

1. 서 론
2. 연구방법
2.1 데이터 수집
2.2 YOLOv8
2.3 이미지증강
2.4 평가지표
3. 연구결과
3.1 재난유형 판별 결과
3.2 정량적 모델 성능 평가
3.3 재난 유형별 탐지 성능 및 한계 분석
4. 결 론
1. 서 론
재난은 자연적으로 발생하거나 인재로 인해 발생하기에 예측에 한계가 있어 심각한 피해가 초래된다(Cicek and Kantarci, 2023; Bhattacharjee et al., 2019). 과거 재난은 대부분 농작물과 농경지에 대한 피해가 많이 발생했다. 2000년대 이후에는 사회적 재난의 발생 빈도가 높아졌으며, 신종재난과 다양한 재난이 동시에 발생하는 복합재난의 발생이 빈번해졌다(Lee and Lee, 2014). 또한 기후변화로 인해 재해 및 피해 규모의 증가, 재난 발생 원인의 다양성 등 재난의 특성이 변화하고 있어 최근 재난의 양상이 과거에 경험하지 못한 신종복합 재난으로 변화하고 있다(Lee, 2019; Lee et al., 2021). 이처럼 예측하기 힘든 형태의 다양한 재난과 연쇄적으로 발생하는 복합재난이 발생하기에 초기대응의 역량 강화가 요구되고 있다(Na et al., 2019; Lee and Kim, 2019).
재난대응의 출발점은 정확하고 신속한 재난 탐지이다. 화재와 홍수와 같은 재난은 발생 직후 확산 속도가 매우 빠르기에 초기 대응이 지연될수록 피해 확대를 초래할 수 있다. 따라서 신고된 재난에 대해 재난 유형을 조기에 감지하고 신속하게 탐지하는 것은 재난 대응에서 핵심적인 역할을 한다. 재난관리 및 재난 초기대응을 위해 IoT (Internet of Things), AI (Artificial Intelligence), 위성영상, 스마트폰 등과 같은 다양한 첨단 기술을 적용하고 있다. 특히 갑작스럽게 발생하는 재난의 경우 신속한 초기 대응이 매우 중요한데, 초기 대응의 시작은 주로 재난 목격자의 신고로 시작된다(Choi et al., 2018; Kim et al., 2023). 전국에 다량의 CCTV가 연결되어 있으나 주로 도로 및 철도에 설치되어 전국적으로 발생하는 다양한 재난 상황을 파악하는데 한계가 있다. 반면 스마트폰을 활용한 시민제보는 시간적, 공간적으로 구애받지 않고, 다양한 위치에서 수집된 고해상도 이미지 및 재난 상황에 대한 정보를 수집할 수 있기에 신속하고 지속적인 재난현장 정보를 취득할 수 있다. 현재의 스마트폰은 과학적 관측에 활용할 수 있는 다양한 센서가 장착되어 있으며, 높은 화소의 카메라가 보편적으로 탑재되어 있어 재난관리에 필요한 광범위하고 실시간의 정보를 신속하게 생성 및 전파하는데 매우 효과적이다(Paul et al., 2018; Lukyanenko et al., 2016; Guerrini et al., 2018; Irwin, 2018).
모바일에 탑재되어 있는 카메라의 화소수가 증가하고 관련 소프트웨어 및 분석 기법이 고도화됨에 따라 다양한 영상처리 연구가 활발히 진행되고 있다(Ahn et al., 2014). Daly and Thom (2016)은 블루마운틴 산불 사례를 대상으로 Flickr에서 수집한 이미지를 활용하여 화재 여부를 자동 분류하는 방법을 제안하였다. 색상 정보를 포함한 특징 추출 기법(ColorSIFT)과 서포트 벡터 머신(Support Vector Machine, SVM; 이하 SVM)을 적용하여 화재 이미지 분류 모델을 개발하였으며, 화재·비화재 이미지 분류에서 재현율 91%, 정밀도 93%를 달성하였다. Antzoulatos et al. (2020)은 이미지, 영상, 센서 데이터를 융합하여 화재 피해 심각도를 실시간으로 평가하는 멀티레이어 분석 기법을 제시하였으며, Faster R-CNN (Faster Region-Based Convolutional Neural Network)을 활용해 인물, 차량, 연기 등을 탐지하고, 시각·텍스트·센서 정보를 단계적으로 결합하여 평가 정확도를 향상시켰으며, 이를 통해 다중 데이터 융합 기반의 실시간 재난 모니터링 가능성을 입증하였다. Asif et al. (2021)은 소셜미디어 재난 이미지를 활용하여 재난 유형과 비상 대응을 자동 분류하는 딥러닝 기반 파이프라인을 제안하였다. 구조·봉사·기부, 생필품 공급, 피해자, 경고·주의, 사회활동 영향 6개 시각적 정보 범주로 구성된 재난 대응 분류체계(disaster response taxonomy)를 구축하고, VGG-16과 YOLOv4를 적용하여 이미지 내 재난 관련 객체 탐지를 진행하였다. 또한 정보 융합(Decision Table 및 AHP) 기법을 통해 범주를 매핑한 결과, 약 96%의 분류 정확도를 달성하여 소셜미디어 이미지 기반 재난 대응 지원의 가능성을 확인하였다.
재난현장 주변의 시민제보는 재난 발생 상황과 전개 과정을 명확히 인지할 수 있기에 방송사들은 재난방송을 위해 다양한 매체를 활용하여 시민제보 영상과 사진을 적극적으로 접수하여 보도자료에 활용하고 있다. 이처럼 모바일의 발전으로 인해 다양한 정보와 재난현장의 이미지를 실시간으로 취득할 수 있다. 시민제보 영상은 재난 발생의 실시간성을 확보할 수 있으나, 다양한 촬영 환경과 이미지 품질 편차로 인해 탐지의 정확성을 보장하기 어렵다는 한계가 있다. 따라서 실제 재난 현장에서 신속하고 신뢰성 있는 탐지를 위해서는 데이터 다양성에 강건한 고성능 탐지 모델이 요구된다.
기존 연구들은 주로 소셜미디어나 공개 이미지 데이터셋을 활용하여 화재 또는 홍수 등 단일 재난 유형을 탐지하는 데 초점을 두었다. 그러나 이러한 연구들은 정형화된 데이터셋과 제한된 학습 환경에 의존하기 때문에, 실제 재난 상황에서 발생하는 복합적 재난 유형에 대한 일반화 성능이 낮다는 한계가 있다. 본 연구에서는 다양한 재난의 이미지에 대해 유형 탐지 및 분류를 진행했다. 연구의 핵심 목표는 다양한 재난 유형을 탐지하고 분류하는 기술을 개발하는데 있다. 다양한 이미지 증강 기법을 적용하여 데이터의 표현력을 확장하고, 모델이 다양한 환경변화에 유연하게 적응할 수 있도록 하였다. 이는 모델의 일반화 성능과 학습 안정성을 향상시키기 위한 전략적 접근으로 볼 수 있다. 연구 대상은 일상생활에서 빈번하게 발생하고 흔한 재난 중 공공안전과 밀접하게 연관된 화재(산불, 차량, 건물)에 진행했다(Wu et al., 2024). 그리고 자연재난 피해액 중 피해액의 83%를 차지하는 홍수로 발생할 수 있는 2차 재난인 포트홀, 도로균열을 포함하여 총 6개의 재난에 대한 연구를 수행했다(Kim and Kang, 2022).
본 연구는 단일 재난 감지에 한정된 기존 연구와 달리 여러 재난 유형을 하나의 파이프라인에서 통합적으로 탐지하고 분류할 수 있는 범용 재난 탐지 프레임워크를 제시했다는 점에 있다. 이를 통해 실제 재난 현장에서의 실시간 활용성과 탐지 정확도를 향상시킨 고성능 재난 탐지 기술의 가능성을 제시한다.
2. 연구방법
2.1 데이터 수집
재난 유형에 대한 객체 탐지 모델을 구축하기 위해 웹 크롤링(Web Crawling)을 활용한 이미지 수집을 수행하였다. 산불화재, 차량화재, 빌딩화재, 포트홀, 도로균열, 홍수에 대해 세분화된 검색 키워드를 설정하여 크롤링을 진행하였다. 수집된 원본 데이터는 해상도 정규화, 노이즈 제거, 중복 및 비관련 이미지 제거 등의 전처리 과정을 거쳐 학습에 적합한 형식으로 정제하였고, 실험에 사용된 이미지는 총 3,245장이다. YOLO 기반 객체 탐지 모델 학습을 위한 애노테이션(annotation) 작업을 수행하였다. 라벨링은 Fig. 1과 같이 바운딩 박스(Bounding Box)를 기준으로 진행되었으며, 각 객체를 사각형 영역으로 감싸는 방식으로 이루어졌다. 바운딩 박스는 객체의 경계를 명확히 하고 위치를 정의할 수 있는 대표적인 방식으로, 좌상단 좌표(x, y)와 너비(width), 높이(height)를 주요 속성으로 포함한다(Geiß et al., 2023). 이러한 방식은 객체의 위치와 크기를 단순하고 효과적으로 표현할 수 있으며, 모델 학습에 필요한 핵심 정보를 제공한다. 모든 애노테이션은 Roboflow 플랫폼을 활용하여 수행되었고, 각 객체에는 클래스 레이블이 부여되어 YOLO 학습 포맷에 맞춰 저장되었다. Fig. 2와 같이 전체 데이터셋은 모델의 학습, 검증 및 성능 평가를 위해 8:1:1 비율로 훈련(train), 검증(validation), 시험(test) 데이터셋으로 분할하였다. 훈련 데이터셋은 모델 학습에 사용되었으며, 검증 데이터셋은 학습 과정에서의 성능 확인 및 과적합 방지를 위해 활용하였다. 시험 데이터셋은 학습에 포함되지 않은 독립적인 데이터로 최종 성능 평가에 사용하였다. 또한 모델의 신뢰성과 일반화 성능을 확인하기 위해 K-Fold 교차검증을 병행하여 다양한 데이터 분할 환경에서의 성능을 검증하였다.

2.2 YOLOv8
본 연구에서는 수집된 재난 이미지 데이터를 기반으로 객체 탐지 모델을 학습하기 위해 YOLO (You Only Look Once) 계열의 최신 버전인 YOLOv8을 활용하였다. YOLO는 단일 신경망을 통해 객체의 위치와 클래스를 동시에 예측하는 실시간 객체 탐지 알고리즘으로, 빠른 속도와 높은 정확도를 제공하여 재난 현장의 조기 인지 및 실시간 대응에 적합하다(Redmon et al., 2016).
선행 연구들은 주로 단일 재난 유형(예: 산불 화재, 건물 화재, 특정 홍수 지역)에 국한하여 객체 인식 모델(CNN, Faster R-CNN 등)을 적용하였으며, 제한된 데이터셋과 환경 조건으로 인해 실제 다양한 상황에서의 일반화에 한계가 있음을 선행연구에서 나타났습니다(Cheng et al., 2024; Gragnaniello et al., 2024; Saleh et al., 2024). 또한 도로균열 탐지의 경우 조명, 그림자, 오염 등 환경적 요인과 균열의 형태적 특성으로 인해 성능이 저하될 수 있는 것으로 연구되었습니다(Yuan et al., 2024).
YOLOv8은 기존 YOLOv5, YOLOv6, YOLOv7과 비교하여 네트워크 구조의 단순화 및 성능 최적화를 통해 정확도와 처리 속도 모두에서 개선된 결과를 보이며, 실시간 객체 탐지 분야에서의 활용 가능성을 크게 확장하였다(Terven et al., 2023). 특히, 백본 구조의 경량화 및 변형된 Detect Head를 통해 다양한 해상도 및 작업 환경에서도 안정적인 성능을 유지할 수 있도록 설계되었다. 최근 YOLOv9, YOLOv10, YOLOv11이 개발이 되었으나 YOLOv8은 상위버전들에 비해 정확도와 추론속도 모두에서 우수한 균형을 보여 실시간 응용에 적합한 것으로 나타났다(Sharma et al., 2024; Santos Junior et al., 2025). 이러한 선행 연구들의 비교결과를 통해 다양한 분야에서 안정적이고 신뢰할 수 있는 성능을 나타내는 YOLOv8을 선정하였다.
본 연구에서는 일반 객체 탐지에 대해 사전 학습된 YOLOv8 모델(pretrained model)을 기반으로 전이 학습(transfer learning)을 수행하였다. 이를 통해 재난 유형 탐지라는 특정 도메인에 적합하도록 모델을 미세 조정(fine-tuning)하였으며, 커스텀 데이터셋을 활용하여 학습 성능을 향상시켰다.
2.3 이미지증강
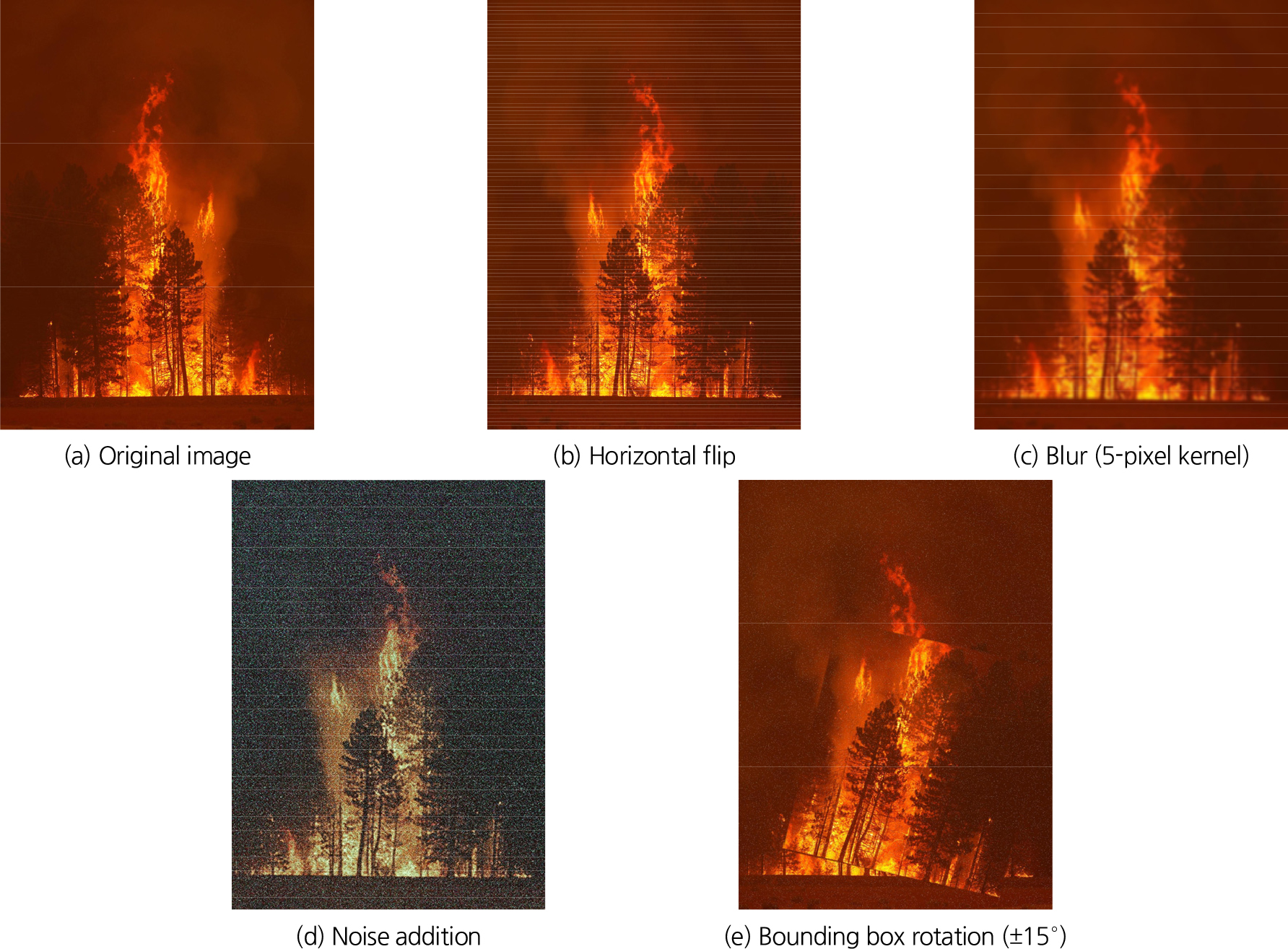
데이터 증강기법은 모델의 일반화 성능을 높이기 위해 필수적으로 활용된다(Kim and Ahn, 2024). 본 연구에서는 원본 이미지를 기반으로 각 훈련 이미지당 4개의 변형 이미지를 추가 생성하여 학습 데이터의 다양성을 확보하였다(Fig. 3). 좌우 반전(Flip, Horizontal)을 통해 다양한 촬영 방향성을 반영하고, 흐림(Blur) 처리로 최대 5픽셀까지 초점 불명확성을 모사하였다. 또한, 노이즈(Noise)를 추가하여 실제 현장에서 발생할 수 있는 센서 간섭이나 화질 저하 상황을 재현하였으며, 바운딩 박스 회전(Rotation)은 -15°에서 15° 범위 내에서 회전시켜 다양한 관찰 각도를 반영하였다. 이러한 기법들을 적용하면 Fig. 3과 같으며, 해당 기법들을 통해 모델이 다양한 환경 변화에 적응할 수 있도록 데이터의 표현력을 강화하였다.
2.4 평가지표
딥러닝 기반 객체 탐지 모델을 이용하여 시민제보 이미지를 기반으로 재난 유형을 탐지·분류하였으며, 모델의 성능평가는 탐지 정확도와 분류 정확도를 동시에 고려하기 위해 일반적으로 다양한 지표가 사용된다. 본 연구에서는 모델의 학습과정 대한 평가를 위해 정밀도(Precision), 재현율(Recall), AP (Average Precision), mAP (mean Average Precision)를 주요 지표로 활용하였다. Precision과 Recall은 재난 유형 분류의 정확성과 탐지율을 각각 나타내며, AP는 특정 재난 유형에 대한 Precision-Recall 곡선 아래 면적으로 정의된다. mAP는 모든 재난 유형의 AP 평균으로, 모델의 전체 탐지 성능을 대표한다.
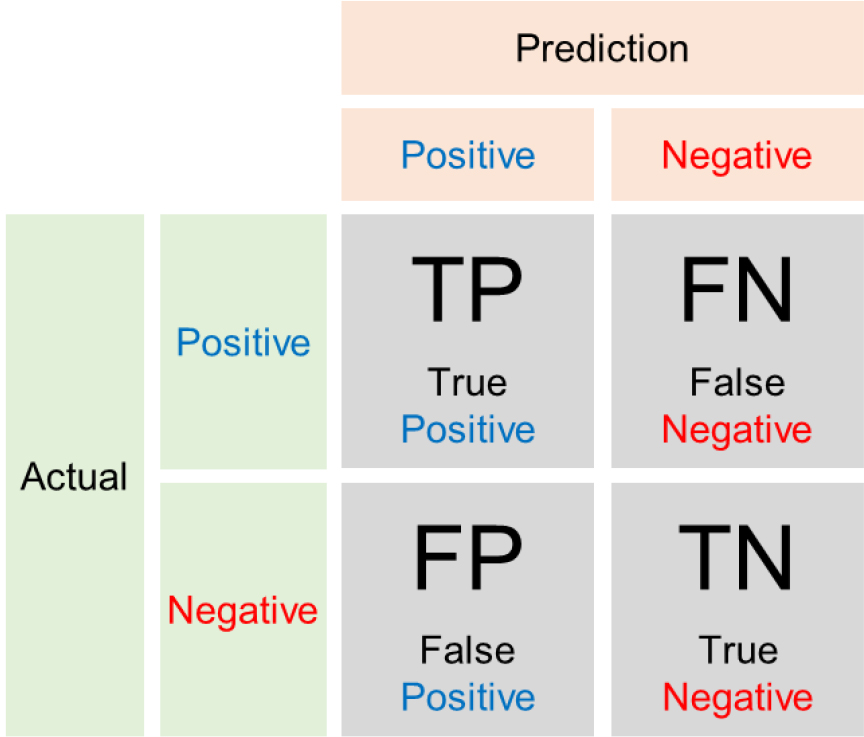
Fig. 4와 같이 TP (True Positive)는 실제 Positive인 데이터를 모델이 Positive로 예측한 경우를 말하며 모델이 예측 대상을 올바르게 탐지한 경우를 의미한다. FP (False Positive)는 실제 Negative인 데이터를 모델이 Positive로 예측한 경우를 의미한다. FN (False Negative)는 실제 Positive인 데이터를 모델이 Negative로 예측한 경우를 의미한다. TN (True Negative)는 실제 Negative인 데이터를 모델이 Negative로 예측한 경우를 의미한다. 정밀도(Precision)는 Eq. (1)로 정의되며, 모델이 Positive로 예측한 샘플 중 실제로 Positive인 비율을 나타낸다. 재현율(Recall)은 Eq. (2)으로 정의되며, 실제 Positive 샘플 중에서 모델이 정확히 탐지한 비율이다(Saito and Rehmsmeier, 2015; Oksuz et al., 2018).
mAP은 Eq. (3)와 같이 여러 클래스의 AP를 평균 낸 값으로, 전체 클래스에 대한 객체 탐지 성능을 종합적으로 평가하는 지표이다. Eq. (3)에서 여기서, N은 클래스의 수를, APi는 클래스 i에 대한 정밀도-재현율 곡선으로부터 계산된 면적값을, 그리고 1/N은 전체 클래스의 AP 값을 평균하기 위한 계수를 각각 의미한다. 이러한 지표들은 모두 값이 클수록 모델의 객체 탐지 성능이 우수함을 나타낸다.
모델 구축 이후 모델의 성능을 평가하기 위해 Test 데이터셋을 활용하였으며, 성능평가에는 F1-confidence curve, Precision-confidence curve, Recall-confidence curve, Precision-Recall curve, 정규화 혼동행렬(normalized confusion matrix)을 종합적으로 분석하였다. F1-confidence curve는 Precision과 Recall의 균형적 성능을 confidence score에 따라 시각화하며, Precision-confidence와 Recall-confidence 곡선은 신뢰도 임계값 변화에 따른 각각의 지표 변화를 확인할 수 있다. Precision-Recall curve는 클래스별 탐지 균형을 평가하는 데 활용되며, 혼동행렬은 각 클래스 간 오분류 패턴을, 정규화 혼동행렬은 클래스 불균형의 영향을 최소화하여 상대적 정확도를 확인할 수 있다.
따라서 본 연구에서는 모델의 Train/Validation 단계의 평가 지표(Precision, Recall, AP, mAP)와 모델의 Test 단계의 추가 지표들을 병행 활용하여 모델의 성능을 평가하였다.
3. 연구결과
본 연구에서는 6가지 재난 유형을 YOLO 기반 딥러닝 객체 탐지 모델을 통해 분류하고 인식하였다. 모델의 학습과정 및 성능평가는 손실함수감소추이와 주요 성능지표(Precision, Recall, mAP) 및 시각화를 통해 수행되었다. 실험에 사용된 데이터셋은 총 3,245장의 이미지로 구성되어 있으며 학습, 검증, 시험 데이터는 각각 80%, 10%, 10%로 분리하여 활용하였다.
3.1 재난유형 판별 결과
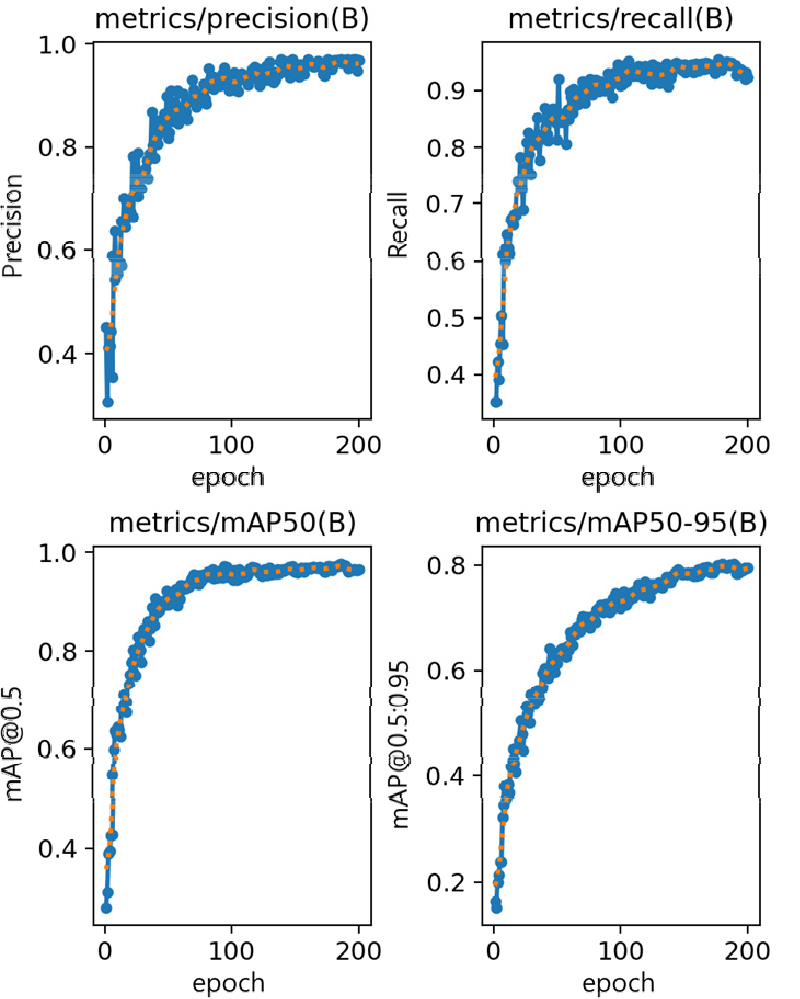
모델의 학습 과정에서는 손실 함수(loss)의 변화를 모니터링하며 모델의 수렴 여부와 일반화 성능을 평가하였다. 손실 항목은 box loss, classification loss (cls loss), distribution focal loss (dfl loss)로 구성되며, Fig. 5에서 확인할 수 있듯이 200 epoch 학습이 진행되는 동안 모든 손실지표는 안정적으로 감소하는 추세를 나타냈다. 이는 모델이 객체의 위치와 클래스 정보를 점진적으로 정밀하게 학습하고 있음을 보여주며, 과적합 현상 없이 충분히 수렴했음을 시사한다. 검증 데이터셋에서도 유사한 손실 감소 패턴이 관찰되었으며, Precision, recall, mAP@50, mAP@50-95 등의 성능 지표는 학습이 진행됨에 따라 지속적으로 향상되어 최종적으로 안정적인 고성능 수준에 도달했다(Fig. 5). 이러한 결과는 모델의 신뢰성과 일반화 능력이 충분히 확보되었음을 뒷받침한다.
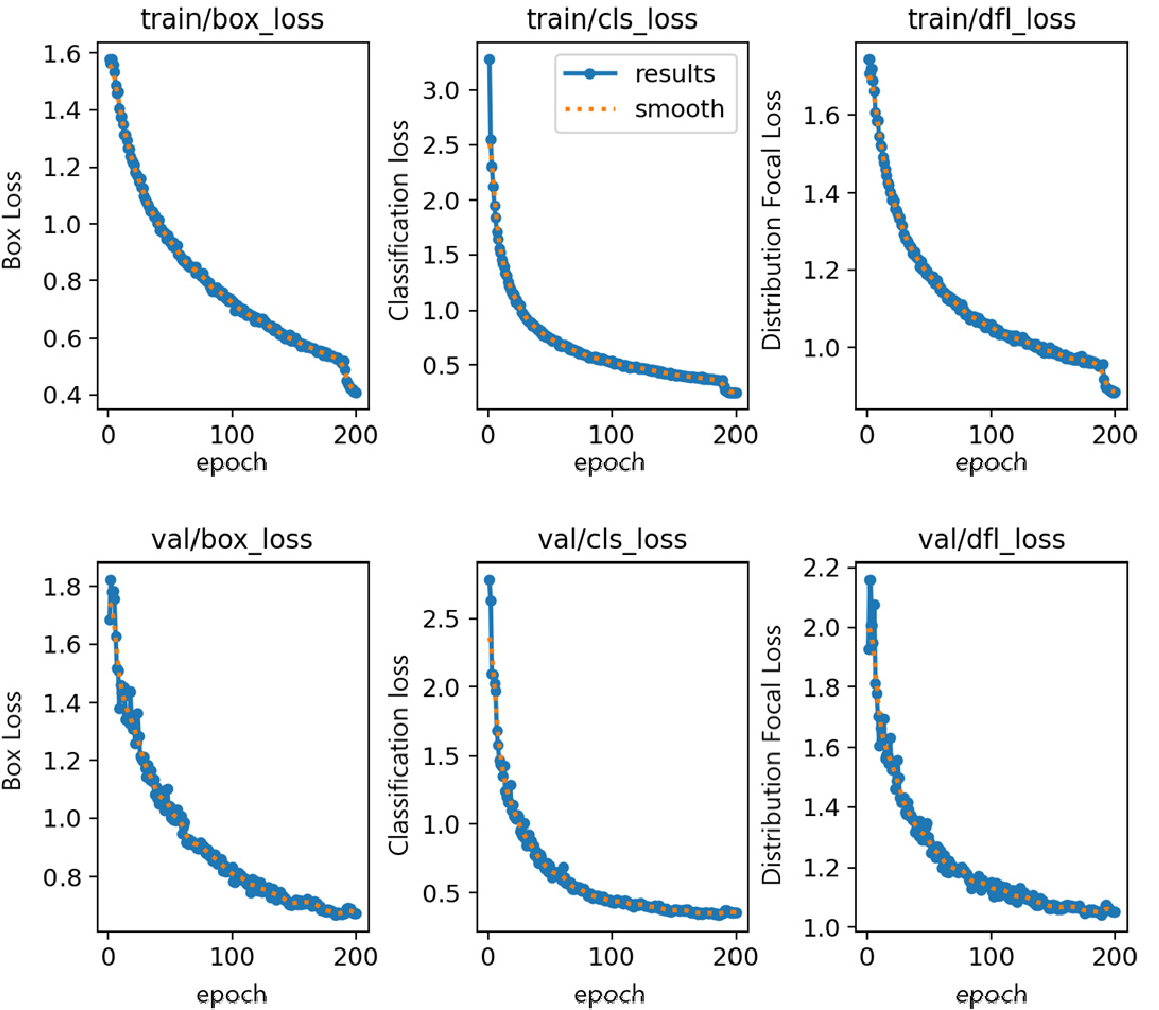
모든 손실 지표는 epoch이 증가함에 따라 안정적으로 감소하는 추세를 나타냈다. 이는 모델이 객체의 위치와 클래스 정보를 점진적으로 정확히 학습하고 있으며, 과적합 없이 학습이 이루어졌음을 보여준다. 검증 데이터셋에서도 유사한 손실 감소 패턴이 나타났으며, precision, recall, mAP@50, mAP@ 50-95 등의 성능 지표는 지속적으로 향상되는 경향을 보였다(Fig. 6). 이러한 결과는 모델의 신뢰성과 일반화 능력이 충분히 확보되었음을 뒷받침한다.
구축된 모델에 대해 교차검증을 진행했다. 전체 데이터를 5개의 fold로 분할했으며, 평균 성능은 Precision = 0.958 ± 0.007, Recall = 0.938 ± 0.012, mAP@0.5 = 0.968 ± 0.008, mAP@0.5-0.95 = 0.792 ± 0.006로 나타났다(Table 1). 모든 fold에서 안정적인 성능을 보였으며, fold 간 변동이 크지 않아 구축된 모델이 단일 데이터 분할에 의존하지 않고, 데이터셋 전반에서 일관된 탐지 성능을 유지함을 시사한다.
Table 1.
Performance of the proposed YOLOv8-based model using 5-fold cross-validation
3.2 정량적 모델 성능 평가
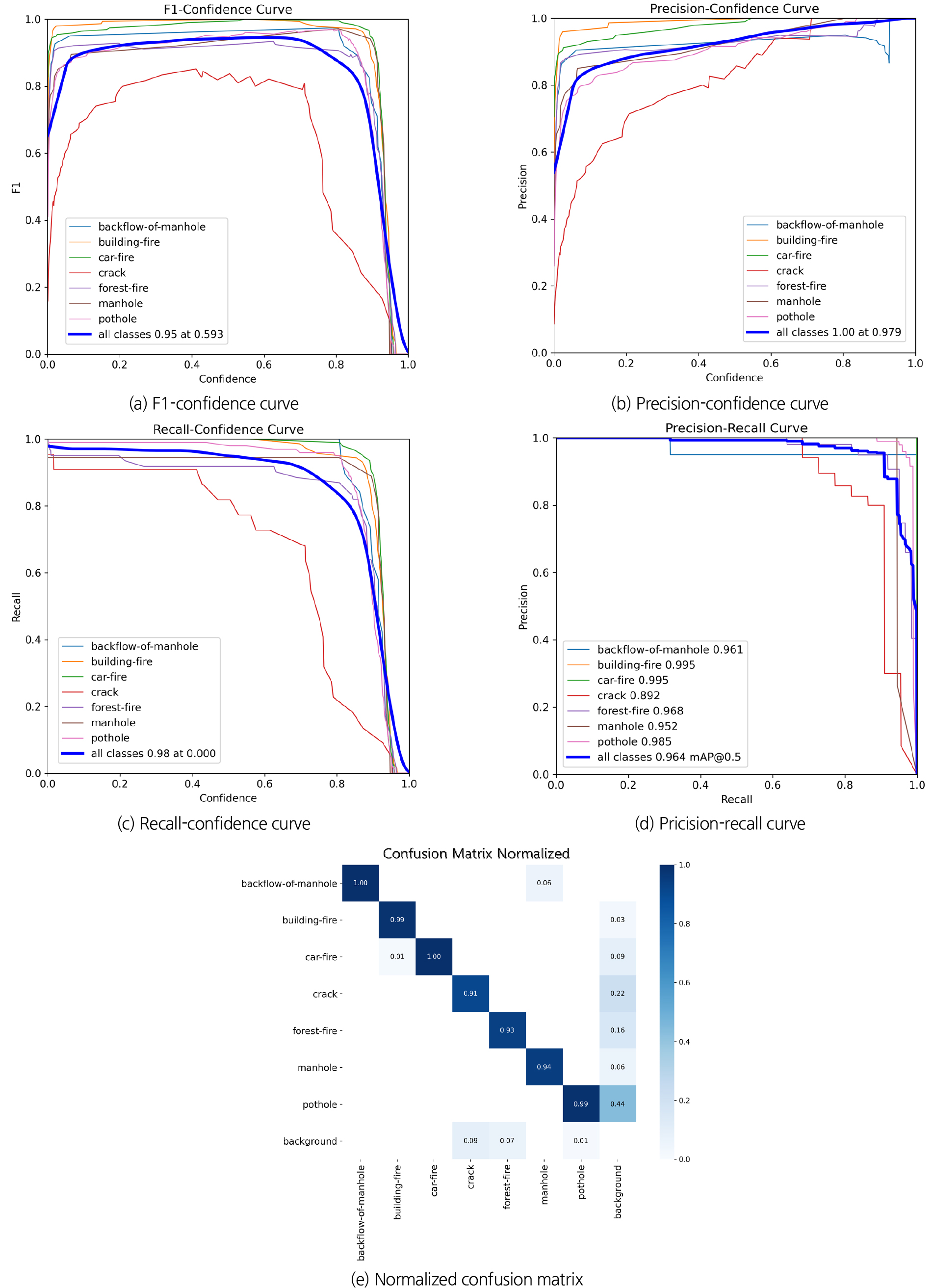
모델 구축 과정에 포함되지 않은 독립적인 Test 데이터셋(10%)을 활용하여 구축된 재난유형 판별 모델에 대한 성능을 평가했다(Table 2). 전체 유형에 대한 평균 성능은 Precision = 0.956, Recall = 0.937, mAP@0.5 = 0.964, mAP@0.5-0.95 = 0.792로 나타나, 제안 모델이 test 환경에서도 높은 탐지 정확도와 일반화 성능을 유지함을 확인할 수 있었다. 각 유형에 대한 성능을 분석한 결과, 빌딩화재, 차량 화재, 포트홀은 각각 mAP@0.5 = 0.995, 0.995, 0.985로 우수한 탐지 성능을 나타냈다. 반면 도로 균열은 mAP@0.5 = 0.892, mAP@0.5-0.95 = 0.558로 상대적으로 낮은 탐지 성능을 보였으며, 또한 forest-fire 역시 배경과의 색상·질감 유사성으로 인해 다소 낮은 성능을 기록하였다.
Table 2.
Detection performance of the proposed YOLOv8-based model on the independent test set
Fig. 7(a)의 F1 - Confidence Curve에서는 confidence threshold가 낮을 때는 F1-score가 다소 불안정하게 나타났으나, 약 0.59 부근에서 전체 F1-score가 0.95에 도달하며 가장 안정적인 값을 기록하였다. 이는 모델이 해당 threshold에서 정밀도와 재현율 간의 균형을 가장 잘 유지함을 의미한다. 그러나 도로 균열의 경우 threshold 변화에 민감하여 다른 클래스에 비해 F1-score 변동 폭이 컸으며, 이는 균열 탐지가 불규칙한 형태와 작은 크기 때문에 threshold 설정에 따라 성능이 크게 달라질 수 있음을 보여준다. Fig. 7(b)의 Precision - Confidence Curve에서는 confidence threshold가 증가함에 따라 대부분 precision 값이 점차 상승하여 0.97 이상에서는 거의 1.0에 수렴하였다. 빌딩화재, 차량화재, 포트홀은 threshold가 높아질수록 오탐이 거의 발생하지 않는 양상을 보였으나, 도로 균열은 precision이 상대적으로 낮고 threshold 변화에 따라 값이 불안정하였다. 이는 균열 탐지 과정에서 배경 잡음이나 유사 패턴을 잘못 인식할 가능성이 상대적으로 높다고 사료된다. Fig. 7(c)의 Recall - Confidence Curve에서는 낮은 threshold 구간에서는 recall이 0.9 이상으로 높게 유지되었으나 threshold가 증가함에 따라 점차 감소하는 경향을 보였다. 도로 균열은 recall 곡선의 하락 폭이 특히 크며 threshold가 높아질수록 실제 균열을 놓칠 가능성이 있는 것으로 나타났다. 이는 도로 균열 탐지를 위해 threshold 조정이 중요한 변수임을 보여준다. Fig. 7(d)의 Precision - Recall Curve에서는 전체 mAP @0.5가 0.964로 계산되었으며, 대부분 곡선이 우상단에 위치하여 높은 precision과 recall을 동시에 확보한 것으로 나타났다. 특히 빌딩화재와 차량화재는 거의 완벽에 가까운 탐지 성능을 보였다. 반면 도로 균열은 곡선이 상대적으로 낮게 위치하여 precision과 recall이 모두 떨어졌는데, 이는 모델이 균열을 탐지하는 과정에서 놓침과 오탐이 동시에 빈번히 발생했음을 의미한다. Fig. 7(e)의 Confusion Matrix에서는 대부분의 클래스가 대각선에서 0.9 이상의 정확도를 기록하여 올바른 분류가 이루어졌음을 확인할 수 있었다. 빌딩화재와 차량화재는 거의 완벽하게 분류되었으나, 도로 균열은 일부가 배경이나 산불 화재로 잘못 분류되었다. 이는 균열이 작은 객체이면서 주변 환경과 시각적 유사성이 높아 배경이나 다른 유형의 재난과 혼동될 가능성이 크다는 것을 보여준다.
3.3 재난 유형별 탐지 성능 및 한계 분석
Bounding Box 시각화 결과에서도 모델이 객체의 위치를 적절히 감지하고 있으며, 실제 재난 이미지(화재, 파손, 침수 등)에서 높은 신뢰도(confidence score)를 보였다(Fig. 8). 특히 차량 화재나 홍수 (맨홀역류사고)와 같은 동적 상황에서도 모델이 신속하고 정확하게 객체를 구분하고 있음을 확인하였다.

본 연구에서 대상으로 한 재난 유형들에 대해 대부분 높은 탐지율을 보였다. 이는 재난 유형 탐지에 대한 YOLOv8 적용 가능성을 보여준다. 하지만 산불화재 및 도로 균열에서 상대적으로 낮은 성능을 보였다. 산불은 화염과 연기가 주변 배경(산림, 토양, 하늘 등)과 색상·질감이 유사하여 구분이 어려우며, 특히 연기의 형태가 불규칙적으로 변화하여 작은 규모의 화재 탐지 누락 가능성이 있다(Cheng et al., 2024). 또한 화재 탐지 성능이 화재 크기(픽셀 크기)와 배경 활동도(Activity level)에 따라 크게 달라지며, 사람·차량과 같은 동적 객체가 많은 장면에서는 오탐률이 높아질 수 있다(Gragnaniello et al., 2024). 산불 감시 연구 대부분이 제한된 데이터셋에 의존하여 다양한 환경·기상 조건을 충분히 반영하지 못하는 한계가 있기에 실제 환경에서의 일반화 성능이 떨어질수도 있다(Saleh et al., 2024). 도로균열도 탐지에 있어 낮은 성능을 나타냈다. 도로 균열 탐지 성능 저하 요인으로는 환경적 요인(조명 변화, 그림자, 반사광, 오염 등), 균열의 형태적 특성(불규칙한 형상, 다양한 크기, 미세 균열), 데이터셋 한계(다양한 도로 조건 미반영, 일반화 부족)등이 될 수 있기에 실제 현장에서 탐지 성능 저하가 발생할 수 있다(Yuan et al., 2024).
본 연구의 학습 데이터셋은 총 3,245장으로 규모가 제한적이며, 특정 재난 유형(화재 및 홍수)에 집중되어 있어 실제 다양한 환경에서 일반화 성능이 저하될 가능성이 있다. 특히 야간·역광·강우·강설 등 다양한 기상·조명 조건과 여러 지역·국가에서 수집된 데이터가 부족하다. 이러한 한계는 모델의 적용 범위를 제한할 수 있으며, 향후 연구에서는 데이터셋 확장, 불규칙 패턴 재난(예: 도로균열)용 고급 전처리 및 증강 기법, 기상·위치·드론 영상 등 다원적 데이터와의 융합을 통한 멀티모달 학습이 필요하다. 이를 통해 모델의 일반화 성능과 신뢰성을 더욱 강화할 수 있을 것으로 사료된다.
4. 결 론
재난은 다양한 원인으로 인해 발생이 되며, 예측하기 힘든 형태의 다양한 재난과 연쇄적으로 발생하는 복합재난이 발생하기에 초기대응의 역량 강화가 요구되고 있다. 최근 첨단기술을 활용하여 재난 초기대응 및 재난관리에 적용하고 있다. 초기대응의 시작은 주로 재난 목격자의 신고로 시작되는데, 이는 스마트폰을 활용한 이미지 기반의 시민제보가 대부분이다. 스마트폰 기반은 높은 화소 카메라가 보편적으로 탑재되어 있어 재난관리에 필요한 광범위하고 실시간의 이미지 정보를 신속하게 생성, 전파하는데 매우 효과적이다. 이처럼 시민제보를 통해 다양한 재난현장의 이미지를 실시간으로 취득할 수 있지만, 다양한 촬영환경과 이미지 품질 편차로 인해 탐지의 정확성을 보장하기에 한계가 있어 데이터 다양성에 대한 고성능 탐지 모델이 요구된다.이에 본 연구에서는 이미지를 기반으로 6가지 재난 유형 탐지 및 분류할 수 있는 YOLOv8 기반 객체 탐지 모델을 개발하였다. 수집된 재난 이미지를 전처리 및 애노테이션한 후, 데이터 증강 기법을 적용하여 모델의 일반화 성능을 향상시켰으며, 이를 통해 다양한 재난 환경에서도 높은 탐지 정확도를 유지할 수 있도록 하였다.
제안된 모델은 Precision = 0.956, Recall = 0.937, mAP@0.5 = 0.964, mAP@0.5-0.95 = 0.792의 정확도를 나타냈으며, 그중 차량·건물 화재와 홍수 관련 재난에서 우수한 성능을 보였다. 이는 모델이 재난 현장에서 다양한 객체를 신속하고 정확하게 식별할 수 있는 성능을 확보했음을 의미한다. 화재는 도심 뿐만 아니라 다양한 지역에서 가장 빈번하고 피해 규모가 큰 재난 중 하나로, 조기 탐지 여부에 따라 피해 확산이 크게 좌우된다. 맨홀 역류는 도시 수문관리와 직접적으로 관련되는 수자원 공학적 재해로 도시 내 배수 시스템과 직접적인 연관성이 있다. 특히, 최근 기후변화로 인해 국지성 호우 발생 빈도가 증가하면서, 맨홀 역류는 도시 수문관리와 공공안전에 직결되는 수공학적 재해로 의미를 가진다. 향후 연구에서는 강우 및 범람 등과 같이 직접적인 수재해 재난 유형을 추가하여 수자원 공학적 기여 강화가 필요하다고 사료된다. 반면 도로 균열과 같이 시각적 패턴이 불규칙하고 경계가 존재하지 않는 클래스에서는 상대적으로 낮은 탐지 성능을 보였다. 이는 클래스의 데이터 다양성과 불균일성이 모델 학습에 제약이 있는 것으로 해석된다. 따라서 향후 연구에서는 불규칙 패턴을 다루기 위한 추가 데이터 확충, 전처리 기법, 특징 강화 알고리즘 등의 적용이 필요할 것으로 판단된다.
본 연구는 시민제보 이미지 기반의 재난 탐지라는 접근으로 시각적 데이터 기반 재난 관리 연구를 진행하여 재난 현장의 조기 인지와 신속한 대응 체계 구축에 기여할 수 있다. 제안된 모델은 발생 빈도가 높은 화재(산불, 차량, 건물), 도로 손상(포트홀, 도로균열), 도시기반 시설(맨홀, 맨홀역류)을 효과적으로 탐지할 수 있음을 확인하였다. 특정 재난의 경우 이미지를 활용하여 정확한 재난 유형을 판별하는데 한계가 있다. 추후 양질의 재난 이미지와 표준 DB구축이 진행된다면 정확도 높고 세부적인 재난 유형 판별이 가능할 것으로 사료되며 피해 최소화와 재난 관리 체계 고도화에 기여할 수 있을 것으로 사료된다. 더 나아가, 시민제보를 활용한 재난 신고가 많이 이루어지는데, 본 연구는 시민제보의 허위신고 및 가짜 재난 이미지의 판별에도 기여할 수 있어 재난 상황에서의 의사결정 지원에도 중요한 의미를 가진다. 본 연구와 같은 AI 영상 분석 기술 고도화가 진행된다면 시민제보 뿐만 CCTV 영상을 활용한 체계 마련에 기초자료로 활용될 수 있을 것이다. 그리고 다양한 재난 데이터(시민제보, 드론 영상, 기상, 위치 정보 등)와 연계한다면 AI 기반 지능형 재난 상환관리 체계와 스마트시티 기반의 재난 모니터링, 의사결정 지원 체계에 기여할 수 있을 것으로 판단된다.
