

1. 서 론
2. 연구방법
2.1 가뭄의 정의
2.2 Copula 함수
2.3 Bayesian Copula 기반 이변량 가뭄 지역빈도해석
3. 연구결과
3.1 대상유역
3.2 분석결과
4. 결 론
1. 서 론
가뭄은 강우량이 부족한 현상이 장기간에 걸쳐 발생하는 기상재해를 말하며, 이러한 가뭄현상은 전 세계적으로 다양한 요인에 의해 발생되고 있다. 국지성 호우에 의해 발생되는 돌발홍수와 같이 단기간에 발생하는 자연재해와 달리 가뭄은 특정 지역에 국한되지 않고 수개월에 걸쳐 진행되며, 지속된 시간에 비례하여 피해가 증가함에 따라 정상적인 강우패턴으로 회복된 뒤에도 장기간에 걸쳐 가뭄의 영향이 지속된다(Park and Lee, 2018). 특히 2013~2015년 우리나라에는 예측하지 못한 유례없는 가뭄이 발생한 바 있으며, 이와 같은 기존 기상패턴과 다른 극한가뭄에 대한 심각성이 대두되고 있다(Kim et al., 2017). 이처럼 최근 발생빈도가 커지고 있는 가뭄에 대해 용수공급 관리측면에서 효율적인 대응 및 대안 수립을 위해서는 가뭄을 정량적으로 평가하는 연구가 선행되어야 하며(Lee and Son, 2016), 국내외에서는 가뭄의 특성을 위험도 관점에서 평가하기 위한 방안으로 가뭄빈도해석이 수행되고 있다(Kim et al., 2017). 이밖에 국내외 연구를 살펴보면 선제적인 가뭄에 대비하기 위해 위성자료 및 빅데이터 등을 활용한 가뭄 예측인자 발견에 대한 다양한 연구가 진행되고 있지만, 가뭄의 자연현상을 물리적으로 설명하기에는 한계가 존재하며, 가뭄 전이과정 또한 명확한 규명이 어려운 실정이다.
수문자료에 대한 빈도해석은 일반적으로 단일 확률변수를 기준으로 이루어지는 단변량(univariate) 해석 방법이 활용되며, 신뢰성 있는 빈도해석 결과를 도출하기 위해서는 많은 자료의 수를 확보하는 것이 필수적이다. 빈도해석을 통해 도출되는 재현기간은 특정 강도의 수문학적 극치사상이 발생하는 평균적인 발생 주기로서 수자원 계획측면에서 가장 기본적인 설계인자로 활용된다(Kwak et al., 2012). 그러나 수문학 분야에서 자료의 해석 시 사용되는 자료들의 대부분은 관측연수가 짧으며, 미계측 유역의 경우 해당 유역에 대한 측정자료가 존재하지 않는 등 제한적인 자료로 인한 표본오차로 인해 지점빈도해석(point frequency analysis)시 통계적으로 신뢰성이 결여되는 단점이 있다(Kwon et al., 2013). 이러한 문제점들을 해결하기 위한 대안으로 지역빈도해석(regional frequency analysis) 방법이 제안되었으며, 다수의 연구에 의해 지역빈도해석의 효율성이 확인되었다(Potter, 1987; Hosking and Wallis, 2005; Oh et al., 2006; Lee and Kwon, 2011). 국내에서도 지역빈도해석에 대한 연구가 다양하게 진행되었다. Oh et al. (2008)은 우리나라 강우관측소를 6개 지역으로 구분하여 지역빈도해석 방법을 통해 확률강우량을 산정하여 비교하였으며, Nam et al. (2008)은 Procrustes analysis를 통해 최소 변수를 선정하고, 요인분석(factor analysis)과 군집해석(cluster analysis)을 적용하여 구분된 동질 지역을 바탕으로 확률강우량을 산정하여 국내 적용성을 검토하였다. Kwon et al. (2013)은 기존 지역빈도해석 방법에 계층적 Bayesian 기법을 적용하여 해석결과에 대한 불확실성을 정량적으로 분석하였으며, Kim et al. (2014)는 지역특성(위도, 경도, 고도)과 기후학적 특성을 계층적 Bayesian 모형 안에서 연계하여 극치수문변량의 공간적 해석 및 불확실성 분석이 가능한 지역빈도해석 기법을 제시하였다.
앞서 언급하였듯이 특정 극치사상 자료에 대한 특성을 분석 시, 일반적으로 단변량 중심의 지점빈도해석이 수행된다. 그러나 두 가지 이상의 변량이 서로 상관성을 가지는 경우 다변량(multivariate) 지점빈도해석 이 요구되며, 이를 단변량으로 해석하는 경우 재현기간의 과소추정 등의 문제점이 발생할 수 있다. 최근 이러한 점을 개선하기 위하여 다변량 빈도해석에 관한 연구가 지속적으로 진행되고 있다(Kwon and Lall, 2016; Vaziri et al., 2018). 특히, 가뭄의 경우, 강도(intensity)뿐만 아니라 지속기간(duration), 심도(severity)도 매우 중요한 인자로 고려되고 있다. 특히, 가뭄 지속기간과 심도의 경우 두 인자간의 상관성이 매우 크기 때문에 단변량 가뭄빈도해석 보다 다변량으로 가뭄빈도해석을 수행하는 것이 가뭄위험도 평가측면에서 유리하다고 알려져 있다(Shiau and Shen, 2001; Kim et al., 2017).
Skalr (1959)가 제시한 Copula 함수는 자유로운 주변확률분포(marginal probability distribution) 선택과 결합확률분포(joint probability distribution)의 추정이 용이하다는 장점이 있어 최근 10년 동안 활용성이 크게 증대되고 있으며, 여러 분야에 다양한 목적으로 적용되고 있다. 수문학 분야에서도 다변량의 극치 값을 다루기 위해 Copula 함수를 기반으로 수행된 연구가 다수 진행된바 있다(Fernández and Salas, 1999; Bonaccorso et al., 2003; Canclliere and Salas, 2010; Kwon and Lall, 2016; Kim et al., 2017). 이처럼 Copula 함수를 활용한 다수의 이변량 빈도해석에 대한 연구가 진행되었지만, 대부분의 연구는 지점빈도해석에 국한되었으며, 유사한 통계적 특성을 가지는 지역 내 관측소의 수문특성을 단순히 자료를 Pooling 하는 것에서 벗어나 확률분포특성을 체계적으로 고려한 연구는 미진한 실정이다.
이러한 점에서 본 연구에서는 이변량 빈도해석 시 널리 활용되고 있는 Archimedean Copula 함수를 활용하였으며, 확률분포 매개변수의 불확실성을 정량화하기 위하여 Bayesian 기법과 연계한 Bayesian Copula 기반 이변량 가뭄 지역빈도해석 모형을 제안하고자 한다. 본 연구에서는 주변확률분포와 Copula 함수의 매개변수를 동시에 추정하기 위하여 주변확률분포와 주요 Archimedean Copula 함수의 우도함수(likelihood function)를 연계하였으며, 기존의 지역빈도해석 방법과는 다르게 각 지점에 확률분포를 추정하되 상위단계에서 각 지점의 매개변수들이 서로 연계가 가능하도록 계층적(hierarchical)으로 모형을 구성하여 매개변수의 사후분포(posterior distribution)를 추정하였다.
본 연구는 Kim et al. (2017)이 제시한 이변량 Bayesian Copula 지점빈도해석 모형을 지역빈도 개념으로 확장하는데 목적이 있다. 이에 선행 연구와 동일한 자료를 활용하여 모형을 검증하였으며, 2013-2015년도에 한강유역에서 발생한 가뭄에 대한 이변량 지역빈도해석을 수행하여 동일 지역의 지점빈도해석 결과와 비교함으로써 본 연구에서 활용한 방법의 국내 적용특성을 검토하였다.
본 논문의 구성은 다음과 같다. 1장에서는 본 연구 내용의 전반적인 내용에 대해 서술하였으며, 2장에서는 가뭄의 정의 및 Coupla 함수, 간략한 Bayesian 기법과 개발된 이변량 가뭄 지역빈도해석 모형에 대해 설명하였다. 3장에서는 개발된 Bayesian Copula 기반 이변량 가뭄 지역빈도해석의 실제 가뭄사상에 대한 적용 결과를 제시하였으며, 4장에서는 결론 및 향후 연구방향에 대해 서술하였다.
2. 연구방법
지점 및 지역빈도해석은 국내외에서 많은 연구들이 수행되었기에 본 절에서는 가뭄의 정의 및 Copula 함수, Bayesian 방법에 대한 핵심적인 부분만 간략히 기술하였으며, 본 연구에서 개발한 Bayesian Copula 기반 이변량 가뭄 지역빈도해석 모형에 대해 상세히 수록하였다.
2.1 가뭄의 정의
가뭄이란 어느 지역에서 일정 기간 이상 평균 이하의 강우로 인해 강우량 부족이 장기화 되는 현상으로, 판단 기준에 의해 기상학적(meteorological), 농업적(agricultural), 수문학적(hydrological), 사회경제적(socioeconomic) 가뭄으로 분류하여 정의된다. 본 연구에서는 일정기간 평균 강우량보다 적은 강우로 인해 건조한 날이 지속되는 기상학적 가뭄에 대한 지역빈도해석을 수행하였으며, Yevjevich (1967)에 의해 제안된 연속이론(run theory)을 통해 대상유역에 대한 가뭄을 정의하였다. 연속이론에 대한 기본적인 정의는 Fig. 1과 같다.
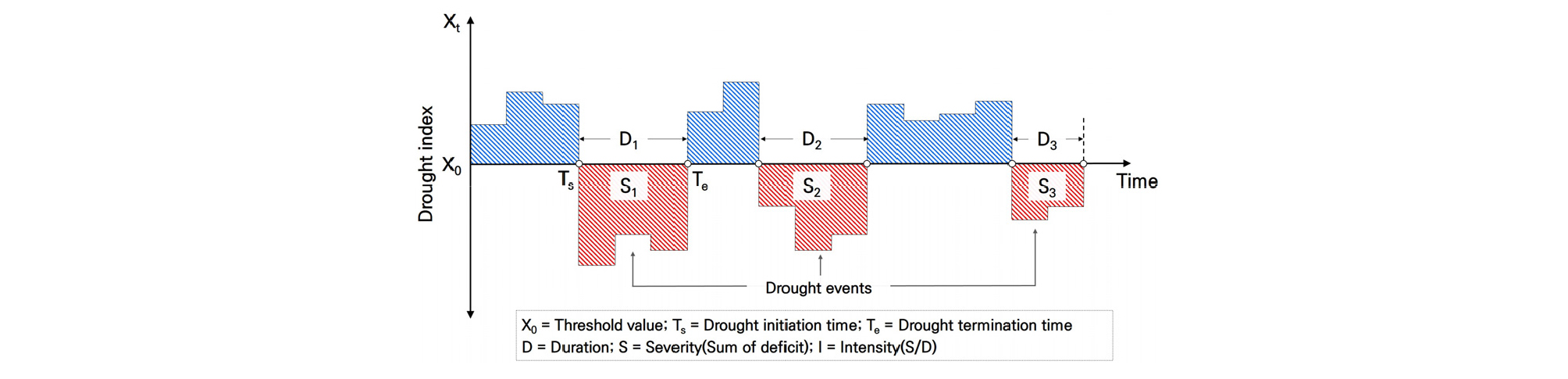
Fig. 1에 도시된 개념과 같이, 연속이론은 수문변수 Xt가 정의된 특정 값(threshold value) X0이하로 떨어졌을 때, 이를 사건이 일어난 사상(event)으로 정의한다. 최근 국내외에서는 가뭄빈도해석과 관련된 연구를 수행하는데 있어, 가뭄의 복합적 특성을 고려하기 위해 지속시간과 심도를 활용한 이변량 가뭄빈도해석 연구가 활발히 진행되고 있다(Hong and Lee, 2011; Kim et al., 2017). 이에 본 연구에서는 기상청 관측자료를 활용하여 산정된 Anomaly를 통해 가뭄사상을 구분하였으며, 산정된 Anomaly의 시계열이 0이하로 떨어졌을 때, 가뭄의 시작부터 종료까지 기간을 의미하는 가뭄 지속기간, 떨어진 양의 총합을 강우부족량을 의미하는 가뭄 심도로 정의하였으며, 가뭄 지역빈도해석을 위한 주요 변량으로 활용하였다.
앞서 언급하였듯이, 본 연구에서는 기상학적 측면의 가뭄해석을 수행하고자 한강유역에 위치한 기상청 강우관측소 중 유사한 통계적 특성을 나타내는 관측소를 선별하였다. 가뭄빈도해석시 결과에 대한 신뢰성을 확보하기 위해서는 장기간의 강우량 자료가 요구된다. 확률분포를 활용한 수문자료의 통계적 분석시, 강우량 자료는 최소 30년 이상이 필요하지만, 50년 이상의 강우량 자료를 사용할 것을 권장하고 있다(Guttman,1999). 본 연구에서는 1974년부터 2015년 사이에 관측된 강우량 자료를 이용하여 연속이론에 따른 가뭄 특성인자를 추출하였다. 가뭄 특성인자 추출을 위하여 기상청 강우관측소의 정상년 강우량을 기준으로 월강우량 자료를 6개월마다 누적하였으며, 가뭄의 절단수준을 결정하기 위하여 Eq. (1)을 통해 강우의 Anomaly를 산정하였다.
| $$A_{(y,m)}=\frac{(R_{(y,m-5)}+R_{(y,m-4)}+\;\cdots\;+R_{(y,m)})}n$$ | (1) |
여기서 각각 y, m은 Anomaly의 연도, 월을 나타내며, n은 월강우량의 누적 개월 수, R(y, m)은 6개월 누적 강우량, A(y, m)은 해당 년 월의 Anomaly를 의미한다. 최종적으로 Eq. (2)를 통해 가뭄을 구분하였으며, 여기서 은 자료기간에 대한 m월의 Anomaly 평균을, Xt는 가뭄상태를 의미한다.
| $$X_t=A_{(y,m)}-\overline{A_m}$$ | (2) |
2.2 Copula 함수
Copula 함수는 Sklar (1959)에 의해 처음 제시되었으며, 두 개 이상의 확률변수들 사이의 복합한 의존성을 파악하는데 있어 용이한 기법이라 알려져 있다. 1990년대 후반을 기점으로 다양한 이론 및 방법론이 정립되었으며, 현재까지도 Copula 함수는 통계 및 경제 분야 등 여러 분야에 적용이 이루어지고 있다(Joe, 1997; Nelsen, 2007; Radice et al., 2016). 최근 수문학 분야에서도 다변량 분석시 Copula 함수를 활용한 다수의 연구가 진행되었으며(Kim et al., 2016), 특히 가뭄과 같이 복합인자가 동시에 발생하는 변량의 경우 상호 의존성이 뚜렷하기 때문에 가뭄빈도해석 시 Copula 함수의 적용을 통해 다양한 장점을 활용할 수 있다. 수문학 분야에서 사용되는 변량의 경우 분포 형태가 비대칭적이면서, 꼬리(tail)가 두꺼운 극치값(극대 또는 극소)값을 보이는 경향이 강하다. 따라서 이러한 자료의 꼬리 부분에 대한 분포를 다루는데 있어 Copula 함수 활용이 타당하다고 알려져 있다(Kim et al., 2016). 특히, 가뭄의 경우 일반적으로 복합적인 인자가 동시에 고려되기 때문에 가뭄에 대한 빈도해석시 단변량 가뭄빈도해석보다 다변량의 인자를 고려한 가뭄빈도해석의 적용이 정량적인 가뭄위험도 평가측면에서 유리하다고 알려져 있다(Shiau and Shen, 2001).
Copula 함수는 2개 이상의 주변확률분포를 이용하여 결합 확률분포를 구축하는 역할을 하며, 기본적으로 누가분포함수가 입력자료로 활용된다. 본 연구에서는 Copula 함수의 적용 시 비교적 과정이 간편하고 다양한 확률분포형 적용이 가능한 Archimedean Copula 함수를 활용하였다. 대표적으로 이용되는 Copula 함수는 Clayton, Frank, Gumbel Coupla 등이 있으며, 각각의 함수식을 Table 1에 정리하였다.
Table 1. The Archimedean copula functions used in this study
| Name of copula | Bivariate Copula | Parameter |
| Clayton | ||
| Frank | ||
| Gumbel |
Shiau and Shen (2001)은 변량간 결합확률분포를 활용하여 가뭄과 비 가뭄의 지속기간이 기하학적 분포를 따른다는 가정 하에 평균 가뭄사상 발생 간격을 산정하였다. 본 연구에서 산정한 가뭄의 분포를 고려할 때 가뭄의 지속기간(TD)과 심도(TS)에 대한 재현기간은 Eq. (3)과 같이 정의된다.
| $$T_D=\frac{E(L)}{1-F_D(d)}$$ | (3a) |
| $$T_S=\frac{E(L)}{1-F_S(s)}$$ | (3b) |
여기서, L은 가뭄 사상 간의 간격(inter-arrival time), E(L)은 평균가뭄발생 간격이며, FD(d), FS(s)는 가뭄의 지속기간 및 심도에 대한 누가분포함수(cumulative distribution function, CDF)이다. 이는 Shiau (2006)에 의해 정의된 지속기간과 가뭄 심도를 활용한 이변량 가뭄 지역빈도해석 식의 입력 값으로 활용되며, 식의 형태는 Eq. (4)와 같다.
| $$T_{DDS}=\frac{E(L)}{P(D\geq d\;\mathrm{and}\;S\geq s)}=\frac{E(L)}{1-F_D(d)-F_S(s)+C(F_D(d),\;F_S(s))}$$ | (4a) |
| $${T'}_{DDS}=\frac{E(L)}{P(D\geq d\;\mathrm{or}\;S\geq s)}=\frac{E(L)}{1-C(F_D(d),\;F_S(s))}$$ | (4b) |
여기서, E(L)은 평균가뭄발생 간격이며, TDDS는 가뭄 지속기간과 심도가 모두 초과할 확률(D ≥ d and S ≥ s)일 때 결합재현기간(joint return period), T'DDS는 가뭄 지속기간과 심도 중 하나가 초과할 확률(D ≥ d or S ≥ s)을 의미한다.
2.3 Bayesian Copula 기반 이변량 가뭄 지역빈도해석
최근 수문학 분야에서는 관측자료에 대한 지점빈도해석시 제한적인 자료의 길이로 인해 신뢰성이 결여되는 문제점을 해결하기 위한 대안으로 지역빈도해석 방법을 활용한 연구가 진행되었으며, 다수의 연구에서 효율성이 확인되었다. 그러나 빈도해석 수행시 자료 및 모형의 매개변수에서 나타나는 불확실성 정도와 이에 따른 설계수문량에 신뢰성에 대한 연구는 미진한 실정이다. 기존 이변량 가뭄빈도해석 결과의 경우, 산정된 빈도의 불확실성 구간에 대한 정량적 제시가 어려우며, 특히 자료연한이 짧은 자료를 대상으로 분석이 이루어지는 경우 해석결과에 대한 신뢰성을 판단하는데 어려운 단점이 있다(Kim et al., 2017). 이에 본 연구에서는 불확실성 평가에 대표적으로 활용되는 Bayesian 방법을 기존 Copula 함수 이론과 결합한 이변량 가뭄 지역빈도해석 기법을 개발하였다. 제시된 모형을 통해 기존의 강우관측소별 가뭄 지점빈도해석 과정으로부터, 지역의 가뭄특성을 전반적으로 고려하여 선별된 유사한 가뭄특성을 갖는 지점을 통합적으로 고려하여 하나의 지역화 된 가뭄빈도해석 결과를 제시하였다. Bayesian 기법을 도입하여 동일한 지역적 조건에 대한 모형의 최적화된 매개변수가 추정될 수 있도록 하였으며, 이분화 되어 있던 계산 과정을 통합하여 주변확률분포와 Copula 함수의 우도(likelihood)가 동시에 추정될 수 있도록 모형을 구성하였다.
Bayesian 확률은 두 확률 변수의 조건부확률(conditional probability)을 나타내는 정리로, A라는 사건이 발생할 때 확률(P(A))을 기준으로 B라는 새로운 자료의 증가에 의해서 정보가 갱신되며 최종적으로 사건이 일어날 확률(P(A|B)) 사이의 관계를 나타낸다. 여기서 P(A)는 사전확률(prior probability), P(A|B)는 사후확률(posterior probability)을 말한다(Gelman et al., 2004). Bayesian을 통한 매개변수 추정기법은 기존 방법들(최우도법, 모멘트법, 확률가중모멘트법)과는 다르게 매개변수를 확률변수로 취급한다. 즉, 매개변수가 단일 값이 아닌 확률분포의 형태로 부여되어 최종적으로 매개변수의 사후분포를 추정하는데 목적을 두며, Bayes 정리(Bayes’s rule)를 기반으로 한다. Bayes 정리에 대한 기본적인 개념은 다음과 같다. 주어진 확률변수 y와 매개변수들의 집합 가 있을 때, 두 확률변수들의 결합확률분포는 Eq. (5)와 같이 사전분포 와 우도 의 곱으로 표현할 수 있다. Bayes 정리에서 매개변수 와 변량 y의 조건부확률과 주변확률의 관계는 Eq. (6)과 같으며, Eq. (7)에서 좌변 는 사후분포를 나타내며 사전분포와 우도 의 곱으로 추정될 수 있다(Gelman et al., 2003).
| $$p(\theta,y)=p(\theta)\;p(y\vert\theta)$$ | (5) |
| $$p(\theta\vert y)=\frac{p(\theta,\;y)}{p(y)}=\frac{p(\theta)\;p(y\vert\theta)}{p(y)}$$ | (6) |
| $$p(\theta\vert y)\propto p(y\vert\theta)\;p(\theta)$$ | (7) |
본 연구에서 개발한 Bayesian Copula 기반 이변량 가뭄 지역빈도해석 모형의 주요 장점은 다음과 같다. 기존 연구에서 수행되는 분석절차는 각 변량의 주변확률분포를 독립적으로 산정 후 Copula 모형에 적용하여 빈도해석이 수행되는 반면, 제시된 모형에서는 이분화 되어 있던 계산 과정을 통합하여 주변확률분포와 Copula 함수가 동시에 추정된다. 모형을 개발하기에 앞서, 지속시간과 심도의 주변확률분포는 대표적인 적합통계량 선정방법 중 하나인 BIC (Bayesian information criterion)를 기준으로 각각 최소의 BIC값을 갖는 확률분포형을 선택하였다. BIC 통계량을 산정하는 일반적인 식은 Eq. (8)과 같이 나타낼 수 있다(Findley, 1991).
| $$BIC=-2\mathrm{In}\;(\widehat L)\;+\;k\mathrm{In}\;(n)$$ | (8) |
이때, 은 우도함수를 의미하며, n은 자료의 개수, k는 매개변수의 개수를 의미한다. 본 연구에서 활용된 가뭄 지속시간 및 심도에 대한 확률분포형은 각각 대수정규분포(Log-normal distribution) 및 감마분포(Gamma distribution)로 채택되었으며, 각각의 확률분포형에 대한 누가확률밀도함수는 Eqs. (9) and (10)과 같다.
| $$f(x)=\frac1{x\sigma\sqrt{2\pi}}e^{-\frac{(\log{(x)-\mu)}^2}{2\sigma^2}}$$ | (9) |
| $$f(y)=\frac{\tau^ky^{k-1}e^{-\tau y}}{\Gamma(k)}$$ | (10) |
여기서 는 평균, 는 분산, k는 형상, 는 크기 매개변수를 의미하며, 는 감마함수를 의미한다.
본 연구의 목적은 대상유역에 대한 지역빈도해석을 통해 통계적으로 신뢰성 있는 결과를 도출하는데 목적이 있다. 이에 자료의 분포 형태를 바탕으로 각각의 Archimedean Copula (Clayton, Gumbel, Frank)함수에 대한 우도를 추정하였으며, 우도가 가장 크게 나온 Frank Copula 함수를 대상유역에 대한 최적 함수로 선정하였다. 최종적으로 지속기관과 심도에 대한 각각의 분포형과 Frank Copula 함수와 결합하여 결합우도함수(joint likelihood function)로 유도하면 Eq. (11)과 같이 나타낼 수 있다.
여기서 LF는 Frank Copula의 결합우도함수를 의미하며, i는 대상유역의 강우관측소 지점수, j는 각각의 지점에서 발생한 가뭄사상 횟수를 나타낸다. Eq. (11)은 앞서 제시된 Table 1의 Frank Copula 함수와 가뭄 특성인자의 주변확률분포인 대수정규분포와 감마분포를 우도함수 형태로 나타낸 것이다. 본 연구에서는 제시된 식을 활용하여 각 매개변수 및 도출된 결과에 대한 불확실성 구간을 정량적으로 산정할 수 있는 계층적 Bayesian 모형으로 확장하였다. 즉, 대상유역에 모든 지점의 특성인자를 Eq. (11)의 대수정규분포 매개변수()와 감마분포 매개변수(), 그리고 Copula 함수 매개변수()의 사전분포는 Eqs. (12)~(16)과 같이 부여하였다. 매개변수 와 같은 경우 음(-),양(+)의 값을 모두 고려해야하기 때문에 정규분포를 부여하였으며, 매개변수 의 경우 양(+)의 값만 고려하기 위하여 감마분포를 부여하였다. Copula 함수 매개변수 는 Copula 이론의 기본 가정에 근거하여 균등분포로 가정하였다.
| $$\mu_i\;\sim\;N(\mu_a,\sigma_a)$$ | (12) |
| $$\sigma_i\;\sim\;\Gamma(k_a,\tau_a)$$ | (13) |
| $$k_i\;\sim\;\Gamma(k_b,\tau_b)$$ | (14) |
| $$\tau_i\;\sim\;\Gamma(k_c,\tau_c)$$ | (15) |
| $$\theta_i\;\sim\;U(\theta_\min,\;\theta_\max)$$ | (16) |
여기서 N은 정규분포를, 는 감마분포를, U는 균등분포를 의미한다.
매개변수들의 사전분포()는 자료를 기반으로 하는 정보적 사전분포(informative priors)와 자료에 크게 상관하지 않는 비정보적 사전분포(noninformative priors)가 있으며, 비정보적 사전분포로는 정규분포, 균일분포, 지수분포가 대표적으로 활용된다(Gelman et al., 2004; Lee et al., 2010). 앞서 언급한 바와 같이 사후분포는 사전분포와 우도함수의 곱으로 계산되며, 매개변수 추정을 위한 자료가 충분한 경우 우도함수가 비교적 정확하게 추정이 가능하기 때문에 사후분포 추정에 있어서 주도적인 역할을 하게 되며 사전분포의 중요성은 상대적으로 작아진다. 그러나 사전분포에 대한 정보가 명확하지 않은 상태에서 상대적으로 좁은 범위를 갖는 사전분포를 적용하게 되면 사후분포 추정에 있어 신뢰성이 결여되는 문제점이 발생한다. 즉, 우도가 최대가 되는 지점으로 사후분포의 중심으로 이동하지 못하고 멈추게 되며, 실제 매개변수의 분포와는 상이한 왜곡된 매개변수를 추정하는 결과를 초래할 수 있다.
본 연구에서는 각각의 가뭄변량에 대해 최우도법을 통해 통계적 특성으로부터 정보적 사전분포를 활용하여 사후분포를 추정하였으며, 는 각각의 분포에서 추정되는 매개변수를 나타낸다. 각각의 매개변수에 대한 사전분포는 Eqs. (17)~(21)과 같이 부여하였다.
| $$\mu_a\;\sim\;N(1,\;0.1)$$ | (17a) |
| $$\sigma_a\;\sim\;\Gamma(0.1,\;0.1)$$ | (17b) |
| $$k_a\;\sim\;\Gamma(80,\;0.4)$$ | (18a) |
| $$\tau_a\;\sim\;\Gamma(60,\;0.4)$$ | (18b) |
| $$k_b\;\sim\;\Gamma(60,\;0.4)$$ | (19a) |
| $$\tau_b\;\sim\;\Gamma(60,\;0.4)$$ | (19b) |
| $$k_c\;\sim\;\Gamma(60,\;0.4)$$ | (20a) |
| $$\tau_c\;\sim\;\Gamma(285,\;0.01)$$ | (20b) |
| $$\theta_\min\;\sim\;N(10,1)\vert(0,\sim)$$ | (21a) |
| $$\theta_\max\;\sim\;N(30,0.1)\vert(\theta_\min,\;50)$$ | (21b) |
위에서 정의된 우도함수와 매개변수들의 사전분포를 Eq. (5)에 대입하여 정리하면 Eq. (22)와 같이 나타낼 수 있으며, 이를 통해서 매개변수들의 사후분포 추정이 가능해진다.
| $$p(\mathit\circleddash\vert D)=\frac{p(\mathit\circleddash,\;D)}{p(D)}\propto p(D\vert\mathit\circleddash)\bullet p(\mathit\circleddash)$$ | (22) |
여기서 는 본 연구에서 추정되는 매개변수를 나타내며, 는 매개변수 사전분포를 나타낸다. 최종적으로 우도함수를 나타내는 는 Eq. (23)과 같이 표현할 수 있다.
| $$p(D\vert\mathit\circleddash)=\prod_{i=1}^I\prod_{\;j=1}^J\;L(x_{i,\;j},\;y_{i,\;j}\vert\mu_i,\;\sigma_i,\;k_i,\;\tau_i,\;\theta_i)$$ | (23) |
여기서 I는 기상청 강우관측소의 개수를 나타내며, J는 각 지점에서 발생한 가뭄의 개수를 의미한다. 위에서 정의된 우도함수와 매개변수들의 사전분포들을 Eq. (22)에 대입시킴으로서 Eq. (24)와 같이 사후분포를 식으로 나타낼 수 있다.
본 연구에서는 Eq. (24)의 모든 매개변수를 추정하기 위하여 Bayesian 모형 기반의 깁스샘플링(Gibbs sampling) 기법을 활용하였으며, 각각의 매개변수에서 추정된 샘플(sample)을 활용하여 사후분포를 산정하였다. 깁스샘플링은 Markov Chain Monte Carlo (MCMC) 기법의 대표적인 방법으로서 이미 오래전부터 물리학 분야에서 복잡한 수식의 해를 찾기 위해서 사용되던 방법이었으나, Gelfand and Smith (1990)에 의하여 Bayesian 모형에 도입되어 이후 Bayesian 통계 추정 시 가장 기본이 되는 수치해석 기법이라 할 수 있다(Gelman and Hill, 2006). 또한 깁스샘플링은 조건부 확률분포를 이용하여 두개 이상의 확률 변수의 연속적인 표본을 생성하는 매우 효율적인 알고리즘으로 알려져 있으며, 저차원 분포로부터의 표본 생성으로 구성되기 때문에 복잡한 제한조건도 쉽게 처리할 수 있다는 장점이 있다(Geman and Geman, 1984).
깁스샘플링에 대한 자세한 내용은 기존 연구문헌들을 참조할 수 있다(Kwon et al., 2008; Lee and Kwon, 2011). 본 연구에서는 모형의 수렴(convergence) 여부를 확증하기 위해서 3개의 Chain을 독립적으로 시행하여 샘플링(sampling)이 효과적으로 혼합(mixing)되도록 하였으며, 최종적으로 MCMC 결과에 대한 Trace Plot와 Gelman-Rubin 통계량 검정결과를 이용하여 Markov Chain의 수렴 여부를 통계적으로 판단하였다.
3. 연구결과
본 연구에서는 기존의 Bayesian Coupla 지점빈도해석 연구(Kim et al., 2017)에서 수행된 한강유역에 대하여 동일한 자료를 활용하여 2013-2015년도 한강유역의 가뭄을 평가하였으며, Bayesian 기법과 Copula 함수를 연계한 이변량 지역빈도 해석모형을 활용하여 한강유역의 가뭄 지역빈도해석 결과를 기존의 지점빈도해석 모형과 비교하여 제시하였다.
3.1 대상유역
한강은 서울을 관통하는 우리나라 중부의 최대 하천으로서 크게 북한강과 한강으로 구성되어 있으며, 한강유역은 한반도 중심부(위도 36°30'~38°55'N, 경도 126°24'~129°02'E)에 위치하고 있다. 유역면적은 약 25,594 km2로 한반도 국토면적의 약 23%를 차지하고 있으며, 태백산맥과 소백산맥 등 높은 산맥이 두 개의 방향으로 펼쳐져 있어 같은 유역 내에서 상이한 지리적, 기후학적 특성을 보여주고 있다. 한강유역의 연평균 강우량은 약 1,253 mm이며, 이 중 2/3 이상의 강우(894 mm, 연평균 강우량의 71%)가 여름철(6월~9월)에 집중된다(Kim et al., 2012).
본 연구에서는 선행연구에서 활용한 한강유역의 동일한 18개의 강우관측소 자료를 활용하여 가뭄을 구분하였으며, 이변량 가뭄빈도해석을 위한 최적 Copula 함수를 선정하기 위하여 각 관측소별 세 가지 Copula (Clayton, Gumbel, Frank) 함수에 대한 우도를 산정하였다. 결과적으로 Frank Copula 함수가 한강유역의 이변량 지역빈도해석 모형에 적합한 함수로 선정되었으며, 한강유역의 지형적 특성을 고려하여 지역빈도해석을 수행하기 위하여 Frank Copula 함수의 우도 추정 결과를 바탕으로 한강유역에 위치한 기상청 강우관측소 중 본 연구에 적합한 강우관측소를 선별하였다. 최종적으로 18개 강우관측소 중 우도의 크기 차이가 현저하게 나타나는 3개의 강우관측소(속초, 대관령, 강릉)를 제외한 15개의 기상청 강우관측소를 선별하였다. Fig. 2는 본 연구에서 활용한 한강유역 내 위치한 15개의 기상청 관측소를 도시한 결과를 나타내며, Table 2는 관측소별 속성정보를 나타낸다.
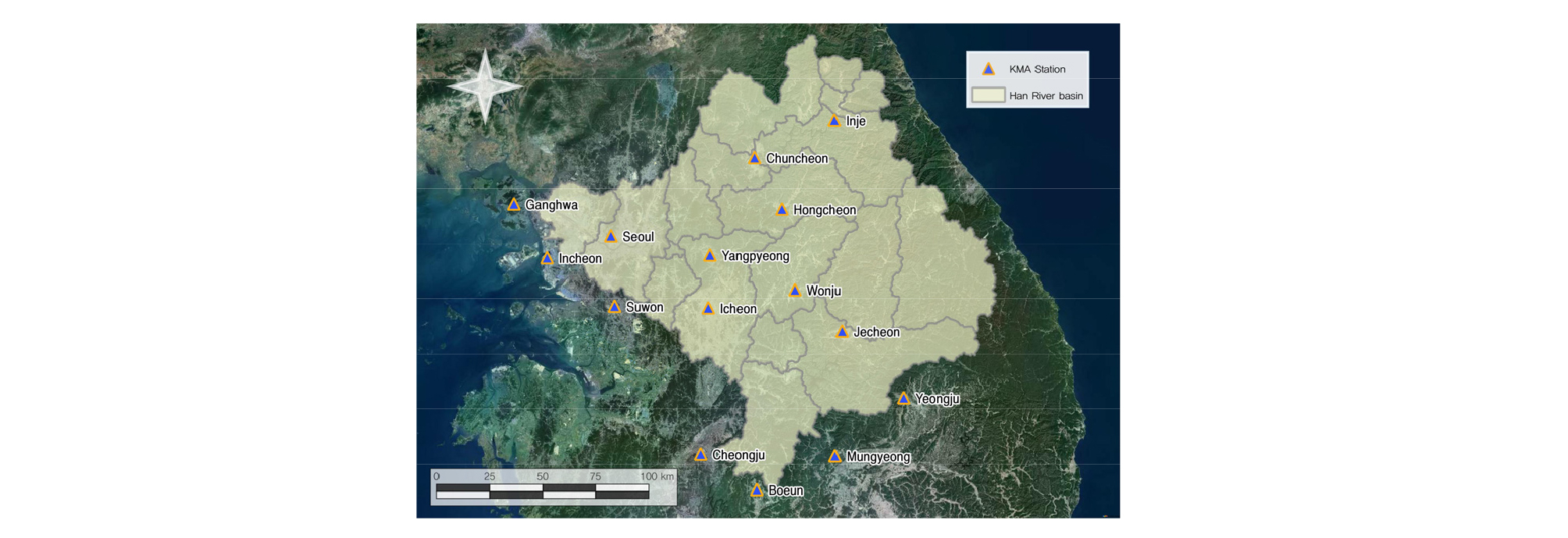
Table 2. Geographical characteristics of 15 weather stations operated by Korea Meteorological Adminstration (KMA)
3.2 분석결과
3.2.1 가뭄 특성인자 추출 및 확률분포형 선정
본 연구에서는 한강유역 내 기상청 관측 강우자료를 6개월 누적강우량으로 변환하여 Eqs. (1) and (2)에 따라 가뭄빈도해석을 위한 변량(지속시간, 심도)을 추출하였다. Table 2에 수록된 한강유역의 강우관측소 중 서울 관측소의 연속이론에 따른 가뭄을 구분한 결과 및 연도별 가뭄변량 산정결과를 Figs. 3 and 4에 대표로 도시하였으며, Fig. 3에 도시된 서울 관측소의 Anomaly를 살펴보면 2013-2015년도에 발생했던 가뭄 지속시간과 심도가 이전에 발생했던 가뭄보다 아주 극심했던 것을 시각적으로 확인 할 수 있다.
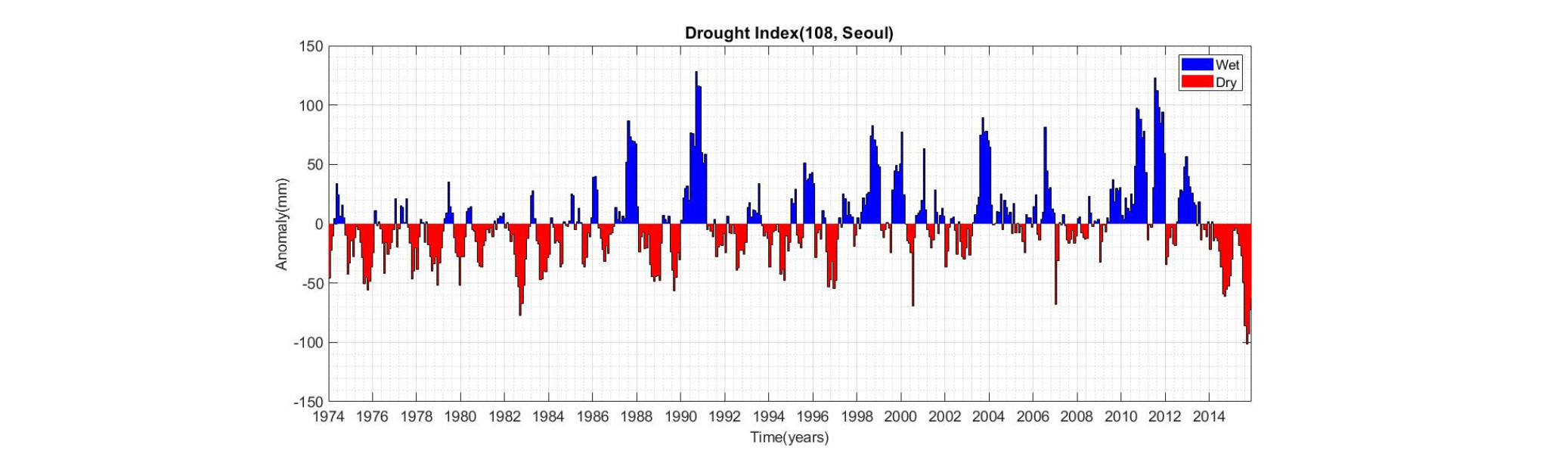
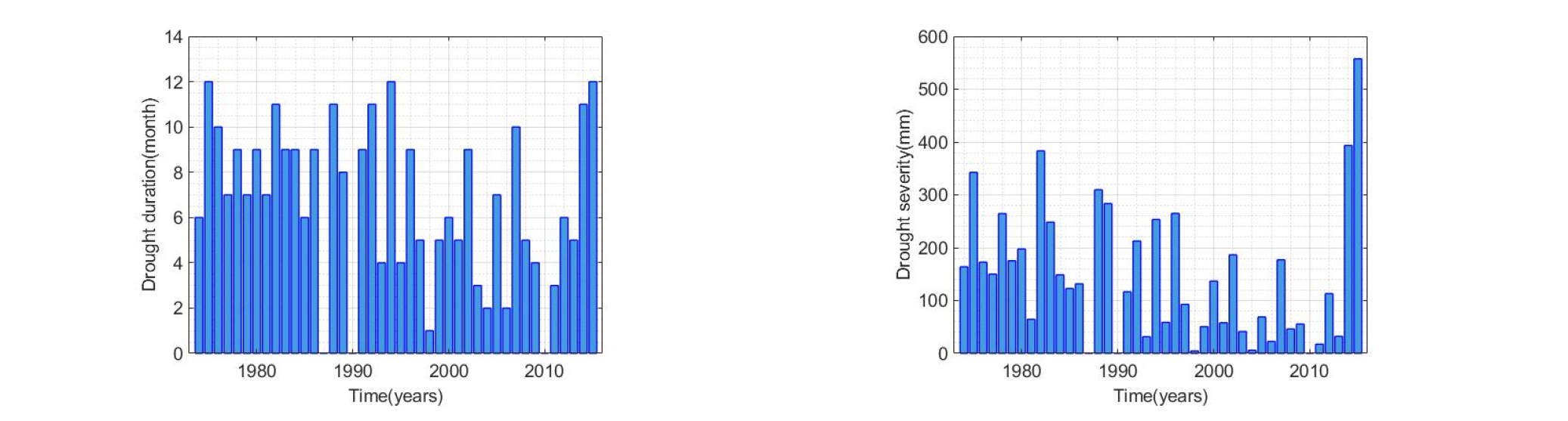
Table 3은 본 연구에서 활용한 기상청 지점별 가뭄 특성인자를 정량적으로 제시한 결과이며, 대부분의 관측소에서 2013-2015년도에 이전에 발생했던 강우 누적 부족량 보다 약 2-3배 정도 극심한 가뭄 사상을 보이고 있는 것을 확인 할 수 있다. 예를 들어 서울 강우관측소의 경우, 2013-2015년 가뭄의 지속시간 및 강도가 전체기간으로부터 추출된 가뭄지속시간 및 강도와 동일하며 결과적으로 최근 가뭄이 역사적으로 가장 극심한 가뭄(지속기간 24개월, 심도 1205.1 mm)으로 분류될 수 있다. 이 외에도 춘천, 인천, 수원, 강화, 양평, 인제 홍천 관측소를 살펴보면 2013-2015년 사이에 발생한 가뭄이 관측 이래 가장 극심한 가뭄이며, 다른 관측소의 경우에도 이전에 발생했던 가뭄에 상응하는 가뭄 패턴을 보이고 있는 것을 정량적으로 확인할 수 있다.
Table 3. Information on the gauging stations used in this study and the basic statistics for the drought characteristics. The values in parenthesis represent the maximum duration and severity calculated from the 2013-2015 drought
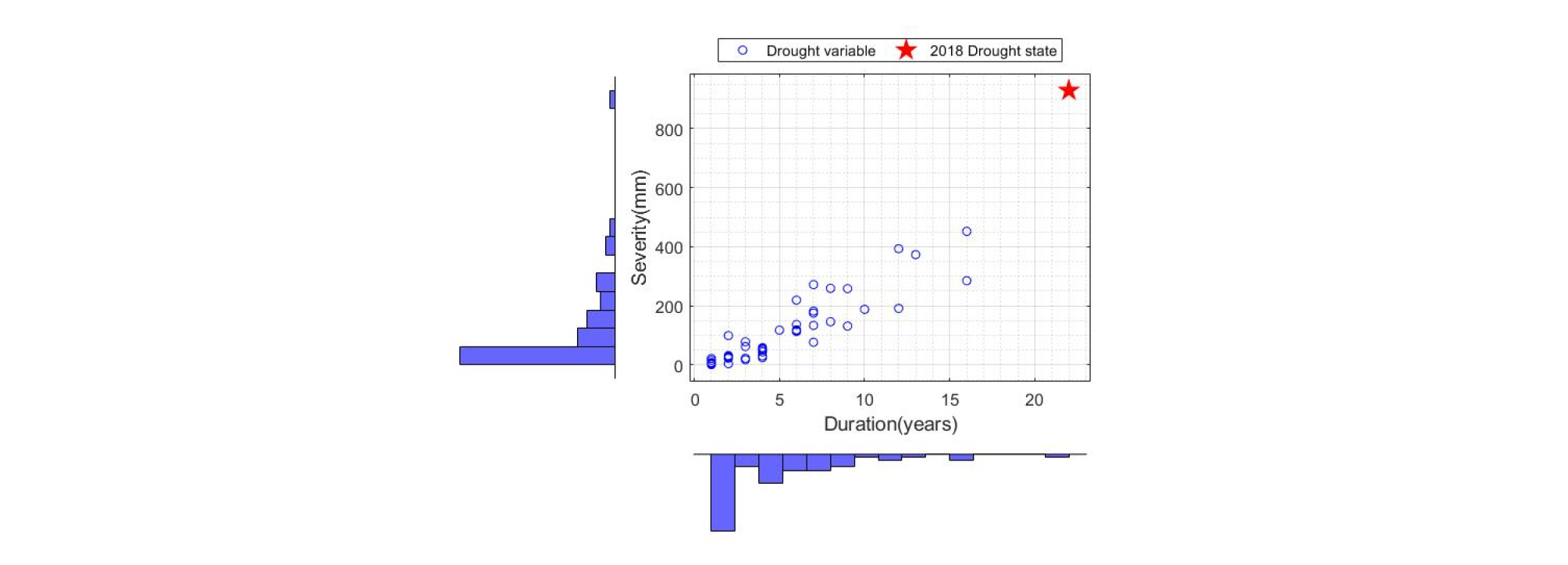
본 연구에서는 도출된 가뭄 특성인자를 대상으로, 한강유역 전반의 평균적인 특성을 확인하고자 유역평균 강우량을 산정하여 인자를 도출하였으며, 그 결과를 Fig. 5에 도시하였다. Fig. 5의 결과를 살펴보면, 한강유역 전반의 평균적인 가뭄 특성과 “빨간별”로 나타낸 2013-2015년의 가뭄상태가 상당히 상이하다는 것을 시각적으로 확인할 수 있다. Table 3과 Fig. 5에서 확인할 수 있듯이, 2013-2015년 사이에 한강유역에 발생한 가뭄은 전반적으로 가뭄 지속시간 및 심도가 이전에 발생했던 가뭄보다 지속시간이 길고, 강우누적부족량 역시 크게 부족했던 것을 보여주고 있다.
일반적으로 우도만을 가지고 최적분포형을 선택하는 경우, 모분포의 자유도가 후보모델의 자유도보다 낮은 경우 잘못된 확률분포를 선택할 확률이 높은 단점이 있다(Akalke, 1974). 따라서 본 연구에서는 이변량 Copula 함수의 가뭄 특성인자에 대한 적합한 확률분포형을 선택하기 위한 방법으로 우도, 매개변수 개수, 자료 수 등을 적절하게 고려할 수 있는 BIC 통계량 결과를 활용하였다. BIC는 자료가 해당 모형에 적합한 정도를 평가하는 척도 중 하나이며, 널리 알려져 있는 Akaike information criterion (AIC)와 Deviance information criterion (DIC)와 유사한 개념으로서 산정된 값이 작을수록 보다 적합한 모형이라고 알려져 있다.
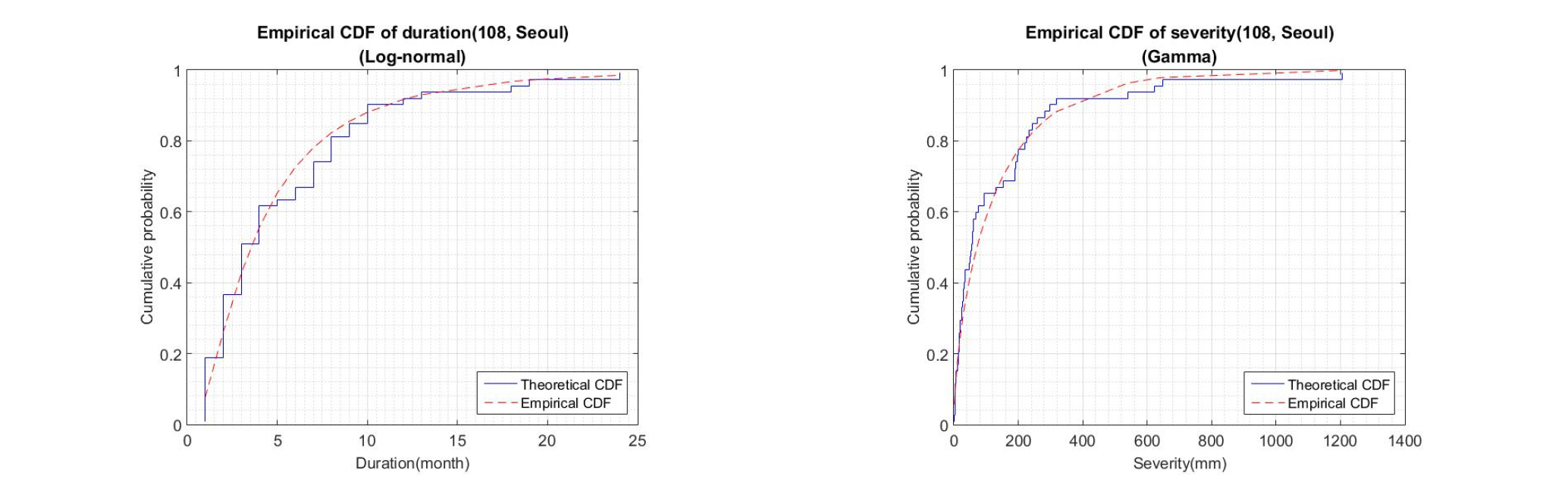
국외에서 수행된 가뭄에 대한 연구를 살펴보면, 가뭄 심도의 경우 감마분포가 적절한 확률분포형으로 잘 알려져 있다(Zelenhastic and Salvai, 1987; Mathier et al., 1992; Shiau and Shen, 2001; Shiau, 2006). 본 연구에서는 BIC 값을 기준으로 가뭄 지속기간과 가뭄 심도에 대한 최적 주변확률분포형으로 대수정규분포와 감마분포를 선정하여 연구를 진행하였다. 가뭄심도의 경우 BIC를 기준으로 일부 지점에서 대수정규분포가 최적분포형으로 고려되고 있으나, 감마분포와 BIC값의 차이가 크지 않고 지역빈도해석을 위해서 본 연구에서는 감마분포를 가뭄심도 평가를 위한 주변확률밀도함수로 선정하였다. 각각의 확률분포형에 따른 BIC 산정결과는 Table 4에 제시하였으며, Fig. 6은 각각의 인자에 대한 확률분포형의 CDF를 비교하여 도시한 결과이다. 도시된 그림을 통해 가뭄 지속시간과 심도 모두 각각의 확률분포형을 잘 따르고 있는 것을 확인 할 수 있다.
Table 4. BIC values for different marginal distributions across KMA weather stations. The distribution with the lowest BIC is preferred
3.2.2 Bayesian Copula 기반 이변량 가뭄 지역빈도모형 해석 결과
본 연구에서는 Kim et al. (2017)에 의해 제시된 Bayesian Copula 기반 이변량 가뭄 지역빈도해석 모형을 유역의 기상학적 특성을 반영한 지역빈도해석 모형으로 확장하였으며, Bayesian Copula 함수 모형에 대한 검증은 기존 연구에서 확인할 수 있다. 결합확률 관점에서 이변량 지역빈도해석의 결합재현기간 TDDS는 단변량 가뭄빈도해석 결과의 최소, 최대값, 그리고 T'DDS보다 커야 하며, 이는 Eq. (25)와 같이 정리하여 나타낼 수 있다.
| $$T'_{DDS}\;\leq\;\min\;\lbrack\;T_{DD},\;T_{DS}\rbrack\;\leq\;\max\;\lbrack T_{DD},\;T_{DS}\rbrack\;\leq T_{DDS}$$ | (25) |
이변량 가뭄 지역빈도해석을 수행하기에 앞서, 재현기간(2, 5, 10, 30, 50, 100년)에 따른 가뭄 지속기간, 심도에 대한 단변량 가뭄빈도해석을 수행하였으며, 결과를 Table 5에 제시하였다. 분석결과, 각각의 기상청 강우관측소의 평균가뭄발생 간격(E(L))은 약 8~10개월을 갖는 것으로 확인되었다.
Table 5. The quantiles of the drought variables according to the return periods
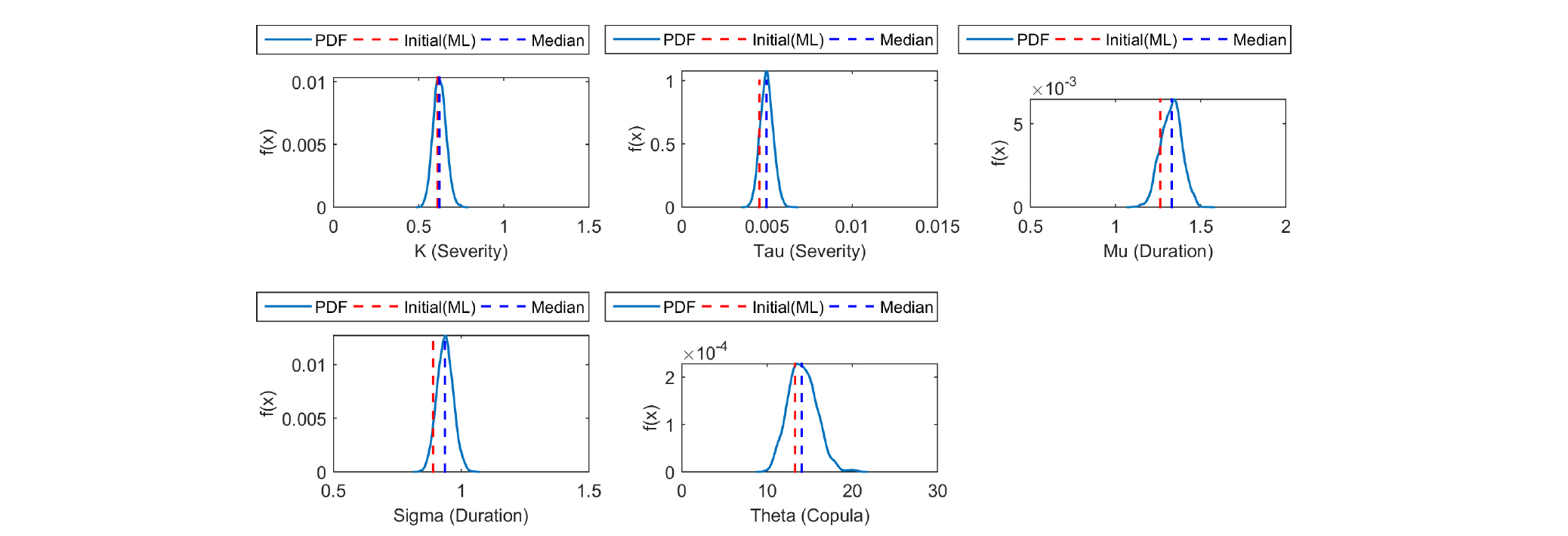
앞서 언급하였듯이, 모든 매개변수를 직접적으로 추정하기는 현실적으로 많은 어려움이 따른다. 이에 본 연구에서는 Bayesian Copula 기반 이변량 가뭄 지역빈도해석 모형의 매개변수를 추정하기 위하여 MCMC 기법 중 깁스샘플링 기법을 활용하였다. 매개변수의 수렴여부를 확인하기 위해 Bayesian Copula 기반 이변량 가뭄 지역빈도해석 모형 내에서 3개의 Chain을 독립적으로 시행하였으며, 7,000번의 샘플링 모의(iteration)를 수행하여 5,000개는 제거(burn-in)하고 최종적으로 수렴된 2,000개의 샘플을 활용하여 각 매개변수의 사후분포를 추정하였다. 연쇄가 무한대로 진행될 때, 검정 통계량의 값이 1에 가까워지면 Chain에 의해 생성된 매개변수들이 동일한 분포로 수렴한다는 것을 의미한다(Gelman et al., 2004). 본 연구에서는 모의된 사후분포 추정 시 수치적으로 안정성을 확인하기 위하여, 독립된 3개의 Markov Chain으로 부터 얻어진 2,000개의 샘플에 대한 Gelman-Rubin 검정 통계량을 산정하였으며, 모의된 샘플링이 정상적으로 혼합(mixing) 되었는지 확인하였다. 최종적으로 모의된 사후분포에 대한 Gelman-Rubin 통계량 값의 대부분이 1에 매우 가깝다는 것을 확인하였으며, 이는 5,000번 이후의 모의된 샘플들이 정상적으로 수렴되었음을 나타낸다. Fig. 7은 대표적으로 서울 강우관측소의 매개변수 사후분포를 추정한 결과를 도시하였다. Fig. 7에서 빨간 점선은 모형의 매개변수 최적화를 위해 최우도법을 통해 추정된 초기 값을 나타내며, 파란 실선은 매개변수의 사후분포를, 파란점선은 최적화된 매개변수의 중앙값(median)을 나타낸다.
최종적으로 한강유역에 위치한 15개의 기상청 강우관측소 모두 앞서 제시된 Eq. (25)의 관계가 성립하는 것을 확인하기 위하여, 불확실성 구간과 함께 Table 6에 2013-2015년 가뭄에 대한 결합재현기간 산정결과를 제시하였으며, 모두 성립하는 것을 확인하였다. 여기서, Table 6에 제시된 값은 Bayesian Copula 기반 이변량 가뭄 지역빈도해석 모형을 통해 도출된 결합재현기간을 정량적으로 산정한 결과이며, 도출된 가뭄 지역빈도해석 결과(quantile 50%)를 불확실성 구간(quantile 2.5%, quantile 97.5%)과 함께 제시한 결과를 나타낸다.
Table 6. The univariate and joint return period and their 95% credible intervals for the 2013-2015 drought event
2013-2015년 사이에 발생한 가뭄사상에 대한 결합재현기간 산정결과, 대부분의 관측소에서 100년 빈도를 초과하는 것으로 나타났으며, 일부 지점에서는 재현기간이 1,000년이 넘는 극치사상을 나타내는 것으로 평가되었다. 특히, Table 3에 제시된 결과 중 가뭄이 가장 극심했던 지역으로 평가된 강화 관측소의 경우 10,000년 이상의 재현기간을 상회하는 것으로 평가되었으며, 불확실성을 고려하더라도 2013-2015년 발생한 가뭄의 강도가 과거와는 상당히 다른 크기를 갖는 것으로 판단할 수 있다. 그럼에도 불구하고 이러한 결과는 가뭄분석을 위해 사용된 자료의 부족으로 인해 나타나는 표본오차로 판단할 수 있다.
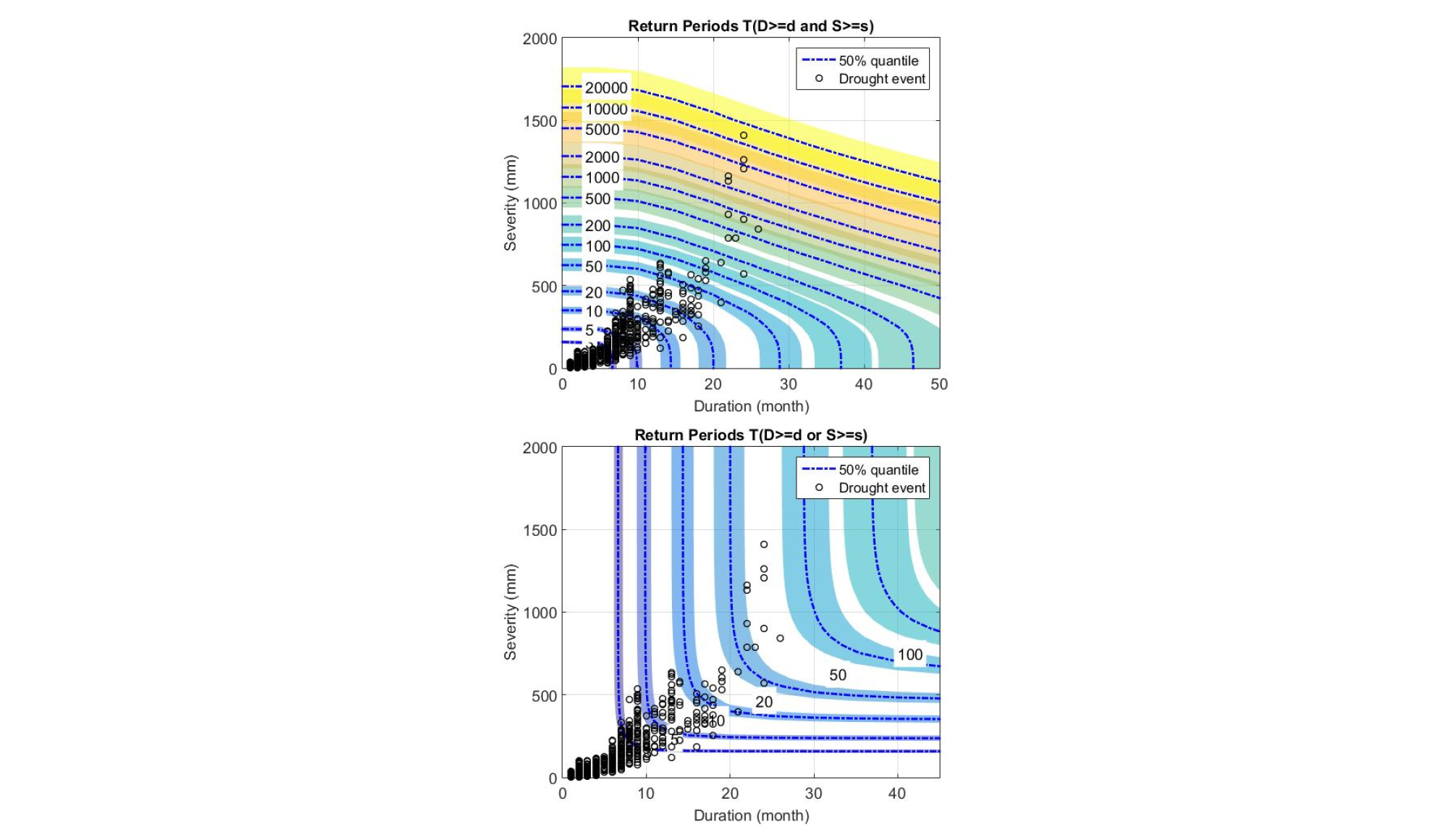
Fig. 8은 대표적으로 서울관측소 지점에 대하여 기존 이변량 지점빈도해석 결과 및 본 연구에서 수행한 이변량 지역빈도해석 결과를 비교하여 도시하였다. Fig. 8에서 “빨간별”은 2013-2015년도에 발생한 가뭄 상태를, “검은원”은 해당 관측소에서 발생했던 과거 가뭄사상을 나타내며, 파란색 점선은 불확실성 구간의 중앙값을, 보라색부터 노란색까지 음영(shade)되어 있는 부분은 매개변수에 불확실성으로 인해 나타내는 빈도별 가뭄지속기간 및 가뭄심도의 불확실성 구간을 나타낸다.
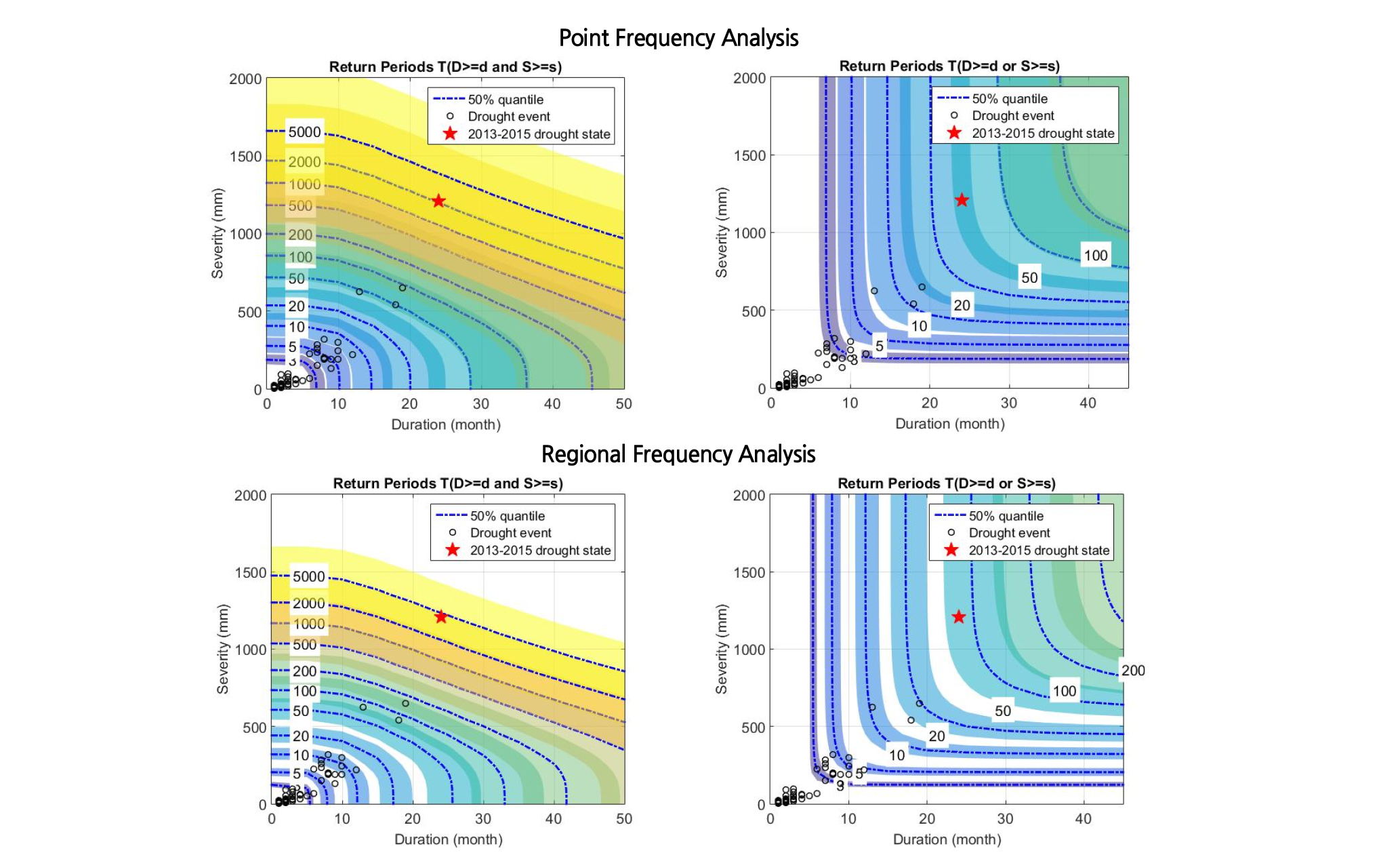
앞서 언급하였듯이, Bayesian 기법은 기존 최소자승법 및 최우도법과는 다르게 모든 매개변수에 확률분포를 부여하고 최종적으로 사후분포를 추정이 가능하기 때문에 매개변수의 불확실성을 객관적으로 정량화 할 수 있다는 장점이 있다. Fig. 8에서 확인할 수 있듯이, 지점빈도해석의 불확실성 구간이 지역빈도해석 결과에 비해서 상대적으로 크게 추정되는 것을 확인할 수 있다. 즉, 본 연구에서 제안한 가뭄 지역빈도해석 방법의 경우, 기존 지점빈도해석에 비해 불확실성 구간이 확연히 개선된 것을 시각적으로 확인할 수 있다. 평균적으로 판단해보면 지점빈도해석의 비해, 지역빈도해석의 불확실성 구간이 약 3배 가까이 감소하는 것으로 평가되었다. 이는 유사한 특성을 갖는 강우관측소를 선별하여 사전분포를 할당하고, 유역 내 강수지점별로 분석된 계산 과정을 통합하여 주변확률분포와 Copula 함수의 매개변수를 동시에 추정됨에 따라 본 연구에서 제안하는 지역빈도해석 과정에서 간접적으로 자료의 개수를 증가시키는 역할을 하는 것으로 판단할 수 있다. 즉, 본 연구에서 개발한 Bayesian Copula 기반 이변량 가뭄 지역빈도해석 모형으로 산정된 결합재현기간의 경우, 기존 이변량 지점빈도해석 방법 결과와 유사한 결과가 도출 되었으나, 최적 매개변수의 추정과 더불어 불확실성을 줄이는데 있어서 상대적으로 우수한 결과가 도출됨을 확인할 수 있다.
최종적으로 Bayesian 기법에 의해서 추정된 Hyper Parameter를 활용하여 한강유역 전체에 대한 이변량 가뭄지역빈도 해석이 가능하며, 이를 Fig. 9에 도시하였다. 모든 매개변수는 Hyper Parameter로부터 추정되며, 대상지역 전체를 대표하는 매개변수라고 할 수 있다. 즉, Hyper Parameter는 모든 지점에서 개별적으로 추정되는 매개변수의 상위 매개변수로 결과적으로 지역화 된 매개변수로 고려될 수 있다. 앞서 언급한 바와 같이, 유역에 대한 가뭄지점빈도 해석 시 부족한 자료의 수로 인해 발생하는 매개변수의 불확실성이 크게 감소되는 것을 확인할 수 있으며, 지역적인 가뭄특성을 효과적으로 평가할 수 있는 방안으로서 본 연구에서 제안된 방법론이 적합성을 갖는 것으로 판단할 수 있다.
4. 결 론
본 연구에서는 가뭄 지속기간 및 심도를 활용한 기존의 이변량 가뭄 지점빈도해석 모형에서, 이변량 가뭄 지역빈도해석 개념으로 확장을 통해 한강유역의 2013-2015년 사이에 발생한 가뭄에 대해 평가하였다. 이변량 가뭄빈도해석시 모형의 매개변수 최적화 및 결과에 대한 불확실성을 정량화하기 위하여 Bayesian 모형을 Copula 모형과 연계한 새로운 가뭄 지역빈도해석 방안을 제시하였으며, 본 연구결과를 통해 도출된 결과는 다음과 같이 요약할 수 있다.
1) 본 연구에서는 2013-2015년도 한강유역 가뭄을 평가하기 위하여 한강유역에 위치한 기상청 강우관측소 중 동질한 통계적 특성을 갖는 관측소를 선별하였다. 1974년부터 2015년까지 기록된 월강우량 자료의 6개월 누적 Anomaly를 활용하여 연속이론에 따른 가뭄 지속기간 및 심도를 산정하여 가뭄 특성인자로 활용하였으며, Copula 함수에 적용하기 위하여 각각의 인자에 대한 확률분포형을 선택하였다. 그 결과, 가뭄 지속기간과 심도에 대한 확률분포형으로 대수정규분포, 감마분포가 적정 확률분포형으로 선택되었다.
2) 기존 Bayesian 기법과 Copula 함수를 연계한 지점빈도해석 방법에 지역빈도해석 개념을 도입하여 이변량 지역빈도해석 모형으로 확장하였으며, 제시된 이변량 지역빈도해석 모형을 활용하여 2013-2015년도 한강유역 가뭄을 정량적으로 평가하였다. 결과적으로 대부분의 관측소에서 결합재현기간이 100년 빈도 이상을 갖는 것으로 평가되었으며, 일부 지역에서는 1,000년 이상의 빈도를 갖는 극치사상으로 평가되어, 불확실성을 고려하더라도 2013-2015년 발생한 가뭄의 강도가 과거와는 상당히 다른 크기를 갖는 것으로 판단할 수 있다.
3) 이변량 지점빈도해석 결과의 경우, 추정된 빈도의 불확실성 구간 또한 매우 크게 추정된 점을 고려할 때 1,000년 이상의 빈도는 표본 오차로 인해 나타나는 사항으로 판단할 수 있다. 즉, 최근 가뭄이 과거 40년 동안 발생한 가뭄과는 심도측면에서 큰 차이를 나타낸다는 점에서 이들 가뭄사상의 재현기간은 자료부족으로 인해 과대추정 될 개연성이 크다는 의미로 평가할 수 있다. 그러나 지역빈도해석 개념을 도입함으로써, 유사한 특성을 갖는 강우관측소를 선별하여 사전분포를 할당하고, 이분화 되어 있던 계산 과정을 통합하여 주변확률분포와 Copula 함수가 동시에 추정됨에 따라 불확실성 구간이 상대적으로 작게 추정됨을 확인하였다.
4) 최종적으로 Bayesian 기법을 통해 지역화 된 매개변수를 활용하여 한강유역의 대표 이변량 가뭄 지역빈도해석 결과를 불확실성 구간과 함께 도시하였다. 결과적으로, 지역의 전반적인 가뭄특성을 고려하기 위한 가뭄해석시 보다 안정적인 결과를 도출하기 위해서는 지점별 자료의 수를 충분히 고려한 가뭄 지역빈도해석 수행이 필요할 것으로 판단된다. 더불어 본 연구에서 제안된 방법론은 가뭄빈도해석 시 지역의 가뭄특성을 개별지점으로부터 지역으로 연계하여 반영할 수 있다는 측면에서 유리한 장점을 확인할 수 있었다.
향후 가뭄취약지역에 대한 행정·유역 단위의 이변량 가뭄 지역빈도해석을 수행함으로써 신뢰성 있는 가뭄 위험도 분석이 가능하며, 재현기간에 따른 강우부족량을 기반으로 한 극한가뭄 시나리오의 생성을 통해 상황별 용수공급능력 평가가 함께 이루어진다면, 물 배분 의사결정 및 가뭄대책 수립 등 향후 가뭄관리의 효율성을 극대화 할 수 있는 중요한 근거를 제공하는 기초자료로써 활용될 수 있을 것으로 사료된다.
