

1. 서 론
2. 강수량 전망 값을 이용한 지하수 가뭄 전망
2.1 강수량과 지하수위 상관관계
2.2 강수량과 지하수위 관측 자료의 시공간적 범위 설정
2.3 SPI와 SGI의 상관성 분석
3. 인공신경망을 이용한 지하수 가뭄 전망 모형
3.1 인공신경망 모형
3.2 인공신경망을 이용한 SPI-SGI 상관관계 학습
4. 모형 적용 및 평가
5. 결 론
1. 서 론
국가 가뭄 예․경보를 위한 생․공용수 분야 가뭄정보는 용수공급 체계에 따라 연결된 급수지역의 수원(댐, 저수지, 하천 등) 상황을 토대로 지역별 가뭄현황을 분석하고 있다. 또한 가뭄전망을 위해 기상청에서 제공하는 1~3개월 강수전망을 이용한 강우-유출분석을 수행하고, 수원별 수문전망을 토대로 가뭄전망 자료를 생성하고 있다. 미급수지역의 경우 기존 SPI6 (6개월 누적 표준강수지수)를 이용한 간접적인 가뭄판단을 개선하기 위해 미급수지역의 주요 수원인 지하수위 관측 자료를 활용한 표준지하수지수(standardized groundwater level index; SGI) 가뭄판단 기법을 본 연구의 전편을 통해 제시하였다. 지하수위 관측 자료를 이용해 산정된 SGI와 판단기준 범위에 의해 과거 및 현재의 월별 지하수 가뭄 정도는 판단할 수 있으나, 가뭄 예․경보에 활용하기 위해서는 1~3개월 SGI 전망이 동시에 이루어질 필요가 있다.
지하수위를 전망하는 기법은 물리적 모형 또는 해석적 모형을 이용한 지역별 모델링 기법이 주로 이용된다. 하지만 이러한 방법은 모형의 구축과 매개변수 최적화 등에 많은 시간과 노력이 소요되며, 입력되는 자료의 변화나 공간적인 분석 대상의 조정 등에 유연한 대처가 어렵고 모형의 실행 자체도 까다로운 경우가 많다. 더군다나 분석 대상이 전국단위(167개 시․군 또는 3,482개 읍․면․동)로 확장되고, 분석 주기가 월간, 주간으로 빈번해질 경우 모형의 구축, 최적화, 갱신되는 입력 자료의 반영 및 실행 등이 빠르게 수행되기 어려운 것이 현실이다. 또한 가뭄 예․경보 일정상 기상청의 강수전망 자료가 매월 1일에 제공되면, 하루 이틀 사이에 전국에 대한 가뭄 분석을 완료한 후 부처 간 협의, 지자체 확인 등을 거쳐 10일에 발표해야 하는 상황에서 복잡한 물리모형은 적용 및 활용에 한계가 있다.
본 연구에서는 기상청의 강수전망 자료를 이용하여 지역별 지하수 가뭄을 전망할 수 있는 기법 개발을 목적으로 하였다. 가뭄 예․경보를 위해 매월 주기적으로 지하수 공급․사용지역의 가뭄판단을 지하수 관측자료 기반으로 수행하고, 기상전망 자료를 이용한 지하수 가뭄전망 분석이 빠르게 이루어질 수 있는 기법의 개발에 주안점을 두었다. 따라서 강수 아노말리의 거동과 지하수위 거동 간의 지체시간을 둔 상관관계에 주목하였으며, 지하수위 관측 시계열의 자기상관성을 동시에 고려할 수 있는 데이터 기반 모형(data-driven model)을 통해 지하수 가뭄을 전망할 수 있는 기법을 개발하고자 하였다.
2. 강수량 전망 값을 이용한 지하수 가뭄 전망
강수량과 지하수위와 같이 자료간의 상관성이 높고, 선행 원인과 응답 관계가 분명한 자료의 경우, 장기간 관측된 자료를 확보할 수 있다면 데이터 기반의 수치적 예측모형 구축이 충분히 가능하며, 이 경우 자료의 처리와 실행이 매우 빠르고 쉬워진다는 장점이 있다. 따라서 본 연구에서는 기계학습(machine learning) 기법의 일종인 인공신경망(artificial neural network; ANN)을 이용해 지속기간별 표준강수지수(SPI1~12)와 표준지하수지수(SGI)의 상관관계에 기초한 데이터 기반 지하수 가뭄 전망체계를 구축하고 전국 시․군에 대해 적용하였다.
2.1 강수량과 지하수위 상관관계
수문순환 과정에서 지하수의 함양은 강우의 침루(percolation) 에 의해 이루어진다. 이 과정은 지표수나 복류수 유출보다 오랜 시간이 걸리지만, 강수로부터 발생되는 유출 및 토양수분의 변화와 하천유출까지 상호 연관되어 있는 전체적인 수문순환 과정의 중요한 구성요소이다. 가뭄으로 인한 수문학적 상태변화 및 연관된 영향에 관해서는 Changnon (1987)의 문헌에 자세히 언급된 바 있다. 강수량의 부족은 용수의 공급원인 하천 유출량, 저수지 저류량, 토양수분, 지하수 함양량 등 여러 수문인자들에 시차를 두고 영향을 미치게 된다. 따라서 강수량의 부족이 가뭄을 유발하는 가장 큰 원인인자가 될 것이며, McKee et al. (1995)가 강수 부족을 지수화하여 가뭄의 정도를 판단할 수 있는 표준강수지수를 개발하게 된 이유이기도 하다.
강수량의 과부족이 수문순환 과정의 다른 인자들에 시차를 두고 영향을 미치는 과정은 여러 연구들을 통해 확인할 수 있다(Changnon et al., 1988; Lee and Koo, 2000; Yang et al., 2006; Jan et al., 2007; Yang and Ahn, 2008; Van Loon, 2015; Yeh et al., 2016). 강수량과 지하수위의 상관관계를 다룬 연구들에서 주로 다루어지는 내용은 강수가 지하수위 응답으로 이어지는데 걸리는 지체시간의 지역적 특성에 대한 분석이 많다. 다른 한편으로는 대수층 지하수 흐름 방정식과 물수지 방정식 등을 이용해 지하수위 변동을 해석적으로 예측하기 위한 연구도 있다(Park, 2007).
강수의 과부족과 지하수위 변동의 상관관계는 Fig. 1을 통해 쉽게 확인이 가능하다. Fig. 1은 평균 대비 과부족을 알 수 있는 강수 아노말리에서 강수량이 매우 부족한 기상학적 가뭄이 시차를 두고 지하수까지 어떻게 전파되는지를 보여준다. 지하수위에 영향을 미치는 인자는 물론 강수량만은 아니다. 하지만, 강수의 과부족이 지하수위의 거동에 영향을 미치는 중요한 인자임에는 틀림없다. 지하수위의 변화는 강수량의 증감, 하천유량의 증감, 하천수 및 지하수 채수량의 변화, 지하 대수층 매질상태의 변화 및 기타 지표의 함양 작용 등에 영향을 받지만, 지속적으로 진행되는 가뭄 특성은 지하수 수위의 강하 패턴과 유사하다고 알려져 있다(Kim et al., 2006).
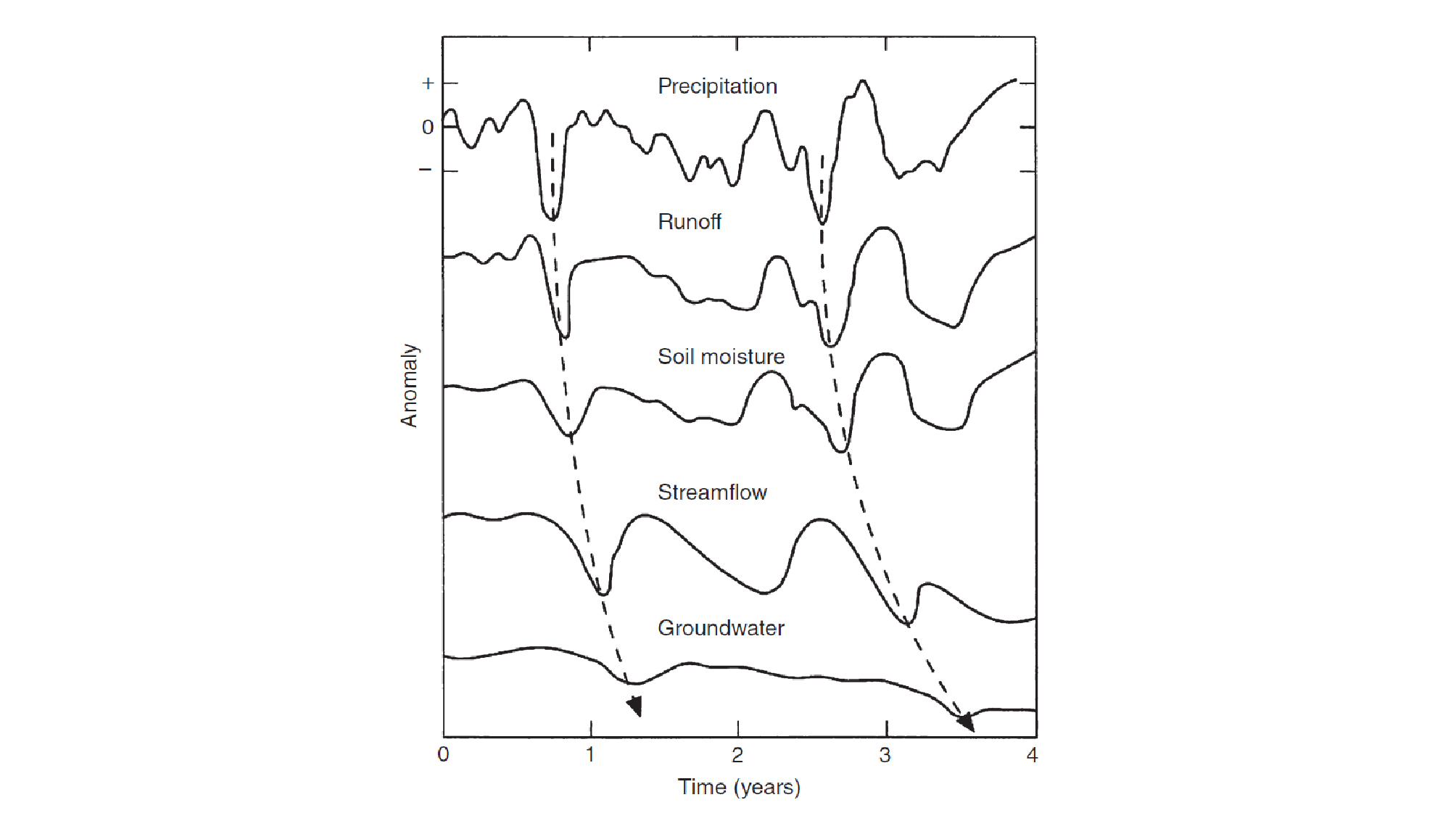
2.2 강수량과 지하수위 관측 자료의 시공간적 범위 설정
강수와 지하수위 간의 상관관계는 명확하게 드러나지 않는 경우가 많다. 지질의 특성에 따라 강수와 지하수의 상호 거동 특성이 달라진다. 특히 지하수 관측정이 암반층에 설치된 경우 그 관계를 규명하기 어려운 경우가 빈번히 발생한다. 더욱이 지하수위의 변동에 영향을 미치는 인자가 강수량이 유일한 것은 아니기 때문에, 강수에 의한 지하수의 응답 특성이 인근에 위치한 관측소들의 관측 자료로부터 명쾌하게 해석되기 어렵다. 따라서 강수 아노말리와 지하수의 상관성에 대한 분석에서는 전체적인 자료의 경향성이 일치하는 것을 확인하기 위해 적절한 시․공간적 범위를 설정하고 해당 범위에 속하는 자료들의 평균값 등을 이용하고 있다. 즉, 자료의 시․공간적 해상도를 낮춤으로써 민감하게 움직이는 자료의 노이즈를 제거하고 거시적인 자료 거동 특성의 상관성을 명확하게 확인하고자 함이다.
본 분석에서 사용한 강우관측지점 및 지하수위 관측지점은 공간적으로 정확히 일치하지는 않는다. 따라서 둘 간의 상관성을 규명하기 위해서는 맞비교가 가능한 관측소를 설정하거나 가중치 등을 부여해 자료를 합산하는 방법으로 비교할 자료를 전처리 하는 과정이 필요하다. 하지만 앞서 언급한 바와 같이 강수와 지하수위는 명쾌하게 일대일 상관관계를 보이는 경우를 찾기 어렵다. 따라서 가뭄 예․경보를 위해 필요한 공간 범위인 시‧군 범위로 자료의 공간범위를 일치시켜 관측소들이 차지하는 면적비율에 따라 가중치를 부여하여 평균함으로써 자료의 해상도를 낮추는 효과와 함께, 특정 관측소의 이상치 발생이 전체 자료의 상관도에 미치는 영향을 최소화 하고 강우에 응답하는 지하수의 전체적인 경향성을 잘 반영할 수 있도록 했다. 자료의 시간단위는 월단위에 맞추어 강수량은 월강수량 합계, 지하수위는 월평균 수위를 이용하였다. SPI의 경우 ‘74년 1월부터 ’16년 12월까지 동일 기간 자료를 이용하여 관측소별 SPI 및 지역별(시‧군별) SPI를 산정하였다. SGI의 경우 관측소별 자료 기간이 달라, 최장 ‘95년 12월부터 ’16년 12월까지 가용한 전체 자료를 이용하였다. 선정된 강우관측소와 지하수 관측소의 위치정보를 이용해 티센망(Thiessen network)을 구축하고, 각 관측소가 해당 시‧군에서 차지하는 면적 비율을 가중치로 적용하여 시․군별로 평균한 SPI와 SGI를 산정하였다. 분석을 위해 이용된 관측 자료의 개요와 변환과정을 Fig. 2에 도시하였다.

Table 1은 관측소별, 월별로 산정된 SGI를 지역별로 면적평균하기 위해 167개 시‧군 경계를 기준으로 해당 시․군에 기여하는 지하수위 관측소와 해당 면적비율을 산정한 예를 보여준다.
Table 1. Examples of Thiessen polygon area ratio of each groundwater station
2.3 SPI와 SGI의 상관성 분석
앞 절에서 공간적 범위를 일치시켜 산정된 지역 SPI와 SGI 시계열 중 천안시를 예로 도시하면 Fig. 3과 같다. 그림에서 검은색 굵은 선이 SGI를 나타낸 것이고, 가는 선들은 SPI1~ SPI12에 해당하는 값을 도시한 것이다. 월강수량과 월평균 지하수위를 이용했기 때문에 한 달 이내의 응답 시차를 미세하게 보여주지는 못한다. 하지만 공간적으로 지역화 된 값을 이용하기 때문에, 전반적인 증가, 감소 거동의 경향을 반영하는 것을 확인할 수 있다.
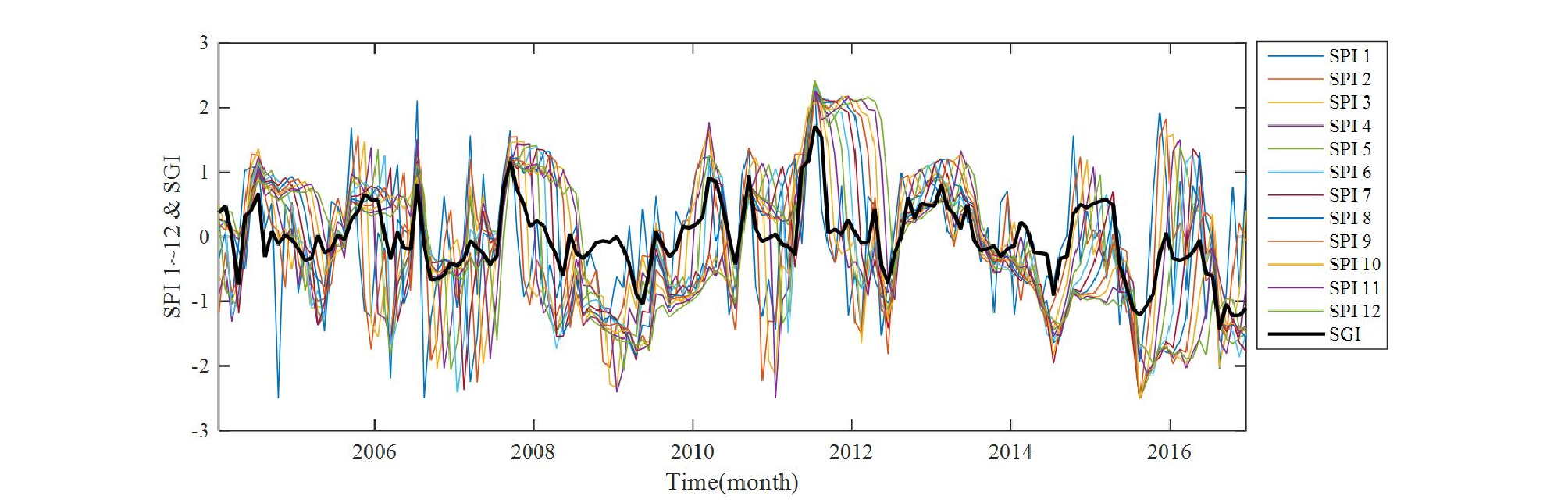
SGI와 12개의 SPI 지수들 각각에 대해 상관성을 분석하여, 지하수위 거동 전망을 위한 예측인자로서 SPI를 이용하는 것에 대한 적정성을 검토함과 동시에 강수 누적 기간에 의한 지하수위 거동의 응답특성을 확인하고자 하였다. Table 2는 청주, 음성 및 천안 지역에 대한 SGI와 SPI 상관성 분석 결과의 예시이다. 지역별로 두 가지 방법으로 산정한 SGI를 비교하였다. 하나는 지역에 기여하는 관측소들의 SGI를 산술평균한 값과 SPI1~12 간의 상관성을 분석한 결과이고, 다른 하나는 티센망으로 면적가중 평균한 SGI를 SPI와 비교한 결과이다. Fig. 4는 상관성 분석 결과를 직관적으로 비교하기 위해 충청도 26개 시‧군 지역을 예로 도시한 그림이다. 그림에서 행(row)은 하나의 시․군 지역에 해당하고, 각 시․군별로 12개의 열(column)은 각각 SPI1~SPI12에 해당한다. 각 블록의 색은 분석된 상관도에 따라 상관성이 높을수록 검은색으로, 낮을수록 흰색으로 표현하였으며, 12개의 SPI 중 SGI와 가장 높은 상관성을 갖는 SPI에 상관계수를 표시하였다. 즉, 맨 위에 있는 청주시의 경우 7번째 열에 해당하는 SPI7이 상관계수 0.743으로 12개 지속기간별 SPI 중 SGI와 가장 높은 상관성을 보이는 것을 의미한다.
Table 2. Examples of correlation coefficients between SGI and SPI1~12
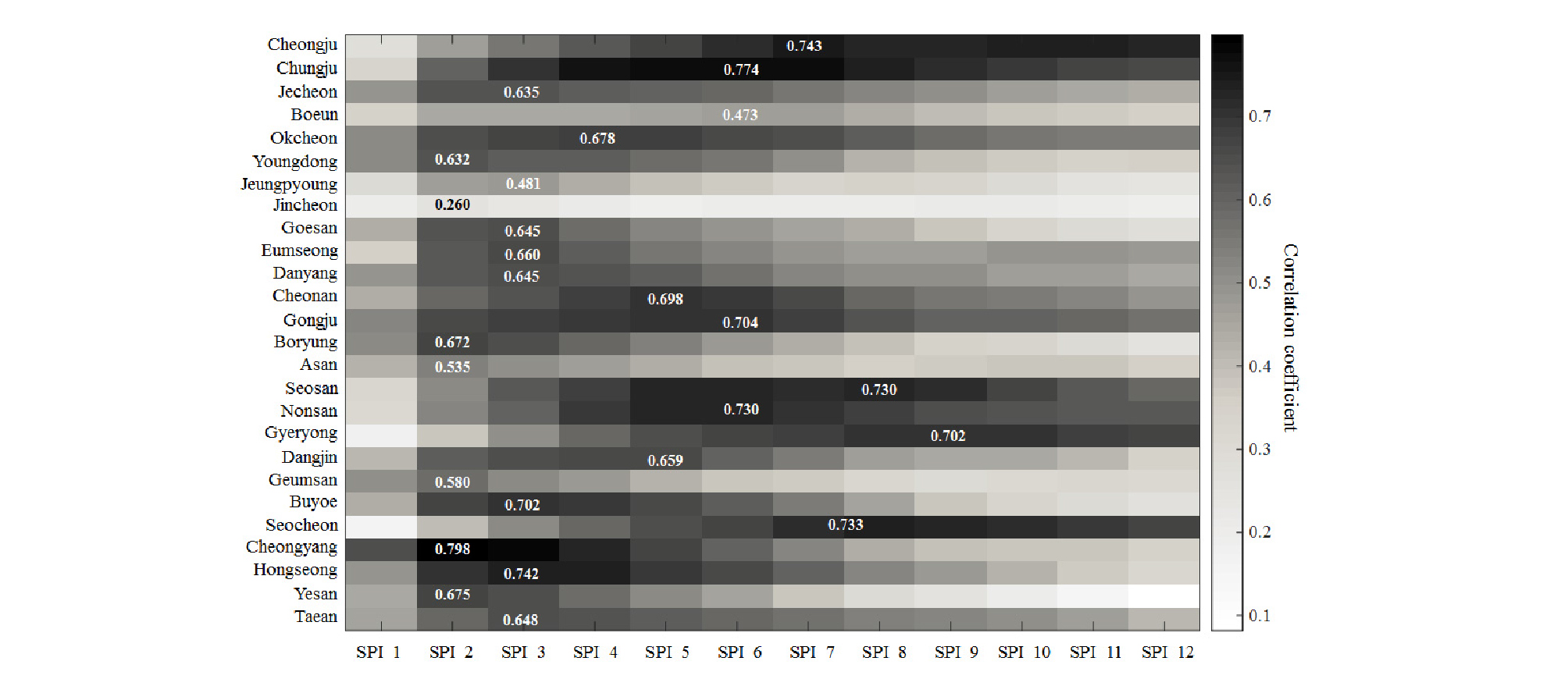
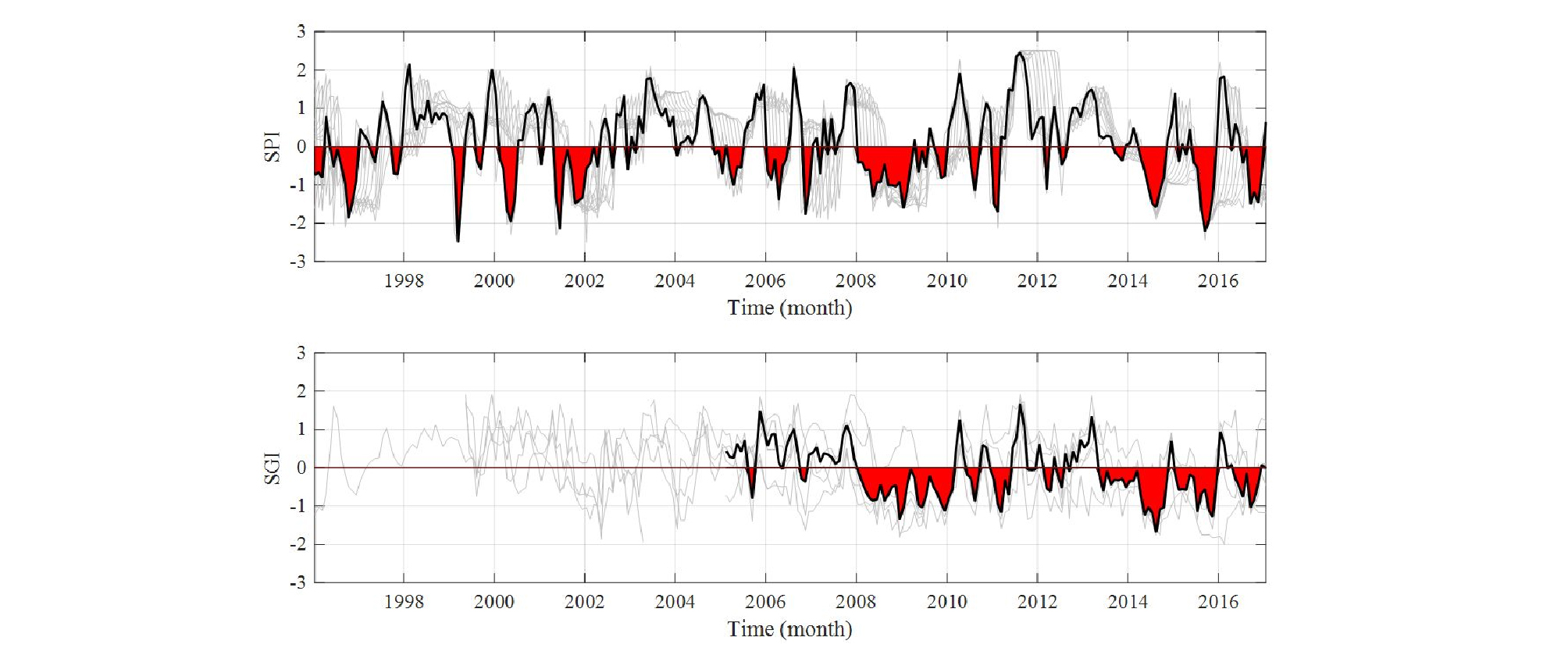
Fig. 5에 예시한 음성군의 경우 SPI3가 SGI와 가장 높은 상관성을 보였으며, 음의 값을 갖는 기간에 색을 입혀 두 지수가 표현하는 가뭄시기를 비교 도시하였다. 강수량과 지하수위 관측기간의 차이로 SGI의 자료 기간이 SPI에 비해 짧다.
3. 인공신경망을 이용한 지하수 가뭄 전망 모형
지역별 SGI를 이용한 가뭄 모니터링 기법은 선행 논문에서 제시한 바 있으며, 그 과정은 Fig. 6의 왼쪽 부분인 Groundwater drought monitoring 부분에 해당한다. 본 연구의 목적인 지하수 가뭄 전망을 위해서는 SGI로 대변되는 지하수위의 거동이 어떻게 될 것인지 전망하는 것이 필요하다. 본 연구에서는 지속기간별 SPI와 SGI의 상관관계를 인공신경망을 이용하여 학습시킨 후 기상청의 기상전망 자료로부터 산정한 지역별 SPI 전망 값을 학습된 인공신경망에 입력하여 SGI를 전망하였다. 전체적인 전망과정은 Fig. 6에 도시하였다.
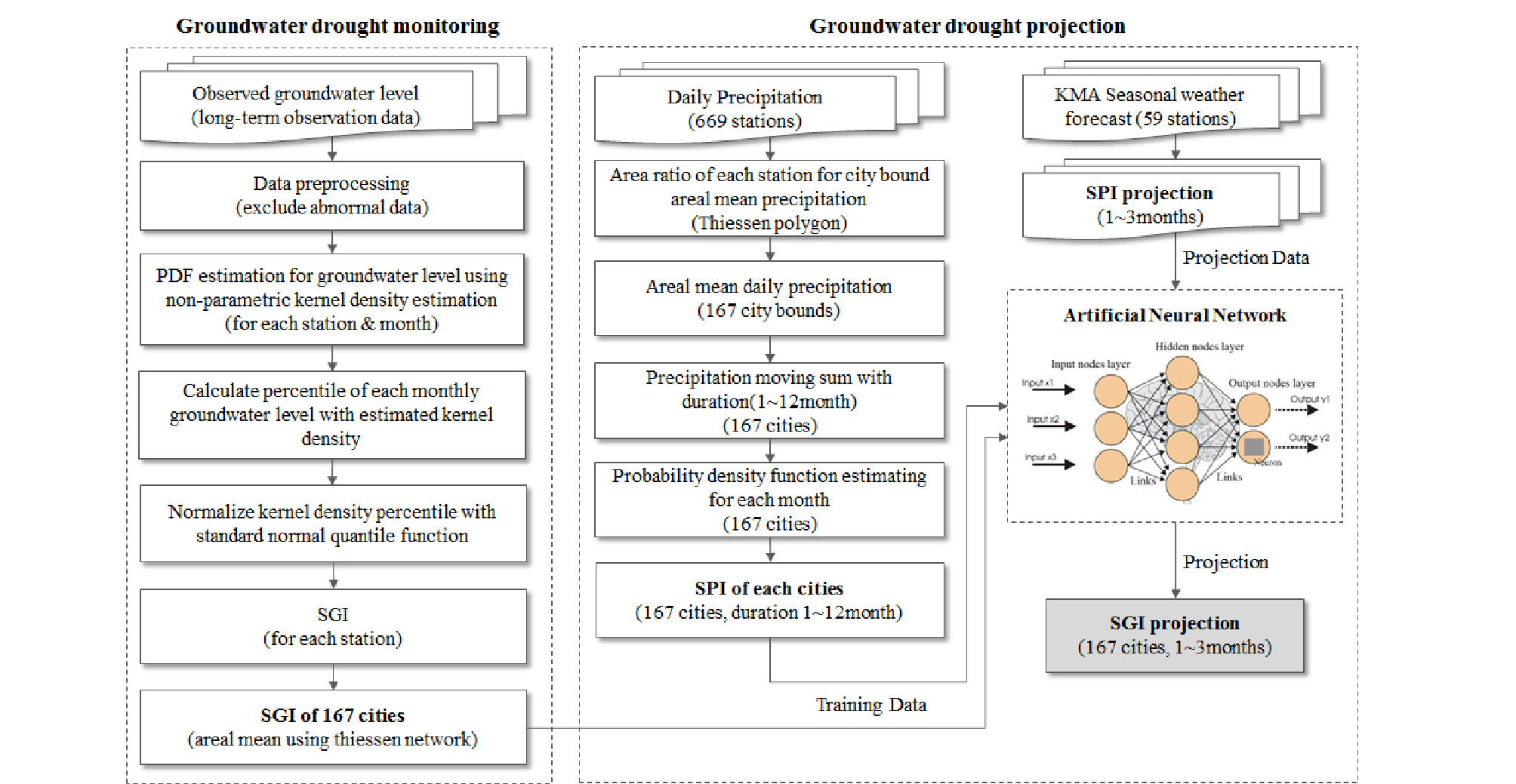
3.1 인공신경망 모형
인공신경망은 머신러닝의 한 종류로서 생물학의 신경망(동물의 중추신경계, 특히 뇌)에서 영감을 얻은 통계학적 학습 알고리즘이다. 머신러닝이란 간단히 말해 “데이터를 이용한 모델링 기법”이다. 인공신경망은 머신러닝의 다양한 모델 중 신경망을 이용한 모델을 일컫는다(Van Gerven and Bohte, 2017). 본 연구에서는 인공신경망의 종류 중 NARX (Nonlinear Autoregressive model process with eXogenous input) 모델을 이용하였다. NARX 모델은 주어진 시스템의 입력 값과 출력 값을 이용해 비선형성을 갖는 임의의 시스템을 식별해 내는 비선형 시스템 식별 기법 중 하나이다. NARX에서 ‘AR’은 자기회귀(autoregressive)를 의미하는 것으로 현재 시간에서의 시스템 출력 값은 과거의 시스템 입력 값은 물론, 출력 값에도 의존하여 결정됨을 의미한다(Kim, 2014; Diaconescu, 2008). NARX 모델의 수학적 정의는 아래 식과 같다.
| $$y(t)=f(y(t-1),\;y(t-2),\;\cdots,\;y(t-n_y),\;u(t-1),\;u(t-2),\;\cdots,\;u(t-n_u))$$ | (1) |
여기서 종속변수인 출력 값 y(t)의 다음 값은 이전 출력 값 및 독립 입력 값(외부 입력) u(t)의 이전 값에 회귀된다. 은닉층의 전달함수는 탄젠트-시그모이드 함수를 사용하며, 출력층은 리니어 함수를 사용한다. NARX 모형의 구조는 Fig. 7과 같다(Hagan et al., 2014).
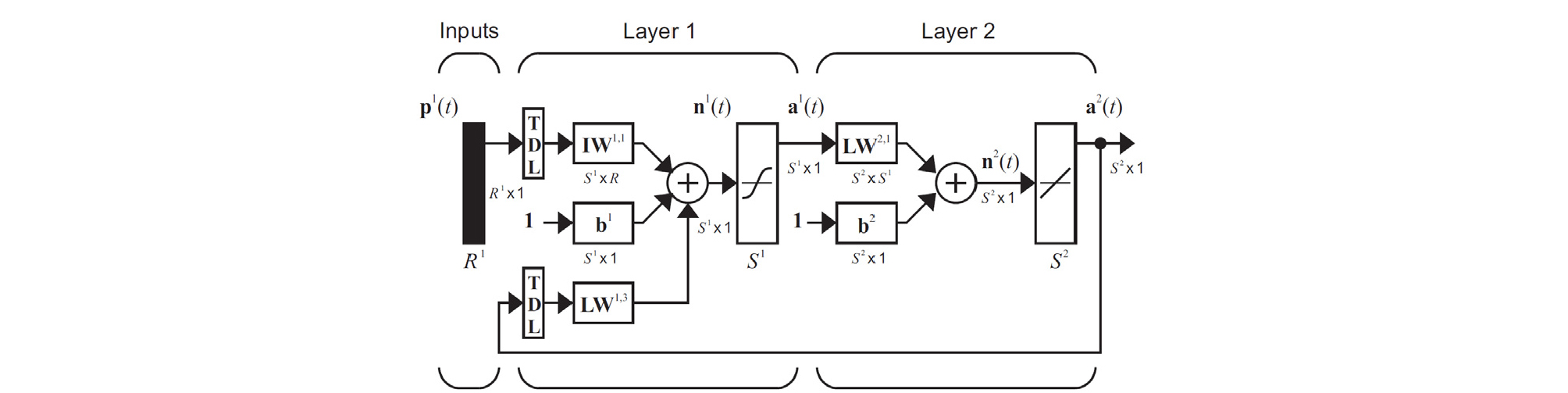
3.2 인공신경망을 이용한 SPI-SGI 상관관계 학습
인공신경망 모델의 일반화를 위한 핵심 사항은 데이터를 설명하는 가장 단순한 모델을 찾는 것이다. 인공신경망의 관점에서 가장 간단한 모델은 가장 적은 수의 뉴런(노드)을 포함하는 모델이다. 그러므로 일반화가 잘된 인공신경망을 구성하려면 주어진 데이터에 적합한 가장 단순한 모델을 찾아야 한다.
인공신경망 모델을 구성하는 방법으로는 성장(growing), 가지치기(pruning), 전역탐색(global search), 정칙화(regularization), 조기중단(early stopping) 등 5가지 방법이 있다(Hagan et al., 2014). 성장은 인공신경망에서 뉴런 없이 시작한 다음 성능이 적당해질 때까지 뉴런을 추가하는 방법이다. 가지치기는 많은 개수의 뉴런에서 시작하여 성능이 크게 떨어질 때까지 한 번에 하나씩 뉴런을 제거해 나가는 방법이다. 전역탐색 방법은 유전 알고리즘과 같은 전역최적화 방법으로 가능한 모든 뉴런에 연결된 가중 값과 바이어스를 검색하여 데이터를 설명하는 가장 단순한 모델을 찾는 방법이다. 조기정지 방법은 학습 횟수가 증가함에 따라 모든 뉴런의 가중 값과 바이어스 연결 관계를 사용하여 평균오차가 ‘0’에 가까워지지만, 과적합(overfitting)의 가능성이 높아진다. 그러므로 이런 단계에 도달하기 전에 학습을 종료하는 방법이다. 정칙화는 학습과정에서 비용함수에 가중 값과 바이어스 합을 포함하는 항을 추가하여 불필요한 뉴런사이의 연결을 없애 과적합을 방지하려는 방법이다.
앞 절에서 상관성 분석을 통해 가장 높은 상관성을 보인 SPI 하나만을 입력 자료로 활용할 수도 있으나, 다른 지속기간을 갖는 SPI도 단순 상관성분석 결과로는 쉽게 보이지 않는 영향인자로 작용할 수 있기에, 본 연구에서는 SPI 1~12 전체를 외부 입력 자료로 구축하고 신경망 학습 과정에서 각 SPI별 가중치를 스스로 결정하도록 하였다. 또한 모델의 구성은 입력 자료의 두 배수 이상인 30개의 뉴런부터 시작하여 가지치기 방법을 이용하여 은닉층 뉴런수를 12개로 설정하였다. 신경망 훈련 알고리즘은 Bayesian Regularization Backpropagation을 적용하였다. Bayesian Regularization 방법은 베이지안 이론을 사용하여 학습단계별로 두 항의 가중치를 구하여 인공신경망을 학습시킨다. 자세한 사항은 Hagan et al. (2014)의 문헌을 참고할 수 있다.
인공신경망 학습 정확도 검증을 위해, 구축된 자료세트를 이용해 신경망을 학습시키는 과정에서, 랜덤으로 자료의 15%를 검증을 위한 블라인드 자료로 처리해 학습된 네트워크의 성능을 검증토록 하였다. Fig. 8은 전체 자료의 85%에 해당하는 훈련 자료와, 15%에 해당하는 검증 자료 그리고 자료 전체에 대해 목표 값과 출력 값의 상호 비교가 가능하도록 자료를 도시하고, 선형회귀분석을 통한 상관계수 도출 결과에 대한 예시이다. 그림을 통해 인공신경망을 통해 출력되는 값이 자료 범위 중 큰 구간 또는 작은 구간에서 과대 또는 과소 추정 되는지 여부를 직관적으로 확인할 수 있다. 또한 훈련자료와 검증자료 및 전체 자료의 상관계수가 모두 고르게 높게 나오는지를 확인함으로써 훈련자료의 상관계수만 높은 과적합 상황을 방지할 수 있다. 본 연구에서는 전국 167개 시․군별로 인공신경망 모형을 학습시켜 정량적으로 전망된 강수량으로부터 산정한 SPI 1~12 전망 값을 이용하여 SGI를 전망할 수 있도록 하였다.
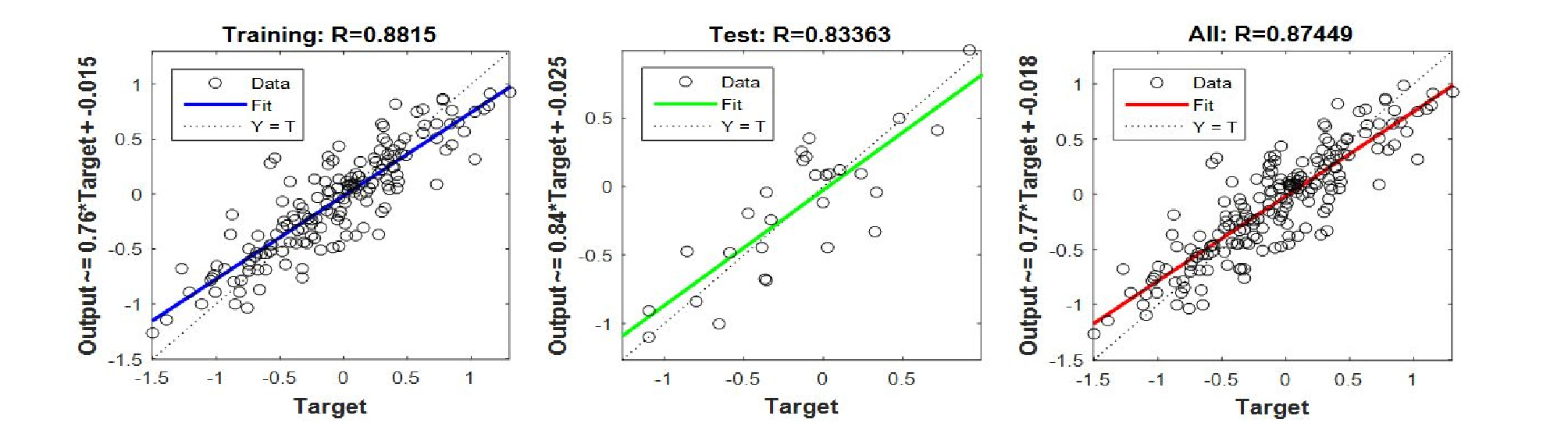
4. 모형 적용 및 평가
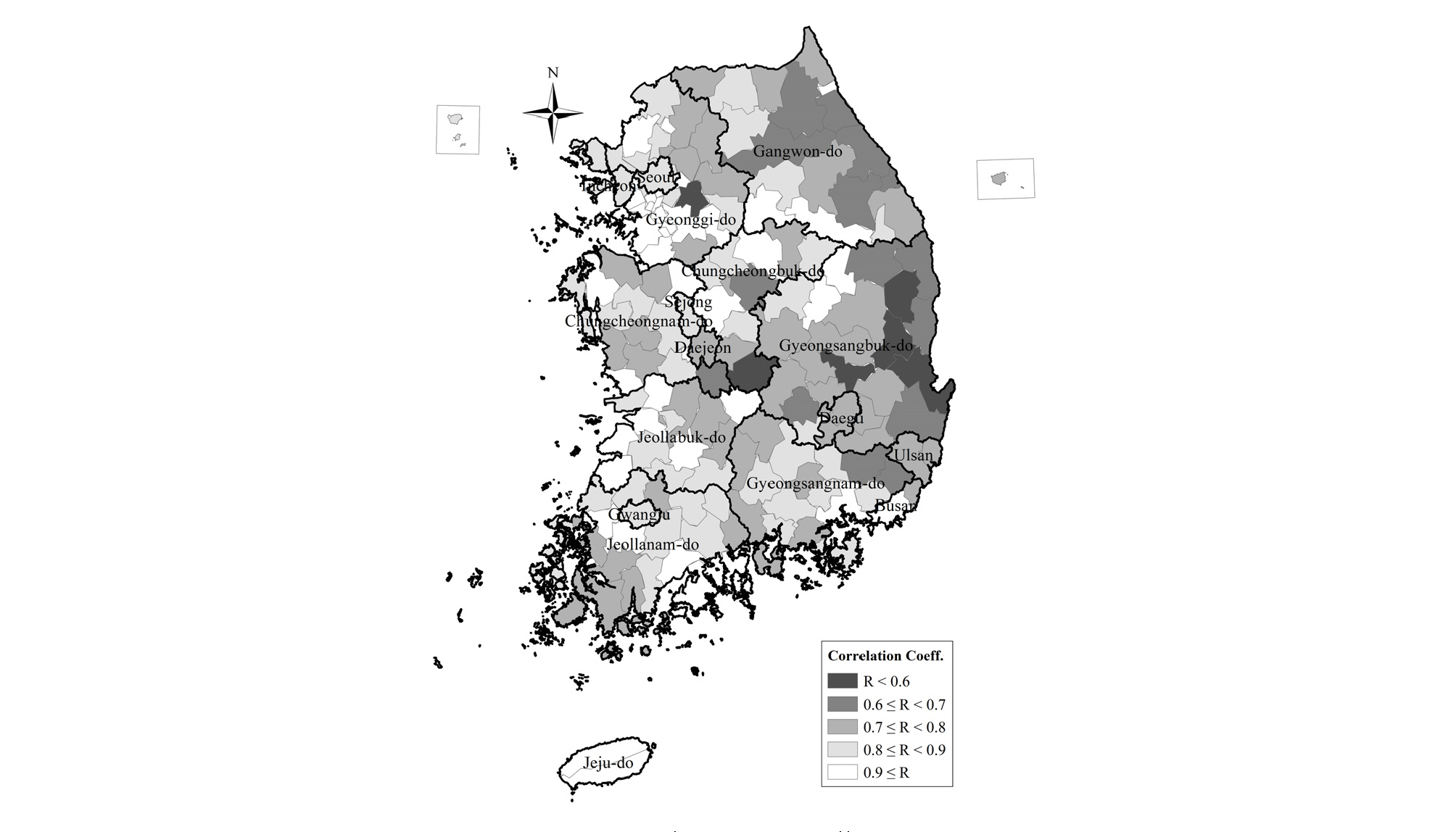
본 연구를 통해 학습된 시․군별 인공신경망 모형의 적용성을 평가하기 위해, 관측된 SGI 값에 해당하는 목표 값(target)과 인공신경망을 통해 출력된 SGI 값(output) 간의 상관도를 분석하였다. 본 상관도 분석 결과는 모형의 학습에 이용된 ‘16년 12월까지의 기간 내에서 Target과 Output의 상관도를 보여주는 것으로 모델의 적용이 이루어진 ’17년 이후의 결과는 본 절의 마지막 부분에 별도로 언급하였다. 학습에 이용된 전체 기간에 대한 평가 결과 Table 3에 도시한 바와 같이 상관계수가 0.7 이상인 곳이 전체 167개 시․군별 모형 중 146개(87%)이다. 상관계수는 0.9 이상일 경우 매우 상관이 높은 것으로, 0.7 이상이면 상관이 높은 것으로, 0.4~0.7이면 확실히 상관이 있는 것으로 해석한다. 따라서 지역별 인공신경망 모형의 출력 결과는 목표 값과 높은 상관성을 갖는 것으로 해석할 수 있다. 상대적으로 상관도가 낮은 지역은 강수와 지하수 응답 특성이 명확한 선형 상관성에 의해 해석되기 어려운 자료 특성을 보이는 곳으로, 시범적용을 거쳐 모형 개선이 필요할 것이다. Fig. 9는 전국 167개 시․군별 ANN 모형 평가 결과를 색으로 구분하여 표시한 것이다.
Table 3. Correlation coefficient between ANN output and target SGI
| Correlation coefficient (R) | R≥0.9 | 0.9>R ≥0.8 | 0.8>R ≥0.7 | 0.7>R ≥0.6 | 0.6>R |
| Total 167 Sigun (%) | 43 (25.7%) | 51 (30.5%) | 52 (31.1%) | 15 (9.0%) | 6 (3.6%) |
기상청에서는 매월 1일 전국 59개 기상관측소 지점의 1~3개월 강수전망 자료를 제공하고 있다. 지점별 강수전망 값은 앞서 ANN모델 구축을 위해 사용한 167개 시․군과 동일한 범위의 면적평균 값으로 환산할 수 있다. 시․군별로 환산된 강수 전망 값은 관측 강수량과 결합하여 현재 이후 3개월까지의 시․군별(167개), 지속기간별(1~12개월) SPI 산정을 가능케 한다. 현재의 시점을 t라고 하고, 1개월 후 전망시점을 t+1이라고 했을 때, t+1 시점의 SGI 전망을 위해 인공신경망 모형이 필요로 하는 Input Data Set과 예측된 결과인 Output의 관계는 Fig. 10과 같다. 3.1절에서 언급한 바와 같이 NARX 모형에서는 관측된 SGI가 Target으로만 이용되는 것이 아니라 자기회귀모형과 같이 이후 시간의 출력을 위한 입력 값으로 이용되며, 여기에 지속시간별 SPI들이 외부 입력 값으로 모형의 출력에 영향을 미치게 된다.
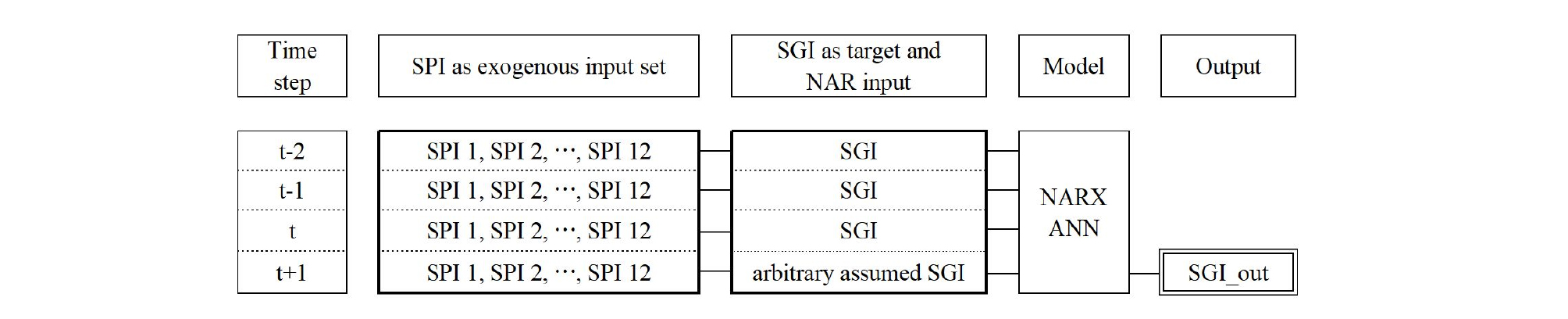
Fig. 11은 음성군을 예로 ‘17년 11월 말 현재 기준으로 모형 적용 결과를 도시한 것이다. 그림 상단에 모형 학습 및 적용기간이 구분되어 있다. ’16년 말까지의 자료를 이용하여 ANN 모형을 학습시켰으며, ‘17년 1월 이후는 학습된 모형을 적용한 출력 값이다. 또한 현재 이후 3개월 기간은 기상청에서 전망한 월 강수량 장기전망 값으로부터 산정된 SPI 전망 값을 이용해 SGI를 3개월까지 예측한 것이다. 그림에서 첫 번째 굵은 실선은 현재 시점까지의 관측 SGI 값이며, 점선들은 학습기간과 적용기간에 해당하는 모형 출력 SGI 값이다. 그림 오른쪽 끝부분의 원형표식 실선은 현재 이후 3개월간의 SGI 예측 값을 표시한 것이다.
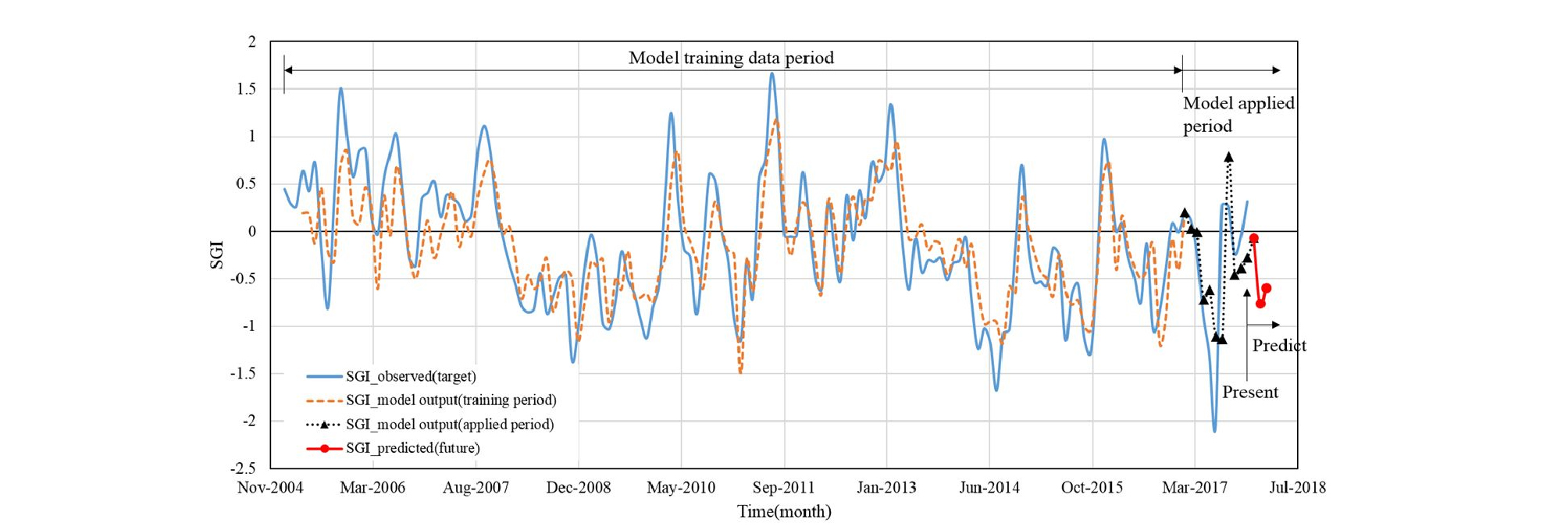
음성군 ANN모델의 학습 및 적용기간을 구분한 모델 평가결과는 Table 4와 같다. 모형의 학습에 이용된 기간과 적용된 기간을 구분하여 관측 SGI와 모델 출력 SGI 사이의 평균제곱근 오차(RMSE)와 상관계수를 비교하였다. 현재시점 이후인 ‘17년 12월부터 ’18년 2월까지 3개월은 기상청 장기전망 강수량으로부터 산정된 예측 SPI를 이용한 결과이기 때문에, 구축된 신경망 모형의 정확도가 아니라 기상전망의 정확도에 좌우되는 부분이기에 본 논문에서 평가하기에는 무리가 있다. 적용된 결과는 훈련기간의 결과에 비해 평균 제곱근 오차가 증가하고 상관계수는 낮아졌지만, Fig. 11의 적용기간 그래프가 보이는 바와 같이 SGI의 증가 및 감소 경향은 잘 모의하고 있는 것을 확인할 수 있다.
Table 4. Correlation coefficient between ANN output and target SGI
| Data period | RMSE (root mean square error) | Correlation coefficient | |
| Model training | 2005.01 ~ 2016.12 | 0.386 | 0.819 |
| Model apply | 2017.01 ~ 2017.11 | 0.622 | 0.565 |
5. 결 론
본 연구에서는 국가 가뭄 예․경보의 생․공용수 분야 가뭄정보 분석 자료의 하나로서 지하수위 관측 자료 및 기상전망 자료를 이용한 미급수지역 가뭄 전망 기법을 개발하였다. 전편의 연구를 통해 미급수지역의 주 수원인 지하수의 수위현황을 가뭄 판단에 활용할 수 있는 SGI 가뭄 모니터링 기법을 개발하였으며, 본 연구에서는 기상청의 강수량 정량 전망 자료를 이용하여 지하수위 변동을 빠르게 전망할 수 있는 기법을 개발하고자 하였다. 이를 위해 지속기간별 SPI와 SGI의 상관관계 및 SGI의 자기회귀 특성을 NARX 인공신경망을 이용하여 학습시켜 시․군별 예측모형을 구축하였다. 또한 시․군별로 전망된 강수량으로부터 산정된 지속기간별 SPI와 학습된 지역별 인공신경망 모형을 이용하여 시․군별 SGI를 예측할 수 있도록 하였다. 개발된 기법을 통해 미급수지역의 주요 수원인 지하수위 상황을 현재까지의 지하수위 관측 값과 기상청 장기 강수전망 자료를 이용하여 빠르게 전망함으로써 국가 가뭄 예․경보 분석의 지역별 가뭄정보 생성 및 판단의 기초자료로 활용이 가능토록 하였다.
