

1. 서 론
2. 다지점 Neyman-Scott Rectangular Pulse Model (NSRPM)
2.1 Neyman-Scott Rectangular Pulse Model (NSRPM)
2.2 다지점 NSRPM 모형
2.3 모형의 매개변수 최적화
3. 적용 및 고찰
3.1 적용 유역 및 강수자료
3.2 모형 적용 결과
4. 결론 및 토의
1. 서 론
수자원 계획 및 수공구조물 설계에서는 다양한 시공간적 규모의 강수량 자료가 요구된다. 특히, 짧은 자료 연한으로 인한 표본오차(sampling error)는 수자원계획에 있어 신뢰성을 저해하는 주요 원인으로 작용한다(Wheater et al., 2006). 이러한 점을 감안하여 추계학적 모형을 이용한 다양한 시간규모에서 강수자료의 확충에 대한 연구는 지속적으로 이루어지고 있다. 추계학적 강수모의를 수행하는데 있어서 가장 핵심적인 사항은 과거 강수자료의 특성 즉, 평균, 분산, 자기상관계수, 왜곡도 등과 같이 강수시계열의 통계적 특성을 다각적으로 재현할 수 있어야 한다는 점이다(Boughton and Droop, 2003; Kim et al., 2014a; So et al., 2015; Kim et al., 2016a). 최근의 추계학적 강수 모의기법은 단순 강수모의에 그치지 않고, 기후변화에 영향을 평가할 수 있는 상세화(downscaling) 기법으로 활용성이 증대되고 있다(Kim et al., 2014b).
강수량을 모의하는데 있어서 강수의 시간규모는 중요한 요소 중 하나이다. 강수의 시간규모가 작을수록 강수량을 모의하는데 어려움이 가중된다. 즉, 일강수량보다는 시간강수량 모의에 어려움이 따른다. 이는 시간강수량의 모의뿐만 아니라 이를 통해 얻어지는 다양한 지속기간의 강수량의 통계적 특성도 동시에 재현하는 것이 요구되기 때문이다. 다시 말해서, 1시간 강수량을 모의한 후 3, 6, 9, 12, 24 시간 등 다양한 지속기간의 강수량으로 변환하였을 때 이들 강수시계열의 통계적 특성도 동시에 만족해야한다는 것을 의미한다.
국내외에서 일강수량 이하의 시간강수량 모의를 위에서 구형펄스모형(Rectangular Pulses Model) 기반의 강우모형이 일반적으로 활용된다. 강우모의를 위한 구형펄스모형 중에서 지점 강우모형(point process model)인 Bartlet-Lewis Rectangular Pulse Model (BLRPM, Rodriguez-Iturbe et al., 1987a, 1987b)과 Neyman-Scott Rectangular Pulse Model (NSRPM, Rodriguez-Iturbe et al., 1987a)이 가장 대표적인 모형이라 할 수 있다. 두 모형 모두 Poisson Cluster 프로세스 기반의 모형으로서 세부적인 부분에서 일부 차이가 있으나 연속적인 시간강수모형으로 일단위 이하 시간 규모의 통계특성을 재현하는데 유용하며, 다양한 시간 규모에 대하여 대부분의 통계특성을 비교적 정확하게 재현하는 것으로 알려지고 있다(Rodriguez-Iturbe et al., 1987a, 1987b). 그러나 매개변수 추정 및 극치강수량 추정에 있어 NSRPM 모형이 BLRPM 모형에 비해 다소 유리한 점이 있는 것으로 알려지고 있다(Velghe et al., 1994; Cowperwait et al., 1996). 이러한 점에서 본 연구에서는 NSRPM 모형을 기반으로 연구를 진행하였다.
초기 NSRPM을 개선하기 위해서 강우세포의 지속시간에 대한 확률분포형이 추가되었으며, 이를 통해 강우의 군집특성을 보다 현실성 있게 고려할 수 있는 모형으로 확장되었다(Rodriguez-Iturbe et al., 1988; Entekhabi et al., 1989). 따라서, NSRPM은 총 5개의 매개변수와 이를 모의하기 위한 확률분포형으로 구성된다. BRLPM 모형과 NSRPM 모형 모두에서 매개변수 추정을 위한 연구가 다수 진행되었다. 기존 최적화 방법에 경우 매개변수가 수렴되지 않는 사례가 다수 발생하며, 특히 우리나라와 같이 강수의 변동성이 큰 경우 매개변수들에 대한 민감도가 커서 매개변수 수렴에 어려움이 있다(Verhoest et al., 1997). 최근에는 이러한 문제점을 개선하기 위한 노력으로 BRLPM 모형에 대해서 Downhill Simplex Method (DSM), Simplex-Simulated Annealing (SSA), Particle Swarm Optimization (PSO), Shuffled Complex Evolution (SCE) 등 전역 최적화기법과 다양한 목적함수들을 조합한 연구를 진행하였다(Cho et al., 2012; Kim and Olivera, 2012; Vanhaute et al., 2012; Kim et al., 2013a; Kim et al., 2013b).
우리나라의 경우 현재 10분 단위 이하로 강우가 계측되고 있지만, 1970~1980년대 강우관측 초기 일단위 이하의 자료가 계측되지 않아 시간단위 강수에 대한 분석 시 신뢰성이 저하되는 단점이 있다. 이러한 점에서 국내에서는 포아송 클러스터 기반의 강우모의기법과 관련된 연구는 다음과 같이 다수 진행되었다. Kim and Yoo (2008)는 관측강우의 시간적 군집특성을 적절하게 재현해 주는 강우모형을 선정하기 위하여 포아송 과정에 근거한 모형들을 비교한 바 있다. Kyoung et al. (2008)은 카오스 이론을 적용하여 기후변화의 영향이 반영된 일강우 자료를 시간단위 자료로 분해하는 연구를 진행하였다. Kim et al. (2013c)은 기존 BLRPM 모형을 이용하여 다수의 시간강수시계열을 생성한 후 이를 수문모형의 입력자료 활용하였으며, 이를 통해 홍수량 모의 시 BLRPM의 적용성을 평가하였다. 평가결과 극치강수량이 과소 추정되는 문제점을 확인했으며, 이와 연계하여 홍수량의 과소 추정에 대한 문제점과 해결책을 제시하였다(Park et al., 2015).
유역단위에서 강수량 모의기법을 활용하기 위해서는 단일 강수지점이 아닌 유역내의 다수의 강수지점에 대해서 적용 가능한 모형으로 확장할 필요가 있다. 즉, 유역내의 단일 지점이 아닌 다수의 지점에 대해서 공간적인 상관성(spatial coherence)이 고려된 연속적인 강수시계열을 구축할 필요가 있으며, 이를 통해서만 유역단위에서 활용가능한 면적강수량을 도출하는 것이 가능하다. 이러한 다지점 강수모의기법은 최근 다수의 연구가 진행되고 있으나 주로 일강수모의기법에 국한되어 적용되고 있다. 즉, 여러 강수지점에 대한 시공간적 강우모의를 위해서 K-nearest Re-sampling Models (Apipattanavis et al., 2007; Rajagopalan and Lall, 1999), Hidden Markov Models (Ailliot et al., 2009; Charles et al., 1999; Hughes et al., 1999; Khalil et al., 2010; Kwon et al., 2009; Kwon et al., 2013), Generalized Chain-dependent Process Models (Zheng and Katz, 2008a; Zheng and Katz, 2008b; Zheng et al., 2010; So et al., 2015), Copula-based Models (Bardossy and Pegram, 2009; Li et al., 2013) 등이 개발되었다. 그러나, 일단위 이하의 강수모의기법에는 매우 제한적으로 연구가 진행되었다(Fowler et al., 2005; Brocca et al., 2013). 국내에서도 다지점 시간강수모의기법에 대한 개발 및 적용은 이루어진 바가 없으며 이러한 점에서 본 연구에서는 기존 NSRPM의 다지점 모형으로 확장하여 적용성을 평가하였다.
1장에서는 기존 연구동향 및 목적에 대해서 서술하였으며, 2장에서는 최적화 방안을 포함하여 다지점 NSRPM 모형에 대한 이론적 배경을 제시하였다. 3장에서는 서울 우이천유역의 5개의 강수지점을 대상으로 방법론의 적용성을 평가하였다. 마지막으로 4장에서는 결론 및 토의 사항과 더불어 향후 연구방향에 대해서 간략히 제시하였다.
2. 다지점 Neyman-Scott Rectangular Pulse Model (NSRPM)
본 절에서는 Rodriguez-Iturbe (1988)에 의해서 제안된 NSRPM 모형에 대한 이론적인 배경과 적용방안에 대해서 기존 문헌을 중심으로 요약 정리하였으며, 최종적으로 다지점 모형으로서 확장방안을 제시하였다.
2.1 Neyman-Scott Rectangular Pulse Model (NSRPM)
Rodriguez-Iturbe et al. (1987a, 1987b)는 기존 구형펄스모형(rectangular pulse model) 계열의 강수모의기법이 실제 강수의 군집특성을 효과적으로 고려하지 못하는 단점을 개선하기 위하여 제안되었다. 단일지점에 적용되는 NSRPM 모형은 강우의 물리적인 발생특성과 연계된 매개변수들을 통하여 강수를 모의하는 모형으로서 적용성이 우수한 것으로 알려지고 있으며, 다음의 4가지 과정과 확률분포를 통해 정의될 수 있다. 개념적으로 모형을 묘사하여 나타내면 Fig. 1과 같다.
|
Fig. 1. A schematic representation of the NSRPM. The “red circles” indicate storm origins while the “stars” represent the origins for raincells |
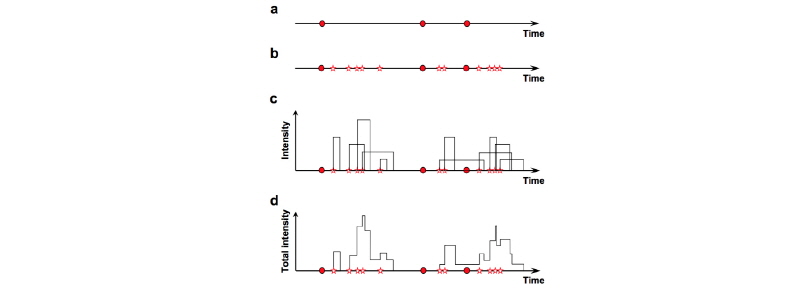
첫째, 강수의 발생시점들(storm origins)은 매개변수 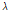 를 가지는 Poisson 과정을 따른다고 가정한다.
를 가지는 Poisson 과정을 따른다고 가정한다.
둘째, 강수의 발생시점들에서는 매개변수  를 가지는 Poisson 분포로부터 강우세포(rain cells)의 수 C를 발생시킨다. 강수세포들이 놓이는 시점은 강수의 발생시점들로부터 매개변수
를 가지는 Poisson 분포로부터 강우세포(rain cells)의 수 C를 발생시킨다. 강수세포들이 놓이는 시점은 강수의 발생시점들로부터 매개변수 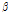 를 가지는 지수분포를 통해 독립적으로 분포된다.
를 가지는 지수분포를 통해 독립적으로 분포된다.
셋째, 각각의 강수세포들은 지속시간동안 일정한 강우강도를 나타낸다. 여기서 지속기간(hr) 및 강우강도(mm/hr)는 서로 독립이며 매개변수  와
와 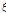 를 가지는 지수분포를 따른다고 가정한다.
를 가지는 지수분포를 따른다고 가정한다.
넷째, 전체적인 강우강도는 모든 강우세포의 강우강도의 누적을 통해 산정된다.
따라서, NSRPM 모형의 매개변수는 총 5개로서 Table 1과 같으며 강수의 물리적 생성을 위해서 활용된 확률분포형의 매개변수를 의미한다. Table 1에 최적화를 위해서 사용된 매개변수의 범위도 제시하였다.

NSRPM 모형의 통계학적 모멘트는 Eq. (1) - (3)과 같이 정의될 수 있으며, 향후 최적화를 위한 기본식으로 활용된다. 여기서 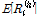 은
은 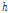 시간 동안의 강우량 평균을 의미이며
시간 동안의 강우량 평균을 의미이며 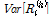 는
는 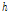 시간 동안의 강우량의 분산을 나타낸다. 마지막으로
시간 동안의 강우량의 분산을 나타낸다. 마지막으로 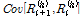 은
은 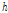 시간 동안의 강우량의 지체시간(lag time)
시간 동안의 강우량의 지체시간(lag time) 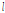 에 따른 공분산을 나타낸다.
에 따른 공분산을 나타낸다.
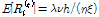 (1)
(1)
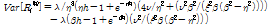 (2)
(2)
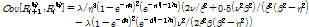 (3)
(3)
2.2 다지점 NSRPM 모형
본 연구에서 제안하는 다변량 상관성을 고려한 다지점 강수모의 기법의 원리는 다음과 같다. 먼저, 다지점에서 독립적으로 발생된 모의 강수시계열을 관측 강수시계열의 공간상관성을 가지는 시계열로 재구성한다. 즉, 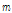 개의 각 관측지점에서
개의 각 관측지점에서  개의 길이를 가지는 강수량의 열벡터(row vector)를
개의 길이를 가지는 강수량의 열벡터(row vector)를 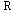 이라고 하면 지점간의 Pearson 상관계수는 Eq. (4)와 같이 나타낼 수 있다.
이라고 하면 지점간의 Pearson 상관계수는 Eq. (4)와 같이 나타낼 수 있다.
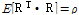 (4)
(4)
여기서, 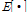 는 변량들 사이에 기댓값을 나타내며,
는 변량들 사이에 기댓값을 나타내며, 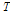 는 전치행렬을 의미한다.
는 전치행렬을 의미한다.
일반적으로 단일지점에서 적용되는 NSRPM 모형의 경우 각 지점에서 모형을 적용하는 경우 두 지점간의 상관성은 거의 존재하지 않게 된다. 즉, 자료의 수가 증가함에 따라서 Eq. (4)의 상관계수는 0으로 수렵하게 된다. 따라서, 지점간의 상관성을 복원하기 위해서는 벡터 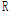 을 적절하게
을 적절하게 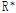 로 변환시키는 과정이 필요하며, 이를 통해 실제 지점간의 상관계수
로 변환시키는 과정이 필요하며, 이를 통해 실제 지점간의 상관계수 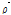 와 유사한 값을 가지게 된다. 본 연구에서는 상관성을 복원하기 위한 방법으로 Cholesky 분해와 순위상관계수(rank correlation)를 고려한 샘플링 방법론(Owen, 1994)을 활용하였다. 상관성 복원을 목표로 하는 강수시계열의 상관계수는 다음과 같이 나타낼 수 있다.
와 유사한 값을 가지게 된다. 본 연구에서는 상관성을 복원하기 위한 방법으로 Cholesky 분해와 순위상관계수(rank correlation)를 고려한 샘플링 방법론(Owen, 1994)을 활용하였다. 상관성 복원을 목표로 하는 강수시계열의 상관계수는 다음과 같이 나타낼 수 있다.
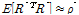 (5)
(5)
상관성을 복원하기 위한 변화과정으로서 상관행렬  와
와 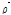 는 양의 정부호(positive definite)이면서 대칭인 행렬이므로 Eq. (6)과 (7)과 하삼각 행렬(lower triangular matrix)
는 양의 정부호(positive definite)이면서 대칭인 행렬이므로 Eq. (6)과 (7)과 하삼각 행렬(lower triangular matrix) 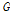 와
와 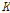 를 가지는 Cholesky 분해가 가능하다. 따라서, 벡터
를 가지는 Cholesky 분해가 가능하다. 따라서, 벡터 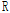 에서
에서 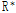 로의 변환은 Eq. (8)을 통해 이루어질 수 있으며, 변환된
로의 변환은 Eq. (8)을 통해 이루어질 수 있으며, 변환된 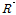 행렬의 상관계수는 실제 지점간의 상관계수
행렬의 상관계수는 실제 지점간의 상관계수 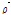 와 거의 같은 값을 가지게 된다.
와 거의 같은 값을 가지게 된다.
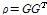 (6)
(6)
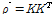 (7)
(7)
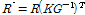 (8)
(8)
상관성을 복원하기 위한 두 번째 단계로서 순위상관계수를 고려하게 된다. 즉, 수정된 행렬 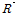 를 기준으로 열(row) 단위에서 순위(ranking)를 산정한다. 크기의 순위로 구성된 행렬과 동일한 크기 순서로 원자료
를 기준으로 열(row) 단위에서 순위(ranking)를 산정한다. 크기의 순위로 구성된 행렬과 동일한 크기 순서로 원자료 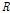 을 재배치함으로서 목표로 하는 관측지점간의 상관계수는
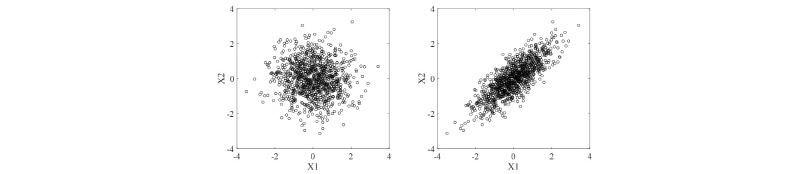
을 재배치함으로서 목표로 하는 관측지점간의 상관계수는 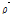 와 정확하게 일치하지 않지만 유사한 상관계수로 복원이 가능하다.
와 정확하게 일치하지 않지만 유사한 상관계수로 복원이 가능하다.
실제 관측자료에 적용하기에 앞서 모의실험을 수행하여 모형의 적합성을 평가하였다. 즉, 정규분포로부터 무작위로 모의된 2개의 변량에 대해서 상관계수 0.8을 가지는 변량으로 재복원하는 모의실험을 수행하였다. 독립적으로 무작위변량을 발생시킨 후 본 연구에서 제시된 방법을 통해 자료를 재배치한 후 상관성을 평가한 결과 Fig. 2와 같이 거의 유사한 상관성을 가지면서 복원되는 것을 확인할 수 있다.
|
Fig. 2. An experimental study for reconstruction of correlated variables using data transformation and rank correlation |
2.3 모형의 매개변수 최적화
모형의 적용에 앞서 지점별로 매개변수를 추정하는 것이 필요하며, 본 연구에서는 강수모의자료의 계절성을 고려하며, 월별로 매개변수를 추정하여 연구를 진행하였다. 매개변수 최적화를 위한 목적함수는 앞서 NSRPM 모형의 통계학적 모멘트를 나타내는 Eq. (1)-(3)을 기본적으로 이용하였다. 즉, 모의된 가상의 강우시계열과 관측시계열과의 통계적 유사성을 기준으로 매개변수를 결정하는 과정을 수행하였으며, Eq. (9)의 목적함수를 최소화시키는 매개변수의 집합을 도출하였다.
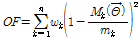 (9)
(9)
여기서, 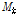 는 매개변수의 집합
는 매개변수의 집합 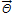 (
(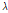 ,
, 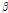 ,
,  ,
,  ,
, 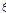 )로부터 모의된 가상 강우시계열로부터 추정된 통계값인 평균, 분산, 자기상관계수 등을 나타내며 본 연구에서는 Eq. (1)~(3)을 의미한다.
)로부터 모의된 가상 강우시계열로부터 추정된 통계값인 평균, 분산, 자기상관계수 등을 나타내며 본 연구에서는 Eq. (1)~(3)을 의미한다. 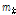 는 관측 통계값으로서 가상 강우시계열과 동일하게 평균, 분산, 자기상관계수 등의 상수항을 나타낸다. 여기서, 첨자
는 관측 통계값으로서 가상 강우시계열과 동일하게 평균, 분산, 자기상관계수 등의 상수항을 나타낸다. 여기서, 첨자  는 위에서 언급된 강수의 통계값의 종류를 나타내며,
는 위에서 언급된 강수의 통계값의 종류를 나타내며, 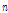 은 매개변수 추정을 위해서 사용된 통계값의 전체 개수를 의미한다. Eq. (9)의 목적함수에 주요 성분인
은 매개변수 추정을 위해서 사용된 통계값의 전체 개수를 의미한다. Eq. (9)의 목적함수에 주요 성분인 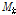 는 매개변수의 함수로 정의되는 비선형성이 매우 큰 특성을 가지고 있으며, 동시에 다양한 집성시간(aggregation time)에 대한 통계값도 고려해야 한다. 본 연구에서는 1시간과 24시간 등 2개의 집성시간을 고려하여 매개변수를 추정하였다. 이와 더불어 단지 5개의 매개변수를 가지고 다수의 통계치를 복원해야 하는 등 최적화 관점에서 어려움이 따른다. Rectangular Pulse 모형 계열에 최적화 대한 연구는 국내외에서 다수 이루어지고 있다(Hill, 1996; Onof et al., 2000; Cowpertwait et al., 2007; Kim et al., 2016).
는 매개변수의 함수로 정의되는 비선형성이 매우 큰 특성을 가지고 있으며, 동시에 다양한 집성시간(aggregation time)에 대한 통계값도 고려해야 한다. 본 연구에서는 1시간과 24시간 등 2개의 집성시간을 고려하여 매개변수를 추정하였다. 이와 더불어 단지 5개의 매개변수를 가지고 다수의 통계치를 복원해야 하는 등 최적화 관점에서 어려움이 따른다. Rectangular Pulse 모형 계열에 최적화 대한 연구는 국내외에서 다수 이루어지고 있다(Hill, 1996; Onof et al., 2000; Cowpertwait et al., 2007; Kim et al., 2016).
본 연구에서는 기존 강수모의기법을 다지점 모형으로 확장하는 것을 주요 목적으로 하고 있으며, 최적화에 대한 내용은 기존 방법론을 채택하여 진행하였다. 즉, 비선형 최적화 알고리즘인 Simplex Search 방법(Lagarias et al., 1998)을 이용하여 매개변수를 추정하였다. Simplex Search 방법은 수치해석이나 해석적 접근이 아닌 직접매개변수 추정방법으로서 비선형의 최적화 문제에 효율성 있는 접근이 가능하다.
3. 적용 및 고찰
3.1 적용 유역 및 강수자료
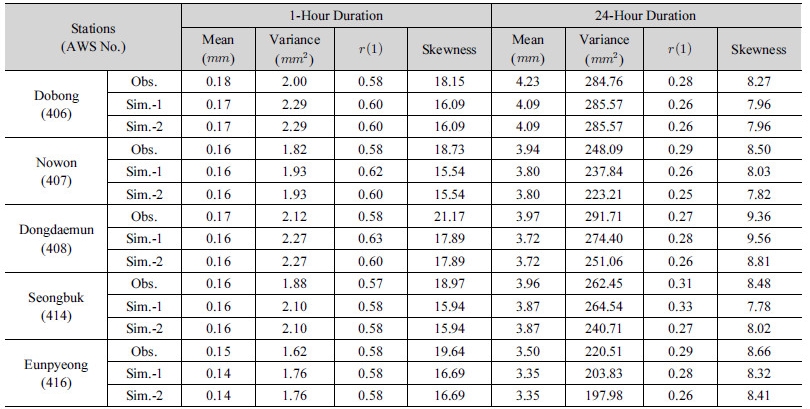
본 연구에서는 서울 우이천 유역을 대상으로 연구를 진행하였다. 우이천 유역의 경우 시간강수량 자료가 이용 가능한 기상청 AWS 지점은 모두 6개로서 Table 2와 같다. 이 중 강북지점을 제외한 5개 지점은 1997년부터 2015년까지 1시간단위 강수량 자료의 이용이 가능하다. 반면 강북지점의 관측개시연도는 2002년으로서 타 지점들에 비해 6년가량 자료의 연한이 짧다. 본 연구에서는 이러한 점을 고려하여 강북지점을 제외한 5개 지점을 대상으로 연구를 진행하였다. 본 연구에서 활용된 강수지점들의 강우의 일반적인 통계적 특성을 요약하면 Table 2의 Obs.와 같다.
Table 2. A comparison of statistics between observation and simulation for 1-hour and 24-hour duration |
|
3.2 모형 적용 결과
모형 적용에 앞서 각 지점별, 월별 NSRPM 모형의 매개변수를 추정하여 Fig. 3에 나타내었다. 매개변수 추정은 앞서 2.3절에 언급한 바와 같이 비선형 최적화 알고리즘인 Simplex Search 방법을 이용하였으며, Table 1에서 제시하고 있는 매개변수 범위를 고려하였다. 매개변수의 범위를 물리적으로 명확하게 정의하기는 사실상 어려울 뿐만 아니라, 일반적으로 사용되는 최적화 방법에서는 제시된 매개변수 범위 내에서 최적의 조합을 찾아내는 과정으로, 매개변수의 범위를 다르게 주면 추정되는 매개변수 또한 다른 값을 가리키게 된다. Fig. 3에서 보는 바와 같이 매개변수의 계절적 특성이 일반적으로 나타나고 있으나, 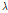 ,
,  등은 제시된 매개변수의 범위에서 최대값으로 추정되고 있다. 이러한 문제점은 매개변수의 범위를 수정해도 나타나는 문제점으로서 기본적으로 보다 개선된 매개변수 추정방법의 필요성이 있다 하겠다. 따라서, 다양한 최적화 방안들이 개발 및 적용되고 있지만, 본 연구에서는 최적화 부분에 대한 자세한 연구는 진행하지 않고, 다지점 모형으로 확장성을 우선적으로 평가하는데 주력하였다.
등은 제시된 매개변수의 범위에서 최대값으로 추정되고 있다. 이러한 문제점은 매개변수의 범위를 수정해도 나타나는 문제점으로서 기본적으로 보다 개선된 매개변수 추정방법의 필요성이 있다 하겠다. 따라서, 다양한 최적화 방안들이 개발 및 적용되고 있지만, 본 연구에서는 최적화 부분에 대한 자세한 연구는 진행하지 않고, 다지점 모형으로 확장성을 우선적으로 평가하는데 주력하였다.
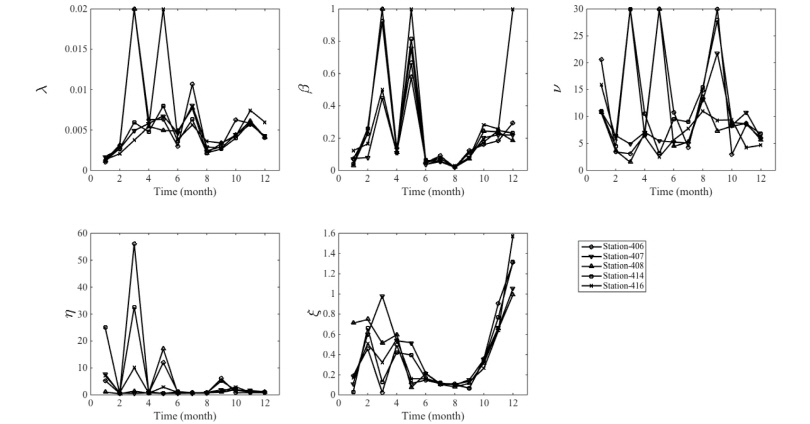
본 연구에서 제시된 방법론을 토대로 100년(100년×365일×24시간)의 강수량을 모의하여 관측값과 비교하여 Table 2에 나타내었다. Table 2에서 “Sim.-1”이라고 표시되어 있는 값은 일반적으로 시간강수량 모의시 적용되는 방법론으로서 각 지점을 독립적으로 가정하고 모의한 1차 모의시계열을 대상으로 추정된 통계치를 1시간과 24시간으로 나누어 나타내었다. 제시된 결과와 같이 모든 통계치에서 관측값을 효과적으로 복원하는 것을 확인할 수 있었다. 다만, 왜곡도는 전반적으로 모의값이 과소 추정되는 결과를 확인할 수 있었으며 결과적으로 극치값과 연관된 확률강수량 추정 시에는 문제점이 나타날 수 있을 것으로 판단된다. Table 2에서 “Sim.-2”라고 표시되어 있는 값은 “Sim.-1”에서 모의된 값을 2.2절에서 제시된 방법론을 토대로 재구성된 시계열로부터 추정된 통계값들을 나타낸다. 본 연구에서는 유역의 공간상관성을 복원하기 위해서 지점별로 독립적으로 구축된 시계열을 상관성을 가지도록 재구성하였으므로, 1시간 지속시간 강수의 경우 자기상관계수를 제외한 대부분의 통계치는 독립적으로 구축된 시계열과 동일한 값을 가지게 된다. 자기상관계수의 경우에도 기존 방법론과 큰 차이를 나타내지 않고 있으며 효과적으로 시간강수계열의 특성을 복원하고 있음을 확인할 수 있었다. 24시간 지속시간 강수의 경우에도 평균의 경우 독립적으로 구성된 시계열과 통일한 값을 갖는다. 평균을 제외한 분산, 자기상관계수, 왜곡도 등은 독립적으로 구성된 강우시계열과 일부 차이를 나타내고 있지만, 유사한 모의가 되고 있음을 확인할 수 있다. 특히, 강우의 시계열을 재구성함에 있어 나타날 수 있는 자기상관계수의 왜곡현상이 없이 모의가 가능하였다. 왜곡도의 경우 1시간 지속시간에 비해 개선된 결과를 나타내고 있으며, 관측 값과의 상대적인 편차도 크지 않음을 확인할 수 있었다.
앞서 언급하였듯이 시간강수량 모의 시 계절성을 복원하기 위하여 Fig. 3과 같이 월별로 매개변수를 추정하여 NSRPM 모형을 지점별로 12개로 구성하였다. 모의된 시계열로부터 계절별로 통계치를 모두 추출하였으나, 지면관계상 도봉(406)과 노원(407)지점만 Fig. 4에 수록하였다. Fig. 4와 같이 대부분의 통계치에서 연주기를 효과적으로 모의하고 있음을 확인할 수 있었으며, 나머지 3개 지점에서도 유사한 결과를 확인할 수 있었다. 다만, 2개 강수지점 모두 1시간 지속시간에서 6-9월에 왜곡도가 상대적으로 과소 추정되고 있으며 이는 결과적으로 극치강수량에 과소추정으로 나타나게 된다.
| |
Fig. 4. The estimated statistics from the simulated hourly rainfall sequences for station 406(a) and 407(b) | |
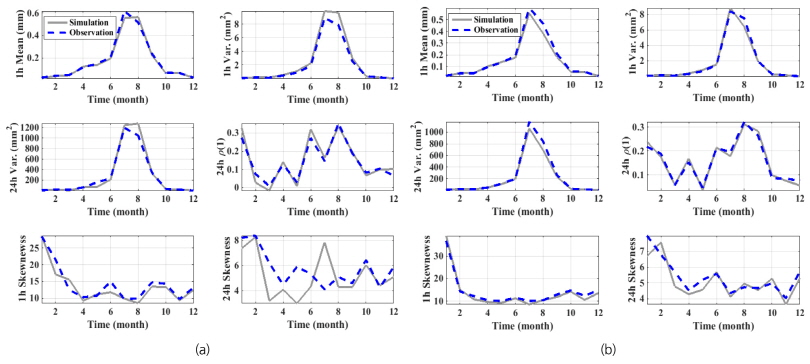
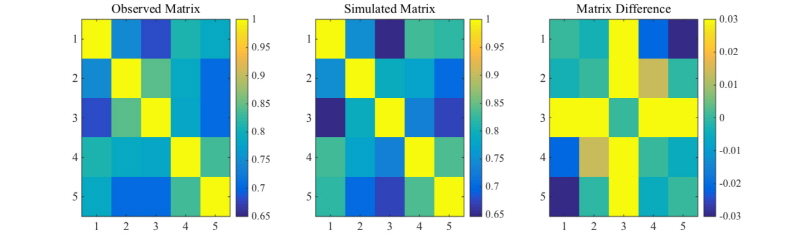
Fig. 5에서는 모의된 자료로부터 연최대강수량을 추출하여 관측값과 확률지를 통해 비교하였다. 확률지는 Gumbel 확률지를 활용하였으며, 예상했던 바와 같이 1시간 지속시간의 경우 극치값이 과소 추정되고 있으며, 24시간 지속시간의 경우 상대적으로 개선된 결과를 보여주고 있다. 모의된 시계열에 대한 지점간의 상관행렬을 추정하여 Fig. 6에 나타내었다. 관측 자료와 모의된 자료의 지점간의 상관행렬은 큰 차이를 나타내지 않고 있으며, 이는 2개의 행렬의 차이를 계산해보면 더욱 뚜렷하게 확인할 수 있다. 즉, 관측행렬과 모의행렬의 차이를 나타내는 마지막 행렬의 경우 전체 범위가 ±0.03을 넘지 않고 있다.
| |
Fig. 5. The probability plots of the simulated hourly extreme rainfalls for station 406(a) and 407(b) | |
| |
Fig. 6. The spatial correlations for the observed and simulated rainfall sequences, and their differences |
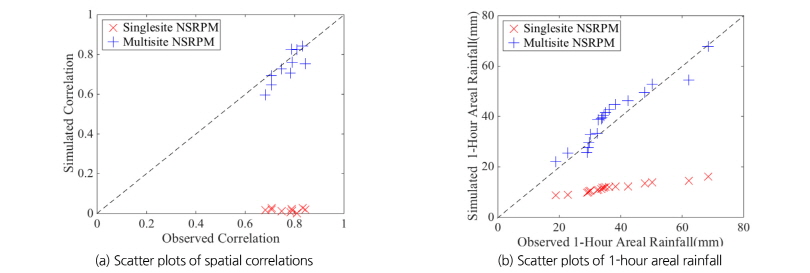
최종적으로 다지점 NSRPM 강수모의기법의 적합성을 추가적으로 검토하기 위해서 지점간의 공간상관계수를 관측값과 비교하여 Fig. 7(a)에 나타내었다. 단일지점 NSRPM 모형의 경우 관측값과 상이하게 상관성이 유지되지 않는 반면 다지점 모형은 관측값과 유사한 공간상관성을 유지하는 것을 확인할 수 있다. 유역내 강수지점간의 공간상관성을 유지시키는 가장 큰 이유 중 하나는 유역면적강수량을 복원하는데 있다. 즉, 유역의 공간상관성이 유지되지 않는 경우 면적강수량이 과소추정 될 수 있다. 이러한 점은 Fig. 7(b)에서 명확하게 확인할 수 있다. 유역내 5개 지점으로부터 연최대치 1시간 면적강수량을 관측값과 모의값을 비교한 경우로서 단일지점 모형의 경우 관측값에 비해 모의값이 크게 과소 추정되고 있으나, 다지점 모형의 경우 관측값과 큰 차이없이 복원되는 것을 확인할 수 있다.
4. 결론 및 토의
우리나라 도시하천의 홍수분석은 기본적으로 관측수문자료의 부재로 인해 신뢰성 있는 분석과 계획 수립이 어려운 현실이다. 즉, 홍수량 자료가 충분치 않아 강우-유출모형을 이용한 설계가 이루어지고 있으나, 이마저도 짧은 지속시간에 대한 강수량 자료가 충분치 않아 도달시간이 매우 짧은 도시유역의 특성을 효과적으로 반영하기 어렵다. 이러한 점에서 국외에서는 강우모의기법 개발과 함께 이와 연계한 강우-유출모형 분석 절차 수립에 다양한 연구들이 진행되고 있다. 본 연구에서는 강우-유출모형을 연계한 홍수분석 절차 개발에 앞서, 유역단위에서 활용 가능한 강우모의기법을 개발하는데 연구의 목적을 두었다. 본 연구를 통해 얻은 결론 및 토의를 요약정리하면 다음과 같다.
첫째, 본 연구에서는 기존 NSRPM 모형을 활용하여 우이천 유역에 독립적으로 적용한 결과 시간강수량 뿐만 아니라 일강수량의 통계치를 효과적으로 복원하는 것을 확인할 수 있었다. 즉, 강수의 평균, 분산, 자기상관계수, 왜곡도 등이 대부분의 계절에서 관측치와 유사한 통계치로 추정되고 있었다. 그러나, 왜곡도의 경우 타 통계치에 비해 다소 과소추정이 이루어지고 있었다.
둘째, 극치강수량을 추출하여 관측치와 확률지를 통해 평가해본 결과 특히 1시간 강수량에서 과소추정 영향이 크게 나타나고 있었다. 이는 왜곡도의 과소 추정으로 기인하는 부분으로서, 향후 매개변수 추정 시 목적함수의 개선 및 매개변수 추정 방법론의 개선이 필요할 것으로 판단된다. 즉, 매개변수들의 상관성을 명확하게 고려한 매개변수 추정 방법의 개발이 필요할 것으로 판단되며, 이를 통해 고차모멘트의 추정 시의 문제점을 개선하고 동시에 매개변수의 인지성(identifiability)을 높이는 것이 필요할 것으로 판단된다.
셋째, 본 연구의 주요목적인 다지점 강수모형으로의 확장을 위해서 Cholesky 변환과 순위상관계수를 활용하였으며, 모의자료뿐만 아니라 서울 우이천유역 5개 지점간의 적용하여 적용성을 검증하였다. 적용결과 공간상관성을 효과적으로 복원하는 것을 확인할 수 있었으며, 이와 더불어 복원 후에도 대부분의 통계치 또한 그대로 유지되는 것으로 평가되었다.
향후 연구로서 강우-유출 모형과 연계한 모의기법 개발을 통해 다수의 홍수자료를 생산할 수 있는 체계를 구축하고 이를 최종적으로 홍수빈도해석을 통해 도시유역단위에서의 설계홍수량 산정을 위한 절차로 확장하고자 한다.
