

1. 서 론
2. 이론적 배경
2.1 동수역학적 모형
2.2 기계학습 모형
3. 한강 본류 구간에 대한 모형의 구축 및 적용
3.1 동수역학적 모형
3.2 기계학습 모형 및 혼합모형
4. 결과 및 고찰
4.1 HM, LSTM1, LSTM2 및 HM+LSTM3 적용결과의 비교 분석
4.2 ANN 기반 모형들과 LSTM 기반 모형들의 적용결과 비교 분석
5. 결 론
1. 서 론
홍수시 하천의 수위를 예측하기 위한 홍수위 계산모형으로 수리학적 모형이 널리 사용되고 있다. 수리학적 모형은 흐름이 연속적으로 변화하는 경우 연속방정식과 운동량 방정식을 수치적으로 해석함으로써 특정 시간 및 지점에서 수위와 유속을 계산하는 모형으로서 물리적 현상과 하천의 자연조건이 반영된 물리 기반의 계산모형이다. 그러나 정교한 물리적 계산모형일지라도 모형에서 발생하는 불확실성, 초기조건 및 경계조건의 불확실성, 모형 매개변수의 불확실성에 따라 모형 계산값과 관측값 간의 오차가 수반된다(Ricci et al., 2011).
더욱 정확한 홍수위 예측을 위하여 모형의 모의 오차들을 데이터 기반의 후처리 방법들에 의하여 보정할 수 있다. 이러한 오차보정 모형은 물리 기반의 동수역학적 모형의 구축 과정에서 고려되지 않았던 물리적 과정들에 관한 유용한 정보들을 추출하고, 이렇게 추가적으로 얻어진 정보들이 동수역학적 모형의 시스템적 편차들을 제거할 수 있어야 한다. 동수역학적 흐름모형은 물리적 법칙들에 기반하고 있는 반면, 데이터 기반 모형들은 데이터들 간의 관계를 이용한다는 점에서 이 두 종류의 모형들은 상호 보완적인 성격을 갖는다고 할 수 있다(Abebe and Price, 2003; Konapala et al., 2020; Yang et al., 2020).
개념적인 수문모형과 데이터 기반의 오차보정 모형을 혼합하여 강우-유출 모형의 하천유량 예측을 개선하기 위한 여러 연구들이 수행된 바 있다. Konapala et al. (2020)은 장단기 기억 신경망(long short term memory, LSTM) 기계학습 알고리즘을 사용하여 수문학적 모형의 오차를 모의하였다. Cho and Kim (2022) 또한 LSTM을 사용하여 WRF-Hydro 모형의 오차를 산정하였다. 이러한 상호보완적 모델링에 의한 접근방법은 지하수 문제와(Xu and Valocchi, 2015; Xu et al., 2014) 저수지 수위 예측에도(Azad et al., 2022) 적용된 바 있다. 그러나, 이러한 접근방법을 수리학적 모형, 특히 홍수예측을 위한 개수로 부정류 모의에 적용한 사례는 매우 드물다. Torres-Rua et al. (2012)은 관개용수 관리를 위한 수로 흐름에 대한 수리학적 모의모형의 오차 보정을 위하여 데이터 기반 모형을 사용하였다. Abebe and Price (2003)는 1차원 확산파 방정식을 사용하는 홍수추적 모형의 오차 예측을 위하여 데이터 기반 모형이 효과적으로 적용될 수 있음을 보였다. 이상과 같은 연구들에 사용된 데이터 기반 모형들로는 자기상관(autoregressive) 모형, 자기상관 이동평균(autoregressive moving average) 모형, 유전자 알고리즘(genetic algorithm) 및 인공신경망(artificial neural network, ANN) 모형 등이 있다. 물리 기반 모형과 오차보정을 위한 데이터 기반 모형을 결합한 혼합모형에 대한 개념도는 Fig. 1과 같다.
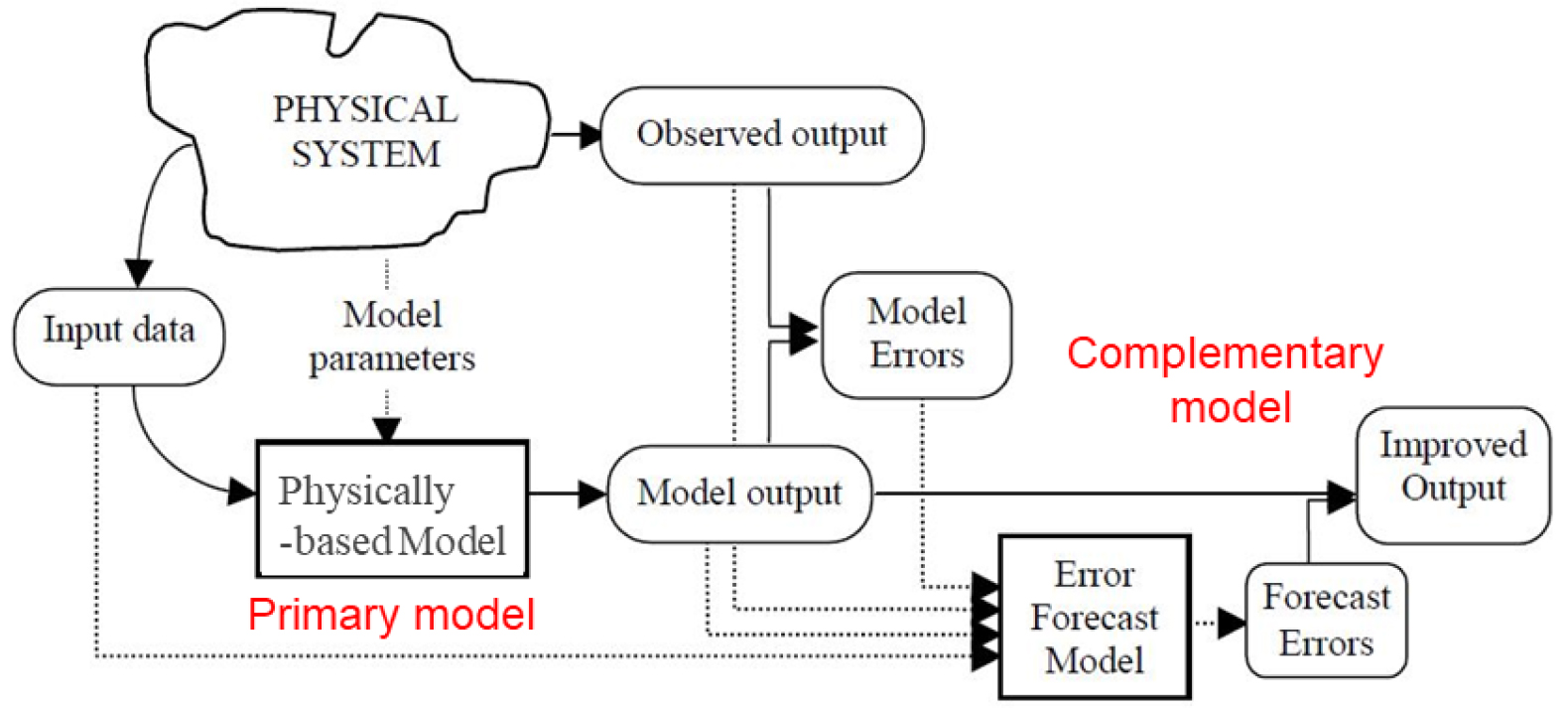
Li and Jun (2022)은 동수역학적 모형을 보완하기 위한 오차보정 모형으로서 ANN 모형을 혼합하여 사용함으로써 홍수위 예측 능력을 획기적으로 개선할 수 있음을 보였다. 본 연구에서는 Li and Jun (2022)에서 제시한 기계학습 혼합모형의 정확도를 높이고자 시계열 자료의 분석에 뛰어난 LSTM을 활용하여 한강 본류 구간에 대하여 혼합모형을 구축하였다. 수립된 LSTM 기반 혼합모형의 성능을 평가하기 위하여 계산결과의 정확성을 동수역학적 모형 및 단순 기계학습 수위 예측모형의 경우와 비교하였다. 또한 단순 기계학습 모형 및 혼합모형 각각에 대하여 LSTM을 사용할 경우의 정확성을 ANN을 사용할 경우와 비교하여 평가하였다.
2. 이론적 배경
2.1 동수역학적 모형
한강 본류의 잠실 수중보와 신곡 수중보가 고정보와 가동보로 이루어져 있어 하도형 및 월류형 흐름이 함께 발생함으로 이를 모의하기 위하여 폐합형 수계 모형을 적용하였다. 하도형 흐름에 관한 수로 지배방정식은 다음과 같은 연속방정식 및 운동량 방정식으로 구성된다.
여기서 는 유량, 는 수위를 나타내며, 와 는 각각 공간과 시간 변수를 나타낸다. 는 통수단면적을, 는 통수능을 각각 나타낸다. 𝛼는 운동량 보정계수로 1로 가정하였다. 는 중력가속도이며, 통수능 는 다음과 같이 나타낼 수 있다.
여기서 은 동수반경을 나타내며, 은 Manning의 조도계수이다.
월류형 흐름에 관한 수로 지배방정식은 다음과 같다.
여기서 와 는 각각 잠긴 위어형 흐름과 자유 월류형 흐름에 대한 월류유량계수이며, 는 월류부의 바닥표고, 는 월류부의 유효폭이다. 와 는 월류 구조물의 상류 및 하류 수위를, 와 는 월류유량을 각각 나타낸다.
절점 지배방정식은 연속방정식 Eq. (6)과 등수위 조건식 Eq. (7)로 구성된다.
여기서 은 수로 로부터의 유입량 또는 수로 로의 유출량이며, 는 외부 유출입량을 나타낸다. 는 절점의 갯수이며, 는 절점 에 연결된 수로의 갯수이다. 는 절점 와 를 연결하는 수로의 절점 측 끝단 계산점에서의 수위를 나타낸다.
하도형 흐름에 관한 수로 지배방정식을 Preissmann의 4점 음해법에 의하여 차분화하면 수로상의 각 계산점에서의 수위 및 유량과 절점 수위에 관한 비선형 연립방정식이 구성되며, 그 해는 Newton-Raphson 방법을 적용하여 구한다(Cunge et al., 1980). Newton-Raphson 방법을 적용하여 구성되는 수위 및 유량 보정치에 관한 선형 연립방정식의 해법으로는 수로에 대한 전방 소거, 절점 수위 보정치의 계산 및 수로에 대한 후방 대입으로 구성되는 폐합형 double-sweep 알고리즘을 사용한다.
2.2 기계학습 모형
기계학습(machine learning)은 자료를 활용하여 인공지능을 구현하는 것을 말하며, 최근에는 컴퓨터의 연산 능력의 급격한 향상에 따라 인공신경망 모형, 순환신경망(recurrent neural network, RNN) 모형 등과 같은 심화학습(deep learning) 모형들이 널리 적용되고 있다. 인공신경망 모형은 양질의 대용량 자료가 가용할 경우 특정 수문 시계열 예측에서 우수한 결과가 도출되는 것으로 알려져 있다(Jung et al., 2018). 인공신경망 모형에 관한 상세한 내용은 Li and Jun (2022)에 기술되어 있다.
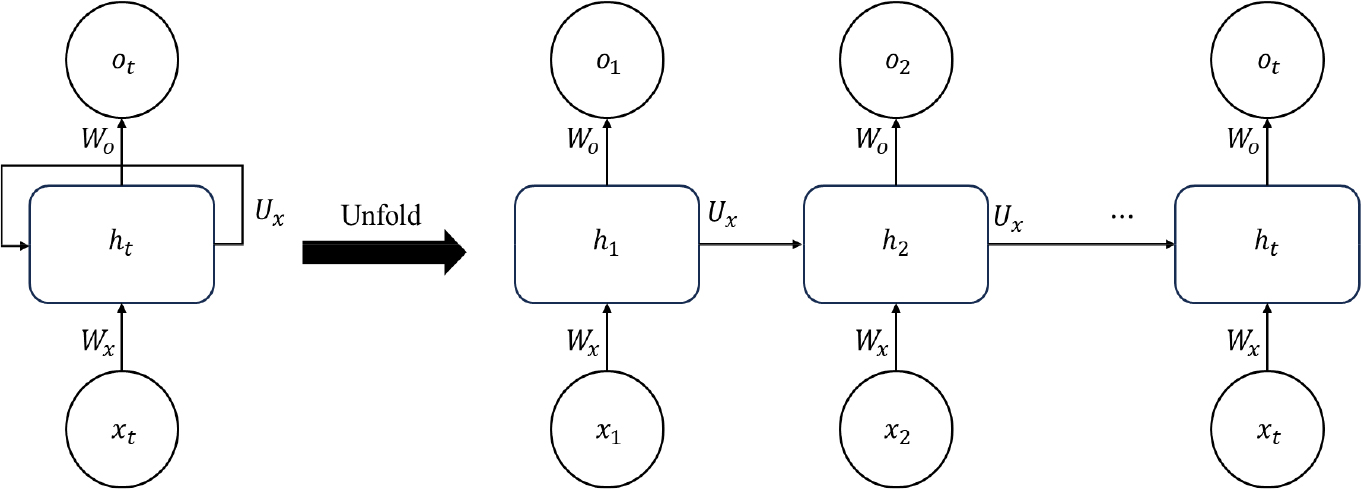
RNN은 시계열과 같은 순차적인 데이터, 즉 입력의 순서가 중요한 자료를 처리하는데 적합하며, 자연어 처리, 음성인식, 시계열 예측 등 다양한 영역에서 활용된다. RNN의 기본 구조는 Fig. 2와 같다. RNN은 내부에 있는 순환구조로 인해 현재 정보에 이전 정보가 쌓이면서 시간에 따라 누적된 정보를 처리할 수 있는 신경망이다. RNN은 은닉층에서 활성화 함수를 거쳐 나온 결과를 출력층으로 보내면서 다음 은닉층 노드 계산의 입력값으로 사용한다. 단일층 RNN의 기본 수식은 Eq. (8)과 같다(Lipton et al., 2015).
여기서 𝜎는 활성화 함수로 주로 tanh나 sigmoid 함수가 사용된다. 는 이전 시간 단계에서의 가중치이며, 는 현재 시간 단계의 가중치를 나타낸다. 은 이전 시간 단계의 은닉상태이며, 는 현재 시간 단계 에서 은닉상태를 나타낸다. 여기서 은닉상태란 메모리 셀이 출력층 방향 또는 다음 시점인 +1로 보내는 값을 말한다. 는 편향을 나타낸다. RNN은 시퀀스 자료를 처리하기 위해 여러 시간 단계에서 수식이 반복되는 구조를 가진다. 시간 단계 에서의 출력은 다음 Eq. (9)와 같이 계산된다(Lipton et al., 2015).
여기서 는 현재 시간 단계 에서 출력을 나타내며, 는 은닉상태에서 출력으로 가중치를 나타낸다. 는 편향을 나타낸다. RNN은 비교적 짧은 시퀀스에서는 좋은 성능을 보이나 긴 시퀀스에서 기울기 소실 문제(vanishing gradient problem)가 발생할 수 있다. 입력 길이가 긴 만큼 신경망은 깊어지고 기억해야할 시계열의 자료 또한 많아지게 된다. RNN은 앞서 언급했듯이 이전 시간 자료를 참고한다. 따라서 기울기가 1보다 작은 수가 계속 곱해지므로 0에 수렴하게 된다. 이는 데이터에 대한 기억이 희미해지는 것으로 기울기 소실이라 한다. 이러한 기울기 소실 문제를 해결하기 위하여 Hochreiter and Schmidhuber (1997)은 LSTM 모형을 대안으로 제시하였다. LSTM은 기울기 소실 문제를 완화하면서 긴 시퀀스에 대한 정보를 효과적으로 기억할 수 있는 메커니즘을 제공한다. 이를 통해 시계열 예측에서 LSTM은 뛰어난 성능을 보인다.
LSTM의 구조는 Fig. 3과 같다. LSTM은 메모리 이동 셀 및 데이터의 흐름을 조절하는 3개의 비선형 게이트의 구조(망각, 입력, 출력)로 이루어져 있다(Hochreiter and Schmidhuber, 1997). 망각 게이트 는 과거 정보 를 삭제하기 위한 게이트로서 Eq. (10)과 같이 나타내며, 현재 입력변수인 를 sigmoid 함수를 적용하여 0과 1 사이의 값을 얻어 현재 상태와 곱하여 정보의 삭제를 결정한다.
여기서 𝜎는 활성화 함수를 나타내며 와 는 망각 게이트의 가중치를, 는 편향을 나타낸다.
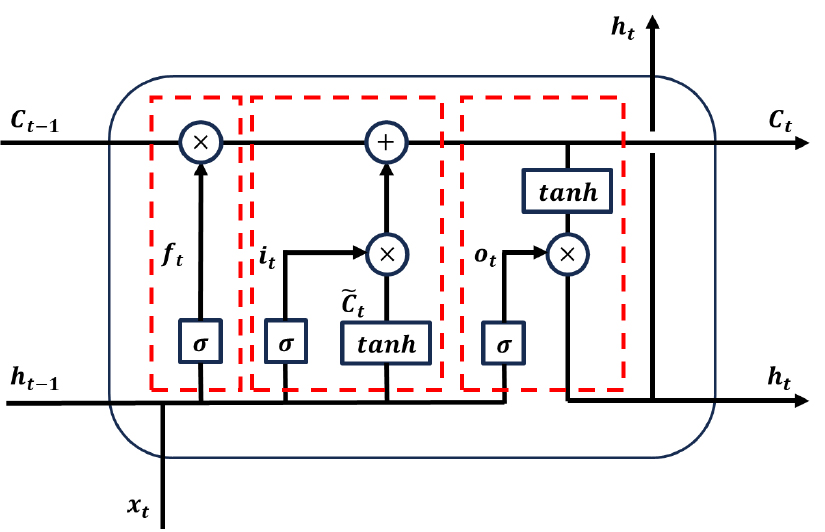
입력 게이트 는 Eq. (11)과 같이 나타내며, 현시점의 데이터 와 과거 은닉층의 값에 가중치를 곱하고 더한 결과에 sigmoid 함수를 적용하여 Cell에 포함 정도를 결정한다. 그 후 tanh 함수를 활용하여 새로운 값들인 를 생성한다.
여기서 와 는 입력 게이트의 가중치를 나타낸다.
마지막으로 출력 게이트 는 Eq. (12)와 같이 나타내며, 최종 출력값을 결정하는 과정으로 Eq. (13)와 같이 tanh 함수를 이용하여 활성화 셀 와 곱을 통해 특정 시점의 정보 를 출력하게 된다.
3. 한강 본류 구간에 대한 모형의 구축 및 적용
3.1 동수역학적 모형
한강 하류구간 중 팔당댐부터 전류 수위관측소까지의 69 km 구간을 대상으로 하여 모형을 구성하였다. 구간 내 수위관측소로 팔당대교, 반포대교, 한강대교, 행주대교, 전류 등 5개가 있으며, 유입 지천으로 왕숙천, 탄천, 중랑천 및 안양천 등 4개 지천을 모형에 포함하였다. 구간 내에 위치한 잠실 및 신곡 수중보는 모두 부분적으로 수문이 설치되어 있으며, 홍수시에는 수문이 완전히 개방되어 고정보 부분에서는 월류형 흐름이 가동보 부분에서는 수로형 흐름이 각각 발생하게 된다. 모형의 구성을 나타내는 모식도는 Fig. 4와 같다.
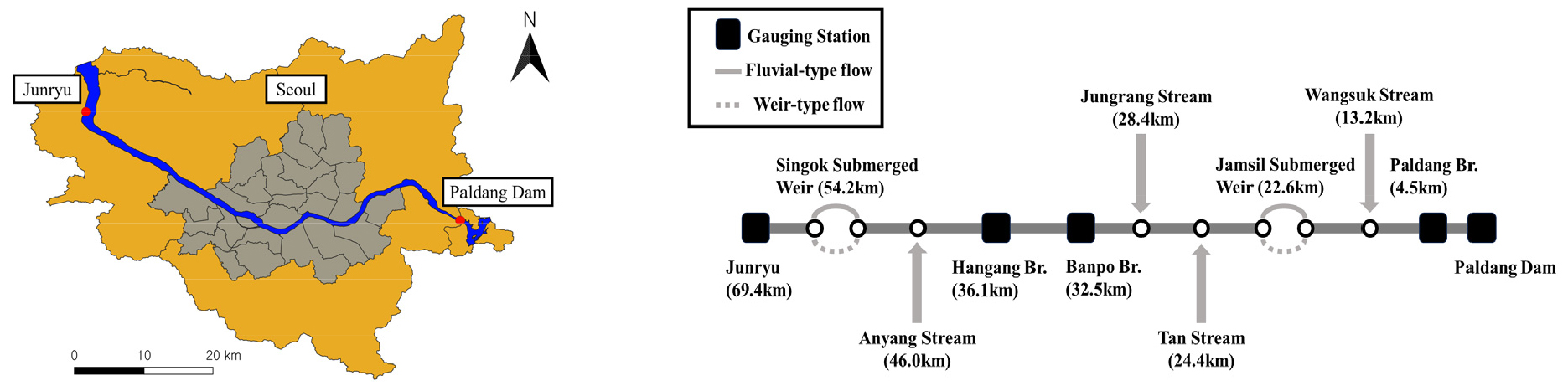
상류단 경계조건으로 팔당댐의 유출량을 부여하였으며, 하류단 경계조건으로 모형의 전류 수위관측소 지점에서의 관측치를 부여하였다. 팔당대교, 반포대교 및 한강대교에서의 수위 관측치는 모형의 보정 및 검증에 사용하였다. 왕숙천, 탄천, 중랑천 및 안양천의 관측 유입량을 모형의 입력자료로 부여하였다. 모형의 상류단 및 하류단인 팔당댐 및 전류 수위관측소 지점과 왕숙천, 탄천, 중랑천 및 안양천 등 4개 지천의 유입지점, 잠실 및 신곡 수중보의 직상류 및 직하류에 각각 절점이 위치하도록 하였다. 수중보 직상류 및 직하류의 절점들은 두 개의 수로로 연결되며, 그 밖의 절점들은 인접 절점들과 각각 한 개의 수로로 연결된다. 따라서 전체 모형은 총 10개의 절점과 11개의 수로로 구성되며(Fig. 4), 계산점의 수는 156개이다. 주어진 홍수사상에 대하여 200시간 동안 상류단 및 하류단의 경계조건을 홍수사상 초기의 팔당댐 방류량 및 전류 수위관측소 지점 수위로 동일하게 부여하여 정상류 상태에 도달한 상태에서 홍수사상에 대한 부정류 모의계산을 수행하였다.
동수역학적 모형의 적용을 위해서는 모형 매개변수인 Manning 조도계수의 정량화가 필요하다. 본 연구에서는 한강 본류 구간을 왕숙천 유입지점 상류 및 하류의 2개 구간으로 구분한 후 각 구간마다 서로 다른 조도계수를 갖도록 하는 가변 매개변수 모형을 구성하였다. 왕숙천 유입지점을 기준으로 하도구간을 구분한 것은 왕숙천 하류는 정비하천 구간인데 반하여, 상류 구간은 하상변동과 횡단면의 변화가 심하여 하류구간과는 상당히 다른 하도특성을 나타내고 있기 때문이다. Manning 조도계수는 일반적으로 하도 구간 및 유량에 따라 변화하므로 로 표현할 수 있으며, Manning 조도계수와 유량과의 관계를 나타내는 수학적 함수로는 다음 Eq. (14)와 같이 멱함수를 채용하였다(Li et al., 2018; Li and Jun, 2018).
여기서 는 구분된 하천구간의 수로서, 본 연구에서는 =2이다. 𝛼와 𝛽는 멱함수의 계수들로서 구간별로 상이한 값을 갖기 때문에 모형 전체적으로는 4개의 매개변수(, , , )를 갖게 된다.
매개변수 최적 추정을 위한 목적함수로는 Eq. (15)와 같이 팔당대교, 반포대교 및 한강대교 지점에서의 매 시각 수위 관측치와 계산치 간의 오차 제곱의 합이 최소화되도록 하였다.
여기서 와 는 시간 , 관측지점 에서의 관측 수위와 계산수위를 각각 나타내며, 첨자 = 1, 2, 3은 각각 팔당대교, 반포대교 및 한강대교 지점을 의미한다. 최적추정 방법으로서 Gauss-Marquardt-Levenberg 알고리즘이 적용되었으며, 이를 위하여 상용 소프트웨어인 PEST (Doherty, 2000)를 이용하였다.
2010년부터 2022년 사이에 발생한 홍수사상 중 팔당댐 방류량과 팔당대교, 반포대교, 한강대교 및 전류 수위관측소 지점 관측치가 모두 가용한 18개의 홍수사상에 대한 관측자료를 사용하여 모형의 보정 및 검증을 수행하였다. 이들 18개 홍수사상에 대한 팔당댐 방류량 최대값의 범위는 5,865-18,167 m3/s이다. 팔당댐 최대 방류량의 크기 순서대로 정리된 18개의 홍수사상(Table 1) 중 홀수번째 사상 9개에 대하여 모형 매개변수의 추정을 수행하였다.
Table 1.
Flood events used for model calibration and validation
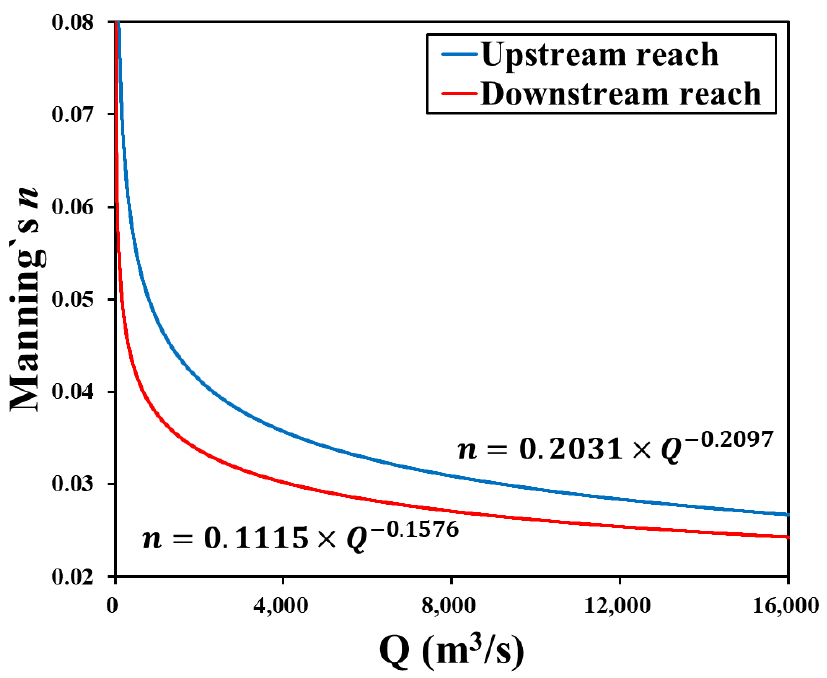
각 홍수사상의 매개변수 추정 결과로부터 구간별 Manning 조도계수와 유량 관계식(Eq. (14))을 구한 후, 9개 식의 기하 평균식으로 모형의 조도계수-유량 관계식을 결정하였다. 즉, Eq. (14)의 α에 대해서는 기하평균값을, β에 대해서는 산술평균값을 각각 구하여 모형의 매개변수로 취하였다. 이와 같이 결정된 조도계수-유량 관계를 Fig. 5에 나타내었다. 상류구간과 하류구간 모두 유량이 커질수록 조도계수가 감소하는 경향이 일관되게 나타나고 있다. 또한 동일한 유량에 대하여 왕숙천 유입지점 상류 구간의 조도계수가 하류구간에 비하여 큰 것으로 나타나고 있는데, 이러한 경향들은 Li and Jun (2018) 및 Li and Jun (2022)의 결과와 일치한다. 추정된 매개변수들을 사용하여 짝수 번째 홍수사상 9개를 대상으로 모형의 검증을 수행하였다. 모형의 보정에 따른 계산수위와 관측수위 간의 제곱평균제곱근 오차(RMSE)는 0.215 m로, 검증에 따른 오차는 0.299 m로 각각 나타났다. 이는 모형의 보정 및 검증에 따른 RMSE가 각각 0.205 m 및 0.308 m로 나타난 Li and Jun (2022)의 경우와 유사한 정확도를 보임을 알 수 있다.
3.2 기계학습 모형 및 혼합모형
동수역학적 모형과 기계학습 혼합모형의 수립 및 적용의 주요 절차는 아래와 같다.
(1) 동수역학적 모형의 수립 및 적용
(2) 동수역학적 모형에 의한 계산값과 관측 데이터 간의 비교에 의한 모형 오차 산정
(3) 여러 상태변수들(관측 수위, 댐방류량, 이전 시간의 모형 오차 등)을 입력변수로 사용하여 동수역학적 모형의 오차를 추정하는 기계학습 모형을 구축
(4) 기계학습 모형에 의하여 추정된 오차만큼 동수역학적 모형의 결과를 보정
이러한 절차를 나타내는 흐름도는 Fig. 6과 같다. 동수역학적 모형을 우선 실행하고, 이어서 오차 보정을 위한 기계학습 모형을 적용한다. 이러한 혼합모형은 기계학습 모형이 모형 오차와 데이터 시계열들과의 관계를 학습함으로써 동수역학적 모형의 오차에 내재된 체계적인 패턴을 찾아낼 수 있다는 가정에 기반한다. 본 연구에서는 동수역학적 모형의 오차를 추정하기 위한 기계학습 모형으로 ANN 모형과 LSTM 모형을 사용하였다.
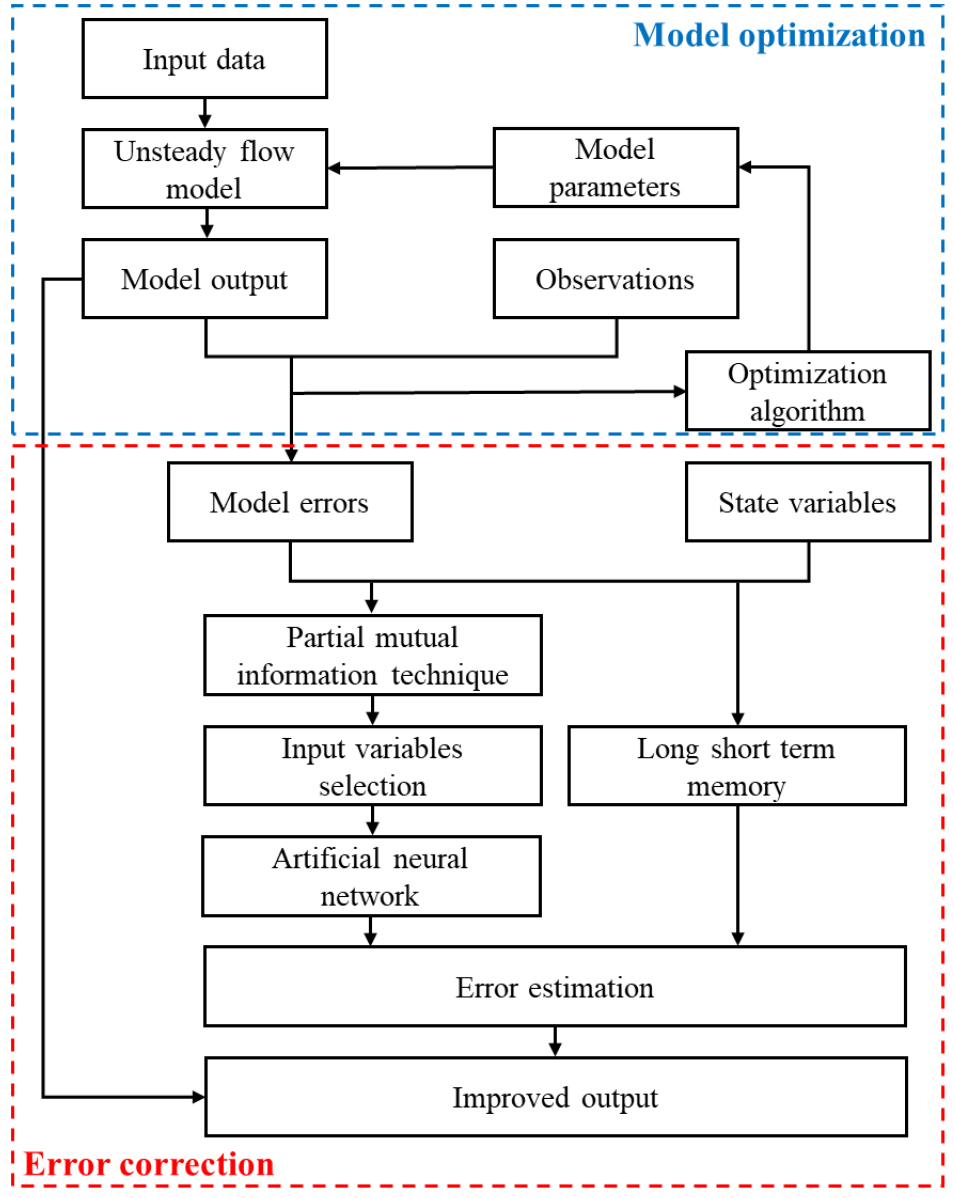
ANN 모형 구축에 있어서는 PMI (He et al., 2011; May et al., 2008a, 2008b; Yue et al., 2020) 기반의 입력변수 선정 방법을 이용하여 입력변수들을 추출하였다. PMI 기반의 ANN 모형 구축에 관한 상세한 내용은 Li and Jun (2022)에 기술되어 있다. 팔당댐부터 전류 수위관측소 지점까지의 홍수파 도달시간은 대략 3시간 이내일 것으로 추정되므로 4시간 이상 경과한 상태변수들은 입력변수 후보에서 제외하였다. 따라서 PMI 기법을 활용한 입력변수 선정 방법을 통해 현재부터 3시간 전까지의 입력변수 후보들 가운데 ANN 모형에 적합한 입력변수를 선정하여 모형을 구축하였다. 은닉층은 1개층으로 구성하였으며, 뉴런 수는 1-10개 중 시행착오법을 통하여 가장 정확한 결과를 주는 뉴런 수를 선택하여 모형을 구축하였다.
LSTM 모형의 입력변수로 3시간 이전까지의 상태변수들을 반영하여 모형을 구축하였다. 은닉층은 1-3개로 후보를 선정하였으며, 뉴런 수는 1부터 10까지의 후보를 선정하였다. 이 후보들 중 시행착오법 및 랜덤서치 기법을 활용하여 가장 정확한 결과를 주는 은닉층과 뉴런 수를 선정하였다. MinMaxscaler 변환을 통하여 시계열 자료의 정규화를 진행하였으며, 학습에 활용하는 자료의 길이(시퀀스 길이)는 4로 정하여 현재 시간부터 3시간 이전의 자료를 한 번에 학습에 활용하도록 모형을 구축하였다. 즉, 본 연구에서의 시계열 자료는 1시간 단위로 구성되어 있기 때문에 시퀀스 길이가 4일 경우 t-3부터 t까지의 자료가 활용되었음을 의미한다.
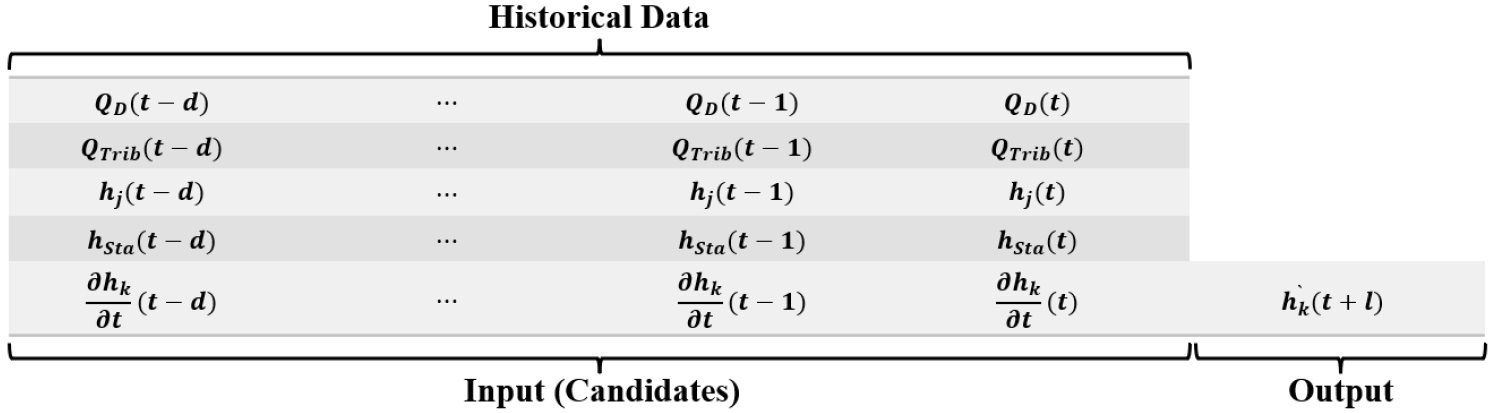
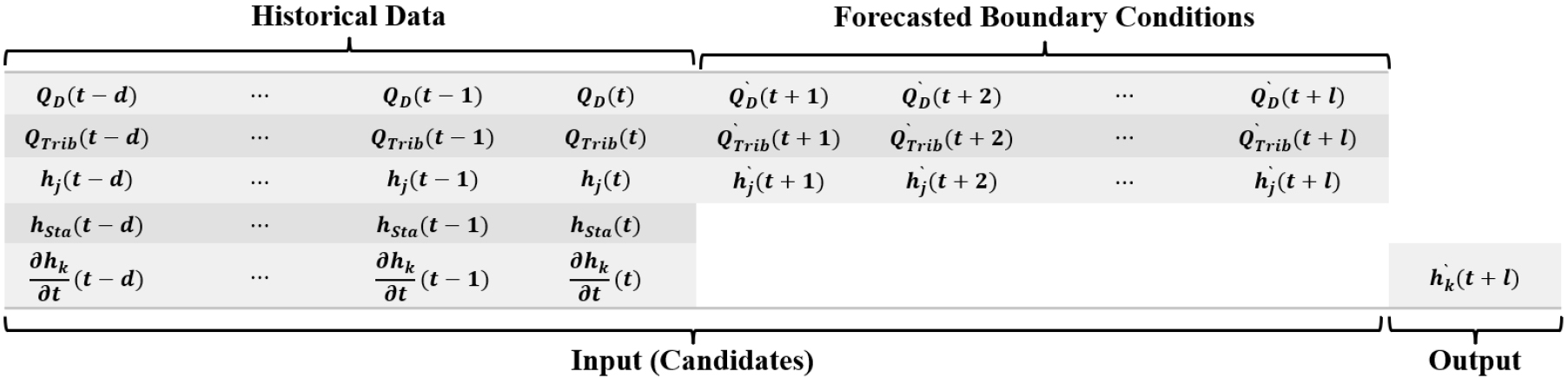
본 연구에서는 동수역학적 모형(HM), 두 종류의 단순 기계학습 모형 및 혼합모형 등 크게 4개 모형을 구축, 적용하여 그 성능을 비교하였다. 기계학습 모형으로 ANN 및 LSTM 모형을 각각 적용하였으므로, 구축된 모형들은 크게 7가지 모형(HM, ANN1, ANN2, HM+ANN3, LSTM1, LSTM2, HM+LSTM3)으로 세분된다. ANN1 및 LSTM1은 팔당댐 방류량, 지천유입량 및 수위 관측자료를 입력변수로 사용하여 각 지점의 수위를 예측하는 기계학습 모형이다. ANN2 및 LSTM2는 ANN1 및 LSTM1 모형의 입력변수에 시간 에서의 동수역학적 모형의 경계조건들을 입력변수로 추가하여 수위를 예측하도록 수립된 기계학습 모형이다. HM+ANN3 및 HM+LSTM3는 동수역학적 모형의 오차 보정을 위한 혼합모형으로서 이전 시간까지 계산된 수위의 오차(동수역학적 모형 계산값과 관측값과의 차이) 시계열이 입력 후보변수로 추가된다.
Fig. 7은 ANN1 및 LSTM1, Fig. 8은 ANN2 및 LSTM2, Fig. 9는 ANN3 및 LSTM3에 대한 입력 (후보) 및 출력 변수들을 각각 제시하고 있다. 와 은 현재까지의 팔당댐 방류량 측정값들과 이후 시간에 대한 방류량 예측값들을 각각 나타낸다. 와 은 현재까지의 지천 유입량 관측값들과 이후 시간에 대한 지천 유입량 예측값들을 각각 나타내며, 와 는 현재까지의 전류 수위관측소 지점 관측값들과 이후 시간에 대한 예측값들을 각각 나타낸다. 는 수위관측소 관측 수위를, 는 동수역학적 모형에 의하여 계산된 수위관측소 지점에서의 계산수위를 각각 나타낸다. 는 관측소 에서 관측 수위의 시간 변화율을 나타내며, 는 동수역학적 모형에 의해 계산된 수위의 시간 변화율이다. 는 관측소 지점에 대한 예측 수위이며, 는 동수역학적 모형에 의한 계산수위의 오차를 나타낸다.
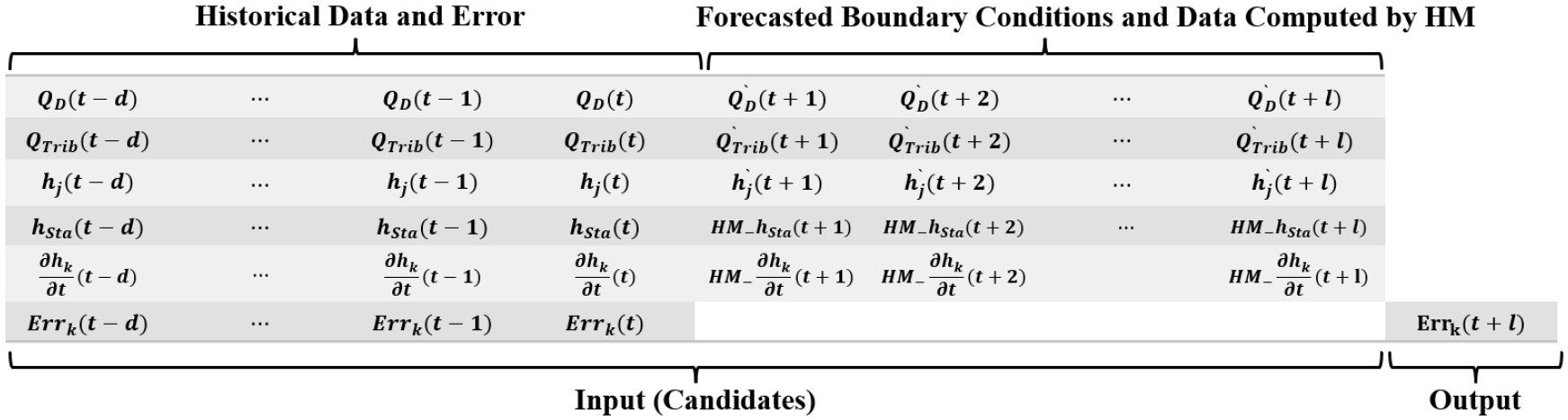
4. 결과 및 고찰
예측 선행시간 1시간, 2시간 및 3시간인 각각의 경우에 대하여(Fig. 7, Fig. 8 및 Fig. 9에서 =1, 2, 3) 팔당대교, 반포대교 및 한강대교 지점에 대한 기계학습 모형들을 구축하였다. 동수역학적 모형의 보정에 사용된 9개의 홍수사상 자료를 기계학습 모형들의 학습에 사용하였으며, 동수역학적 모형의 검증에 사용된 9개의 홍수사상 자료는 기계학습 모형들의 검증에 사용하였다(Table 1).
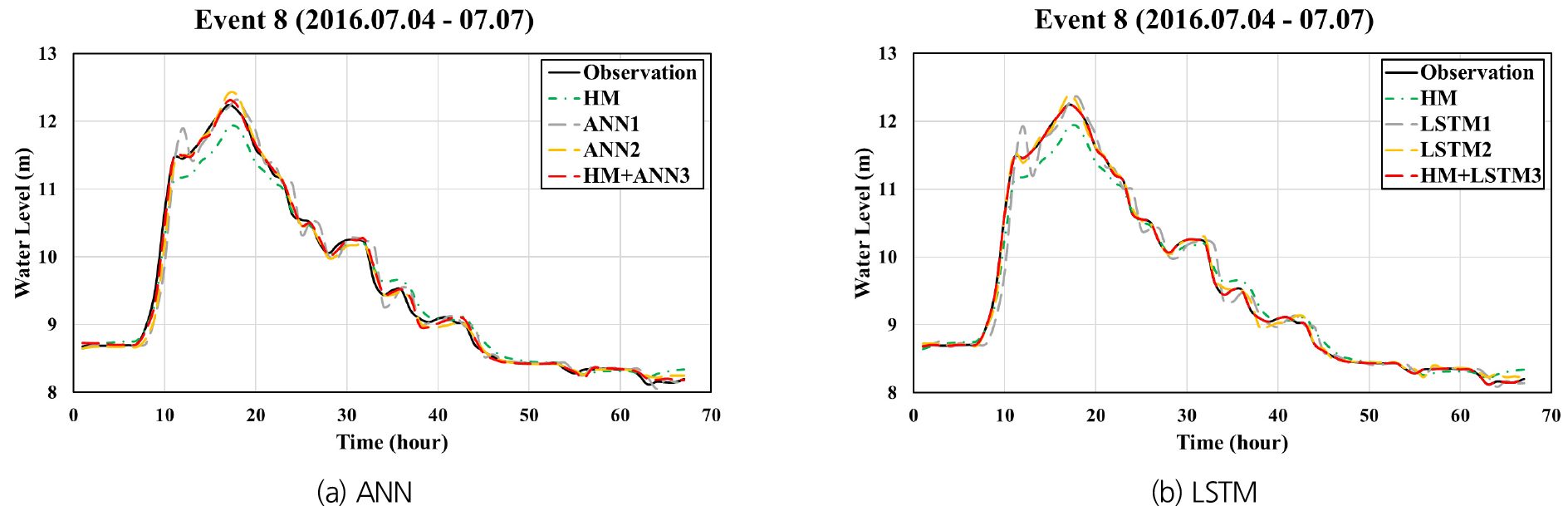
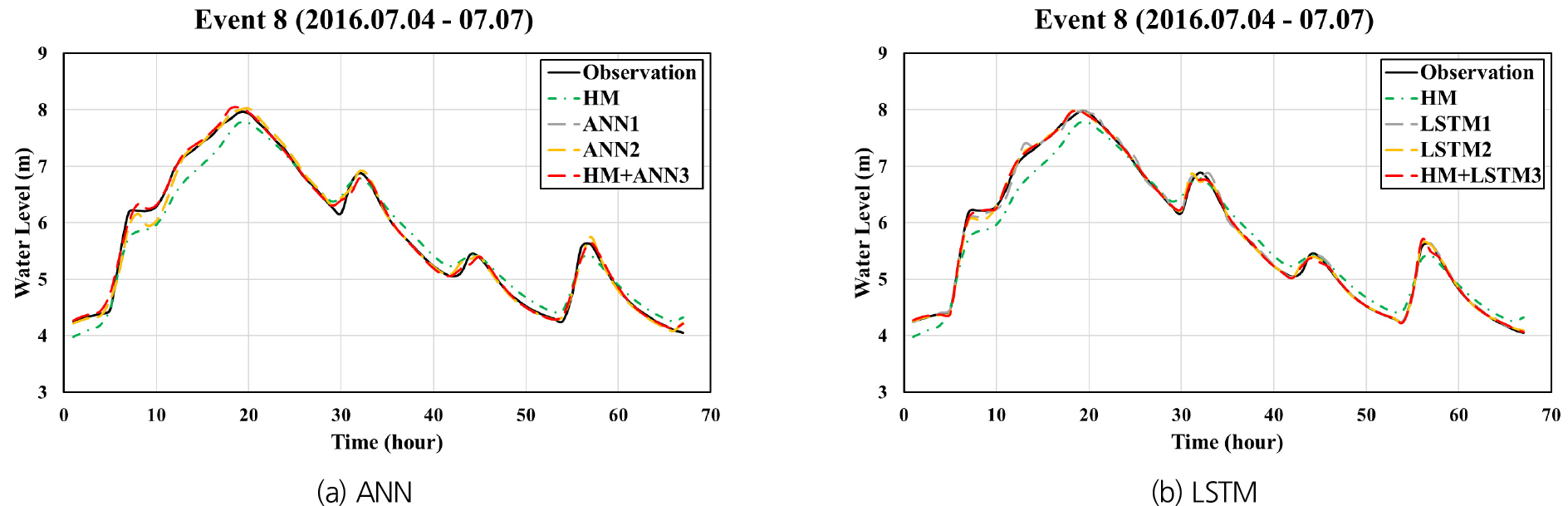
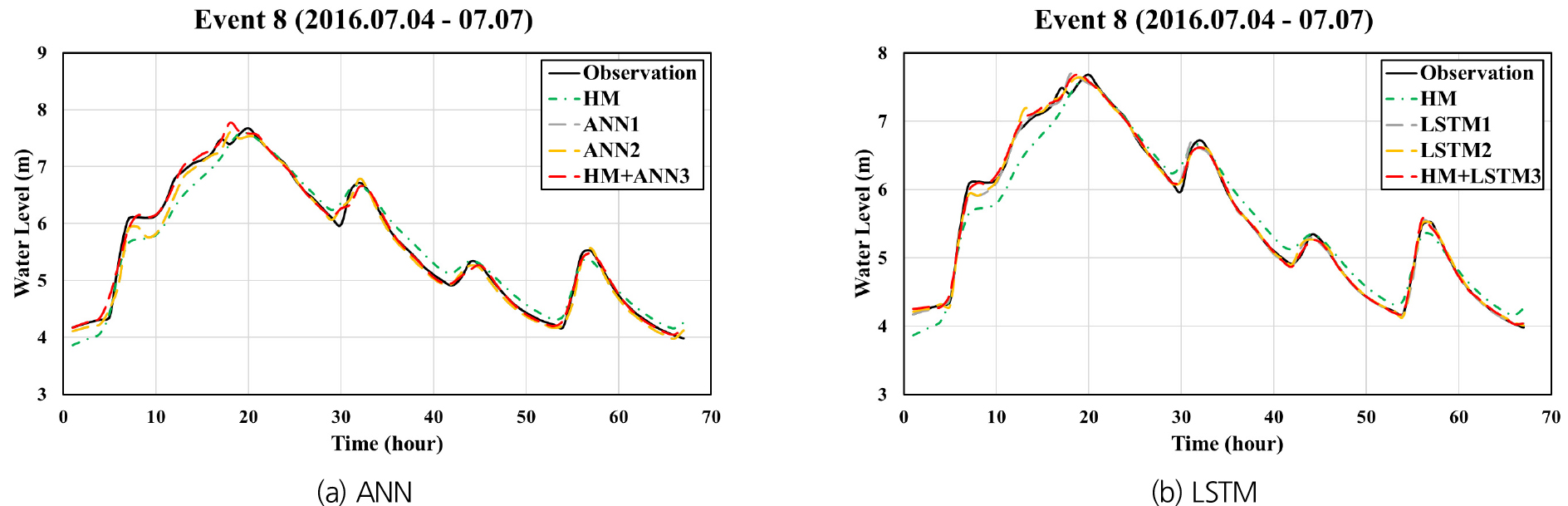
Figs. 10, 11, 12는 홍수사상 8을 대상으로 각각 팔당대교, 반포대교 및 한강대교 지점에 대하여 예측 선행시간 1시간으로 예측된 수위 수문곡선을 동수역학적 모형으로 계산된 수문곡선 및 관측 수문곡선과 함께 나타낸 것이며, Figs. 13, 14, 15는 예측 선행시간 3시간인 경우에 대한 계산결과들을 나타내고 있다. ANN1과 LSTM1의 경우 예측 선행시간 3시간으로 계산된 결과들이 선행시간 1시간일 때에 비하여 관측치와의 차이가 현저하게 큰 반면, HM+ANN3와 HM+LSTM3은 선행시간 3시간인 경우에도 매우 정확한 예측이 가능함을 보여주고 있다.
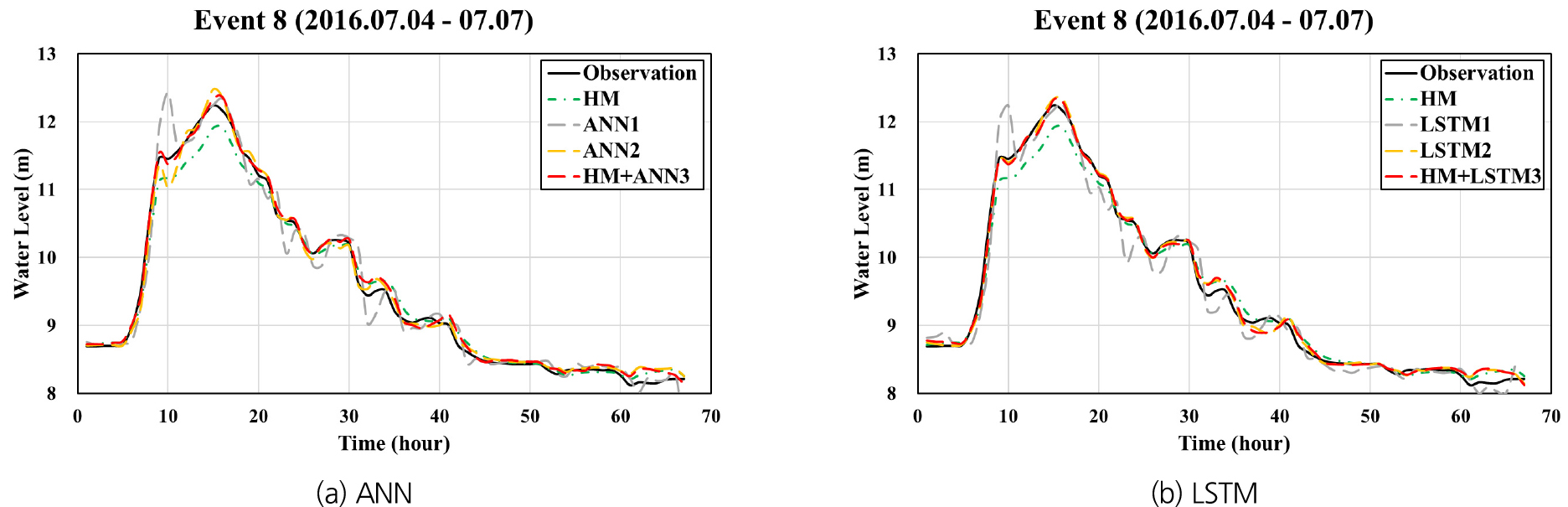
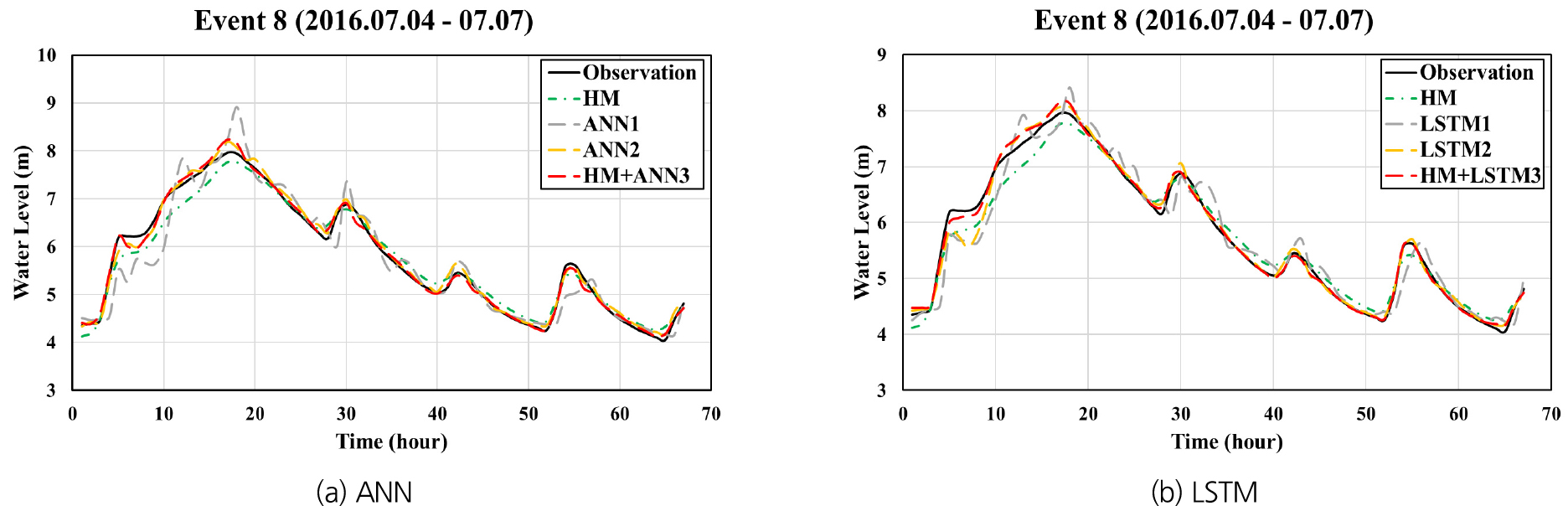
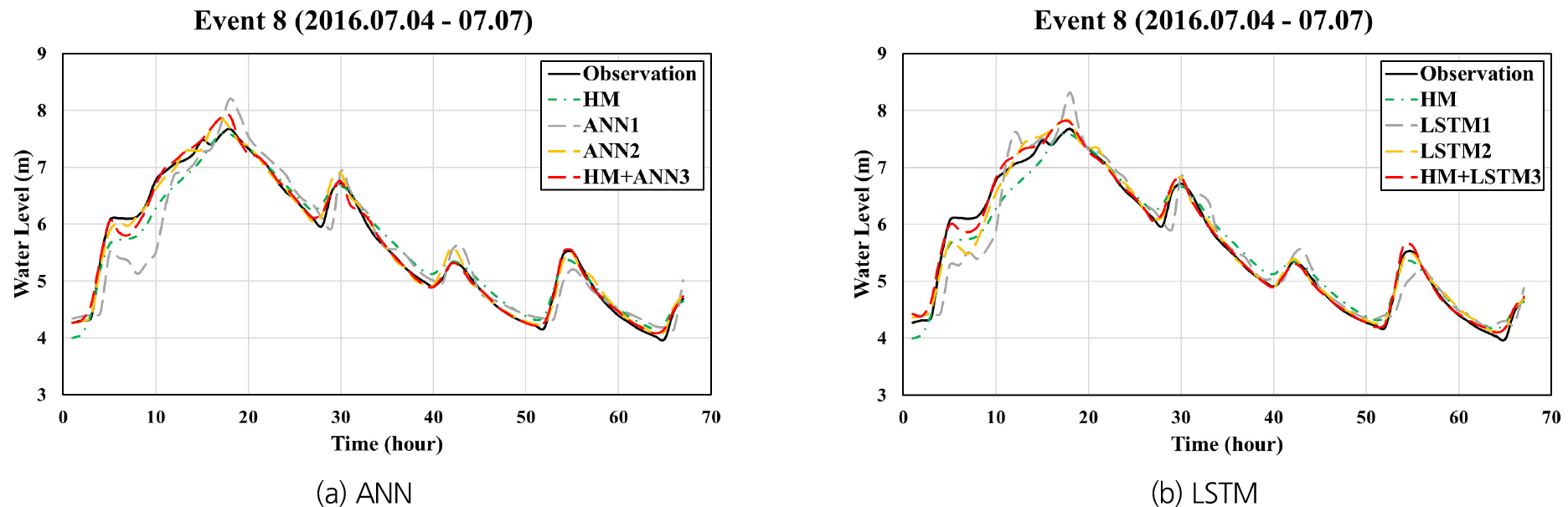
4.1 HM, LSTM1, LSTM2 및 HM+LSTM3 적용결과의 비교 분석
예측모형들의 정확성을 비교 평가하기 위하여 예측수위와 관측수위 간의 RMSE를 산정하였다. Fig. 16은 HM, LSTM1, LSTM2 및 HM+LSTM3 등 4개 모형의 학습 또는 보정 단계에서 산정된 9개 홍수사상에 대한 평균 RMSE 값들을 비교하여 나타낸 것이다. HM의 정확도는 다른 모형들에 비하여 모든 지점에서 현저하게 낮음을 알 수 있다. LSTM1, LSTM2 및 HM+LSTM3의 경우 예측 선행시간이 증가할수록 예측의 정확도가 감소함을 보이고 있다. 이러한 경향은 LSTM1의 경우에 특히 두드러지게 나타나서, 팔당대교 지점에 대한 3시간 선행 예측의 경우 LSTM1에 대한 RMSE가 HM의 경우보다도 크게 나타났다. 이는 LSTM1이 입력변수로 현재까지 관측된 데이터 만을 사용하여 수위를 예측하기 때문에 예측 선행시간이 증가할수록 예측의 불확실성이 커지는 것으로서 예상 가능한 결과라 할 수 있다.
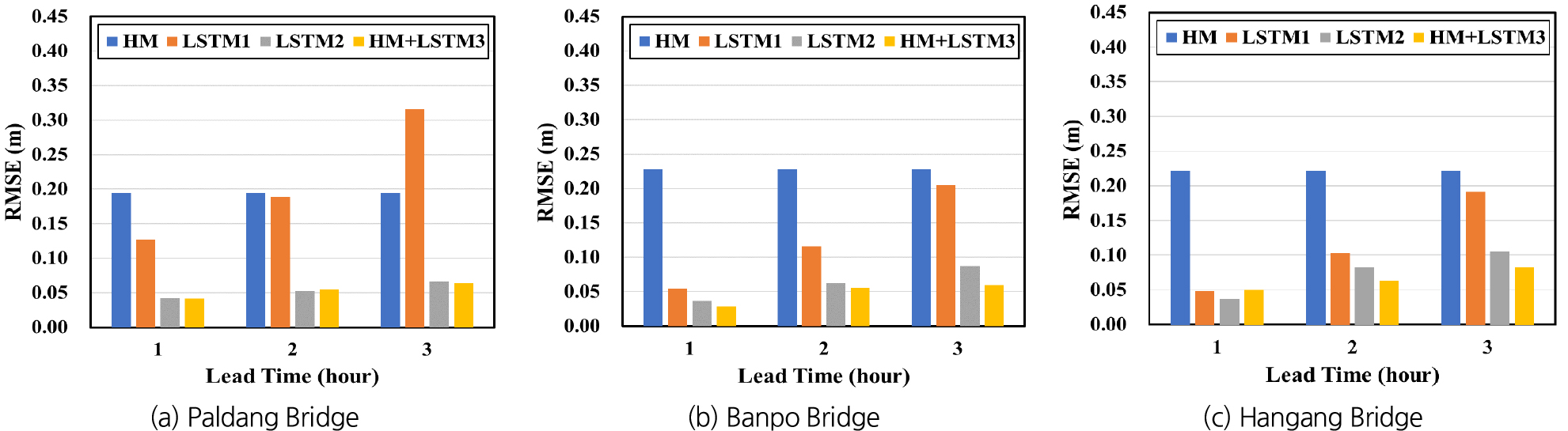
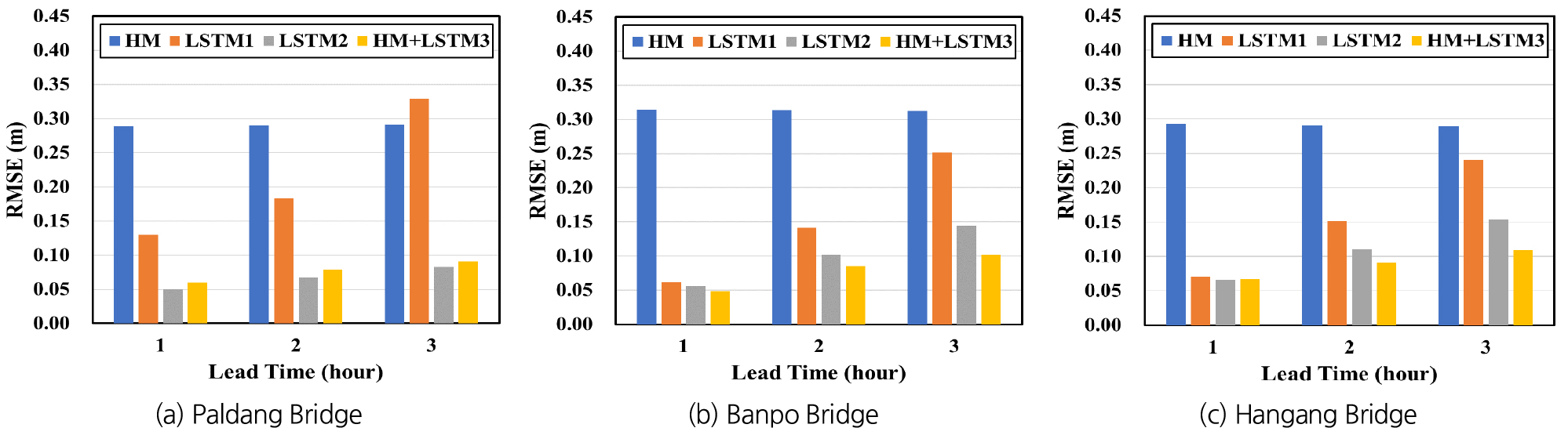
LSTM2와 HM+LSTM3는 LSTM1에 비하여 상당히 높은 예측 정확도를 보이며, 이는 예측 선행시간이 증가할수록 더욱 현저하게 나타났다. LSTM2와 HM+LSTM3에 대한 RMSE를 비교해 보면 팔당대교 지점에 대해서는 유사한 정확도를 보이고 있으며, 반포대교와 한강대교 지점에 대해서는 한강대교 지점 예측 선행시간 1시간의 경우를 제외하면 HM+LSTM3가 LSTM2에 비하여 정확한 예측 결과를 보였다. 동수역학적 모형(HM)에 대한 평균 RMSE가 25-30 cm인 반면, LSTM2와 HM+LSTM3의 경우에는 5-10 cm로서 이들 모형이 홍수예측의 정확성을 크게 개선할 수 있음을 보이고 있다
Fig. 17은 HM, LSTM1, LSTM2 및 HM+LSTM3 등 4개 모형의 검증 단계에서 산정된 9개 홍수사상에 대한 평균 RMSE 값들을 비교하여 나타낸 것이다. 모형들간의 상대적인 정확도, 예측 선행시간에 따른 RMSE의 변화 경향들이 대부분 모형의 학습 또는 보정 단계에서 나타난 결과와(Fig. 7) 유사함을 보이고 있다. 단, 팔당대교 지점의 경우 LSTM2가 HM+LSTM3에 비하여 다소 정확한 결과를 보이는 것으로 나타났으며, 반포대교 및 한강대교 지점에 대해서는 HM+LSTM3가 가장 정확한 결과를 보이는 것으로 나타났다. LSTM2와 HM+LSTM3의 경우에는 예측 선행시간의 증가에 따른 RMSE의 증가가 LSTM1에 비하여 상당히 완만하게 나타나고 있다.
Fig. 16과 Fig. 17을 비교해 보면 HM의 경우 모형 검증 단계에서의 RMSE가 학습 단계에서의 RMSE에 비하여 약 10 cm, LSTM1, LSTM2 및 HM+LSTM3 등 기계학습 모형들에 대해서는 약 5 cm 내외로 증가함을 보이고 있다. 그럼에도 불구하고 HM+LSTM3의 경우에는 모든 지점에 대하여 예측 선행시간 3시간의 경우에도 10 cm 이하의 RMSE를 나타내고 있다. 이는 보통 30 cm 이상의 RMSE를 보이는 동수역학적 모형의 홍수예측 정확성을 획기적으로 개선할 수 있음을 나타내는 결과라고 할 수 있다.
4.2 ANN 기반 모형들과 LSTM 기반 모형들의 적용결과 비교 분석
Fig. 18 및 Fig. 19는 ANN을 이용한 기계학습 모형들과 LSTM을 이용한 모형들의 학습 및 검증 단계에서 산정된 각각 9개 홍수사상에 대한 평균 RMSE 값들을 비교하여 나타낸 것이다. ANN을 적용한 기계학습 모형들의 경우에도 예측 선행시간이 증가할수록 예측의 정확도가 전반적으로 감소하는 경향이 있고, 특히 ANN1의 경우에 이러한 경향이 현저하게 나타남을 알 수 있다. LSTM1과 ANN1의 RMSE를 비교해 보면 모형의 학습 및 검증 단계 모두 LSTM1이 ANN1보다 대부분 정확한 예측 결과를 보이고 있다. 이는 LSTM 모형이 ANN 모형보다 시계열 데이터의 예측 성능이 뛰어남을 나타내는 결과라 할 수 있다.
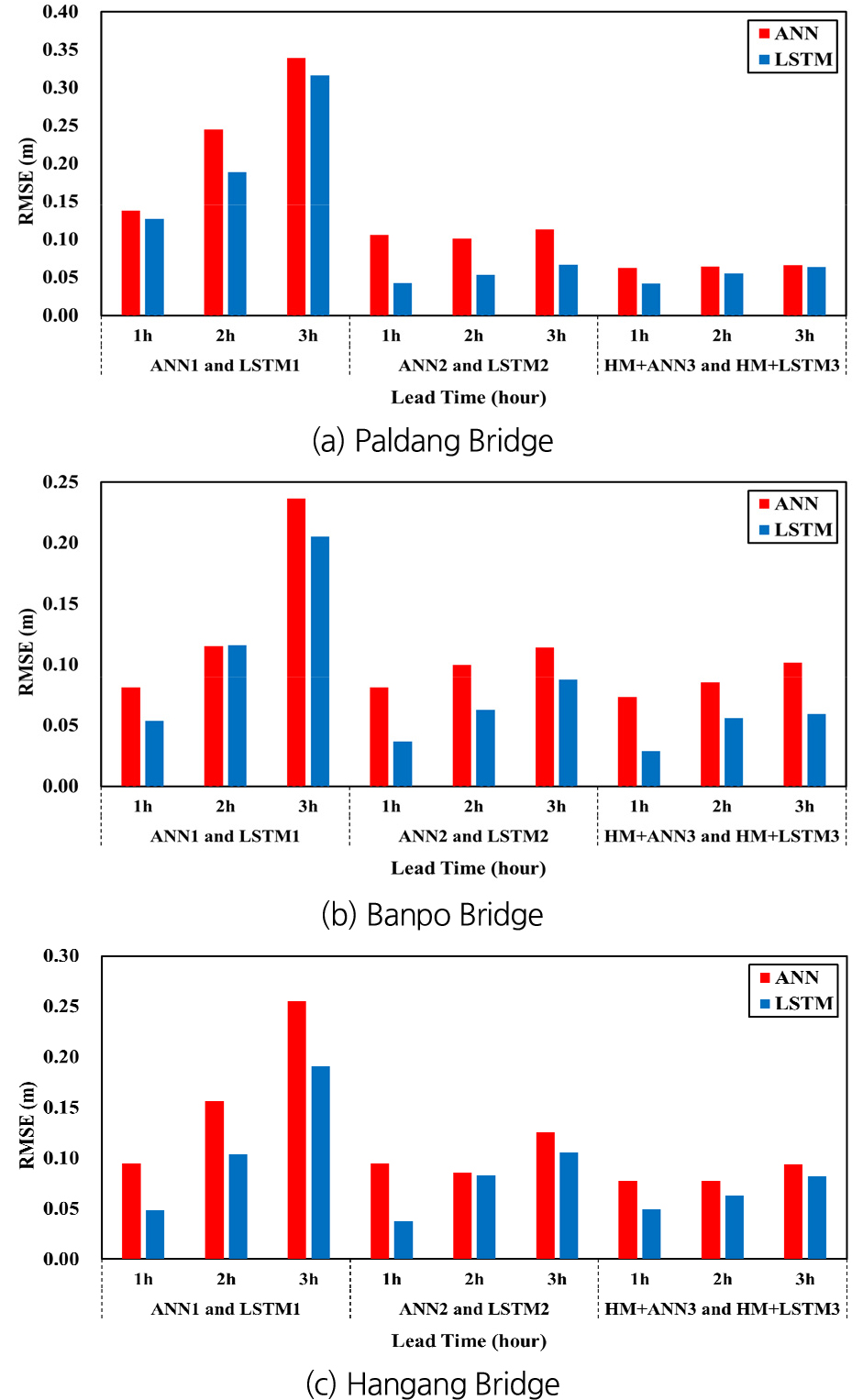
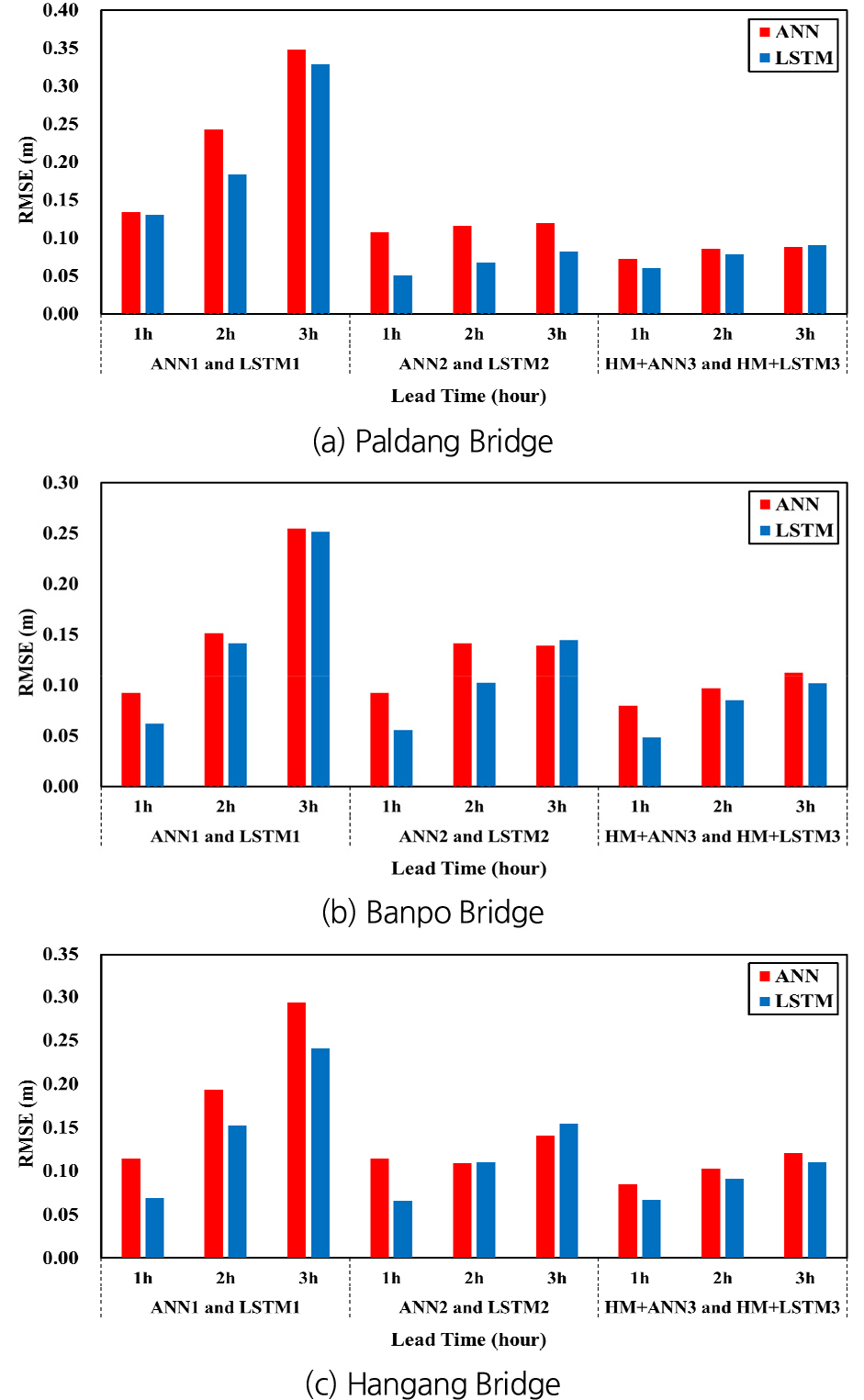
ANN2는 ANN1에 비하여 상당히 높은 예측 정확도를 보이며, 이는 예측 선행시간이 증가할수록 더욱 현저한 것으로 나타났다. LSTM2의 경우에는 예측 선행시간이 증가함에 따라 정확도가 감소하는 경향이 뚜렷하게 보인 반면, ANN2의 경우에는 이러한 경향이 일관되게 나타나지 않고 있다. LSTM2와 ANN2의 RMSE를 비교해 보면, 모형의 학습단계에서는 모든 지점에서 예측 선행시간에 관계없이 LSTM2가 ANN2보다 정확한 예측 결과를 보였다. 모형의 검증단계에서도 전반적으로 LSTM2가 ANN2에 비하여 정확한 결과를 보이고 있으나, 반포대교와 한강대교 지점에 대한 3시간 선행 예측의 경우에는 ANN2의 RMSE가 LSTM2에 비하여 작게 나타났다.
HM+ANN3과 ANN2의 RMSE를 비교해 보면 모형의 학습 및 검증 단계 모두 모든 지점에서 예측 선행시간에 관계없이 HM+ANN3가 ANN2보다 정확한 예측 결과를 보이고 있다. HM+LSTM3의 경우와 마찬가지로 HM+ANN3의 경우에도 예측 선행시간이 증가함에 따라 예측의 정확도가 감소함을 나타내고 있다. HM+LSTM3와 HM+ANN3의 RMSE를 비교해 보면, 모형 학습 단계에서는 모든 지점에서 예측 선행시간에 관계없이 HM+LSTM3의 RMSE가 더 작게 나타났다. 검증 단계에서도 마찬가지로 팔당대교 지점에 대한 3시간 선행 예측의 경우를 제외하면 HM+LSTM3이 HM+ANN3보다 작은 RMSE를 보이고 있다.
이러한 결과들을 종합하면 LSTM을 기반으로 구축된 LSTM1, LSTM2 및 HM+LSTM3가 ANN을 기반으로 한 ANN1, ANN2 및 HM+ANN3보다 각각 우수한 성능을 보이며, 이들 모형 중 가장 예측 성능이 뛰어난 HM+LSTM3은 Li and Jun (2022)에 의하여 개발된 HM+ANN3 보다 개선된 예측 성능을 보임을 알 수 있다.
5. 결 론
하천 홍수위 예측의 정확성을 제고하기 위하여, 본 연구에서는 물리 기반의 동수역학적 모형과 데이터 기반의 LSTM 모형을 혼합하여 적용하는 방법을 제시하였다. 한강 하류 구간에 대한 동수역학적 모형으로 Manning 조도계수와 유량과의 관계를 멱함수로 나타내는 가변 매개변수 분포형 모형을 수립하고, 최적화에 의한 매개변수의 추정을 수행하였다. 최적화된 동수역학적 모형에 의한 계산수위와 관측수위 간의 홍수사상 평균 RMSE는 모형의 보정 및 검증 단계에서 각각 0.215 m 및 0.299 m로, Li and Jun (2022)의 경우와(각각 0.205 m 및 0.308 m) 유사한 정확도를 나타냈다.
동수역학적 모형(HM)과 LSTM 모형을 결합한 혼합모형의 정확성을 평가하기 위하여 동수역학적 모형, 두 개의 LSTM 모형(LSTM1 및 LSTM2) 및 혼합모형(HM+LSTM3)에 대한 비교평가를 수행하였다. LSTM1 모형은 현재까지의 관측 데이터만을 활용하는 데이터 기반 수위 예측 모형이며, LSTM2 모형은 현재까지의 관측 데이터뿐만 아니라 동수역학적 모형의 입력자료로 필요한 경계조건 예측값을 추가적인 입력변수로 포함하도록 한 LSTM 모형이다. 혼합모형의 경우에는 LSTM2 모형의 경우와 동일한 입력변수에 추가적으로 동수역학적 모형에 의한 수위 및 수위의 시간 변화율 예측값 및 3시간 전부터 현재까지의 시간별 수위 계산값과 관측값 간의 오차가 오차보정 모형(LSTM3)의 입력변수로 포함된다.
여러 모형들의 성능을 예측수위와 관측수위 간의 RMSE를 통하여 비교해 본 결과, 혼합모형이 개별적인 동수역학적 모형 또는 LSTM 모형들에 비하여 우수한 성능을 보이는 것으로 나타났다. 동수역학적 모형의 정확도는 다른 모형들에 비하여 모든 지점에서 현저하게 낮음을 알 수 있었다. LSTM1의 경우 예측 선행시간이 증가할수록 예측의 정확도가 감소하는 경향이 두드러지게 나타나서, 팔당대교 지점에 대한 3시간 선행 예측의 경우 동수역학적 모형의 경우보다도 RMSE가 크게 나타났다. 이는 기계학습 모형의 입력변수로 현재까지 관측된 데이터만을 사용할 경우 예측 선행시간이 증가할수록 예측의 불확실성이 커짐을 시사하는 결과라 할 수 있다. 반면에 LSTM2와 혼합모형의 경우에는 예측 선행시간의 증가에 따른 RMSE의 증가가 완만하며, 예측 선행시간이 증가할수록 LSTM1에 비하여 상당히 높은 예측 정확도를 보이는 것으로 나타났다. LSTM2와 혼합모형에 대한 RMSE를 비교해 보면 팔당대교 지점에 대해서는 유사한 정확도를 보이고 있으나, 전반적으로 혼합모형이 LSTM2에 비하여 정확한 예측 결과를 보였다.
기계학습 모형으로 LSTM 대신 ANN을 이용한 모형들(ANN1, ANN2 및 HM+ANN3; Li and Jun, 2022)을 구축하여 동일한 분석을 수행, 그 결과를 비교하였다. ANN을 적용한 기계학습 모형들의 경우에도 여러 모형들 간의 상대적인 예측 정확도 및 예측 선행시간이 증가에 따른 변화 경향은 LSTM을 적용한 기계학습 모형들의 경우와 유사한 것으로 나타났다. 또한 LSTM을 기반으로 구축된 LSTM1, LSTM2 및 HM+ LSTM3가 ANN을 기반으로 한 ANN1, ANN2 및 HM+ANN3보다 각각 전반적으로 예측 결과를 보였다. 이는 LSTM 모형이 ANN 모형보다 시계열 데이터의 예측 성능이 우수함에 따른 결과라 할 수 있다.
결국 동수역학적 모형과 LSTM 모형을 결합한 혼합모형이 동수역학적 모형 또는 LSTM 모형을 개별적으로 적용하는 경우에 비하여 탁월한 성능을 보일 뿐만 아니라, 동수역학적 모형과 ANN 모형을 결합한 혼합모형(Li and Jun, 2022)보다도 향상된 결과를 보였다. 예측 선행시간 3시간의 경우에도 모든 지점에 대하여 RMSE가 10 cm 이하로, 보통 30 cm 이상의 RMSE를 보이는 동수역학적 모형의 홍수예측 정확성을 획기적으로 개선할 수 있는 것으로 나타났다.
본 연구에서의 분석결과는 본 연구에서 자료로 사용된 홍수사상들의 홍수 규모 내에서 유효하며, 극한 홍수 등 대규모의 홍수에 대해서는 추가적인 분석이 필요할 것이다.
