

1. 서 론
2. 연구지역 및 자료
2.1 대상 지역
2.2 관측 자료
2.3 강우사상 선정
3. 연구방법
3.1 다중입출력(Multi-Input & Multi-Output, MIMO) LSTM 모형의 구조
3.2 모델 구축 및 하이퍼파라미터 최적화
3.3 모델 예측성능 평가
4. 결 과
4.1 대곡교 지점 예측성능
4.2 궁내교 지점 예측성능
5. 결론 및 토의
1. 서 론
기후변화에 따른 강우 패턴의 불확실성과 돌발홍수 발생 빈도 증가는 하천 홍수위 예측의 중요성을 더욱 부각시키고 있다. 홍수위 예측은 홍수 위험 관리, 저지대 침수 대응, 수자원 운영, 도시하천 유지관리 등 다양한 실무적 의사결정과 직결되며, 특히 첨두 수위(peak stage)의 재현과 예측선행시간(lead time)에 따른 신뢰성 확보는 실시간 대응 체계의 핵심 요소이다.
전통적인 물리기반 홍수모형은 물리적 해석이 가능하고 강우-유출 과정의 기작을 설명할 수 있다는 장점이 있으나, 복잡한 매개변수 보정, 높은 자료 요구도, 예측 계산의 부담 등으로 인해 실시간 및 단기 예측 상황에서 효율성이 제한될 수 있다(Wu et al., 2023; Tawalbeh et al., 2023). 이러한 한계를 보완하기 위해 데이터 기반(data-driven) 접근법이 새로운 대안으로 주목받고 있으며, 특히 LSTM (Long Short-Term Memory)은 비선형성, 비정상성, 장단기 의존성 등 수문 시계열의 특성을 효과적으로 학습할 수 있어 홍수 예측 분야에서 활용이 증가하고 있다(Hu et al., 2018; Li et al., 2020). 여러 선행 연구들은 LSTM이 물리모형의 계산 부담이나 매개변수 민감도 등의 약점을 보완하며 높은 예측 성능을 보일 수 있음을 제시하였으나(Kratzert et al., 2018; Hunt et al., 2022), 이는 기계학습 기반 모델이 물리모형을 완전히 대체한다기보다는 반응 시간이 짧은 도시 유역 등에서 물리모형의 계산 복잡성과 보정 부담을 완화하거나, 실시간 예측에서 보조적·보완적 역할을 수행할 수 있다는 점을 강조한다. 따라서 물리기반 접근과 자료기반 접근은 상호 대체적 관계가 아니라, 예측 목적·자료 조건·유역 특성에 따라 상호보완적으로 활용될 수 있다.
국내에서도 AI 기반 홍수예측 연구가 꾸준히 수행되어 왔다. Kim et al. (2022)은 AI 기반 홍수위 예측 및 예·경보 기법을 개발하여 실무 적용 가능성을 검토하였으며, Jeong et al. (2018)은 감조하천을 대상으로 LSTM 모형의 적용성을 평가하였다. 또한 Lee (2021)는 실시간 홍수예측을 위한 AI 기반 모델을 구축하여 물리모형의 운영상 한계를 보완할 수 있음을 제시하였다. 국외에서도 Atashi et al. (2022)가 Red River를 대상으로 딥러닝 기반 수위 예측 모델을 적용하여 다양한 입력 조합에 따른 예측 성능을 비교하는 등, AI 기반 수위 예측의 활용 가능성이 폭넓게 검토되고 있다.
이러한 국내·국외 연구들은 대부분 단일 리드타임(single lead time) 예측 성능 또는 전체 기간 평균 RMSE·NSE 등 종합 지표 평가에 중점을 두고 있으며, 예측선행시간이 길어질 때 모델 성능이 어떻게 변화하는지(lead-time-dependent performance)를 체계적으로 분석한 연구는 매우 부족한 실정이다.
이에 본 연구는 다중입출력(Multi-Inout Multi-Output) LSTM 모델을 활용하여 10분 단위 수위 데이터를 기반으로 단기(10분)부터 장기(360분)까지 다중 예측선행시간별 예측을 수행하였다. 다중입출력(MIMO) 방식은 단일 모델 실행으로 여러 미래 시점을 동시에 산출하므로, 순차적으로 예측을 갱신하는 재귀적(recursive) 방식에 비해 오차 누적(error accumulation)이 적고, 각 리드타임별 개별 모델을 학습하는 직접(direct) 방식보다 학습 효율성이 높은 것으로 알려져 있다(Ben Taieb et al., 2012).
따라서 본 연구는 MIMO-LSTM 구조가 도시하천 수문 조건에서 어느 리드타임까지 신뢰 가능한 성능을 제공하는지를 실증적으로 규명하고, 이를 통해 실시간 홍수예보 시스템에서 AI 기반 예측모형의 시간적 적용한계(temporal validity limit)를 제시하는 것을 목표로 한다. 특히 예측선행시간 증가에 따라 첨두 및 하강 구간에서의 신뢰성 변화 시점을 분석함으로써, AI 기반 홍수예측 모형의 적용 범위와 실무적 활용성을 객관적으로 제시하고자 한다.
2. 연구지역 및 자료
2.1 대상 지역
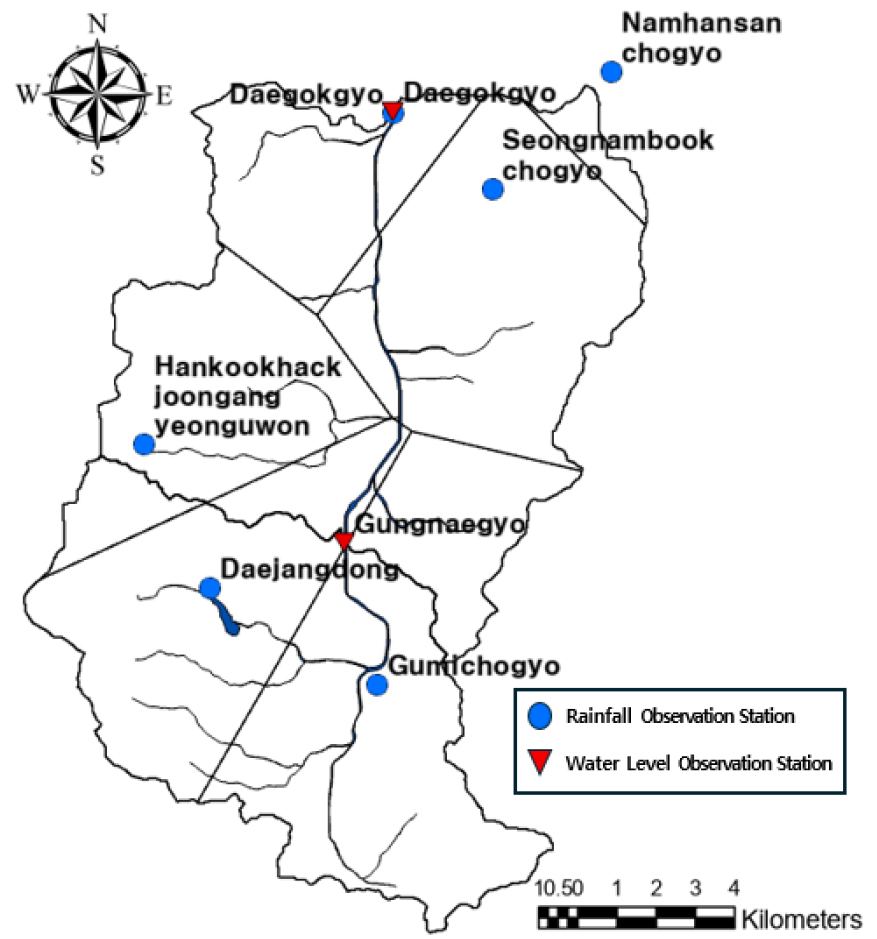
본 연구는 한강 수계의 지류 하천인 탄천 유역을 대상으로 하며, 대곡교(서울시 구간)와 궁내교(성남시 구간) 지점을 주요 수위 예측 지점으로 설정하였다. 탄천은 경기도 용인시 기흥구에서 발원하여 성남시 중심부를 남북 방향으로 관통한 뒤 서울특별시 강남구를 지나 한강으로 유입되는 도시 하천으로, 전체 유로 연장은 약 35.6 km이며, 유역면적은 약 302 km2에 달한다. 이 중 약 15.7 km 구간이 성남시를 흐르며, 분당천, 운중천 등 다수의 지류 하천이 본류에 합류하는 복합적인 하천 체계를 형성하고 있다.
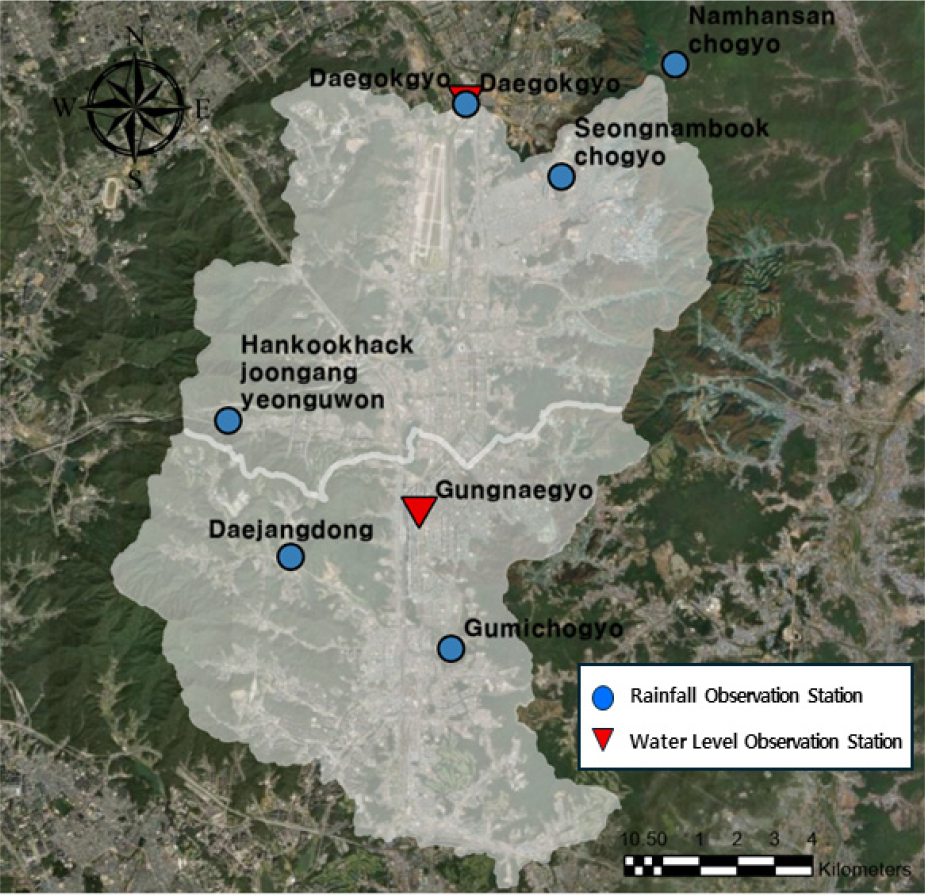
탄천 유역은 중·하류 지역의 도시화율이 높아 불투수면 비율이 큰 전형적인 도시형 유역으로, 강우 발생 시 침투·저류보다는 직접유출이 우세하게 나타나는 특성을 보인다. 또한 상류에서 하류로 갈수록 경사가 완만해지는 분지형 지형 구조를 갖고 있어, 강우 강도의 변화가 수위 시계열에 즉각적으로 반영되는 짧은 유출 지체시간(short response time)과 급격한 수위 변동(high temporal variability)이 나타난다. 이와 같은 수문·지형적 요인은 강우-수위 간 인과 관계가 명확하게 드러나는 도시하천의 특성을 구성한다. 이러한 특성은 시계열 기반 딥러닝 모델의 적용에 적합한 조건을 제공한다. LSTM은 시점 간 비선형성, 급격한 상승·하강 구간, 단기 의존성을 학습하는 데 강점을 갖고 있기 때문에, 강우 변화가 수위에 빠르게 반응하는 도시형 유역에서는 입력 시계열과 출력 시계열 간 관계를 보다 효과적으로 포착할 수 있다. 특히 첨두 발생 시점과 같은 주요 변화 구간에서 시계열의 구조적 패턴을 재현하는 데 유리하다는 점에서 탄천 유역은 LSTM 기반 리드타임별 수위 예측 성능 평가를 하기 위한 적절한 대상지역으로 판단된다. Fig. 1은 탄천 유역 내 수위 관측소(대곡교, 궁내교)와 강우 관측소 6개 지점의 공간적 분포를 나타낸다.
2.2 관측 자료
2.2.1 수위 관측 자료
수위 자료는 국가수자원관리종합정보시스템(WAMIS)을 통해 수집하였으며, 탄천 상류부에 위치한 궁내교 수위관측소(성남시 분당 지역)와 그 하류부에 위치한 대곡교 수위관측소(서울시 강남구 구간)에서 측정된 10분 단위 시계열 자료를 활용하였다. 궁내교는 성남시 분당 지역의 수문 특성을, 대곡교는 서울시 강남구 구간의 수위 변화를 대표한다. 두 관측소의 세부 정보는 Table 1에 제시하였다.
Table 1.
Water level observation station
2.2.2 강우 관측 자료
강우 자료는 탄천 유역 내 및 인근 지역에 위치한 6개 강우관측소에서 수집된 10분 단위 시계열 자료를 사용하였다(Table 2). 관측소는 남한산초교, 대곡교, 한국학중앙연구원, 대장동, 성남북초교, 구미초교이며, 모두 환경부에서 운영·관리하고 있다.
본 연구에서는 탄천 본류의 궁내교와 대곡교 지점을 출구점(outlet)으로 하는 두 개의 소유역(sub-basin)을 구분하였다. 대곡교 소유역에는 6개, 궁내교 소유역에는 3개의 강우관측소가 포함되는 것으로 나타났으며(Fig. 2), 각 소유역 내 강우관측소의 영향면적은 Thiessen 다각형으로 산정하였으며, 이를 통해 유역별 입력변수 구성을 결정하였다. 다만, 본 연구의 학습 입력자료는 유역 평균 강우량이 아니라 선택된 개별 강우관측소의 실측 시계열 자료를 그대로 사용하였다. 이는 LSTM 모델이 다변량 입력을 동시에 학습할 수 있다는 장점을 활용하여, 공간적으로 분산된 강우 패턴을 보존하고 각 수위 지점의 유역 특성을 반영하기 위함이다. 따라서 Thiessen 다각형은 가중평균 산정을 위한 도구라기보다는, 각 수위 관측소와 연결되는 강우관측소 집합을 정의하기 위한 공간적 분할 도구로 활용되었다.
Table 2.
Rainfall observation station
2.3 강우사상 선정
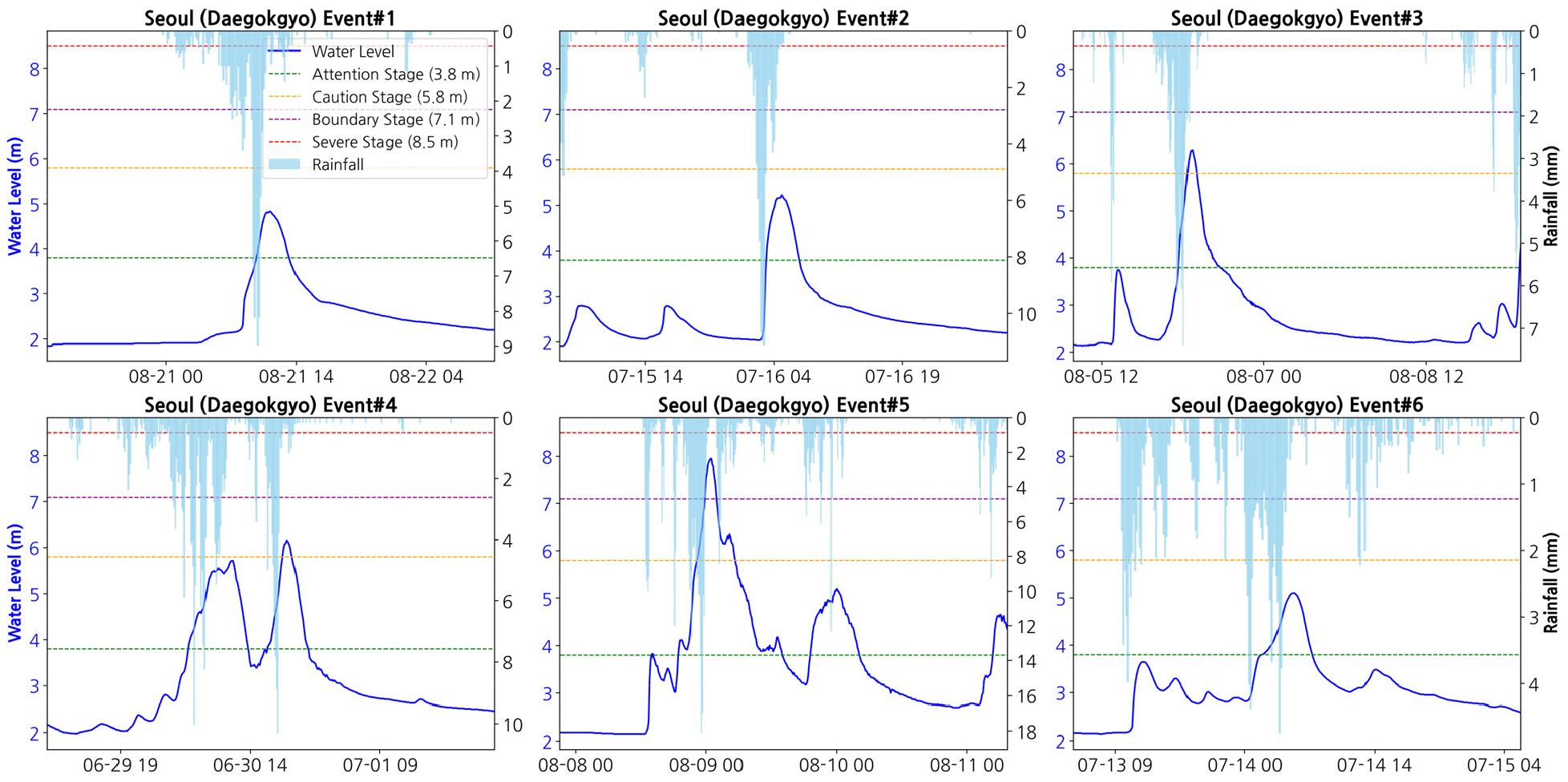
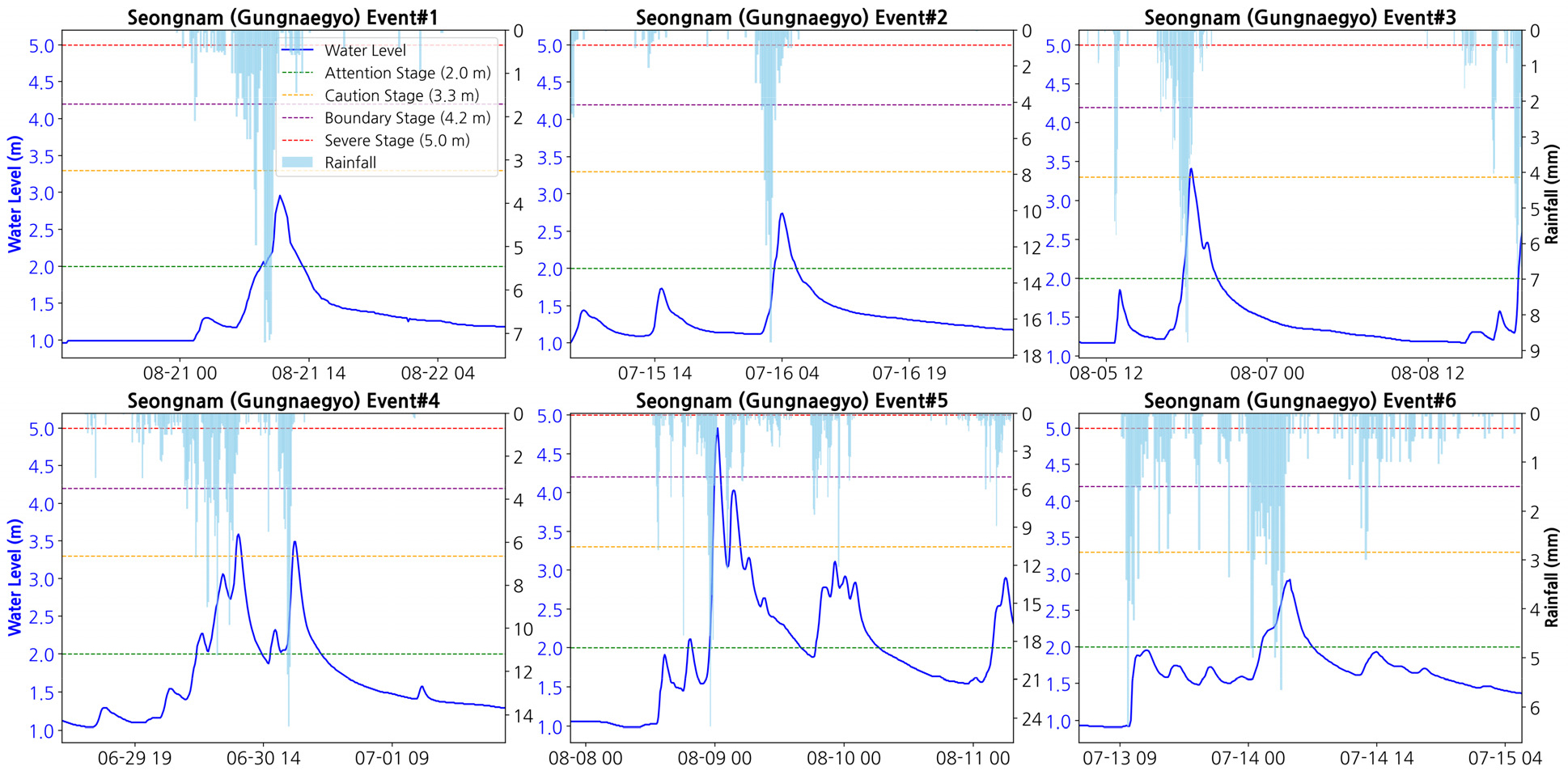
수위 예측 모델의 효과적인 학습을 위해서는 하천의 복잡한 수문학적 반응이 명확하게 드러나는 시기를 중심으로 데이터셋을 구성하는 것이 필수적이다. 특히 하천 수위는 강우량과 비선형적인 관계를 가지며, 홍수 발생 시기에는 급격한 수위 변화와 함께 강우-유출 간의 복잡한 상호작용이 나타난다. 이러한 특성을 고려하여 본 연구에서는 한강홍수통제소에서 공식적으로 발령한 대곡교 지점의 홍수특보 이력을 기준으로 주요 강우사상을 선정하였다.
대곡교는 탄천 유역의 하류 지점으로서 한강홍수통제소의 홍수특보 발령지점으로 지정되어 있으며, 2014년 1월 1일 00시부터 2024년 5월 23일 00시까지의 기간 동안 발령된 홍수특보 이력을 분석하여 총 6개의 주요 강우사상을 선정하였다(Figs. 3 and 4). 선정된 강우사상들은 홍수주의보 또는 홍수주의보 및 경보가 동시에 발령된 시기로 구성되어 있으며, 각 사상은 49시간 30분에서 99시간 10분까지의 다양한 지속시간을 가진다.
각 강우사상의 데이터 구성은 홍수특보 발령 시점을 중심으로 전후 24시간의 시계열 자료를 포함하도록 설계하였다. 이러한 구성을 통해 모델 학습에 필요한 과거 4시간의 입력 데이터와 향후 12시간의 예측 대상 데이터를 안정적으로 확보할 수 있으며, 홍수 발생 전후의 수문학적 변화 과정을 종합적으로 반영할 수 있다. 또한 강우 데이터의 공간적 대표성을 확보하기 위해 티센 다각형 기법을 적용하여 유역 내 다수의 강우 관측소로부터 면적 가중 평균 강우량을 산정하였으며, 각 사상별 평균 강우량은 Table 3에 제시하였다.
Table 3.
Average rainfall per event (mm)
| Event#1 | Event#2 | Event#3 | Event#4 | Event#5 | Event#6 | |
| Daegokgyo | 110.92 | 119.43 | 225.69 | 273.63 | 545.42 | 163.83 |
| Gungnaegyo | 106.60 | 126.43 | 273.85 | 298.61 | 515.31 | 192.98 |
최종적으로 선정된 6개 강우사상은 각각 독립적인 실험 단위로 활용되어 다중입출력 LSTM 모델의 성능 평가 및 검증에 사용된다. 이들 사상은 모두 실제 홍수 발생 시기의 데이터로 구성되어 있어 모델이 실제 홍수 상황에서의 복잡한 수위 변화를 효과적으로 학습할 수 있는 기반을 제공한다.
3. 연구방법
3.1 다중입출력(Multi-Input & Multi-Output, MIMO) LSTM 모형의 구조
시계열 예측에 널리 활용되는 순환신경망(Recurrent Neural Network, RNN)은 시간적 의존성을 학습할 수 있다는 장점을 가지지만, 장기 시계열을 다룰 경우 기울기 소실(vanishing gradient) 문제로 인해 장기 정보를 충분히 반영하지 못하는 한계를 가진다(Bengio et al., 1994). 이를 개선하기 위해 Hochreiter and Schmidhuber (1997)가 제안한 장단기 기억망(Long Short-Term Memory, LSTM)은 게이트(gate) 구조를 통해 불필요한 정보를 제거하고 필요한 정보를 장기간 보존함으로써 복잡한 비선형 시계열의 학습 안정성과 예측력을 향상시켰다. LSTM의 내부 연산 구조는 Fig. 5와 같으며, 시점에서의 입력벡터 , 이전 시점의 은닉 상태 , 셀 상태 을 입력으로 받아 망각 게이트(Forget Gate), 입력 게이트(Input Gate), 출력 게이트(Output Gate)의 연산을 수행한다. 각 게이트는 시그모이드 함수 𝜎(•)를 통해 0~1 사이의 값을 출력하며, 정보의 유지·갱신 여부를 결정한다.
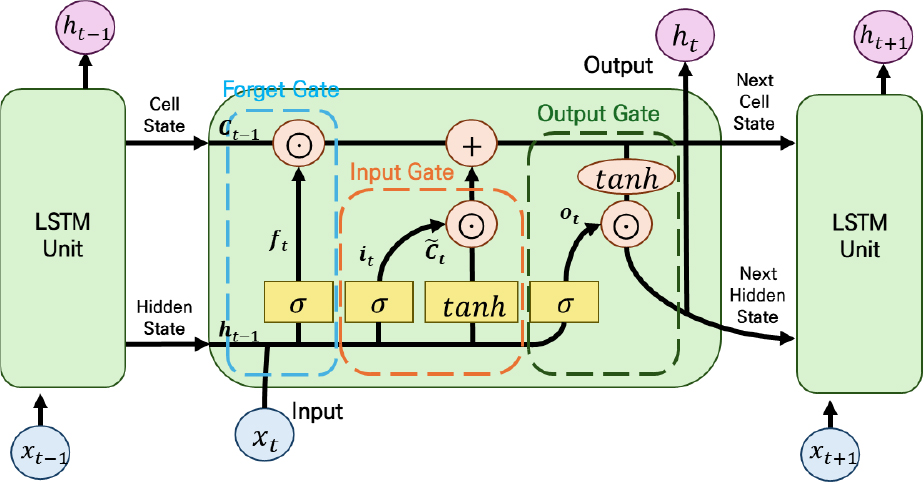
먼저, 망각 게이트는 이전 상태에서 어떤 정보를 유지할지를 결정한다.
여기서 와 는 각각 입력 가중치 행렬과 은닉 가중치 행렬, 는 편향 벡터이다.
입력 게이트는 새로운 정보를 셀 상태에 반영할지를 결정하고, 새로운 기억 후보(Candidate Cell)는 현재 입력과 이전 은닉 상태로부터 생성된 잠재 정보를 계산한다.
그 후, 셀 상태는 이전 기억과 새로운 정보를 결합하여 다음과 같이 갱신된다.
여기서 ⊙는 요소별 곱(element-wise multiplication)을 의미한다.
마지막으로, 출력 게이트는 셀 상태의 일부를 은닉 상태로 전달하여 최종 출력을 생성한다.
이와 같이 LSTM은 시간에 따른 연속적 입력을 순차적으로 처리하면서 단기기억(은닉 상태)과 장기기억(셀 상태)을 함께 학습하여 시계열의 장기 의존성을 효과적으로 반영한다.
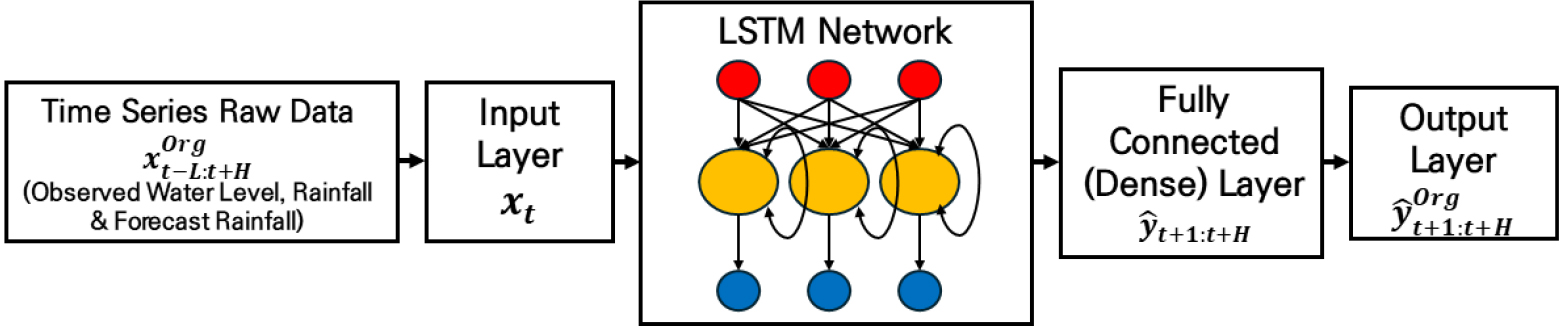
본 연구에서는 기존 LSTM의 내부 연산 구조를 변경하지 않고, 동일한 셀 구조를 유지한 상태에서 입력·출력의 구성 방식을 다중입력(Multi-Input)·다중출력(Multi-Output, MIMO) 형태로 확장하여 적용하였다. 즉, 본 연구에서의 MIMO-LSTM은 새로운 LSTM 셀을 설계한 것이 아니라, 하나의 LSTM 네트워크가 여러 입력 변수를 동시에 받아 여러 리드타임의 수위를 한 번에 산출하도록 입력 벡터와 출력 벡터의 차원(configuration)을 다중화한 모델링 전략으로 해당 구조는 Fig. 6과 같다. MIMO-LSTM은 두 개의 LSTM 인코더를 통해 과거 관측자료(수위, 강우)와 미래 예보 강우자료를 동시에 입력받아 단일 모델 실행으로 다수의 예측 시점을 병렬적으로 산출하는 구조를 가진다. 입력 시퀀스는 과거 강우 와 수위자료 , 그리고 예보 강우자료 를 포함하며 다음과 같이 정의된다.
여기서 은 입력시퀀스 길이(sequence length), 는 최대 예측선행시간(forecast horizon)을 의미한다. 원시 입력(Original Data) 는 표준화(정규화) 과정을 거쳐 모델의 입력 벡터 로 변환된다.
이후 정규화된 입력 는 LSTM Network를 통과하여 은닉상태 로 갱신되고, 마지막 완전연결층(FC Layer; fully connected layer)을 통해 다중 리드타임의 수위 예측 으로 변환된다. 이를 수식으로 표현하면 다음과 같다.
여기서, 는 출력 가중치 행렬, 는 출력 편향 벡터로서 LSTM의 은닉상태를 다중 출력 벡터로 매핑하는 역할을 수행한다. 해당 예측값은 정규화된 스케일 상의 값이므로, 실제 수위 단위로 복원하기 위해 역정규화(denormalization) 과정을 수행하여 아래와 같이 변환된다.
이 과정을 통해 MIMO-LSTM은 한 번의 연산으로 H개의 미래 시점 을 동시에 예측하게 된다.
MIMO (Multi-Input Multi-Output) 구조는 단일 LSTM 네트워크가 여러 입력 변수를 동시에 받아 향후 다수의 예측 시점을 일괄적으로 산출하는 방식으로, 기존의 재귀적(recursive) 또는 직접(direct) 예측 전략과 비교하여 몇 가지 장점을 가진다.
첫째, 모든 리드타임(t+10~t+360분)을 한 번의 연산으로 산출하는 one-shot 예측 방식이기 때문에, recursive 방식에서 발생하는 반복 계산과 오차 누적(error accumulation)을 방지할 수 있다.
둘째, 출력 벡터 내에 존재하는 시간적 상관성(lead-time dependency)을 동시에 학습하므로, 각 시점을 독립적으로 예측하는 direct 방식 대비 더 일관된 시계열 재현이 가능하다.
셋째, 하나의 모델만 학습·관리하면 되므로, H개 모델을 개별적으로 훈련해야 하는 direct 방식에 비해 계산 자원과 운영 비용이 크게 절감된다.
넷째, 단일 모델로 단·중·장기 예측을 모두 생성할 수 있어, 실시간 홍수예보와 같이 빠른 응답이 요구되는 운영 환경에 적합하다.
다만, 출력 차원이 커짐에 따라 학습 데이터의 다양성이 충분하지 않을 경우 장기 리드타임에서 성능 저하가 나타날 수 있다. 따라서 다중입출력 구조의 장점과 함께, 예측선행시간 증가에 따른 성능 변화와 적용 가능한 시간적 범위를 검토하는 것이 중요하다. 본 연구는 이러한 관점에서 MIMO-LSTM 구조를 적용하여 다양한 리드타임 구간의 수위 예측 성능을 분석하고, 특히 첨두 및 저수위 구간에서의 신뢰성 한계를 실증적으로 평가하고자 한다.
3.2 모델 구축 및 하이퍼파라미터 최적화
3.2.1 입력 데이터
본 연구의 다중입력(Multi-Input) 구조는 유역 내 강우의 공간 분포를 반영하기 위해 6개 강우 관측소의 시계열을 동시에 활용하는 방식이다. 도시하천 유역은 강우의 공간 이질성이 크고 국지적 집중호우의 영향이 크게 작용하기 때문에, 하나의 강우 관측소만을 사용하는 단일 입력(single input) 구성은 수위 변화를 설명할 수 있는 정보가 충분하지 않아 비교 실험의 의미가 제한적이다. 이러한 이유로, 본 연구는 실제 홍수 예측 환경과 동일한 다중입력 구조를 기본 전제로 모델을 구성하였다.
입력 데이터는 2장에서 제시한 강우 및 수위 시계열을 기반으로 구성하였으며, 모든 입력 변수와 출력 변수는 0-1 범위에서 정규화(Min-Max Scaling)하였다. 결측치는 1시간 미만의 단기 결측은 선형보간(linear interpolation)으로 보정하였으며, 1시간 이상 연속 결측이 발생한 경우에는 해당 구간을 분석에서 제외하여 전처리 기준의 일관성을 유지하였다. 데이터셋 분할은 시점 단위가 아닌 강우사상(event) 단위로 수행하였다. 총 6개 사상 중 Event 1·2·5·6을 학습(training) 세트로, Event 3을 검증(validation) 세트로, Event 4를 최종 테스트(test) 세트로 지정하였다. Event 5는 전체 사상 중 첨두 규모가 가장 큰 사례로, 다양한 수문 조건을 학습하도록 하기 위해 학습 세트에 포함하였다. 반면, Event 5를 테스트 세트로 사용할 경우 단일 사상의 극한 특성이 테스트 성능에 과도하게 반영되어 모델의 일반화 성능 평가가 왜곡될 우려가 있어 제외하였다. Event 4는 강우-수위 상승·하강 패턴이 비교적 전형적이며, 모델의 일반화 성능을 평가하는 데 적합하다고 판단하여 테스트 세트로 선정하였다. 다양한 학습-검증-테스트 조합을 모두 고려한 전수 교차검증(cross-validation) 방식은 연구 범위를 벗어나므로 수행하지 않았으나, 사상 구성에 따른 모델 민감도 분석은 향후 연구 방향으로 제시하였다.
본 연구는 LSTM 모델이 다변량 입력을 동시에 처리할 수 있다는 점을 적극적으로 활용하여 입력 변수를 설계하였다. 입력 변수는 각 수위 관측소에 대응되는 강우 관측소 집합의 개별 시계열을 그대로 사용하였다. 이는 공간적으로 분산된 강우 패턴을 보존하여 지점별 유역 반응 특성을 보다 충실히 학습하도록 설계하였다. 따라서 Thiessen 다각형은 가중평균 강우량 산정이 아닌, 각 수위 관측소와 연결되는 강우관측소의 입력 변수 집합 정의 도구로 활용되었다. 또한 입력에는 예보 강우(forecast rainfall)를 포함하였다. 다만 본 연구에서의 예보 강우는 실제 기상청 예보가 아닌 과거 실측 강우를 일정 시차만큼 이동시켜 생성한 자료이다. 즉, 100% 정확한 예보라는 이상적 가정을 전제한 것이며, 실제 현업 적용 시에는 예보 오차로 인해 모델 예측 성능이 달라질 수 있다. 본 연구에서는 360분(36 step)까지의 예측을 수행하였으므로, 입력 자료에도 동일한 구간의 예보 강우(T+1~T+36)가 포함되었다. 이는 모델이 장기 예측선행시간에서 강우-수위 반응을 학습할 수 있도록 설계된 것이다. 이러한 점은 본 연구의 한계로, 후속 연구에서는 실제 예보 자료를 반영한 불확실성 평가가 필요하다.
3.2.2 모델 구성 및 하이퍼파라미터 설정
본 연구의 다중입출력 LSTM 모델은 입력된 과거 수위·강우 및 예보 강우 자료를 기반으로, 향후 360분(36 step, 10분 간격) 동안의 수위를 동시에 예측하도록 설계하였다. 모델 학습 과정에서 손실 함수는 전체 예측선행시간에 대한 평균제곱오차(MSE)를 사용하였으며, 옵티마이저로는 Adam을 적용하였다. 조기 종료(Early Stopping), 모델 체크포인트(Model Checkpoint), CSVLogger, TensorBoard 등의 Keras 콜백을 활용하여 학습 안정성을 확보하였다.
또한, Keras Tuner의 Random Search 기법을 활용하여 다중입출력 LSTM 모델의 하이퍼파라미터를 탐색하였다. 탐색 공간은 입력 시퀀스 길이(seq_len, 12-36 step, 12 step 간격), LSTM 은닉 유닛 수(units, 64-256, 64 간격), 드롭아웃 비율(0.0-0.5, 0.1 간격), 학습률(1e-2, 1e-3, 1e-4), 배치 크기(16-64, 16 간격)로 설정하였다. 각 조합은 최대 100 epoch까지 학습되었으며, 조기 종료(Early Stopping, patience=10)와 최적 가중치 복원 기능을 통해 과적합을 방지하였다. Random Search는 총 20회 시행(trial)하였으며, 각 시행은 두 번 반복 실행(executions_per_trial=2)하여 평균 성능으로 평가하였다. 탐색 결과 최적 조합은 Table 4에 요약하였다.
Table 4.
Final optimized hyperparameters of the proposed MIMO-LSTM model
| site | Sequence Length (min) | Input Dimension | LSTM Units | Dense | Dropout | Batch Size | Optimizer | Output |
| Daegokgyo | 120 | 7 | 192×2 | 128 (ReLU) | 0.1 | 16 |
Adam (lr = 0.01) |
36 step (360min) |
| Gungnaegyo | 360 | 4 | 64×2 | 0 |
3.3 모델 예측성능 평가
3.3.1 RO (Rolling Origin) 기법
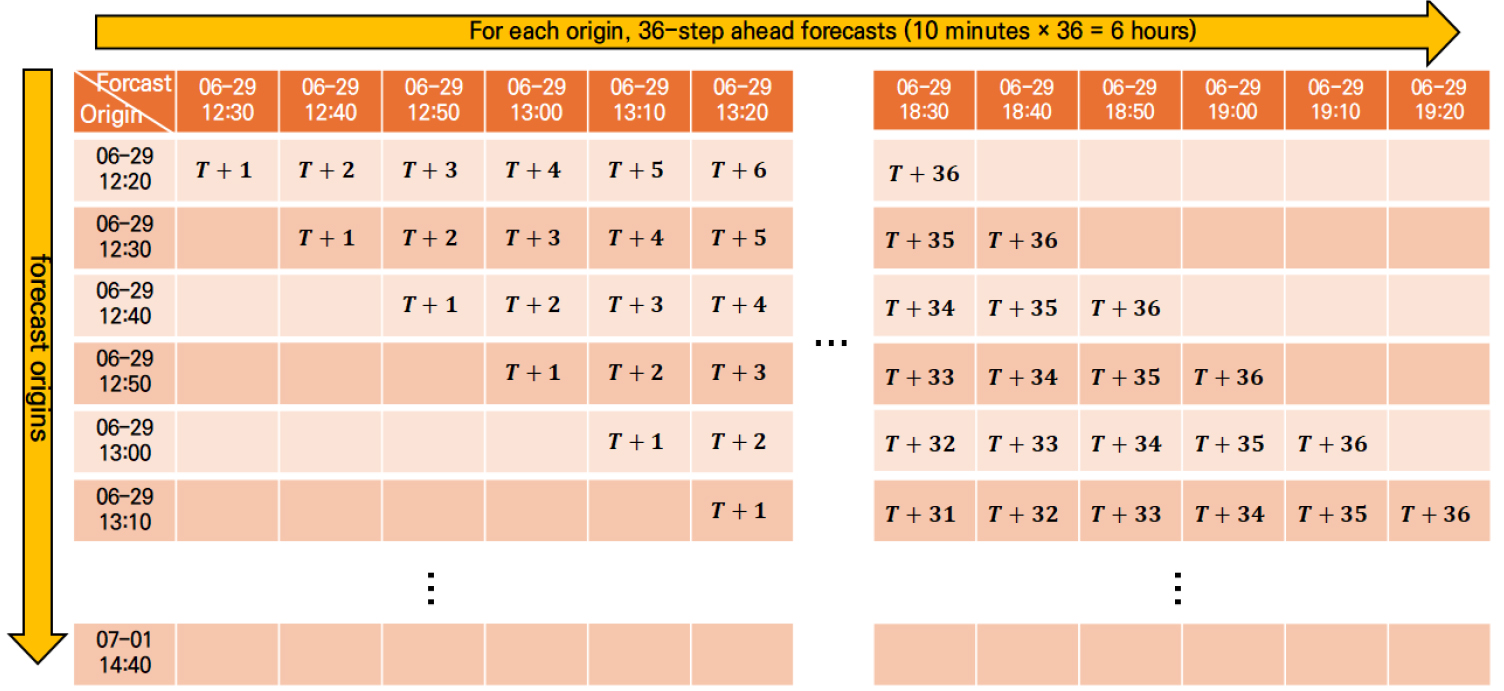
시계열 예측 모델의 일반화 성능을 평가하기 위해서는 학습 구간과 검증 구간을 어떻게 설정하느냐가 매우 중요하다. 전통적으로는 단일 hold-out 구간을 두는 방식이 사용되어 왔으나, 이는 평가 결과가 특정 시점 분할에 의존한다는 한계가 있다. 이를 개선하기 위해 Tashman (2000)은 Rolling Origin Evaluation (ROE) 기법을 제안하였다. RO 기법은 예측 기준 시점(forecast origin)을 순차적으로 이동시키면서 반복적으로 예측과 평가를 수행하는 방식으로, 데이터의 시계열적 구조를 보존하면서도 다양한 훈련-검증 조합을 확보할 수 있다는 장점이 있다(Tashman, 2000).
수학적으로, 시계열 가 주어졌을 때, 예측 기준 시점 에서의 -스텝 선행 예측은 다음과 같이 표현된다.
여기서 는 학습된 예측 함수, 𝜃는 모델 파라미터이다. 이후 기준점을 만큼 이동시키고 동일한 과정을 반복한다. 최종적으로 RO 기반 예측 오차는 다음과 같이 집계된다.
여기서 는 롤링 반복 횟수, 은 손실 함수(MSE, MAE 등)이다.
이 방법은 이후 다양한 시계열 연구에서 널리 활용되어 왔다. 예를 들어, Abolghasemi et al. (2022)은 RO 방식을 계층적 시계열(hierarchical time series) 모델 검증에 적용하여, 장기 예측선행시간에서의 불확실성까지 안정적으로 평가할 수 있음을 보였다.
Fig. 7은 본 연구에서 적용한 RO 평가 절차를 도식적으로 나타낸 것이다. 각 기준시점(origin)에서 36-step ahead (360분) 예측이 수행되며, 이후 시점으로 기준시점을 이동시키면서 동일한 절차를 반복한다. 이를 통해 단기~장기 예측선행시간별 예측 성능을 체계적으로 평가할 수 있다. 본 연구에서는 이러한 RO 방식을 적용하여, 궁내교(Event#4)에서는 총 327회, 대곡교(Event#4)에서는 총 291회의 기준시점별 실험을 수행하였으며, 각 기준시점에서 모두 36개의 예측값을 산출하였다. 이를 통해 다중입출력 LSTM 모델의 예측선행시간별 성능을 정량적으로 검증하였다.
본 연구에서는 수위 예측 모델의 성능을 다각적으로 평가하기 위하여 통계적 적합도 지표와 수문학적 신뢰성 지표를 병행하여 활용하였다. 통계적 지표로는 평균제곱근오차(RMSE), 평균절대오차(MAE), Nash-Sutcliffe 효율계수(NSE)를 사용하였다. RMSE와 MAE는 전반적인 예측 오차 크기를 정량화하며, NSE는 모의값이 관측값의 분산을 얼마나 잘 설명하는지를 평가한다.
수문학적 지표로는 PBIAS (Percent Bias)와 QER (Quantitative Error of Peak Ratio)를 적용하였다. PBIAS는 예측값이 전반적으로 과대추정 또는 과소추정되는 경향을 평가하며, QER은 홍수 예측에서 중요한 첨두 유량(peak flow)의 예측 정확성을 검증하기 위해 사용되었다. 각 지표의 정의와 계산식은 Table 5에 정리하였다. 이를 통해 단일 시점의 평균 성능뿐 아니라, 첨두 및 저수위 구간에서의 모델 안정성을 종합적으로 평가할 수 있다.
Table 5.
Flood advisory periods and selection of rainfall events
4. 결 과
본 장에서는 구축된 다중입출력 LSTM 모델의 성능을 대곡교와 궁내교 지점에 대해 각각 평가하고, 이후 두 지점을 종합적으로 비교·논의하였다. 모델 평가는 전체 36-step (360분) 예측 결과를 단기(1-6 step), 중기(7-18 step), 장기(19-36 step) 구간으로 구분하여 요약 지표 형태로 제시하였으며, 대표 예측선행시간(step 1, 6, 12, 24, 36)에 대한 시계열 비교 및 산점도 분석을 통해 리드타임 증가에 따른 성능 변화를 구체적으로 검토하였다. 또한 첨두 구간4, 확대 분석을 통해, 예측선행시간별 첨두 수위 재현 성능을 평가하였다. 본 연구에서는 Moriasi et al. (2007)의 제안에 따라, NSE ≥ 0.5, PBIAS ±25 % 이내, QER ±20% 이내일 경우 모형 성능이 실무적으로 유효한 수준으로 간주하고자 한다. 이러한 임계 기준을 통하여 예측선행시간별 안정적 예측 가능 구간을 해석하였다.
4.1 대곡교 지점 예측성능
대곡교 지점의 리드타임별 예측 성능은 Table 6에 요약되어 있으며, 구간별로 다음과 같은 특징이 나타났다. 첫째, 단기 구간(1-6 step, 10-60분)에서는 가장 안정적인 성능이 확인되었다. NSE는 0.9613, RMSE는 0.2218 m, MAE는 0.1695 m로 오차가 매우 작았으며, QER 역시 약 -4.3%로 첨두 수위의 과소추정이 크지 않았다. 이는 MIMO-LSTM이 단기 강우-수위 반응의 비선형 특성을 효과적으로 학습하고 있음을 의미한다.
Table 6.
Performance metrics averaged over lead-time intervals at Daegokgyo
둘째, 중기 구간(7-18 step, 70-180분)에서는 모델 성능이 점진적으로 저하되었다. 7-12 step에서 NSE는 0.8698, RMSE는 0.3990 m로 증가하였고, 13-18 step에서는 NSE가 0.6040, RMSE는 0.6982 m로 악화되었다. 특히 QER이 -7%~-8% 수준으로 확대되며 첨두 수위 과소추정이 뚜렷하게 나타났다. 이는 리드타임 증가에 따른 예측 불확실성의 누적을 반영하는 결과로 해석된다.
셋째, 장기 구간(19-36 step, 190-360분)에서는 성능 저하가 더욱 두드러졌다. 19-24 step의 NSE는 0.2023까지 하락하여 설명력이 크게 감소했으며, 25-30 step에서 NSE는 -0.1787, 31-36 step에서는 -0.3885로 음수로 전환되었다. 장기 구간 RMSE는 0.99-1.30 m 수준까지 증가하였고, QER 역시 -8%에서 -11% 사이로 확대되어 첨두 규모 및 시점 재현성의 신뢰도가 크게 저하되었다.
종합적으로, 대곡교는 단기(1-6 step)까지는 신뢰할 수 있는 수준의 예측이 가능했으나, 중기 이후부터는 예측 정확도의 감소, 장기(25 step 이후)에서는 모델의 설명력 상실이 확인되었다. 이러한 성능 저하는 장기 리드타임에서의 시계열 평활화 경향과 첨두 수위의 체계적 과소추정이 복합적으로 영향을 미친 결과로 판단된다.
앞서 제시한 구간별 성능 지표 분석(Table 6)에서 확인한 바와 같이, 예측선행시간이 증가함에 따라 모델의 성능이 점진적으로 저하되는 경향이 나타났다. 이를 직관적으로 확인하기 위해 대표 step (1, 6, 12, 24, 36)에 대한 실제 수위와 예측 수위를 비교하였다(Figs. 8 and 9). 이는 LSTM이 단기 의존성 학습에는 효과적이나, 장기 구간에서는 누적된 불확실성과 첨두 수위 타이밍 오차가 발생할 수 있음을 보여준다.
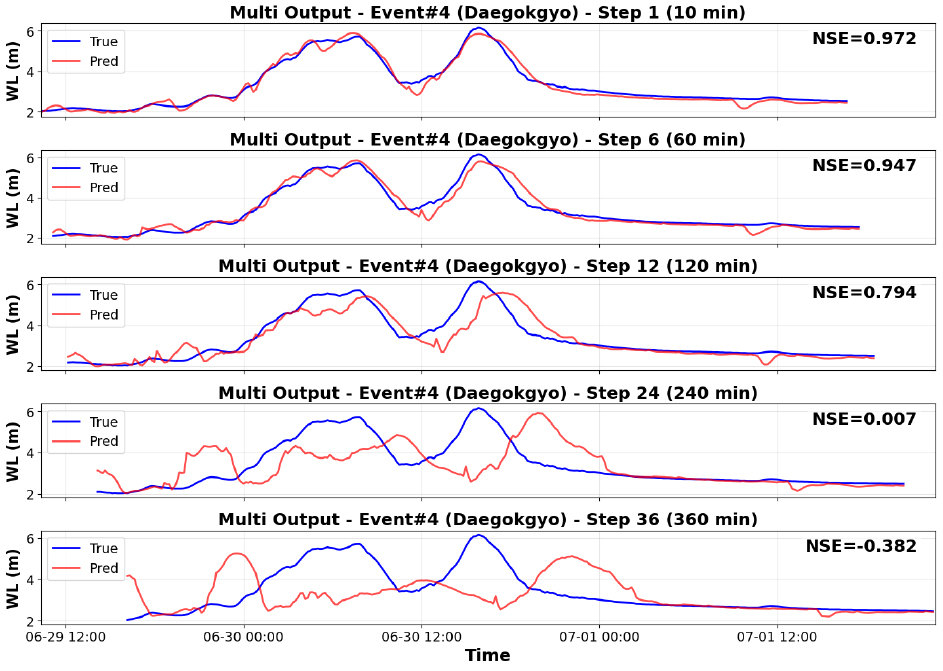
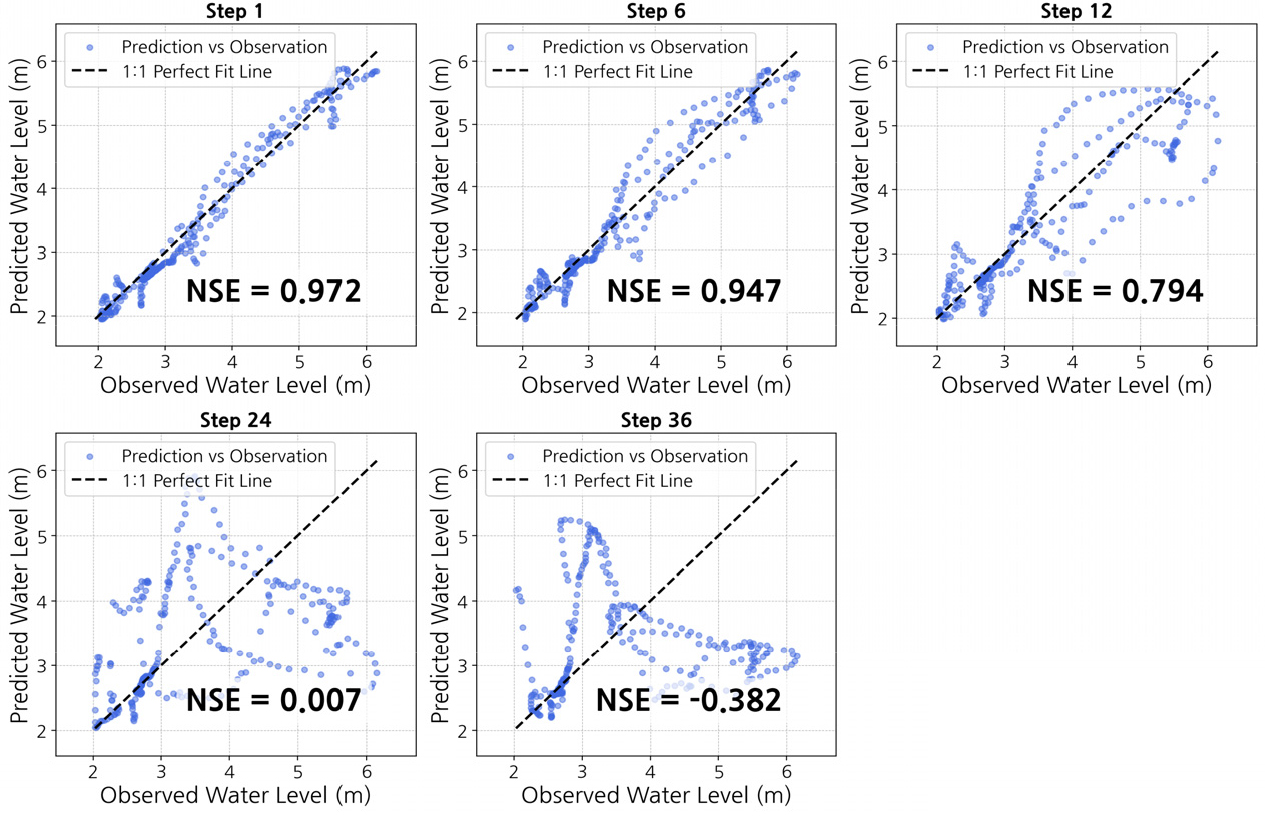
Fig. 10은 대곡교 지점(Event#4)에 대해 예측 step 구간을 (1-6, 7-18, 19-27, 28-36)으로 그룹화하여 첨두 수위 구간을 확대 비교한 결과를 나타낸 것이다. 검은색 실선은 관측 수위를, 다양한 색의 곡선은 각 step 예측 결과를 의미한다.
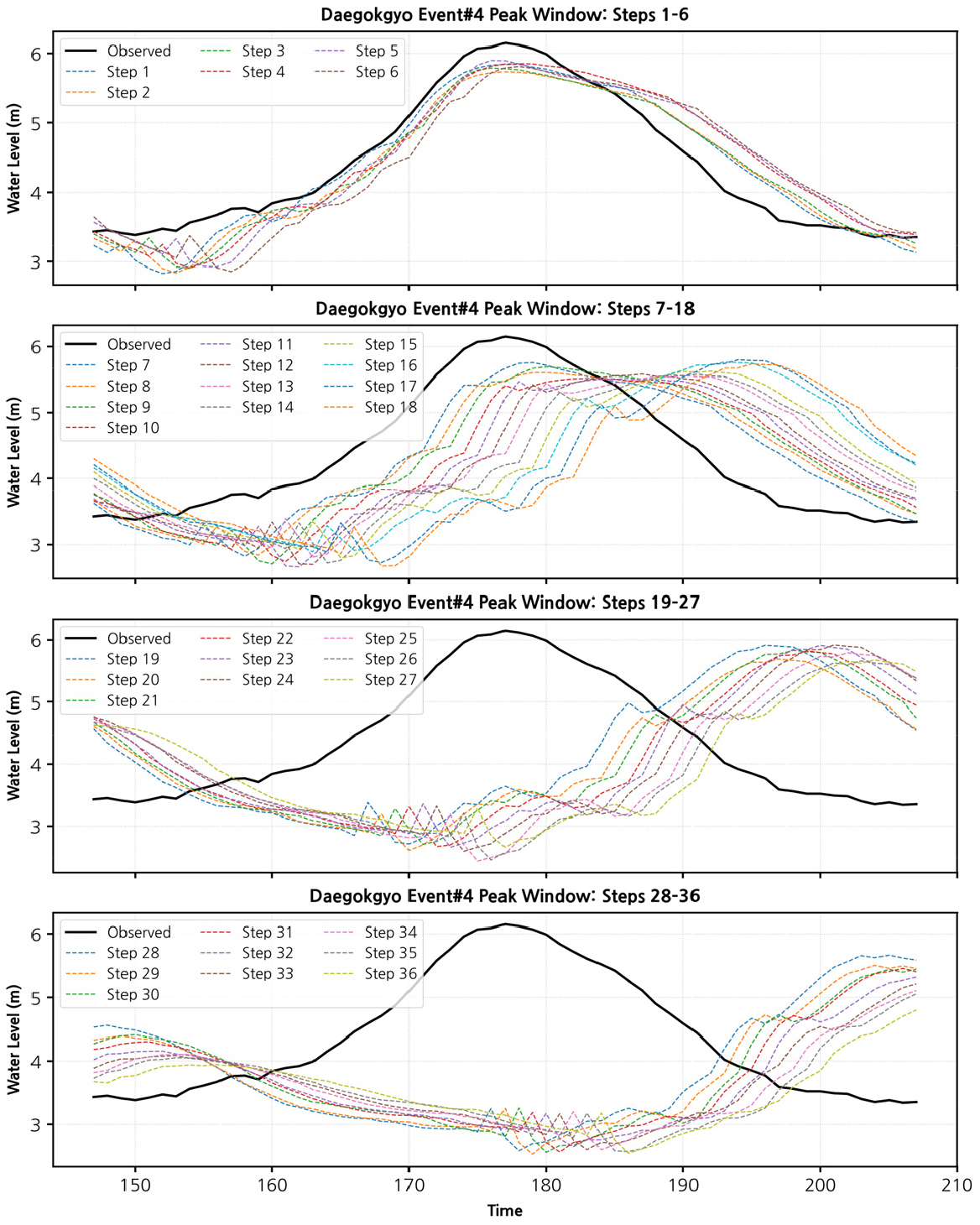
단기 구간(1-6 step)에서는 관측 첨두값의 시점과 규모가 비교적 잘 재현되었으며, 특히 step 1-3에서는 첨두 수위가 거의 일치하여 단기 예측의 높은 신뢰성을 확인할 수 있다. 그러나 중기 구간(7-18 step)에서는 첨두 규모가 체계적으로 과소 추정되었고, 발생 시점도 지연되는 경향이 관찰되었다. 장기 구간(19-27, 28-36 step)으로 갈수록 이러한 불확실성은 더욱 두드러져, 예측 곡선들이 점차 평활화(smoothing)되며 관측 첨두값의 급격한 상승·하강 양상을 재현하지 못했다. 특히 28-36 step에서는 첨두 수위가 약 1 m 이상 낮게 예측되었고 곡선들이 수렴하면서 파형 변동성이 크게 축소되었다. 이는 대곡교 지점에서 첨두 수위 예측의 안정적 예측선행시간이 약 2~3시간 이내임을 시사한다.
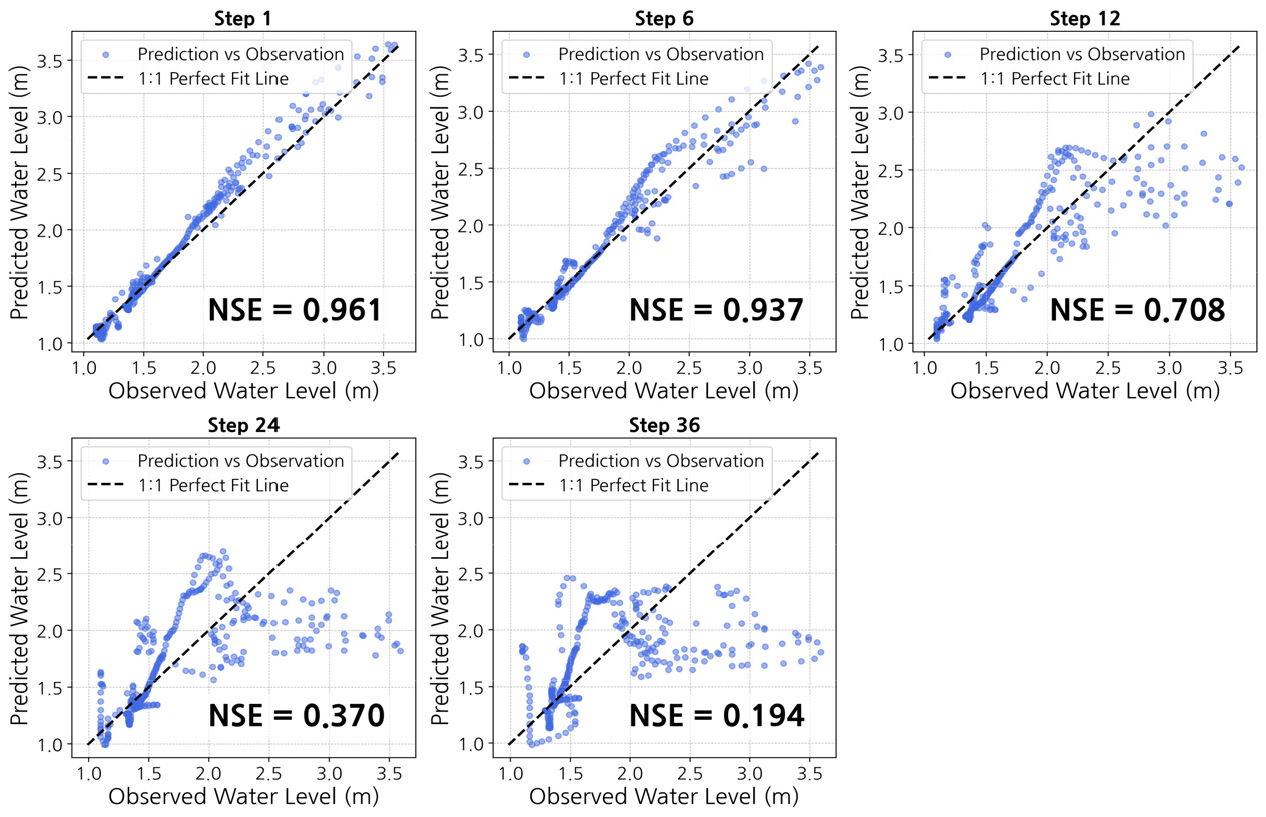
4.2 궁내교 지점 예측성능
궁내교 지점의 리드타임별 성능은 Table 7에 요약되어 있으며, 전체 36 step (360분) 예측 결과는 다음과 같은 특징을 보였다. 첫째, 단기 구간(1-6 step, 10-60분)에서는 매우 우수한 성능이 확인되었다. NSE는 0.9447, RMSE는 0.1388 m, MAE는 0.0973 m로 대곡교와 유사한 수준의 안정적인 예측이 이루어졌으며, QER 역시 0.39%로 첨두 수위의 과대·과소추정이 거의 발생하지 않았다.
Table 7.
Performance metrics averaged over lead-time intervals at Gungnaegyo
둘째, 중기 구간(7-18 step, 70-180분)에서는 예측 성능이 점진적으로 저하되었다. 7-12 step의 NSE는 0.8135, RMSE는 0.2508 m이며, 13-18 step에서는 NSE가 0.5720, RMSE는 0.3847 m까지 증가하였다. 또한 QER은 약 -10%에서 -21% 수준으로, 첨두 수위가 과소추정되는 경향이 뚜렷해졌다. 이는 리드타임 증가에 따라 강우-수위 관계의 비선형성이 누적되면서 예측 불확실성이 확대된 결과로 해석된다.
셋째, 장기 구간(19-36 step, 190-360분)에서는 성능 저하가 본격적으로 나타났다. 19-24 step의 NSE는 0.4070, RMSE는 0.4520 m, 25-30 step에서는 NSE 0.2955, RMSE 0.4897 m, 31-36 step에서는 NSE가 0.2095, RMSE가 0.5155 m까지 악화되었다. QER은 장기 구간에서 -27%~-32%로 확대되어, 첨두 규모 및 시점 재현성의 신뢰도가 크게 낮아졌다.
한편, 궁내교는 대곡교와 비교할 때 장기 리드타임에서도 상대적으로 양호한 성능을 유지한 점이 특징적이다. 대곡교는 25 step 이후 NSE가 음수로 전환되며 설명력을 상실한 반면, 궁내교는 최종 36 step에서도 양(+)의 NSE (0.2095)를 유지하였다. 이는 궁내교가 유역 중류에 위치하여 상류 및 지류 유량이 합류된 후의 비교적 완만한 수위 변동 특성을 반영하기 때문으로 볼 수 있다. 반대로, 대곡교는 한강 본류의 수위 상승, 역행수(backwater) 영향 등 외생 수문 조건의 영향을 받아 장기 구간에서 예측 불안정성이 더 크게 나타났다고 해석할 수 있다. 이러한 지점별 차이는 유역 내 위치 및 수문 구조가 장기 예측의 안정성에 중요한 역할을 한다는 점을 시사한다.
앞서 제시한 step별 성능 지표(Table 7)에서 확인한 바와 같이, 성남시 궁내교 지점에서도 예측선행시간이 증가할수록 모델 성능이 점차 저하되는 양상이 나타났다. 이를 직관적으로 확인하기 위해 대표 step (1, 6, 12, 24, 36)에 대한 실제 수위와 예측 수위를 비교하였다(Figs. 11 and 12).
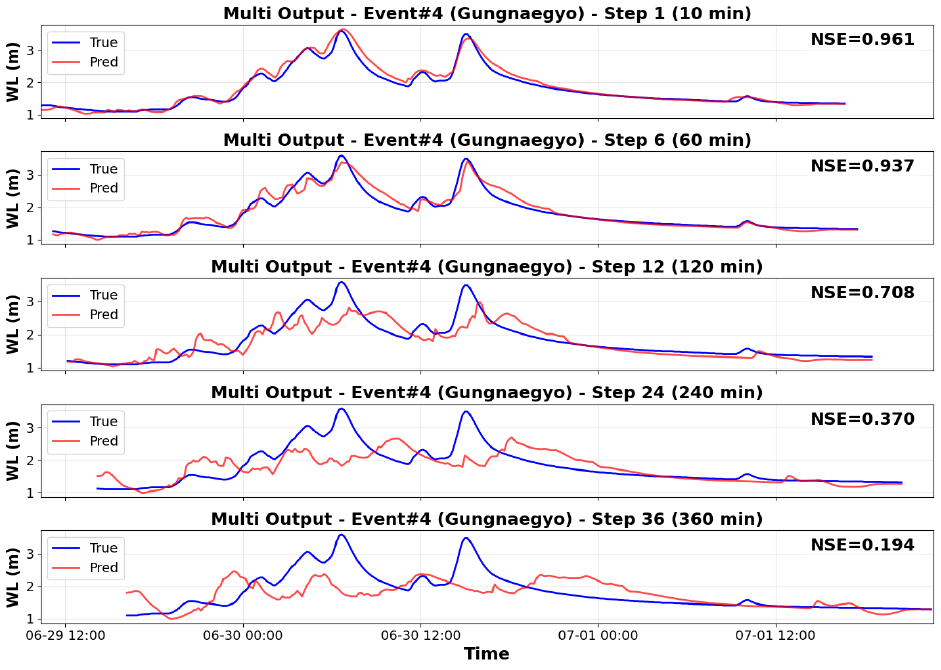
단기 예측선행시간(1-6 step)에서는 관측 수위의 변동을 안정적으로 재현하며, 첨두 구간도 비교적 정확하게 모의하였다. 그러나 중기 구간(12 step)부터는 첨두 수위의 크기와 발생 시점에서 불일치가 확대되었으며, 장기 구간(24, 36 step)에서는 전반적인 수위 변화 패턴조차 따라가지 못하는 한계가 확인되었다. 특히 예측선행시간이 길어질수록 첨두 수위를 과소추정하거나 평탄하게 예측하는 경향이 두드러졌다.
이는 LSTM 모델이 단기 의존성 학습에는 효과적이나, 장기 예측선행시간에서는 불확실성의 누적과 시차 오차가 커지면서 첨두 수위 예측 안정성이 저하될 수 있음을 보여준다.
Fig. 13는 성남시(궁내교) 지점(Event#4)의 첨두 수위 구간을 대상으로 예측 step을 (1-6, 7-18, 19-27, 28-36)으로 구분하여 비교한 결과를 제시한다. 궁내교 역시 단기 구간(1-6 step)에서는 관측 첨두와의 대응이 양호하여 시점과 크기를 안정적으로 재현하였다. 그러나 7-18 step에서는 첨두 발생 시점과 규모의 불일치가 확대되었으며, 첨두 수위가 점차 과소 추정되는 경향이 나타났다. 이후 19-27 step에서는 예측 곡선들이 관측 값에 비해 평활화 되며 첨두의 급격한 변동성을 충분히 포착하지 못했다. 28-36 step에서는 이러한 경향이 더욱 뚜렷해져, 첨두 수위 저평가와 시점 지연이 동시에 나타나 장기 예측선행시간에서의 재현성이 크게 저하되는 모습을 보였다.
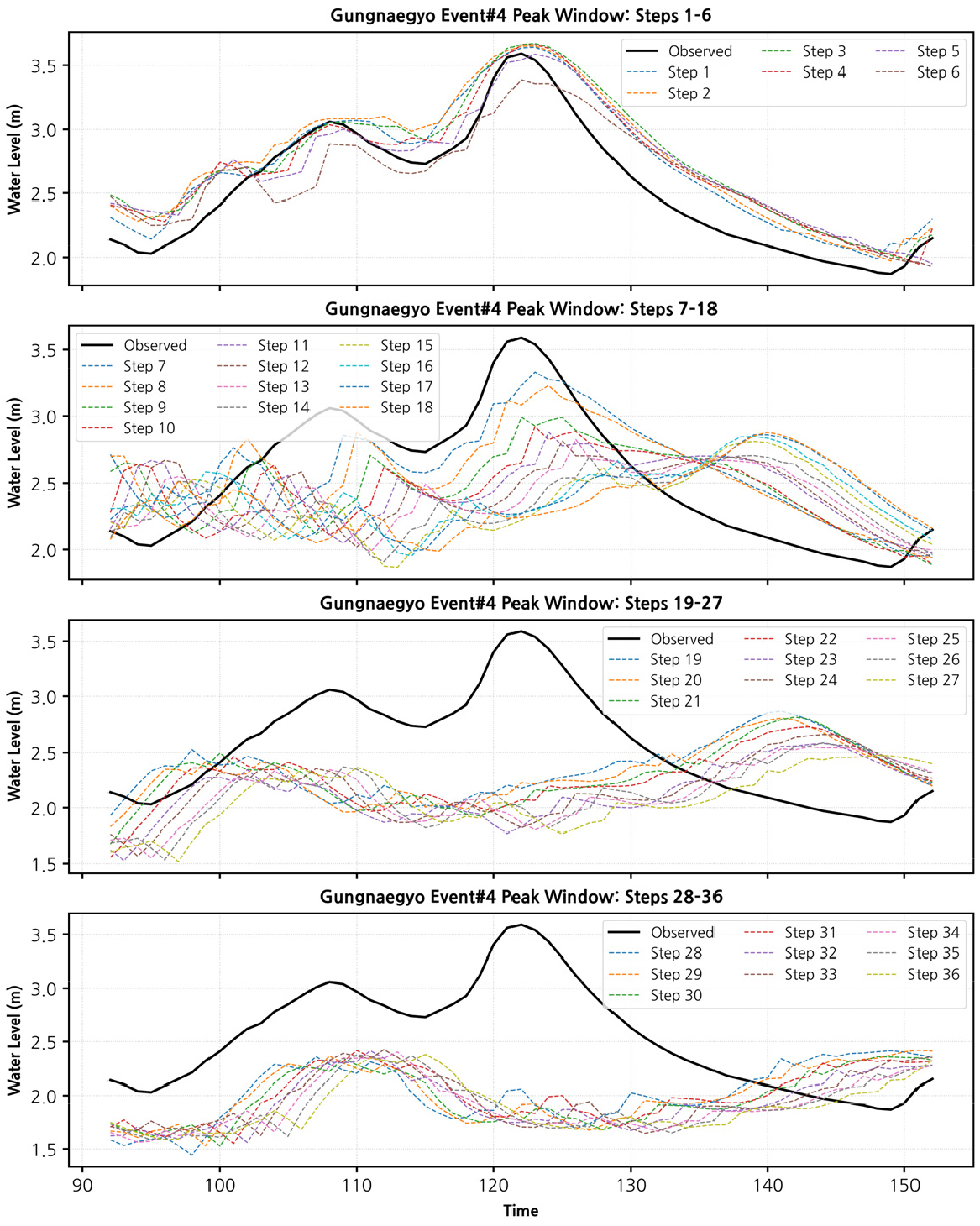
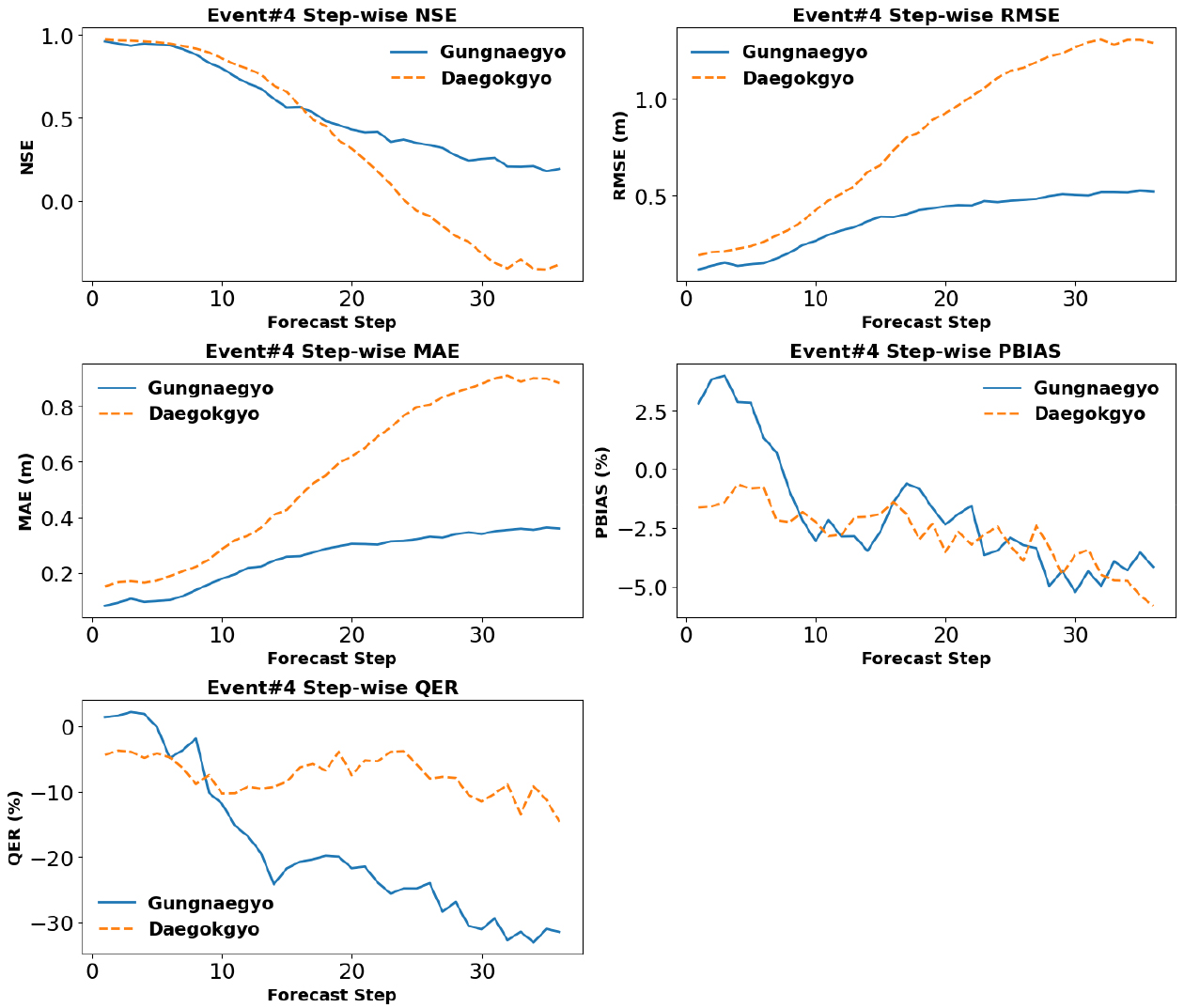
Fig. 14는 테스트셋(Event #4)을 대상으로 궁내교와 대곡교의 예측선행시간별(step-wise) 성능 지표 변화를 비교한 결과이다. 두 지점 모두 1-12 step 구간에서는 NSE 0.7 이상, RMSE 0.33 m 이하로 우수한 예측 성능을 보였으나, 예측선행시간이 증가함에 따라 성능 저하가 점차 뚜렷하게 나타났다. 특히 대곡교는 24 step 이후 급격한 성능 감소를 보인 반면, 궁내교는 하류부 위치로 인한 상류·지류 유입의 누적 및 완충 효과로 수위 시계열이 상대적으로 평활화되면서 장기 리드타임에서도 비교적 안정적인 성능을 유지하는 것으로 해석된다.
한편, 본 연구에서 사용한 예보 강우는 실제 기상청 예측 자료가 아니라 과거 관측 강우를 시차 이동하여 생성한 이상적으로 정확한 예보라는 가정에 기반한다. 따라서 본 연구에서 제시된 리드타임별 예측 성능은 예보 오차가 반영되지 않은 최적 조건에서 얻은 결과이며, 실제 현업 적용 시에는 예보 오차로 인해 장기 리드타임에서 더 큰 성능 저하가 발생할 수 있다. 이러한 점은 본 연구의 중요한 한계 중 하나이며, 향후 연구에서는 실제 예보 자료를 반영한 불확실성 분석이 필요하다.
5. 결론 및 토의
본 연구에서는 다중입출력 LSTM 모델을 적용하여 성남시 궁내교(상류)와 서울시 대곡교(하류) 지점에서의 하천 수위를 최대 36 step (360분, 10분 간격)까지 예측하였다. 주요 결론은 다음과 같다.
첫째, 단기 예측(1-6 step, 10-60분) 에서는 두 지점 모두 높은 정확도를 확보하였다. 대곡교에서는 NSE 0.972, RMSE 0.191 m, MAE 0.152 m를 기록하였으며, 궁내교에서도 NSE 0.961, RMSE 0.117 m, MAE 0.083 m로 유사하게 우수한 성능을 보였다. 이는 다중입출력 LSTM 모델이 단기 강우-수위 반응의 비선형성을 효과적으로 학습할 수 있음을 보여준다.
둘째, 중기 예측(7-18 step, 70-180분) 에서는 예측 성능이 점진적으로 저하되었다. 대곡교에서는 12 step에서 NSE 0.794로 하락하였고, 궁내교에서는 NSE 0.708을 기록하는 등 두 지점 모두 RMSE 및 QER 증가가 동반되었다. 특히 첨두 수위는 -10%~-20% 수준으로 과소추정되는 경향이 나타났다.
셋째, 장기 예측(19-36 step, 190-360분)에서는 성능 저하가 두드러졌다. 대곡교는 25-30 step 이후 NSE가 음수로 전환되었으며, 31-36 step에서는 -0.3885까지 하락하여 장기 구간에서 예측력이 유효하지 않음을 보여주었다. 반면 궁내교는 동일한 장기 구간에서도 NSE가 0.20~0.41 수준의 양수 값을 유지하며 상대적으로 안정적인 예측 성능을 보였다. 이는 지점 특성 및 수문 구조 차이가 장기 리드타임 예측 안정성에 직접적으로 영향을 미친 결과로 해석된다.
넷째, 첨두 구간 확대 분석 결과, 두 지점 모두 첨두 수위의 시점과 규모를 안정적으로 재현할 수 있는 예측선행시간은 약 1-2시간(1-12 step)으로 제한되었다. 12 step (≈120분)을 초과하는 구간부터는 첨두 발생 시점의 지연과 규모의 과소추정(QER의 음의 방향 확대)이 일관되게 확인되었으며, 19-36 step (≈190-360분)에서는 수위 파형이 평활화되어 첨두 재현성이 급격히 저하되었다. 이는 다중입출력 구조에서도 예측선행시간이 길어질수록 모델의 학습 한계와 강우-유출 과정의 비선형 불확실성이 누적적으로 반영된 결과로 해석된다.
또한, 지점별 차이 분석 결과, 상류부에 위치한 궁내교는 국지 강우의 공간적 변동성과 단기 유출 반응의 민감성으로 인해 예측 불안정성이 크게 나타난 반면, 하류부 대곡교는 상류 및 지류 유입의 누적과 완충 효과로 인해 수위 시계열이 평활화되어 장기 리드타임에서도 비교적 완만한 성능 저하를 보였다. 이러한 수문학적 구조 차이는 인공지능 기반 모형의 예측 안정성에 직접적인 영향을 미치는 요인으로 해석된다.
본 연구는 몇 가지 한계를 가진다. 첫째, 예보 입력으로 사용된 강우는 실제 기상청 예측이 아닌 과거 강우의 시차 이동 자료로 구성되었다. 따라서 본 연구에서 제시된 리드타임별 성능은 예보 오차가 반영되지 않은 최적 조건에서의 결과이며, 실제 운영 환경에서는 특히 장기 리드타임에서 추가적인 불확실성이 발생할 수 있다. 둘째, 모델 학습·검증·평가에 사용된 6개 강우사상은 2014-2024년 대곡교 홍수특보 발령 이력에서 선정된 큰 규모의 사상들로 구성되어 있다. 이는 실제 홍수 상황을 반영한다는 장점이 있으나, 학습 표본 수가 제한되고 중·소규모 사상이 포함되지 않아 모델의 일반화 성능을 평가하는 데 한계가 있다. 향후 연구에서는 사상 선정 기준을 확대하여 다양한 규모의 홍수·비홍수 사례를 포함할 필요가 있다. 셋째, 본 연구는 실제 홍수예보 운영과 동일한 조건을 반영하기 위해 다중입력 구조를 전제로 분석을 수행하였다. 도시하천에서는 강우의 공간적 이질성이 크기 때문에 단일입력 구성은 실제 적용성과 수문학적 타당성이 떨어져 본 연구에서 비교 실험을 수행하지 않았다. 다만 입력 변수 구성을 단계적으로 단순화하여 다중·단일입력 간 성능 차이를 분석하는 것은 향후 다중입력 구조의 효용성을 검증하기 위한 중요한 확장 과제로 남는다.
또한 장기 리드타임에서 확인된 첨두 규모의 과소추정과 첨두 발생 시점의 지연 경향은 홍수주의보·경보 발령, 배수펌프장 및 수문 운영, 저지대 대피 결정 등 실시간 홍수 대응 의사결정에 직접적인 위험을 초래할 수 있다. 예측 수위가 실제보다 낮게 산정되거나 첨두 도달 시점이 지연될 경우 대응이 늦어져 침수피해가 확대될 가능성이 있으며, 이는 운영적 측면에서 모델 성능 해석 시 특별한 주의를 요구한다. 반면 단기(1-2시간 이내) 리드타임에서는 본 연구의 MIMO-LSTM 모형이 실무 적용 가능한 수준의 안정적인 성능을 보였으므로, 이 범위에서는 인공지능 기반 모형을 주요 의사결정 도구로 활용할 수 있을 것으로 판단된다. 다만 장기 리드타임에서는 물리기반 모형과의 병행 활용, 보수적 경보 기준 설정, 불확실성 정보의 병행 제시 등과 같은 보완적 운용 전략이 필요하다. 향후 연구에서는 첨두 발생 시점의 오차(peak timing error)를 정량적으로 평가하고, 실제 운영 의사결정에 미치는 영향을 체계적으로 분석함으로써 모형의 적용 범위를 보다 정교하게 검증할 필요가 있다.
결론적으로, 본 연구는 다중입출력 LSTM 모형을 이용하여 도시하천 수위의 리드타임별 예측 성능 변화를 정량적으로 제시하고, 인공지능 기반 홍수예측 모형의 시간적 적용 한계와 운영상 고려사항을 제시하였다는 데 의의가 있다. 향후 다양한 유역·사상 및 입력 구성을 포괄하는 추가 연구를 통해, 본 연구에서 도출된 결과를 일반화하고 AI-물리 모형의 통합 활용 가능성을 보다 정교하게 검토할 필요가 있다.
