

1. 서 론
2. 계측자료의 수집‧분석
2.1 침수 계측자료 분석
2.2 강우자료 분석
3. 침수예측 모델 설계
3.1 자료 전처리
3.2 상관관계 분석
3.3 예측모델 설계 및 성능분석
4. 결 론
1. 서 론
최근 한반도 평균 강수량은 7월과 8월에 증가추세에 있으며, 6월에는 감소 추세가 나타났다. 6월부터 8월까지 평균 강수의 증가 폭은 50년 동안 0.65 mm/day로 95% 신뢰수준에서 유의하지 않은 것으로 나타났다(KMA, 2024). 특히 도시지역에서의 인명피해는 재난관리에 있어서 매우 중요한 사항이다. 2022년 8월 서울에서는 시간당 140 mm 이상의 극한 호우로 인하여 약 5,800대의 차량이 침수되었으며, 11명이 사망하였다(Seoul Metropolitan Government, 2023). 23년에도 집중호우로 인해 지하차도가 침수되어 사망자가 발생하는 등 집중호우로 인한 피해는 계속해서 발생하고 있다.
이와 같은 자연 재난과 관련하여 과학적이고 선제 재난안전관리가 강조되고 도시 침수 예측, 침수 데이터 활용 기술이 요구되고 있다. Global Market Insight의 보고서에 따르면 레벨 센서의 글로벌 시장은 2022년 40억 달러로 평가되고 있으며, 2032년까지 약 7%의 성장을 보일 것으로 예상한다(Gujar and Vishwakarma, 2023). 도시 침수를 예측하고 관리하기 위해 하천과 같은 계측장비의 구축과 계측데이터를 확보하는 등 미래 기술에 대한 준비가 필요하다. 부산시에서는 IoT와 CCTV 기반의 실시간 침수 예․경보 시스템을 개발하였으며, 실시간 수위상승 임계값을 기반으로 한 침수 경고와 영상 분석을 통한 침수지역 자동 판별 기능을 제공한다(부산시 도시침수 통합정보시스템, safecity.busan.go.kr). 그러나 IoT 센서로 계측된 데이터는 단순 모니터링에만 활용하고 있으며, 실제 예측을 위한 정보로 활용되지 못하고 있다. 미국 환경보호국에서는 센서, IoT 등 스마트 기술을 적용하여 실시간 빅데이터 분석, 시각화 및 의사결정에 활용하고 있다(EPA, 2018).
우리나라도 이제 도시지역에서 침수와 관련된 정보를 계측하고 관리하여 데이터 기반의 침수 관리를 위해 준비를 하여야만 한다. 국립재난안전연구원에서는 2018년부터 도시지역의 침수심을 계측할 수 있는 도시 침수 계측장비를 설치‧운영하고 있다(NDMI, 2022). 이에 본 연구에서는 다년간 구축된 계측데이터를 이용하여 침수 예측에 활용할 수 있는 계측데이터 기반의 침수 예측모델을 개발하고자 한다.
2. 계측자료의 수집‧분석
국립재난안전연구원에서 설치한 침수 계측장비는 울산, 부산, 인천, 천안, 창원에 약 66기가 설치되어 있다. 그러나 침수 계측장비의 설치 시기에 따라 계측 주기, 데이터의 전송시간이 서로 다르며, 이에 따라 계측의 시작 시각, 종료 시각이 장비마다 차이가 발생한다. 본 연구에서는 자료의 연속성과 지속성, 그리고 예측모델을 개발하는 데 필요한 침수 계측데이터가 가장 많은 부산시 사상구 새벽시장을 대상으로 분석하고자 한다. 부산시 사상구 새벽시장에 설치된 침수 계측장비는 2018년에 설치하였으며, 정확한 위치는 위도 35.1534, 경도 128.9825이다. 침수 계측장비에 침수심 계측을 위해 사용된 센서는 Table 1과 같다.
Table 1.
Specifications of flood measurement sensor
Type Specification | e-Tape | PLN/PLA |
| Accuracy | <0.25 mm | ±0.15%FS |
| Measurement Range | 0.823 m | 350 m |
| Voltage | Max 10 V | 11~22 VDC |
| Operation Temperature | -9~65°C | -20~80°C |
침수 계측 데이터와 함께 학습에 사용될 기상자료는 기상청 기상자료개방포털에서 확보할 수 있는 종관기상관측소(Automated Synoptic Observing System, ASOS)와 방재기상관측소(Automatic Weather System, AWS)의 자료를 사용하고자 하였으며, 침수 계측장비가 설치된 위치와 가장 가까운 거리의 관측소의 강우자료를 사용하였다.
2.1 침수 계측자료 분석
침수 계측장비에는 지표의 침수심을 측정할 수 있는 e-Tape 센서와 빗물받이의 수위를 측정할 수 있는 투입식 레벨 센서 PLN/PLA 센서가 설치되어 있다. 각 센서의 사양은 Table 1과 같으며, 대상지점인 부산 사상구 새벽시장에서 관측된 침수 데이터는 Fig. 1과 같다. P는 압력식 센서의 침수 계측데이터이며, e는 e-Tape 센서로부터 계측된 지표 침수 계측데이터이다.
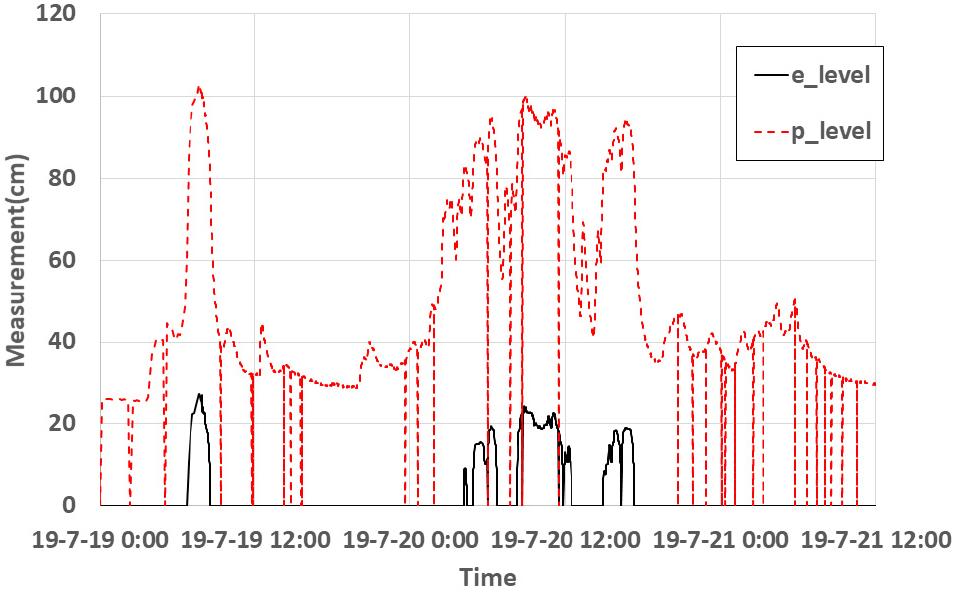
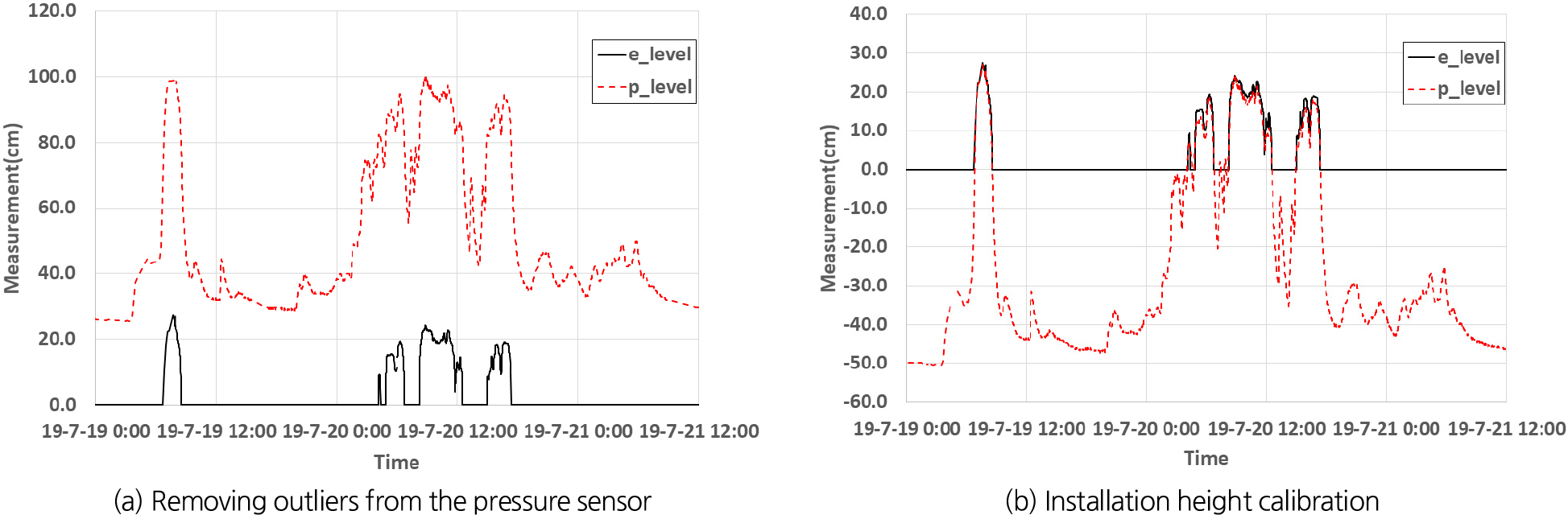
지표의 침수심을 측정할 수 있는 e-Tape 센서는 접촉식 센서로 오염물로 인한 오측이 발생할 수 있는 단점이 있다. 따라서, 비교적 일정한 데이터가 관측된 압력식 센서의 계측값을 활용하여 보정할 필요가 있다. 또한 압력식 센서도 불규칙하게 오계측이나 결측(0)이 발생함에 따라, 압력식 센서의 불규칙한 0값을 제거하고 전후 데이터를 이용하여 선형보간하였으며(Fig. 2(a)), 빗물받이에 설치된 압력식 센서의 설치고를 보정하여 두 센서의 침수심 측정 범위를 일치화하였다(Fig. 2(b)).
2.2 강우자료 분석
강우 관측소는 침수 계측장비가 설치된 위치로부터 가장 가까운 3개의 관측소를 대상으로 2018년 1월부터 2021년 12월까지의 데이터를 수집하였다. 본 연구에서 사용한 강우 데이터의 관측소와 침수 계측장비와의 거리는 Table 2와 같다.
Table 2.
Distance from inundation site to rainfall stations
Station Location | Sasang | Busanjin | Busan (Radar) |
| Busan A | 2,276 m | 3,408 m | 4,157 m |
| Busan B | 2,287 m | 3,390 m | 4,150 m |
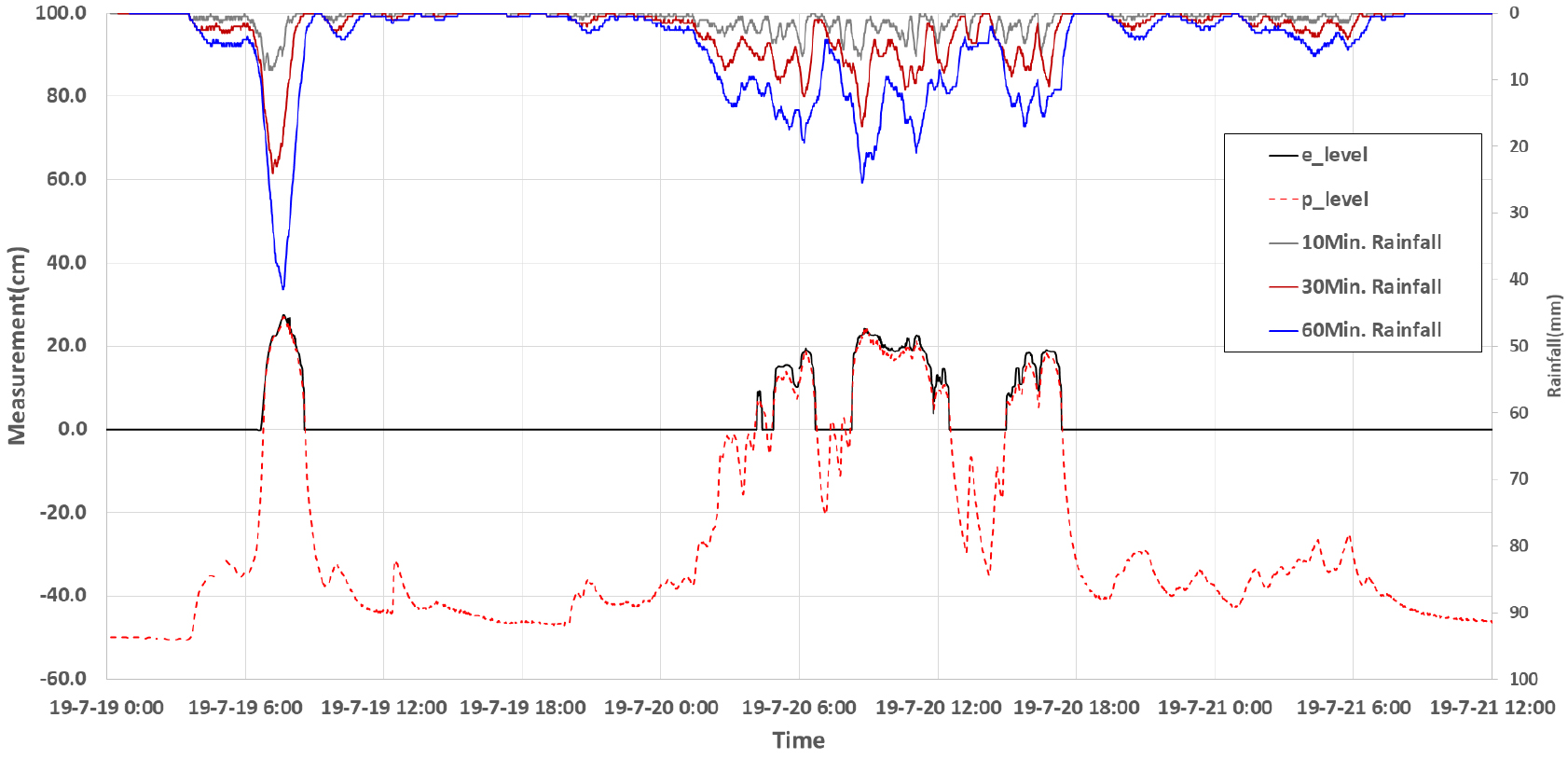
가장 가까운 사상관측소의 1분 단위의 강우 데이터를 10분, 30분, 60분, 120분, 180분, 360분에 대한 지속 시간별 누적강우량 분석 결과는 Table 3과 같으며, 침수가 계측된 사례인 2019년 7월 19일부터 21일까지 가장 가까운 관측소에 대한 지속 시간별 누적강우량과 침수 계측데이터는 Fig. 3과 같다. 강우와 침수심 발생과의 관계를 보면 30분 10 mm 이상, 60분 15 mm 이상의 강우에서 지표에서의 침수 계측이 시작한다. 그러나 하나의 특정 지속시간 강우에 의해 발생한다고 보기에는 어렵다. 또한 특정 강우량과 침수심이 1:1의 상관관계를 갖고 있지는 않는 것으로 분석되었다.
Table 3.
Rainfall accumulation by duration for major events
3. 침수예측 모델 설계
침수 계측장비로부터 계측한 자료와 강우 데이터를 이용한 예측모델은 e-Tape 센서로부터 계측자료와 압력식 센서로부터 계측자료의 계측 간격에 따른 시간동기화 등의 전처리와 침수 발생과 관계가 있는 강우를 파악하기 위하여 지속 시간별 강우량의 산정이 필요하다. 또한 지속 시간별 강우량 중 침수 발생과 관계성이 높은 강우량을 찾기 위한 상관성 분석과 중요도 분석을 통해 학습자료를 선정해야 한다.
3.1 자료 전처리
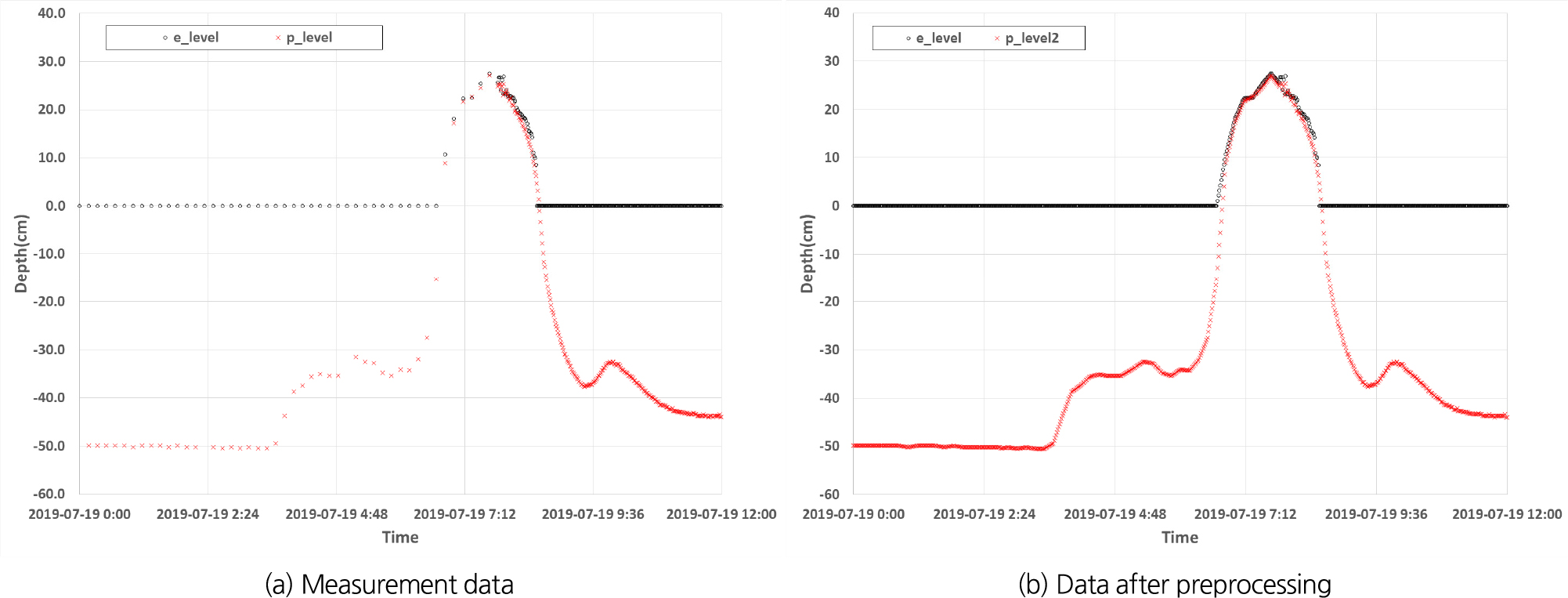
자료 전처리에서는 우선 침수 계측장비로부터 계측된 데이터를 최소 계측 단위인 1분 단위로 동기화하여야 한다. 이때 계측 간격의 차이에 의해 발생하는 결측 데이터는 이전값 또는 다음 값 이용, 이동평균, 보간법 중 주변 데이터에 대해 선형적 일관성을 갖는 것을 기준으로 보완할 수 있는 선형보간법을 사용하였다. 그 결과 총 7,681개의 데이터에서 총 40,794개로 증가하여 약 4배 이상의 데이터가 생성되었다. 데이터 전처리 전과 후의 데이터양의 변화와 전후 계측데이터는 Table 4와 같으며, 전처리 전과 후의 비교 예시는 Fig. 4와 같다. Case 7의 경우 센서의 오작동으로 계측할 수 없어 최종 자료에서는 제외하였다.
Table 4.
Summary of preprocessing results for learning data
3.2 상관관계 분석
3.2.1 상관관계 분석
상관관계 분석은 피어슨 상관관계를 이용하였다. -1에서 1까지의 범위로 -1이나 1에 수렴할수록 음이나 양의 상관관계가 있으며, 0에 수렴할수록 상관관계가 없다. 상관관계 분석 결과 Table 5와 같이 모든 지속 시간별 강우량은 지표 침수심(e_level), 빗물받이 침수심(p_level)과 양의 상관관계를 갖는 것으로 분석되었다. 120분, 180분 누적강우량이 0.8 이상의 높은 상관관계가 있었으며, 30분, 60분, 360분의 누적 강우도 0.6 이상의 상관관계가 있는 것으로 분석되었다.
Table 5.
Pearson correlation coefficients between accumulated rainfall and inundation depths
3.2.2 중요도 분석
XGBoost (Extreme Gradient Boosting)와 Random forest를 이용하여 입력변수와 종속변수 간의 관련성과 변수들의 중요도를 분석하였다. XGBoost는 다양한 의사결정나무를 조합하여 사용하는 앙상블 알고리즘으로 첫 번째 의사결정트리에서 분류가 실패하면 가중치를 추가하여 다음 의사결정트리로 넘겨주는 것을 반복하여 최종 출력데이터 대비 입력데이터의 중요도를 산정한다. 기존의 Gradient Tree Boosting과 비교하여 병렬처리가 가능하여 학습 속도가 빠르고, 정확성이 높으며, 과적합을 방지하는 등의 장점이 있다. 학습자료 훈련을 위해 9:1의 비율로 훈련데이터와 테스트 데이터를 구성하였으며, 그 결과 지표면 센서는 1분을 제외하고 유사한 범위로 분석되었으며, 압력식 센서는 360분이 가장 높은 것으로 분석되었다(Table 6).
Table 6.
Feature importance of accumulated rainfall using XGBoost
Random Forest는 다양한 의사결정나무를 통해 학습하여 학습된 결과를 종합하여 회귀, 분류하는 모델로, 대용량 데이터 처리에 효과적이며, 과적합 문제를 최소화할 수 있으나 각각의 의사결정나무를 형성, 학습시키기 때문에 상대적으로 모델의 구현과 결과 도출에 시간이 오래 걸린다. 학습과 테스트 비율을 XGBoost와 비교하기 위해 동일하게 9:1로, 시계열의 앞 9를 학습데이터로 뒤의 1을 테스트 데이터로 구성하였다. 분석 결과 Table 7과 같이 XGBoost와는 달리 120분 강우량이 지배적인 것으로 나타났다.
Table 7.
Feature importance of accumulated rainfall using Random Forest
3.3 예측모델 설계 및 성능분석
3.3.1 예측모델 설계
시계열 예측을 위한 모델에는 RNN (Recurrent Neural Network), LSTM (Long Short-Term Memory), GRU (Gated Recurrent Unit), CNN (Convolutional Neural Network), Transformer 등이 있으며, 모델별 고유한 구조적 특성과 예측성을 보인다.
RNN은 순차적 데이터 처리에는 적합하나, 장기적인 의존성 학습에는 한계가 있다. 특히 기울기(Gradient) 소실 문제가 발생하기 쉽다(Hochreiter and Schmidhuber, 1997). GRU는 LSTM보다 구조가 단순하며, 계산 효율성이 높다. 그러나 시계열 길이가 길어질수록 예측성이 떨어지는 경향이 있다(Chung et al., 2014). CNN 기반의 모델은 병렬처리가 가능하며, 연산 속도가 빠르다. 그러나 시계열 순서를 충분히 반영하기 어렵고 장기 패턴 학습에는 한계가 있다(Wang et al., 2017). 최근 주목받고 있는 Transformer는 병렬 연산이 가능하며, 장기 패턴에 대한 의존성도 효과적으로 학습할 수 있으나, 대규모 학습 데이터와 연산을 위한 자원이 필요하다는 단점이 있다(Vaswani et al., 2017).
본 연구에서는 시계열 예측 모델 중에서도 장기 의존성 학습에 강점을 가지며, 다수의 강우 데이터 입력을 통해 하나의 침수 값을 예측할 수 있는 구조인 LSTM을 선택하였다. 특히, 선행 연구서는 LSTM이 강우-유출 예측에서 전통적인 수문 모델보다 뛰어난 성능을 보여주였으며(Kratzert et al., 2018), 침수상황에 실시간 적용 강능성을 제시한 바 있다(Le et al., 2019).
본 연구에서는 7개의 지속 시간별 누적강우량을 통해 하나의 침수심을 예측하는 many-to-one 방법을 적용하였다. 은닉층을 총 4개로 구성하였으며, 은닉층별 Node의 수는 각 20개, 50개, 100개, 20개로 설정하였다. 하이퍼파라미터는 Table 8과 같다.
Table 8.
Hyper parameter
| Hyper parameter | Input value |
| Function | relu |
| Epochs | 100 |
| Batch size | 60 |
| Optimizer | adam |
| Sequence Length | 120 |
학습자료는 총 40,781개로 train data와 test data는 9:1로 구성하였으며, train test split의 옵션 중 shuffle은 false로 설정하였다. 이는 순서가 랜덤으로 설정되는 것이 아닌 입력된 순서 즉 시계열 순서로 설정되어 2021년 8월 23일 20시 42분을 기준으로 이전값은 train data, 이후 값은 test data로 나누어졌다. 랜덤 값이 아닌 시계열로 학습과 테스트를 구성한 것은 이후 예측되어야 하는 값들이 이전값을 기준으로 학습되는 시계열 데이터의 특성을 고려한 것이다.
모델 최적화를 위한 목적함수는 상관계수(Correlation Coefficient), 평균오차(Mean Absolute Error, MAE), 평균제곱근오차(Root Mean Square Error, RMSE) 중 상관계수를 사용하였다. 그 이유는 시계열에 따른 예측 결과로써 침수패턴을 가장 잘 반영할 수 있는 것이 상관계수라 판단했기 때문이다.
상관계수는 피어슨 상관계수를 활용하였으며, 다음의 식으로 산정할 수 있다.
여기서, , 는 각각의 데이터 값이며, , 는 각 변수의 평균, ,는 각 변수의 표준편차, 는 X와 Y의 공분산을 의미한다.
평균오차와 평균제곱근오차는 다음의 Eqs. (3) and (4)로부터 구할 수 있다.
여기서, 는 실제 값이며, 는 예측값이다.
3.3.2 성능분석
모델의 성능분석은 실제 강우가 발생하였을 때 침수를 예측한 성능을 분석한 결과로 무강우일 때 침수심 ‘0’을 예측하여 모델의 성능분석에 오류를 가져올 수 있는 것을 최소화하였다. 성능분석 지표로는 상관계수, 평균오차, 평균제곱근오차에 대해 분석하였으며, 특정 값을 잘 예측하는 결과보다 침수 패턴을 잘 모의할 수 있는 상관계수에 중점을 두었다. 모델 성능 분석 결과 지표 센서는 상관계수 0.949, 평균오차 1.211 cm, 평균제곱근오차 3.166 cm, 압력식 센서는 상관계수 0.945, 평균오차 4.136 cm, 평균제곱근오차 7.157 cm로 모두 상관계수는 0.94 이상의 높은 값을 나타냈으며, 평균오차에서는 지표 센서가 조금 더 좋은 결과를 보여주었다.
Fig. 5와 같이 최대 침수심 발생 지점에서 모델에서 과대 산정하거나, 일부 과소 산정하는 결과가 보였는데, 이는 다양한 침수패턴에 대한 학습자료의 부족으로 판단된다. 그러나 전체 침수패턴을 보면 침수 시점과 종료 시점, 최대 침수심 등을 잘 예측하는 것으로 나타났다.
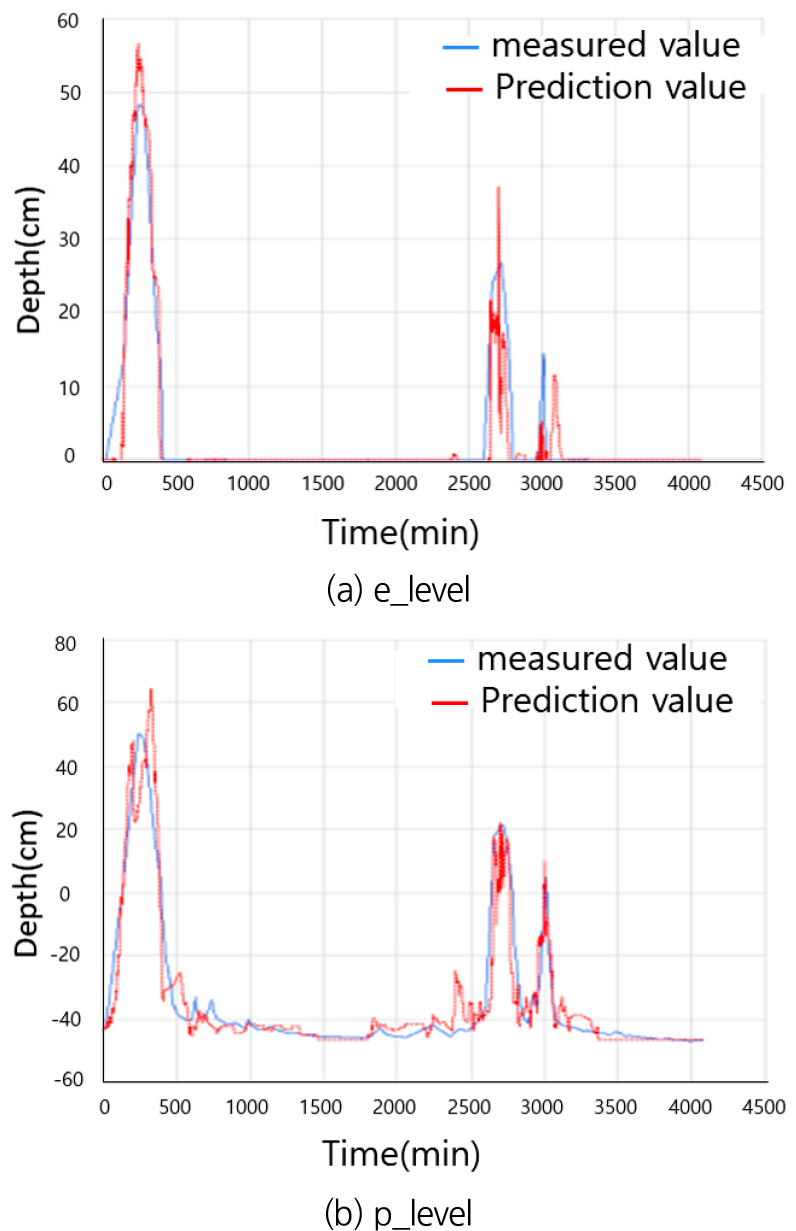
전체적인 모델의 성능평가에서는 좋은 성능을 나타내는 것으로 나타났으나 최대 침수심에서 실제 관측값보다 과대산정되거나 발생시각의 차이가 발생하였다. 이는 학습데이터의 양적 한계로 판단되며, 향후 다양한 침수 계측데이터가 추가된다면 오차를 줄여 나갈 수 있을 것으로 기대된다.
4. 결 론
그동안 침수 분석에는 비교적 단순한 1차원 모델부터 가장 많이 사용되고 있는 2차원 모델, 그리고 3차원 모델까지 대부분 수치해석 모형에 의존하고 있었다. 그러나 수위가 계측되는 하천과 달리 도시 침수해석은 비교, 검증 등의 수단이 없었다. 본 연구에서는 침수 모니터링에 사용되고 있는 침수계측센서로부터 계측된 값을 이용하여 침수 예측에 활용할 수 있는 가능성을 검토하고자 다년간 계측된 센서 데이터를 이용한 예측모델을 설계하고 성능을 검토하였다. 그 결과 침수패턴을 잘 예측할 수 있으며, 상관계수 또한 0.9 이상의 매우 높은 값을 보여주었다.
현재 모델은 실시간 강우 데이터와 침수심과의 관계를 분석하여 침수를 예측할 수 있는 모델이다. 그러나 향후 예측 강우를 함께 학습한다면 더욱 빠른 침수 예측을 통해 재난 관리자가 사전에 침수 대응을 할 수 있는 의사결정을 지원할 수 있을 것으로 기대된다.
그러나, 본 논문에서 제시한 연구 결과는 가능성일 뿐 실제 현장에 적용하기에는 많은 과제가 남아있다. 첫 번째, 도시 내수침수 모니터링 및 계측을 위한 센서의 보급을 통해 많은 침수 위험 지역에 설치가 이루어져야 하며, 두 번째, 양질의 데이터를 확보하고 관리할 수 있는 유지관리 체계와 시스템 구축이 필요하다. 다만 이를 위해서는 많은 예산이 투입되어야 하며, 다년간의 데이터 확보를 위해서는 긴 시간이 걸릴 것으로 예상된다. 세 번째, 최대 침수 계측 범위는 60 cm이하로 더욱 다양한 침수 계측 범위를 갖는 데이터 확보가 필요하다. 마지막으로 본 연구는 단일 지점을 기반으로 학습 및 예측을 수행하였으나, 향후 다지점 데이터를 융합하거나 공간적 관계를 학습할 수 있는 GNN (Graph Neural Network) 또는 ConvLSTM 등의 공간-시간 기반 모델로 확장함으로써 일반화 가능성을 더욱 높일 수 있을 것으로 기대된다.
