

1. 서 론
2. 기본이론
2.1. LSTM 알고리즘
2.2 실시간 예측성능지표
2.3 실시간 오차보정기법
3. LSTM 예측모형 구축
3.1 연구대상 유역
3.2 입력자료
3.3 모델 구성
4. LSTM 기반 AI 홍수예측모형의 예측결과
5. 실시간 예측성능 평가 및 보정기법 적용
5.1 실시간 예측성능 평가
5.2 실시간 오차보정기법 적용
6. 결 론
1. 서 론
최근 전 세계적으로 기후변화가 가속화되면서 국지적 집중호우, 돌발성 강우, 비정상적인 장마 지속 등 극한 강우 현상이 증가하고 있다. 이러한 변화는 예측이 어려운 단시간 고강도 강우를 빈번하게 발생시키며, 도시 지역의 불투수면적 증가와 함께 홍수위험을 더욱 가중시키고 있다. 이로 인해 기존의 홍수관리 체계에서는 감당하기 어려운 규모의 홍수 피해가 여러 지역에서 반복되고 있다. 특히 동남아시아 지역은 지형적 특성, 급속한 도시화, 사회·경제적 취약성 등이 복합적으로 작용하여 홍수피해가 집중되는 경향이 크다. 해수면 상승, 태풍, 열대성 저기압, 집중호우 등의 기후재난이 매년 발생하며, 수천만 명의 주민들이 직접적인 위험에 노출되는 상황이 지속되고 있다.
인도네시아는 지난 수십 년간 급격한 도시 확장과 인구 집중이 이루어지면서 수도권뿐 아니라 반둥(Bandung) 지역을 포함한 주요 도시권에서 홍수위험이 크게 증가하였다. 특히 반둥은 찌따룸강 상류(Upper Citarum River)의 분지 지형에 위치하고 있어 강우가 집중될 경우 배수 지체와 범람이 쉽게 발생하는 구조적 취약성이 내재하고 있다. 이러한 문제를 해소하기 위해 인도네시아 공공사업부(Ministry of Public Works, MPW)는 2017년 한국의 무상원조사업(ODA) 지원을 통해 찌따룸강 상류 유역에 대해 홍수예경보시스템을 구축하여 운영하고 있으나, 최근 도시화·토지 이용 변화·기상 변동성의 증대로 기존 예측체계만으로는 신속하고 정확한 홍수예측에 한계가 존재한다.
필리핀 역시 대표적인 홍수취약 국가로, 수도권(Metro Manila)을 흐르는 마리키나강(Marikina River) 유역은 반복적인 홍수피해 지역으로 알려져 있다. 특히 San Mateo 지역은 마리키나강 중상류에 위치하여 상류 산악지형에서의 급격한 유출 증가가 하류 지역의 침수로 이어지기 쉬운 지형학적 특성을 가지고 있다. 여기에 도시 팽창과 하천 협곡부의 지형 특성이 결합되면서 단시간 홍수와 하천 범람이 잦아, 신속하고 정확한 홍수예측의 중요성이 더욱 높아지고 있다. 필리핀 정부 또한 기존의 물리 기반 홍수예경보시스템의 한계를 인식하고, 다양한 형태의 데이터 기반 예측기술의 도입을 검토하고 있는 상황이다.
최근 급속도롤 발전하고 있는 인공지능 기술은 홍수예측 분야에서도 기존 물리 기반 홍수예측모형을 보완할 수 있는 대안으로 평가되고 있다. 특히 딥러닝(Deep Learning) 기반 시계열 자료 처리 기법은 강우-유출 과정의 비선형성과 시간 의존성을 모델링하는 데 강점을 보여 여러 연구에서 핵심적인 방법론으로 자리 잡았다. Jiang et al. (2020)은 LSTM (Long Short-Term Memory)의 구조적 특성을 활용하여 다양한 유역의 강우-유출 패턴을 학습시킨 모형이 물리 기반 모형에 비해 계산량이나 계산시간이 크게 감소함을 확인하였다. 또한 Hu et al. (2021)은 도시유역을 대상으로 CNN과 LSTM을 결합한 하이브리드 구조를 제안해 단기 침수 수위를 정밀하게 재현하였는데, 이는 딥러닝 모형이 복잡한 도시 환경에서도 유효한 대안이 될 수 있음을 보여준 대표적 사례이다. Fang et al. (2021)은 LSTM을 기반으로 홍수 예측뿐만 아니라 홍수취약성을 공간적으로 평가하는 프레임워크를 제시하면서 의사결정지원체계 구축 가능성을 제시하였다.
예측선행시간 기반 홍수예측 연구 또한 활발히 이루어지고 있다. Le et al. (2019)은 강우·유출 자료를 입력으로 하는 LSTM 기반 유량예측 모형을 개발하여 기존 경험적 모형보다 향상된 예측 정확도를 보고하였다. Tran and Song (2017)은 Trinity River 유역의 수위예측 문제를 대상으로 RNN, BPTT (Back Propagation Through Time) 기반 RNN, LSTM의 수위예측결과를 비교하였으며, 수위가 급변하는 구간에서도 LSTM이 가장 안정적인 성능을 나타냄을 확인하였다. 이러한 결과들은 LSTM이 홍수와 같이 비선형적이고 급격한 변화를 포함하는 수문 시계열을 학습하는 데 적합한 구조임을 시사한다.
국내에서도 다양한 규모의 유역을 대상으로 인공지능 기반 홍수예측 연구가 수행되고 있다. Kim et al. (2023)은 필리핀 Eastern Visayas지역 CarayCaray유역에 DNN과 LSTM을 적용하여 홍수예경보 시스템에 활용 가능한 예측모형을 구축하였다. Kim et al. (2022b)은 왕숙천을 대상으로 단시간 선행예측 성능을 분석해 LSTM의 적용성을 강조하였다. Jung et al. (2021b)은 섬진강 구례 지점을 대상으로 LSTM을 적용하여 SVM (Support Vector Machine) 및 MLP (Multi-Layer Perceptron) 기반 예측모형보다 우수한 성능을 확인하였으며, Lee et al. (2021)은 태화강 유역에 LSTM을 적용하여 물리 기반 하도추적 모형보다 계산 효율성과 성능 모두에서 경쟁력이 있음을 제시하였다. 또한 Park and Kim (2020)은 상류지점 수위를 활용한 LSTM 기반 모듈을 실제 하드웨어-소프트웨어 시스템으로 구현하였고, Yoo et al. (2019)은 한강대교 수위 예측에 NARX 신경망을 적용하여 ANN 및 RNN과 비교한 결과를 제시하였다.
최근 인공지능 기반 홍수예측 연구는 단순히 예측 정확도를 향상하는 데 그치지 않고, 예측오차가 발생하는 구조를 정량적으로 분석하고 이를 실시간으로 보정하는 기법을 개발하는 방향으로 연구의 범위가 확장되고 있다. AI기반 예측모형은 복잡한 비선형성을 학습하는 데 강점을 보이지만, 여전히 예측오차가 누적되거나 구조적 편향이 반복되는 문제가 존재하며, 이러한 오차를 어떻게 보정할 것인가가 최근 연구의 핵심 주제로 부상하고 있다.
Zhang et al. (2022)은 딥러닝 기반 예측에서 발생하는 잔차(residual)의 시계열 패턴을 별도의 학습 모듈로 다시 학습하여 예측값을 보정하는 2단계 보정(two-stage correction) 구조를 제안하였다. 이 연구는 잔차의 패턴을 재활용함으로써 예측의 최종 정확도를 높일 수 있음을 보였으나, 잔차의 과거 시계열 특성에만 의존한다는 점에서 실시간 예측 안정성이나 현재 시점의 신뢰도 변화를 반영하지 못하는 한계가 명확히 존재한다. Kim et al. (2021)은 설마천 유역을 대상으로 예측선행시간별 잔차의 방향성을 분석하여 선형 보정계수를 적용하는 방법을 제시하였다. 예측선행시간에 따라 달라지는 잔차 특성을 정량적으로 분석한 점에서 의의가 있으나, 보정계수가 고정적으로 적용되기 때문에 시간적 변화나 실시간 불확실성 증가를 반영하지 못하는 한계가 있다. Choi et al. (2023)은 실시간 RMSE 기반 성능지표를 활용하여 보정 강도를 조정하는 개념을 제시하였다. 이는 단일 시점의 예측 안정성을 반영한 보정 방식을 제시하였으나, 예측오차의 방향성을 일관되게 개선하는 데에는 한계가 있었다.
이처럼 기존 보정 연구들은 크게 잔차 재학습 기반 보정, 예측선행시간별 고정 보정계수 적용, 실시간 단일 지표 기반 보정으로 분류할 수 있다. 특히 여러 연구에서 LSTM 기반 홍수예측 모형은 첨두수위 직전의 급격한 상승구간에서 일관된 과소산정(underestimation) 경향이 반복적으로 보고되었으며(Kim et al., 2022a; Jung et al., 2021a), 이는 모델 구조적 특성으로 인해 발생하는 전형적인 systemic bias로 해석된다. 이러한 현상은 단순 잔차 보정이나 고정계수 방식으로는 해결하기 어렵고, 예측오차의 방향성과 시점별 신뢰도를 통합적으로 반영한 보정체계가 필요함을 시사한다. 기존 딥러닝 기반 홍수예측 연구는 주로 예측 성능 자체의 향상에 집중해 왔으며, 잔차 기반 보정기법도 일부 제안되었으나, 예측이 이루어지는 각 시점의 모델의 안정성과 오차 크기를 정량적으로 평가하고, 그 결과에 따라 보정 강도가 자동으로 조정되는 실시간 보정 기법에 대한 연구는 미흡한 실정이다.
본 연구에서는 RMSE 기반 실시간 성능지표를 활용하여 예측 시점별 신뢰도를 정량적으로 평가하고, 예측선행시간별 오차 특성을 반영하여 예측값을 연속적으로 보정하는 새로운 운영형 알고리즘을 제안한다. 제안된 알고리즘은 예측모형의 내부 상태를 갱신하는 형태의 모형 상태 갱신 기법(state updating approaches) 기법과 달리, 모형 출력값을 대상으로 신뢰도 기반의 보정량을 실시간으로 조절하는 사후(post- processing) 방식이라는 점에서 차별성을 가진다. 특히 예측모형의 내부 상태를 갱신하는 형태의 모형 상태 갱신 기법이 모형의 상태추정에 기반하여 모형 초기조건을 최적화하는 절차인 반면, 본 연구의 접근은 예측선행시간별 RMSE 패턴과 잔차 방향성을 활용하여 예측값 자체를 직접 조정한다는 점에서 구조적·개념적 차이를 가진다. 이를 통해 LSTM과 같은 비선형 딥러닝 모형에서 초기조건을 최적화하는 절차의 한계를 보완하고, 운영환경에서 즉시 활용 가능한 경량화된 실시간 보정 체계를 제안하고자 한다.
2. 기본이론
2.1. LSTM 알고리즘
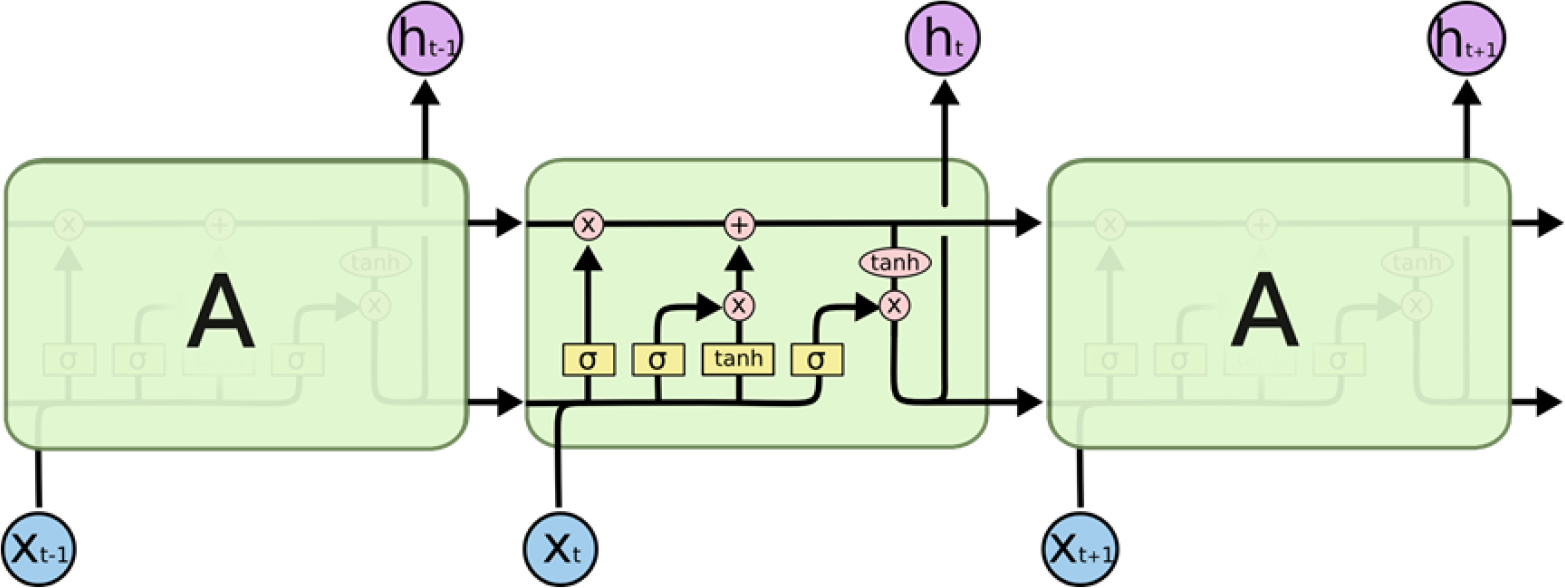
LSTM은 Hochreiter and Schmidhuber (1997)가 제안한 순환신경망(Recurrent Neural Network, RNN)의 확장 구조로, 긴 시계열에서 발생하는 장기 의존성(long-term dependency) 문제를 효과적으로 해결하기 위해 개발된 모델이다. 전통적인 RNN은 오차역전파 과정에서 기울기 소실(vanishing gradient)과 기울기 폭발(exploding gradient) 문제가 발생하여 장기간의 정보를 학습하기 어렵다는 한계가 있다. LSTM은 내부에 셀 상태(cell state) 라는 정보를 보존·전파하는 구조를 두고, 입력게이트(input gate), 망각게이트(forget gate), 출력게이트(output gate)로 구성된 게이트 시스템을 도입함으로써, 시계열 데이터에서 단기 변화와 장기 패턴을 동시에 반영할 수 있다.
LSTM의 핵심은 시간 단계에서 입력 시계열과 이전 상태의 정보를 활용해 다음 상태를 계산하는 과정이다. 망각게이트는 셀 상태에서 제거해야 할 정보를 조절하고, 입력게이트는 새로운 정보를 얼마나 반영할지를 결정한다. 최종적으로 출력게이트는 셀 상태를 기반으로 예측 단계에서 필요한 정보를 출력으로 전달한다. 이러한 구조는 홍수와 같이 비선형적이며 급격하게 발생하는 첨두가 포함되는 수문 시계열의 특성을 반영하는 데 매우 효과적이다(Fig. 1).
2.2 실시간 예측성능지표
LSTM 기반 AI 홍수예측모형의 성능평가를 위하여 홍수위 예측에 대한 전반적인 평가를 위하여 통계변량인 Nash- Sutcliffe 효율성 계수(Nash-Sutcliffe model Efficiency coefficient, NSE), 평균 제곱근 오차(Root Mean Squared Error, RMSE)를 활용하였다(Table 1).
Table 1.
Fit Indicators and equations for validating prediction accuracy
NSE는 모형의 예측능력을 평가하는 통계적 지표로 -∞~1의 범위에서 나타나며, NSE가 1에 가까울수록 예측값이 관측값의 시계열 경향을 잘 반영하는 것으로 판단할 수 있고, RMSE (Root Mean Squared Error)는 예측값과 관측값이 얼마나 일치하는지를 나타낸다. 예측값과 관측값이 정확하게 일치할 때 RMSE는 0이며, 불일치하는 정도가 증가할수록 RMSE값은 커지게 된다.
그러나 위에서 제시된 성능 지표들은 특정 예측시점에서 예측이 얼마나 신뢰할 만한지 판단하기 어렵다는 한계를 가진다. 특히 홍수 발생 시에는 수위 상승 및 하강 속도의 변화가 급격하므로, 예측 시점마다 모델의 안정도와 오차를 실시간으로 정량화하는 성능지표가 필요하다. 이를 보완하기 위해 본 연구는 예측시점()에서 예측선행시간(𝜏)에 따른 레퍼런스 RMSE를 정의하고, 이를 기반으로 수위대별 허용 오차와 비교하여 실시간 신뢰도 지표()를 정의하였다. 예측시점()에서 예측선행시간(𝜏)의 RMSE는 최근 36개 시점의 예측값과 관측값의 차이(예측값-관측값) 를 기반으로 다음과 같이 계산한다.
여기서, 𝜏는 10분 간격으로 10~360분까지 총 36개의 예측선행시간, 는 시점 에서 예측선행시간 𝜏의 RMSE, 는 시점에서 𝜏분 뒤 관측수위, 는 시점에서 𝜏분 뒤 예측수위이다.
Eq. (1)은 관측자료가 존재하는 평가 기간에 대하여 산정되는 것으로 특정 시점의 예측값만 평가하는 것이 아니라, 해당 시점 이전의 일정 시간 동안 모델이 동일한 예측선행시간에 대해 얼마나 안정적으로 예측하였는지를 실시간으로 반영하는 신뢰도 기반 오차 지표로 활용된다.
모형의 예측오차가 어느 수준까지 허용될 수 있는지를 평가하기 위해 각 지점의 홍수단계정보를 기반으로 허용 RMSE를 정의하였다.
여기서, 는 경보수위 이하의 관측수위에서 허용 RMSE, 는 경보수위 초과하는 관측수위에서의 허용 RMSE, 은 주의보수위, 은 경보수위, 는 심각수위이다.
홍수위험단계 수위를 기준으로 허용 RMSE를 정의함으로써 지역별 절대수위 규모의 차이를 비교하고, 예측 신뢰도를 상대적 지표로 평가할 수 있도록 하였다. 각 단계의 허용 비율은 수위등급 간 상대적 변화폭, 홍수 발생 시 수위 변동의 자연적 변동성, 그리고 예측 불확실성 범위를 종합적으로 고려하여 설정하였다. 이러한 상대적 기준은 지역 간 수위 스케일 차이를 정규화하여 서로 다른 유역에 적용된 예측모형에 대해서도 일관된 신뢰도 평가가 가능하도록 하였다.
예측시점에서의 허용 RMSE는 관측수위가 어느 구간에 속하는지에 따라 결정된다. 수위대별로 다른 허용 오차 기준을 적용함으로써 실제 홍수 상황에서 요구되는 예측 신뢰도를 반영하였다.
예측선행시간별로 예측모형이 신뢰할 수 있는 수준의 예측을 수행했는지를 판단하기 위해, 허용 RMSE를 초과하지 않는 시점들을 모아 대표 RMSE 집합을 구성하였다.
여기서, 는 허용 RMSE를 만족하는 시점들의 집합이다.
이 집합에 포함되는 시점의 RMSE 평균을 해당 예측선행시간의 레퍼런스(reference) RMSE ()로 정의한다.
레퍼런스 RMSE와 현재 시점의 RMSE를 비교하여 모형의 실시간 예측성능을 평가하기 위해 실시간 성능지표를 정의한다.
여기서, 는 실시간 성능지표이다.
실시간 성능지표()는 특정 예측시점에서 동일한 예측선행시간에 대해 발생한 예측오차의 크기와 변동성을 반영한 값으로, 단일 시점의 오차가 아닌 과거 예측 안정성을 기반으로 신뢰도를 평가한다는 점에서 기존의 단순 RMSE 평가와 차별성을 가진다.
는 허용 RMSE 대비 실측 RMSE의 상대적 차이를 이용하여 계산되며, 그 값이 1에 가까울수록 해당 예측선행시간에서 모형이 안정적으로 동작하고 있음을 의미한다. 반대로 가 낮게 나타나는 경우는 최근 동일 예측선행시간에서 예측오차가 반복적으로 증가하고 있음을 의미하며, 이는 예측시점의 모형 신뢰도가 떨어진 상태임을 나타낸다. 는 예측선행시간별로 상이한 오차 특성을 실시간으로 반영할 수 있도록 설계되었으며, 홍수 시와 같이 관측 시계열 변화폭이 크고 비선형성이 강한 상황에서 예측 안정성을 동적으로 평가할 수 있는 장점을 가진다. 특히 RMSE는 절대오차를 기반으로 하므로 지역별 수위 크기 차이에 민감하지만, 는 허용 RMSE와 비교하는 상대평가 구조이므로 지역 간 스케일 차이를 보정한 일반화된 신뢰도 지표로 활용할 수 있다. 이와 같이 정의된 는 예측시점별 모형의 신뢰 가능성을 정량적으로 판단할 수 있게 하며, 단순 오차 검증을 넘어, AI 예측모형의 운영 환경에서 예측의 상태를 실시간적으로 판단하는 기능을 수행하는 지표로 할 수 있다.
2.3 실시간 오차보정기법
본 연구에서 제시한 실시간 성능지표는 모델의 예측값에 대한 안정성 수준을 나타내지만 발생하는 오차에 대한 방향성까지는 반영하지 못한다. 이를 해결하기 위해 예측모델의 각 예측선행시간에서 예측 경향을 정량화하여 활용한다. 관측수위와 예측수위의 차이를 전체 예측기간에 대해 평균하여 편향을 산정하였다.
여기서, 는 예측시점()에서 예측선행시간(𝜏)의 관측값, 는 예측시점()에서 예측선행시간(𝜏)의 예측값, 은 유효 시계열 길이이다.
편향()은 예측기간 동안 예측값이 관측값 대비 얼마나 과소 또는 과대 산정되었는지를 나타내는 척도이다. 이를 실시간 성능지표와 결합하여 예측모형의 보정을 위한 신뢰도 기반 편향 보정식을 다음과 같이 정의하였다.
Eq. (8)에서 는 예측의 신뢰도가 낮을수록 보정량이 커진다는 의미를 갖으며, 는 예측의 구조적 편향을 보정하는 역할을 한다. 이 보정식은 모형의 예측을 실시간 안정성에 따라 편향 보정 강도를 동적으로 조절하는 방식이다. 이 구조는 예측이 불안정할수록 큰 보정을 적용하고, 안정적일수록 보정을 최소화하며 보정의 방향성은 편향의 방향을 따른다.
3. LSTM 예측모형 구축
3.1 연구대상 유역
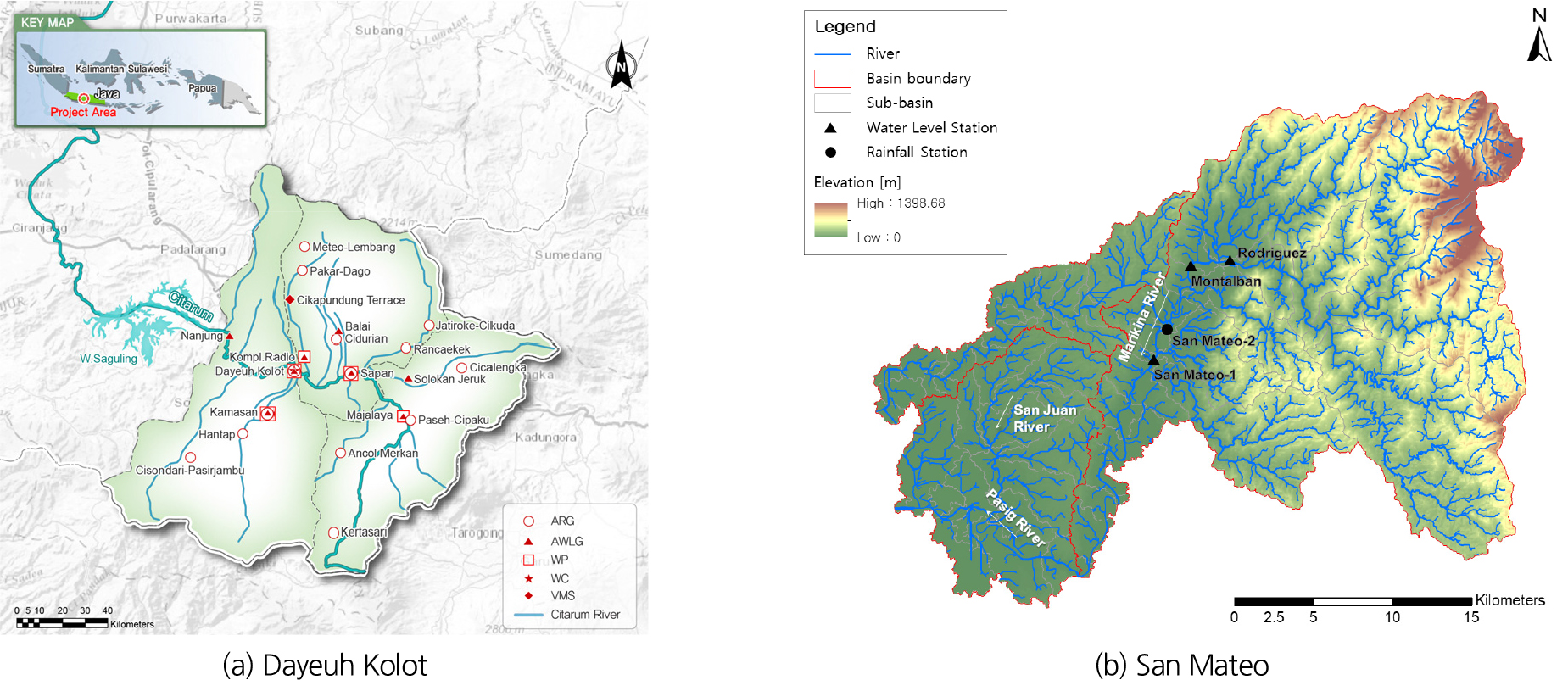
본 연구는 동남아시아에 위치한 두 개의 대표적 홍수취약 지역을 대상으로 예측모형을 구축하였다. 첫 번째 대상지인 필리핀 San Mateo 지역은 메트로 마닐라 동부의 마리키나(Marikina)강 상류에 위치하며, 산악지형과 도시 지역이 혼재된 복합 지형구조를 갖는다. 연 강수량이 2,000 mm 이상으로 많고, 태풍 및 몬순기후 영향에 따른 단시간 집중호우가 빈번하여 강우에 따른 수위 변화의 반응이 빨라서 수위 변동성이 크게 나타나는 것이 특징이다. 두 번째 대상지인 인도네시아 Dayeuh Kolot 지역은 서자바 반둥 리젠시 남부의 광범위한 저지대로, 찌따룸(Citarum)강 중류부에 위치한 대표적 상습침수 지역이다. 이 지역은 전체적으로 평탄하고 배수 능력이 제한되어 있으며, 도시화로 인한 불투수면 증가로 강우 시 첨두수위가 급격히 상승하고 침수가 장기간 지속되는 경향을 보인다. 2개 지역 모두 지형적 제약과 급격한 강우 특성으로 인해 수위 변동에 대한 예측 난이도가 높은 지역으로 다양한 홍수 양상을 나타내는 열대권 유역의 특성을 대표한다는 점에서 본 연구의 예측모형 성능 평가에 적합한 대상지로 선정하였다(Fig. 2).
3.2 입력자료
본 연구에서는 필리핀 San Mateo 지역의 마리키나강에 위치한 San Mateo-1 수위관측소 지점과 인도네시아 찌따룸강에 위치한 Dayeuh Kolot 수위관측소 지점을 목표수위관측소로 선정했다. 이는 홍수취약 구역에 위치한 지역의 하류에 있는 수위관측소를 목표관측소로 선택함으로써 상류에 위치한 강우관측소 및 수위관측소 등의 참조관측소를 최대한 많이 확보하여 활용하기 위해서이다. 2개 관측소 모두 10분 단위의 강우와 수위 관측 자료의 확보가 가능하다. 필리핀은 2018년 1월 4일부터 2025년 7월 10일까지의 강우 및 수위자료를 수집하였으며, 인도네시아는 2016년 7월 1일부터 2025년 10월 31일까지의 강우 및 수위자료를 수집하였다. 강우 및 수위자료를 검토하여 결측 및 이상치 보정을 수행했으며, 8시간 이상 지속되는 무강우 기간은 입력자료에서 제외하여 학습자료를 구축함으로써 학습의 효율성을 높이고자 하였다. 전처리후의 강우 및 수위자료는 Fig. 3에 나타냈다. 필리핀은 2021년 5월~2024년 12월 자료는 학습자료(training data)로 활용되며, 인도네시아는 2017년 1월~2024년 12월 자료는 학습자료(training data)로 활용하였다. 이 중 후반부 20%는 검증(validation)에 활용되고 모델에서 자동으로 추출된다. 2025년 관측자료는 시험(test)에 활용하였다. 각각의 기간 및 자료의 수는 Table 2에 나타냈다. 필리핀 San Mateo-1과 인도네사아 Dayeuh Kolot 수위관측소를 목표관측소로 하고, 상류의 강우 및 수위관측소를 참조관측소로 하여 선행예보시간(현재시점 기준으로 10~360분 후)에 따른 수위예측이 가능하도록 LSTM 모형 개발을 위한 입력자료를 구축하였다. 학습자료에 해당하는 X는 현재시점의 강우와 수위자료이며, 예측값에 해당하는 Y는 10~360분 후의 수위로 설정하였다(Table 3).
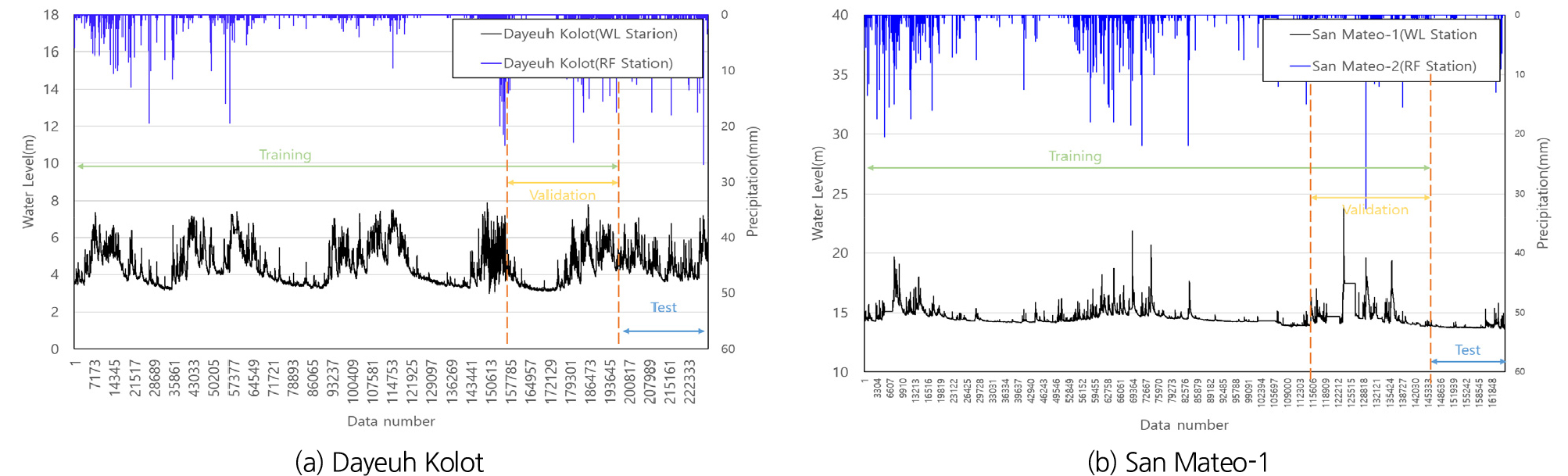
Table 2.
Structure of input dataset for LSTM models
Table 3.
Structure of input dataset for LSTM models
3.3 모델 구성
인공지능 기반 수위예측 모델을 구축하기 위해서는 학습 과정에 투입되는 파라미터(parameter)의 적절한 선정이 핵심 요소가 된다. 본 연구에서는 예측 성능을 안정적으로 확보하기 위해 모델 구조, 입력 시퀀스, 최적화 전략 등 학습 파라미터 전반을 체계적으로 구성하였다. 모델의 비선형성을 충분히 확보하기 위해 LSTM 계층의 활성화 함수는 ‘ReLU’를 적용하였으며, 최적화 알고리즘은 수문 시계열 데이터에서 자주 발생하는 스케일 차이와 경사 소실 문제를 효과적으로 완화할 수 있는 ‘Adam Optimizer’를 사용하였다. 손실함수는 연속적인 수위 값을 학습한다는 점을 고려하여 평균제곱오차(Mean Squared Error, MSE)를 적용하였다.
모델 구조는 입력자료의 시간 의존성을 충분히 학습하도록 다층 LSTM 구조로 설계하였다. 기본 LSTM 계층과 더불어 총 3개의 은닉층(hidden layer)를 추가하여 예측 변수 간의 비선형·장기 의존 관계를 깊이 있게 학습할 수 있도록 하였으며, 과적합을 방지하기 위해 각 계층마다 ‘Dropout rate’를 적용하였다. 입력자료의 시계열 특성 반영을 위해 시퀀스 길이(sequence length)는 24로 설정하였는데, 이는 본 연구에서 사용한 10분 간격 관측자료 기준으로 직전 4시간(24개 시점)의 정보를 모델이 포함하도록 설계한 것이다.
입력 및 출력 변수의 구성은 연구대상 유역의 수문 특성을 충실히 반영하도록 설계하였다. 수위, 강우, 누적강우, 조위, 유역 평균강우 등 예측에 유효한 변수들을 X 변수로 구성하였으며, 출력(Y 변수)은 10분 간격의 예측선행시간별 수위로 설정하여 총 36개(10~360분)의 예측값을 동시에 산정하도록 하였다. 학습 과정에서는 ‘MinMaxScaler’를 통해 X, Y 데이터를 0~1 범위로 정규화하여 변수 스케일 차이로 인한 학습 불안정을 예방하였다.
또한, 모델 학습 시 과적합을 억제하기 위해 ‘Early stopping’과 ‘Model checkpoint’를 적용하여 검증 오차가 최소가 되는 시점의 가중치를 저장하도록 하였다. ‘Batch size’, ‘Learning rate’, ‘Hidden layer unit’ 등 세부 파라미터는 실험적 사전 분석을 통해 안정적 수렴과 예측 성능 향상을 보이는 값으로 설정하였다. 각 파라미터의 구성은 Table 4에 정리하였다.
4. LSTM 기반 AI 홍수예측모형의 예측결과
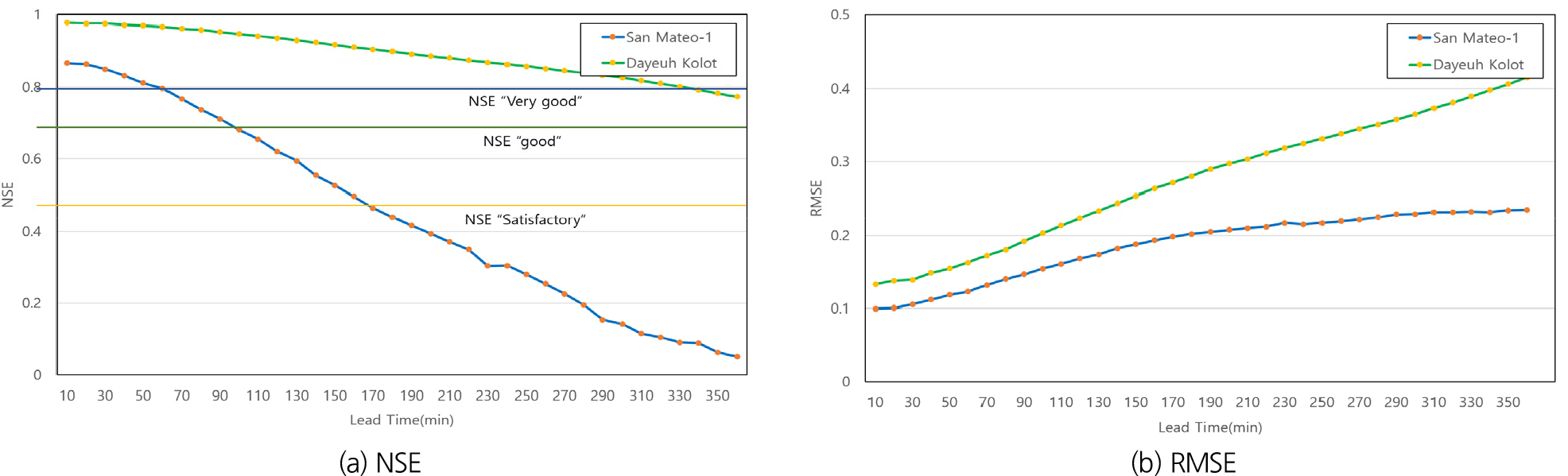
예측선행시간별 예측 성능 비교 결과를 Fig. 3에 나타내었다. 필리핀의 San Mateo-1 지점은 예측선행시간이 10분일 때 RMSE가 0.099 m, 360분일 때 0.234 m로서 약 2.36배 정도 증가하며 전형적인 오차 누적 패턴을 보였다. 이에 비해 NSE는 0.866에서 0.050까지 급격히 감소하여 예측선행시간이 길어지면 예측능력이 거의 상실되는 양상을 나타냈다. 이는 필리핀 지역의 수위 절대값과 변동폭이 크기 때문에 작은 예측 오차도 관측 분산 대비 상대적 비중을 크게 차지하여 NSE가 빠르게 악화되는 수문 반응 특성에 기인한다. 반면 인도네시아 Dayeuh Kolot 지점은 RMSE가 0.133 m에서 0.415 m까지 약 3.12배 증가하여 필리핀보다 RMSE 증가폭이 더 컸으나, NSE는 0.977에서 0.772로 완만하게 감소하며 예측선행시간이 길어지더라도 예측곡선의 형태를 안정적으로 재현하는 것으로 나타났다. 이는 인도네시아의 수위 절대값이 작고 변동폭이 완만하여 모델이 전체적인 수위 변화 패턴을 비교적 쉽게 학습할 수 있었기 때문이며, 절대 오차는 증가하더라도 곡선 형태의 유사성이 유지되면서 NSE가 높은 수준에서 보전된 것으로 해석된다. 이러한 결과는 지역별 수위 크기와 변동성 차이가 평가 지표에 직접적으로 영향을 미친다는 점을 보여주며, 동일한 예측모형이라도 유역 특성에 따라 RMSE와 NSE의 해석이 다르게 나타날 수 있음을 나타낸다(Fig. 4).
5. 실시간 예측성능 평가 및 보정기법 적용
5.1 실시간 예측성능 평가
본 연구에서는 각 지점의 특정 예측시점(prediction time)을 기준으로 예측선행시간 10~360분의 예측 성능을 비교하였다. 각 지점의 예측기간 중 최대 관측수위를 기록한 홍수사상의 3시간 전을 예측시점으로 하여 AI 홍수예측모형의 예측성능을 평가하였다. Dayeuh Kolot 지점은 2025년 5월 6일 15:20을 대상으로 하였고, San Mateo-1 지점은 2025년 10월 31일 20:30을 분석 대상으로 하였다. 각 예측선행시간에서 제시된 수치는 예측오차(또는 RMSE), 실시간 성능지표, 편향 및 허용 RMSE 등 예측 안정성을 판단하는 핵심 지표들이다(Table 5).
Table 5.
Prediction performance evaluation for maximum flood event
Dayeuh Kolot 지점의 예측시점에서의 RMSE는 예측선행시간이 증가함에 따라 예측오차가 일관되게 증가하다가 예측선행시간 300~360분 구간에서 다소 완화되는 패턴을 보였다. 이는 해당 지점의 예측모형이 단기 및 중기(60~180분) 구간에서는 비교적 안정적이나, 장기 예측선행시간(240분 이후)에서는 오차가 누적되는 전형적 패턴을 보여준다. 특히 주목할 점은 예측선행시간 전체 구간에서 예측성능지표가 모두 0으로 나타났다. 이는 현재 Dayeuh Kolot 지점에서는 AI 홍수예측모형이 최대 관측수위에 대해 예측신뢰도가 없다는 것을 의미한다.
San Mateo-1 지점은 Dayeuh Kolot과 상이한 특징을 보였다. 예측시점에서의 RMSE는 예측선행시간 180분에서 오차가 가장 크게 증가하였다. 이는 중기 예측선행시간(120~180분 뒤)에서의 예측 불확실성이 가장 크며, 유역의 실제 수문 반응 특성을 모델이 구현해내는데 어려움을 보였다. 반면 예측선행시간 60분에서는 오차가 0.049로 매우 낮게 나타났다. 이는 San Mateo-1 지점이 단기 예측에는 매우 안정적인 응답 특성을 가진다는 것을 보여준다. 예측성능지표 산정결과 또한 예측선행시간 60분에서 0.681을 나타내며 예측선행시간이 짧은 구간에서 모형의 신뢰도가 매우 높음을 나타내었다.
Dayeuh Kolot 지점에서는 단기 및 중기 예측에서 안정적이며 편향이 거의 없었고, San Mateo-1 지점에서는 단기 예측정확도는 매우 높지만 중기 예측에서 불확실성이 크게 증가하는 2개 지점간에 예측 민감도 차이가 뚜렷하게 나타났다. 이는 해당 지역의 수문 반응 양상, 우수·하천 응답시간, 강우 집중도 등 지역적 특성이 반영된 결과로 해석된다.
5.2 실시간 오차보정기법 적용
LSTM 홍수예측모형에 의한 예측 오차를 개선하기 위하여 실시간 오차보정기법을 적용하였다. 적용 결과 2개 지점 모두 예측선행시간 증가에 따라 예측 정확도가 개선되었으며, 특히 중·장기 예측선행시간에서 보정효과가 뚜렷하게 나타났다. Table 6과 Fig. 5는 보정 전·후의 NSE 및 RMSE와 개선율을 예측선행시간별로 정리한 것이다.
Table 6.
Comparison of calibration results (NSE, RMSE)
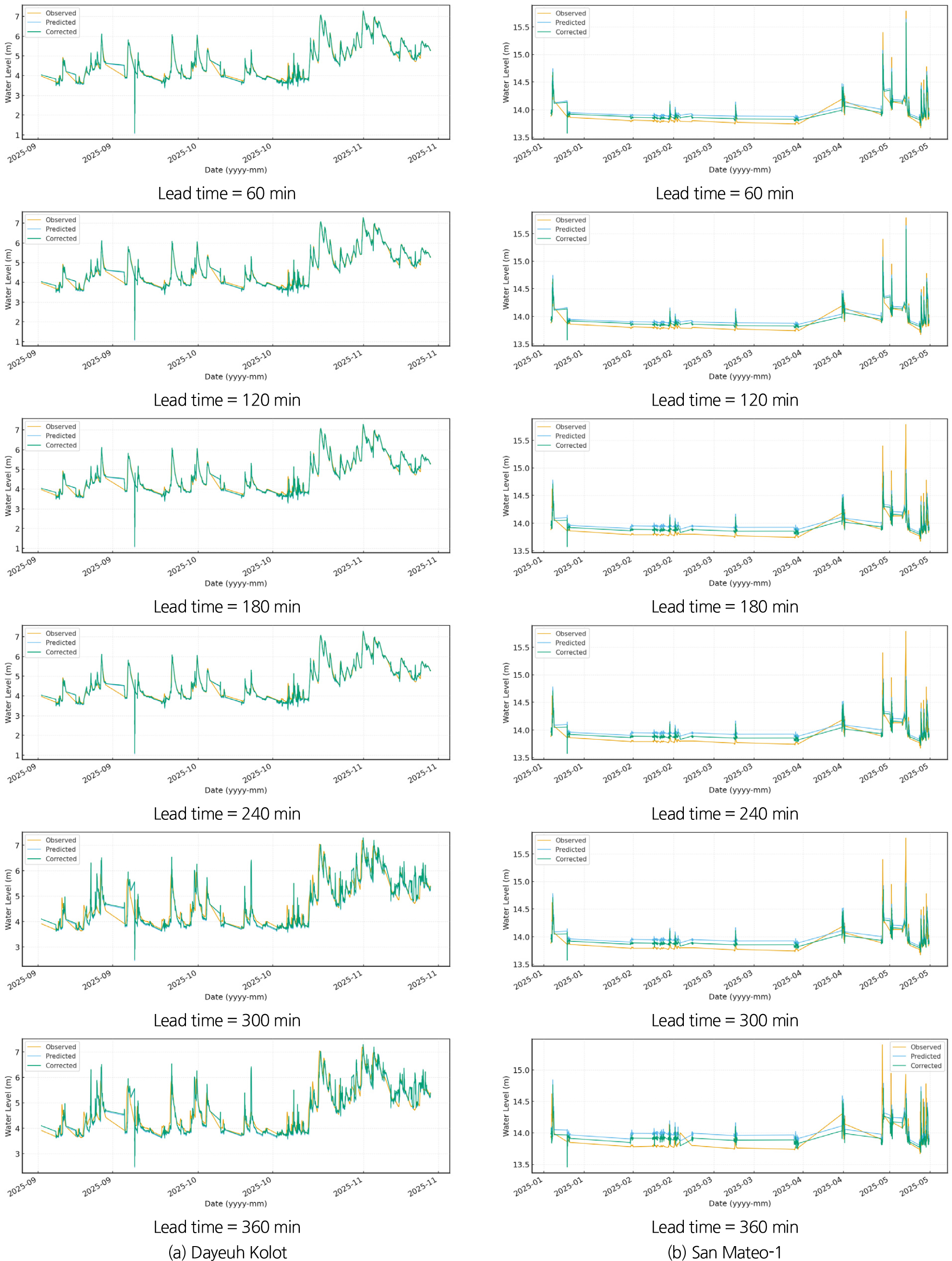
Dayeuh Kolot 지점에서는 전체 예측구간에서 NSE가 소폭 증가하고 RMSE가 미세하게 감소하였다. NSE 개선율은 예측선행시간 60분에서 0.21%였으나, 예측선행시간이 증가함에 따라 180분에서 0.22%, 300분에서 0.24%로 점진적으로 상승하였다. RMSE 개선율 또한 예측선행시간이 길어짐에 따라 절대값이 감소하는 경향을 보였다. 개선 폭 자체는 크지 않지만, 선행시간 증가에 따라 개선율이 완만하게 상승하는 경향은 분명하게 관찰되었다.
San Mateo-1 지점에서는 이러한 경향이 더욱 뚜렷하게 나타났다. NSE 개선율은 예측선행시간 60분에서 6.41%였으나, 120분에서 8.39%, 180분에서 15.49%, 240분에서 25.66 %, 300분에서는 85.82%, 360분에서는 216.00%까지 증가하였다. 예측선행시간이 길어질수록 보정효과가 상대적으로 크게 나타나는 구조적 패턴이 명확히 확인되었다. RMSE 역시 전체 예측구간에서 감소하였으며, 그 감소율은 예측선행시간 60분에서 -13.82%, 300분에서 -7.42%, 360분에서 -5.96 %로 유지되어 보정 전 대비 오차가 지속적으로 줄어드는 경향을 보였다.
2개 지점 모두에서 예측선행시간 증가에 따라 개선율이 증가하는 경향이 동일하게 나타났으며, 이는 실시간 오차보정기법이 장기 예측선행시간에서 상대적 성능 향상을 제공하는 특성을 보였음을 의미한다. 예측선행시간 증가에 따라 보정효과가 점진적으로 누적되면서 상대적 개선율이 증가하는 경향은 명확하게 확인된다.
이는 제안된 실시간 오차보정기법이 기본 성능이 우수한 지점에서는 안정적인 미세 조정 효과를 제공하고, 성능이 낮은 지점에서는 구조적인 예측 개선을 유도하는 차별적 효율성을 갖고 있음을 보여준다. 종합적으로 볼 때, 본 연구의 실시간 신뢰도 기반 오차보정기법은 2개 지점 공통으로 예측 정확도 향상에 기여하였으며, 이는 제안한 보정기법이 다양한 유역 특성에 대해 높은 실용성을 가진 보편적 보정기법임을 나타낸다.
6. 결 론
본 연구는 LSTM 기반 홍수예측모형의 실시간 적용성을 향상하기 위해 시점 기반 RMSE를 활용한 예측성능지표와 예측선행시간별 구조적 편향을 결합한 새로운 오차보정 기법을 제안하고, 이를 인도네시아 Dayeuh Kolot 및 필리핀 San Mateo 지점에 적용하여 성능을 검증하였다. 보정 기법 적용전에는 2개 지점 모두에서 예측값이 관측값보다 낮게 산정되는 과소산정 경향이 뚜렷하게 나타났으며, 특히 장기 예측선행시간에서 편차가 확대되는 특성이 확인되었다.
이러한 문제를 개선하기 위해 적용한 실시간 성능지표는 예측의 안정성과 불확실성을 시점별로 반영하는 유효한 지표로 사용되었고, 구조적 편향 정보를 결합한 보정 알고리즘은 중·장기 예측선행시간에서의 RMSE를 유의미하게 감소시켰다. 보정 후 수문곡선은 첨두수위 및 하강 구간에서 관측값에 더욱 근접하는 형태를 보였으며, 이는 제안한 기법이 단순한 오차 감소 이상의 효과, 즉 홍수 사상 전체의 동적 패턴 재현성을 개선하는 역할을 수행했음을 의미한다.
보정결과는 절대오차의 감소 폭이 크지 않음에도 불구하고, 예측선행시간이 증가할수록 상대적 개선율이 점진적으로 상승하는 경향을 보였다. 예측선행시간별 상대적 개선 패턴과 그 구조적 의미를 중심으로 해석하는 것이 적절하다. 특히 중·장기 예측구간에서의 개선율은 예측 불확실성이 증가하는 상황에서 보정기법이 일정 수준의 안정성 확보에 기여할 수 있음을 보여주며, 이는 보정기법의 적용 가능성을 평가하는 데 중요한 근거가 된다.
본 연구에서 제안한 보정기법은 예측선행시간별별 오차 특성을 이용한 후처리 기반 방식으로, 특정 모델의 구조에 의존하지 않는다. 따라서 본 연구에서 활용한 LSTM기반 모델 외에도 다양한 예측모델에 일반적으로 적용 가능한 확장성을 가진다. 향후 연구에서는 실시간 성능지표의 정의와 보정 알고리즘을 보다 정교화하여 수문학적 상황 변화에 더욱 민감하게 반응할 수 있는 동적 보정체계로 확장할 필요가 있다. 예측모형의 구조적 편향은 사상 규모, 수위 변화율, 유역의 반응 특성 등에 따라 서로 다르게 나타날 수 있으므로, 편향을 단순 평균이 아닌 상황별 가중치 또는 시점별 특징에 따른 변량과 연계하여 계산하는 방안이 요구된다. 또한 본 연구의 분석은 단일 모형 기반으로 수행되었으나, 다양한 딥러닝 구조에 동일 기법을 적용하여 기본 예측모형의 성능을 높이고 보정 방식의 일반성과 안정성을 다각도로 검증할 필요가 있다. 더 나아가 예측모형과 보정모듈을 강우·유량·댐 운영·조위 등 다변량 정보와 통합하는 확장 연구가 이루어진다면, 기상·수문·운영 정보를 아우르는 종합적 실시간 홍수예측 체계로 발전할 수 있을 것이다. 이러한 후속 연구를 통해, 본 연구에서 제안한 실시간 보정 기법은 기후변화에 따른 홍수위험 증가에 대응하는 실용적 예측 도구로 활용할 수 있을 것이며, 향후 홍수예경보 시스템의 운영 효율성과 대응 정확도를 크게 향상시키는 기반 기술로 활용될 것으로 기대된다.
