 관측소의 적설량을 산출한 다음 전국을 대상으로 상관계수를 측정하였다. 결과를 Fig. 14의 Hexagonal Density Plot에 보였다. Fig. 14의 x축은 관측 일최심신적설, y축은 ANN을 사용하여 추정한 일최심신적설을 나타낸다.
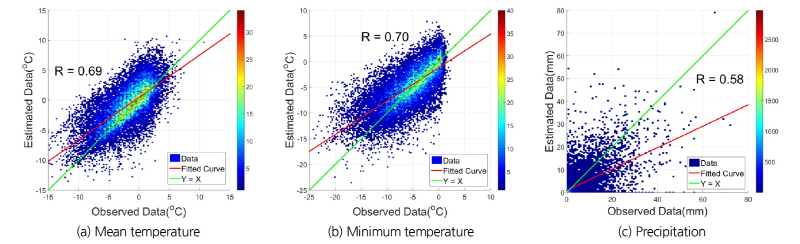
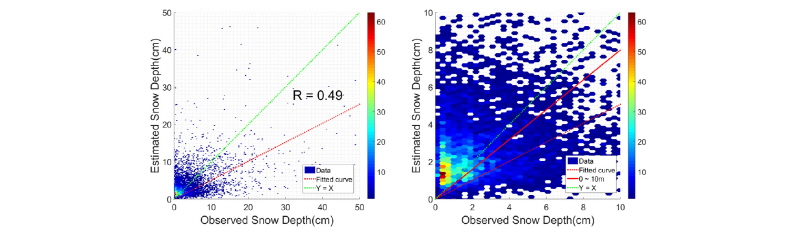
Fig. 14는 x축을 관측값으로 y축을 추정값으로 하여 상관도를 분석한 결과다. Fig. 14에서 좌측 그래프는 일최심신적설의 전 구간을, 우측 그래프는 일최심신적설의 0~10cm 구간만 나타냈다. 입력자료를 추정하였을 경우, 상관계수는 0.49로 관측자료가 존재하는 경우보다 0.3정도 낮았지만 Kriging으로 추정했을 때보다 약 0.1만큼 큰 값을 유지하였다. 상대적으로 데이터가 가장 많은 0~10cm 구간에서 추세선의 기울기(빨간 직선)가 0.71로 전 구간에서의 기울기(빨간 점선) 0.51보다 0.20이 증가하였다.
5. 결 론
본 연구에서는 인공 신경망 모형을 이용하여 일최심신적설을 추정하였다. 인공신경망은 어떻게 설계하는지에 따라 성능이 달라지기 때문에 시행 착오 법으로 최적의 구조를 찾는 작업을 먼저 진행하였다. Table 2와 같이 설계했을 때 교차검증 상관계수가 0.88로 가장 높았다.
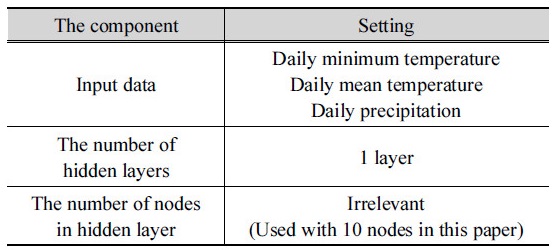
입력자료를 두 가지 경우로 나눠서 검증하였다. 관측자료를 인공신경망모형의 입력자료로 활용하는 경우 교차검증 상관계수는 0.87 이었고, 관측자료를 Ordinary Kriging 공간보간(OK)기법으로 추정하는 경우의 교차검증 상관계수는 0.49 이었다. 두 경우 모두 OK기법으로 관측 일최심신적설을 공간보간한 경우의 교차검증 상관계수인 0.40보다 좋은 성능을 보였다. 관측지점별로 자료를 분류하여 분석한 경우, 인공신경망과 OK기법의 교차 검증 상관계수의 격차가 매우 큰 지역도 존재하는데, 그 이유는 공간보간에 활용할 수 있는 주변 관측자료의 수가 적은 경우 OK기법의 성능이 크게 저하되기 때문이다. 이러한 결과는 일최심신적설을 추정할 때, 해당 지역의 일강우량, 일최저기온, 일평균기온을 알 수 있다면 인공지능을 활용하는 경우가 주변에서 관측된 일최심신적설을 공간보간하는 경우보다 더욱 정확한 결과를 얻게 해준다는 점과 입력자료의 정확도가 인공신경망 모형의 정확도에 많은 영향을 미친다는 점을 의미한다. 고도와 인공신경망 모형의 성능을 비교한 결과, 고도가 낮은 지역에서의 인공지능의 상관계수는 높은 지역의 상관계수보다 높았다.
본 연구의 방법론을 실용화 하는 경우 강설 발생 후 빠르게는 수시간 이내에 우리나라 전역에 걸친 적설량의 산출이 가능하다. 본 연구의 결과가 폭설지역의 즉각적인 판별을 통해 재해위험저감에 기여할 수 있기를 기대한다.
