

1. 서 론
2. 방법론
2.1 강우빈도해석
2.2 다중 일을 고려한 비모수 시간상세화 기법
3. 연구 지역
4. 데이터 설명
4.1 관측 데이터
4.2 기후 시나리오 데이터
5. 응용 프로그램 방법론
5.1 기존의 홍수량 산정방법
5.2 기후변화시나리오를 활용한 홍수량 산정방법
6. 결 과
6.1 기후변화 시나리오를 활용한 확률강우량 산정결과
6.2 기후변화를 고려한 첨두홍수량 산정결과
7. 요약 및 결론
1. 서 론
최근 기후변화로 홍수가 빈번해지고 2000년대 이후 태풍 루사(2002), 매미(2003), 에니위아(2006), 볼라벤(2012) 등 많은 양의 강우를 동반한 태풍의 발생빈도가 잦아지고 있다.
Kim (2015)은 집중호우 및 강력한 태풍의 증가로 시설 안전성이 하락하고 피해가 증가하고 있다고 언급했다. 또한 2011년 우면산 산사태와 같이 순간적인 폭우로 수해를 입는 경우가 과거와 달리 점차 증가하고 있는 실정임을 언급했다.
Kim (2003)에 따르면 2002년 태풍 루사의 주된 피해원인은 치수 안전도를 훨씬 넘는 미증유의 많은 양의 강우이며 이로 인해 기존의 건설되어 있던 많은 제방과 저수지가 제 성능을 유지할 수 없었던 것으로 분석하였으며 극심한 강우로 인한 산사태, 홍수유출, 하천 시설물의 붕괴와 범람 등이 발생하였다(경북 김천, 강원도 강릉/양양 등).
Maeng et al. (2014)은 비룡저수지와 원남저수지의 가능최대강우량을 이용하여 홍수위를 추적하고 수문학적 안정성을 검토한 바 있다. 두 저수지 모두 최고수위가 저수지를 월류하지는 않았지만 여유고가 부족하여 수문학적 안정성은 확보하지 못하는 것으로 분석하였다. 그로 인하여 구조적인 대책과 비구조적인 대책을 제시하였고, 가능최대 홍수량은 설계기준에 의해 산정된 200년 빈도의 확률강우량에 비해 1.5~2.85배 높은 첨두홍수량을 산정됨을 알 수 있었다.
또한 Chae et al. (2013)은 Probable Maximum Flood (이하 PMF)를 산정하기 위한 단위도의 최적 매개변수를 추정하였다. PMF산정을 위한 단위도의 최적 매개변수 산정을 위해 HEC-HMS의 매개변수 민감도 분석을 통하여 민감한 매개변수를 선정하고 극한 홍수량을 모의하기 위해 최대 단위도 개념을 도입하여 저류상수, 도달시간, Curve Number (유출곡선지수, 이하 CN) 등을 산정하였고 저류상수와 도달시간은 경험식에 의한 매개변수, 유역특성인자를 이용한 매개변수에 비해 감소하였다. 이와 같이 극한 홍수에 대한 안전하고 효과적인 대책이 필요함과 더불어 현재 설계되어있는 댐의 설계홍수량의 위험성에 대한 검토도 필요할 것으로 사료되었다.
Fig. 1의 파란색 선은 남강댐의 시간당 연 최대치 유입량 자료를 나타낸 것이다. 빨간색 선은 남강댐의 200년 빈도 설계홍수량인 10,400 m3/sec를 나타낸다. 그러나 남강댐의 경우 200년 빈도로 설계된 홍수량을 6회 초과하는 관측값이 기록되었다. 이는 2000년 이후 발생한 많은 양의 강우를 동반한 태풍의 영향으로 판단된다. 유입량의 변동폭이 상대적으로 큰 구간을 3가지 구간으로 분류하였으며 이에 대한 평균을 초록색 선으로 도시하였다. 이 또한 마찬가지로 2000년 이후 급격하게 상승하는 것을 확인할 수 있으며 이로부터 남강댐의 홍수량 추정 시 기후변화 요소까지 감안해야 할 필요성을 나타내고 있다.

2. 방법론
본 연구 홍수량을 산정한 방법은 C1~C2로 구분하여 나타내었다. C1은 현재 실무에서 가장 많이 사용되는 방법으로 관측강우량 자료로부터 강우-유출모형을 형성하여 홍수량을 산정하는 방법이다. C2는 관측된 자료에 미래 기후 시나리오(RCP4.5/8.5)를 적용하여 산정한 강우량 자료를 더하여 홍수량을 산정하는 방법으로 미래의 홍수량 값을 산정하기 위해 실시한 방법이다. 빈도해석방법에 대한 매개변수를 산정하는 방법은 아래 절에 기술하였다.
2.1 강우빈도해석
강우빈도해석방법으로 홍수량을 산정하기 위해 Gumbel분포의 확률밀도함수(Probable Density Function, PDF, 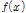 )와 확률누가함수(Cumulative Distribution Function, CDF,
)와 확률누가함수(Cumulative Distribution Function, CDF, 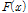 )은 각각 Eq. (1)~(2)로 나타낼 수 있다.
)은 각각 Eq. (1)~(2)로 나타낼 수 있다.
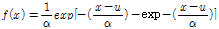 (1)
(1)
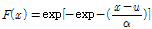 (2)
(2)
또한 본 연구에서 강우량자료로부터 확률강우량을 산정하기 위해서 확률 가중 모멘트법(Probability Weighted Moment, PWM)으로 Gumbel분포의 매개변수를 산정하여 확률강우량을 산정하였다. 이때 L-Moment방법과의 관계를 이용하여 매개변수를 산정할 수 있다(Hosking and Wallis, 1990). 적용된 식은 Eq. (3)과 같다.
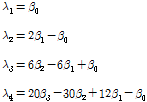 (3)
(3)
여기서 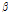 는 확률 가중 모멘트로서 매개변수인
는 확률 가중 모멘트로서 매개변수인 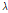 를 추정하기 위해 아래의 Eq. (4)과 같이 정의한다(Greenwood et al., 1979).
를 추정하기 위해 아래의 Eq. (4)과 같이 정의한다(Greenwood et al., 1979).
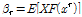 (4)
(4)
여기서 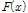 는 오름차순으로 정렬한
는 오름차순으로 정렬한 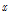 값의 CDF이다.
값의 CDF이다. 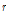 은 모멘트 차수를 의미한다. 또한 Eq. (5)를 이용하여 L-Moment비를 산정할 수 있다.
은 모멘트 차수를 의미한다. 또한 Eq. (5)를 이용하여 L-Moment비를 산정할 수 있다.
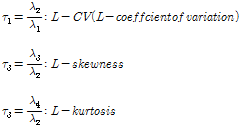 (5)
(5)
위에서 산정된 선형조합과 L-Moment비를 이용하면 Gumbel분포의 매개변수를 산정할 수 있다. 이때의 식은 Eq. (6)과 같으며 빈도별 확률강우량은 Eq. (7)를 통해 산정할 수 있다.
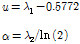 (6)
(6)
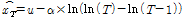 (7)
(7)
여기서, 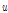 는 Location Parameter,
는 Location Parameter, 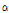 는 Scale Parameter,
는 Scale Parameter, 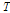 는 재현기간(Return Period),
는 재현기간(Return Period), 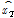 는 재현기간별 Gumbel분포의 Quantile값을 의미한다.
는 재현기간별 Gumbel분포의 Quantile값을 의미한다.
2.2 다중 일을 고려한 비모수 시간상세화 기법
본 연구에서는 일단위 기반의 기후변화 시나리오자료를 시간단위로 상세화하기 위하여 k-nearest neibor resampling (KNNR)과 유전 알고리즘(Genetic Algorithm, GA)를 혼합한 비모수 통계적 시간상세화기법을 사용하였다. 비모수 통계적 시간상세화 기법은 Lee et al. (2010)이 Colorado 강의 연 하천유량을 월 유량으로 분해하는데 적용한 바 있으며 더 나아가 Lee and Jeong (2014)는 진주지점을 대상으로 일강우자료를 시강우자료로 상세화하여 시간단위의 통계학적 특성을 재현해내는 기법을 개발하였다. 추가적으로 Lee et al. (2014)는 Lee and Jeong (2014)에서 제안한 방법을 경남지역의 기후변화 시나리오(RCP 4.5, 8.5)에 적용하였다. 과거의 연구는 오직 하루를 기준으로 시간상세화를 수행함에 따라 강우가 가지는 연속성을 고려하지 못하여 극치강우 측면에서 과소산정을 초래하는 문제점을 가지고 있었다. 따라서, 본 연구에서는 이를 보완한 다중 일을 고려한 비모수 시간상세화 기법을 적용하였다.
일단위 변수를 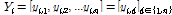 , 이에 상응하는 시간단위 변수를
, 이에 상응하는 시간단위 변수를 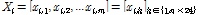 라 할 수 있다. 여기서,
라 할 수 있다. 여기서, 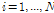 ,
, 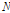 은 자료의 길이,
은 자료의 길이, 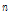 은 특정 다중 일의 갯수(예 5일),
은 특정 다중 일의 갯수(예 5일), 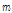 은 특정 다중 일의 시간 개수(
은 특정 다중 일의 시간 개수(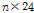 시간)를 의미한다. 즉, 특정 다중 일의 강수량
시간)를 의미한다. 즉, 특정 다중 일의 강수량 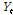 에 대하여 시간상세화를 하게 되면
에 대하여 시간상세화를 하게 되면 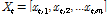 가 된다. KNNR의 변수
가 된다. KNNR의 변수  는 Lee and Ouarda (2011)에 의해 가장 일반적이며
는 Lee and Ouarda (2011)에 의해 가장 일반적이며
간단한 선택 방식인 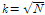 로 설정하여 분석을 수행하였다.
로 설정하여 분석을 수행하였다.
시간상세화를 위해 첫 번째로 특정 다중 일의 강수 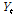 와 관측된 다중 일 강수
와 관측된 다중 일 강수 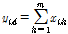 의 거리(distance)를 계산한다(Eq. (8)).
의 거리(distance)를 계산한다(Eq. (8)).
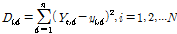 (8)
(8)
산정된 거리를 오름차순으로 정리하고  번째까지 최소거리를 가지는 시간지표(index)를 저장한다. 두 번째로 결정된
번째까지 최소거리를 가지는 시간지표(index)를 저장한다. 두 번째로 결정된  개의 시간지표 중 랜덤하게 1개를 추출하고 Eq. (9)와 같이 가중확률을 부여한다.
개의 시간지표 중 랜덤하게 1개를 추출하고 Eq. (9)와 같이 가중확률을 부여한다.
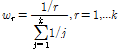 (9)
(9)
세 번째로 두 번째에서 선택된 시간지표의 시간단위 값(hourly values)을 Eq. (10)과 같이 할당한다. Eq. (10)의  는 선택된 시간지표를 의미한다.
는 선택된 시간지표를 의미한다.
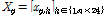 (10)
(10)
일반적으로 GA는 다양한 유전자의 재배열을 통해 새로운 개체를 생산하고 이중에서 목적함수의 매개변수를 추정하는 방법으로 주로 이용된다. 하지만 본 연구의 목적은 부모의 유전자를 물려받아 통계학적으로 유사성을 가지는 개체를 생산하는 것이므로 GA의 주요 개념을 적용하였지만, 기존 자료의 통계학적 특성을 유지하는 새로운 개체를 생산해 낸다는 점에서 차이점이 있다. 따라서, GA의 목적함수 및 제약조건이 생략되며 GA의 혼합과정 이후 우수한 개체를 선택하는 방법은 적용되지 않은 Simple GA를 사용하였다. 네 번째로 GA의 혼합과정은 크게 3가지(재생, 교차, 변이)로 분류되며 다음과 같다.
(1) 재생: 위의 첫 번째에서 세 번째까지의 분석절차를 통해 하나의 부가적인 시간지표를 추가로 선택하고 이를 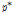 로 할당하며 Eq. (11)와 같다.
로 할당하며 Eq. (11)와 같다.
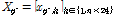 (11)
(11)
(2) 교차: 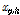 의 각 요소를 Eq. (12)의 조건식을 통해
의 각 요소를 Eq. (12)의 조건식을 통해 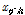 로 교체한다.
로 교체한다.
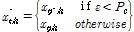 (12)
(12)
여기서, 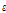 은 0과 1사이에 균등하게 분포된 난수를 의미한다(uniform random number)이다.
은 0과 1사이에 균등하게 분포된 난수를 의미한다(uniform random number)이다.
(3) 변이: 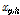 의 각 요소를 Eq. (13)의 조건식을 통해
의 각 요소를 Eq. (13)의 조건식을 통해 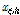 로 교체한다.
로 교체한다.
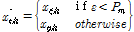 (13)
(13)
다섯 번째로 GA로 혼합된 시간단위 값들을 다음의 합산조건이 보존되도록 조정하고 마지막으로 필요한 자료가 생성될 때까지 첫 번째에서 다섯 번째를 반복한다.
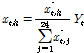 (14)
(14)
Eq. (12)의 교차(Crossover)의 확률 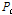 와 Eq. (13)의 변이(Mutation)의 확률
와 Eq. (13)의 변이(Mutation)의 확률 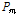 에 관하여 Lee et al. (2010)에 의해 연구되었으며 이에 대한 자세한 설명은 Lee et al. (2010)의 논문을 참고할 수 있다.
에 관하여 Lee et al. (2010)에 의해 연구되었으며 이에 대한 자세한 설명은 Lee et al. (2010)의 논문을 참고할 수 있다.
3. 연구 지역
본 연구에서는 여러 가지 홍수량 산정방법(C1~C5)으로 홍수량을 산정하고 그 방법을 5장에 상세히 기술하였다. 또한 현재 설계되어있는 남강댐의 설계홍수량과의 비교를 위해 기존 남강댐의 홍수량 산정 보고서를 조사하여 본 연구결과와 비교하고자 하였다. 비교 대상인 보고서는 남강댐 관리단에서 작성한 K-Water (2014)에서 남강댐의 현재 설계홍수량을 비교하고 PMF의 경우 비교적 최근 홍수량을 산정하고 Ministry of Land and K-Water (2011)의 자료와 비교하였다.

본 연구의 대상지점인 남강댐 유역의 형상은 Fig. 2과 같다. 전체유역은 그림과 같이 총 12개의 소유역으로 분할하여 그림에 나타내었고, 수문곡선의 합성과 Muskingum추적을 통하여 홍수량을 산정하였다. 검은 선의 다각형은 ArcGIS프로그램을 이용하여 도시한 Thiessen다각형이며 본 연구의 Thiessen망 산정 결과 남강댐 유역에 지배면적을 가지고 있는 강우 관측소는 총 6개(산청, 합천, 거창, 남원, 임실, 진주)였다. 그 중 가장 넓은 지배면적을 차지하는 관측소는 산청 관측소였으며 가장 적은 지배면적을 차지하는 관측소는 임실관측소였다. 각 관측소의 위치는 Fig. 2에 ●로 나타내었다.
각 관측소가 유역 전체에 차지하는 Thiessen면적비는 Table 4에 기술하였다. 또한 각 소유역의 Thiessen면적비와 유역 면적은 각각 Table 5의 2열과 3~8열에 기술하였다. 소유역 내의 파란색 글자는 본 연구의 홍수량 산정시 소유역의 번호를 나타내었으며 마찬가지로 Table 5에 나타내었다.
홍수량 산정시 위의 Thiessen가중치를 이용하여 C1-S의 경우 Yoon et al. (2012)에 따라 홍수량을 산정하였다.
4. 데이터 설명
4.1 관측 데이터
본 논문에서 사용된 관측데이터는 남강댐 유역 인근에 위치하는 관측소들의 시강우 자료를 사용하였다. 여러 관측소들 중에서 기상청 관할 관측소의 신뢰성이 가장 높게 판단되므로 본 연구에서는 기상청관할의 관측소만을 사용하였다. 사용된 기상 관측소는 총 6개소로 산청, 합천, 거창, 남원, 임실, 진주 관측소이며 위치 및 관측기간 등은 아래 Table 3에 나타내었다. 관측년수는 진주관측소의 경우 관측 기간이 1969~2014년으로 46개년이며, 진주를 제외한 관측소의 경우 관측 기간이 1973~2014년으로 42개년이다.
관측강우량을 확률강우량으로 변환하여 홍수량을 산정할 경우 각 관측소별로 확률강우량을 산정한 다음 Table 2의 Thiessen면적비를 적용하여 홍수량을 산정하였다.
Table 1. Thiessen rates at each rainfall station | ||||||
Name of Rainfall Stations | Sancheong | Hapcheon | Geochang | Namwon | Imsil | Jinju |
Thiessen Rates | 0.5563 | 0.0567 | 0.1627 | 0.0855 | 0.0021 | 0.1366 |
4.2 기후 시나리오 데이터
국립기상연구소의 보고서에 따르면 기상청은 기후변화 대응을 위하여 전지구, 동아시아, 한반도 기후변화 시나리오를 산출하고 있다. 이 연구에 사용된 기후변화 전망 자료는 기상청이 영국 기상청의 지역기후모델(HadGEM3-RA)을 도입하여 생성한 한반도 지역기후 시나리오자료이며, 모델의 영역은 우리나라를 중심으로 중국 및 일본의 일부 지역을 포함 한다(Walters el al., 2011).
HadGEM3-RA의 수평 분해능은 격자 거리 12.5 km로 동서 및 남북 방향으로 각각 200 × 180개의 격자로 구성되었고, 연직 분해능은 지상에서 40 km 고도까지 38개의 층으로 구성되었다. 대규모 강제력 정보가 제공되는 측면경계 완충격자는 모델 최외곽 8개 격자점이, 측면경계 강제력은 6시간 간격의 전지구 기후변화 전망 자료가 사용되었다. 전지구 기후변화 전망자료 또한 기상청이 영국기상청으로부터 도입한 대기-해양-해빙 결합모델(HadGEM2-AO)을 이용하여 산출하였으며 수평 격자 거리는 약 135 km (동서방향 1.875°, 남북방향 1.25°)이다(Collins et al., 2008).
HadGEM3-RA의 역학 체계 및 물리과정은 전지구모델의 대기 모델과 유사하며 비정수 역학계이다. 또한 밀도를 제외한 모든 예단변수에 대하여 Semi-Lagrangian 이류를 적용하였다. 또한 특정 지역을 모델 영역으로 설정할 경우 지구의 극점을 수치적으로 이동시켜 모델 영역의 중심이 적도 지역에 위치하게 하는 적도 위경도 격자체계(equatorial latitude- longitude grid system)을 가진다. 이와 같은 좌표계의 특성은 지도 투영법을 적용하여 직각 좌표계를 사용하는 일반적인 지역기후모델과 구분되는 것으로, 모델 영역이 광범위 할 경우에도 지도인자로 인한 왜곡현상이 발생하지 않는다. 따라서 모델 영역의 확장이 비교적 용이하다는 장점이 존재하였다(Sung et al., 2012).
우리나라가 위치한 동아시아 지역은 지리적 특성이 매우 복잡하고 기후 변동성이 크기 때문에 극한기후 현상을 전망하기 위하여 수평 해상도 수십~수 km이상의 상세한 지역기후변화 시나리오 자료를 요구한다(Boo et al., 2004; Boo et al., 2006; Im and Kwon, 2007; Koo et al., 2009). 따라서, 본 연구에서는 우리나라의 미래 극한 강수 전망을 위하여 12.5 km 분해능의 HadGEM3-RA에서 생산한 RCP 4.5와 8.5의 지역기후 시나리오 자료를 활용하였다.
5. 응용 프로그램 방법론
5.1 기존의 홍수량 산정방법
현재 우리나라에서는 홍수량 산정시 일반적으로 Yoon et al. (2012)에 따른다. 첨두 홍수량자료로 시계열의 빈도해석을 하는 방법은 직접 홍수량 자료 계열을 빈도 해석하여 설계홍수량이나 확률홍수량을 산정하는 방법이다. 또한 이론적으로도 가장 직접적이고 최상의 방법이라 할 수 있다. 그러나 우리나라의 경우 홍수량의 관측년수가 짧은 지역이 대부분이며 홍수위 자료로부터 수위-유량곡선식을 작성하여 산정한 홍수량 자료의 신뢰도는 상당히 낮기 때문에 시계열 빈도해석의 어려움이 있다. 또한 댐 건설 전후의 홍수량 자료의 불연속성 때문에 더욱 빈도해석이 어렵다.
따라서 우리나라에서 적용되는 방법은 강우-유출모형을 통하여 유출량을 산정하는 방법으로 홍수량을 산정하게 된다. 이 방법은 상대적으로 풍부한 강우자료를 이용하여 홍수량을 산정할 수 있다. 그러나 이 방법은 강우-유출 관계가 선형성을 가진다는 가정을 전제로 하는 방법이다. 강우-유출모형은 단위도 방법을 사용한다.
5.2 기후변화시나리오를 활용한 홍수량 산정방법
본 연구의 홍수량 산정에서는 2가지 Case의 홍수량 산정방법으로 홍수량을 산정하였다. Case별 산정방법은 다음 Table 4와 Fig. 7에 나타내었다. Table 4는 각각의 Case의 산정방법별 원자료와 매개변수 추정 방법, 분석방법, 자료 년수, 유출모형, 임계지속기간을 기술하였다.

C1-S의 경우 실무에서 일반적으로 사용되는 홍수량 산정방법으로 Clark 단위도법을 적용하고 강우-유출 모형을 형성하여 홍수량을 산정할 수 있었다. 즉, 위의 산정된 확률강우량을 통하여 HEC-1프로그램을 사용하여 Clark 단위도법으로 홍수량을 산정하게 된다. 임계지속기간은 지속기간별로 홍수량 산정시 가장 큰 홍수량이 산정되는 지속기간을 임계지속기간이라 한다. 본 연구의 경우 가장 일반적으로 사용되는 C1-S의 홍수량을 산정해본 결과 유역의 임계지속기간이 18시간으로 산정되었다. 따라서 C2-S45/85의 경우에도 임계지속기간을 18시간으로 적용하였다. 재현기간(Return Period)의 설정은 200년 빈도와 10,000년 빈도로 각각 산정하였다. 남강댐의 경우 설계 홍수량은 200년 빈도로 산정되어 있기 때문에 같은 재현기간으로 산정한 홍수량 값을 비교하기 위함이고 10,000년 빈도의 경우 가능최대홍수량(Probable Maximum Flood, PMF)을 산정할 때 이용되는 재현기간이다.
C1-S의 경우 과거 관측된 실측 강우량 자료를 통하여 확률 강우량을 산정하였다. C2-S45는 C1-S에서 사용한 관측강우량 자료에 RCP 4.5의 미래기후 시나리오 강우량 자료를 적용하여 RCM자료를 산정 후 홍수량 산정모델에 적용하여 홍수량을 산정하게 된다. C2-S85의 경우는 RCP 8.5의 미래기후 시나리오 강우량 자료를 적용하여 RCM자료를 산정하게 된다.
본 연구에서는 강우-유출 모의를 위해 유역추적법은 Muskingum방법, 유역추적법은 Clark 단위도 방법을 적용하였다. Muskingum방법의 주요 매개변수인 저류상수 K는 부정류 모형을 통해 산정된 홍수파의 도달시간을 이용한 남강 하천기본계획(변경) (부산지방국토관리청, 2009)에서 산정한 값을 적용하였으며 Clark 단위도 방법의 경우 주요 매개변수는 도달시간 Tc, 저류상수 R, 유출곡선지수 CN로 남강유역 수자원개발조서(국토해양부, 2011)에서 제시한 값을 적용하였다. 남강유역 수자원개발조서(국토해양부, 2011)에서 기왕최대 홍수사상(태풍 RUSA)를 포함한 총 8개의 호우사상(1990년 1개 호우사상, 2000년 3개 호우사상, 2001년 1개 호우사상, 2002년 2개 호우사상, 2003년 1개 호우사상)에 대하여 매개변수 최적화를 수행하여 제시된 매개변수로 추가적인 매개변수 검보정이 필요하지 않을 것으로 판단하여 실시하지 않았다.
본 연구의 홍수량은 C1-S, C2-S45/85에 대하여 재현기간 200년 빈도(남강댐의 설계홍수량의 재현기간 빈도), 10,000년 빈도(최적치 개념의 설계홍수량 빈도)로 산정되었다. 홍수량의 비교 분석은 2014년의 현재까지의 자료로부터 산정한 홍수량(각 200년, 10,000년 빈도의 C1-S)과 미래경향성을 적용하여 2050년까지의 자료로 산정한 홍수량(각 200년, 10,000년 빈도의 C1-S, C2-S45/85)의 차이를 비교하여 홍수량 산정시 미래경향성 자료의 중요성에 대해 분석하였다. 2100년까지의 자료도 비교가 가능하나 이는 현실적으로 맞지 않는 값을 주는 경향이 있어 본 연구에서는 배제하였다.
6. 결 과
6.1 기후변화 시나리오를 활용한 확률강우량 산정결과
본 연구는 2000년대 이후 급격하게 증가한 강우자료로부터 홍수량을 산정(C1-S)하고 그밖에 미래 기후 시나리오를 적용한 강우량으로부터 산정한 홍수량(C2-S45/85)과 남강댐의 설계홍수량(200년 빈도, 10,400 m3/sec)을 비교해보고 안전성을 검토하고자 하였다. 목적에 따른 홍수량 산정을 위해 산정한 200년 빈도와 10,000년 빈도의 강우량 자료는 Table 5와 Table 6에 나타내었다.
모든 Case의 홍수량 산정결과 임계지속기간은 18시간으로 산정되었다. 따라서 확률강우량 또한 18시간의 지속기간을 가진 확률강우량만을 나타내었다. C2-S45와 C2-S85의 경우 미래 기후 시나리오 RCP4.5와 RCP8.5에 대하여 비모수 시간상세화 기법을 통해 100개의 시간상세화 모의결과를 추출하였으며 Gumbel 분포형을 이용하여 강우빈도해석을 수행하였으고 100개 모의결과 중 중앙값(Median)을 Table 5, 6에 제시하였다.
6.2 기후변화를 고려한 첨두홍수량 산정결과
200년의 빈도로 홍수량을 산정한 이유는 현재 설계되어있는 남강댐의 설계홍수량의 재현기간이 200년 빈도이기 때문이다. 홍수량의 비교는 먼저 현재 우리나라의 실무에서 일반적으로 가장 많이 사용되는 C1-S의 방법과 각각 비교하였다. 또한 현재 관측된 자료들로만 홍수량을 산정했을 경우와 미래경향성을 고려한 자료를 비교하기 위하여 본 연구에서 산정한 홍수량을 2014년까지와 미래 경향성을 고려하여 산정한 2050년까지의 자료로 산정한 홍수량을 통하여 그 차이를 비교하였고, 그 결과를 Table 7에 나타내었다. 그 결과 본 연구에서 산정한 모든 Case의 첨두홍수량은 현재 남강댐의 설계홍수량보다 크게 산정되었다. 상세한 내용은 아래와 같다.
앞서 언급함과 같이 C2-S45/85의 경우 RCP4.5와 RCP8.5 시나리오에 따라 각각 100개 세트의 확률강우량을 산정하여 홍수량을 산정하였다. 따라서 100세트의 값 중 Median값과 C1-S의 산정홍수량을 비교하고 100개 세트 중 max값과 min값을 따로 나타내었다. 그 결과는 Fig. 4과 Table 8에 나타내었다. 산정된 홍수량의 크기는 C2-S85 (22,748 m3/sec)의 홍수량이 가장 크게 산정되었으며 C1-S의 홍수량(16,347 m3/sec)이 가장 작게 산정되었다. 그 값의 차이는 Median값으로 비교하였을 경우 C1-S와 C2-S45의 경우 4,783 m3/sec의 홍수량 차이가 있었고, C1-S와 C2-S85의 경우 6,701 m3/sec의 홍수량 차이가 있었다. 이는 정상성 빈도해석을 적용하여 산정한 홍수량의 경우보다 더 극한의 강우 사상을 나타내는 미래 기후 시나리오(RCP 4.5 and RCP 8.5)를 적용함에 의해 기인한 것으로 판단되며 RCP 4.5의 시나리오보다 RCP 8.5의 시나리오가 더 극한의 강우 사상을 발생시킴을 의미한다.

Table 8. Peak flows (CMS) of C1-S, C2-S45 and C2-S85 with 200 year return period | |||
Return Period (200 Years) | Max (m3/s) | Median (m3/s) | Min (m3/s) |
C1-S | - | 16,347 | - |
C2-S45 | 21,978 | 21,130 | 19,777 |
C2-S85 | 23,786 | 22,748 | 21,859 |
현재의 자료로부터 산정한 홍수량과 미래 경향성을 고려한 자료로 산정한 홍수량을 그룹화 시키면 아래의 Table 7과 같다.
C1-S의 경우 현재시점과 미래시점에서 보았을 때 정상성을 가정한 부분이기 때문에 양쪽에 모두 나타내었다. 또한 미래시점의 경우 RCP 8.5시나리오를 적용한 C2-S85의 값이 가장 크게 산정되었다. 이는 미래 경향성을 고려할 경우 산정되는 홍수량은 더욱 커짐을 알 수 있다. 또한 C2-S85 값이 현재 설계되어있는 남강댐의 설계홍수량보다 2배 가까운 수치였으며, 현재 실무에서 가장 많이 사용되고 있는 C1-S방법으로 산정한 홍수량보다도 약 33% 크게 산정되었다. 따라서 현재 설계되어 있는 남강댐의 설계홍수량은 상당히 낮게 산정되어있기 때문에 C2-S85와 같은 미래 경향성을 고려하여 운영적인 측면 및 향후계획을 더욱 세심하게 해야 할 것으로 판단된다.
10,000년 빈도의 홍수량을 산정한 목적은 댐 파괴에 대한 안정성을 검토해보기 위함이다. 세계 다른 나라들의 댐 설계 기준이 되는 홍수량을 채택하는 기준 은 10,000년 빈도와 PMF이다. 10,000년 빈도로 산정한 홍수량은 200년 빈도보다 정상성 빈도해석을 적용한 홍수량(C1-S)의 경우 55%, 미래기후 시나리오 자료로 산정한 홍수량(C2-S45/85)의 경우 약 57% 크게 산정되었다. 또한 200년 빈도의 경우와 마찬가지로 현재 관측된 자료들로만 홍수량을 산정했을 경우와 미래경향성을 고려한 자료를 비교하기 위하여 본 연구에서 산정한 홍수량을 2014년까지와 미래 경향성을 고려하여 산정한 2050년까지의 자료로 산정한 홍수량을 통하여 그 차이를 비교하였다. 그 결과를 Table 9에 나타내었다. 결과는 200년 빈도와 마찬가지로 본 연구에서 산정한 모든 Case의 산정홍수량은 현재 남강댐의 설계홍수량보다 크게 산정되었다. 또한 모든 Case별 산정홍수량은 각각 200년 빈도보다 크게 산정되었다. 상세한 내용은 아래와 같다.
Case별 비교에서는 C1-S (25,397 m3/sec)와 C2-S45 (33,275 m3/sec)의 홍수량을 비교할 경우 Median값을 기준으로 7,878 m3/sec의 차이가 발생하였으며 C1-S와 C2-S85 (35,670 m3/sec)의 홍수량을 비교할 경우 10,273 m3/sec의 차이가 발생하였으며 그 결과는 Fig. 5과 Table 10에 나타내었다. 이는 200년 빈도와 마찬가지로 정상성 빈도해석을 적용하여 산정한 홍수량의 경우보다 더 극한의 강우 사상을 나타내는 미래 기후 시나리오 (RCP 4.5 and RCP 8.5)를 적용함에 의해 기인한 것으로 판단된다. 아울러 경향성에 의한 영향 및 분포형의 차이와 매개변수 추정방법의 차이로 각 관측소의 확률강우량이 크게 산정되어 홍수량이 크게 산정된 것으로 판단된다.

현재시점과 미래시점에서 산정된 홍수량들의 Case는 아래 Table 9에 나타내었다. 미래 경향성을 고려하여 산정한 홍수량 중에서는 미래기후 시나리오 RCP 8.5를 적용한 홍수량이 가장 크게 산정되었다.
7. 요약 및 결론
본 연구에서는 남강댐 유역의 홍수량을 여러 가지 Case에 대하여 산정하고 남강댐의 홍수량 산정의 적정성에 대하여 분석해 보았다. 본 연구에서 시행한 홍수량 산정방법은 재현기간 200년 빈도와 10,000년 빈도에 대해 관측 강우량 자료로부터 정상성 빈도해석 방법을 적용하여 산정한 홍수량(C1-S), 미래 기후 시나리오를 적용하여 산정한 홍수량(C2-S45 (RCP 4.5), C2-S85 (RCP 8.5))이 있었다.
임계지속기간의 경우 현재 설계치와 최적치 개념의 설계홍수량(200년 빈도, 10,000년 빈도)의 경우 임계지속기간이 18시간으로 산정되었다. 이 결과는 남강유역 수자원 개발조사 보고서에서 나타난 결과와 같았다. 홍수량 산정 결과 값은 200년 빈도와 10,000년 빈도에 따라 현재의 개념으로 산정하는 홍수량 산정 방법(2014년의 시점의 자료)과 미래 예측을 통하여 홍수량을 산정하는 방법(2050년 시점의 자료로 산정)으로 구분하였다. 그 결과는 Table 11에 전체적으로 나타내었다. 그 결과 미래 기후변화의 경향성에 의해 확률강우량이 증가하는 Case에서 홍수량은 200년 빈도와 10,000년 빈도 모두 현재시점에서보다 미래시점에서 산정된 홍수량이 크게 산정되었으며 RCP 8.5시나리오를 적용하여 산정한 C2-S85의 홍수량이 가장 크게 산정이 되었다. 또한 댐 파괴에 대한 안전성을 판단하는 기준이 되는 10,000년 빈도 미래시점에서 가장 크게 산정된 홍수량은 200년 빈도와 마찬가지로 RCP8.5를 적용한 C2-S85 가장 크게 산정되었다. 이로부터 미래기후변화의 경향성을 고려하면 보다 큰 설계홍수량을 적용해야 할 것으로 판단된다.
본 연구에서 산정한 홍수량 결과에 따르면 200년 빈도로 설계되어 있는 현재 남강댐의 설계홍수량인 10,400 m3/sec는 다소 낮게 설계되어 있는 것으로 판단된다. 또한 2003년에 보강을 하여 또 다른 보강사업을 시행하기 어려울 뿐만 아니라 남강댐으로 유입을 지체시키는 보강댐을 둘러싼 갈등이 빚어지고 있는 상황이다. 뿐만아니라, 홍수시 대부분의 유량을 사천으로 유출시킴으로써 사천만의 해양생태계를 파괴시키고 연안지역의 어민피해 및 홍수위험성을 증대시키고 있어서 이에 대한 대책 마련도 시급한 실정이다. 따라서 다방면에 대한 연구를 통해 기후변화에 대비 및 대응과 동시에 하류지역(사천만 지역)의 피해 저감 방안 등이 앞으로 더욱더 연구되어져야 할 것이다.
