

1. 서 론
2. 대상 유역 선정 및 자료의 특성
3. 확률홍수량의 비교․ 분석
3.1 유량자료의 검정 및 최적 확률분포형 선정
3.2 홍수빈도해석법과 설계강우-유출 관계 분석법에 의한 확률홍수량 비교 분석
3.3 설계강우-유출 관계 분석법에 대한 회귀보정식 개발
3.4 회귀보정식의 적용성 검증
3.5 유역의 크기 및 치수안정성을 고려한 회귀보정식의적용
4. 결 론
1. 서 론
최근 기후변화에 효과적으로 대응하기 위한 수공구조물의 안정성 있는 설계를 위해 신뢰성 높은 설계홍수량 산정에 대한 필요성이 커지고 있다. 설계홍수량이란 홍수특성, 홍수빈도, 그리고 홍수피해 가능성과 사회 경제적 요인을 함께 고려한 후 최종적으로 수공구조물의 설계기준으로 채택하는 첨두유량으로 정의된다(Jeong, 2007). 설계홍수량 산정법은 홍수량 자료의 연최대치계열을 통계학적으로 빈도해석하는 홍수빈도해석법(flood frequency analysis, FFA)과 강우량 자료를 빈도해석하여 확률강우량을 산정한 후 강우-유출모형을 이용하여 설계홍수량을 산정하는 설계강우-유출 관계 분석법(design rainfall-runoff analysis, DRRA)으로 대별된다(Yoon et al., 2013). 홍수빈도해석법은 충분한 양의 홍수량 자료를 사용할 수 있다면, 가장 적합한 방법이다. 미국의 경우, 홍수량 자료가 풍부하여 홍수빈도해석법을 이용해 설계홍수량을 산정하는 지침(Bulletin 17B)을 수자원설계에 적용하고 있다(United States Geological Survey, 2006). 그러나, 우리나라의 경우 홍수량에 대한 관측 자료가 매우 적기 때문에 홍수빈도해석법을 적용할 경우 산정된 설계홍수량의 신뢰성이 높지 않다. 또한 미계측 유역이 많기 때문에 홍수빈도해석법으로 설계홍수량을 산정할 수 없는 경우가 많다. 이에 대한 대안으로 우리나라 수자원 실무에서는 설계강우-유출 관계 분석법을 적용하고 있다. 설계강우-유출 관계 분석법은 비교적 관측자료가 풍부한 강우자료를 빈도해석하여 확률강우량을 산정하고, 이를 강우-유출 모형에 적용하여 확률홍수량을 산정하는 방법이다.
그러나, 홍수빈도해석법과 설계강우-유출 관계 분석법을 같은 유역에 적용하는 경우라도 계산된 확률홍수량이 크게 다른 경우가 많다. 특히, 설계강우-유출 관계 분석법이 홍수빈도해석법보다 확률홍수량을 크게 산정한다. 그 이유 중 하나는 자료의 개수가 다르기 때문이다. Boughton and Hill (1997)은 빅토리아 지역의 설계강우-유출 관계 분석법과 홍수빈도해석법에 의해 산정된 설계홍수량을 비교했다. 홍수자료의 수가 적거나 일부분만을 사용하였을 때, 홍수빈도해석법에 의한 설계홍수량이 최대 80%까지 과소산정되었다. McKerchar and Macky (2001)은 뉴질랜드의 Timaru 유역 등 6개 유역에 대하여 홍수빈도해석과 설계강우-유출 관계 분석법 그리고 지역빈도해석법에 의한 확률홍수량을 비교하였다. 관측 기간이 짧은 홍수량 자료를 사용할 경우, 홍수빈도해석법에 의한 확률홍수량을 실제 관측치와 비교해보았을 때, 다른 두 방법보다 신뢰성이 낮은 것으로 결론 내렸다. Calver et al. (2009)는 영국 전역에서 107개의 계측 유역을 미계측 유역이라 가정하고 홍수빈도해석법과 설계강우-유출 관계 분석법의 미계측 유역에 대한 적용성을 분석하였다. 그 결과 모든 방법에서 50년 빈도의 설계홍수량이 최대 ±35%의 오차가 발생했다.
두 번째 이유는 강우-유출 사이의 비선형성 때문이다. 설계강우-유출 관계 분석법에 사용되는 대표적인 유출모의 프로그램인 HEC-HMS 모형은 Clark 단위유량도 개념을 사용하고 있다(Lee, 2015). Sherman (1932)는 하천 강우-유출 자료를 분석하고, 강우-유출 사이의 관계는 선형 및 시간불변이라고 가정하여 단위유량도를 개발했다. 그러나, 실험실에서 수행되는 유출 모의뿐만 아니라 실제 유역의 강우-유출 관계는 뚜렷한 비선형성이 나타나지만, 단위유량도의 선형성 가정이 간단하고 그 결과가 대부분의 공학적 목적에 부합하기 때문에 아직 유용하게 적용되고 있다(Lee, 2015). Lee et al. (2011)은 우리나라 전역에 위치한 15개 댐 유역의 강우량과 홍수량 자료를 비교해 보았을 때 과거에 비해 강우량이 평균 17.6% 증가하는 동안 홍수량은 평균 42.0% 증가한 사실을 밝혀 재현기간에 따른 강우와 홍수량이 선형성을 가지지 않는다고 주장하였다. 또한, Choi et al. (2015)는 강우-홍수 사이의 선형성 가정을 전제로 하는 설계강우-유출 관계 분석법의 문제점을 개선하기 위해 홍수빈도해석법과 설계강우-유출 관계 분석법 그리고 호우사상에 대한 강우-유출 해석을 수행한 후 연최대홍수량을 추출하고 이를 빈도해석하는 방법을 비교․분석했다. 그 결과 산정된 설계홍수량의 오차값은 유역면적에 따라 달라진다는 결론을 도출하였다.
세 번째 이유로는 유역의 특성인자의 차이를 들 수 있다. 「하천설계기준․해설」에 따르면 하도흐름의 유하시간이 매우 짧은 소유역에서는 도달시간이 매우 짧게 산정되므로 합리식과 단위도법 등 모든 방법에서 비홍수량이 과다 산정된다(Korea Water Resources Association, 2005). Rogger et al. (2012)는 홍수빈도해석법과 설계강우-유출 관계 분석법에 의한 확률홍수량에서 차이가 발생하는 원인을 알아내기 위해 연속 유출모형을 이용한 몬테칼로 모의(Monte Carlo Simulation)를 수행했으며, 이를 통해 100년 빈도 설계홍수량의 경우, 유역의 저류량에 따라 결과가 달라진다는 것을 예증하였다. 더욱이 우리나라의 경우 Clark 단위도법을 하도추적과 같이 적용하면 기존에 고시된 홍수량보다 크게 증가하는데, 이를 조정하기 위해 유역의 저류상수를 임의로 조정하고 있다(Yoon et al., 2013).
따라서 본 연구에서는 설계강우-유출 관계 분석법으로 확률홍수량을 산정할 수밖에 없는 우리나라 상황을 고려하여, 미계측 유역에서 설계강우-유출 관계 분석법으로 산정되는 설계홍수량을 홍수빈도해석법으로 산정되는 확률홍수량에 근접할 수 있도록 보정하는 관계식을 도출하고 적용성을 검증하였다.
2. 대상 유역 선정 및 자료의 특성
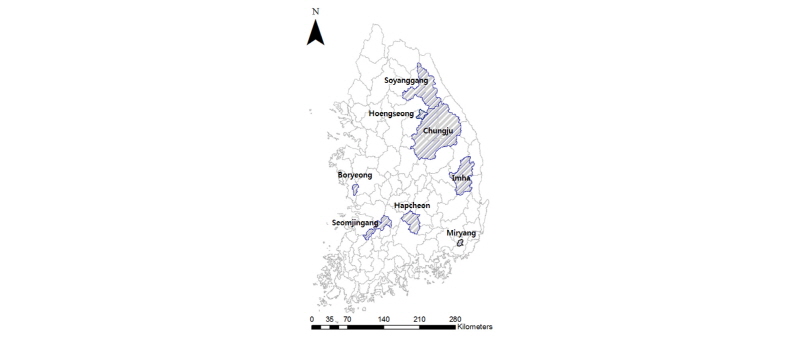
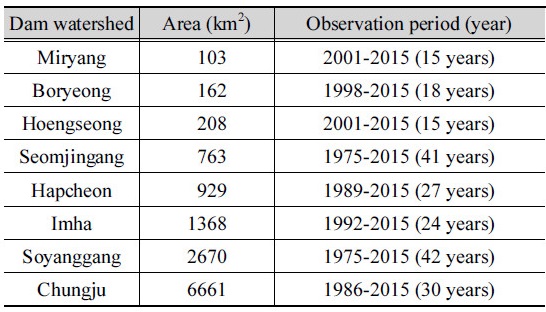
본 연구에서는 제안된 회귀보정식을 검증할 수 있도록 홍수량 및 강우량 자료를 충분히 확보하여 홍수빈도해석법과 설계강우-유출 관계 분석법으로 설계홍수량을 산정할 수 있는 유역을 대상유역으로 선정하였다. 선정된 유역은 밀양(Miryang)댐, 보령(Boryeong)댐, 횡성(Hoengseong)댐, 섬진강(Seomjingang)댐, 합천(Hapcheon)댐, 임하(Imha)댐, 소양강(Soyanggang)댐, 충주(Chungju)댐 유역 등 8개의 유역으로 K-water 홈페이지(http://www.kwater.or.kr)에서 강우량과 홍수량 자료, 그리고 유역면적 등 유역특성자료를 수집하였다. 대상유역의 위치는 Fig. 1에 표시한 바와 같고, 유역면적의 크기와 관측자료의 기간을 Table 1에 제시하였다.
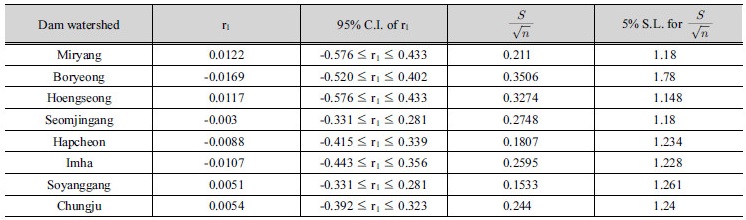
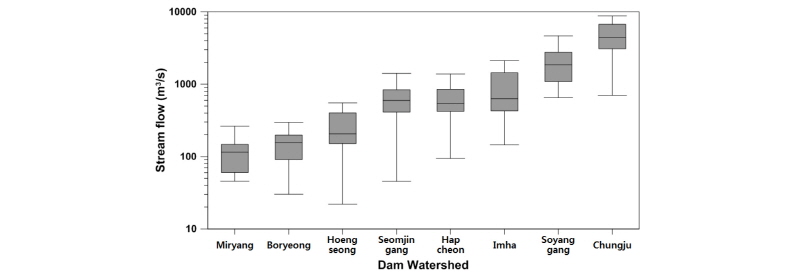
본 연구에서 선정한 대상유역의 일유량 자료를 수집 후, 연최대유량계열을 구축하여 홍수빈도해석법을 통해 설계홍수량을 산정했다. 구축된 연최대유량계열 자료를 상자그림으로 도식화하여 Fig. 2에 나타냈으며, 유량자료에 대한 독립성 및 동질성 검정 수행 결과는 Table 2와 같다. 각 유역의 유량자료에 대한 1차 계열 상관계수 (r1) 및 95% 신뢰구간(confidence interval, CI)을 바탕으로 유량자료의 독립성을 검정한 결과, 관측 유량자료는 수문학적 지속성이 거의 없는 무작위 계열로 시간에 대하여 독립적인 것으로 분석되었다. 또한 Eq. (1)을 이용하여 유량자료에 대한 동질성 검정(Machiwal and Jha, 2012)을 수행한 결과, 모든 유역에서 검정 통계량이 5% 유의수준(significant level, CL)의 임계값보다 작게 나타나 유량자료들은 동질적 모집단에 속해 있는 것으로 분석되었다.
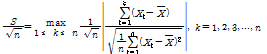 (1)
(1)
여기서, S는 시간 동질성에 대한 민감도이며, n은 자료의 개수, Xt는 유량계열이며, 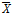 는 유량자료계열의 평균값이다.
는 유량자료계열의 평균값이다.
3. 확률홍수량의 비교․분석
3.1 유량자료의 검정 및 최적 확률분포형 선정
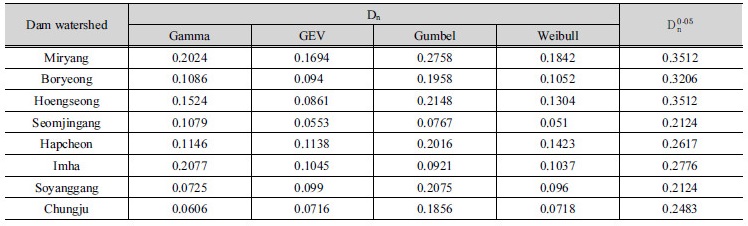
본 연구에서는 Gamma (P-II) 분포, 일반극치(GEV) 분포, Gumbel (Type-I) 분포, Weibull (Type-III) 분포에 대한 모수를 확률가중모멘트법을 이용하여 추정하고, Kolmogorov- Smirnov (K-S) 검정을 통하여 확률분포형의 적합성을 검정하였다. Table 3은 유역별 검정 통계량(Dn)과 5% 유의수준에 대한 임계값(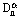 )을 나타냈다. Kim and Heo (2006)에 의하면, 자료의 수가 적을 때, 대체적으로 2변수 Gamma 분포가 적합하며, Gumbel과 GEV 분포는 자료의 수가 많아질수록 적합하다. 또한 수문자료의 최대치 또는 최소치 계열을 분석하는 경우, 즉 최대 홍수와 극한 가뭄 등의 분석에는 GEV 분포가 적절하다(Lee, 2015). 따라서 본 연구에서는 Table 3과 기존 연구결과를 바탕으로 GEV 분포를 최적 확률분포형으로 선정했다.
)을 나타냈다. Kim and Heo (2006)에 의하면, 자료의 수가 적을 때, 대체적으로 2변수 Gamma 분포가 적합하며, Gumbel과 GEV 분포는 자료의 수가 많아질수록 적합하다. 또한 수문자료의 최대치 또는 최소치 계열을 분석하는 경우, 즉 최대 홍수와 극한 가뭄 등의 분석에는 GEV 분포가 적절하다(Lee, 2015). 따라서 본 연구에서는 Table 3과 기존 연구결과를 바탕으로 GEV 분포를 최적 확률분포형으로 선정했다.
3.2 홍수빈도해석법과 설계강우-유출 관계 분석법에 의한 확률홍수량 비교 분석
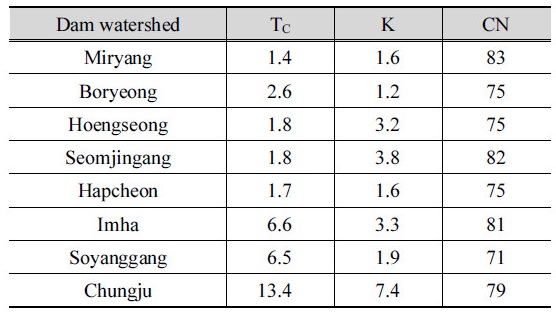
본 연구에서는 설계강우-유출 관계 분석법을 적용하기 위해 우선 K-water 홈페이지에서 제공하는 면적평균강우량을 대상으로 빈도해석을 실시하여 확률강우량을 산정하였다. 면적평균강우량은 대상 유역 내의 지점강우자료를 Thiessen 가중평균법과 면적우량환산계수를 적용하여 계산한 값이다. 또한, 「확률강우량도 개선 및 보완 연구」 (Ministry of Land, Infrastructure, and Transport, 2011)를 참고하여 확률분포형은 GEV 분포형을 적용하고 Huff 4분위법(3분위 적용)을 이용하여 강우주상도를 작성한 후, HEC-HMS 모형을 이용하여 홍수량을 산정하였다. HEC-HMS 모형에 사용된 매개변수인 도달시간(TC), 저류상수(K), 그리고 유출곡선지수(CN) 등은 Table 4와 같이 Park (2013)에서 제시한 값을 사용했다.
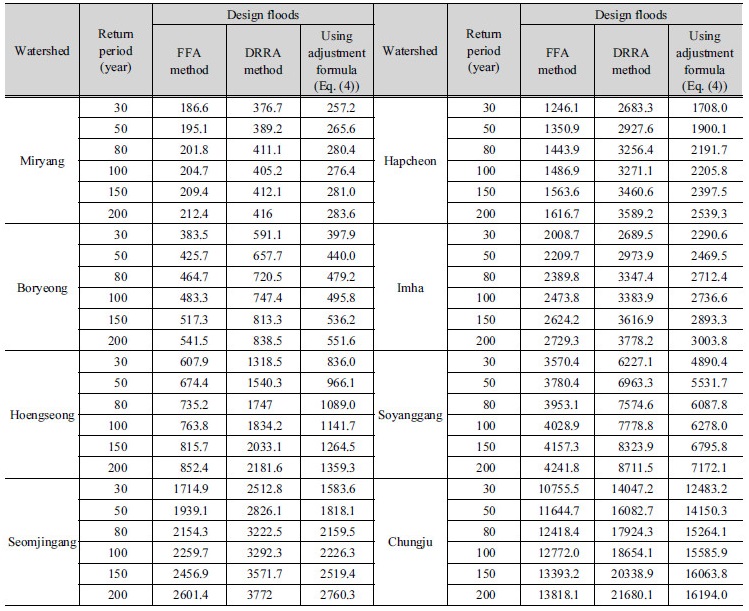
본 연구에서는 8개의 대상유역에 대해서 홍수빈도해석법과 설계강우-유출 관계 분석법을 적용하여 산정한 확률홍수량을 비교․분석하였다. 소하천설계기준, 하천설계기준, 유역종합치수계획 등에서 설계기준으로 주로 사용되는 재현기간 30년, 50년, 80년, 100년, 150년, 200년에 해당하는 확률홍수량을 홍수빈도해석법과 설계강우-유출 관계 분석법으로 산정하여 Table 5에 제시하였다. 비교 결과, 대상 유역 전반적으로 설계강우-유출 관계 분석법으로 산정된 확률홍수량이 홍수빈도해석법으로 산정된 확률홍수량보다 크게 산정되는 것으로 나타났다. 즉, 밀양댐 유역은 99.3%, 보령댐 유역은 55.1%, 횡성댐 유역은 138.0%, 섬진강댐 유역은 46.3%, 합천댐 유역은 120.1%, 임하댐 유역은 36.9%, 소양강댐 유역은 91.5%, 충주댐 유역은 44.6% 과다 산정되었고, 평균적으로 79% 과다 산정되는 것으로 나타났다.
3.3 설계강우-유출 관계 분석법에 대한 회귀보정식 개발
Yoon et al. (2005)은 미계측 유역에 적용가능한 지표홍수 빈도곡선을 개발하였고, Choi et al. (2015)은 연 최대 호우사상을 강우-유출모형에 적용하여 연최대홍수량을 산정하고, 이를 대상으로 홍수빈도해석을 수행하여 확률홍수량을 산정하였다. 그러나 이러한 방법으로 산정한 확률홍수량은 유역 특성에 따라 정확도가 다르게 나타난다. 본 연구에서는 기본적으로 홍수빈도해석에 의한 방법으로 확률홍수량을 산정하는 것이 적절한 것으로 판단하고, 홍수량 자료가 부족한 우리나라의 현실을 고려하여 설계강우-유출 관계 분석법으로 산정된 확률홍수량을 홍수빈도해석법으로 산정한 확률홍수량에 가깝게 보정하기 위하여 회귀보정식을 개발하였다. 전체 대상유역에 대하여 재현기간별 확률홍수량을 각각 홍수빈도해석법과 설계강우-유출 관계 분석법을 이용하여 산정한 후, Table 6에 제시된 비선형 회귀곡선 10개를 대상으로 비교․분석을 수행하였다.
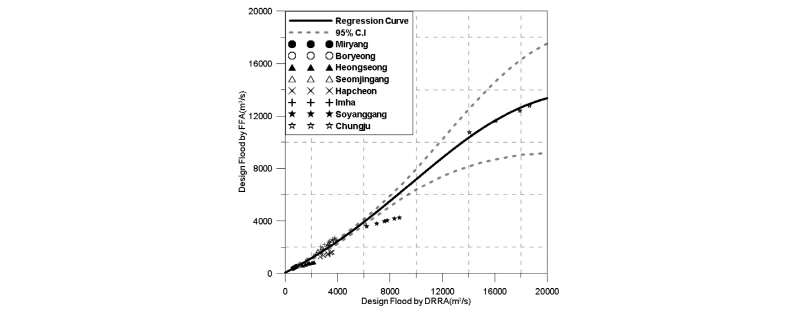
Table 6에서 x는 설계강우-유출 관계 분석법으로 산정된 확률홍수량(m3/s)이며, y는 홍수빈도해석법으로 산정된 확률홍수량(m3/s)이다. 본 연구에서는 결정계수(R2)를 기준으로 회귀곡선식의 적절성을 평가하였다. 다중회귀분석일 경우에는 독립변수들 사이의 다중공선성 문제를 고려하기 위해서 수정결정계수를 이용하기도 하지만, 본 연구에서 적용하는 회귀모형은 단순회귀모형으로 다중공선성에 대한 문제는 발생하지 않았다. Table 6에 제시된 결정계수를 바탕으로 Rational Model 회귀식이 적정 회귀식으로 선택되었으며, 이를 적용한 회귀곡선과 95% 신뢰구간을 Fig. 3에 도시하였다.
Table 6. Regression equations of flood quantiles from flood frequency analysis and design rainfall-runoff analysis method 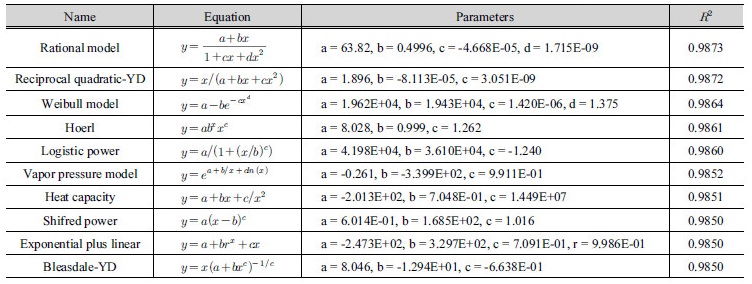 |
3.4 회귀보정식의 적용성 검증
본 연구에서 제시한 확률홍수량의 회귀보정식에 대한 실제 적용성을 검토하기 위하여 Leave-One-Out Cross-Validation (LOOCV) 방법과 Skill Score (SS)를 이용하였다. LOOCV 방법은 분산 등의 통계치를 계산할 때, 이상치의 영향을 줄이거나 확인하기 위해 사용하는 방법이다. 통계치 계산에 n개의 자료를 사용할 때, 그 중 하나의 자료를 제외한 (n-1)개의 자료를 이용하여 통계치를 작성한 후 이를 검증하는 방법이다. SS는 특정한 예측기법의 상대적 성능 평가 기법으로써 일반적으로 Eq. (2)와 같이 표현된다(Wilks, 2001).
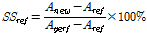 (2)
(2)
여기서, Aperf는 완벽한 예측의 정확도, Aref는 기존 방법의 예측 정확도, Anew는 새로운 방법의 예측 정확도이다.
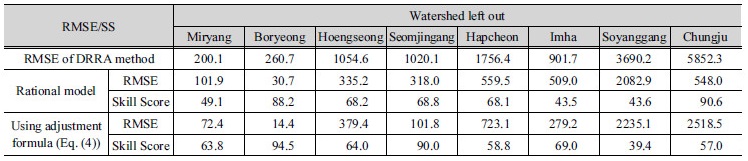
본 연구에서는 우선 8개의 유역 중 1개 유역을 제외하고 나머지 7개의 유역을 대상으로 회귀보정식을 개발한 후, 제외시킨 유역의 설계강우-유출 관계 분석법으로 산정된 확률홍수량을 회귀보정식으로 보정하여 확률홍수량을 산정하였다. 3가지 방법으로 산정된 확률홍수량은 Eq. (3)을 이용하여 2가지 방법(설계강우-유출 관계 분석법과 회귀보정식을 적용한 방법)에 대한 평균 제곱근 오차(Root Mean Square Error, RMSE)를 산정하였다.
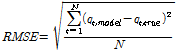 (3)
(3)
여기서, qt,true는 참값으로 본 연구에서는 홍수빈도해석법으로 산정된 확률홍수량(m3/s)이며, qt,model은 비교되는 값으로 본 연구에서는 각각 설계강우-유출 관계 분석법과 회귀보정식을 적용하여 산정된 확률홍수량(m3/s)이다. RMSE는 설계홍수량의 산정하는 방법의 정확도를 나타내는 지표로 사용될 수 있으므로, Eq. (2)의 예측 정확도로 활용할 수 있다. 따라서 Aperf는 0이 되며, Aref는 홍수빈도해석법과 설계강우-유출 관계 분석법으로 산정된 확률홍수량 사이의 평균제곱근오차이고, Anew는 설계강우-유출 관계 분석법에 보정식을 적용하여 산정된 확률홍수량과 홍수빈도해석법으로 산정된 확률홍수량 간의 평균제곱근오차이다.
Table 7은 각각의 유역에 대하여 Leave-One-Out Cross- Validation (LOOCV) 방법을 적용하고 RMSE와 Skill Score을 산정한 결과이다. 회귀보정식을 적용했을 경우, 확률홍수량의 정확성이 평균적으로 65.0% 향상되었다.
3.5 유역의 크기 및 치수안정성을 고려한 회귀보정식의 적용
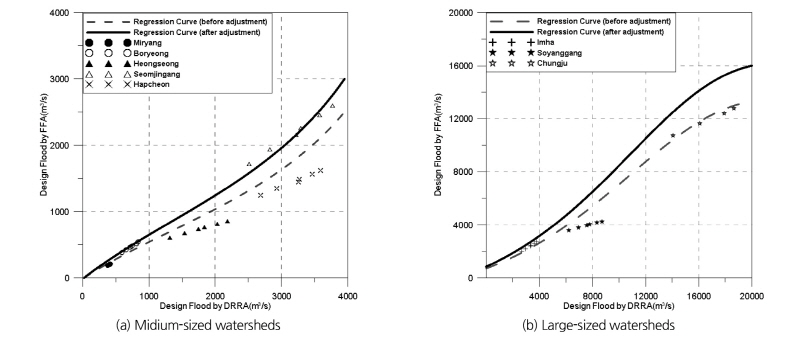
Yoon et al. (2005)와 Choi et al. (2015)에 의하면, 확률홍수량을 산정하는 대안적 방법을 적용했을 때, 유역면적의 크기에 따라 정확도가 달라진다. 유역면적 25 km2와 1,000 km2를 기준으로 유역을 구분할 수 있는데(Jeong, 2007), 본 연구에서는 선정된 대상유역 중 소규모 유역(A ≤ 25 km2)의 조건을 만족시키는 유역은 없기 때문에 중규모 유역(25 km2 ≤ A ≤1,000 km2) (밀양댐, 보령댐, 횡성댐, 섬진강댐, 합천댐)과 대규모 유역(A ≥ 1,000 km2) (임하댐, 소양강댐, 충주댐)으로 구분하여 홍수빈도해석법과 설계강우-유출 관계 분석법으로 산정된 확률홍수량에 대한 회귀분석을 수행하였다. 또한, 참값으로 가정한 홍수빈도해석법의 확률홍수량보다 낮게 보정될 경우(보령댐, 섬진강댐, 임하댐, 충주댐 등), 치수적 안전성을 확보할 수 없기 때문에, 이에 대한 추가적인 조정(20% 상향조정)을 실시하였다. 그 결과는 Eq. (4)와 같고, Fig. 4는 회귀보정식을 도시한 것이다. Eq. (4)를 적용한 확률홍수량은 Table 5에 제시하였다.
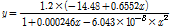 (중규모 유역) (4a)
(중규모 유역) (4a)
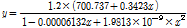 (대규모 유역) (4b)
(대규모 유역) (4b)
여기서, x는 설계강우-유량 관계 분석법으로 산정한 확률홍수량(m3/s)이고, y는 보정된 확률홍수량(m3/s)이다.
Eq. (4)를 적용한 후 산정한 RMSE와 Skill Score는 Table 7에 제시되어 있다. Eq. (4)를 적용했을 경우, 확률홍수량의 정확성이 평균적으로 67.1% 향상되었다. 따라서 유역의 크기를 고려하여 회귀보정식을 산정하고 적용했을 경우에는 설계홍수량 산정의 정확도가 평균적으로 2.1% p 증가한 것으로 나타났다.
4. 결 론
본 연구에서는 설계홍수량을 산정하기 위해서 실무에서 적용되는 설계강우-유출 관계 분석법이 홍수빈도해석법보다 확률홍수량을 크게 산정한다는 것을 예증하고, 이를 개선하기 위한 대안을 제시하였다. Choi et al. (2015)은 설계강우-유출 관계 분석법의 기본 가정인 강우-홍수 사이의 선형성 가정에 문제가 있다는 것을 예증한 바 있다. 본 연구에서는 홍수빈도해석법과 설계강우-유출 관계 분석법으로 산정되는 설계홍수량의 차이는 강우-홍수관계의 비선형성뿐만 아니라 다른 원인도 복합적으로 작용한다고 판단하고, 설계강우-유출 관계 분석법으로 산정되는 확률홍수량을 홍수빈도해석법으로 산정되는 확률홍수량에 근접하게 보정하는 회귀보정식을 개발하였다.
본 연구의 결과, 설계강우(24시간 지속기간)-유출 관계 분석법으로 산정한 설계홍수량이 홍수빈도해석법보다 약 79% 과대산정되었으며, 본 연구에서 제안한 보정식을 적용할 경우, 설계강우-유출 관계 분석법으로 산정된 확률홍수량보다 평균적으로 정확도가 약 65.0% 향상되었다. 또한, 유역의 크기를 고려했을 경우, 유역을 고려하지 않았을 경우에 비해 정확도가 약 2.1%p 증가하였다. 기존 선행연구에서는 확률홍수량 산정법을 제시하고 특정 유역면적 이상인 유역에 적용이 가능했던 반면, 본 연구에서 제시한 확률홍수량 산정법은 유역 규모별로 회귀보정식을 제시함으로써 보다 활용성을 높였다.
본 연구는 관측 홍수량이 충분하지 않은 우리나라의 현실을 고려하여 현재 수자원실무에서 적용하는 설계강우-유출 관계 분석법의 오차를 줄이기 위한 대안을 제시하였으며, 이의 실제 적용성을 검증하였다. 본 연구의 결과는 설계홍수량 산정의 신뢰성을 높일 수 있는 대안이 될 수 있다고 판단되지만, 설계홍수량의 보정 과정에는 미계측 유역 특성과 관련된 불확실성이 크기 때문에 이에 대한 영향을 반영하는 방법을 개발할 필요가 있다. 특히 자료 및 유역 특성의 지역적 동질성은 실무적 관점에서 반드시 고려해야 하는 문제이고, 댐 하류 지역에서의 확률홍수량 산정은 치수안정성 확보를 위해서 종합적으로 고려해야 한다.
