

1. 서 론
2. Transient Storage Model (TSM)
3. 저장대모형 매개변수 산정법
3.1 최적화 기법의 목적함수
3.2 최적화 기법 이론
4. 적 용
4.1 적용 하천
4.2 적용 결과
5. 결 론
1. 서 론
유해 화학물질 등 오염물질이 하천에 유입되면 수질을 악화시키기 때문에 수자원 관리 실무자들에게 하천에서의 물질혼합은 중요한 의미를 갖는다. 자연하천에서는 여울, 소, 표면수 지하수 혼합층의 상호작용 등의 자연적인 요인과 교량 및 보와 같은 인공적인 요인 등으로 인해 흐름이 교란되어 전단 경계층으로 구분되는 저장대가 형성된다(Jackson et al., 2013). 하천에 유입된 물질은 본류대에서 이송․확산 과정을 거치게 되지만 일부 물질은 유속이 느린 저장대에 포획되었다가 시간이 지난 후에 다시 본류대로 재방출되어 물질 혼합거동을 복잡하게 하는데, 이러한 저장대 물질교환 메카니즘을 반영한 복잡한 오염물질 거동의 해석을 위해 여러 현상학적 모형을 개발하고자 하는 노력들이 이루어져 왔다(Bencala and Walters, 1983; Seo and Maxwell, 1992; Choi et al., 2000; Wörman et al., 2002; Deng et al., 2004; Marion and Zaramella, 2005; Boano et al., 2007).
다양한 저장대 모형 중 Bencal and Walters (1983)의 Transient Storage Model (TSM)은 모의 결과가 정확하고 물리화학적으로 해석 가능하다는 특성이 있어 가장 광범위하게 이용되고 있다(Boano et al., 2014). TSM을 이용하기 위해서는 Kf (본류대 분산계수), Af (본류대 면적), As (저장대 면적), 그리고 (저장대 교환계수)의 네 가지 매개변수의 산정이 필요하다. 이 매개변수들은 실측된 농도곡선과 TSM을 통해 모의된 농도곡선의 유사도를 비교하는 역산모형을 통해 산정될 수 있다. 이러한 역산모형 중 OTIS-P (Runkel, 1998)는 매개변수 산정을 위해 가장 널리 이용되는 모형으로, 비선형 회귀법을 매개변수 산정 최적화 방법으로 채택하고 있다. 하지만 관련 선행 연구(Harvey and Bencala, 1993; Harvey et al., 1996; Wagner and Harvey, 1997; Wagener et al., 2002; Ward et al., 2017)에서, 이 모형은 알려지지 않은 매개변수 값에 대해서 일정하지 않은 지역해에 수렴한다는 한계가 보고된 바 있다. 이러한 지역해 수렴 문제를 극복하기 위해 Kerr et al. (2013)는 다중구역 TSM의 매개변수 산정 문제에 Shuffled Complex evolution-University of Arizona (SCE- UA)를 활용하였다. 하지만 SCE-UA는 Chu et al. (2010)에 의해 차원 축소로 인한 지역해 문제가 보고된 바 있다. Ward et al. (2017)은 TSM 매개변수 산정에 있어 전역해를 찾고 더 나아가 지역해 문제 등의 불확도를 분석하기 위해 Monte-Carlo 모의기법을 채택하여 OTIS-Monte Carlo Analysis Toolbox (OTIS- MCAT)을 제안하였다.
Wolpert and Macready (1997)는 최적화 문제에서 모든 문제에서 항상 우수한 완벽한 기법이 없음을 논리적으로 증명하였다. 이에 따라 더욱 견고하고 효율적인 방법을 찾기 위해 여러 최적화방법을 결합시킨 A Multialgorithm Genetically Adaptive Method for Single Objective Optimization (AMALGAM-SO) (Vrugt and Robinson, 2007; Vrugt et al., 2009), Borg (Hadka and Reed, 2013), 그리고 Shuffled Complex-Self Adaptive Hybrid EvoLution (SC-SAHEL) (Naeini et al., 2018) 등과 같은 다양한 최적화 기법들이 개발되어 왔다. 그 중 SC-SAHEL은 수리 수문 분야에서 성공적으로 적용된 바 있는 SCE-UA의 기본적인 구조에 여러 가지 진화 알고리즘들을 동시에 적용할 수 있도록 개선한 전역 최적화기법이다. 이 방법에서는 Competitive Complex Evolution (CCE), Modified Competitive Complex Evolution (MCCE), 수정 Frog Leaping (FL), Differential Evolution (DE), 그리고 수정 Grey Wolf Optimizer (GWO)의 다섯가지 진화 알고리즘을 제공한다. 그리고 SC-SAHEL은 SCE-UA와 기본 구조가 동일하기 때문에 적용할 진화 알고리즘으로 CCE 또는 MCCE를 하나씩만 사용하여 최적화를 수행하였을 때 각각 SCE-UA와 Shuffled Complex strategy with Principle Component Analysis, developed at the University of California, Irvine (SP-UCI)와 같이 널리 이용되는 전역 최적화 방법과 동일하여 타 전역 최적화기법들과 비교하기에 용이하다는 장점이 있다.
본 연구에서는 크게 두 가지 조건아래 전역해 수렴성과 효율성을 고려하여 목적함수와 최적화 기법의 조합을 비교 분석하였다. 비교 분석을 위해 실무적으로 의미 있는 자연하천에서 수행된 추적자 실험 결과를 이용하여 TSM 매개변수의 산정 및 분석을 수행하였다. 저장대 매개변수 산정의 최적화 조건으로서 첫 번째로 최적화 목적함수를 평균 절대오차, 평균 제곱오차, 최대오차, 그리고 결정계수 네 가지 농도곡선의 유사도를 선정하였다. 둘째로, SC-SAHEL 최적화 프레임워크를 이용해 CCE, MCCE, DE, FL, 그리고 GWO의 다섯 진화알고리즘을 각각 하나씩만 적용하였을 때와 다섯 진화 알고리즘들을 동시에 병렬적용 하였을 때(이하 SC-SAHEL)의 여섯 가지 전역 최적화 알고리즘을 비교하였다. 각 조합의 전역해 수렴성을 비교하기 위해 각 조합별로 평가된 목적함수 값을 비교하였다. 또, 목적함수 평가 횟수와 직결된 각 최적화기법의 진화 횟수를 비교함으로써, 수렴속도를 비교하였다. 결과적으로 분석을 통해 TSM 매개변수를 산정하기 위한 효율적이고 안정적인 조합의 목적함수와 최적화 기법에 대해 제시하였다.
2. Transient Storage Model (TSM)
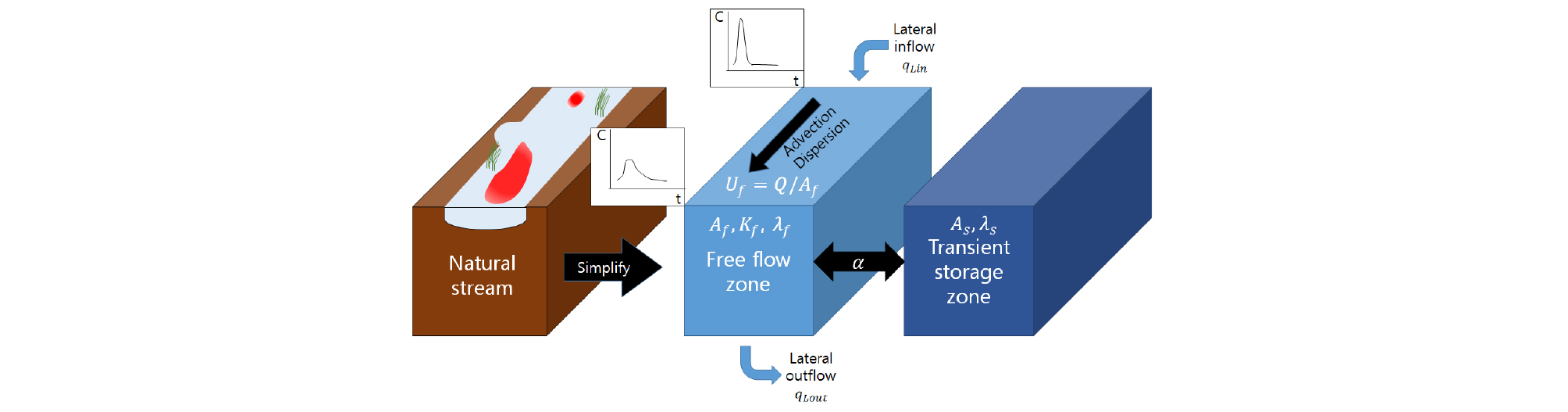
TSM은 Fig. 1과 같이 복잡한 자연하천을 이송과 분산이 일어나는 본류대와 물질이 일시적으로 저장되고 방출되는 저장대로 단순화한 모형으로 Bencala and Walters (1983)에 의해 제안되었다. 하천 측방 유출입량과 유입된 물질의 반응계수를 고려하여 Runkel에 의해 One-dimensional Transport with Inflow and Storage (OTIS)가 개발되었고, 저장대 물질교환효과를 고려한 모형으로서 가장 널리 알려져있다(Boano et al., 2014). TSM 및 OTIS의 지배방정식은 본류대에서의 이송․분산을 표현한 Eq. (1)과 물질이 포획 및 재방출되는 메카니즘이 이송 및 분산이 없는 저장대에 수직으로 교환이 이루어진다는 가정 하에 Eq. (2)와 같이 표현된다.
| $$\frac{dC_s}{dt}=\alpha\frac{A_f}{A_s}(C_f-C_s)-\lambda_sC_s$$ | (2) |
여기서, t는 시간(s); 는 모의 구간내에서 공간 좌표(m); Cf, Cs, 그리고 CL는 각각 본류대, 저장대, 그리고 측면유출입 농도(ppb); Q는 유량(m3/s); Kf는 본류대 분산계수(m2/s); Af와 As는 각각 본류대와 저장대의 면적(m2); 는 저장대 교환계수(1/s); qL은 측면 유출입 유량(m3/s/m); 와 는 각각 본류대와 저장대에서의 반응계수(1/s)이다.
3. 저장대모형 매개변수 산정법
3.1 최적화 기법의 목적함수
일반적으로 TSM의 매개변수는 추적자실험으로부터 취득된 농도자료와 특정 TSM 매개변수로 모의된 농도곡선의 유사도를 비교해 가장 적합한 곡선을 생성하는 TSM 매개변수 조합을 찾아내는 소위 역산모형을 통해 산정한다. 이 때 매개변수 값은 두 곡선간의 유사도를 최적화 문제의 목적함수로 하고 TSM 매개변수를 최적화 문제의 변수로 하는 문제를 풀어 얻게 되는데 본 연구에서는 주로 이용되는 최적화 프레임워크로서 SCE-UA, SP-UCI, 그리고 SCE-UA에 결합된 바 있는 진화 알고리즘들을 취사선택할 수 있는 SC-SAHEL 최적화 프레임워크를 이용하였다. 본 장에서는 이 연구에 적용된 최적화 조건들에 대한 내용을 서술하였다.
본 연구에서는 곡선의 유사도를 판단하는 척도로서 평균 제곱오차, (1-결정계수)*100, 최대오차, 그리고 평균 절대오차의 네 가지 기준을 최적화 목적함수로서 적용 및 비교하였다. 추적자 주입 실험에서 하류 측선에서 관측된 농도 값, 특히 농도 곡선의 꼬리 부분은 측정값이 작은 경우가 많기 때문에 평균 제곱오차, 최대 오차, 평균 절대오차의 값을 관측된 하류 농도곡선의 첨두농도인 max(Cobserved)로 나누고 100을 곱해 퍼센트로 정규화 된 값을 목적함수로 취하였다. 결정계수는 최대 1의 값을 가지는 척도로 값이 클수록 적합함을 의미하기 때문에 다른 목적함수들과 같이 극소점을 찾는 문제로 바꾸기 위해 (1-결정계수)*100을 목적함수로 취하였다. 결정계수를 이용한 목적함수는 Maximum Squared Error (MSE) 값을 첨두농도가 아닌 평균 오차로 스케일링한 값으로, 이 척도를 이용해 TSM 매개변수 산정에 있어 농도곡선의 스케일링 영향을 알아보고자 하였다. 이 연구의 대상이 되는 네 가지 목적함수들은 아래 Eqs. (3)~(6)과 같이 계산된다.
평균 제곱오차(PMSE, Percent Mean Squared Error) (%)
| $$=\frac{\overline{{(C_{observed}-C_{simulated})}^2}}{\max\;(C_{observed})}\ast100$$ | (3) |
평균 최대오차(PME, Percent Maximum Error) (%)
| $$=\frac{\max\;(C_{observed}-C_{simulated})}{\max\;(C_{observed})}\ast100$$ | (4) |
평균 절대오차(PMAE, Percent Mean Absolute Error) (%)
| $$=\frac{\overline{\vert C_{observed}-C_{simulated}\vert}}{\max\;(C_{observed})}\ast100$$ | (5) |
(1-결정계수)*100=
| $$(1-R^2)\ast100=\frac{\sum{(C_{observed}-C_{simulated})}^2}{\sum{(C_{observed}-\overline{C_{observed}})}^2}\ast100$$ | (6) |
여기서, Cobserved와 Csimulated는 각각 관측된 농도곡선과 TSM으로 모의된 농도곡선의 벡터; 는 농도벡터의 평균값이다.
3.2 최적화 기법 이론
3.2.1 SC-SAHEL (Suffled Complex-Self Adaptive Hybrid EvoLution)
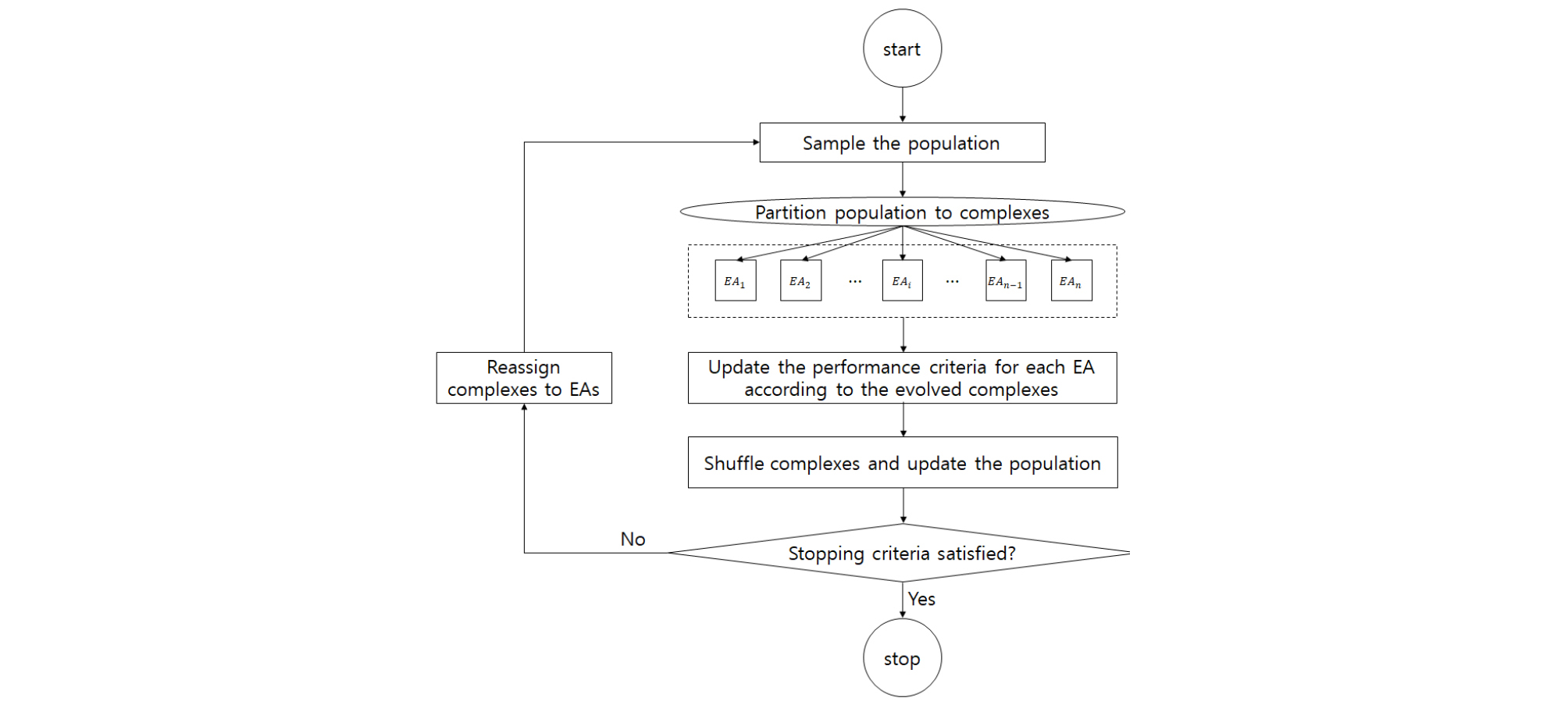
SC-SAHEL은 기본적으로 SCE-UA의 일반적인 구조를 이용한 병렬 최적화방법이다. Nelder-Mead 심플렉스를 기초로 CCE 진화 알고리즘을 이용한 전역최적화 방법인 SCE- UA와 달리, SC-SAHEL은 CCE를 비롯해 MCCE, DE, FL, 그리고 GWO의 진화알고리즘들(Evolutionary Algorithms, EAs)을 병렬적으로 이용하여 전역해 수렴성을 개선하도록 고안된 적응적 전역 최적화 방법이다. SC-SAHEL은 무작위로 선택된 모집단 샘플을 여러 개의 콤플렉스로 분할하여 콤플렉스마다 진화 알고리즘을 각각 적용하여 전역해를 찾아간다. 이 때 SC-SAHEL에서 여러 개의 진화 알고리즘들을 채택하게 되면 초기 샘플링 과정에서는 균등하게 콤플렉스를 분배하고 아래의 Eq. (7)로 계산되는 EMP (Evolutionary Method Performance)를 기반으로 하여 진화 단계마다 콤플렉스의 수를 각 진화 알고리즘별로 새로 분배하게 된다.
| $$EMP\;(Evolutionary\;Method\;Performance)=\;\frac{mean(F)-mean(F_N)}{mean(F)}$$ | (7) |
여기서, F와 FN은 각각 진화 전과 후의 목적함수 값이다. 콤플렉스 할당의 예를 들면, 총 콤플렉스가 8개이고, 4가지의 진화알고리즘을 사용하였을 때 초기 콤플렉스 분배가 (2-2-2-2)와 같다면, EMP를 바탕으로 한 성능이 가장 낮은 진화알고리즘의 콤플렉스를 가장 성능이 우수한 알고리즘의 콤플렉스로 할당하게 되어 (3-2-2-1)와 같이 적응적으로 콤플렉스를 분배한다. 하지만 모든 알고리즘마다 최소 하나의 콤플렉스를 할당받는다. 그리고 각 진화알고리즘방법을 통해 할당된 콤플렉스들의 매개변수 값을 변화시키고 콤플렉스들을 혼합해 모집단을 업데이트한다. 수렴 기준을 만족하지 않으면, 위의 과정을 반복한다. 위에 서술한 SC-SAHEL의 계산과정은 Fig. 2의 순서도와 같다.
3.2.2 Competitive Complex Evolution (CCE)
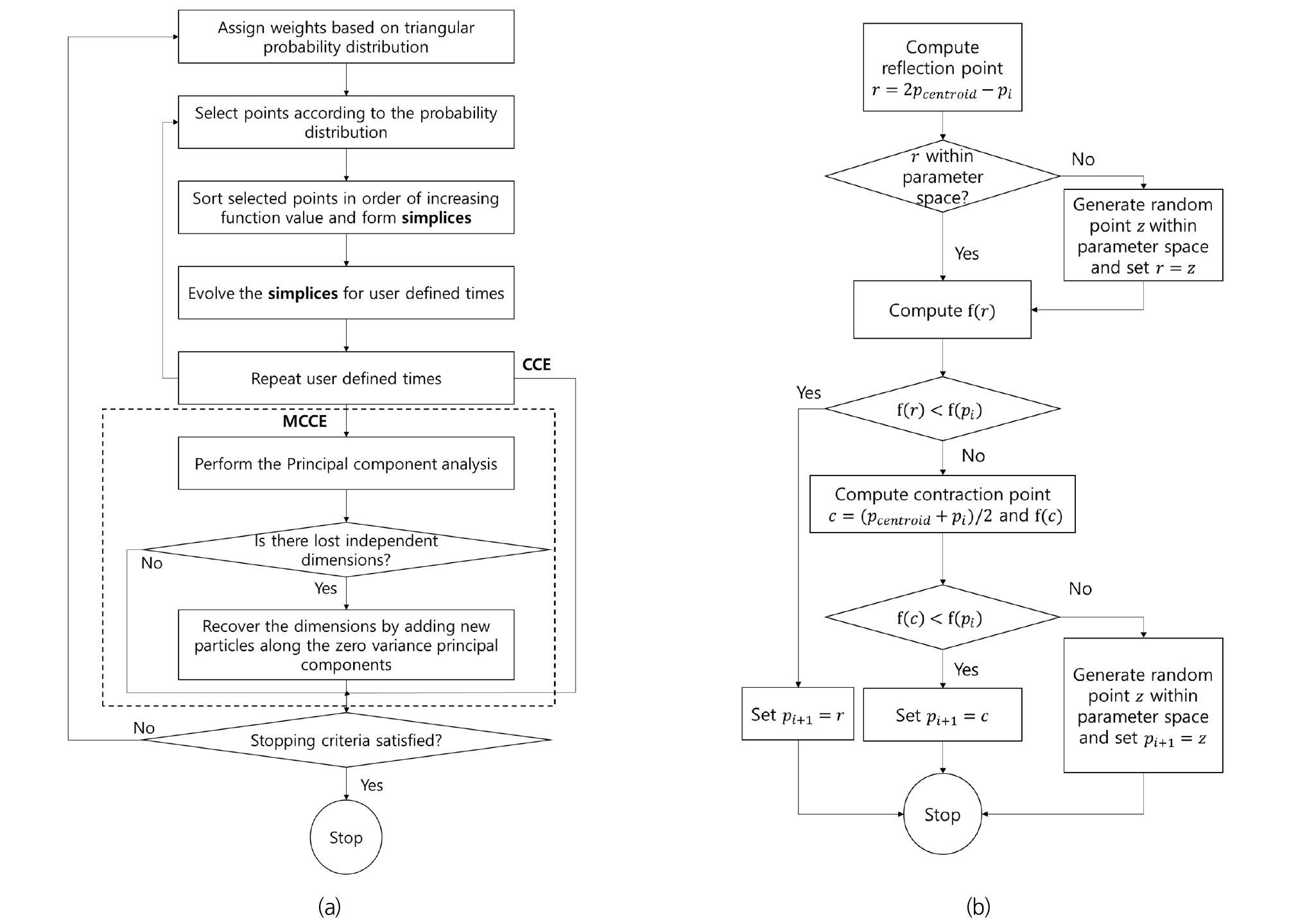
CCE는 Duan et al. (1993)이 제안한 SCE-UA에서 채택하고 있는 진화 알고리즘으로 Holland (1975)에 의해 제안되었다. 이는 Nelder-Mead 심플렉스 방법(Nelder and Mead, 1965)을 바탕으로 하고 있으며, 목적함수 값이 불확실한 경우에 많이 쓰인다. 이 방법은 CCE는 모집단의 값을 목적함수 값에 따라 오름차순으로 정렬한 뒤에 콤플렉스 수에 따라 분배한다. 콤플렉스 내에 샘플링된 변수 값을 삼각 확률분포에 따라 무작위로 선택하고 심플렉스를 구축한다. 그리고 변수 값들의 평균을 구한 뒤에 그에 따른 반사-확장-축소를 반복하는 심플렉스 최적화를 콤플렉스 별로 수행하게 된다. CCE의 계산과정은 Fig. 3에 도시된 바와 같다. Fig. 3에서 pcentroid는 콤플렉스 내 변수의 샘플 평균 값; r과 f (r)은 각각 반사 연산으로 계산된 변수 값과 목적함수 값; z와 f (z)는 각각 변수 공간 내에서 무작위로 생성된 값과 그 변수에서의 목적함수 값; c와 f (c)는 축소 연산으로 계산된 변수 값과 목적함수 값이다. CCE는 견고하고, 비용적으로도 효율적이라고 평가되는 진화 알고리즘이다. 하지만 최적화 과정이 진행될수록 차원 축소로 인해 지역해에 수렴할 가능성 커진다는 단점이 있다.
3.2.3 Modified Competitive Complex Evolution (MCCE)
Chu et al. (2010)은 CCE 방법이 고차원의 매개변수 공간에서는 모집단의 특성을 잃게 되는 현상을 보고하였다. 기본적으로 CCE와 같은 직접 검색 진화 방법은 해당 콤플렉스의 진화 이전 세대의 변수 범위가 전역해를 포함하여야 진화 이후의 세대가 전역해에 수렴하는 특성이 있는데, 전체 샘플링 공간의 특성을 잃게 되면 콤플렉스가 전역해를 포함하지 못해 국부 지역해에 수렴하는 결과를 낳게 된다. 이 문제를 해결하기 위해 Chu et al. (2010)은 주성분 분석을 활용한 SP-UCI를 제안하였다. SP-UCI에서 채택하는 방법은 MCCE로 기본적인 진화 구조는 CCE와 동일하다. 그러나 MCCE에서는 매 진화과정마다 주성분 분석을 수행하여 변수 공간의 차원을 유지한다. 만약 진화를 하면서 n 개의 차원을 잃게 되면 마지막 n 개의 주성분의 분산이 0이 되는데, 이 때 차원을 잃은 분산이 0인 주축에 새로운 개체를 추가하는 방법으로 초기 변수 공간의 차원을 유지한다. MCCE의 연산 과정을 Fig. 3에 파선으로 된 상자로 표시하였다. MCCE 방법은 CCE의 지역해 문제를 개선한 방법으로, CCE와 마찬가지로 견고하고 효율적이라는 장점이 있다.
3.2.4 Modified Differential Evolution (DE)
DE는 Storn and Price (1997)이 제안한 강력하고 또한 단순한 알고리즘으로 알려져 있다. DE는 최적해를 찾기 위해서 샘플된 변수들 중 가장 목적값이 높은 변수 벡터와, 무작위로 선택된 두 개의 벡터를 차분한 값에 변이율을 곱하여 새로운 세대의 변수 값을 생성한다. DE의 진화과정은 Eq. (8)과 같이 표현될 수 있다.
| $$p_{i+1}=p_{i,\;best\;}+w(p_{i,a}-p_{i,b})$$ | (8) |
여기서, pi+1는 i+1번째 진화의 변수벡터; pi,best, pi,a, pi,b는 각각 i번째 진화 때 최적 변수와 무작위로 선택된 두 변수 벡터; 는 변이 계수이다.
DE는 Mariani et al. (2011)에 의해 SCE-UA 방법에 결합되어 기존의 SCE-UA보다 견고한 최적해를 얻는 것으로 보고된 바 있다. 반면 수렴 속도가 타 진화알고리즘들에 비해 비교적 느리다는 단점이 있다. 따라서 Naeini et al. (2018)은 기존의 DE를 다음과 같이 수정한 DE방법을 SC-SAHEL에 적용하였다. 그들은 변이율 의 값을 수정하였는데, 우선, 4분의 1의 변이율을 적용하고, 특히 첫 번째 진화 단계에서는 2분의 1의 변이율을 적용하였다. 만약 자녀 세대에서 개선된 목적함수 값이 생성되지 않으면 콤플렉스의 변수 범위 내에서 무작위로 다시 샘플이 이루어진다.
3.2.5 Modified Frog Leaping (FL)
FL 방법은 Particle Swarm Optimization (PSO)의 개념을 지역적으로 적용시켜 SCE-UA에 진화알고리즘으로써 적용하고자 Eusuff and Lansey (2003)에 의해 개발되었다. Eusuff et al. (2006)은 불연속적인 문제에서 FL과 유전 알고리즘 (Genetic Algorithm, GA)를 비교했을 때 결과 FL이 비교적 최적해에 빠르게 수렴함을 보였다.
FL은 콤플렉스 내에서 샘플링 객체들이 가장 적합한 목적함수를 가진 객채를 향해가는 과정을 가장 우수한 개구리를 향해 도약하는 개구리들로 개념화한 방법이다. CCE에서 진화할 개체를 무작위로 선택하는 것과 마찬가지로 우수한 객체들을 향해 수렴시키기 위해 삼각 확률분포를 바탕으로 도약할 객체를 선택하게 된다. 그리고 가장 낮은 적합도의 객체는 각 진화단계마다 Eq. (9)로 계산된 도약거리(S)만큼 변수 값이 수정되어 Eq. (10)과 같이 새로운 변수 값을 가지게 된다.
| $$p_{i+1}=p_{i,\;worst}+S$$ | (10) |
여기서, rand는 0에서 1 사이의 무작위 수; S는 진화단계별 변수의 변화량; Smax는 허용된 최대 도약 길이이다. 만약 새로운 목적함수 값이 이전의 목적함수 값보다 적합하지 않으면 다시 도약한 값을 계산하여 목적함수 값을 계산한다. 이 때 다시 계산된 목적함수 값이 여전히 적합도가 나쁜 경우와 변수 공간을 벗어난 경우에는 무작위로 가능한 공간에서 새로운 객체로 대체하게 된다.
SC-SAHEL에서는 연속 문제에 적용하기 위해 네 가지의 사항이 수정되었다. FL이 기본적으로 불연속 문제에서 정의된 알고리즘이기 때문에 SC-SAHEL에서는 변수 공간을 연속된 공간에서 정의하였다. 둘째로, 기존의 FL은 전체 모집단에서 우수하고 열등한 객체를 정하지만, SC-SAHEL에서는 다른 진화 알고리즘의 정보가 FL의 콤플렉스에 영향을 미치게 하지 않도록 목적함수 평가 값을 콤플렉스 내로 한정하였다. 셋째로는 도약을 반복할 때 도약 하는 정도의 기준을 다르게 하였다. 마지막으로 두 번째 수정사항과 마찬가지로 무작위로 새로운 개구리를 생성할 때 할당된 콤플렉스의 변수공간 내에서 샘플링을 하도록 수정되었다.
3.2.6 Modified Grey Wolf Optimizer (GWO)
Mirjalili et al. (2014)는 회색늑대가 사냥을 할 때 먹잇감에 접근하고, 먹잇감 주위를 맴돌다가 공격하는 세 단계의 체계에 영감을 받아 회색늑대의 계급사회와 사냥 방법을 모방한 GWO라는 메타 휴리스틱 알고리즘을 개발하였다. Mirjalili et al. (2014)에 따르면 GWO를 여러 공학문제에 적용했을 때 GA나 PSO와 같은 유명한 최적화 알고리즘들과 비교해서 우수한 성능을 보인다고 보고되었다.
GWO의 알고리즘은 늑대의 계급사회에서 가장 하위 계급의 늑대들이 상위 늑대들을 따르는 것을 모방한다. 첫 번째로, 늑대가 먹이 주위를 맴도는 것을 수학적으로 표현하기 위해 목적함수가 가장 높은 목적함수 값을 먹잇감으로 설정하였을 때 다음 식과 같이 만큼의 무작위 계수가 곱해진 위치와 각 개체의 거리를 늑대가 먹잇감의 주위를 맴돌 때의 원의 반지름으로 가정한다.
여기서, 그리고 는 각각 첫 번째부터 세 번째까지 높은 적합도를 보이는 개체와 최적해와의 거리; 그리고 은 각각 첫 번째부터 세 번째까지 높은 적합도를 보이는 개체의 위치 보정 계수이며 이 값은 Eq. (12)와 같이 계산된다.
| $$\overrightarrow{\;C}=2\bullet\overrightarrow{\;r_{C\;}}$$ | (12) |
여기서, 는 0에서 1 사이의 무작위 계수이다. 그리고 최적화 문제에서는 실제 먹잇감의 위치를 모르기 때문에 목적함수 적합도가 가장 높은 개체 3개의 위치를 Eq. (13)과 같이 계산되는 잠재적인 위치에 대한 정보로 참조하게 된다.
| $$\overrightarrow{\;A\;}=2\overrightarrow{a\;}\bullet\overrightarrow{\;r_A\;}-\overrightarrow{\;a\;}$$ | (14) |
여기서, 그리고 는 각각 첫 번째부터 세 번째까지 높은 적합도를 보이는 개체의 위치 보정 계수; 는 진화가 거듭될수록 2에서 0까지 선형적으로 줄어드는 계수; 는 0에서 1 사이의 무작위 계수이다. 진화 대상이 되는 개체의 다음 위치는 다음 식과 같이 변수와 상위 3개체의 잠재적 위치와의 상대 위치벡터를 평균한 만큼 최적해로 접근하게 된다.
| $$\overrightarrow{\;X_{i+1}}=\;\frac{\overrightarrow{\;X_1}+\overrightarrow{\;X_2}+\overrightarrow{\;X_3}}3\;$$ | (15) |
FL과 마찬가지로 GWO 또한 자손 세대가 부모 세대보다 우수하지 못할 경우에 콤플렉스 내에서 다시 샘플링을 하도록 SC-SAHEL에서 수정되어 적용되었다. 그리고 다른 콤플렉스의 정보가 상호 영향을 미치는 것을 막기 위해 적응적으로 변화율을 적용하는 기존의 알고리즘에서 3가지 다른 변화율을 적용하였다.
4. 적 용
4.1 적용 하천
본 연구에서 TSM 매개변수 산정을 위해 NIER (2015)에 의해 수행된 청미천 실험자료를 활용하였다. 해당 실험은 2015년 10월에 경기도 여주시 점동면 현수리에 위치한 청미천에서 수행되었다. 총 연장 3,550 m의 실험 대상구간은 교량이 위치한 청미천의 사행구간으로, 이러한 하천의 사행과 수공구조물은 하천의 주 흐름을 교란시켜 물질 혼합에 기여한다고 알려져 있다(Jackson et al., 2013). 이러한 면을 고려하여 청미천이 저장대 매개변수 산정을 위한 대상 하천으로 적합하다고 판단하였다.
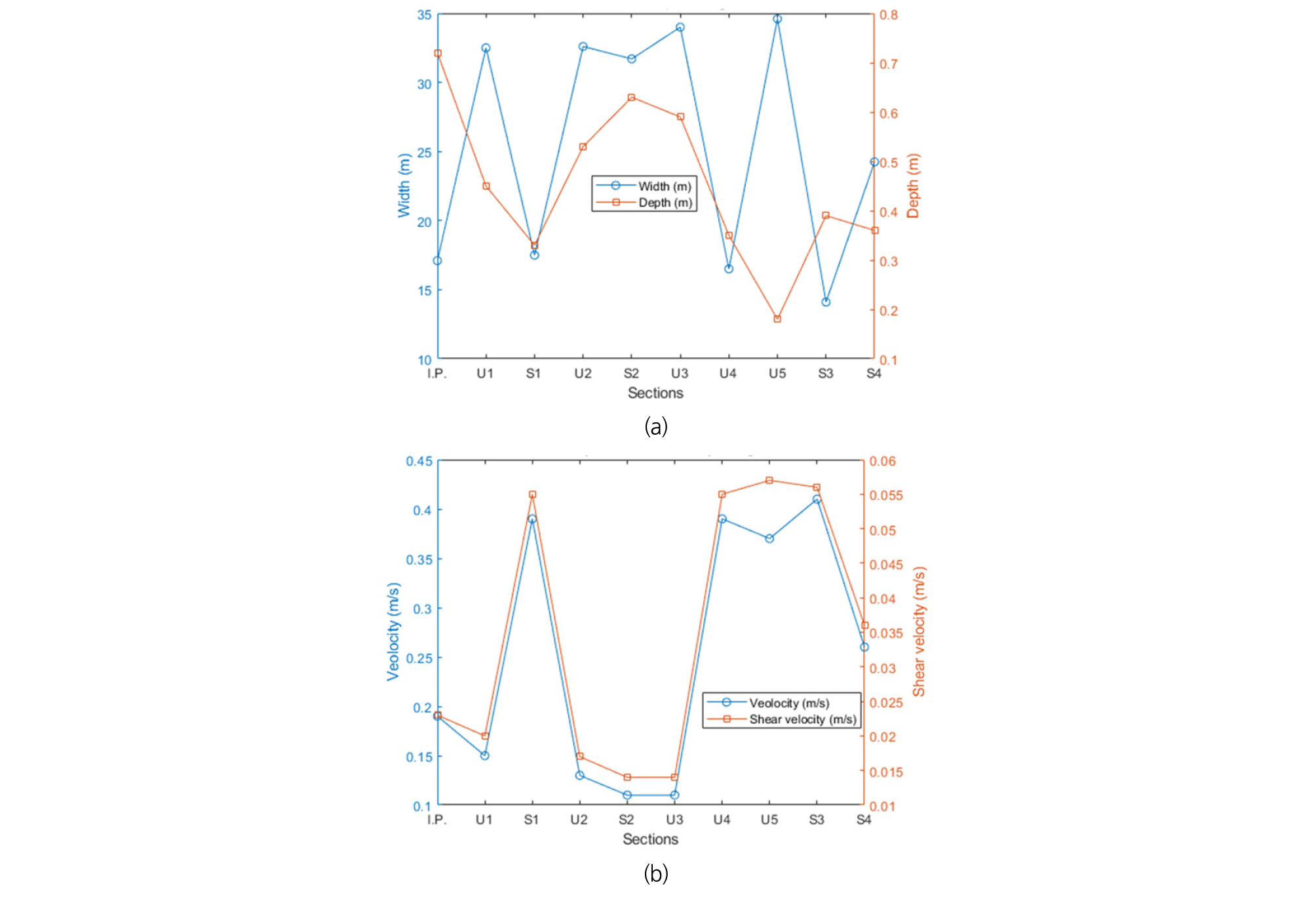
실험 당일 하천 유량은 2.26 cms였으며, 수리량은 주입지점으로부터 총 10개의 측선에서 측정되었고, 그 중 4개의 측선에서는 농도곡선의 측정이 이루어졌다. 각 측선에서의 평균 유속과 수심의 측정은 RDI사의 StramPro ADCP를 이용해 이루어졌다. 각 측량지점에서 측정된 수리량은 Table 1과 같다. Fig. 4 and Table 1에서 I.P와 U#로 표시된 부분은 각각 주입지점과 수리량만 측정된 측선이고, S#로 표시된 곳은 수리량과 추적자 농도가 함께 계측된 측선이다. Table 1의 마찰유속 는 다음 Eq. (16)과 같이 계산되었다.
| $$U^\ast=\sqrt{ghS_0}$$ | (16) |
Table 1. Hydraulic data measured in Cheong-mi Creek (NIER, 2015)
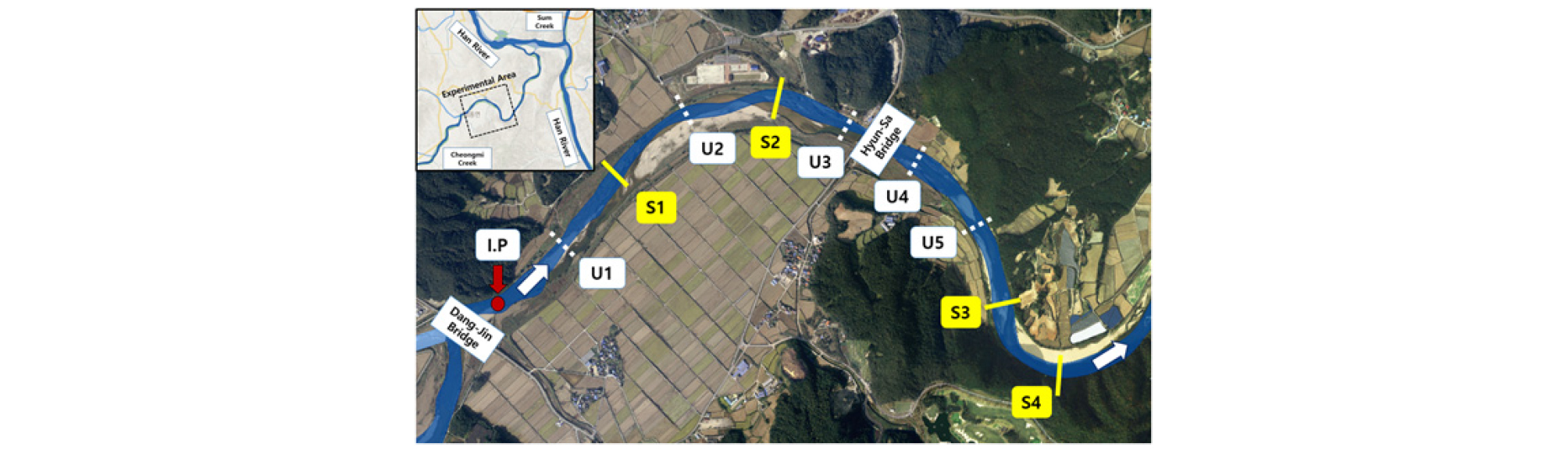
여기서, 는 중력가속도(m/s2); h는 수심(m); 그리고 S0는 하상경사이다. 하상경사는 매닝 계수를 0.037로 하여 매닝 식을 계산한 값을 이용하였고, 매닝 계수는 Arcement and Schneider (1989)를 참고하여 결정하였다. Fig. 5(a)에는 지형적 인자인 폭 및 수심을 측정 단면 별로 꺾은선 그래프로 도시하였고, Fig. 5(b)에는 유속과 마찰유속의 수리적 인자를 단면별로 도시하였다. Fig. 3에서 표시하였듯이 측선 U3과 U4에 현사교가 위치하였고, 이로 인해 흐름단면이 순간적으로 크게 축소하였다. 단면 축소의 영향으로 인해 U4이후로 유속이 증가하고, S4에서는 급한 사행으로 유속의 감소가 관측되었다.
추적자 실험에서는 보존성이며 관측에 용이하다고 알려진 형광물질인 Rhodamine WT 0.2 kg을 주입하고, Rhodamine WT 농도를 측정하기 위해 YSI-600OMS 형광센서를 이용하였다. 각 측정 센서는 측선마다 폭 방향으로 일정한 간격을 두고 각 3개씩 설치되었다. 추적자 주입은 1차원 혼합거동의 분석을 위해 설계되었으며, 농도곡선을 계측하는 첫 번쩨 측선 S1의 위치는 Kilpatrick and Wilson (1989)의 완전혼합거리 Eq. (17)를 바탕으로 결정되었으며, 이 실험의 경우 약 300 m 이후에는 하천 단면 전체에 대하여 완전혼합이 이루어지는 것으로 계산되었다. 따라서 S1의 위치 940 m에서는 혼합이 이루어진 농도곡선의 관측이 가능하다.
| $$L_0=0.1{(\frac1n)}^2\frac{UW^2}{E_z}$$ | (17) |
여기서, L0은 물질 주입지점으로부터 완전혼합되기까지의 거리(m); n은 한 측선에서 폭 방향 계측점의 개수; U는 평균 유속(m/s); W는 평균 폭(m); Ez는 횡방향 혼합계수(m2/s)이다.
4.2 적용 결과
4.2.1 모의 조건
SC-SAHEL은 초기 샘플링 단계에서 등분포 무작위 샘플링 방법과 Latin Hypercube sampling (LHS) 방법을 제공한다. LHS는 매개변수 공간의 범위 내에서 균일한 샘플링을 하는 것으로 알려져 있다. 따라서 이 연구에서는 초기 샘플링 시작 지점이 최적화 결과에 미치는 영향을 배제하는 목적으로 샘플링 방법으로 LHS를 채택하였다. 본 연구에서 매개변수 산정을 위해 설정한 샘플 수 및 수렴 조건은 Table 2와 같다. 활용된 최적화 기법의 모집단 샘플링 크기는 콤플렉스의 수와 콤플렉스의 크기의 곱으로 계산되며, 본 연구에서는 10개의 콤플렉스가 9의 크기를 가지고 있으므로 각 진화 단계별로 90번씩 TSM을 모의하여 목적함수를 평가하였다. Table 2에서 maxn, StopStep, StopIMP, 그리고 StopSP는 최적화 정지 기준에 대한 최적화 변수들이다. 여기서 maxn은 목적함수 최대 평가 횟수; StopStep은 목적함수 향상율을 계산하기 위해 설정된 진화 단계 수; StopIMP는 StopStep이 m일 때 마지막 m 진화 단계 안에서 최소 목적함수 향상율; StopSP는 최소 매개변수 공간의 범위를 의미한다.
Table 2. Optimization settings for parameter estimation
본 연구에서는 케이스 특이성을 최대한 배제하기 위해 적용 대상 추적자실험에서 가용한 4개소의 관측 농도곡선 자료를 모두 이용하였다. TSM 매개변수의 산정을 위해서는 모의를 위해 상류 경계조건으로서 상류에서 관측된 농도곡선과, 모의 비교 대상으로서 하류에서 관측된 농도곡선 총 2개의 농도곡선 자료가 필요하다. 따라서 4개소에서 관측된 농도곡선을 2개씩 조합한 6개의 농도곡선 조합 경우에 따라 모두 매개변수 산정을 수행하였다. 그리고 매개변수 산정의 불확도를 고려하여, 케이스별로 각 3번씩 매개변수를 수행하였다.
4.2.2 목적함수에 따른 결과 분석
Table 3에 각 목적함수별로 주입 물질이 유하한 구간의 길이와 각 구간에서 산정된 4개의 TSM 변수 값, 그리고 물질의 반응효과(TSM에서는 저장대 물질교환 효과)와 이송 효과의 비율인 실험적 Damkohler 수(DaI)의 계산값을 정리하였다. Wagner and Harvey (1997)는 TSM 매개변수 산정에 있어서, DaI 값을 계산했을 때, 0.5 ≤ DaI ≤ 10의 범위에서 불확도가 낮음을 보였고, 그 이후 계산된 DaI 값은 산정된 TSM 매개변수 값이 합리적인지를 간접적으로 보는 척도로 이용되고 있다. DaI는 다음 Eq. (18)과 같이 계산된다.
Table 3. Estimated TSM parameters on Cheong-mi Creek experiment
| $$DaI=\;\frac{\alpha L_{reach}(1+{\displaystyle\frac{A_f}{A_s}})}{Q/\;A_f}$$ | (18) |
여기서, Lreach은 유하 거리(m)이다. 청미천에서 각 목적함수마다 산정된 매개변수를 바탕으로 계산된 DaI값은 최소 1.2273에서 최대 6.0944로 계산되어, 매개변수들이 합리적으로 산정된 것으로 판단할 수 있다. 매개변수 산정 결과 6개 구간 모두에서 PMAE가 목적함수일 때 PME에 비해 큰 Kf와 Af, 작은 As와 가 산정되었다. 그리고 PMSE와 (1-R2)가 목적함수일 때 같은 매개변수 값이 산정되었으며, 이는 PME와 PMAE를 목적함수로 하여 산정된 매개변수들의 사잇값이다. 선택된 측선에 따라 산정된 매개변수 값을 비교하기 쉽게 Fig. 6에 목적함수별로 산정된 값을 설정된 상류 측선과 하류 측선 번호를 이어서 구분하여 도시하였다. 이 그림에서 보면 목적함수별로 Af와 As가 보이는 차이에 비해 Kf와 의 차이가 크게 나타나는 것을 알 수 있다. 또한 이 매개변수 산정 결과는 설정된 구간별로 중복되는 구간에서 산정된 매개변수 값과 구간내의 측선들로 산정한 매개변수 값이 직접적으로 비교될 수 없음을 보이고 있으며, 이 결과는 Gooseff et al. (2013)이 밝힌 바와 동일한 결과이다. 이와 같이 6개의 측선 조합 모두에서 산정된 값이 다르기 때문에 본 연구에서는 6개의 구간에서 각각 최적화 조건의 평가를 수행하였다.
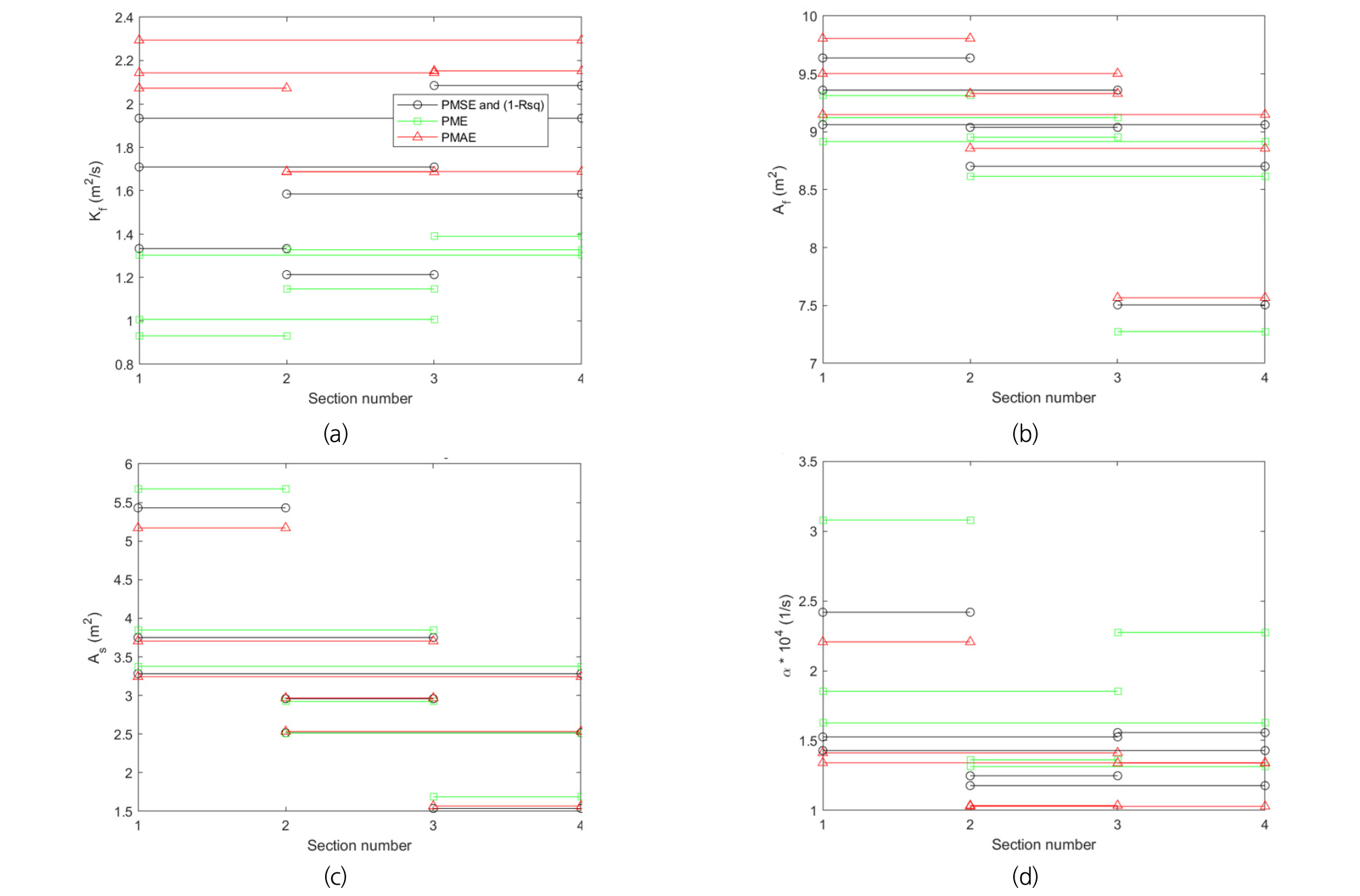
Fig. 7에는 6개의 다른 구간 조합 중에 본류대 분산계수 차이가 가장 크게 나타나는 S1-S2 구간에서 산정된 매개변수를 이용해 모의된 농도곡선과 관측 농도곡선을 비교하였다. 저장대 효과가 클수록 농도곡선에서 가파른 상승부와 두껍고 긴 꼬리부분이 관측되는 것으로 알려진 바와 같이 분산효과를 작게, 저장대 효과를 크게 평가한 PME의 경우에는 상승부가 가파르고 하강부가 두꺼운 형태의 농도곡선을 생산해 실측치보다 낮은 첨두농도와 실측치보다 높은 하강부의 농도가 나타났다. 반면 분산효과를 크게, 저장대 효과를 작게 평가한 PMAE는 상승부 곡선이 비교적 완만하게 모의되어 다른 목적함수로 하였을 때 생성된 농도곡선의 값보다 상승부의 오차가 큰 것을 볼 수 있다. 이를 통해 높은 본류대 분산계수로 인한 혼합효과가 낮은 저장대 물질교환으로 인한 혼합효과와 상쇄되어 크게는 분산계수가 두 배 가까이 차이가 남에도 불구하고 비슷한 농도곡선을 생산하는 것을 확인할 수 있다.
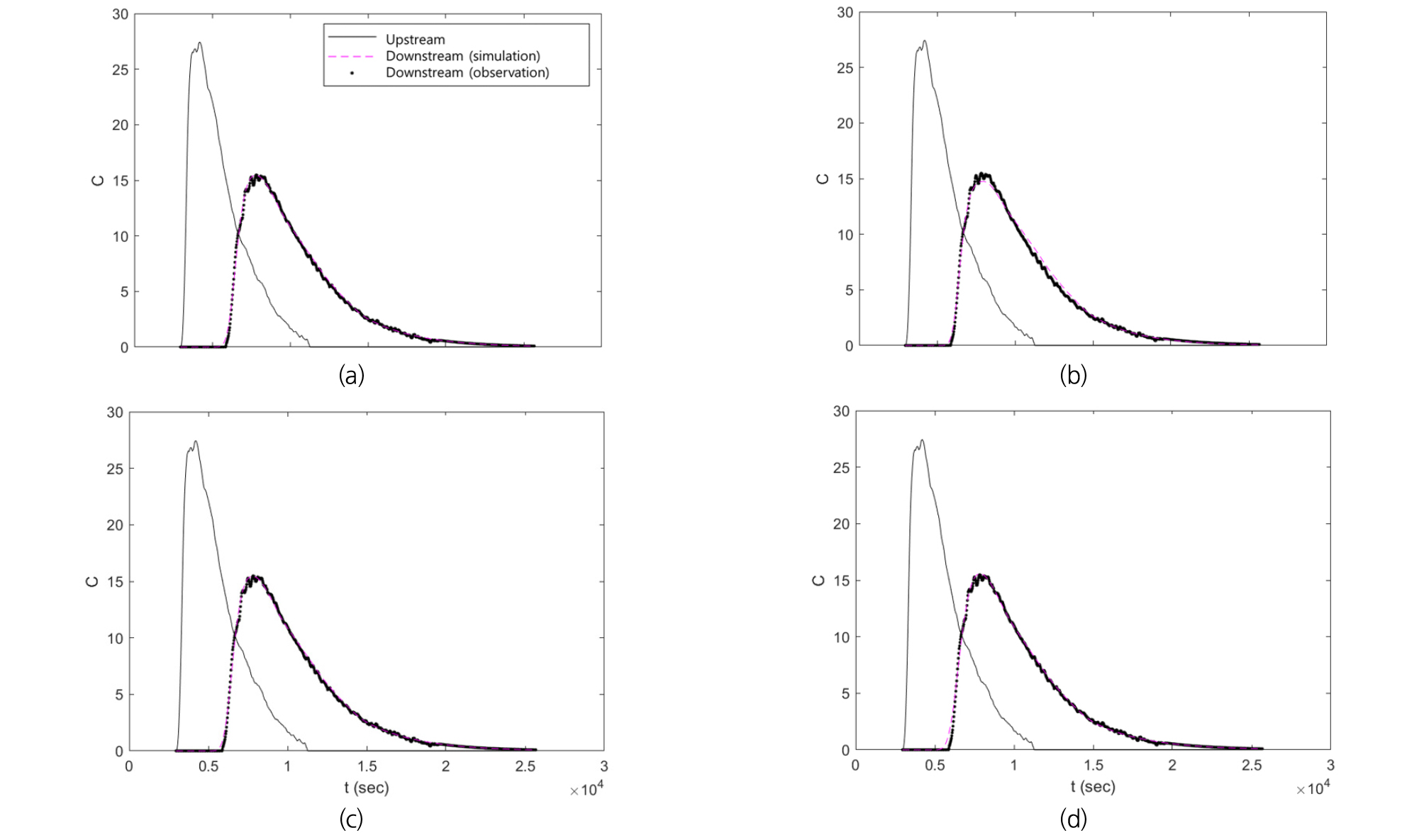
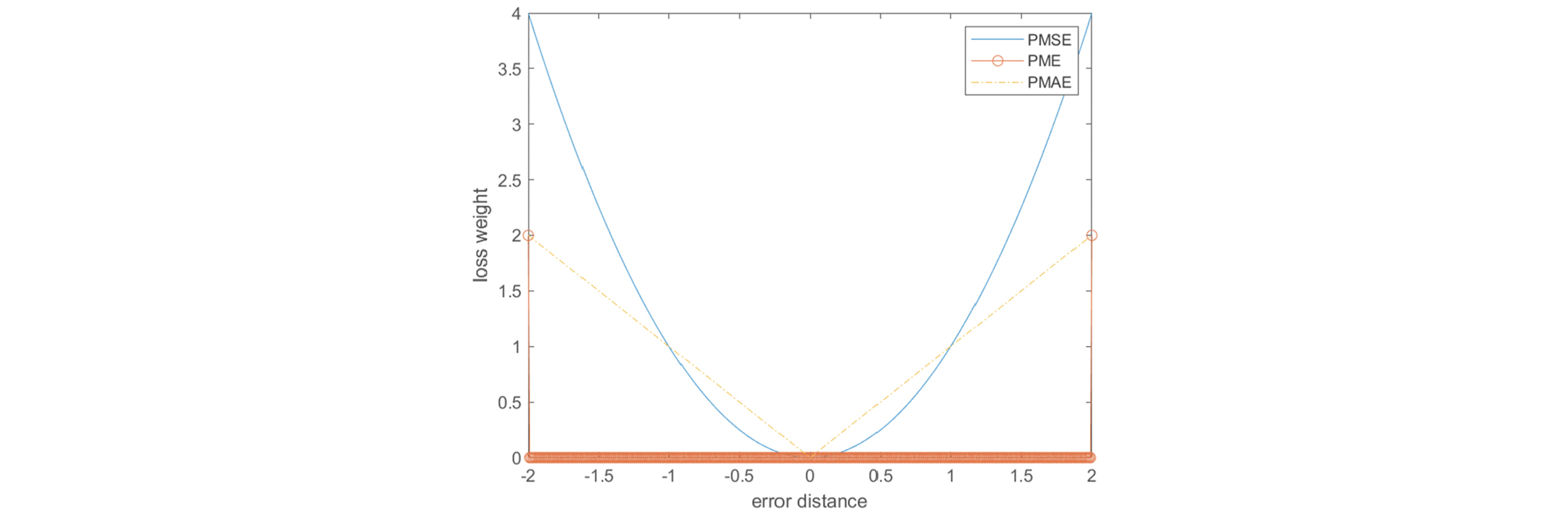
Fig. 8은 목적함수에 따라 다른 매개변수 값이 산정된 원인을 설명하기 위해 PMSE, PME, 그리고 PMAE의 오차의 크기에 따른 가중치를 [-2 2]의 범위에서 그린 그래프이다. 본 연구에서 대상이 되는 목적함수들은 손실함수 측면에서 각각 PMAE는 L1 노름, PMSE와 결정계수는 L2 노름, PME는 L∞ 노름으로 볼 수 있다. Fig. 8은 고차 노름일수록 큰 오차 값에 가중치가 크고, 작은 오차 값에 대한 가중치가 작다는 사실을 보여준다. 이런 특성으로 인해 L2 노름은 이상점을 과대평가하고 L1 노름은 추정선과 가까운 값을 과대평가하는 것으로 알려져 있다(Zhu et al., 2008). Fig. 7에 도시된 바와 같이 S1-S2 구간에서 관측된 농도곡선은 첨두 농도에서 큰 변동 값이 관측된다. 이러한 관측 농도곡선의 특징을 고려하였을 때, PME는 오차벡터의 성분 중 가장 큰 성분 값에만 가중치를 주는 함수기 때문에 농도곡선의 꼬리부분에서 오차가 생기더라도 비교적 큰 첨두값의 변동으로 인한 오차가 최소화되는 농도곡선을 최적해로 찾게 되는 것으로 판단된다. 반면 PMAE는 작은 오차값에 대한 가중치가 다른 목적함수에 비해 높기 때문에 오차벡터에서 길이를 많이 차지하는 꼬리부분에 과적합하여 상승부에서 비교적 부정확한 결과가 나타났다. PMSE와 결정계수를 통해 산정된 매개변수로 모의한 곡선은 PME와 PMAE의 중간 정도의 형태를 가지고 있어 농도곡선의 상승부의 오차와 꼬리부분의 오차가 모두 비교적 적은 보수적인 결과를 생산하였다.
4.2.3 진화 알고리즘을 고려한 결과 분석
Table 4는 각 진화 알고리즘들과 목적함수의 적합성을 비교하기 위해서 3번씩의 매개변수 산정 시 계산된 목적함수 값 및 진화 횟수의 평균과 범위를 정리한 결과이다. 사용된 최적화 기법은 모집단의 크기와 진화 횟수만큼 목적함수를 평가하게 되기 때문에 최적화 기법의 수렴 속도의 척도로써 진화 횟수를 계산 및 비교하였다. Table 4의 각 행에서 최적화 기법 및 목적함수마다 평균이 가장 낮은 값, 즉 최소화 문제에서 적합도가 가장 높은 값을 굵은 글씨로 표시하였다.
Table 4. The mean, minimum, and maximum values of the model fitness value and number of evolution using the SC-SAHEL with single-EA and multi-EA (Bold: best performance method)
최종적으로 수렴한 최적해들 중에 실측 농도곡선과 가장 닮은 곡선을 생산하는 매개변수가 산정된 경우를 성공적으로 매개변수를 산정 한 경우로 보면, 모든 최적화 기법에서 목적함수를 PMSE로 했을 때에 성공적으로 매개변수를 산정하는 횟수가 가장 많았다. 대부분의 구간에서 PMSE는 다른 목적함수에 비해 안정적인 값으로 수렴한 반면, 구간을 S1-S2로 설정했을 때에는 MCCE 방법이 1회 지역해에 수렴하였다. 이러한 경향은 PME와 결정계수를 목적함수로 하였을 때도 동일하게 나타났다. 다른 목적함수들에 비해 PMAE는 굵은 글씨로 표시된 케이스가 1개씩으로 지역해에 많이 수렴하였는데, S2-S3구간과 S3-S4구간에서는 각각 3개와 4개로 하류로 갈수록 매개변수가 안정적으로 최적해에 수렴하였다. 하류로 갈수록 농도곡선의 시간이 길어 평균 오차 값을 계산할 때 따라 농도의 주기적 변동 값 하나하나가 가지는 가중치가 낮아져서 하류의 농도곡선으로 매개변수를 산정할 때 상류의 농도곡선을 이용하는 것보다 비교적 안정적으로 매개변수 산정이 이루어지는 것으로 판단된다.
각 최적화 조건의 수렴성을 보다 쉽게 비교하기 위해서 성공적으로 매개변수 산정이 이루어진 횟수와 성공률을 Table 5와 같이 정리하였다. 여기에서 총 매개변수 산정 횟수는 DE 방법의 성공률이 93%로, 가장 수렴성이 좋은 방법으로 나타났다. 그리고 전체 성공률인 81%보다 높은 방법 중에서는 SC-SAHEL과 FL이 각각 88%와 86%로 뒤따르는 결과를 보였다. 목적함수들을 바탕으로 평가하면 PMSE가 99%로 가장 높은 성공률을 보였고 비슷한 값인 결정계수가 97%로 성공횟수가 2회 낮은 결과를 보였다. 결정계수의 매개변수 산정 실패는 S1-S2에서 나타났는데, 이 경우에서 첨두농도로 스케일링한 PMSE 값이 평균 제곱오차로 스케일링했을 때보다 수렴성이 좋은 결과를 보였다. PME와 PMAE는 각각 89%와 37%로 낮은 결과가 나타났다. 이 또한 4.2.2에서 논의한 바와 같이 손실함수로 측면으로 보았을 때 PME는 작은 크기의 오차에 가중치가 낮아 절대 크기가 작은 꼬리 부분의 변화에 둔감하고 PMAE는 작은 크기의 오차에도 가중치가 다소 커서 농도곡선의 주기적 변동 값에 민감하게 반응하기 때문인 것으로 보인다. 매개변수 산정 성공률이 비교적 낮은 PME와 PMAE의 성공률을 바탕으로 평가했을 때 DE와 SC-SAHEL이 각각 72%와 61%의 성공률을 보여 비교적 불확실한 문제에서도 매개변수 산정을 성공적으로 수행할 수 있는 방법으로 판단된다.
Table 5. Number and ratio of successful parameter estimations
Table 6에는 수렴 속도와 최적화 효율성을 비교하기 위해 최적화 조건 별로 평균 진화 횟수와 Eq. (19)와 같이 계산되는 한 번의 성공적인 매개변수 산정의 기대 진화 횟수를 계산하여 정리하였다. 기대 진화횟수가 적을수록 전역해에 수렴하는 것에 대한 효율성이 좋은 방법이라고 말할 수 있다.
Table 6. Mean evolution number of Cheong-mi Creek TSM parameter estimation (Exp#: expected number)
| $$\mathrm{Expected}\;\mathrm{evolution}\;\mathrm{number}=\;\frac{evolution\;number}{success\;rate}$$ | (19) |
모든 최적화 기법과 목적함수의 평균 진화횟수와 기대 진화횟수는 각각 69회, 86회로 나타났으며 가장 계산비용이 적은 방법은 평균 46회 진화한 MCCE로 나타났다. 그리고 CCE, SC-SAHEL, FL이 50회에서 58회로 비슷한 결과를 보였다. 모든 목적함수에서의 결과를 포함했을 때 기대 진화횟수가 가장 적은 방법은 59회로, 전체 기대 진화횟수인 86회보다 약 1.45배 빠르게 수렴하였다. 목적함수별 평균 진화 횟수는 결정계수가 56회, PMSE가 57회로 PME와 PMAE보다 빠른 수렴 속도를 보였다. 기대 진화횟수는 PMSE와 결정계수 두 목적함수 모두 58회로 기대 진화횟수가 200회로 가장 큰 PMAE보다 최대 3배 이상 빠른 기대 진화횟수가 계산되었다.
Tables 4, 5, and 6의 결과에서 네 가지 비교 대상 목적함수들 중에서는 매개변수 산정 성공률, 산정 속도, 기대 진화횟수 세 가지 척도 모두에서 PMSE를 목적함수로 하는 것이 가장 우수한 결과를 보이는 것으로 밝혀졌다. 최적화 기법들을 비교하였을 때는 DE를 사용하는 것이 가장 매개변수 산정 성공률이 높았으나 수렴 속도가 다른 방법들에 비해 GWO 다음으로 느렸으며 따라서 기대 진화횟수 또한 GWO 다음으로 크게 나왔다. PMSE를 목적함수로 했을 때 기대 진화횟수가 MCCE 방법이 가장 낮았으나 이 방법은 PMAE가 목적함수일 때에는 성공 횟수가 1회로 다른 방법에 비해 현저히 낮아 비교적 불확실한 문제에서는 성공률이 떨어지는 결과를 보였다. 앞서 서술한 면을 종합적으로 고려하면 네 가지 목적함수 모두에서 성공률이 높고 PMSE가 목적함수일 때 MCCE 다음으로 기대 진화 횟수가 낮은 SC-SAHEL 방법이 TSM 매개변수 산정 문제에 있어 가장 적합하다고 판단된다.
5. 결 론
본 연구에서는 자연하천의 수질관리를 위해 광범위하게 이용되는 TSM의 매개변수를 결정하기 위한 최적화 기법을 비교하였다. 첫 번째 지표로서 평균 제곱오차, 결정계수, 최대오차, 평균 절대오차 총 4개의 목적함수를 비교하였다. 또한 SC-SAHEL 최적화 프레임워크를 이용해 CCE, MCCE, DE, FL, GWO 등의 전역 최적화를 위한 진화 알고리즘들에 대해 SCE-UA 및 SP-UCI와 같이 각각 하나만 썼을 때와 여러 알고리즘을 병렬로 적용하였을 때를 평가하였다. 최적화 기법을 비교하기 위해 청미천에서 수행된 추적자 주입 실험 자료를 이용해 TSM 매개변수를 최적화 조건별로 3번씩 산정하였다. 각 목적함수들과 최적화기법의 조합에 따른 목적함수 값과 목적함수 평가 횟수를 비교하여 TSM 매개변수 산정을 위한 최적화 기법과 목적함수의 적합성을 평가하였다.
매개변수 산정 성공률 측면에서는 전체 성공률 평균이 81%이고 평균보다 높게 나타난 방법으로는 DE가 93%, SC- SAHEL이 88% FL이 86%로 나타났다. 목적함수들을 다르게 적용하여 성공률을 계산한 결과 PMSE가 99%로 다른 목적함수들보다 우수한 결과를 보였다. 그리고 각 최적화 조건별로 수렴 속도를 비교하기 위해 계산한 진화 횟수와 한 번의 성공적인 매개변수 산정에 기대되는 진화 횟수를 계산하였다. 평균 진화 횟수는 MCCE가 평균 46회로 가장 빨랐으나 기대 진화횟수에서는 SC-SAHEL이 52회로 가장 우수한 결과를 보였다. 결정계수를 목적함수로 했을 때 56회, PMSE가 57회로 89회의 PME와 74회의 PMAE 결과보다 빠른 수렴속도를 보였으며, 기대 진화횟수 또한 PMSE와 결정계수가 58회로 다른 목적함수보다 계산 비용 면에서 우수하였다.
정리하면 목적함수로서는 PMSE가 모든 기준에서 다른 대상 목적함수들보다 우수한 것으로 나타났다. 최적화 기법으로는 DE방법이 가장 안정적으로 해에 수렴하지만 수렴 속도가 느리다는 단점이 있었고, MCCE는 수렴속도가 빠르지만 PMAE와 같이 불확실성이 높은 문제에서는 성공률이 매우 낮다는 단점이 있다. 그리고 SC-SAHEL 방법은 성공률 면에서는 DE 다음으로 우수하고 수렴 속도도 MCCE와 비슷한 결과를 보였으며 전체 케이스에서 평균 기대 진화횟수는 가장 우수하였다.
자연하천에는 지역성 및 불규칙성이 산재하고 있다는 특성상 본 연구는 적용 대상의 수가 적다는 한계가 있다. 이런 자연하천의 불규칙성을 고려하면 MCCE는 PMSE의 기대 진화횟수는 적지만 전체 성공률이 낮기 때문에 최적화기법을 SC-SAHEL로 하고 목적함수를 PMSE로 설정하여 TSM의 매개변수를 산정하는 것이 다른 최적화기법과 목적함수를 조합하였을 때보다 안정적이고 빠르게 최적해에 수렴할 것으로 기대된다. 따라서 평가 결과에 의거해 SC-SAHEL을 이용해 관측된 농도곡선에 대한 생산된 농도곡선의 PMSE를 목적함수로 하는 매개변수 산정 프레임워크를 제안하는 바이다. 본 연구에서 제시된 최적화 조건을 이용하면 TSM 매개변수에 대해 선행연구에서 이용된 방법들의 지역해 반환 문제 및 계산 비용의 문제가 개선될 것으로 판단된다.
