

1. 서 론
2. 연구방법
2.1 자료의 검정
2.1.1 1차 계열상관 검정
2.1.2 동질성 검정
2.1.3 이상치 검정
2.1.4 불일치척도 검정
2.1.5 지역 동질성 검정
2.2 확률가중모멘트와 L-모멘트의 관계
2.3 최적 확률분포형의 선정
2.3.1 L-모멘트비도
2.3.2 평균가중거리
2.3.3 ZDIST
3. 자료의 검정 결과
3.1 연최대유량 자료의 검정 결과
3.2 최적 확률분포형의 선정 결과
4. 결 과
4.1 지역홍수빈도 관계식 유도과
4.2 홍수량 산정 방법의 비교 검토 및 검증
5. 결 론
1. 서 론
댐, 여수로, 하천 제방 등 수리시설물의 설계 그리고 재해 예방을 위해서는 대상 유역의 극한 홍수의 발생빈도와 설계홍수량을 결정할 필요가 있다. 설계홍수량은 대상 유역의 출구지점에서의 홍수량에 대한 관측자료를 이용하여 수문학적 빈도해석을 통해서 추정할 수 있다. 수문학적 빈도분석은 유량자료의 통계적 특성을 이용하여 설계홍수량을 추정하는데 유용한 분석방법으로 지점빈도분석과 지역빈도분석으로 구분할 수 있다. 지점빈도분석은 재현기간이 짧고, 신뢰할 수 있는 유량자료가 충분히 많을 때 유용하다(Institute of Hydrology, 1999). 그러나 관측 유량자료가 적을 경우 지점빈도분석을 통해 추정한 설계홍수량의 불확실성이 매우 커지게 된다. 따라서 유량의 관측 기간이 재현기간 T보다 작은 경우에는 지점빈도분석은 적절하지 않으며, 유량의 관측 기간이 T에서 2T일 때는 지점빈도분석과 지역빈도분석을 동시에 수행하여 설계홍수량을 추정하는 것이 권장되고 있다(Heo et al., 2007). 또한 지점 관측자료의 차이로 인한 분산의 증가보다 관측자료 개수의 증가에 따른 분산의 감소가 훨씬 크고 분석의 정확도가 전반적으로 개선되기 때문에 홍수빈도분석은 지점별로 각각 수행하는 것보다는 지역적으로 수행되는 것이 통계학적으로 유리하다(Lee and Heo, 2001). 지역빈도분석은 수문학적 동질성을 가지는 유역에서 여러 관측 지점의 유량자료에 대한 적합한 확률분포형을 결정하고 지점 및 지역 단위의 설계홍수량을 추정하는 것으로 유량자료가 충분하지 않거나 극한 홍수량을 추정하는데 보다 효율적이고 적절한 방법이다(Chow et al., 1988).
지역홍수빈도분석의 목적은 지역 내 관측된 유량자료를 이용하여 지역에 공통으로 적용할 수 있는 설계홍수량 산정 공식을 개발하는 것이다. 즉, 이용 가능한 자료로부터 지역 특성인자와 홍수량 그리고 재현기간 사이의 상관관계를 수립하고 지역의 대표 확률분포형을 선정하여 설계홍수량을 산정하는 것이다. 따라서 지역 유량자료는 서로 독립적이고 동질성을 가져야 한다.
Hosking and Wallis (1997)에 의해 L-모멘트를 이용한 지역홍수빈도분석이 개발된 이후, 지역홍수빈도분석은 인도, 중국, 파키스탄, 터키 등 여러 나라의 미계측 유역에 적용되었다(NIH, 1998; Kumar et al., 2003; Jingyi and Hall, 2004; Hussain, 2011; Seckin et al., 2013, 2014; Yarrakula et al. 2015). 예를 들어, 인도의 National Institute of Hydrology (NIH)는 인도의 7개 관측소에 대하여 유량자료를 분석하고 L-모멘트를 이용한 지역홍수빈도분석을 통하여 지역홍수빈도 관계식을 개발하였다(NIH, 1998). Kumar et al. (2003)은 인도의 Middle Ganga Plain 지역에 대해서 L-모멘트비도와 ZDIST 기준을 바탕으로 GEV 분포를 최적 분포로 결정한 후 지수홍수법(Index-Flood method)을 이용하여 지역홍수빈도 모형을 개발하였다. Jingyi and Hall (2004)는 중국 Gan- Ming River 유역의 86개 유량관측소에 대하여 지역홍수빈도분석을 실시하고, 미계측 유역의 홍수량을 추정하기 위한 지역홍수빈도 관계식을 개발하였다. Hussain (2011)은 파키스탄 Punjab 지역에서 L-모멘트법을 활용한 지역홍수빈도분석을 수행한 바 있다. Seckin et al. (2013)은 L-모멘트를 이용한 지역홍수빈도분석 결과와 인공신경망을 이용한 결과를 비교 검토한 후, 연최대유량을 추정하여 터키 East Mediterranean River에 적용하였다. Seckin et al. (2014)는 터키 Seyhan River 유역의 미계측 지점에 대한 홍수빈도관계를 도출하여 GLO 분포를 최적 확률분포로 선정한 바 있다. 또한, Yarrakula et al. (2015)는 인도의 Subernarekha River 유역에 대하여 L-모멘트를 이용한 지역홍수빈도분석을 실시하여 최적 확률분포형을 피어슨-Ⅲ 분포로 선정한 바 있다.
우리나라의 경우, Lee et al. (1998)이 L-모멘트법을 활용하여 강우자료에 대한 확률밀도함수의 매개변수를 결정하고 Wakeby 분포를 바탕으로 설계강수량을 추정하였다. Lee and Heo (2001)는 한강유역의 연최대강우 자료를 대상으로 L-모멘트법을 이용한 지역빈도분석과 지점빈도분석을 실시하여 결과를 비교하여 지역빈도분석의 우수성을 제시하였다. Lee et al. (2004)은 연최대홍수량 자료에 13개 확률분포형을 적용하여 L-모멘트법을 이용하여 매개변수를 추정하고 적정 확률분포형을 선정하였다. Jeong et al. (2009)은 강원도 지역의 극치강수분포를 파악하기 위해 지역빈도분석 방법과 크리깅 기법을 이용한 공간분석을 실시하여 강원도의 강수분포를 분석하였으며, 지역빈도분석 결과 GLO 확률분포형이 강원도에 가장 적합한 확률분포형인 것으로 나타났다. Kim et al. (2014)는 지역특성과 기후학적 특성을 계층적 Bayesian 모형 안에서 연계하여 공간적 분석이 가능한 지역빈도해석 모형을 개발하였다. Kim et al. (2015b)는 한강유역을 대상으로 관측된 홍수량 자료가 홍수빈도분석 결과에 미치는 영향을 평가하여 수위와 수위-유량관계에 대한 불확실성에 대한 원인을 설명하였다. 또한, Kim et al. (2015a)는 기후변화 시나리오에 의해 모의된 강우자료에 지역빈도해석을 적용하여 미래의 확률강우량을 산정하고 21세기 말에는 현재보다 25% 이상 확률강우량이 상승하는 것으로 예측하였다.
미국은 지역빈도분석을 수행할 경우 log-Pearson type-Ⅲ(LP-3) 확률분포형을 적용할 것을 권장하고 있는 반면(U.S Water Resources Council, 1981), 영국은 generalized logistic (GLO) 확률분포형을 권장하고 있다(Institute of Hydrology, 1999). 우리나라의 경우, 하천유량에 대한 관측자료가 충분히 확보되지 않았기 때문에 지금까지 연최대유량을 이용한 지역홍수빈도분석에 대한 연구는 충분히 수행되지 못하였다. 따라서 미국이나 영국처럼 지역홍수빈도분석을 위한 최적 확률분포형에 대한 지침이 개발된 적이 없다. 하지만, Heo et al. (2007)은 우리나라 378개 우량관측지점의 강우량 자료를 이용한 지역빈도분석을 수행하고 적정 분포로 GLO 확률분포형을 제시한 바 있다.
우리나라에서 지역홍수빈도분석에 의한 설계홍수량 산정식을 제안한 연구 결과를 살펴보면, Ko (1988)는 전국 24개 수문관측소에서 수집된 홍수량 자료로 빈도해석을 실시하여 재현기간-설계홍수량 관계식(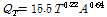 )을 제안하였으나, 전국을 단일 함수식으로 적용하였으며, 유역의 수문특성을 반영할 수 없는 단점이 있다. 또한, MLIT (1993)과 Kim and Won (2004)는 5대강 유역(한강, 낙동강, 금강, 영산강, 섬진강)에 대하여 연최대치 유량계열을 수집하고 지역빈도 및 지점빈도 결과를 비교 검토한 후, 빈도별 비홍수량(q)과 유역면적(A)을 단순 상관시켜
)을 제안하였으나, 전국을 단일 함수식으로 적용하였으며, 유역의 수문특성을 반영할 수 없는 단점이 있다. 또한, MLIT (1993)과 Kim and Won (2004)는 5대강 유역(한강, 낙동강, 금강, 영산강, 섬진강)에 대하여 연최대치 유량계열을 수집하고 지역빈도 및 지점빈도 결과를 비교 검토한 후, 빈도별 비홍수량(q)과 유역면적(A)을 단순 상관시켜 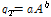 의 형태로 경험식을 제시한 바 있다. 그러나 이러한 형태의 경험식은 여전히 유역의 수문특성을 반영할 수 없는 단점을 가지고 있다.
의 형태로 경험식을 제시한 바 있다. 그러나 이러한 형태의 경험식은 여전히 유역의 수문특성을 반영할 수 없는 단점을 가지고 있다.
이와 같이 지역빈도분석에 대한 다양한 연구가 수행되고 있지만, 지금까지 우리나라에서 수행된 연구들은 지역빈도해석을 통하여 확률강우량에 대한 적정 확률분포형을 선정하는데 국한되어 있을 뿐, 설계홍수량을 산정하는 지역 빈도-홍수량 관계식을 유도하는 연구는 충분히 수행되지 않았다. 또한 우리나라 수자원 실무에서는 미계측 지역에 대한 빈도별 홍수량을 추정하기 위해 지점강우빈도분석과 강우-유출 모형을 이용하고 있는 실정이다. 이는 지역홍수빈도분석에 대한 연구가 상대적으로 미흡하고 계산과정에 대한 지침이 없으며, 유량 관측 자료가 충분하지 않기 때문이다. 지점빈도해석을 통해 확률강우량을 산정하고 강우강도-지속기간-빈도(IDF) 곡선을 구축하고 설계강우량을 시간적으로 분포시켜 강우-유출 모형에 적용하여 유출량을 산정하는 일련의 계산 과정은 설계홍수량의 추정에 불확실성을 증가시키는 주요 요인이다. 그러나 최근 하천의 유량조사 및 계측기기의 발달에 따른 유량자료의 신뢰성이 증가하고 있으며, 충분한 관측자료의 확보를 위한 지속적인 투자와 노력으로 인하여 미계측 지역에 대한 지역홍수빈도분석의 적용가능성이 커지고 있다.
따라서, 본 연구에서는 금강유역 연최대유량 자료를 이용한 미계측 지역의 지역홍수빈도분석의 적용성을 검토하고 지역홍수빈도 관계식을 제안하였다. 이에 금강유역의 7개 관측지점에서 확보한 연최대유량 자료를 이용하여 지역홍수빈도분석을 수행하였다. L-모멘트 방법을 이용하여 매개변수를 추정하고 이질성척도 및 지역동질성 검사를 실시하였다. 또한, L-모멘트비와 ZDIST 기준에 따라 지역의 최적 분포를 결정하여 지역홍수빈도 관계식을 도출한 후 적용성을 검증하였다.
2. 연구방법
지역빈도분석은 적은 관측자료를 가진 지역에서 상대적으로 긴 재현기간의 설계수문량을 산정하기 위하여 제안된 방법이다. 즉, 지역 내 관측소 마다 자료의 갯수는 다르지만 수문학적으로 동질한 지역 및 동일한 확률분포형으로부터 추출된 자료로 간주하고 확률수문량을 산정하는 것이다. 따라서 수문학적 동질성 검정과 확률분포함수의 매개변수의 추정 그리고 최적 확률분포형의 선정 등의 절차가 수행되어야 한다.
2.1 자료의 검정
2.1.1 1차 계열상관 검정
유량자료계열의 자료 간에 독립성이 있는지를 판별하는 일반적인 척도는 1차 계열상관계수(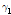 )로 Eq. (1)과 같다.
)로 Eq. (1)과 같다.
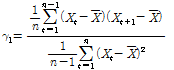 (1)
(1)
여기서, 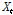 는 유량계열이며,
는 유량계열이며, 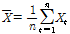 로 유량자료계열의 평균값이다.
로 유량자료계열의 평균값이다.
연최대치 유량자료의 독립적 특성은 통계적 계산을 이용하여 계산할 수 있으며, 1차 계열상관계수를 구성하는 각 유량자료의 수 n이 크지 않을 경우 경험공식에 의한 95% 신뢰구간은 Eq. (2)와 같다(Salas et al., 1980)
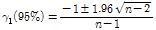 (2)
(2)
유량계열로부터 계산된 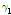 이 Eq. (2)로 표시되는 신뢰구간 내에 포함되면 수문학적 지속성이 거의 없는 무작위 시계열이라 간주하고 신뢰구간 바깥에 위치하면 지속성이 있는 계열로 판단한다.
이 Eq. (2)로 표시되는 신뢰구간 내에 포함되면 수문학적 지속성이 거의 없는 무작위 시계열이라 간주하고 신뢰구간 바깥에 위치하면 지속성이 있는 계열로 판단한다.
2.1.2 동질성 검정
자료의 오차와 비일관성을 제거하고 동질의 자료인지에 대하여 검정을 할 필요가 있으며, 동질성에 대한 검사는 평균의 부분 합계나 누적 편차를 기준으로 실시한다. 유량 관측소에서의 동질성 검사(homogeneity test)는 Eq. (3)과 같다(Machiwal and Jha, 2012).
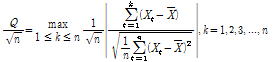 (3)
(3)
여기서, Q는 시간 동질성에 대한 민감도이며, n은 자료의 개수이다. Machiwal and Jha (2012)에 의하면 유의수준 5%에서 자료의 개수가 20개일 경우 동질성 검정의 임계값은 1.22이다.
2.1.3 이상치 검정
수문자료의 분포에서 위쪽이나 아래쪽으로 격리되는 이상치의 존재는 부적절한 통계학적 매개변수를 추정하게 하고, 설계수문량 산정에서 큰 불확실성을 초래한다. 이상치의 유무를 검증하기 위해서는 Grubbs and Beck (G-B) 검정을 실시하며, G-B 검정의 10% 유의수준에서의 통계량 Kn은 Eq. (4)에 의해 구할 수 있다(Grubbs and Beck, 1972).
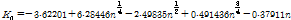 (4)
(4)
여기서, Kn은 표본크기와 10% 유의수준에 따른 통계량이다. G-B 검정값이 고이상치보다 크거나 저이상치보다 작을 경우 불확실성이 초래하게 된다. G-B 검정에 의한 이상치 검정의 고·저이상치 산정식은 Eqs. (5) and (6)과 같다.
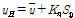 (5)
(5)
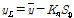 (6)
(6)
여기서, yH와 Sy는 표본에 대한 자연대수의 평균치와 표준편차이다.
2.1.4 불일치척도 검정
지역빈도분석에서 각 지점의 자료들에 대한 일치 정도를 검증하는 것은 매우 중요하다. 이를 목적으로 L-모멘트비(L-변동계수, L-왜곡도, L-첨예도)를 이용하여 지점자료의 불일치척도(Di)를 계산한다. Di는 소유역내 어떤 지점의 L-모멘트 값과 다른 지점의 L-모멘트 값을 비교하여 차이를 확인함으로써 자료의 오류를 판단하는데 이용된다. Di는 각 지점의 특성을 고려한 지역의 범위를 타원이라 가정하면 일치 정도가 높을수록 각 지점들은 타원의 중심으로, 낮을수록 타원 밖으로 밀려나게 된다. 이러한 불일치척도(Di)를 통하여 지역내 지점들을 하나의 그룹으로 간주될지 다른 지역으로 구분될 것인지를 판단할 수 있다. Di는 각 지점에서의 모멘트비를 이용하여 Eq. (7)과 같이 계산된다(Hosking et al., 1985).
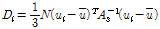 (7)
(7)
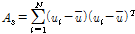 (8)
(8)
여기서, 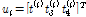 는
는 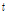 ,
, 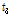 ,
, 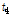 를 구성하는 벡터이며,
를 구성하는 벡터이며, 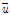 는 지점을 산술평균한 값, As는 표본자료의 공분산으로 Eq. (8)에 의해서 산정된다.
는 지점을 산술평균한 값, As는 표본자료의 공분산으로 Eq. (8)에 의해서 산정된다. 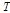 는 전치행렬이다.
는 전치행렬이다.
일반적으로 대상지점이 15개 이상일 경우, 임계값은 Di≤3으로 제안되어 있으나, 15개 이하의 지점을 포함하는 지역에서는 자료수와의 관계를 검토해야 한다(Hosking and Wallis, 1997).
2.1.5 지역 동질성 검정
지역빈도분석에서 지역 동질성(regional homogeneity)이란 지형학적인 의미가 아닌 각 지점에서의 통계적 특성이 동일하다는 것이다. 지역내 지점들의 수문학적 동질성을 평가하기 위해서 이질성 척도(H)를 산정한다. Hosking (1990)은 이질성 척도를 자료의 이산도(dispersion)를 모의 발생시킨 평균과 이산도의 차, 모의 발생시킨 표준편차의 비로 제시한 바 있으며, Eq. (9)와 같이 계산된다.
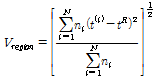 (9)
(9)
여기서, t(i)는 자료 개수(ni)를 가지고 있는 지점 i에 대한 표본 L-모멘트이며, tR은 자료 개수(ni)를 가중한 평균 L-모멘트이다.
동질성을 가진 지역에서의 모든 지점은 같은 모집단 L-모멘트를 가질 수 있다고 가정한다. 하지만 표본의 변동성으로 인하여 표본 L-모멘트가 서로 다를 수 있기 때문에 동질성을 가진 지역에서 예측되는 이산도는 그룹의 표본 L-모멘트간의 이산도 및 각 지역 내 모집단의 이산도로 산정할 필요가 있다. 동질성을 가진 지역에서 예측할 수 있는 이산도를 추정하기 위한 이질성 척도 H는 관측된 이산도와 모의 발생시킨 표준편차의 비로 정의되며, 이질성 척도 H는 Eq. (10)을 이용하여 산정한다.
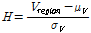 (10)
(10)
여기서, 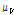 와
와 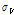 는
는  의 L-모멘트비를 Kappa 분포형에 적합시킨 후 모의 발생하여 계산된 평균과 표준편차이다.
의 L-모멘트비를 Kappa 분포형에 적합시킨 후 모의 발생하여 계산된 평균과 표준편차이다.
표본 L-변동계수를 고려한 H1과 표본 L-왜곡도를 고려한 H2, 표본 L-첨예도를 고려한 H3를 기준으로 이질성 여부를 판단할 수 있으며, Hosking and Wallis (1997)은 L-모멘트비에 따라 이질성 척도를 H1 (L-변동계수), H2 (L-왜곡도), H3 (L-첨예도)로 구분하여, H<1이면 동질성 지역(acceptably homogeneous), 1≤H<2이면 동질성 지역일 가능성이 있고(possibly homogeneous), H≥2이면 이질성 지역(definitely heterogeneous)으로 판단하였다.
2.2 확률가중모멘트와 L-모멘트의 관계
확률가중모멘트법은 모집단의 확률가중모멘트가 표본자료의 확률가중모멘트와 같다고 가정하여 매개변수를 추정하는 방법으로 Eq. (11)과 같이 정의된다(Greenwood et al., 1979).
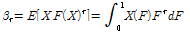 (11)
(11)
여기서, F(X)는 누가확률분포함수, r은 모멘트차수, E[·]는 기대값이다.
L-모멘트는 확률가중모멘트의 선형조합으로 일반적인 형태로 표시하면 Eq. (12)와 같다(Hosking et al., 1985; Hosking and Wallis, 1997).
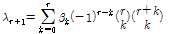 (12)
(12)
L-모멘트법은 기존의 모멘트와 유사한 L-모멘트비를 사용할 수 있으므로 적정 확률분포형을 선정하거나 수문학적 동질유역을 구분할 때 특히 유리하다. L-모멘트를 이용한 변동계수, 왜곡도, 첨예도를 정의하면 Eqs. (13)~(15)와 같다(Hosking, 1990).
L-변동계수: 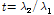 (13)
(13)
L-왜곡도: 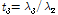 (14)
(14)
L-첨예도: 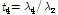 (15)
(15)
L-모멘트법은 통계학적 효율성 면에서 확률가중모멘트법과 동일하나 L-모멘트비를 사용함으로써 일반 모멘트법과 유사한 L-변동계수, L-왜곡도, L-첨예도를 적용함으로써 수문자료의 적정 확률분포형을 판별할 수 있다(Hosking and Wallis, 1997).
2.3 최적 확률분포형의 선정
본 연구에서는 5개의 3변수 확률분포함수에 대하여 매개변수를 산정하고 최적 확률분포형을 선정하였다. 각 분포의 매개변수는 지역 L-모멘트비의 값에 대입하여 산정하였다. 각 매개변수의 적합도를 평가하기 위하여 L-모멘트비도와 평균가중거리(AWD) 그리고 ZDIST 방법을 적용하여 적합성을 평가하였다.
2.3.1 L-모멘트비도
L-모멘트비도(L-moment ratio diagram)는 다수의 확률분포형을 비교하여 최적 확률분포형을 결정하는데 유용한 방법으로 제시되었다(Hosking, 1990). L-모멘트비를 이용하여 최적 확률분포형을 선정하는 방법에는 표본에 대한 L-왜곡도와 L-첨예도의 평균 지점을 도시하는 방법, 표본에 대한 L-모멘트비의 최적 선도를 도시하여 비교하는 방법이 있다. L-모멘트비도는 각 확률분포의 L-왜곡도와 L-첨예도의 관계를 이용하여 L-모멘트비도를 작성하고 연최대홍수량의 L-왜곡도와 L-첨예도의 무차원 L-모멘트를 도시하여 어떤 확률분포형에 근접한지 확인할 수 있다.
2.3.2 평균가중거리
지역빈도분석에서 최적 확률분포 선정을 위한 정량적인 평가를 위해서 평균가중거리(average weighted distance, AWD)가 사용된다(Kroll and Vogel, 2002). 평균가중거리는 Eq. (16)에 의해 계산할 수 있다.
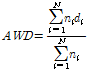 (16)
(16)
여기서, 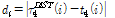 이며, N은 지역내 지점 개수, ni는 지점 i의 관측자료 갯수, t4는 L-첨예도,
이며, N은 지역내 지점 개수, ni는 지점 i의 관측자료 갯수, t4는 L-첨예도, 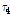 는 각 확률분포형에서의 L-첨예도이다. 산정된 평균가중거리가 가장 작은 값을 가지는 확률분포형이 가장 적합한 것으로 판단할 수 있다.
는 각 확률분포형에서의 L-첨예도이다. 산정된 평균가중거리가 가장 작은 값을 가지는 확률분포형이 가장 적합한 것으로 판단할 수 있다.
2.3.3 ZDIST
동질성을 가진 지역 내 각 지점들에서 적합한 확률분포형을 선정하는 척도로 적합도를 나타내는 ZDIST를 사용한다. 동질한 지역 내 각 지점별 자료계열의 L-모멘트의 평균은 지역적인 특성을 충분히 대표하므로 검정하고자 하는 확률분포형이 이들 평균값들과 일치하는가를 검사함으로써 적정 확률분포형을 선정한다.
적합성 척도 Z는 L-첨예도 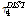 와 표본 모멘트의 소유역 평균치
와 표본 모멘트의 소유역 평균치 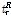 과의 차이값과 Kappa 분포형을 이용하여 모의발생시켜 구한 분산(
과의 차이값과 Kappa 분포형을 이용하여 모의발생시켜 구한 분산(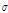 )의 비로 정의하며(Hosking and Wallis, 1997), Eq. (17)과 같다.
)의 비로 정의하며(Hosking and Wallis, 1997), Eq. (17)과 같다.
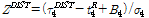 (17)
(17)
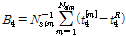 (18)
(18)
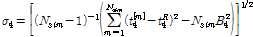 (19)
(19)
여기서, 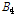 는 소유역 평균값의 편의이고
는 소유역 평균값의 편의이고 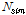 은 모의발생 수이다. ZDIST가 0에 가까울수록 확률분포형의 자료에 대한 적합도가 높다고 할 수 있으며, 유의수준 10%에서
은 모의발생 수이다. ZDIST가 0에 가까울수록 확률분포형의 자료에 대한 적합도가 높다고 할 수 있으며, 유의수준 10%에서 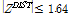 로 제시한 바 있다(Hosking and Wallis, 1993).
로 제시한 바 있다(Hosking and Wallis, 1993).
3. 자료의 검정 결과
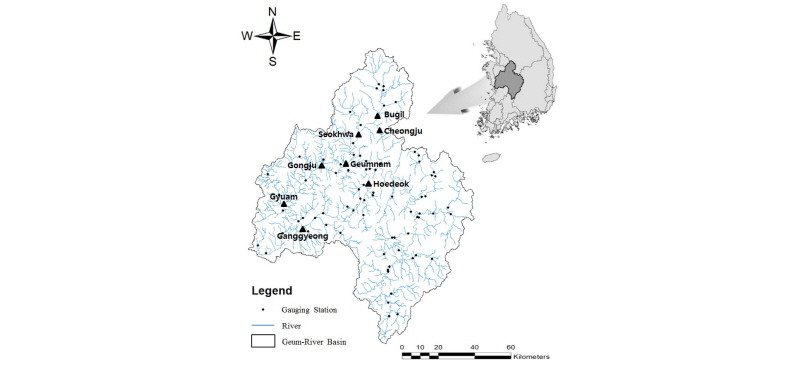
본 연구에서는 금강유역의 국토교통부 관할 수위관측소 중 자료기간이 20년 이상인 곳을 대상유역으로 선정하였다. 선정된 관측소는 규암, 공주, 석화, 회덕, 북일, 금남, 청주 등 7개 관측소로 국가수자원관리종합정보시스템(http://www. wamis.go.kr)에서 연최대유량 자료를 수집하여 지역빈도분석을 실시하였다. 수집된 연최대유량에 대하여 1차 계열상관 검정, 동질성 검정, 이상치 검정, 불일치척도 검정을 실시하였으며, 지역동질성 검정을 통하여 수문학적 동질성을 평가하였다. 최적 확률분포형 선정을 위하여 L-모멘트비도와 평균가중거리(AWD) 그리고 ZDIST를 산정하였다. Fig. 1은 금강유역 및 선정된 수위관측소의 위치를 보여주고 있으며, Table 1은 선정된 관측소의 연최대유량에 대한 기본통계량을 정리한 것이다.
 (m3/s)
(m3/s)3.1 연최대유량 자료의 검정 결과
금강유역의 각 관측소에 대하여 1차 계열상관 검정을 수행하였다. 각 관측소에 대한 유의수준 95% 신뢰구간은 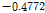
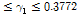 이며, 1차 계열상관 검정 결과 가장 작은 값은 회덕관측소로 -0.099, 가장 큰 값은 규암관측소로 0.0584이었다. 모든 관측소의 유량자료에 대한 1차 계열상관 검정 결과, 관측 유량자료는 수문학적 지속성이 거의 없는 무작위 계열로 시간에 대하여 독립적인 것으로 분석되었다. 또한, 본 연구에서 적용한 각 관측소의 자료의 개수는 21개로 동질성 검정을 위한 유의수준 5%에 대한 임계값은 1.222이다(Machiwal and Jha, 2012). 동질성 검정 결과, 청주관측소에서 가장 큰 검정 통계량인 1.1493이 나타났으며, 모든 관측소에서 유의수준 5%에 대하여 만족하여, 관측자료는 동질적 모집단에 속해 있는 것으로 분석되었다.
이며, 1차 계열상관 검정 결과 가장 작은 값은 회덕관측소로 -0.099, 가장 큰 값은 규암관측소로 0.0584이었다. 모든 관측소의 유량자료에 대한 1차 계열상관 검정 결과, 관측 유량자료는 수문학적 지속성이 거의 없는 무작위 계열로 시간에 대하여 독립적인 것으로 분석되었다. 또한, 본 연구에서 적용한 각 관측소의 자료의 개수는 21개로 동질성 검정을 위한 유의수준 5%에 대한 임계값은 1.222이다(Machiwal and Jha, 2012). 동질성 검정 결과, 청주관측소에서 가장 큰 검정 통계량인 1.1493이 나타났으며, 모든 관측소에서 유의수준 5%에 대하여 만족하여, 관측자료는 동질적 모집단에 속해 있는 것으로 분석되었다.
불일치척도를 검정하기 위해 금강유역의 각 지점에서의 L-모멘트비(L-변동계수, L-왜곡도, L-첨예도)를 산정하여 지점자료의 불일치척도(Di)를 분석하였다. Hosking and Wallis (1997)이 제안한 7개 관측 지점의 불일치척도 임계값은 1.917이며, 금강유역의 불일치척도 분석 결과 가장 큰 값은 청주지점으로 1.330, 가장 작은 값은 공주지점으로 0.65로 분석되었으며, 관측소별 자료의 일치 정도는 양호한 것으로 판단된다.
1차 계열상관(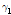 ) 검정 결과, 동질성 검정(
) 검정 결과, 동질성 검정(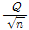 ) 결과, 불
) 결과, 불
일치척도(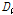 ) 검정 결과는 Table 2와 같다.
) 검정 결과는 Table 2와 같다.
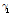
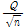
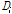
불확실성을 검증하기 위하여 Grubbs and Beck (G-B) 검사를 통해 이상치의 유무를 검정하였다. 자연로그로 변환하여 이상치 검정을 실시하였으며, 유의수준 10%에 대하여 모든 지점에서 만족하고 관측자료에서 이상치는 없었다. 관측소별 이상치 검정 결과는 Table 3과 같다.
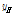 )*
)*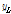 )
) )
) )
)금강 유역내 지점들의 수문학적 동질성을 평가하기 위해 이질성 척도를 산정하였다. 이를 계산하기 위해 Kappa 분포형에 적합시켜 매개변수를 추정하고 500회 반복수행하여 이질성 척도를 산정하였다. 이질성척도 산정 결과 H1, H2, H3은 각각 -0.235, 0.136, 0.092로 산정되어 Hosking and Wallis (1993, 1997)이 제안한 H<1을 만족하여 동질성이 있는 것으로 분석되었다. 지역 동질성 검정 결과는 Table 4와 같다.
금강유역의 연최대유량에 대한 자료의 검정 결과, 모든 지점에서 검정기준을 통과하는 것으로 분석되었다.
Table 4. Regional Homogeneity Test for Geum-River Basin | |||
|
|
| |
Value | -0.235 | 0.136 | 0.092 |
Results | Acceptably homogeneous | Acceptably homogeneous | Acceptably homogeneous |
3.2 최적 확률분포형의 선정 결과
본 연구에서는 generalized extreme value (GEV), log-normal (LN-Ⅲ), Pearson type-Ⅲ (P-Ⅲ), generalized logistic (GLO), generalized Pareto (GPA) 확률분포형에 대한 매개변수를 추정한 다음, 적합성을 검정하고 이를 통하여 적정 확률분포형을 선정하였다. Table 5는 각 확률분포형의 매개변수 산정결과로 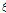 는 위치 매개변수,
는 위치 매개변수, 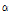 는 규모 매개변수,
는 규모 매개변수,  는 형상 매개변수이다.
는 형상 매개변수이다.
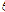 )
)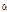 )
) )
)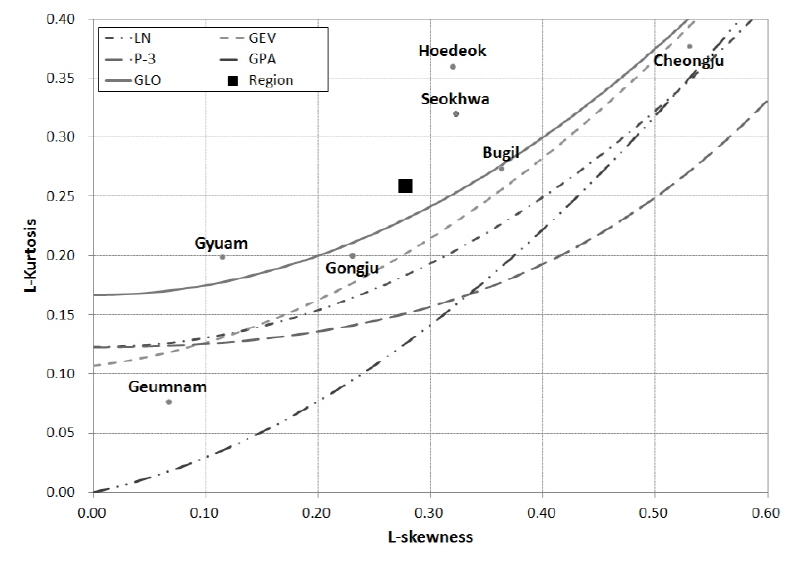
본 분석에서는 사용된 GEV, LN-Ⅲ, P-Ⅲ, GLO, GPA 분포의 L-왜곡도와 L-첨예도의 관계를 L-모멘트비도에 도시하고 금강유역 7개 관측지점에서의 연최대유량에 대한 L-왜곡도와 L-첨예도를 Fig. 2와 같이 도시하였다.
금강유역의 최적 확률분포형 선정을 위한 정략적인 평가를 위하여 평균가중거리(AWD)와 ZDIST를 산정하였다. 산정된 평균가중거리가 가장 작은 값을 가지는 확률분포형이 가장 적합하다고 판단할 수 있으며, 금강유역의 평균가중거리 산정 결과 가장 작은 값을 가지는 확률분포형은 GLO 분포형인 것으로 분석되었다. 또한, ZDIST는 0에 가까울수록 적정 확률분포형으로 판단할 수 있으며, 각 분포형 가운데 가운데 GLO 확률분포형이 가장 적합한 것으로 분석되었다. 유의수준 10%인 |ZDIST|≤1.64를 만족하며 최저값으로 산정된 확률분포형은 GLO 분포형인 것으로 분석되었다. Table 6은 각 확률분포형의 평균가중거리 산정결과와 ZDIST 검정 결과이다.
Table 6. Average Weighted Distance (AWD) and ZDIST Values for Candidate Distributions | |||||
Test | GEV | LN-Ⅲ | GLO | P-Ⅲ | GPA |
AWD | 0.06294 | 0.09394 | 0.04825 | 0.10435 | 0.12037 |
|ZDIST| | 1.26 | 0.47 | 0.08 | 0.65 | 1.50 |
지역 L-모멘트비와 AWD 그리고 ZDIST의 분석 결과, 본 연구의 대상지역인 금강유역의 최적 확률분포형은 GLO 확률분포형으로 선정되었다.
4. 결 과
4.1 지역홍수빈도 관계식 유도
금강유역의 지역홍수빈도 관계식을 개발하기 위하여 7개 지점에 대하여 적정 확률분포형으로 선정된 GLO 확률분포형을 이용하였다. GLO 확률분포의 재현기간(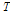 )에 대한 홍수빈도 관계식은 Eq. (20)과 같다(Rao and Hamed, 2000).
)에 대한 홍수빈도 관계식은 Eq. (20)과 같다(Rao and Hamed, 2000).
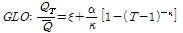 (20)
(20)
여기서, 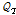 는 재현기간에 해당하는 홍수량,
는 재현기간에 해당하는 홍수량, 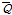 는 연최대유량의 평균이다.
는 연최대유량의 평균이다.
GLO 확률분포형의 매개변수는 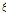 = 0.8300,
= 0.8300, 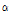 = 0.3389,
= 0.3389,  = -0.2781로 추정되었으며, 금강유역의 지역홍수빈도 관계식에 반영하면 Eq. (21)과 같다.
= -0.2781로 추정되었으며, 금강유역의 지역홍수빈도 관계식에 반영하면 Eq. (21)과 같다.
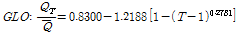 (21)
(21)
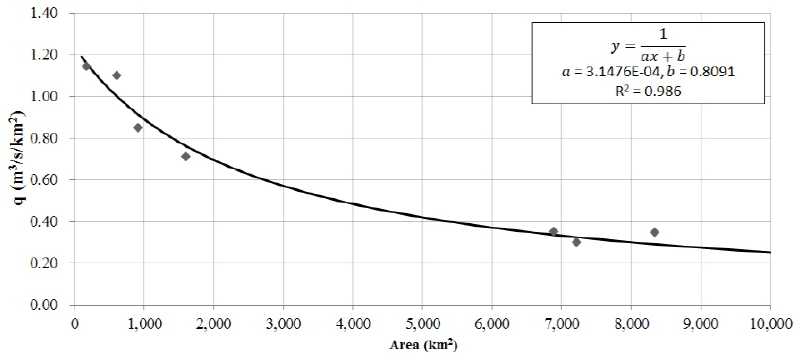
미계측 유역의 설계홍수량을 산정하기 위해서는 유역의 연최대유량의 평균( )를 산정해야 하는데, 본 연구에서는 단위면적(km2)당 홍수량을 고려하여 금강유역의 평균 연최대유량을 산정하였다. Fig. 3과 같이 7개 관측지점에 대하여 면적-단위면적당 평균 연최대유량을 회귀하면 Eq. (22)와 같다.
)를 산정해야 하는데, 본 연구에서는 단위면적(km2)당 홍수량을 고려하여 금강유역의 평균 연최대유량을 산정하였다. Fig. 3과 같이 7개 관측지점에 대하여 면적-단위면적당 평균 연최대유량을 회귀하면 Eq. (22)와 같다.
 (22)
(22)
|
Fig. 3. Relationship between q (Mean Unit Discharge) and Catchment Area with Observed Data of 7 Stations |
무차원의 성장계수(growth factor)는 재현기간(T)으로 계산할 수 있으며, 유역의 평균 연최대유량에 해당하는 다양한 재현기간에 대한 홍수량을 산정할 수 있다. 금강유역의 GLO 분포를 적용한 빈도별 성장 계수는 Table 7과 같다.
또한, 연최대유량의 누가발생확률을 결정하기 위하여 Eq. (23)의 Weibull의 도시위시공식을 적용하였다.
Table 7. Growth Factors ( | |||||||||
Return Period (year) | 2 | 5 | 10 | 25 | 30 | 50 | 100 | 150 | 200 |
Growth Factors | 0.830 | 1.403 | 1.857 | 2.561 | 2.720 | 3.208 | 3.985 | 4.512 | 4.922 |
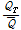 ) of GLO Distribution for Geum-River Basin
) of GLO Distribution for Geum-River Basin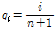 (23)
(23)
여기서, qi는 비초과확률(non-exceedance probability)이고, n은 연최대자료계열을 구성하고 있는 자료의 총수, i는 자료를 내림차순으로 나열했을 때의 순위이다.
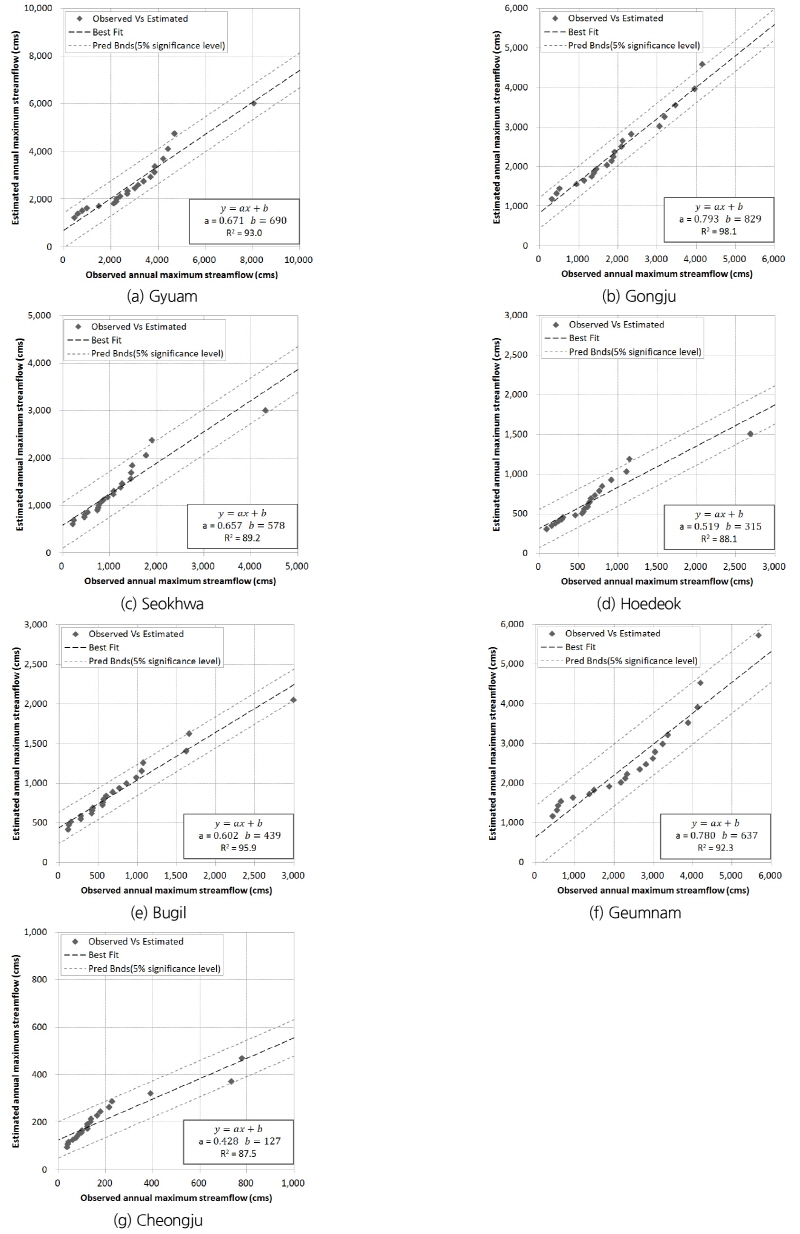
지역홍수빈도관계를 통하여 비초과확률을 산정하고 예측된 홍수량과 각 지점의 계측된 홍수량을 비교하였다. 각 지점에 대한 관측치 대비 예측홍수량의 Q-Q 그래프를 Fig. 4에 도시하였다.
지역홍수빈도 관계식을 이용하여 산정된 홍수량의 신뢰도 검정을 위해 본 연구에서는 빈도분석에 의해 구해진 재현기간별 홍수량의 95% 유의수준에 대하여 검정하였다. Fig. 4의 결과에서 보는 바와 같이 규암, 청주, 석화, 회덕의 경우 1점을 제외하고는 모두 신뢰구간 내에 포함되었으며, 나머지 관측소는 모두 신뢰구간 내에 포함되고 있다는 것을 확인할 수 있다. GLO 확률분포형을 적용시킨 금강유역의 7개 관측소에 대하여 회귀함수의 결정계수(R2)의 범위는 0.875~0.981로 모든 지점에 대하여 양호한 것으로 검토되었다.
4.2 홍수량 산정 방법의 비교 검토 및 검증
본 연구에서 제안한 지역홍수빈도 관계를 이용한 확률홍수량의 적용성을 평가하기 위하여 기 고시된 「금강수계하천기본계획(변경)」(MLTMA, 2009)에서 산정한 홍수량 자료와 비교 검토를 수행하였다. 홍수량 자료의 비교는 적용된 관측연수의 차이로 인하여 유역면적이 비교적 작은 지점인 석화, 회덕, 북일, 청주관측소에 대하여 검토하였다. 검토 결과, 회덕 관측소를 제외한 나머지 관측소에서 본 연구결과 대비 20% 내외로 차이가 발생하며 30년 빈도 이상에서는 고시된 홍수량에 비하여 크게 산정되는 경향이 있고 30년 빈도 이하에서는 작게 산정되는 경향이 있는 것으로 분석되었다. 본 연구에서 적용된 7개 관측소의 관측기간은 21년(1995년~2015년)인데 반해, 고시된 홍수량은 41개 관측지점의 최대 44년의 시강우 자료를 이용하여 홍수량을 산정한 것이다. 홍수량 산정 방법에 따른 각 빈도별 홍수량 산정 결과는 Table 8과 같다.
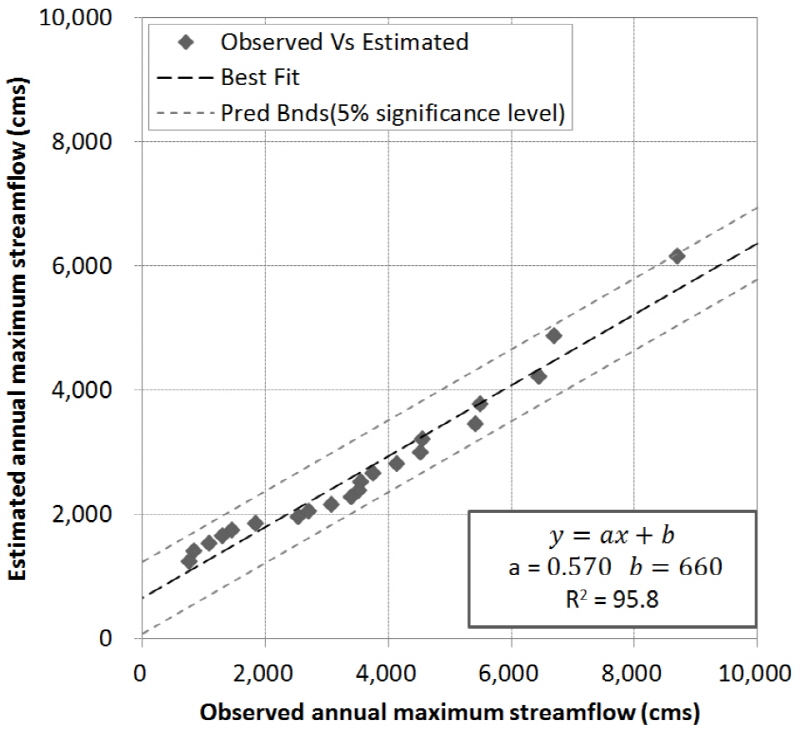
본 연구에서 도출된 지역홍수빈도 관계식을 이용하여 금강유역의 하구에 위치한 강경 관측소에 대하여 지역홍수빈도 관계식을 검증하였다. 강경관측소의 관측연수는 다른 관측소와 동일한 21년이고, 유역면적은 9,379.6 km2으로 본 연구에서 제안한 금강유역의 단위면적당 홍수량 관계를 적용하여 단위면적에 해당하는 연최대유량의 평균값을 산정하였다. 산정된 GLO 확률분포형의 매개변수를 적용하여 강경관측소에서의 예측된 홍수량과 계측된 홍수량을 비교하였다. Fig. 5는 강경관측소에 대한 관측치 대비 예측홍수량의 Q-Q 그래프로 95% 유의구간을 산정한 결과 모두 신뢰구간 내에 포함되며, 결정계수(R2)는 0.990으로 양호한 것으로 판단된다. 도출된 결과로부터 금강유역의 GLO 확률분포형이 적절한 것으로 검증되었다.
5. 결 론
본 연구에서는 금강유역에 대하여 L-모멘트법을 이용하여 지역홍수빈도 관계식을 도출하였다. 이를 위하여 금강유역의 7개 관측소를 대상으로 관측연수 21년의 유량자료에 대하여 L-모멘트법을 이용한 지역홍수빈도분석을 실시하였다. 분석 결과, 금강유역의 최적 확률분포형으로 GLO 분포형이 선정되었으며, 지역홍수빈도 관계식을 제안하였다. 강우자료를 이용한 지점빈도분석 결과와의 비교 검토를 통하여 본 연구의 결과에 대한 적절성을 확인하였다. 따라서 금강유역의 미계측 유역에 대한 효율적인 수공구조물 설계 및 재해 예방관리에 적절히 활용되기를 기대한다.
앞으로 유량자료에 대한 지속적인 관측을 통하여 지점자료들이 축척된다면, 기존에 적용되고 있는 강우-유출관계 모형에 의한 설계홍수량 산정 방법보다 통계적으로 더 신뢰할 수 있는 지역홍수빈도분석이 더 활발히 실무에 적용될 것으로 예상된다. 이를 위해서 수위-유량 관계곡선식의 신뢰성 확보와 다수의 지점 자료 확보, 수리시설물의 영향 등을 고려하여 양질의 유량자료를 취득하기 위한 노력이 필요할 것이다. 또한, 금강유역의 경우 4대강 사업의 일환인 백제보, 공주보, 세종보가 있어 완공된 이후의 자료는 홍수조절의 영향을 받기 때문에 검·보정을 통한 자연유출량으로의 변환이 필요할 것으로 판단된다.
