

1. 서 론
2. 대상자료
3. 방법론
3.1 확률가중모멘트법을 적용한 Gumbel 분포의 매개변수 추정
3.2 Bayesian 방법을 이용한 확률분포 매개변수 추정방법
3.3 Bayesian Markov Chain Monte Carlo 모의
4. 빈도해석 및 불확실성 평가 결과
5. 자료기간에 따른 빈도해석 및 불확실성 평가 결과
6. 결 론
1. 서 론
빈도해석은 강우량을 입력 자료로 사용하는 강우빈도해석과 홍수량을 입력 자료로 사용하는 홍수빈도해석이 있다. 설계홍수량 산정에는 홍수량자료를 활용한 홍수빈도해석이 이론적으로 가장 적합한 방법이나(Jung and Yoon, 2007), 관측자료 부족, 댐 등 유역의 인위적인 변화로 인한 자연유량 취득의 어려움, 자료의 신뢰성 문제 등으로 분석에 많은 제약이 동반된다. 그러므로 우리나라에서는 강우빈도해석으로 설계홍수량을 산정한 후 유출 모형으로 유출량을 모의함으로써 확률홍수량과 설계홍수량을 산정하는 방법이 주로 사용되고 있다(Ministry of Land, Transport and Maritime Affairs, 2012). 강우빈도해석 시, 대상 자료가 GEV, Gamma, Gumbel 등의 확률분포형을 따른다고 가정하여 확률분포형에 해당하는 매개변수를 최우도법, 모멘트법, 확률가중모멘트법 및 L-모멘트법 등의 방법을 사용하여 추정함으로써 확률강우량이 산정된다. 그러나 추정되는 설계빈도에 비해 상대적으로 작은 자료 연한으로 50년 빈도 이상의 설계강우 산정 시 상당한 불확실성이 내재되어있으나, 이에 대한 정량적인 평가는 미진한 상태이다.
수공구조물의 적절한 설계홍수량의 선정을 위하여 다양한 분포형과 매개변수 추정방법을 활용한 강우빈도해석 기법에 대한 연구가 수행되고 있다. Kim et al. (1995)는 빈도해석에서 널리 사용되는 5개의 분포형에 대해 모멘트법과 확률가중모멘트법을 비교함으로써, 우리나라의 짧은 기간의 자료계열에는 확률가중모멘트법이 적용성이 높음을 제시하였다. Lee (2004)은 매개변수, 비매개변수 방법으로 산정한 확률강우량을 비교함으로써, 각각의 매개변수 추정기법의 한계를 보완한 새로운 기법의 필요성을 제시하였다. 그 밖에 Park et al. (2014)는 관측연수보다 많은 비연초과치 강우 자료를 활용한 빈도해석 방법을 제시하였으며, Yoon et al. (2012)는 혼합 확률분포를 활용한 빈도해석기법 제시함으로써 정확도 높은 확률강우량을 산정하기 위한 다양한 연구가 시도되었다. 하지만 수문분석 과정에서는 수문자료의 측정 및 수집 과정, 수문모형의 적용과정에서 불확실성이 개입되어 있으며, 확률강우량 산정과정에서도 확률분포모형의 적용 및 매개변수 산정과정에서 불확실성을 포함하게 된다(Hong et al., 2001). 기존의 매개변수 추정기법은 재현기간에 따른 확률강우량의 단일 결과를 추정하기에 적합하며, 불확실성을 제시하는데 한계가 존재한다. 본 연구에서는 Bayesian 기법을 적용하여 강우빈도해석시의 불확실성을 정량적으로 표현하고자 한다.
강우빈도해석에서 불확실성은 확률강우량의 신뢰구간을 활용하여 표현할 수 있다. 신뢰구간을 산정하기 위하여 근사식을 활용한 다양한 연구가 진행되었으나, 근사식을 사용할 경우에는 확률분포의 매개변수 추정과정에서 정규성, 선형성 등의 가정이 이루어져 불확실성 산정 시에 과다추정이 발생될 수 있다.(Kim and Lee, 2008; Reis Jr. and Stedinger, 2005) 근사식을 이용한 불확실성 추정방법 대신에 Bootstrap으로 자료를 발생시켜 신뢰구간 산정, Bayesian 기법을 이용하여 불확실성을 나타내는 연구가 수행되었다(O’Connell et al., 2002; Reis Jr. and Stedinger , 2005; Tasker, 1987). Bayesian 기법은 근사식을 사용하기 위한 가정조건이 필요하지 않아 기존의 방법보다 우수하며(Kim and Lee, 2008), Bayesian 방법은 매개변수의 사후분포(posterior distribution)를 제공하여 매개변수의 불확실성 구간을 제시함으로써, 기존의 방법에 비해 매개변수 추정 시 신뢰성 있는 접근이 가능하다(Congdon, 2001). O’Connell et al. (2002)는 모멘트 기법 기반 매개변수 추정기법들이 측정 오차(measurement error)를 고려한 빈도해석의 수행에는 한계가 있음을 제시하며 Bayesian 홍수빈도해석 기법을 제시하였다. Coles and Pericchi (2003)과 Coles et al. (2003)은 Bayesian MCMC (Markov chain Monte Carlo) 알고리즘을 활용하여 GEV 분포모형의 매개변수를 추정한 사례가 있으며, Reis Jr. and Stedinger (2005)는 Bayesian MCMC 기법을 적용하여 확률강우량 및 홍수위험도에 대한 신뢰구간을 추정하였다. Kim and Lee (2008a), Kim and Lee (2008b)는 Bayesian MCMC 기법으로 저수량의 점 빈도해석을 수행하여, 최우도법의 근사식을 이용하였을 때보다 불확실성 구간을 감소시킨 결과를 도출하였다. Han et al. (2009) 은 Bayesian MCMC 기법으로 산정한 확률강우량과 ARMA 모형과 Bootstrap 방법으로 산정한 결과의 신뢰구간을 비교하여 Bayesian 기법을 적용하였을 경우 좁은 신뢰구간이 산정됨을 확인하였다.
본 연구에서는 Bayesian 기법을 적용하여 강우빈도해석을 수행함으로써, 확률분포의 매개변수 추정과 더불어 매개변수의 불확실성을 평가하고자 한다. 자료의 기간이 비교적 긴 서울지점을 대상으로 하여, Gumbel 분포모형에 적용하여 강우빈도해석 시 나타나는 불확실성을 검토하였다. 자료 연한에 따른 매개변수 불확실성의 변동성을 제시하기 위하여 강우 자료의 기간을 다르게 하여 확률강우량을 산정하였으며, 확률모멘트법으로 산정한 확률강우량의 신뢰구간과 비교분석하였다.
2. 대상자료
본 연구에서는 강우자료의 확보가 용이하며 신뢰할 수 있는 기상청 강우자료를 이용하여 분석하였다. 서울지점의 1961년부터 2014년까지(54년)의 강우자료를 활용하였으며, 16개의 지속시간별(Table 1에서 지속시간 참고) 연최대 강우량을 추출하여 사용하였다.
관측 자료의 보유 년수에 따른 변화양상을 살펴보기 위하여 54년 기간의 강우자료를 3가지 기간으로 분류하였다. Case Ⅰ은 34년 기간의 자료(1961부터 1994년까지), Case Ⅱ는 44년 기간의 자료(1961부터 2004년까지), Case Ⅲ은 54년 기간의 자료(1961부터 2014년까지)로 구성되어있으며, 지속시간별 강수자료의 통계적 특성을 Table 1에 제시하였다.
Table 1을 통하여 자료기간이 늘어나면서 평균과 분산은 증가하며 특히, 최근의 자료 변동성이 과거 기간에 비해 상대적으로 크게 나타남을 확인 할 수 있다. 자료기간이 증가할수록 변동계수(coefficient of variation)의 경우 대부분의 지속시간에서 증가경향이 크게 나타났으며, 첨예도(Kurtosis)는 대부분의 지속시간에서 감소하고 있다. 이는 자료의 분포의 좌우 폭이 커지면서 나타난 현상으로 판단된다.
본 연구에서는 Ministry of Land, Transport and Maritime Affairs (2012)를 참고하여 Gumbel 분포와 확률가중모멘트법을 활용하였으며, Gumbel 분포의 유의수준 5%에 대한 적합도 검정(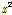 , KS, CVM, PPCC) 결과는 Table 2와 Fig.1과 같다. Fig.1에서는 가정된 Gumbel 분포형의 적합성을 시각적으로 판단하기 위해 Gumbel 확률지(probability plot)에 도시한 결과로 이론적인 곡선식에 매우 적합성이 뛰어난 것을 확인할 수 있었다. Table 2를 보면 Case에 따른 검정 결과를 나타내며, 적합성 검정 결과로 굵게 표시된 부분(4건)을 제외하고 대부분의 결과가 통계적으로 유의함을 확인하였다.
, KS, CVM, PPCC) 결과는 Table 2와 Fig.1과 같다. Fig.1에서는 가정된 Gumbel 분포형의 적합성을 시각적으로 판단하기 위해 Gumbel 확률지(probability plot)에 도시한 결과로 이론적인 곡선식에 매우 적합성이 뛰어난 것을 확인할 수 있었다. Table 2를 보면 Case에 따른 검정 결과를 나타내며, 적합성 검정 결과로 굵게 표시된 부분(4건)을 제외하고 대부분의 결과가 통계적으로 유의함을 확인하였다.
Table 2. Goodness-of-fit test results for the different durations and periods (seoul station) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
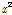
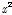
3. 방법론
본 절에서는 확률가중모멘트법에 근거한 매개변수 추정과 이에 따른 신뢰구간 추정방법을 요약하였다. 이와 더불어 Bayesian 기법 기반의 매개변수 추정과 불확실성을 평가하는 방안에 대해서 서술하였다.
3.1 확률가중모멘트법을 적용한 Gumbel 분포의 매개
변수 추정
국내에서는 Gumbel 분포와 매개변수 추정방법으로는 확률가중모멘트법이 일반적으로 활용되고 있다(Ministry of Land, Transport and Maritime Affairs, 2012). 확률가중모멘트법은 모멘트법과 마찬가지로 모집단의 확률가중모멘트는 표본자료의 확률가중모멘트와 같다는 가정아래 확률분포의 모수를 추정한다. 변수를 오름차순으로 정렬하고, 작은 값에는 작은 가중치를 큰 값에는 큰 가중치를 부여하여 모수를 추정하는 방법으로 표본자료의 크기가 작거나 왜곡된 자료일 경우에도 비교적 안정적인 결과를 도출할 수 있다(Lee, 2006). 정렬된 자료에 각 자료 점에서 발생확률의 차수승인 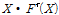 등을 이용하여 확률가중모멘트를 산정한다. 누가확률분포함수
등을 이용하여 확률가중모멘트를 산정한다. 누가확률분포함수 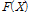 를 갖는 확률변량
를 갖는 확률변량 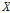 에 대한 모집단의 확률가중모멘트는 Eq. (1)과 같이 표현된다.
에 대한 모집단의 확률가중모멘트는 Eq. (1)과 같이 표현된다.
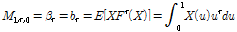 (1)
(1)
여기서  과
과  은 확률가중모멘트,
은 확률가중모멘트,  는 확률변량,
는 확률변량,  는 누가확률분포함수의 비초과확률,
는 누가확률분포함수의 비초과확률, 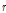 은 모멘트 차수로 정수,
은 모멘트 차수로 정수,  는 기댓값,
는 기댓값, 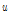 는 비초과확률
는 비초과확률 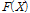 의 치환 값이다. 비초과확률을 사용하여 확률가중모멘트를 구할 경우
의 치환 값이다. 비초과확률을 사용하여 확률가중모멘트를 구할 경우 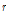 값에 따른 모멘트는 Eqs. (2a)∼(2d)와 같다.
값에 따른 모멘트는 Eqs. (2a)∼(2d)와 같다.
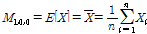 (2a)
(2a)
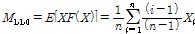 (2b)
(2b)
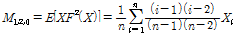 (2c)
(2c)
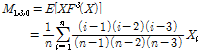
(2d)
여기서, 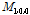 ,
, 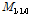 ,
, 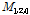 ,
,  은 표본의 확률가중모멘트,
은 표본의 확률가중모멘트, 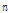 은 표본자료의 개수,
은 표본자료의 개수, 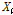 는 오름차순으로 정렬된
는 오름차순으로 정렬된 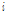 번째 자료이다. 이어서, 본 연구에서 적용하는 Gumbel 분포의 확률밀도함수와 누가확률밀도함수는 Eqs. (3a), (3b)와 같이 나타낼 수 있다.
번째 자료이다. 이어서, 본 연구에서 적용하는 Gumbel 분포의 확률밀도함수와 누가확률밀도함수는 Eqs. (3a), (3b)와 같이 나타낼 수 있다.
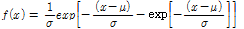 (3a)
(3a)
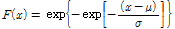 (3b)
(3b)
여기서, x는 강우 자료로 Case Ⅰ,Ⅱ,Ⅲ의 강우가 입력 자료로 활용되며, 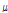 는 위치 매개변수(location parameter)와
는 위치 매개변수(location parameter)와 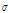 는 규모 매개변수(scale parameter)를 나타낸다. 확률가중모멘트법에 의한 매개변수 추정은 Gumbel 분포의 매개변수
는 규모 매개변수(scale parameter)를 나타낸다. 확률가중모멘트법에 의한 매개변수 추정은 Gumbel 분포의 매개변수 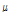 와
와 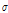 의 Eqs. (4a)와 (4b)를 활용한다(Greenwood et al., 1979; Hosking and Wallis, 1986a).
의 Eqs. (4a)와 (4b)를 활용한다(Greenwood et al., 1979; Hosking and Wallis, 1986a).
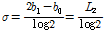 (4a)
(4a)
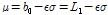 (4b)
(4b)
여기서, 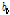 와
와 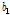 은 확률가중모멘트(Eq. (2a)와 (2b) 참고)이며,
은 확률가중모멘트(Eq. (2a)와 (2b) 참고)이며, 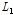 과
과 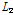 는 1차, 2차 L-모멘트이며,
는 1차, 2차 L-모멘트이며, 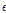 은 Euler’s 수로 0.5772157 이다. 확률가중모멘트법을 활용하여 산정된 매개변수는 Gumbel 분포에 적용되어 단일한 값의 확률강우량이 산정된다. 산정된 확률강우량의 불확실성은 신뢰구간을 활용하여 나타낼 수 있으며, 확률가중모멘트법으로 산정된 확률강우량의 신뢰구간은 Eq. (5)를 사용하여 계산된다.
은 Euler’s 수로 0.5772157 이다. 확률가중모멘트법을 활용하여 산정된 매개변수는 Gumbel 분포에 적용되어 단일한 값의 확률강우량이 산정된다. 산정된 확률강우량의 불확실성은 신뢰구간을 활용하여 나타낼 수 있으며, 확률가중모멘트법으로 산정된 확률강우량의 신뢰구간은 Eq. (5)를 사용하여 계산된다.
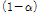 confidence interval
confidence interval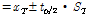 (5)
(5)
여기서, 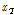 는 확률분포 모형에 적용하여 산정된 재현기간 T에 대한 확률강우량,
는 확률분포 모형에 적용하여 산정된 재현기간 T에 대한 확률강우량, 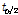 는 t 통계량으로
는 t 통계량으로 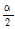 에 해당하는 x축 좌표를 의미하며,
에 해당하는 x축 좌표를 의미하며, 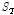 는 표준 오차(standard error)를 나타낸다. 재현기간
는 표준 오차(standard error)를 나타낸다. 재현기간 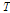 에 따른 표준 오차
에 따른 표준 오차 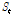 는 Eqs. (6a)와 (6b)를 활용하여 계산된다(Hamed and Rao, 1999).
는 Eqs. (6a)와 (6b)를 활용하여 계산된다(Hamed and Rao, 1999).
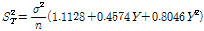 (6a)
(6a)
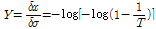 (6b)
(6b)
여기서, 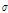 는 앞에서 산정한 규모 매개변수, n은 활용된 강우자료의 수이며, Y는 Gumbel 분포의 x에 대한 역함수를 규모매개변수로 미분한 값으로, Eq. (6b)에 제시하였다. 예를 들어, 확률가중모멘트법으로 산정한 재현기간 10년의 확률강우량의 95% 신뢰구간을 산정하고자 할 경우,
는 앞에서 산정한 규모 매개변수, n은 활용된 강우자료의 수이며, Y는 Gumbel 분포의 x에 대한 역함수를 규모매개변수로 미분한 값으로, Eq. (6b)에 제시하였다. 예를 들어, 확률가중모멘트법으로 산정한 재현기간 10년의 확률강우량의 95% 신뢰구간을 산정하고자 할 경우, 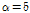 가 되며 10년 재현기간의 강우량과 이에 해당하는 표준오차(Eq. (6a),(6b)참고)를 산정하여 Eq. (5)에 적용하면 다음과 같이 나타낼 수 있다.
가 되며 10년 재현기간의 강우량과 이에 해당하는 표준오차(Eq. (6a),(6b)참고)를 산정하여 Eq. (5)에 적용하면 다음과 같이 나타낼 수 있다.
95% CI (7)
(7)
확률가중모멘트법을 이용한 매개변수의 추정은 단순모멘트방법에 의한 추정보다 편의가 작고, 표본수가 작은 경우 최우도방법보다 정확도가 높다. 특히, 이상치가 있는 경우에도 왜곡특성을 크게 나타내지 않고 자료수가 충분하지 못한 경우에도 영향을 덜 받는 상대적인 장점을 지니고 있다(Hamed and Rao, 1999).
3.2 Bayesian 방법을 이용한 확률분포 매개변수 추정
방법
Bayesian을 통한 매개변수 추정기법은 기존 방법들(최우도법, 모멘트법, 확률가중모멘트법)과는 다르게 매개변수를 하나의 확률변수로 취급한다. 즉, 매개변수가 단일 값이 아닌 확률분포의 형태로 부여되며 최종적으로 매개변수의 사후 분포(posterior distribution)를 추정하는데 목적을 두며, Bayes’ 정리(Eq. (8))를 기반으로 한다.
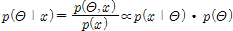 (8)
(8)
여기서, 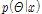 은 사후 분포로, 2장에서 제시한 강우자료가 Gumbel 분포(
은 사후 분포로, 2장에서 제시한 강우자료가 Gumbel 분포(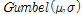 )를 따른다고 가정하며,
)를 따른다고 가정하며, 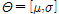 으로 Gumbel 분포에 대한 전체매개변수들의 집합을 나타낸다.
으로 Gumbel 분포에 대한 전체매개변수들의 집합을 나타낸다. 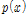 는 관측자료 x의 주변분포(marginal distribution),
는 관측자료 x의 주변분포(marginal distribution), 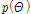 는 매개변수들의 사전분포를,
는 매개변수들의 사전분포를, 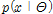 는 극치자료 x의 우도함수(likelihood function) 의미하므로 Eq. (9)와 같이 나타낼 수 있다.
는 극치자료 x의 우도함수(likelihood function) 의미하므로 Eq. (9)와 같이 나타낼 수 있다.
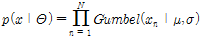 (9)
(9)
여기서, 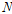 은 강수시계열의 자료연수를 나타낸다. 매개변수들의 사전분포(
은 강수시계열의 자료연수를 나타낸다. 매개변수들의 사전분포(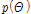 )는 자료를 기반으로 하는 Informative 사전분포와 자료에 크게 상관하지 않는 Noninformative 사전분포가 있으며, Noninformative 사전분포로는 정규분포, 균일분포, 지수분포가 대표적으로 활용된다(Gelman et al., 2004, Lee et al., 2010). 사전분포를 결정하는데 있어서 공액분포, 즉 사전분포와 사후분포가 동일하게 결정되는 사전분포를 활용하는 것이 매개변수 추정에 안정성을 도모할 수 있으나, 본 연구와 같이 공액분포 추정이 어려운 경우, 비공액분포를 사용하는 것이 일반적이다(Gelman et al., 2004, Lee et al., 2010). 이러한 점에서 본 연구에서는 사전분포로 각각의 매개변수를 정규분포와 Gamma 분포로 가정하였다(Eqs. (10a)∼(10b) 참고). 다시 말해, 위치매개변수에 대한 사전분포로서 분산이 큰 Diffuse 정규분포를 활용하였으며, 분산에 대해서는 음의 값을 방지하기 위하여 Gamma 분포를 활용하였다.
)는 자료를 기반으로 하는 Informative 사전분포와 자료에 크게 상관하지 않는 Noninformative 사전분포가 있으며, Noninformative 사전분포로는 정규분포, 균일분포, 지수분포가 대표적으로 활용된다(Gelman et al., 2004, Lee et al., 2010). 사전분포를 결정하는데 있어서 공액분포, 즉 사전분포와 사후분포가 동일하게 결정되는 사전분포를 활용하는 것이 매개변수 추정에 안정성을 도모할 수 있으나, 본 연구와 같이 공액분포 추정이 어려운 경우, 비공액분포를 사용하는 것이 일반적이다(Gelman et al., 2004, Lee et al., 2010). 이러한 점에서 본 연구에서는 사전분포로 각각의 매개변수를 정규분포와 Gamma 분포로 가정하였다(Eqs. (10a)∼(10b) 참고). 다시 말해, 위치매개변수에 대한 사전분포로서 분산이 큰 Diffuse 정규분포를 활용하였으며, 분산에 대해서는 음의 값을 방지하기 위하여 Gamma 분포를 활용하였다.
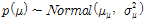 (10a)
(10a)
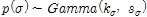 (10b)
(10b)
여기서, 위치매개변수 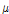 는
는 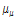 와
와 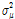 를 갖는 정규분포를 따르며,
를 갖는 정규분포를 따르며, 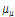 와
와 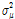 는 하위단계에서 다시 한 번 정규분포와 Gamma 분포를 따르도록 2단계의 계층적 Bayesian 모형으로 구성하였다. 동일하게 규모매개변수
는 하위단계에서 다시 한 번 정규분포와 Gamma 분포를 따르도록 2단계의 계층적 Bayesian 모형으로 구성하였다. 동일하게 규모매개변수 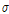 는
는 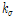 와
와 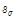 를 갖는 Gamma 분포를 따르며,
를 갖는 Gamma 분포를 따르며,  와
와 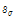 는 하위단계에서 모두 Gamma 분포를 따르도록 하였다. 본 연구에서는 Gumbel 분포의 2개의 매개변수가 모두 불확실성을 가지고 있다는 가정아래 확률적 추론(statistical inference)을 수행하였으며, 2개의 매개변수에 대한 결합 확률밀도함수(joint distribution)는 Eq. (11)과 같다.
는 하위단계에서 모두 Gamma 분포를 따르도록 하였다. 본 연구에서는 Gumbel 분포의 2개의 매개변수가 모두 불확실성을 가지고 있다는 가정아래 확률적 추론(statistical inference)을 수행하였으며, 2개의 매개변수에 대한 결합 확률밀도함수(joint distribution)는 Eq. (11)과 같다.
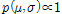 (11)
(11)
Eq. (9)∼(11)에서 정의되는 매개변수들의 사전분포들을 Eq. (8)에 대입시킴으로서 매개변수들의 사후분포를 Eq. (12)와 같이 추정할 수 있다.
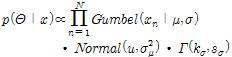 (12)
(12)
Eq. (12)에서 모든 매개변수에 대한 적분을 통해 직접적으로 추정하는 것은 불가능하며, 본 연구에서는 앞서 언급한 Markov Chain Monte Carlo (MCMC)방법을 도입하여 매개변수들의 사후분포를 추정하게 된다. 본 연구에서는 MCMC 방법 중 깁스표본법(gibbs sampling)을 이용하여 사후분포를 추정하였다.
3.3 Bayesian Markov Chain Monte Carlo 모의
Bayesian MCMC기법은 사후분포를 추정하는데 있어서 다변량에 대한 복잡한 적분을 위해서 적용되는 수치해석 기법으로 매개변수 추정하는 수단으로 활용되고 있다(Kwon and Moon, 2008). 일반적인 Monte Carlo기법은 확률변수들 간의 독립성을 가정으로 이루어지는 샘플링 방법이라면, MCMC기법은 다변량에 대해서 종속성을 기준으로 조건부 샘플링이 가능한 방법이라 할 수 있다. 즉, 주어진 다변량 확률분포가 복잡하고 iid (independent identically distributed) 난수 대신 Markov Chain에 근거한 난수를 추출하는데 적합하다. Markov Chain을 통해 다변량 확률분포를 따르는 난수를 재현하기 위해서는 반복 시행을 통해 분포에 수렴시키는 과정이 필요하다. 따라서 MCMC기법은 Bayesian 통계 기법에서 사후분포의 추론을 위해서 활용될 수 있으며 매개변수들 간의 결합 확률 특성을 고려한 해석을 가능하게 한다.
MCMC기법의 대표적인 방법으로 메트로폴리스-헤스팅 알고리즘(Metropolis-Hastings algorithm)과 깁스표본법 등이 있으며, 본 연구에서는 깁스표본법을 이용하였다. 깁스표본법은 원하는 다변량 확률분포에서 iid 표본을 추출하는 것이 복잡할 때 사용하는 방법으로써 2개의 변수를 갖는 다변량 확률분포를 이용하여 설명하면 다음과 같다. 2개의 변수를 갖는 다변량 확률밀도함수를 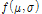 라고 하자. 깁스표본법은 확률밀도함수로부터 직접 표본을 추출할 수는 없으나 각각의 변수들의 대해서 다른 두 변수들이 주어졌을 때의 조건부 분포가 알려져 있고 이로부터의 표본추출이 가능한 경우에 사용할 수 있다. 알고리즘을 간단히 정리하면 다음과 같다.
라고 하자. 깁스표본법은 확률밀도함수로부터 직접 표본을 추출할 수는 없으나 각각의 변수들의 대해서 다른 두 변수들이 주어졌을 때의 조건부 분포가 알려져 있고 이로부터의 표본추출이 가능한 경우에 사용할 수 있다. 알고리즘을 간단히 정리하면 다음과 같다.
[1] Gumbel 분포의 두 매개변수에 대한 초기 값
(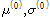 )을 부여한다.
)을 부여한다.
[2] 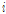 번째 난수 벡터 (
번째 난수 벡터 (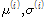 )가 주어졌을 때
)가 주어졌을 때 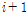 번
번
째 난수 벡터를 다음과 같은 조건부 분포에서 추출
한다.
(1) 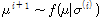
(2) 
[3] 위의 과정을 충분히 반복한 후 초기의 일정부분
난수를 제거한 이후의 난수들을 이용한다. 이러한
제거과정을 Burning이라고 하며 Bayesian 해석에
서 일반적으로 요구되는 단계이다.
(George and Mcculloch, 1993)
위의 방법에서 깁스표본법은 현재시점의 매개변수들의 값은 정확하게 바로 직전의 추출된 값들이 사용되게 되며, 따라서 조건부 분포에서 추출된 난수들이 안정 상태에 도달하는 것이 주어진 다변량 확률분포를 정확히 따르는 난수가 되는 척도가 되며 깁스표본법을 구현하는데 가장 중요한 부분이 된다.
4. 빈도해석 및 불확실성 평가 결과
본 연구에서는 기상청 서울지점의 강우자료(Case Ⅰ,Ⅱ,Ⅲ)를 Gumbel 분포 모형에 적용하여 빈도해석을 수행하였다. 확률가중모멘트법으로 추정된 매개변수와 Bayesian 방법을 통해 추정된 확률강우량을 비교하였다. 재현기간별 확률강우량의 비교에 앞서, 2가지 방법에 매개변수를 비교하여 Figs. 2∼3에 도시하였다.
Figs. 2∼3에서 검정 실선은 기존 방법인 확률가중모멘트법으로 산정된 매개변수를 활용하여 산정한 확률강우량으로, 단일 값으로 표현된다. Bayesian 방법은 매개변수를 사후분포(파란색 선)로 나타낼 수 있으며, 빨간색 실선은 사후분포의 중앙값(Median)을 나타낸다. Bayesian 방법으로 추정한 매개변수는 단일 값이 아닌 사후분포이며, 매개변수 추정시의 불확실성을 포함하고 있다. 사후분포의 중앙값을 기준으로 위치매개변수  는 확률가중모멘트법과 매우 비슷하게 산정되었으며, 확률가중모멘트법에 비해 약간 크며, -2∼3 차이가 났다. 그러나 규모매개변수
는 확률가중모멘트법과 매우 비슷하게 산정되었으며, 확률가중모멘트법에 비해 약간 크며, -2∼3 차이가 났다. 그러나 규모매개변수  는 대부분 확률가중모멘트법이 크게 산정되었으며, -1∼11 차이가 나타나고 있음을 확인 할 수 있었다. 이어서, 산정된 매개변수를 바탕으로 확률강우량을 계산한 결과를 Fig. 4와 Table 3에 나타내었다.
는 대부분 확률가중모멘트법이 크게 산정되었으며, -1∼11 차이가 나타나고 있음을 확인 할 수 있었다. 이어서, 산정된 매개변수를 바탕으로 확률강우량을 계산한 결과를 Fig. 4와 Table 3에 나타내었다.
|
Fig. 2. A comparison of location parameter( |
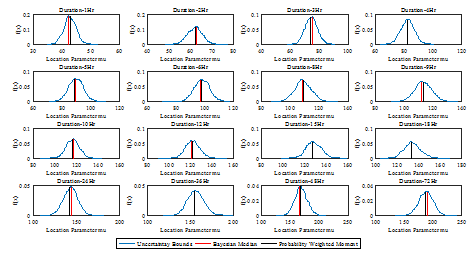
 ) for the different durations using PWM and hierarchical bayesian model (1961∼2014)
) for the different durations using PWM and hierarchical bayesian model (1961∼2014)
|
Fig. 3. A comparison of scale parameter( |
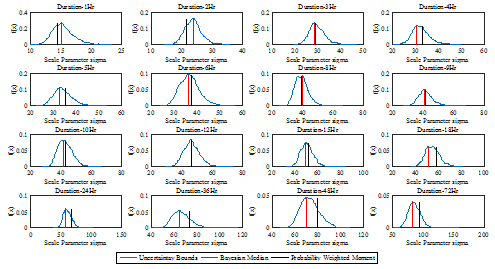
 ) for the different durations using PWM and hierarchical bayesian model (1961∼2014)
) for the different durations using PWM and hierarchical bayesian model (1961∼2014)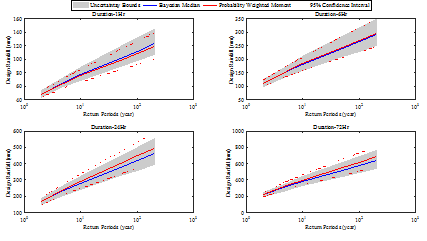
Table 3. Design rainfalls for the different durations using PWM and hierachical bayesian model (mm) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Table 4. Confidence interval (PWM) and Uncertainty Bound (Bayesian) of Design Rainfalls (mm) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Fig. 4에서 파란색 선은 Bayesian 방법으로 산정된 중앙값, 회색 영역은 Bayesian 방법의 불확실성 범위를 나타낸다. 빨간색 선은 확률가중모멘트법을 이용하여 산정된 확률강우량과 신뢰구간을 나타낸다. 지속시간이 1∼3시간에서는 Bayesian 법이 0.3∼4.7% 크게 산정되었으나 지속시간 4시간 이후에는 확률가중모멘트법을 이용한 빈도해석 방법이 0.2∼7.6% 크게 산정되었다.
신뢰구간은 기본적으로 정규분포를 가정하여 해석하기 때문에 실제 극치자료의 분포 특성을 반영하지 못하고 좌우대칭 형태를 갖는다. 이에 반해 Bayesian 방법은 가정된 Gumbel 분포의 특성이 효과적으로 반영되어 불확실성 구간도 Gumbel 분포의 형태를 가지는 것을 확인할 수 있다. 추정되는 빈도가 커짐에 따라 불확실성 구간도 우측 꼬리측이 커짐을 확인할 수 있다. Bayesian 방법의 불확실성 범위와 확률가중모멘트법의 신뢰구간을 비교하여 Table 4에 나타내었다. 97.5% 값에서 2.5% 값을 빼면 불확실성 범위의 크기를 구할 수 있으며 두 방법의 크기 차이는 (A)-(B)로 나타낼 수 있다. 일부를 제외하고 Bayesian 방법의 불확실성 구간이 작게 산정되는 것을 확인할 수 있었다.
5. 자료기간에 따른 빈도해석 및 불확실성 평가 결과
자료기간에 따른 확률강우량과 불확실성 분석을 위해 자료를 3가지 CASE로 구분하여 분석하였다. 앞서 언급한 바와 Case Ⅰ은 1961∼1994년 34개년, Case Ⅱ는 1961∼2004년 44개년, Case Ⅲ은 1961∼2014년 54개년의 경우를 대상으로 자료기간의 따른 확률강우량의 변화 및 이에 따른 불확실성 변화를 평가하였다. 먼저 확률가중모멘트법은 CASE Ⅰ에서 Ⅱ로 자료기간이 증가 되었을 때 확률강우량은 약 2.9∼3.7(지속시간 1시간 기준) 증가하였으나 CASE Ⅱ에서 Ⅲ로 증가 할 때는 오히려 약 0.7∼1.5 감소하는 것으로 나타났다. Bayesian 방법도 비슷한 결과를 보였으며 CASE Ⅰ에서 Ⅱ로 변할 때 2.4∼3.0 증가하였으나 CASE Ⅱ에서 Ⅲ로 증가 할 때는 1.0∼2.1 감소하는 것으로 나타났다. 지속시간이 증가할수록 확률강우량 값의 차이가 커지나 증가에서 감소하는 패턴은 전반전으로 유사하게 나타났다. 이는 1990년 초반에 발생한 극치사상으로 인한 확률강우량의 증가로 판단된다.
|
|
(a) Case Ⅰ | |
|
|
(b) Case Ⅱ | |
|
|
(c) Case Ⅲ | |
| |
Fig. 5. A comparison of design rainfalls along with different data length | |
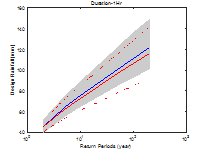
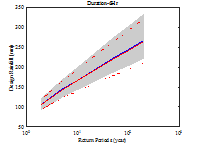
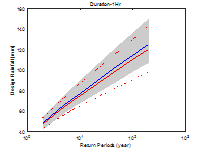
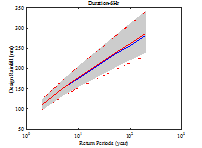
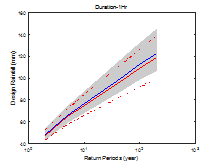
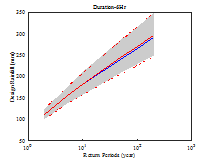
Table 5. A comparison of uncertainty range for the different durations and periods (for 10-year design rainfall, mm) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Table 6. Design rainfalls for the different durations using PWM and hierachical bayesian model (mm) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Table 7. Monte carlo experiment for assessing uncertainty bounds and confidence intervals given different data length (for 10-year design rainfall, mm) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
관측 자료 증가 및 자료 구간에 따라 Bayesian 방법의 불확실성 범위와 확률가중모멘트법의 신뢰구간을 비교하였다. 두 방법 모두 관측 자료연수가 증가함에 따라 불확실성 범위가 전반적으로 줄어드는 것으로 나타났으나, CASE 2구간에서 12시간 이상의 지속시간의 경우 자료연수에 증가에도 불구하고 불확실성이 감소하지 않는 것으로 평가되었다. 이러한 결과는 빈도해석 시 자료가 증가함에도 불구하고 추정되는 매개변수의 불확실성이 줄어들지 않음을 의미한다. 이는 증가된 자료가 본 연구에서 적용된 Gumbel 분포와 적합성이 상대적으로 크지 않음을 나타낸다. 다시 말해서, 1990년 초반에 발생한 극치사상들은 확률분포에서 다소 벗어난 형태의 이상치로 작용하였을 가능성이 크며 결과적으로 매개변수의 불확실성을 증가시키는 역할을 한 것으로 판단된다.
본 연구에서는 자료 개수의 증가에 따라 불확실성 크기의 변화를 좀 더 정량적으로 살펴보기 위해 서울관측지점의 지속시간별 년최대치 자료로부터 34(Case Ⅳ), 44(Case Ⅴ), 54(Case Ⅵ)개의 자료를 무작위로 10개의 자료 셋을 추출하는 Monte Carlo 모의를 실시하였으며, 각 Case별 빈도해석 결과의 불확실성 구간 및 신뢰구간을 Table 7에 나타내었다. 즉, 총 54년 연최대치강수량 자료로부터 각 Case별(34년, 44년, 54년)로 해당하는 강수자료를 10개의 자료 셋을 추출하고 이를 대상으로 매개변수 추정 및 확률강수량을 추정하였다. Monte Carlo모의를 수행한 이유는 자료의 표본오차로 인한 영향을 상쇄하고자 진행되었다. Monte Carlo 모의를 통한 불확실성의 변화양상을 평가한 결과 불확실성 범위가 자료가 증가하면서 불확실성 범위가 줄어드는 것이 뚜렷해지는 것을 확인 할 수 있었다. CASE Ⅳ와 CASE Ⅵ의 불확실성 범위를 기준으로 평가해보면 확률가중모멘트법은 평균적으로 14%, Bayesian 방법은 29%의 불확실성 구간의 감소를 확인할 수 있었다. 상대적으로 작은 표본으로 인한 빈도해석의 불확실성 즉, 표본오차로 인한 불확실성이 매우 크며, 이를 정량적으로 해석하고 빈도해석 결과에 대한 신뢰성을 평가하는 과정이 수문량을 결정하는데 있어서 필요할 것으로 사료된다.
6. 결 론
본 연구에서는 우리나라 빈도해석 시 가장 많이 사용되는 Gumbel 분포형을 기준으로 매개변수의 추정과 불확실성을 평가하는데 있어서 우수한 성능을 발휘하는 Bayesian방법을 도입하여 서울지역의 확률강우량의 불확실성을 정량적으로 평가하였으며, 기존 확률가중모멘트방법과 비교하였다. 본 연구를 통하여 도출된 결론은 다음과 같다.
1) 확률가중모멘트법과 Bayesian 방법의 매개변수 산정 결과 비교에서는 중간 값을 기준으로 위치매개변수는 매우 유사한 결과를 나타낸 반면에 규모매개변수의 경우 확률가중모멘트법이 상대적으로 크게 산정되었다. 이러한 이유로 지속시간이 짧은 1∼3시간에서는 Bayesian 방법이, 지속시간이 4시간 이상에서는 확률가중모멘트법이 일부 크게 산정되었다.
2) 확률가중모멘트법의 신뢰구간이 Bayesian 방법의 불확실성 구간보다 전반적으로 크게 나타났다. 신뢰구간의 경우 정규분포를 따르기 때문에 좌우대칭의 형태를 갖는 반면에 Bayesian 방법의 불확실성은 Gumbel 분포로부터 유도되어, 보다 현실적인 불확실성 평가가 가능하였다.
3) 자료의 구간 및 기간에 따른 확률강우량의 불확실성을 평가한 결과 자료에 증가에 따른 불확실성 감소를 확인할 수 있었으며, Bayesian 방법이 자료 증가에 따른 불확실성 범위 감소가 보다 뚜렷하게 나타나는 것을 확인할 수 있었다.
본 연구에서는 극치확률분포 매개변수의 불확실성을 정량화하고 최종적으로 지속시간 및 재현기간에 따른 확률강수량의 불확실성 구간을 제시하였다. 향후 연구로서 지역빈도해석모형에서의 추정되는 확률강수량의 불확실성을 평가할 수 있는 방안에 대한 연구와 더불어, 강우-유출모형의 불확실성까지 종합적으로 고려하여 확률홍수량의 불확실성 평가 절차 및 방안을 수립하는 연구가 필요할 것으로 판단된다.
