

1. 서 론
2. 방법론
2.1 연구 개요
2.2 이미지 인코더
2.3 프롬프트 인코더
2.4 마스크 디코더
2.5 V-FloodNet
2.6 성능 평가 방법
3. 적 용
3.1 모델 구동 환경 및 매개변수 설정
3.2 적용 데이터 세트
4. 결 과
4.1 미세 조정 결과
4.2 모델 성능 비교
5. 결 론
1. 서 론
최근 홍수로 인해 전 세계적으로 인명 피해 및 재산 피해가 급격하게 증가하고 있다(Rentschler et al., 2022; 2023). 홍수 피해가 증가한 원인으로는 대표적으로 기후 변화로 인한 극한 강우 현상의 증가가 있으며, IPCC 6차 평가 보고서에서도 기후 변화에 따른 기상 이변의 빈도와 강도가 증가하고 있다고 밝혔다(IPCC, 2022). 2022년 재해연보에 따르면 우리나라의 경우 홍수와 관련된 호우·태풍에 의한 최근 10년간 평균 피해액은 연간 3천억 원에 달하며 그 값이 연도별로 점차 증가하는 경향을 볼 수 있다. 기존 홍수방어 대책은 극한 호우로 인한 홍수 피해 저감에 한계가 있어, 실시간 홍수 탐지 및 모니터링 방법이 주목받고 있다.
기존 연구에서는 홍수 영역을 탐지하기 위해 주로 위성 이미지(Khanuja, 2019; Pi et al., 2021; Wu et al., 2023)가 사용되었으며, 지상 카메라를 활용한 실시간 홍수 탐지 및 모니터링 연구도 수행된 바 있다(Tauro et al., 2016; Jun et al., 2024; Kwon and Lee, 2024). 위성 이미지는 소유역 및 하천 단위의 공간 해상도와 위성 데이터 수집 주기의 한계로 비교적 긴 시간해상도를 가지며, 이에 따라 대규모 수체 영역 변화 감지에 주로 활용된다. 반면, 지상 카메라 이미지의 경우 특정 관측 지점에서 촬영된 하천 구간 단위의 공간 해상도를 가지고 있으며, 실시간으로 상황 파악이 가능하다는 점에서 홍수 탐지 및 모니터링에 강점을 가진다. 이러한 특징을 활용하여 국내에서는 재난감시용 하천 CCTV나 방범용 CCTV를 통해 수위, 홍수 유출량을 산정하거나 침수심을 분석한 연구들이 존재한다(Kim et al., 2014; Kwon et al., 2023; Kim, 2024).
지상 카메라 이미지 데이터를 활용한 홍수 영역 탐지의 경우 다양한 환경 요인(조명 변화, 반사, 장애물 등)으로 인해 정확한 수체 영역 구분이 어려울 수 있어 딥러닝 기반의 수체 영역 분할 기법(Segmentation)이 주로 활용되고 있다(Muhadi et al., 2020; Fang et al., 2021; Bukhari et al., 2024; Nagaiah et al., 2024).
딥러닝 기반 수체 영역 분할 기법에서는 모델 학습을 위해 수체 영역만 따로 구분하는 마스킹 과정을 거친 참값(Ground Truth) 이미지가 필요하다. 위성 이미지는 모델 학습을 위한 데이터 구축 연구(MODIS Water Mask, JRC Global Surface Water Dataset 등)가 활발히 진행되어 참값 이미지로 사용할 수 있는 데이터 세트가 충분히 확보된 반면, 지상 카메라로 촬영한 이미지는 수체 영역이 실시간으로 변화하기 때문에 각 프레임별로 수체 영역만 따로 구분하여 참값 이미지를 생성하는 전처리 작업이 필수적이다(NASA, n.d.; Pekel et al., 2016). 해당 과정은 딥러닝 기반 수체 영역 분할 모델의 구축을 지연시키는 대표적인 문제점으로 지적되어왔다(Shorten and Khoshgoftaar, 2019). 이러한 문제를 해결하기 위해 다양한 접근이 시도되었으나, 최근 파운데이션 모델과 프롬프트 개념을 기반으로 한 Segment Anything Model (SAM)이 제안되었다(Kirillov et al., 2023).
파운데이션 모델이란 레이블이 지정되지 않은 광범위한 데이터 집합에 대해 훈련된 대규모 인공지능 모델이며 미세 조정(Fine-tunning)을 통해 하위 작업에 적용될 수 있다(Bommasani et al., 2021). 대규모 데이터로 사전 학습이 이루어졌기 때문에 하천에 특화된 데이터로 학습하지 않은 경우에도 하천 이미지의 특성을 반영할 수 있다. 프롬프트는 파운데이션 모델이 수행하고자 하는 세부 작업에 대한 정보를 입력받아 추가적인 학습 없이도 작업과 관련된 고품질의 출력을 획득하는 방법이다. 수체 영역에 대한 프롬프트를 사용자로부터 입력받으면 해당 프롬프트에 대응하는 수체 영역을 예측할 수 있다.
SAM은 이미지 분할의 파운데이션 모델로, 프롬프트 입력을 통해 추가 학습 없이도 수체 영역 분할을 진행할 수 있다. 수자원 및 방재 분야에서는 SAM을 활용하여 저수위 예측 및 도로 침수 분석을 위한 모델을 개발하거나(Kim et al., 2024; Lim et al., 2024), 위성 자료의 적용성을 평가하고 모델 성능을 비교하는 연구가 진행되었다(Lee et al., 2024; Moghimi et al., 2024).
최근 SAM의 후속 모델로 동영상을 실시간으로 처리하는 성능이 크게 개선된 Segment Anything Model 2(SAM 2)가 개발되었다(Ravi et al., 2024). 해당 모델을 활용한다면 비교적 적은 학습 데이터로도 미세 조정을 통해 높은 정확도의 수체 영역 분할 결과를 도출할 수 있을 것으로 예상된다.
SAM 2를 활용한 특화 모델 개발이 활발히 이루어지고 있는 반면(Ayzenberg et al., 2024; Yan et al., 2024; Zhu et al., 2024), 홍수 탐지를 위한 수체 영역 분할 모델 구축은 실시간 탐지 성능 확보 및 다양한 환경 변화에 따른 정확도 유지의 어려움으로 아직 연구가 충분히 이루어지지 않은 상태이다. 특히 홍수 상황에서는 다양한 환경 요인에 의해 기존 분할 성능이 저하될 가능성이 높으므로, 수체 영역 분할 성능을 개선하기 위한 연구가 필요하다.
따라서 본 연구에서는 파운데이션 모델을 활용할 경우 수체 영역 분할 성능이 유의미하게 증가할 것이라는 연구 가설을 설정하였으며, SAM 2를 적용하여 파운데이션 모델 기반의 수체 영역 분할 모델을 구축하였다. 지상 카메라 이미지를 사용함에 따라 프롬프트 없이도 예측할 수 있도록 모델을 개선하였으며, 기존 수체 영역 분할 모델인 V-FloodNet 및 수체 영역 분할에 특화되지 않은 SAM 2와 성능을 비교하였다.
2. 방법론
2.1 연구 개요
본 절에서는 파운데이션 모델인 SAM 2의 구조와 수체 영역 분할 특화 모델의 구축 방법론에 관해 서술한다. 수체 영역 분할 모델은 주로 이미지를 읽어 모델이 해석할 수 있도록 정보를 추출하는 모듈인 이미지 인코더와 추출된 정보를 통해 이미지 내의 수체 영역을 예측하는 모듈인 마스크 디코더로 구성된다(Minaee et al., 2021). 또한 파운데이션 모델은 사용자의 입력인 프롬프트를 전달받는다(Wang et al., 2023). 프롬프트 전달의 예를 들면, 수체 이미지 위에 분할 대상을 점으로 표시 혹은 박스로 감싸는 방식으로 모델에 명시적으로 전달한다.
본 연구에서 제시하는 수체 영역 분할 특화 SAM 2의 구축 방법은 Fig. 1과 같다. SAM 2의 기본 이미지 인코더 Hiera (Ryali et al., 2023)의 가중치를 동결시켜 사전 학습된 방대한 이미지 정보를 최대한 활용하고자 하였으며, 프롬프트 인코더와 마스크 디코더를 학습 대상으로 설정해 수체 영역에 대한 모델의 인식 정확도를 개선하였으며 Fig. 1에서는 각각 “Frozen”, “Trainable”로 표기하였다. 또한 모델의 자동화를 위해 프롬프트 입력을 선택적으로 적용할 수 있도록 변경하였다.
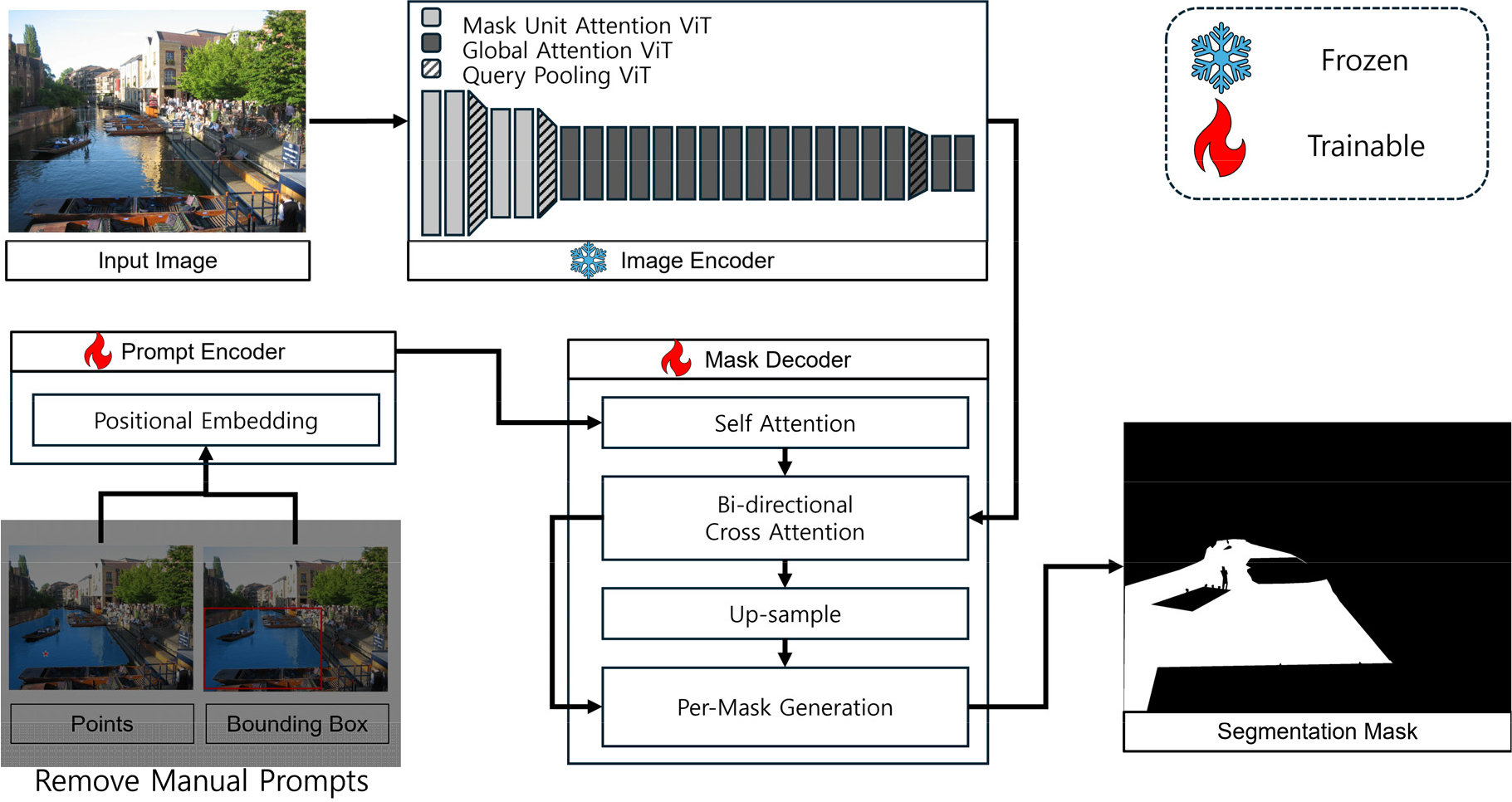
수체 영역 분할 특화 SAM 2의 성능을 검증하기 위해 다음 두 모델과 비교를 진행하였다. 먼저, 프롬프트를 전달받는 기존 SAM 2 모델은 수체 영역의 참값(Ground Truth) 범위 내 무작위로 선택한 세 지점을 프롬프트로 입력하여 예측을 진행하였다. 또한 기존 연구에서 소개한 수체 영역 분할 모델인 V-FloodNet을 사용하여 수체 영역 분할 성능을 비교하였다.
2.2 이미지 인코더
SAM 2의 이미지 인코더는 기존 비전 트랜스포머(Vision Transformer, ViT)의 비효율적인 구조를 개선하여 처리 속도가 빠른 Hiera 인코더를 사용하였다. Hiera는 계층적 구조와 지역적 어텐션을 도입하여 연산 효율을 높이고 속도를 개선하였다. 트랜스포머의 핵심이 되는 어텐션 메커니즘은 학습되는 가중치인 쿼리(Query, Q), 키(Key, K), 값(Value, V)의 세 행렬에 대한 연산으로 Eq. (1)과 같다. 활성화 함수(σ)는 소프트맥스(Softmax) 함수를 사용하였다.
2.3 프롬프트 인코더
SAM 2와 같은 파운데이션 모델은 프롬프트 엔지니어링을 통해 모델의 예측 과정에서 사용자의 의견을 반영할 수 있다는 강점을 보인다. SAM 2에서는 시각적 프롬프트 튜닝(Visual Prompt Tuning) 기법을 사용하였으며, 해당 기법은 이미지 인코더 전체를 미세 조정한 경우보다도 높은 성능을 기대할 수 있다(Jia et al., 2022).
시각적 프롬프트는 사용자가 이미지 위에 마커나 경계 박스를 직접 표시하여 모델에 정보를 전달하는 방식이다. 예를 들어, 사용자가 물체의 위치를 점으로 찍거나, 관심 영역을 사각형으로 감싸면, 모델은 해당 정보를 반영하여 수체 영역을 보다 정확하게 분할할 수 있다.
시각적 프롬프트로부터 전달된 사용자 입력 t는 d차원 이미지 상의 위치 i에 대응되는 벡터 p로 표현되며, 이는 i가 짝수(i = 2k)인지 홀수인지(i = 2k+1)인지에 따라 Eq. (2)와 같이 정의된다. 여기서 k는 정수이다. 해당 수식에서 t에 대한 wk 값은 고정된 값으로 사용되며 SAM 2에서는 개념을 처음 제시한 Vaswani (2017)의 1/(100002k/d)을 적용되었다. SAM 2는 사용자의 시각적 프롬프트를 모델에 전달하여 상호작용이 가능하나, 실시간 수체 영역 분할을 위하여 이를 선택적으로 적용할 수 있도록 모델을 학습하였다.
2.4 마스크 디코더
본 연구에서는 마스크 디코더를 학습시켜 수체 영역 분할에 특화된 SAM 2를 구축하였다. 마스크 디코더는 이미지 인코더에서 추출한 데이터의 특성을 기반으로 실제 수체 영역이 어느 부분에 속하는지 예측하는 역할을 하며, SAM 2에서는 이미지의 특성과 사용자의 프롬프트 사이의 유사도를 기반으로 분할 대상을 예측한다.
프롬프트 인코더의 출력을 e, 이미지 인코더의 출력을 i라 할 때 마스크 디코더의 내부 연산 결과 값 h는 i의 쿼리, 키, 값인, , 를 기반으로 생성되며 Eq. (3), (4), (5), (6)와 같다. e에서의 셀프 어텐션(Self-attention)을 통해 각 입력마다의 중요도 e'를 생성한 후 e’의 쿼리를 i의 키와 값을 크로스 어텐션(Cross-attention)하여 i’를 생성한다. i’를 다층 퍼셉트론(Multi-Layer Perceptron, MLP)에 전달해 e’’로 변환하여 i와 e’’에 대해 크로스 어텐션을 적용해 h를 생성한다. 그 후 h에 대해 역합성곱(Deconvolution) 연산을 적용하면 최종적인 수체 영역 분할 마스크가 생성된다.
2.5 V-FloodNet
SAM 2와 비교할 기존 수체 영역 분할 모델로 Liang et al. (2023)의 V-FloodNet을 사용하였다. 해당 모델은 ADE20K 등 지상 카메라 기반 수체 이미지 1912장을 통해 학습한 이미지 수체 영역 분할 모듈과 6개 영상에서 추출한 2361개 프레임으로 학습한 동영상 수체 영역 분할 모듈로 구성된다.
SAM 2 또한 동영상과 이미지를 모두 처리할 수 있는 모델로, 이미지는 이전 프레임 정보가 없는 동영상처럼 처리한다. 따라서 V-FloodNet과 SAM 2는 입력받는 데이터의 성격이 동일할 뿐만 아니라 본 연구에서 구축하고자 하는 모델과 유사한 학습 데이터를 가졌다. 이에 따라 V-FloodNet을 수체 영역 분할 특화 SAM 2의 비교 대상 모델로 선정하였다.
2.6 성능 평가 방법
혼동행렬(Confusion Matrix)은 분류 알고리즘의 성능을 평가하는 지표로, 예측 값과 실제 값 간의 관계를 Table 1과 같이 4개의 주요 항목으로 표현할 수 있다. 이 중 거짓 긍정(False Positive, FP)은 수체 영역이 아닌 픽셀을 수체 영역으로 분류하는 경우로 과대추정이라 표현한다. 거짓 부정(False Negative, FN)은 수체 영역인 픽셀을 수체 영역이 아니라고 분류하는 경우로 과소추정이라 표현한다. 본 연구에서 적용한 성능 평가 방법은 각 이미지에 대한 참값 y와 예측 결과 으로 계산하는 Intersection over Union (IoU, Eq. (7))이다. n 개의 데이터에 대해 예측한 IoU의 평균은 Eq. (8)과 같이 표현할 수 있으며, 이를 통해 모델 성능의 정량적 비교가 가능하다.
3. 적 용
3.1 모델 구동 환경 및 매개변수 설정
학습 환경의 운영체제는 64bit 기반 23H2 버전의 Windows 11 Home 판을 사용하였다. 하드웨어는 3.60 GHz의 8코어 AMD Ryzen 7 3700X 프로세서와 32 GB RAM, NVIDIA사의 GeForce GTX 1660 Super이며, 모델 구축에 사용한 프로그램은 Python 3.12.5 기반 Pytorch 2.4.0+cu124 버전이다. 그래픽 처리 장치를 이용해 모델 학습을 수행하는 CUDA는 12.6 버전을, NVIDIA 드라이버는 560.94 버전을 적용하였다. 또한 Pytorch와 Numpy, Python random module의 난수 생성기의 값(Random Seed)을 42로 고정하였다.
본 연구에서는 초매개변수 선정을 위해 격자 탐색을 사용하였다. 격자 탐색은 사전에 정의한 초매개변수의 모든 조합을 실험하며 최적의 초매개변수 조합을 산출하는 방법이다. 탐색한 초매개변수는 이미지 인코더의 구조와 학습률을 설정하였다.
모델의 재사용성을 위하여 검증 데이터 추론 결과가 가장 높은 경우의 모델 파라미터를 저장하고 5번의 학습 에포크 반복 동안 모델 성능 향상이 없는 경우 학습을 종료하는 조기 종료(Early Stopping) 기법을 적용하였다. 그 외의 초매개변수인 최적화 알고리즘과 손실 함수는 기존 SAM 2 모델 학습에 사용된 값을 적용하였다. 배치의 크기는 컴퓨터 자원을 고려하여 4로 조정하였으며, 최대 탐색 에포크는 20으로 설정하였다. 학습의 시간 효율을 높이기 위하여 입력 이미지의 너비와 높이를 최대 1024로 설정하여 원본 이미지의 비율에 맞춰 모델에 전달하였다.
3.2 적용 데이터 세트
딥러닝 모델 학습에 있어 데이터 세트 선택은 그 성능을 결정하는 중요한 요소 중 하나이기 때문에 본 연구에서는 Blanch et al. (2023)의 RIWA (River Water Segmentation Dataset) v2 벤치마크 데이터 세트를 사용하였다. RIWA v2 데이터 세트는 극심한 강우 및 홍수와 같은 재난 상황에서 지상 카메라로 촬영된, 하천 이미지 분할에 특화된 데이터 세트이므로, 본 연구에서 구축하고자 하는 모델의 학습 데이터로 적합하다.
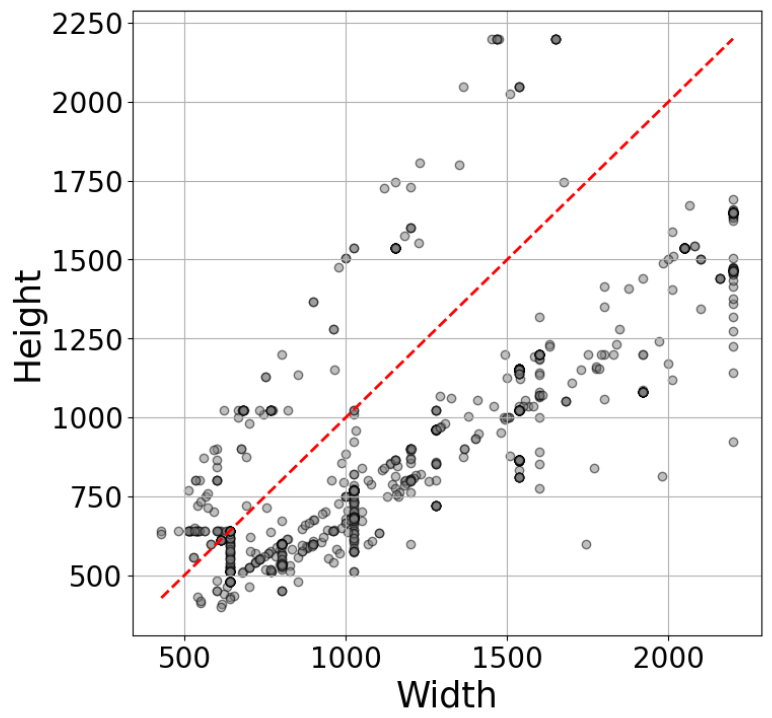
RIWA v2의 학습 데이터 세트에 포함된 이미지는 1,142개이며 검증 데이터 세트와 실험 데이터 세트는 각 167개, 323개의 이미지로 구성된다. RIWA v2의 전체 데이터 세트의 이미지 크기 분포는 Fig. 2와 같다. 해당 데이터 세트에서 Full HD (1920×1080) 이상의 크기를 지닌 이미지 비율은 15.44%이다.
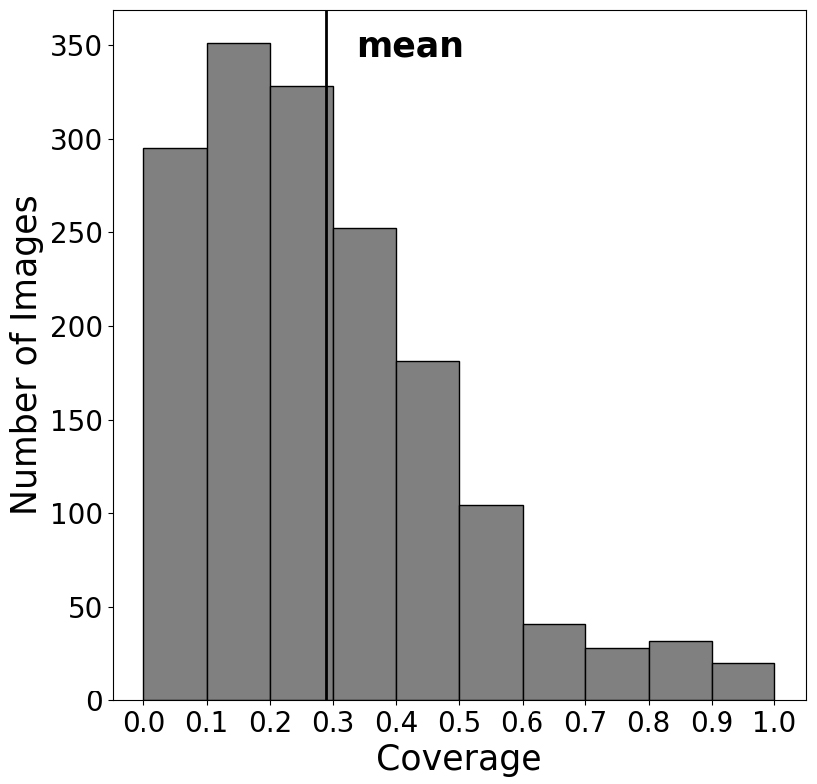
각 이미지에서 참값으로 설정된 수체 영역의 비중은 Fig. 3과 같다. 전체 이미지에서의 수체 영역 비율의 평균은 28.75 %이다. 참값의 비중은 이미지에서 분할하고자 하는 객체의 특성을 반영하는 정도이기 때문에 해당 값이 적을수록 예측 성능이 감소하는 경향성을 보인다.
4. 결 과
4.1 미세 조정 결과
격자 탐색을 진행한 학습률의 값은 각각 0.00001, 0.00005, 0.0001로 선정하여 기존 학습 결과를 크게 훼손하지 않는 범위에서 학습을 진행하였다. 이미지 인코더는 Hiera Tiny, Small, Base+ 중 선택하였으며 그 외의 이미지 인코더를 사용할 경우 GPU 용량 한계로 인해 추론 시간의 급격히 증가함을 확인하여 탐색공간에서 제외하였다.
그 결과, Hiera Base+ 이미지 인코더를 사용하여 학습률 0.0001로 6 에포크를 학습한 경우 학습 평균 IoU 0.8651, 검증 평균 IoU 0.6856로 검증 데이터에 대하여 성능이 가장 뛰어남을 확인하였다(Fig. 4).
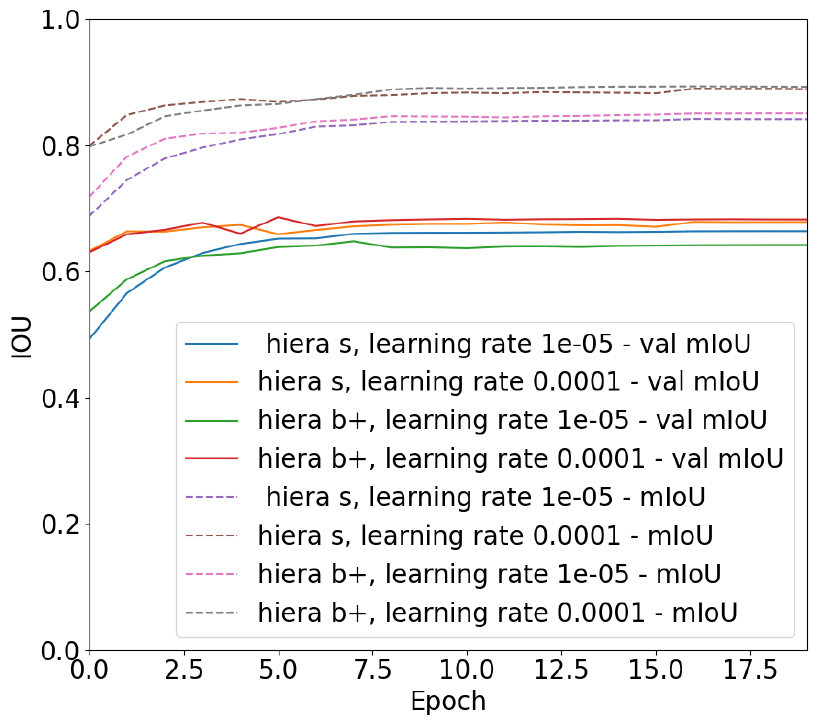
손실 함수는 SAM 2에서 실험을 통해 가장 좋은 손실로 입증된 Focal loss와 Dice loss를 20:1로 혼합하여 사용하였다. Focal Loss는 데이터 내의 참값 영역과 배경 사이의 불균형을 효과적으로 해결할 수 있으며, 손실 함수의 초매개변수인 감마와 알파 값은 해당 손실 함수를 처음 소개한 Lin et al. (2017)에서 추천한 2와 0.25를 적용하였다. 최적화 알고리즘으로는 SAM 2에서 적용한 AdamW를 사용하였다.
4.2 모델 성능 비교
V-FloodNet는 평균 IoU 70.33%를 기록하였으나 기존 SAM 2는 평균 IoU 79.37%로 V-FloodNet에 비해 상당히 개선된 성능을 보였다. 또한 수체 영역 분할 특화 모델의 경우 프롬프트를 적용하지 않았음에도 불구하고 평균 IoU 80.49%를 기록하여 가장 좋은 성능을 보였다(Table 2).
Table 2.
Model performace
| Model | Mean IoU |
| V-FloodNet | 0.7033 |
| SAM 2(Base) | 0.7937 |
| SAM 2(Fine-tuned) | 0.8049 |
모델 성능 차이가 유의미한지 확인하기 위해 각 모델별 테스트 데이터 세트에서의 IoU 결과를 기반으로 통계 분석을 진행하였다. 데이터가 정규 분포를 따르지 않음을 확인한 후, 비모수 검정을 통해 각 IoU 세트의 분포가 유의 수준을 벗어나는 것으로 나타나 모델 간 성능 차이가 유의미함을 확인하였다.
V-FloodNet을 통한 수체 분할 예측 시에 혼동 행렬 상 FP와 FN에 해당하는 과대추정과 과소추정 비율이 각각 4.61%, 4.21%로 나타났으며, 기본 SAM 2 모델의 경우 수체 영역 분할 결과 과대추정이 평균 1.43%, FN에 해당하는 과소추정은 평균 3.56%로 나타났다. 본 연구에서 제시한 모델의 경우 과대추정이 평균 3.03%, 과소추정이 평균 2%로 프롬프트를 사용하는 경우에 비하여 과소추정이 감소하였음을 확인하였다.
Fig. 5는 각 모델을 통해 예측한 테스트 세트에서의 수체 영역 분할 결과의 예시이다. 기본 SAM 2에 전달한 프롬프트의 위치는 이미지 내에 세 점으로 표시하였으며 수체 영역 분할 특화 SAM 2의 경우에는 프롬프트를 전달하지 않은 결과를 분석하였다. 수체 영역 분할 결과 323 장 중 IoU 0.5 이하의 심각한 불일치로 예측된 경우는 VFloodNet, SAM 2, 수체 영역 분할 특화 SAM 2에서 각 71장(21.98%), 36장(11.14%), 39장(12.07%)으로 나타났다.
수체 영역을 과소추정 하는 데이터는 다음과 같다. 빛 반사로 인해 수체 영역의 급격한 질감 변화가 있는 경우 16.43%를 차지하였다(Fig. 5(a)). 이는 야간 및 일조 조건에 따라 과소추정이 일어날 수 있음을 보여준다. 또한 수표면에 반사된 물체로 인한 잘못된 예측은 전체 테스트 결과의 약 8.21%를 차지하였으며 수표면의 질감에 크게 영향을 받는 것을 확인하였다(Fig. 5(b)). 장애물에 의해 수체 영역이 가려진 경우는 약 19. 86%를 차지하였으며, 기본 SAM 2와 수체 영역 분할 특화 SAM 2 모두 V-FloodNet에 비하여 성능에서 유의미한 개선이 있었다(Fig. 5(c)). 이를 통해 일정한 특성을 갖는 이미지는 수체 영역 분할에 과소추정을 유발하는 경향이 있음을 확인하였다. 대조적으로 자갈 및 식생을 수체 영역으로 잘못 예측하거나(Fig. 5(d)), 흐린 배경과 수체 영역을 혼동한 경우(Fig. 5(e)) 과대추정되는 경향을 확인하였으며, 비중은 불일치 데이터 중 각각 10.27%, 8.9%로 나타나 과소추정에 비하여 과대추정의 비중이 낮은 것으로 확인되었다. 오탐지한 수체 영역에 대하여 프롬프트를 기반으로 결과를 개선한다면 보다 효율적인 학습이 가능할 것으로 기대되며, 이에 대한 후속 연구가 필요할 것으로 예상된다.

5. 결 론
본 연구에서는 실시간 홍수 탐지 목적으로 기존 SAM 2 구조에서 프롬프트 인코더와 마스크 디코더 부분을 개선하여 수체 영역 분할에 특화된 모델을 구축하였다. 이미지 내 수체 영역의 위치를 알려주는 프롬프트를 선택적으로 적용하여 수체 영역 분할이 가능하도록 하였으며, 기존 수체 영역 분할 모델인 V-FloodNet과의 성능 비교를 진행하였다. 수체 영역 분할 성능은 IoU 80%를 달성하여 기존 모델인 V-FloodNet의 70.33%에서 9%p의 성능 개선을 보였다. 또한 혼동행렬 상에 나타나는 과대추정과 과소추정을 분석하여, 해당 비율이 기존 모델에 비해 3.79% 감소함을 보였으며 통계적으로 유의미한 차이임을 실험을 통해 확인하였다. 이를 통해 수체 영역 특화 모델이 더 높은 정확성과 분할 과정에서의 효율성을 가짐을 확인할 수 있었다.
본 연구에서 제안한 수체 영역 분할 특화 모델은 홍수 모니터링 시스템에 적용되어 조기 경보 및 실시간 홍수 상황 모니터링에 기여할 수 있을 것으로 기대된다. 또한 개선된 모델 구조를 통해 홍수 탐지 및 홍수 범위 산정 과정에서의 자동화가 가능할 것으로 기대된다. 향후 연구에서는 수체 이미지 인식을 저해하는 요소에 대해 모델의 강건성 및 수체 영역 분할 정확도를 개선하는 프롬프트 기반의 방법론이 필요할 것으로 예상된다.
