

1. 서 론
2. 정상성 지역빈도해석
2.1 서 론
2.2 수문학적 동질지역 구성
2.3 홍수지수법을 이용한 확률수문량 산정
2.4 정상성 지역빈도해석 절차
3. 비정상성 지역빈도해석
3.1 서 론
3.2 동질지역 구성
3.3 비정상성 지역빈도해석 절차
4. 최근 연구동향
5. 결 론
1. 서 론
수문자료의 빈도해석은 관측된 자료에 대한 기본적인 통계량(평균, 분산, 변동계수, 표준편차, 왜곡도, 첨예도)에 적합한 확률분포형을 선정하고 이를 이용하여 수공구조물의 설계 및 분석에 필요한 확률수문량(설계수문량)을 산정하거나 이에 대응하는 설계빈도 또는 재현기간을 구하는 절차이다. 수공구조물의 설계빈도는 그 종류에 따라 상이하나 그 규모와 중요도에 따라 파괴 시에 막대한 인적·물적 피해를 초래할 수 있으므로 해당 설계빈도에 대해 수문자료의 통계적 특성을 고려한 정확한 확률수문량을 산정하는 것은 매우 중요하다고 할 수 있다. 일반적으로 빈도해석 기법은 지점빈도해석(at-site frequency analysis)과 지역빈도해석(regional frequency analysis)으로 분류할 수 있다. 지점빈도해석에서는 주어진 지점의 자료만을 이용하여 확률수문량을 산정하며, 지역빈도해석에서는 대상 지점을 포함하여 수문학적으로 동질한 것으로 판단되는 주변 지점들의 자료를 모두 포함하여 확률수문량을 산정한다. 여기서 수문학적 동질성이란 지역빈도해석 기법의 수행을 위한 가장 기본적이고 강한 가정으로 하나의 지역을 구성하는 여러 지점의 자료들이 모두 동일한 모분포를 갖는다는 것이다.
일반적으로 수공구조물의 설계빈도는 100년 또는 200년 이상의 긴 재현기간을 가지므로 해당 재현기간에 대해 정확한 확률수문량을 산정하기 위해서는 대상 지점에 충분한 기간의 관측자료가 확보되어야 한다. 주어진 지점의 자료가 신뢰할 만한 확률수문량을 구하기에 충분한 자료기간을 가지고 있는 경우 지점빈도해석이 대상 지점의 관측자료를 가장 잘 반영할 수 있는 적합한 기법이라고 할 수 있다. 그러나 이에 대한 명확한 기준이 없고 대부분의 대상 지점은 수공구조물의 설계빈도보다 짧은 기간의 수문관측자료를 보유하고 있으며 수문관측자료가 없는 미계측 지점인 경우도 있다. 지역빈도해석 기법은 이러한 미계측 지점 및 관측자료의 보유기간이 짧은 지점에 대하여 보다 정확하고 신뢰할 수 있는 확률수문량을 산정하기 위한 목적으로 개발되었으며, 현재까지 많은 연구결과에서 지역빈도해석을 통해 산정된 확률수문량이 지점빈도해석을 통해 산정된 결과보다 더 정확한 것으로 알려져 있다(Lettenmaier et al., 1987; Hosking and Wallis, 1997; Alila, 1999; De Michele and Rosso, 2001; Heo et al., 2007; Nam et al., 2015a; Yin et al., 2016; Liang et al., 2017; Wang et al., 2017).
지역빈도해석 기법으로는 홍수지수법(index flood method), 지역형상추정법(regional shape estimation method), 계층적 베이지안 모델링(hierarchical Bayesian modeling), FORGEX (focused rainfall growth extension) 기법 등이 있다. 홍수지수법은 지역 내 서로 다른 지점의 자료들의 통계량을 결합하는 합리적이면서도 간편한 방법으로 미국, 남아프리카, 뉴질랜드, 호주 등지에서 확률강우량 산정 지침으로 널리 사용되고 있다(Svensson and Jones, 2010). 또한, Hosking and Wallis (1997)에 의해 홍수지수법을 이용한 L-모멘트 기반의 지역빈도해석 절차가 정립된 이후, 이를 기반으로 한 지역빈도해석 방법 및 확률수문량 산정에 관한 다양한 연구들이 현재까지 전 세계적으로 활발히 진행되고 있다. 우리나라의 경우 Heo et al. (2007)과 Lee et al. (2007)에서 378개 강우관측지점에 대해 수행한 홍수지수법 기반의 지역강우빈도해석과 Kim et al. (2016a; 2016b)에서 충주댐 상류유역을 대상으로 수행한 홍수지수법 기반의 지역홍수빈도해석이 대표적이다. 지역형상추정법은 자료의 평균과 분산의 경우 각 지점 별로 산정하고 자료의 왜곡도에 영향을 주는 형상매개변수의 경우 지역 내 지점들의 평균을 적용하여 확률수문량을 산정하는 기법으로 지점빈도해석과 홍수지수법의 중간형태의 기법이라고 할 수 있다. 계층적 베이지안 모델링은 확률수문량 산정을 위한 지역 내 각 지점의 확률분포형 매개변수들이 상위단계의 또 다른 확률분포로부터 추정되며, 모든 매개변수들의 사후분포를 베이지안 추론을 통해 추정하는 기법이다. 계층적 베이지안 모델링은 매개변수의 지역화 뿐 아니라 불확실성을 정량화할 수 있다는 장점이 있으며 국내·외적으로 다양한 연구가 수행되고 있다. 우리나라의 경우 Kwon et al. (2013)은 지역강우빈도해석을 위한 계층적 베이지안 모델링의 적용성 및 우수성을 확인하였으며, Kim et al. (2014)과 Kim et al. (2017a)은 지형적 특성, 극치강우의 scale 특성 등을 generalized linear model을 통해 확률분포형의 매개변수로 고려한 계층적 베이지안 모델링을 이용하여 지역강우빈도해석을 수행한 바 있다. FORGEX 기법은 Flood Estimation Handbook (IH, 1999)에서 제안된 기법으로 대상 지점에 대하여 네트워크를 구성하고 이를 확장하면서 확률수문량을 산정하는 방법으로 가장 큰 특징은 기존의 지역빈도해석에서 수행하는 지역구분 절차를 대상 지점을 중심으로 단계적 네트워크를 구성하는 것으로 대신한다는 점이다. 우리나라의 경우 Kim et al. (2008)과 Kim et al. (2016c)이 FORGEX 기법을 적용하여 지역강우빈도해석을 수행한 바 있다.
한편 최근 산업화, 도시화 등과 같은 인위적 요인으로 인한 기후변화는 강수, 증발산, 유량과 같은 수문자료에 대한 평균적인 추세와 극치사상을 변화시키고 있다(Milly et al., 2008). 이러한 기후변화를 고려한 기후모델의 예측 결과를 살펴보면 향후 온실기체 배출량 및 대기 중 농도 변화를 의미하는 대표농도경로(representative concentration pathways, RCP) 시나리오에 따라 전 세계적으로 평균 기온 및 강수량이 크게 변화할 것으로 예상되고 있다(IPCC, 2014). 이와 같은 조건에서 빈도해석의 수행을 위한 또 하나의 중요한 기본가정인 자료 또는 그 통계적 특성이 시간에 따라 변하지 않는 정상성(stationarity)은 더 이상 유효하지 않다. 실제 관측된 수문자료에서도 뚜렷한 비정상성(nonstationarity)을 보이는 경우가 지속적으로 나타나고 있으며, 경향성 분석, 회귀분석, 변동성 분석 등의 방법을 통해 자료의 비정상성을 분석할 수 있다. 이와 같이 수문자료에 비정상성이 존재하는 경우 이를 고려할 수 있는 다양한 비정상성 지역빈도해석 기법이 제안되고 있다.
비정상성 지역빈도해석 기법의 경우 위에서 설명한 홍수지수법 또는 계층적 베이지안 모델링 내의 매개변수에 비정상성을 고려하는 연구가 현재 가장 널리 수행되고 있으며, 일반적으로 자료의 비정상성과 관련이 있는 다양한 공변량(covariate)이 포함된 비정상성 확률분포형을 적용하여 확률수문량을 산정하게 된다. 연최대치 자료계열(annual maximum series)의 경우 Gumbel (GUM), generalized extreme value (GEV) 분포형이 비정상성 확률분포형으로 가장 널리 사용되고 있으며, 이러한 분포형의 위치 또는 규모매개변수를 공변량에 대한 함수로 나타냄으로써 비정상성 확률분포형을 정의한다. 이 때, 비정상성 확률분포형에 대한 공변량으로는 시간항(time)이 주로 사용되었으나, 자료의 비정상성에 대한 물리적 의미를 설명할 수 있는 SOI (Southern Oscillation Index), ENSO (El Niño Southern Oscillation), NAO (North Atlantic Oscillation), SST (Sea Surface Temperature), PDO (Pacific Decadal Oscillation) 등과 같은 대기·해양 순환과 관련된 대규모 기후지수(climate indices)들이 널리 이용되고 있다(Cannon, 2010; Kwon and Lee, 2011; López and Francés, 2013; Silva et al., 2016; Agilan and Umamahesh, 2017; Jung et al., 2019).
본 총설논문에서는 현재 전 세계적으로 가장 널리 적용되고 있는 홍수지수법을 중심으로 정상성 및 비정상성 수문자료에 대한 지역빈도해석과 관련하여 현재까지 수행되어온 연구 및 그 절차를 소개하고 지역빈도해석 기법에 대한 최신 연구동향을 살펴보고자 한다. 2장에서는 홍수지수법 기반의 정상성 지역빈도해석에 대한 기본적인 설명 및 관련 선행연구, 적용 절차를 상세하게 기술하며, 3장에서는 지역빈도해석에서의 비정상성 적용 원리와 다양한 비정상성 홍수지수모형 및 선행연구를 소개하고 비정상성 지역빈도해석 적용 절차를 상세히 기술한다. 4장에서는 수문자료의 지역빈도해석과 관련하여 적용사례 및 다양한 기법 개발 등을 포함한 최신 연구동향을 정리하고. 마지막으로 결론을 기술하며 논문을 마무리한다.
2. 정상성 지역빈도해석
2.1 서 론
빈도해석 시 관측자료 년 수가 길수록 적은 불확실성을 가지며 보다 신뢰할 수 있는 확률수문량을 산정할 수 있다. 지역빈도해석은 지점빈도해석과 비교하여 보다 많은 자료를 활용함으로써 확률수문량의 정확도 향상 또는 미계측 지점에 대한 확률수문량 산정을 목적으로 적용된다. 다시 말해, 단일 관측지점의 관측자료만을 사용하는 지점빈도해석과 달리 지역빈도해석에서는 동일한 모분포를 따르는 것으로 판단되는 지점들을 하나의 지역으로 구성하고 이 지역에 포함된 모든 지점들의 관측자료를 활용하여 빈도해석을 수행하기 때문에 보다 정확하고 불확실성이 적은 확률수문량을 산정할 수 있다. 이는 대상 지점자료에 대한 시간적 한계를 공간적으로 보상하는 것이라고 할 수 있다(Schaefer, 1990; Nandakumar, 1995).
정상성 지역빈도해석에서는 대상 지점의 확률수문량 산정을 위해 동질지역으로 구분된 지역 내의 다른 지점들의 관측자료를 활용하게 되며, 이때 활용되는 모든 관측자료는 시간에 따라 자료 및 그 통계적 특성이 변하지 않는 정상성을 가정한다. 다양한 지역빈도해석 기법들 중 홍수지수법은 가장 대표적인 지역빈도해석 기법으로 전 세계적으로 널리 활용되고 있다. Darlymple (1960)에 의해 제안된 홍수지수법은 다음과 같은 기본가정을 가진다. ① 한 지점에서 관측된 수문자료는 서로 독립이며 동일한 확률분포형을 가진다(iid 가정). ② 동질지역 내에서 관측된 수문자료들은 서로 다른 지점들 간에 종속성(dependence)이 없다. ③ 지역 내 각 지점의 수문자료를 지점조정요소(site-specific scaling factor)로 표준화한 자료들은 동일한 확률분포형을 가진다. Darlymple (1960)은 각 지점의 연 최대치 홍수량의 평균값을 지점조정요소로 사용하여 관측자료를 표준화 하였다. 즉, 연최대치 홍수량 자료 계열을 연 최대치 홍수량의 평균값으로 나눠줌으로써 표준화된 자료를 통해 홍수빈도해석을 수행함에 따라 이 방법이 홍수지수법으로 불리게 되었다. 이후 홍수빈도해석 뿐 아니라 강우빈도해석에서도 연 최대치 강우 자료 계열의 평균을 지점조정요소로 적용하여 자료 계열을 표준화하였으며(NERC, 1975; Hosking et al., 1985; Hosking and Wallis; 1997), 이에 따라 수문자료의 지역빈도해석 시 자료 계열의 표본평균을 지점조정요소로 사용하는 것이 대중화 되었다. 지역 내의 표준화된 자료들을 활용하여 추정된 확률분포형을 재현기간에 대한 빈도값으로 나타낸 곡선인 지역성장곡선(regional growth curve)에 각 지점 자료의 표준화에 사용된 지점조정요소(홍수지수)를 곱해줌으로써 대상 지점의 확률수문량을 산정하게 된다. 정상성 지역빈도해석의 절차는 크게 수문학적 동질지역 구성과 홍수지수법 적용을 통한 확률수문량 산정으로 구분할 수 있다.
2.2 수문학적 동질지역 구성
수문학적 동질지역의 구성은 관측지점의 군집화를 통한 지역 구성, 불일치척도 및 이질성척도를 통한 지역동질성 검토로 이루어진다. 지형적 편의성이나 전문가의 의견에 따라 주관적으로 지역을 구성할 수도 있으나, 일반적으로 수문기상학적 변수, 지리적 변수, 통계적 변수와 같은 다양한 지점 특성치를 활용한 다변량 분석을 통해 지역을 형성하게 된다. 군집해석(cluster analysis)은 지역 형성을 위한 기법들 중에서 많은 연구에서 적용되고 있는 비교적 객관적인 방법으로 single linkage, complete linkage, average linkage, median, Ward 기법 등과 같은 계층적 군집화(hierarchical clustering) 기법과 K-means, adaptive K-means, K-medoids, Fuzzy clustering, self-organizing map 기법 등과 같은 비계층적 군집화 기법이 있다(Härdle and Simar, 2003). Nam et al. (2015a)은 지리적 변수와 다양한 수문기상학적 변수를 활용한 Fuzzy C-means 기법 및 Ward 기법을 사용하여 우리나라를 5개의 수문학적 동질지역으로 구분하였으며, 구분된 지역에 대한 모의실험을 통해 홍수지수법이 지역형상추정법 및 지점빈도해석과 비교하여 동질지역에서 가장 우수한 성능을 보임을 확인하였다. Shin et al. (2018)은 우리나라의 이변량 수문자료(연최대치 강우량-지속기간 자료)에 대한 지역구분을 최초로 수행하였다. K-medoids 기법을 통해 최종적으로 구분된 5개의 지역에 대하여 이질성척도를 통해 동질성을 검토함으로써 우리나라 강우자료에 대한 다변량 지역빈도해석의 적용가능성을 확인하였다. Ahn et al. (2018)은 지리적, 수문기상학적, 통계적 변수들을 활용하여 인공신경망 기법 중 하나인 자기조직화지도(self-organizing map) 기법을 활용하여 우리나라를 총 6개의 수문학적 동질지역으로 구분한 결과, 선행 연구와 유사하지만 보다 더 동질한 지역으로 구분됨을 통해 자기조직화지도 기법의 적용성 및 우수성을 확인하였다.
불일치척도(Discorcance measure, Di)는 위와 같은 방법을 통해 구성된 지역에서 지역 내에 포함된 지점들의 수문자료에 대한 통계적 특성이 그 지역과 전체적으로 일치하는지 알아보기 위한 척도로 다양한 L-모멘트비(L-변동계수, L-왜곡도계수, L-첨예도계수)에 의해서 측정된다. Di가 특정 한계값을 초과하는 경우 지점 i는 동일한 지역 내의 다른 지점들과 불일치한 것으로 판단할 수 있으며, 이러한 경우 해당 지점을 제외시킬 수 있다. Table 1은 지역 내 지점 수에 따른 불일치척도의 한계값을 나타낸 것이다.
이질성척도(Heterogeneity measure, H)는 구분된 지역의 통계적 특성이 동질한지를 최종적으로 판단할 수 있는 척도로 실제 지역가중평균 L-모멘트비와 모의실험을 통해 생성된 지점 자료들의 L-모멘트비와의 오차를 기반으로 정의된다. 이질성척도는 L-변동계수를 활용하는 경우 H1, L-변동계수와 L-왜곡도계수를 활용하는 경우 H2, L-왜곡도계수와 L-첨예도계수를 활용하는 경우 H3으로 정의되며, 이들 중 H1의 성능이 가장 좋은 것으로 알려져 있으나, 사용하는 기법에 따라 다른 기준을 적용할 수 있다(Lu, 1991; Heo, 2016). 그러나 실제 지역빈도해석의 적용 연구에서는 H1이 수문학적 지역 동질성을 확인하는 척도로 현재까지 널리 활용되고 있다. H1 ˂ 1인 경우 동질한(acceptably homogeneous) 지역, 1 ≤ H1 ˂ 2인 경우 이질가능(possibly heterogeneous) 지역, H1 ≥ 2인 경우 이질한(definitely heterogeneous) 지역으로 정의할 수 있다(Hosking and Wallis, 1997).
불일치척도는 구분된 지역 내 지점 수문자료의 통계적 특성이 지역평균 통계량과 비교하여 얼마나 차이가 나는가를 정량화한 수치로 각 지점 별로 산정되며, 이질성척도는 구분된 지역의 동질성을 판단하는 척도로 각 지역 별로 산정되는 값이다. 따라서, 다양한 기법들을 통해 1차적으로 구분된 지역에 대하여 이질성척도를 통해 지역 동질성을 검토한 후, 이질한 것으로 나타나는 지역에 대해 불일치척도가 Table 1에서 제시된 한계값을 초과하는 지점 또는 가장 큰 값을 가지는 지점들을 제외시킴으로써 지역을 재조정할 수 있다.
Table 1. Critical values for the discordancy statistic Di (Hosking and Wallis, 1997)
2.3 홍수지수법을 이용한 확률수문량 산정
2.2절에서 설명한 기법들을 통해 최종적으로 결정된 수문학적 동질지역에 대하여 지역을 대표할 수 있는 적정 확률분포형을 선정하고, 이를 홍수지수법에 적용하여 지역 내 각 지점들의 확률수문량을 산정하게 된다. 확률분포형의 경우 지점빈도해석과 마찬가지로 gamma (GAM), GEV, generalized logistic (GLO), generalized Pareto (GP), GUM, kappa (KAP), normal (NOR), Weibull (WBU) 분포형 등 다양한 확률분포형을 활용할 수 있다. 지역빈도해석에서는 적정 확률분포형을 선정하는 척도로 적합성척도(goodness-of-fit measure, Z)를 사용한다. 적합성척도는 지역의 통계적 특성을 대표하는 지역 내 각 지점별 자료의 L-모멘트의 지역가중평균이 적용하고자 하는 확률분포형의 L-모멘트와 얼마나 일치하는가를 비교함으로써 적정확률분포형을 선정하는 방법이다. 신뢰구간 90%를 고려한 적용 분포형의 적합성 인정 기준은 ≦ 1.64이며(Hosking and Wallis, 1993), 여러 분포형에 대하여 위 조건을 만족하는 경우에는 이 0에 가장 가까운 분포형을 가장 적합한 확률분포형으로 선정한다. 여기서 선정된 확률분포형을 홍수지수법의 지역성장곡선에 적용함으로써 최종적으로 확률수문량을 산정한다.
홍수지수법은 동질 지역을 대표하는 지역성장곡선과 지역 내 각 지점의 홍수지수를 곱하여 확률수문량을 산정하는 방법이다. N개의 지점들로 구성된 지역 내에서 지점 i의 표본크기가 ni라고 할 때, 그 지점의 수문관측자료의 계열은 로 나타낼 수 있다. 이러한 지역에 대하여 아래의 Eq. (1)과 같이 홍수지수모형을 적용할 수 있다.
| $${Q^i}_T=\mu_i\times q_T,\;\;\;i=1,\;\cdots,\;N$$ | (1) |
여기서, 는 재현기간 T에 대한 지점 i에서의 확률수문량, 는 지점 i에서의 지점조정요소인 홍수지수, 는 재현기간 T년에 대한 지역성장곡선 값을 의미한다. 의 산정을 위해서는 먼저, 각 지점의 관측자료를 홍수지수()로 표준화해야 하는데, 아래의 식과 같이 지점 i에서의 자료 계열 를 그 평균으로 나누어주는 방법이 일반적이다.
| $$p_i(t)=P_i(t)\;/\;\mu_i,\;t=1,\;\cdots,\;n_i$$ | (2) |
각 지점의 표준화된 자료 계열 에 대하여 지점 L-모멘트비를 계산하고, 이를 각 지점의 표본크기 (ni)에 대하여 가중평균함으로써 지역가중평균 L-모멘트비를 구하게 된다. 산정된 지역가중평균 L-모멘트비를 이용하여 최종 선정된 확률분포형에 대한 매개변수를 추정하고, 이를 통해 재현기간 T에 대한 지역성장곡선 를 산정한다. Eq. (1)과 같이 홍수지수 와 지역성장곡선 를 곱해줌으로써 최종적으로 재현기간 T에 대한 지점 i에서의 확률수문량 를 산정할 수 있다.
2.4 정상성 지역빈도해석 절차
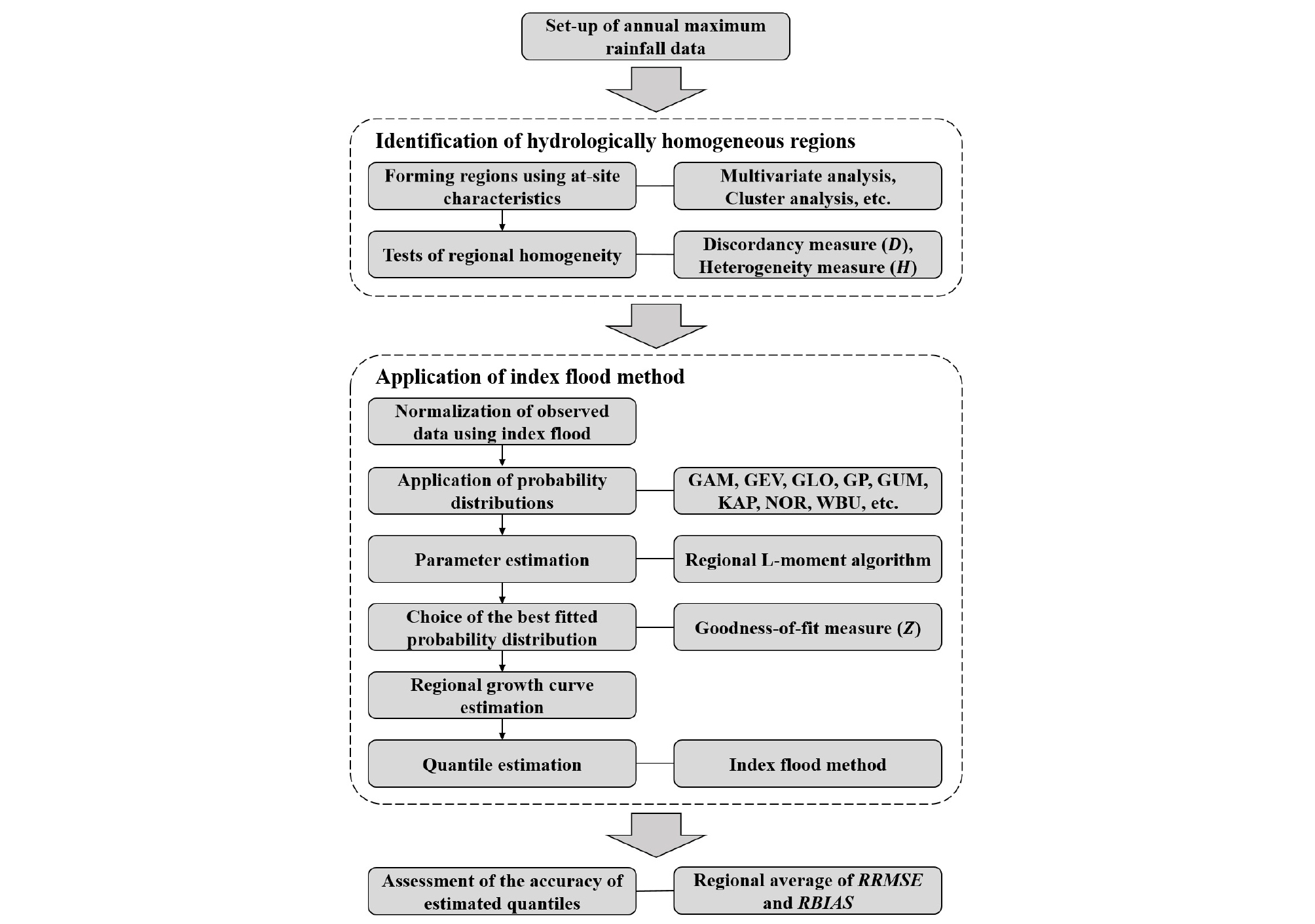
수문자료의 정상성 지역빈도해석의 절차는 Fig. 1과 같다. 먼저, 지역빈도해석 수행을 위한 관측지점들에 대하여 수문자료를 수집하고 연최대치 자료 계열을 구축한다. 다음으로 수문학적 동질지역 구성을 위하여 관측지점들에 대해 다양한 지리적, 수문기상학적, 통계적 지점 특성치들을 수집하고 다변량분석, 군집해석 등을 통해 지역을 구분한다. 이질성척도(H)를 이용하여 지역동질성을 검토하며, 구분된 지역이 이질한 것으로 판단되는 경우 각 지점 별로 산정된 불일치척도를 활용하여 지역 구분을 재조정함으로써 최종적으로 수문학적 동질지역을 결정하게 된다. 다음으로, 홍수지수를 통해 각 지점의 수문자료 계열을 표준화하고 다양한 확률분포형을 적용하여 매개변수를 추정한다. 이 때 적용 확률분포형의 매개변수 추정방법으로 지역 L-모멘트 알고리즘을 사용할 수 있다. 적용 확률분포형에 대한 적합성척도(Z)를 통해 적정 확률분포형을 선정하게 되며, 이를 기반으로 재현기간 T에 따른 지역성장곡선을 산정한다. Eq. (1)과 같이 대상 지점의 홍수지수와 지역성장곡선을 곱함으로써 확률수문량을 산정하게 된다. 적용된 지역빈도해석기법의 성능은 일반적으로 Monte Carlo 모의실험을 통해 평가할 수 있는데, 주로 지점빈도해석과의 성능 비교를 위해 수행되며 각 방법에 대해 산정된 확률수문량의 지역 평균 RRSME (relative root mean square error) 또는 지역 평균 RBIAS (relative bias)를 비교함으로써 성능을 비교·평가한다.
3. 비정상성 지역빈도해석
3.1 서 론
기후변화 및 도시화 등의 영향으로 빈도해석에 비정상성을 고려하기 위한 다양한 연구가 전 세계적으로 수행됨에 따라 비정상성 지역빈도해석 모형 개발에 대한 관심도 점차적으로 높아지고 있다. 비정상성 지역빈도해석에 대한 연구는 동질지역을 대표하는 지역성장곡선과 지역 내 각 지점의 홍수지수를 곱하여 대상 지점의 확률수문량을 산정하는 기존의 정상성 홍수지수법에 비정상성을 고려하는 비정상성 홍수지수모형을 중심으로 이루어지고 있다. 비정상성 홍수지수모형은 지역성장곡선 또는 홍수지수를 시간항(t)에 대한 함수로 나타냄으로써 정의되며, 성장곡선과 홍수지수 중 어디에 비정상성을 고려하는가에 따라 아래와 같은 식으로 나타낼 수 있다.
| $${Q^i}_T(t)=\mu_i(t)\cdot q_T$$ | (3) |
| $${Q^i}_T(t)=\mu_i\cdot q_T(t)$$ | (4) |
| $${Q^i}_T(t)=\mu_i(t)\cdot q_T(t)$$ | (5) |
Eq. (3)과 같이 홍수지수에 비정상성을 고려하는 비정상성 홍수지수모형은 홍수지수를 시간에 대한 함수로 정의하며, 이는 지역성장곡선의 산정을 위한 각 지점 자료의 표준화 과정에서 자료 계열을 단순히 평균으로 나누어주는 것이 아니라 경향성을 제거하는 것을 의미한다. 따라서 자료의 평균에 대한 경향성만을 고려하는 경우, 홍수지수를 단순히 원자료의 회귀분석 등을 통해 시간에 대한 다항식 로 정의하고 Eq. (2)와 동일하게 원자료 계열 를 로 나누어줌으로써 자료의 경향성을 제거할 수 있다. 자료의 평균 및 분산에 대한 경향성을 모두 고려하는 경우, 홍수지수를 정규화(standardization) 함수의 형태로 정의할 수 있다. 예를 들어, 지점 i에서의 원자료의 시간종속 평균과 표준편차를 각각 , 로 정의하는 경우, 아래의 식을 통해 원자료 계열 를 표준화할 수 있다.
| $$p_i(t)\;=(P_i(t)-\varepsilon_i(t))/\sigma_i(t),\;\;\;\;t=1,\;\cdots,\;n_i$$ | (6) |
표준화된 자료 계열 는 경향성이 제거되었으므로 기존의 정상성 홍수지수법과 동일하게 정상성 확률분포형을 적용하여 지역성장곡선()을 추정하게 되며, 이를 통해 재현기간 T에 대한 지점 i에서의 확률수문량 를 아래 Eq. (7)과 같이 산정할 수 있다.
| $${Q^i}_T(t)=\varepsilon_i(t)\;+\;\sigma_i(t)\cdot q_T$$ | (7) |
Cunderlik and Burn (2003)은 캐나다 지역의 연최대치 일유입량 자료의 1, 2차 모멘트에 비정상성을 가정하고 자료의 경향성을 제거한 후 지역성장곡선을 산정함으로써 비정상성 지역빈도해석을 수행한 바 있으며, Markiewicz et al. (2006)은 선형함수로 정의된 평균과 표준편차를 최소제곱법을 통해 산정하고, 이를 홍수지수로 활용하는 비정상성 홍수지수모형을 제안하였다. Sung et al. (2018)은 우리나라 연최대치 강우자료 계열에 대하여 선형함수로 정의된 평균의 기울기를 Sen의 기울기 추정법(Sen, 1968)을 통해 추정하고 이를 원자료에서 제거한 후, 지역성장곡선을 산정하는 비정상성 지역빈도해석 기법을 제안하였다.
Eq. (4)는 지역성장곡선에 비정상성을 고려하는 비정상성 홍수지수모형으로 기존의 홍수지수법과 동일하게 Eq. (2)를 이용하여 자료를 표준화한다. 하지만 표준화된 자료 계열 에 대하여 기존의 정상성 확률분포형이 아닌 비정상성 확률분포형을 적용하여 비정상성 지역성장곡선()을 산정하게 된다. 이 때, 비정상성 확률분포형의 매개변수 추정에서는 L-모멘트법의 적용이 어려우므로 최우도법(maximum likelihood estimation method)을 이용하는 것이 일반적이다. 표준화된 자료에 대하여 각 지점 별로 추정된 비정상성 확률분포형의 매개변수를 표본크기(ni)에 대하여 가중평균하여 비정상성 지역성장곡선의 매개변수를 산정할 수 있다. O’Brien and Burn (2014)은 이러한 비정상성 홍수지수 모형을 적용하여 캐나다 지역의 연최대치 일유입량 자료에 대한 비정상성 빈도해석을 수행한 바 있다. 각 관측지점의 자료 계열 평균을 홍수지수로 활용하여 자료를 표준화하였으며, 표준화된 자료에 다양한 비정상성 확률분포형을 적용함으로써 비정상성 지역성장곡선의 매개변수를 산정하였다. 이 외에도 자료의 표준화 과정 없이 Eq. (4)의 홍수지수()를 포함한 모든 매개변수를 최우도법을 통해 한 번에 추정하는 비정상성 홍수지수법을 적용한 지역빈도해석 연구가 수행된 바 있다(Hanel et al., 2009; Roth et al., 2012; Kim, 2018).
Eq. (5)는 홍수지수와 지역성장곡선 모두에 비정상성을 고려하는 비정상성 홍수지수모형으로 비정상성 홍수지수를 통해 1차적으로 경향성을 제거하고 비정상성 확률분포형을 적용하여 비정상성 지역성장곡선을 산정하는 방법이다. Nam et al. (2015b)은 각 지점자료에 경향성을 고려한 비정상성 조건 하에서 가상 지역을 구성하고 정상성 홍수지수모형 및 Eqs. (3)~(5)에서 제시된 3가지 비정상성 홍수지수모형에 대한 성능평가를 통해 Eq. (3)과 Eq. (4)의 비정상성 홍수지수모형이 Eq. (5)의 비정상성 홍수지수모형보다 우수한 성능을 보임을 확인하였다.
3.2 동질지역 구성
비정상성 지역빈도해석을 적용하는 경우에도 동질지역 구분이 필요하다. 하지만 비정상성 지역빈도해석을 위한 지역구분 방법이 따로 개발되어 있는 것은 아니며, 수문관측자료의 변동이나 경향성과 같이 비정상성을 대표할 수 있는 요소들을 활용하여 동질지역을 구성할 수 있다. 지역동질성 검토의 경우에도 비정상성 지역빈도해석을 위한 척도가 개발되어 있지 않으며, 현재 비정상성 지역빈도해석과 관련된 연구들에서는 기존의 이질성척도(H)를 이용하고 있는 상황이다. O’Brien and Burn (2014)은 Mann-Kendall 경향성 분석을 통해 유의한 경향성이 나타나는 지점들을 대상으로 비정상성 홍수지역빈도해석을 수행하였으며, 지역구분을 위해 지리적 변수를 비롯하여 연최대치 일유입량 발생일과 그 변동성을 수문학적 변수로 활용한 계층적 군집화 기법(hierarchical clustering technique)을 적용하였다. 또한, Eq. (4)와 같이 지역성장곡선에 비정상성을 고려한 홍수지수모형을 사용하였므로 연최대치 일유입량 자료 계열에서 양의 경향성을 가지는 지점들과 음의 경향성을 가지는 지점들로 구분하여 최종적으로 지역을 구성하였다. 지역동질성 검토의 경우 기존의 이질성척도(H)를 동일하게 적용하였다. Sung et al. (2018)은 먼저 지점 별로 자료의 경향성을 제거하고 이를 이용하여 지역성장곡선을 산정하는 Eq. (3)과 유사한 형태의 비정상성 홍수지수모형을 적용하였다. 경향성이 제거된 자료에 대하여 지역성장곡선을 추정하므로 위도, 경도, 고도와 같은 지형적요소만을 활용한 계층적 군집화 방법을 적용하여 지역을 구분하였으며, 이질성척도(H1, H2, H3)를 적용하여 지역동질성을 검토하였다.
이와 같이 비정상성 지역빈도해석에서는 비정상성을 홍수지수에 고려하는 홍수지수모형(Eq. (3))을 적용하는지 아니면 지역성장곡선에 고려하는 비정상성 홍수지수모형(Eq. (4))을 적용하는지에 따라 동질지역 구성을 위해 고려할 수 있는 요소가 달라질 수 있다. 비정상성을 홍수지수에 고려하는 경우 경향성이 제거된 자료를 통해 지역성장곡선을 산정하므로 기존의 지역구분방법을 활용할 수 있다. 그러나 비정상성을 지역성장곡선에 고려하는 경우 자료 계열의 경향성의 기울기나 부호 등과 같은 비정상성 특성들을 고려하여 동질지역을 구성해야 한다.
3.3 비정상성 지역빈도해석 절차
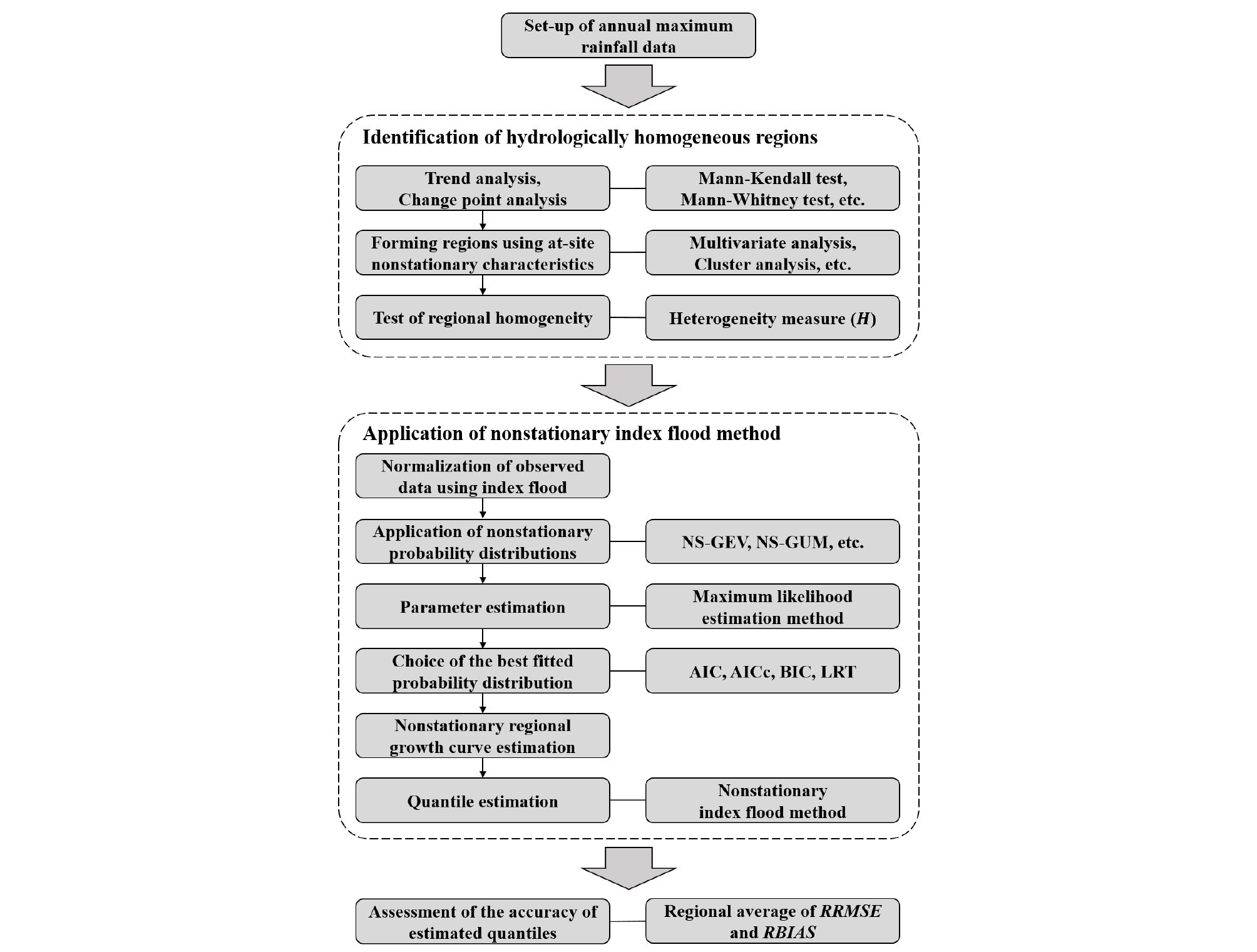
비정상성 지역빈도해석의 경우 어떠한 비정상성 홍수지수모형을 적용하는지에 따라 그 절차가 달라질 수 있다. 홍수지수에 비정상성을 고려하는 비정상성 홍수지수모형(Eq. (3))의 경우 표준화를 통해 경향성이 제거된 자료에 대하여 기존의 정상성 지역빈도해석 절차와 동일한 방법으로 수행할 수 있다. 본 장에서는 지역성장곡선에 비정상성을 고려하는 비정상성 홍수지수모형(Eq. (4))을 적용하는 비정상성 지역빈도해석 절차에 대하여 기술한다(Fig. 2 참조). 먼저, 구축된 연최대치 자료 계열에 대하여 경향성 분석 또는 변동성 분석 등을 통해 자료의 비정상성 여부를 확인한다. 경향성 분석 방법으로는 Mann-Kendall test가 가장 보편적으로 사용되며, 이 외에도 T-test, 비선형 회귀분석, Hotelling-Pabst test, Sen test 등이 있다. 변동성 분석 방법으로는 Mann-Whitney test, sign test, simple T-test, simple F-test, modified T-test, modified F-test 등이 사용된다. 이러한 분석 결과를 통해 도출되는 비정상성 인자들을 고려하여 지역을 구분한다. 이 때, 비정상성 자료에 대한 지역동질성 척도는 아직 개발되지 않은 상황이며 기존의 이질성척도(H)를 활용하여 지역동질성을 검토할 수 있다. 다음으로, 홍수지수를 통해 각 지점의 수문자료 계열을 표준화하고 다양한 비정상성 확률분포형을 적용하여 지역성장곡선 산정을 위한 매개변수를 추정한다. 비정상성 확률분포형의 매개변수 추정방법으로는 최우도법을 사용하며, 각 지점에 대해 추정된 비정상성 확률분포형의 매개변수를 각 지점의 표본크기(ni)에 대하여 가중평균함으로써 비정상성 지역성장곡선의 매개변수를 산정한다. 비정상성 확률분포형으로는 비정상성 Gumbel 분포형(NS-GUM), 비정상성 GEV 분포형(NS-GEV)이 가장 널리 사용되고 있다. 적용 비정상성 확률분포형에 대한 적정 확률분포형 선정방법으로는 Akaike information criterion (AIC), corrected AIC (AICc), Bayesian information criterion (BIC), likelihood ratio test (LRT) 등을 사용할 수 있다(Katz, 2013; Kim et al., 2017b). 최종적으로 선정된 비정상성 확률분포형을 통해 재현기간 T에 따른 비정상성 지역성장곡선을 산정하게 되며, Eq. (4)와 같이 대상 지점의 홍수지수와 비정상성 지역성장곡선을 곱함으로써 확률수문량을 산정한다. 적용된 비정상성 지역빈도해석기법의 성능은 정상성의 경우와 마찬가지로 Monte Carlo 모의실험을 통해 평가할 수 있다.
4. 최근 연구동향
수문자료의 지역빈도해석은 Hosking and Wallis (1997)에 의해 정립된 절차를 적용하여 강우, 홍수, 가뭄 등과 관련된 극치수문자료들에 대하여 확률수문량을 산정하고 분석하는 연구들이 최근까지도 전 세계적으로 활발하게 수행되고 있으며, 이와 관련하여 최근 3년 이내에 수행된 연구를 Table 2에 요약하여 정리하였다. 강우빈도해석의 경우 다양한 군집화 기법이 적용되고 있으며, 군집화 기법에 대한 성능 비교(Zaifoglu et al., 2018; Cassalho et al., 2019), 군집화 기법에서의 최적의 변수사용(Fathian and Dehghan, 2019)과 관련된 연구 등이 수행되고 있다. 홍수빈도해석의 경우 대상 유역기반으로 지역빈도해석을 수행하여 확률홍수량을 산정하는 연구들이 수행되고 있다.
Table 2에서 정리한 지역빈도해석 적용 연구 이외에도 기존의 지역빈도해석에서 가장 중요한 절차인 지역 동질성 척도, 적정분포형 선정방법 개선을 위한 연구들이 수행되고 있다. Requena et al. (2017)은 이질성척도(H1, H2)를 포함하여 Anderson-Darling 통계량, L-CV 신뢰구간 기반 척도, Gini 계수 등과 같은 다양한 척도들에 대한 성능평가를 위해 모의실험을 수행하였으며, Gini 계수 및 L-CV 신뢰구간 기반 척도가 지역 동질성 척도로 좋은 대안이 될 수 있음을 제안하였다. Lilienthal et al. (2018)은 왜곡도가 큰 자료 및 지점들 간 상관성이 큰 지역에 대한 동질지역 구분을 위해 trimmed L-moment와 copula함수 기반의 이질성척도를 개발하고 그 성능을 평가하였다. Hu et al. (2019)은 확장된 Xie-Benn 지수가 결합된 Fuzzy C-means 기법을 적용하여 동질지역을 구분하고, 구분된 지역에 대한 적정분포형 선정을 위해 적합성척도(Z), bivariate extension goodness-of-fit measure, L-모멘트비도를 결합한 새로운 적정분포형 선정지수를 개발 및 적용함으로써 동질지역 구성과 지역분포형 선정에서 발생할 수 있는 불확실성을 최소화할 수 있는 지역빈도해석 절차를 제안하였다.
Table 2. Application research trend of regional frequency analysis in hydrological data
| Name/References | Region | Data | Clustering | Comments |
| Liang et al. (2017) | Taihu basin, China | AM daily precipitation | Geographical convenience | - Compare the performance between ASFA and RFA |
| Wang et al. (2017) | Mainland, China | Gridded AM precipitation | Fuzzy C-means method | -Compare the performance between ASFA and RFA |
| Darwish et al. (2018) | United Kingdom | AM hourly precipitation | K-menas method | - Calculate 5, 10, 25, and 50-year return level - Compare the results with the previous study |
| Forestieri et al. (2018) | Sicily, Italy | AM hourly precipitation | K-menas method | - Estimate depth-duration-frequency curves |
| Zaifoglu et al. (2018) | Northern Cyprus | AM daily precipitation | Ward's method with various time series clustering | - Compare the performance between various time series clustering approaches |
| Cassalho et al. (2019) | Rio Grande do Sul State, Brazil | AM daily average discharge | K-means, Fuzzy C-means, K-harmonic means, Genetic K-means | - Compare the performance between various clustering methods |
| Drissia et al. (2019) | Kerala, India | AM daily average discharge | Geographical convenience | - Derive multiple regression for estimating discharge quantiles at ungauged site |
| Fathian and Dehghan (2019) | Lake Urmia Basin, Iran | AM daily precipitation | Ward's method | - Find the appropriate weighted variables for clustering |
| Leščešen and Dolinaj (2019) | Pannonian Basin, Central Europe | AM daily average discharge | Basin based | - Provide discharge quantiles |
| McCollum and Beighley (2019) | Weser River Basin, Germany | AM daily average discharge | Basin based | - Calculate 100 and 500-year discharge quantiles - Compare the results with the previous study |
| ※ AM : annual maximum, ASFA : at-site frequency analysis, RFA : regional frequency analysis | ||||
다변량 지역빈도해석 기법은 강우사상 뿐만 아니라 가뭄사상에 대한 지역빈도해석을 위해 주로 사용되는 방법으로 최근에도 이와 관련한 다양한 연구들이 진행되고 있다. Abdi et al. (2017a)은 다변량 지역빈도해석에서의 순위기반 불일치척도 및 최적화방법 기반 지역 매개변수 추정방법을 제안하고 모의실험 및 실제 가뭄사상을 통해 그 성능을 평가하였다. Šimková (2017)는 다변량 지역빈도해석 시 지점들 간의 상관성이 큰 지역에 적합한 새로운 이질성척도를 개발하고 모의실험 및 실제 강우사상을 통해 그 우수성을 확인하였다. Abdi et al. (2017b)은 다변량 지역빈도해석에서 사용되는 copula함수의 매개변수 추정을 위한 최적화 기법을 제안하고 기존의 모멘트법 기반 결과와 비교함으로써 그 우수성을 확인하였다. Mortuza et al. (2019)은 기후변화자료에 대한 이변량 가뭄빈도해석을 통해 현재와 미래의 가뭄특성을 평가하였다.
계층적 베이지안 모델링 또한 현재 활발하게 연구되고 있는 지역빈도해석 기법이다. García et al. (2018)은 GEV 분포형 매개변수가 시간적·공간적으로 변화하는 정규분포를 따르는 계층적 베이지안 모형을 구축하였으며, 스페인 지역의 강우자료에 대한 비정상성 지역빈도해석을 수행하였다. Assis et al. (2018)은 계층적 베이지안 모형의 매개변수 추정을 통해 지역구분 및 확률강우량을 산정하는 지역빈도해석 기법을 제안하였다. Bracken et al. (2018)은 연최대치 적설량, 유량, 수위에 대한 다변량 비정상성 지역빈도해석을 위하여 비정상성 GEV 분포형, copula함수가 결합된 계층적 베이지안 모형을 개발하였다. Thorarinsdottir et al. (2018)은 홍수지역빈도해석을 위하여 GEV 분포형 매개변수가 각 지점의 지형적·수문학적 변수들에 대한 선형모형으로 이루어진 계층적 베이지안 모형을 구축하고 불확실성 평가를 통해 보다 안정적인 확률홍수량 산정이 가능함을 확인하였다.
이 외에도 머신러닝 기법을 활용한 회귀식 기반의 지역빈도해석 기법(Ouali et al., 2017), 대상 지점 중심으로 지역을 구성하고 지역 GEV 분포형을 적용하는 지역빈도해석 기법(Asadi et al., 2018), 각 지점의 경향성을 고려할 수 있는 비정상성 모분포 홍수지수모형 기반의 비정상성 지역빈도해석 기법(Kim, 2018) 등과 같은 다양한 기법들이 연구되고 있다.
비정상성 지역빈도해석 시 비정상성 확률분포형을 적용하여 확률수문량을 산정하는 경우, 비정상성 규모매개변수의 형태와 비정상성 재현기간 적용은 매우 중요한 문제이며 현재까지 연구가 계속되고 있다. 먼저, 확률분포형의 규모매개변수에 비정상성을 고려하는 경우 공변량에 관계없이 항상 양수 조건을 만족하는 지수함수 형태가 일반적으로 사용되고 있다(Coles, 2001). 그러나 지수함수는 시간이 증가함에 따라 그 값이 급격히 증가 또는 감소하는 특성을 가지므로 보다 안정적인 함수의 적용이 필요하다. Jang et al. (2015)은 비정상성 확률분포형의 규모매개변수를 지수, 선형, 로그함수로 정의하고 모의실험을 통해 각 함수에 대한 적용성을 비교한 바 있으나, 아직까지 지수, 선형, 다항함수를 포함한 다양한 형태의 비정상성 규모매개변수가 적용되고 있다(Chen et al., 2017; Asadi et al., 2018; Ouarda and Charron, 2019). 비정상성 재현기간은 Salas and Obeysekera (2014)에서 제안된 개념으로 비정상성 확률분포형은 시간에 따라 계속적으로 변화하므로 어떤 규모의 수문사상에 대한 재현기간 역시 시간에 따라 변한다는 것이다. 이러한 비정상성 재현기간을 지점 및 지역빈도해석에 적용하여 설계수문량을 산정하는 연구는 현재까지 활발히 수행되고 있다(Read and Vogel, 2015; Kang et al., 2019; Mondal and Daniel, 2019).
5. 결 론
본 총설논문에서는 확률수문량 산정을 위한 지역빈도해석 기법을 수문자료의 특성에 따라 정상성 지역빈도해석과 비정상성 지역빈도해석으로 구분하고 각 방법의 기본이론과 절차 및 적용 사례를 국내·외 문헌을 바탕으로 상세히 설명하였다. 지역빈도해석 기법은 미계측 지점 또는 수문관측자료의 보유기간이 짧은 지점에 대하여 보다 정확하고 신뢰할 수 있는 확률수문량을 산정하기 위해 개발된 빈도해석 방법이다. 따라서 100년 이상의 긴 재현기간을 기준으로 이루어지는 수공구조물의 설계에 있어서 우리나라의 경우 수문관측자료 보유년수가 상대적으로 짧은 것을 감안할 때 지역빈도해석 기법의 적용은 필수적이다. 현재 환경부에서는 2019년도에 제시한 「홍수량 산정 표준지침」을 통해 확률강우량 산정 시 정상성 지역빈도해석의 적용을 권고하고 있으며, 우리나라 615개 강우관측지점의 강우자료에 대하여 2장에서 설명한 홍수지수법 기반의 정상성 지역빈도해석을 적용하고 지역구분 및 확률강우량 산정 결과를 부록에 수록하고 있다. 따라서 향후 이러한 지역빈도해석 결과를 활용하여 우리나라 전 지역에 대해 보다 안정적이고 신뢰할 수 있는 확률수문량 산정이 가능할 것으로 판단된다.
비정상성 지역빈도해석 기법의 경우 아직 정립된 방법론이 없고 초기 연구단계에 있으나 정상성 지역빈도해석과 마찬가지로 그 절차가 동질지역 구성과 홍수지수법 적용의 순서로 이루어지므로, 각 절차에 비정상성을 고려할 수 있는 다양한 연구들이 수행되어야 할 것이다. 동질지역 구성과 관련한 연구 주제로는 다양한 비정상성 인자의 선정, 인공지능(artificial intelligence)과 관련한 최신 기법의 적용을 통한 지역구분, 비정상성 자료에 대한 이질성 척도 개발 등이 있으며, 홍수지수법 적용의 경우 다양한 형태의 비정상성 홍수지수법 적용, 비정상성 홍수지수법에서의 최적 확률분포형 선정 등에 대한 연구가 필요하다. 이 외에도 비정상성 확률분포형 적용 시에 발생할 수 있는 비정상성 재현기간, 규모매개변수의 형태와 같은 중요한 이슈들이 아직까지 해결되지 않은 상황이다. 따라서 위에서 제시한 비정상성 지역빈도해석 기법과 관련한 다양한 연구를 통해 향후 수문자료의 비정상성을 고려하면서도 합리적이고 정확한 확률수문량을 산정할 수 있는 기법 및 절차가 개발될 수 있기를 기대한다.
