

1. 서 론
2. 연구방법
2.1 대상유역 및 자료
2.2 원격상관성 분석
2.3 예측모형 구성 및 예측인자 선정
3. 연구결과
3.1 원격상관성 분석결과
3.2 월 강수량 예측결과
4. 결 론
1. 서 론
안정적인 수자원의 운영 및 관리를 위해서는 가용수자원의 원천이 되는 강수량의 정확한 예측이 필수적이며, 특히, 계절예측에 해당하는 한 달에서 수개월 시간 규모의 장기예측은 가뭄과 홍수, 폭염을 비롯한 기상이변으로 인한 재해를 대응하고 안정적인 수자원 확보를 위해 매우 중요하다. 강수량 및 기온 등과 같은 기상요소를 예측하기 위한 방법으로 예측모형이 많이 활용되고 있는데, 접근방법에 따라 크게 2가지로 구분할 수 있다. 하나는 역학모형을 이용하는 것으로서 대기-해양-지면에서의 유체현상을 설명하는 다양한 방정식을 통해 수치해를 구하는 방법으로 기후모형인 GCM (General circulation model)이 많이 활용되고 있다. 두 번째 방법은 과거의 기상자료와 대기-해양-지면 자료들간의 통계적 관계를 통해 예측하는 방법으로, 유사법, 시계열모형, 다중회귀모형, 정준상관모형, 인공신경망모형 등이 활용되어 왔다.
호주, 미국, 영국, 일본 등을 비롯하여 국내 기상청에서는 수치적 역학모형을 이용하여 강수량과 기온에 대한 월 및 계절 예측정보를 국가 차원에서 제공하고 있다. 모델링 및 컴퓨팅 기술의 발달에 따라 복잡하고 비선형적인 역학적 현상들을 재현함으로써 수일 미만의 단기 예측성은 높아지고 있으나, 초기 기상요건에 따른 불확실성과 수치모형의 적분시간에 따른 오차의 증가 등으로 수개월 단위 이상의 장기예측 정확도는 여전히 미흡한 상황이다. 반면 통계적 모형은 역학적 모형에 비해 예측성이 불안정하다는 단점이 있으나, 상대적으로 모형 구성이 유연하며 관측자료 및 연관된 자료의 축적에 따라 예측기간과 예측성을 개선할 수 있는 가능성을 가지고 있어 많은 연구자들에 의해 다양한 통계적 기반의 예측이 시도되고 있다(Kim et al., 2020).
그간 우리나라에서 강수량 예측을 위해 수행된 통계적 접근의 연구들을 보면, 대규모 대기·해양 기후패턴과 월 또는 계절단위 강수특성과의 원격상관성 분석, 그리고 상관성을 기반으로 강수량 예측을 위한 통계적 모형 구성에 관한 연구가 많이 진행되어 왔다.
Kim et al. (2005)은 봄철 강수량과 AO (Arctic oscillation), SCAND (Scandinavia pattern), NP (North Pacific pattern) 지수와의 유의한 관계를 분석한 바 있으며, Ahn and Kim (2005)은 겨울철 강수량과 관련하여 AO, NINO3.4 (East central tropical Pacific SST (5N-5S, 170-120W)), EAWMI (East Asian winter monsoon index) 등이 상관성이 높고, 여름철 강수량은 NEASRA (Northeast Asian summer rainfall anomaly)와 양의 상관성이 있다고 분석하였다. Kim et al. (2007)은 각 월별로 상관성이 높은 5개의 기후지수를 선별하여 예측모형인 다중회귀모형의 예측인자로 활용하였다. Kim et al. (2008)의 연구에서는 12월 강수량이 ENSO (El Niño-Southern oscillation)와 관련된 ESL (Equatorial eastern Pacific sea level pressure), ESO (Equatorial SOI), MEI (Multivariate ENSO index), ONI (Oceanic Niño index), SOI (Southern oscillation index) 등의 기후지수와 유의한 상관관계가 있음을 제시하였으며, Choi et al. (2013a)과 Choi et al. (2015)은 WP (Western Pacific) 지수와 우리나라 4월 강수량 간에 강한 양의 상관관계를 확인한 바 있다. Lee and Choi (2013)는 AO 지수와 우리나라 61개 기상관측지점의 봄철 여러 기후변동성을 분석한 결과, 강수량과의 상관성은 크지 않다고 밝힌 바 있다. Choi et al. (2013b)은 우리나라 60개 기상관측지점의 6월 강수량과 6월의 AAO (Antarctic oscillation) 사이에 강한 양의 상관성을 확인하였으며, Choi et al. (2014)의 연구에서는 네팔의 여름 몬순과 우리나라의 여름철(6~9월) 강수량 사이에 유의할 수준의 상관성이 있다고 분석하였다. Ahn et al. (2015)은 우리나라 14개 지점 강수량과 39개의 대규모 기후지수를 교차상관분석하여 NINO1+2 (Extreme eastern tropical Pacific SST (0-10S, 90W-80W)), NINO3.4, NINO3 (Eastern tropical Pacific SST (5N-5S, 150W-90W)) 등이 유의한 상관관계에 있음을 확인하였다. Lee and Kwon (2015)에서는 인도양과 북서태평양 지역의 기후특성을 예측인자로 하는 정준상관모형을 구성하여 우리나라가 속한 동아시아 지역의 여름철 강수량 예측을 시도하였으며, Ham et al. (2017)은 열대 대서양 해수면 온도의 변동성과 우리나라 여름철 강수량 사이의 상관성을 분석한 바 있다. Kim et al. (2017)은 3개월 선행 NAO (North Atlantic oscillation) 패턴과 우리나라 봄 가뭄 사이의 지연상관성을 분석하여, WP 보다는 NAO가 가뭄 예측에 유용할 것으로 판단하였다. Jo and Ahn (2017)는 NOAA 기후지수들 중에서 우리나라 3~4월 강수량과 상관성이 높은 3개 지수(North Pacific index, Siberian High index, Indian Ocean Basin Mode index)를 선정하여 예측모형 구성에 활용하기도 하였다. Park et al. (2018)은 우리나라 각 수계별로 상관성이 높은 예측인자를 이용하여 Bayesian MCMC (Markov Chain Monte Carlo) 예측모형과 인공신경망 예측모형을 구성하고, 여름철 강수량 전망결과를 비교한 바 있다. Lee et al. (2020)은 한강권역을 대상으로 5월과 6월 강수량 예측을 위해 38종의 전지구 기후지수에 대한 상관성을 분석하여 인공신경망모형의 예측인자로 활용하였다. Lee and Chang (2021)의 연구에서는 PDO (Pacific decadal oscillation), AO, NINO3.4 등의 기후지수와 계절 강수량과의 상관성을 제시하고 있다.
상기 연구들에서도 나타난 바와 같이 통계적 예측모형으로 과거부터 다중회귀모형이 많이 활용되어 왔으며, 최근에는 빅데이터를 기반으로 하는 인공신경망모형의 활용성이 점차 높아지고 있다. 인공신경망모형은 입력변수가 불완전한 경우에도 반복학습을 통해 분류 및 예측을 최적화하여 오차를 줄여나갈 수 있기 때문에 다중공선성 등의 한계를 갖고 있는 회귀분석기법에 비해 폭넓은 적용이 가능한 장점을 가지고 있다.
이와 같이 전지구적인 기후패턴과 우리나라 기상특성과의 상관성 분석에 대한 연구는 통계적 모형을 구성하기 위한 첫 단계로서 많이 수행되어 왔으며, 우리나라의 월 또는 계절 강수량과 관련하여 상관성이 높은 기후지수들을 제안하고 있다. 다만, 우리나라의 기후특성과 전지구적인 기후패턴의 경년변동성으로 인해 분석기간에 따라 기후지수들과의 상관성 또한 달라질 수 있다. Kim et al. (2005)의 연구에 의하면, 우리나라 봄철 강수량과 관련해서 1980년대 이전까지는 AO, SCAND의 영향이 크게 나타났으나, 1980년대 이후로는 NP의 영향력이 증가하는 것으로 나타났다. Lee and Choi (2013)의 연구에서는 AO와 봄철 강수량 간에 유의한 상관성이 없는 것으로 제시되고 있다. 또 다른 한계는 Kim et al. (2020, 2021b)에서 기술한 것처럼, 기존 예측과 관련된 연구들의 대부분이 분석기간을 보정과 검증기간으로 구분하여 최적화된 결과를 제시하고 있기 때문에, 분석에 사용하지 않은 기간 또는 미래기간에 대한 예측성을 판단하기 어렵다는 것이다. 즉, 기존 연구들에서 제시하는 원격상관성이나 예측모형은 특정 기간에 대해 도출된 결과이므로 중장기적인 전지구적 기후변화를 반영하기 위해서는 분석기간에 따라 탄력적으로 예측인자를 선별하고 예측모형을 구성할 필요가 있다. 이에 대한 해결책으로 Kim et al. (2020, 2021b)의 연구에서는 각 예측대상월에 대해 과거 40년간의 예측대상값과 기후지수자료에 대한 상관성 분석을 통해 최적의 예측인자를 선별하여 다중회귀모형기반의 예측모형을 구성한 바 있다.
본 연구에서는 Kim et al. (2020, 2021b)의 연구에서 수행된 방법을 기준으로, 금강권역을 대상으로 하는 통계적 기반의 월 강수량 예측모형을 구성하였다. 예측모형으로서 최근 많이 활용되고 있는 다중회귀모형과 인공신경망모형의 두 가지 형태의 통계적 모형을 구성하였다. 두 가지 모형 모두 공통적으로 예측시점과 예측대상월에 따라 예측대상(월 강수량)과 상관성이 높은 기후지수를 선별하여 예측인자로 활용하였다. 각각의 예측모형으로부터 도출된 미래기간(1~12개월 선행기간)에 대한 월 강수량 예측결과를 비교·분석하여 통계적 모형에 의한 금강유역의 월 강수량 예측 가능성을 평가하였다.
2. 연구방법
2.1 대상유역 및 자료
대상유역인 금강권역은 Fig. 1과 같이 수자원단위지도 상 대권역인 금강을 포함하여 삽교천, 금강서해, 만경동진을 모두 포함하며, 전체면적은 약 17,925 km2이다.
예측대상인 금강권역의 월 강수량은 Fig. 1 및 Table 1에 제시된 것과 같이 총 15개의 기상청 종관기상관측(automated synoptic observation system, ASOS) 지점의 자료를 티센면적평균하여 활용하였으며, Kim et al. (2020, 2021b)의 연구에서와 같이 관측소별 미계측 및 결측기간 등을 고려하여 기간에 따라 가변형 티센망을 구성하여 면적평균값을 도출하였다.
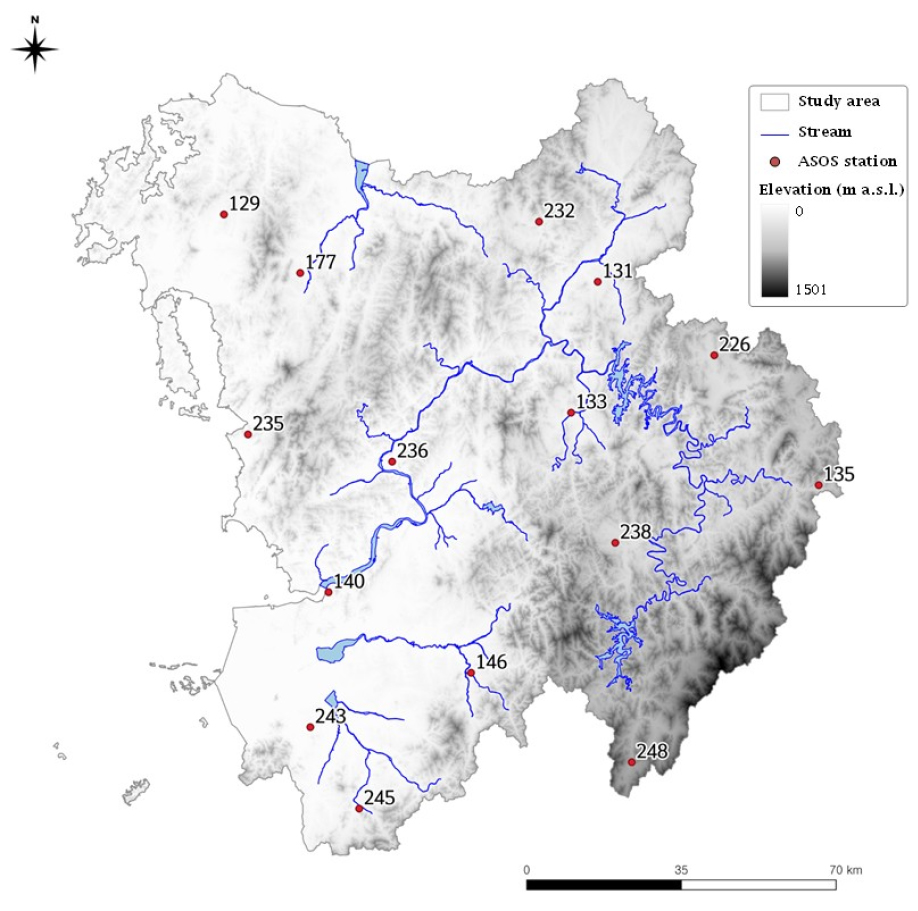
예측인자로는 Kim et al. (2021b)에서 활용한 바와 같이 미국의 해양대기청(National Oceanic and Atmospheric Administration NOAA) 등에서 월 단위로 제공하고 있는 글로벌 기후지수 39종과 금강권역의 기상인자 8종(강수량, 평균기온, 상대습도, 평균해면기압, 일조시간, 평균풍속, 평균운량, 소형증발량)을 활용하였다. 강수량과 평균기온을 포함하는 금강권역 기상인자에 대해서도 결측 등에 의한 미계측기간을 고려하여 가변형 티센망을 이용하여 월 단위 면적평균값을 산정하여 활용하였다.
분석을 위해 예측대상(강수량)과 예측인자 모두 1948~2021년의 월 단위 자료를 활용하였으며, 1991~2021년을 대상으로 예측모형을 구성하고 예측성을 평가하였다. 예측인자로 활용한 47종의 기후지수는 Table 2와 같으며, Kim et al. (2021b)에서 제시한 것과 동일하다.
본 연구에서는 Kim et al. (2020, 2021b)의 연구에서 활용한 다중회귀모형 외에 추가로 인공신경망모형을 이용한 예측모형을 구성하여 2가지 형태의 예측모형 구성에 따른 예측성을 비교하였다.
Table 1.
ASOS stations used in this study
Table 2.
Predictors used in this study (Kim et al., 2021b)
2.2 원격상관성 분석
기존의 Kim et al. (2020, 2021b)의 연구에서 분석한 것처럼, 예측모형을 구성하는 최적의 예측인자를 선정하기 위하여 예측대상월을 기준으로 과거 40년간의 예측대상(강수량)과 47종의 기후지수에 대한 1~18개월 선행자료와의 지연상관성을 분석하였다. 본 연구는 월 강수량에 대한 선행예측이 목적이므로, 예측대상과 기후지수자료 간의 동시상관성은 고려하지 않았다.
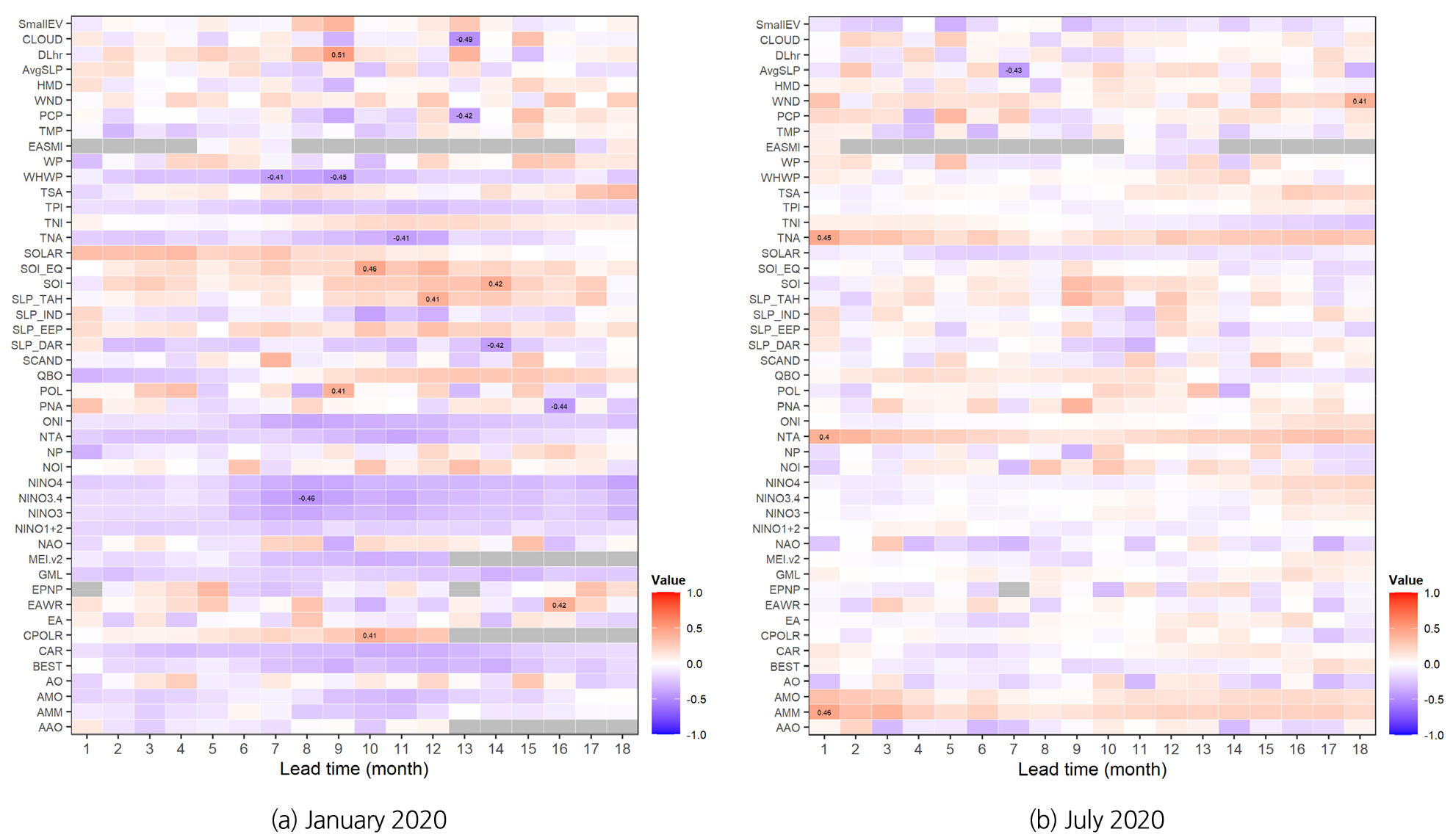
예를 들어, Fig. 2(a)는 2020년 1월의 강수량을 예측하기 위해 과거 40년간(1980~2019년)의 1월 강수량 자료와 각 기후지수의 선행기간별 자료(선행기간이 1개월이면 1979~2018년의 12월 자료, 선행기간이 18개월이면 1978년부터 2017년의 7월 자료)와의 상관도를 분석한 것이다. 푸른색은 음의 상관도를 나타내며, 붉은 색은 양의 상관도를 나타낸다. 회색은 상관도 분석에 필요한 자료가 결측 또는 부족한 것을 의미한다. 즉, 푸른색과 붉은색이 짙을수록 상관성이 높다고 할 수 있다. Evans (1996)가 제안한 것처럼 통계적으로 보통(moderate) 수준으로 볼 수 있는 0.4 이상(절대값 기준)인 경우에는 수치도 함께 표기하였다. 마찬가지로 Fig. 2(b)는 2020년 7월의 강수량을 기준으로 한 과거 강수량과 선행기간별 기후지수자료와의 상관도를 나타낸 것이다.
Fig. 2(a)에 분석된 것처럼 과거 1980~2019년의 1월 강수량 자료와의 상관도는 9개월 선행 DLhr가 0.51, 13개월 선행 CLOUD가 -0.49, 8개월 선행 NINO3.4가 -0.46 등으로 높게 나타났으며, Fig. 2(b)와 같이 1980~2019년의 7월 강수량과의 상관도는 1개월 선행 AMM 0.46, 1개월 선행 TNA 0.45, 7개월 선행 AvgSLP -0.43 등으로 높게 나타났다.
이와 같이 매월 예측대상월을 기준으로 과거 자료에 대한 상관도 분석을 통해 상관도가 높은 기후지수자료를 예측인자로 선별하여 예측모형을 구성함으로써 예측대상월에 따라 유동적인 예측모형을 활용하였다. 이는 기존의 예측인자가 고정된 모형에 비해 복잡하고 예측모형 구성이나 예측값의 도출에 시간이 더 소요되는 단점이 있으나, 주기적 또는 중장기적으로 변화하는 전지구 기후특성 및 대상유역의 기상변화를 능동적으로 반영하여 예측모형을 구성할 수 있는 장점이 있다고 볼 수 있다.
2.3 예측모형 구성 및 예측인자 선정
각 예측대상월별로 분석된 원격상관성을 기반으로 상관도가 높은 10개의 기후지수를 선별하여 이를 예측인자로 하는 예측모형을 구성하였다.
다중회귀모형 기반의 예측모형은 아래와 같이 Kim et al. (2021b)에서 제시된 것과 동일한 형태로 구성하였으며, 단계적 회귀분석(stepwise regression) 방법을 적용하여 최적의 예측인자를 다시 선별하였다.
여기서, Y : 예측대상인 월 강수량(mm), : 회귀계수, : 과거자료로부터 분석된 예측대상과 상관성이 높은 10개의 기후지수, : 잔차항이다.
회귀모형을 도출하는 과정에서 독립변수간에 다중공선성을 가지거나 예측대상월에 대해 0보다 작은 값을 도출하는 회귀모형은 제외하였다. 또한, 예측모형의 적합도를 높이고 예측결과의 불확실성을 최소화하기 위해 과거 40년간 자료에 대해 임의로 20년간 자료를 선별하여 예측모형을 구성하고 나머지 기간에 대해 검증하는 교차검증을 무작위 반복하여 최종적으로 월별 1000개의 예측모형을 선별하고, 선별된 예측모형으로부터 1000개의 예측값을 도출하였다.
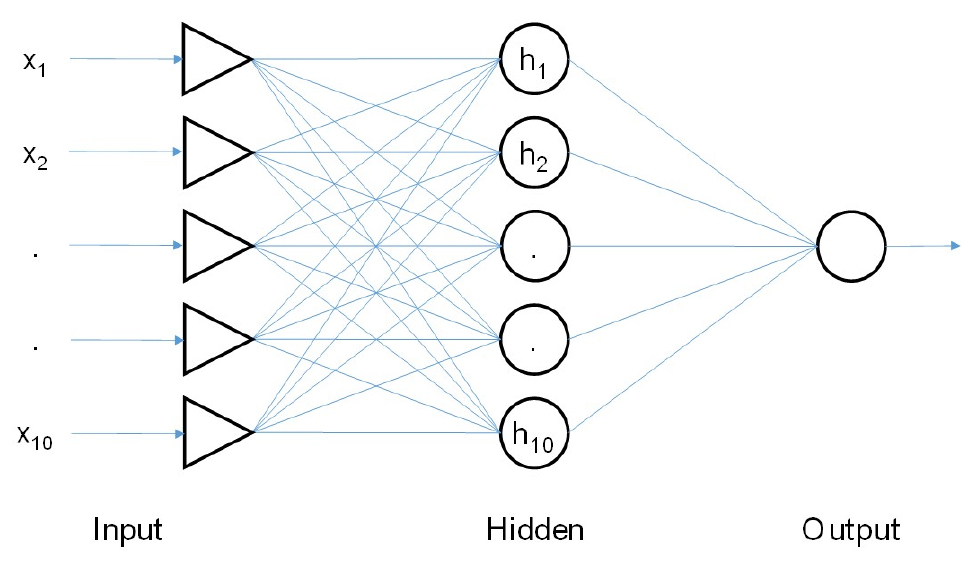
인공신경망모형은 일반적으로 입력층과 출력층, 그리고 두 개 층을 연결하는 은닉층으로 구성되어 있다. 본 연구에서는 Fig. 3과 같이 각 예측대상월에 따라 선정된 10개의 기후지수를 모두 예측인자로 활용하여, 입력층과 은닉층의 크기는 10개, 은닉층 수는 1개의 형태를 갖는 인공신경망모형을 구성하였다.
인공신경망모형 또한 다중회귀모형과 마찬가지로 과거 40년간의 자료에 대해 무작위로 20년간 자료를 선별하여 모형을 구성하고, 나머지 기간의 자료를 검증에 활용하여 각 월별로 적합도가 높은 1000개의 예측모형을 도출하였다.
본 연구에서 예측모형으로 활용되는 인공신경망모형 및 다중회귀모형은 모두 기존 연구들에서 제시하는 것과 다르게, 예측인자가 고정된 형태의 모형이 아니라 예측시점을 기준으로 분석된 원격상관성 결과에 따라 예측인자를 선별하여 활용하는 유동된 형태의 모형이다.
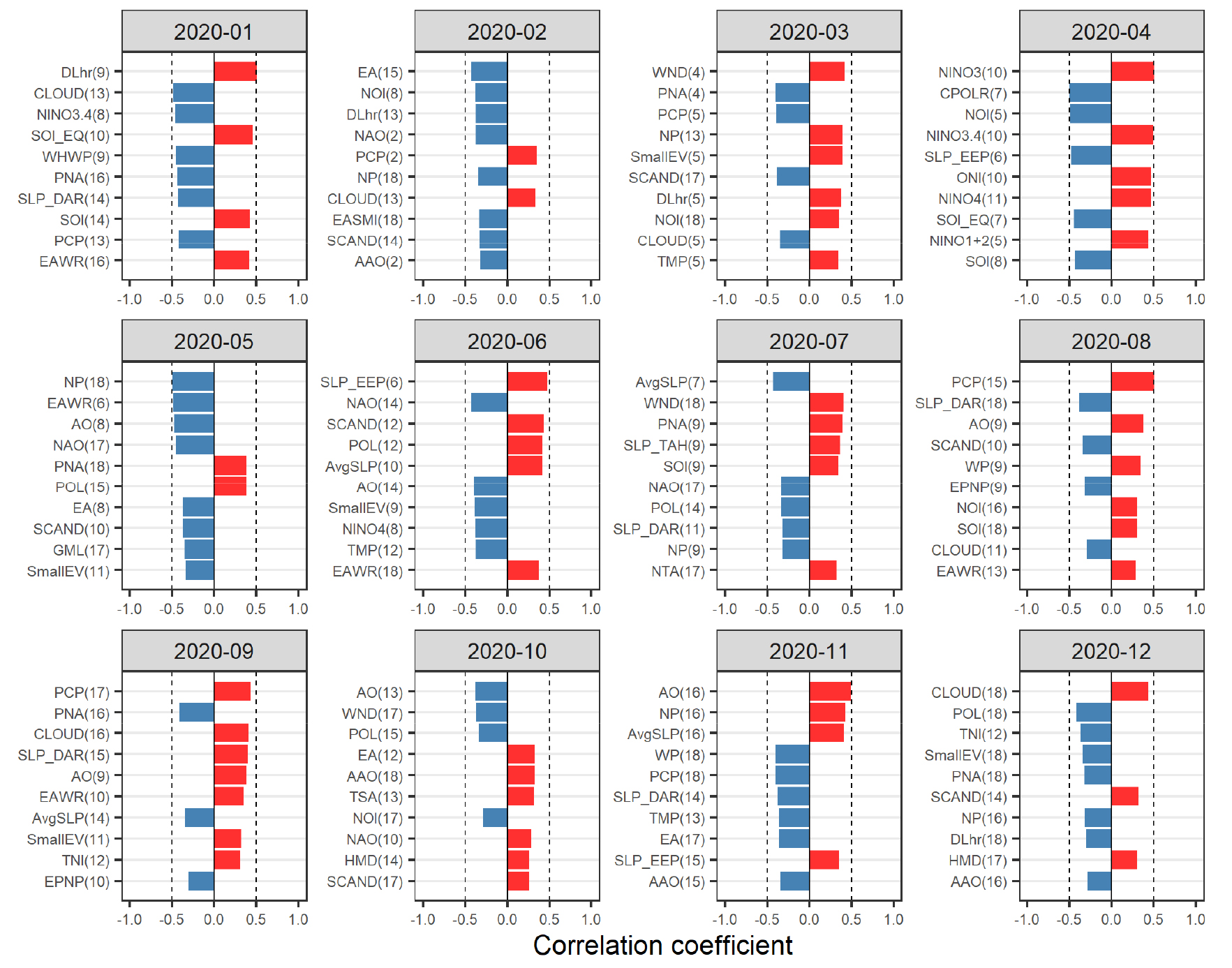
다음의 Fig. 4는 2019년 12월을 예측시점으로 한 경우, 2020년 1~12월의 월별 강수량 예측모형에 활용된 기후지수를 나타낸 것이다. 기후지수 뒤의 ( ) 안의 숫자는 예측대상자료를 기준으로 한 기후지수자료의 선행기간을 나타낸 것이다. 예를 들어, Fig. 4의 2020년 7월 강수량 예측모형에 활용된 기후지수 중 AvgSLP(7)의 상관도가 가장 높은 것으로 분석되었는데, 이는 2020년 7월을 기준으로 과거 40년(1980년~2019년)의 7월 강수량과 이보다 7개월 이전에 해당하는 1979년~2018년의 12월 AvgSLP 자료의 상관성이 가장 높게 분석되었음을 의미한다. 또한, 앞선 Fig. 2(b)의 분석에서 보면, 과거 40년(1980년~2019년)의 7월 강수량과 AMM(1), TNA(1)의 기후지수자료와의 상관도가 각각 0.46, 0.45로 가장 높은 것으로 나타났으나, Fig. 4의 2020년 7월 예측모형에서는 해당 기후지수자료가 예측인자로 활용되지 못한 것을 알 수 있다. 이는 2020년 7월은 예측시점(2019년 12월)을 기준으로 7개월 선행예측이기 때문에 이보다 선행기간이 짧은 AMM(1)과 TNA(1)은 예측인자로 활용되지 못했음을 의미한다. 즉, 예측시점과 예측월에 따라 탄력적으로 상관성이 높은 기후지수를 예측인자로 활용하였다.
3. 연구결과
3.1 원격상관성 분석결과
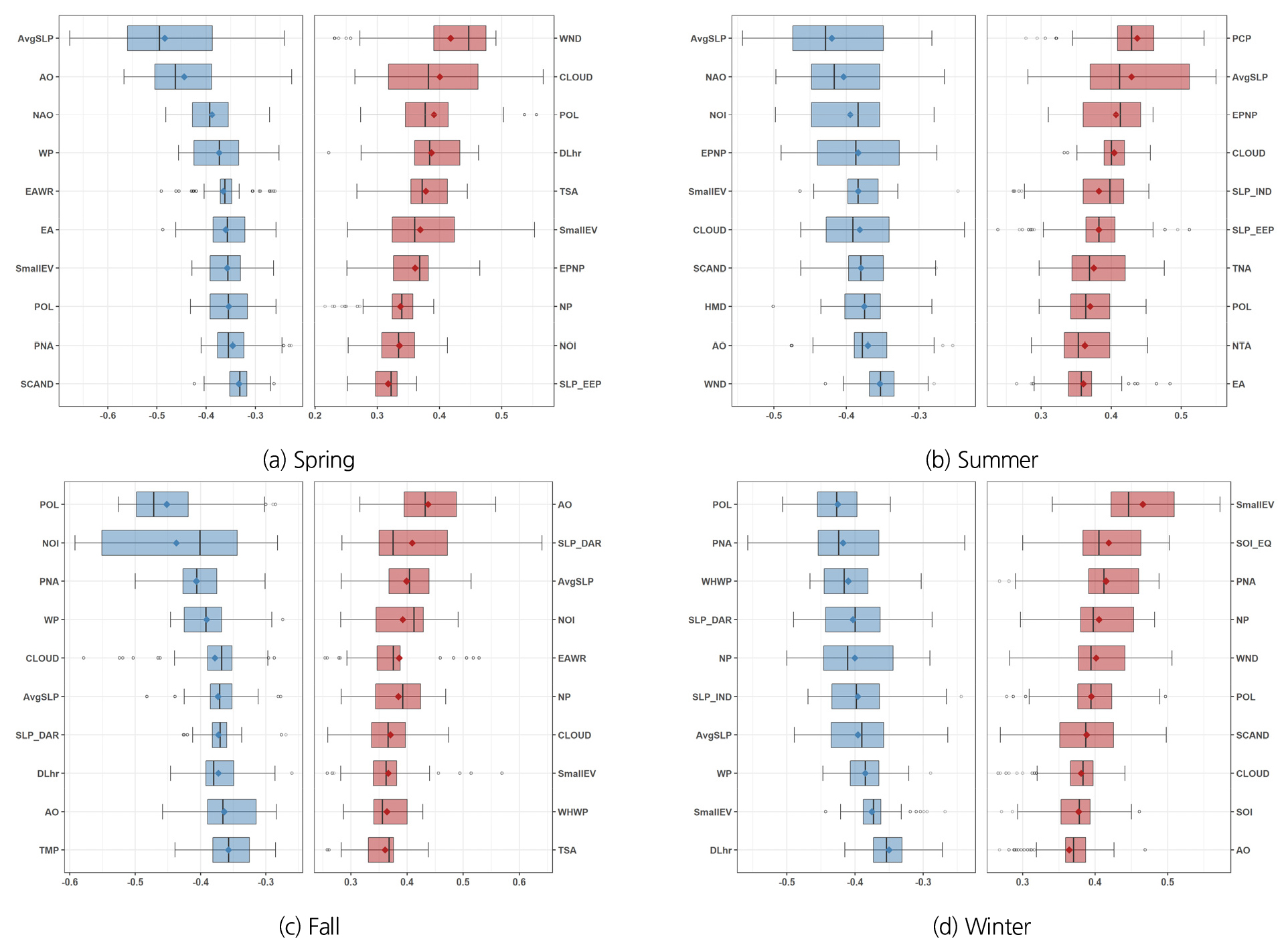
앞서 기술한 바와 같이 본 연구에서는 예측시점과 예측대상월에 따라 다양한 기후지수가 예측인자로 활용되었다. Fig. 5는 1991년~2021년에 대해 각 월별로 분석된 원격상관성 결과를 기반으로 대상유역인 금강권역의 강수량에 영향을 주는 기후지수를 계절별로 정리한 것이다. 상관도의 절대값이 0.4 이상인 기후지수 중에서 빈도수가 많은 상위 10개 기후지수를 양과 음으로 구분하여 선별하였으며, 선별된 기후지수와의 상관도 분포를 박스플롯 형태로 제시하였다. 계절별로 좌측의 푸른색은 음의 상관성이 높은 기후지수 10개를 나타내며, 우측의 붉은 색은 양의 상관성이 높은 기후지수 10개이다. 각 기후지수별 상관도의 평균값은 박스플롯 안에 푸른색과 붉은 색 점으로 표기되어 있다.
기존 Cho et al. (2016)의 연구에서는 안동댐 유역의 월 강수량 예측인자로 2월에 AO(5), 5월에 AO(8), 6월에 NAO(6) 등의 지수를 사용한 바 있으며, Kim an Park (2010)은 우리나라 60개 기상관측소 월 강수량과 기후지수의 상관도를 분석한 결과에서는 2월에 AO(5), 6월에 NAO(6) 등의 상관도가 높게 나타났다. Kim et al. (2007)은 우리나라 12개 기상관측소의 10월 강수량 예측을 위해 상관도가 높은 AO(4)를 이용하여 다중회귀모형을 제안한 바 있다. Kim et al. (2008)에서는 우리나라 12개 기상관측소의 월 강수량과 글로벌 기후지수들의 상관성 분석을 통해 AO(5)는 2월 강수량, NAO(6)는 6월 강수량, NOI(5)는 11월 강수량에 영향을 주는 것으로 분석하였다.
Fig. 5와 같이 본 연구에서도 AO가 봄철, 여름철, 가을철의 강수량과 상관도가 높으며, NAO는 여름철 강수량과 NOI는 가을철 강수량과 상관도가 높은 것으로 유사한 결과를 도출하고 있다. 따라서 전반적인 상관도 경향은 기존 연구와 크게 다르지 않음을 알 수 있다. 다만 각 월별 예측모형을 구성하는 단계에서는 기존 연구와 다르게 예측시점과 선행예측기간에 따라 탄력적으로 예측인자를 활용하고 있기 때문에, 기후 및 기상의 변화 특성을 능동적으로 반영함으로써 보다 최적화된 예측모형 구성이 가능하다.
3.2 월 강수량 예측결과
기후지수와의 원격상관성을 기반으로 구성된 예측모형은 예측시점을 기준으로 미래 1~12개월에 대한 선행예측이 가능하며, 예측모형 구성과정에서의 불확실성을 고려하여 각 예측대상월별로 교차검증된 1000개의 예측모형을 구성하여 1000개의 예측결과를 도출하게 된다.
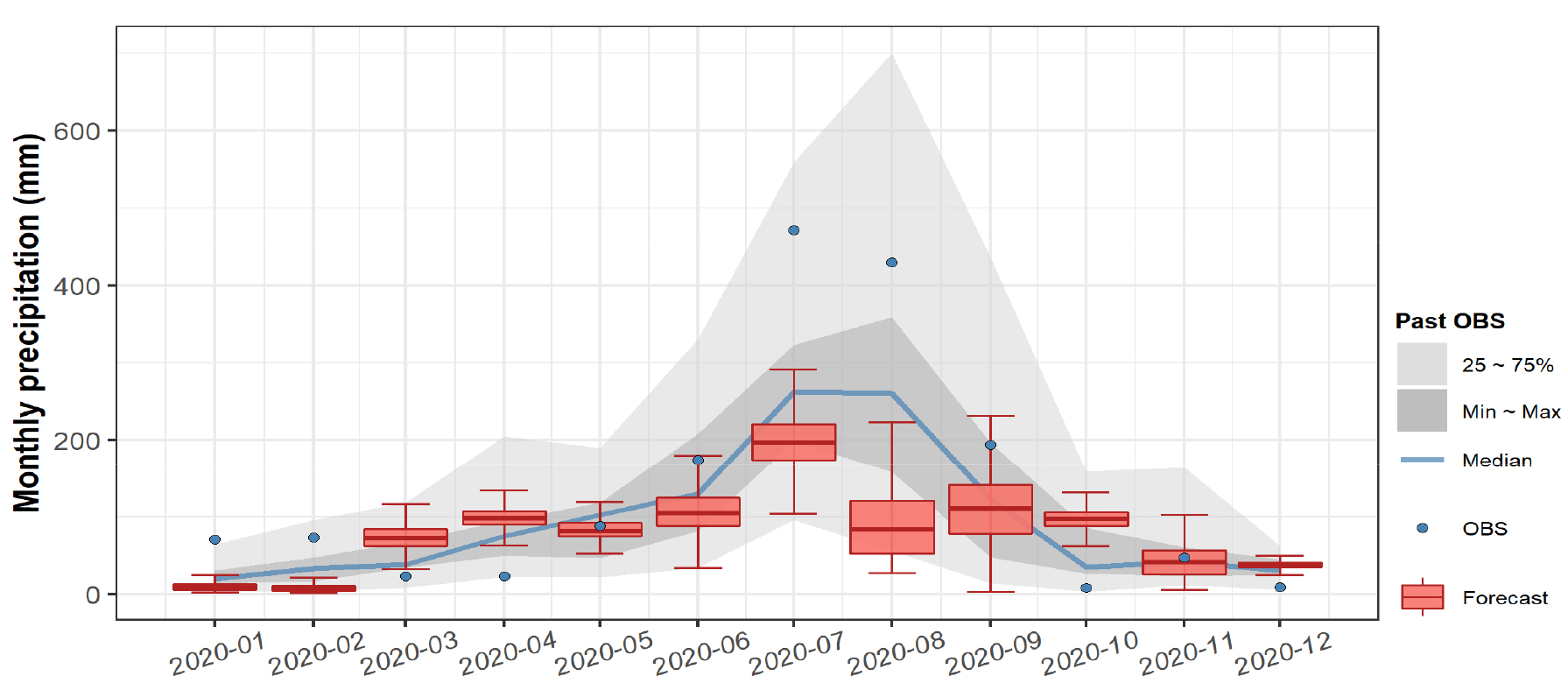
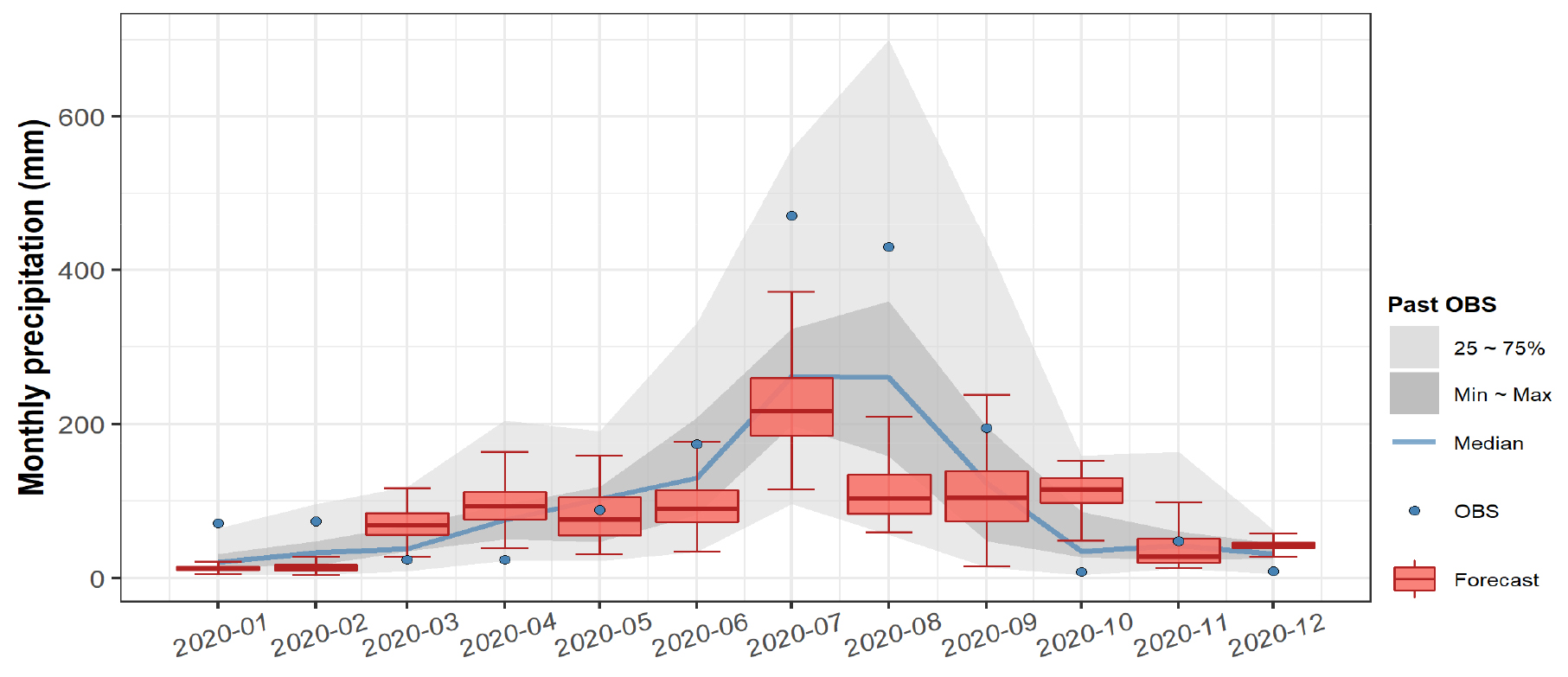
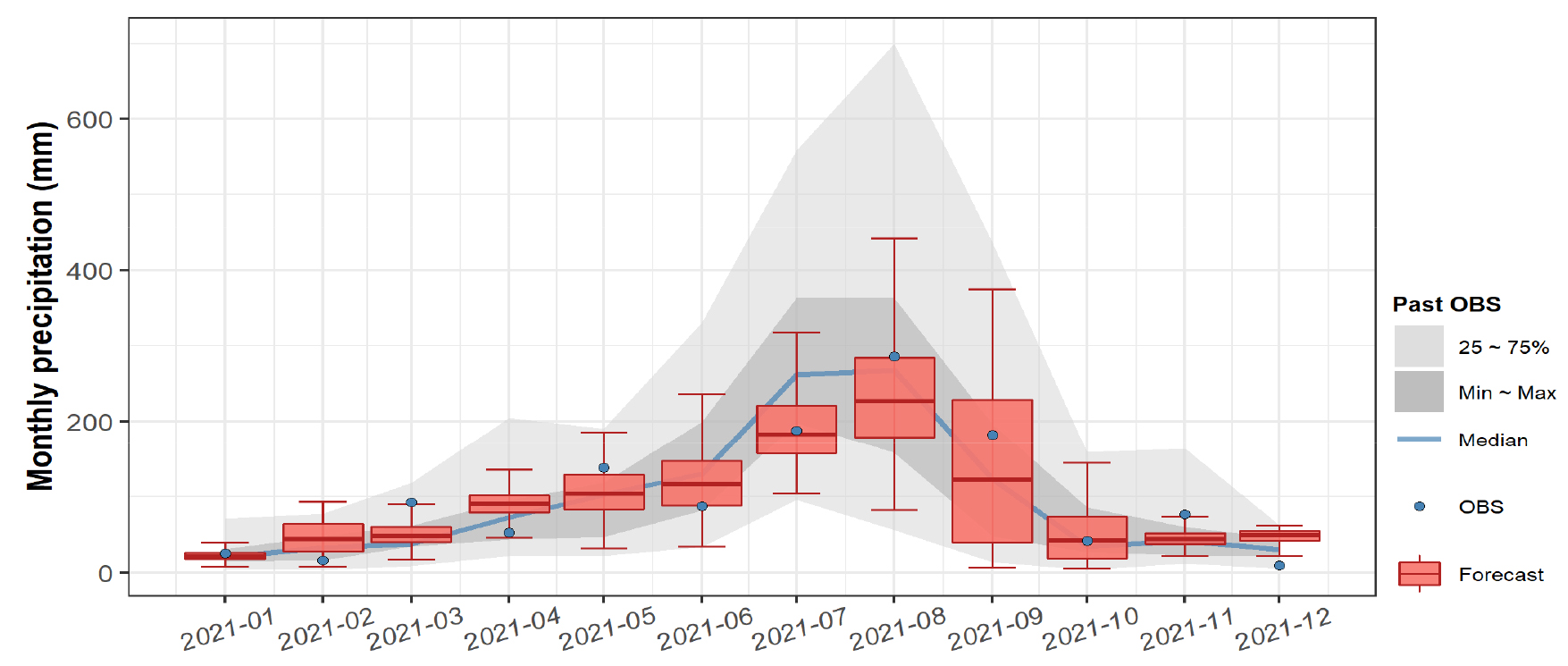
예를 들어, Figs. 6 and 7은 Fig. 4에서 제시된 각 월별 선별된 10개의 예측인자를 기반으로 각각 다중회귀모형과 인공신경망모형을 구성하여, 2019년 12월에 예측한 2020년 1월부터 2020년 12월에 대한 월별 강수량 예측결과이다. 2020년 1월은 1개월 선행예측에 해당하며, 2020년 12월은 12개월 선행예측에 해당한다. 박스플롯은 1000개의 예측값으로 도출된 예측범위를 나타내며, 회색 음영은 해당 월을 기준으로 과거 30년간의 동일 월에서의 관측값의 범위를 나타낸 것이다. 푸른색 선은 과거 관측값의 중앙값이고, 푸른색 점은 각 월의 실제 관측값에 해당한다.
우리나라의 강수량 특성상 집중호우 및 태풍 등의 영향으로 여름철 예측결과의 불확실성이 상대적으로 크게 나타났으며, 2020년 1~4월, 7~8월, 10월, 12월 등 대부분의 월에서 예측값과 관측값의 차이가 크게 나타났다. 2020년 대전·세종·충남 기상기후보고서(DROM, 2021)에 의하면, 2020년은 특히 역대 가장 긴 장마철과 집중호우라는 이상기상이 발생했던 시기로, 강수량을 기준으로 차이가 크게 나타난 월들 모두 역대 상위 및 하위 10위 이내에 해당되는 것으로 제시되고 있다. 따라서, 본 연구에서와 같이 관측자료의 통계적 특성을 기반으로 구성된 통계적 예측모형 특성상 과거와 상이한 형태의 기상현상이 발생하는 경우에는 예측 정확도가 상대적으로 떨어질 가능성이 높다. 이는 Figs. 6 and 7에 나타난 것처럼 다중회귀모형뿐만 아니라 인공신경망모형에 의한 예측결과 모두 예측성이 떨어지는 것으로 나타났다.
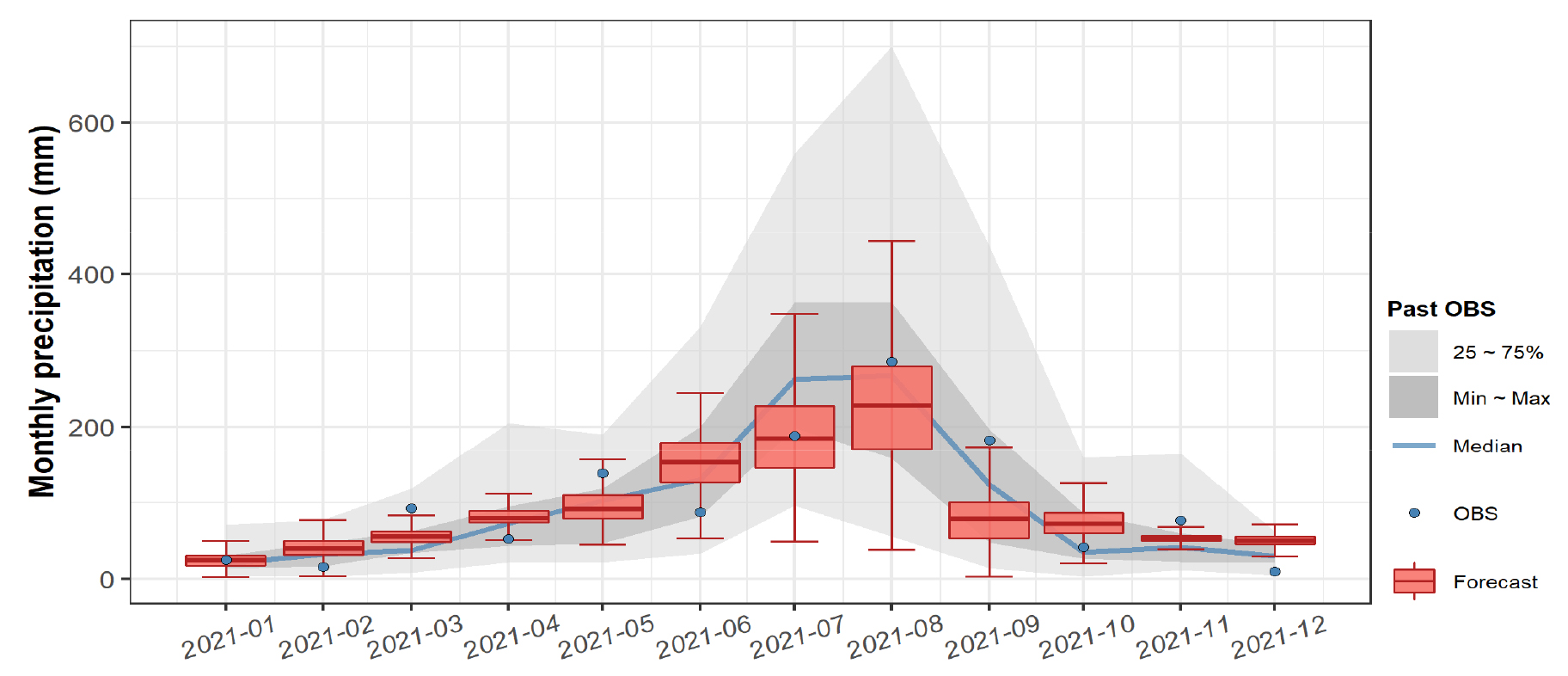
반면 2020년 12월에 예측한 2021년의 월별 강수량 예측결과는 Figs. 8~9와 같이 일부 기간을 제외하면 다중회귀모형이나 인공신경망모형에 의한 예측값 모두 관측치와 잘 부합되는 것으로 나타나고 있다. 이는 해당 기간의 관측값이 대체로 과거의 통계적 경향에서 크게 벗어나지 않았기에 통계적 예측모형에 의해 잘 모의된 것으로 판단된다.
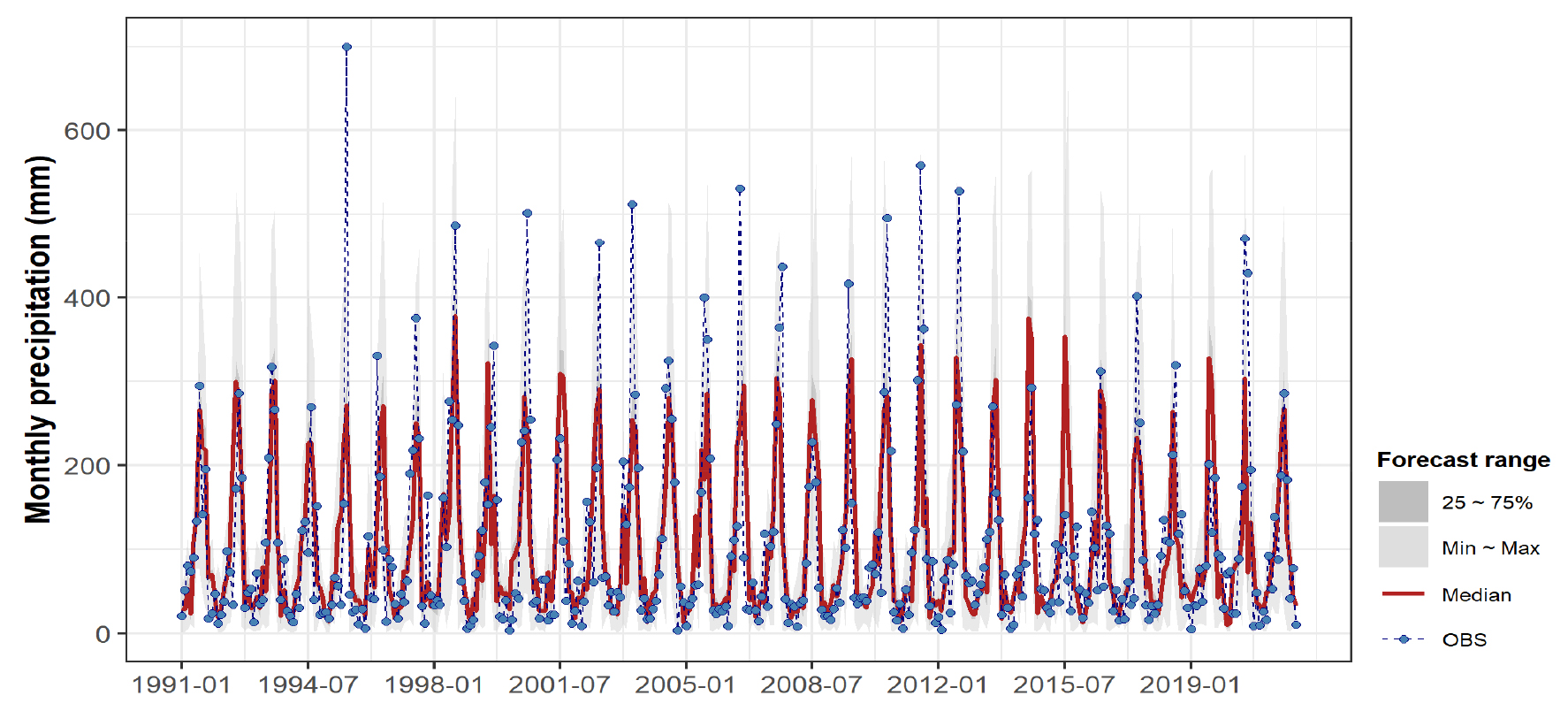
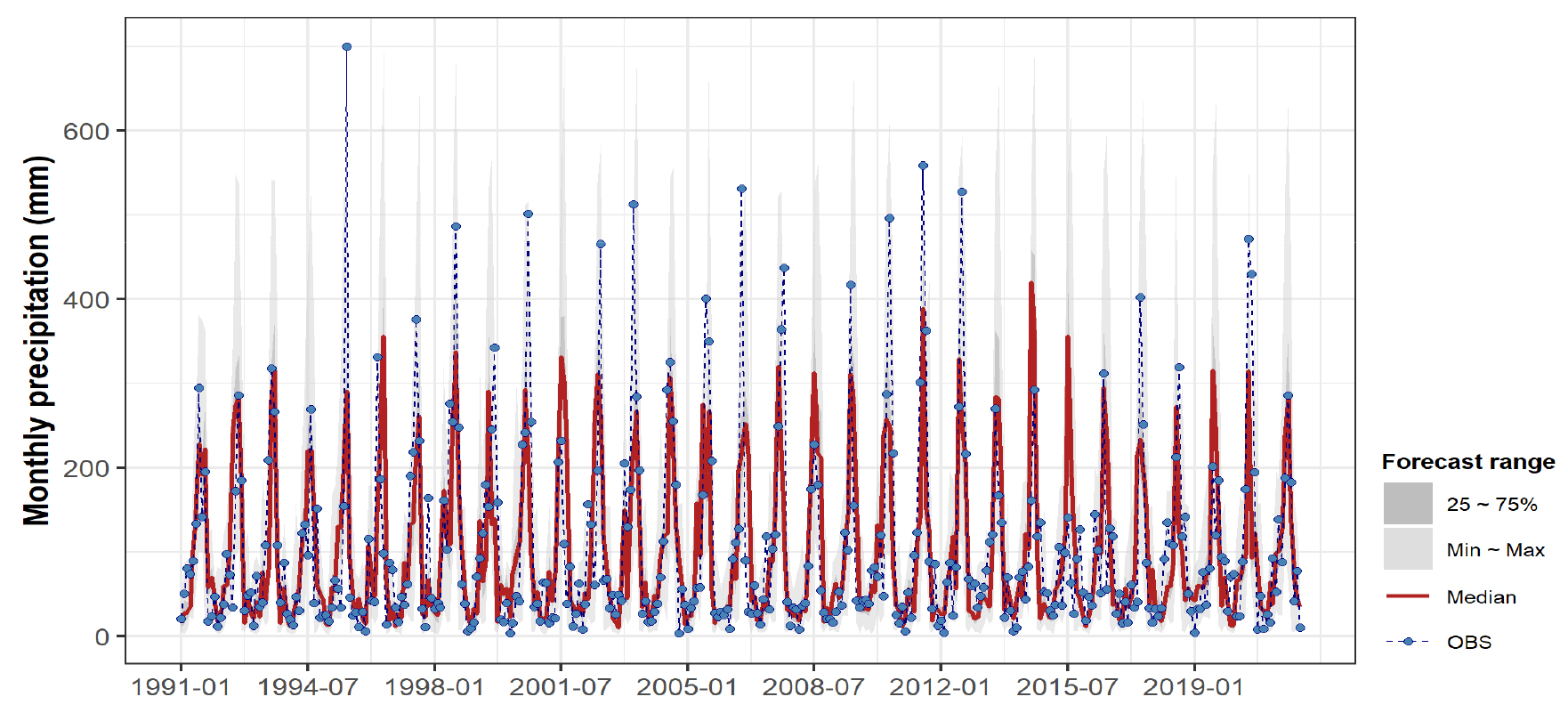
Figs. 10 and 11은 전체 분석기간(1991~2021년)을 대상으로 다중회귀모형과 인공신경망모형에 의한 월별 강수량 예측결과를 나타낸 것이다. 회색음영은 예측치의 범위를 나타내며, 붉은색 선은 예측치의 중앙값, 그리고 파란색 점과 점선은 해당월의 관측치이다.
여름철을 중심으로 예측 불확실성이 높고 관측치와의 차이도 큰 특성을 보이는데, 특히 집중호우 및 태풍이 잦았던 1995년 여름철을 비롯하여 2000년, 2003년, 2006년, 2011년, 2020년 여름철과, 반대로 평년대비 강수량이 매우 적었던 2015년 여름철 등은 예측치와 관측치의 차이가 상대적으로 크게 나타났다.
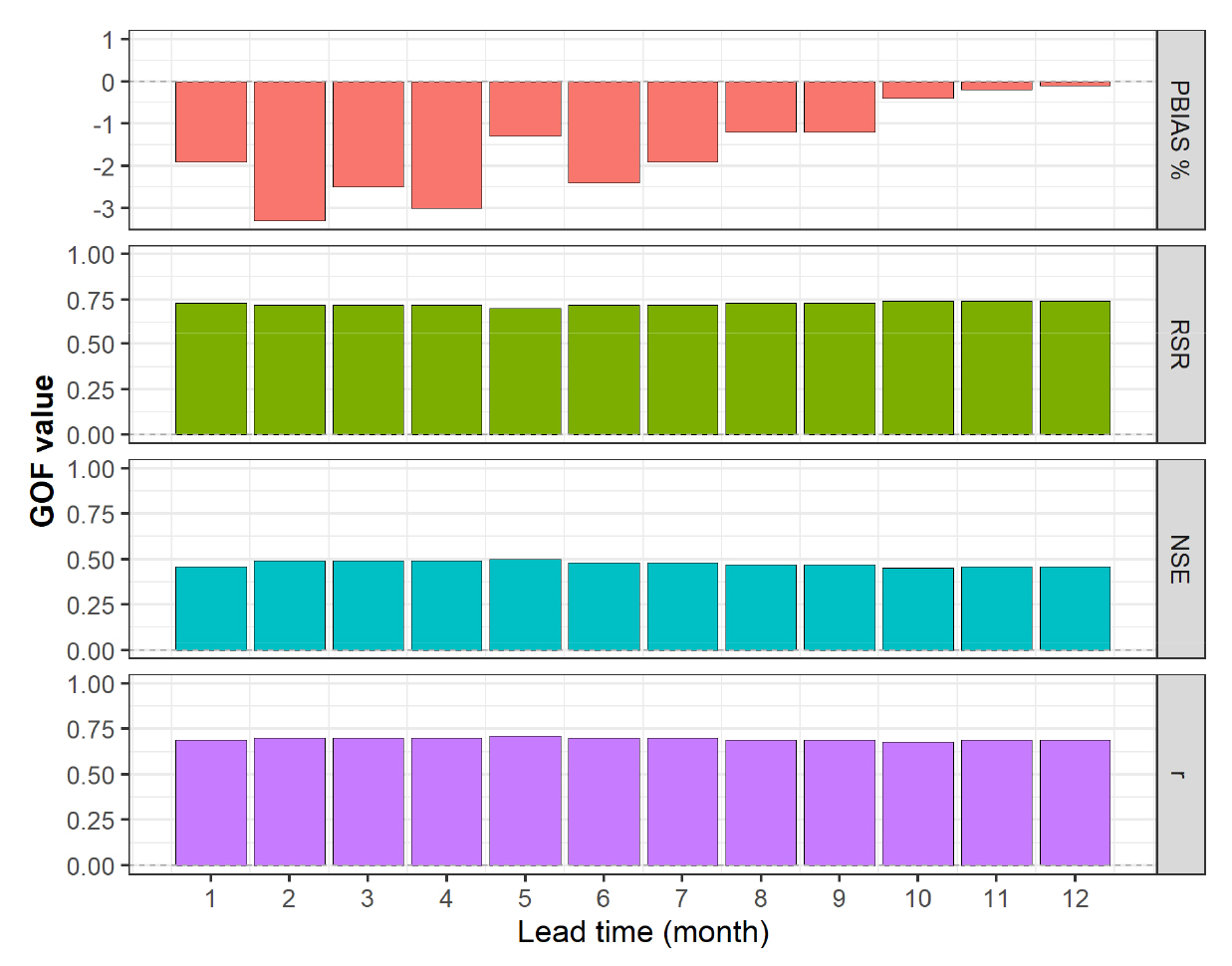
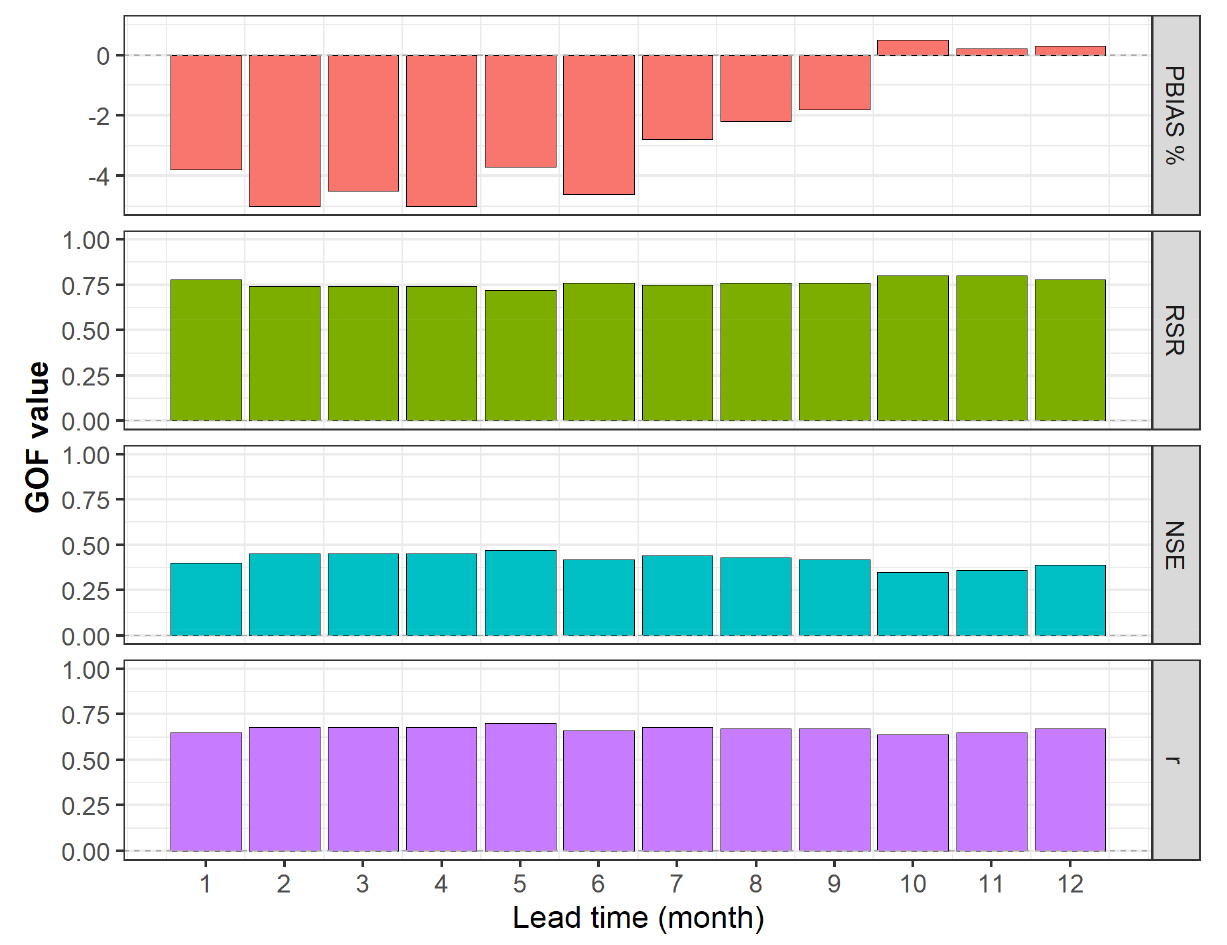
Figs. 12 and 13은 각각 다중회귀모형과 인공신경망모형에 의한 각 월별 예측치의 평균값과 실제 관측값 사이의 적합도를 평가하기 위해 PBIAS (Percent bias), RSR (Ratio of RMSE to the standard deviation of the observations), NSE (Nash-Sutcliffe efficiency), r (Pearson correlation coefficient) 등을 예측선행기간에 따라 나타낸 것이다. Fig. 12의 다중회귀모형의 경우 PBIAS -3.3~-0.1%, RSR 0.70~0.74, NSE 0.45~0.50, r 0.69~0.70으로 분석되었으며, Fig. 13의 인공신경망모형에 의한 예측결과의 선행기간별 적합도는 PBIAS -5.0~+0.5%, RSR 0.72~0.80, NSE 0.35~0.47, r 0.64~0.70로 나타났다. Moriasi et al. (2007)의 연구에서 제시한 각 지수별 평가등급과 비교하였을 경우, PBIAS는 Very good, RSR과 NSE는 Unsatisfactory 수준으로 평가된다.
상기 4개의 적합도 결과에 의하면 다중회귀모형에 의해 도출된 예측치의 평균값이 인공신경망모형 결과보다 다소 양호하다고 볼 수 있다. 본 연구와 같은 방법으로 동일한 기간에 대해 다중회귀모형을 이용하여 한강권역의 강수량을 예측하였던 Kim et al. (2021a)의 연구에서는 PBIAS -0.3~+1.7%, RSR 0.69~0.72, NSE 0.48~0.52, r 0.70~0.73으로 유사한 적합도를 보인 바 있다.
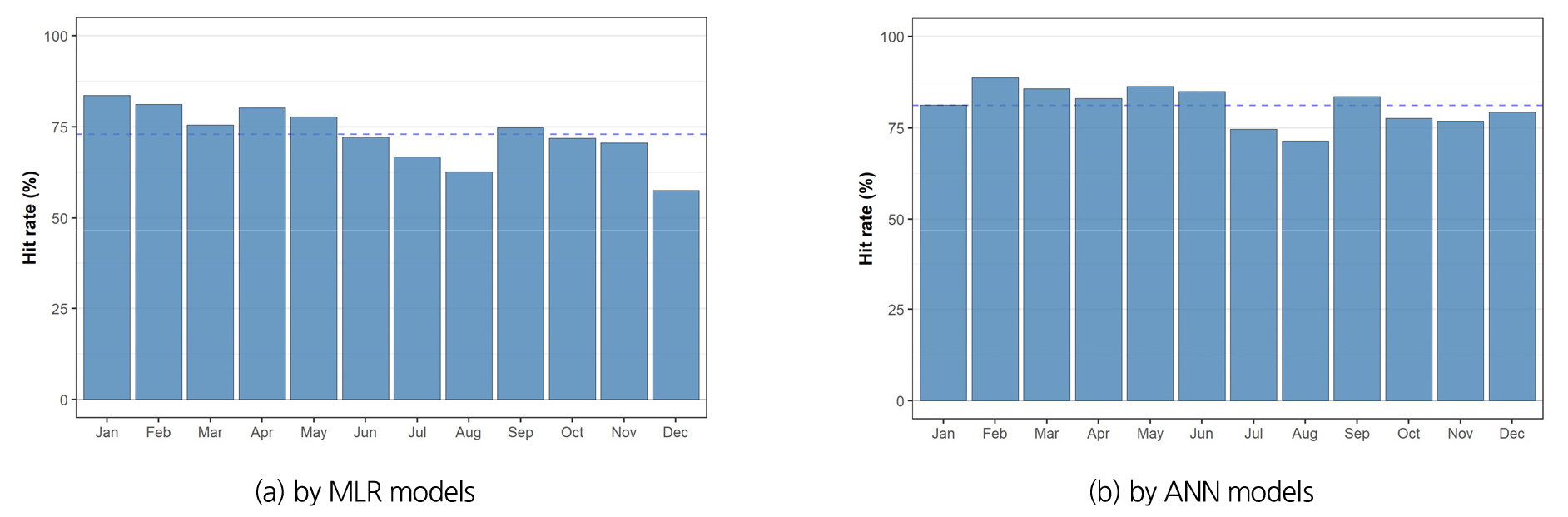
Fig. 14는 분석기간 중 매월 예측치의 범위(최소~최대) 안에 관측치가 포함될 확률을 월별로 취합하여 정리한 것으로, 다중회귀모형에 의한 결과는 57.5~83.6%의 범위(평균 72.9%), 인공신경망모형의 경우에는 71.5~88.7%(평균 81.1%)로 분석되었다. 다중회귀모형에 비해 인공신경망에 의한 평균 적중률이 높고, 월별 차이도 상대적으로 크지 않은 것으로 나타나고 있다. 두 모형 모두 여름철에 해당하는 7월과 8월의 예측성이 낮게 나타난 반면, 1~5월, 9월은 상대적으로 높은 값을 보이고 있다. 기존에 한강권역의 강수량에 대한 분석했던 Kim et al. (2021a)의 연구에서도 7월의 적중률이 가장 낮게 분석된 바 있다.
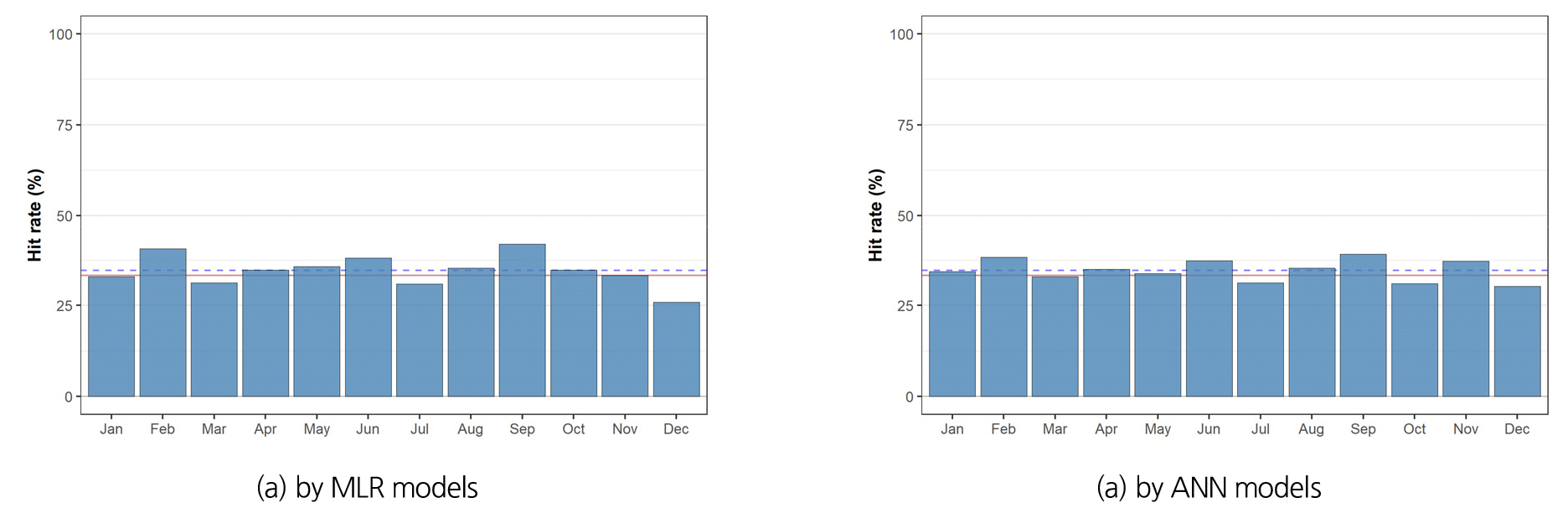
Fig. 15는 분석기간 전체에 대해 매월 분석된 예측치에 대한 3분위 확률을 월별로 취합한 것으로, 예측대상월을 기준으로 과거 30년간의 동일 월의 관측값을 크기에 따라 3개 구간으로 구분하여, 예측대상월의 실제 관측값이 속하는 구간에 대한 예측확률을 산정한 것이다. 따라서, 3분위 예측확률이 33.3% 이상일 경우 예측성이 있는 것으로 판단할 수 있다. Fig. 15(a)에서 다중회귀모형의 경우에는 25.9~41.9%(평균 34.6%), Fig. 15(b)의 인공신경망모형의 결과는 30.3~39.1%(평균 34.7%)이다. 3분위 확률을 기준으로 한 예측성은 두 모형간의 전체 평균값은 차이가 없으나, 인공신경망모형이 다중회귀모형에 비해 월별 차이가 크지 않은 것으로 나타났다. 모든 월에 대한 평균은 두 모형 모두 33.3% 이상으로 예측성이 있다고 나타났으나, 다중회귀모형의 경우 3월, 7월, 12월, 인공신경망모형은 7월과 10월, 12월 등에서 예측성이 낮은 것으로 분석되었다. 이는 전기간에 대한 평균적인 값으로서 앞서 기술한 바와 같이 예측시점 및 예측대상기간, 과거자료의 통계적 특성 등에 따라 상이한 예측성을 나타낼 수 있다.
4. 결 론
안정적인 수자원의 운영 및 관리를 위해서는 가용수자원의 원천이 되는 강수량의 정확한 예측이 필수적이며, 특히, 계절예측에 해당하는 한 달에서 수개월 시간 규모의 장기예측은 가뭄과 홍수, 폭염을 비롯한 기상이변으로 인한 재해를 대응하고 안정적인 수자원 확보를 위해 매우 중요하다.
본 연구에서는 통계적 기반의 다중회귀모형과 인공신경망모형을 이용하여 금강권역의 월 강수량 예측을 수행하였다. 예측모형을 구성하는 최적의 예측인자를 선정하기 위하여 예측대상월을 기준으로 과거 40년간의 예측대상(강수량)과 47종의 기후지수에 대한 1~18개월 지연상관성을 분석하였다. 예측대상월별 선행예측기간에 따라 상관도가 높은 10개의 기후지수를 선별하여 예측인자로 활용하였다. 다중회귀모형의 경우에는 단계적 회귀분석(stepwise regression) 방법과 다중공선성 검토 등을 통해 선별된 10개의 기후지수 중에서 다시 최적의 기후지수를 선별하여 예측모형을 구성하였으며, 인공신경망모형에서는 10개의 기후지수를 모두 예측인자로 활용하였다. 두 종류의 예측모형 모두 과거 40년간 자료를 기반으로 무작위 교차검증을 수행하여 예측대상월별로 총 1000개의 최적화된 예측모형과 예측값을 도출하였다.
예측결과에 대한 예측성은 예측값의 평균값, 예측값의 범위(최소~최대), 예측값의 3분위 확률 등 3가지 방법으로 평가하였다. 먼저 1991~2021년에 대한 각 월별 예측값의 평균값과 실제 관측값을 비교한 적합도는 다중회귀모형의 경우 PBIAS -3.3~-0.1%, RSR 0.70~0.74, NSE 0.45~0.50, r 0.69~0.70으로 분석되었으며, 인공신경망모형에 의한 예측결과의 적합도는 PBIAS -5.0~+0.5%, RSR 0.72~0.80, NSE 0.35~0.47, r 0.64~0.70로, 다중회귀모형에 의해 도출된 예측치의 평균값이 인공신경망모형보다 관측치에 좀 더 근접한 것으로 나타났다. 각 월별 1000개 예측값에 의한 예측범위 안에 관측치가 포함될 확률을 분석한 결과에서는 다중회귀모형이 57.5~83.6%(평균 72.9%), 인공신경망모형의 경우에는 71.5~88.7%(평균 81.1%)로 인공신경망모형 결과가 우수한 것으로 나타났다. 마지막으로 과거 30년 자료를 3개 구간으로 구분하여 관측값과 예측값이 동일구간에 포함될 3분위 예측확률을 분석한 결과는 다중회귀모형의 경우에는 25.9~41.9%(평균 34.6%), 인공신경망모형은 30.3~39.1%(평균 34.7%)로 나타났다. 3분위 예측확률을 기준으로 한 예측성은 두 모형간의 전체 평균값은 크게 차이가 없으나, 인공신경망모형이 다중회귀모형에 비해 월별 차이가 크지 않은 것으로 나타났다. 또한 두 모형 모두 평균 33.3% 이상으로 평균적인 예측성은 확보되었다고 판단된다.
이상과 같이 분석기간 전체에 대한 두 모형의 예측성 차이는 비교적 크지 않은 것으로 나타났으며, 상기의 결과는 분석기간 및 예측대상월에 따라 상이하게 나타날 수 있기 때문에 특정 모형의 예측성이 우수하다고 단정하기는 쉽지 않다. 다만, 예측범위에 대한 적중률이나 3분위 예측확률로부터 판단할 때 예측성에 대한 월별 편차는 인공신경망모형의 결과가 상대적으로 양호하다고 볼 수 있다. 그러나, 통계적 모형의 한계로 인해 본문에서 제시한 2020년의 예와 같이 과거 관측자료와 상이한 역대급 상위/하위에 속하는 강수특성을 보이는 경우에는 예측 정확도가 상대적으로 떨어질 가능성이 높다. 예측인자로 활용되는 기후지수의 이상변동 또한 예측 불확실성을 높일 수 있다. 향후 이상기후 조건(돌발적인 태풍이나 집중호우, 또는 반대로 일시적인 가뭄 등)을 반영할 수 있는 예측인자의 추적과 이를 고려한 예측모형의 지속지인 보완이 필요할 것으로 생각된다.
