

1. 서 론
2. 연구방법
2.1 Multi Layer Perceptron (MLP)
2.2 Layer-wise Relevance Propagation (LRP)
2.3 대상유역 및 자료구축
3. 연구결과
3.1 수온(Water Temperature, WT)
3.2 용존산소량(Dissolved Oxygen, DO)
3.3 수소이온농도(hydrogen ion concentration, pH)
3.4 엽록소-a (Chlorophyll-a, Chl-a)
4. 결 론
1. 서 론
하천 및 저수지는 생활용수, 농업용수 및 공업용수 등을 취수하는 중요한 장소이다. 그러나 최근 도시화 및 산업화가 진행됨에 따라 수질오염은 많은 지역에서 심각한 문제가 되고 있다(Park et al., 2006). 따라서, 수자원 관리와 수질오염 방지는 필수적이며, 수자원 관리 및 수질오염 방지를 위해서는 높은 정확도를 기반으로 하천과 저수지의 수질을 예측하는 것이 필요하다(Lu and Ma, 2020).
기존에는 수질을 예측하기 위해 미국 환경 보호청(United Sates Environmental Projection Agency)에서 개발한 QUAL2E 및 CE-QUAL-W2 등 수리 및 수질해석 모형이 사용되었다(Drolc and Končan, 1999; Ahn et al., 2014). 하지만, 수리 및 수질해석 모형은 구축하는데 많은 비용과 시간이 필요하며 각 요인간의 관계를 나타내는 계수를 명확하게 설정하는 것이 어렵다는 단점이 있다(Lee and Lee, 2018). 수리 및 수질해석 모형의 단점을 개선하기 위해 최근 인공신경망(Artificial Neural Network, ANN)을 이용하여 하천 및 저수지의 수질을 예측하는 연구가 진행되었다.
ANN은 사람의 신경망에서 신호가 전달되는 방식을 모방하여 제안되었다. McCulloch and Pitts (1943)는 ANN의 기초논리를 수학적 방법을 이용하여 제안하였으며 Rosenblatt (1958)은 Perceptron의 개념을 제안했다. Rumelhart et al. (1986)은 Backpropagation-through-time을 적용한 Recurrent Neural Network (RNN)를 제안하였다. 이후, RNN의 기울기 소실(Vanishing gradient) 문제를 개선하기 위해 Hochreiter and Schmidhuber (1997)는 Long Short-Term Memory (LSTM)를 제안하였으며 Chung et al. (2014)은 Gated Recurrent Unit (GRU)을 제안하였다.
하천 및 저수지의 수질을 예측하기 위해 ANN을 활용한 국내 연구로는 Ahn et al. (2001)이 ANN을 이용하여 금강 공주지점의 용존산소량(Dissolved Oxygen, DO), 생화학적 산소요구량(Biochemical Oxygen, Demand, BOD) 및 총질소(Total-Nitrogen, T-N)를 예측하였다. Lim et al. (2020)은 ANN 중 LSTM을 이용하여 실시간 수질 자료를 수집할 수 있는 부산 온천천의 DO를 예측하였다. Kim et al. (2021)은 보현산댐 및 영천댐을 대상으로 유해남조류 발생에 영향을 미치는 수질인자의 특성중요도 분석을 수행하였으며, ANN을 이용하여 특성중요도가 높았던 수온(Water Temperature, WT)과 T-N을 학습 및 예측하였다.
국외 연구로는 Dogan et al. (2008)이 ANN을 이용하여 BOD를 예측하기 위해 입력자료(Input data)에 따른 예측 정확도를 분석하였다. Wang et al. (2008)은 엽록소-a (Chlorophyll-a, Chl-a)를 예측하기 위해 ANN 중 Multi Layer Perceptron (MLP)을 사용하였다. Haghiabi et al. (2018)은 머신러닝(Machine learning) 중 하나인 Support Vector Machine과 ANN을 이용하여 이란 남서부에 위치한 Tireh 강의 수질인자를 예측하였다.
ANN은 수자원 분야에서 광범위하게 사용되고 있으나 내부의 연산 과정이 복잡하고 출력값에 대한 근거를 파악할 수 없는 Black-box 형태라는 단점이 있다(Chun et al., 2021). 최근에는 ANN의 결과에 대한 근거를 파악하고 신뢰성을 높이기 위한 연구가 진행되고 있다. 설명가능한 인공지능(eXplainable Artificial Intelligence, XAI) 기술은 딥러닝의 연산과 최종 결과를 해석하기 위해 출력값이 산출되는 과정을 설명 가능하도록 하는 기술을 의미한다(Roh and Park, 2021). 대표적인 XAI 기술로는 Local Interpretable Model-agnostic Explanations (LIME), SHapley Additive exPlanations (SHAP) 및 Layer-wise Relevance Propagation (LRP) 등이 있다(Ribeiro et al., 2016; Lundberg and Lee, 2017; Bach et al., 2015). 특히, XAI 기술 중 LRP는 딥러닝(Deep learning)에 가장 적합하다(Nahm, 2022).
LRP를 이용한 연구로는 Arras et al. (2017)이 영화감상평에 대해 Bi-directional LSTM을 이용하여 5개의 범례로 구분하고 LRP를 이용하여 모델을 분석하였다. Lee and Han (2021)은 코스피지수의 증감을 예측하기 위한 Bi-directional LSTM을 해석하기 위해 LRP를 사용하였으며, 각 변수들이 결과에 미치는 영향을 분석하였다. Wu et al. (2022)은 진동 데이터를 기반으로 베어링 상태를 예측하는 LSTM을 해석하기 위해 LRP를 사용하였으며, LRP를 이용한 해석을 통해 LSTM의 효율성을 개선하였다. 다양한 분야에서 XAI 기술이 사용되고 있으며, 문장 분류 및 경제 등 많은 분야에서 LRP가 사용되었으나 수자원 분야에서 XAI 기술을 적용한 연구는 부족한 실정이다.
본 연구는 낙동강에 위치한 다산 수질관측소의 WT, DO, 수소이온농도(hydrogen ion concentration, pH) 및 Chl-a를 학습한 MLP를 분석하기 위해 LRP를 적용하였다. LRP를 기반으로 산출된 관련성 점수(Relevance score)가 낮은 입력자료를 제거하여 수질을 예측하기 위한 최적의 입력자료를 선정하였으며, MLP의 예측결과에 대한 분석을 실시하였다.
2. 연구방법
2.1 Multi Layer Perceptron (MLP)
ANN 중 하나인 MLP는 입력층(Input layer), 출력층(Output layer) 및 하나 이상의 은닉층(Hidden layer)으로 구성된 퍼셉트론 구조이다. 입력층은 신경망의 입력자료를 받고 출력층은 신경망의 출력값을 내보낸다. 입력층과 출력층 사이에 있는 은닉층은 입력층에서 받은 자료를 가공하여 출력층으로 전달한다.
은닉층이 없는 Single Layer Perceptron은 비선형적 문제해결이 불가능하다는 단점이 있으나 MLP는 하나 이상의 은닉층이 있기 때문에 비선형적 문제해결이 가능하다. MLP는 비선형적 문제해결 능력을 갖고있어 다양한 수자원 분야에서 사용되었다(Lee et al., 2013; Zhou et al., 2020). Lee and Lee (2023)는 MLP의 은닉층 개수에 따른 수문학적 유입량 예측성능을 검토하였으며, 각 은닉층의 노드는 10개이고 은닉층은 5개인 구조가 가장 높은 학습정확도를 보이는 것을 확인하였다. 본 연구는 Lee and Lee (2023)의 연구를 참고하여 은닉층을 5개로 설정하였으며, 각 은닉층의 노드는 10개로 설정하였다. 설정된 은닉층 및 노드의 개수는 수문학적 유입량 예측성능에 우수한 성능을 나타냈으며, 수질 예측을 위한 MLP는 해당 구조를 참고하였다. Fig. 1은 MLP의 구조이다.
Fig. 1에서 wm,n(l,l+1)는 l번째 층의 m번째 노드와 l+1번째 층의 n번째 노드 사이의 가중치(Weight)이며, bnl은 l번째 층, n번째 노드의 편향(Bias)이다. Eq. (1)은 MLP의 연산과정이다.
여기서, fact는 활성화 함수(Activation function)이며, xnl+1은 l+1번째 층, n번째 노드의 출력값이다.

MLP는 옵티마이저(Optimizer)를 기반으로 반복학습을 진행하여 MLP 출력값과 관측값간의 오차가 최소가 되는 가중치 및 편향을 탐색한다. MLP의 옵티마이저 중 Adaptive moment (Adam)는 수문학적 유출 예측에 비교적 우수한 성능을 나타냈다(Mahsa and Lee, 2018). MLP 은닉층의 출력값은 활성화 함수를 통해 결정된다. MLP의 활성화 함수 중 Rectified linear unit (Relu)은 사용성이 좋으며 연산시간이 짧다는 장점이 있다(Yoo et al., 2020). 본 연구는 MLP의 옵티마이저와 활성화 함수를 각각 Adam 및 Relu로 설정하였다. Eq. (2)는 Relu 함수의 식이다.
여기서, x는 활성화 함수에 입력되는 값이며, Relu 함수는 0 이하의 값은 0으로 출력하고 0을 초과한 값은 그대로 출력한다.
2.2 Layer-wise Relevance Propagation (LRP)
훈련된 ANN을 분석하기 위한 방법 중 하나는 각 입력자료가 ANN의 출력값에 대해 얼마나 기여하는지를 분석하는 것이다. LRP는 Bach et al. (2015)가 제안한 XAI 기술이다. LRP는 ANN의 출력값인 f(x)에 대하여 각 층의 노드별로 기여도(Contribution)를 추적하여 각 입력자료의 관련성 점수를 산출하는 방법이다. LRP는 ANN의 연산과정인 순전파(Forward propagation)의 반대방향으로 상관성 전파(Relevance propa gation)를 실시하여 입력자료의 관련성 점수를 산출한다. Fig. 2는 순전파 및 상관성 전파의 모식도이다.
Fig. 2에서 Rml은 l번째 층, m번째 노드의 관련성 점수이다. LRP의 과정에서 각 층의 관련성 총합은 같으며, 관련성 총합은 f(x)와 같다. Eqs. (3) and (4)는 각 노드 관련성 점수 Rml을 산출하는 식이다.
여기서, sign()은 부호를 나타내기 위한 함수로 음수는 -1, 0과 양수는 1로 출력한다. 또한, ϵ은 분모가 0이 되는 것을 방지하고 수학적 안정화를 위한 작은 실수이다. Carbone et al. (2022)는 ϵ을 0.1로 설정하였으며, 본 연구도 ϵ을 0.1로 설정하였다.

Eqs. (3) and (4)를 이용하여 상위층에서 하위층 방향으로 노드의 관련성 점수를 산출한다. 특히, 출력층의 경우 출력층의 관련성 점수는 ANN의 출력값인 f(x)로 설정한다. 관련성 점수를 반복적으로 산출하여 최종적으로는 출력값에 대한 각 입력자료의 관련성 점수를 산출할 수 있다.
2.3 대상유역 및 자료구축
본 연구는 수질인자를 예측하기 위해 MLP를 학습시켰다. XAI 기술 중 LRP를 이용하여 학습된 MLP를 분석하여 각 입력자료의 관련성 점수를 산출하였다. 관련성 점수가 낮은 입력자료를 제거하여 수질인자 예측정확도가 가장 높은 최적의 입력자료를 선정하였다. 또한, LRP를 이용하여 MLP의 예측에 대한 분석을 실시하였다.
연구의 대상유역은 낙동강 유역에 위치한 다산 수질관측소로 선정하였다. 다산 수질관측소는 2012년에 수질 자동측정소를 설치하였으며, 일 단위 수질자료 취득이 가능하다. 다산 수질관측소의 하류 4km 지점에는 매곡취수장과 강정취수장이 위치해 있다.
MLP의 출력자료는 다산 수질관측소에서 측정하는 WT, DO, pH 및 Chl-a의 t일 자료로 설정하였다. MLP의 입력자료는 t-1일의 대구시, 영천군, 구미시, 상주시 및 의성군의 일 평균기온 및 일 강수량 자료, 성주대교, 도성교 및 매곡리 수위관측소의 수위 자료 및 다산 수질관측소의 WT, DO, pH 및 DO로 설정하였다. 또한, 입력 및 출력자료는 모두 일 단위 자료를 사용하였다. Table 1은 MLP의 입력자료이다.
Table 1.
Input data of MLP
입력자료 중 기상자료는 기상자료개방포털에서 취득하였으며, 수위자료는 국가수자원관리종합정보시스템에서 취득하였다. 또한, 수질자료는 물환경정보시스템에서 취득하였다. 다산 관측소의 수질을 학습하기 위한 자료는 2014년부터 2020년 자료를 사용하였으며, 2021년 자료는 학습된 MLP의 예측정확도 평가를 위한 예측자료로 사용하였다. Fig. 3은 대상유역 및 관측소 위치이다.

2.3.1 데이터 전처리
입력 및 출력자료의 최대값과 최소값의 차가 큰 경우에는 가중치 및 편향의 탐색범위가 넓어지기 때문에 넓은 범주의 자료는 ANN의 정확도 저하의 원인이 될 수 있다(Mok et al., 2020). 따라서, ANN의 학습 및 예측을 실시하기 전에 원자료(Raw data)를 가공하는 데이터 전처리(Data pre-processing)가 필요하다. Nawi et al. (2013)은 넓은 범주의 자료를 가공하는 전처리 기법인 Min-Max Normalization (MMN), Z-score normalization 및 Decimal-scaling normalization의 성능을 비교하였으며, MMN의 성능이 우수한 것을 확인하였다. 따라서, 본 연구는 MMN을 이용하여 데이터 전처리를 실시하였다.
MMN은 각 입력자료의 최대값과 최소값을 기반으로 0과 1사이의 값으로 변환하는 방법이다. MMN을 실시하면 최대값은 1로 변환되며 최소값은 0으로 변환된다. MMN을 실시하기 위한 수식은 Eq. (5)와 같다.
여기서, αdMMN은 MMN을 실시한 d일의 값이며 αd는 d일의 원자료, αmax는 원자료의 최대값, αmin은 원자료의 최소값이다.
3. 연구결과
본 연구는 MLP를 이용하여 낙동강 다산 수질관측소의 수질인자(WT, DO, pH 및 Chl-a)를 학습 및 예측하였다. MLP의 학습을 위한 손실함수(Loss function)는 Mean Squared Error (MSE)로 설정하였으며, MLP의 예측오차도 MSE를 이용하여 평가하였다. Eq. (6)은 MSE 수식이다.
여기서, N은 자료의 개수, Oi는 관측값, Pi는 예측값이다.
3.1 수온(Water Temperature, WT)
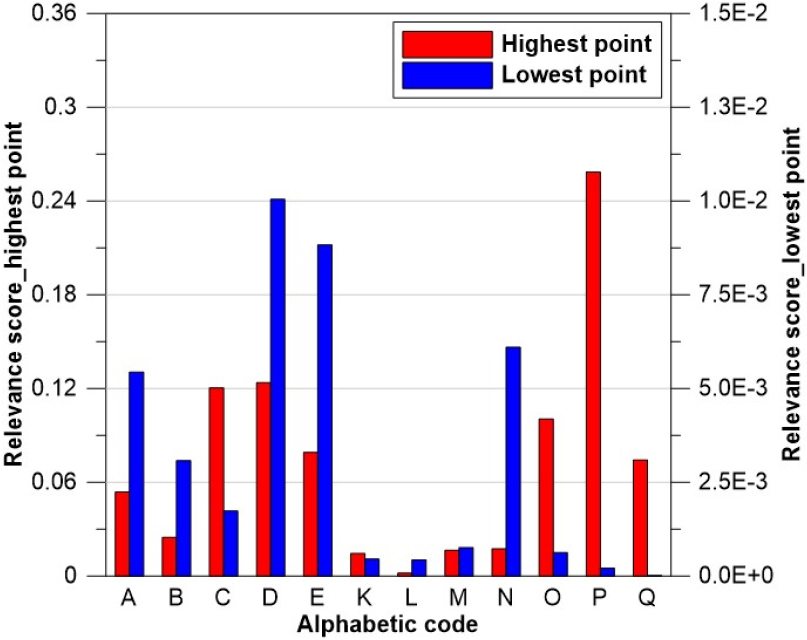
전체 입력자료를 사용하여 WT를 학습한 MLP를 기반으로 LRP를 실시하여 각 입력자료에 대한 관련성 점수를 분석하였다. 분석된 입력자료의 관련성 점수를 기반으로 관련성 점수가 낮은 순서대로 입력자료를 제거하여 수질예측을 위한 최적의 입력자료를 선정하였다. Fig. 4는 전체 입력자료를 이용하여 WT를 학습한 MLP의 각 입력자료 별 관련성 점수의 합이다.
Fig. 4에 따르면, WT에 대한 관련성 점수의 합은 N (WT)이 가장 높았다. 또한, 일 강수량의 관련성 점수의 합이 다른 입력자료들보다 비교적 낮게 산출되었다. 일 강수량 자료 중 G (영천군 일 강수량)의 관련성 점수가 가장 낮은 것으로 나타났다. WT를 제외한 자료 중 C (구미시 일 평균기온)가 가장 높게 나타났으며, 구미시 기상관측소의 위치가 낙동강 본류에 가장 인접해 있기 때문인 것으로 분석된다. Table 2는 WT에 대해 관련성 점수가 낮은 순서대로 제거된 입력자료를 Case에 따라 나타낸 것이다.

Table 2에 따르면, Case 2부터 Case 6까지 제거된 자료는 모두 일 강수량 자료이다. Case 7은 일 강수량 자료 및 다산 수질관측소의 Chl-a 자료가 제거된 입력자료이다. Fig. 5는 각 Case에 따른 입력자료를 이용하여 WT를 학습한 MLP의 WT 학습결과이며, Fig. 6은 각 Case에 따른 MLP의 WT 예측결과이다.
Table 2.
Removed data according to LRP results for MLP learning WT
| Removed data | |
| Case 1 | - |
| Case 2 | G |
| Case 3 | G, J |
| Case 4 | G, J, H |
| Case 5 | G, J, H, F |
| Case 6 | G, J, H, F, I |
| Case 7 | G, J, H, F, I, Q |
Fig. 5에 따르면, Case 6의 학습 MSE가 약 0.1336으로 가장 낮았으며, Case 1에서 학습 MSE가 약 0.1712로 가장 높았다. 또한, Case1부터 Case 6까지 학습 MSE가 감소하였으나, 1일 이전의 Chl-a 자료를 제거한 Case 7의 학습 MSE는 증가하였다. Fig. 6에 따르면, Case 6의 예측 MSE가 약 0.1727로 가장 낮았다. Case 2부터 Case 6까지는 모든 입력자료를 학습자료로 사용한 Case 1보다 예측 MSE가 감소하였으나 Case 7은 예측 MSE가 Case 6보다 증가하였다. Case 별 WT 학습 및 예측결과에 따라 WT를 학습 및 예측하기 위해서는 일 강수량을 모두 제거한 Case 6이 가장 적합한 것으로 분석된다. Fig. 7은 WT를 학습한 Case 6의 MLP 예측결과이며, Fig. 8은 Case 6 예측결과의 WT 최저 및 최고 지점에 대한 LRP 결과이다.

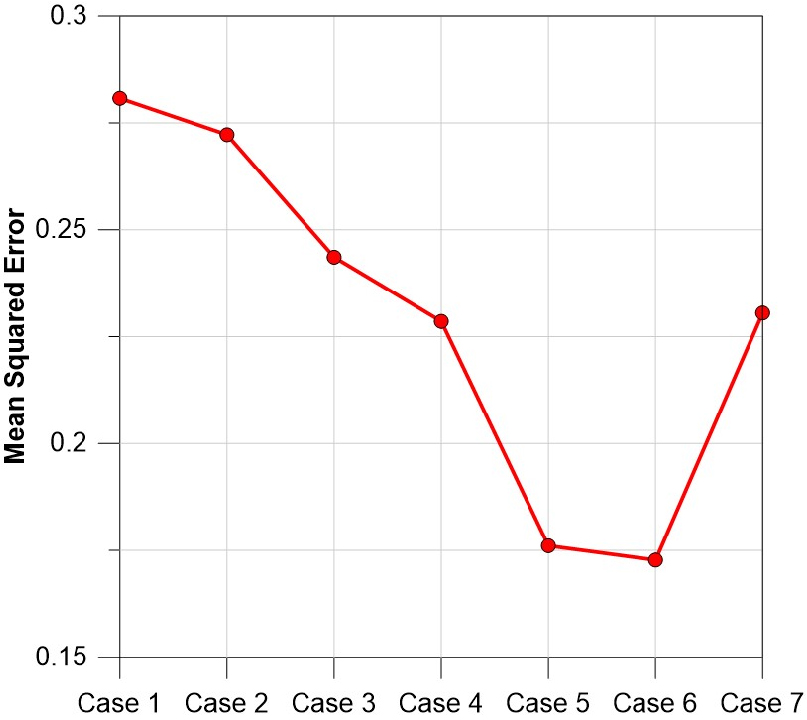

Fig. 8에 따르면 최고점(8월 26일)에서의 관련성 점수는 N (WT)이 가장 높게 나타났다. 최고점에서 다른 인자들은 비교적 매우 작게 나타났으나, D (상주시 일 평균기온)가 WT를 제외하고 관련성 점수가 높게 산출되었다. WT를 제외하고 상주시 일 평균기온의 관련성 점수가 가장 높게 산출된 이유는 8월 5일의 일평균 기온 자료 중 상주시의 일평균 기온의 전일 대비 증가량이 약 3.2%로 가장 크기 때문인 것으로 분석된다. 최저점(1월 8일)에서의 관련성 점수는 C (구미시 일 평균기온)가 가장 높았으며, 전반적으로 일 평균기온 자료의 관련성 점수가 크게 산출되었다. 최고점인 홍수기에는 유량이 많아 물의 온도를 변화시키기 위한 열량이 많이 필요하기 때문에 기온이 아닌 WT의 관련성 점수가 높은 것으로 분석된다.

3.2 용존산소량(Dissolved Oxygen, DO)
DO를 예측하기 위한 최적의 입력자료를 선정하기 위해 LRP를 이용하여 DO를 학습한 MLP를 분석하였다. 또한, 최적의 입력자료를 사용하여 학습한 MLP의 예측결과에 대한 분석을 실시하였다. Fig. 8은 전체 입력자료를 이용하여 DO를 학습한 MLP의 각 입력자료 별 관련성 점수의 합이다.
Fig. 9에 따르면, DO에 대한 관련성 점수의 합은 O (DO) 및 P (pH)가 가장 높았다. 또한, 일 강수량의 관련성 점수의 합이 다른 입력자료들보다 비교적 낮게 산출되었다. 일 강수량 자료 중 F (대구시 일 강수량)의 관련성 점수가 가장 낮은 것으로 나타났다. pH의 관련성 점수가 높은 이유는 수소원자와 산소원자의 공유결합으로 인해 물 분자에서 산소가 방출되기 때문에 pH와 DO가 밀접한 관련이 있는 것으로 분석된다. 또한, 많은 연구에서 pH와 DO를 측정하고 상관성을 분석하였으며 두 인자간의 상관도가 높은 것으로 나타났다(Sheng and Xu, 1993; Luo, 2002; Luis et al., 2010). Table 3은 DO에 대해 관련성 점수가 낮은 순서대로 제거된 입력자료를 Case에 따라 나타낸 것이다.

Table 3.
Removed data according to LRP results for MLP learning DO
| Removed data | |
| Case 1 | - |
| Case 2 | F |
| Case 3 | F, I |
| Case 4 | F, I, H |
| Case 5 | F, I, H, J |
| Case 6 | F, I, H, J, G |
| Case 7 | F, I, H, J, G, L |
Table 3에 따르면, Case 2부터 Case 6까지 제거된 자료는 모두 일 강수량 자료이다. Case 7은 일 강수량 자료 및 도성교의 수위 자료가 제거된 입력자료이다. Table 3에 따르면, Case 2부터 Case 6까지 제거된 자료는 모두 일 강수량 자료이다. Case 7은 일 강수량 자료 및 도성교의 수위 자료가 제거된 입력자료이다. Fig. 10은 각 Case에 따른 입력자료를 이용하여 DO를 학습한 MLP의 DO 학습결과이며, Fig. 11은 각 Case에 따른 MLP의 DO 예측결과이다.


Fig. 10에 따르면, Case 6의 학습 MSE가 약 0.2343으로 가장 낮았으며, Case 1에서 학습 MSE가 약 0.2773으로 가장 높았다. 또한, Case1부터 Case 6까지 학습 MSE가 감소하였으나, 1일 이전의 도성교 수위 자료를 제거한 Case 7의 학습 MSE는 증가하였다. Fig. 11에 따르면, Case 6의 예측 MSE가 약 0.2588로 가장 낮았다. Case 2부터 Case 6까지는 모든 입력자료를 학습자료로 사용한 Case 1보다 예측 MSE가 감소하였으나 Case 7은 예측 MSE가 Case 6보다 증가하였다. Case 별 DO 학습 및 예측결과에 따라 DO를 학습 및 예측하기 위해서는 일 강수량을 모두 제거한 Case 6이 가장 적합한 것으로 분석된다. Fig. 12는 DO를 학습한 Case 6의 MLP 예측결과이며, Fig. 13은 Case 6 예측결과의 DO 최저 및 최고 지점에 대한 LRP 결과이다.

Fig. 13에 따르면, 최고점(1월 14일)에서의 관련성 점수는 P (pH) 및 O (DO)가 가장 높게 나타났으며 다른 인자들은 비교적 작게 나타났다. 최저점(8월 10일)에서의 관련성 점수는 N (WT) 및 C (구미시 일 평균기온)가 가장 높게 산출되었다. 최고점에서 pH의 관련성 점수가 높게 산출된 이유는 DO가 가장 높게 측정된 날의 pH는 약 9.0으로 매우 높아 관련성 점수가 큰 것으로 분석된다. 최저점에서 WT의 관련성 점수가 높게 산출된 이유는 DO가 가장 낮게 측정된 날은 WT가 약 31℃로 높아 WT가 증가함에 따라 물의 산소용해도가 낮아져 DO가 크게 감소한 것으로 분석된다.

3.3 수소이온농도(hydrogen ion concentration, pH)
pH를 예측하기 위한 최적의 입력자료를 선정하기 위해 LRP를 이용하여 pH를 학습한 MLP를 분석하였다. 또한, 최적의 입력자료를 사용하여 학습한 MLP의 예측결과에 대한 분석을 실시하였다. Fig. 14는 전체 입력자료를 이용하여 pH를 학습한 MLP의 각 입력자료 별 관련성 점수의 합이다.
Fig. 14에 따르면, pH에 대한 관련성 점수의 합은 P (pH) 및 O (DO)가 가장 높았다. 또한, 일 강수량의 관련성 점수의 합이 다른 입력자료들보다 비교적 낮게 산출되었다. pH에 대한 DO의 관련성 점수가 높은 이유는 3.2절에서 언급한 바와 같이 pH와 DO가 밀접한 관련이 있기 때문인 것으로 분석된다. Table 4는 pH에 대해 관련성 점수가 낮은 순서대로 제거된 입력자료를 Case에 따라 나타낸 것이다.
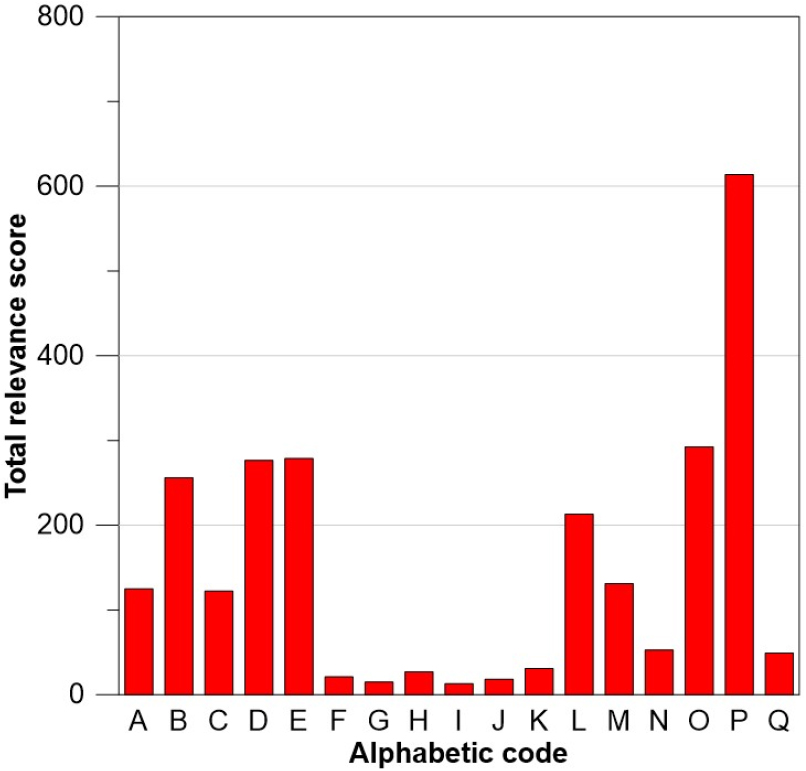
Table 4.
Removed data according to LRP results for MLP learning pH
| Removed data | |
| Case 1 | - |
| Case 2 | F |
| Case 3 | F, H |
| Case 4 | F, H, G |
| Case 5 | F, H, G, I |
| Case 6 | F, H, G, I, J |
| Case 7 | F, H, G, I, J, K |
Table 4에 따르면, Case 2부터 Case 6까지 제거된 자료는 모두 일 강수량 자료이다. Case 7은 일 강수량 자료 및 성주대교의 수위 자료가 제거된 입력자료이다. Fig. 15는 각 Case에 따른 입력자료를 이용하여 pH를 학습한 MLP의 pH 학습결과이며, Fig. 16은 각 Case에 따른 MLP의 pH 예측결과이다.
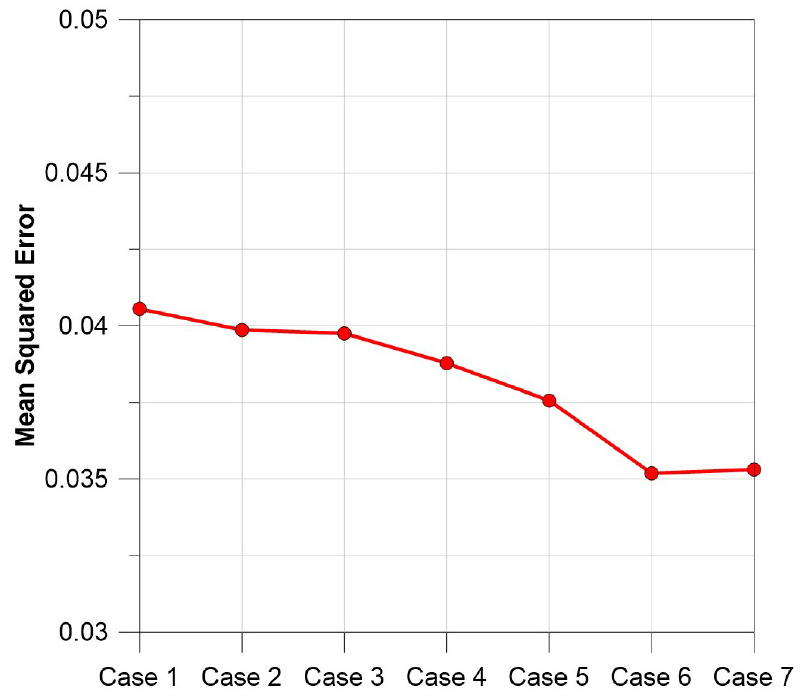
Fig. 15에 따르면, Case 6의 학습 MSE가 약 0.0351로 가장 낮았으며, Case 1에서 학습 MSE가 약 0.0406으로 가장 높았다. 또한, Case1부터 Case 6까지 학습 MSE가 감소하였으나, 1일 이전의 Chl-a 자료를 제거한 Case 7의 학습 MSE는 증가하였다. Fig. 16에 따르면, Case 6의 예측 MSE가 약 0.0367로 가장 낮았다. Case 2부터 Case 6까지는 모든 입력자료를 학습자료로 사용한 Case 1보다 예측 MSE가 감소하였으나 Case 7은 MSE가 Case 6보다 증가하였다. Case 별 pH 학습 및 예측결과에 따라 pH를 학습 및 예측하기 위해서는 일 강수량을 모두 제거한 Case 6이 가장 적합한 것으로 분석된다. Fig. 17은 pH를 학습한 Case 6의 MLP 예측결과이며, Fig. 18은 Case 6 예측결과의 pH 최저 및 최고 지점에 대한 LRP 결과이다.
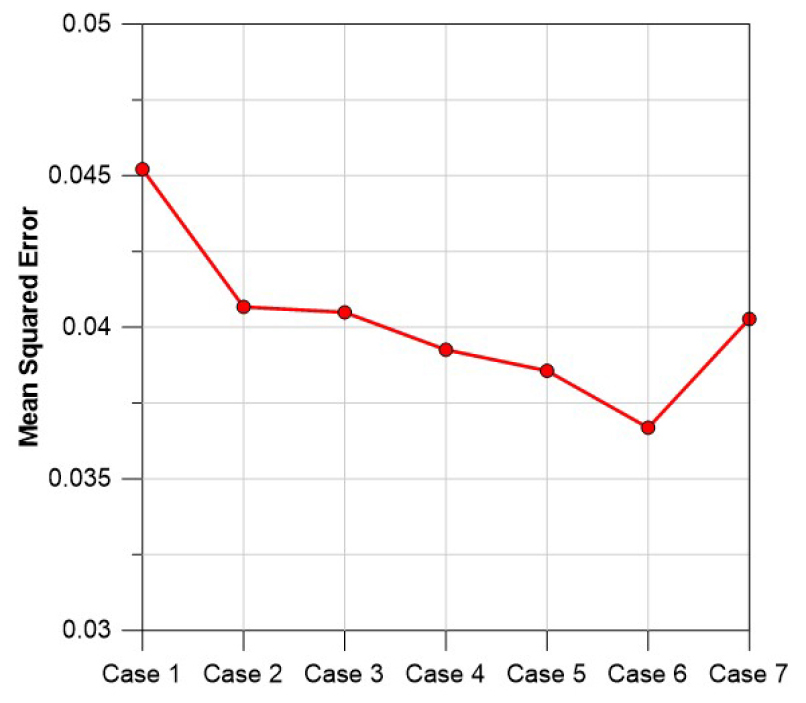

Fig. 18에 따르면, 최고점(6월 3일)에서의 관련성 점수는 P (pH)가 가장 높았다. 최고점에서 다른 인자들은 비교적 매우 작게 나타났으나, pH를 제외하면 D (상주시 일 평균기온)가 가장 높게 나타났다. 최저점(8월 25일)에서의 관련성 점수는 D (상주시 일 평균기온) 및 E (의성군 일 평균기온)가 가장 높게 산출되었다. pH의 최고점 예측은 pH의 영향이 지배적이었으며, 최저점 예측은 상주시 및 의성군의 일 평균기온의 영향이 가장 큰 것으로 분석된다. pH는 기온이 증가함에 따라 수온이 증가하여 물이 이온화가 활발해지면서 pH가 감소한다. 따라서, 여름철인 8월과 9월 사이에 pH가 감소한 것으로 판단된다. 특히, 비교적 거리가 먼 상주시와 의성군의 일 평균기온의 관련성 점수가 높게 나타난 이유는 학습자료 기간 중 8월과 9월의 일 평균기온 자료의 평균값 대비 2021년 8월 24일 기온의 상승이 상주가 2.7%로 가장 높았으며, 의성이 2.4%로 두 번째로 높았기 때문인 것으로 분석된다.
3.4 엽록소-a (Chlorophyll-a, Chl-a)
Chl-a를 예측하기 위한 최적의 입력자료를 선정하기 위해 LRP를 이용하여 Chl-a를 학습한 MLP를 분석하였다. 또한, 최적의 입력자료를 사용하여 학습한 MLP의 예측결과에 대한 분석을 실시하였다. Fig. 19는 전체 입력자료를 이용하여 Chl-a를 학습한 MLP의 각 입력자료 별 관련성 점수의 합이다.

Fig. 19에 따르면, Chl-a에 대한 관련성 점수의 합은 N (WT) 및 Q (Chl-a)가 가장 높았다. 또한, 일 강수량의 관련성 점수의 합이 다른 입력자료들보다 비교적 낮게 산출되었다. Chl-a는 WT, DO 및 pH와 다르게 입력자료의 관련성 점수가 비교적 낮은 것으로 나타났다. Chl-a에 대한 입력자료의 관련성 점수가 비교적 낮은 이유는 Chl-a가 수계 환경 내의 식물 플랑크톤의 세포수에 따라 결정되며, 생물학적 지표인 Chl-a는 유기체의 복잡한 생존 메커니즘으로 인해 화학적 및 물리적 지표보다 환경적 요소와의 직접적인 관련성이 낮기 때문인 것으로 분석된다. Table 5는 Chl-a에 대해 관련성 점수가 낮은 순서대로 제거된 입력자료를 Case에 따라 나타낸 것이다.
Table 5에 따르면, Case 2부터 Case 6까지 제거된 자료는 모두 일 강수량 자료이다. Case 7은 일 강수량 자료 및 매곡리의 수위 자료가 제거된 입력자료이다. Fig. 20은 각 Case에 따른 입력자료를 이용하여 Chl-a를 학습한 MLP의 Chl-a 학습결과이며, Fig. 21은 각 Case에 따른 MLP의 Chl-a 예측결과이다.
Table 5.
Removed data according to LRP results for MLP learning Chl-a
| Removed data | |
| Case 1 | - |
| Case 2 | F |
| Case 3 | F, J |
| Case 4 | F, J, I |
| Case 5 | F, J, I, G |
| Case 6 | F, J, I, G, H |
| Case 7 | F, J, I, G, H, M |
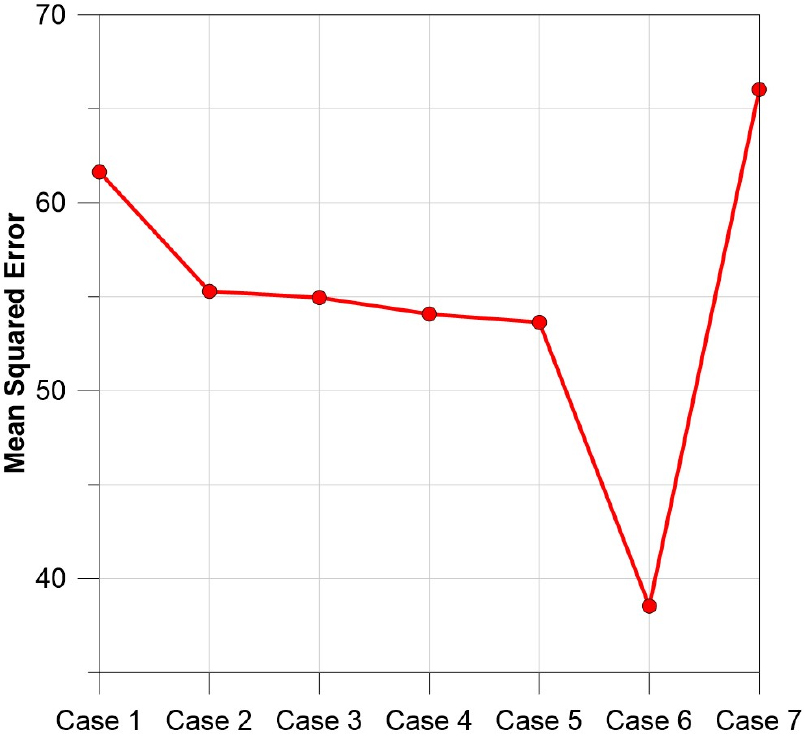

Fig. 20에 따르면, Case 6의 학습 MSE가 약 38.5363으로 가장 낮았으며, Case 7에서 학습 MSE가 약 66.0314로 가장 높았다. 또한, Case1부터 Case 6까지 학습 MSE가 감소하였으나, 1일 이전의 매곡리의 수위 자료를 제거한 Case 7의 학습 MSE는 증가하였다. Fig. 21에 따르면, Case 6의 예측 MSE가 약 47.2565로 가장 낮았다. Case 2부터 Case 6까지는 모든 입력자료를 학습자료로 사용한 Case 1보다 예측 MSE가 감소하였으나 Case 7은 예측 MSE가 Case 6보다 증가하였다. Case 별 Chl-a 학습 및 예측결과에 따라 Chl-a를 학습 및 예측하기 위해서는 일 강수량을 모두 제거한 Case 6이 가장 적합한 것으로 분석된다. Fig. 22는 pH를 학습한 Case 6의 MLP 예측결과이며, Fig. 23은 Case 6 예측결과의 Chl-a 최저 및 최고 지점에 대한 LRP 결과이다.

Fig. 23에 따르면, Chl-a는 최고점(5월 30일) 및 최저점(5월 19일)에서 모든 입력자료의 Chl-a에 대한 관련성 점수가 비교적 낮은 것으로 나타났다. 다른 수질 인자와 다르게 Chl-a에 대한 입력자료의 관련성 점수가 낮은 이유는 유기체의 복잡한 생존 메커니즘 때문인 것으로 분석된다.

4. 결 론
본 연구는 Black-box 형태로 내부의 연산을 분석하기 어려운 딥러닝을 해석하기 위한 XAI 기술 중 LRP를 이용하여 수질예측을 위한 MLP를 분석하였다. LRP를 이용하여 WT, DO, pH 및 Chl-a를 예측하기 위한 최적의 입력자료를 선정하였다. 또한, 최적의 입력자료를 이용하여 학습한 MLP의 각 수질인자의 최고점 및 최저점의 예측결과를 LRP를 이용하여 분석을 실시하였다. 본 연구의 결론은 다음과 같다.
1. 일 강수량 자료는 MLP의 수질인자 예측 정확도 향상을 위해 입력자료에서 제외될 필요가 있다. 일 강수량 자료가 MLP의 수질인자 학습에 부정적인 영향을 미치는 이유는 일 강수량 자료의 대부분이 0으로 구성되어 있기 때문인 것으로 분석된다.
2. MLP의 WT 학습에서는 1일 이전의 수온의 영향이 큰 것으로 분석되었다. MLP의 WT 예측에서는 최고점에서 1일 이전의 WT의 영향이 가장 크고 최저점에서는 일 평균기온의 영향이 큰 것으로 분석된다.
3. MLP의 DO 학습에서는 1일 이전의 DO 및 pH의 영향이 비교적 큰 것으로 분석되었다. MLP의 DO 예측에서는 최고점에서 1일 이전의 pH 및 DO의 영향이 크고 최저점에서는 WT의 영향이 큰 것으로 분석되었다.
4. MLP의 pH 학습에서는 1일 이전의 pH 및 DO의 영향이 큰 것으로 분석되었다. MLP의 pH 최고점 예측은 pH의 영향이 지배적이었으며, 최저점 예측은 상주시 및 의성군의 일 평균기온의 영향이 가장 큰 것으로 분석되었다.
5. MLP의 Chl-a 학습 및 예측에서는 다른 수질인자 학습 및 예측과 다르게 유기체의 복잡한 메커니즘으로 인해 다양한 수질인자의 관련성 점수가 낮은 것으로 분석되었다.
4개의 수질인자 예측에서 모두 강수량 자료를 제거한 Case 6이 가장 낮은 예측 MSE를 나타냈으며, 이후 예측 MSE가 증가하는 것으로 나타났다. 따라서, Case 7에서 더 많은 자료를 제거할 경우 관련성 점수가 높은 자료가 제거되어 예측 MSE가 증가할 것으로 판단된다. XAI 기술에 대한 연구가 미비한 수문 및 수자원 분야에 LRP를 적용하여 기존에 해석하는데 한계가 있었던 딥러닝의 해석이 가능할 것으로 기대된다. 또한, 본 연구에서 설정한 MLP의 구조는 수문학적 유입량 예측에 우수한 성능을 보인 구조이기 때문에 추후 연구에서 수질 예측을 위한 최적의 MLP 구조를 선정하여 LRP를 적용할 필요가 있는 것으로 판단된다.
