

1. 서 론
2. 연구방법
2.1 연구범위 및 연구대상 지점
2.2 자료 수집
2.3 분석 방법
3. 결과 및 고찰
3.1 토지피복 조성에 따른 Cluster 구분과 PCA 분석
3.2 PO4-P 항목의 활용
3.3 모델 성능 평가
3.4 SHAP 기반 변수 기여도, 방향성 및 패턴 분석
4. 결 론
1. 서 론
최근 수십 년간 급속한 도시화와 산업화는 하천으로 유입되는 총질소(T-N, mg/L)와 총인(T-P, mg/L) 등 주요 영양물질의 농도를 증가시켜 수질 악화와 부영양화, 조류 번성, 용존산소 고갈, 수생태계 교란 등 심각한 환경 문제를 초래하고 있다(Yu et al., 2025; Lin et al., 2024). 특히 생물권으로 유입되는 인(P, mg/L)의 양은 기존 인산염 매장량에 부담을 줄 정도로 약 4배 증가하였으며(Wang et al., 2024), 질소(N, mg/L) 또한 화학비료, 도시 하수, 가축 분뇨 등 다양한 경로를 통해 지속적으로 유입되어 수환경의 질적 저하를 가속화하고 있다(Kim et al., 2023). 이러한 영양물질의 인위적 유입은 시계열적으로 지연되거나 조기 감지가 어려운 특성을 지녀, 사전 대응에 한계를 보이고 있는 실정이다(Zhang et al., 2025). 특히 국내 한강권역과 같은 대규모 유역에서는 상류와 하류 간의 오염원 분포 특성이 상이하여 지역별 맞춤형 수질 관리 전략이 필수적으로 요구된다. 한강권역은 높은 인구밀도와 산업화·도시화로 인해 타 수계에 비해 산업단지와 생활시설에서 배출되는 수질오염물질의 영향이 크며, K-eco (2022)은 향후 이 지역에서 수질오염사고 발생 가능성이 더욱 높아질 것으로 예측하면서 사고예방 대책의 시급성을 강조한 바 있다. 이를 위해 본 연구에서는 한강, 남한강, 북한강 수계에 속한 단위유역 말단 지점 데이터를 통합하여 공간적 특성을 반영한 T-N과 T-P 농도 산정 모델을 구축하였다. 단위유역 말단에 위치한 37개 수질측정망 데이터를 활용하여 유역을 대표할 수 있는 수질 자료를 확보하였다. 더 나아가 토지피복/토지이용(Land Cover/Land Use, LCLU) 자료는 유역의 수질 특성을 공간적으로 이해하는 데 중요한 보조지표로 활용될 수 있다. LCLU 매핑은 특히 강수량이 적고 불규칙하며 토양 구조가 취약한 건조 지역에서 경관 변화를 이해하는 데 필수적이며(Azedou et al., 2025), 지형지물의 특성과 인위적 이용에 따라 토지를 분류하고 공간 분포, 변화 양상, 이용의 지속 가능성에 관한 정보를 제공함으로써 수질 관리 정책 수립에 중요한 근거를 제공한다(Bai et al., 2018). 본 연구에서는 단위유역별 LCLU 데이터를 결합하여 지역적 특성을 보다 정밀하게 반영함으로써, 수질 산정 모델의 성능 향상 가능성을 검토하였다. 그러나 기존의 물리 기반 수질 모니터링 시스템은 고가 장비 설치 및 유지비용, 제한된 지점 중심의 측정으로 인한 공간 해상도 부족, 실시간 데이터 확보 어려움 등 구조적 한계를 가지고 있다(Zhang et al., 2022; Singh et al., 2024). 이러한 문제를 해결하기 위해 현장(in-situ) 센서와 더불어 머신러닝(Machine Learning, ML) 기반 가상 센서(Virtual Sensors)가 대안으로 주목받고 있다(Chaves et al., 2025). 가상 센서는 일부 수질 인자만으로 다른 인자의 농도를 추정할 수 있는 데이터 기반 접근법으로서 비용 효율성과 실시간성을 확보할 수 있으며, 물리 센서 설치의 공간적 제약이나 비용 문제를 보완하는 데 효과적이다(Martin et al., 2021; Andrade et al., 2022). 최근에는 고빈도 센서 자료와 ML 기법을 결합하여 T-N과 T-P를 간접 예측하는 연구가 활발히 수행되고 있다. 예를 들어 Harrison et al. (2021)은 EC, 탁도, 형광성 용존 유기물(fDOM), WT, 토양 수분 등의 센서 데이터를 입력으로 랜덤 포레스트(Random Forest) 기반 소프트 센서를 구축하여 NO3-N 및 T-N을 높은 정확도로 예측하였고, Zhang et al. (2024)은 중국 9개 유역 131개 관측소의 고빈도 센서 자료를 활용하여 여러 ML 알고리즘을 비교한 결과, Extra Trees Regression이 T-N 및 T-P 예측에 우수한 성능을 보임을 제시하였다. 또한 Li et al. (2024)은 하·폐수처리 공정을 대상으로 Bi-LSTM 기반 다중 하위시스템 협업형 소프트 센서를 제안하여, 다양한 운전 조건에서 암모니아성 질소 농도를 안정적으로 예측하는 등, 2020년 이후 ML 기반 가상 센서를 활용한 수질 예측 연구가 빠르게 확산되고 있다. 그러나 기존 연구들은 주로 단일 모델에 의존하거나 지역별 특성을 충분히 반영하지 못하고 모델 해석 가능성 측면에서도 한계를 보인다(Murphy et al., 2015). 수질 오염원의 공간적 특성은 인구 밀도, 토지이용, 산업 활동, 하천 지형 등 다양한 요인에 따라 달라지므로 동일한 산정 모델을 전역에 일괄 적용하는 방식은 산정 정확도를 저하시킬 수 있다. 이러한 문제를 해결하기 위해서는 clustering을 통한 지역 특성 반영, 물리-가상 복합 센서 기반의 데이터 융합, 비선형성과 지역적 이질성을 고려한 머신러닝 회귀모델 설계, 그리고 Shapley Additive Explanations (SHAP) 기반 변수 기여도 분석을 통한 해석 가능성 확보가 통합적으로 이루어져야 한다. 본 연구는 이러한 한계를 극복하고자 한강권역에 속한 단위유역 말단 측정망 데이터를 통합하여 공간적 clustering을 수행하고, 물리 센서 데이터와 가상 센서 데이터를 융합한 복합 센서 기반 머신러닝 산정 모델을 구축하며, Multiple Linear Regression (MLR), Random Forest (RF), Extreme Gradient Boosting (XGB) 등 다양한 회귀모델을 적용하여 T-N과 T-P 농도 산정 성능을 비교 및 분석하고, SHAP 분석을 통해 변수별 기여도를 평가함으로써 실시간 수질 관리와 오염원 대응 체계 마련에 필요한 과학적 근거를 제공하고자 한다. 이를 통해 본 연구는 clustering, 토지피복 자료, 머신러닝을 결합한 복합 모델링 접근법의 가능성을 제시함과 동시에 지역 맞춤형 수질 관리 및 실시간 대응 기술 개발에 기여할 수 있을 것으로 기대된다.
2. 연구방법
2.1 연구범위 및 연구대상 지점
본 연구는 수질오염사고 발생 가능성이 높고 다양한 오염원이 복합적으로 작용하는 한강권역을 연구대상 지점으로 선정하였다. 한강권역은 서울·경기 지역을 포함해 약 2,600만 인구의 생활·산업 활동이 집중되어 있으며, 산업화와 도시화로 인해 타 수계에 비해 수질오염물질의 발생 가능성이 현저히 높은 지역이다(K-eco, 2022). 특히 상류에서 유입되는 오염부하가 직접 집수되는 팔당호는 수도권 식수의 핵심 공급원으로, 최근 폭염과 강우 패턴 변화로 인한 녹조 발생이 빈번해지고 있어 한강유역환경청이 2025년 팔당호 녹조 대책을 본격적으로 시행할 정도로 수질안전에 대한 우려가 커지고 있다(HRBEO, 2025). 이에 본 연구는 한강, 남한강 및 북한강 수계를 포함한 한강권역 전역의 단위유역 말단 지점을 대상으로 T-N과 T-P 농도 산정을 수행하였다. 단위유역 말단 지점은 상류에서 유입되는 수질 특성을 종합적으로 반영할 수 있어 수계 전반의 수질 상태를 대표하는 데 적합하다. 따라서 본 연구에서 구축한 데이터는 향후 실시간 수질 관리 및 수질오염 사고 예방 대책 마련을 위한 과학적 근거로 활용될 수 있다.
2.2 자료 수집
본 연구에서는 환경부 물환경정보시스템(http://water.nier.go.kr)에서 제공하는 국가 수질측정망 자료를 활용하였다. 자료 수집 기간은 2016년 1월부터 2025년 5월까지이며, 본 연구에서는 수소이온농도(pH), 용존산소(DO, mg/L), 전기전도도(EC, µS/cm), 수온(WT, °C), 클로로필-a (Chl-a, µg/L), 부유물질(SS, mg/L), 질산성 질소(NO3-N, mg/L), 암모니아성 질소(NH3-N, mg/L), 용존 인산염 인(PO4-P, mg/L), 총질소(T-N), 총인(T-P) 등 총 11개 항목을 활용하였다. 이 중 pH, DO, EC, WT, Chl-a, SS, NO3-N, NH3-N은 기술적으로 센서 기반 실시간 모니터링이 가능한 변수들이다. 다만 국가 수질측정망에서는 운영 특성상 NO3-N과 NH3-N이 주로 실험실 습식 분석값으로 제공되지만, 두 항목은 국제적으로 센서 기술이 가장 널리 상용화된 영양염 항목으로 향후 자동측정망 확충 시 실시간 관측으로 전환될 가능성이 높다. 반면 PO4-P, T-N, T-P는 현재 센서 기술의 부재 또는 높은 비용적 제약으로 인해 실시간 측정이 어려운 항목이며, 이에 따라 본 연구에서는 해당 변수들에 대해 실험실 분석 자료를 활용하였다. 이상의 센서 기반 자료와 실험실 분석 자료를 함께 이용하여 가상 센서 기반 T-N 및 T-P 농도 산정 모델을 구축하였으며, 입력 변수 목록은 Table 1에 제시하였다.
Table 1.
Descriptive statistics of water quality variables collected from 37 terminal monitoring sites in the Han, Namhan, and Bukhan River sub-basins
연구대상 지점은 한강, 남한강 및 북한강 수계에 위치한 37개 단위유역 말단 수질측정망이며, 활용한 지점은 Fig. 1에 제시하였다. 유역 특성을 반영하기 위해 환경공간정보서비스에서 제공하는 2024년 기준 중분류(Level-2) 토지피복지도를 활용하였다. 해당 토지피복도는 총 22개 항목으로 구성되며, 각 단위유역 경계 내 토지피복 면적을 집계하여 항목별 면적 비율(%)을 산정하였다. 전체 49개 단위유역 중 토지피복 자료가 제공되지 않은 12개 유역을 제외한 37개 유역을 최종 분석에 활용하였다.
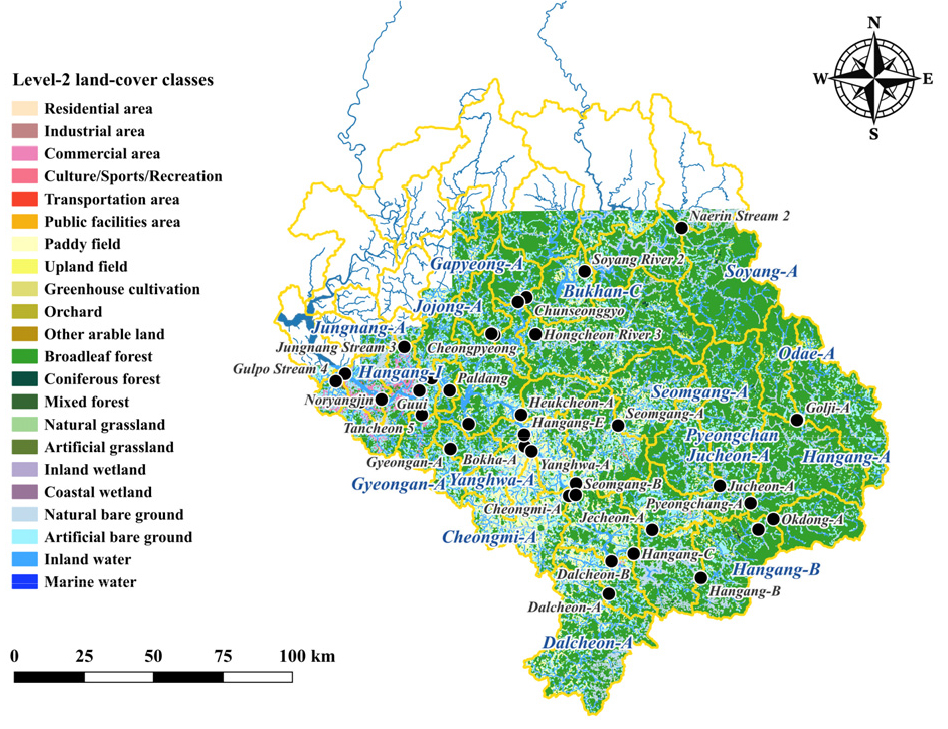
토지피복도는 장기적인 공간 구조를 나타내는 지표로서, 단기적인 변동성이 큰 수질 자료와 달리 비교적 안정적인 특성을 갖는다. 이에 본 연구에서는 장기 수질 자료(2016-2025년)와의 시간 차이가 존재하더라도 단위유역의 land-cover 특성을 반영하기 위한 대표값으로 최신 자료인 2024년 중분류(Level-2) 토지피복도를 활용하였다.
2.3 분석 방법
2.3.1 Clustering
본 연구에서는 단위유역 말단 37개 지점을 대상으로 토지피복 중분류(Level-2) 항목별 면적 비율(%)을 입력 변수로 활용하여 clustering 분석을 수행하였다. 이를 위해 단위유역 경계와 토지피복 지도를 중첩한 뒤, 각 중분류 항목별로 분할된 폴리곤의 면적을 지점별로 합산하고, 지점별 총면적으로 나누어 면적 비율을 산정하였다. 특정 지점에 존재하지 않는 항목은 결측치 처리 대신 0%로 대체하였다. 변수 간 분산의 차이로 인한 거리 왜곡을 완화하고 수치적 안정성을 확보하기 위해 모든 변수에 대해 평균 0, 표준편차 1의 z-score 표준화를 적용하였다. Clustering에서 군집 수 k는 2에서 5 사이의 범위에서 탐색하였으며, 단일 샘플로 구성된 군집이 발생하지 않도록 최소 군집 크기를 제한하였다. 비교 대상 알고리즘으로는 Balanced Iterative Reducing and Clustering using Hierarchies (BIRCH), Gaussian Mixture Model (GMM), Hierarchical Agglomerative Clustering (HAC), K-means를 적용하였다. 알고리즘-k 조합별로 Silhouette 계수, Davies-Bouldin 지수, Calinski-Harabasz 지수를 산출하였고, GMM에 대해서는 추가로 Bayesian Information Criterion (BIC)을 평가하였다. 이후 각 평가 지표의 순위를 산정하여 평균한 종합 점수를 바탕으로 최적의 알고리즘-k 조합을 선정하였다. Fig. 2는 clustering 분석에 활용된 Level-2 토지피복 항목의 공간적 특성을 대표적으로 제시한 것으로, (a) 도시화가 집중된 지역과 (b) 농업·산림 중심의 비도시 지역이 나타내는 상이한 land-cover 패턴을 시각적으로 보여준다.

BIRCH는 계층적 군집화의 원리를 적용한 방법으로, 메모리 사용량과 계산 시간 측면에서 다른 계층적 기법보다 효율적이어서 대규모 데이터 clustering에 적합하다(Rashidov et al., 2024). 데이터 요약을 통해 원자료 대비 데이터셋의 크기를 크게 축소함으로써 효율성을 달성하며(Li et al., 2023), 점진적 병합·분할을 지원하여 단일 스캔만으로도 대규모 시계열 데이터를 효과적으로 분석할 수 있다(Fontanini and Abreu, 2018).
GMM은 데이터 분포가 알 수 없는 매개변수를 가진 다수의 가우시안 분포들의 혼합으로 이루어져 있다고 가정하는 확률적 모형이다(Kim et al., 2024). GMM은 확률에 기반하여 가우시안 분포를 통해 군집을 통계적으로 구분한다(Nam et al., 2024). BIC에 기반해 최적의 성분 수를 산정함으로써, 관측된 데이터에 보다 적합하도록 각 가우시안 분포의 매개변수를 반복적으로 보정하였다(Hossain, 2025). GMM은 각 데이터가 여러 개의 가우시안 분포 중 하나에서 생성된다고 가정하는 확률적 clustering 기법으로, 각 cluster의 평균과 공분산을 추정하여 데이터의 분포적 특성을 효과적으로 반영할 수 있다(Kim et al., 2019).
HAC는 1963년 Ward가 제안한 이후 널리 활용되어 왔으며(Randriamihamison et al., 2021), agglomerative과 divisive으로 구분된다. 두 접근은 개념적으로 유사하나 최종 해는 서로 다를 수 있으며(Kaufman and Rousseeuw, 1990), 초기 단계에서는 divisive 방식이 상대적으로 강건한 반면 agglomerative 방식은 이해하기 쉽고 가장 널리 사용된다(Macnaughton-Smith et al., 1964; Jain et al., 1999). Agglomerative 방식의 결과는 보통 군집 간 거리 정의에 근거한 agglomeration criterion의 선택에 의해 좌우된다(Tokuda et al., 2022).
K-means Clustering은 데이터를 신속하게 cluster로 분할할 수 있는 계산 효율적 방법으로, 사용 용이성과 구현의 간편성 덕분에 폭넓게 활용되어 왔다(Zou and Ren, 2023). 비지도 학습을 대표하는 고전적 알고리즘으로서(Chong, 2021), 사전에 cluster 수 k를 지정한 뒤 각 샘플과 해당 cluster의 centroid 사이 제곱거리의 총합(SSE)을 최소화하는 목적함수를 반복적으로 최적화한다(Ikotun et al., 2023).
2.3.2 Data model 활용
본 연구는 하천 내 T-N 및 T-P 농도 산정을 위해 비선형 회귀 모형인 RF와 XGB를 적용하고, 비교 기준으로 선형 회귀 모형인 MLR을 함께 구축하였다. 모든 연속형 변수는 학습 이전에 z-score 표준화를 적용하였다. MLR은 입력변수와 목표변수 간 선형 관계를 최소제곱법으로 추정하는 구조로 계산 효율성과 해석 용이성이 높다(Xu et al., 2024). RF는 다수의 결정 트리를 앙상블하여 일반화 성능을 높이는 비선형 모형으로, 부트스트랩 샘플링과 무작위 변수 선택을 통해 과적합을 억제한다(Breiman, 2001). XGB는 그래디언트 부스팅 기반의 앙상블 기법으로, 약한 학습기를 순차적으로 결합하여 높은 예측 성능과 결측값 처리에 유연하며, 비선형 상호작용 및 다중공선성 문제에 상대적으로 강건하다(Belmiro et al., 2023; Wang et al., 2023; Chen et al., 2023). 전처리 및 학습 과정은 데이터 누수를 방지하기 위해 scikit-learn의 Pipeline을 활용하여 표준화 등 모든 변환을 교차검증 학습 폴드 내에서만 수행하였고 검증 폴드에는 동일한 변환을 적용하였다. 모형 간 공정한 비교를 위해 동일한 데이터 분할 및 난수 시드(random_state= 42)를 사용하였다. RF와 XGB의 주요 하이퍼파라미터는 GridSearchCV와 내부 10겹 교차검증을 통해 최적화하였으며, MSE가 가장 낮은 조합을 최종 설정으로 채택하였다. 성능 평가는 학습 데이터에 대해 10겹 교차검증을 수행하여 R2의 평균과 표준편차를 도출하였고, RMSE, MAE, MSE를 보조 성능 지표로 함께 산출하였다. 또한 전체 데이터의 20%를 독립 검증 세트로 분리하여 성능을 재검증하였다. 모든 회귀 모형은 사전 도출된 cluster를 기반으로 각 수계별로 독립적으로 구축하여 공간적 이질성을 반영하였다. 특히 RF와 XGB는 SHAP 기반 해석을 통해 변수 중요도와 영향 방향성을 시각적으로 분석함으로써 산정 결과의 해석 가능성과 타당성을 검토하였다.
2.3.3 PCA 분석
본 연구의 주성분분석(Principal Component Analysis, PCA)은 한강권역 37개 단위유역 말단의 토지피복 중분류 면적 비율 (%)을 대상으로 수행하였다. 토지피복 항목들은 도시·농업·산림 등 기능적 특성이 유사한 항목 간 상관성이 높아 다중공선성이 존재하므로, PCA는 이러한 상관구조를 축약하여 토지 이용의 주요 잠재 구배(underlying gradients)를 도출하고, 이를 통해 cluster 간 토지피복 구성 차이를 구조적으로 비교·해석하기 위한 목적으로 활용되었다. 또한 PCA biplot은 개별 항목의 기여 방향성과 지점별 토지피복 패턴을 직관적으로 시각화할 수 있어, 이후 수행한 SHAP 기반 변수 영향 패턴의 차이를 환경적 맥락에서 해석하기 위한 기초 축을 제공한다.
PCA는 상관된 변수 간 정보를 축약하고 전체 분산을 설명하는 소수의 주성분(Principal Component, PC)을 도출하여 자료 구조를 요약하는 차원 축소 기법이다(Ma et al., 2024; Yang et al., 2004). 주성분 수는 스크리 플롯의 굴절점과 누적 설명분산(≥ 60%) 기준을 활용하여 결정하였으며, 시각화는 첫 번째 및 두 번째 주성분(PC1, PC2)을 이용한 biplot으로 구성하였다. biplot에서는 지점별 PC 점수를 점(point)으로, 각 토지피복 항목의 로딩을 화살표(vector)로 표현하였으며, 로딩 절대값이 | loading | ≥ 0.35 이상인 항목만 시각화하였다. Cluster 라벨은 시각적 비교를 위한 보조 정보로 추가하였으며, PCA 산정 과정에는 반영되지 않았다. 분석은 Python의 scikit-learn PCA 모듈을 기반으로 전처리-분석-시각화 전 단계를 파이프라인화하여 재현성을 확보하였다.
2.3.4 SHAP 분석
본 연구에서는 T-N 및 T-P 농도 산정 모델의 입력 변수에 대한 상대적 중요도와 산정값 형성 과정에서의 기여도를 정성적·정량적으로 분석하기 위해 변수 중요도 평가와 SHAP (SHapley Additive exPlanations) 기반 해석을 병행하였다. 변수 중요도 평가는 트리 기반 모델(Random Forest, XGBoost)의 내장 속성인 feature importance를 활용하여 각 입력 변수의 상대적 영향력을 산출하고 시각적으로 비교하였다. 보다 정밀한 모델 해석을 위해 SHAP 분석을 도입하여 개별 변수 값이 예측 결과에 미치는 기여 정도와 영향 방향(양 ·음)을 정량적으로 평가하였다. SHAP 값은 shap.summary_plot을 활용한 beeswarm 형식으로 시각화하였으며, 이를 통해 변수 분포 전반에서의 기여 특성을 확인하였다. 모델 유형에 따라 MLR 모델에는 KernelExplainer를, 트리 기반 모델에는 Tree Explainer를 각각 적용하였다. SHAP은 협력 게임 이론의 Shapley 값을 기반으로 개별 특성의 기여도를 산출하는 사후 해석(post hoc explanation) 프레임워크로, 비선형 모델을 포함한 다양한 예측 모델에 대해 일관된 해석을 가능하게 한다(Lundberg and Lee, 2017). 또한 SHAP 기반 해석은 단순한 변수 중요도 산정을 넘어 예측값 형성 과정에서의 변수 기여를 직관적으로 해석할 수 있는 도구로 활용되고 있다(Li et al., 2025).
3. 결과 및 고찰
3.1 토지피복 조성에 따른 Cluster 구분과 PCA 분석
3.1.1 Cluster 기반 토지피복 구성 분석
단위유역 말단 수질측정망 37개 지점에 대해 토지피복 중분류 항목별 면적을 집계하고, 이를 각 지점의 총 면적으로 나누어 면적비율(%)을 산정한 뒤, 이를 입력 변수로 활용하여 clustering을 수행한 결과 총 3개의 cluster가 도출되었다. Cluster 수(k)는 Silhouette 계수 및 Davies-Bouldin 지수 등 내부 평가 지표를 바탕으로 탐색하였으며, HAC (k=3)과 BIRCH (k=3)가 모두 우수한 성능을 보여 k=3이 타당함을 확인하였다. 최종적으로 HAC (k=3)을 채택한 이유는 Ward 연결 방식이 cluster 내 분산을 최소화하여 구조적으로 명확한 군집 형성이 가능하고, 본 연구의 표본 수에서는 BIRCH의 대용량 처리 이점이 크게 작용하지 않기 때문이다.
도출된 cluster의 토지피복 구성은 Table 2에 요약되어 있으며, ‘Top-3 land-cover’는 각 cluster 내에서 평균 면적비율이 높은 상위 3개 항목을 의미한다. 또한 Urban/Impervious, Agriculture & Vegetation, Water & Wetland의 세 가지 집계 지표를 정의하여 해석의 직관성을 높였다. Cluster 1(n=9)은 broadleaf forest (30.9%), residential area (12.9%), artificial grassland (10.8%) 중심으로 도시화 요소가 혼재된 복합형 특성을 보인다. Cluster 2(n=6)는 broadleaf forest (24.6%), paddy field (14.5%), upland field (13.7%) 구성으로 농업 지배형 특징을 나타낸다. Cluster 3(n=22)는 broadleaf forest (43.8%), coniferous forest (24.7%), mixed forest (7.8%) 분포로 산림 지배형 특성을 보이며, Urban/Impervious 비율은 가장 낮게 나타났다.
Table 2.
Summary of land-cover composition by cluster, showing the top three Level-2 classes and aggregated group percentages
3.1.2 PCA 분석 기반 토지피복 구배 해석
본 연구에서 사용된 토지피복 코드는 A (Artificial bare ground, 인공나지), B (Artificial grassland, 인공초지), C (Broadleaf forest, 활엽수림), D (Commercial area, 상업지역), E (Coniferous forest, 침엽수림), F (Culture/Sports/Recreation, 문화·체육·휴양지역), G (Greenhouse cultivation, 시설재배지), H (Industrial area, 공업지역), I (Inland water, 내륙수), J (Inland wetland, 내륙습지), K (Mixed forest, 혼효림), L (Natural bare ground, 자연나지), M (Natural grassland, 자연초지), N (Orchard, 과수원), O (Other arable land, 기타재배지), P (Paddy field, 논), Q (Public facilities area, 공공시설지역), R (Residential area, 주거지역), S (Transportation area, 교통지역), T (Upland field, 밭), U (Coastal wetland, 연안습지), V (Marine water, 해양수)로 구성된다.
Cluster 간 구성 차이를 구조적으로 파악하기 위해 수행한 PCA 결과는 Fig. 3에 제시하였다. 37개 지점의 토지피복 비율은 두 개의 주요 구배로 요약되었다. PC1(39.5%)은 상업지역(D), 주거지역(R), 공업지역(H), 교통지역(S), 공공시설지역(Q), 인공나지(A) 등 도시화·불투수 항목에서 높은 양(+)의 로딩을 보이는 반면, 활엽수림(C), 침엽수림(E), 자연초지(M), 자연나지(L) 등 자연피복 항목에서 음(-)의 로딩을 나타내어 도시화-자연 피복 구배(urban-natural gradient)를 구성하였다. PC2 (26.2%)는 논(P), 밭(T), 기타재배지(O), 과수원(N), 시설재배지(G), 혼효림(K) 등 농업·식생 기반 항목에서 높은 양의 로딩을 보여 농업 ·식생 구배(agricultural-vegetation gradient)를 형성하였다. 이러한 항목별 로딩값은 Table 3에 정량적으로 요약하였으며, PC1・PC2 축을 구성하는 주요 토지피복 변수가 어떤 방향성과 기여도를 갖는지 확인할 수 있다.
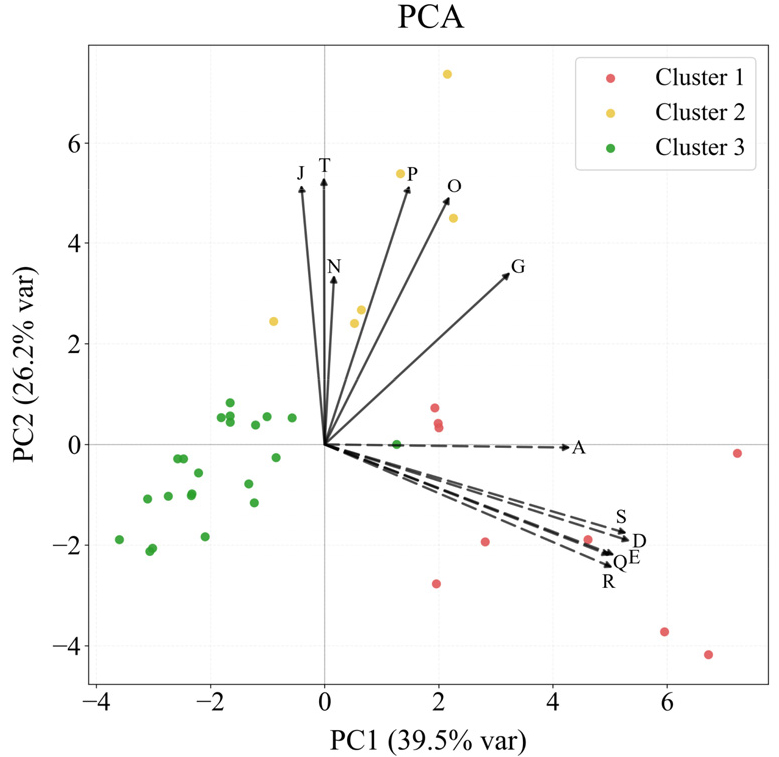
Table 3.
Loadings of major Level-2 land-cover variables for the first two principal components (PC1 and PC2)
Fig. 3의 biplot에서 점(point)은 각 단위유역의 PC 점수로서 토지피복 구성의 상대적 위치를 의미하고, 화살표(vector)는 각 항목의 PC 로딩으로 해당 변수가 주성분축을 결정하는 기여 정도를 나타낸다. 화살표 길이가 길수록 해당 항목이 특정 주성분을 강하게 규정하며, 점이 화살표 방향으로 멀리 위치할수록 해당 토지피복 항목의 비중이 높은 지점을 의미한다. 또한 화살표 간 예각은 높은 공변성을, 둔각은 상반된 경향을 시사한다.
PC1과 PC2의 축 특성은 clustering 결과와도 일관된 해석을 제공하였다. Cluster 1은 PC1이 높고 PC2는 낮은 위치에 분포하여 도시화·불투수 특성이 강한 지점에 해당하며, cluster 2는 PC2가 높은 영역에 분포해 농업 및 개방지 특성이 우세한 지점을 반영한다. 반면 cluster 3은 PC1과 PC2 모두 낮거나 음의 값을 보이며 자연피복 중심의 산림 지배형 지점으로 해석된다. 즉, PCA는 clustering 결과를 도시화-농업-자연이라는 명확한 환경 구배 위에서 구조적으로 설명해주는 지표로 기능하였다.
3.2 PO4-P 항목의 활용
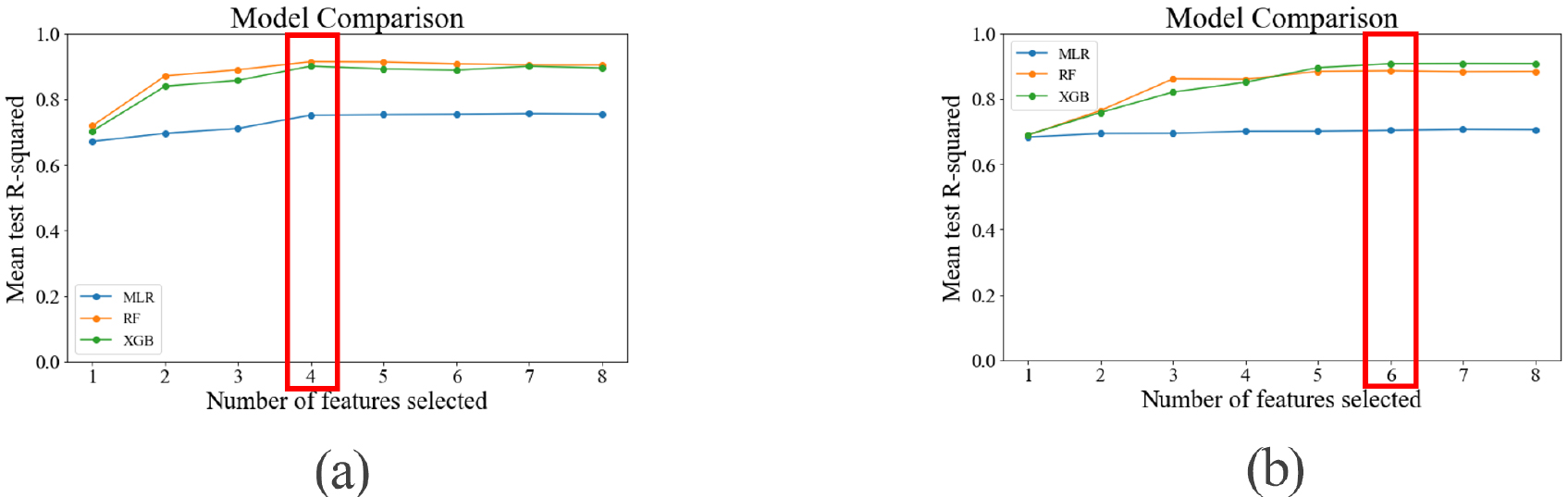
본 연구에서는 실험실 분석을 통해 8일 간격으로 제공되는 PO4-P 자료의 시간 해상도 한계를 보완하고 센서 기반 고해상도 자료와의 융합을 가능하게 하기 위해, PO4-P 값을 7일(1주) 이동평균(rolling mean) 방식으로 환산하였다. 자동측정망에서 수집된 일 단위 자료에 대해 누락값을 제외한 동일 기간의 최근 7일 데이터를 집계하여 대표값으로 산정하였으며, 이는 단기 변동에 따른 잡음을 완화하면서도 실험실 기반 농도 추세를 유지할 수 있는 전처리 방법이다. 이렇게 환산된 PO4-P 주간 평균값은 DO, pH, EC, WT, SS 등 자동측정망 센서 자료와 동일한 일 단위 시간 해상도로 재정렬한 후 입력 변수에 결합하여 실험실 기반 항목과 고해상도 센서 항목을 동시에 포함하는 하이브리드 입력 데이터셋을 구성하였다. 이러한 절차는 PO4-P의 측정 주기 차이를 최소화하여 T-P 산정 모델에서 해당 항목의 활용 가능성을 평가하기 위한 예비적 접근으로, 향후 PO4-P의 실시간 센서 기술이 보편화될 경우 적용성이 확대될 수 있음을 확인하는 데 목적이 있다. 모델 성능 비교 결과는 Fig. 4에 제시하였다. Fig. 4(a)는 센서 기반 자료와 주간 평균 PO4-P를 결합한 하이브리드 모델의 성능 변화를 나타내고, Fig. 4(b)는 기존의 8일 간격 수질측정망 자료만을 활용한 경우의 성능을 제시하여 T-P 산정 성능 차이를 비교·평가하였다. 다만, 본 분석은 PO4-P 측정 주기 차이를 고려한 현실적 자료 융합 방안을 제시한 것으로, 향후 실시간 센서 도입 시 적용 가능성을 검토하는 데 의의가 있다.
3.3 모델 성능 평가
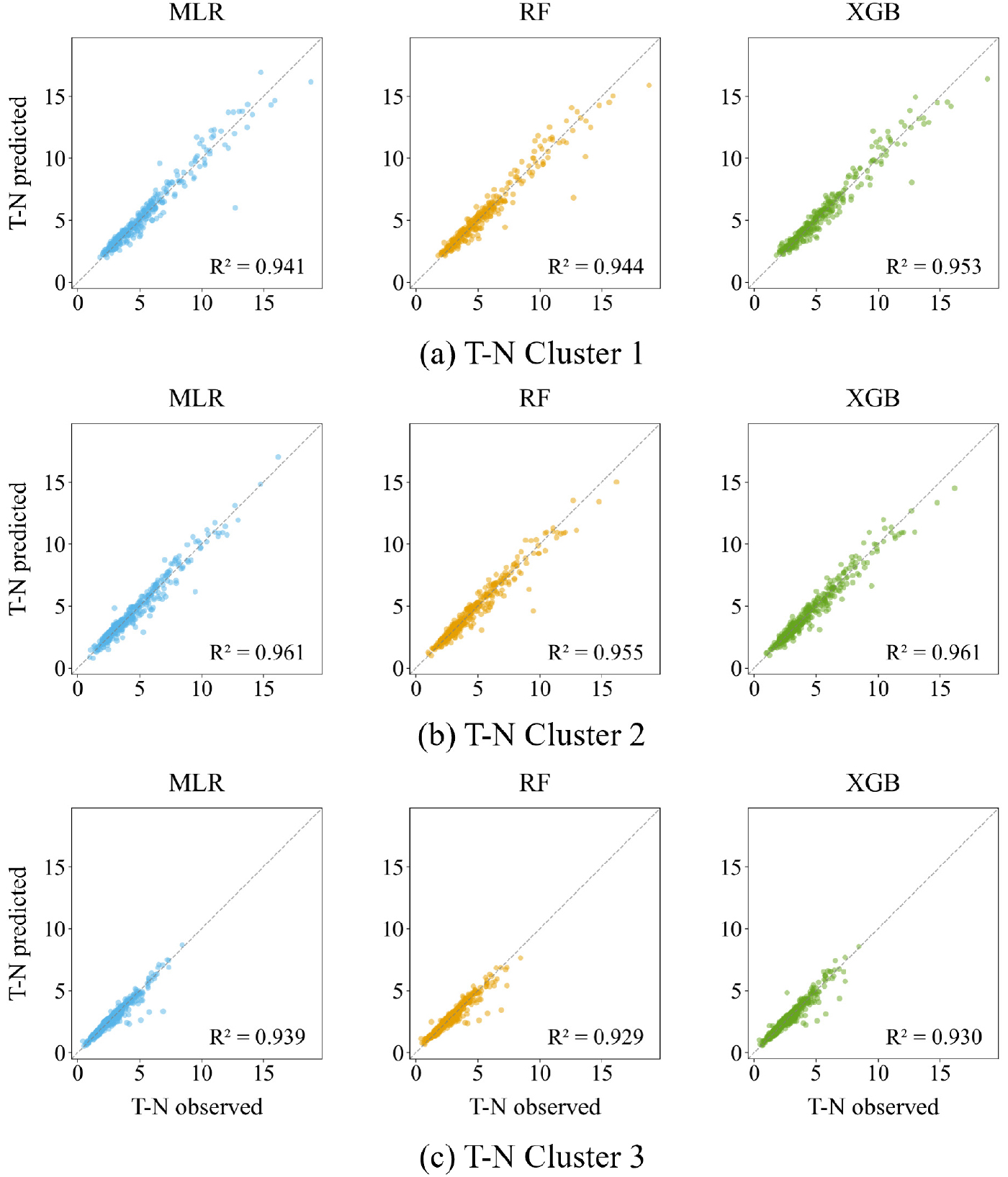
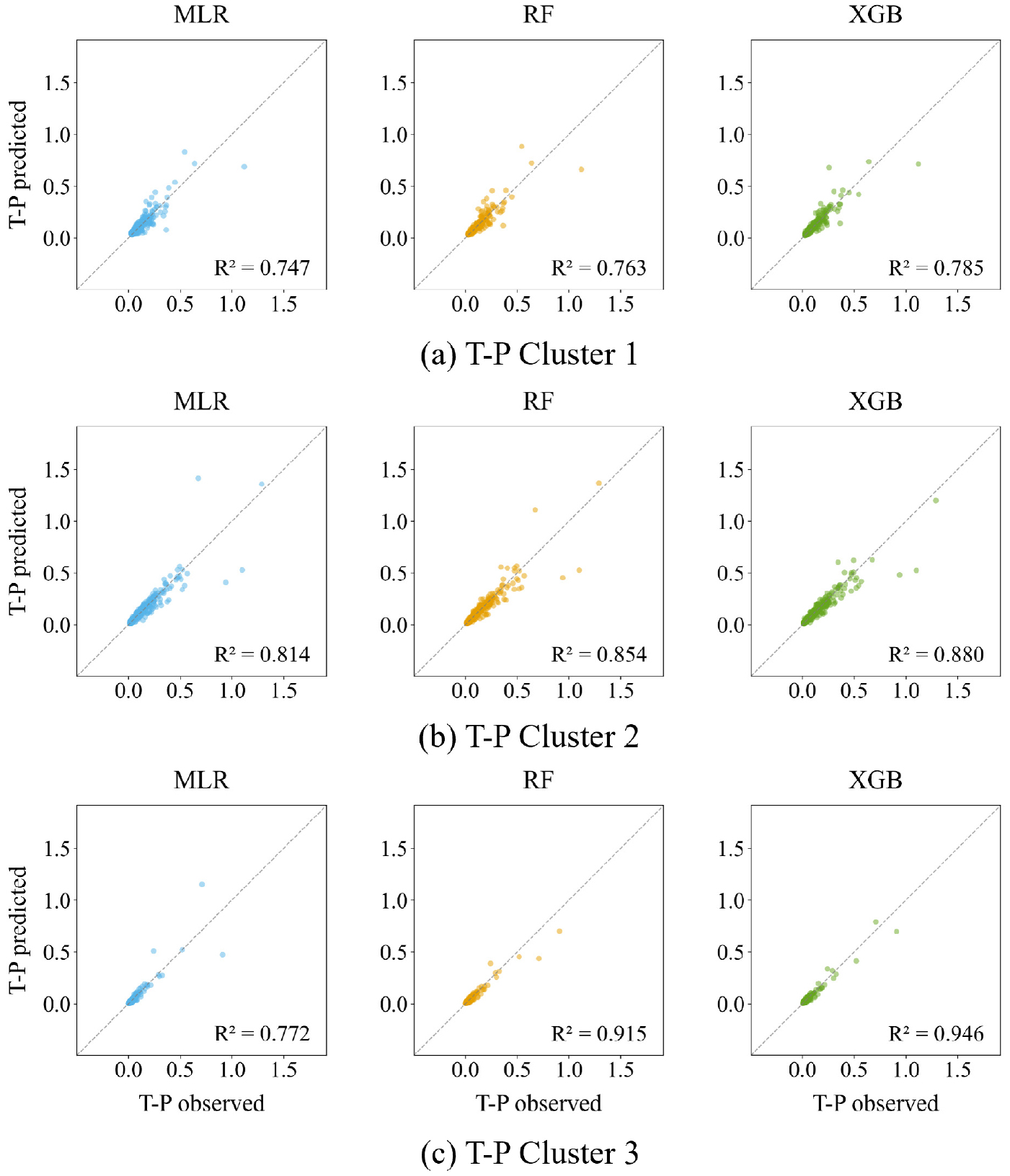
본 연구에서는 T-N 농도 산정 모델의 입력 변수로 pH, DO, EC, WT, Chl-a, SS, NO3-N, NH3-N을 사용하였고, T-P 농도 산정 모델에서는 여기에 PO4-P를 추가하여 분석을 수행하였다. Cluster 기반의 산정 모형 성능은 R2, 평균제곱근오차(RMSE), 평균절대오차(MAE) 등의 평가 지표를 통해 비교 및 분석하였다. 그 결과, 전체적으로 앙상블 기반 모델(Random Forest, XGBoost)이 선형 회귀 모델(MLR)보다 우수한 산정 정확도와 안정적인 일반화 성능을 보였다. 특히 T-P 산정에서 모델 간 성능 차이가 더욱 두드러졌으며, 이는 PO4-P의 추가가 산정 정확도 향상에 실질적으로 기여했음을 시사한다. T-N 농도 산정 결과의 시각화는 Fig. 5에 제시하였다. 세 가지 모델 모두에서 관측값과 산정값 간의 높은 상관성을 보였으며, cluster별로 살펴보면 다음과 같다. Cluster 1에서는 XGB가 R2 = 0.953으로 가장 우수한 성능을 나타냈고, cluster 2에서는 MLR과 XGB 모두 R2 = 0.961로 동일한 수준의 성능을 기록하였다. Cluster 3에서는 MLR이 R2 = 0.939로 상대적으로 가장 우수한 결과를 보였다. RF는 세 cluster에서 모두 비교적 고른 성능을 나타냈으나, 세 모델 간 성능 차이는 미미한 수준이었다. 전체 cluster 평균 기준으로 Test R2는 MLR이 0.947, RF가 0.942, XGB가 0.948로 나타났으며, 평균 Test RMSE는 각각 약 0.479(MLR), 0.493(RF), 0.461(XGB)로 계산되었다. 세 모델 간 RMSE 최대 차이는 0.032로 전체 값 대비 약 6%에 불과하였다. MAE 또한 세 모델 모두 약 0.21 수준으로, 평균적인 절대 오차 기준에서 모델 간 성능 차이는 매우 작았다. 과적합 여부를 판단하기 위해 학습 단계에서의 교차검증 설명력(Train-CV R2)과 검증 데이터 기반 설명력(Test R2)을 비교한 결과, MLR과 RF는 각각 평균 +0.002, XGB는 -0.003의 차이를 보여, 과적합 없이 안정적인 일반화 성능을 확보한 것으로 나타났다. 세 모델 모두 성능과 안정성 측면에서 높은 수준의 수질 산정 가능성을 확인하였다.
T-P 농도 산정 결과의 시각화는 Fig. 6에 제시하였다. T-P 농도 산정 모델의 cluster 전체 평균 Test R2는 MLR에서 0.777, RF에서 0.844, XGB에서 0.870으로, XGB가 가장 우수한 성능을 나타냈다. 특히 XGB는 MLR 대비 평균 R2를 약 0.093 향상시켰으며, 평균 RMSE를 약 21%, 평균 MAE를 약 19% 감소시켰다. 모든 cluster에서 XGB가 가장 뛰어난 정확도를 보였고, 가장 높은 R2는 cluster 3에서 기록된 0.946이었다. 한편, T-N 산정과 비교했을 때 T-P 산정에서는 모델 간 성능 격차가 더 크게 나타났다. T-N에서는 세 모델 간 R2 최대 차이가 0.012 이내로 매우 작았던 반면, T-P에서는 cluster 3에서 MLR과 XGB 간 R2 차이가 약 0.175에 달했다. 이는 P의 농도 변화가 N에 비해 보다 복잡하고 비선형적인 지배 요인의 영향을 받는 특성을 반영한다. 즉, P 농도는 강우 유출, 토지 이용 특성, 퇴적물 재부유, 점 ·비점오염원의 복합적인 기여 등 다양한 비선형 요인의 영향을 받으며, 이러한 요인들이 지역(cluster)별로 상이하게 작용함에 따라 농도 산정의 불확실성이 증가한다. 일반화 성능 측면에서, MLR은 평균 Train-CV R2 대비 Test R2의 차이가 +0.091로 가장 크게 나타나 데이터 분할에 따른 성능 변동성이 상대적으로 큰 것으로 확인되었다. 반면, RF와 XGB는 각각 +0.012와 -0.012 수준으로 나타나 과도한 성능 편차 없이 비교적 안정적인 일반화 성능을 보였다.
T-P 농도 산정에 기여한 주요 입력 변수로는 EC, SS, NH3-N, PO4-P가 모든 cluster에서 공통적으로 포함되었으며, pH, NO3-N, Chl-a 또한 빈번히 선택되었다. 반면, DO와 WT는 상대적으로 낮은 빈도로 포함되었다. 이는 T-P 농도 산정에서 EC, SS, NH3-N, PO4-P가 핵심적인 설명 변수로 작용함을 시사한다.
3.4 SHAP 기반 변수 기여도, 방향성 및 패턴 분석
T-N 및 T-P 농도 산정 모형에서 입력 변수의 상대적 기여도를 분석하기 위해 각 산정 모델(MLR, RF, XGB)에 대해 cluster별로 SHAP 기반 평균 절대값(Mean Absolute SHAP Value)을 산정하였다. Fig. 7과 같이 T-N 산정에서는 세 모델 모두에서 NO3-N이 가장 일관된 기여도를 보였으며, NH3-N과 EC가 그 뒤를 이었다. 특히 cluster 1에서는 EC의 기여도가 다른 변수 대비 높게 나타나, 이온 강도 계열 항목이 T-N 농도 산정에 주요한 설명 변수가 됨을 시사하였다. 반면, pH, DO, WT는 전 cluster에서 낮은 기여도를 보여 상대적 중요성이 낮은 것으로 분석되었다. T-P 농도 산정의 경우, PO4-P와 SS가 모든 cluster 및 모델에서 가장 두드러진 기여도를 보였으며, 특히 cluster 2에서는 Chl-a의 기여도가 상승하는 특징이 나타났다. 이는 T-P 산정 시 조류 성장(Chl-a)과 입자성 오염물질(SS), 이온성 인화물(PO4-P)의 복합적 작용이 cluster에 따라 다르게 반영됨을 의미한다. 또한 변수별 기여도 순위는 모델 간 전반적으로 유사하게 나타나 산정 결과의 견고성을 뒷받침하였다. Mean Absolute SHAP Value는 변수의 기여도 크기만을 요약하므로, 변수와 목표값 간의 양(+) ·음(-)의 영향 방향성은 직접적으로 제공하지 않는다. 이에 대한 세부 해석은 Fig. 8 및 Fig. 9에서 산점도와 함께 제시하였다. 이러한 cluster별 기여도 차이는 토지피복 특성에 기인하며, 도시화·불투수 비중이 높은 cluster 1에서는 하·폐수 기원의 EC·NH3-N 영향이 강화되고, 농업지 우세의 cluster 2에서는 SS, PO4-P 및 Chl-a와 같은 비점오염, 영양물질 관련 인자가 크게 작용하며, 산림지 주도의 cluster 3에서는 배경농도 중심의 NO3-N 기여가 두드러지는 구조적 차이를 반영한다.
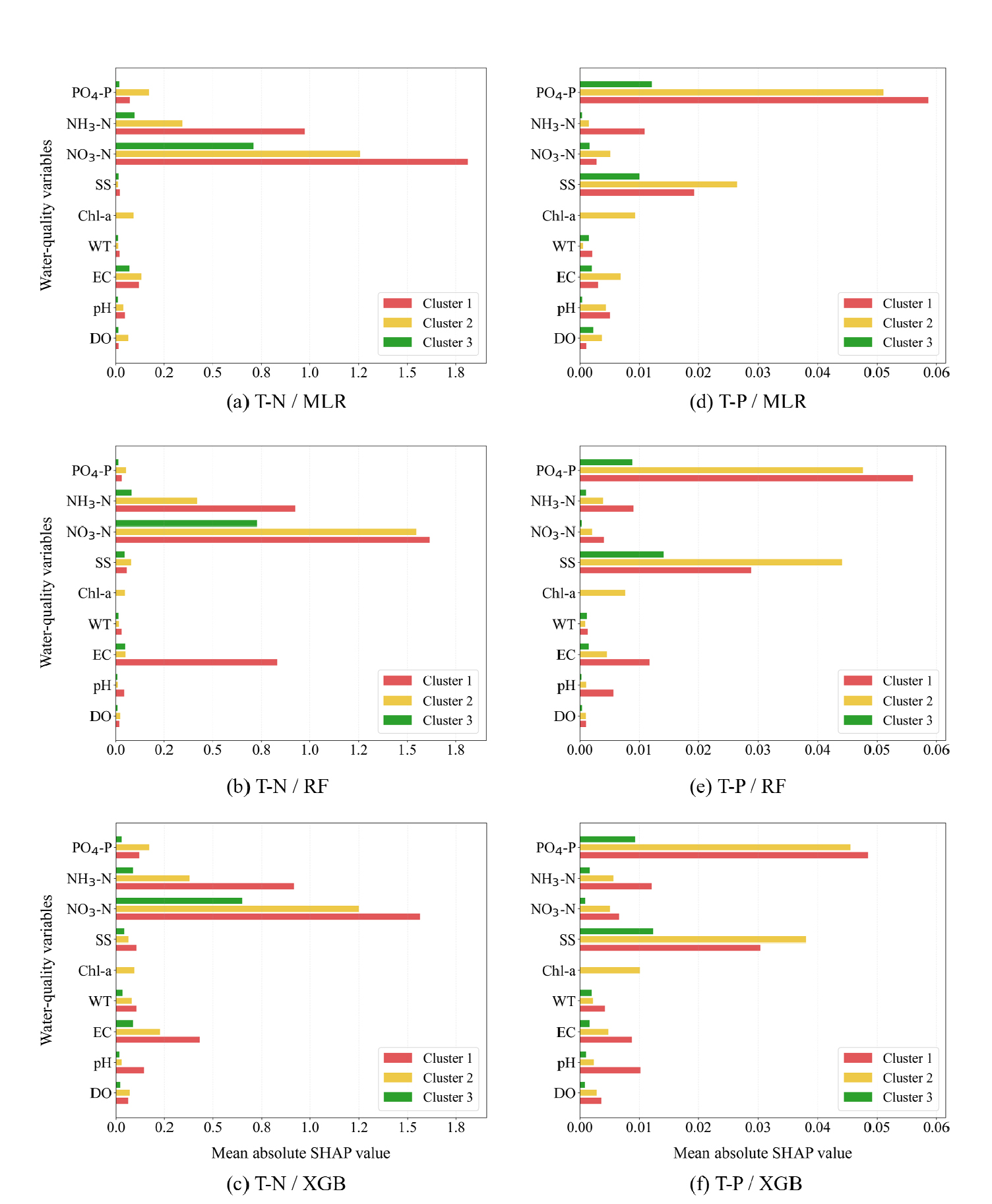
Fig. 8은 각 산정 모델에서 SHAP 값을 cluster별로 부호를 유지한 채 평균한 결과로, 개별 변수의 증가가 산정된 농도를 상승시키는지(+) 또는 감소시키는지(-)를 나타낸다. T-N 산정 모델에서는 모든 cluster 및 모델에서 NO3-N이 일관되게 음의 영향을 보여 NO3-N 농도가 증가하는 구간에서 SHAP 값이 음(-)으로 나타난 것은 해당 cluster 및 모델 조건에서 다른 질소 형태(NH3-N 등)의 상대적 기여가 더 크게 작용함을 의미한다. 반면 NH3-N은 특히 cluster 1에서 모든 모델에서 강한 양의 기여를 보여 NH3-N 증가가 해당 cluster에서 T-N 농도 상승을 주도하는 주요 요인임을 시사한다. T-P 산정에서는 SS가 cluster 2에서 뚜렷한 양의 영향을 나타내어 고형물 농도가 인 농도 산정에 직접적으로 기여함을 확인할 수 있었다. 반면 cluster 3에서는 모델에 따라 SHAP 기여 방향이 상이하게 나타나, P 농도 산정 과정에서의 비선형성과 지역적 이질성이 크게 작용함을 보여준다. PO4-P 변수의 경우 cluster 및 모델에 따라 기여 방향이 변화하였으며, 이는 해당 변수가 수계 조건에 따라 상이한 작용 메커니즘을 가짐을 의미한다. 특히 RF 및 XGB 모델에서는 cluster 1에서 PO4-P가 일관되게 양(+)의 영향을 보인 반면, cluster 3에서는 음(-)의 영향을 보여 cluster 간 및 모델 간 해석 시 주의가 요구된다. 이러한 signed SHAP 분석은 Fig. 7에서 제시한 절대값 기반 변수 기여도와 달리 변수 증가에 따른 농도 예측의 방향성과 모델 간 일관성 여부를 함께 평가할 수 있는 해석적 보완 도구로 활용될 수 있다. 이러한 방향성 차이는 각 cluster의 지배적 토지 이용 및 오염원 배출 특성에 기인하며, 도시화 지역(cluster 1)은 NH3-N 및 EC를 중심으로 한 생활 ·산업계 기여가 두드러지고, 농업지(cluster 2)는 SS 및 PO4-P 기반의 비점오염 영향이 강하게 나타난다. 반면 산림지역(cluster 3)은 자연적 배경 농도에 의한 상대적으로 단순한 반응 특성을 보여 수질 형성 구조의 차이가 SHAP 기여 방향성에도 반영된 것으로 해석된다.
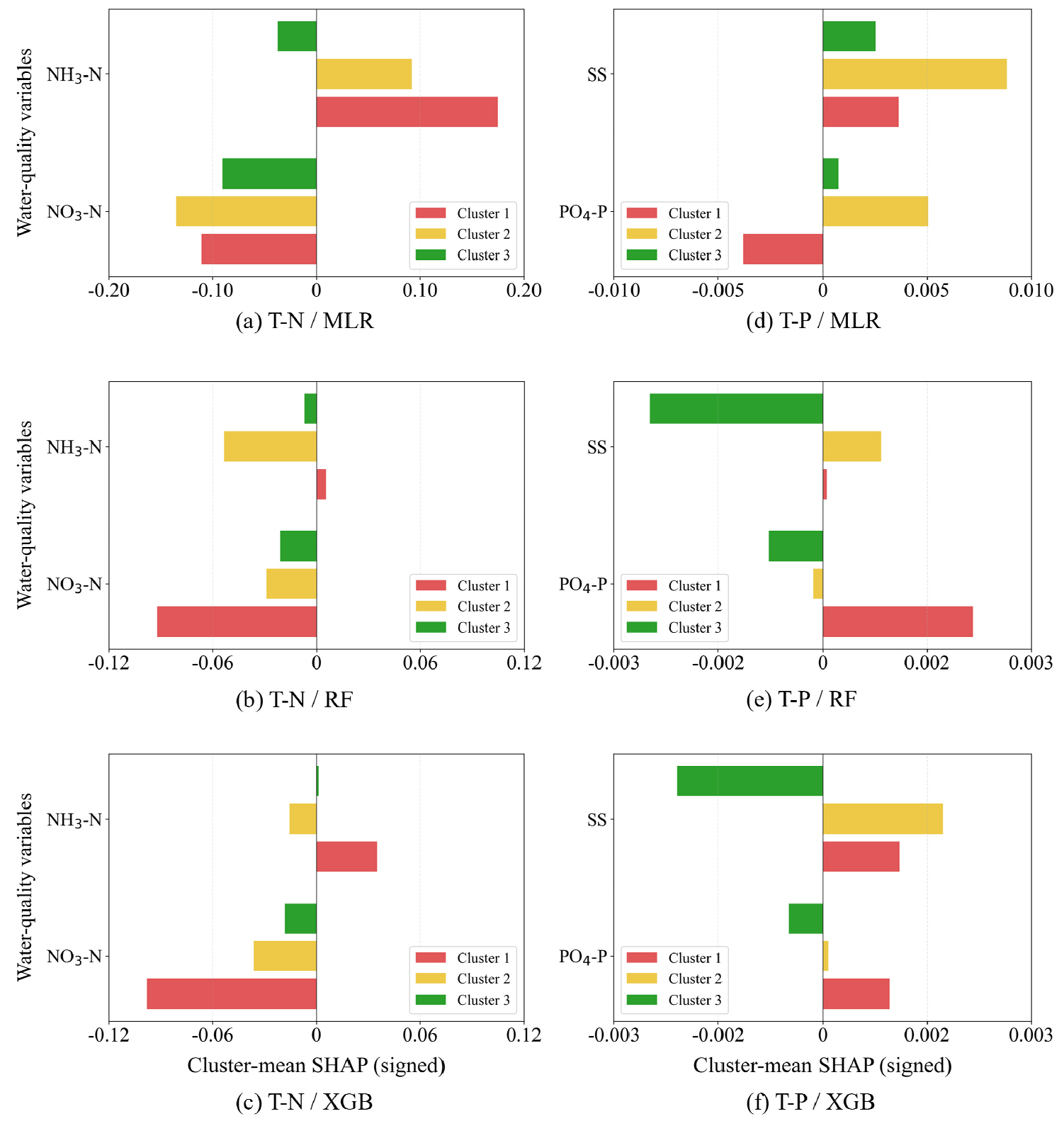
Fig. 9는 주요 수질항목과 T-N 및 T-P 농도 간의 조건부 관계를 시각화한 SHAP 의존도(dependence) 플롯으로, 변수의 영향 방향성과 반응 민감도를 정성적으로 해석할 수 있도록 구성하였다. 여기서 ‘영향 방향성’은 특정 변수 값의 증가가 예측된 농도를 상승(+) 또는 감소(-)시키는지를 나타내는 SHAP 값의 부호(sign)를 의미하며, ‘민감도’는 변수 값 변화에 따라 SHAP 값이 변화하는 정도, 즉 반응 기울기를 의미한다. 각 패널은 국소적 패턴과 데이터 분산 특성을 보존하기 위해 개별 축 범위를 유지하였으며, SHAP 값이 양(+)일 경우 해당 변수의 증가가 목표 농도를 높이는 경향을, 음(-)일 경우 낮추는 경향을 나타낸다.
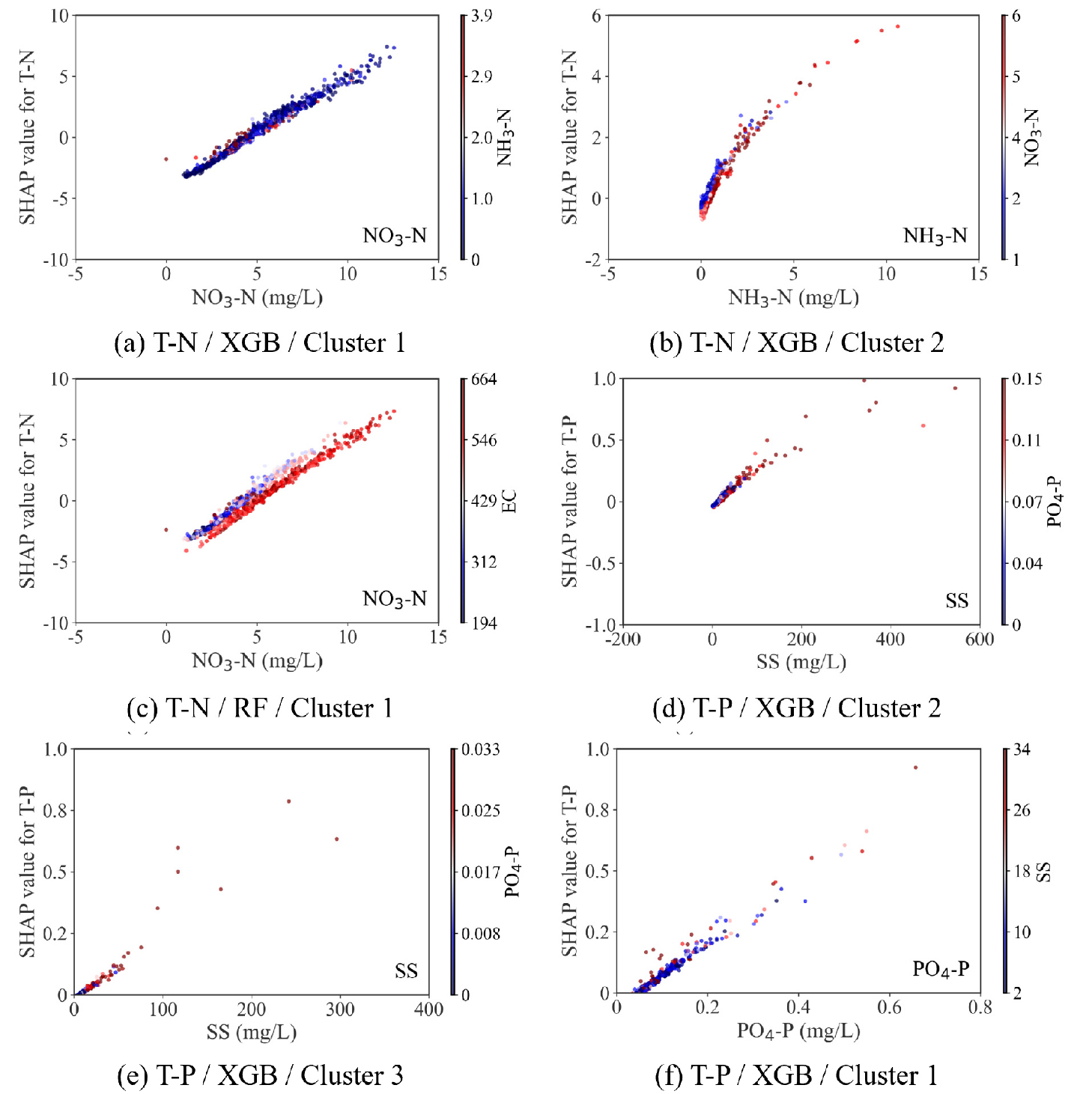
T-N 농도 산정 결과를 살펴보면, (a) T-N / XGB / Cluster 1은 NO3-N 농도가 증가할수록 SHAP 값이 선형적으로 증가하는 뚜렷한 양(+) 방향성과 높은 민감도를 보였다. (b) NH3-N / XGB / Cluster 2는 특히 저농도 구간에서 SHAP 값의 증가폭이 가파르게 나타나 민감한 응답 특성을 보였으며, (c) T-N / RF / Cluster 1은 (a)와 유사한 우상향 패턴을 재현하여 트리 기반 모델 간 방향성 일관성을 확인할 수 있었다. 두 모델 간 SHAP 값의 크기 차이는 비선형성, 변수 간 상호작용, 하이퍼파라미터 구조 차이를 반영하는 것으로 해석된다.
T-P 산정에서는 (d)와 (e)의 SS(XGB) 결과에서 SS 증가에 따라 SHAP 값이 증가하는 포화형(saturation-type) 양(+) 방향성이 공통적으로 나타났으며, 동일 농도 범위에서 cluster 2가 cluster 3보다 더 큰 민감도를 보였다. (f) T-P / XGB / Cluster 1의 PO4-P는 저농도 구간에서 SHAP 값 증가폭이 크게 나타났으며 전체적으로 완만한 양(+) 방향성을 보였다. 각 패널의 산점도 색상은 SHAP 알고리즘이 자동으로 선택한 상호작용 변수의 값을 나타내며, (a) NH3-N, (b) NO3-N, (c) EC, (d-e) PO4-P, (f) SS가 이에 해당된다. 이는 해당 변수의 독립적 효과를 의미하기보다는, 상호작용이 나타나는 지점을 식별하기 위한 보조적 정보로 해석하는 것이 적절하다.
마지막으로, 이러한 cluster별 반응곡선 차이는 토지피복 및 오염원 구조의 이질성에서 기인한다. 도시화 지역(cluster 1)은 생활·산업계 오염 영향이 커 NH3-N, EC, PO4-P의 반응 기울기(민감도)가 크고 양(+)의 영향 방향성이 두드러진다. 농업지(cluster 2)는 SS 및 Chl-a 기반의 비점오염·조류 증가 반응의 민감도가 높게 나타나는 반면, 산림지역(cluster 3)은 배경농도가 낮아 대부분의 변수에서 완만한 민감도와 음(-) 또는 약한 양(+) 방향성을 보였다. 즉, 토지이용 특성의 차이가 변수 영향 메커니즘의 구조적 차이를 만들어내며, 이는 T-N· T-P 산정 모델의 cluster별 SHAP 패턴 차이로 구체화된다.
4. 결 론
(1) 본 연구는 한강권역 내 37개 단위유역 말단 수질측정망을 대상으로, 가상 센서를 기반으로 한 T-N 및 T-P 농도 산정 모델을 구축하고, 산정 정확도 향상을 위한 토지피복 기반의 clustering 기법을 적용하였다. 산정 모델로는 MLR, RF 및 XGB 기법을 활용하였으며, 각 모델의 성능은 R2, RMSE, MAE 등을 통해 평가되었다. 그 결과, T-N 농도 산정에서는 세 모델 간 성능 차이가 미미한 반면, T-P 농도 산정에서는 cluster 및 모델 간 성능 편차가 뚜렷하게 나타나, 오염원 특성의 비선형성과 cluster 간 수질 반응의 이질성이 보다 강하게 작용함을 확인하였다.
(2) SHAP 기반 변수 중요도 분석 결과, T-N 농도 산정에는 NO3-N, NH3-N, EC의 영향력이 컸고, T-P 농도 산정에는 SS와 PO4-P가 주요 변수로 나타났다. SHAP 의존도 분석을 통해 이러한 변수들의 기여 방향성과 반응 형태를 시각적으로 확인하였으며, 단조 증가, 포화형 반응 등 실제 수질 거동과 유사한 패턴이 도출되었다. 특히 PO4-P와 SS는 cluster에 따라 부호와 민감도가 상이하게 나타나, P 농도 산정의 복잡성과 수계 내 공간적 이질성을 동시에 시사하였다. 이러한 SHAP 기반 해석은 모델의 블랙박스성을 완화하고, 산정 결과의 원인 기반 이해를 가능하게 한다는 점에서 의의가 있다.
(3) 본 연구는 cluster별 수질 반응 특성을 반영한 센서 조합 구성 및 산정 변수 관리 전략 수립에 실질적인 시사점을 제공한다. T-N 관련 변수의 경우, NO3-N와 NH3-N은 농도 수준과 기원이 서로 크게 다르기 때문에 단일한 유입 관리 전략으로 일괄 적용하기에는 한계가 있으나, SHAP 분석 결과 두 항목 모두 cluster별로 T-N 산정에 중요한 설명 변수를 이루는 것으로 나타났다. 이에 따라 도시·산업계 중심 유역에서는 NH3-N의 점오염·생활계 기여도를 고려한 관리가, 농촌·산림 혼합형 유역에서는 NO3-N의 배경농도 및 비점오염 특성을 고려한 관리가 각각 필요함을 시사한다. 한편, T-P 농도 저감을 위해서는 모든 cluster에서 공통적으로 높은 기여도를 보인 SS와 PO4-P의 관리가 핵심적임을 확인하였다. 또한 토지피복 기반 clustering 기법은 이러한 유역별 반응 특성을 체계적으로 반영할 수 있는 분석 수단으로서, 향후 실시간 예측 기반 수질 관리 시스템의 지역 맞춤형 의사결정 지원을 위한 기초자료로 활용될 수 있다.
(4) 향후 연구에서는 본 연구에서 확인된 변수별 기여도 및 cluster 간 반응 특성을 기반으로, cluster별 맞춤형 센서 네트워크 설계, 산정 변수 최적화, 강우-유출 및 토지이용 정보의 통합 등 다차원적 확장이 가능하다. 더불어, 산정 결과를 기반으로 한 실시간 대응 알고리즘 및 물환경관리 시나리오 구축을 통해 복합 오염원이 존재하는 대도시 수계에서의 수질 안정성 제고에 기초자료로 기여할 수 있을 것으로 기대된다.
