

1. 서 론
2. 연구방법
2.1 대상유역 및 입력자료
2.2 강우-유출모형
2.3 Copula 함수를 활용한 강우-유출모형 매개변수 지역화 모형 개발
3. 연구결과
3.1 강우-유출모형 매개변수 최적화 결과
3.2 강우-유출모형 매개변수 지역화 결과
4. 결 론
1. 서 론
가뭄, 홍수 등 수재해 대응을 위한 대책 수립 측면에서 유역의 자연유출량 산정은 가장 필수적으로 선행되어야 하는 핵심적인 사항이다. 환경부에서 매년 제공되고 있는 수문조사연보에 따르면, 국내 수자원 전문기관에서 약 490개 지점에 수위관측소를 설치하여 주요 지점에 대한 유출량을 실시간으로 모니터링하고 수위 및 유량 정보를 제공하고 있다. 그러나 주요 지점을 제외한 유역에서는 양질의 유량 자료의 취득이 어려우며, 측정지점의 하천 단면 변화에 따라 정기적으로 수위-유량 관계 곡선식의 보정을 통해 유출량을 산정하고 있다.
유역에 시공간적으로 양질의 실측 유량자료를 확보한 경우, 강우-유출모형의 매개변수 최적화 작업을 통해 신뢰성 있는 자연유출량 모의를 수행할 수 있다. 그러나 완전한 자연유출량 자료는 취득이 어려우며, 강우량 자료와 비교해 상대적으로 자료 연한이 짧아 유역특성에 적합한 매개변수 추정시 불확실성이 크게 발생하는 단점이 있다(Chae et al., 2018). 미계측유역의 경우, 지역 홍수빈도분석, 강우-유출 모의에 의한 동역학적 분석 방법, 확률강우량과 강우-유출 관계 분석 방법 등을 통해 자연유출량을 산정할 수 있으나, 수자원 실무에서는 계측유역에 대한 유출량 산정 결과를 활용하여 유역의 면적비를 적용하여 미계측유역 유출량을 간접적으로 추론하는 방법이 일반적으로 활용되고 있다(Kim et al., 2018).
기존에 수행된 미계측유역 홍수량 추정과 관련된 연구를 살펴보면, 확률강우량의 확률분포 선정과 강우-유출모형의 매개변수 추정에 관한 연구가 주로 수행되었으며, 유역특성을 반영한 미계측유역 홍수량 추정 연구는 다소 미진하였다(Kwon et al., 2004). 최근 미계측유역의 정확한 확률홍수량 산정을 위한 극치 홍수사상 재현, 지형인자를 활용한 유역의 홍수량 추정 및 매개변수 불확실성 분석 연구 등 미계측유역의 확률홍수량 예측을 위한 국내외 연구가 진행되고 있다. 국내외 연구에서 제시된 연구방법들은 공통적으로 홍수량 추정을 위해서 강우-유출모형의 매개변수를 실측 강우-유량 자료를 통해 검보정 하거나 지형자료를 이용한 경험식을 이용하여 추정한다(Kim et al., 2018). 그러나 우리나라의 중소규모 유역은 대부분 미계측유역인 측면을 고려했을 때, 면적비나 비홍수량을 이용한 경험적인 방법은 적절한 유출량 산정 방법이라 볼 수 없다. 본 연구에서는 강우-유출모형의 유출 특성을 결정하는 주요 매개변수를 Bayesian 이론으로 최적화하였으며, Copula 함수를 활용한 유역특성인자를 선정 및 표준유역별 매개변수를 지역화하는 방법을 개발하였다. 본 연구의 흐름도는 Fig. 1과 같다.
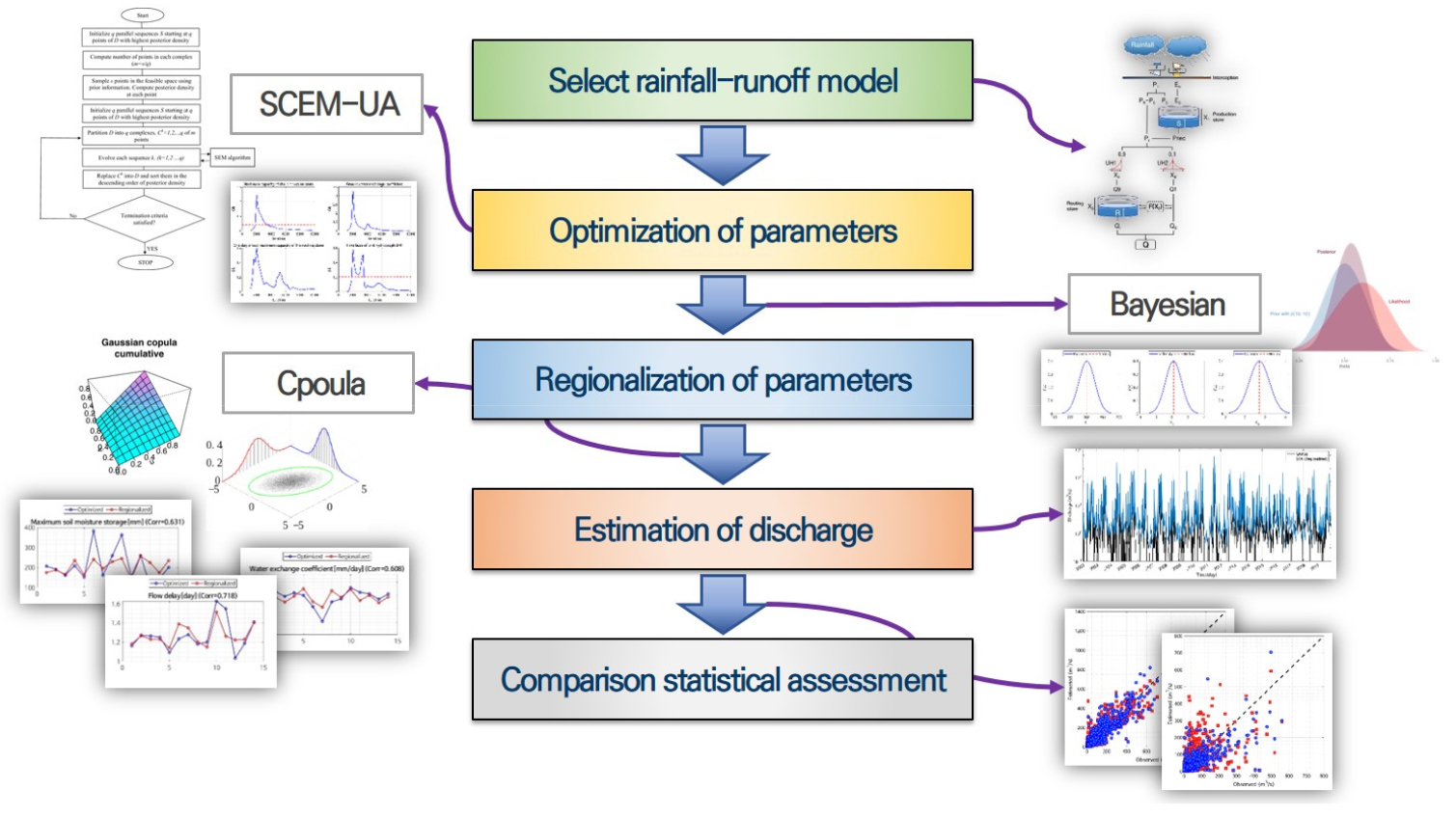
최근 우리나라에서 수행된 강우-유출모형 관련 연구 동향을 살펴보면, 유역특성을 고려한 강우-유출모형 매개변수의 지역화에 관한 연구가 다수 진행되었다. Lee and Moon (2007)은 확률분포 강우-유출 모델(PDM)의 매개변수를 물리적 유역 특성치에 따른 회귀방정식 형태의 Jackknife 방법을 활용하여 지역화하였다. Lee and Kang (2007)은 미계측유역의 장기유출을 모의하기 위해 15개 유역을 대상으로 수정 3단 TANK 모형의 매개변수를 지역화하였으며, 충주댐과 설마천 유역에 대해 검증하였다. Lee et al. (2009)은 미계측유역에 대한 SWAT 모형을 적용하기 위하여 다변량 통계기법인 주성분 분석과 계층적 군집 분석을 연계한 매개변수 지역화 기법을 제안하였다. Kang et al. (2013)은 저수지 상류 유역의 미계측유역에 대한 유출량을 산정하기 위해 TANK 모형의 구성성분 개선 과정을 거쳐 매개변수를 지역화하였으며 적용성을 평가하였다. Kim et al. (2015)은 Sacramento 강우-유출모형의 매개변수를 최적화하고 각 매개변수의 사후분포를 도출하고 유역특성을 다중 선형 회귀분석을 적용하여 매개변수를 결정하여 지역화를 실시하였다. Chang et al. (2019)은 금강권역에 위치한 미계측유역의 유출량을 추정하기 위해 강우-유출모형의 매개변수를 결정하고 선형 회귀분석을 수행하여 지역화 모형을 제시한 바 있다.
본 연구에서 제안하는 강우-유출모형의 매개변수 지역화 방법이 기존에 활용되는 미계측유역 유출량 추정 방법과 다른 점은 두 가지로 요약할 수 있다. 첫째, Bayesian 모형을 이용하여 매개변수 추정 및 불확실성을 정량화하였으며, 매개변수의 사후분포(posterior distribution)로부터 추출되는 다수의 매개변수를 지역화에 활용하였다. 둘째, 최적화된 강우-유출모형의 매개변수와 유역특성인자 사이의 상관성을 고려하기 위하여, Copula 함수를 이용한 지역화 방법을 제안하였다. 최종적으로, 제시된 방법론에 대하여 통계적인 적합성을 평가하기 위해 교차검증 관점에서 지역화된 매개변수의 상관성 및 자연유출량 모의결과를 비교하였다.
2. 연구방법
2.1 대상유역 및 입력자료
자연유량이란 하천의 유역이 개발되지 않아 인위적 행위에 의한 유량 변화가 없는 상태에서의 하천유량을 의미한다. 자연유량 산정방법은 관측자료를 이용하여 산정하는 방법과 장기유출모형을 이용한 방법 등 두 가지로 구분할 수 있다. 관측자료를 이용하여 산정하는 방법은 실측유량에 인위적인 영향에 해당하는 순물소모량을 반영하여 자연유출량을 산정하며, 장기유출모형에 의한 방법은 강우량 자료로부터 유역특성을 반영하여 산정한 유출량을 자연유출량으로 적용한다. 장기유출모형을 통한 자연유출량 산정시 강우-유출모형의 매개변수 산정이 필요하다. 매개변수 산정시 일반적으로 대상유역은 물수요가 거의 없고, 신뢰성 있는 실측자료가 존재하는 하천이나 댐 상류 유역을 선정하여 분석한다(Kim et al., 2015). 미계측유역에 적용을 위한 매개변수 지역화 분석시 강우-유출모형의 최적화된 매개변수 산정은 필수적이며, 지역화 분석에 사용된 지점의 실측자료에 대한 정확도가 매우 중요하다(Lee and Kang, 2007). 우리나라는 대부분 주요하천에서 유량 관측이 이루어지고 있다. 그러나 보, 수문과 같은 수자원 관리 목적으로 설치된 시설물에 의해 하천이 관리됨에 따라 수위-유량 관측지점에서의 자료를 자연유량으로 보기에는 많은 제약이 있다.
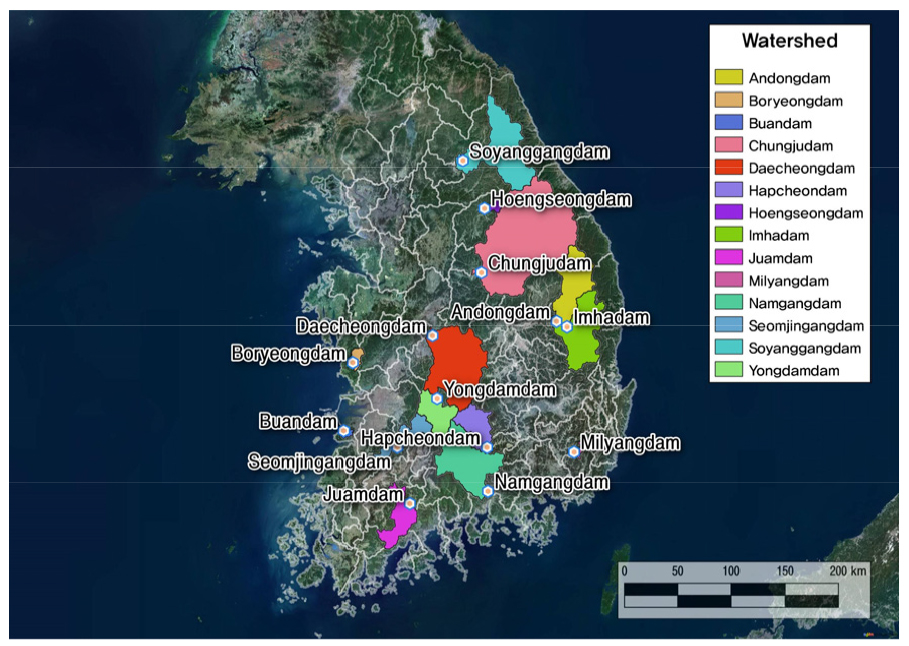
본 연구에서는 매개변수 지역화를 위한 대상 유역으로 K-water에서 운영 중인 댐 중 비교적 장기간 관측자료를 보유하고 있으며, 자료에 대한 신뢰도가 높은 관측유입량 자료를 제공하고 있는 14개의 다목적댐을 선정하였으며, 댐 상류 유역에 있는 12개 수위-유량 관측소를 선별하였다.
강우-유출모형을 활용하기 위하여 14개 댐의 관측 유입량 자료를 자연유출량으로 가정하였으며, 입력자료는 표준유역별 일단위 면적평균강우량, 잠재증발산량 자료를 활용하였다. 강우자료는 환경부, 기상청, K-water에서 제공하는 일단위 강우자료를 활용하여 티센법(thiessen method)에 따른 면적비를 통해 산정하였으며, 잠재증발산량 자료는 전국 95개 기상청 강우관측소 지점의 증발산량을 계산하여 유역의 평균값을 산정한 후, 최종적으로 FAO-56 Penman-Monteith 방법(Allen et al., 1998)을 통해 산정하였다.
매개변수 지역화를 위한 최적 유역특성인자는 유역면적 및 평균 폭, 평균 길이, 평균 표고, 평균 경사, 단일형상계수, 유출곡선지수(curve number, CN) 등을 선정하였다. Fig. 2는 본 연구의 대상 유역으로 선정된 다목적댐 위치를 도시하였다.
2.2 강우-유출모형
강우-유출이란 수문학적으로 지표면에 떨어진 강수의 일부가 지표면이나 토층, 지하수를 통해 하천으로 흐르는 일련의 과정을 말하며, 특정기간(시간, 일, 월 등)에 따라 실제 내린 강수량으로 인한 유출량이나 설계강우량을 통해 유출수문곡선을 산정한다. 이러한 수문학적 과정을 수학적인 형태로 연계하여 모의할 수 있도록 구축한 모형을 강우-유출모형이라 정의하며, 모형에 대한 접근법으로는 단순히 범위를 설정하는 방법, 경험에 의한 방법, 결정론적인 방법에서부터 3차원 물리적 모델, 확률론적 모델, 과정 중심 모델 등이 있다. 상기의 접근법들은 시·공간적인 크기, 필요한 정보의 종류 등에 따라 각각 장·단점을 가지고 있으며, 대표적으로 물리적 강우-유출모형과 개념적 강우-유출모형으로 구분된다. 물리적 강우-유출모형은 유역 수문 순환과정의 원리를 수학적인 공식으로 산정할 수 있도록 구성된 모형이며(Grayson et al., 1992), 물리적인 수문 순환과정을 경험적으로 추정된 매개변수에 의해 분석될 수 있도록 단순화된 모형을 개념적 강우-유출모형이라 한다(Vieux, 2001). 이때, 경험적 강우-유출모형은 해당 유역의 특성에 적합하도록 반복적인 매개변수 최적화 과정을 거친 후 활용된다.
이러한 강우-유출모형은 모형 구조 및 입력자료로 인해 불확실성이 나타나게 된다. 즉, 입력자료의 불확실성은 강수, 기온, 증발산량과 같은 수문기상 자료의 시공간적 규모 및 관측 신뢰도에 의해 결정되는 불확실성이다. 매개변수도 불확실성이 존재하며, 사용되는 입력자료가 충분하지 않은 경우 매개변수의 불확실성을 증가시키는 원인으로 작용한다. 이외에도 모형의 최적 매개변수 추정시 매개변수 사이의 독립성 가정과 더불어 사용되는 최적화 기법의 제약조건에 따른 불확실성 등 다양한 방식으로 매개변수의 불확실성을 증가시키게 된다. Yu et al. (2021)는 46개 강우-유출모형의 국내외 적용사례, 매개변수 개수 및 모형의 유량 재현성 통계결과 등을 종합적으로 평가하여 고수위 및 평·갈수기에 대한 최적 강우-유출모형을 제시하였다. 본 연구에서는 강우-유출모형 선정시 다양한 평가기준 중 저유량의 예측 정확성 측면에서 모형의 수행능력을 중점적으로 고려하였으며, 최종적으로 적은 개수의 매개변수를 갖음에도 불구하고 상대적으로 상대적으로 유량모의가 우수하다고 알려져 있는 GR4J (Ge'nie Rural a 4 parame tres Journalier) 모형을 최적 강우-유출모형으로 선정하였다.
2.2.1 GR4J 강우-유출모형
GR4J 모형은 저류지 개념(reservoir concept)을 이용한 대표적인 집중형 강우-유출모형으로써 Edijatno and Michael (1989)에 의해 처음 3개의 매개변수를 갖는 GR3J 형태로 제안되었다. 이후, Perrin et al. (2003)은 모형의 수학적 구조를 변경하여 지금의 GR4J 모형의 형태인 4개의 매개변수를 이용한 일 단위 집중형 강우-유출모형으로 확장하였다. Duan et al. (2006)은 MOPEX (The model parameter estimation experiment)을 통해 대표적으로 사용되는 9개의 강우-유출모형 중 GR4J 모형이 매개변수의 개수가 제한적임에도 불구하고 비교적 우수한 결과가 도출됨을 검증하였다.
장기간의 일 유출량을 모의하기 위해 GR4J 모형은 최대 토양수분 저류량 이하의 토양수분 저류량에서 침루(percolation)하는 수분을 고려하여 유출을 형성하는 강수만을 고려하며, 이후 홍수추적량을 선형방법, 비선형방법으로 분리하여 최종유출을 도출한다. GR4J 모형의 장점은 다른 모형에 비해 수문학적 순환과정에서 이용되는 많은 매개변수를 사용하지 않고 최소한의 매개변수를 가지며, 이전 GR3J 모형보다 저유량에 대한 모의가 개선된 점에 있다. 앞서 언급하였듯이, GR4J 모형은 매개변수의 수가 적고 모형의 구조가 간결하여 다른 강우-유출모형에 비해 비교적 분석 소요시간이 짧으며, 유역 내 하천의 형태가 단순할수록 우수한 모의결과를 제공한다. 그러나 대권역 같이 유역의 크기가 클 경우, 일반적으로 복잡한 하천 형태를 내포하고 있어 GR4J 모형 유출량 모의결과의 재현성능이 떨어지는 단점이 있으며, 이러한 경우 유역을 분할하여 분석을 수행해야 한다.
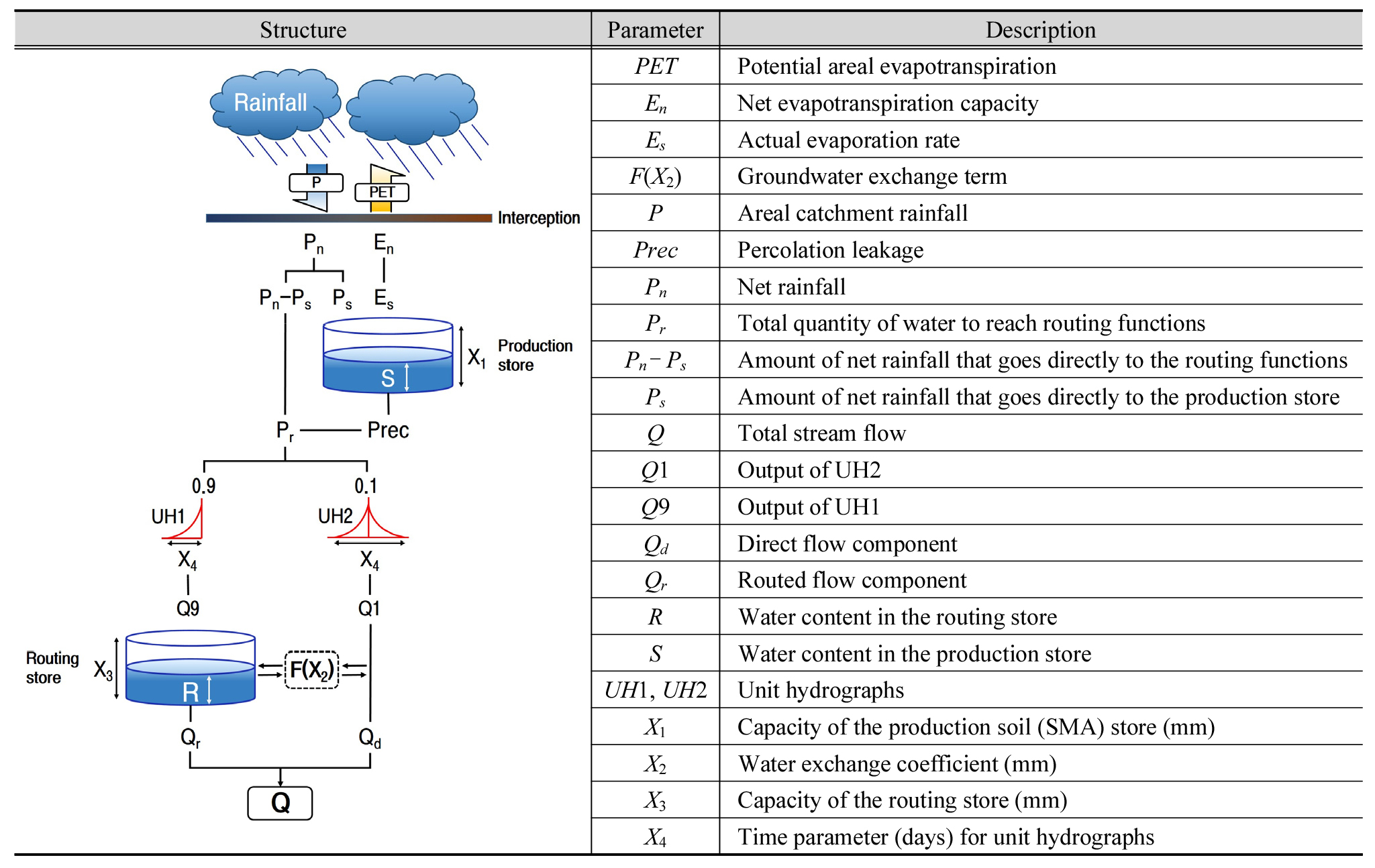
GR4J 모형은 X1부터 X4까지 4개의 매개변수를 가지며 차단(interception), 토양수분저류(production store), 홍수추적(routing store)의 3단계 과정을 거쳐 연속적 일단위 강우-유출과정이 계산되며, 시간변수를 제외한 모든 단위는 mm로 표현된다(Im et al., 2012). GR4J 모형의 개념적 강우-유출 산정 과정 및 매개변수에 대한 설명은 Fig. 3과 같다.
2.2.2 SCEM-UA 매개변수 최적화
강우-유출모형의 매개변수는 유역의 강우-유출 관계 및 지형적 특성을 종합적으로 고려해야 하며, 최적 매개변수를 선정하는 것은 모형의 적용성 측면에서 매우 중요하다. 매개변수 최적화(optimization)는 기존 실측자료를 기반으로 추정된 모의결과에 대한 통계적 검증을 통해 목적함수의 수렴(convergence) 여부를 판단 및 반복(iteration) 과정을 거쳐 신뢰성 있는 매개변수를 추정하는 방법이다. 최적화 기법은 찾고자 하는 해의 요구 수준에 따라 크게 전역최적화 기법(global optimization method)과 지역최적화 기법(local optimization method)으로 구분되며(Bagirov et al., 2005), 전역최적화 기법은 매개변수의 수렴을 위해 다소 긴 시간이 요구되지만 지역최적화 기법에 비해 신뢰성 측면에서 매개변수 추정에 유리하다(Kim et al., 2020). 본 연구에서는 강우-유출모형의 최적 매개변수를 추정하기 위하여, 전역최적화 기법 중 우수한 성능을 보이며, 다양한 수문모델의 매개변수 추정시 발생하는 불확실성을 정량화할 수 있는 SCEM-UA (shuffled complex evolution metropolis-university of Arizona) 알고리즘을 활용하였다(Vrugt et al., 2003).
SCEM-UA 알고리즘은 Vrugt et al. (2003)을 통해 제시되었으며, SCE (shuffled complex evolution, Duan et al., 1992)기법과 MCMC (Monte-Carlo markov chain)의 장점을 조합하여 최적의 매개변수 집합(set)을 추정하는 최적화 기법이다(Kim et al., 2020). SCEM-UA 알고리즘은 매개변수의 사후분포 추정을 위해 Bayesian 기법을 활용한다. 먼저, SCEM-UA 알고리즘은 매개변수 의 사전분포(prior distribution) 에 의해 정의된 매개변수의 물리적 범위 내에서 무작위로 추출된다. 사후분포 는 설정된 매개변수를 Bayesian MCMC 모의를 통해 추정된다. SCEM-UA 알고리즘의 계산과정을 간략히 단계별로 살펴보면 다음과 같다.
1) 모집단 크기(s)와 구간(complex) 개수(q)를 결정하고, 각 구간에 해당하는 자료의 개수(m = s/q) 계산
2) 사전분포에서 표본(sample) 을 무작위로 추출한 후 Eq. (1)을 이용하여 격자별 사후분포 추정(L은 정규분포라는 가정에 따른 매개변수 집단의 우도(likelihood), N은 자료의 개수를 의미)
3) N개의 사후확률을 내림차순으로 정리하여 Eq. (2)와 같은 배열 D의 형태로 저장(D의 첫 번째 행은 최고의 적합도를 갖는 점을 나타냄)
4) 각 구간의 시작점을 S1, S2, …, Sq와 같이 초기화(Sq는 배열 를 의미, j = 1, 2, …, q)
5) 배열 D를 C1, C2, …, Cq와 같이 m개의 점을 갖는 구간 q로 분할
6) SEM (sequence evolution metropolis) 알고리즘을 통해 연속적으로 변화하며 사후확률 추정(새로운 매개변수의 사후확률과 최초 생성된 각 구간에 포함된 매개변수에 대한 사후확률을 비교, 적합도가 낮을 경우 새로 생성된 매개변수가 채택되며, 적합도가 높을 경우 최초 매개변수를 그대로 사용하여 새로운 구간(Ck, k = 1, 2, …, q)을 생성
7) 기존의 구간을 새로운 구간으로 대체하여 배열 D를 재분석하고, 사후확률에 따라 매개변수를 오름차순으로 정리
8) 수렴한계에 만족하면 최적화 매개변수 추정 완료(수렴한계에 만족하지 않을 경우, 단계 5로 돌아가 매개변수 보정 반복 수행)
2.3 Copula 함수를 활용한 강우-유출모형 매개변수 지역화 모형 개발
2.3.1 유역특성인자
수문모형의 매개변수 지역화를 위한 영향인자 선정시 유출량과 상관관계가 높은 변수들을 선정하기 위하여 저수지의 인자를 활용하거나(Merz and Bloschl, 2004), 전문가들이 선정한 수문기상과 밀접한 관련이 있는 지형 인자를 선택하는 방법(Parajka et al., 2005) 등이 활용되었다. 본 연구에서는 환경부에서 운영중인 국가수자원종합정보시스템(water management information system, WAMIS)을 통해 자료의 취득이 용이하며, 유출량과의 회귀분석을 통해 6개의 유역특성인자(유역면적, 유역평균길이, 유역평균폭, 유역평균표고, 유역평균경사, 단일형상계수)를 선정하였으며, 유역의 물리적 유출정도를 고려하기 위하여 기존의 유역특성인자에 유출곡선지수를 추가하였다. Tables 1 and 2는 본 연구에서 선정한 다목적댐 14개소, 수위-유량 관측소 12개소에 대한 유역특성인자이다.
Table 1.
Dam watersheds used in this study and their topographical characteristics
Table 2.
Water stage stations used in this study and their topographical characteristics
2.3.2 Copula 함수 기반 GR4J 모형 매개변수 지역화
본 연구에서는 유역특성인자와 최적화된 매개변수 사이의 상관성을 유지하는 동시에 각 변수들의 분포 특성을 동시에 고려하기 위하여 Copula 함수를 활용한 강우-유출모형 매개변수의 지역화 방법을 개발하였다. Copula 함수는 자유로운 주변확률분포의 선택과 결합확률분포의 추정이 용이하다고 잘 알려져 있으며, 상호연관성을 가지는 2개 이상의 수문변량을 모의하는데 Copula 함수를 활용한 연구가 진행되고 있다(Kim et al., 2016). 특히 Copula 함수를 활용하는 경우, 다변량 인자 사이의 종속성 구조(dependence structure)를 유지하면서 모의가 가능하므로 매개변수와 유역인자의 물리적인 관계를 보다 정확하게 고려할 수 있으며, 분석과정의 불확실성도 고려할 수 있는 장점이 있다.
Copula 함수는 2개 이상의 주변확률분포를 이용하여 결합확률분포를 구축하는 역할을 하며, 기본적으로 누가분포함수가 입력자료로 활용된다(Kim et al., 2019). 본 연구에서는 최적 Copula 함수를 선정하기 위하여 다른 함수에 비해 과정이 간편하며, 다차원의 변량에 대한 적용 가능한 Gaussian Copula 함수를 활용하였다. Gaussian Copula는 변량 사이의 상관성을 상관계수로 나타내 다변량 자료의 분석 시 활용성이 우수하고 알려져 있다.
각각의 변량에 대한 주변확률분포를 선정하기 위하여, 확률분포형의 유효성을 판단할 수 있는 Bayesian 정보 기준(Bayesian information criterion, BIC)를 활용하였다. BIC 통계량은 우도(likelihood)와 매개변수의 개수를 고려하여 추정되며, 일반적인 식의 형태는 Eq. (3)과 같이 나타낼 수 있다(Findley, 1991).
Eq. (3)에서 k는 매개변수의 수, n은 자료의 수 및 L은 우도함수를 의미한다. 우도가 크고, 동시에 매개변수의 수가 적을 때 최적의 BIC 값을 가지며, 분포형 별로 BIC를 추정하기 위한 우도함수는 Eq. (4)와 같이 나타낼 수 있다.
여기서 f는 매개변수 를 가지는 확률밀도함수를 나타내며, x는 벡터 형태의 자료, n은 자료의 수를 의미한다. 일반적으로 우도만을 가지고 최적 분포형을 선택하는 경우 모분포의 자유도가 후보모델의 자유도보다 낮은 경우 잘못된 모분포를 선택할 확률이 높은 단점이 있다(Akaike, 1974). 본 연구에서는 BIC 값을 이용하였으며 최소 BIC를 갖는 분포형을 최적 확률분포형으로 선택하였다. 주요 인자별 주변확률분포 추정 결과는 Table 3에 정리하였다.
Table 3.
Selection of marginal distribution for GR4J model parameters and topographical factors
3. 연구결과
3.1 강우-유출모형 매개변수 최적화 결과
3.1.1 GR4J 모형 매개변수 최적화 결과
본 연구에서는 GR4J 모형의 매개변수 최적화를 위해 K-water에서 운영중인 다목적댐을 중심으로 총 14개소를 선별하여 분석을 수행하였다. 분석기간은 자연유출량으로 가정한 댐별 유입량 관측시작일를 기준으로 매개변수를 최적화를 수행하였으며, Perrin et al. (2003)이 제시한 범위 일반적인 GR4J 모형의 매개변수 범위는 Table 4와 같다.
Table 4.
Ranges of parameters in GR4J model (Perrin et al., 2003)
| Parameter | Lower Bound | Upper Bound |
| X1 (mm) | 1 | 2000 |
| X2 (mm) | -10 | 15 |
| X3 (mm) | 1 | 300 (30) |
| X4 (day) | 1 | 15 |
GR4J 모형의 매개변수 X3는 일단위 최대 홍수추적저류량(maximum routing store storage, X3 > 0)를 나타낸다. X3는 토양안에 저장되어 있는 유량을 의미하며, 토질의 종류와 습도에 따라 변화한다. GR4J 모형의 기저유량 변환 값은 매개변수 X2와 X3에 의해 산정된다. 이때 X2 는 지하수의 변화량으로 기저에서 유량 변화를 의미하며 음수일 경우 대수층에 유출이 발생되며, 양수일 경우 Routing store로 유입된다.
본 연구에서는 GR4J 모형의 매개변수 최적화를 위해 선정한 다목적댐 14개소의 유입량 전체 구간 중 특히 저유량 부분에서의 모의 성능을 최대화 할 수 있도록 특정한 조건을 부여하였다. 즉, 모의되는 자연유출량 결과의 저유량에 대한 결과가 보다 정확한 추정이 가능할 수 있도록 모형을 구성하기 위하여 매개변수 X3의 최대 범위를 30으로 제한하였다.
매개변수 최적화 수행시, 본 연구에서는 MCMC 기법을 통해 각각의 매개변수에 대한 사후분포를 추정하였다. Markov Chain의 수렴를 평가하는 방법은 Trace Plot을 이용한 시각적 분석이나 통계학적 방법(Gelman-Rubin, Geweke, Raftery-Lewis, Heidelberg-Welch 등)이 널리 알려져 있다(Brooks and Gelman, 1998; Brooks and Roberts, 1998). 본 연구에서는 매개변수 X1, X2, X4에 대하여 10,000번의 모의를 수행하였으며, GR4J 모형의 매개변수의 수렴성을 확인하기 위해서 Fig. 4의 왼쪽 그림과 같이 추적 곡선(Trace plot)을 도시하여 1차적으로 판단하였다. 최종적으로 수렴성을 확인하기 위해 Gelman-Rubin 검정 통계량을 이용하였으며, 모두 1.2 이하에서 1로 수렴하는 것을 나타낸다(Gelman et al., 2004; Gelman et al., 2013). Fig. 4의 오른쪽에 도시된 바와 같이, 모든 지점에서 추정된 사후분포에 대한 Gelman-Rubin 검정 통계량이 대부분이 1에 수렴함을 확인하였으며, 이는 약 5,000번 이후의 모의된 표본(sample)이 정상적으로 수렴되었음을 의미한다.
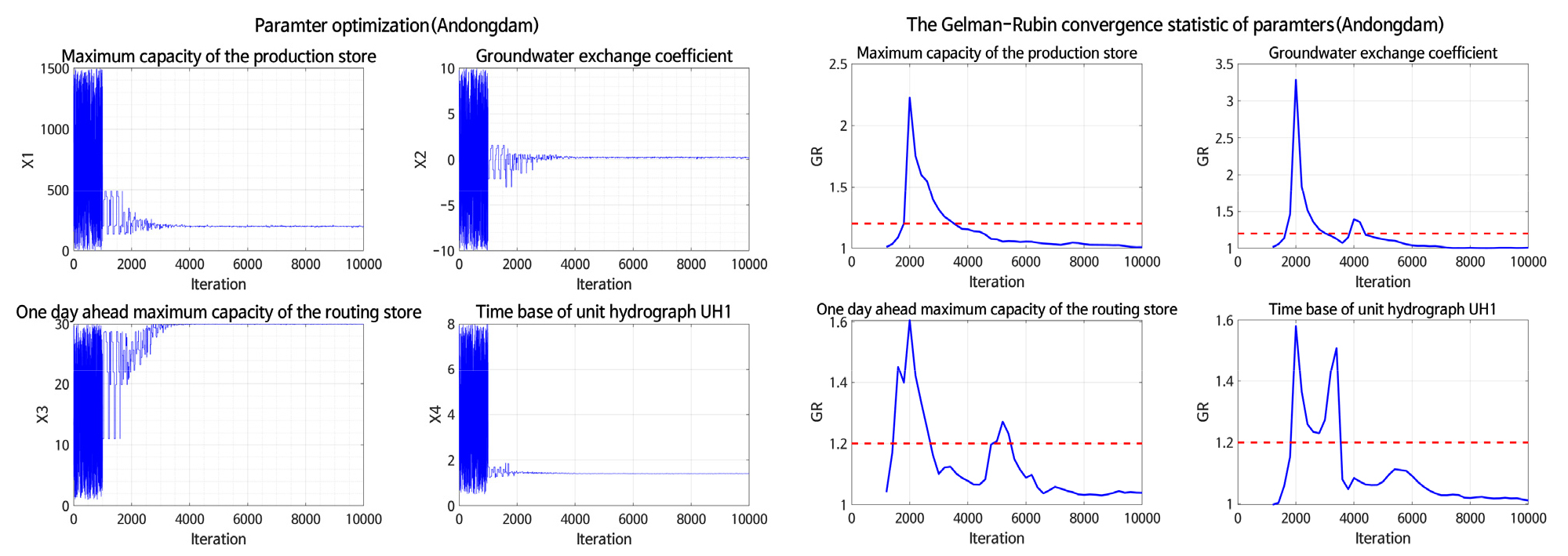
최종적으로 모의된 10,000번의 매개변수 X1, X2, X4에 대하여 9,000번은 제거(burn-in), 이후 남은 1,000개의 표본을 활용하여 각각의 매개변수에 대한 사후분포를 추정하였다. 앞서 언급하였듯이, SCEM-UA 기법을 활용할 경우, 강우-유출모형의 매개변수 최적화 과정에서 있어 사후분포를 통해 각각의 매개변수에 불확실성을 정량적으로 제시할 수 있는 장점이 있다. Table 5는 MCMC를 통해 추정된 매개변수의 사후분포에 따른 불확실성 범위를 나타내며, 각각의 매개변수별 2.5%, 50%, 97.5% 등 세가지 분위(quantile)를 추출하여 매개변수의 불확실성 구간을 추정하였다.
Table 5.
Credible interval of model parameters derived from posterior distributions
Fig. 5는 대표적으로 안동댐 유역의 수렴된 9,000번 이후의 표본 1,000개 대한 매개변수를 핵밀도함수를 통해 도시한 결과이며, 파란색 선은 매개변수의 사후분포, 빨간색 선은 각각의 매개변수에 대한 중앙값(median)을 나타낸다.
모형을 통해 모의된 결과의 적합성을 평가하기 위한 수단으로 다양한 통계적 방법들이 제안되었다. 본 연구에서는 편의(Bias), 평균제곱근오차(root mean squre error, RMSE), 상관계수(correlation coefficient, CC), 일치계수(index of agreement, IoA), 표준화 된 평균 제곱근 오차(normalized root mean squared error, NRMSE)를 활용하여 댐 유입량과 GR4J 모형 매개변수 최적화에 따른 자연유출량 모의결과의 예측 성능을 평가하였다.
Bias는 추정결과가 한 쪽 방향으로 치우침에 따라 나타나는 편향정도를 의미하며, RMSE는 참값과 모의된 결과에 대한 차이를 표현하는 척도로 0에 가까울수록 모형이 우수함를 의미한다. CC, IoA는 모형의 효율성을 나타내는 무차원 기준으로 1에 근접할수록 모의능력이 우수함을 나타내며, NRMSE는 다른 집단 간 오차를 표준화하여 평가하기 위한 방법으로, 0에 가까울수록 모의된 결과가 참값과 유사하다는 것을 의미한다. 다목적댐 14개소에 대한 관측 유입량 자료와 GR4J 모형 매개변수 최적화에 따른 유출량 모의결과에 대한 통계적 분석결과는 Table 6과 같다.
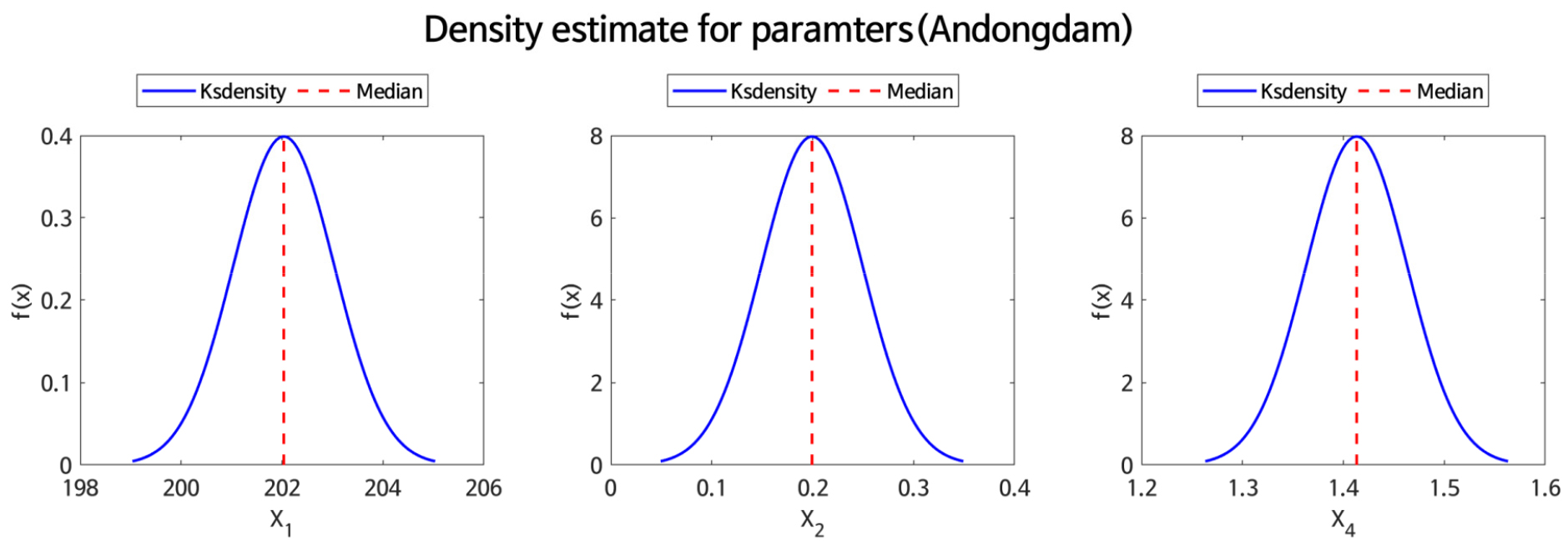
Table 6.
A comparison through statistical assessment measures between observed and simulated streamflow (Optimization)
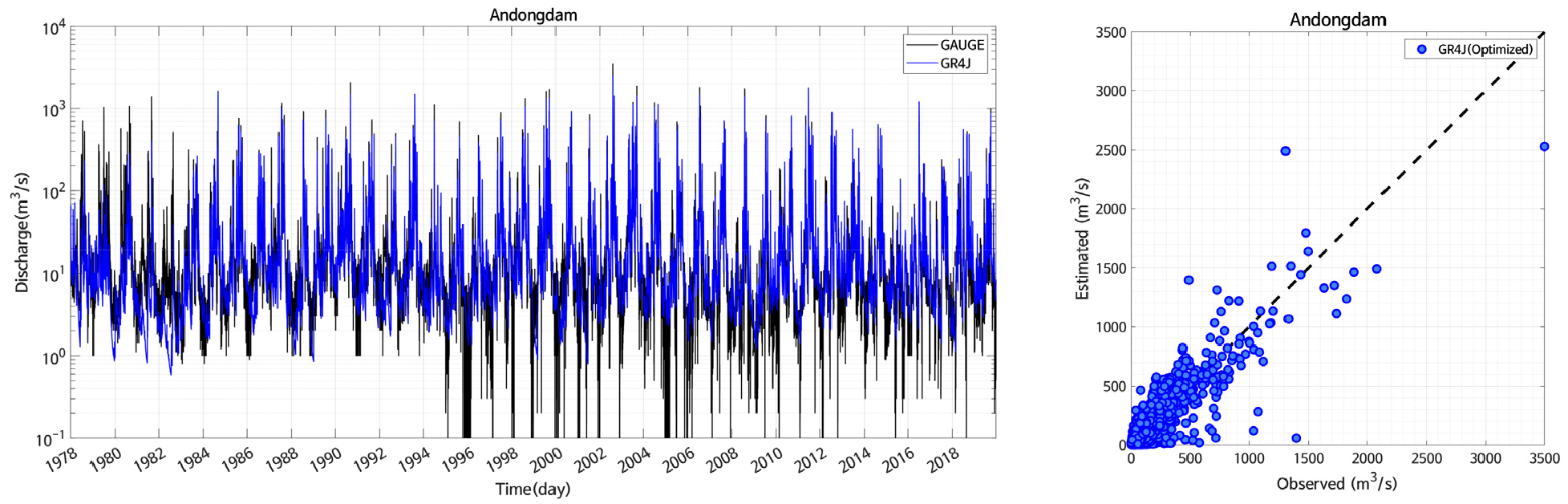
통계적 분석 결과, 전반적으로 SECM-UA 기법을 통해 추정된 매개변수를 이용하여 산정한 자연유출량은 관측 유입량과 높은 상관성을 보이며, 개별 통계적 지표를 통해서도 모의 정확도를 확인할 수 있다. Fig. 6의 왼쪽 그림은 안동댐에 대하여 SCEM-UA 기법을 통해 최적화된 GR4J 매개변수를 이용한 일단위 자연유출량 산정결과를 도시한 결과이며, 검은 선은 관측 유입량, 파란 선은 GR4J 모의유량을 의미한다. 지면 제약으로 인해 모든 유역에 대해서 결과를 도시하지 않았지만, 모형 매개변수 개수가 상대적으로 적음에도 불구하고 통계적 지표뿐만 아니라, 시각적으로도 고유량 및 저유량 모두에서 관측 유량의 변동성을 효과적으로 모의하는 것을 확인할 수 있었다. Fig. 6의 오른쪽 그림은 안동댐 유입량과 모의결과에 대한 1:1 상관성을 비교하여 도시한 결과이다.
3.2 강우-유출모형 매개변수 지역화 결과
Copula 함수를 활용한 GR4J 모형 매개변수의 지역화 과정은 다음과 같다. 첫째, 본 연구에서 선정한 충분한 기간의 관측 유입량 자료가 확보된 다목적댐 지점 14개소와 댐 상류의 수위관측소 12개소 유역을 대상으로 최적 매개변수를 산정한다. 둘째, 유역의 단일형상계수(unit shape factor)의 크기에 따른 매개변수 지역화 적용조건을 구분함으로써 물리적으로 유역특성인자와 최적화된 매개변수 사이의 유효한 상관관계를 갖는 유역특성인자를 선정한다. 본 연구에서 강우-유출모형의 매개변수와 유역특성인자의 지형학적 상관관계를 파악한 결과, 매개변수 지역화 적용조건을 구분하는 단일형상계수의 분류 조건을 2로 선정하였다. 단일형상계수는 유역면적의 제곱근에 대한 최원유로연장의 비로 정의되며, Eq. (5)를 통해 산정할 수 있다. 이때 Ru는 단일형상계수를 의미하며, Aw는 유역면적, Lb는 최원유로연장을 의미한다.
셋째로, 선정된 유역특성인자와 강우-유출모형 매개변수의 분포특성을 가장 잘 나타내는 주변확률분포를 선정하였으며, Copula 함수를 활용하여 결합확률밀도함수를 구축한다. 즉, 상대적으로 취득이 용이한 미계측유역의 지형특성인자를 조건부로 하여 기 구축된 결합확률밀도함수로부터 MCS (Monte Carlos simulation)를 통해 매개변수 집합을 동시에 추출할 수 있다.
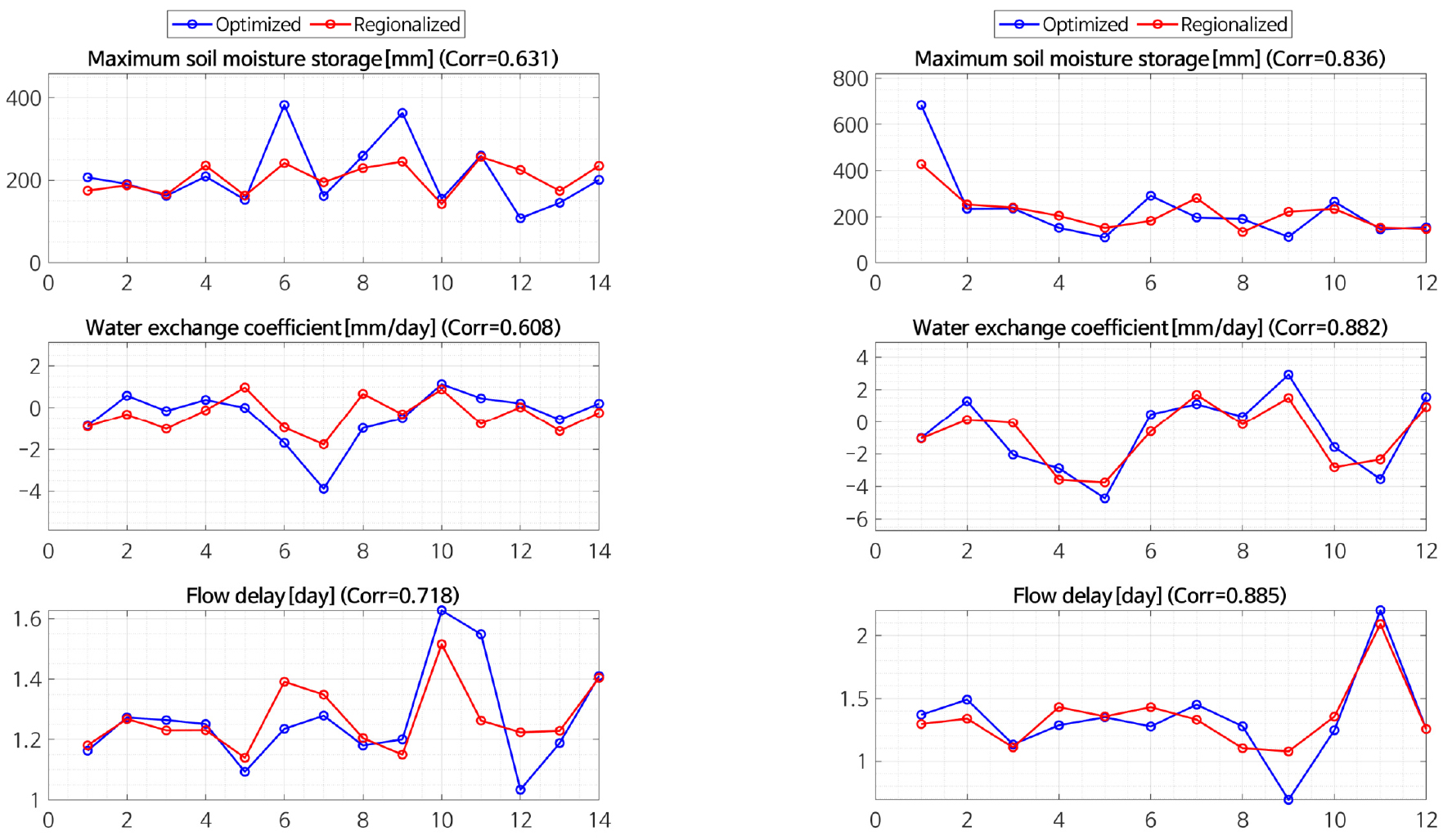
본 연구에서는 10,000,000번의 모의를 통해 유역특성인자와 최적 매개변수 사이의 상관성을 갖는 지역화된 매개변수 표본을 생성하였다. 최종적으로 교차검증(cross-validation) 관점에서 지역화된 매개변수에 대한 적합성을 검토하였으며, Fig. 7에 14개 다목적댐 및 12개 수위관측소 유역의 최적 매개변수와 지역화된 매개변수에 대하여 교차검증 결과를 도시하였다. 최적 매개변수와 지역화된 매개변수의 통계적 특성 검토 결과, 다목적댐 유역에서는 약 0.6, 수위-유량 관측소 유역에서는 약 0.8 이상의 상관성을 보이는 것을 확인하였다. 다목적 댐 유역의 경우, 상대적으로 상관성이 낮게 산정되었으나, 수위관측소 유역과 같이 유역의 크기가 작아질수록 매개변수의 상관성이 개선되는 것을 확인할 수 있었으며, 강우-유출모형의 지역화 시 유역의 크기와 연관이 있는 것으로 판단된다. 일반적으로 유출분석 시 고려되는 미계측유역의 경유 유역의 크기가 중·소규모임을 감안하였을 때, 매개변수를 추정하는 측면에서 본 모형의 결과는 유의성을 갖는 것으로 볼 수 있다.
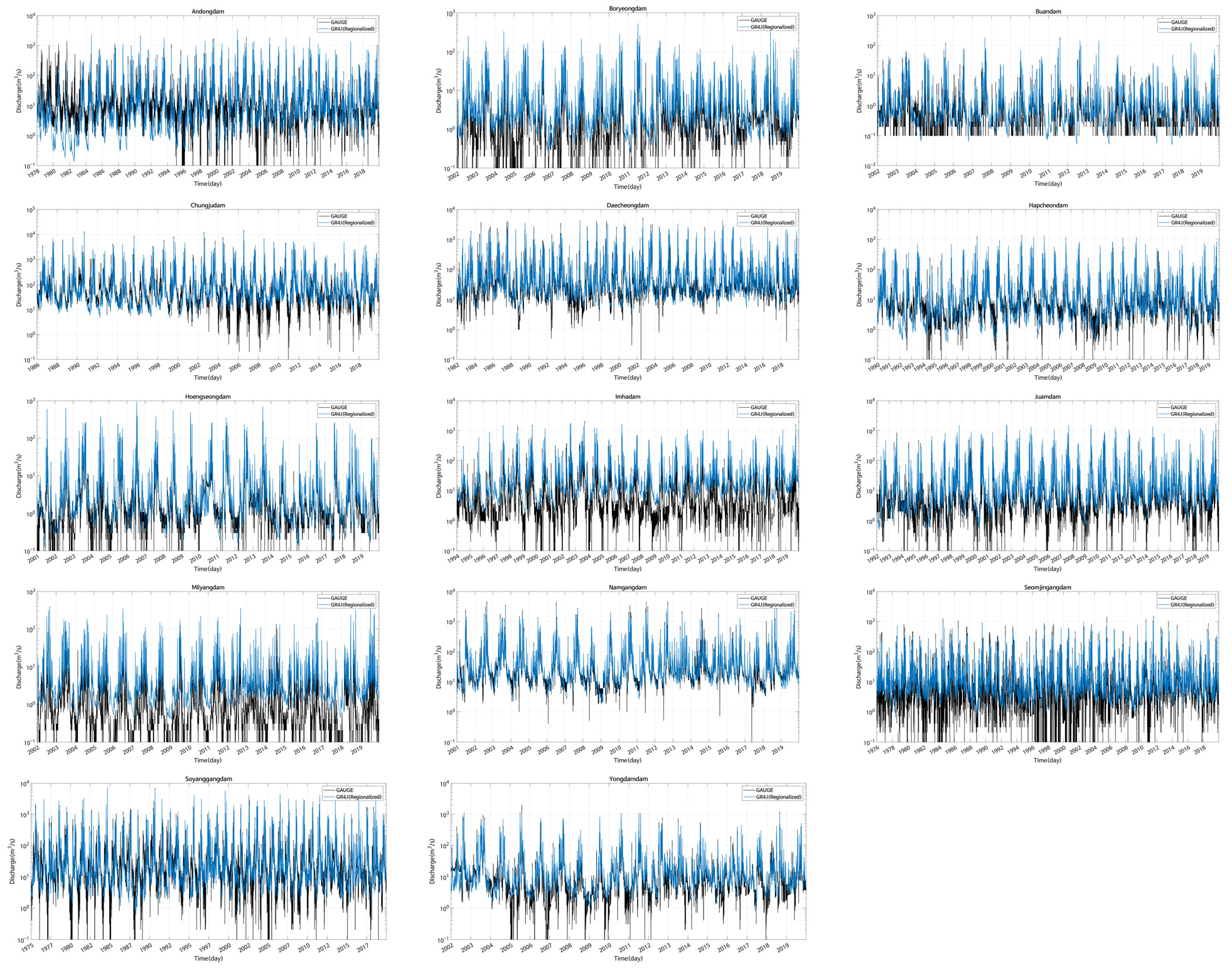
최종적으로 다목적댐 14개소의 유역을 미계측유역으로 가정하여, 지역화 모형을 통해 추정된 매개변수에 따른 자연유출량을 모의하였다. Table 7은 다목적댐 유역의 지역화된 매개변수를 활용하여 추정된 자연유출량 모의결과에 대한 통계적 분석결과를 나타내며, Fig. 8은 지역화된 매개변수를 활용한 자연유출량 모의결과와 댐 유입량과 함께 비교하여 도시한 결과이다. 매개변수 최적화시 활용한 통계적 지표와 동일한 방법을 통해 지역화 결과에 대한 적합성을 평가하였으며, 결과적으로, 대부분 댐 유역에서 평균적으로 통계적 지표가 0.8 이상의 높은 결과를 보이는 것을 확인할 수 있다. 지역 매개변수를 활용한 유출량 모의 평가 결과에서 횡성댐, 주암댐 등 일부 유역은 모의 재현성이 다소 떨어져 보일 수 있으나, 미계측 유역에 대한 장기유출량을 추정하는 측면에서 본 모형의 결과는 유의성을 갖는 것이라 판단된다.
Table 7.
A comparison through statistical assessment measures between observed and simulated streamflow (Regionalization)
다목적댐 14개소의 관측 유입량 자료와 함께 도시하여 시각적으로 검토한 결과, 대체로 모의된 자연유출량이 관측유량과 높은 상관성을 가지며 유출특성이 재현되는 것을 확인할 수 있다. 이는 본 연구에서 유역특성인자의 상호의존성을 직접적으로 고려한 결과로 평가될 수 있다. 본 연구에서 제안한 모형은 유역의 특성을 고려하여 미계측유역에 대한 강우-유출모형의 매개변수 정보를 제공함과 동시에 강우-유출 매개변수 사이의 상관성을 고려한다는 점에서 기존 지역화 방법론과 차별성을 갖는다. 즉, 강우-유출모형 매개변수와 유역특성인자의 상관성을 고려하여 동시에 모의함으로써 모형의 매개변수에 대한 물리적인 특성을 재현하는데 유리할 것으로 판단된다.
4. 결 론
본 연구에서는 다목적댐 관측 유입량 자료를 활용해 댐 상류 유역의 강우-유출모형 매개변수를 최적화하였으며, 강우-유출모형 매개변수를 지역화하여 자연유출량 재현성능을 평가하였다. 강우-유출모형 매개변수 최적화시 발생되는 매개변수의 불확실성을 정량화하기 위해 Bayesian 이론을 활용하였으며, 유역특성인자 및 최적 매개변수의 분포특성 및 상관성을 종합적으로 고려하기 위해 Copula 함수를 활용한 매개변수 지역화 방안을 제시하였다. 본 연구를 통해 도출된 결과를 정리하면 다음과 같이 요약할 수 있다.
1) 대표 수문모형으로 비교적 간단한 절차를 통해 자연유출량을 산정할 수 있는 개념적 일단위 강우-유출모형인 GR4J 모형을 선정하여 K-water에서 운영하는 다목적댐 14개소 중권역 및 댐 상류 수위관측소와 인접해 있는 유역에 대한 매개변수 최적화에 따른 자연유출량 재현성능을 관측유량과 비교하여 최적 매개변수에 대한 유의성을 검토하였다.
2) 강우-유출모형의 매개변수 최적화 과정에서 발생할 수 있는 불확실성을 정량적으로 고려하기 위하여 Bayesian 이론을 기반으로 최적화를 수행하였으며, 매개변수의 사후분포로부터 추출되는 다수의 매개변수를 지역화에 활용하였다. 최적 매개변수를 활용한 강우-유출모형 매개변수 지역화 수행시 추정된 지역 매개변수의 적용성을 확보하기 위하여, 최적 매개변수 결과와 해당 유역의 특성을 갖는 인자에 대한 상관관계를 파악해 유역특성인자를 선별하였으며, 최적화된 강우-유출모형의 매개변수와 유역특성인자 사이의 상관성을 고려하기 위하여, Copula 함수를 활용한 매개변수 지역화 모델로 확장하였다.
3) 교차검증 관점에서 지역화된 매개변수 추정 결과와 최적 매개변수 사이의 유의성을 확보하기 위해 상관성 분석을 수행한 결과, 중권역에서 약 0.6이상, 댐 상류 유역에서 약 0.8 이상을 보임에 따라 유역특성인자 사이의 의존성이 반영된 지역화된 매개변수가 추정되었다고 평가할 수 있다.
4) 최종적으로 지역 매개변수를 활용한 자연유출량 모의결과와 댐 관측 유입량을 함께 도시하여 본 연구에서 제안한 매개변수 지역화 모형에 대한 적합성을 평가하였다. 결과적으로 기존 관측 유입량 값과 약 0.8 이상의 높은 상관성이 나타나는 것을 확인할 수 있었으며, 특히 저유량의 예측 정확성 측면에서 모형의 수행능력을 중점적으로 고려하였음에도 불구하고, 상대적으로 전반적인 유량의 크기에 따른 평균제곱근오차의 값이 크지 않으며 매개변수 최적화 결과와도 큰 차이가 발생하지 않음에 따라, 지역 매개변수를 활용한 자연유출량의 재현성능이 우수하다고 볼 수 있다. 즉, 본 연구에서 제안한 방법론은 미계측유역의 강우-유출모형 매개변수 추정시 유역특성을 고려한 지역 매개변수의 추정이 가능하다는 측면에서 유리한 장점을 확인하였다.
본 연구에서 제시한 강우-유출모형의 매개변수 지역화 모형은 매개변수 최적화 과정에서 발생하는 불확실성을 정량화하여 해석결과에 대한 신뢰성을 확보하였으며, 유역특성인자와 최적 매개변수 사이의 의존성을 직접적으로 고려함으로 미계측유역의 자연유출량을 추정하는 도구로서 활용성이 높을 것으로 판단된다. 향후 연구에서는 자연유출 특성을 갖는 유역을 추가적으로 확보하여 매개변수에 대한 신뢰성 개선이 필요하다. 또한, 본 연구에서 언급한 인자 이외의 인자를 추가적으로 고려하여 매개변수 지역화 과정에서 발생하는 불확실성을 저감할 수 있는 대안과 함께, 저유량 부분에 대한 모의성능을 향상하여 신뢰성 있는 자연유출량 모의 기법의 개발이 필요할 것으로 판단된다.
