

1. 서 론
2. 연구방법
2.1 단일 사상 강우-유출 모형을 통한 홍수량 산정 방법
2.2 Dynamically Dimensioned Search Algorithm
2.3 DDS 알고리즘과 연계한 HEC-1 모형 매개변수 최적화
3. 대상유역 및 자료
4. 결 과
4.1 경험식 및 단일 강우-유출 사상 기반 매개변수 최적화
4.2 다중 강우-유출 사상 기반 매개변수 최적화 결과
5. 결 론
1. 서 론
수자원의 조사 및 관리에서부터 다양한 수자원 관련 시설물들을 합리적으로 계획하고 설계하기 위해서는 적절한 기준과 절차에 의하여 수문량 산정이 요구되며, 이러한 규정은 홍수량 산정 표준지침(ME, 2019)에서 명시하고 있다. 특히, 표준지침 내 제안된 홍수량 산정절차는 크게 빈도해석 방법과 강우-유출관계에 따른 방법으로 구분되어있으나, 홍수량 빈도해석에 의한 방법은 홍수량 자료가 부족하여 실질적으로는 강우-유출모형 방법을 활용하고 있다. 즉 홍수량을 모의하고자 국내에서는 단일 홍수사상에 대하여 모의가 가능한 HEC-HMS 또는 HEC-1 모형과 같은 단일사상 강우-유출 모형이 주로 활용되고 있다. 본 연구에서 활용한 HEC-1 모형은 내부적으로 수문곡선을 산정하기 위한 다양한 이론을 제공하고 있다는 점이 장점이며, Clark, Snyder, SCS 방법 등 합성단위도 방법 중 유역의 특성에 맞는 방법을 고려하여 분석할 수 있다. 그러나 Snyder, SCS 방법 등은 수문곡선을 유도하기 위해 적용한 지형적 특성 반영이 필요하기 때문에 국내의 유역에 직접 적용하기에는 어려움이 따른다. 반면, Clark (1945)에 의해 처음 소개된 Clark 단위도법은 순간단위도법의 개념을 도입된 방법으로, 실무에서는 2000년대 이후로 Clark 단위도법을 가장 많이 채택하고 있다(MLIT, 2021). 그러나, 설계 시 홍수량 산정을 위해서는 유역면적이 비교적 큰 경우에는 소규모의 유역으로 구분하여야 하며, 구분된 유역 내 홍수량 산정을 위한 지형정보 및 정확한 수문기상 정보 취득이 필요하다. 특히, 본 연구에서 활용한 Clark 단위도법은 유역특성인자와 관련이 있는 도달시간과 저류상수를 매개변수로 활용하고 있어, 매개변수는 지형 특성을 활용한 경험적 회귀식 등을 통해 매개변수를 간접적으로 추정되고 있다(Reshma et al., 2018).
이러한 점에서 매개변수 산정 시 유역의 특성이 반영되는 방식에 따라 유역 면적과 함께, 유역경사, 유로연장 등을 고려하는 다양한 경험적 연구가 수행되어왔다. 일반적으로 홍수량 산정은 분석 단위를 전체 면적으로 두고 수행하지 않으며, 전체유역을 소유역으로 분할하고 각 소유역에서의 유량을 유역추적(watershed routing)과 하도추적(channel routing)으로 분류하여 최종적으로 합산하는 방식으로 수행된다. 따라서, 소유역의 크기나 개수 등이 상당히 중요한 요소로 인식되어 소유역 수에 따른 민감도와 관련된 연구들이 다수 수행되었다. 국내에서는 중규모 유역에 대하여 적정 소유역 분할을 수행한 결과, 일정 분할개수 이전에는 분할개수가 증가함에 따라 첨두유량은 증가하고 첨두시간은 감소하였으나, 일정 분할개수를 초과하는 경우에 이러한 경향이 감소하는 것이 확인되었다(Lee et al., 2013). 또한, 소유역 개수의 증가에 따른 첨두유량의 정확도 개선 효과는 크지 않은 것으로 평가되었다(Hromadka, 1986). 따라서, 연구의 방향성은 경험식을 활용하는 방법 또는 가용한 입력자료가 충분한 경우 매개변수를 직접적으로 추정하는 방법이 연구되고 있다(Chua and Wong, 2010; Sarkar and Kumar, 2012; Kan et al., 2015; Natarajan and Radhakrishnan, 2019). 따라서, 최근 연구에서는 계측유역에 대해서는 물리적 매개변수를 직접 최적화하거나, 미계측 유역에 대해서는 지역화에 따른 경험식 등이 주로 제안되고 있다. 유역의 매개변수 중 하나인 도달시간의 경우 계측유역에서는 측정된 자료를 활용하여 수문곡선을 작도하여 변곡점까지의 시간으로 산정한다. 반면, 미계측유역의 경우에는 유역면적, 유로연장, 유역 형상 매개변수 등 다양한 유역특성인자를 활용한 회귀식이 주로 활용하고 있다. 그러나, 매개변수 지역화는 제한된 계측유역을 대상으로 수행하므로 불확실성이 크며, 특히 미계측 지역으로 전이 시 상이한 지역적 특성으로 인해 물리적인 강우-유출 관계를 효과적으로 재현하는데 어려움이 따른다. 따라서, 대상 유역의 강우-유출관계를 정확하게 평가하기 위해서 대상 유역의 수문기상 자료 및 지형적인 특성을 고려하여 경험식을 산출하는 연구가 활발히 진행되었다(Yoon and Park, 2002; Ahmad et al., 2009; Che et al., 2014; Jung et al., 2014).
경험식을 적용하는 방안 이외에도 강우-유출 정보가 존재한다면 강우-유출 모형의 최적 매개변수를 추정하기 위하여 최적화 방법을 고려할 수 있으며 최적화 방법, 대상자료, 목적함수 등에 따라 최적 매개변수 다르게 추정될 수 있다. 이러한 강우-유출 모형은 사용목적에 따라 장기간의 전반적인 유출 양상을 평가할 수 있는 연속 강우-유출모형(continuous rainfall-runoff model)과 특정사상에 대한 홍수량을 평가하는데 활용하는 단일사상 강우-유출모형(event-based rainfall-runoff model)로 구분된다. 연속강우유출모형은 GR4J, TANK, SACRAMENTO 모형 등이 제시되어 있으며, 단일사상 강우-유출모형은 HEC-1, HEC-HMS 등 다양한 모형들이 제시되어 있다. 그러나, 강우-유출 모형은 목적에 맞게 활용되어야 하며, 모형이 다양하여 유역에 알맞은 모형을 선정할 필요가 있다. 더욱이 최적 매개변수를 추정하기 위한 최적화 도구의 선정까지 포함하여 연구 목적, 모형 선정, 최적화 도구 선정은 강우-유출 모형을 적용하는 데 있어서 중요한 요소이므로 최종적으로 관측 유량과 비교하여 모의 결과가 적절한지 평가하는 것이 매우 중요하다(Duan et al., 1992). 모형 선정의 관점에서 모형 성능에 대한 평가 및 비교가 수행되는 것이 일반적이나, 본 연구에서는 실무에서의 적용성을 고려하여 국내에서 홍수량 산정에서 대표적으로 활용되고 있으며, 본 연구의 대상 유역인 섬진강 유역의 경험적인 매개변수(MLIT, 2021)가 제시되어 있는 HEC-1 단일사상 강우-유출 모형을 활용하고자 한다.
본 연구에서는 섬진강 하천기본계획에서 제시된 홍수량 산정지점의 Clark 매개변수에 대하여 최적 매개변수를 산정하여 현재 적용되고 있는 매개변수와 비교하여 홍수량을 평가하고 섬진강 유역을 대표할 수 있는 매개변수를 산정하는 방법을 제시하였다. 최적화 방식은 현재 「홍수량 산정 표준지침」에서도 명시하고 있는 검정(calibration) 및 검증(validation)을 활용하는 부분은 동일하나, 표준지침에서는 최적화를 위한 해석 방법 및 최적화 목적함수 등과 같은 절차에 대한 내용이 구체적으로 제시되어 있지 않다는 점에서 본 연구에서는 최적화 관련 과정을 구체적으로 제시하고자 한다. 기존 「홍수량 산정 표준지침」에는 최적화와 관련한 방법론 및 분석 체계가 명확하게 제시되지 않아, 실무에서는 매개변수 최적화가 일반적으로 생략되고 있다. 즉, 관측 강우-유출 관계 구축, 관측 자료 활용 방법 및 최적화 적용 절차에 대한 실무적 적용이 어려워 일반적으로 경험식의 적용하거나 제한적인 관측 자료를 활용하여 검정 및 검증 과정을 수동적으로 진행하고 있으며 다소 주관적인 접근 방법을 취하고 있다. 그러나, 이러한 주관적인 방법으로 매개변수를 추정하는 경우 강우-유출 관계의 물리적인 특성을 유지하기 어려우며 불확실성을 증가시키는 요인으로 작용한다. 따라서, 이용 가능한 강우-유출 정보를 활용함과 동시에 물리적 제약조건 하에서 HEC-1 모형의 최적 매개변수를 탐색하는 것이 매우 중요하다. 그러나, 단일사상 강우-유출모형에 최적화 기법을 활용하여 매개변수를 산정하는 경우, 강우-유출 사상에 따라서 추정되는 도달시간 및 저류상수가 매번 변화하고 유역 내 홍수량 산정지점에 따라서 매개변수가 유지되지 않아 일관된 매개변수 추정 자체가 어렵다. 즉, 강우-유출 모형 매개변수를 각각의 지점에 따른 강우-유출 사상에 따라 매개변수를 독립적으로 추정하는 경우 매개변수가 다르게 추정되며, 매개변수의 물리적인 범위를 초과하는 등의 문제점이 발생한다. 장기간의 강우-유출 정보를 활용하는 연속강우-유출모형의 경우, 매개변수 추정 시 비교적 안정적인 매개변수 추정과 함께 매개변수의 변동성을 감소시킬 수 있다. 반면, 최대 24-48시간의 강우-유출 자료를 대상으로 이루어지는 단일 강우-유출모형의 최적화의 경우 사용되는 강우-유출 자료의 특성에 따라 변동성이 매우 클 수 밖에 없으며 이에 따른 홍수량 추정결과에 대한 불확실성도 크게 된다.
이러한 점에서 본 연구에서는 물리적 범위(제약조건) 하에서 다수의 강우사상을 동시에 고려하여 대표 매개변수를 추정할 수 있는 방법을 제안하는데 목적이 있다. 이를 통해 일관된 대표 매개변수 추정과 함께 강우-유출 모의에 정확성도 개선하는데 기여하고자 한다. 본 연구에서는 국내의 홍수량 산정 표준지침에 따라 유출량을 산정하고 이에 대한 최적화 방법으로 수문학적 매개변수 산정에 자주 활용되는 DDS (Dynamically Dimensioned Search) 알고리즘을 활용하여 매개변수 추정 절차를 제시하였다.
본 논문의 구성은 다음과 같다. 1장에서는 현재 국내의 단기사상 강우-유출 모형 내부의 매개변수 추정 방법 및 유역 특성을 고려한 최적 매개변수 산정과 한계점을 밝히고 매개변수 최적화의 중요성을 기술하였으며, 이에 대한 연구의 목적 및 필요성에 대하여 명시하였다. 2장에서는 국내 홍수량 산정방법의 구체적인 사항과 최적화 도구인 DDS 알고리즘의 개요를 기술하였으며, 이를 활용하여 HEC-1 모형에서 DDS 알고리즘 적용방식을 요약하였다. 3장에서는 본 연구의 대상 유역인 섬진강 유역의 홍수량 산정 지점에 대하여 구체적으로 서술하였으며, 4장에는 홍수량 산정 방법을 기존의 경험식을 활용한 방법, 개별 사상에 적용한 최적화 방법 및 다수의 홍수사상을 고려한 최적화 방법을 비교 및 평가하였다. 마지막으로 본 연구의 결론 및 한계점에 대한 향후 연구를 5장에 수록하였다.
2. 연구방법
2.1 단일 사상 강우-유출 모형을 통한 홍수량 산정 방법
국내에서 실무적으로 적용되고 있는 홍수량 산정방법은 홍수량 빈도해석법과 강우-유출모형을 활용한 방법으로 구분하고 있다. 홍수량 빈도해석 방법은 홍수량 자료가 많은 경우, 가장 정확하게 확률홍수량을 산정할 수 있는 방안으로 알려져 있으나, 우리나라의 경우 수자원 관리를 위하여 인공구조물 및 하천수 취득 등 다양한 원인에 의하여 자연유량의 취득이 어려워 적용가능한 유역이 제한적이다. 따라서, 홍수량 산정 표준지침에 의해 홍수량 자료가 없는 미계측 유역에 대하여 강우빈도해석을 통해 추정된 설계강수량을 강우-유출모형을 통해 홍수량으로 변환하고 이를 설계홍수량으로 간주하여 설계에 활용하는 것이 일반적인 방법이다.
소유역에 대한 강우-유출모형 적용 시, 홍수수문곡선 계산은 필수적인 과정이다. 국내에서는 250 km2 이상의 유역의 경우 단위도법을 적용하기 위하여 다수의 소유역과 하도구간으로 분할하여 유출량을 계산하고 있다. 국내에서 적용하고 있는 합성단위도법은 Clark, Snyder, SCS, Nakayasu 단위도법을 활용하고 있으며, 이중 Clark, Snyder, SCS 단위도법이 HEC-1 프로그램에 홍수량 산정을 위한 단위도법으로 제시되고 있다. 그러나, Snyder, SCS 단위도법은 단위도가 유도된 유역의 지형특성을 토대로 구성되어 있다. Snyder 단위도 방법은 지형특성인자와 경험공식을 연결하여 단위도를 작성하며, SCS 단위도 법은 미국 토양보존국(U.S. Soil Conservation Service)에서 미국 내 여러 유역에서 도출한 단위도를 해석하여 첨두유량과 첨두시간과의 관계를 경험식으로 제시한 방법이므로, 우리나라에 적용하기 위해서는 매개변수의 재추정이 필요하다. 매개변수 최적화에도 불구하고, Snyder, SCS 단위도법에 비해, 물리적 특성에 기반한 Clark 단위도법이 가장 적용성이 높은 방법으로 인식되고 있으며, 국내의 실무에서도 Clark 단위도법이 주요 방법으로 채택하고 있다.
현재 홍수량 산정 표준지침에 제시된 Clark 단위도법의 매개변수 결정하는 방법은 크게 두 가지 방식으로 구분된다. 첫째, 대부분의 지방하천 및 국가하천에서 활용하고 있는 경험공식에 의한 도달시간과 유역 저류상수 값을 최종 매개변수 값으로 채택하는 방법이다. 기존에는 Clark 단위도법의 매개변수인 도달시간(TC) 과 저류상수(K)의 산정을 위해 국외에서 개발된 경험공식을 적용하여 도달시간은 Kirpich 공식, Rziha 공식, Kraven 공식(I), Kraven 공식(II) 등 다양하게 적용하였으나, 2012년 국토해양부에서 발간한 「설계홍수량 산정요령」에서는 연속형 Kraven 공식을 제안하였으며, 저류상수는 일반적으로 Sabol 공식(Sabol, 1988)이 적용되었다. 그러나, 국외에서 개발된 경험공식은 연구를 수행한 대상 유역의 특성이 반영된 결과이므로 국내의 유역 특성을 반영하기 어렵다. 따라서, 국내의 유역특성을 고려하기 위하여 「홍수량 산정 표준지침」에서는 서경대 공식(ME, 2019)을 따르도록 규정되어 있다. Eqs. (1) and (2)는 기존에 국내에서 활용한 도달시간 및 저류상수의 경험공식인 연속형 Kraven 공식, Sabol 공식이며, Eqs. (3) and (4)는 현재 「홍수량 산정 표준지침」에서 지정한 도달시간 및 저류상수 산정식인 서경대 공식이다.
연속형 Kraven 공식에서 Tc는 도달시간(min)이며, L은 유로연장(km), V는 평균유속(m/s)이며, 서경대 공식은 모두 동일하나, 유역 최원점 표고와 홍수량 산정지점 표고의 고도차(m)인 H를 적용하여 산정한다. 또한, 저류상수 산정식인 Sabol 공식에서 K는 저류상수(hr), L은 유로연장(hr), A는 유역면적(km2)이며, 도달시간은 도출된 도달시간에서 분 단위를 시 단위로 수정하여 적용한다. 그러나, 서경대 공식에서는 유역면적과 저류능력을 고려하여 계수()를 적용하도록 명시하고 있다.
둘째, 분석지점 유역에 대한 호우사상별 강우-유출 기록이 있는 경우에 활용할 수 있는 방법이다. 이 경우는 경험공식에 의한 도달시간과 유역 저류상수를 초기값으로 하여 강우-유출모형에 의해 계산되는 수문곡선과 실측 수문곡선간의 오차를 최소화하도록 추정하는 방법을 통해 매개변수를 산정한다.
그러나, 단일사상 강우-유출모형의 최적화 방안은 자료에 의존하여 매개변수가 보정되므로 물리적으로 가능한 범위 내에서 최적 매개변수를 선정하는 것이 중요하다. 따라서, 본 연구에서는 소유역의 특성을 유지하고자 일관된 매개변수를 추정하고 다수의 강우사상에 대하여 대표할 수 있는 방안을 마련하고자 한다.
2.2 Dynamically Dimensioned Search Algorithm
본 연구에서는 DDS 알고리즘을 활용하여 Clark 단위도법의 매개변수를 추정하였다. DDS 알고리즘은 휴리스틱 전역 탐색 알고리즘으로, 휴리스틱 알고리즘 방식은 부족한 정보 및 시간제약을 고려하여 실현 가능한 최적해를 탐색하는 방법이다(Tolson and Shoemaker, 2007).
다수의 소유역을 대상으로 이루어지는 단일사상 강우유출모형의 특성을 고려할 때 최적화를 위한 다수의 매개변수로 인해 기존 알고리즘을 적용하는 경우 연산 시간이 오래 걸리게 된다. 본 연구에서 활용되는 DDS 알고리즘은 탐욕 알고리즘(greedy algorithm)을 적용하여 항상 최적의 결과를 보장하지 않으나 시간적·공간적 제약이 존재하여 최적해를 구하기 어려운 경우 우수한 결과를 산출할 수 있어 유역 매개변수 검정에 용이하게 적용될 수 있다.
1) DDS 알고리즘의 입력값을 설정한다. DDS 알고리즘의 입력값은 4가지로 구성되어 있다. 첫 번째로 이웃점 탐색 시 교란을 위한 매개변수의 크기()를 결정한다. 두 번째, 반복 최대 횟수()를 설정한다. 세 번째, D개의 결정변수에 대한 매개변수 최솟값() 및 최댓값()범위를 설정한다. 네 번째, 매개변수의 초기값()을 설정한다.
2) 부터 시작하여 초기값 에 대한 목적함수(F)를 평가한다.
3) 이웃점({N})에 포함하기 위해 D차원의 결정변수에서 J를 무작위로 선정한다. 현재 반복 횟수의 함수의 함수로 {N}에 포함될 확률을 계산한다. 결정변수가 현재 반복 횟수의 함수로 {N}에 포함될 확률을 산정한다.
차원 에 대하여 확률 P에 따라 {N}에 d를 추가하며, {N}이 없는 경우 d를 무작위로 선정한다.
4) 집합 {N}에 포함된 의 결정변수의 경우, 표준정규분포로부터 무작위 변수를 사용하여 를 교란하고 필요한 경우 결정변수 경계를 고려한다.
5) 현 최적값과 새로 생성한 값 과 비교하여 최적값을 선택한다.
6) 반복 횟수가 최대 횟수()에 도달하면 중지하고, 최대 횟수에 도달할 때까지 3)으로 돌아가 반복 수행을 하여 최적값을 산정한다.
DDS 알고리즘은 사용자가 지정한 최대 반복 횟수()를 활용하는 방식으로, 초기에는 전역적으로 최적해를 탐색하나, 반복 횟수가 증가함에 따라 국부적인 탐색을 수행하는 알고리즘이다. 특히, 최적해 산정시 현재 최적해로 판단되는 값으로부터 무작위로 선택된 차원에서 표준정규분포에 의하여 무작위로 후보점이 선택된다.
2.3 DDS 알고리즘과 연계한 HEC-1 모형 매개변수 최적화
홍수 수문곡선 계산 프로그램인 HEC-1 프로그램은 Hydrologic Engineering Center (HEC)의 연구진에 의해 개발된 프로그램으로, 실제 하천 유역의 복잡한 일련의 과정들을 간단한 수리수문학적 개념을 활용하여 유출량을 산정할 수 있다. 매개변수를 최적화하기 위해서는 매개변수 추정에 요구되는 모든 유역의 관측 유량자료가 요구되나, 실제로는 하류유역 일부에서만 관측유량이 이용가능하기 때문에 추정되는 매개변수들이 유역의 물리적 범위 및 특성을 반영하는데 어려움이 있다. 이러한 문제점은 개별 강우-유출 사상을 최적화하는 경우 더욱 두드러지게 나타난다. 따라서, 다수의 관측 강우-유출 사상을 이용하여 여러 소유역의 매개변수를 동시에 추정함으로서 기존 방법에 비해 일관되고 물리적 특성을 효율적으로 반영한 매개변수 추정을 기대할 수 있다.
일반적으로 강우-유출 모형에서 발생하는 불확실성에 가장 영향을 주는 요소는 해석모형, 강우-유출자료, 모형 매개변수로 알려져 있다. 특히 이러한 매개변수를 추정하기 위한 최적화 방법에서 중요한 점은 정확하게 매개변수를 추정할 수 있으면서도 계산시간이 적게 소비되어 효율적으로 최적 매개변수를 산정하는 것이 매우 중요하다. 본 연구에서 활용한 DDS 알고리즘은 수문모형 최적화에 활용되는 대표적인 SCE (Duan et al., 1992) 알고리즘보다 효과적이고 효율적으로 매개변수를 추정할 수 있다는 장점이 있다(Tolson and Shoemaker, 2007). 따라서, 본 연구에서는 DDS 알고리즘 기반으로 Clark 단위도법의 2개의 매개변수를 추정하였다. 그러나, 단일강우-유출모형이라는 점에서 일반적인 연속강우-유출모형에서 적용하는 매개변수 추정방식과는 다르게 일부 가정사항을 제시하였다. 연속강우-유출모형의 경우 워밍업(warm-up) 기간을 거쳐서 모형의 모의결과가 초기값에 의존하지 않는 상태까지 도달하는 것에 비해 단일사상 강우-유출모형은 워밍업 기간 없이 선행함수조건을 고려하는 방식으로 초기상태를 보정할 수 있다(Berthet et al., 2009). 단일사상 강우-유출모형에서 매개변수는 워밍업 기간 없이 모형 내에 입력한 선행 토양 함수 상태에 따라 물리적인 계산을 수행하므로, 현재의 토양상태를 사용자가 직접 선택하는 문제가 발생하며, 이에 따라 유출량 분석 시 첨두시간 및 유출체적 등의 계산 시 불확실성이 가중되게 된다. 특히, 선행토양함수 조건은 5일 선행 강우량을 기준으로 하여 CN (curve number)은 변화하므로 의존관계가 매우 크고 CN은 초기 강우량, 직접 유출량 및 초기손실계수에 따라 산정되므로, 유역의 토지피복 및 지형 특성과 공간적 변동성 등은 반영하기 어려운 문제점이 있다(Ajmal et al., 2015).
따라서, 본 연구에서는 개별 강우-유출 관계에서 선행토양함수 조건을 모두 동일하게 가정하고 매개변수를 추정하였으며, 이에 대한 구체적인 사항은 3절에 명시하였다. 초기 토양 상태와 더불어 매개변수가 동일 유역 내에서 강우사상에 따라 최적 매개변수가 변화하는데, 이는 최적화 방법이 개별 강우-유출 자료에 의존하여 매개변수를 최적화하기 때문이다. 이러한 분석 체계는, 각 매개변수들이 가지는 물리적 범위가 효과적으로 고려되지 못하고 있는 단점이 있으며, 추정된 매개변수 또한 신뢰성 있는 매개변수라고 보기 어렵다. 따라서, 매개변수의 범위를 물리적으로 가능한 범위로 한정하여 매개변수 최적화를 수행하였다. 상기의 기본적인 가정사항을 토대로 다수의 강우사상을 동시에 반영한 최적 매개변수 탐색 방법을 제시하고자 한다.
상기의 기본 가정을 전제로 하여 매개변수 최적화는 목점함수가 수렴하는 방향으로 진행되고 최종적으로 관측 유량과 비교하여 최적 매개변수를 탐색하게 된다. 최적 매개변수 탐색은 목적함수를 최소 또는 최대화하여 수행되며 이에 대한 DDS 알고리즘의 요구되는 기본적인 설정이 필수적이다. DDS 알고리즘의 초기 설정에 필요한 변수는 차원 개수(D), 교란 척도 매개변수(), 최대 반복 횟수(), 매개변수 최솟값(), 매개변수 최댓값()으로, 총 5개의 기본 입력 설정을 제시하였다. 알고리즘의 D는 차원 개수를 의미하며, 연구에서는 해당 홍수량 산정지점의 소유역 개수와 동일하다. 교란을 위한 척도 매개변수는 기본값이 0.2로 하였으며, 최대 반복 횟수는 충분히 수렴할 수 있도록 200회를 수행하였다. 본 연구에서는 최적화를 위한 목적함수로 NSE (Nash Sutcliffe Efficiency)를 채택하여 소유역의 최적 매개변수를 추정하였으며, 목적함수와 최적화 식은 Eq. (11)과 같다. 기존 단일 사상 강우-유출 모형에 대한 최적화 과정과는 다르게 본 연구에서는 다수의 강우-유출 사상을 동시에 고려할 수 있도록 목적함수를 구성하였다. 즉, 다수의 강우-유출 관계를 만족하는 매개변수 추정을 위해서 개별 사상별 목적함수를 병렬적으로 연결하여 하나의 목적함수로 구성하였다.
는 특정 강우-유출 사상 e의 번째 관측유량이며, 는 단기강우-유출 모형을 적용하여 모의된 결과의 번째 모의유량을 의미한다. Eq. (11)에 목적함수의 특징을 고려하여 목적함수 값을 음의 값으로 변화한 후, 이를 최소화하는 방향으로 최적 매개변수를 추정한다. DDS 알고리즘이 이행되는 과정을 시각적으로 가시화되어 목적함수의 수렴을 확인할 수 있다. 최대 반복 횟수()는 이용자가 가시화된 결과를 확인하여 수렴 여부를 판단하여 적절히 조정하게 되고, 본 연구에서는 최대 반복 횟수를 200회로 지정하여 매개변수가 수렴하는 것을 확인하였다. 최종적으로, 최대 반복 횟수에 도달하면 알고리즘은 중지되어 최적 매개변수에 따라 모의결과를 산출한다. 특정 유역의 모든 사상에 대하여 최적화를 수행하고자 각 사상에 대한 목적함수를 합산하여 매개변수를 평가하였으며, 강우-유출 관계가 존재하는 유역이 여러개 존재하는 경우, 순차적으로 상류 유역에 대한 매개변수 최적화 하고 그 결과를 하류에 적용하여 상류 유역의 최적화된 매개변수를 유지하였다. 이러한 과정을 통해 본 연구에서는 다수의 강우-유출 자료를 활용한 소유역별 공통 매개변수를 산출하였다.
NSE는 모형의 수행능력을 정량적으로 평가하는 방법으로, 현재까지도 모형의 적합정도를 판단하는 기준으로 활용되고 있다(Very good: NSE ≥ 0.7, Good: 0.5 ≤ NSE < 0.7, Satisfactory: 0.3 ≤ NSE < 0.5, and Unsatisfactory: NSE < 0.3). 여기서, NSE가 0.3 이상이면 대체적으로 적합한 모형임을 의미한다(Nash and Sutcliffe, 1970; Kalin et al., 2010). Fig. 1은 섬진강유역을 대상으로 본 연구에서 제안하는 다수의 강우-유출 자료를 활용한 최적화 방법론에 대한 개념도를 나타낸다.
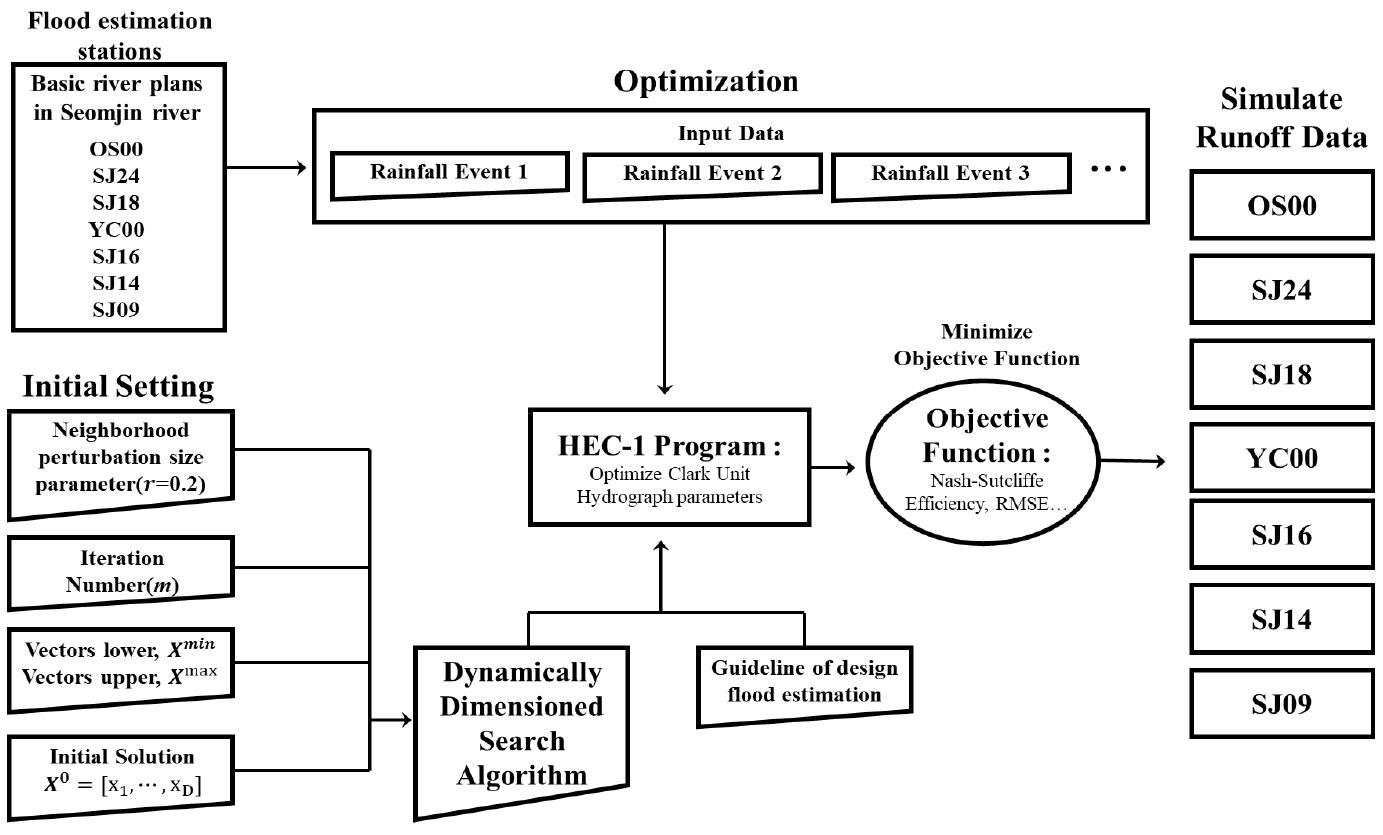
3. 대상유역 및 자료
본 연구에서는 섬진강 유역을 대상으로 DDS 알고리즘을 활용하여 매개변수 최적화를 수행하였다. 대상유역인 섬진강 유역은 대하천 유역으로, 유역의 특성을 고려하기 위하여 섬진강댐 하류유역을 7개 지점인 임실군 일중리(OS00), 오수천 합류전(SJ24), 대강수위표지점(SJ18), 요천 합류후(YC00), 요천대교(SJ16), 보성강 합류후(SJ14) 및 송정수위표 지점(SJ09)을 중심으로 소유역을 분리하고 홍수량 산정지점을 지정하였다. 실무적으로 활용이 가능하도록 홍수량 산정지점에 해당하는 소유역의 대표지점 강수량 및 홍수량을 활용하여 매개변수를 추정하고자 한다. 유역도 및 홍수량 산정지점은 Fig. 2와 Table 1에 제시하였다.
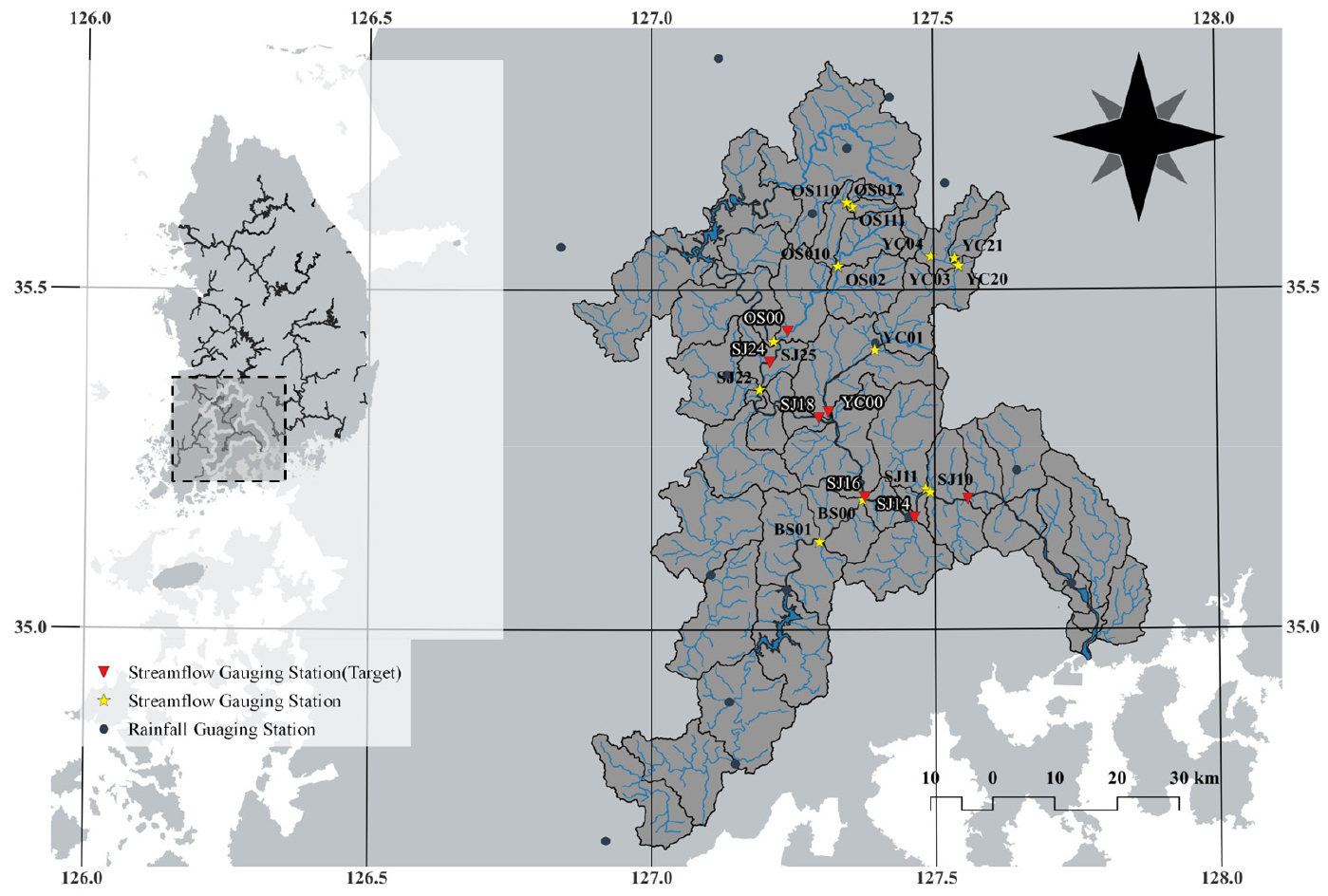
Table 1.
Hydrological stations in Seomjin watershed
2.3절에서 기술한 선행토양함수 조건을 가정하기 위하여 HEC-1 프로그램 내의 토양의 선행토양함수조건을 「홍수량 산정 표준지침」에서 명시한 바와 동일하게 설계안전을 고려하여 유출률이 가장 높은 AMC-Ⅲ조건을 적용하여 CNⅢ를 채택하였으며, 각 소유역의 CNⅢ 매개변수를 Table 2에 명시하였다. 강우-홍수량 자료는 다년동안 발생한 홍수 사상 중 비교적 홍수 사상의 자료의 품질이 비교적 양호한 기간을 선정하였으며, 2013년 7월, 2014년 7월, 2020년 7월에 발생한 강우 및 홍수 사상으로 선정되었다. 강우 자료는 환경부, 수자원공사 및 기상청에서 제공하는 섬진강 유역 내 지점 중 30년 이상의 시우량 자료가 확보된 지점과 우량관측소의 위치가 적절히 분포할 수 있도록 20년 이상의 시우량 자료가 확보된 주암댐 및 쌍계 관측소를 추가로 선정하여 티센 방법을 기반으로 유역 내 면적강우량을 산정하였다(MLIT, 2021).
일반적으로 유역의 홍수수문곡선 계산을 위해서는 유역면적이 250 km2 이하의 소유역에 대하여 유출량을 산정하고 분할된 소유역에 단위도를 적용하여 하도구간에 대하여 홍수추적을 축차적으로 수행하여 최종적으로 홍수수문곡선을 합성하는 방식이다. 따라서, 본 연구에서는 최적화를 순차적으로 진행하여 전 유역에 대하여 소유역별로 공통적으로 활용할 수 있는 매개변수를 산정하였다. 2021년에 발행된 섬진강 하천기본계획에서는 HEC-1 프로그램을 활용한 바가 명시되어 있다. 따라서, 매개변수의 초기값 및 선행토양함수조건은 2021년 발행된 섬진강 하천기본계획에 명시된 자료를 활용하였으며, Table 2에 명시한 바와 같다. 또한, 최적화시 매개변수인 도달시간 및 저류상수의 범위는 현실적으로 가능한 범위에서 조정이 가능하도록 최소 0.5시간에서 최대 8시간 사이로 지정하였다.
Table 2.
Sub-basin in Seomjin basin and initial value
4. 결 과
4.1 경험식 및 단일 강우-유출 사상 기반 매개변수 최적화
본 연구에서는 「섬진강 하천기본계획」에 명시된 홍수량 산정지점에 대하여 첫째, 기존의 기본계획에 명시된 경험식에 따라 산정된 매개변수와 둘째, 단일사상에 대한 최적 매개변수, 셋째, 다수사상에 대한 최적 매개변수에 따른 홍수량을 비교하였다. 본 절에서는 경험식에 따라 산정된 매개변수와 단일사상에 따라 산정된 매개변수의 홍수량 결과를 비교하였다.
일반적으로 최적화 알고리즘은 주어진 입력자료에 의존하여 최적 매개변수를 탐색하므로, 각 분야에 알맞게 구체적인 제약조건을 제시하여야 한다. 본 연구에서는 유역특성인자 등은 고려하지 않고 도달시간 및 저류상수의 가능한 매개변수의 범위만을 제시하였다. 물리적으로 불가능한 결과와 각 홍수량 산정지점에서 자료에 따라 상류의 홍수량 산정지점의 매개변수가 변화하는 것을 방지하기 위해 상류에서 산정된 매개변수의 범위를 제한하고 하류의 매개변수만을 탐색하여 순차적으로 최적화를 수행하였다. 즉, 최적화된 상류의 매개변수는 고정되어 하류의 매개변수 산정 시에는 하류의 매개변수만이 최적화된다.
기존의 기본계획에 명시된 경험식에 따라 산정된 매개변수를 활용하여 2013년 7월, 2014년 7월 및 2020년 7월의 홍수량을 산정하였다. 일부 지점을 제외하고 대부분의 지점에서 홍수량이 과대 및 과소 추정하는 결과가 나타났다. 따라서, 특정사상의 입력 자료에 따라 최적 매개변수를 산정하여 기존의 매개변수와 비교하여 두 방식에 따른 홍수량 차이를 비교하였다. 각각의 사상에 대하여 매개변수를 산정한 결과, 기존의 매개변수와 상당한 차이가 존재하며, Fig. 3에 도시된 바와 관측 홍수량을 모의하는데 있어서 경험식을 활용방법에 비해 개선된 재현 능력을 확인하였다. 그러나, 예상한 바와 같이 특정사상에 대하여 DDS 알고리즘을 활용하여 매개변수를 산정한 결과 사상별로 최적 매개변수가 서로 다른 것을 Table 3에서 확인할 수 있다. 이는 강우의 시공간적 변동성과 모든 소유역별로 강우-유출 자료가 존재하지 않는 것으로 기인한다. 이로 인해 매개변수의 물리적인 특성을 유지하지 못하게 되며, 이러한 문제점을 개선하기 위하여 가급적 강우-유출 사상들을 분리하여 최적화하는 방법보다 다수의 사상들을 동시에 최적화하여 매개변수를 추정하는 것이 보다 합리적일 것으로 판단된다.
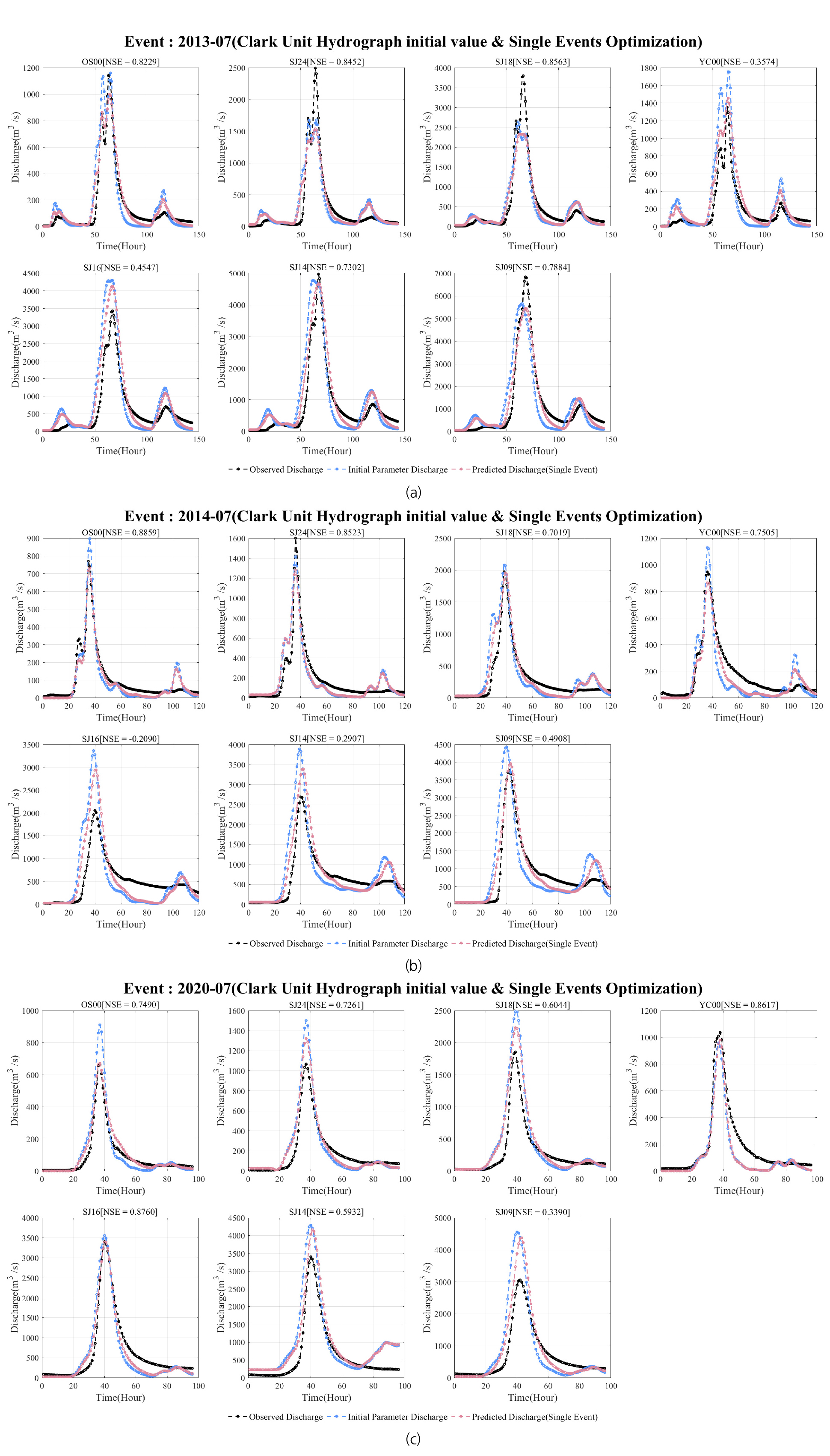
Table 3.
Estimated parameters of the Clark unit hydrograph methods using DDS algorithm
4.2 다중 강우-유출 사상 기반 매개변수 최적화 결과
앞 절에서 언급한 바와 같이 단일 강우-유출 사상에 대하여 매개변수 최적화를 수행한 결과, 대부분의 홍수량 산정지점에서 기존 경험식에 의해서 추정된 홍수량 보다는 개선된 결과를 나타내었다. 그럼에도 불구하고 일부 홍수량 산정지점에서는 홍수량이 과소 및 과대 추정되는 것을 확인하였다. 홍수사상에 따라 차이가 있지만, 2013년 사상에서는 과소추정이 두드러지게 나타나고 있는 반면 2014년과 2020년 사상들에서는 과대 추정되는 특징을 나타내고 있다. 또한, 본 연구에서 가장 중요한 검토대상 중 하나인 매개변수 산정 결과가 각 사상마다 상이하다는 것을 확인할 수 있으며, 이는 향후 홍수량 예측 측면에서 강우-유출 모형을 활용하는 경우 대표 매개변수 결정하는데 있어서 어려움이 따른다. 따라서, 이를 매개변수의 물리적인 특성을 반영하면서 해석 대상이 되는 강우-유출 사상을 모두 만족하는 최적 매개변수 산정이 필수적이다. 즉, 앞서 언급한 바와 같이 다수의 강우-유출 사상을 모두 고려하면서 강우-유출 관계의 일반적인 특성을 효과적으로 재현할 수 있는 매개변수를 산정하는 것이 핵심 사항이다.
다수의 강우-유출 관계를 이용하여 매개변수를 추정하는 경우 앞 절에서 개별 강우-유출 매개변수 추정에서 얻은 성능 이상을 발휘하거나 최소한 동일한 관측 유량 재현능력을 가지는 것이 필요하다. 즉, 개별 사상을 중심으로 매개변수를 추정하는 경우 관측 유량 재현 측면에서는 더욱 유리하지만 물리적인 범위를 벗어나는 문제와 매개변수의 변동성이 커지는 문제점을 가지고 있다. 따라서, 이러한 매개변수의 물리적 범위 및 변동성 측면에서 개선효과를 얻으면서 최소 동일한 재현 능력을 확보하는 것이 본 연구의 주요 목적이다.
Table 3은 개별 및 다수의 사상을 통해 산정된 매개변수들을 나타낸다. 결과에서 보듯이 개별 사상별로 매개변수를 추정하는 경우 매개변수의 변동성이 매우 큰 반면 다수의 강우-유출 관계를 고려하는 경우 3개의 사상을 모두 만족하는 매개변수로 수렴하는 것을 확인할 수 있다. Table 4는 단일 및 다수의 강우-유출 자료를 이용하여 최적화된 매개변수를 통해 추정된 유출량에 대하여 NSE를 비교한 결과를 나타내고 있다. 즉, NSE는 최적화 시 목적함수로 활용된 통계 지표로서, 대부분의 경우에서 통계적으로 유의한 차이를 발견할 수 없는 반면 일부 사상에서는 개선된 결과를 나타내고 있다. 또한, 모든 홍수량 산정지점에서 공통 매개변수를 활용하여 홍수량을 모의한 결과 NSE가 0.7을 상회하는 결과를 나타내어 ‘매우좋음’에 해당하는 등 적합성이 높다고 판단되며 다수의 사상을 동시에 고려하여 매개변수를 산정하더라도 홍수량을 효과적으로 재현하고 있는 것을 확인할 수 있었다(Fig. 4). 따라서, 매개변수의 물리적인 특성을 유지함과 동시에 유역의 대표 매개변수를 추정한다는 측면에서 장점을 제공하고 있다고 판단된다.
Table 4.
Comparisons of NSE between single event and multi-events optimization
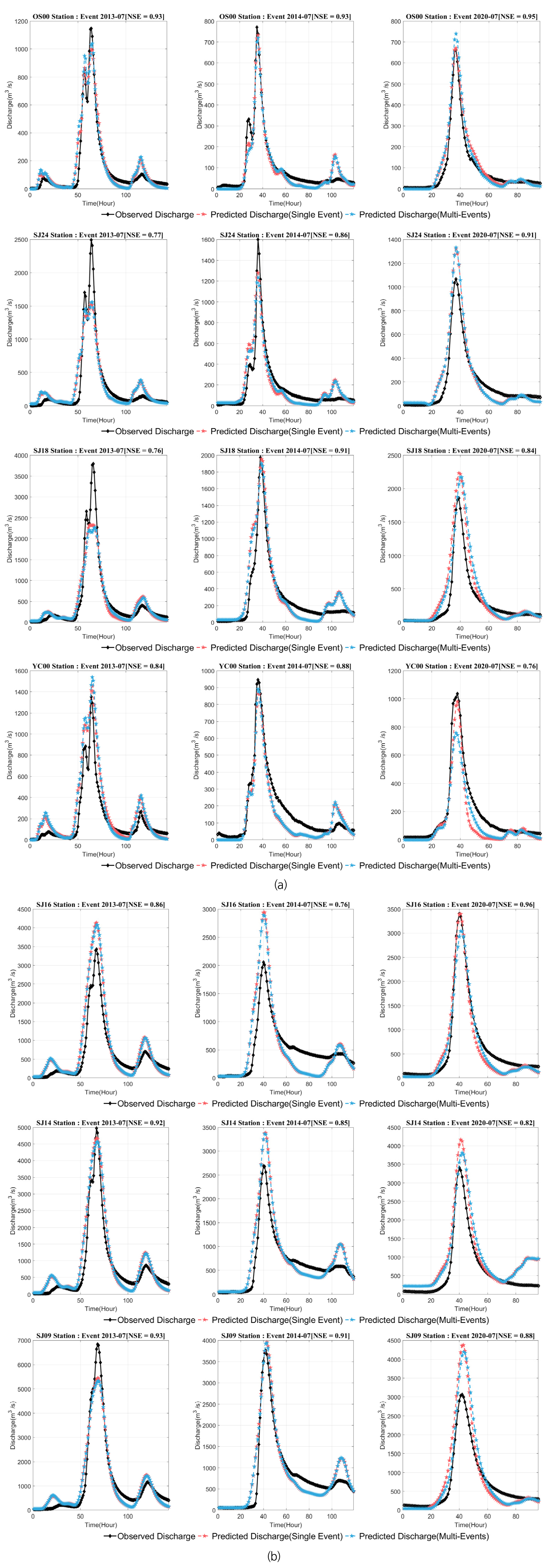
동시 최적화를 통해 산정한 매개변수를 활용하여 산정한 홍수량을 각 강우사상에 대한 재현성 평가를 위하여 상관계수(correlation coefficient, CC), 편의(bias), 일치계수(index of agreement, IoA), 및 평균제곱근오차(root mean square error, RMSE)를 활용하였다. IoA, CC 검증은 1에 가까울수록, RMSE는 값이 작을수록 적합성이 높다는 것을 의미한다. 최적화 결과에 대한 통계적 검증은 Eqs. (12)~(14)와 같다.
Table 5는 평균제곱근오차, 일치계수, 상관계수 등을 비교한 결과이다. 대부분의 사상에서 공통매개변수를 사용하는 경우에서 개선된 모의능력을 확인할 수 있으며, 특히 다중 강우-유출 자료를 활용하여 최적화를 수행한 경우 RMSE 개선 효과가 크게 나타났다. 이는 첨두홍수량 재현에 유리하다는 점을 나타낸다.
Table 5.
Statistical measures over different optimization scheme based on single and multi events
5. 결 론
실무에서 홍수량 산정 시 대표적으로 활용하고 있는 HEC-1 모형의 경우, 관측 자료를 통한 매개변수의 최적화 없이 지형인자를 고려한 경험공식을 일반적으로 활용하고 있다. 과거에는 매개변수 추정을 위한 신뢰성 있는 관측 유량자료의 부족으로 매개변수 최적화가 기본적으로 어려웠으나, 최근 10년 동안 주요 관측지점에 대해서 수위-유량관계곡선 개발이 이루어졌으며, 국가하천 본류 구간에서는 대부분 관측유량 자료가 이용 가능하다. 이러한 점에서 적어도 국가하천 구간에 대해서는 관측유량을 활용한 매개변수 최적화가 가능하며 홍수량 산정 시 신뢰성 개선을 위해 반드시 필요한 과정이다. 그러나, 홍수량 산정 시 매개변수를 최적화하는 명확한 기준이 없으며 주로 사용자의 경험적 판단으로 매개변수가 추정되어 활용되고 있다. 또한, 최적화가 시행되더라도 개별 강우-유출 사상들을 대상으로 최적화가 시행되어 매개변수들의 변동성이 크다. 실제 적용성 측면에서 대표 매개변수 추정이 어려워, 개별 사상별로 추정된 매개변수를 단순 평균하여 사용하고 있다(Kim et al., 2020). 따라서, 본 연구에서는 DDS 최적화 알고리즘을 활용하여 다수의 홍수사상에 대하여 홍수량 산정지점별 매개변수를 공통적으로 추정할 수 있는 기법을 개발하였다. 본 연구를 통하여 도출되는 결론은 다음과 같다.
첫째, 섬진강 하천기본계획에 명시된 Clark 단위도법의 매개변수를 활용하여 홍수량 산정 시, 홍수량을 과대 또는 과소 추정하는 문제점을 확인하였다. 특히, 상하류 모두에서 관측유량과 차이를 나타내고 있으며 2013년 사상에서는 과소추정이 두드러지게 나타나고 있다. 2014년과 2020년 이벤트들에서는 과대 추정되는 것을 확인할 수 있었다.
둘째, 개별 강우-유출 사상을 DDS 알고리즘을 활용하여 매개변수를 산정한 결과 사상별로 최적 매개변수가 서로 다르며 물리적인 범위를 중심으로 변동성이 커 대표 매개변수를 결정하는데 어려움이 있었다. 매개변수 추정 시 변동성 증가는 강우의 시공간적 변동성과 함께, 유역 내 일부 홍수량 산정지점 기준으로 강우-유출 자료만이 이용 가능하여 매개변수의 식별성(identifiability)이 낮은 이유로 판단된다.
셋째, 추정되는 매개변수의 변동성 확대에 따른 문제점을 개선하기 위하여, 본 연구에서는 다수의 사상들을 동시에 고려한 매개변수 최적화 방법을 제안하였으며, NSE를 목적함수로 하여 매개변수를 최적화하였다. 개별 사상들을 통합적으로 고려하여 최적매개변수를 산정하는 경우 매개변수의 물리적인 특성을 유지함과 동시에 유역의 공동 매개변수 효율적으로 추정이 가능하였다. 홍수량 재현 측면에서도, 공통 매개변수를 사용하더라도 NSE 기준으로 개별적으로 최적화를 수행한 경우와 유사하거나 보다 개선된 결과를 확인할 수 있었으며, 모형 정확도도 전반적으로 ‘매우좋음’에 해당하는 것으로 평가되었다.
본 연구의 강우-유출모형 매개변수 최적화 방식은 비교적 짧은 시간에 적정 매개변수 범위 내에서 대표(공동) 매개변수를 산정할 수 있는 장점이 있어 실무에 활용하기 용이하다고 할 수 있으며, 동시에 매개변수의 물리적 특성을 유지하여 최적화할 수 있다는 장점을 확인할 수 있었다. 향후 연구에서는 가정한 선행토양함수 조건을 다르게 부여하여 다양한 목적함수를 적용한 최적화 방법과 함께, 강우의 시공간적 변동성에 따른 매개변수 민감도를 평가하여 비정상성을 가지는 매개변수의 함수적 관계를 제시하고자 한다.
