

1. 서 론
2. 대상유역 및 자료
2.1 용담댐 유역
2.2 강우자료
3. 방법론
3.1 연구 절차
3.2 이표본 Kolmogorov-smirnov 검정
3.3 Mann-Kendall 경향성 검정
3.4 확률밀도함수
4. 결과 및 토의
4.1 d4PDF 자료의 이용
4.2 d4PDF 자료의 검증
4.3 확률강우량 산정
5. 결 론
1. 서 론
극한 가뭄 및 홍수와 같은 이상기후 현상이 최근 빈번히 관측되고 있으며, 이와 같은 현상은 심각한 재해 및 재난의 원인이 된다(Seneviratne et al., 2012; Christidis et al., 2015; Fischer and Knutti, 2015). 특히, 극한 호우사상은 대규모 수재해를 야기시키며, 이는 극심한 사회 경제적 피해로 이어진다(e.g. Bandaru et al., 2020; Hirota et al., 2019; Shimpo et al., 2019). 이에 따라, 극한 규모의 호우사상을 추정하여 수공구조물의 설계강우량을 평가함으로써 극한 호우현상의 피해를 완화하는 방안을 검토하는 것이 더욱 중요해졌다(Hwang et al., 2018; Alam and Elshrbagy, 2015; Kumar et al., 2021).
관측 강우량을 이용하여 산정되는 설계강우량은 빈도해석을 토대로 산정된다. 설계강우량의 빈도해석 과정은 수집된 관측 강우량에 확률밀도함수를 적용하여 초과 확률(Exceedance probability)로 나타내고, 이 초과 확률에 따라 확률강우량으로 표현되는 과정이다. 여기서, 초과 확률이 낮을수록 저빈도·고강도의 강우 규모를 나타내며, 이 초과 확률은 재현기간(Return period)으로 표현될 수 있다. 재현기간을 증가시키면서 더 큰 규모의 강우량을 산정할 수 있으며, 수공구조물 및 하천 규모에 따라 다른 재현기간을 나타내는 확률강우량을 설계강우량으로 이용한다.
이와 같은 통계적 방법이 적용되는 이유는 대상 지역에서 수집된 강우 자료의 관측 기간이 짧기 때문이다. 빈도해석 방법의 적용 없이, 짧은 관측 기간의 강우 자료만으로는 일반적으로 수공구조물의 설계강우량에 널리 적용되는 50년 또는 100년 이상의 재현기간을 표현하기 어렵다. 이를 극복함으로써 관측 강우량을 이용하여 대규모 설계강우량을 산정하기 위해, 빈도해석은 적용되어야 하며, 빈도해석 과정 중 가장 중요한 절차는 적절한 확률밀도함수를 선정하는 것이다.
적절한 확률밀도함수의 선정을 위해 여러 연구가 수행되었다(Bobee et al., 1993; Cunnane, 1989; Haddad et al., 2015; Johnson et al., 2012; Sharma and Singh, 2010). 하지만, 확률강우량을 산정하기 위해 제시된 확률분포는 다양하고 확률분포마다 다른 확률강우량을 제시하기 때문에 적절한 확률밀도함수를 선정하는 것은 어려운 과정이다(Haddad and Rahman, 2011). 게다가, 짧은 기간 동안 수집된 강우자료에 확률밀도함수를 적용해도 상당히 긴 재현기간에 대한 극한 규모의 확률강우량 값은 신뢰하기 어렵다(Ben Alaya et al., 2018; Klemeš, 2000, 1987, 1986). 결과적으로, 작은 표본크기를 이용한 빈도해석 과정은 긴 재현기간을 갖는 극한 규모의 강우량 산정에 큰 불확실성을 나타낸다(Ishii and Mori, 2020). 따라서 이런 한계점을 극복하여 장기간의 재현기간을 갖는 확률강우량을 적절히 제시하기 위해서는 대규모 표본크기를 이용하여 빈도해석 과정에서 발생하는 불확실성을 최소화해야 한다.
최근에 관측 자료 및 극한 강우 사상의 부족 문제를 해결하여 전례 없는 극한 기후현상을 평가하고자 일본의 기상연구소(Meteorological Research Institute, MRI)는 대규모 기후 앙상블 모의실험을 수행하였다. 그 후, 이 모의실험의 결과를 토대로 “미래 기후변화에 관한 정책 결정을 위한 데이터베이스인 d4PDF (Database for Policy Decision Making for Future Climate Change) 데이터베이스”를 구축하였다(Ishii and Mori, 2020; Mizuta et al., 2017). 이 d4PDF 자료의 현재 기후조건에 따른 모의실험 결과는 총 50개의 앙상블로 이루어져 있다. 하나의 앙상블당 1951년부터 2010년까지 60년간 기상 및 기후 자료를 생성 및 제공한다. 모든 앙상블의 자료로부터 3,000개의 연 최대 기상 및 기후 자료를 수집할 수 있다. 총 3,000개의 연 최대 자료를 표본으로써 이용함으로써 d4PDF는 극한 기후 사상 및 수집된 관측 자료의 부족을 해결하여 극한 기상현상 분석에 도움이 될 것이다.
이에 따라, 최근 몇몇 연구들은 발생 확률이 낮은 극한 홍수와 가뭄 현상들에 대해서 위험도를 평가하기 위해 d4PDF 데이터베이스를 적용했다. Yang et al. (2018)은 d4PDF의 장기간 기상자료를 이용하여 폭풍 해일의 장기간 영향을 평가했다. 또한, 낮은 빈도를 나타내는 극한 규모의 폭풍 해일을 분석하였다. Tanaka et al. (2021)은 d4PDF의 3,000개의 연 최대 강우량들을 이용하여 일본의 109개의 유역에 대해서 홍수 위험도를 분석했다. 또한, Tanaka et al. (2020)은 d4PDF 자료를 이용해 3,000년의 재현기간까지 표현할 수 있는 강우의 확률분포를 생성하여 각 초과 확률강우량에 따른 홍수피해 면적을 분석하였다. 이외에도, 관측 기상자료를 이용함에 따라 매우 낮은 확률 또는 매우 긴 재현기간을 갖는 극한 기상현상 표현 시 발생하는 불확실성을 극복함으로써 d4PDF 자료는 극한 규모의 기상현상 분석에 광범위하게 활용되었다(Döll et al., 2018; Faye et al., 2018; Ishii and Mori 2020; Kay et al., 2015; Lavender et al.. 2018; Mori et al.. 2019; Yang et al.. 2018).
따라서, 본 연구는 우리나라에서 매우 긴 기간의 재현기간과 극한 규모를 나타내는 합리적인 확률강우량 산정에 대규모 기후 앙상블 모의결과 기반의 d4PDF 자료가 활용될 수 있는지 검토하는 것을 목적으로 수행한다. 또한, 관측 강우량과 우리나라에서 널리 이용되는 확률밀도함수인 Gumbel 분포와 GEV (General extreme value) 분포를 적용하여 확률강우량을 산정한 후, 두가지 분포로부터 산정된 확률강우량 사이의 편차를 분석하여 확률밀도함수 적용에 따른 불확실성을 분석한다. 산정된 관측 강우의 두 확률강우량과 d4PDF의 확률강우량의 편차를 분석하여 d4PDF를 이용하여 산정된 확률강우량의 적용 가능성에 대해 검토한다. 이 모든 분석은 짧은 기간의 재현기간부터 매우 긴 기간의 재현기간을 갖는 확률강우량으로 표현함으로써 관측기간과 재현기간의 차이가 증가함에 따른 편차의 경향성을 확인하여 어떤 불확실성이 발생하는지에 집중하여 수행한다.
2. 대상유역 및 자료
2.1 용담댐 유역
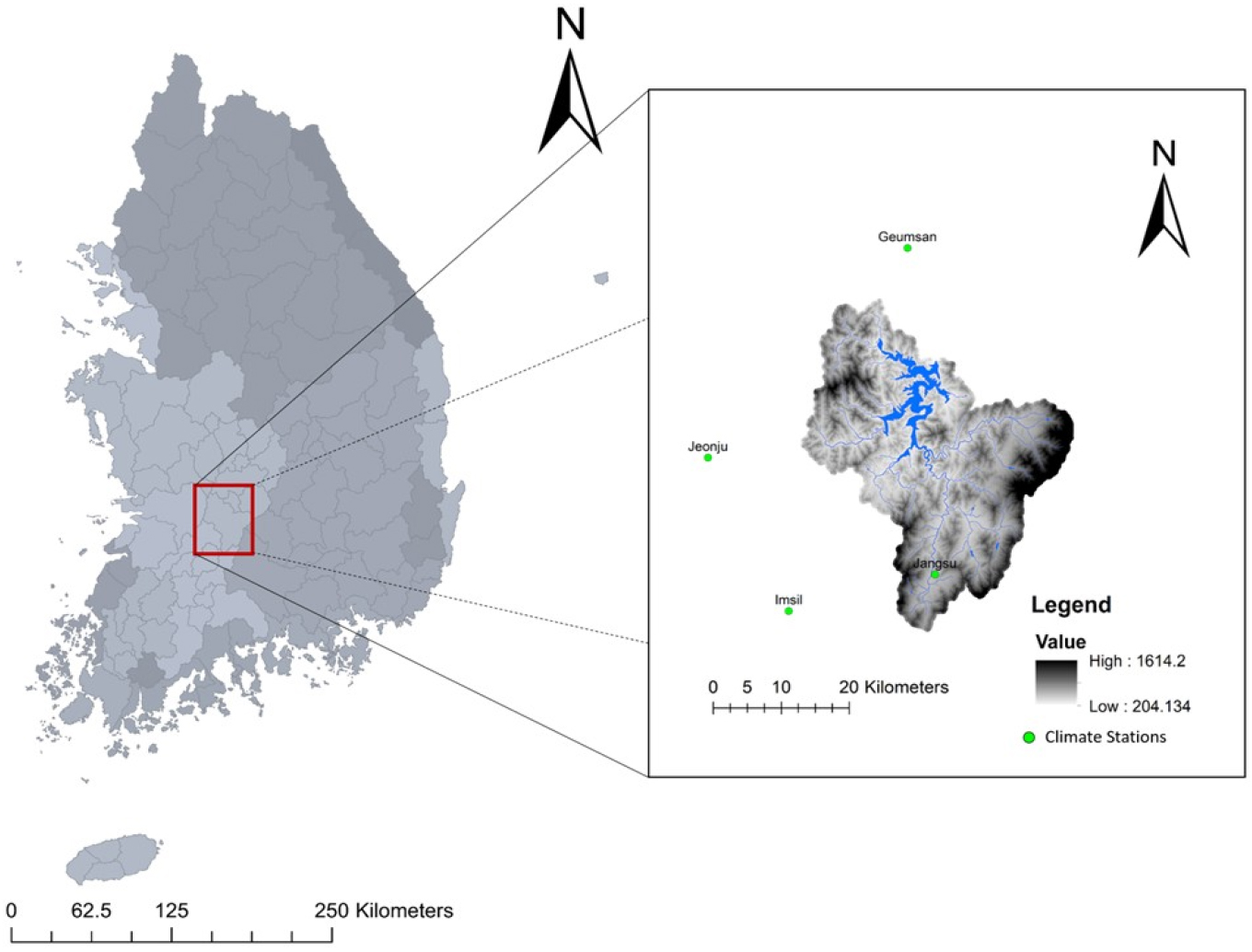
2020년 한반도는 장기간 지속된 ‘장마’의 영향으로 다수의 유역에서 대규모 수재해가 발생했다. 특히, 용담댐 유역에서 대규모 호우사상이 발생했으며, 이틀 동안 378 mm의 강우량을 기록했다. 이 규모는 최근 55년 동안 용담댐 유역에서 발생한 호우사상 중 최대 규모이다(Felix et al., 2021). 이에 따라, 최근 용담댐 유역은 수재해 예방 및 대응에 필요성이 증가하였고, 극한강우량에 대한 검토가 필요하다고 판단하여 본 연구는 Fig. 1과 같이 용담댐 유역 내외에 위치한 4개의 기상청 산하의 관측소(금산, 임실, 전주, 장수 관측소)를 대상으로 수행되었다.
용담댐 유역은 Fig. 1과 같이 전북 진안군 안천면 삼락리에 위치하였다. 용담댐 유역은 금강유역의 최상류이다. 유역 면적은 930 km2로 금강 전체 유역 면적 9,886 km2의 약 9.45%를 차지하고 있다. 유로 연장은 65.0 km, 동서 간 최대 길이 39.5 km, 남북 간 최대 길이 49.2 km, 유역의 평균 폭은 14.29 km로, 금강 전체 유역 형상에 비해 비교적 정방형 유역 형태를 가지고 있다. 따라서 금강 전체 유역에 비해 홍수파 도달 시간이 짧고 첨두홍수량도 크다.
2.2 강우자료
2.2.1 관측 자료
본 연구에서는 Table 1과 같이 용담댐 유역 내외에 위치한 기상청 산하의 관측소를 이용하였다. 확률밀도함수를 적용하여 산정된 확률강우량은 관측 강우량의 수집 기간이 길수록 더 높은 신뢰도를 나타낼 수 있다. 기상청에서 관리하는 관측소들은 비교적 다른 관측소들보다 더 긴 수집 기간을 갖는다. 이 4개의 관측소는 다른 주변의 관측소들보다 비교적 장기간 강우자료를 얻기 용이하다. Table 1과 같이 장수 관측소를 제외한 모든 관측소에서는 1973년부터 2020년까지의 강우자료를 이용하였으며, 장수 관측소에서는 1988년부터 2020년까지의 강우자료를 이용하였다.
Table 1.
The description of observed data collected from KMA at 4 stations
2.2.2 d4PDF 자료
일본의 기상연구소(MRI)는 고해상도전지구 대기모델 (General Circulation Model, GCM) 및 고해상도 영역 대기모델(Regional Climate Mode, RCM)을 사용하여, 지금까지 없었던 다수의 앙상블 실험을 수행함으로써, 극단 기상의 재현 변화에 대해 논의가 가능한 d4PDF 데이터베이스를 구축하였다. d4PDF 자료의 해상도는 60 km의 격자 크기를 가지며, NHRCM (Non-hydrostatic Regional Climate Model) 모형을 이용하여 20 km까지 다운스케일링(downscaling) 되었다(Sasaki et al., 2008). 20 km의 해상도를 가지는 d4PDF 자료는 수평 격자 크기는 211 × 175로 일본, 한반도 및 아시아 대륙 동부를 포함한다. d4PDF는 역사적 기후 실험(현재 기후조건), 비 온난화 실험, 4℃ 온도 상승 실험(미래 기후조건)을 통해 구축된 데이터베이스로 구성되어 있으며 본 연구에서는 역사적 기후 실험으로부터 얻어진 현재 기후조건의 d4PDF 자료를 사용한다.
현재 기후조건의 d4PDF 자료는 관측된 해수면 온도, 해빙 온실가스 농도 변화, 황산성 에어로졸 농도 변화, 오존 농도 변화, 화산성 에어로졸 농도 변화를 입력조건으로 모의하여 구축되었다. 구축된 자료는 50개의 앙상블로 구성되며, 각 앙상블은 서로 다른 초기조건에서 해빙과 해수면 온도에 작은 섭동을 더하여 계산된 값이다. 하나의 앙상블은 1951년부터 2010년까지 60년 동안의 기상자료를 제공하기 때문에 총 3,000개의 연 최대 일 강우량을 이용하는 것이 가능하다.
3. 방법론
3.1 연구 절차
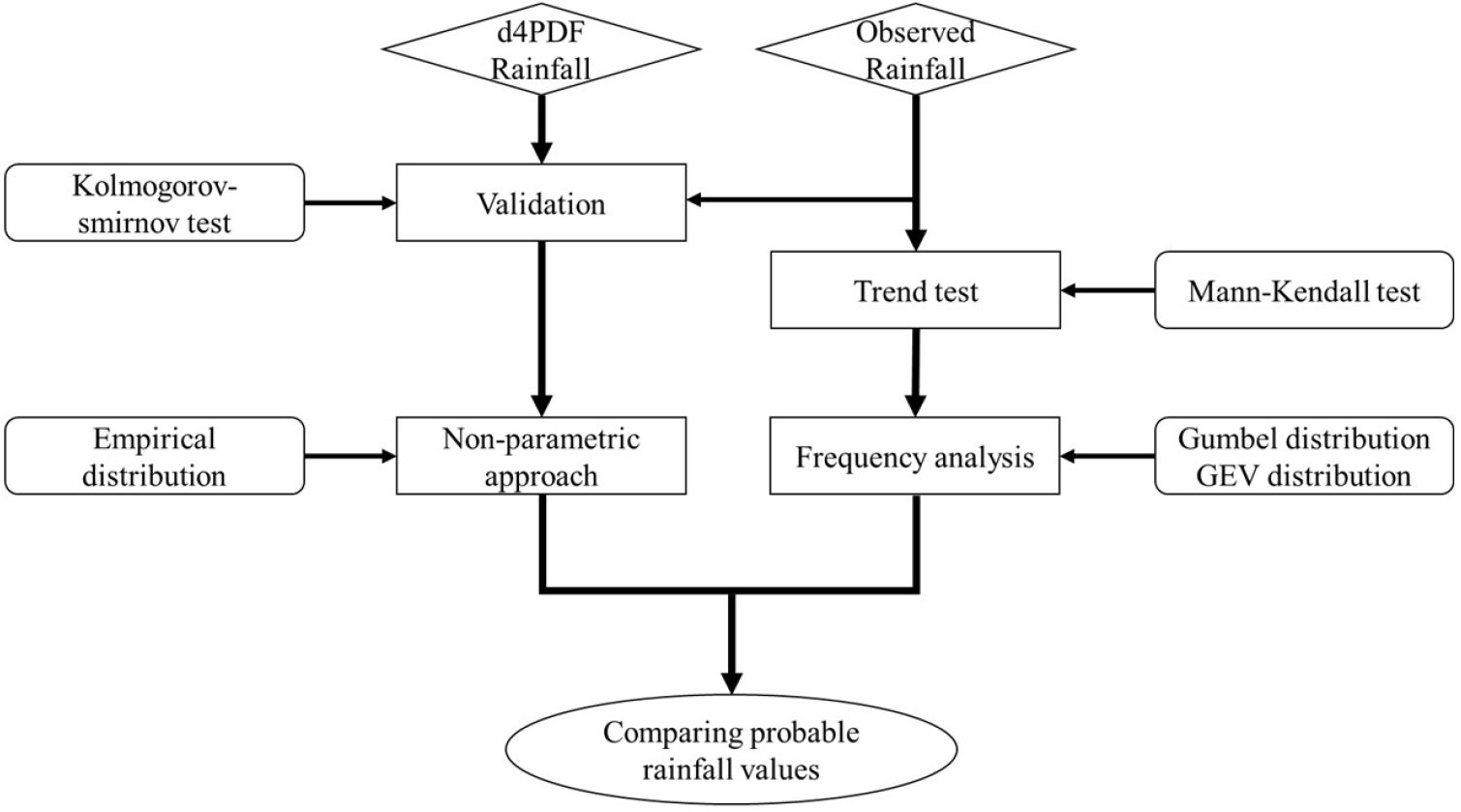
Fig. 2는 연구절차를 나타내며 자세한 설명은 아래와 같다.
1) 대기모형을 통해 모의하여 생성된 d4PDF의 강우자료는 충분한 신뢰성을 검토할 필요가 있다. 이에 따라, 실제 관측 강우자료와 비교를 통해 d4PDF 강우자료의 신뢰성 검토를 수행했다. 이 과정에서 이표본 Kolmogorov-smirnov 검정(Two-sample Kolmogorov-smirnov test)을 수행하여 신뢰할만한 자료인지 제시한다.
2) 관측된 강우자료가 기후변화에 따른 비정상성이 확인되는지 검토하기 위해 각 관측소의 연 최대 일 강우량에 대해 경향성 검정을 실시한다. 그 이유는 어떤 방법의 빈도해석 방법이 적용되어야 할지 검토하기 위해서이다. 경향성 검정에는 Mann-Kendall 검정이 이용되었다.
3) 신뢰성이 확인된 d4PDF의 강우자료를 이용하여 확률강우량을 산정한다. d4PDF 자료로부터 3,000개의 연 최대 일 강우량을 이용할 수 있기 때문에 확률밀도함수의 적용과 같은 빈도해석 방법을 적용하지 않고, 비모수적 접근법(Non-parametric approach)에 따라 연 최대 일 강우량을 규모별로 나열하여 확률분포를 표현할 수 있으며, 이를 통해 초과 확률로 환산하여 확률강우량을 산정하는 것이 가능하다. 그러므로, 본 연구는 비모수적 접근법에 따라 확률적으로 나열된 분포형으로부터 10년에서 1000년의 재현기간을 갖는 d4PDF 자료의 확률강우량을 산정한다.
4) 경향성 검정이 완료된 관측 강우자료에 확률밀도함수를 적용하여 확률강우량을 산정한다. 확률강우량을 산정하기 위해 적용되는 확률밀도함수는 Gumbel 분포와 GEV 분포이며 분포에 적용되는 매개변수는 L-moment 방법을 기반으로 산정된다. 각 확률밀도함수를 적용하여 4개 관측소 모두에 대해 10년부터 1000년의 재현기간을 갖는 확률강우량을 산정한다.
5) 마지막으로 d4PDF 자료를 이용하여 산정된 확률강우량과 관측자료를 이용하여 산정된 확률강우량을 비교함으로써 d4PDF 자료가 장기간 재현기간을 나타내는 극한강우량 제시에 활용 가능한지에 대한 검토를 수행한다.
3.2 이표본 Kolmogorov-smirnov 검정
Kolmogorov-Smirnov (K-S) 검정은 표본을 기준 확률분포와 비교하거나 두 표본을 비교하는 데 사용할 수 있는 비모수 검정이다. K-S 검정의 통계량은 두 표본의 분포 함수 사이의 거리를 정량화하여 나타낼 수 있다. K-S 검정의 통계량은 Eq. (1)과 같이 산정될 수 있다.
여기서 n은 모집단 x의 관측값 수, F1,n (x)과 F2,m은 첫 번째와 두 번째 표본의 경험적 분포 함수(Empirical distribution function)를 의미한다. 산정된 통계량 Dn,m이 작을수록 두 표본은 유사한 확률분포형을 나타낸다는 것을 의미한다. 또한, 유의수준 5%에서 P 값(P-value)이 0.05보다 작다면 두가지 표본은 다른 확률분포형을 나타낸다는 것을 의미한다.
3.3 Mann-Kendall 경향성 검정
본 연구는 관측 강우자료의 경향성 분석을 위해 널리 사용되는 Mann-Kendall 검정을 이용하였다. 이 방법은 비모수적 방법으로 수문기상 자료의 공간 및 시간적 경향을 파악하기 위해 널리 사용되는 통계적 방법이다. 비모수적 검정 방법은 자료의 왜곡(Skew)으로 인해 발생하는 문제를 피할 수 있기 때문에 널리 사용된다(Smith, 2000). 이 검정 방법은 Mann (1945)에 의해 공식화 되었으며, Kendall (1975)에 의해 검정통계 분포 방법이 제안되었다.
Mann-Kendall 통계량 S는 다음과 같이 산정된다.
경향성 분석의 적용은 서열화된 시계열 xi (i=1, 2, 3, …, n-1)와 xj (j=i+1, 2, …, n)를 대상으로 수행된다.
n≥10일 때 통계치 S는 대략 다음과 같이 주어진다.
ti는 i에 해당하는 관측치의 수이다.
Mann-Kendall 검정의 통계량 Z는 다음과 같은 표준 정규분포를 따른다.
통계량 Z 값은 양수 혹은 음수인가에 따라 증가경향과 감소경향을 나타낸다. 위 식을 통해 Z통계량을 계산한 다음 P 값(P-value)을 구하여 그 Z의 유의성을 검증하여 경향성을 판단한다. 만일 P ≤α(유의수준)이면 귀무가설은 기각되고 대립가설을 채택하여 경향성이 있는 것으로 판단한다. 따라서 Mann-Kendall의 식에서 Z 값의 부호는 경향성의 증가 또는 감소 특성을 나타내며 유의수준이 0.05일 경우 P ≤0.05이면 통계적으로 의미 있는 값으로 고려된다.
3.4 확률밀도함수
3.4.1 Gumbel 분포
Gumbel 분포는 GEV 분포형의 형상 매개변수가 0인 경우에 해당하는 2변수 확률분포형으로서 우리나라에서 강우자료를 이용한 확률강우량 산정에 널리 이용되는 분포형이다. Gumbel 분포는 매개변수가 2개이기 때문에 대상 자료의 분포 양상을 표현하는 데 있어서 매개변수가 3개인 GEV 분포형에 비해 그 성능이 다소 떨어지는 단점이 있으나 한 두개의 극치 값에 지나치게 영향을 받지 않아 비교적 안정적인(Robust) 추세를 나타내는 장점이 있다. Gumbel 분포의 함수는 다음 식과 같이 주어진다(Gumbel, 1958).
여기서, α는 크기 매개변수, x0는 위치 매개변수이며, Gumbel 분포의 왜곡도계수(Coefficient of skewness)는 1.1396으로 고정된 상수값을 갖는다.
3.4.2 GEV 분포
GEV 분포형은 Gumbel 분포와 달리 위치 매개변수, 크기 매개변수, 형상 매개변수 총 3가지의 매개변수로 구성되어진 확률분포형이다. GEV 분포도 Gumbel 분포와 마찬가지로 우리나라에서 널리 이용되는 확률분포형이다. GEV 분포의 함수는 다음과 같이 표현된다.
여기서 β는 형상 매개변수이다.
GEV 분포는 형상 매개변수 β에 따라 3가지 형태의 분포형으로 구분된다.
β = 0 이면 Gumbel 분포, β < 0이면 Log-Gumbel 분포, β > 0이면 Weibull 분포로 결정된다.
4. 결과 및 토의
4.1 d4PDF 자료의 이용
몇몇의 연구는 저빈도·고강도의 극한 기상 현상을 조사하고 평가하기 위해, 전 지구적 모델(General Circulation Model, GCM)의 산출물을 이용해 왔다(Zhang et al., 2006; Ji and Kang, 2015; Tang et al., 2016). 이와 같은 연구는 오직 하나 또는 소수의 GCM 모형의 예측 자료를 이용하였다. 하지만, 소수의 GCM모형을 이용한 연구는 극한 기후 현상을 규명하는데 많은 불확실성을 나타낸다(Duan et al., 2019). 그 이유는 일반적으로 극한 기후 현상은 평균 기후 현상보다 더 큰 변동성을 나타내기 때문이다. 예를 들어, 연간 최대 일 강우량은 연간 평균 강우량보다 더 큰 변동성을 나타낸다. 이런 극한 현상의 변동성은 앙상블의 갯수가 작을수록(소수의 GCM 모형 산출물) 크게 발생하며, 이 큰 변동성은 극한 기후 현상을 예측하고 평가하는데 불확실성을 증가 시킨다(Li et al., 2015; Mote et al., 2016). 결과적으로, GCM모형의 예측 값의 신뢰성에 대한 문제는 여전히 제기되고 있다. 하지만, 대규모 기후 앙상블 모의실험 결과 기반의 d4PDF 자료의 이용은 기후 모형의 예측 불확실성을 최소화할 수 있는 강점이 있다.
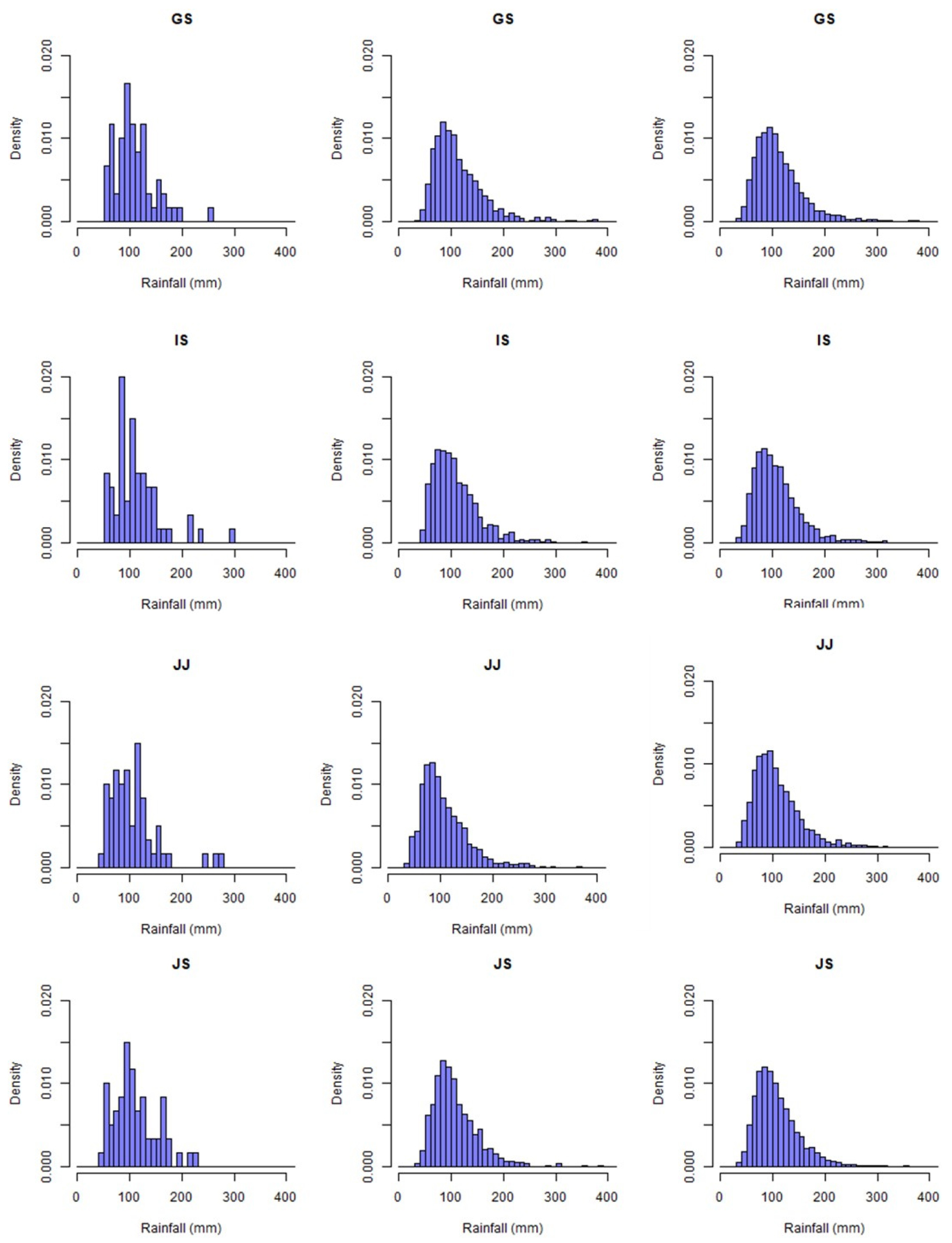
이에 따라, d4PDF의 특징 및 이용에 따른 강점에 대해 나타내기 위해 Fig. 3을 작성하였다. Fig. 3은 d4PDF 자료의 연 최대 일 강우량을 히스토그램으로 나타낸 결과이다. 첫번째 열은 관측소마다 하나의 앙상블에서 수집된 60년 동안의 연 최대 일 강우량을 밀도에 따라 나타낸 것이다. 즉, 이 그래프는 앞서 언급한 하나 또는 소규모 대기모형 모의자료로부터 작성된 연 최대 일 강우량의 히스토그램을 나타낸다. Fig. 3의 첫 번째 열에서 확인할 수 있듯이 하나의 앙상블 자료로부터의 히스토그램은 매끄러운 분포를 나타낼 수 없었고, 크고 작은 노이즈가 발생하여 강우의 규모별 빈도를 정확하게 파악하기 어려웠다. 특히, 금산과 전주의 경우, 200 mm의 강우량까지 0.002에 가까운 밀도를 나타내다가 250 mm까지는 0의 밀도를, 극치 부분인 250 mm 이상에서는 다시 0.002에 가까운 밀도를 나타냈다. 이는 하나의 대기모형 모의자료만으로는 극치 부분에 매끄러운 분포를 나타내지 못하고, 극치 값에서 대기모형을 이용한 예측의 신뢰성을 제시하기 어렵다는 것을 의미한다.
두번째 열은 15개의 앙상블에서 수집된 900개(60년 15개)의 연 최대 일 강우량을 히스토그램으로 나타낸 것이다. 마지막 열은 모든 앙상블에서 수집된 3000개(60년×50개)의 연 최대 일 강우량을 히스토그램으로 나타낸 것이다. 15개의 앙상블의 히스토그램에서 모집단의 크기가 증가하면서 매끄러운 분포를 나타낼 수 있었고, 노이즈가 크게 감소하였다. 총 앙상블의 히스토그램에서는 노이즈 없이 상당히 매끄러운 분포를 나타낼 수 있었다. 특히, 하나의 모의자료를 이용하는 것과는 달리 극치 부분에서 매끄러운 분포를 나타냈다. 결과적으로, 하나 또는 소규모 대기모형 모의자료의 이용은 예측 값에 대한 신뢰성을 보장할 수 없고 극치 값에서는 상당한 불확실성을 나타내는 반면, 대규모 앙상블 모의자료는 대규모 표본을 이용함으로써 기후모형의 예측 강우자료에 대한 불확실성을 최소화하여 극치에 해당하는 저빈도·고강도의 강우 값을 제시하는 것이 가능하다.
4.2 d4PDF 자료의 검증
이번 장에서는 d4PDF로부터 추출된 강우자료가 신뢰할 수 있는 자료인지 검토를 수행하였다. Fig. 4는 d4PDF의 관측 연 최대 일 강우량과 각 앙상블에서 추출된 연 최대 일 강우량을 규모에 따라서 누적밀도함수(Cumulative density function, CDF)와 비초과확률로 나타낸 그래프이다. 이 CDF 상에서 연 최대 일 강우량은 특정 강도의 강우가 다시 발생할 것으로 예상되는 기간인 재현기간으로도 나타냈다. 삼각형 점은 관측된 연 최대 일 강우량을 CDF로 표현한 것이다. 선 그래프는 d4PDF의 50개의 앙상블을 하나의 앙상블마다 나타낸 것이며, 하나의 선은 60년 동안에 연 최대 일 강우량을 CDF로 표현한 것이다. 원형 점은 50개 앙상블에서 추출된 모든 3000개의 연 최대 일 강우량을 규모에 따라 하나의 CDF로 표현한 것이다. Fig. 4에서 확인할 수 있듯이 d4PDF의 3000개 연 최대 일 강우량으로 표현된 CDF 그래프는 관측 강우량의 CDF에 잘 따르는 것으로 확인 되었다. 특히, 임실과 전주 관측소에서 5년까지의 작은 재현기간까지와 관측 강우의 분포에 극치 부분에 해당하는 50년에 가까운 재현기간에서 d4PDF의 CDF는 관측 강우의 CDF와 낮은 편차를 나타냈다.
본 연구는 관측 강우의 분포와 d4PDF 강우의 분포의 편차 및 신뢰성을 정량적으로 나타내기 위해 관측소마다 이표본 K-S 검정을 수행하였다. Table 2는 K-S 검정 결과인 검정 통계량 값(Dn,m)과 P 값(P-Value)을 나타낸다. 그 결과, 모든 관측소에서 P 값이 0.05 이상으로 산정되었고, 이것은 d4PDF 강우는 관측 강우의 분포에 상당히 유사한 분포 형태를 나타낸다는 것을 의미한다. 특히 임실과 전주는 상당히 높은 P 값을 나타냈으며, 낮은 검정통계량을 나타냈다. 이 결과는 대기모형으로부터 예측된 d4PDF는 신뢰할만한 강우자료를 제시한다는 것을 의미한다.
Table 2.
The result of Kolmogorov-Smirnov test
| Location | Dn,m | P-Value |
| Geumsan | 0.189 | 0.061 |
| Imsil | 0.131 | 0.355 |
| Jeonju | 0.157 | 0.170 |
| Jangsu | 0.234 | 0.055 |
d4PDF의 신뢰성과 관련하여 여러 선행 연구들이 수행되었고, 충분히 신뢰할만하다고 언급되어왔다(Hanittinan et al., 2020; Ishii and Mori, 2020; Tanaka et al., 2018, 2020, 2021). 특히, Tanaka et al. (2018)은 관측 강우량과 히스토그램을 통한 비교를 통해 d4PDF의 강우자료는 대기모형의 해상도에 따른 작은 편향을 내포하지만, 충분히 관측 강우량에 상응한다고 제시하였다. 따라서 본 연구는 d4PDF에서 추출된 강우자료가 충분히 신뢰할만하다고 판단하고 진행되었다.
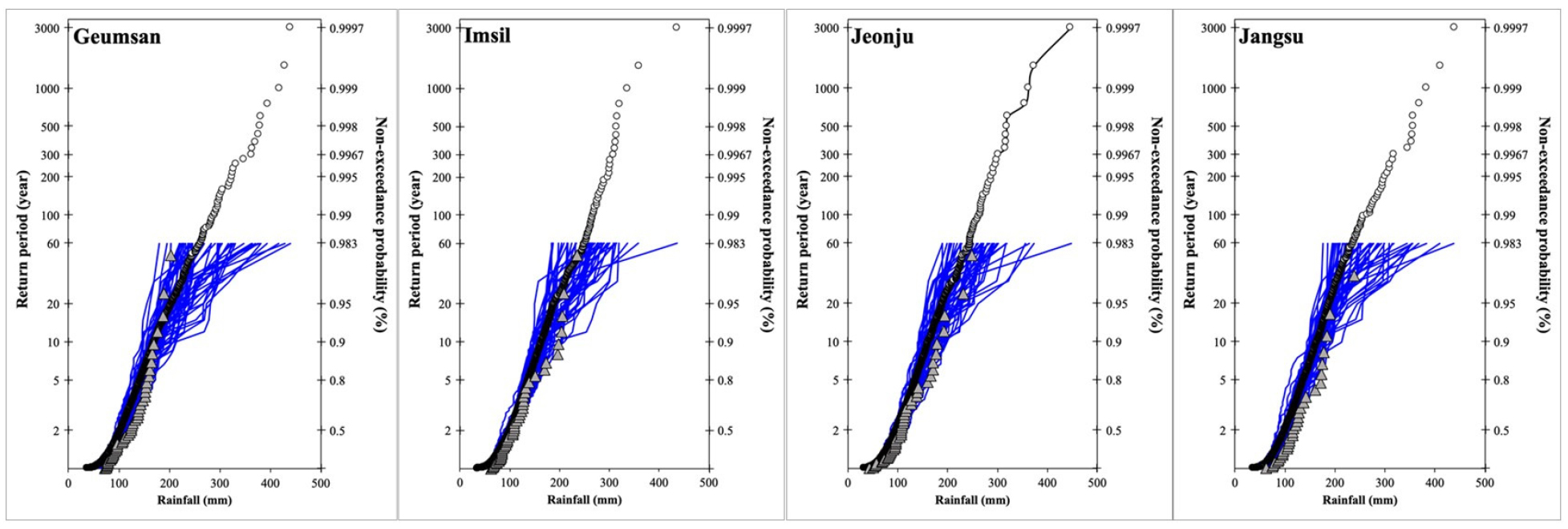
Fig. 4.
Cumulative density function graphs for Non-exceedance probabilities of four regions located in the Yongdam-dam basin. The line represents the 60 annual maximum 1-day rainfall for each ensemble of d4PDF. The triangle represents the observed annual maximum 1-day rainfall. The circle represents the 3000 annual maximum 1-day rainfall for all ensembles of d4PDF
4.3 확률강우량 산정
4.3.1 관측 강우량을 이용한 확률강우량 산정
이번 장에서는 관측 강우량을 이용하여 10년부터 1000년까지의 재현기간을 나타내는 확률강우량을 산정했다. 우리나라의 국가 하천과 대규모 수공구조물은 100년 이상의 재현기간을 갖는 확률강우량을 이용하여 설계되고 있다. 하지만 Table 1과 Fig. 4에서 확인할 수 있듯이 금산, 임실, 전주 관측소는 48년, 장수 관측소는 33년의 관측 기간을 갖기 때문에 기존 관측 강우자료로는 100년 이상의 재현기간을 표현하는 것이 어렵다. 이에 따라, 100년 이상의 긴 재현기간을 나타내는 확률강우량을 산정하기 위해 빈도해석 과정이 적용되어야 한다.
빈도해석 과정에서 강우자료가 경향성을 나타낸다면 비정상성 빈도해석이 수행되어야 하기 때문에 강우자료에 대해 경향성에 대한 검토가 필요하다. 본 연구는 Mann-Kendall 검정을 이용하여 각 관측소의 강우자료에 대해서 경향성 검정을 수행하였다. Table 3은 선정된 관측소의 강우자료에 대해서 경향성 검정을 수행한 결과를 나타낸다. 그 결과, 4개 관측소 모두 5% 유의수준에서 통계적으로 유의한 경향성이 없는 것으로 나타났기 때문에 4개 관측소 모두 비정상성 빈도해석을 수행하지 않았다.
Table 3.
The result of Mann-Kendall test
| Location | Z-value | P-value |
| Geumsan | 0.477 | 0.633 |
| Imsil | 1.541 | 0.123 |
| Jeonju | -0.715 | 0.474 |
| Jangsu | 0.632 | 0.527 |
본 연구는 빈도해석 과정에서 한국에서 널리 이용되는 Gumbel 분포와 GEV 분포를 관측 강우량에 적용하여 10년부터 1000년까지의 재현기간을 나타내는 확률강우량을 산정했다. 산정된 결과는 Fig. 5와 같고, 삼각형 점은 Gumbel 분포를 적용하여 산정된 확률강우량을 나타내며, 사각형 점은 GEV 분포를 적용하여 산정된 확률강우량을 나타낸다. Fig. 5에서 확인할 수 있듯이 전주와 장수 관측소의 강우자료에 GEV 분포와 Gumbel 분포를 적용하여 산정된 10년부터 1000년까지 확률강우량은 상당히 유사하게 산정되었다. 하지만, 금산과 임실 관측소에서 두가지 분포를 적용하여 산정된 확률강우량 사이에 큰 편차가 발생하였다. 50년의 재현기간까지는 두 확률강우량이 상당히 유사하게 나타났지만, 재현기간이 증가할수록 두 확률강우량의 편차가 증가하였다.
앞서 언급했던 바와 같이, 관측 강우량을 이용한다면 짧은 관측 기간의 문제를 해결하기 위해 Gumbel, GEV 분포와 같은 확률밀도함수를 적용하여 확률분포화를 수행함으로써 관측 기간보다 긴 재현기간을 갖는 확률강우량을 산정해야 한다. 하지만, 긴 재현기간을 나타내기 위한 확률밀도함수 선정에는 많은 어려움이 있고(Haddad and Rahman, 2011), Fig. 5의 금산과 임실 관측소와 같이 선정된 확률밀도함수에 따라 산정된 확률강우량은 큰 편차를 나타낼 수 있다. 게다가, 산정된 확률강우량은 표본크기(관측 기간)에 따라서 큰 불확실성을 나타낼 수 있다(Ishii and Mori, 2020). 이와 같은 불확실성은 Fig. 5에서 재현기간이 증가할수록 두 확률밀도함수로 산정된 확률강우량의 편차가 증가하는 패턴으로부터 확인할 수 있다. 이것은 나타내려는 재현기간과 표본크기(관측 기간)의 차이가 증가할수록 신뢰하기 어려운 확률강우량을 제시할 수 있다는 것을 의미한다. 따라서 이와 같은 장기간의 재현기간을 나타내는 확률강우량을 산정할 때 작은 표본크기 및 확률밀도함수의 적용에 따른 불확실성을 극복할 수 있는 방안이 필요하다.
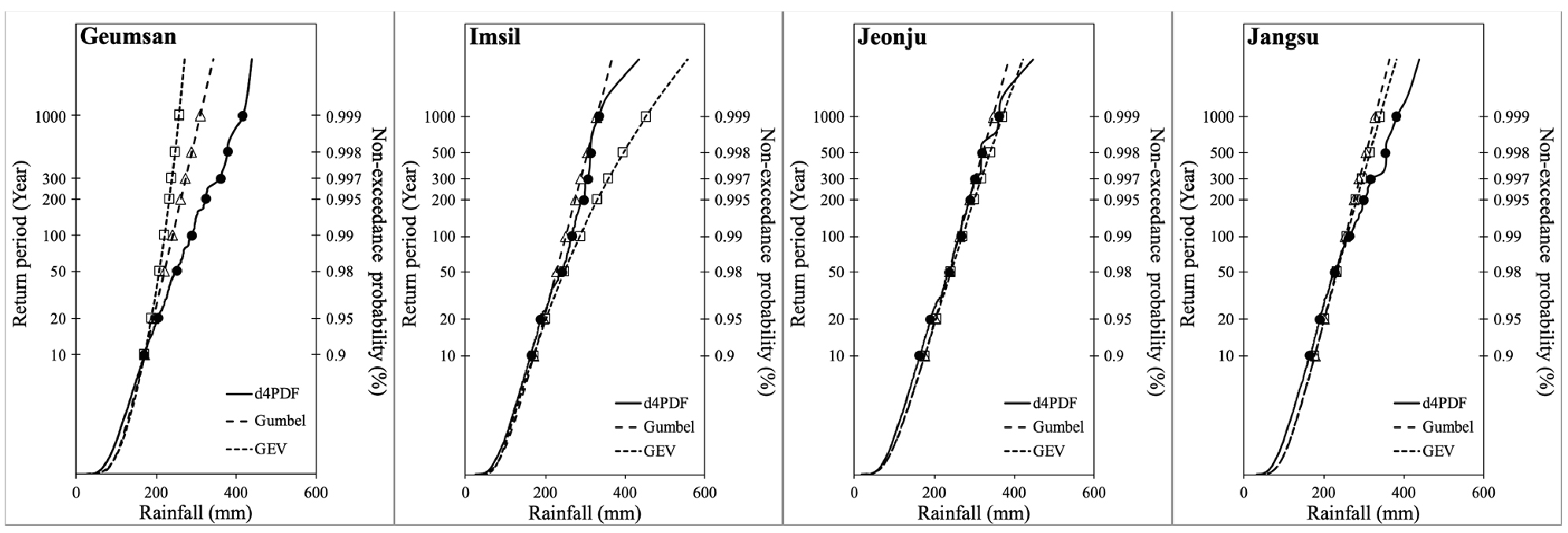
Fig. 5.
Probable rainfall values representing the return period from 10 to 1000 years. Circle points represent the probable rainfall estimated using the d4PDF. Square points represent the probable rainfall estimated using the observed data and GEV distribution. Triangle points represent the probable rainfall estimated using the observed data and Gumbel distribution
4.3.2 d4PDF 강우량을 이용한 확률강우량 산정
앞선 장에서 언급했던 작은 표본크기에 따른 한계점과 확률밀도함수 적용에 따른 불확실성을 극복하기 위해 본 연구는 대규모 기후 앙상블 모의자료인 d4PDF를 장기간 재현기간을 갖는 확률강우량 산정에 적용해보았다. Fig. 4의 선 그래프와 같이, d4PDF 하나의 앙상블은 60년의 표본크기를 갖고 50개의 앙상블을 이용할 수 있기 때문에 3000개의 표본을 제시하는 것이 가능하다. 이 3000개의 표본크기를 이용한다면 통계적 빈도해석 방법을 이용하지 않고, 매우 긴 기간을 재현기간을 나타내는 확률강우량을 산정하는 것이 가능하다. Fig. 4의 원형 점 그래프와 같이, 3000개의 표본을 규모에 따라 나열한다면 확률밀도함수를 적용하지 않고, 비모수적 접근법을 기반으로 강우의 확률분포를 나타내는 것이 가능했다. 결과적으로, 대규모 기후 앙상블 모의실험으로부터 구축된 d4PDF의 이용은 매우 큰 표본크기로부터 어떤 통계적 모형이나 방법론을 사용하지 않아, 빈도해석 과정에서 발생하는 불확실성을 최대한 배제하여 강우의 규모별 확률분포를 표현하는 것이 가능하다.
따라서 본 연구는 d4PDF 자료로부터 추출된 3000개의 연 최대 일 강우량을 이용하여 10년부터 1000년까지의 재현기간을 나타내는 확률강우량을 산정했다. d4PDF 자료로부터 산정된 확률강우량은 Fig. 5의 원형 점과 같이 나타냈으며, 관측 강우량을 이용하는 것과 달리 3000개의 표본을 이용하기 때문에 확률밀도함수 적용과 같은 빈도해석을 수행하지 않고, 3000개의 연 최대 일 강우량을 규모에 따라 나열하여 비모수적 접근법으로 산정되었다. Fig. 5에서 확인할 수 있듯이 관측 강우량의 확률강우량과 마찬가지로 재현기간이 증가할수록 d4PDF의 확률강우량은 증가하는 형태를 나타낸다.
4.3.3 확률강우량의 비교
이전 장에서 산정된 관측 강우량의 확률강우량과 d4PDF의 확률강우량을 비교하였다. Fig. 5에서 확인할 수 있듯이 전주와 장수 관측소는 두 확률강우량이 상당히 유사하게 산정되었다. 임실 관측소에서는 Gumbel 분포로 산정된 확률강우량이 d4PDF의 확률강우량과 상당히 유사했지만, GEV분포로 산정된 확률강우량은 d4PDF의 확률강우량과 큰 편차를 나타냈다. 금산 관측소에서 d4PDF의 확률강우량은 두가지 분포로 산정된 확률강우량에 대해 모두 상당한 편차를 나타냈다.
본 연구는 이 편차를 정량적으로 나타내기 위해 Table 4를 작성했다. Table 4는 관측 강우의 확률강우량에 대한 d4PDF의 확률강우량의 차이를 나타낸다. 그 결과, 전주 관측소에서 d4PDF의 확률강우량은 두가지 분포형을 적용한 확률 10% 이하의 편차를 나타냈다. 장수 관측소의 경우, 300년의 재현기간까지는 10% 이내의 편차를 나타냈지만, 매우 긴 재현기간인 500년과 1000년에서는 10% 이상의 편차를 나타냈다. 임실 관측소에서는 d4PDF의 확률강우량은 Gumbel 분포를 적용한 확률강우량에 대해 모든 재현기간에서 10% 이내의 편차를 나타냈다. 하지만, GEV 분포를 적용한 확률강우량에 대해서는 200년의 재현기간부터 10% 이상의 편차를 나타냈고, 500년과 1000년의 재현기간에서는 30%에 가까운 매우 큰 편차를 나타냈다. 금산 관측소에서는 d4PDF의 확률강우량이 두가지 분포 모두로 산정된 확률강우량에 대해 50년의 재현기간부터 10% 이상의 편차를 나타냈다. 재현기간이 증가할수록 편차가 증가하였으며, 극치 부분에 해당하는 매우 긴 500년, 1000년의 재현기간에서 Gumbel 분포는 25%, GEV 분포는 35%에 가까운 상당한 편차를 나타냈다. 결과적으로 전주를 제외한 모든 관측소에서 d4PDF의 확률강우량은 재현기간이 관측 기간에 가까울수록 관측 강우의 확률강우량과 낮은 편차를 나타냈으며, 재현기간과 관측 기간의 차이가 증가할수록 두 확률강우량의 편차가 증가하였다. 이는 짧은 관측 기간 동안 수집된 관측 강우량과 확률밀도함수의 적용은 관측 기간보다 재현기간이 증가할수록 확률강우량 산정에 큰 불확실성을 야기할 수 있다는 것을 의미한다.
하지만, 두 확률강우량의 비교에서 관측 강우량과 확률밀도함수의 적용에 따른 불확실성 이외에, d4PDF 자료의 이용에 따라서도 몇몇 불확실성을 내포할 것이다. 다른 기후모형 자료와 마찬가지로 d4PDF 자료는 강우 예측에 불확실성을 나타낼 수 있으며, d4PDF 자료의 격자 형태의 강우 자료는 실제 지점 강우 자료와의 편향이 발생할 수 있을 것이다. 그럼에도 불구하고, d4PDF 자료는 대규모 앙상블로 구성되어 Fig. 3과 같이 노이즈 없이 매끄러운 빈도분포를 나타내어 소수의 기후모형 자료를 이용하는 것보다 높은 정확성을 나타냈다. 또한 4개의 관측소에서 관측 강우량의 확률강우량과의 비교를 통해 임실에서 100년까지 전주에서 1000년까지 장수에서 300년까지 상당히 유사한 두 확률강우량을 나타냈기 때문에 d4PDF는 적절한 확률강우량 제시한다. 게다가, d4PDF는 확률밀도함수와 같은 빈도해석 방법이 사용되지 않았기 때문에 통계적인 분석으로부터 발생하는 불확실성을 최대한 배제하여 강우의 규모별 빈도분포를 표현하는 것이 가능한 장점이 있다. 결과적으로, 기존 기후모형의 예측 자료는 몇몇 불확실성을 내포할 수 있지만, 대규모 기후 앙상블 모의실험으로부터 구축된 d4PDF 자료는 기후모형의 예측 불확실성과 통계적 해석 적용에 따른 불확실성을 최소화함으로써 극치 호우사상의 규모를 평가하는데 충분히 활용가치가 있다.
Table 4.
The deviation of the probability rainfall values estimated using the d4PDF for those estimated from each probability distribution (%)
5. 결 론
본 연구에서는 대규모 기후 앙상블 모의 결과를 기반으로 산출된 d4PDF 데이터베이스를 이용하였다. 이 자료를 이용해 용담댐 유역 내외에 위치한 4개의 관측소에 대해 확률밀도함수와 같은 빈도해석 방법의 적용 없이 장기간 재현기간을 나타내는 확률강우량을 제시하여 비교함으로써 기존 관측 강우량을 이용한 확률강우량 산정에 대한 불확실성을 확인할 수 있었다. 재현 기간과 관측 기간의 차이가 증가할수록 기존 관측 강우의 확률강우량은 d4PDF의 확률강우량과의 편차가 증가할 뿐만 아니라 금산과 임실 관측소에서 두가지 확률밀도함수에 따라 산정된 두 확률강우량의 편차도 증가하였다. 이것은 확률밀도함수 선정에 따라서 신뢰하기 어려운 확률강우량을 제시할 수 있으며, 이는 재현기간이 증가할수록 불확실한 확률강우량을 제시한다는 것을 의미한다. 반면에 d4PDF는 대규모 표본으로부터 매우 극한 규모의 장기간 재현기간을 나타내는 확률강우량을 산정할 수 있고, 확률밀도함수 적용으로부터 내포될 수 있는 불확실성을 최소화하여 극한 규모의 확률강우량을 제시할 수 있다. 제시된 d4PDF의 확률강우량은 기존 설계강우량 이상의 규모를 나타냈던 2018년 7월 서일본 호우사상(Bandaru et al., 2020; Hirota et al., 2019)과 같이 최근 발생하는 극한강우량의 규모에 대한 면밀한 평가에 활용될 수 있을 것이다. 게다가, d4PDF는 현재 기후조건뿐만 아니라 미래 기후조건하에 생성된 자료를 제공하기 때문에 현재 기후조건 대비 미래 기후조건에서의 확률강우량 및 강우 특성의 변화를 분석함으로써 기후변화에 따른 극한강우량의 변화 및 평가에 활용될 수 있을 것이다.
하지만, d4PDF 자료는 기후모형으로부터 모의된 자료이기 때문에 예측 불확실성의 문제점을 추후 충분히 고려되어 활용되어야 한다. 또한 본 연구에서의 d4PDF 자료는 지점 강우와의 해상도 차이에 따른 편향이 발생할 수 있을 것이기 때문에 추후 편향에 대한 추가적인 불확실성 검토 및 고려할 수 있는 방안이 제시되어야 한다. 게다가, 본 연구에서는 용담댐 유역에서만 d4PDF 자료의 활용성 및 가장 적합한 확률강우량의 확률분포를 제시한 것이기 때문에 우리나라에 위치한 다양한 지역에서 적용성을 평가해 볼 필요가 있다.
