

1. 서 론
1950년 이래로 다수의 극한 기상 및 기후 현상이 나타나고 있다. 이러한 변화 중 일부는 인간 활동과 관련된 것으로 기온상승과 극한 해수면 증가 및 많은 지역에서의 호우 빈도와 강도가 증가하고 있다(Pachauri and Meyer, 2014). 우리나라의 가뭄은 통계적으로 5~7년 주기를 가지고 발생하나, 최근 기후변화로 인해 가뭄 발생주기가 짧아지고 국지적인 가뭄이 이전보다 빈번하게 발생하고 있다(Kim et al., 2017). 가뭄에 대응하기 위해서는 우선 가뭄 상황을 평가하는 것이 중요한데 이때 사용하는 것이 수문학적 가뭄지수이다. 수문학적 가뭄지수의 종류에는 SPEI (Standardized Precipitation-Evapotranspiration Index), SDI (Streamflow Drought Index), WBDI (Water Budget-based Drought Index)가 있다. SPEI는 강수량과 잠재증발산량의 차이로 계산하며(Vicente-Serrano et al., 2010), SDI는 하천유량을 산정하여 수문학적 가뭄을 평가하기 위해 개발하였다(Nalbantis and Tsakiris, 2009). WBDI는 지표면 유출과 지하수 유출량을 강수와 증발산의 차이로 정의하는 물수지 방정식을 기본개념으로 활용한다(Sur et al., 2020). 이와 같이 가뭄지수를 산정할 때는 강수량 뿐만 아니라 하천유량과 잠재증발산량, 지하수 유출량 같은 수문인자를 이용한다. 이 중 하천 유량의 경우 갈수기에는 측정이 어려워 정작 자료가 필요한 가뭄 상황 평가 시 정확한 자료 확보가 어렵다는 한계가 있다.
수문기상자료가 충분하지 않은 경우 추계학적 모의(stochastic simulation)를 통해 관측 자료의 통계적 특성을 유지하면서 자료를 확충할 수 있다. 이 때, 가장 기본적인 형태를 가지는 추계학적 모형으로 자기회귀모형(Autoregressive Model, AR)을 고려할 수 있다. 이전 연구에서는 홍수 시 하천의 하천수위 예측이나, 강수 시 지하수 복원량 분석 등 외부 유입에 대한 강수 시에 중점을 맞춰 수문학적 지속성(persistence)이 큰 각각 변수에 대해 AR 모형을 토대로 분석이 수행되었다(Kim and Yeo, 2014; Lee et al., 1993; Liu et al., 2021; Mirzavand and Ghazavi, 2015; Yi et al., 2004;. Zanotti et al., 2019). 하지만, 하천수위와 지하수위와 같이 서로 상호연관성을 가지는 수문요소들을 독립적으로 모의를 하는 경우 서로 상호영향을 주고받는 수문요소에 대해서 독립적으로 추계학적 모의를 수행하기 때문에 상호정보의 손실과 함께 이들 모의 자료를 활용하는 2차 분석에서 물리적 특성을 유지하는데 어려움이 가중될 수 있다. 하천수위 및 지하수위와 같이 AR 모형으로 각각 모의를 하기 보다는 두 변수의 상관관계를 반영하는 VAR 모델을 통해 효과적으로 하천수위를 모의할 수 있다.
따라서 본 연구에서는 각 변수의 수문학적 종속성 및 상호 연관된 변수들의 종속성을 동시에 고려할 수 벡터자기회귀모형(Vector Autoregressive Model, VAR)을 구축하여 적용성을 검토하였다. 또한 매개변수의 추정 및 불확실성을 효과적으로 평가하기 위하여 Bayesian 추론 방법을 연계하여 모형을 구축하였다.
2. 방법론
본 연구의 수행과정은 다음과 같다. 2016년부터 2020년까지의 5년간의 지하수위와 하천수위의 일자료를 시계열 형태로 구축한 후, 각 인자의 자기상관성과 두 인자 간의 교차상관성을 고려하여 연구 수행 지점을 선정하였다. 즉, VAR 모형을 기반으로 지하수위와 하천수위의 관계를 나타내는 지하수위-하천수위 추계학적 모의 모형을 구축하였다. VAR모형에 대한 비교 모형으로 추계학적 모의기법 중 가장 간단한 형태이며 상호작용을 고려하는 항이 없는 AR 모형을 구축하였다. VAR 및 AR모형 모두 매개변수는 Bayesian 모형을 통해 추정하였다. 모형의 적합성의 정량적인 비교를 위해 Bayesian 모형들 간에 상대적 우수성을 검증하기 위한 목적으로 주로 활용되는 Deviance Information Criterion (DIC) 정보를 고려하였다.
2.1 대상자료
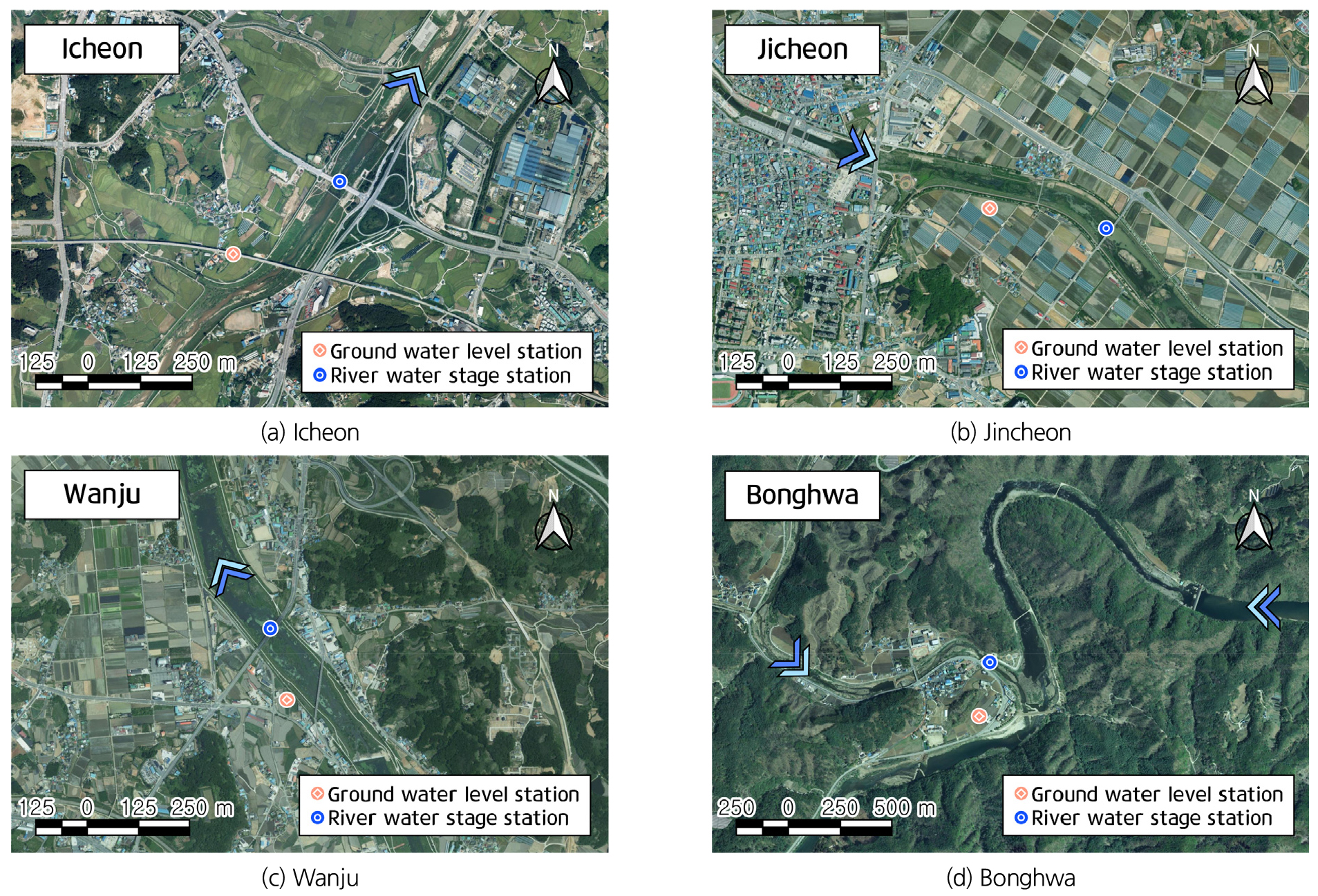
연구 대상인 수문인자 중 지하수위는 국가지하수정보센터에서, 하천수위는 국가수자원관리종합정보시스템에서 제공하는 관측지점의 일자료를 이용하였다. 모형을 구축하기 위해서는 지하수위와 하천수위가 유의미한 상관성을 보일 정도로 지하수위 관측정과 하천수위 관측소 간의 거리가 가깝고, 관측지점 사이에 하천 지류의 유입 또는 다른 수문 인자의 개입이 적은 곳을 선정해야 한다. 모형 모의 시 그 자료가 길면 길수록 적합도가 커지지만 보유한 관측자료가 10년 이상인 관측소가 447개소로 56%에 불과하여 최대한 많은 관측지점을 활용할 수 있는 일단위 기준 5년의 자료 연한을 모의를 위해 필요한 자료 기간으로 결정하였다. 지하수위 관측정과 하천수위 관측소 중 최근 5년(2016~2020년) 일단위 시계열 자료를 보유 하고 있으며 상관관계가 높아야하는 조건을 만족하여 선정된 관측정-관측소는 이천율현-이천시(복하교), 진천진천-진천군(신정교), 완주용진-완주군(제2소양교), 봉화명호-봉화군(풍호리)으로 하천수위 및 지하수위 각각 4개의 관측소로 구성된다. 각각의 관측소 쌍을 해당 관측소가 위치하는 행정구역명인 이천 지점, 진천 지점, 완주 지점, 봉화 지점으로 명명하였다. 해당 관측소 쌍의 기본 정보는 Table 1과 같으며, 관측소 쌍의 지형 및 위치정보는 Fig. 1에서 확인할 수 있다.
이 네 지점의 관측정-관측소 사이 거리는 모두 1 km 이내이며, 관측정과 관측소 사이에 취수장이나 하(폐)수 방류와 같은 외부 인자가 존재하지 않는다. 실제 하천수위와 지하수위 일자료 간의 상관관계를 확인하기 위해 자료 간의 상대적인 시간 지연(lag)에 따른 상관계수(correlation coefficient, CC)를 보여주는 교차상관관계(cross-correlation)를 검토하였다. - Fig. 2는 하천수위에 대한 지하수위의 lag에 따른 상관계수를 나타낸 그래프로 파란선은 두 변수가 상호관계가 있는 최저치의 상관계수를 나타내는 선이며, 빨간선은 lag에 해당하는 상관계수를 나타낸 바(Bar)이다. 이 그래프에서 확인할 수 있듯이 네 지점 모두 일자료 간에 시간 지연이 존재하지 않는 경우(lag = 0)의 상관성이 가장 큰 값을 나타냈다. 따라서 본 연구에서는 모형에 상호 상관관계를 고려하는 모형에서 같은 시점의 자료를 사용하였다. 추정된 상관계수는 모두 0.8 이상으로, 높은 상관관계를 보여, 네 지점의 관측정-관측소 쌍의 일자료들이 상호연관 된 변수임이 확인되었으며, VAR 모형을 적용하기에 적합하다고 판단할 수 있다(Table 1).
Table 1.
Basic information on stations considered in this study and their correlations
2.2 벡터자기회귀모형 및 매개변수 추정 방법
본 절에서는 변수의 독립적인 모의를 수행하는 AR 모형과 각 변수의 시간적 종속성을 고려하는 동시에 상호연관 된 변수의 상호 시간적 종속성을 고려한 VAR 모형을 요약하여 제시하였으며, 매개변수 추정을 위한 Bayesian 기법의 이론적인 배경을 수록하였다.
2.2.1 자기회귀모형(AR)과 벡터자기회귀모형(VAR)
대표적인 시계열모형인 일변수 AR 모형은 Yule (1927)이 제안한 모형으로, 단일 변수의 과거 값으로 현시점의 값을 예측하는 모형이다. AR 모형의 기본적인 형태는 Eq. (1)과 같다.
여기서 는 시계열의 t번째 변수의 값을 나타내며, 는 AR 계수로 변수에 대한 가중치를 나타낸다. 는 모형에서 현 변수의 값을 추론하기 위해 고려하는 이전 변수의 개수이고, 는 평균이 0, 분산이 인 백색잡음과정(white noise process)이다. 본 연구에서는 두 변수에 대해 모의하기 떄문에 Eq. (1)을 각각 변수에 적용하여, 구하려는 값의 한 단계 과거 시점의 값만을 사용하는 1차() AR 모형을 사용하였다. 시점의 하천수위와 지하수위를 각각 라고 할 때, 각 변수에 대한 1차 AR 모형의 형태는 Eqs. (2) and (3)와 같다. 여기서, 는 각 변수의 평균을 제거하여 평균이 0인 시계열로 변환하였다.
여기서, 와 는 모형의 매개변수로 이전 변수에 대한 가중치를 나타낸다. 와 는 평균이 0, 분산이 과 인 백색잡음과정(white noise process)이다. 이 모형에서는 두 변수가 서로에게 끼치는 영향은 없으며, 단지 각각의 이전 자료에만 영향을 받는다. 이러한 독립적으로 추계학적 모의를 수행하기 때문에 정보손실과 상호 연관된 해석 시 비교적 정확도가 떨어져 문제점을 나타낼 수 있다.
이에 Sims (1980)은 자기회귀모형의 한계를 보완하여 변수들의 상관관계를 반영한 분석이 가능한 다변수 자기회귀모형인 VAR 모형을 제안하였다. VAR 모형은 두 변수를 예측할 시 변수 간에 상관관계가 있다는 가정 아래, 두 변수의 과거 값에 매개변수를 두어 각 변수의 현시점의 값을 예측하는 모형이다. 상관성을 가지고 있는 시점의 두 변수를 라고 할 때 다음 Eqs. (4) and (5)와 같이 상호작용을 고려한 1차 VAR 모형을 구축할 수 있다.
여기서, 와 는 모형의 매개변수로 는 평균이 0, 분산이 인 백색잡음과정이다. VAR 모형의 항과 항은 AR 모형의 항과 항과 동일하게 각 변수 자기 자신의 과거 자료에 의한 영향을 반영하는 항이며, VAR 모형의 항과 항은 AR에 존재하지 않는 항으로 상호작용을 하는 변수의 과거 자료에 가중치를 주어 이를 시점의 값을 모의한다. 만일, 두 변수 간에 가장 큰 상관계수를 보이는 시간 지연이 0이 아닌 시점 a일 경우, 이를 반영하여 t-1 시점의 값이 아닌 t-(a+1) 시점을 입력자료로 활용해 lag에 대한 반영할 수 있다.
2.2.2 베이지안(Bayesian) 추론을 활용한 모형의 매개변수 산정
AR 모형과 VAR 모형 모두 매개변수로 과거 자료에 가중치를 두어 각 변수를 산정하며 본 연구에서는 Bayesian 추론을 통해서 매개변수를 산정하였다. Bayesian 추론기법은 매개변수 최적화 및 불확실성 정량화를 목적으로 매개변수가 단일 값이 아닌 확률분포형태로 존재하며 결합확률분포는 사전분포와 우도의 곱으로 표현된다는 Bayes 정리를 기반으로 사후분포를 추론하는 방법이다. 해당하는 내용을 식으로 표현하면 아래와 같다.
여기서, 는 사전분포(prior distribution), 는 우도(likelihood), 는 사후분포(posterior distribution)를 나타낸다. 이를 기반으로 한 MCMC (Markov Chain Monte Carlo) 방법을 통해 사후분포를 추정하였다. MCMC 방법은 매개변수들의 사전확률분포로부터 개별 표본을 추출하고 이를 조건부로 하여 연쇄적인 표본을 추출하는 방식이다. 복잡한 다변량 관계를 조건부 분포를 통해 효율적으로 모형화할 수 있는 장점을 제공한다.
본 연구에서 변수 는 정규분포로 가정하였으며, 평균 , 분산 인 정규분포의 확률밀도함수는 아래의 Eq. (7)과 같다. 지하수위 및 하천수위 등 2개 확률변수의 분포함수를 정규분포로 가정하여 AR 모형의 우도함수를 정의하면 Eqs. (8) and (9)와 같다. 모형 매개변수의 사전분포는 Eqs. (10)~(13)과 같다. 정규분포의 공액분포(conjugate distribution)인 정규분포와 Gamma분포를 매개변수의 사전분포로 적용하여 해석상의 효율성을 가지도록 하였다.
AR 모형과 동일하게 VAR 모형의 경우에도 지하수위 및 하천수위 등 2개 확률변수의 분포함수를 정규분포로 가정하였으며 VAR 모형의 우도함수를 정의하면 Eqs. (14) and (15)와 같다. 모형 매개변수의 사전분포는 Eqs. (16)~(21)와 같다. AR모형과 같이 정규분포의 공액분포(conjugate distribution)인 정규분포와 Gamma분포를 매개변수의 사전분포로 적용하였다.
VAR 모형은 AR 모형에 상관관계가 있는 변수의 값이 추가되어 종속 변수에 대한 설명력이 증가하지만 그에 따른 매개변수의 개수가 2배 증가함으로써, 과적합이 일어날 가능성이 커진다. 따라서 가장 적합한 모형선정을 위해 본 연구에서는 지표 산정 시 사후평균을 이용하여 Bayesian 추론 분석에 적합한 지표인 DIC (Deviance Information Criterion)를 사용하였다. Spiegelhalter et al. (2002)가 소개한 DIC는 우도와 매개변수의 개수에 따른 모형의 복잡성 정도로 정의되며 MCMC를 통해 추출된 표본을 통해 얻을 수 있으며 Eq. (22)과 같이 나타낼 수 있다.
여기서, 는 자료 에 대한 모형 매개변수 집합 의 우도함수(likelihood function)로서 앞서 정의된 Eqs. (8), (9), (14) and (15)로 대체될 수 있으며, 는 유효 매개변수 개수(effective number of parameters)이다. DIC는 그 값이 작을수록 해당하는 모형이 적합도가 높은 모형임을 나타낸다.
2.2.3 매개변수 추정 결과 및 모형 비교
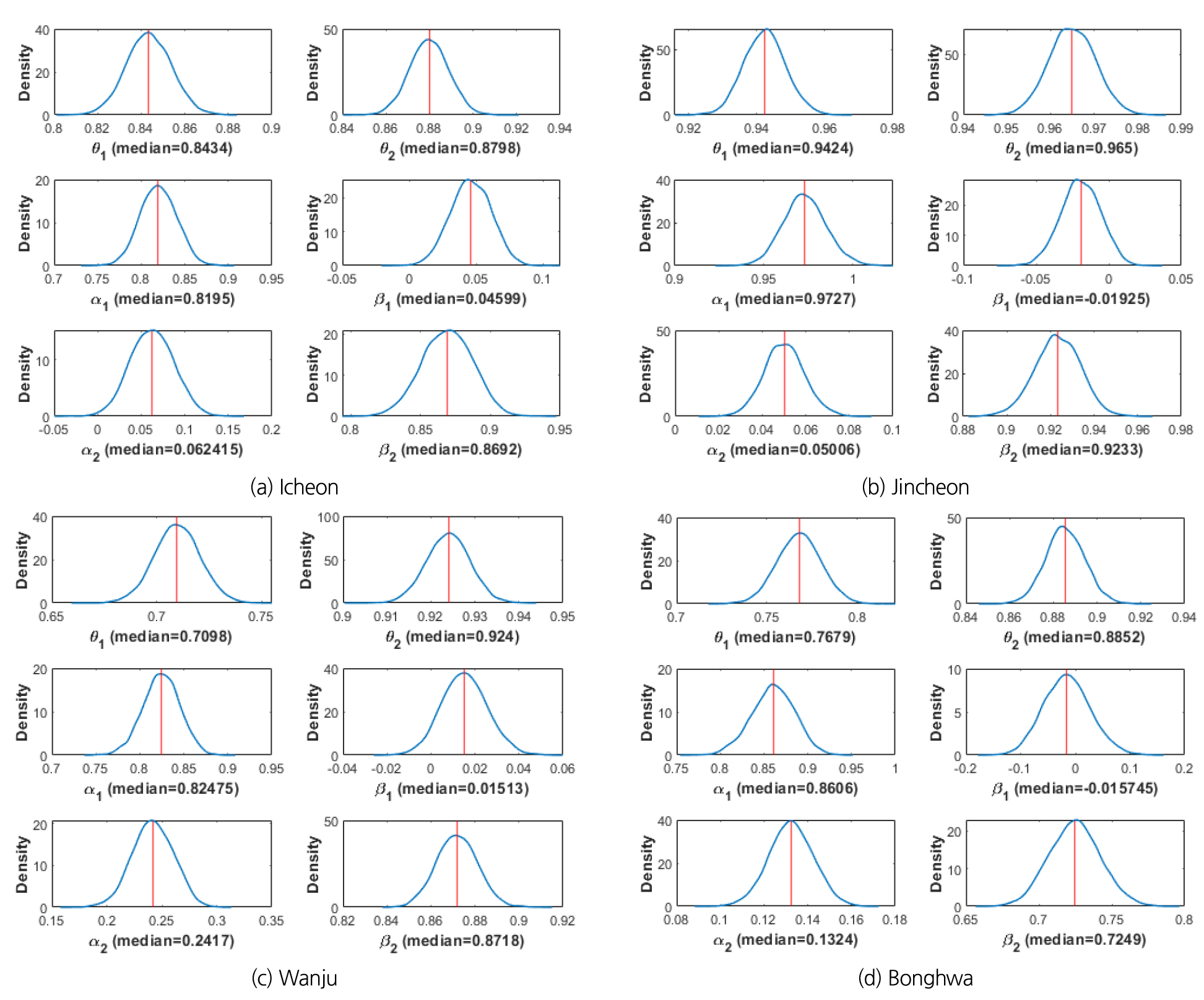
AR 모형 및 VAR 모형 구축하여 Bayesian 매개변수 추정을 위해 Eqs. (8), (9), (14) and (15)를 기반으로 MCMC 모의를 6,000번 수행하여, Eqs. (2)~(5)의 매개변수()의 사후분포를 추정하였고, 이 사후분포로부터 구한 매개변수의 중앙값을(median)을 Table 2에 정리하였다.
Bayesian 방법으로 추정된 매개변수 각각의 사후분포는 Fig. 3과 같다. Eqs. (10) and (11), (16)~(19)에서 매개변수의 사전분포를 정규분포로 가정했기 때문에 모의결과로 얻어진 사후분포도 정규분포 형태를 띤다.
Table 3는 MCMC 모의를 통해 산정된 DIC이다. DIC는 그 값이 작을수록 모형이 더 적합성이 있다는 척도이다. 은 VAR 모형의 모의에 대한 DIC 결과값을, 는 AR 모형의 모의에 대한 DIC 결과값을 나타내며, 은 VAR모형이 AR모형의 DIC차이를 나타내며 AR모형에 비해 VAR모형에 모형 적합도의 개선정도를 나타낸다. VAR 모형과 AR 모형의 DIC 값을 비교하여 모형 적합성을 평가한 결과 네 지점 모두 VAR 모형이 AR 모형에 비해 개선된 값을 나타내었다.
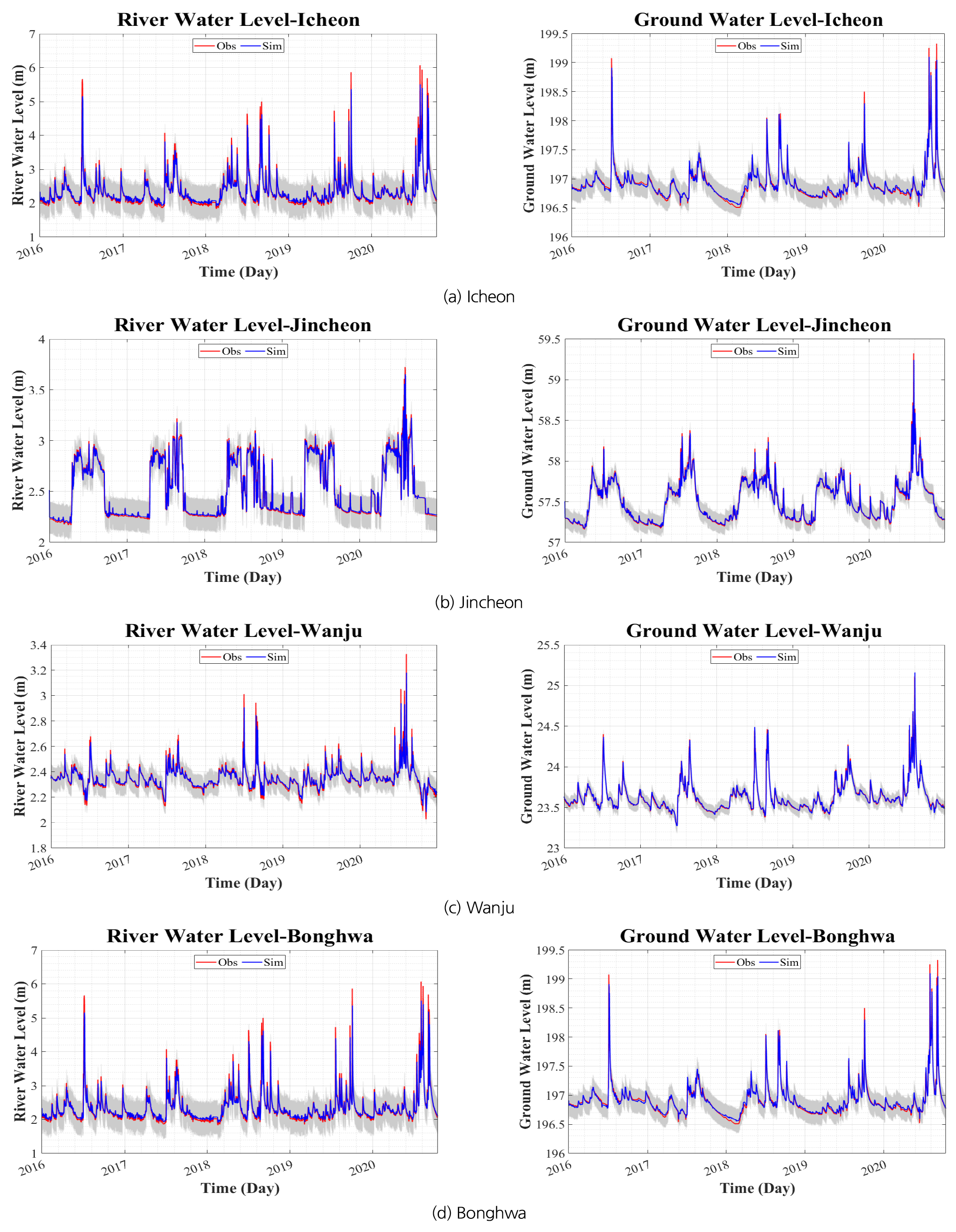
VAR 모형의 매개변수를 사용하여 모의한 지하수위와 하천수위의 결과와 관측값을 비교한 그래프는 Fig. 4와 같다. 파란선은 베이지안 추론을 이용하여 6,000번 모의된 수위의 중앙값을 나타내며 회색 구간은 모의의 신뢰구간이며, 빨간선은 관측값이다. Fig. 4의 극대값은 강수가 주된 요인이며, 이는 외부에서 유입된 인자이기 때문에 VAR 모형 구축 시 고려되지 않아 그에 따른 오차를 보인다. 이에 비해 저수위일 경우 VAR 모형을 활용하여 모의한 하천수위와 지하수위는 관측치에 대한 재현성이 높다.
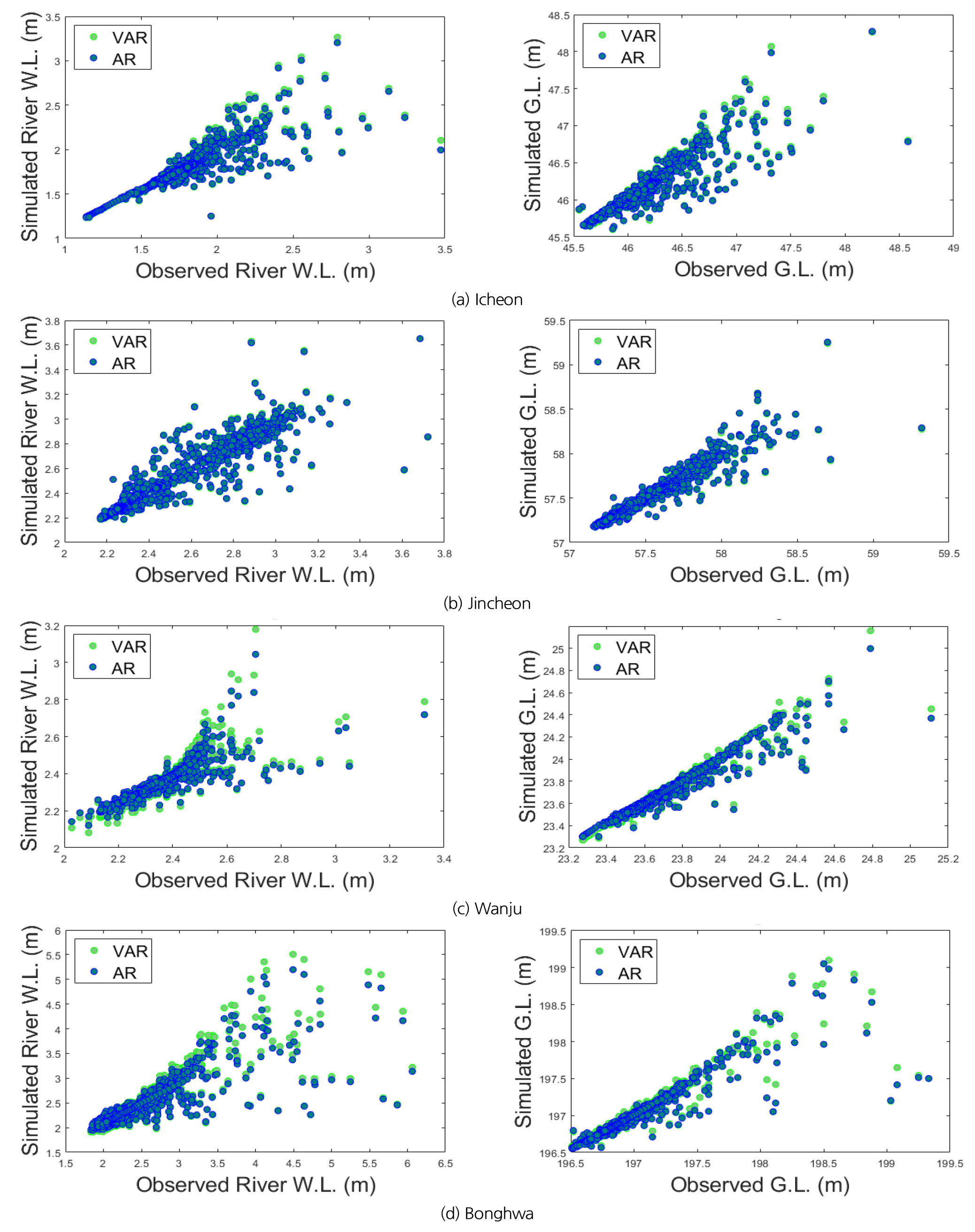
Fig. 5는 VAR 모형과 AR 모형의 모의값을 관측값과 비교 하기 위한 산점도이며, VAR 모형 모의값이 AR 모형의 모의값에 비해 더 큰 양의 상관관계를 보인다. 산점도에서도 수위의 값이 커질수록 상관관계가 감소하는데 Fig. 4에서 극대값에서 오차가 컸던 것과 마찬가지로 외부인자 유입에 의한 것으로 판단된다.
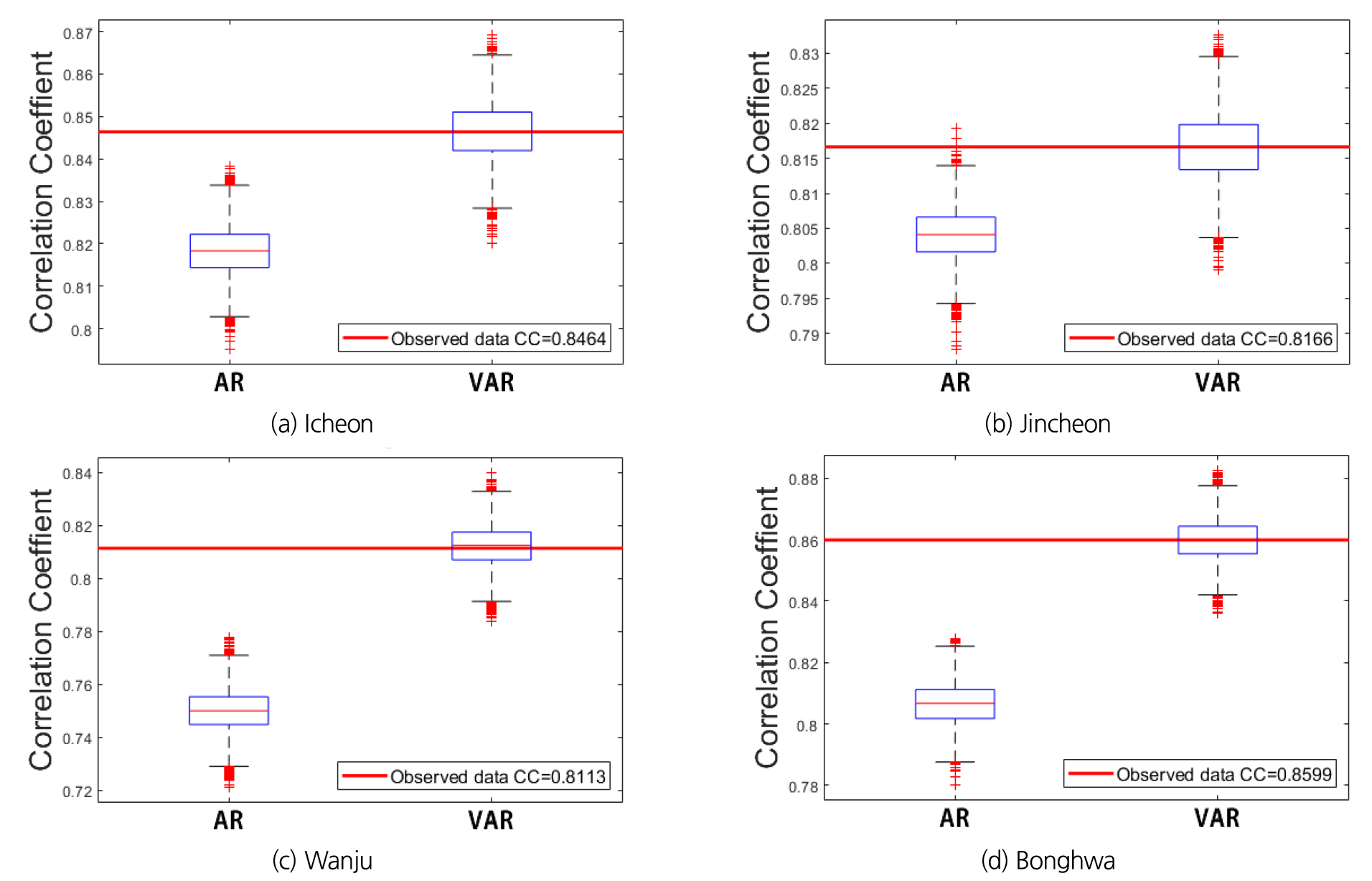
VAR 모형과 AR 모형으로 모의한 하천수위와 지하수위의 상관계수를 서로 비교했을 때 VAR 모형의 상관계수가 관측된 지하수위와 하천수위의 상관계수에 수렴하는 것을 Fig. 6를 통해 확인할 수 있다. 이를 통해 VAR 모형이 AR 모형에 비해 하천수위와 지하수위 간의 관측값의 상호관계를 유실하지 않고 관측값과 유사한 모의 결과를 보여줌을 알 수 있다.
변수 및 지점별 모의값과 관측값 비교 시 하천수위와 지하수위 모두 강한 양의 상관관계를 나타내었다(Fig. 5). 상관계수의 범위는 지하수위의 경우 0.90과 0.97 사이의 값이, 하천수위의 경우 0.85와 0.96 사이의 값으로 추정되었다. 본 연구의 목표는 수문학 및 농업적 가뭄에 중요한 척도가 되는 지하수위를 하천수위의 변동까지 반영하여 모의 정확도를 높이는 것이다. 즉, 지점별 지하수위의 관측값과 모의값의 상관계수가 개선되어, VAR 모형의 적합성이 더 우수한 것을 확인할 수 있었다.
지점별로 비교하면, 진천 지점과 완주 지점이 이천 지점과 봉화 지점에 비해 높은 상관성을 보이는데 이는 Fig. 2에서 지하수위 관측정과 하천수위 관측소의 위치 관계를 확인하면 그 이유를 추론할 수 있다. 모든 지점이 관측정과 관측소 간의 거리가 1 km 이내로 가깝고 관측정과 관측소 사이에 하천 지류의 유입 등이 없었지만, 이천 지점과 봉화 지점의 경우 상대적으로 상호 수위에 영향을 끼칠 수 있는 요소가 존재하는 것으로 판단된다. 이로 인해 이천과 봉화 지점에서는 비교적 낮은 상관성을 보이는 결과를 보였으며 보다 상세한 영향분석을 통해 영향인자 발굴과 이를 모형에 활용하는 방안 모색도 필요할 것으로 판단된다.
Table 2.
Comparisons of estimated parameters between AR and VAR models
3. 결 론
경기도 이천시와 충청북도 진천군, 전라북도 완주군, 경상북도 봉화군에 위치한 네 지점 하천수위와 지하수위 각각의 자기상관성 및 상호관계성을 확인하였으며 AR 모형과 VAR 모형 구축 및 각각에 대한 매개변수를 산출하였다. 두 모형의 모의값을 비교해 본 결과 두 모형 모의값과 관측값 간 모두 CC 0.8 이상의 강한 선형 관계를 보인다. 특히, 자기회귀모형은 수위가 낮을수록 강한 선형 관계를 가지므로, 하천수위와 지하수위 간의 상관 정보를 손실하지 않고 모의가 가능한 VAR 모형으로 모의된 지하수위를 활용하여 갈수기 또는 동절기의 하천수위 오측에 대한 보정 또는 결측치를 대체할 수 있을 것으로 판단된다.
1) 본 연구의 대상 지점 모두 VAR 모형에서 하천 수위의 모의 값이 지하수위 관측값과 강한 선형 관계를 보인다. 특히 수위가 낮을수록 선형 관계가 더욱 뚜렷하게 나타나고 있다. 따라서, 동절기 저수위 또는 갈수 시 하천 수위를 정확히 측정하기 어려울 때 지하수위를 활용해 하천수위를 파악할 수 있을 것으로 기대된다.
2) 하천수위가 높아질수록 지하수위와의 관계가 분산되는 형태를 나타내는데 이는 하천 수위가 높은 경우인 홍수 시에는 하천 수위가 지하수위에 영향을 끼칠 만큼 오래 지속되지 않거나 상호 연관성이 홍수 시에는 상대적으로 크지 않은 이유로 판단된다.
3) 본 연구에서는 지하수와 하천 간의 물의 이동을 중점적으로 고려하였으나, 수위는 그 외 기상인자(강수량, 증발산량 등)에 의한 영향을 받으므로 향후 연구에서는 지하수위와 하천수위의 상호관계에 기상인자를 추가하여 모형을 개선할 수 있을 것으로 기대된다.
