

1. 서 론
2. 방법론
2.1 연구 개요
2.2 이미지 분할 모델
2.3 이미지 분류 모델
2.4 수위 인식 모델의 성능평가 방법
3. 대상 시설 및 영상정보 수집 현황
3.1 연구 대상 시설
3.2 실측 영상정보 자료 수집 및 현황
4. 딥러닝 기반 농업용 저수지의 수위 인식 모델 구현
4.1 이미지 분할 모델 구축
4.2 수위 인식을 위한 분류 계급구간 설정
4.3 딥러닝 기반 수위 인식 모델의 매개변수와 구동 환경
5. 실험 결과
5.1 이미지 분할 모델의 모의 결과
5.2 수위 인식 모델의 학습성능 검토
5.3 대상 시설 간의 학습성능 비교
6. 결 론
1. 서 론
농업용 저수지는 농업용수를 안정적으로 공급하는 것을 목표로 하는 주요 생산기반시설로, 전국 17,240개 소가 설치되어 있다. 우리나라의 농업용수 중 60% 정도가 농업용 저수지에서 공급되고 있으며(MLTMA, 2011), 저수지에서 공급된 물은 관개용수로의 취수문을 거쳐 용수 지선에 유입되고, 구역별 수혜면적에 따라 할당된 지점 논의 관개용수로 사용된다. 최근 몇 년 동안 우리나라에서는 기후변화로 인해 집중호우와 가뭄 등과 같은 수재해 발생 빈도가 증가하고 있으며, 이로 인해 농업용수의 공급, 운영 및 관리에도 어려움이 심화되고 있다(ME, 2020). 한국농어촌공사의 가뭄백서에 따르면, 2012년에는 무강우 기간이 지속되면서 저수율이 20% 이하로 급격하게 감소하여 충청남도 지역에 농업 가뭄이 발생하였으며, 2014년에도 또한 평년 대비 강수량이 25% 정도 적게 발생하였으며, 이로 인해 강원도 원주시와 경기도 강화시에 농업 가뭄이 발생한 바 있다. 또한, 최근 2022년에는 전라북도 지역에 평년 대비 강수량이 35% 정도 적게 발생함으로써, 농업 가뭄이 발생한 사례도 있었다(ME, 2022).
앞서 기술한 바와 같이 다양한 문제점들이 발생하고 있으며, 안정적인 농업용수의 공급을 위해서는 농업용 저수지 또한 일반적인 저수지와 동일하게 가뭄 시 원활한 용수 공급과 집중호우 시 홍수 피해 예방을 위한 탄력적인 운영이 중요하다고 할 수 있다. 농업용 저수지의 탄력적인 운영을 위해서는 현재 저수지의 저수량을 정확하게 파악하는 것이 선행되어야 한다. 농업용 저수지의 저수량은 일반적인 저수지와 동일하게 저수위를 측정하여 추정하게 된다. 다만, 자동수위관측기가 설치된 농업용 저수지가 전체 저수지의 10% 정도 밖에 되지 않아 정확한 저수량 정보를 빠르게 확보하는 것은 거의 불가능하다고 할 수 있다. 이에 따라, 농업용수를 효율적으로 이용하기 위해서는 농업용수의 효과적인 공급 및 관리 체계 구현을 위한 실시간 저수위 혹은 저수량 추정이 시급한 실정이다.
하천의 경우 하천 수위 혹은 홍수량 추정 연구들이 활발히 보고되고 있다. 다만, 하천의 경우도 농업용 저수지와 같이 모든 구간의 수위 혹은 홍수량이 계측되고 있지 않기에, 영상정보(예, 드론 및 폐쇄회로 텔레비전(closed-circuit television; CCTV) 등)를 활용한 연구가 확대되고 있다. 예로, Maehara et al. (2016)은 하천에서 필터링 기술을 통해 수집된 CCTV 이미지를 객체 분할 처리하여, 이미지의 픽셀 수를 기반으로 하천의 수위를 추정하였으며, Li et al. (2022)의 경우 유역 내 지점의 영상정보를 활용하여 표면유속 측정 기법(Optical flow)를 통해 유역 내 한 지점의 홍수량을 예측하기도 하였다. 또한, 인공지능의 대중화로 인해 딥러닝 모델의 이미지 처리 방법을 활용한 하천 수위 또는 홍수량 추정을 위한 연구도 소개되고 있다. Maehara et al. (2019)는 딥러닝 모델인 CNN (Convolutional Neural Network)을 바탕으로 하천 수위를 추정한 바 있다. 또한, Chaudhary et al. (2019)는 소셜미디어를 통해 수집된 이미지를 바탕으로, 딥러닝 모델인 R-CNN을 활용하여 이미지의 객체 분할을 통해 하천의 홍수위 산정 방법론을 제안하였다. 유역 내에서 홍수 시 수위 추정을 위해 홍수 시 수면 변화를 비디오를 통해 계산하여 수위를 추정한 사례도 있다(Muste et al., 2011; Le Boursicaud et al., 2016; Creutin et al., 2003; Perks et al., 2020). 하지만, 기술한 연구들은 영상정보의 해상도에 따라 홍수량 또는 수위 추정 모델의 성능이 크게 달라진다는 한계가 있다는 것을 확인하였다. 따라서, 상기 한계점을 극복하기 위해, 인공지능을 활용한 CCTV 영상정보의 품질을 개선하고, 처리할 수 있는 기법을 개발한 연구도 많이 진행되고 있다(Li et al., 2019; Dhara et al., 2020; Pumo et al., 2021; Dal Sasso et al., 2023).
꼭 농업용 저수지가 아니더라도, 농업 분야에서 농업용수 공급량을 정량적으로 추정하기 위한 연구가 수행된 바 있다(Hong et al., 2014; Kim et al., 2016; Lee et al., 2020; Bang et al., 2021). Hong et al. (2014)는 실시간 수위 계측값을 기반으로 한 관개용수로의 공급량을 추정하고 평가한 바 있다. Kim et al. (2016)은 계측 지점의 수위 센서를 통해 수집된 이미지 자료가 농업용수 관리 측면에서 중요함을 강조하였으며, 농업용수의 공급량 추정을 위한 경제적인 수위 계측망 구축을 위한 방법론을 제안한 바 있다. 이외에도, 농업용수 공급량 추정에도 딥러닝 모델을 제안한 연구들이 소개된 바 있다(Yang et al., 2021; Kim et al., 2022). 특히, Kim et al. (2022)는 관개용수로 내에 수위를 측정하기 위해 CCTV 영상정보를 추출하고, 이미지 분류 방법과 분할 방법을 토대로 관개용수로 수위 산정 모델을 개발한 바 있다. 하천의 경우 앞서 정리한 것과 같이, CCTV와 같은 영상자료를 활용한 홍수량 또는 수위 추정에 관한 연구를 고도화하기 위해 영상정보 품질 개선, 인공지능 기반의 추정 기술 등이 활발히 개발되고 있지만, 농업 분야에서는 인공지능 기반한 시계열 자료 위주의 연구만 주로 진행되고 있으며, 영상정보를 활용한 연구는 미비하다.
본 연구에서는 농업 분야에서 지금까지 거의 시도되지 않았던 영상정보의 이미지 자료를 활용하여 딥러닝 기반 농업용 저수지의 수위 인식 모델을 개발하였다. 제안한 모델은 크게 세 가지 단계((1) 이미지 자료 구축; (2) 이미지 분할; 그리고 (3) 이미지 분류)로 구현된다. 개발된 모델은 두 농업용 저수지(G저수지와 M저수지)에 적용하였으며, 각 저수지의 실측 영상정보 이미지와 수위 자료를 분석하여 분류 계급구간을 각각 설정하였다. 이후 해당 계급구간에 정확하게 예측했는지 검토를 통해 농업용 저수지 수위 인식 모델의 성능을 평가하였고, 그 적용성을 검토하였다. 최종적으로, 개발한 수위 인식 모델의 한계점과 향후 연구 방향에 대한 제언 등을 논의하였다.
2. 방법론
2.1 연구 개요
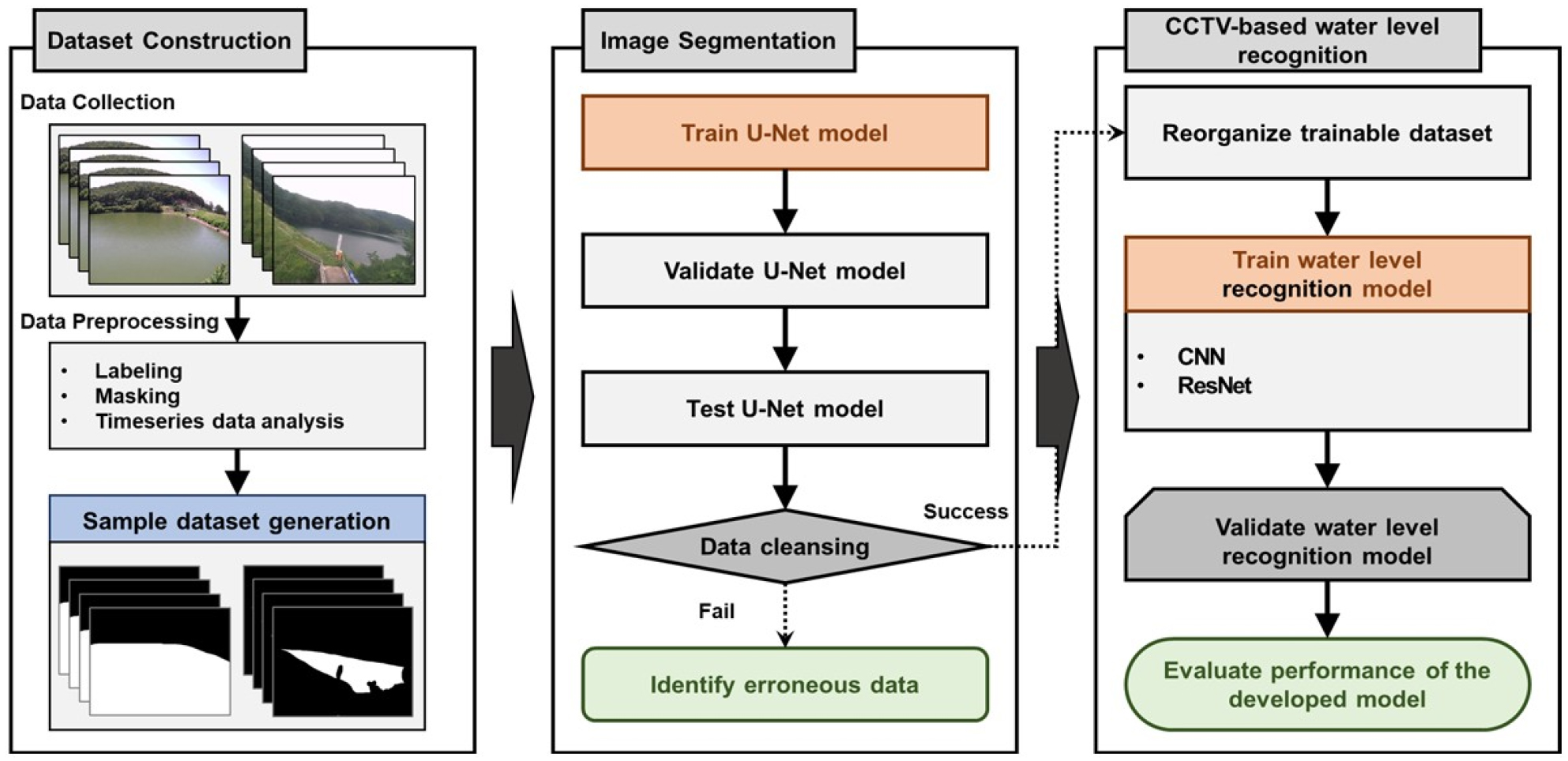
본 연구에서는 농업용 저수지의 CCTV 이미지를 활용한 딥러닝 기반 수위 인식 모델을 개발하였으며, 앞서 언급한 바와 같이 크게 세 단계로 구현된다(Fig. 1).
첫 번째는 이미지 자료 구축 단계로, 수집한 CCTV 영상정보를 분석 및 검토하여 딥러닝 모델에 활용할 수 있는 형태로 전처리한다. 다음으로, 전처리된 이미지 자료를 U-Net을 활용하여 딥러닝 모델이 학습할 수 있는 형태로 이미지 자료를 분할(특징화)한다. 이때 각 이미지의 수위 인식 모델 가용 여부 또한 결정한다. 마지막 단계는 가용 이미지 자료를 입력 이미지 자료로 활용, 이를 분류하여 수위를 인식하는 단계이다. 딥러닝 모델은 CNN과 ResNet을 선정하였으며 각 모델에서 도출한 수위 인식 결과를 토대로 각 모델의 성능을 평가하였다. 개발 모델은 두 곳의 대상 농업용 저수지에 적용됨으로써, 그 효율성을 검증하였다.
2.2 이미지 분할 모델
이미지 분할은 픽셀마다 클래스(class)를 할당하는 작업을 의미하며, 일반적으로, 사물에 대해 각 영역의 클래스에 따라 색상을 부여하여 이미지 영역을 분할하고 이를 통해 원하는 사물을 구분하는 과정이다. 이미지 분할은 Semantic segmentation과 Instance segmentation으로 분류되며, 전자는 각 픽셀이 어떤 클래스인지 구분하는 것에 초점을 둔 것이고, 후자는 같은 사물 내에서 서로 다른 개체의 특징까지 구분하는 것에 목적이 있다. 이미지 분할 영역에서 널리 활용되고 있는 딥러닝 모델은 FCN (Fully Convolutional Network), SegNet, U-Net, DEEPLAB V3 등이 있다(Long et al., 2015; Badrinarayanan et al., 2017; Ronneberger et al., 2015; Chen et al., 2017). 본 연구에서는 대표적으로 잘 알려진 U-Net을 기반으로 이미지 분할 모델을 개발하였다.
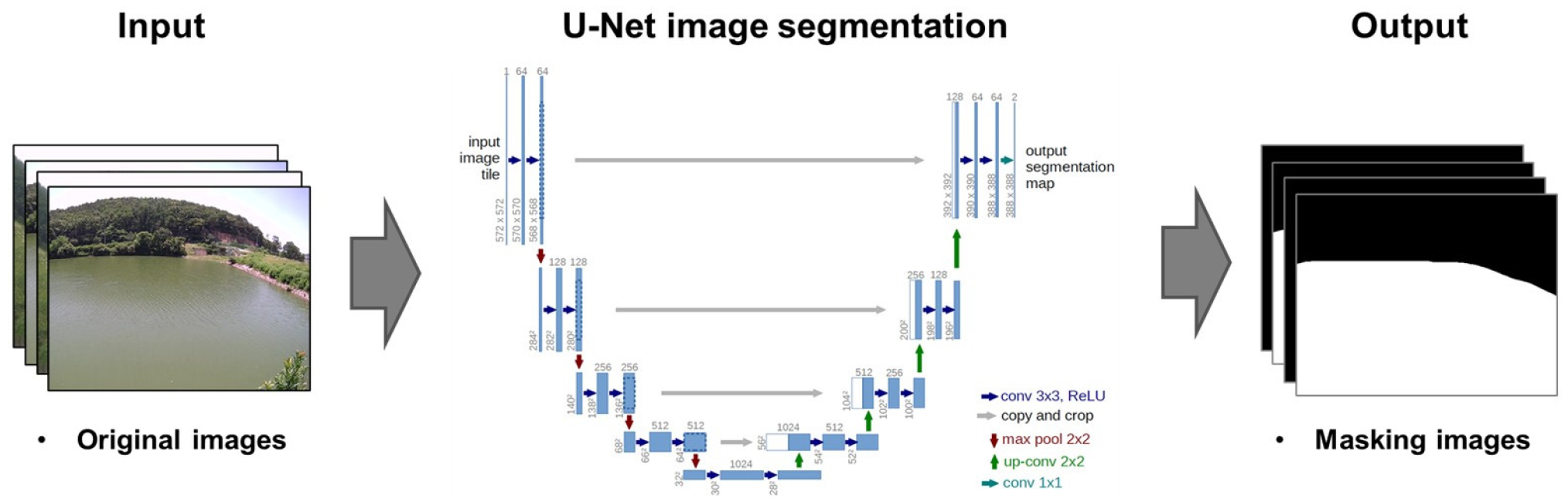
U-Net은 Ronneberger et al. (2015)에 의해 생체 의학의 이미지 세분화를 위해 제안되었다. U-Net은 U자 형태로 구성되며, Fig. 2는 본 연구에서 이미지 분할 모델 구축을 위해 활용된 U-Net의 구조를 나타낸 것이다. 왼쪽의 수축 경로(contracting path)에서의 블록은 3×3 합성곱 두 개로, 오른쪽의 확장 경로(expansive path)에서의 블록도 3×3 합성곱 두 개로, 총 네 개로 구성되어 있다. 그리고, 각 블록은 최대 풀링(max pooling)을 이용해 크기를 줄이면서 다음 블록으로 넘어간다. 반면, 오른쪽 확장 경로에서는 합성곱 블록에 추가 합성곱을 더해 구축 과정에서 줄어든 크기를 다시 증가하는 형태로 구성되어 있다. 따라서, 크기가 다양한 이미지의 객체를 분할하기 위해, 크기가 다양한 특징맵을 병합할 수 있도록 다운샘플링과 업샘플링을 순서대로 반복하는 구조로 이루어져 있으며, 이를 통해 학습을 효율적으로 할 수 있는 장점이 있다. U-Net은 속도가 빠르다는 것과 계산 과정 내에서 상충관계 문제가 발생하지 않는다는 장점이 있다.
2.3 이미지 분류 모델
이미지 분류는 컴퓨터가 이미지 속의 특정 대상 혹은 사물이 무엇인지 분류하는 것이다. 1990년대에 등장한 LeNet으로부터 시작하여 다양한 딥러닝 모델이 개발되었으며, 이미지 분류 영역에서 널리 활용되고 있는 딥러닝 모델은 CNN, AlexNet, VGGNet, GoogLeNet, ResNet, EfficientNet 등이 있다(Lecun and Bengio, 1995; Hinton et al., 2012; Simonyan and Zisserman, 2014; Szegedy et al., 2014; He et al., 2016; Tan and Le, 2019). 본 연구에서는 딥러닝 모델 중 CNN과 ResNet을 선정하였다.
2.3.1 CNN
CNN은 이미지 분류, 검출, 탐지를 위해 제안되었으며(LeCun and Bengio, 1995), 이를 적용한 관련 연구들이 널리 수행되고 있다. CNN은 이미지의 특징을 추출(feature extraction)하는 단계와 분류(classification)하는 단계로 구분된다. CNN은 합성곱 층(convolution layer)과 풀링 층(pooling layer), 그리고 정류선형유닛(Rectified Linear Unit, ReLU)와 같은 핵심 요소로 구성된다. 합성곱 층은 입력과 출력을 어떤 신호로 받아들이며, 가중치를 작은 크기의 필터 형태로 나타낸 가중치 커널이 있다는 것이 특징이다. 즉, 아무리 입력자료의 차원이 높아도 커널의 크기를 작게 설정하면 매우 적은 수의 가중치로 신경층을 정의할 수 있다. 풀링 층은 몇 개의 출력 값들을 요약하여 자료의 크기를 줄이는 역할을 하며, 이 과정을 통해 입력자료의 잡음이나 왜곡을 해소하는 효과를 나타낸다. 마지막으로, 정류선형유닛은 램프 함수의 활성을 가지는 비선형 뉴런으로, 기존 기계학습 기술의 인공신경망 등에서 활용되던 시그모이드(Sigmoid) 함수가 가지고 있던 여러 단점(예, 계산 효율, 역전파 알고리즘의 기울기 오류 현상 등)을 동시에 해결한다.
2.3.2 ResNet
일반적으로, 신경망의 깊이가 깊어질수록 딥러닝의 성능이 좋아지지만, 이에 따라 매개변수의 수가 증가함으로써 학습 시간이 길어지고, 기울기가 소실되는 등의 여러 문제가 발생한다. 이러한 이유로, 신경망은 깊이가 깊어질수록 성능이 좋아지다가 일정한 한계에 다다르면, 오히려 성능이 나빠진다. ResNet은 잔차 블록(Resdual block)의 개념을 도입하여 이러한 문제를 해결하기 위해 제안되었다(He et al., 2016). 잔차 블록은 숏컷(Shortcut, skip connection)을 제공하며, 이러한 숏컷을 기반으로 한 블록인 항등 블록(Identity block)과 합성곱 층으로 구성된 합성곱 블록을 통해 학습 성능이 개선된다. ResNet의 구조는 이러한 항등 블록과 합성곱 블록을 겹겹이 쌓아서 구성된다.
2.4 수위 인식 모델의 성능평가 방법
이미지 분할 및 분류 영역에서, 딥러닝 모델의 성능을 정량적으로 평가하기 위해서는 일반적으로 혼동행렬(confusion matrix)을 사용한다(Fig. 3). 이는 예측값이 실제 관측값을 얼마나 정확히 예측했는지 보여주는 행렬로 통계적 가설검정 시 사용되는 개념이다. Fig. 3에서, True Positive (TP)는 실제 참값을 참으로 예측한 정답이며, False Positive (FP)는 실제 거짓인 값을 참으로 예측한 오답, False Negative (FN)는 실제 참값을 거짓으로 예측한 오답, True Negative (TN)는 실제 거짓인 값을 거짓으로 예측한 정답에 대한 개념을 의미한다.

혼동행렬은 딥러닝 모델의 평가를 위한 정확도(accuracy), 정밀도(precision), 재현율(recall), F1 Score, IoU Score 등과 같은 지표 산정에 활용된다. 먼저, 정확도는 True Positive (TP) 혹은 False Negative (FN)를 예측한 비율로 가장 직관적으로 모델의 성능을 나타낼 수 있는 평가지표이다. 정확도는 아래 식과 같이 나타낸 것이다(Eq. (1)).
정밀도란 딥러닝 모델이 실제 참으로 분류한 것 중에서 참인 것의 비율을 나타낸 것이며, 아래와 같은 식으로 표현된다(Eq. (2)).
재현율은 실제 참(TP와 FN)으로 분류한 것 중에서 모델이 실제 참(TN)이라고 예측한 것의 비율을 나타낸 것이다(Eq. (3)). 정밀도와 재현율은 상호보완적으로 사용할 수 있으며, 두 지표가 모두 높을수록 좋은 모델로 평가할 수 있다.
F1 Score는 정밀도와 재현율의 조화 평균으로 계산되는 평가지표이다(Eq. (4)). F1 score는 이미지 자료의 레이블이 불균형한 구조일 경우, 모델의 성능을 정확하게 평가할 수 있으며, 성능을 하나의 숫자로 표현할 수 있다.
IoU Score는 이미지 내에서 실제 객체의 영역과 예측된 객체를 정량적으로 나타내는 지표이다(Eq. (5)). 이는 성능평가 지표 중 직관적인 지표로 가장 잘 알려져 있으며, 예측된 이미지와 정답 이미지 간의 중첩된 부분을 이들의 합집합으로 나누어 계산된다.
3. 대상 시설 및 영상정보 수집 현황
3.1 연구 대상 시설
본 연구에서 개발한 모델은 두 농업용 저수지에 적용되었다. 대상 저수지는 M저수지와 G저수지로 모두 충북지역에 위치한다(Fig. 4). 두 저수지 모두 한국농어촌공사로부터 운영 및 관리되고 있으며, CCTV를 통해 수집된 이미지 자료를 사전에 검토하여 절대적인 이미지 자료의 수량이 충분히 확보된 지점으로 선정하였다. M저수지의 총 유역면적은 85 ha으로 총저수량은 412,000 m3이며, G저수지는 총 유역면적은 120 ha, 총저수량은 750,000 m3이다.
3.2 실측 영상정보 자료 수집 및 현황
두 대상 저수지 모두 한국농어촌공사 시설로, 공사의 CCTV 통합시스템을 통해 각 대상 시설에 대한 영상정보를 수집하였다. 두 저수지 모두 2020년 6월 21일 00시부터 2022년 7월 18일 23시까지 1시간 단위로 측정된 영상정보를 각각 총 18,168장씩 수집하였다. 다만, 지점별로 결측된 영상정보 또는 가용할 수 없는 영상정보(야간 촬영 영상정보, 장애물 등)를 제외하면(Fig. 5), M저수지는 총 2,780장, G저수지는 총 1,755장만 가용 가능하였다. 수집된 영상정보의 해상도는 두 곳 대상 저수지 모두 1920×1080 픽셀이다. 또한 각 영상정보에 대응되는 저수위 및 저수율 시계열 자료도 수집하였다. M저수지는 최소 177.93 m (저수율 49.0%)부터 최대 179.57 m (저수율 101.3%)까지, G저수지는 최소 195.39 m (저수율 42.7%)부터 최대 197.76 m (저수율 105.1%)까지 각각 분포하고 있으며, 0.01 m의 측정 오차를 가지고 있다.


4. 딥러닝 기반 농업용 저수지의 수위 인식 모델 구현
4.1 이미지 분할 모델 구축
제안한 모델의 학습 및 검증을 위해 가장 중요한 과정은 이미지 분할 모델 구축으로, 가장 먼저 수집한 영상정보의 라벨링과 마스킹을 수행하였다. 영상정보 라벨링은 해당 영상정보의 날짜, 시간, 그리고 수위가 순차적으로 구분하여 작성하였다. 최종 모델에서는 마스킹 작업이 자동으로 수행되지만, 이미지 분할 모델의 초기 학습을 위한 기초 영상정보는 연구자가 직접 수행하였다. 본 연구에서 연구자가 직접 수행한 마스킹한 영상정보는 M저수지와 G저수지에 대해 각각 150장씩이다. 또한, 딥러닝 모델에서 입력 이미지로 허용될 수 있는 크기 또는 배율이 한정되어 있기에, 영상정보를 모델에 입력하기 전에 원본 이미지의 1920×1080 픽셀을 512×512 픽셀로 변환하여 개발 모델에 입력하는 전처리 작업을 수행하였다. 다만, 최종 출력으로 구성된 이미지는 원래의 해상도로 복원하는 과정을 다시 반복 수행하였다. 이미지 분할 모델의 학습률은 0.001, 기존 영상정보의 스케일은 0.2로 설정하여 학습하였다. 개발 모델 설계 시에 학습, 검증, 평가에 대한 영상자료 분포 비율은 7:1:2로 설정하여 학습하였고, 개발 모델 검증 후에 나머지 영상정보 자료의 마스킹 작업을 별도로 수행하였다.
4.2 수위 인식을 위한 분류 계급구간 설정
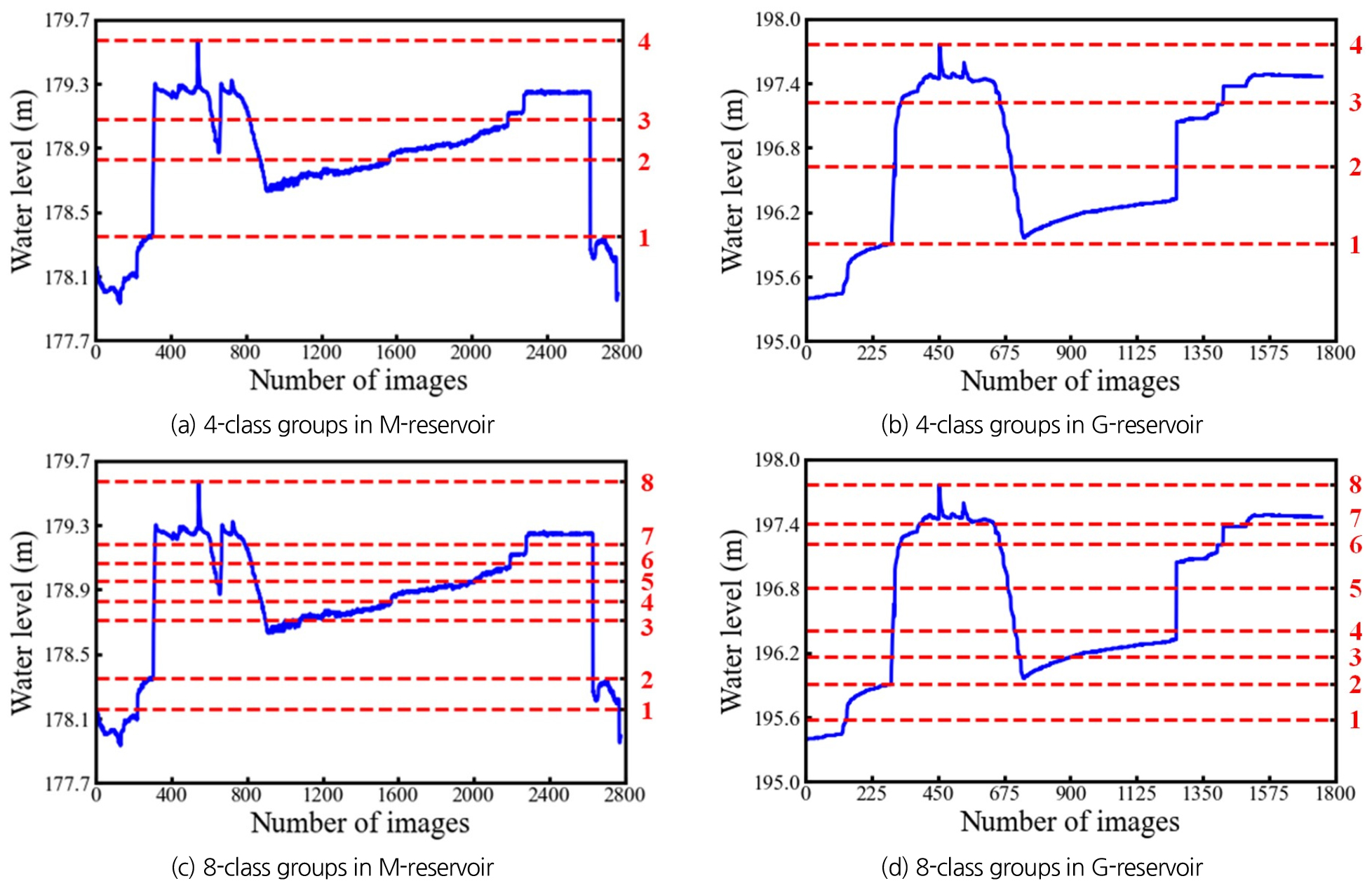
본 연구에서 제안한 모델은 이미지 분류 방법에 기반한 딥러닝 모델로 정확한 수위 분류를 위한 계급구간의 설정이 필요하며, 두 저수지에서 수위 조건이 상이하기에 독립적인 계급구간이 설정되어야 한다. 수위 인식을 위한 분류 계급구간은 Jenks의 자연분류법(natural breaks)에 기반하여 설정하였다. Jenks의 자연분류법은 각 분류 구간의 데이터 양을 유사하게 할당하여 실험 결과의 왜곡을 줄일 수 있는 것으로 알려져 있다. 본 연구에서는 수위 인식을 위한 분류 계급구간은 총 4개 혹은 8개 그룹으로 각각 설정하였다. Fig. 6은 각 대상 시설별 수위 인식을 위한 분류 계급구간의 분포도를 나타낸 것이다. 각 분류 계급구간은 4개 그룹일 경우, 1부터 4까지, 그리고 8개 그룹일 경우, 1부터 8까지 단위 그룹으로 정의하였으며, Figs. 6(a)~6(d)의 빨간색 숫자로 표기하였다.
4.3 딥러닝 기반 수위 인식 모델의 매개변수와 구동 환경
본 연구에서는 총 두 가지 딥러닝 모델(CNN과 ResNet)을 기반으로 농업용 저수지의 수위 인식 방법론을 개발하였다. 딥러닝 모델을 구현하기 위해서, Python 프로그램을 사용하였으며, Tensorflow를 기반으로 실험하였다. 모형의 구동을 위한 하이퍼 매개변수(hyperparameter)는, 옵티마이져(optimizer), 에포크(epoch), 손실함수(loss function) 등으로 구성된다. 옵티마이저의 경우 Tensorflow에서 제공하는 Adam 방법(Kingma and Ba, 2014)을 적용하였고, 에포크는 200회로 설정하였다. 손실함수는 Keras에서 제공하는 SCCE (Sparse Categorical Cross Entropy)를 적용하였고, 신경망의 효율을 높이기 위해, 배치의 크기는 16으로 학습하였다. 이외에도 Tensorflow의 Keras에서 제공하는 기본 기능을 사용하여 배치 정규화(Batch normalization), ReLu 활성화 함수, 3×3의 커널 크기(kernel size)를 고려하였다. 모델 구동은 2019년 출시된 64-bit 윈도우 10 체제의 컴퓨터를 기반으로 실험을 진행하였으며, 하드웨어는 3.70 GHz의 인텔(R) Core (TM) i9-19000X CPU, 256 GB RAM, NVIDIA의 GeForce RTX 3090 GPU를 탑재하였다.
5. 실험 결과
5.1 이미지 분할 모델의 모의 결과
U-Net을 통해 이미지 분할 모델을 구축 후 학습 결과는 Fig. 7과 같다. 분석 결과, 실제 정답 영상정보를 정확한 픽셀 수만큼 분류한 결과를 왼쪽 상단(TP, 물의 픽셀로 구분)과 오른쪽 하단(TN, 물이 아닌 픽셀로 구분)에 나타나 있으며, FP (왼쪽 하단)과 FN (오른쪽 상단)의 경우, 실제 정답 영상정보와 동일한 픽셀로 나타내지 못한 경우를 각각 의미한다. 거의 정확도가 99% 수준에 이르는 우수한 성능임을 확인하였다. 특히, 학습된 모델의 학습, 검정, 평가 기반의 모델 모두에서, FP와 FN에 오류로 발생한 확률이 매우 작은 것으로 확인되었다. 이의 의미는 대부분의 이미지를 이미지 형태에 맞게 적절한 픽셀 수로 영상정보를 분할 또는 구분한 것과 같은 의미이다.
Table 1에 개발 모델의 평가지표 계산 결과, 모델의 성능과 손실을 제시하였다. 분석 결과, 학습 시, 검증 시에 대한 수렴된 손실 값은 0.008과 0,040으로 대체로 낮게 도출되었다. 마찬가지로, 모델의 성능도 학습 시에 약 99%, 검정 시에 96~98% 수준의 높은 성능을 보였다. 평가지표 간의 약간의 차이가 다소 존재하지만, 전체적으로 좋은 성능을 나타낸 것으로 확인되었다.
대상 시설에 따라 구축된 학습 모델로부터 생성된 예측 영상정보와 정답 영상정보의 비교를 수행하였다. Fig. 8은 예측 영상정보와 정답 영상정보 간의 비교 결과이다. 이는 객체 분할을 위해, 예측 영상정보의 성능을 픽셀 수의 차이로 얼마나 정확한지, 정확하지 않은지를 판단한 것이다. 비교 결과, 영상정보의 해상도(512×512) 기준 총 픽셀은 262,144개로 전체 픽셀 수 중 약 1,000개 픽셀 안팎의 오차를 나타낸 것으로 확인하였다. 따라서, 개발된 이미지 분할 모델은 우수한 성능을 나타내고 있음을 확인할 수 있다. 정리하면, 본 연구의 대상 시설인 M저수지와 G저수지에 대한 수위 인식 모델에 입력으로 활용할 수 있는 영상정보는 신뢰할 수 있는 자료임을 확인할 수 있었다.
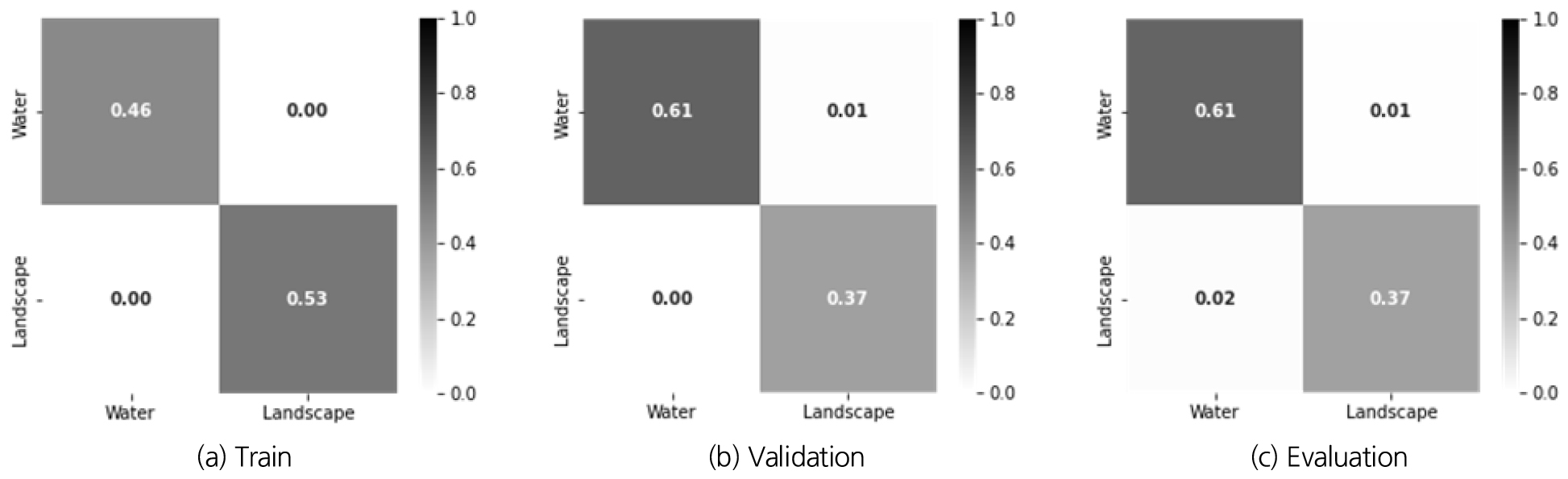
Table 1.
Accuracy and loss results obtained from the proposed data generation model
| Final loss | Accuracy | Precision | Recall | F1 score | IoU | |
| Train | 0.008 | 99.32% | 99.69% | 99.99% | 99.66% | 99.32% |
| Validation | 0.040 | 97.78% | 97.62% | 98.81% | 98.21% | 96.49% |
| Test | - | 98.71% | 99.72% | 98.21% | 98.94% | 97.92% |

5.2 수위 인식 모델의 학습성능 검토
본 연구는 Jenks의 자연분류법(Jenks, 1967)을 고려하여 분류 계급구간을 4개 그룹과 8개 그룹으로 설정하였다. 다음 소절에는 각 대상 시설별 독립적으로 개발된 모델의 정확도 및 손실, 각 분류 계급구간에 할당되는 수위 값을 얼마나 잘 예측했는지 학습성능을 검토하였다.
5.2.1 M저수지
Table 2는 M저수지의 개발 모델에 대한 손실과 정확도 결과를 정리하여 제시하였다. 본 연구에서 결과를 포함하지 않았지만, 개발 모델의 에포크가 진행됨에 따라 손실과 정확도가 안정적으로 수렴하였다. 분류 계급구간이 4개 그룹일 경우, CNN과 ResNet 기반으로 수위 모델의 모의된 손실 결과는 각각 0.66, 0.54로 확인되었다. CNN과 ResNet에 대한 정확도 결과의 경우에도, 0.75와 0.78로 각각 계산되었다. 손실과 정확도는 분류 계급구간이 4개 그룹일 경우, 두 모델 모두 우수한 성능을 보이는 것으로 확인되었다. 반면에, 분류 계급구간이 8개 그룹으로 증가하면, 손실은 증가하고, 정확도는 감소하였다. 이는 한정적인 영상정보 자료가 더 많은 그룹으로 분할되어 하나의 분류 계급구간 당 영상정보 자료가 충분하지 못하기 때문이다. 이러한 이유로, 두 가지의 분류 계급구간에 따라, 모델의 종류와 상관없이 계급구간의 수가 증가할수록 수위 인식 모델의 학습성능이 저하된다는 점을 확인하였다.
Table 2.
Loss and accuracy results of the proposed water level estimation model in M-reservoir
앞서 언급한 바와 같이, 분류 계급구간이 4개 그룹일 경우, 두 모델의 학습성능이 비슷한 수준임을 확인하였다. 다만, 분류 계급구간이 8개 그룹으로 증가할 경우, CNN의 정확도는 0.75에서 0.33으로 대폭 감소하는 반면, ResNet의 정확도는 0.78에서 0.60으로 상대적으로 적게 감소하는 것으로 나타났다. 실제로 ResNet은 잔차 블록이라는 개념을 통해 영상정보의 특징이 유실되지 않도록 하는 모델의 특징으로 인해, 적은 수의 영상정보로도 CNN보다 우수한 성능으로 효율적인 훈련이 가능하다고 알려져 있다(He et al., 2016; Serte et al., 2022).
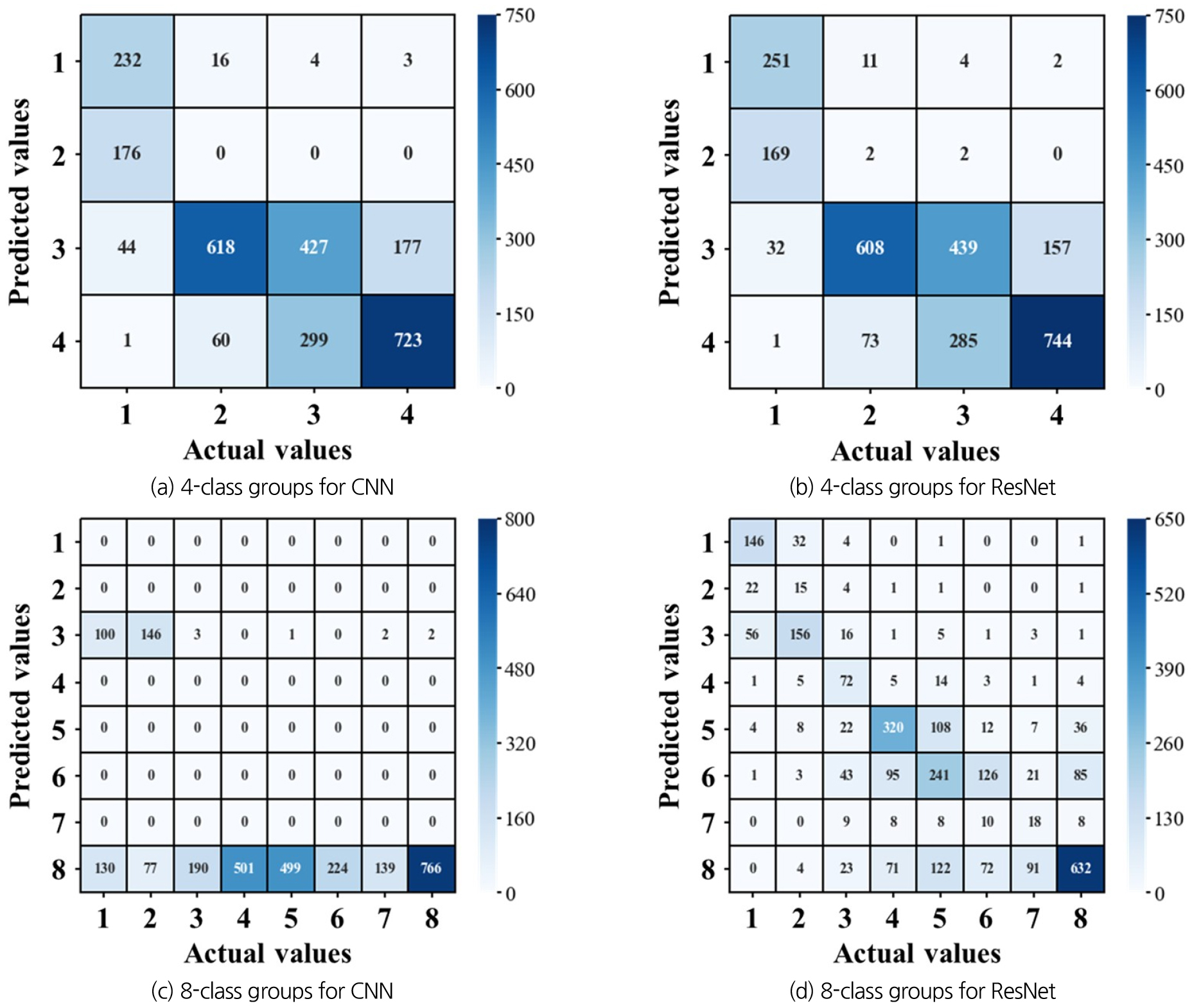
Fig. 9는 동일한 결과의 혼동행렬을 나타낸다. Fig. 9에 제시한 혼동행렬 결과에서, 가로는 실제 분류 계급구간에 대한 기준을 의미하고, 세로는 예측 분류 계급구간에 대한 기준을 의미한다. 즉, 왼쪽 상단에서 오른쪽 하단의 대각선에 위치해 있는 결과는 실제 정답 영상정보를 설정한 분류 계급구간에 정확하게 예측한 결과를 의미한다. 반면에, 나머지 결과들은 실제 정답 영상정보에 할당되는 분류 계급구간에 분류하지 못함을 의미한다.
분석 결과, 분류 계급구간이 4개 그룹일 경우, 두 모델의 학습성능이 비슷한 수준이며, 영상정보를 각 분류 그룹에 해당하도록 잘 분류한 것을 확인하였다. 다만, 분류 계급구간이 8개 그룹으로 증가할 경우, CNN 기반의 수위 인식 모델은 거의 예측하지 못하는 것을 확인하였다. 이는 앞서 언급한 바와 같이, 각 분류 계급구간에 충분한 수의 영상정보가 확보되지 않은 이유로, 모델이 잘 학습할 수 없었기 때문에 학습성능 저하라는 결과가 도출되었다. 반면에, ResNet의 경우, 분류 계급구간이 8개 그룹일 경우, 실제 영상정보에 해당하는 분류 계급구간에 분류하는 경우도 있었으나, 정확도가 낮아짐을 확인할 수 있었다.
또한, 분류 계급구간이 8개인 경우, CNN과 ResNet 기반의 수위 인식 모델 모두에서 예측 분류 계급구간을 과대추정하는 경향이 확인되었다. 실제로, 단위 그룹의 분류 계급구간에 속하는 자료임에도 불구하고, 대부분의 이미지를 8번 그룹에 분류하는 것으로 확인되었다(혼동행렬의 가장 아래 부분). 이는 단위 그룹별로 학습할 수 있는 충분한 영상정보 수가 확보되지 않아 개발 모델 학습이 어려웠던 것으로 판단되며, 이로 인해 정확도가 낮은 결과가 도출된 것으로 판단된다. 만약, 단위 그룹별 충분한 수의 영상정보가 확보된다면, 현재 개발 모델 보다 우수한 성능의 학습 결과를 도출할 수 있을 것으로 판단한다.
5.2.2 G저수지
먼저, Table 3은 G저수지의 개발 모델에 대한 손실과 정확도 결과를 정리하여 제시하였다. 마찬가지로, 분류 계급구간이 4개 그룹일 경우, CNN과 ResNet 기반으로 수위 모델의 모의된 손실 결과는 각각 0.51, 0.45로 확인되었다. 또한, CNN과 ResNet에 대한 정확도 결과의 경우에도, 0.85로 두 모델 같은 값으로 계산되었다. 앞서 기술한 바와 같이, 분류 계급구간이 4개 그룹일 경우, 두 모델 모두 우수한 학습성능을 보임을 확인할 수 있다. 다만, 분류 계급구간이 8개 그룹으로 증가하게 되면, M저수지의 결과와 마찬가지로 손실은 증가하고, 정확도는 감소하는 것으로 확인되었다. 이는 한정적인 영상정보 이미지로 모델을 학습해야 하는데, 하나의 분류 계급구간에 충분한 수의 영상정보 자료가 확보되지 못했기 때문이다. 두 모델 간의 비교 결과도, M저수지와 마찬가지인 CNN이 ResNet보다 특징을 더 많이 유실하는 구조로 알고리즘이 구성되어 있기에, 학습성능 또한 낮음을 확인할 수 있었다.
Table 3.
Loss and accuracy results of the proposed water level estimation model in G-reservoir
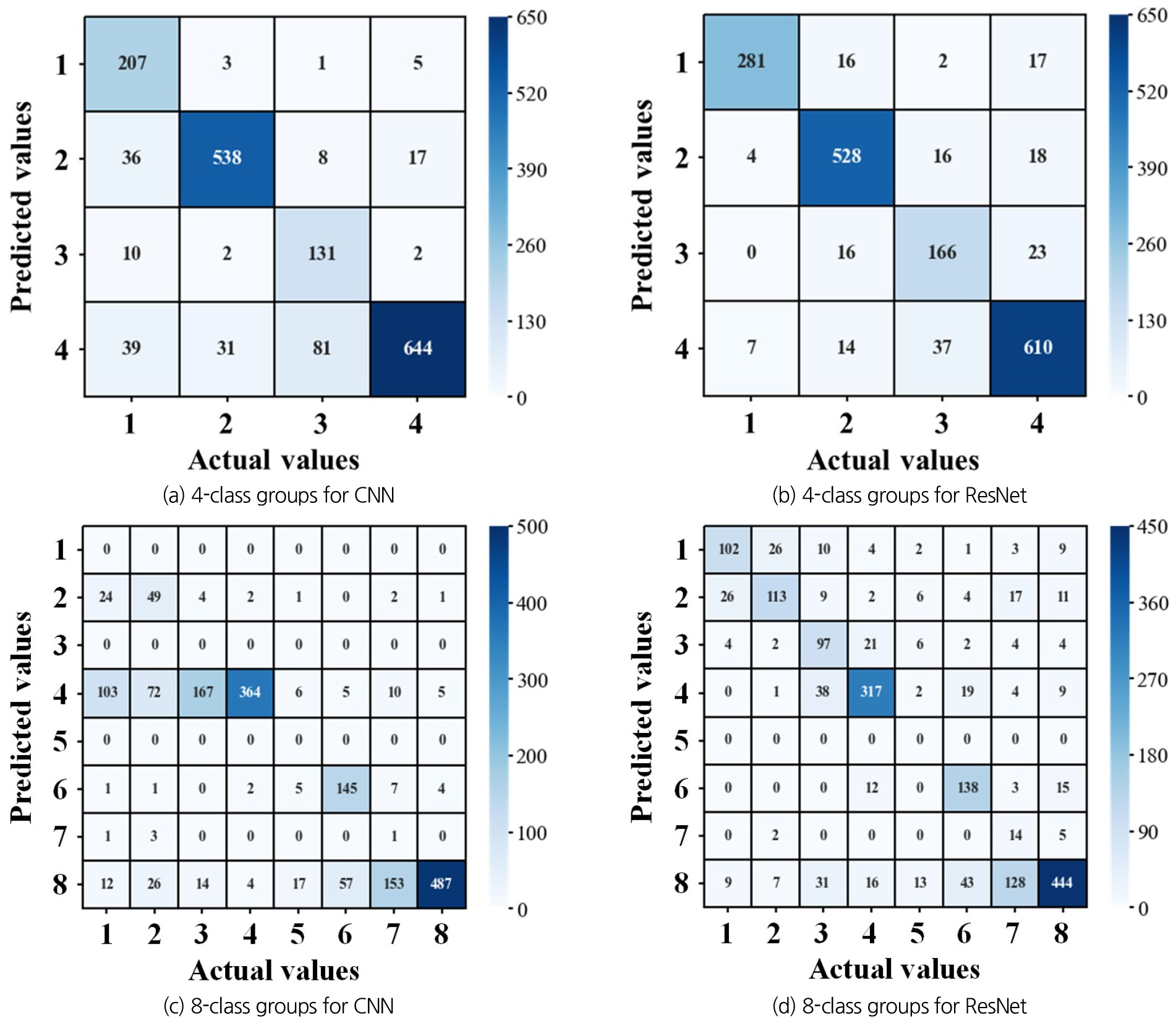
Fig. 10은 동일한 결과를 혼동행렬 방법으로 제시한 것이다. Fig. 9와 마찬가지로, 왼쪽 상단에서 오른쪽 하단의 대각선에 위치해 있는 결과는 실제 정답 영상정보를 설정한 분류 계급구간에 정확하게 예측한 결과를 의미한다. 분석 결과, 분류 계급구간이 4개 그룹일 경우, 두 모델의 학습성능이 비슷한 수준을 나타냈음을 확인하였다. 다만, 분류 계급구간이 8개 그룹으로 분류 계급구간이 증가하면 CNN 기반의 수위 인식 모델은 거의 해당 분류 계급구간에 영상정보를 잘 분류하지 못하였다. 특히, CNN 기반의 수위 인식 모델에서 M저수지의 모의 결과와 다른 점은 분류 기준 5번 그룹에 해당하는 분류 계급구간에 할당된 영상정보의 수가 너무 부족하므로, 해당 구간에 대한 영상정보는 두 모델 모두 예측하지 못하였다. 해당 영상정보들은 바로 인접한 계급구간에 잘못 분류되어 예측한 결과를 보임을 확인하였다.
이러한 이유로, 인접한 분류 계급구간에 영상정보가 잘못 분류되는 현상이 발생하기도 하였다. 더 자세히, M저수지의 분석 결과에서 언급한 것과 마찬가지로, 분류 계급구간이 8개인 경우, CNN과 ResNet 기반의 수위 인식 모델 모두에서 예측 분류 계급구간에 대해 과대추정 또는 과소추정하는 경향이 확인되었다. 이는 M저수지와는 상이한 결과로, G저수지에서는 4번 그룹과 8번 그룹으로 과대추정 또는 과소추정된 결과가 도출된 것임을 확인할 수 있었다. 결국에는 앞서 언급한 바와 같이, 분류 계급구간에 충분한 수위 영상정보가 확보되지 않았으므로, 모델이 학습하기 어려운 이유임을 시사할 수 있다.
반면에, ResNet의 경우, 분류 계급구간이 8개 그룹일 경우, 실제 영상정보에 해당하는 분류 계급구간에 잘 분류하였으나, 정확도 측면에서는 분류 계급구간이 4개 그룹일 때보다 낮아짐을 확인할 수 있었다. 이는 M저수지와 동일하게 결국 이미지 자료가 충분히 확보되지 않았기 때문이다. 따라서, 분류 계급구간에 대한 자료 불균형 문제가 예측 분류 계급구간에 대해 과대추정 또는 과소추정과 같은 문제를 기인하는 것으로 시사한다.
5.3 대상 시설 간의 학습성능 비교
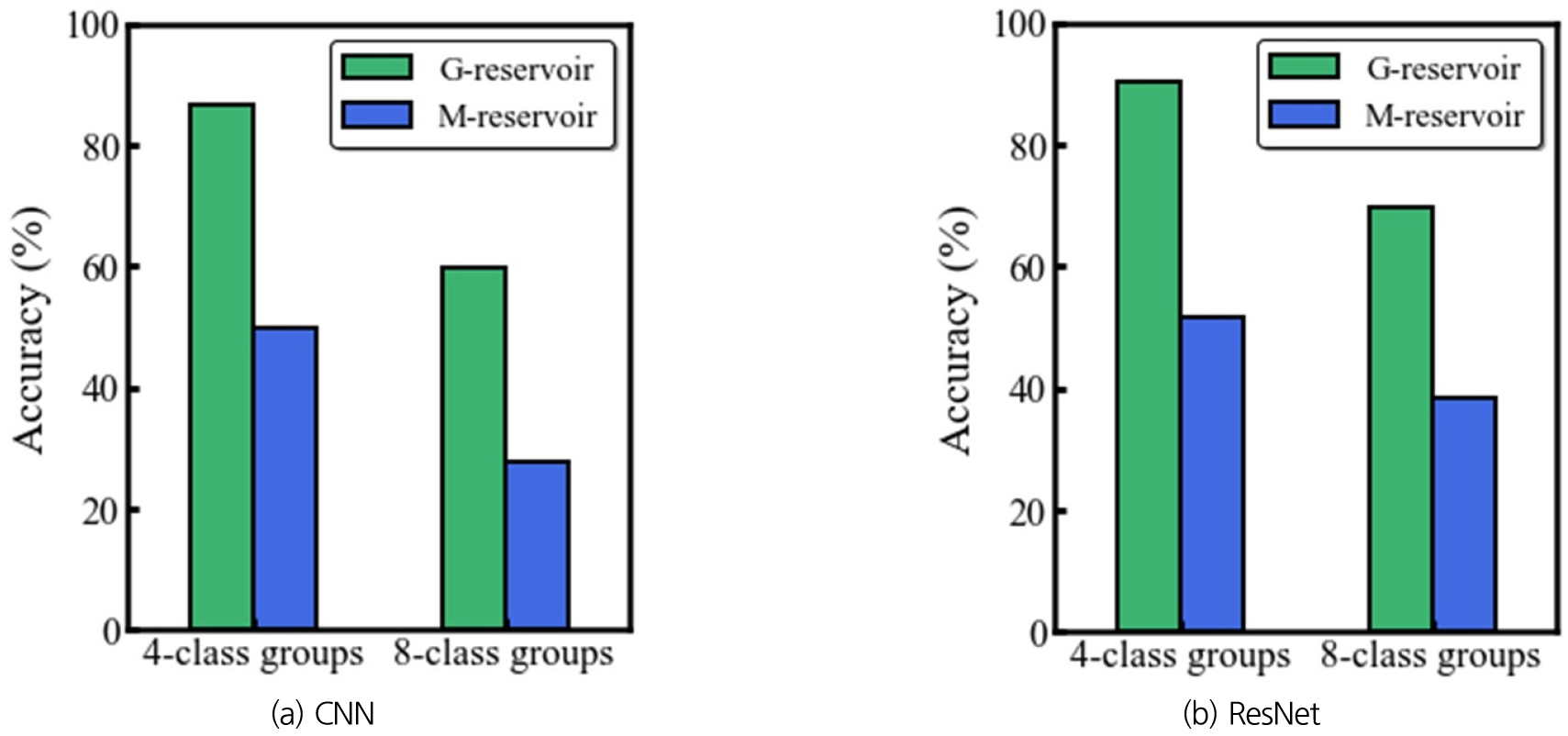
앞서, M저수지와 G저수지에 두 가지의 딥러닝 모델을 기반으로 수위 인식 모델을 개발하였으며, 각 개발 모델의 정확도 지표를 바탕으로 학습성능을 비교하였다. Fig. 11은 M저수지와 G저수지의 수위 인식 모델 간의 정확도를 계산하여 시각화하였다.
G저수지는 M저수지에 비해 더 적은 수의 이미지 자료를 가용할 수 있음에도 불구하고, 두 가지 딥러닝 모델에서 모두 훨씬 우수한 학습성능을 나타내었다. CNN 기반의 수위 인식 모델에서는 약 25~40% 정도의 정확도 차이를 보이고 있으며, ResNet 기반의 수위 인식 모델에서는 약 30~40% 정도의 정확도 차이를 나타내고 있다. 앞서 언급한 것과 같이, 영상정보의 이미지 자료가 부족한 것이 개발 모델에 대한 학습성능의 저하 원인의 표면적인 원인이라 할 수 있다. 실제로, 두 대상 시설에 따라 수위 인식 모델 개발 시에 활용할 수 있는 영상정보의 이미지 자료는 서로 다른 규모의 차이를 나타내고 있다. 특히, M저수지를 대상으로 한 수위 인식 모델은 G저수지보다 입력 이미지 자료가 더 많았음에도 불구하고, 그 학습성능이 더 낮았다. 이러한 이유는 모델에 입력되는 이미지 자료, 즉 수위 변화에 따른 이미지 내에 물을 포함한 픽셀의 수의 편차와 관련이 있는 것으로 나타났다.
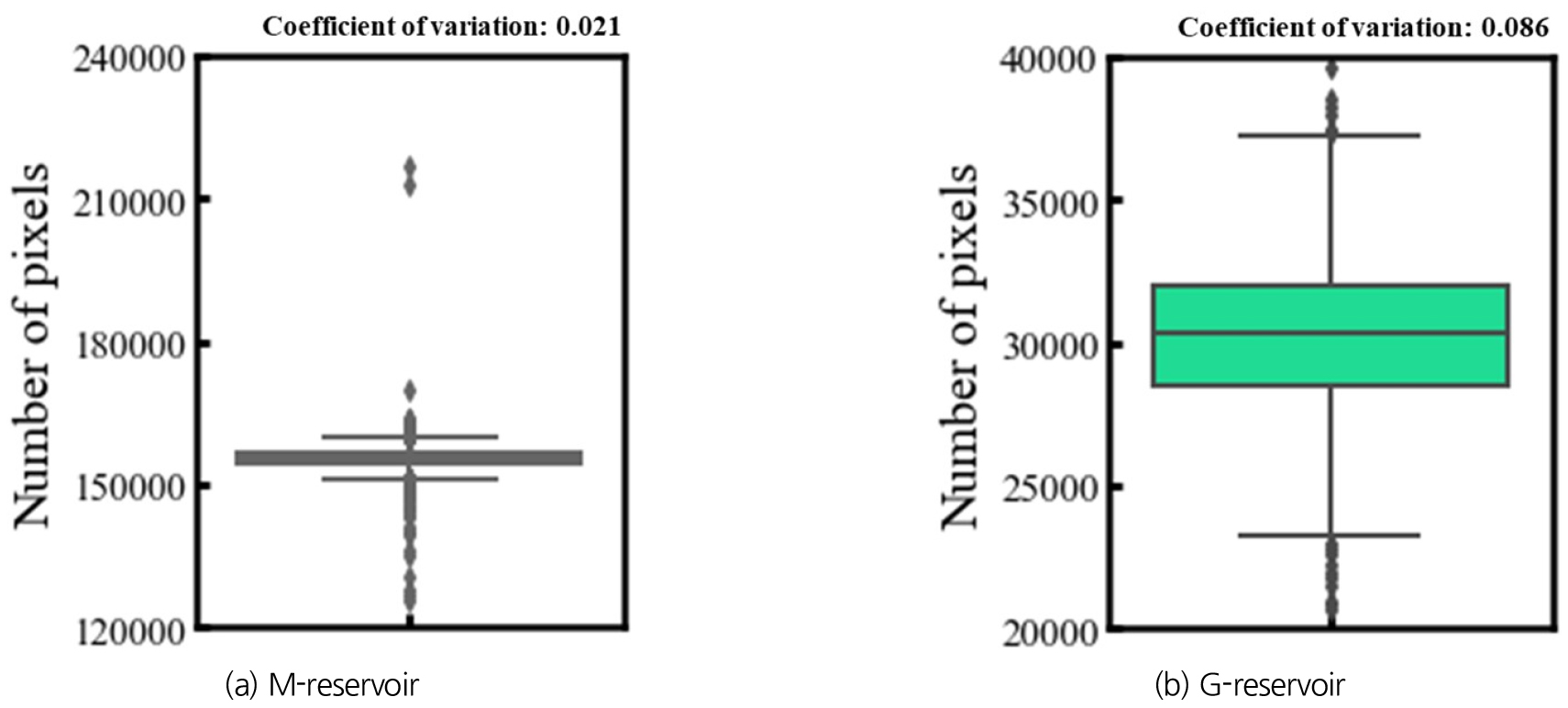
Fig. 12는 수위 변화에 따른 이미지 내에 물을 포함한 픽셀 수의 변화를 정량화하여 시각화한 결과이다. 수위 변화에 따른 픽셀 수의 변동성 비교 시, G저수지가 M저수지에 비해 변동 폭이 더 큰 것을 확인할 수 있었다. 또한, 수위 변화에 따른 픽셀 수의 변동계수도 확인한 결과, G저수지는 0.08, 그리고 M저수지는 0.02로 각각 계산되었다. 특히, G저수지의 이미지 자료의 변동성이 M저수지에 비해 약 4배 이상임을 확인할 수 있었다.
상기 결과를 통해, M저수지의 이미지에서 수위 변화에 따른 픽셀 수의 변동이 작다는 것은 이진화된 이미지에서 수위에 따른 객체 영역의 범위 변화가 미미하다는 것을 의미한다. 즉, 모델이 학습을 진행할 때, 입력된 이미지로부터 수위와 관련된 특징을 잘 추출하기 어렵다는 것과 같다. 이로인해, G저수지에 비해 M저수지의 학습성능은 전반적으로 낮게 도출된 것임을 확인할 수 있었다. 반면에, G저수지의 이미지는 수위를 포함하는 객체 영역의 범위 변화가 크다. 이는 입력된 이미지로부터 수위와 관련된 특징을 잘 추출하여 높은 학습성능을 나타냈다. 앞서 분석한 결과를 토대로, 이미지 내에 물을 포함한 픽셀 수에 대한 편차는 수위 인식 모델의 학습성능과 관련이 있음을 입증할 수 있었다.
6. 결 론
본 연구에서는 영상정보를 활용한 딥러닝 기반 농업용 저수지의 수위 인식 모델을 개발하였다. 개발한 모델은 크게 (1) 이미지 자료 구축; (2) 이미지 분할; 그리고 (3) 이미지 분류세 단계로 구성된다. 개발 모델은 두 농업용 저수지(G저수지와 M저수지)에 적용되어, 수위 실측값과 예측값의 비교를 통해 농업용 저수지의 수위 인식 모델에 대한 딥러닝 모델 간 성능을 평가함으로써 모델을 검토하였다. 검토 결과를 요약하면 다음과 같다.
1) 이미지 분할 모델의 학습성능 정확도는 우수한 성능(약 99%)임을 확인하였다. 이를 통해, 본 연구의 대상 시설인 M저수지와 G저수지에 대한 수위 인식 모델의 입력 자료로 활용할 수 있는 영상정보는 신뢰할 수 있는 자료임을 입증하였다.
2) CNN을 기반으로 한 수위 인식 모델은 분류 계급구간이 증가하면, 학습성능이 급격하게 감소하는 반면에 ResNet을 기반으로 한 수위 인식 모델은 일정 수준의 학습성능을 유지하는 것을 확인하였다. 이는 입력 자료로 확보된 영상정보의 수가 충분하지 않아 발생하는 문제임을 확인하였다.
3) 농업용 저수지의 영상정보 이미지 내에 물을 포함한 픽셀 수에 대한 편차는 수위 인식 모델의 학습성능과 관련이 있음을 입증하였다. 즉, 각 영상정보 이미지별 객체 영역의 범위 변화가 미미하다면, 딥러닝 모델이 입력된 이미지로부터 특징을 추출할 때 고유한 특징을 추출할 수 없음을 시사한다. 반면에, 이미지별 객체 영역의 범위 변화가 크다면, 고유한 특징을 더 잘 추출할 수 있는 효과가 있음을 확인하였다.
향후 연구에서 해결해야만 하는 한계점도 있다. 본 연구에서는 제한된 영상정보 자료를 활용하여 최대한 효율을 증대할 수 있는 수위 인식 방법론을 제안하였지만, 향후 개발 모델의 고도화를 위해서는 충분한 수의 영상정보 자료를 확보해야만 한다. 다만, 절대적인 영상정보 자료의 수 뿐만 아니라, 수위 분포에 따른 분류 시 각 분류에 해당하는 영상정보 자료 수가 편중되지 않게 나타나야 한다. 개발한 모델이 시계열 자료보다 영상자료에 따른 수위 정보가 중요하기에 급격한 수위 변화가 발생할 경우 좀 더 짧은 시간 간격으로 자료를 수집할 필요가 있다. 이뿐만 아니라, 드론과 같은 이동식 장비를 통해 영상정보 자료를 확보한다면 이를 활용할 수 있는 보다 고도화된 수위 인식 모델로 개선이 가능할 것이다. 마지막으로, 학습 이미지가 부족하다는 단적인 예로, 학습 모델의 성능을 향상하기 위해서는 자료 증식과 같은 방법을 활용하는 것이다. 그 예로는 이미지의 명도, 채도, 대비 등을 조정하는 다양한 방안들이 존재한다. 이를 통해, 모델의 학습성능을 고도화할 수 있음을 시사한다.
