

1. 서 론
2. 지역홍수빈도분석의 특성과 분석방법
2.1 지역홍수빈도분석의 특성과 연구범위
2.2 지역홍수빈도분석의 절차
2.2.1 자료검사
2.2.2 동질 지역의 확인
2.2.3 빈도함수의 선정
2.2.4 빈도함수의 추정
3. 공간자료의 확장
3.1 유출모형을 이용한 공간자료 확장개념의 도입
3.2 대상유역의 선정과 공간자료 확장
3.2.1 대상유역의 선정과 유출모형 매개변수 설정
3.2.2 소유역별 공간자료 확장 및 평가
4. 공간확장자료를 이용한 지역홍수빈도분석
4.1 공간확장자료 활용의 타당성 평가
4.2 충주댐 상류유역의 지역홍수빈도해석
4.2.1 동질성의 물리적인 설명
4.2.2 지역의 적정확률분포형 선정 및 분위수 산정
5. 요약 및 결론
1. 서 론
수자원의 확보 및 관리를 위해서 하천을 중심으로 한 수공구조물을 계획, 설계, 시공하고 있으며, 이러한 수공구조물에는 댐과 같은 저류용 시설물과 제방과 같은 홍수방어용 시설물 그리고 취수보와 같은 이수시설물 등이 있다. 이러한 수공구조물의 설계를 위한 기본이 되는 홍수량으로 빈도홍수량이 이용되고 있다. 특정 재현기간에 따른 홍수량인 빈도홍수량을 분석하는 절차를 홍수빈도분석이라 한다. 일반적으로 홍수빈도분석은 연중 순간최대홍수량 자료계열을 구축한 후, 그에 따른 통계량 즉, 평균, 표준편차, 왜곡도 등을 이용하여 빈도분석을 수행하는 절차를 의미한다. 그러나, 대부분의 수공구조물은 홍수량 자료가 미흡한 지역이거나, 자료가 없는 지역인 소위, 미계측유역에 구축되기 때문에 미계측유역에서의 홍수량을 획득하는 절차가 수문해석에서 중요하게 된다.
미계측유역의 홍수량을 해석하는 기본 개념은 홍수량을 해석하는 수문학적인 방법론에 근거하는데 일반적으로 가까운 계측유역의 홍수량 자료에 의해서 추론하는 지역홍수빈도분석 방법, 확률강우량과 강우-유출관계를 이용하는 방법, 그리고 강우모의모형에 의한 동역학적인 분석방법으로 크게 대별할 수 있다. 본 연구에서 초점이 될 지역홍수빈도분석 방법은 주위 계측유역의 기관측된 홍수량 자료의 빈도 특성치와 유역특성인자 등을 이용하여 홍수량을 지역화함으로써 미계측유역의 홍수량을 추정하는 방법이다. 반면, 나머지 두 방법은 모두 강우에 의해서 홍수량을 추론하는 방법으로 수문학의 기본적인 분석방법인 강우-유출관계를 이용한다. 설계호우-단위도법의 경우, 장기간의 강우량 자료로 분석한 확률강우량과 강우-유출관계를 이용하여 홍수량의 수문곡선과 첨두유량을 모두 추정할 수 있기 때문에 설계상황에 매우 유용한 방법(NERC, 1975; SCS, 1985, IE, 1987)이다. 하지만, 이 방법에 포함된 많은 절차의 불확실성으로 인해 미계측유역에 적용하는데는 상당한 선행분석이 요구된다. NERC (1975), Pilgrim (1987), Lamb (1999) 등은 강우-유출관계에 관련된 절차의 불확실성 및 매개변수의 고정을 위해서 기 계측유역에서의 빈도홍수량에 대한 다양한 분석이 필요함을 지적하였다. 강우모의모형에 의한 동역학적인 분석방법은 Eagleson (1972)에 의해 제안된 유도분포기법(derived distribution method)과 물리적인 유출이론에 근거한 방법으로서 강우모형에 의한 강우-유출관계를 이용하는데, 지형형태학적 순간단위도(geomorphologic instantaneous unit hydrograph), 운동파방법(kinematic wave method) 등이 이용되었다(Hebson and wood, 1982; Cordova and Rodriquez-Iturbe, 1983; Díaz-Granados et al., 1984). 이 방법들은 모두 호우에 따른 토양수분조건과 강우의 공간적인 이질성을 무시하고 있다. Moughamian et al. (1987)과 Raines and Valdes (1994) 그리고 Kim (1998)에 의해 그동안 제안된 방법들과 계측된 자료에 의한 빈도홍수량을 비교한 결과에 따르면, 이 방법은 침투모형의 매개변수 설정과 사용된 강우분포의 특성치에 따라 너무 민감하게 작용하였다.
이상과 같이 미계측유역의 홍수량을 추정하기 위해 이용되는 방법들은 관측된 자료로 분석된 빈도홍수량을 이용하여 검증되거나 절차상의 매개변수를 고정하는 작업이 필요함을 알 수 있다. 이는 실제로 미계측유역의 홍수량을 추론하기 위해서는 어떠한 방법이든 관측된 홍수자료를 이용한 홍수빈도분석의 결과가 표준이 된다는 것을 의미하며, 각 방법별 보완을 위해서도 홍수빈도분석 특성치의 해석은 무엇보다도 중요함을 알 수 있다. 특히, 주위의 관측된 홍수량 자료를 이용하여 미계측유역의 홍수량을 추론하는 지역홍수빈도분석 방법은 관측홍수량 자료의 신뢰성 및 자료의 한계 등에 따라서 직접적인 영향을 받기 때문에 분석에 이용되는 관측자료의 기록기간, 자료의 신뢰성, 관측 밀도 등이 깊게 관련되어 있다.
우리나라의 경우 수문관측 100년이란 관측역사(MLTM, 2010)를 가졌음에도 불구하고, 실제로 홍수량 자료를 이용하여 미계측유역을 위한 홍수빈도분석을 연구한 것은 지극히 적다고 할 수 있다. Yoon (1973), Ko (1977), Yang and Ko (1981) 등에 의해서 시도되었고, 이러한 결과가 실제 설계시에 일부 영향을 미쳤다. MC (1993)에서는 가능한 관측자료를 수집, 발췌하여 지역홍수빈도분석을 시도한 바 있으나, 유역특성과의 특별한 관계를 찾지 못하였다. 이후, Kim and Won (2004)에 의해서 전국적인 지역홍수빈도분석 시도가 있었고, 이 결과는 MCT (2004, 2007)의 지침 및 가이드라인의 중요 잣대로 사용된 바 있으나, 분석에 이용된 자료가 댐의 영향을 받은 자료도 포함되는 등 자료의 공간적인 고려에 대한 세밀한 검토가 없었다. 그 이유는 지역빈도분석에 사용된 자료의 신뢰성은 물론, 지역화하기 위한 관측기간 및 공간분석을 위한 관측자료 군의 밀도가 충분치 않았기 때문이다. 이에 반해 미국과 영국 등의 경우 충분한 관측홍수량 자료를 바탕으로 지역홍수빈도분석의 물리법칙(Gupta et al., 2007; Dawdy et al., 2012)과 미계측유역에서의 홍수빈도의 예측(Hrachowitz et al, 2013) 등 미계측 유역의 홍수빈도특성을 파악하기 위한 많은 발전을 이루고 있다. 그러나 Gupta et al. (2007)이 지적한 바와 같이 우리나라는 물론 전 세계 대부분의 개발국가에서는 관측된 홍수자료의 밀도가 적기 때문에 지역홍수빈도분석의 결과는 쉽게 신뢰성을 얻기 어려운 실정이다. 따라서, Kim et al. (2013, 2014)은 하나 이상의 신뢰성있는 관측 홍수수문곡선 자료를 근거로 사상성 강우-유출모형을 이용하여, 공간적으로 다지점의 홍수수문곡선을 생성할 수 있음을 제안한 바 있다.
따라서, 본 연구에는 공간자료 확장기법에 의해 발생된 첨두홍수량 자료를 이용하여 지역홍수빈도분석의 가능성을 검토하고자 하였다. 이를 위해서 먼저 지역홍수빈도분석의 특성과 연구방법에 대하여 논의하고, 충주댐 상류유역을 대상으로 공간적으로 확장된 자료와 관측자료 간의 통계적인 특성과 지역홍수빈도분석을 위한 각종 가정에 대하여 고찰하고자 하였다.
2. 지역홍수빈도분석의 특성과 분석방법
2.1 지역홍수빈도분석의 특성과 연구범위
지역홍수빈도분석은 관측홍수량 자료의 통계적인 특성치를 이용하여 분석하기 때문에 관측자료 특성을 얼마나 잘 이용하느냐에 따라 그 정확도가 크게 좌우된다. 첫번째, 홍수빈도분석을 위한 자료기록기간에 관련된 것으로 이는 확률의 모분포 가정에 대한 것이다. 두번째는 미계측유역을 위한 정보를 공고히 하기 위한 공간적인 자료가용 여부이다. 세번째는 관측오차의 영향을 줄이기 위해서는 신뢰성 있는 자료가 중요하다.
Burnham (1980)에 의하면 지역빈도분석은 홍수량 자료가 없거나 자료기기간이 매우 짧은 미계측유역의 경우, 자료기록기간이 충분한 지역에서 빈도분석한 결과치와 유역특성인자간의 관계를 해석하는 것으로 정의하였으며, 해석방법에 따라 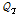 의 통계적 추정법, 모멘트 추정법, 지수홍수법, 전이법 등으로 분류하였다. 각 분석방법은 주어진 상황과 분석목적에 따라 달리 이용될 수 있으나, 오늘날 대체로 Dalrymple (1960)이 제안한 지수홍수법이 가장 널리 이용된다. WMO (1989)는 Hosking (1990)이 제안한 지수홍수법을 지역홍수빈도분석의 표준방법으로 권장한 바 있고, USGS(Dawdy et al., 2012)와 최근 유럽에서 수행되고 있는 Floodfreq-Cost Action ES0901 (Castellarin et al., 2012)에서 가장 널리 이용되고 있는 방법으로 소개하고 있다.
의 통계적 추정법, 모멘트 추정법, 지수홍수법, 전이법 등으로 분류하였다. 각 분석방법은 주어진 상황과 분석목적에 따라 달리 이용될 수 있으나, 오늘날 대체로 Dalrymple (1960)이 제안한 지수홍수법이 가장 널리 이용된다. WMO (1989)는 Hosking (1990)이 제안한 지수홍수법을 지역홍수빈도분석의 표준방법으로 권장한 바 있고, USGS(Dawdy et al., 2012)와 최근 유럽에서 수행되고 있는 Floodfreq-Cost Action ES0901 (Castellarin et al., 2012)에서 가장 널리 이용되고 있는 방법으로 소개하고 있다.
지수홍수법은 홍수지수와 분위수(또는 무차원 재현기간별 홍수량)로 이루어지며, 분석을 위해서는 관측자료의 통계적인 특성의 표현과 지역화를 위한 유역의 동질성 구분이 매우 중요하다. 또한, 미계측유역을 위한 홍수지수의 특성치를 지형학적 특성인자와 수문기상학적인 인자를 이용하여 예측하는 과정이 요구된다. 다시 말하면, 두 가지의 분리된 절차를 수행하는데, 첫번째는 유역과 자료간의 동질성을 가정하여 유역내의 분위수 거동이 같은 과정을 이루게 하는 절차와 두번째는 지수홍수가 미계측유역에서 어떤 거동을 가지는지에 대한 분석 절차를 갖는다. 일반적으로 전자의 분석에서는 통계적으로 유역내 자료간의 동질성의 가정과 그에 따른 자료의 통계적인 성질이 중요하고(Stedinger and Lu, 1995; Eng et al., 2005), 후자의 분석에는 지수홍수를 설명하게 하는 주로 유역특성으로 대표되는 독립인자의 설정이 중요하게 된다.
지수홍수법의 방법론에 대한 연구(Hosking and Wallis, 1997), 불확실성에 대한 연구(Stedinger and Lu, 1995) 그리고 미계측유역에서의 유역면적에 대한 멱함수론에 대한 연구(Gupta et al., 2007; Oden et al., 2003) 등 많은 연구가 수행되었다. 대부분 미계측유역에서 빈도홍수량을 어떻게 추정하느냐에 대한 것이며, 홍수빈도분석의 통계적인 기작은 물론 시공간 규모의 물리적인 홍수량 특성치의 변화 문제가 중요한 연구대상이었다(Dawdy et al., 2012; Hrachowitz et al., 2013). 그러나 지역홍수빈도분석의 많은 발전이 있었고, 미계측유역의 빈도홍수량의 추정에 상당한 성과를 얻었음에도 불구하고, Dawdy et al. (2012)은 지역홍수빈도 분석상에 여전히 남아 있는 다음과 같은 문제를 지적하였다.
‘지역홍수빈도분석 방법에 많은 발전이 있었음에도 불구하고, 이 방법에는 여전히 홍수량을 나타내는 물리적인 지식을 포함하고 있지 못하고 있다. 과연 USGS 지역홍수빈도분석 방법으로 도출된 결과를 홍수를 유발하는 물리적인 메커니즘으로 이해할 수 있을 것인가’
이러한 지적은 지역홍수빈도분석 방법이 단지 관측된 홍수량 자료의 성질에만 의존하기 때문에 그 결과의 생성기작을 물리적인 측면 즉, 강우-유출과정으로 설명할 수 없기 때문에 나온 것이다. 즉, 지역홍수빈도분석 방법이 관측자료의 통계적인 특성치의 한계를 뛰어넘지 못함을 나타낸 것이라 할 수 있다. 따라서 강우-유출관계를 이용한 공간자료 확장기법을 이용하여 지역홍수빈도분석을 수행하고자 하는 본 연구목적과 더불어 지역홍수빈도분석에서 필수적인 동질성의 통계적인 해석을 물리적인 의미로 검토하였다. 또한 확장된 자료를 이용하여 지역확률분포형의 선정기법도 검토하였다.
2.2 지역홍수빈도분석의 절차
2.2.1 자료검사
지역빈도해석에서는 다른 통계분석과 마찬가지로 전반적인 자료의 검토를 통하여 오류나 비일관성에 대한 검증을 실시하여야 한다. 이를 목적으로 지점자료의 L-Moment 형태로 이산도를 나타내는 불일치척도 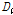 (discordancy measure)는 지역내 지점간의 L-Moment를 비교하여 차이를 확인함으로써 자료의 오류를 판단하는데 이용된다. 다시 말해서 불일치척도
(discordancy measure)는 지역내 지점간의 L-Moment를 비교하여 차이를 확인함으로써 자료의 오류를 판단하는데 이용된다. 다시 말해서 불일치척도 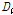 를 통하여 지역내 지점들을 하나의 그룹으로 간주시 전반적으로 일치정도가 가장 떨어지는 지점들을 선정할 수 있다.
를 통하여 지역내 지점들을 하나의 그룹으로 간주시 전반적으로 일치정도가 가장 떨어지는 지점들을 선정할 수 있다. 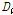 는 각 지점에서의 L-CV, L-skewness, L-kurtosis를 이용하여 Eq. (1)과 같이 정의한다(Hosking et al., 1985).
는 각 지점에서의 L-CV, L-skewness, L-kurtosis를 이용하여 Eq. (1)과 같이 정의한다(Hosking et al., 1985).
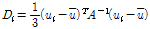 (1)
(1)
여기서, 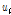 는 지점
는 지점 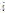 의 L-Moments ratio인
의 L-Moments ratio인 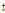 ,
, 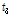 ,
, 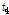 를 포함하는 벡터로서
를 포함하는 벡터로서 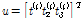 로 정의되며,
로 정의되며, 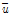 는 유역내 지점들
는 유역내 지점들 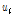 의 산술평균,
의 산술평균, 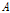 는 표본자료의 공분산이다. Eq. (1)에서
는 표본자료의 공분산이다. Eq. (1)에서 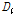 값이 큰 지점은 그 지역내의 다른 값과 일치성이 없다는 의미로 자료의 오류를 확인해 보아야 한다.
값이 큰 지점은 그 지역내의 다른 값과 일치성이 없다는 의미로 자료의 오류를 확인해 보아야 한다.
2.2.2 동질 지역의 확인
지역빈도해석을 하기 위해 대상유역을 여러 개의 소유역으로 나누는데 있어서, 기본 가정은 각 소유역별 확률분포가 같다는 것이다. 따라서, 소유역별 자료계열의 수문학적인 동질성을 평가하기 위한 기준으로 이질성척도(heterogeneity measure)를 산정한다. 동질지역에서 예측할 수 있는 이산도를 추정하기 위한 이질성척도 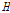 는 자료의 이산도를 모의발생시킨 평균과 이산도의 차, 그리고 모의발생시킨 표준편차의 비로 정의하며 Eq. (3)와 같다(Hosking and Wallis, 1997).
는 자료의 이산도를 모의발생시킨 평균과 이산도의 차, 그리고 모의발생시킨 표준편차의 비로 정의하며 Eq. (3)와 같다(Hosking and Wallis, 1997).
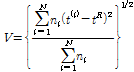 (2)
(2)
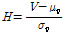 (3)
(3)
여기서, 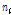 는 지점별 자료수,
는 지점별 자료수, 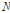 은 유역내 지점수,
은 유역내 지점수, 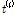 는 표본 L-Moment,
는 표본 L-Moment, 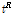 는
는 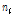 에 가중한 표본자료 집단의 평균 L-CV, 그리고
에 가중한 표본자료 집단의 평균 L-CV, 그리고 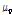 ,
, 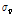 는
는 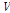 를 표본자료 집단의 평균 L-Moment인 1,
를 표본자료 집단의 평균 L-Moment인 1, 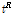 ,
, 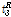 ,
, 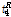 를 kappa 분포형에 적합시킨 다음, 충분한 횟수의 모의발생을 실시하여 계산된
를 kappa 분포형에 적합시킨 다음, 충분한 횟수의 모의발생을 실시하여 계산된 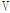 의 평균 및 표준편차이다. Hosking and Wallis(1997)는 사용된 L-Moments ratio에 따라 이질성척도
의 평균 및 표준편차이다. Hosking and Wallis(1997)는 사용된 L-Moments ratio에 따라 이질성척도 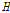 를
를 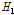 (L-CV),
(L-CV), 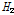 (L-skewness), 그리고
(L-skewness), 그리고 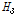 (L-kurtosis)의 세 가지 형태로 제시하였으며,
(L-kurtosis)의 세 가지 형태로 제시하였으며, 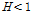 이면 동질성 지역,
이면 동질성 지역, 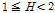 이면 이질성 지역일 가능성이 있는 유역,
이면 이질성 지역일 가능성이 있는 유역, 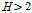 이면 이질성 지역으로 분류된다고 제시하였다.
이면 이질성 지역으로 분류된다고 제시하였다.
2.2.3 빈도함수의 선정
일반적으로 확률분포형의 위치매개변수와 형상매개변수는 지역 전체에 대한 평균과 L-CV, L-kurtosis로부터 산정하며, 적합성척도 Z는 L-Moment로 구한 각 분포형에서의 L-skewness와 L-kurtosis가 관측된 자료의 L-skewness와 L-kurtosis를 지역에 대한 평균값에 일치하는가를 검사하는 것이다. 각 분포형에 대한 적합성척도는 Eq. (4)와 같다.
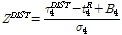 (4)
(4)
여기서, 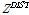 가 0에 가까울수록 적합도가 높다고 할 수 있으며, 적합성 인정의 최소 기준은
가 0에 가까울수록 적합도가 높다고 할 수 있으며, 적합성 인정의 최소 기준은 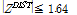 와 같다(Hosking and Wallis, 1997).
와 같다(Hosking and Wallis, 1997).
2.2.4 빈도함수의 추정
지역빈도함수는 각 지점의 분포함수를 추정하고 추정치들을 지역평균함으로써 구할 수 있다. 가장 효율적인 방법은 가중평균을 이용하여 각 지점의 L-Moments를 조합하는 방법이며, 이 방법을 지역 L-Moments 알고리즘(regional L-Moments algorithm)이라 한다(Hosking and Wallis, 1997).
3. 공간자료의 확장
3.1 유출모형을 이용한 공간자료 확장개념의 도입
지역홍수빈도분석은 대상으로 하는 유역내의 여러 관측홍수량 자료특성을 하나의 성질로서 나타내는 것으로, 가능한 공간적으로 많은 자료를 요구한다. 우리나라에서는 장기간의 관측자료를 보유한 관측소가 있다 할지라도 그 자료가 관측기간 중간에 인위적인 구조물에 의한 영향을 받았거나, 인근에 다른 관측소가 없거나 또는 몇몇 지점에 불과하여 지역홍수빈도분석을 수행하기에는 너무 미흡다고 할 수 있다. 이러한 이유로 Kim et al.(2013, 2014)은 공간자료 확장기법을 제시하였다. 이 방법은 기본적으로 연속형 분포형(distributed) 모형의 기본개념에서 출발한다. 잘 구축된 연속형 분포형 유출모형이 있다고 가정하면, 이 모형이 실제유역에 적용될 때는 강우-유출에 관련된 모든 매개변수가 검정과정을 거쳐 고정되어 입력자료인 기상자료에 따라서 유역내 어느 지점에서도 유출을 모의할 수 있게 된다. 이러한 자료의 모의를 사상성 분포형 유출모형으로 수행한다고 가정한다면, 홍수사상의 측면에서는 초기조건만이 변동하게 되는 현상을 가지게 된다. 따라서 초기조건을 추론할 수 있도록 유역내에 한지점 이상의 관측소에서 관측된 사상성 홍수수문곡선이 있다면 사상성 분포형 유출모형으로도 연속형 분포형 유출모형과 같은 정도로 유역내에 다공간의 유출수문곡선을 추정할 수 있게 된다. 물론 이러한 개념은 공간적으로 잘 분포화된 집중형(lumped) 유출모형으로도 적용이 가능할 수 있다.
현재 한강홍수통제소에서는 집중형 강우-유출모형을 분포화시켜서 홍수예경보의 주력모형으로 사용하고 있으므로 Kim et al.(2013, 2014)은 이 모형을 이용하여 공간적으로 자료를 확장하는 방법을 소개하였다. 본 연구에서는 지역홍수빈도분석에 대한 특성치들에 대해서 통계적인 분석 뿐만 아니라 이를 물리적인 의미를 설명하기 위해서 Kim et al.(2013, 2014)에서 이용한 공간확장 방법을 이용하였다.
3.2 대상유역의 선정과 공간자료 확장
3.2.1 대상유역의 선정과 유출모형 매개변수 설정
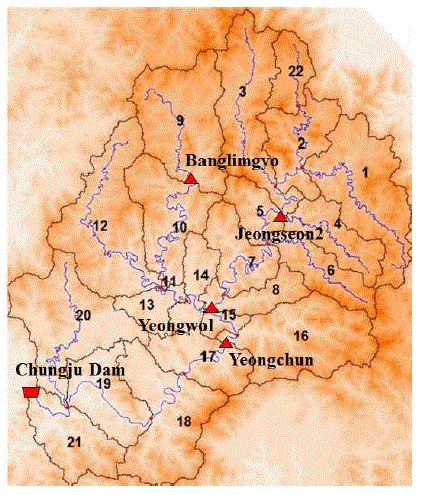
공간적으로 자료를 확장하고, 확장자료의 특성을 분석하기 위해서 가능한 인위적으로 홍수량의 흐름을 변동시킨 경험이 적은 유역인 충주댐 유역을 대상유역으로 선정하여, 22개 소유역으로 구분하였다. 관측홍수량 구축을 위해 정선2, 영월, 방림교, 영춘 수위관측지점과 충주댐 지점을 활용하였다(Fig. 1). Table 1에는 각 소유역별로 자체면적, 누가면적과 해당 홍수량 관측지점을 명기하였다.
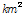 )
)위와 같이 22개 소유역으로 구분된 대상유역에 대하여 홍수량 자료의 공간확장을 위해 저류함수 모형을 적용하였다. 저류함수모형의 지배방정식은 유출저류고(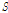 )와 유효유출고(
)와 유효유출고(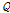 )와의 관계를 나타내는 Eq. (5)와 같다.
)와의 관계를 나타내는 Eq. (5)와 같다.
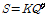 (5)
(5)
여기서, 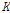 와
와 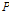 는 유역의 특성을 나타내는 저류함수의 매개변수이다. Eq. (5)을 이용하여 소유역별 홍수량 자료를 모의하기 위한 매개변수
는 유역의 특성을 나타내는 저류함수의 매개변수이다. Eq. (5)을 이용하여 소유역별 홍수량 자료를 모의하기 위한 매개변수 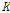 ,
, 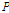 ,
, 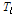 등은 각 홍수사상에서 구한 사상별 매개변수를 이용하여 지형인자(유역면적
등은 각 홍수사상에서 구한 사상별 매개변수를 이용하여 지형인자(유역면적 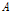 , 유로연장
, 유로연장 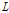 , 하도경사
, 하도경사 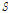 )와의 관계식을 설정하였다. 자세한 사항은 Kim et al.(2013)에 기술되어 있다. 이를 이용한 소유역별 공간자료 확장 및 평가에 관한 내용(Kim et al., 2013; 2014)을 요약하면, 3.2.2절과 같다.
)와의 관계식을 설정하였다. 자세한 사항은 Kim et al.(2013)에 기술되어 있다. 이를 이용한 소유역별 공간자료 확장 및 평가에 관한 내용(Kim et al., 2013; 2014)을 요약하면, 3.2.2절과 같다.
3.2.2 소유역별 공간자료 확장 및 평가
저류함수법을 이용하여 충주댐 유역을 22개 소유역으로 구분하여, 특정 홍수사상의 경우에 대하여 하나의 지점의 홍수수문곡선을 모의함으로써 그 특성에 따라 나머지 소유역의 홍수특성을 모의하였다. 모의기간은 1986년부터 2010년까지의 홍수사상에서 매년 하나 이상의 최대홍수사상을 선별하였다. 이는 지역홍수빈도분석의 특성치를 분석하기 위함이다. 공간장의 모의를 위한 기준점으로 충주댐, 영월1, 영월2 수위관측지점이 이용되었다. 물론 각 기준점은 유출모의 비교기준으로 사용되기도 하였다. 예를 들어, 특정 사상의 경우 충주댐 지점에서 관측자료를 이용하여 모의한 경우 비교 기준으로 영월1과 영월2 지점의 관측홍수량이 이용되었고, 영월1 지점이 모의의 기준지점인 경우는 충주댐과 영월2 지점이 비교기준으로 이용되었다. 이러한 방법으로 사상별로 사용된 관측소가 모의를 위한 기준지점으로 또는 비교기준으로 이용되기도 하는 것은 각 사상별로 수문곡선의 신뢰도가 다르기 때문이었다. 수문곡선의 신뢰도에 대해서는 Kim et al. (2015)에 좀 더 구체적으로 기술되어 있다. 사상별로 홍수사상을 모의한 경우를 살펴보면, 특정 호우사상에 대한 기준점에서 홍수수문곡선을 최적화하는데, 저류함수법에 관련된 매개변수인 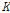 ,
, 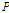 ,
, 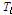 의 지역적인 관계를 고정하고, 유효우량을 산정하는 초기 변량인
의 지역적인 관계를 고정하고, 유효우량을 산정하는 초기 변량인 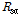 만으로 기준점에서 홍수수문곡선을 최적화하였다. 이렇게 추정된
만으로 기준점에서 홍수수문곡선을 최적화하였다. 이렇게 추정된  를 충주댐 유역의 나머지 소유역에 일정하게 적용하여 각 소유역의 홍수수문곡선을 산정하였다. 특정 호우사상의 홍수수문곡선은 관측된 초기 최저유량에 근거하여 기저유출법으로 분리한 사상을 의미한다. 따라서, 각 소유역의 기저유출의 모의는 기준지점의 기저유량을 유역면적비법에 의거하여 적용하였다.
를 충주댐 유역의 나머지 소유역에 일정하게 적용하여 각 소유역의 홍수수문곡선을 산정하였다. 특정 호우사상의 홍수수문곡선은 관측된 초기 최저유량에 근거하여 기저유출법으로 분리한 사상을 의미한다. 따라서, 각 소유역의 기저유출의 모의는 기준지점의 기저유량을 유역면적비법에 의거하여 적용하였다.
공간확장의 정도에 대한 평가는 공간확장의 기준점으로 정한 3 지점의 자료가 모두 확보된 기간을 정하여 Nash-Sut
cliffe Efficiency (NSE)를 비교하였다(Kim et al., 2014). 이는 해당유역의 한 지점의 유출자료를 활용하여 다른 소유역에 홍수유출자료를 공간확장할 때에 발생하는 오차를 확인하기 위함이다. 영월1 지점을 중심으로 공간확장시 발생하는 충주댐과 영월2 지점에서의 평균 NSE는 영월1 지점이 0.82를 획득할 때 충주댐, 영월2 지점은 각각 0.81, 0.88의 값을 나타내었다. 이는 영월1을 중심으로 공간확장시 영월1 지점에서 발생하는 오차의 크기가 충주댐과 영월2 지점의 오차 크기와 비슷하게 분포하고 있는 것으로 분석되었다.
4. 공간확장자료를 이용한 지역홍수빈도분석
4.1 공간확장자료 활용의 타당성 평가
충주댐 상류유역을 대상으로 홍수량 공간확장 기법을 적용하여, NSE를 기준으로 각 사상별로 생성된 홍수량 확장자료의 신뢰성을 확보하였다(Kim et al., 2013; 2014). 추가적으로 확장자료를 이용한 지역홍수빈도해석을 위해서는 통계적인 특성치를 평가하는 것이 필요하다. 따라서 대상유역내에 위치한 정선2, 영월, 방림, 영춘 수위관측지점과 충주댐 지점의 관측자료와 확장자료의 1986-2010년 기간동안의 연최대홍수량 계열에 대하여 각각 Hosking and Wallis(1997)가 제안한 지역홍수빈도해석 절차를 수행하였다. 여기에서는 확장자료를 활용한 지역홍수빈도해석의 타당성을 평가하기 위해 관측자료와 확장자료의 L-mements와 분위수를 중심으로 비교・검토하였다.
우선 지역빈도해석을 위해서는 자료의 오류나 비일관성에 대한 전반적인 검증을 실시하여야 한다. 이를 위해 지점자료들의 L-moments(L-CV, L-skewness, L-kurtosis)를 이용한 불일치 척도(discordancy measure) 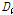 를 검토하였다. Table 2에서 확인할 수 있는 바와 같이 관측자료와 확장자료의 각 지점별
를 검토하였다. Table 2에서 확인할 수 있는 바와 같이 관측자료와 확장자료의 각 지점별 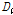 는 관측자료와 확장자료의 모든 지점에서 지역내의 지점수에 따른 한계값 1.333(지점수가 5개일 경우)보다 작은 통계치를 나타내었다. 이는 분석지점들이 하나의 지역으로 가정하였을 경우, 자료의 오류 및 불일치하는 지점이 없음을 의미한다(Hosking and Wallis, 1997).
는 관측자료와 확장자료의 모든 지점에서 지역내의 지점수에 따른 한계값 1.333(지점수가 5개일 경우)보다 작은 통계치를 나타내었다. 이는 분석지점들이 하나의 지역으로 가정하였을 경우, 자료의 오류 및 불일치하는 지점이 없음을 의미한다(Hosking and Wallis, 1997).
Table 2. Summary statistics for observed and simulated flood data | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
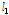
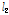
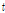
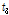
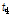
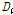
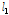
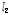
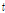
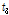
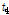
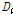
다음 단계로 각 지점별로 관측자료와 확장자료에 대한 L-moments를 비교・검토하였다. Table 2에는 지점별 관측자료와 확장자료에 대하여 각각 산정된 L-location(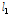 ), L-scale(
), L-scale(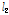 ), L-CV(
), L-CV(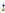 ), L-skewness(
), L-skewness(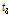 ), L-kurtosis(
), L-kurtosis(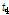 )를 제시하였다. 관측자료에 비해 확장자료의 L-location(
)를 제시하였다. 관측자료에 비해 확장자료의 L-location(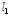 ), L-scale(
), L-scale(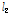 ), L-CV(
), L-CV(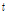 ), L-skewness(
), L-skewness(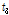 ), L-kurtosis(
), L-kurtosis(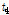 )은 각각 평균적으로 0.8, 15.0, 22.2, 31.2, 43.2 % 큰 값을 나타내었다. 분석지점별 경향을 분석하기 위해 Fig. 2에서 관측자료와 확장자료의 L-moments를 비교하여 도시하였다. 평가지표로 Nash-Sutcliffe Efficiency (NSE, Nash and Sutcliffe, 1970)를 구해보면, L-location(
)은 각각 평균적으로 0.8, 15.0, 22.2, 31.2, 43.2 % 큰 값을 나타내었다. 분석지점별 경향을 분석하기 위해 Fig. 2에서 관측자료와 확장자료의 L-moments를 비교하여 도시하였다. 평가지표로 Nash-Sutcliffe Efficiency (NSE, Nash and Sutcliffe, 1970)를 구해보면, L-location(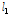 ), L-scale(
), L-scale(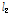 ), L-skewness(
), L-skewness(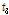 )에 대하여 각각 0.99, 0.88, 0.04으로 분석되었다. 일반적으로 수문모형의 효율을 설명할 경우, NSE는 0.5 이상이면 모의능력이 만족범위에 있다는 것을 의미한다(Moriasi et al., 2007). 따라서, 2변수 확률분포형의 매개변수 추정에 필요한 L-location과 L-scale은 NSE가 만족범위에 해당되므로, 지역빈도해석 수행시 2변수 확률분포형을 이용할 경우, 확장자료의 활용이 가능한 것으로 분석되었다. 하지만, 3변수 확률분포형의 매개변수 추정에 필요한 L-skewness의 경우에는 0.04의 값으로 만족할만한 모의능력을 보여주지 못하고 있다. 그러나, NSE가 0에 가까운 값의 의미는 확장자료가 관측자료의 평균값을 모의하고 있다는 것으로, 지수홍수법(Index flood method)에 의한 지역빈도해석에서 분포형의 shape parameter(일반적으로 L-skewness)는 지역적 평균값(regional average)을 이용하므로, 확장자료의 활용에 문제가 없을 것으로 판단된다.
)에 대하여 각각 0.99, 0.88, 0.04으로 분석되었다. 일반적으로 수문모형의 효율을 설명할 경우, NSE는 0.5 이상이면 모의능력이 만족범위에 있다는 것을 의미한다(Moriasi et al., 2007). 따라서, 2변수 확률분포형의 매개변수 추정에 필요한 L-location과 L-scale은 NSE가 만족범위에 해당되므로, 지역빈도해석 수행시 2변수 확률분포형을 이용할 경우, 확장자료의 활용이 가능한 것으로 분석되었다. 하지만, 3변수 확률분포형의 매개변수 추정에 필요한 L-skewness의 경우에는 0.04의 값으로 만족할만한 모의능력을 보여주지 못하고 있다. 그러나, NSE가 0에 가까운 값의 의미는 확장자료가 관측자료의 평균값을 모의하고 있다는 것으로, 지수홍수법(Index flood method)에 의한 지역빈도해석에서 분포형의 shape parameter(일반적으로 L-skewness)는 지역적 평균값(regional average)을 이용하므로, 확장자료의 활용에 문제가 없을 것으로 판단된다.
L-moments의 통계치 검토에 의해 지역빈도해석시 3변수 확률분포형 선정이 가능할 것으로 판단하였다. 따라서, 홍수빈도해석에 널리 이용되고 있는 GEV분포(general extreme value distribution)를 선정하여(NERC, 1975), 관측자료와 확장자료에 대하여 각각 분위수를 산정하여 비교・도시하였다(Fig. 3). 두 계열의 분위수는 재현기간 2, 10, 50, 100년에 따라 –2.3, 6.9, 8.7, 8.6 %의 오차범위를 나타내어, 지역빈도해석 수행시 지점별 관측자료 자체의 불확실성(Kim et al., 2015)에 비하여 작은 오차로 분석 되었다.
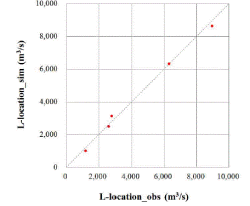
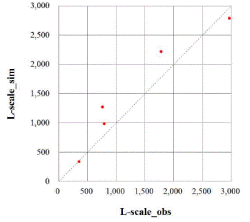
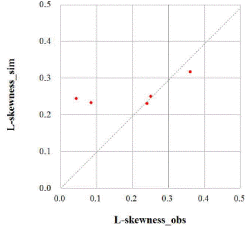
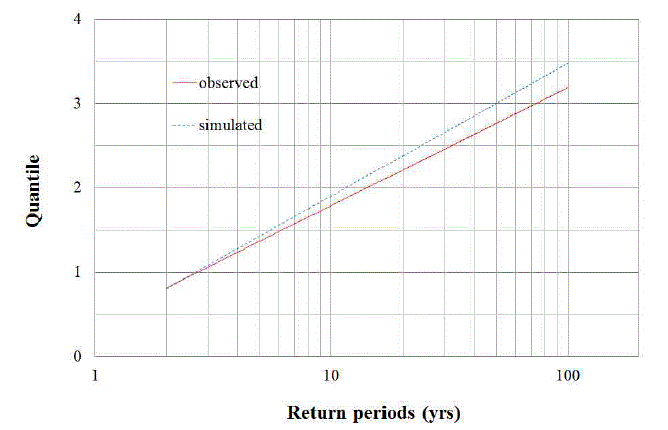
Table 3. Summary statistics for accumulated and independent basins | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
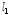
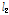
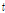
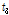
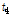
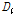
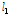
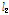
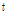
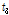
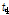
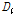
여기에서는 홍수량의 공간확장기법을 이용하여 다수지점의 홍수량 자료를 확보하여, 지역홍수빈도해석 수행을 위한 타당성을 평가하였다. 이를 위해 관측자료와 확장자료 계열의 지역홍수빈도해석을 위한 통계적 특성치인 L-moments와 분위수를 중심으로 비교하여 고찰한 결과, 확장자료를 이용한 지역홍수빈도해석 수행이 가능할 것으로 판단된다.
4.2 충주댐 상류유역의 지역홍수빈도해석
앞서 지역홍수빈도해석 수행을 위한 공간확장자료의 활용이 타당하다는 결론을 도출하였다. 따라서, 대상유역으로 선정한 충주댐 상류유역을 22개의 소유역으로 구분하여, 보다 많은 지역정보(22개 지점의 홍수량 자료계열)를 구축하여 지역홍수빈도해석을 수행하였다.
4.2.1 동질성의 물리적인 설명
여기에서는 불일치척도(discordancy measure, 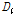 )를 이용한 자료의 동질성과 이질성척도(heterogeneity measure,
)를 이용한 자료의 동질성과 이질성척도(heterogeneity measure, 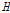 )를 이용한 유역의 동질성에 대하여 검토하였다. 추가적으로 소유역별 이질성을 구체적으로 설명하기 위해 누가유역과 자체유역으로 구분하여 분석하였다.
)를 이용한 유역의 동질성에 대하여 검토하였다. 추가적으로 소유역별 이질성을 구체적으로 설명하기 위해 누가유역과 자체유역으로 구분하여 분석하였다.
첫 번째로 자료의 동질성을 검토하기 위해 22개 지점에 대하여 누가유역과 자체유역별로 각각 분석한 L-moments와 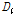 값을 제시하였다(Table 3). 먼저, 22개 분석지점들을 하나의 지역으로 가정하였을 경우, 자료의 오류 및 불일치하는 지점이 없는지
값을 제시하였다(Table 3). 먼저, 22개 분석지점들을 하나의 지역으로 가정하였을 경우, 자료의 오류 및 불일치하는 지점이 없는지 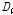 의 산정결과(지점수 N>15일 경우, Di<3를 만족해야 함)를 검토해보면, 모두 3이하의 값을 보였다. 이는 모든 지점들이 하나의 지역으로 간주하였을 경우, 자료의 동질성을 보인다는 것을 의미한다. 그러나,
의 산정결과(지점수 N>15일 경우, Di<3를 만족해야 함)를 검토해보면, 모두 3이하의 값을 보였다. 이는 모든 지점들이 하나의 지역으로 간주하였을 경우, 자료의 동질성을 보인다는 것을 의미한다. 그러나, 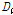 값이 만족범위 이내에 있지만, 누가유역, 자체유역 두 경우 모두 22번 소유역에서 각각 2.91, 2.57로 상대적으로 이질한 유역으로 나타났다. 22번 유역의 경우, 대관령 기상관측지점이 위치한 충주댐 최상류 소유역으로 다른 유역들에 비하여 강수량이 상대적으로 많기 때문이다.
값이 만족범위 이내에 있지만, 누가유역, 자체유역 두 경우 모두 22번 소유역에서 각각 2.91, 2.57로 상대적으로 이질한 유역으로 나타났다. 22번 유역의 경우, 대관령 기상관측지점이 위치한 충주댐 최상류 소유역으로 다른 유역들에 비하여 강수량이 상대적으로 많기 때문이다.
두 번째로 지역의 동질성은 지점자료의 통계적 특성치와 동질지역에서 기대되는 통계적 특성치를 비교하여 검증할 수 있다. 통계적 특성치로 L-moments는 이러한 목적에 적합한 통계량이다(Hosking and Wallis, 1997). Hosking and Wallis (1997)는 사용된 L-Moments에 따라 이질성척도 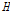 를
를 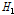 (L-CV),
(L-CV), 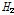 (L-CV, L-skewness),
(L-CV, L-skewness), 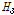 (L-CV, L-kurtosis)의 세 가지 형태로 제시하였으며,
(L-CV, L-kurtosis)의 세 가지 형태로 제시하였으며, 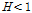 이면 동질지역,
이면 동질지역, 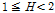 이면 이질지역일 가능성이 있는 유역,
이면 이질지역일 가능성이 있는 유역, 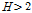 이면 이질지역으로 분류된다고 제시하였다. Table 4에 제시된
이면 이질지역으로 분류된다고 제시하였다. Table 4에 제시된 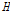 값들을 검토해보면, 누가유역에 대한 분석결과는
값들을 검토해보면, 누가유역에 대한 분석결과는 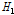 ,
, 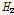 ,
, 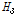 모두 1이하의 값으로 동질지역임을 확인할 수 있다. 특히,
모두 1이하의 값으로 동질지역임을 확인할 수 있다. 특히, 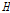 가 음의 값을 가지는 것은 독립적인 지점 빈도분포를 가진 동질지역일 확률보다는 지점별 L-CV 값들의 분산이 작다는 것이며, 이러한 원인은 지점자료들 간의 상관관계로 인한 것이다. 특히,
가 음의 값을 가지는 것은 독립적인 지점 빈도분포를 가진 동질지역일 확률보다는 지점별 L-CV 값들의 분산이 작다는 것이며, 이러한 원인은 지점자료들 간의 상관관계로 인한 것이다. 특히, 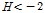 일 경우에는 지점별 빈도분포 간의 매우 높은 교차상관관계를 가진다는 의미이거나, 지점별 L-CV 값들이 매우 가까운 값을 갖도록 하는 자료의 과도한 규칙성(regularity)이 있다는 것을 의미한다(Hosking and Wallis, 1997). 이러한 누가유역의 홍수량 자료계열을 분석한 동질지역의 결과는 Kim et al. (2013)에서 제시한 홍수량 공간확장 기법을 적용하여 각 사상별로 홍수량 확장자료를 생성할 때, 유역전체에 대하여 일정한 강우-유출관계와 충주댐 지점에서 연최대홍수량이 발생한 홍수사상을 적용한 것이 원인으로 판단된다.
일 경우에는 지점별 빈도분포 간의 매우 높은 교차상관관계를 가진다는 의미이거나, 지점별 L-CV 값들이 매우 가까운 값을 갖도록 하는 자료의 과도한 규칙성(regularity)이 있다는 것을 의미한다(Hosking and Wallis, 1997). 이러한 누가유역의 홍수량 자료계열을 분석한 동질지역의 결과는 Kim et al. (2013)에서 제시한 홍수량 공간확장 기법을 적용하여 각 사상별로 홍수량 확장자료를 생성할 때, 유역전체에 대하여 일정한 강우-유출관계와 충주댐 지점에서 연최대홍수량이 발생한 홍수사상을 적용한 것이 원인으로 판단된다.
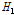
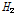
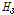
일정한 강우-유출관계와 동일한 홍수사상이라 하더라도, 대상유역 내에서도 강우분포는 공간적으로 불균등한 특성을 보이는 것이 일반적이다. 그러나, 수문학적 개념에서 하류지역의 홍수량은 상류유역의 홍수량의 영향이 반영된 것으로 하류지역으로 내려갈수록 일부 상류 지류유역의 홍수량 거동에 큰 영향을 받지 않는다. 이를 공간적인 강우분포의 측면에서 해석하면, 대상유역 내에서 일부 강우분포가 불균등한 소유역이 존재하더라도 하류유역으로 내려올수록 유역평균강우에 큰 영향을 미치지 못하며, 유역의 전체적인 평균값에 수렴되어져 간다. 따라서, 대상유역내 불균등한 강우분포의 특성이 일정한 강우-유출관계를 적용한 누가유역별 홍수량 자료에 반영되기에는 한계가 있을 것으로 판단된다. 따라서, 추가적으로 자체유역에 대한 홍수량 자료계열을 이용하여 지역내 강우의 불균등한 공간분포 특성을 고찰하였다. Table 4에서 자체소유역에 대한 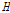 의 분석결과는
의 분석결과는 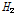 ,
, 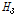 의 경우, 1이하의 값이므로 동질지역으로 분류될 수 있으나,
의 경우, 1이하의 값이므로 동질지역으로 분류될 수 있으나, 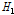 의 경우 5.36으로 이질지역으로 분류된다. 자체유역의 분석결과에 의한 지역의 이질성은 모델링을 통해 일정한 강우-유출관계를 적용하였기 때문에 대상유역내 강우의 공간적인 불균등한 분포를 의미하고 있다.
의 경우 5.36으로 이질지역으로 분류된다. 자체유역의 분석결과에 의한 지역의 이질성은 모델링을 통해 일정한 강우-유출관계를 적용하였기 때문에 대상유역내 강우의 공간적인 불균등한 분포를 의미하고 있다.
이에 대한 보다 자세한 분석을 위해 자체유역에 대한 홍수량 자료의 변동성을 의미하는 L-CV와 강우량의 변동성을 나타내는 지표를 설정하여 Fig. 4에 도시하였다. 강우량의 변동성을 나타내는 지표 R-CV는 Eq. (6)과 같이 설정하였다.
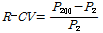 (6)
(6)
여기서, 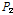 ,
, 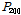 은 각각 재현기간 2, 200년에 해당되는 확률강우량(
은 각각 재현기간 2, 200년에 해당되는 확률강우량(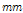 )이다. MLTM(2011)에서 제시한 확률강우량을 이용하여 22개 자체유역별 2, 200년 유역평균확률강우량을 구한 후, R-CV를 산정하였다. Fig. 4에 나타난 바와 같이 충주댐이 위치한 최하류 소유역(21번 소유역)을 제외하고 홍수량, 강우량의 변동성이 상류유역일수록 둘다 커지며, 하류유역일수록 변동성이 작아짐을 확인할 수 있다. Fig. 5에는 21번 소유역을 제외한 홍수량과 강우량의 변동관계를 분석한 것으로 결정계수(
)이다. MLTM(2011)에서 제시한 확률강우량을 이용하여 22개 자체유역별 2, 200년 유역평균확률강우량을 구한 후, R-CV를 산정하였다. Fig. 4에 나타난 바와 같이 충주댐이 위치한 최하류 소유역(21번 소유역)을 제외하고 홍수량, 강우량의 변동성이 상류유역일수록 둘다 커지며, 하류유역일수록 변동성이 작아짐을 확인할 수 있다. Fig. 5에는 21번 소유역을 제외한 홍수량과 강우량의 변동관계를 분석한 것으로 결정계수(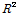 )는 0.682로 높은 상관관계를 보임을 확인할 수 있었다.
)는 0.682로 높은 상관관계를 보임을 확인할 수 있었다.
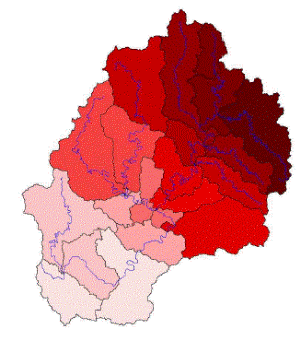
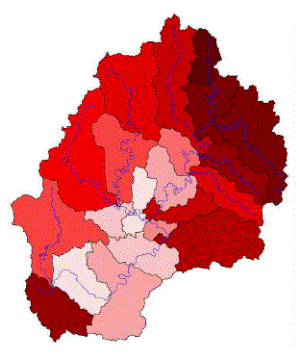
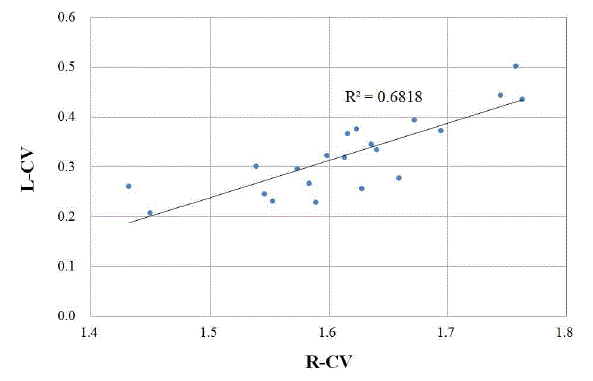
자체유역의 분석결과를 통하여 일정한 강우-유출관계와 동일한 홍수사상으로 수문학적 유사성(hydrological similarity)을 설명할 수 없다는 것은 유역의 지형학적 특성만으로는 유역의 동질성을 규명할 수 없음을 의미한다. 따라서, 강우의 공간적인 변동이 동질성을 설명할 수 있는 주요한 인자임을 구체적으로 증명할 수 있었다.
4.2.2 지역의 적정확률분포형 선정 및 분위수 산정
지역확률분포형을 선정하기 위한 적합성척도(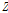 )를 산정한 결과를 Table 5에 나타내었다. Eq. (4)의 기준에 의하면 누가유역의 경우, 분석한 5개의 3변수 확률분포형 모두 적정분포형의 조건을 만족하였으나, 자체유역의 경우, PEARSON TYPE III 분포형만 적정분포형으로 분석되었다.
)를 산정한 결과를 Table 5에 나타내었다. Eq. (4)의 기준에 의하면 누가유역의 경우, 분석한 5개의 3변수 확률분포형 모두 적정분포형의 조건을 만족하였으나, 자체유역의 경우, PEARSON TYPE III 분포형만 적정분포형으로 분석되었다.
추가적으로 Floodfreq에서 제시한 WMA(Weighted Moving Averages) 방법으로 지역의 적정확률분포형 선정을 위한 도시적인 해석을 시도하였다. Fig. 6에는 지점별 L-moments, 3변수 확률분포형의 이론적 관계와 WMA를 이용한 지역 L-moments를 각각 도시하였다. 누가유역의 경우, GEV, LN3 분포를 만족하는 것으로 판단된다. 최종적으로 적합성 척도와 WMA를 이용한 방법을 모두 만족하였으며, 홍수빈도해석에 널리 이용되는 GEV 분포를 최적확률분포형으로 선정하였다. 그에 따른 무차원 성장곡선(분위수)를 산정하였으며, Fig. 7과 같은 결론을 얻었다.
5. 요약 및 결론
수공구조물의 설계를 위한 빈도홍수량 추정은 홍수량 자료가 없는 미계측유역을 대상으로 하는 경우가 대부분이다. 미계측유역에서의 홍수량을 추론하기 위해 지역홍수빈도분석 방법, 설계호우-단위도법, 강우모의모형에 의한 동역학적인 분석방법 등이 있으나, 관측자료에 기반한 빈도홍수량을 이용하여 검증되거나 각 방법론의 적용시 필요한 여러 매개변수를 고정하는 절차가 국내에서는 이루어지지 못하고 있는 실정이다. 이러한 이유는 관측자료의 신뢰성은 물론, 지역화하기 위한 자료기간 및 공간분석을 위한 자료 군의 밀도가 충분하지 못하기 때문이다. 따라서, 본 연구에서는 충주댐 상류유역을 대상으로 강우-유출관계를 이용한 공간자료 확장기법에 의해 발생된 다지점의 첨두홍수량 자료를 이용하여, 지역홍수빈도분석의 가능성을 검토하였다.
먼저, 지역홍수빈도분석의 표준방법인 지수홍수법을 중심으로 공간확장 자료의 활용에 대한 타당성을 검토하였다. 이를 위해 정선2, 영월, 방림교, 영춘, 충주댐 등 5개 지점의 관측자료와 확장자료의 L-moments와 분위수를 검토한 결과, 지수홍수(평균홍수량)보다는 분위수에서 더 큰 오차가 발생하였으나, 오차는 재현기간 100년에서 8.6 %로 관측자료 자체의 불확실성에 비하여 작은 오차로 판단된다. 따라서, 충주댐 상류유역의 22개 지점의 확장자료를 이용하여 지역홍수빈도분석 절차를 수행하였다. 유역의 동질성 가정을 구체적으로 검토하기 위해 수문학적 개념의 누가유역과 독립적인 자체유역으로 구분하여 분석을 시도하였다. 동일한 지역으로 가정한 대상유역의 경우, 자료의 불일치를 나타내는 불일치척도(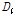 )는 모두 만족범위 이내로 분석되었다. 지역의 동질성을 나타내는 이질성척도(
)는 모두 만족범위 이내로 분석되었다. 지역의 동질성을 나타내는 이질성척도(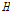 )의 경우, 누가유역에 대한 분석결과는 동질지역임을 확인할 수 있었다. 그러나, 자체유역에 대한 분석결과, 이질지역으로 평가되었으며, 이러한 이유는 모델링을 통해 일정한 강우-유출관계를 적용하였기 때문에 강우의 공간적인 불균등한 분포를 의미한다 할 수 있다. 또한, 홍수량과 강우량의 변동성에 대한 공간적인 분포는 매우 높은 상관관계를 보임에 따라 지역의 동질성을 설명하는데 강우는 주요한 인자임을 구체적으로 증명할 수 있었다. 마지막으로 지역확률분포형을 선정하기 위해 적합성척도(
)의 경우, 누가유역에 대한 분석결과는 동질지역임을 확인할 수 있었다. 그러나, 자체유역에 대한 분석결과, 이질지역으로 평가되었으며, 이러한 이유는 모델링을 통해 일정한 강우-유출관계를 적용하였기 때문에 강우의 공간적인 불균등한 분포를 의미한다 할 수 있다. 또한, 홍수량과 강우량의 변동성에 대한 공간적인 분포는 매우 높은 상관관계를 보임에 따라 지역의 동질성을 설명하는데 강우는 주요한 인자임을 구체적으로 증명할 수 있었다. 마지막으로 지역확률분포형을 선정하기 위해 적합성척도(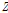 )와 Floodfreq에서 제시한 가중이동평균(WMA) 방법으로 검토한 결과, GEV, LN3 분포가 만족되었으며, 이 중에서 홍수빈도해석에 널리 이용되는 GEV 분포를 선정하였고, 그에 따른 유역의 분위수를 제시하였다.
)와 Floodfreq에서 제시한 가중이동평균(WMA) 방법으로 검토한 결과, GEV, LN3 분포가 만족되었으며, 이 중에서 홍수빈도해석에 널리 이용되는 GEV 분포를 선정하였고, 그에 따른 유역의 분위수를 제시하였다.
본 연구는 미계측유역에 대한 빈도홍수량 추정을 위해 지역홍수빈도분석을 중심으로 국내 관측자료의 한계를 극복하기 위한 시도이다. 지역홍수빈도분석 결과의 신뢰성을 조금 더 확보하기 위해서는 홍수자료 자체만을 분석하는 전통적인 방법론에 추가적으로 강우를 고려할 수 있는 방안이 필요할 것으로 판단된다.
