

1. 서 론
2. 연구방법
2.1 Artificial Neural Network (ANN)
2.2 Multi Layer Perceptron (MLP)
2.3 Optimizer
2.4 Improved Harmony Search (IHS)
2.5 Adaptive moments combined with Improved Harmony Search (AdamIHS)
2.6 대상유역 및 자료구축
3. 연구결과
3.1 평가지표
3.2 학습결과
3.3 예측결과
4. 결 론
1. 서 론
최근 세계적인 기후변화로 인해 국내외에서 홍수와 가뭄의 발생빈도 및 강도가 증가하고 있다(Kim et al., 2019). 또한, 국내의 경우 4대강(한강, 낙동강, 금강 및 영산강)의 하상계수가 평균 약 300으로 유럽의 평균인 약 20보다 매우 높다. 높은 하상계수로 인해 유량의 변동이 크며 수자원을 활용하는데 어려움이 있다(Moon and Lee, 2011). 홍수와 가뭄으로 인한 피해 저감 및 수자원 관리를 위해 댐의 효율적인 운영이 필요하다. 효율적인 댐 운영을 위해서는 높은 신뢰도의 댐 유입량 예측이 필요하다(Eom and Jung, 2019).
기존의 댐 유입량 예측은 개념적 또는 물리적 모형 및 시계열 모형을 활용하였다. 개념적 또는 물리적 모형은 수문학적 특성들을 매개변수화하여 강우-유출 해석을 실시한다. 하지만 개념적 또는 물리적 모형은 매개변수가 증가함에 따라 모의결과의 불확실성이 증가하기 때문에 지형학적, 기상학적 및 지질학적 변수를 모두 반영하는데 어려움이 있다(Jung et al., 2018). 이러한 개념적 또는 물리적 모형의 단점을 개선하기 위해 시계열 모형이 사용되었다.
시계열 모형은 관측된 데이터를 기반으로 통계적 관점에서 입력과 출력 관계를 추정한다. 대표적인 시계열 모형으로 AutoRegressive Moving Average (ARMA) 및 AutoRegressive Integrated Moving Average (ARIMA) 등과 같은 선형 모형이 있다(Valipour et al., 2012; 2013). 하지만 시계열 모형은 선형 구조를 기반으로 하기 때문에 실제의 강수량 및 기온 등 비선형적 요소들을 해석하기 어렵다는 단점이 있다(Han et al., 2021). 최근에는 실제의 강수량 및 기온 등 비선형적 요소들을 해석하기 위해 Support Vector Machine, Random Forest 및 인공신경망(Artificial Neural Network, ANN) 등과 같은 머신러닝(Machine Learning)을 이용한 예측이 진행되었다(Granata et al., 2016; Zhou et al., 2019; Riad et al., 2004).
머신러닝 기법 중 하나인 ANN은 인간의 두뇌가 정보를 처리하는 방식을 모방하여 설계된 기법이다. McCulloch and Pitts (1943)는 수학적 기법으로 ANN의 기초논리를 처음 제시하였으며 Rosenblatt (1958)은 신경망 알고리즘인 퍼셉트론(perceptron)을 제안하였다. Rumelhart et al. (1986)은 오차의 경사를 줄이기 위해 출력값을 역으로 전파하는 역전파(Back propagation)를 제안하였다. ANN은 비선형적 요소들을 고려할 수 있다는 장점이 있어 경제학, 의학 및 공학 등 다양한 분야에서 ANN을 활용한 연구가 진행되었다(Kim, 2004; Choi, 2016; Jeon et al., 2021). 또한, 수문 및 수자원 분야에서 댐 및 하천의 수위를 예측하는 등 ANN을 활용한 다양한 연구가 진행되었다(Park et al., 2018; Park and Chung, 2020; Babaei et al., 2019; Zhang et al., 2018).
ANN은 입력자료와 출력자료 간의 상관관계(가중치 및 편향)를 반복하여 학습한다(Agatonovic-Kustrin and Beresford, 2000). ANN의 종류로는 입력층(Input layer)과 출력층(Output layer) 사이에 은닉층(Hidden layer)이 없는 정방향 모델인 Single Layer Perceptron (SLP), 은닉층이 한 개 이상 있는 정방향 모델인 Multi Layer Perceptron (MLP)이 있다.
ANN은 자료를 입력하는 입력층, 신경망 계산값을 출력하는 출력층 및 입력된 자료를 가공하여 출력층으로 전달하는 은닉층으로 구성되어 있다. 또한, 각 층은 노드들로 구성되어 있다. ANN의 연산자로는 각 뉴런의 출력신호를 결정하는 활성화 함수 및 신경망 출력값과 관측값 간의 오차가 최소가 되는 상관관계를 찾는 optimizer가 있다.
기존 연구들에서 활용된 ANN의 optimizer는 수치미분을 통해 상관관계를 탐색하는 경사하강법(Gradient Descent, GD) 기반의 optimizer를 사용하였다. GD는 기존 해의 목적함수에 대한 기울기와 고정 학습률을 이용하여 새로운 해를 탐색한다. 본 연구에서 optimizer의 개량을 위해 사용된 Adaptive moments (Adam)는 유동적인 학습률 및 과거에 이동했던 방향을 기억하여 추가적으로 이동하는 기법을 적용한 방법이다. Adam은 기존 GD에 비해 유동적인 학습률 및 추가적인 이동을 적용하여 해 탐색성능이 향상되었다. Mahsa and Lee (2018)는 다양한 GD 기반 optimizer 중 Adam을 이용한 ANN이 가장 우수한 수문학적 유출량 예측성능을 나타냄을 확인하였다. 하지만, GD의 추가적인 개량에도 불구하고 Adam을 포함한 GD 기반 optimizer인 Stochastic Gradient Descent (SGD), Adaptive gradient (Adagrad), Root Mean Squared propagation (RMSprop), Adaptive delta (Adadelta), Adamax, Adam 및 Nesterov-accelerated adaptive moment (Nadam)에는 두 가지의 단점이 있다. 첫 번째는 수치미분을 이용하여 새로운 상관관계를 생성하기 때문에 지역 최적값으로 수렴할 가능성이 있다는 점이다(Sedki et al., 2009). 두 번째는 기존에 생성되었던 상관관계에 대한 정보를 저장할 수 있는 구조가 없다는 점이다. optimizer 내의 저장공간 부재로 인해 기존에 생성된 상관관계의 오차가 새로운 상관관계의 오차보다 작아도 새로운 상관관계로 갱신된다. 이로 인해 학습이 진행되어도 최적의 상관관계를 찾지 못할 가능성이 있다.
GD 기반 optimizer의 단점을 개선하기 위해 전역탐색과 지역탐색을 동시에 고려할 수 있으며 기존에 생성되었던 해를 저장하는 구조가 있는 메타휴리스틱 최적화 알고리즘을 사용할 필요가 있다. 메타휴리스틱 최적화 알고리즘은 Linear Programming 및 Non-Linear Programming 등과 같은 수학적 최적화 기법의 비선형적 문제해결 한계를 개선하기 위해 제안되었다(Lee et al., 2016b). 메타휴리스틱 최적화 알고리즘은 기존의 해와 관계없이 해의 전체 범위에서 무작위로 해를 선택하는 전역탐색과 기존의 해를 미세조정하며 새로운 해를 탐색하는 지역탐색을 동시에 고려할 수 있는 구조를 가지고 있다. 또한, 기존에 생성되었던 해를 저장하는 구조가 있어 기존의 해와 새로운 해의 비교가 가능하다. 다양한 메타휴리스틱 최적화 알고리즘은 인공 및 자연적 현상을 모방하여 개발되었다. 대표적인 메타휴리스틱 최적화 알고리즘으로는 유전자 알고리즘(Genetic Algorithm), 개미군집최적화(Ant Colony Optimization), 입자군집최적화(Particle Swarm Optimization) 및 화음탐색법(Harmony Search, HS) 등이 있다(Goldberg and Holland, 1988; Dorigo et al., 2006; Kennedy and Eberhart, 1995; Geem et al., 2001). 다양한 메타휴리스틱 최적화 알고리즘 중 IHS는 구조가 단순하며 탐색 성능이 좋은 HS의 매개변수를 자가적응형으로 개량한 방법이다(Mahdavi et al., 2007).
전역탐색이 가능하며 해의 저장공간이 있다는 장점으로 다양한 분야에서 ANN에 메타휴리스틱 최적화 알고리즘을 적용한 연구가 진행되었다. Göçken et al. (2016)과 Lee et al. (2017)은 메타휴리스틱 최적화 알고리즘을 활용하여 ANN의 은닉층 뉴런수 등과 같은 하이퍼파라미터의 최적값을 탐색했다. Geem et al. (2002), Amjady and Keynia (2011), Lee et al. (2016a) 및 Cho et al. (2022)은 메타휴리스틱 최적화 알고리즘을 활용하여 ANN의 가중치(Weight) 및 편향(Bias)을 최적화하였다. 하지만, 기존에 메타휴리스틱 최적화 알고리즘을 이용하여 가중치 및 편향을 탐색하는 연구들은 단순히 메타휴리스틱 최적화 알고리즘만을 사용하거나 GD와 직렬의 형태로 결합했다는 한계가 있다.
본 연구는 GD 기반 optimizer 중 수문학적 유출 예측에 가장 우수한 성능을 보인 Adam과 IHS의 결합을 통해 Adaptive moments combined with Improved Harmony Search (AdamIHS)를 개발하고 GD 기반 optimizer의 단점을 개선하였다. AdamIHS를 사용한 MLP의 성능을 검토하기 위해 대청댐 유입량을 학습 및 예측하였다. 대청댐 유입량 학습 및 예측을 위한 MLP 입력자료로 대청댐 상류의 하천 수위 및 대청댐 상류에 위치한 용담댐의 방류량을 사용하였다. MLP의 출력자료는 대청댐 유입량을 사용하였다. AdamIHS를 사용한 MLP의 댐 유입량 학습 및 예측성능을 비교하기 위해 GD 기반 optimizer를 사용한 MLP의 학습 및 예측성능을 비교하였다. 또한, 학습 및 예측성능의 향상을 위해 정규화(Normalization) 및 Time Lagged Cross Correlation (TLCC)을 이용하여 데이터 전처리(Pre-processing)를 실시하였다(Ryu and Lee, 2022). 정규화는 데이터 스케일링을 위한 방법이며, TLCC는 지체시간을 고려하기 위한 방법이다.
2. 연구방법
2.1 Artificial Neural Network (ANN)
ANN은 입력자료와 출력자료 간의 상관관계를 반복 학습하여 실제값과 신경망의 출력값의 오차가 최소가 되는 상관관계를 찾는다. ANN은 물리적 관계가 완전히 파악되지 않은 경우에도 많은 양의 데이터 처리를 통해 상관관계를 파악할 수 있는 장점이 있다(Aqil et al., 2007). 데이터 처리를 통해 상관관계를 파악할 수 있다는 장점으로 ANN은 최근 음성 인식, 기상. 주식 시장 및 수문 예측 등 다양한 분야에서 사용되고 있다(Lee et al., 2019).
2.2 Multi Layer Perceptron (MLP)
퍼셉트론은 입력층과 출력층 사이에 은닉층이 없는 SLP와 하나 이상의 은닉층이 있는 MLP로 구분할 수 있다. SLP는 선형적 문제를 해결할 수 있으나 XOR 문제와 같은 비선형적 문제를 해결할 수 없다는 단점이 있다. 비선형적 문제를 해결할 수 없는 SLP의 단점을 개선하기 위해 MLP가 제안되었다. MLP는 은닉층이 하나 이상으로 구성된 신경망을 의미하며 XOR 문제와 같은 비선형적 문제를 해결할 수 있어 비선형성이 큰 자연현상에 대한 해석이 가능하다. Fig. 1은 MLP의 구조를 나타낸 그림이다.
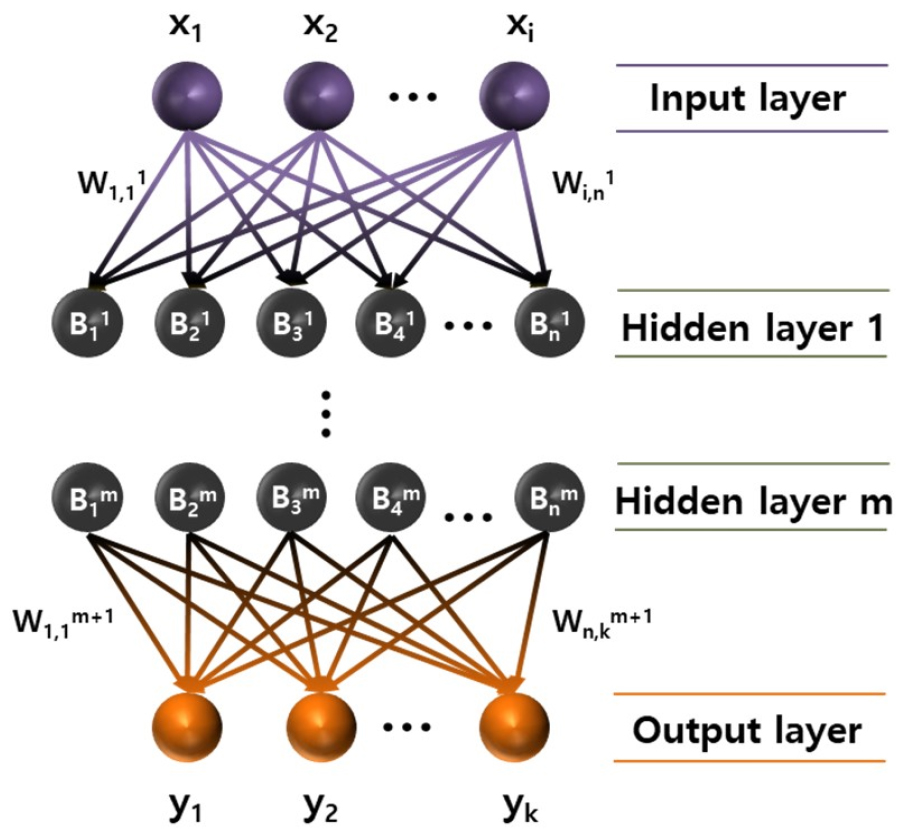
Fig. 1을 보면 MLP는 입력층, 출력층 및 한 개 이상의 은닉층으로 구성되어 있다. 입력층은 입력자료를 받아들이고 출력층은 받아들인 입력자료를 기반으로 신경망을 통해 계산된 값을 출력한다. 은닉층은 입력층으로부터 받은 값을 출력층으로 전달하는데 이때 효과적인 학습 및 예측을 위해 불필요한 정보를 제거하고 정보를 가공하여 출력층으로 전달한다. 또한, Fig. 1에서 W는 가중치, B는 편향을 의미한다. 가중치는 입력된 신호가 출력되는 결과에 미치는 영향을 조절하는 매개변수이며, 편향은 각 노드의 민감도를 조절하는 매개변수이다. 각 층에서 출력되는 값은 활성화 함수(Activation function)를 통해 결정된다. 대표적인 활성화 함수로는 Sigmoid, Hyperbolic tangent (tanh) 및 Rectified linear unit (Relu) 등이 있다. Eqs. (1) and (2)는 MLP의 계산과정을 나타낸 식이다.
여기서, wkp와 vpi는 가중치, bk와 cp는 편향이며, fact는 활성화 함수이다.
본 연구에서는 다양한 활성화 함수 중 사용성이 좋으며 연산시간이 짧은 Relu를 활성화 함수로 사용하였다(Yoo et al., 2020). Eq. (3)은 Relu 함수를 나타낸 식이다.
여기서, x는 각 노드에 전달되는 값이다.
본 연구에서는 MLP의 은닉층 개수를 1개부터 5개로 하였으며 각 은닉층의 노드 개수는 기존 댐 수위 예측연구에서 최적의 노드로 설정된 10개로 설정하여 5개의 모형을 구축했다(Seo et al., 2015). 구축한 5개의 모형을 통해 은닉층 개수에 따른 학습 및 예측성능을 비교하였다. Table 1은 구축한 모형의 은닉층과 각 은닉층의 노드 개수이다.
Table 1.
Models according to the number of hidden layers and nodes
| Model | Hidden layer | Nodes |
| M1 | 1 | 10 |
| M2 | 2 | 10-10 |
| M3 | 3 | 10-10-10 |
| M4 | 4 | 10-10-10-10 |
| M5 | 5 | 10-10-10-10-10 |
2.3 Optimizer
optimizer는 ANN이 입력자료와 출력자료간의 상관관계를 반복 학습할 때 최적의 상관관계를 찾는 연산자이다. 최적의 상관관계는 실제값과 출력값의 오차가 가장 작을 때의 상관관계를 의미하며, optimizer는 ANN의 학습 및 예측성능에 직접적인 영향을 끼친다(Joo et al., 2020). optimizer 중 가장 기초적인 GD는 수치미분을 통해 얻은 기울기를 이용하여 기울기가 0이 되는 지점을 찾는 방법이다. Eq. (4)는 GD의 해 탐색과정을 나타낸 식이다.
여기서, W는 가중치 또는 편향, O는 목적함수를 의미하며, η는 학습률이다.
GD는 초기에 생성된 해를 바탕으로 경사가 0이 되는 지점을 찾는다. GD의 탐색은 수치미분을 이용하여 함수의 기울기를 구하고 기울기가 감소하는 방향으로 새로운 해를 갱신한다. 본 연구에서 제안된 AdamIHS의 학습 및 예측성능을 평가 및 비교하기 위해 사용된 GD 기반 optimizer로는 SGD, Adagrad, RMSprop, Adadelta, Adamax, Adam 및 Nadam이 있다. Eqs. (5a)~(5c)는 본 연구에서 IHS와 결합된 Adam의 해 탐색과정이다.
여기서, 은 분모가 0이 되는 것을 방지하기 위한 상수이며 일반적으로 10-8을 사용한다. 또한, 이전의 해 탐색과정의 영향을 감소시키는 및 는 일반적으로 각각 0.9와 0.999를 사용한다.
본 연구에서 GD 기반 optimizer는 딥러닝 라이브러리인 Tensorflow의 keras를 이용하여 구축하였다. 반복 학습횟수인 Epoch는 3,000번으로 설정하였다. 또한, 학습의 안정성을 평가하기 위해 초기에 생성되는 해를 임의로 설정하여 10번 반복실행하였다.
2.4 Improved Harmony Search (IHS)
IHS는 Mahdavi et al. (2007)이 제안한 알고리즘으로 Geem et al. (2001)이 제안한 HS에 자가적응형 매개변수를 적용하여 개량한 메타휴리스틱 최적화 알고리즘이다. IHS의 매개변수는 Harmony Memory Size (HMS), Harmony Memory Considering Rate (HMCR), Pitch Adjusting Rate (PAR) 및 Bandwidth (Bw)로 구성되어 있다. HMS는 Harmony Memory (HM)의 크기를 뜻한다. HMS는 초기에 무작위로 생성되는 해의 개수를 결정한다. HMCR은 전역탐색 또는 지역탐색을 결정하는 확률 매개변수이다. PAR은 지역탐색을 실시할 경우 미세조정 여부를 결정하는 확률 매개변수로 미세조정을 진행할 경우 Bw만큼 미세조정을 실시한다.
IHS의 매개변수 중 PAR 및 Bw는 시산횟수에 따라 변화하는 자가적응형 매개변수이다. PAR은 최대 PAR (PARmax)과 최소 PAR (PARmin)의 사이에서 현재 반복시산횟수에 따라 선형으로 증가한다. Bw는 최소 Bandwidth (Bwmin)와 최대 Bandwidth (Bwmax)의 사이에서 현재시산횟수에 따라 비선형으로 감소한다. Eq. (6)는 IHS에 적용된 PAR 식이며, Eqs. (7) and (8)은 IHS에 적용된 Bw의 식이다.
여기서, PARmin과 PARmax는 각각 최소 PAR과 최대 PAR이며, Bwmin과 Bwmax는 각각 최소 Bw와 최대 Bw이다. 또한, TI는 최대 반복시산횟수이며, CI는 현재 반복시산횟수이다.
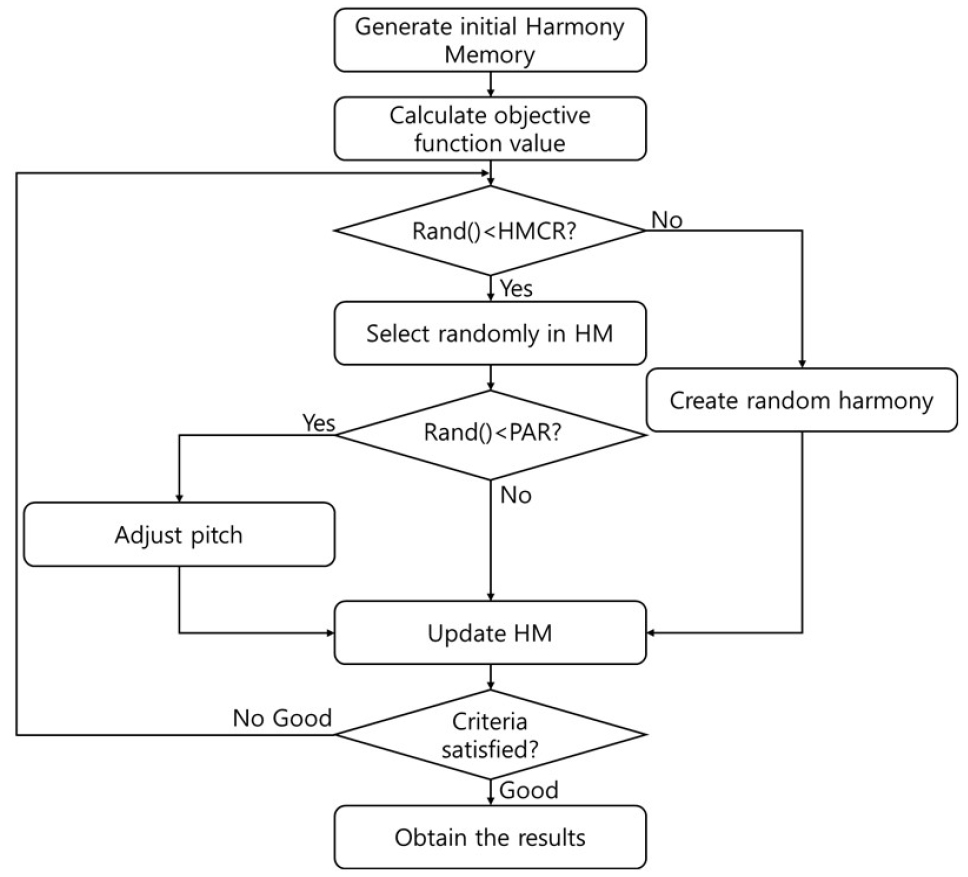
본 연구는 Adam과 IHS의 결합을 통해 GD 기반 optimizer의 단점을 개선하였다. Fig. 2는 IHS의 순서도를 나타낸 그림이다.
Fig. 2를 보면, IHS는 3가지의 방법을 통해 최적의 해를 탐색한다. 첫 번째 방법은 임의로 탐색범위 내의 해를 선택하여 새로운 해를 생성한다. 두 번째 방법은 기존의 해 집단에서 임의로 선택하여 새로운 해를 생성한다. 세 번째 방법은 기존의 해 집단에서 선택된 해를 미세조정하여 새로운 해를 생성한다.
2.5 Adaptive moments combined with Improved Harmony Search (AdamIHS)
본 연구에서 개발된 AdamIHS는 GD 기반 optimizer 중 수문학적 유출 예측에 좋은 성능을 보인 Adam과 HS의 개량형인 IHS가 결합된 구조이다. Adam과 IHS의 결합을 통해 GD 기반 optimizer의 단점인 지역 최적해로의 수렴가능성과 저장공간의 부재를 개선하였다. Fig. 3은 AdamIHS의 순서도를 나타낸 그림이다.
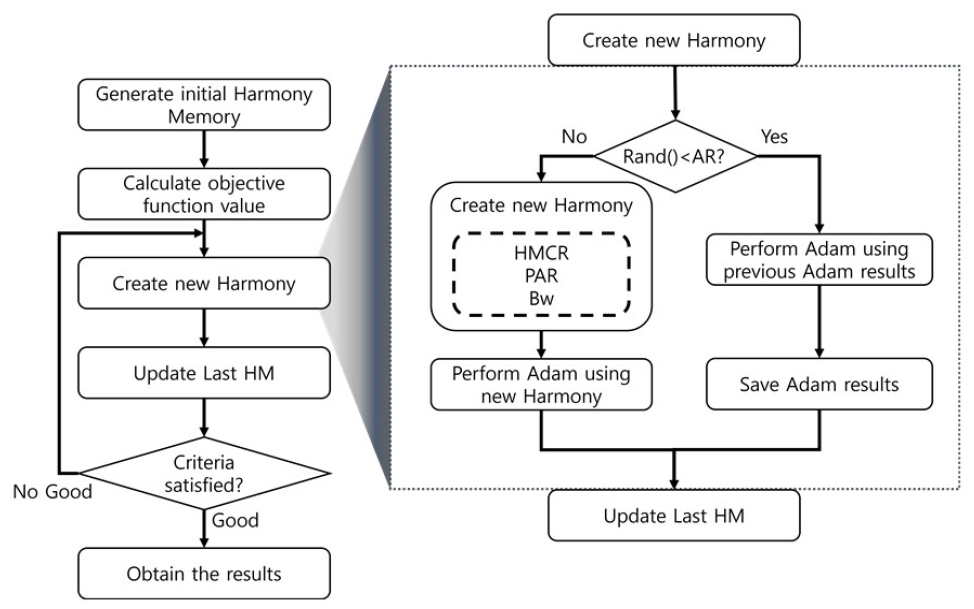
Fig. 3을 보면 AdamIHS는 Adam Rate (AR)를 통해 IHS를 실시할 것인지 Adam을 실시할 것인지 결정한다. IHS를 실시할 경우 IHS를 이용하여 새로운 화음을 생성하고 생성된 화음을 이용하여 Adam을 실시한다. Adam을 실시할 경우 기존에 Adam을 통해 생성된 해를 이용하여 Adam을 실시하고 결과를 저장한다. 본 연구에서 AR은 최대 AR (ARmax)과 최소 AR (ARmin) 사이에서 반복 학습횟수에 따라 선형으로 감소하는 자가적응형 매개변수를 사용하였다. Eq. (9)은 AdamIHS에 적용된 AR의 식이다.
여기서, ARmin과 ARmax는 각각 최소 AR과 최대 AR, TE는 최대 반복 학습횟수이며, CE는 현재 반복 학습횟수이다.
본 연구에서 AdamIHS의 ARmax, ARmin, HMS, HMCR, PARmax, PARmin, Bwmax 및 Bwmin은 각각 1, 0.7, 2, 0.7, 0.3, 0.05, 1E-03 및 1E-05로 설정하였다. 또한, 학습률은 Adam과 동일하게 0.001로 설정하였다. Epochs는 GD 기반 optimizer들과 동일하게 3,000번으로 설정하였으며 10번 반복실행하였다.
2.6 대상유역 및 자료구축
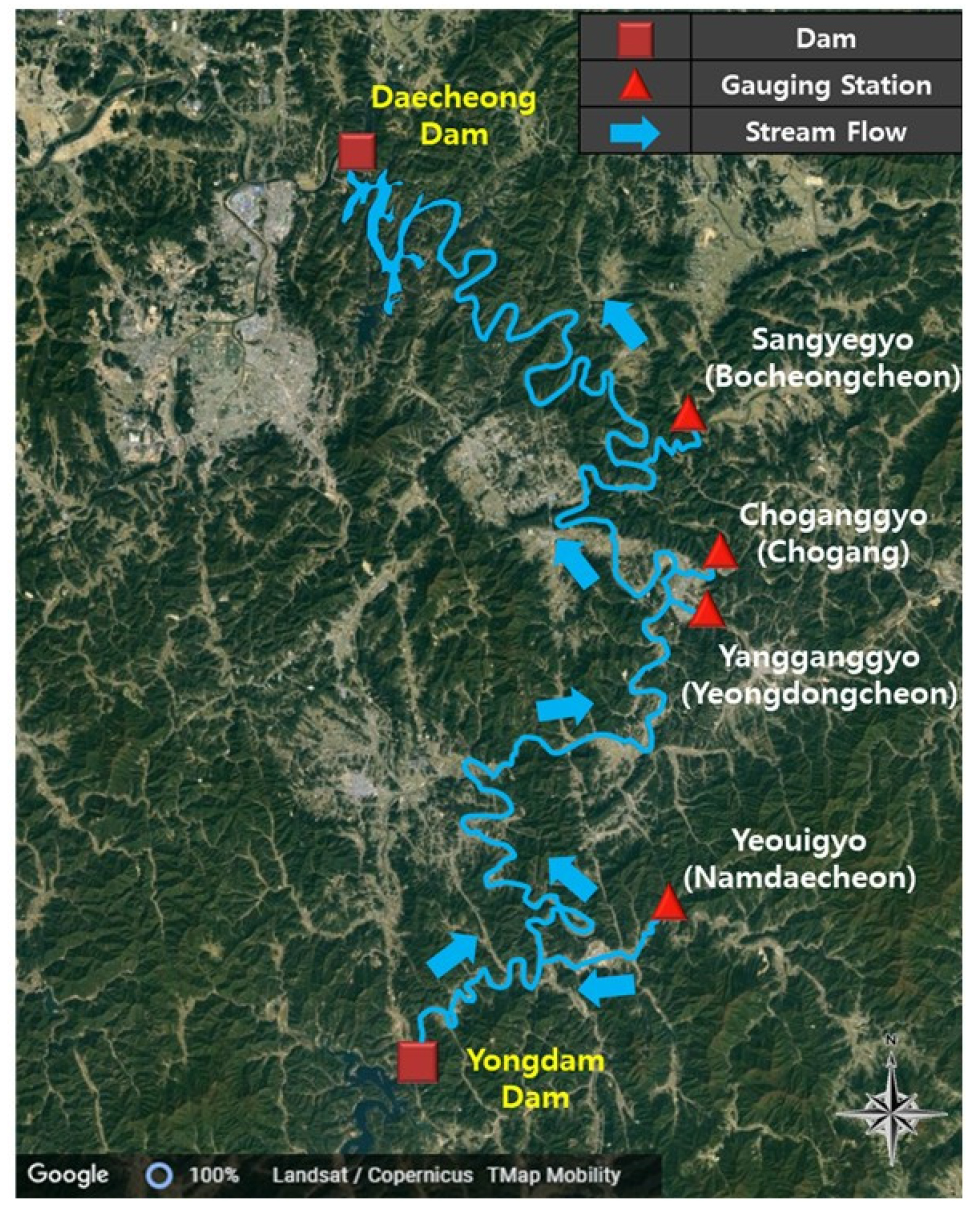
AdamIHS를 optimizer로 사용한 MLP의 예측성능을 비교하기 위해 금강유역에 위치한 다목적댐인 대청댐을 선정하였다. 대청댐의 유역면적은 3,204 km2, 저수면적은 72.8 km2이며, 총저수용량은 1,490백만 m3이다. 대청댐 상류에 위치한 댐으로는 용담댐이 있으며 용담댐의 유역면적은 930 km2, 저수면적은 36.2 km2이며, 총저수용량은 815백만 km3이다. 대청댐 유입량 학습 및 예측을 위한 수위자료 취득을 위해 용담댐부터 대청댐까지의 금강 본류로 합류하는 남대천, 영동천, 초강 및 보청천을 선정하였다. 남대천, 영동천, 초강 및 보청천의 수위자료는 각각 여의교, 양강교, 초강교 및 산계교 수위관측소에서 측정된 수위자료를 취득하였다. 결측치가 존재하는 남대천의 신촌농2교 및 초강의 심천교는 제외하였다. Fig. 4는 대청댐, 용담댐 및 각 수위관측소의 위치를 나타낸 그림이다.
대청댐의 유입량, 용담댐의 방류량 및 각 수위관측소의 수위자료는 국가수자원관리종합정보시스템(Water resources management information system)에서 취득하였다. MLP의 대청댐 유입량 학습 및 예측을 위한 입력자료로는 홍수기의 일단위 하천수위 및 용담댐 방류량을 사용하였으며 출력자료는 대청댐 유입량을 사용하였다. 2010년부터 2019년 홍수기의 자료는 MLP의 대청댐 유입량 학습을 위해 사용하였다. 2020년 홍수기 자료는 GD 기반 optimizer와 AdamIHS의 성능 비교를 위한 예측 자료로 사용하였다.
2.6.1 데이터 전처리
학습 및 예측성능 향상을 위해 입력자료와 출력자료간의 지체시간을 고려할 필요가 있다. 또한, 학습 및 예측 자료의 넓은 범주는 ANN의 학습 및 예측성능 저하의 원인이 된다(Mok et al., 2020). 따라서 학습 및 예측성능 향상을 위해 원자료(Raw data)를 활용하기 좋은 자료로 가공하는 전처리가 필요하다. 본 연구에서는 지체시간을 고려하기 위한 TLCC와 범위의 차가 큰 자료를 동일한 범위로 변환하기 위한 정규화를 이용하여 전처리를 실시하였다.
TLCC는 입력자료와 출력자료간의 상관관계 절대값이 가장 높을 때까지 시간을 지연시켜 상관도가 가장 높은 데이터를 학습 및 예측하는 방법이다. TLCC를 실시하기 위한 상관계수 수식은 Eq. (10)과 같다.
여기서, r은 상관계수, Xi와 Yi는 시계열 값, n은 시계열의 길이를 의미하며, 와 는 각각 Xi와 Yi의 평균값을 의미한다.
정규화는 최대값과 최소값의 차가 큰 자료를 0과 1사이의 값으로 변환하는 방법이다. 정규화의 수식은 Eq. (11)과 같다.
여기서, Yi는 정규화된 변수값, Xi는 실제 변수값, Xmax는 실제 변수값의 최대값이며, Xmin은 실제 변수값의 최소값이다.
Table 2는 TLCC를 실시한 결과 상관계수의 절대값과 상관계수의 절대값이 가장 높게 나타난 지연시간이다.
Table 2에 따르면 모든 입력자료와 댐 유입량 간의 상관계수의 절대값이 높은 지연시간은 1일로 나타났다. 따라서, 대청댐 상류 하천 수위 및 용담댐의 방류량을 1일 지연시켜 학습 및 예측하였다.
3. 연구결과
3.1 평가지표
GD 기반 optimizer와 AdamIHS의 학습 및 예측성능 평가 및 은닉층 개수에 따른 학습 및 예측성능을 평가하였다. 본 연구에서는 학습 및 예측성능 평가를 위해 평균제곱오차(Mean Squared Error, MSE)를 활용하였다. 또한, MSE는 MLP의 학습과정에서 GD 기반 optimizer와 AdamIHS의 목적함수(Objective function)로 사용하였다. MSE의 수식은 Eq. (12)와 같다.
여기서, yo는 관측값, yp는 예측값이며, N은 자료의 개수이다.
3.2 학습결과
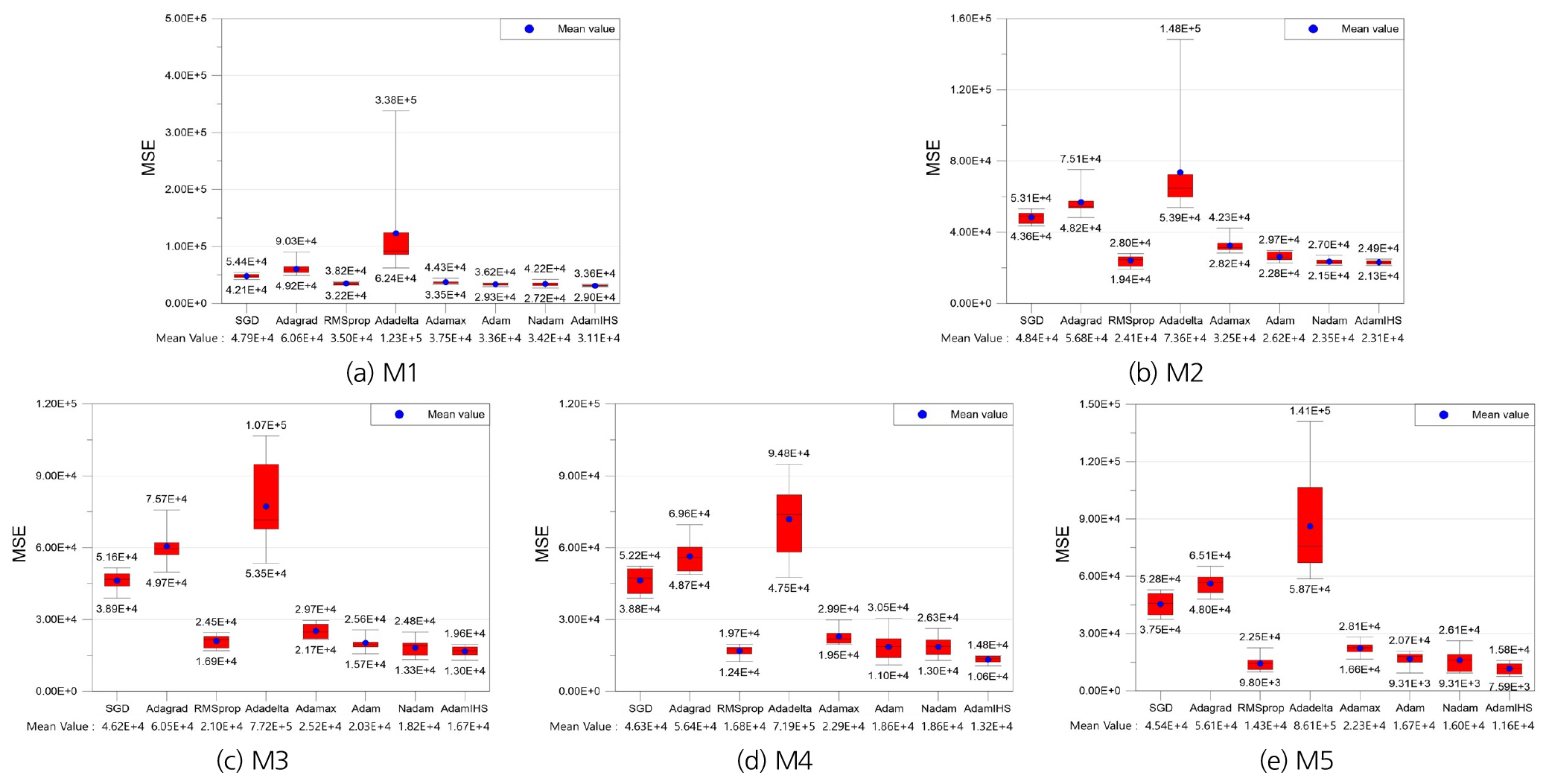
본 연구에서는 GD 기반 optimizer의 단점을 개선하기 위해 제안된 AdamIHS의 학습성능을 평가하기 위해 대청댐의 일단위 유입량을 예측하였다. MLP의 은닉층 개수가 증가할수록 비선형성이 증가하여 학습성능이 변화한다. GD 기반 optimizer 및 AdamIHS를 optimizer로 사용한 MLP의 은닉층 개수에 따른 학습 및 예측성능을 검토하였다. 은닉층의 개수는 1개부터 5개까지로 설정하였다. Table 3은 은닉층 개수에 따른 최적의 optimizer와 최적 optimizer의 학습결과이다. 학습결과는 안정성을 평가하기 위해 10번 반복실행하여 최대값, 최소값 및 평균값을 나타냈다.
Table 3에 따르면, M1부터 M5까지의 모델에서 AdamIHS의 학습성능이 가장 우수한 것으로 나타났다. 또한, 은닉층 개수에 따른 학습결과를 비교하면 은닉층이 5개인 M5의 학습성능이 가장 우수했다. Fig. 5는 은닉층 개수에 따른 GD 기반 optimizer와 AdamIHS의 학습 MSE 분포이다.
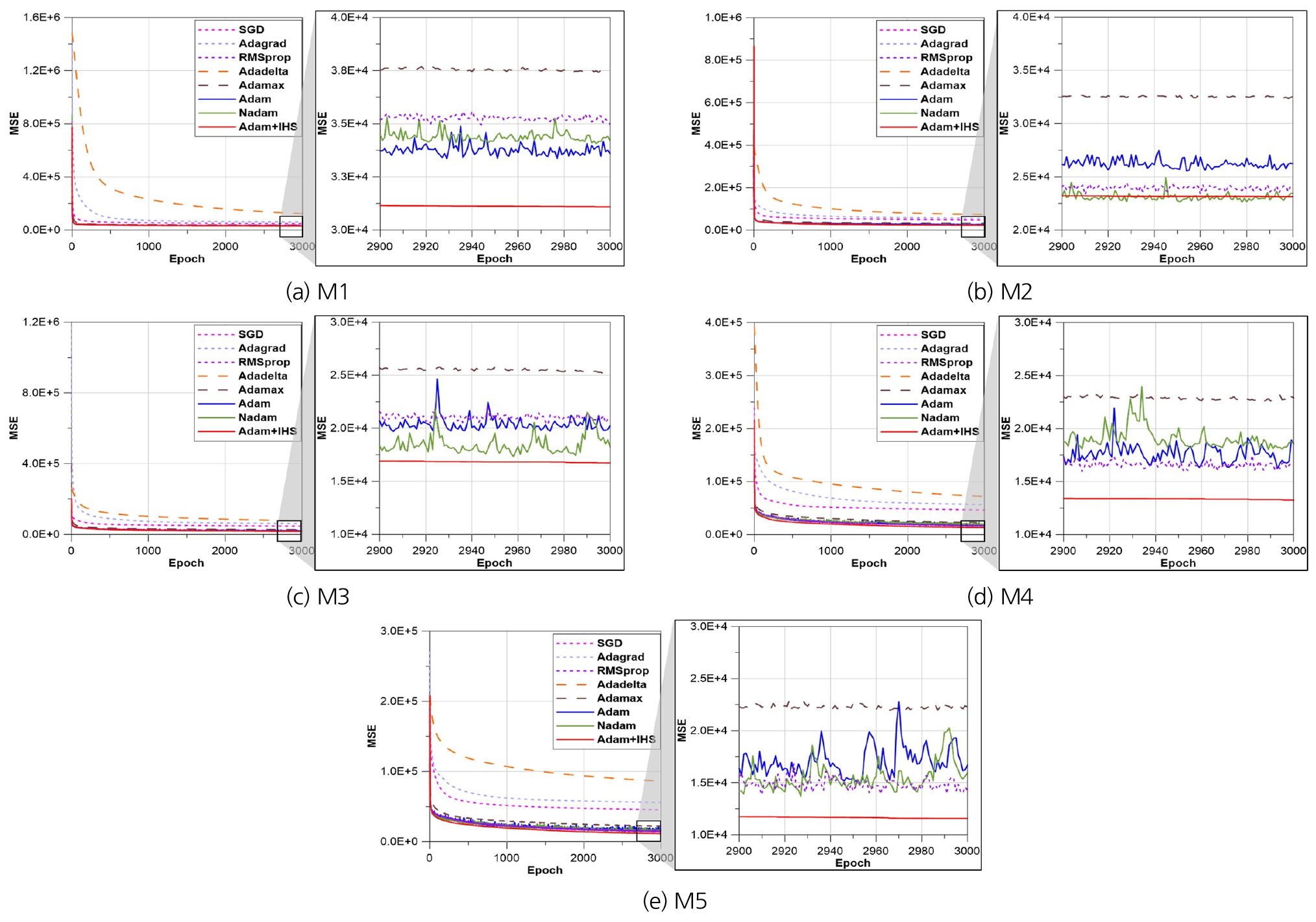
Fig. 5에 따르면, AdamIHS는 학습 MSE 최대값과 최소값의 차가 작아 비교적 학습이 안정적으로 진행된 것으로 분석된다. 또한, M1의 최소값을 제외한 나머지 MSE는 AdamIHS가 가장 작았다. Fig. 6은 M1부터 M5의 학습과정에서 MSE가 감소하는 것을 나타낸 그림이며, 10번 반복하여 취득한 결과의 평균이다.
Fig. 6에 따르면 Adadelta의 MSE가 가장 큰 값에서 수렴하였으며, AdamIHS가 가장 낮은 MSE에서 수렴하였다. 또한, GD 기반 optimizer의 경우 반복 학습 후반부에서 진동하는 것으로 나타났다. GD 기반 optimizer가 반복 학습 후반부에서 진동하는 이유는 AdamIHS와 다르게 생성된 해를 저장하고 비교하는 구조가 없기 때문인 것으로 분석된다. Table 3 및 Figs. 5 and 6을 통해 AdamIHS가 GD 기반 optimizer의 단점을 개선하였으며 학습성능이 향상된 것으로 분석된다.
Table 3.
Best training results of each model
3.3 예측결과
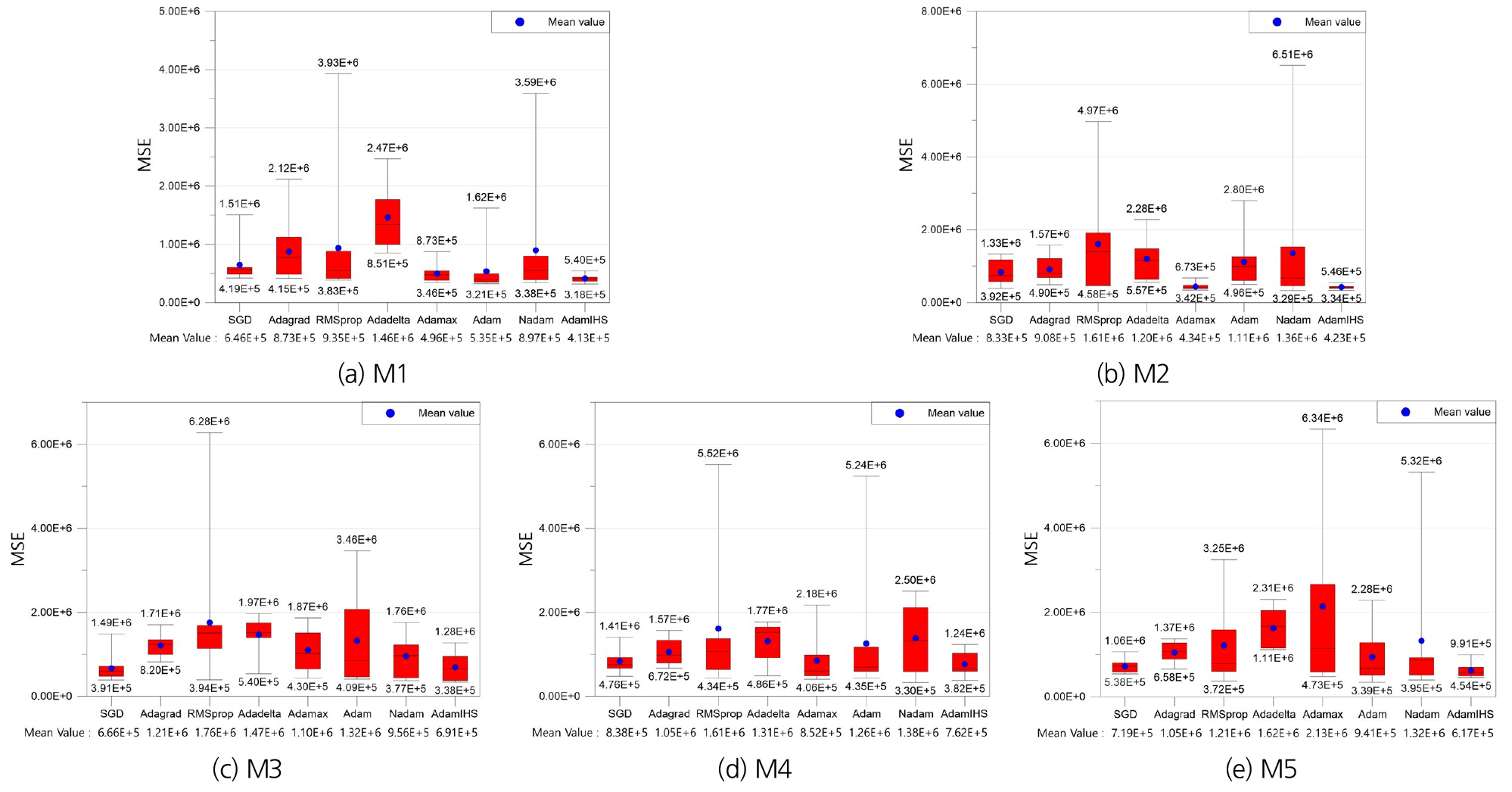
AdamIHS의 예측성능을 검토하기 위해 GD 기반 Optimizer를 사용한 MLP와 AdamIHS를 사용한 MLP의 예측값과 관측값 간의 오차를 평가하였다. 오차를 평가하기 위한 평가지표로 MSE를 사용하였다. 또한, 은닉층 개수에 따른 예측성능도 비교하였다. Table 4는 은닉층 개수에 따른 최적의 optimizer와 최적 optimizer의 예측결과이다. 예측결과는 안정성을 평가하기 위해 10번 반복실행하여 최대값, 최소값 및 평균값을 나타냈다.
Table 4에 따르면, M1부터 M5까지의 모델에서 AdamIHS의 예측성능이 가장 우수한 것으로 나타났다. 또한, 은닉층 개수에 따른 예측결과를 비교하면 은닉층이 1개인 M1의 학습성능이 가장 우수했다. Fig. 7은 은닉층 개수에 따른 GD 기반 optimizer와 AdamIHS의 예측 MSE 분포이다.
Table 4.
Best prediction results of each model
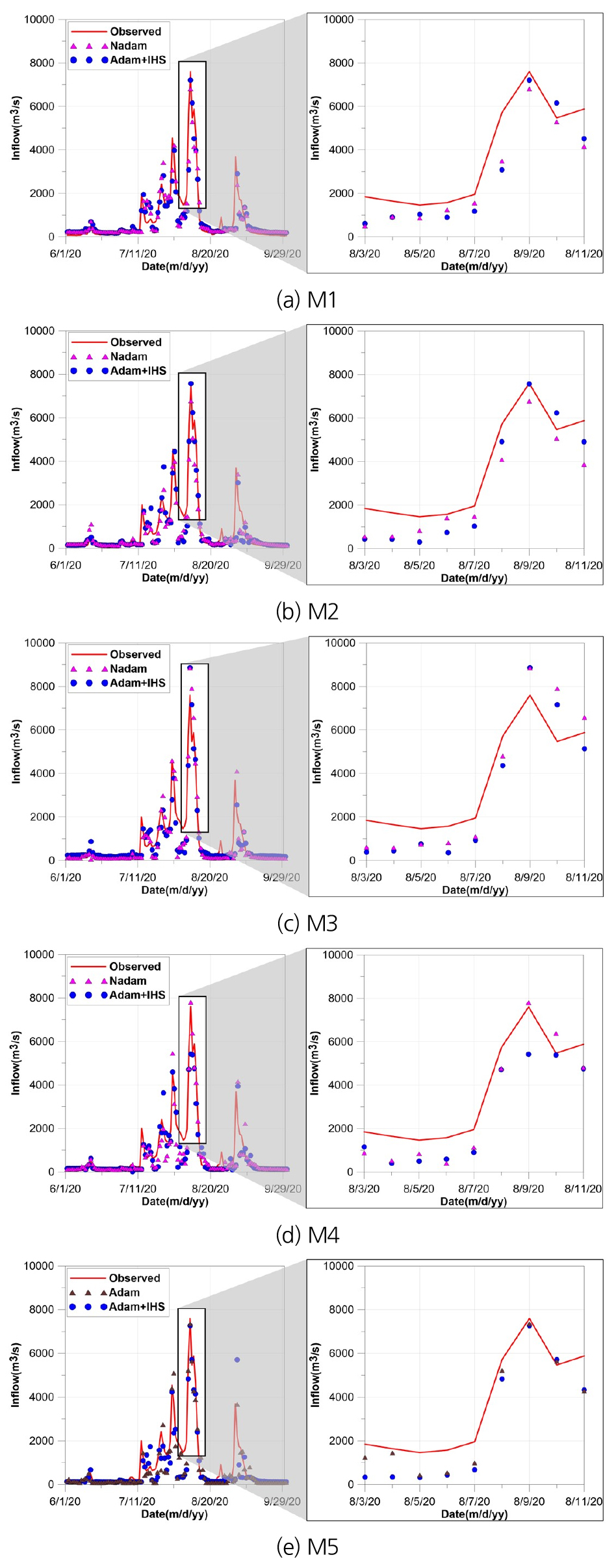
Fig. 7에 따르면, AdamIHS는 예측 MSE 최대값과 최소값의 차가 작아 비교적 예측이 안정적으로 진행된 것으로 분석된다. 또한, M1의 경우 예측 MSE 최대값, 최소값 및 평균값 모두 AdamIHS를 사용한 MLP가 가장 낮았다. M2의 경우, MSE 최대값, 최소값 및 평균값 각각 AdamIHS, Nadam 및 Adamax를 이용한 MLP가 가장 낮았으며 AdamIHS를 사용한 MLP의 MSE 최소값 및 평균값은 두 번째로 낮았다. M3의 경우, 예측 MSE 최대값, 최소값은 AdamIHS를 사용한 MLP가 가장 낮았으며 MSE 평균값은 SGD를 사용한 MLP가 가장 낮았다. M4의 경우, 예측 MSE 최대값 및 평균값은 AdamIHS를 사용한 MLP가 가장 낮았으며 MSE 평균값은 Nadam을 사용한 MLP가 가장 낮았다. M5의 경우, 예측 MSE 최대값 및 평균값은 AdamIHS를 사용한 MLP가 가장 낮았으며 MSE 평균값은 Adam을 사용한 MLP가 가장 낮았다. Fig. 8은 M1부터 M5의 예측 MSE 최소값이 낮은 기존 optimizer와 AdamIHS를 이용한 MLP의 댐 유입량 예측결과 및 관측값이다. 또한, 10번의 반복횟수 중 가장 학습성능이 좋은 모델이 예측한 결과를 나타낸 그래프이다.
Fig. 8(a)에 따르면, 첨두유입에서의 오차는 AdamIHS를 사용한 MLP가 Nadam을 사용한 MLP보다 약 51% 낮았다. AdamIHS를 사용한 MLP의 오차는 약 390.2 m3/s이며, Nadam을 사용한 MLP의 오차는 약 794.3 m3/s이다. Fig. 8(b)에 따르면, 첨두유입에서의 오차는 AdamIHS를 사용한 MLP가 Nadam을 사용한 MLP보다 약 96% 낮았다. AdamIHS를 사용한 MLP의 오차는 약 32.1 m3/s이며, Nadam을 사용한 MLP의 오차는 약 828.0 m3/s이다. Fig. 8(c)에 따르면, AdamIHS를 사용한 MLP의 오차는 약 1,265.4 m3/s이며, Nadam을 사용한 MLP의 오차는 약 1,242.3 m3/s이다. AdamIHS를 사용한 MLP의 오차와 Nadam을 사용한 MLP의 오차는 약 1%로 비슷한 차이를 보였다. Fig. 8(d)에 따르면, 첨두유입에서의 오차는 Nadam을 사용한 MLP가 AdamIHS를 사용한 MLP보다 약 90% 낮았다. AdamIHS를 사용한 MLP의 오차는 약 2,179.7 m3/s이며, Nadam을 사용한 MLP의 오차는 약 201.1 m3/s이다. Fig. 8(e)에 따르면, 첨두유입에서의 오차는 Adam을 사용한 MLP가 AdamIHS를 사용한 MLP보다 약 24% 낮았다. AdamIHS를 사용한 MLP의 오차는 약 328.5 m3/s이며, Adam을 사용한 MLP의 오차는 약 248.6 m3/s이다.
Fig. 8에 따르면, 첨두유입에서의 오차는 AdamIHS를 사용한 은닉층 2개인 MLP가 가장 낮았다. 또한, M1부터 M5까지의 모델들은 낮은 유입량에서 예측성능이 비교적 좋지 않은 것으로 나타났다. 낮은 유입량에서 예측성능이 좋지 않은 이유는 목적함수인 MSE는 큰 값에서의 오차에 민감하게 반응하기 때문인 것으로 분석된다. 은닉층 개수에 따른 학습 및 예측성능을 비교하면, 학습성능은 은닉층이 5개인 M5가 가장 우수하였으나 예측성능은 은닉층이 1개인 M1가 가장 우수하였다. 학습성능과 예측성능의 결과가 다르게 나타난 이유는 은닉층의 개수가 증가함에 따라 학습자료에 대한 과도한 학습으로 일반성이 감소하였기 때문인 것으로 분석된다.
4. 결 론
본 연구는 GD 기반 optimizer의 지역 최적값으로의 수렴 가능성 및 저장공간 부재의 단점을 보완하기 위해 AdamIHS를 제안하였다. AdamIHS를 사용한 MLP의 학습 및 예측성능을 검토하기 위해 홍수기의 일단위 대청댐 유입량을 학습 및 예측하였다. 또한, AdamIHS의 학습 및 예측성능을 GD 기반 optimizer인 GD, Adagrad, RMSprop, Adadelta, Adamax, Adam 및 Nadam과 비교하였다. 은닉층의 개수에 따른 학습 및 예측성능을 비교하기 위해 은닉층의 개수를 1개부터 5개까지의 모델을 구축하여 성능을 비교하였다.
학습결과를 비교하면, M1의 학습 MSE 최소값을 제외한 M1부터 M5의 학습 MSE 최대값, 최소값 및 평균값 모두 AdamIHS를 사용한 MLP가 가장 낮았다. 이를 통해, AdamIHS가 GD 기반 optimizer의 단점을 보완하여 학습성능이 우수한 것으로 분석된다. 또한, AdamIHS가 전역탐색을 통해 비교적 안정적으로 학습한 것으로 분석된다.
예측결과를 비교하면, AdamIHS를 사용한 MLP의 예측성능이 GD 기반 optimizer를 사용한 MLP의 예측성능보다 비교적 우수한 것으로 나타났다. 하지만, 일부 예측성능 평가지표는 학습성능이 AdamIHS가 가장 좋았음에도 불구하고 두 번째로 좋은 것으로 나타났다. 이를 통해, 과적합이 발생하여 학습자료에 최적화된 것으로 분석된다.
추후 연구에서 학습자료의 길이를 늘리고, 학습 과정에서 일부의 노드를 갱신하지 않는 Dropout을 실시하는 등의 과적합 방지를 통해 댐 유입량 예측성능을 향상시킬 수 있을 것으로 기대된다. 또한, 첨두유입에서의 오차뿐만이 아닌 낮은 유입량에서의 예측성능을 향상시키기 위해 첨두 유입량과 전체 유입량을 동시에 고려할 수 있는 다목적 최적화에 대한 연구가 필요하다. 마지막으로 본 연구에서 사용된 IHS의 경우 반복시산횟수에 따라 매개변수 값이 변동하여 매개변수의 최대 및 최소값에 따라 탐색성능이 달라진다는 단점이 있다. 따라서, HM 내 최적의 해와 가장 나쁜 해의 목적함수 계산값에 따라 매개변수가 변동하는 Self-Adaptive Harmony Search 및 매개변수를 자동으로 설정하는 Parameter-Setting-Free Harmony Search를 이용하여 GD 기반 optimizer를 개량하는 연구가 필요하다.
