

1. 서 론
2. 방법론 및 자료
2.1 방법론
2.2 자료
3. 분석 결과
3.1 강우자료와 피해자료의 상관관계 분석
3.2 강우량 및 피해자료를 이용한 피해등급 기준 산정
3.3 Risk Matrix를 이용한 강우량과 피해등급 기준의 합성
4. 결 론
1. 서 론
최근 기상 관련 분석 기술의 발달과 함께 일기 예보의 단기 예측 성능이 크게 향상되었음에도 복합·대형화되는 기상재해로 인해 인명 및 재산 피해가 지속해서 증가하고 있다. 2022년 행정안전통계연보(MOIS, 2022)에 따르면 우리나라에서 태풍 및 호우로 인한 재산 피해액은 2019년 213,455 백만 원이었고, 2020년은 1,317,713 백만 원으로 기록되었으며, 2020년에는 46명의 인명피해가 발생하였다. 2016년에는 사망·실종 7명, 이재민 세대수는 7,221명, 2017년에는 사망·실종 7명, 이재민 세대수는 8,731명이었으나 2020년에는 사망·실종 75명, 이재민 세대수는 20,168명으로 집계되었다. 이러한 원인은 집중호우로 인한 폭우 또는 슈퍼태풍으로 인한 결과라 할 수 있다. 2020년 7월 28일∼8월 11일 호우의 경우 남부지역에 걸쳐 약 101~224 mm에 해당하는 강우량이 발생하였으며, 2022년 8월 8일에는 서울, 인천 등 수도권과 강원도 지역에 하루 100~300 mm 이상의 집중호우가 발생하여 도로와 주택, 차량침수 피해가 발생하였다.
이와 같은 극한강우 또는 이상강우는 그에 따른 피해증가의 중요한 요인으로 자연적 요인, 사회 및 산업 구조적 요인 그리고 마지막으로 현행 일기 예보 시스템의 구조적 원인 등 세 가지로 고려 할 수 있다(KMS, 2016). 첫째 자연적 요인은 기후변화로 인한 극한강우 및 이상강우 발생 가능성이 증가하는것, 둘째 실제 기상 예보 및 특보에 대해 시민의 보호 및 재난관리를 담당하는 유관 기관과 대중이 이해하는 잠재적인 영향의 차이, 셋째 기상 현상의 예보가 중심이 되어 있는 현행 일기예보 내용으로 유관기관이 빠른 의사결정과정을 통해 위험기상 및 재해에 대비할 수 있는 충분한 시간의 부족으로 정리할 수 있다(KMS, 2016). 넷째 날씨가 미치는 영향에 대한 이해가 부족하기 때문에 정식에 적절한 예·특보를 발표한다고 하더라도 적절한 대응 부족으로 매년 전 세계적으로 인명 및 재산피해가 발생한다(WMO, 2015).
이에 기상청에서는 폭염과 한파 재해에 대한 영향도를 고려하여 관심, 주의, 경고, 위험 4단계로 구분하여 영향예보하고 있으나 호우에 대해서는 현재 영향예보를 하지 않고 있다. 앞서 언급한 영향예보는 “기상 현상으로 인해 예상되는 사회 경제적 영향을 위험 및 취약성을 고려하여 상세한 기상 정보와 함께 전달하는 예보”로 정의할 수 있다(KMS, 2016). 이때 “위험 및 취약성”의 경우 동일한 날씨 또는 위험 기상이 일어나는 지역에 따라 위험 및 재해의 정도가 서로 다를 수 있기 때문에 이를 고려한 영향 위험 기상에 대한 정보 및 영향을 전달하는 것이 영향예보이다(KMS, 2016). 즉 기상현상으로 인해 예상되는 사회·경제적 영향을 함께 전달하는 것이 영향예보이다(KMS, 2016).
국·내외 영향예보 관련 현황을 살펴보면, 기상청은 영향예보의 중요성 및 필요성을 인식하고 기존의 기상요소 중심의 서비스에서 사회경제적 수요를 위한 스마트 기상 서비스로의 전환을 목표로 기상-사회 통합형 선진 기상 ‧ 기후 서비스 구현을 위해 4가지 추진전략과 15가지 중점 추진과제를 수립하였다(KMA, 2017). ‘기상비전 2020’은 수요자 중심의 사회경제적 영향이 큰 날씨에 초점을 두고, 관측장비개발, 관측자료의 통합, 수치모델개발, 예보관 역할 정립 등을 통해 이상기상/기후 현상이 야기하는 사회경제적 피해 저감을 위해 추진되고 있다(KMA, 2017). 이러한 노력에도 불구하고 아직까지 우리나라의 영향예보 수준은 시범단계에 머물러 있으며, 영향예보에 대한 국민들의 이해 또한 부족한 실정이다(KMA, 2017). NDMI (2021)에서는 도시침수 영향예보를 위해 AI (머신러닝, 딥러닝)을 이용하여 도시침수 위험수준 추정모델을 개발하고, 침수분야 영향예보를 위한 Risk Matrix 작성기준을 제시하였다. 영국기상청(Met office)은 2011년부터 Warning Impact Risk Matrix를 개발하여 재해영향모델 구축 및 국가재해기상경보시스템을 시행하고 있다. 여기서 Warning Impact Risk Matrix는 비, 바람, 논과 같은 위험기상 발생가능성과 영향정도를 최대 5일 전부터 위험 매트릭스 기반 특보를 적용하고 있으며 여기에 사용되는 기상재해 발생 가능성은 기상모델을 통해 추정하여 사용한다(Lee and Kim, 2019). 미국 기상청(National Weather Service)은 영향기반 의사결정 지원 서비스(Impact-based Decision Support Service, IDSS) 개념을 도입하여 2017년부터 전국가를 대상으로 시행하여 위험기상 브리핑을 제공하고 신속하고 정확한 정보를 전달함으로써 수요자 맞춤형 의사결정에 도움을 준다(KMA, 2017). 일본 기상청은 수문기상 분야에서 홍수 대응에 바로 활용할 수 있는 형태의 가공된 분석정보를 제공하고 있으며 민간에서는 기상영향에 의한 데이터 제공 및 의사결벙지원 서비스 프로그램 LBW (Life Business Weather), HALEX (HAppy Life EXpert)를 제공하고 있다(Lee and Kim, 2019).
영향예보 관련 현황를 살펴보면 공통적으로 영국에서 최초로 제시한 Risk Matrix 작성을 통해 영향예보 기준을 작성하고 있다. Risk Matrix에서 x축은 Risk Impact, Y축은 Likelihood를 의미한다. 국내에서는 Lee et al. (2018)이 호우 영향예보를 위한 한계강우량 산정 방법을 연구하였으며, 강우-유출모형(S-RAT), 침수모형(Flo-2D)을 이용하여 강우-침수심 곡선을 사용하여 1 km × 1 km 해상도의 영향한계강우량을 제시하였다. Lee et al. (2020)은 호우 영향예보 위험수준 산정을 위해 사용되는 수문학정량강우예측(Hydrological Quantitative Precipitation Forecast, HQPF)의 모의 성능을 향상시켜 Lee et al. (2018)의 영항한계강우량과 접목하여 Risk Matrix에 적용하였다. Jung et al. (2020)은 여러 기상현상 중 호우에 대한 영향예보를 국내의 실정에 맞도록 개선하고, 적용하기 위해 33개의 호우영향인자(Impact Library)를 격자단위(1 km)로 구축하고, 표준정규분포법을 이용하여 4개의 위험등급(Minimal, minor, significant, severe)의 기준을 산정하였다. 산정된 기준은 호우영향 대상체인 사람, 시설, 농업, 교통을 중심으로 한 6개의 카테고리(Residential, commercial, utility, community, agriculture, transport)에 대한 호우위험영향(Heavy rain risk impact)를 산정하여 Risk Matrix를 산정하였다.
여기서 Lee et al. (2020)은 Likelihood을, Lee et al. (2020)은 Risk Impact library에 대해 연구를 진행하였으며 최종적으로 Likelihood와 Risk Impact library를 Matrix에 적용하였다. 본 논문에서는 피해자료의 경우 재난으로 인해 손상된 인벤토리의 정보이기 때문에 Risk Impact library에 재해 피해자료를 적용하였으며 Likelihood는 기상 위험인자를 의미하기 때문에 12시간의 누적강우량에 대한 등급을 Risk Matrix에 적용하였다. 먼저 기상청 예보기준과 동일한 3시간 누적강우량, 12시간 누적강우량, 재해기간 최대강우량과 피해자료(이재민 피해, 사상자 수, 피해액)와의 상관 분석을 통해 상관성이 높은 각 변수를 선정하였으며, 선정된 데이터를 이용하여 PERCENTILE과 Jenks Natural Breaks Classification 기법을 통해 등급을 산정하였다. 여기서 Jenks Natural Breaks Classification 기법은 자료를 사용자가 지정한 등급 수에 따라 분류하고 비지도 학습을 통해 등급 내의 분산을 최소화하고 등급 간의 분산을 최대화하는 방법이다. 이렇게 산정된 강우량 등급과 이재민 등급을 Risk Matrix에 적용하였다.
2. 방법론 및 자료
2.1 방법론
2.1 방법론
2.1.1 개요
먼저 기상청과 재해연보에서 제공하고 있는 강우자료와 피해자료를 수집하고 3시간 누적강우량, 12시간 누적강우량과 피해자료와의 상관분석을 위해 Pearson 상관계수를 산정하여 등급기준에 사용할 변수를 선정하였다. 또한 선행연구에서 제시한 PERCENTILE과 Jenks Natural Breaks Classification을 이용하여 강우량 등급기준과 호우피해 등급기준을 산정하였다. 또한 Fig. 1의 Matrix와 같이 x축에 피해자료, y축에 강우량자료를 적용하여 Risk Matrix를 구성하였다.
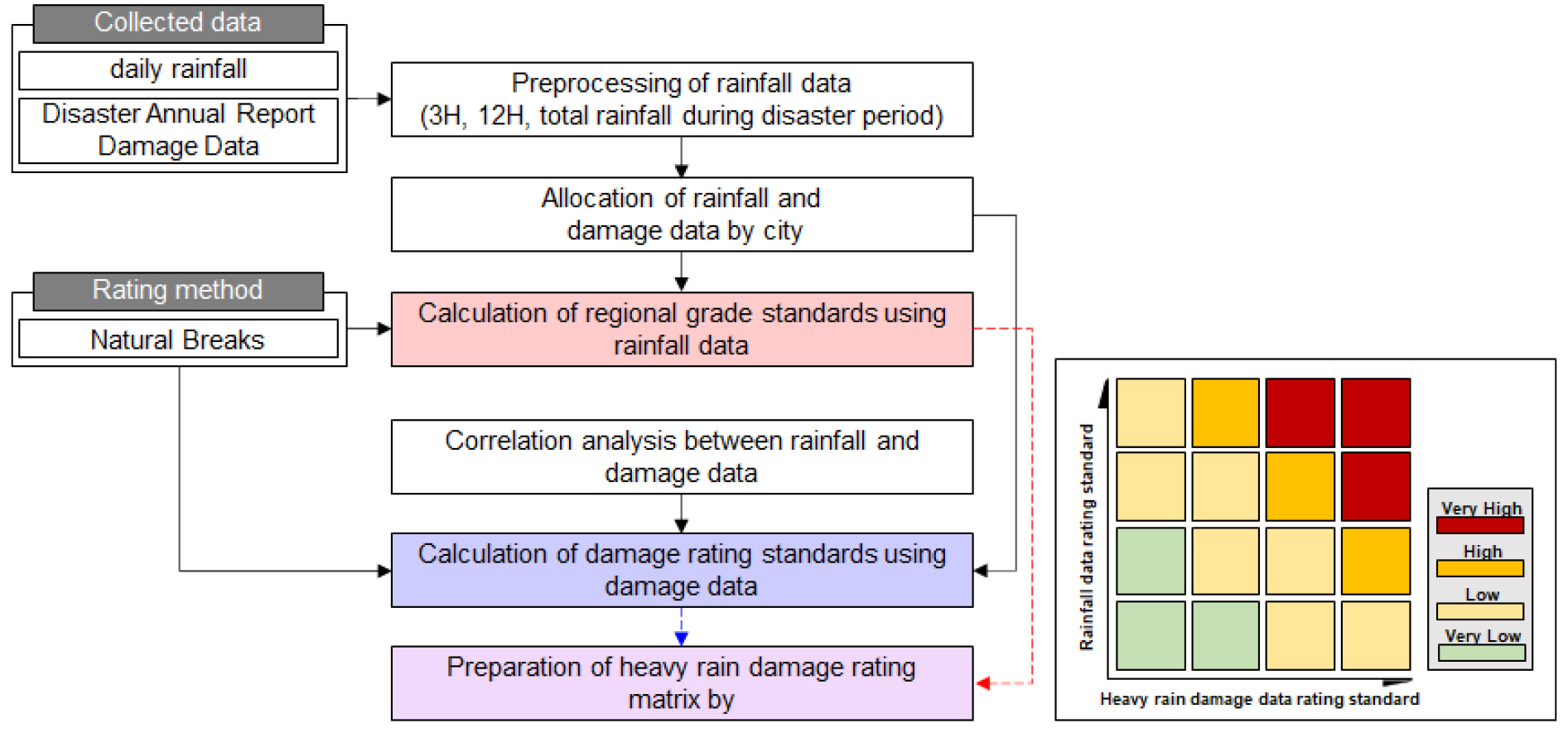
2.1.2 Pearson correlation coefficient
Pearson 상관계수란 두 변수 X와 Y간의 선형 상관 관계를 계량화한 수치이다. Pearson 상관계수는 코시-슈바르츠 부등식에 의해 +1과 -1 사이의 값을 가지며 +1은 완벽한 양의 선형 상관 관계, 0은 선형 상관 관계 없음, -1은 완벽한 음의 선형 상관 관계를 의미하며 상관계수가 -1.0에서 -0.7의 범위에 있다면 매우 강한 음의 상관관계를 의미하며 -0.7에서 -0.3의 범위에 있다면 강한 음의 상관관계, -0.3에서 -0.1의 범위에 있다면 약한 음의 상관관계를 가진다(Kim, 2007; Park et al., 2018). -0.1에서 0.1의 범위에 존재한다면 상관관계가 존재하지 않으며 0.1에서 0.3의 범위에 존재한다면 약한 양의 상관관계를, 0.3에서 0.7 사이에 존재한다면 강한 양의 상관관계, 0.7에서 0.1의 범위 안에 존재한다면 강한 양의 상관관계를 의미하며 식은 다음과 같다(Kim, 2007; Park et al., 2018).
여기서 는 강우량, 는 강우량의 평균, 는 피해자료, 는 피해자료의 평균, 은 자료갯수이다
2.1.3 Jenks Natural Breaks Classification
Jenks Natural Breaks Classification (이하 JNBC)는 1949년 George Frederick Jenks가 고안한 방법으로 데이터의 배열을 자연스러운 등급(Natural Classes)으로 최적화하여 그룹(Data classification)으로 묶는 방법이다. JNBC를 적용하면 같은 등급내 전체 값들의 평균을 기준으로 분산을 최소화 하고 각 등급간의 분산을 극대화 하여 그룹을 생성한다. 먼저 데이터의 평균에 대한 편차 제곱합(SDAM)을 산정한다. 관련식은 각 등급 평균에 대한 편차 제곱합(SDCM)을 산정하여 가장 작은 값을 찾는다. 마지막으로 분산적합도(GVF)를 계산하여 최종적으로 등급을 구분하게 된다. 분산적합도의 범위는 0에서 1로 1에 가까울수록 높은 적합도를 가지는 것을 의미한다.
여기서 는 자료, 는 자료의 평균, 는 등급의 평균을 의미한다.
2.2 자료
2.2.1 기상 자료
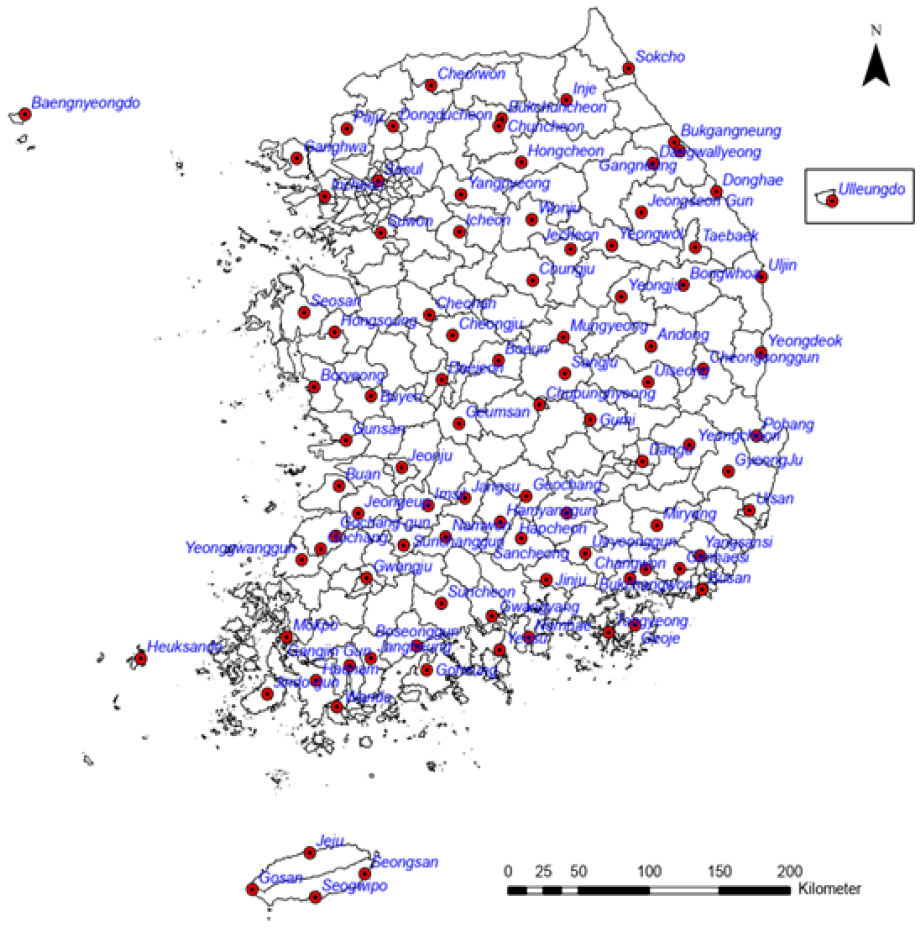
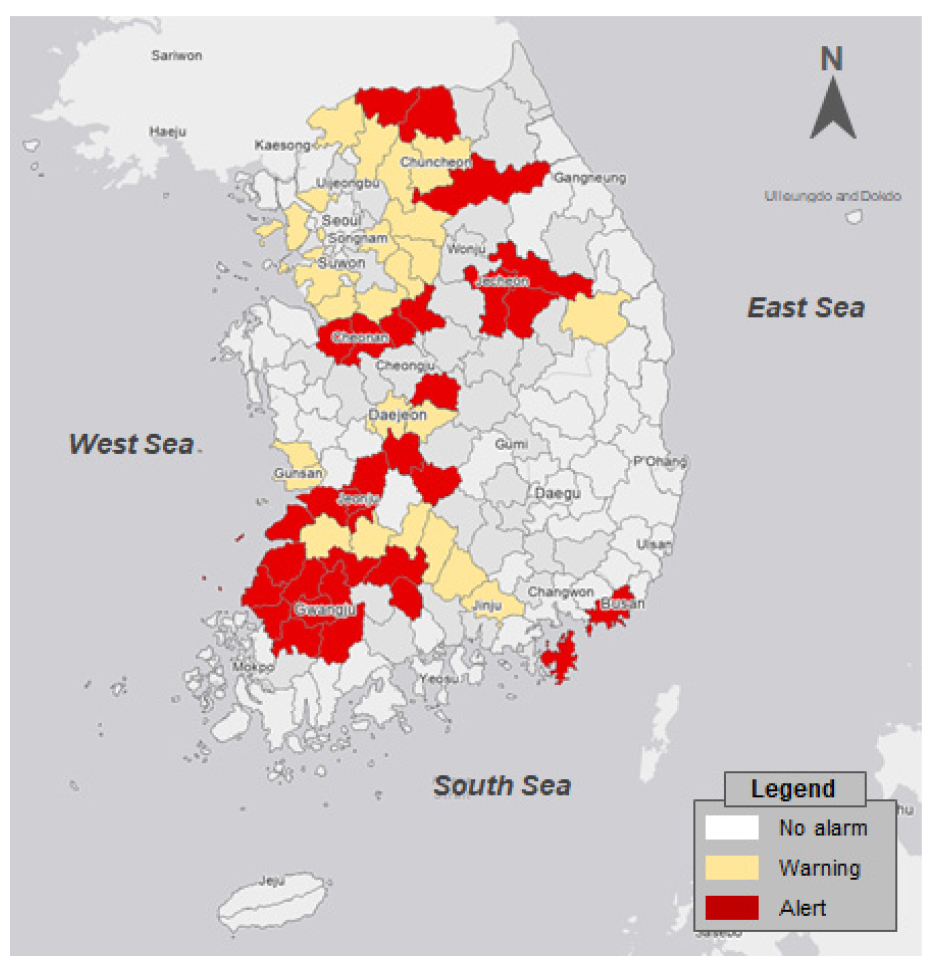
본 논문에서 사용한 기상자료는 기상청 산하 96개 기상관측소의 2018년 05월 06일부터 2020년 12월 31일의 시 단위 데이터를 사용하였으며, 기상관측소 위치도는 Fig. 2와 같다. 앞서 언급한 시단위 강우량 데이터를 3시간 누적강우량, 12시간 누적강우량, 재해기간 최대강우량 데이터로 변환하였다. 또한 각 시·군에 인접 강우관측소의 데이터를 할당하여 각 시·군별 강우량을 구축하였다. Fig. 3은 2020년 7월 28일 호우 당시 호우피해 지역의 호우 주의보, 경보 현황을 기상청 호우 특보 기준에 맞춰 산정하였다.
2.2.2 호우 피해 자료
본 논문에서 사용한 호우재해 피해자료는 이재민수, 사상자수, 피해액 중 1종을 선택하였으며 분석에 사용한 피해자료는 2018년 부터 2020년까지의 재해 이벤트별 피해자료를 사용하였다(Table 1). 전국 기준 총 이벤트 개수는 38건 이벤트이며 전국에서 661건의 재해피해가 발생하였다. 가장 많은 이벤트를 보유한 기간은 2020년 7월 28일 193건이며 두 번째는 2018년 8월 6일 142건이며 두 이벤트 모두 강원도, 경기도, 경상도, 충청도, 전라도 등 전국에서 호우피해가 발생하였다. 각 변수별 기초통계량은 Table 2와 같다.
Table 1.
List of heavy rain disaster events nationwide
3. 분석 결과
3.1 강우자료와 피해자료의 상관관계 분석
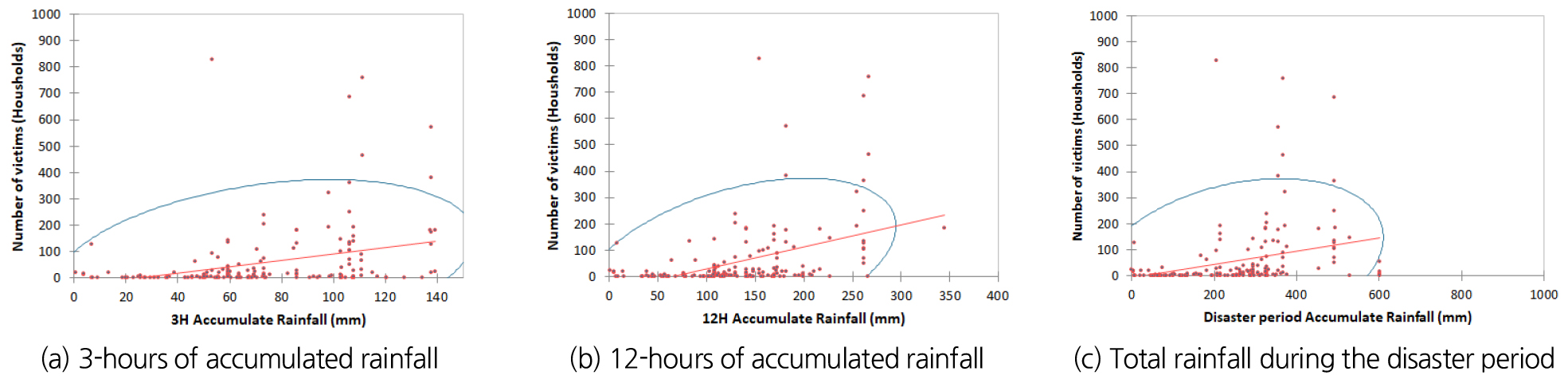
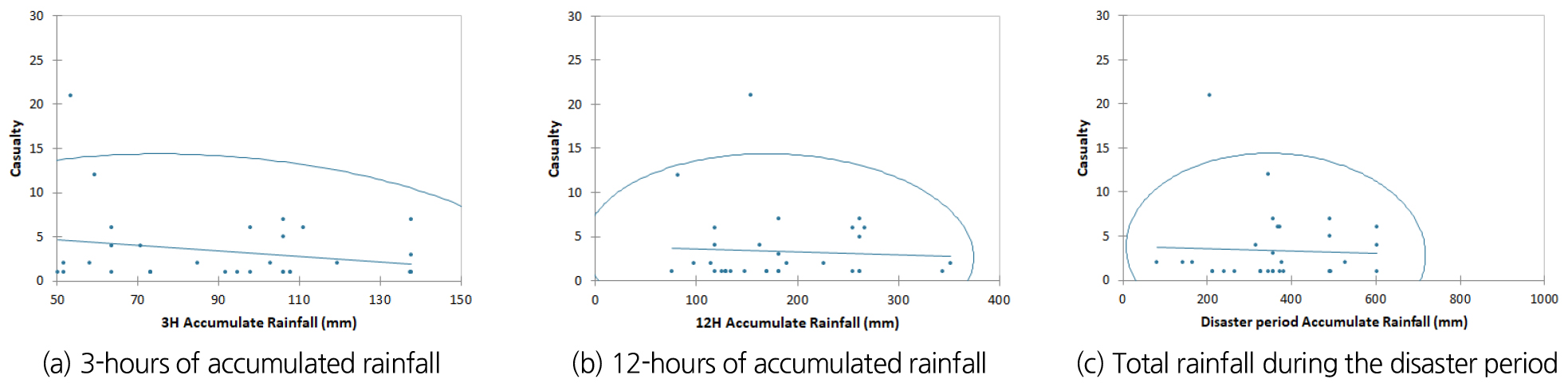
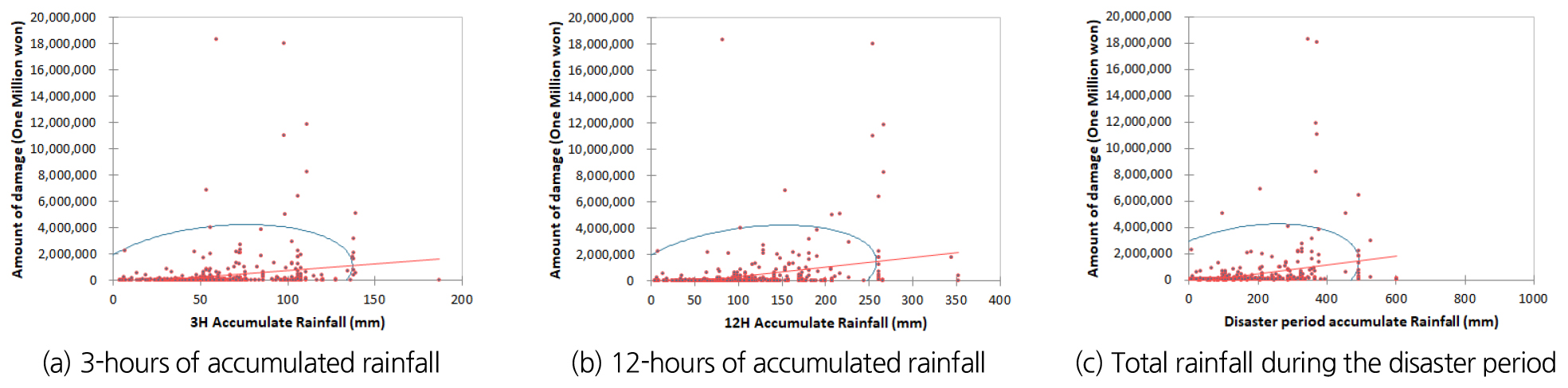
본 논문에서는 강우량 자료(3시간 누적강우량, 12시간 누적강우량, 재해기간 총강우량)와 피해자료(이재민 세대수, 사상자 수, 피해액)간의 상관분석을 통해 호우 피해지수 산정에 사용하고자 하였다. 상관관계분석에 사용된 기법은 Pearson correlation coefficient이다. Table 3은 상관 분석 결과이며 이재민 수의 경우 3시간 누적강우량과의 상관관계는 0.339, 12시간 누적강우량과의 상관관계는 0.472, 재해기간 총강우량은 0.383으로 3시간 누적강우량이 가장 높은 상관 관계를 보였다. 사상자수의 경우 데이터의 표본 수가 적어 상관분석 결과가 5%의 신뢰구간 내에 들어오지 못하였다. 피해액의 경우 3시간 누적강우량과의 상관관계는 0.199, 12시간 누적강우량과의 상관관계는 0.318, 재해기간 총강우량은 0.275로 약한 상관관계를 보였다. 분석결과를 종합하여 보았을 때 12시간 누적강우량과 이재민수를 이용하여 피해등급 기준을 산정하는게 적합하다 판단된다. Figs. 4~6는 상관분석결과에 대한 결과 그림이다.
Table 3.
Correlation analysis results
3.2 강우량 및 피해자료를 이용한 피해등급 기준 산정
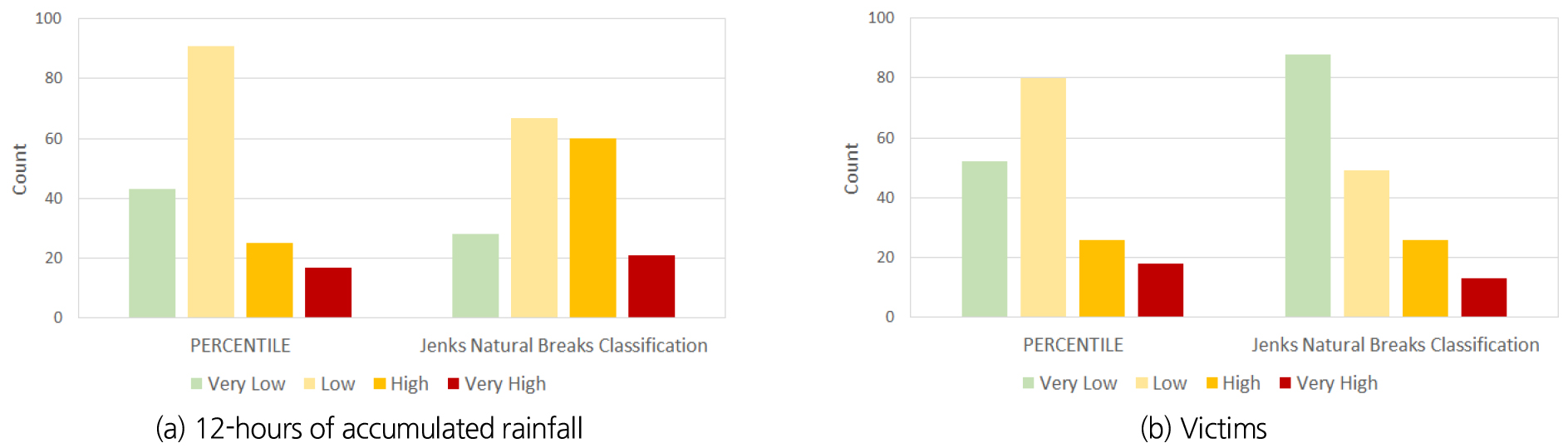
3.1절에서 분석한 상관관계 결과에 따라 본 절에서는 12시간 누적강우량과 이재민 세대수를 이용하여 강우량 등급과, 피해 등급을 각각 산정하였다. 등급산정에 사용된 방법은 KMA (2021)에서 제시한 PERCENTILE (25%, 75%, 90%, 95%)와 JNBC를 이용하였다. Table 4는 12시간 누적강우량 데이터의 군집화 결과이며 PERCENTILE의 경우 Low 구간에서 91개로 가장 많은 데이터가 포함되어 있으며 JNBC의 경우 Low와 High 구간에서 각 각 67개, 60개로 구성 되었다. Table 5는 이재민 세대수의 군집결과이며 Low에서 80개로 가장 많은 데이터가 포함되어 있으며 JNBC의 경우 Very Low에서 88개로 가장 많은 데이터가 포함되어 있다. 각 재해 이벤트를 확인해봤을 때 1에서 8명의 이재민수가 가장 많이 분포하고 있어 VeryLow가 가장 많은 것으로 확인되었다. Fig. 7은 각 결과를 도표화한 것이다.
Table 4.
Results of 12-hour cumulative rainfall data clustering
Table 5.
Results of displaced person data clustering
| PERCENTILE | JNBC | |||
| Class | Count | Class | Count | |
| Very Low | ≧ 2 | 52(30%) | ≧ 8 | 88(50%) |
| Low | 3 ~ 42 | 80(45%) | 9 ~ 61 | 49(28%) |
| High | 43~ 167 | 26(15%) | 62 ~ 183 | 26(15%) |
| Very High | 167 < | 18(10%) | 183 < | 13(7%) |
3.3 Risk Matrix를 이용한 강우량과 피해등급 기준의 합성
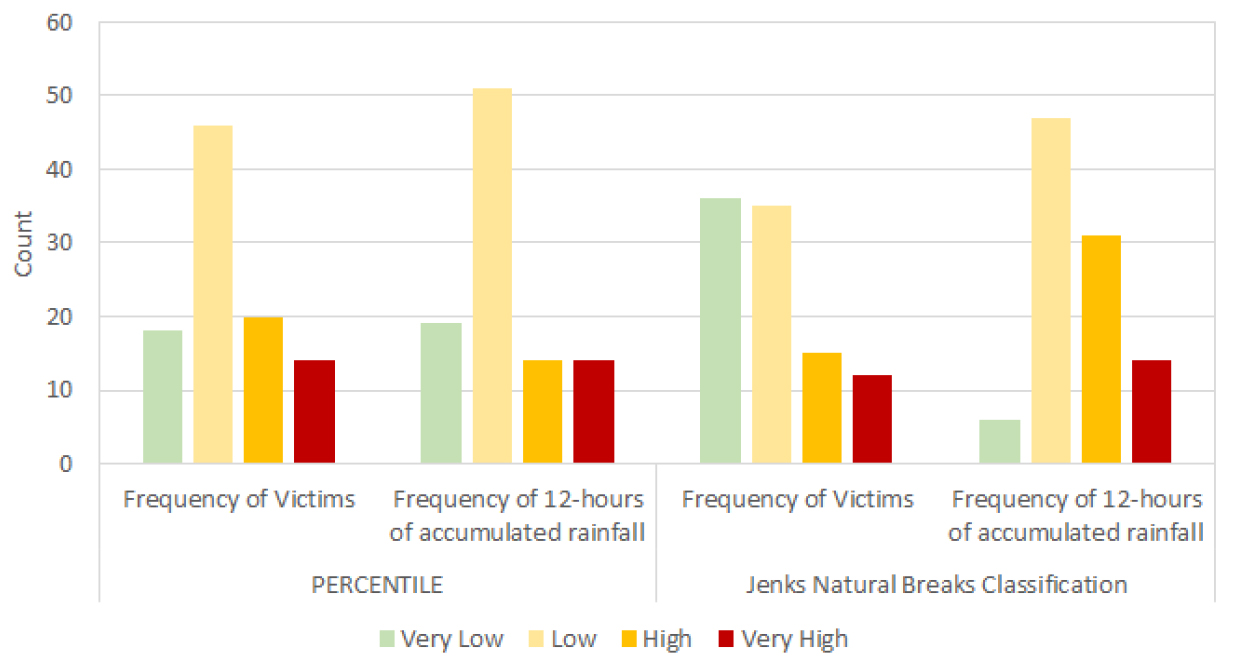
본 연구에서는 강우량 자료와 피해자료와의 합성을 위해 강우량 자료를 12시간 누적강우량 등급기준에 적용해서 나온 등급 값, 호우피해 자료를 피해 등급기준에 적용해서 나온 등급값을 Fig. 1의 연구흐름도에서 제시한 Risk Matrix에 자료를 적용하였다. 여기서 적용 기간은 2020년 7월 28일과 8월 11일의 호우사상에 적용하였다. 적용 결과는 Table 6, Fig. 8이다. 결과를 보면 PERCENTILE이 12시간 누적 강우량 자료와 이재민 세대수와 비슷한 결과를 보이는데 이는 데이터를 25%(Very Low), 75%(Low), 90%(High), 95%(Very High)의 일정한 비율로 산정되기 떄문이다. JNBC의 결과의 경우 이재민 세대수와 12시간 누적 강우량 자료와 다른 결과를 보이는데 Jenks Natural Breaks Classification의 경우 PERCENTILE과는 달리 등급내 전체 값들의 평균을 기준으로 분산을 최소화 하고 각 등급간의 분산을 극대화하는 알고리즘을 가지고 있어 상대적인 결과 값보다 절대적인 결과 값을 산출하기 때문이다.
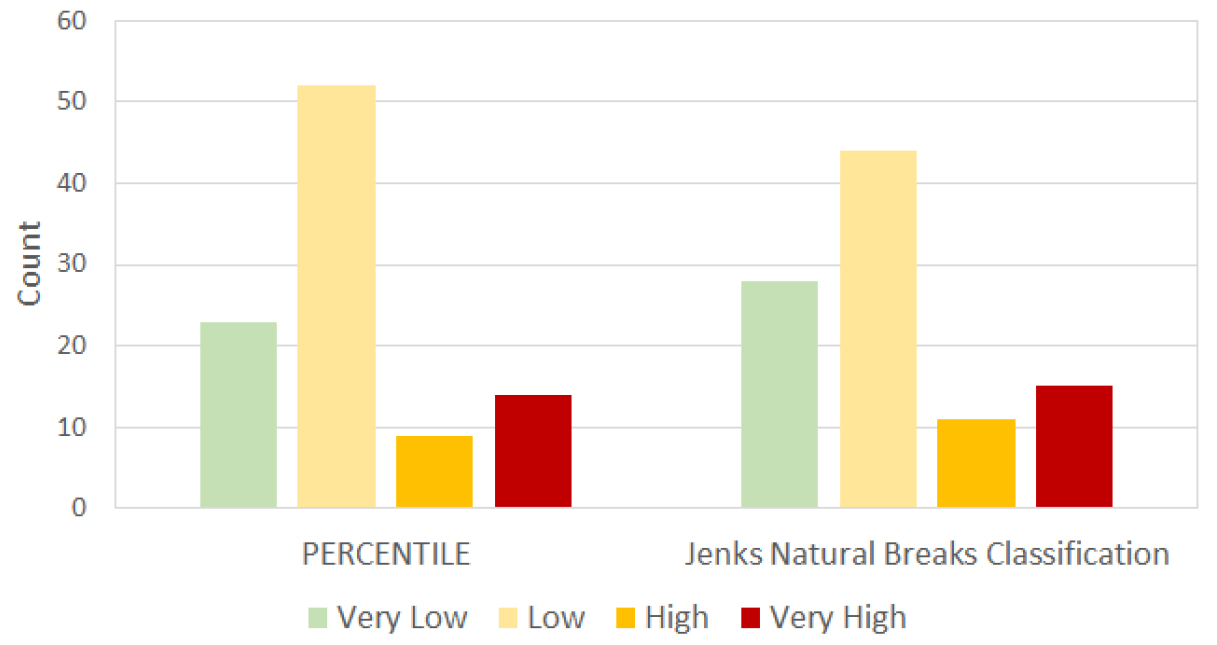
Table 7과 Fig. 9는 Table 6과 Fig. 8의 이재민 세대수와 12시간 누적강우량을 이용하여 Maxtrix에 적용한 결과 이다. Very Low의 경우 JNBC가 28개 지역으로 가장 컷으며 Low의 경우 PERCENTILE이 52로 JNBC 보다 6개의 지역이 더 많았다. High와 Very High의 경우 JNBC가 PERCENTILE보다 더 많은 지역에서 발생하였다.
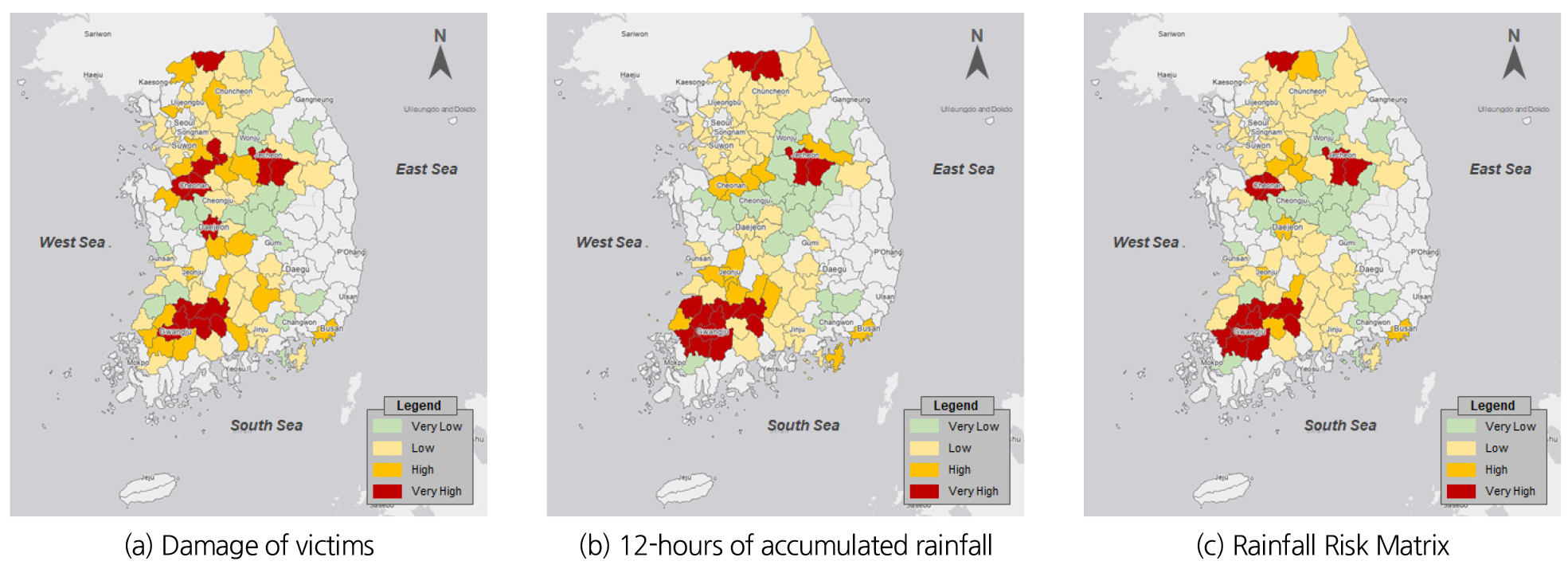
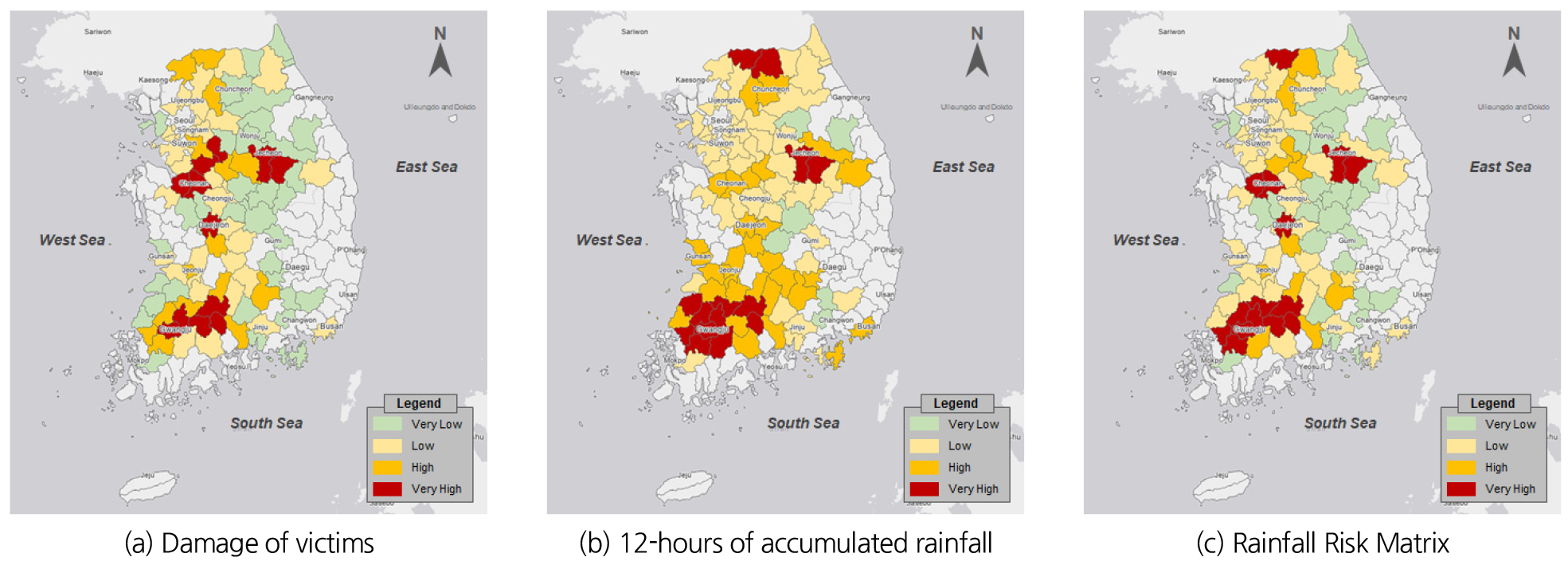
본 연구에서는 분석 결과에 대해 공간적으로 분석하기 위해 2020년 7월 28일 ~ 2020년 8월 11일의 결과를 시군 단위의 지도로 표출하였다(Figs. 10 and 11). 여기서 (a)는 이재민 세대수, (b)는 12시간 누적강우량에 대한 등급 값을 표출한 것이며, (c)는 이재민 세대수와 12시간 누적강우량의 등급값을 Fig. 1의 Risk Matrix에 적용한 결과이다. 먼저 이재민 세대수 결과를 먼저 살펴보면 가장 많은 피해가 발생하였던 영산강, 섬진강유역에서 JNBC 보다 PERCENTILE이 가장 많은 분포를 보였으며, 충청도 지역에서는 유사한 결과를 나타내었다. 강우량의 등급화 결과를 살펴보면 PERCENTILE보다 JNBC의 등급이 높게 산정되었으며, 특히 전라도 지역과 충청도 지역에서 가장 큰 등급을 나타내었다. 또한 Fig. 3의 피해지역 호우특보 현황과 비교해 보면 JNBC가 유사한 것을 확인할 수 있다. Risk Matrix 결과에서 가장 피해가 심했던 세종, 대전, 충남, 충북, 광주, 전남, 전북지역을 살펴보면 PERCENTILE보다 JNBC가 잘 모사한 것을 확인하였다.
Table 6.
Calculation result of the number of rating calculated by applying the 2020.07.28. rainfall event
Table 7.
The result of applying victims data and 12-hours accumulated rainfall data to the risk matrix
| Rating | PERCENTILE | JNBC |
| Very Low | 23(23%) | 28(29%) |
| Low | 52(53%) | 44(45%) |
| High | 9(9%) | 11(11%) |
| Very High | 14(14%) | 15(15%) |
| Total | 98(100%) | 98(100%) |
4. 결 론
본 연구에서는 강우량과 피해자료간의 Risk Matrix를 통한 기상예보 관점에서의 영향 정보를 전달하는 방법을 제시하였다. Risk Matrix는 크게 강우량, 피해자료로 나누어 지며 각각 Very Low, Low, High, Very High로 구분된다. 강우량 자료와 피해자료와의 상관 분석을 통해 먼저 기상청 예보기준과 동일한 3시간 누적강우량, 12시간 누적강우량, 재해기간 최대강우량과 피해자료(이재민 피해, 사상자 수, 피해액)와의 상관 분석을 통해 상관성이 높은 각 변수를 이용하여 강우량과 피해에 따른 등급기준을 산정하고 두 개의 등급기준을 합성하여 하나의 기준을 제시하였다. 본 연구의 결론을 요약하면 다음과 같다.
1) 본 연구에서는 호우피해등급 기준을 산정하기 위해 PERCENTILE (25%, 75%, 90%, 95%)와 JNBC를 이용하였다. 12시간 누적강우량 데이터를 이용하여 강우 등급기준 산정 결과 PERCENTILE의 경우 Low 구간에서 80개로 가장 많은 데이터가 포함되어 있으며 JNBC의 경우 Low와 High 구간에서 각 각 67개, 80개로 구성되었다. 이재민 세대수의 군집결과이며 Low에서 80개로 가장 많은 데이터가 포함되어 있으며 JNBC의 경우 Very Low에서 88개로 가장 많은 데이터가 포함되어 있다.
2) 강우량 자료와 피해자료와의 합성을 위해 강우량 자료를 12시간 누적강우량 등급기준에 적용해서 나온 등급 값, 호우피해 자료를 피해 등급기준에 적용해서 나온 등급값을 강우량, 피해자료 Risk Matrix에 적용하였다. 그 결과 PERCENTILE이 12시간 누적 강우량 자료와 이재민 세대수와 비슷한 결과를 보이는데 이는 데이터를 25%(Very Low), 75%(Low), 90%(High), 95%(Very High)의 일정한 비율로 산정되기 떄문이다. JNBC의 결과의 경우 이재민 세대수와 12시간 누적 강우량 자료와 다른 결과를 보이는데 Jenks Natural Breaks Classification의 경우 PERCENTILE과는 달리 등급내 전체 값들의 평균을 기준으로 분산을 최소화 하고 각 등급간의 분산을 극대화하는 알고리즘을 가지고 있어 상대적인 결과 값보다 절대적인 결과 값을 산출하기 때문이다.
3) 분석 결과에 대해 공간적으로 분석하였을 때 이재민 세대수 결과의 경우 가장 많은 피해가 발생하였던 영산강, 섬진강유역에서 JNBC 보다 PERCENTILE이 가장 많은 분포를 보였으며, 충청도 지역에서는 유사한 결과를 나타내었다. 강우량의 등급화 결과를 살펴보면 PERCENTILE보다 JNBC의 등급이 높게 산정되었으며, 특히 전라도 지역과 충청도 지역에서 가장 큰 등급을 나타내었다. 또한 피해지역 호우특보 현황과 비교해 보면 JNBC가 유사한 것을 확인할 수 있다. Risk Matrix 결과에서 가장 피해가 심했던 세종, 대전, 충남, 충북, 광주, 전남, 전북지역을 살펴보면 PERCENTILE보다 JNBC가 잘 모사한 것을 확인하였다. 이는 퍼센타일의 경우 일정 비율(25% ,75%, 90%, 95%)로 등급 구간을 상대적으로 나누었기 때문에 서로 다른 지역별 기상 특성을 반영하지 못한 것으로 판단되며 JNBC의 경우 등급내 전체 값들의 평균을 기준으로 분산을 최소화 하고 각 등급간의 분산을 극대화하는 알고리즘을 이용하여 등급 간의 차이가 명확하게 구분이 되어 절대적인 결과를 산출하는 장점이 있다.
본 논문에서의 강우에 따른 피해영향을 4개의 단계로 제시하였다. 여기서 피해등급에 이재민 세대수 만을 적용하였지만 추후 다양한 피해자료를 카테고리화 하여 지수형태로 본 연구에서 제시한 Risk Matrix에 적용하고, 전국의 재해피해 대상체 즉 노출, 취약시설에 대한 정보가 포함된다면 극한기상현상 발생시 해당지역에 어떤 피해가 발생하는지에 대한 정보의 제공에 활용될 수 있을 것이라 판단된다. 영향에보를 위해서는 지속적인 대국민 홍보와 상세한 영향예보의 분석, 유관기관, 전문가 집단과의 협의체 구성을 통해 지속적인 교류 및 협업을 통해 상세하게 제시 되어야 할 것이다.
