

1. 서 론
2. 강우 예측 모형 및 자료 수집
2.1 자료의 수집 및 특성
2.2 호우피해 발생 규모 분류 모형
2.3 강우 예측 모형
2.4 모형의 성능 평가
3. 적용 및 결과
3.1 연구 대상지역
3.2 지역별 특성을 고려한 재해 유발 강우 설정
3.3 규모별 호우피해 분류 모델 구축
3.4 강우 예측 모델 구축
3.5 미래 강우에 의한 규모별 호우피해 예측(1ST-모형)
4. 결 론
1. 서 론
최근 지구온난화로 인한 기상 이변이 극심해짐에 따라, 전 세계적으로 집중 호우 및 태풍과 같은 자연 재난으로 인해 매년 심각한 피해가 발생하고 있다. 우리나라의 경우, 최근 10년간 재난으로 인해 연평균 4천 4백억 원 규모의 피해가 발생하였고, 호우에 의한 피해는 연평균 2천 1백억 원으로 약 49%의 높은 비중을 차지하였다(MOIS, 2021).
이러한 피해를 저감하기 위해 국내에서는 수공 구조물과 같은 구조적 대책과 홍수 예·경보와 같은 비구조적 대책을 운영하고 있다. 하지만, 구조적 대책은 생태계 및 환경 보존 등과 대치되는 요소가 존재하고 있다(Bae et al., 2005; Kim et al., 2007; Kang et al., 2007). 이와 같은 이유에서 현재 비구조적 대책에 대한 연구가 점차 관심을 받아가고 있다(Choi et al., 2018; Song et al., 2012, 2014).
대표적인 비구조적 대책으로 현재 기상청(Korea Meteorological Administration, KMA)에서 기상자료를 활용하여 호우특보를 발령하고 국민들에게 긴급 재난 문자 서비스로 정보를 알려주고 있다. 하지만, 호우특보는 전국적으로 일괄된 기준으로 적용되고 주의보와 경보 총 2개로만 이루어져 있다. 이는, 호우피해에 대한 지역적 특성이 반영되지 않고, 서로 다른 방재성능을 가지고 있는 지역에도 동일한 기준을 적용하기 때문에 호우에 대한 효율적인 대응에 어려움이 있고 피해 저감에도 제대로 기여하고 있지 못하는 실정이다(Kim, 2021; Kim et al., 2011; Park and Kang, 2014; Song et al., 2016).
호우피해 발생 기준 설정을 위한 선행연구를 살펴보면, KMA (2007)는 델파이 분석을 통해 2개의 기준으로 운영되고 있는 호우특보(호우주의보, 호우경보)를 4개 기준의 호우특보(예비특보, 주의보, 경보, 중대경보)로 개편되어야 할 필요가 있다고 제안하였다. Kim et al. (2011)은 각 지역에 호우 특성과 지형적 특성 등과 같은 인자들을 고려하여 보다 세밀한 호우특보 기준에 관한 연구가 필요하다고 언급하였다. Kim et al. (2019a)의 연구에서 현재 국내는 기상청에서 제시하고 있는 기상특보 기준을 활용하여 발생할 수 있는 호우 등의 정도를 파악할 수 있지만, 이는 호우피해 발생의 유무가 아닌 기상 정보로부터 파악된 호우 예측 정보이기 때문에 피해 발생 여부에 대해서는 확인이 어렵다고 언급하였다. 선행연구를 살펴보면, 동일한 기준으로 발령되는 기상 특보를 개선하기 위해 지역적 특성을 고려하여 기상 특보 기준을 설정하였으나 피해 규모를 예측하지 못하는 한계점이 존재하였다.
따라서 이러한 한계점을 개선하기 위하여 피해가 발생 할 수 있는 강우 기준을 설정하는 연구들이 수행되었다(Garcia-Urquia, 2016; Cepeda et al., 2010; Oh and Park, 2014). Kim et al. (2018)은 어떤 지역에 피해가 발생할 수 있는 강우 기준인 지역별 재해 유발 강우 기준을 설정하기 위해 피해액을 총 4가지로 분류하였다. Kim et al. (2011)은 기후변화에 의한 강우 특성을 반영하고 호우에 의한 호우피해 발생 가능성과 강우강도 개념을 고려한 합리적인 호우특보 기준을 제시하고자 강우강도에 따른 호우피해 발생 여부를 분석하였으며, 피해발생 누적 확률을 활용하여 피해발생 누적 확률 50%일 때와 80%일 때의 강우 기준을 산정하여 제시하였다. Park and Kang (2014)은 10개의 세부지표로 구성된 자연 재난위험지수를 개발하고 엔트로피 기법으로 지표 항목들 간의 가중치를 부여하여 차등화된 지역별 호우특보 기준을 제시하였다. 하지만, 이러한 선행연구들의 경우 일 단위 강우량을 기준으로 설정하였기 때문에 호우피해 대응에 있어서 효율성이 떨어지는 한계가 존재한다. 호우피해의 경우, 집중호우에 의해 짧은 시간 동안 발생하기 때문에 피해를 파악하는데 어려움이 존재한다.
따라서, 시간 단위의 홍수 피해 발생 기준을 설정하고자 하천의 수위를 활용하여 피해 발생 수위 기준을 설정한 연구들이 수행되었다. Kim et al. (2022)은 실시간으로 홍수위를 예측하고 예측된 홍수위를 이용하여 위험 수준을 발령할 수 있는 기준을 설정하고자 하였으며, 기준을 설정하기 위해 누적분포함수를 활용하여 홍수피해 원인 분류를 위한 수위 기준을 설정하였다. Kim (2021)은 호우에 의한 위험 수준이 유사한 지역을 군집하기 위해 호우피해 위험지수를 산정하였고, 이를 누적분포함수를 활용하여 0%, 25%, 50%, 75%, 100%에 해당하는 경계를 level-1부터 level-4까지 4개의 구간을 정의하였다.
본 연구에서는 선행연구에서의 한계점들을 개선하고자 전국 단위로 동일하게 적용되었던 기상 특보 기준을 지역적 특성을 고려하여 각각의 기상 특보 기준을 산정하였다. 또한, 기존의 일 단위로 산정되던 재해 유발 강우 기준을 시간 단위의 재해 유발 강우 기준으로 재 산정함으로써 공간적 시간적 스케일을 향상시키고자 하였다. 추가적으로 본 연구를 통해 산정된 재해 유발 강우를 활용하여 미래 호우로 인한 피해의 규모를 예측하고자 강우를 예측하고 그에 따른 피해 규모를 분류할 수 있는 AI 모형을 개발하였다.
먼저, 강우 자료와 호우 피해액 자료를 활용하여 누적분포함수를 통해 지역적 강우 특성 및 피해 특성을 고려한 지역별 재해 유발 강우를 시간 단위로 재설정해 주었다. 재설정한 재해 유발 강우의 임계값을 이용하여 4가지의 규모인 No damage, Scale ①, Scale ②, Scale ③을 산정해 주었다. 그다음, 발생할 수 있는 강우량과 재해 유발 강우 기준을 이용하여 피해 규모를 분류할 수 있는 모형을 개발하였으며, 추가적으로 강우를 예측하기 위해 회귀 모형보다 예측력이 우수하다고 알려진 딥러닝 기법들을 활용하여 1시간 후의 강우를 예측하는 모형을 개발하였다. 최종적으로 예측 모형을 통해 예측된 강우를 앞에서 훈련시킨 분류 모형에 적용하여 1시간 뒤 내리는 강우에 의해 발생할 수 있는 호우피해 규모를 분류하였다. 최종적으로 본 연구를 통해 개발된 모형은 1시간 후, 강우에 의한 호우피해 규모를 예측하는 단기 예측 및 분류 모델이므로, 본 연구에서는 이를 1Hour-Short-Term-모형을 간략하게 줄여서 1ST-모형이라고 정의하였다.
1ST-모형의 개발을 위한 전체적인 연구의 흐름도는 Fig. 1에 제시하였다.
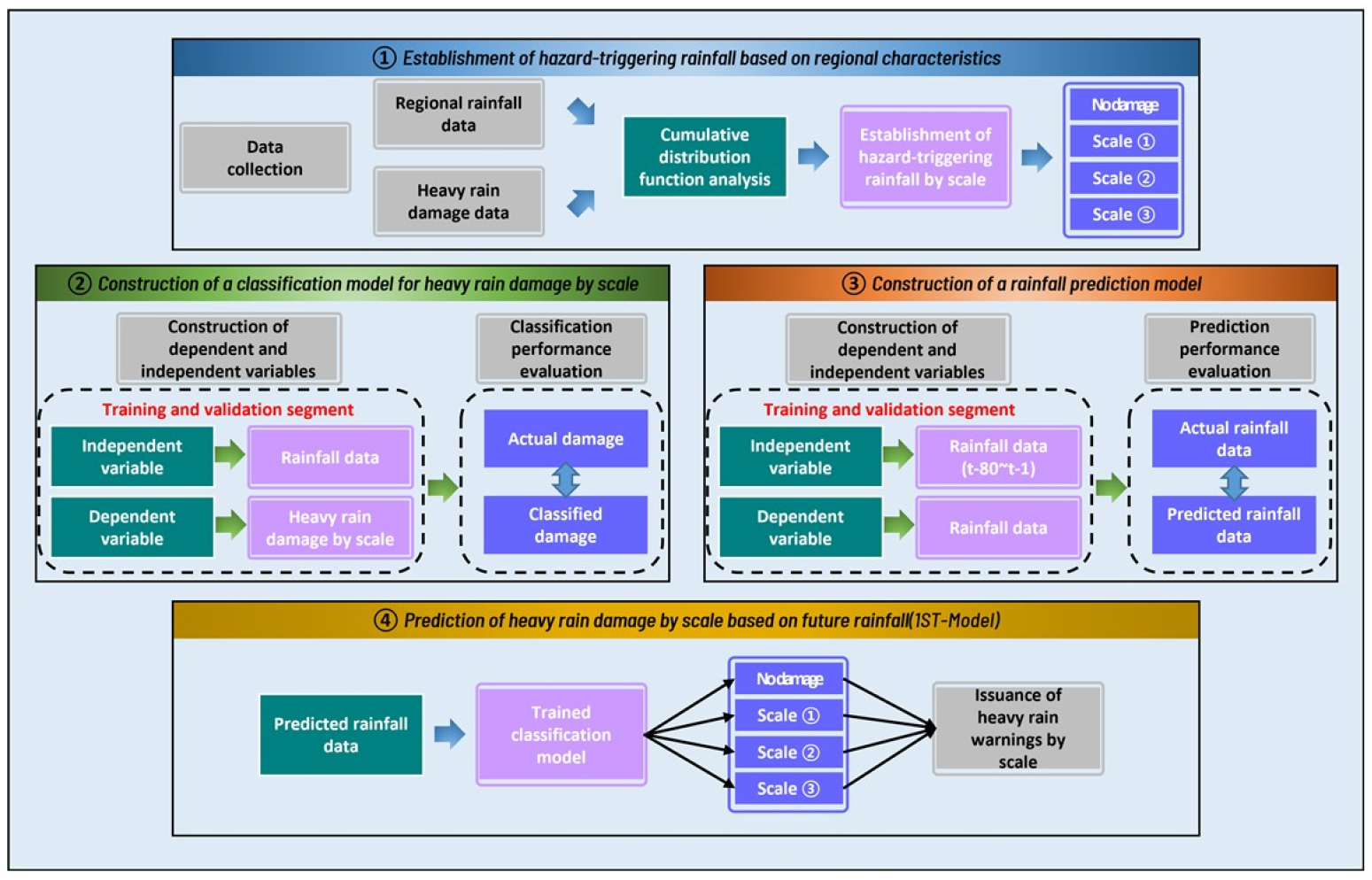
2. 강우 예측 모형 및 자료 수집
2.1 자료의 수집 및 특성
2.1.1 호우피해 자료
본 연구를 진행하기 위해 지역별 호우피해 자료를 수집하고 그 특성을 파악하고자 하였다. 호우피해 자료로는 행정안전부에서 매년 발간하고 있는 재해연보 자료를 기반으로 원인별·기간별·시도별 자료를 조합하여 호우로 인한 지역별 피해 자료를 구성하였다. 재해연보는 총 6가지의 재해 또는 피해로 구분하고 있으며, 이는 공공시설(13개)과 사유시설(10개)의 피해로 구분하고 있다. 또한 공간적인 범위로는 최소 범위인 시군구 단위까지 피해 데이터를 다루고 있다(MOIS, 2021). 본 연구에서 사용한 기상청의 강우 자료와 기간을 동일하게 해 주기 위하여 2005년부터 2019년까지의 호우에 의한 피해 자료를 수집하였다.
2.1.2 강우 자료
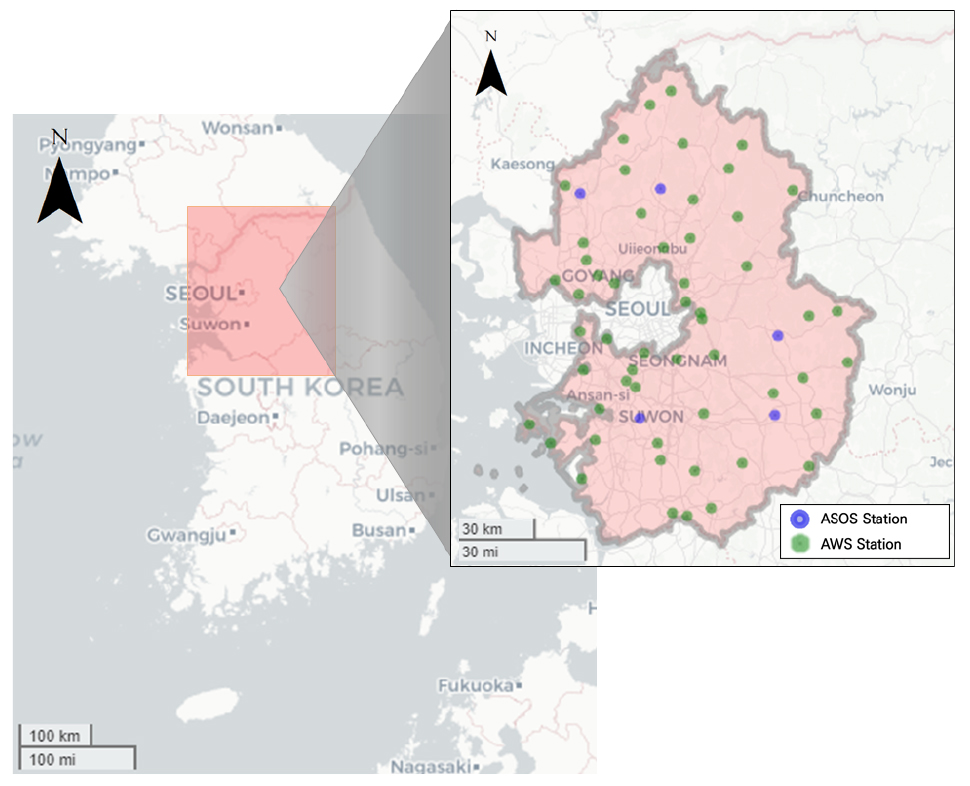
국내에서는 기상청, 환경부, 한국수력원자력 등 많은 부처들과 지자체에서 강우를 측정하고 기록하고 있다. 그중에서도 가장 전문적이고 자료의 질과 양을 확보할 수 있는 곳은 기상청으로, 많은 지점에서 기상 자료를 관측하고 있다. 기상청의 기상관측 장비로는 종관기상관측 시스템(Automated Synoptic Observing System, ASOS)과 방재기상관측 시스템(Automatic Weather System, AWS)의 두 개가 운영되고 있다. ASOS의 경우에는 1904년부터 관측을 시작하여 현재는 103개의 관측소가 운영이 되고 있으며, AWS의 경우, 1997년부터 관측을 시작하여 현재는 510개의 관측소가 운영되고 있다. 하지만 기상관측소가 제대로 운영을 시작한 것은 2000년에 들어서면서 부터이기 때문에 자료의 보유기간이 짧고, 충분한 자료를 가지고 있는 관측소의 개수도 적다. 그래서 본 연구에서는 이러한 단점을 보완하기 위하여 두 관측소의 자료를 모두 활용하였다.
ASOS 5개와 AWS 85개의 자료를 활용하기 위해 관측소의 시군구별 면적 평균 강우량을 적용하여 시군구 단위 면적 환산 강우 자료를 산정하였으며, 이를 통해 보다 정확도 있는 지역별 강우 자료를 구축하고자 하였고, 강우 자료의 수집 기간은 2005년부터 2019년까지이다. 경기도 지역에 존재하는 AWS 관측소와 ASOS 관측소는 Fig. 2와 같다.
2.2 호우피해 발생 규모 분류 모형
2.2.1 랜덤 포레스트
랜덤 포레스트는 의사 결정 나무를 바탕으로 만들어진 앙상블(ensemble) 기계학습 모형으로 부트스트랩(bootstrap) 방식을 적용하여 여러 개의 표본을 생성하며 의사결정나무 모형의 적용을 통해 결과를 결정하는 모형이다. 랜덤 포레스트 모형은 무작위성을 최대로 하기 위해 부트스트랩 표본을 만드는 과정에서 무작위성이 도입되며 의사결정나무 모형의 적합을 하는 과정에서 각 마디(node)에서는 설명 변수를 선택할 때 무작위성을 더한다.
랜덤 포레스트는 각 트리들의 예측들이 비상관화 되게 하며, 결과적으로 일반화 성능을 향상시킨다. 예를 들면 랜덤 포레스트에서 사용되는 앙상블은 자료의 집합 내의 각기 다른 자료를 무작위로 선택하여 여러 개의 의사 결정 나무를 만든다. 그다음 다수결(voting) 방식을 통해 결과를 얻어내게 된다. 랜덤 포레스트는 의사 결정 나무처럼 대용량 자료 처리에 효과적이고, 변수를 이용해도 오류를 발생시킬 변수의 제거 없이 실행되어도 정확도가 높은 경향을 보인다(Choi et al., 2018; Kim and Kim, 2020; Kim et al., 2021; Kim, 2019a; Seo, 2016). Fig. 3은 랜덤 포레스트의 구조를 그림으로 나타낸 것이다.
2.2.2 의사 결정 나무
의사결정나무 모형은 각 독립변수들을 이용하여 예측 가능한 규칙의 합을 만들어내는 알고리즘으로 그 형상이 나무가 가지를 뻗은 모습과 흡사하다고 하여 의사결정나무라고 불린다. 의사결정나무 모형은 의사결정규칙(decision rule)을 도표화하여 대상이 되는 집단을 여러 개의 소집단으로 분류(classification) 또는 예측을 수행하는 분석 방법이다. 의사결정나무는 나무구조와 흡사하게 모형이 표현되기 때문에 사용자가 쉽게 이해할 수 있고, 새로운 개체에 대해서 판별 또는 예측을 수행하기 위해 단순히 뿌리 마디를 추적하면 되므로 새로운 자료에도 의사결정나무를 쉽게 적용시킬 수 있다. 또한 의사결정나무의 구조로부터 어떤 예측변수가 목표변수를 설명하기 위해 더 적합한지를 쉽게 파악할 수 있다(Choi and Kim, 2009; Kim et al., 2021; Um et al., 2007). Fig. 4는 의사결정나무의 구조를 보여주고 있다.
2.3 강우 예측 모형
2.3.1 장단기 메모리
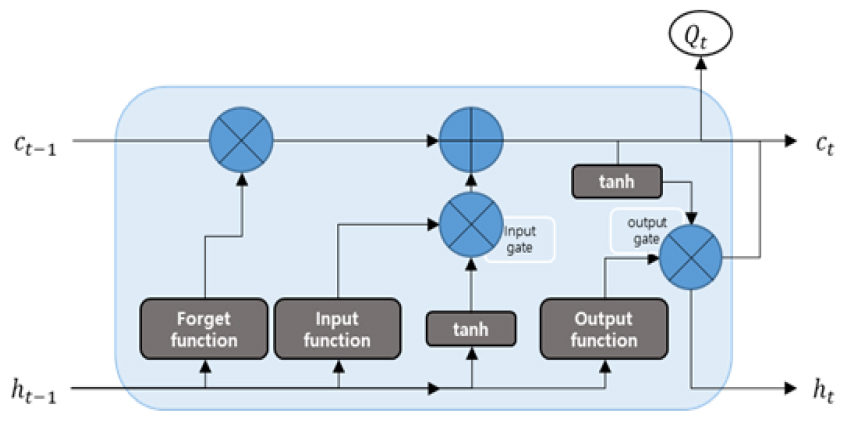
순환 신경망(recurrent neural network, RNN)에서 발생하는 장기 의존성 문제를 해결하기 위해서 장단기 메모리 기법이 Hochreiter and Schmidhuber (1997)에 의해 개발되었다. 장단기 메모리는 일반적인 순환 신경망의 단점인 오차 경사의 기울기 소실(gradient vanishing) 문제를 해결하여 시계열 자료 예측에 유리한 것으로 알려져 있다(Tran and Song, 2017). 장단기 메모리 모형은 망각 게이트(forget gate), 입력 게이트(input gate), 출력 게이트(output gate)가 있어 이전 단계의 정보 중에서 필요 없는 것과 업데이트할 것을 구분하여 다음 단계로 전달한다(Bae and Yu, 2018; Jung et al., 2018; Jung et al., 2021; Kim et al., 2022; Lyu and Lee, 2022). Fig. 5에서는 장단기 메모리의 기본적인 구조를 나타내고 있다.
2.3.2 심층 신경망
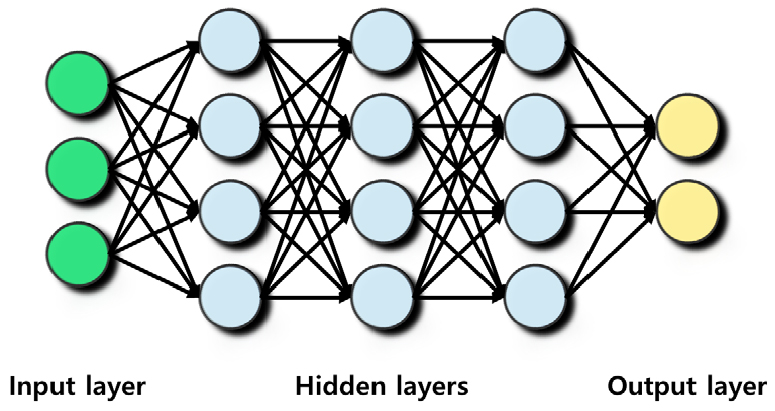
심층 신경망은 입력층과 출력층 사이에 두 개 이상의 은닉층(hidden layer)이 존재하며 인간의 뇌와 비슷한 구조를 가진다. 일반적으로 인공 신경망(Artificial Neural Network, ANN)의 은닉층 2개 이상을 활용하여 심도 있는 학습이 가능하도록 구성된 가장 기본적인 딥러닝이다.
최근 다양한 활성화 함수의 연구 및 드롭아웃 알고리즘 등을 통해 과적합 문제와 긴 학습 시간 등과 같은 문제가 해결되면서, 최근 심층 신경망에 대한 연구가 활발히 진행 중이다(Lee and Kang, 2019; Lee and Shin, 2019). 따라서, 심층 신경망은 복잡한 비선형 관계(non-linear relationship)들을 심도 있게 모델링 할 수 있다(Chun et al., 2020: Kim et al., 2019b; Kim et al., 2020). Fig. 6에서는 심층 신경망의 기본적인 구조를 보여주고 있다.
2.4 모형의 성능 평가
2.4.1 분류 예측 모형의 평가
머신러닝(machine learning) 및 딥러닝(deep learning)으로 학습된 모형들의 성능을 평가하기 위한 방법으로 관측 값과 예측 값에 대한 피해 발생의 참(true)과 거짓(false) 및 긍정(positive)과 부정(negative)의 4가지의 분류기준에 의해 표현하였다. 즉, 호우에 의한 피해가 발생하는 경우를 Damage true, 호우에 의하여 피해가 발생하지 않는 경우를 Damage false라고 정의하였다.
Table 1을 보면, 먼저 관측 값이 Damage true이고 예측된 값도 Damage true이면 TP (True Positive)로 분류하며 정확하게 예측했다고 판단할 수 있다. 이어서 관측 값이 Damage true이고 예측 값이 Damage false인 경우는 FN (False Negative), 관측 값이 Damage false이고 예측 값이 Damage true인 경우는 FP (False Positive), 예측 값과 관측 값 둘 다 Damage false인 경우에는 TN (True Negative)으로 분류할 수 있다.
이를 통해 Table 2와 같이 모형의 성능을 평가할 수 있는 지표들을 산정할 수 있다. 먼저, accuracy의 경우 실제 관측 값이 Damage true인 경우를 예측 값이 Damage true로 예측한 비율을 말하는 것이다. 이와 반대로, error rate는 관측 값이 Damage false를 예측 값이 Damage false로 예측한 비율을 의미한다. sensitivity는 실제 관측 값이 Damage true인 것 중 Damage true라고 예측한 비율을 의미하며, precision은 Damage true를 예측한 것 중 실제 값이 Damage true에 해당하는 비율을 의미한다. 특이도는 실제 값이 Damage false인 것 중 Damage false라고 예측한 비율을 의미한다(Kim, 2021; Kim and Kim, 2021; Lee et al., 2021; Powers, 2011).
Table 2를 통해 ROC (Receiver Operating Characteristics) 곡선을 산정할 수 있으며, 산정된 ROC 곡선의 아래 면적인 AUC (Area Under Curve)를 통해 모형의 성능을 평가할 수 있다. 하지만 AUC를 활용하여 모형을 검증하기 위해서는 Damage true와 Damage false의 비율이 적절하게 분포되는 균형 데이터이어야 평가하기에 적합하며, 불균형 데이터에는 적용하기 어렵다.
본 연구에서는 호우가 발생하고 피해가 발생한 경우의 자료가 적고, 호우가 발생했음에도 피해가 발생하지 않은 경우의 자료는 많이 존재한다. 이는 TP 값이 매우 적음을 의미한다. 따라서 자료 간에 불균형이 심하다고 판단하여 극소수인 TP에 대한 평가를 정밀하게 할 수 있는 F1-Score 평가 지표를 활용하였다. F1-Score를 통해 모형의 정확성을 검증하기 위해 정밀성(precision)와 민감도(sensitivity)를 활용하여야 한다. 만약 여기서 정밀성이 낮게 되면 상당히 많은 예보가 발령되며, 민감도가 낮으면 실제 피해에 대해서 예보를 하지 못하고 지나치게 될 것이다. F1-Score를 산정하는 식을 Eq. (1)에 나타내었는데 F1-Score의 값은 0부터 1 사이에 값을 가지게 되고 그 값이 1에 가까울수록 모형의 성능이 우수하다고 할 수 있다.
여기서, Prec는 정밀성이며, Sens는 민감도이다.
Table 1.
Confusion matrix for performance evaluation of the model
Observation Prediction | True | False |
| Positive | TP (True Positive) | FP (False Positive) |
| Negative | FN (False Negative) | TN (True Negative) |
Table 2.
Each performance evaluation index
| Evaluation Index | Equation |
| Accuracy | |
| Error Rate | |
| Sensitivity | |
| Precision | |
| Specificity |
2.4.2 예측 모형의 평가
모형으로 예측된 결과가 신뢰성이 있는지 판단하기 위해, 평균 제곱근 오차(Root Mean Square Error, RMSE)와 RMSE를 표준화한 NRMSE (Normalized Root Mean Squared Error)를 활용하였다. 제시된 두 방법은 0에 근접할수록 그 값이 정확하다고 할 수 있으며 Eqs. (2) and (3)과 같다.
여기서, 는 실제 값이고 는 예측 값이다(Choi et al., 2018; Choo, 2019; Chung, 2019; Kim et al., 2020; Kim, 2019b; Song, 2019; Tran and Song, 2017).
3. 적용 및 결과
3.1 연구 대상지역
국내에서 가장 많은 재난 피해 비율을 차지하고 있는 호우 피해액 자료를 살펴본 결과, 경기도 지역이 피해액과 피해 빈도가 가장 많이 발생하였다(MOIS, 2022). 따라서 경기도 지역을 연구 대상 지역으로 선정하였으며, Table 3에 각 시와 도에 대한 호우피해 발생 빈도를 나타내었다. 총 2,344개의 호우피해 빈도 중에서 경기도 지역이 632개로 가장 피해가 빈번하게 발생하였다는 것을 확인할 수 있었다.
Table 3.
Frequency of heavy rain damage on the provinces and cities
3.2 지역별 특성을 고려한 재해 유발 강우 설정
본 연구에서는 기존 선행연구들에서 일(daily) 단위로 설정했었던 재해 유발 강우 기준들을 시간(hourly) 단위 재해 유발 강우로 재설정해주고자 하였다. Kim et al. (2018)에서는 호우에 의한 피해가 발생하지 않았으면 무 피해, 금액에 상관하지 않고 피해가 발생했으면 Scale ①, 1억 원 이상에서 피해가 발생했으면 Scale ②, 10억 원 이상에서 피해가 발생했으면 Scale ③으로 기준을 설정하였다. Kim et al. (2018)의 연구에서는 일 단위로 산정된 재해 유발 강우를 시간 단위 재해 유발 강우로 재산정하기 위하여 누적 분포 함수를 적용하였다. 누적 분포 함수를 적용하기 위하여 1천 만원 이하의 피해는 No damage, 1천 만원 초과 1억 원 미만의 피해는 Scale ①, 1억 원 이상 10억 원 미만의 피해는 Scale ②, 10억 원 이상의 피해는 Scale ③으로 범위를 설정하였다. 이러한 방법은 Fig. 7과 같이 적용 될 수 있다.
Fig. 7(a)는 강우에 대한 누적 분포 함수를 산정한 것이며, Fig. 7(b)는 호우에 의한 피해 금액에 대해 산정한 누적 분포 함수이다. 먼저 재해 유발 강우 기준을 설정해주기 위해 앞에서 설명한 것처럼 피해 규모에 따라 4가지의 범주 또는 범위를 설정해 주었다. 그다음, 강우에 대한 누적 분포 함수와 피해 금액에 대한 누적 분포 함수를 중첩하여 Scale에 따른 재해 유발 강우 기준을 설정하였다. 재해 유발 강우 기준은 기존의 호우특보와 비교하기 위하여 누적 강우 12시간을 기준으로 산정하였으며, 각 지역의 추정 재해 유발 강우 기준은 Table 4와 같다.
Table 4를 살펴보면 과천시는 Scale ①에서의 강우 기준이 높게 설정된 것을 확인할 수 있다. 과천시의 데이터를 살펴보면 많은 양의 강우가 발생하였음에도 불구하고 피해가 12회로 적게 발생한 것을 확인할 수 있다. 또한, 반대로 여주시는 Scale ①에서의 강우 기준이 낮게 설정된 것을 확인할 수 있는데 이는 강우가 적게 왔으나 피해가 빈번하게 발생하였음을 의미한다. 구리시는 Scale①의 강우 기준은 낮게 설정되었으나 Scale ③에서는 강우 기준이 높게 설정된 것을 확인할 수 있다. 이는 적은 강우에는 피해가 빈번하게 발생하였으나 많은 강우에는 피해가 적게 발생하였음을 의미한다.
Tables 5~7은 포천시의 재해 유발 강우 기준을 적용하여 피해의 발생 유무를 판단한 것이며 Tables 8 and 9의 경우, 기상청의 호우 특보 기준을 적용하여 피해의 발생 유무를 판단한 것이다. 강우 기준보다 강우가 많이 발생하였으며 실제 피해가 발생한 것은 TP이며, 강우 기준을 넘지 않았으나 실제로는 피해가 발생한 것을 FN라고 한다. 또한 강우 기준을 넘었으나 실제로는 피해가 발생하지 않은 것을 FP이라 하며, 강우 기준을 넘지 않았으며 실제 피해도 발생하지 않은 것을 TN이라 한다. 최종적으로 TP, FP, FN, TN의 산술 조화 평균을 통하여 F1-Score를 산정하였으며 산정 결과는 Table 10과 같다.
Table 10에서 F1-Score를 확인해 보면, 현재 국내 호우특보 기준은 피해에 대한 예측이 어려운 것으로 보이며, 본 연구를 통해 설정된 재해 유발 강우 기준이 더 우수한 결과를 보이는 것을 확인할 수 있었다. 또한, 재해 유발 강우 기준 값이 높아지면 F1-Score의 값이 감소하는 것을 확인할 수 있었다. 이와 같은 이유는 포천시는 현재 국내에서 적용하고 있는 기준 아래에서 피해가 빈번하게 발생하기 때문이며 이를 통해 포천시의 지역적 특성을 고려한 재해 유발 강우의 필요성을 확인할 수 있다.
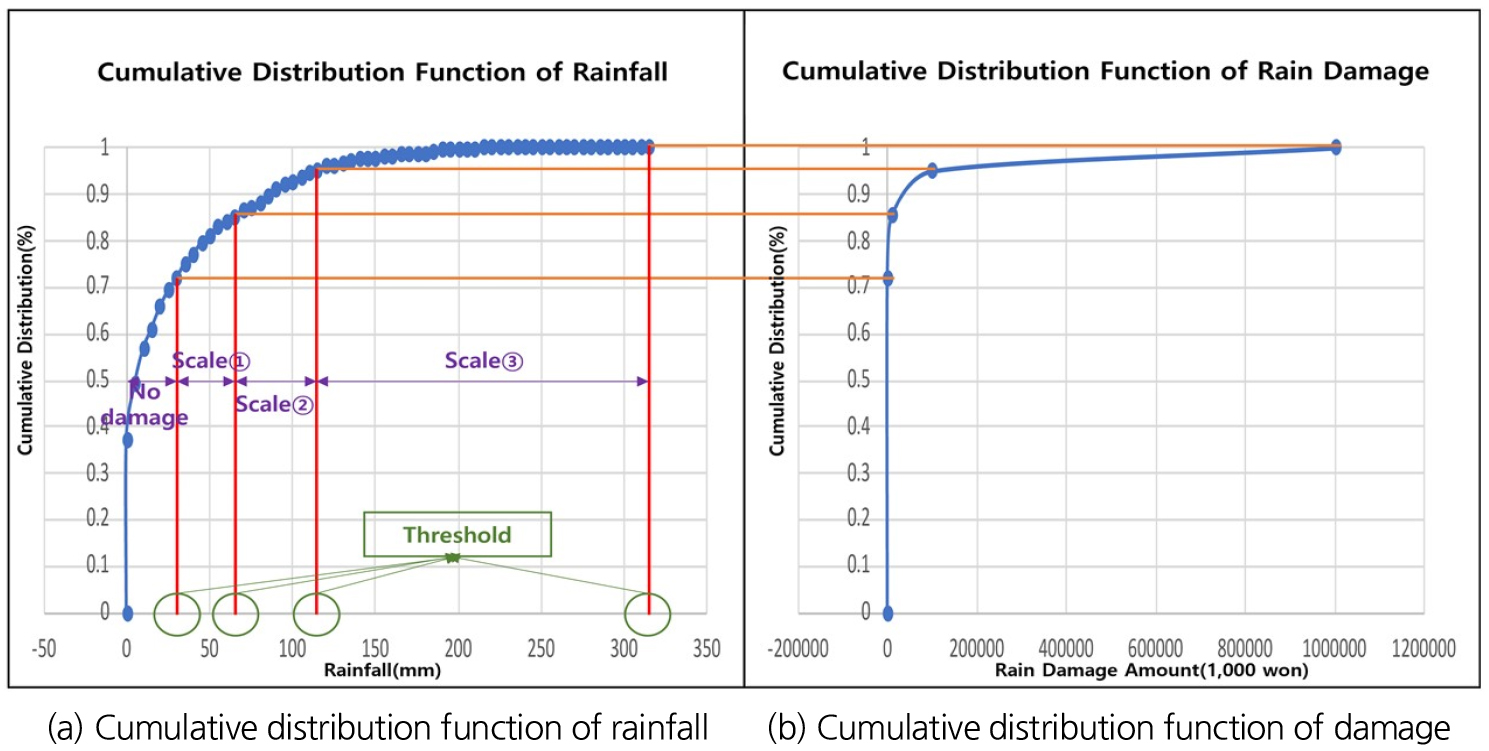
Table 4.
Estimated hazard-triggering rainfall on the cities
Table 5.
Confusion matrix for the estimation of hazard-triggering rainfall (21.4 mm/12 hr)
| Hazard-triggering rainfall (Scale ①) | Predicted | Total | ||
| P | N | |||
| Observed | T | 1,162 | 0 | 1,162 |
| F | 1,958 | 125,602 | 127,560 | |
Table 6.
Confusion matrix for the estimation of hazard-triggering rainfall (24.6 mm/12 hr)
| Hazard-triggering rainfall (Scale ②) | Predicted | Total | ||
| P | N | |||
| Observed | T | 1,044 | 118 | 1,162 |
| F | 1,644 | 125,602 | 127,560 | |
Table 7.
Confusion matrix for the estimation of hazard-triggering rainfall (50.6 mm/12 hr)
| Hazard-triggering rainfall (Scale ③) | Predicted | Total | ||
| P | N | |||
| Observed | T | 513 | 649 | 1,162 |
| F | 301 | 125,602 | 127,560 | |
Table 8.
Confusion matrix for watch of KMA (110 mm/12 hr)
| KMA (Watch) | Predicted | Total | ||
| P | N | |||
| Observed | T | 106 | 20 | 1,162 |
| F | 1,056 | 127,540 | 127,560 | |
Table 9.
Confusion matrix for warning of KMA (180 mm/12 hr)
| KMA (Warning) | Predicted | Total | ||
| P | N | |||
| Observed | T | 17 | 1,145 | 1,162 |
| F | 3 | 127,557 | 127,560 | |
Table 10.
Comparison of F1-Score for standard criteria and Hazard-triggering rainfall
| F1-Score | |
| Hazrd-triggering rainfall (Scale ①) | 0.54 |
| Hazrd-triggering rainfall (Scale ②) | 0.54 |
| Hazrd-triggering rainfall (Scale ③) | 0.52 |
| KMA (Warch) | 0.17 |
| KMA (Warning) | 0.03 |
3.3 규모별 호우피해 분류 모델 구축
앞에서 설정된 재해 유발 강우 기준을 활용하여 No damage, Scale ①, Scale ②, Scale ③으로 구분을 해주었다. 그리고 분류 모델을 훈련시키기 위한 독립변수로는 누적 강우 3시간, 6시간, 9시간, 12시간 강우를 활용하였고, 종속변수로는 앞에서 설정한 피해 규모를 적용하였다. 분류 모형으로는 의사 결정 나무와 랜덤 포레스트 모형을 활용하여 피해 규모 분류 모형을 개발하였으며, 두 개의 모형에 대하여 정확성을 평가하기 위하여 F1-Score를 사용하였다. 두 모형의 성능 평가 결과는 Tables 11 and 12에 나타냈다.
두 모형의 평가 결과를 보면 의사 결정 나무의 F1-Score가 0.53 랜덤 포레스트의 F1-Score가 0.56으로 랜덤 포레스트가 피해 규모를 더 잘 분류하였다. F1-Score의 차이는 크게 나타나지 않았으나, 의사 결정 나무의 경우 실제 피해 규모가 크지만 작은 피해라고 분류한 비율이 높게 나타남을 확인할 수 있다. 이러한 경우 실제 피해 규모는 크지만 피해 규모가 작을 것이라 예측하여 대응 단계를 낮게 설정하게 된다면 더 큰 피해를 야기할 수 있다. 따라서 본 연구에서는 랜덤 포레스트를 최종 분류 모형으로 선정하였다.
Table 11.
Confusion matrix for evaluating predictive performance of decision tree
Table 12.
Confusion matrix for evaluating predictive performance of random forest
3.4 강우 예측 모델 구축
예측 모형은 window 크기가 증가함에 따라 정상 데이터를 왜곡하고 정확성이 감소하는 문제가 발생되었다(Joo et al., 2022). 따라서 본 연구에서는 1시간 앞에 강우를 예측하고자 t-80부터 t-1의 자료를 활용하여 예측에 우수하다는 딥러닝 기법들을 통해 강우를 예측하고 비교 평가하였다.
먼저 장단기 메모리 모형의 경우 Table 13과 같이 모형을 구성하였다.
예측 모형을 활용하여 단기 강우를 예측하기 위한 독립변수로는 t-80부터 t-1의 강우를 활용하였으며 종속변수로는 t의 강우를 활용하였다. 모형의 학습 및 검증을 위하여 포천시의 강우 자료를 수집하였으며 총 자료의 개수는 131,472개로 학습용 데이터는 105,177개, 검증용 자료는 26,295개를 사용하였다. 모형의 매개변수는 Table 14와 같다.
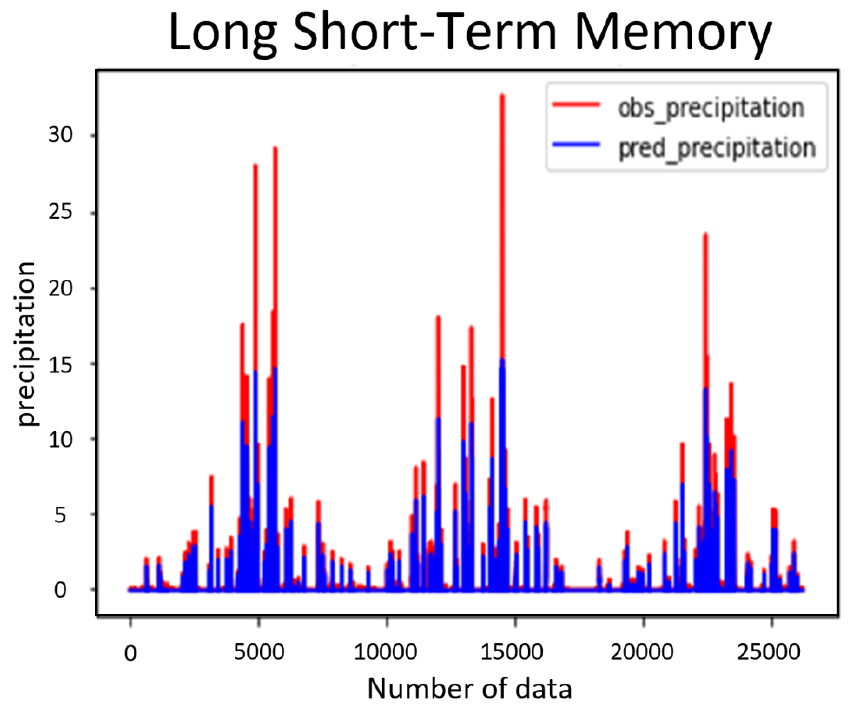
최종적으로 강우 예측 모형을 개발하였으며, Fig. 8에 실제 강우와 장단기 메모리를 통해 산정된 예측 강우를 동시에 도시하여 나타내었다. Fig. 8을 살펴보면 적은 양의 강우는 잘 예측하는 것으로 나타나지만 극한 강우에 대해서는 예측력이 떨어지는 것을 확인할 수 있다. 이는 모형 자체가 이전의 값에 영향을 받기 때문에 발생되는 결과라고 판단된다. 장단기 메모리 모형을 평가하기 위하여 R-square, RMSE, NRMSE를 산정하였으며, 산정 결과는 Table 15와 같다.
심층 신경망의 경우에는 Table 16와 같이 모형을 구축하였다.
심층 신경망의 경우 장단기 메모리 모형과 같이 총 데이터의 개수는 131,472개로 학습용 자료는 105,177개, 검증용 자료는 26,295개를 사용하였다. 모델의 매개변수는 Table 17과 같이 구성하였다.
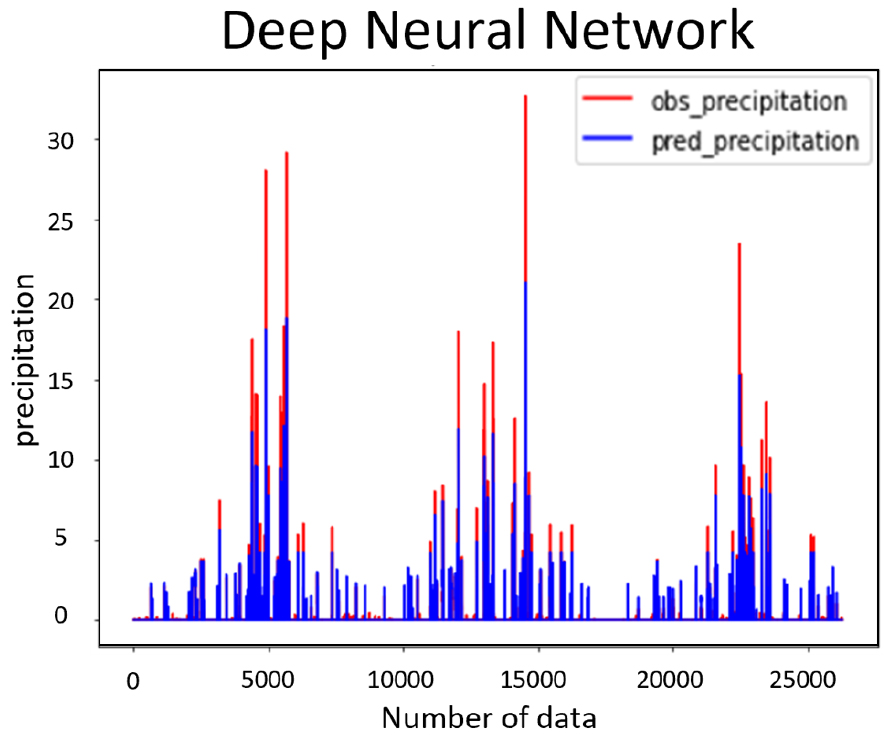
심층 신경망 모형을 통해 예측된 결과와 실제 관측소에서 관측된 결과를 Fig. 9에 표현하였다. Figs. 8 and 9를 비교해 보면 장단기 메모리에서 예측이 힘들었던 극한 강우를 비교적 잘 예측하는 것을 알 수 있다. 심층 신경망이 장단기 메모리보다 극한 값을 더 잘 예측하는 이유는 장단기 메모리의 구조와 같이 이전의 값에 영향을 받지 않으며 입력층과 출력층 사이에 다수의 은닉층을 포함하고 있기 때문에 다양한 비선형적인 관계를 장단기 메모리보다 더 잘 학습하는 것으로 판단된다. 심층 신경망 모형을 평가하기 위하여 R-square, RMSE, NRMSE를 산정하였으며, 산정 결과는 Table 18에 표현하였다.
예측 모형의 성능을 평가한 Tables 15 and 18을 비교해 보면 심층 신경망의 R-square, RMSE, NRMSE의 평가 결과가 장단기 메모리보다 우수한 것을 확인할 수 있다. 따라서 본 연구에서 1시간 후에 발생하는 강우를 예측하기 위한 모델로는 심층 신경망 모형을 선정하였다.
Table 13.
Model summary of long short-term memory model
| Layer (type) | Output Shape | Parameter |
| lstm (LSTM) | (None, 80 ,20) | 1,760 |
| dropout (Dropout) | (None, 80 ,20) | 0 |
| lstm (LSTM) | (None, 20) | 3,280 |
| dropout (Dropout) | (None, 20) | 0 |
| dense (Dense) | (None, 1) | 21 |
Table 14.
Configuring the parameters of the long short-term memory model
| Parameter | Result |
| Epoch | 6 |
| Batch size | 3 |
| validation split | 0.25 |
| optimizer | Adam |
| activation | Relu |
| Loss metric | Mean absolute error |
Table 15.
Evaluation for predictive performance of long short-term memory model
| Evaluation index | Result |
| R-square | 0.45 |
| RMSE | 0.68 |
| NRMSE | 0.02 |
Table 16.
Model summary of deep neural network model
Table 17.
Configuring the parameters of the deep neural network model
| Parameter | Result |
| Epoch | 11 |
| Batch size | 40 |
| Validation split | 0.25 |
| Optimizer | Adam |
| Activation | Relu |
| Loss metric | Mean absolute error |
Table 18.
Evaluation for predictive performance of the deep neural network model
| Evaluation index | Result |
| R-square | 0.84 |
| RMSE | 0.29 |
| NRMSE | 0.009 |
3.5 미래 강우에 의한 규모별 호우피해 예측(1ST-모형)
예측 모형으로 예측한 강우를 앞에서 훈련된 분류 모델에 적용시켰고, 이를 통해 예측 강우가 1시간 뒤에 어느 피해 규모에 해당하는지 분류 및 예측하였다. 본 연구에서는 이와 같은 방법을 1ST-모형이라고 정의하였으며, 최종적으로 분류된 결과를 평가하기 위해 F1-Score를 활용하였다. 최종적인 1ST-모형의 F1-Score 결과는 Table 19에 표현하였다.
모델을 평가한 결과 F1-Score는 0.46이었으며, No damage 다음으로 Scale ①을 가장 잘 분류하였다.
4. 결 론
선행연구 및 국내 호우특보 발령 기준에서 미흡하다고 판단되는 부분인 일 단위 재해 유발 강우 기준을 지역별 호우피해 특성 및 강우 특성을 고려한 시간 단위 재해 유발 강우 기준으로 재설정해 주기 위하여 No damage, 1천 만원 이상 1억 미만의 피해, 1억 원 이상 10억 원 미만의 피해, 10억 원 이상의 피해와 같이 총 4가지의 규모를 설정하였다. 그다음 지역별 호우에 의한 피해 특성을 파악하기 위하여 각 지역별 호우피해 누적 분포 함수와 강우 누적 분포 함수를 산정하였고, 산정된 누적 분포 함수를 중첩하여 각 행정구역에 대하여 강우 특성 및 호우피해 특성을 반영한 재해 유발 강우를 산정하였다. 산정한 재해 유발 강우는 기존의 기상청 호우특보 발령 기준과 비교하기 위하여 12시간을 기준으로 산정하였으며 F1-Score를 산정한 결과 현재 적용되고 있는 기준보다 개선된 효과를 보이는 것을 확인하였다. 이에 더 나아가 호우에 의한 피해의 규모를 분류할 수 있는 모형을 개발하기 위해 머신러닝 기법인 랜덤 포레스트와 의사 결정 나무를 활용하였으며, 랜덤 포레스트의 분류 성능이 의사 결정 나무보다 더 정확도 있는 것을 확인하였다. 이를 통해 본 연구에서는 호우에 의한 피해규모 분류 모형으로 랜덤 포레스트를 선정하였고, 1시간 후에 어느 규모의 피해가 발생할지를 예측하기 위해 1시간 단위 강우를 딥러닝 기법인 장단기 메모리와 심층 신경망을 활용하여 예측하였다. 예측 결과, 심층 신경망의 강우 예측 성능이 장단기 메모리보다 우수한 결과를 얻었으며 이를 통해 강우 예측 모형으로는 심층 신경망을 선정하였다.
최종적으로 예측된 강우를 훈련된 분류 모형에 적용하여 1시간 후에 발생하는 호우에 의한 피해규모를 예측하였다. 분류 모형을 통해 분류된 호우피해 규모를 실제 피해 자료와 비교한 결과 F1-Score가 0.46으로 산정되었으며, 이를 통해 본 연구에서 개발한 1ST-모형이 호우피해 규모를 잘 예측하는 것으로 판단하였다. 따라서 본 연구를 통해 개발된 1ST-모형을 재난 관리 차원에서 활용한다면 피해의 규모를 예측하여 국민들에게 실시간으로 예보할 수 있으므로 자연 재난에 대한 경각심을 일깨워 줄 수 있을 것이다. 또한, 강우에 의한 피해의 발생 여부를 1시간 이전에 예보할 수 있으므로 국민들이 강우에 의한 피해로부터 1시간 이전에 스스로를 방어할 수 있는 시간 확보와 인명 및 재산 피해를 저감하는데 기여할 수 있을 것으로 판단된다.
추가적으로 본 연구를 통해서 얻게 된 한계점을 말하자면, 피해 자료가 일 단위로 되어 있어 이를 시간 단위 자료인 강우 자료와 맞춰주면서 발생되는 문제가 있었다. 예를 들면 2023년 1월 1일부터 2023년 1월 5일까지 피해가 발생했다고 하면, 2023년 1월 01일 00시부터 강우가 내리는 것이 아니라 천천히 강우가 내리고 누적되면서 피해가 발생하게 된다. 이러한 값들이 분류 모형에 영향을 미치기 때문에 분류의 성능이 감소되는 것으로 판단되며 추후 이러한 한계점이 개선되어 시간 단위로 산정된 호우피해 자료가 제공되거나, 강우 사상을 분류하여 모형의 훈련을 진행시킨다면 분류 모형의 정확도가 상당히 높아질 것으로 판단이 된다.
