

1. 서 론
2. 연구방법
2.1 Long Short-Term Memory (LSTM)
2.2 경사하강법 기반 옵티마이저
2.3 Harmony Search (HS) 및 Novel Self-adaptive Harmony Search (NSHS)
2.4 개량형 옵티마이저
2.5 데이터 전처리(Data pre-processing)
2.6 대상 유역 및 자료 구축
3. 연구결과
3.1 학습결과
3.2 예측결과
4. 결 론
1. 서 론
하천 및 저수지는 인간이 음용할 수 있는 식용수를 취수하기 위해 사용되는 중요한 장소이다. 최근 도시화 및 산업화로 인해 하천 또는 저수지를 포함한 많은 지역에서 과거에 비해 수질오염에 대한 문제가 증가하고 있다(Park et al., 2006). 높은 정확도 기반의 하천 및 저수지의 수질예측은 수자원 관리와 수질오염 방지를 위해 필수적이다(Lu and Ma, 2020).
수질을 예측하기 위해 사용된 전통적인 기법은 선형방법을 기반으로 한 Auto-regressive, Moving average 및 Auto-regressive integrated moving average (Cai et al., 2015; Babu and Reddy, 2014; Faruk, 2010). 그러나, 선형방법 기반의 수질예측 기법은 수질인자 간의 비선형 관계를 해석할 수 없기 때문에 한계가 있다(Xiang and Jiang, 2009). 선형방법 기반 수질예측 기법의 단점을 개선하기 위해 수질 인자들의 비선형성을 해석할 수 있는 인공신경망(Artificial Neural Network, ANN)을 활용한 연구가 진행되었다. ANN은 수질 자료 간의 비선형성을 고려하여 예측을 진행하기 때문에 선형방법 기반의 예측기법보다 높은 정확도를 나타냈다(Zhang et al., 2017; Li et al., 2019).
ANN은 기계학습(Machine learning) 중 하나로 인간의 두뇌에서 신호를 처리하는 방식을 모방하여 제안된 기법이다. McCulloch and Pitts (1943)는 수학적 기법을 활용하여 ANN의 기초 논리를 제시하였으며, Rosenblatt (1958)은 Perceptron의 개념을 도입하였다. 이후, Rumelhart et al. (1986)은 ANN을 활용한 학습 및 예측과정에서 Back propagation through time을 이용하는 Recurrent Neural Network (RNN)를 제안하였다. RNN은 시계열 자료 분석에 좋은 성능을 보였다. 그러나 RNN은 자료의 길이가 길어질수록 과거의 자료를 반영하기 어려운 기울기 소실이 발생한다. RNN의 기울기 소실을 해결하기 위해 Hochreiter and Schmidhuber (1997)는 Long Short-Term Memory (LSTM)를 제안하였다. 이후, ANN의 학습과정 중 저장구조의 부재 등 구조적 단점을 개선하기 위해 새로운 ANN에 대한 연구가 진행되었다. Lee and Lee (2022a)는 저장구조의 부재 및 지역해로의 수렴가능성을 개선하고자 ANN과 메타휴리스틱 최적화 알고리즘을 직렬적으로 연결한 새로운 ANN을 제시하였다.
다양한 모형의 ANN은 수집된 데이터의 인자별 비선형성을 고려할 수 있다는 장점으로 인해 많은 분야에서 적용되었다(Ryu and Lee, 2022). Dogan et al. (2008)은 ANN을 활용하여 생물학적 산소요구량(Biochemical Oxygen Demand, BOD) 예측을 위한 민감도 분석 및 예측을 실시하였다. 예측결과는 화학적 산소요구량(Chemical Oxygen Demand, COD)을 활용한 BOD 예측이 가장 우수한 방법임을 보였다. Wang et al. (2008)은 엽록소-a (Chlorophyll-a, Chl-a)를 예측하기 위해 Multi Layer Perceptron (MLP)을 활용하였으며, MLP가 Chl-a 예측에 효과적임을 확인하였다. Akkoyunlu and Akiner (2010)는 용존산소량(Dissolved Oxygen, DO)을 예측하기 위해 ANN을 활용하였다. 예측결과를 통해 ANN이 비선형 회귀법(Nonlinear regression method)보다 좋은 성능을 나타냄을 확인하였다.
ANN은 학습 및 예측과정에서 옵티마이저를 선택하는 것이 중요하다(Zare et al., 2011). 옵티마이저는 복잡한 비선형적 입출력 관계를 근사화하는 ANN의 연산자이다. 옵티마이저는 ANN의 계산값과 출력자료 간의 오차가 가장 작은 매개변수(가중치 및 편향)를 탐색한다. 기존의 연구들에서 사용된 옵티마이저는 수학적 기법인 수치미분을 기반으로 매개변수를 탐색하는 경사하강법 기반 옵티마이저이다. 경사하강법 기반 옵티마이저는 기존에 생성된 매개변수를 기반으로 손실함수(Loss function)에 대한 기울기와 학습률을 통해 새로운 매개변수를 탐색한다.
그러나 경사하강법 기반 옵티마이저는 두 가지의 단점이 존재한다. 첫 번째 단점은 지역 최적해로의 수렴 가능성이다. 경사하강법 기반 옵티마이저는 ANN의 출력값과 데이터 간의 오차가 최소가 되는 상관관계를 탐색하는 과정에서 지역탐색만을 고려한다. 경사하강법 기반 옵티마이저는 전역탐색을 고려하지 않기 때문에 전역 최적값을 찾지 못할 가능성이 있다(Sedki et al., 2009). 두 번째 단점은 해 저장공간의 부재이다. 경사하강법 기반 옵티마이저는 학습을 진행하는 과정에서 기존에 생성된 매개변수에 대한 저장공간이 없다. 매개변수 저장공간의 부재로 인해 기존에 생성된 매개변수의 오차가 새로운 매개변수의 오차보다 작아도 강제적으로 매개변수가 갱신된다(Lee and Lee, 2022b). 따라서, 경사하강법 기반 옵티마이저는 학습이 진행되어도 최적의 매개변수를 탐색하지 못할 가능성이 있다.
두 가지의 단점이 존재하는 경사하강법 기반 옵티마이저의 탐색성능을 개선하기 위해서는 전역탐색이 가능하며, 알고리즘 내 해의 저장공간이 존재하는 메타휴리스틱 최적화 알고리즘을 적용할 수 있다. 메타휴리스틱 최적화 알고리즘은 가능해의 범위에서 임의의 해를 선택하는 전역탐색과 기존에 생성된 해집단의 재조합 및 미세조정을 통해 새로운 해를 선택하는 지역탐색을 통해 최적해를 탐색한다. 또한, 메타휴리스틱 최적화 알고리즘은 알고리즘 내의 저장공간을 통해 기존의 해를 저장하고 새롭게 탐색한 해와의 비교가 가능하다.
본 연구는 경사하강법 기반 옵티마이저를 메타휴리스틱 최적화 알고리즘과 결합하여 개량형 옵티마이저(Improved optimizers)를 개발하였다. 개량형 옵티마이저의 탐색성능을 검토하기 위해 LSTM에 적용하였다. 경사하강법 기반 옵티마이저의 단점을 개선하기 위해 메타휴리스틱 최적화 알고리즘 중 Harmony Search (HS) 및 Novel Self-adaptive Harmony Search (NSHS)를 사용하였다. HS는 구조가 단순하고 최적해 탐색성능이 우수하다. NSHS는 HS의 사용성 및 탐색성능을 개선한 알고리즘이다. 개량형 옵티마이저를 적용한 LSTM의 성능을 검토하기 위해 낙동강에 위치한 다산 관측소의 수질인자인 수온(Water Temperature, WT), DO, pH 및 Chl-a를 학습 및 예측하였다.
2. 연구방법
2.1 Long Short-Term Memory (LSTM)
ANN 중 순환구조를 갖는 RNN은 음성 인식, 언어 처리 및 시계열 자료처리에 좋은 성능을 보였다. 그러나 RNN은 장기간의 자료를 사용하는 경우에 오차 경사의 소실이 발생하여 성능이 저하된다. 이러한 RNN의 단점을 개선하기 위해 RNN의 구조에 셀 상태(Cell state) 및 Gate 개념을 추가한 LSTM이 제안되었다(Hochreiter and Schmidhuber, 1997). LSTM은 Input gate, Forget gate 및 Output gate가 있다. LSTM 내 3개의 Gate는 이전 시점의 불필요한 정보는 지우고 필요한 정보를 기억한다. Input gate는 현재 정보를 현재 시점의 정보를 입력하기 위한 Gate이다. Eqs. (1) and (2)는 Input gate의 연산과정이다.
여기서, it는 Input gate 계산값, 𝜎는 시그모이드 함수, xt는 현재 시점의 입력값, ht-1은 이전 시점의 셀 출력값, Wxi와 Whi는 각각 xt와 ht-1에 대한 input gate의 가중치이며, bi는 input gate의 편향이다. 는 예비 셀 상태, Wxc와 Whc는 각각 xt와 ht-1에 대한 예비 셀 상태의 가중치이며 bc는 예비 셀 상태의 편향이다.
Forget gate는 이전 시점으로부터 전달된 정보를 현재시점에서 제거할지 유지할지를 결정한다. Forget gate 값은 0과 1사이의 값을 가지며 0에 가까울수록 정보가 많이 제거된 것이고 1에 가까울수록 많은 정보를 기억한다. Eq. (3)은 Input gate의 연산과정이다.
여기서, ft는 Forget gate 계산값 , Wxf와 Whf는 각각 xt와 ht-1에 대한 Forget gate의 가중치이며, bf는 Forget gate의 편향이다.
Output gate는 셀 출력값과 셀 상태 계산값을 결정한다. Output gate에서 계산된 셀 출력값과 셀 상태 계산값은 다음 시점(t+1)의 계산에 영향을 미친다. Eqs. (4)~(6)은 Output gate의 연산과정이다.
여기서, ct는 현재 시점의 셀 상태 계산값이며, ct-1은 이전 시점의 셀 상태 계산값이다. ot는 Output gate 계산값, Wxo와 Who는 각각 xt와 ht-1 에 대한 Output gate의 가중치이며, bo는 Output gate의 편향이다. 또한, ht는 현재 시점의 셀 출력값이다. Fig. 1은 본 연구에서 사용된 LSTM의 구조이다.

기존의 수질인자를 예측한 연구 중 Wang et al. (2017)은 LSTM을 이용하여 DO 및 총 인(Total Phosphorus, TP)을 예측하였으며, 은닉층이 1개일 때 뉴런의 개수에 따른 예측성능을 검토하였다. 예측결과는 은닉층의 노드 개수가 15개일 때, 가장 좋은 예측성능을 나타냈다. 따라서, 본 연구는 LSTM의 은닉층 개수를 1개로 설정하였으며, 은닉층의 뉴런 개수는 15개로 설정하였다.
2.2 경사하강법 기반 옵티마이저
ANN의 연산자 중 옵티마이저는 ANN의 출력값과 관측값 간의 오차가 가장 작은 매개변수를 탐색한다. 옵티마이저의 탐색성능은 ANN의 학습 및 예측성능에 직접적인 영향을 미친다(Joo et al., 2020). 옵티마이저 중 가장 기초적인 경사하강법은 수치미분을 통해 얻은 기울기와 학습률을 이용하여 기울기가 0이 되는 지점을 탐색하는 방법이다. Eq. (7)은 경사하강법의 새로운 매개변수 탐색과정을 나타낸 식이다.
여기서, Wt는 새로운 매개변수, Wt-1은 이전 학습의 매개변수, 𝜂는 학습률을 의미하며, LF 는 손실함수이다.
경사하강법은 고정된 학습률을 사용하며, 기존에 이동했던 방향을 기억하지 못한다는 단점이 있다. 이러한 경사하강법의 단점을 개선하기 위해 Momentum 및 Adaptive learning rate를 적용하여 다양한 경사하강법 기반 옵티마이저가 제안되었다. Momentum은 과거에 해를 탐색한 방향을 기억하여 같은 방향으로 추가 이동함으로써 경사하강법의 탐색성능 향상시키는 방법이다. Adaptive learning rate는 경사하강법의 학습률이 일정하다는 단점을 개선하기 위해 학습 과정에 따른 유동적인 학습률을 적용하는 방법이다. 경사하강법 기반 옵티마이저에는 Stochastic Gradient Descent (SGD), Adaptive Gradient (Adagrad), Root Mean Squared propagation (RMSprop), Adaptive delta (Adadelta), A variant of Adam based on the infinity norm (Adamax), Adaptive moments (Adam) 및 Nesterov-accelerated adaptive moments (Nadam)가 있다.
다양한 경사하강법 기반 옵티마이저는 Momentum과 Adaptive learning rate의 적용을 통해 개량되었음에도 불구하고 전역탐색이 불가능하다. 경사하강법 기반 옵티마이저는 초기에 생성되는 매개변수에 따라 지역 최적해에 수렴할 수 있다는 단점이 있다. 또한, 경사하강법 기반 옵티마이저는 기존에 생성된 매개변수를 저장하는 구조가 없어 학습이 진행되어도 최적의 매개변수를 찾지 못할 가능성이 있다. 본 연구는 지역탐색 및 전역탐색을 동시에 고려하고 기존의 탐색된 해를 저장하는 구조가 존재하는 메타휴리스틱 최적화 알고리즘을 이용하여 경사하강법 기반 옵티마이저의 단점을 개선하였다.
2.3 Harmony Search (HS) 및 Novel Self-adaptive Harmony Search (NSHS)
메타휴리스틱 최적화 알고리즘 중 하나인 HS는 악기 연주자들이 즉흥으로 최적의 화음을 찾는 과정을 모방한 알고리즘이다(Geem et al., 2001). HS에서 해(Solution)는 악기 연주자들이 만들어내는 화음에 해당하며, 결정변수(Decision variable)는 악기 연주자들에 해당한다. 또한, 결정변수의 가능해 영역은 악기 연주자들이 연주할 수 있는 음역대에 해당하며, 전역 최적해는 가장 듣기 좋은 화음에 해당한다. HS는 지역탐색과 전역탐색의 반복을 통해 전역 최적해를 탐색한다. Fig. 2는 HS의 탐색과정을 나타낸다.
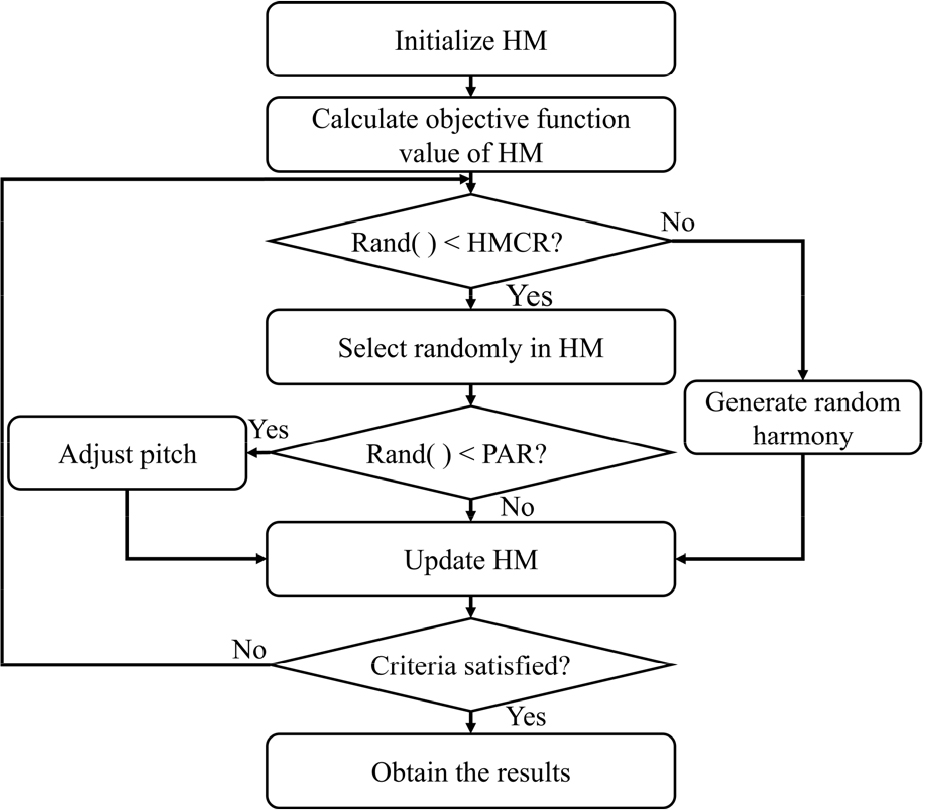
HS의 매개변수는 Harmony Memory Size (HMS), Harmony Memory Considering Rate (HMCR), Pitch Adjusting Rate (PAR) 및 Bandwidth (Bw)가 있다. HMS는 해집단인 Harmony Memory (HM)의 크기이며, HMS만큼의 초기 해를 생성한다. HMCR은 전역탐색을 이용한 새로운 해 탐색 또는 HM을 이용한 새로운 해 탐색을 결정한다. HM을 이용하여 새로운 해를 탐색할 경우에는 HM 내의 각 결정변수에 해당하는 임의의 해를 선택한다. PAR은 HM을 이용하여 생성된 새로운 해의 미세조정 여부를 결정한다. 미세조정을 실시할 경우 Bw만큼 미세조정을 실시한다. HS를 통해 생성된 새로운 해는 HM에 저장된 최악의 해와 비교된다. 새로운 해가 최악의 해보다 좋다면 새로운 화음은 HM에 저장되고 최악의 화음은 HM에서 제거된다.
HS는 건설, 설계 및 로봇공학 등 다양한 분야에서 활용되었다(Manjarres et al., 2013). 하지만, HS는 사용자가 직접 매개변수를 설정해야 하며, 매개변수는 HS의 해 탐색성능 및 수렴에 영향을 미친다(Pan et al., 2010). HS의 매개변수 설정에 대한 단점을 개선하기 위해 다양한 알고리즘이 제안되었다. Parameter setting free harmony search, Almost parameter free harmony search 및 NSHS 등 HS의 매개변수 설정에 대한 단점을 개선한 알고리즘 중 NSHS가 수학문제에서 우수한 탐색성능을 보였다(Choi et al., 2019).
NSHS는 Luo (2013)가 제안한 HS 기반 메타휴리스틱 최적화 알고리즘이다. NSHS는 결정변수의 개수에 따라 HMCR이 결정되며, 결정변수가 많은 문제일수록 큰 HMCR을 갖는다. 또한, NSHS는 연주자들이 최적의 화음을 탐색할 때까지 피치를 미세조정하는 것을 착안하여 PAR을 1로 설정한다. Bw는 학습이 진행됨에 따라 감소된다. Eqs. (8) and (9)는 결정변수 개수에 따른 NSHS의 HMCR 및 Bw의 형태이다.
여기서, n은 결정변수의 개수, Bwk는 현재 반복시산의 Bw, k는 현재 반복시산 횟수이다. 또한, ub 와 lb는 결정변수의 최대값 및 최소값이며, NI는 최대 반복시산 횟수이다. std(f)는 현재 반복시산에서 HM내 해집단의 손실함수 계산값에 대한 표준편차를 의미한다.
HS의 전역탐색은 항상 가능해 영역 내에 임의의 실수를 선택한다. NSHS의 전역탐색은 현재 반복시산에서 HM의 손실함수 계산값에 대한 표준편차에 따라 다르게 수행한다. 표준편차가 0.0001보다 작은 경우 NSHS는 빠른 수렴을 위해 좁은 범위 내에서 새로운 임의의 값을 생성한다. 표준편차가 0.0001보다 큰 경우 NSHS는 더 넓은 범위 내에서 새로운 임의의 값을 생성한다. 또한, NSHS는 항상 미세조정을 실시하기 때문에 미세조정을 실시하기 전의 해인 xi'을 생성한다. NSHS의 xi'은 Eq. (10)과 같이 생성한다.
여기서, xi'은 미세조정을 실시하기 전의 해, xij는 HM 내 j번째 해의 i번째 결정변수 값이며, minj(xij) 과 maxj(xij)는 각각 HM 내 i번째 결정변수의 최소값과 최대값이다. 또한, rnd와 rnd1은 0과 1사이의 임의의 실수이다.
Eq. (10)을 통해 생성된 xi'은 미세조정을 통해 새로운 해인 xinew를 생성한다. Eq. (11)은 NSHS의 새로운 해를 생성하는 식이다.
여기서, rnd2는 -1과 1사이의 임의의 값이다.
2.4 개량형 옵티마이저
본 연구는 경사하강법 기반 옵티마이저의 지역 최적해 수렴 가능성과 해의 저장공간 부재의 단점을 개선하기 위해 경사하강법 기반 옵티마이저와 HS 또는 NSHS의 결합한 개량형 옵티마이저를 개발하였다. 개량형 옵티마이저는 Gradient descent-based optimizer Conducting Rate (GCR)를 통해 경사하강법 기반 옵티마이저를 실시하거나 HS 또는 NSHS를 실시할지를 결정한다. 개량형 옵티마이저의 해 탐색과정은 Fig. 3과 같다.

Fig. 3을 보면, 개량형 옵티마이저는 경사하강법 기반 옵티마이저를 실시할 경우 기존에 경사하강법 기반 옵티마이저를 통해 생성된 매개변수를 이용하여 매개변수를 탐색하고 결과를 저장한다. HS 또는 NSHS를 실시할 경우 개량형 옵티마이저는 지역탐색 및 전역탐색을 통해 새로운 매개변수를 탐색하고 경사하강법 기반 옵티마이저를 실시한다. 이후 새로운 매개변수와 HM 내 최악의 매개변수를 비교하여 HM을 갱신한다. 본 연구에서 GCR은 Maximum GCR (GCRmax)과 Minimum GCR (GCRmin) 사이에서 반복 학습횟수(Epoch)에 따라 선형으로 감소하는 자가적응형 매개변수를 사용하였다. Eq. (12)는 반복 학습횟수에 따른 GCR의 값이다.
여기서, GCRCE는 현재 반복 학습횟수(Current epoch)의 GCR 값, ME는 최대 반복 학습횟수(Maximum epoch)이며, CE는 현재 반복학습 횟수이다.
본 연구는 개량형 옵티마이저를 제안하기 위해 경사하강법 기반 옵티마이저 중 학습성능이 우수한 옵티마이저를 선정하여 HS 또는 NSHS와 결합하였다. 경사하강법 기반 옵티마이저의 학습결과는 3.1절에 나타냈으며, Adam과 Nadam의 학습오차가 가장 작은 것으로 나타났다. 따라서, Adam combined with HS (AdamHS), Adam combined with NSHS (AdamNSHS), Nadam combined with HS (NadamHS) 및 Nadam combined with NSHS (NadamNSHS)를 이용하여 LSTM을 학습하였으며 Adam 및 Nadam의 학습성능과 비교하였다. 또한, 각 옵티마이저를 이용하여 학습된 LSTM의 예측성능을 비교하였다.
2.5 데이터 전처리(Data pre-processing)
인공신경망의 예측 신뢰도를 높이기 위해서는 자료의 노이즈를 줄이고 범위를 조절하는 등의 데이터 전처리가 필수적이다(Joo et al., 2000). 본 연구는 데이터 전처리 기법 중 Principal Component Analysis (PCA)와 Min-Max Normalization (MMN)을 실시하였다. MMN은 데이터 스케일링을 위한 데이터 전처리 기법인 MMN, Z-score normalization 및 Decimal scaling normalization 중 가장 우수한 성능향상을 보였다(Nawi et al., 2013). PCA는 과적합에 대한 위험성을 감소시킴과 동시에 Chl-a를 예측하는 연구에서 원자료를 사용하는 것보다 좋은 예측성능을 나타냈다(Zheng et al., 2021; Cao et al., 1997).
2.5.1 Min-Max Normalization (MMN)
본 연구에서 취득한 자료는 각각 다른 범위를 갖는다. 하지만, 다른 범위를 갖는 시계열 자료는 학습 및 예측성능에 부정적인 영향을 미친다(Mok et al., 2020). 따라서 ANN의 학습을 실시하기 전에 Data scaling을 실시하는 것이 필요하다. MMN은 최소값과 최대값의 차가 큰 자료를 0과 1사이의 값으로 변환하며 입력 및 출력자료의 범위를 같게 하는 기법이다. MMN은 최대값과 최소값을 기준으로 선형변환을 수행한다. MMN은 원자료간의 관계를 유지하는데 효과적이다(Folorunso et al., 2018). MMN을 실시하기 위한 수식은 Eq. (13)과 같다.
여기서, x𝛼MMN는 MMN을 실시한 α일의 새로운 자료, x𝛼는 𝛼일의 원자료이며 xmax와 xmin은 각각 원자료의 최대값과 최소값이다.
2.5.2 Principal Component Analysis (PCA)
PCA는 고차원의 자료를 저차원의 자료로 변환시키는 기법이다. PCA는 데이터의 분산(Variance)을 최대한 보존하면서 저차원으로 변환한다. PCA는 주성분(Principal component)을 생성하기 위해 자료를 수직으로 투영하였을 때 분산이 가장 큰 주축(Principal axes)을 결정한다. 이후, 주축에 자료를 수직으로 투영시켜 주성분을 구한다. 이전에 생성된 주축 다음으로 분산이 큰 주축을 정하고 수직으로 투영시켜 다른 주성분을 구한다. 즉, M×N의 자료 X가 있을 때, X의 공분산 행렬을 만들어 공분산 행렬의 고유값(Eigenvalue)와 고유벡터(Eigenvector)을 구한다. 계산한 고유벡터와 X의 내적을 통해 주성분을 생성한다. 고유값이 가장 큰 고유벡터와 내적한 주성분을 PC1이라고 한다. 두번째로 고유값이 큰 고유벡터와 내적한 주성분이 PC2이다.
PCA를 실시함으로써 문제의 복잡성이 감소하여 연산시간을 줄일 수 있다. 또한, PCA는 노이즈의 제거를 통해 과적합에 대한 가능성을 감소시킬 수 있다(Jin et al., 2005). 일반적으로 최적의 PC를 선택하기 위해 PCA를 통해 생성된 각 성분(Component)의 고유값 분산(Eigenvalues variance)의 누적치 비율이 90%인 것을 기준으로 한다(Hasan and Tahir, 2010).
2.6 대상 유역 및 자료 구축
본 연구는 개량형 옵티마이저를 사용한 LSTM의 학습 및 예측성능 평가를 위해 낙동강유역에 위치한 다산 수질관측소의 수질인자를 학습 및 예측하였다. 다산 수질관측소는 경상북도 고령군에 위치하고 있으며, 실시간으로 수질인자를 측정한다. 다산 수질관측소의 하류 4km 지점에는 매곡취수장과 강정취수장이 있다. 취수장의 수질 개선에 대한 선제적 대응을 위해 다산 수질관측소의 일 단위 수질인자 자료를 사용하였다. Table 1은 학습 및 예측을 위해 사용된 LSTM의 입력 및 출력인자이다.
Table 1.
Input and output variables for the LSTM
Chen et al. (2020)은 ANN을 활용하여 수질을 예측한 연구들의 예측선행길이를 분석하였으며, 예측선행길이를 1로 설정하여 관계를 파악하는 것이 이상적임을 확인하였다. 기존의 연구 동향 분석을 바탕으로 본 연구는 예측선행길이를 1로 설정하였다. LSTM의 학습자료는 2014년부터 2020년 까지의 자료를 사용하였다. 2021년의 자료는 LSTM의 예측성능을 평가하기 위한 예측자료로 사용하였다.
수질자료는 물환경정보시스템(https://water.nier.go.kr/)을 이용하여 구축하였다. 수문 및 기상자료는 각각 국가수자원관리종합정보시스템(http://www.wamis.go.kr/)과 기상자료개방포털(https://data.kma.go.kr)을 이용하여 구축하였다. Fig. 4는 유역도 및 자료를 취득한 관측소의 위치를 표시한 그림이다.

구축된 자료를 이용하여 PCA를 실시한 후 MMN을 실시하였다. Table 2는 구축된 자료를 이용하여 PCA를 실시한 결과 중 누적치 비율이 약 90%인 7개 주성분의 고유값 분산 및 고유값 분산의 누적치이다.
3. 연구결과
본 연구는 경사하강법 기반 옵티마이저의 단점을 개선하기 위해 개량형 옵티마이저를 개발하였다. 개량형 옵티마이저의 성능을 평가하기 위해 LSTM에 적용하여 다산 관측소의 수질인자를 학습 및 예측하였다. 또한, Adam과 Nadam을 적용한 LSTM의 학습 및 예측성능과 비교하였다. Adam 및 Nadam과 결합된 HS 및 NSHS의 매개변수는 우수한 학습성능을 보인 값으로 설정하였다. Table 3은 HS 및 NSHS의 매개변수이다.
Table 3.
Parameters of HS ans NSHS
| Parameter | HS | NSHS |
| Harmony Memory Size | 5 | 5 |
| Harmony Memory Considering Rate | 0.9 | - |
| Pitch Adjusting Rate | 0.2 | - |
| Bandwidth | 0.00001 | - |
Table 3에 따르면, HMCR 및 PAR은 각각 0.9 및 0.2로 설정하였다. Geem (2006)에 따르면 HMCR은 0.7에서 0.9 사이의 값, PAR은 0.05에서 0.2의 값이 바람직하다고 언급하였다. 개량형 옵티마이저의 GCRmax 및 GCRmin은 각각 1과 0.8로 설정하였다. LSTM의 반복학습 횟수인 Epoch는 수질인자를 예측한 Khatri et al. (2021)의 연구에서 설정한 2,000번으로 설정하였다. 또한, 학습 및 예측의 안정성을 평가하기 위해 10번 반복실행하였다. LSTM의 손실함수는 Mean Squared Error (MSE)를 사용하였다. MSE 수식은 Eq. (14)와 같다.
여기서, N은 자료의 개수, xpi는 관측값, xoi는 예측값이다.
각 옵티마이저를 적용한 LSTM의 예측성능을 검토하기 위한 성능지표는 MSE 및 R2를 사용하였다. R2의 수식은 Eq. (15)와 같다.
여기서, 는 관측값의 평균이다.
또한, 예측의 안정성을 평가하기 위해 10번 반복실행의 평균값(Average) 및 최대값(Max), 최소값(Min)을 비교하였다.
3.1 학습결과
경사하강법 기반 옵티마이저 중 학습성능이 우수한 옵티마이저를 선정하였다. 선정된 경사하강법 기반 옵티마이저를 HS 또는 NSHS와 결합하여 개량형 옵티마이저를 개발하였다. Table 4는 경사하강법 기반 옵티마이저를 적용한 LSTM의 학습결과이다.
Table 4.
Training results obtained with each LSTM using GD based optimizers
Table 4를 보면, MSE 최대값과 평균값은 Nadam이 각각 0.002965와 0.002921로 가장 낮았다. MSE 최소값은 Adam이 0.002885로 가장 낮았다. Adam과 Nadam의 MSE 평균값, 최대값 및 최소값이 모두 0.003 이하인 것으로 나타났다. 따라서, Adam과 Nadam을 HS 또는 NSHS와 결합하였다. AdamHS, AdamNSHS, NadamHS 및 NadamNSHS의 성능을 검토하기 위해 Adam 및 Nadam의 학습성능과 비교하였다. Table 5는 Adam, Nadam 및 개량형 옵티마이저를 적용한 LSTM의 학습결과이다.
Table 5를 보면, MSE 평균값 및 최대값이 각각 0.002881 및 0.002889로 NadamHS가 가장 낮았다. MSE 최소값은 AdamNSHS가 0.002836으로 가장 낮았다. 또한, HS 또는 NSHS와 결합한 옵티마이저는 경사하강법 기반 옵티마이저보다 MSE가 낮았다. HS 또는 NSHS를 활용하여 개량된 옵티마이저의 MSE를 비교하면 HS와 결합한 옵티마이저보다 NSHS와 결합한 옵티마이저가 더 낮았다. NSHS는 HS보다 미세조정을 많이 실시하기 때문인 것으로 분석된다. 학습결과를 통해, NadamNSHS을 이용한 학습이 가장 효과적이고 안정적이며 HS와 NSHS의 결합을 통해 경사하강법 기반 옵티마이저의 단점을 개선한 것으로 분석된다. Fig. 5는 학습과정에서 Epoch에 따른 MSE를 나타낸 그림이며, 10번 반복하여 취득한 결과의 평균이다.
Table 5.
Training results obtained with each LSMT using Adam, Nadam and improved optimizers
Fig. 5를 보면, 모든 옵티마이저는 비슷한 초기 수렴속도를 보였다. 하지만, 수렴 그래프의 후반부의 경우 개량형 옵티마이저의 MSE값이 더 낮은 것으로 나타났다. Adam과 Nadam의 경우 MSE값이 증가와 감소가 반복되지만, 개량형 옵티마이저는 계단식으로 감소한다. 개량형 옵티마이저의 해 저장 및 비교 구조의 유무차이인 것으로 분석된다.

학습성능과 함께 경사하강법 기반 옵티마이저와 개량형 옵티마이저를 활용한 LSTM의 학습시간을 비교 및 분석하였다. Table 6은 각 옵티마이저에 따른 평균학습시간을 나타낸 표이다.
Table 6.
Average training time required for LSTM using each optimizer
| Optimizer | Adam | AdamHS | AdamNSHS |
| Trainging times (sec) | 180.37 | 218.45 | 230.85 |
| Optimizer | Nadam | NadamHS | NadamNSHS |
| Trainging times (sec) | 180.47 | 218.25 | 230.08 |
Table 6을 보면, Adam 및 Nadam이 가장 낮은 학습시간을 나타냈으며, AdamNSHS 및 NadamNSHS가 약 230초로 가장 긴 학습시간을 나타냈다. 개량형 옵티마이저의 경우 HS와 NSHS가 전역 및 지역탐색을 통해 최적의 매개변수를 탐색하게 된다. 개량형 옵티마이저의 특성으로 인해 기존 옵티마이저보다 더 오랜시간이 소요되는 것을 알 수 있다.
3.2 예측결과
AdamHS, AdamNSHS, NadamHS 및 NadamNSHS을 적용한 LSTM의 예측성능을 검토하기 위해 Adam과 Nadam을 적용한 LSTM의 예측성능과 비교하였다. 예측성능 평가하기 위한 지표로는 MSE를 사용하였으며 10번 반복실행의 최대값, 최소값 및 평균값을 비교하였다. Table 7은 각 옵티마이저를 사용한 LSTM의 WT 예측결과이다.
Table 7.
Prediction results of WT obtained with LSTM using Adam, Nadam and improved optimziers
Table 7을 보면, WT 예측의 경우 NadamHS를 적용한 LSTM의 MSE 평균값이 약 2.58로 가장 낮았다. NadamHS를 적용한 LSTM의 MSE 최대값 및 최소값이 가장 낮은 값을 보였다. NadamHS를 적용한 LSTM이 평균 및 최대 R2가 가장 높은 것을 알 수 있으며, 최소 R2의 경우 NadamNSHS가 높은 것을 알 수 있다. Adam 및 Nadam을 사용한 LSTM보다 개량형 옵티마이저를 사용한 LSTM의 MSE 평균값, 최대값, 최소값과 R2의 평균값, 최대값, 최소값 모두 낮았다. 개량형 옵티마이저의 예측 오차가 작은 이유는 경사하강법 기반 옵티마이저보다 안정적이고 비교적 정확한 학습이 진행되었으며, 이를 기반으로 예측을 진행했기 때문인 것으로 분석된다. Table 8은 옵티마이저별 LSTM의 DO 예측결과이다.
Table 8.
Prediction results of DO obtained with LSTM using Adam, Nadam and improved optimziers
Table 8을 보면, DO 예측의 경우 MSE 평균값은 AdamHS를 적용한 LSTM이 약 0.785로 가장 낮았다. MSE 최대값 및 최소값은 각각 NadamNSHS 및 AdamNSHS를 적용한 LSTM이 가장 낮았다. 또한, AdamHS를 적용한 LSTM이 평균 R2가 가장 높은 것을 알 수 있으며, 최대 R2의 경우 AdamNSHS, 최소 R2의 경우 NadamNSHS가 높은 것을 알 수 있다. Tale 8을 통해 AdamHS를 적용한 LSTM의 DO 예측이 비교적 안정적인 것으로 분석된다. Table 9는 옵티마이저별 LSTM의 pH 예측결과이다.
Table 9.
Prediction results of pH obtained with LSTM using Adam, Nadam and improved optimziers
Table 9를 보면, pH 예측의 경우 MSE 평균값 및 최대값은 NadamNSHS를 사용한 LSTM이 각각 약 0.048 및 0.05로 가장 낮았다. MSE 최소값은 Nadam을 사용한 LSTM이 약 0.046으로 가장 낮았으나, NadamNSHS를 적용한 LSTM은 두 번째로 낮은 0.047의 MSE 최소값을 보였다. 또한, NadamHS를 적용한 LSTM이 평균 및 최소 R2가 가장 높은 것을 알 수 있다. 따라서, pH의 예측은 NadamNSHS를 적용한 LSTM의 예측이 비교적 안정적인 것으로 분석된다. Table 10은 옵티마이저별 LSTM의 Chl-a 예측결과이다.
Table 10을 보면, Chl-a 예측의 경우 MSE 평균값은 AdamHS를 적용한 LSTM이 약 65.44로 가장 낮았다. MSE 최대값 및 최소값은 각각 AdamNSHS 및 NadamNSHS를 적용한 LSTM이 가장 낮은 값을 보였다. 평균 R2는 NadamHS 가 가장 높았으며, 최대 R2는 NadamNSHS, 최대 R2는 AdamNSHS가 가장 높았다. Chl-a 예측결과를 보면 경사하강법 기반 옵티마이저보다 개량형 옵티마이저를 적용한 LSTM이 더 좋은 예측결과를 나타내는 것을 알 수 있었다. 본 연구에서 사용된 LSTM은 다중출력 구조로 WT, DO, pH 및 Chl-a를 동시에 예측한다. 따라서 4개의 수질인자에 대한 전체적인 예측성능을 검토하기 위해 각 옵티마이저의 예측성능 순위를 산정하였으며, 순위에 대한 평균을 평가하였다. MSE가 낮을수록, R2가 높을 수록 1순위로 산정하였다. Table 11은 수질인자에 대한 MSE의 순위이며, Table 12는 순위에 대한 평균값이다.
Table 10.
Prediction results of Chl-a obtained with LSTM using Adam, Nadam and improved optimziers
Table 11.
Ranking of the prediction results obtained each LSTM using Adam, Nadam and improved optimizers
Table 12.
Average of ranking about prediction obtained each models
| Optimizer | Adam | AdamHS | AdamNSHS |
| Average of ranking | 4.54 | 3.83 | 2.83 |
| Optimizer | Nadam | NadamHS | NadamNSHS |
| Average of ranking | 4.58 | 2.29 | 2.25 |
Table 11 및 Table 12를 보면, NadamNSHS을 적용한 LSTM의 순위에 대한 평균이 약 2.14로 가장 높았으며, Nadam을 적용한 LSTM은 약 4.58로 가장 낮았다. 또한, Adam 및 Nadam을 적용한 LSTM보다 개량형 옵티마이저를 적용한 LSTM의 순위에 대한 평균이 높은 것으로 나타났다. 개량형 옵티마이저의 순위에 대한 평균을 비교하면 NadamNSHS 및 AdamNSHS를 적용한 LSTM이 NadamHS 및 AdamHS를 적용한 LSTM보다 높았다. 따라서, NSHS를 이용하여 개량한 옵티마이저의 성능이 비교적 우수한 예측성능을 나타내는 것으로 분석된다. Figs. 6~9는 각각 WT, DO, pH 및 Chl-a에 대한 NadamNSHS를 적용한 LSTM의 예측값과 관측값을 비교한 그래프이다.
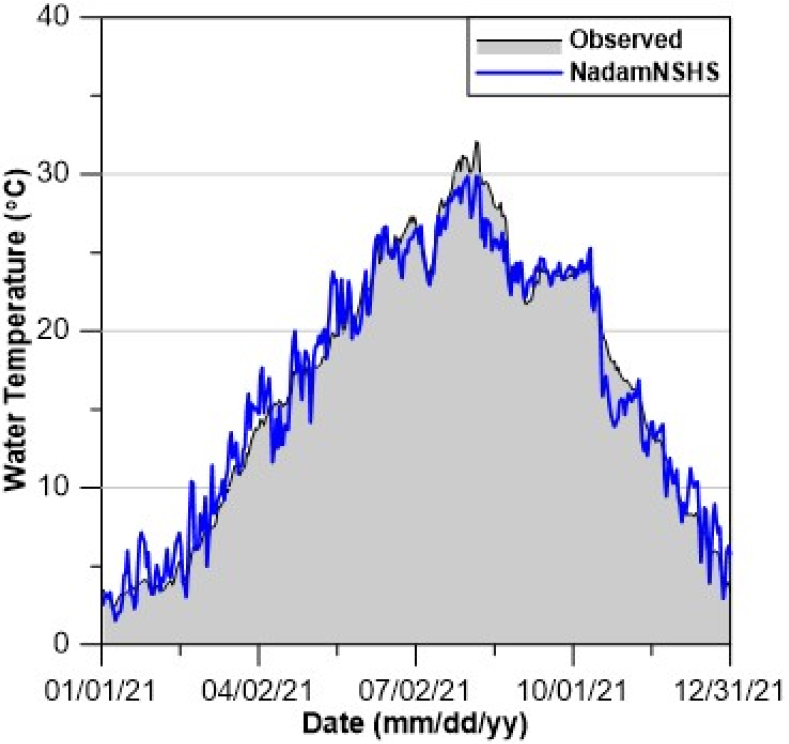

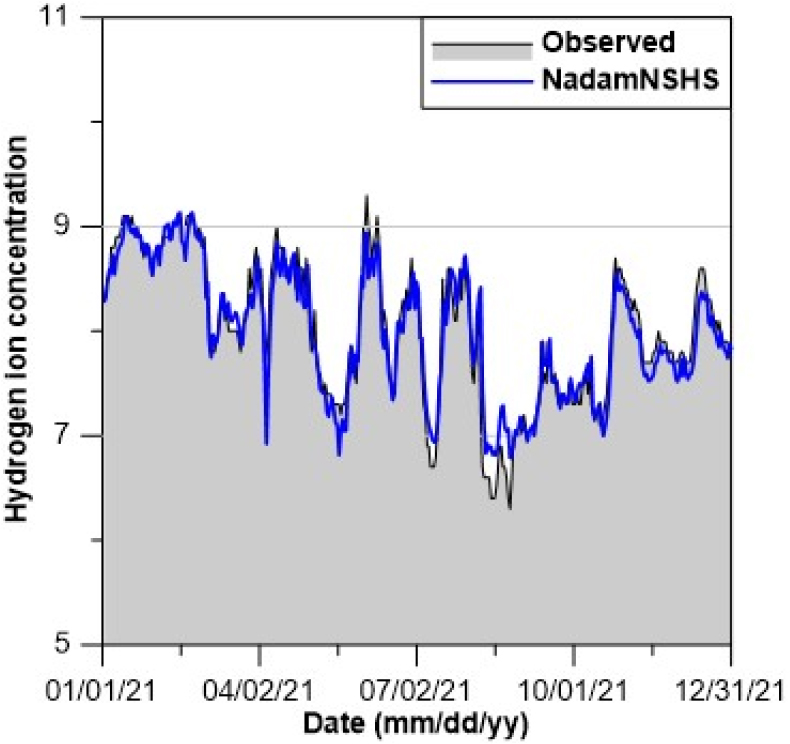
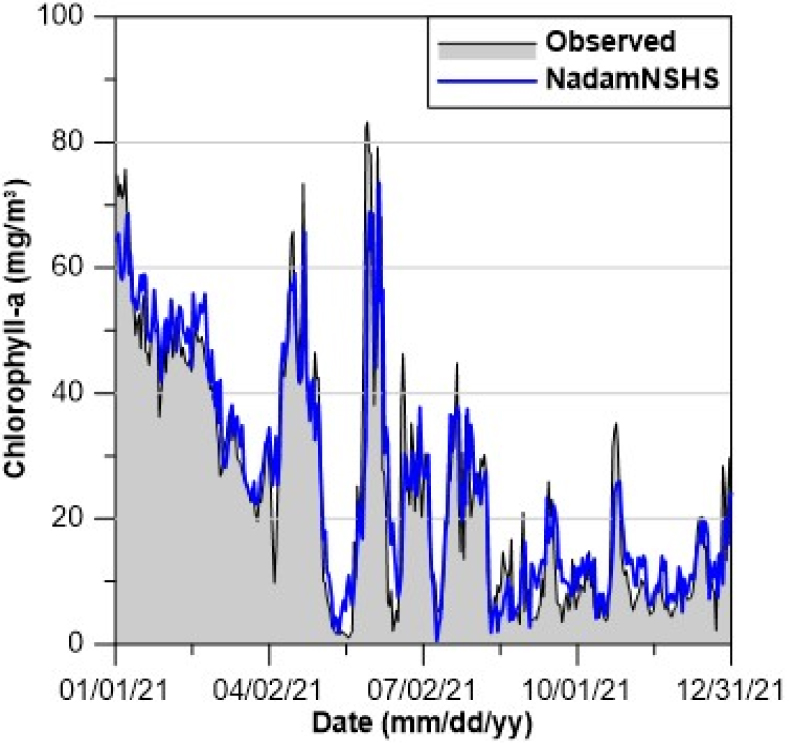
Figs. 6~9를 보면, 최고 WT에서의 오차는 약 2.2oC이며, 최저 DO에서의 오차는 약 1.5 mg/L이다. 또한, 최고 pH 및 최고 Chl-a에서의 오차는 각각 약 0.3과 14.3 mg/m3이다. 수질예측결과를 보면, 경사하강법 기반 옵티마이저와 HS 및 NSHS의 결합을 통해 경사하강법 기반 옵티마이저의 단점을 개선한 것으로 분석된다. 특히, NadamNSHS를 적용한 LSTM이 비교적 높은 학습 및 예측 정확도를 보였으며 높은 정확도의 수질인자 예측이 가능할 것으로 분석된다.
4. 결 론
본 연구는 수질예측 성능의 향상을 위해 경사하강법 기반 옵티마이저의 지역 최적해 수렴 가능성과 해의 저장공간 부재의 단점을 개선한 개량형 옵티마이저를 개발하였다. 개발된 개량형 옵티마이저는 경사하강법 기반 옵티마이저 중 학습오차가 낮은 Adam 및 Nadam을 HS 또는 NSHS와 결합하였다. 개량형 옵티마이저의 학습 및 예측성능 검토를 위해 다산 수질관측소의 WT, DO, pH 및 Chl-a를 학습 및 예측하였으며, Adam 및 Nadam의 학습 및 예측성능과 비교하였다.
학습결과를 비교하면, MSE 최대값 및 평균값에서는 NadamNSHS을 이용한 LSTM 각각 약 0.002899와 0.002881로 가장 낮았다. MSE 최소값에서는 AdamNSHS를 이용한 LSTM이 약 0.002836으로 가장 낮았다. 또한, 개량형 옵티마이저를 이용한 LSTM이 Adam 및 Nadam을 이용한 LSTM보다 낮은 MSE를 보였다.
WT, DO, pH 및 Chl-a를 예측한 결과의 MSE 및 R2 평균값을 비교하면, 각각 NadamHS, AdamHS, NadamNSHS와 AdamHS를 사용한 LSTM이 가장 낮은 MSE 및 가장 높은 R2를 보였다. 4개 수질인자에 대한 전체적인 예측성능을 비교하기 위해 MSE가 낮을수록 R2가 높을수록 1순위로 하여 4개 수질인자의 예측 순위에 대한 평균을 산정하였다. 순위에 대한 평균을 비교하면, NadamNSHS을 사용한 LSTM이 2.25로 가장 높은 순위를 보였다. 또한, HS와 NSHS를 이용한 개량형 옵티마이저를 사용한 LSTM의 순위에 대한 평균이 Adam 및 Nadam보다 높았다.
학습 및 예측결과를 통해 개량형 옵티마이저의 학습 및 예측성능이 경사하강법 기반 옵티마이저보다 우수한 것으로 분석된다. 추후 연구를 통해 LSTM의 구조에 따른 학습 및 예측성능의 분석과 함께 학습시간 단축을 위한 계산과정 검토 및 예측선행시간에 따른 ANN의 예측결과를 분석하여 다산 수질관측소의 수질인자 예측을 위한 최적의 LSTM을 구축할 수 있을 것으로 기대된다. 또한, 본 연구에서 사용된 대상유역의 연구결과를 기반으로 추후 국내에 위치하고 있는 수질관측소에 대한 수질예측 연구를 통해 국내에서 범용적으로 사용할 수 있는 개량형 옵티마이저가 적용된 LSTM을 제안할 수 있을 것으로 기대된다.
