

1. 서 론
2. 적용 모형
2.1 랜덤 포레스트(Random Forest)
2.2 인공신경망
2.3 딥러닝
3. 모형의 적용
3.1 연구유역
3.2 데이터 수집 및 분석
3.3 유해남조류와 수질인자간의 특성중요도 분석
3.4 머신러닝과 딥러닝 모형을 활용한 수온을 통한 유해 남조류 발생예측
4. 결 론
1. 서 론
일반적으로 녹조 현상(Algal bloom)은 여러 오염물질이 강이나 호수로 흘러들어 영양물질이 풍부한 부영양화가 발생하고, 강한 햇빛, 높아진 수온, 물순환의 정체로 남조류가 과다하게 성장하여 물의 색이 짙은 녹색으로 변하는 현상을 말한다. 이 중 일부 남조류는 미량의 냄새물질과 독소(마이크로시스틴, 아나톡신, 삭시톡신 등)를 생성하여 수돗물의 맛을 떨어뜨리고 냄새로 인한 불쾌감을 유발하며, 이 중 독성물질을 배출하는 남조류 4종(마이크로시스티스, 아나베나, 오실라토리아, 아파니조메논)은 유해남조류로 지정하여 관리하고 있다(NIER, 2021).
현재 국립환경과학원에서는 녹조 발생에 선제적으로 대응하기 위해 물리적 모델(EFDC)에 기반하여 유해 남조류 세포수 예측정보를 제공하고 있다(NIER, 2021). 물리적 모델은 지형, 기상자료, 유입 ‧ 유출량, 수질 등 방대한 자료의 구축이 필요하며, 실제 수질의 검증된 물리 역학을 이용하므로 모형에서 요구하는 세밀한 데이터를 구할 수 있을 경우 정확한 수준에서 예측이 가능하지만, 각 인자 간 상호관계를 나타내는 계수가 사전에 명확하게 설정되어야 하는 어려움이 있다. 또한 녹조는 수체별로 영향인자가 다르고 천이과정 등 생태특성이 상이하기 때문에 물리적 모델을 통한 세포 수의 정확한 예측이 어렵다. 이를 해결하기 위해 물리적 모델의 기작을 개선하는 연구가 이루어지고는 있으나, 살아있는 생명체인 녹조에 대해 기상, 수리 ‧ 수문, 수질 등 수많은 인자에 의한 영향을 고려하는 것이 쉽지는 않다.
이러한 한계를 극복하기 위한 방법으로 최근 머신러닝 모형이 많이 도입되고 있다. 이 모형은 물리적 모델에 비해 구조가 간단하고, 각 인자간 사전 정보가 없거나 부족한 경우에도 적용이 가능하며, 모델 구축 및 계산을 짧은 시간에 수행할 수 있는 장점이 있다. 2001년 1월부터 2020년 6월까지 20여 년간 국제 학술지에 게재된 물환경 모델링 연구의 현황 등을 조사한 Cha et al. (2020)에 따르면, 자료기반 모델이 총 1,784편, 기작기반 모델이 총 1,200편 논문에 게재되어 최근 20년간 물환경 모델링 방법으로써 자료기반 모델의 활용도가 더 높은 것으로 나타났다. 이는 4차 산업혁명과 빅데이터 시대에서 자료기반 기술에 대한 막대한 관심 때문이기도 하겠지만, 물환경의 경우 수질 뿐만 아니라 수리․수문․기상 등 미지의 변수가 너무 많기 때문에 자료에서 발견된 패턴과 변수 간의 상관성을 토대로 데이터의 특징을 효율적으로 분석 ‧ 처리할 수 있는 기계학습이 활용도가 높기 때문으로도 생각된다.
데이터 기반 모형으로 수질을 연구한 국내 선행연구로는 NIER (2011), NIA (2017) 등이 있다. 위의 두 보고서에서는 머신러닝모형을 활용하여 낙동강 유역의 다사 관측소를 대상으로 클로로필a 를 예측하였다. NIER (2011)에서는 가장 단순한 형태의 다층퍼셉트론(Multi Layer Perceptron)를 활용하여 대청호의 단기간 조류발생시기를 예측하였다. NIA (2017)에서는 SVM (Support Vector Machine), 랜덤포레스트(Random Forest), 엘만 순환신경망(Elman Recurrent Neural Network, ERNN), 선형회귀분석을 활용해 낙동강 유역의 클로로필a 농도 및 유해남조류세포수를 예측하였다. 또한, KEI (2018)에서는 다층 퍼셉트론(MLP), 단순 RNN, GRU (Gated Recurrent Unit), LSTM (Long Short Term Memory) 알고리듬을 적용하여 가양, 노량진, 팔당 세 지역의 클로로필a 농도를 예측하였다. Jung et al. (2019)은 의사결정나무를 이용하여 낙동강 본류 구간의 남조류 발생특성을 연구하였으며, Hong et al. (2020)은 딥러닝 기술 중 순환신경망 모형을 이용하여 한강 친수활동구간을 대상으로 유해남조류세포수를 직접 예측하였다. 외국의 연구사례로는 Derot et al. (2020)이 k-평균 알고리듬과 랜덤포레스트를 활용하여 Geneva 호수의 플랭크토트릭스(Planktothrix) 남조류 세포수를 예측하였으며, Huang et al. (2017)은 어떤 환경내에 존재하는 미생물들의 총체적인 유전체 집합인 메타게놈을 이용하여 K-NN 분류 알고리듬, 서포트 벡터 머신(SVM), k-평균 클러스터링 알고리듬을 통해 남세균 발생을 예측하였으며, Yu et al. (2021)은 미국 캘리포니아 스크립스 피어(Scripps Pier)와 중국 산둥성 시실리(Sishili) 만을 대상으로 수질인자를 활용하여 ANN, Gradient Boosted Descent Tree (GBDT), K-nearest Neighbor (KNN), SVM 등을 통해 녹조를 예측하였다.
녹조는 초기 단계에서 대량 증식하므로 녹조에 영향을 주는 주요 인자를 고려하여 초기 단계를 예측하는 것이 중요하며, 본 연구에서는 머신러닝과 딥러닝을 활용하여 경북 영천에 소재한 보현산댐과 영천댐을 대상으로 여러 수질측정 항목과 유해남조류 세포수 간의 주요 영향인자를 도출하여 그간 진행된 연구와 비교 ‧ 검토하여 보고, 이 중 상관성이 가장 큰 수온을 입력인자로 ANN, RNN, LSTM, GRU와 같은 머신러닝과 딥러닝 모형을 이용하여 유해남조류 발생예측과 그 정확성을 확인하여 보았다.
2. 적용 모형
물리모형을 통한 예측은 실제 수질의 검증된 물리 역학을 이용하므로, 모형에서 요구하는 세밀한 해상도 데이터를 구할 수 있을 경우 정확한 수준에서 예측할 수 있다. 하지만 물리모형에서 요구하는 수준의 세밀한 공간해상도 데이터는 존재하지 않는다. 수질 예측과 같은 하위 격자망 구성 모형에서는 정확한 값을 알 수 없기 때문에 근사값을 사용하게 된다. 예를 들면, 특정 격자망에서의 ‘수온’은 실제로는 수심별로, 구역별로 일정하지 않으나 하나의 값으로 단순화하여 측정하게 되고 이로 인한 편향(Bias)이 발생할 수 밖에 없다. 또한 물리모형에서 요구하는 미지의 매개변수는 보정(Calibration)한 값을 사용하게 되는데, 적은 데이터로 많은 매개변수를 추정해야 하므로 이에 따른 과다적합이 발생한다. 또한 모듈을 생성하기 위해 각 시간 단계마다 다른 초기조건을 적용해야 하기 때문에 실시간 데이터를 실시간으로 예측하는 것에 비효율적일 수 있다. 다층 퍼셉트론 MLP에서 시작된 딥러닝 알고리듬은 지나친 복잡성을 보완한 합성신경망(Convolution Neural Network) 등장 이후 크게 향상된 예측력을 각 분야에서 증명하고 있다(Hong et al., 2020).
2.1 랜덤 포레스트(Random Forest)
랜덤 포레스트는 Breiman (2001)에 의해 제안된 결정 트리(decision tree) 기반의 알고리즘으로, 다른 성능을 갖는 여러 개의 결정 트리를 결합하여 각 모델에서 예측한 결과에 대해서 다수결이나 평균값을 사용하여 하나의 예측 결과를 도출하는 분류, 회귀 분석 등에 사용되는 앙상블 학습 방법의 일종이다. 랜덤포레스트는 훈련 과정에서 구성한 다수의 의사결정나무가 모여 숲을 이룬 형태로 모델을 학습하며, 숲을 구성하는 방법은 배깅(Bootstrap Aggregating Bagging)을 기초로 한다. 배깅은 원래의 데이터 세트에 대하여 대체(Replacement)를 허용하는 부트스트랩(Bootstrap) 샘플추출방법을 적용하여 다수의 표본집합을 구성하고 각 표본 집합을 학습용 데이터 세트로 하여 분류기 집합을 생성하여 복합 분류기를 생성하는 방식이다. 이러한 랜덤포레스트는 변수의 중요도를 평가하고 모델링에 사용할 변수를 선택하는 데 사용할 수 있다. 랜덤포레스트의 변수 중요도는 변수가 정확도 Accuracy와 노드 불순물(Node Impurity) 개선에 얼마만큼 기여 하는지 측정한다. 정확도 개선에 중요한 변수는 평균정확도 감소(Mean Accuracy Decrease)의 값으로 판단하며, 구축된 나무의 정확도가 특정변수 제거 후 재구축 했을 때 감소되는 정확도의 차이를 변수별로 평균화한 것이다. 분류 정확도를 높이는데 큰 영향을 준 변수일수록 그 변수를 제거했을 때의 정확도 감소량은 커지게 된다. 노드 불순도 개선에 중요한 변수는 평균 지니 감소(Mean Gini Decrease)의 값으로 판단하며, 각 나무가 가지를 뻗어나갈 때마다 선택되는 변수들의 불순도 감소량을 측정하여 전체 나무로부터의 그 평균치 값을 사용한다. 즉 특성변수의 Mean Gini Decrease 값이 높다는 것은 그 만큼 그 변수를 가지고 개체들을 분류하게 되면 불순도를 감소시키는 방향으로 즉, 동일 범주끼리 묶이도록 하는데 일조한다는 것을 의미한다.
본 연구에서는 보현산댐과 영천댐에서 측정된 수질인자를 학습용 데이터로 활용하여 모형을 훈련시키는 지도학습 방법 중 하나인 랜덤 포레스트(Random Forest) 모형의 분류방법을 활용하여 분석을 수행하였으며, 입력변수로 보현산댐과 영천댐의 pH, 수온, T-P, T-N, DO 등 14개 항목의 수질측정 결과를, 목적변수로는 유해남조류 개체 수를 사용하였다.
2.2 인공신경망
인공신경망(Artificial Neural Network, ANN)은 인간 두뇌의 신경망, 신경세포 구조를 모방한 알고리듬이다. 1940년대 초 캐나다의 신경학자인 McCulloch and Pitts (1943)은 신경망 이론을 최초로 개발하였고, 이후 1950년대 말 Robsenblatt이 머신러닝의 기초 알고리즘인 퍼셉트론(single-layer perceptron)이라는 개념을 발표하였으며, 1960년대 초 Widrow and Hoff는 ADALINE (Adaptive Linear Element)라고 부르는 McCulloch와 Pitts의 뉴런(Neuron)를 여러 개 일렬로 사용하였다(Tayfur, 2014). 노드가 여러 계층으로 분리된 다층 퍼셉트론은 Rosenblatt, Minsky와 Papert에 의해 제안되었다.
뉴런의 계층 구조는 입력층과 출력층 사이에 하나의 뉴런만을 갖는 단층퍼셉트론과 하나 이상의 은닉층을 갖는 다층퍼셉트론으로 나뉜다. 다층퍼셉트론 신경망은 입력층(Input layer), 은닉층(Hidden layer), 출력층(Output layer)으로 구성되며, 입력층과 출력층은 입력 유니트와 출력 유니트를 가지고 있는데, 이들은 각각 분류를 위한 파라메타와 얻고자 하는 출력값들을 대표하고 있고, 은닉층이라 불리는 중간층은 각 유니트의 입출력을 비선형으로 함으로써 신경망의 능력을 향상시키기 위한 것이다. 다층퍼셉트론의 학습은 흔히 오류 역전파 알고리듬(Error Backpropagation Algorithm)을 이용하는데, 입력 유니트에 입력신호가 들어오면 이것은 중간층의 각 뉴런으로 전달되고, 이 신호는 다시 출력 뉴런으로 전달된다(Feed Forward), 출력 뉴런의 출력값과 목표값(Target)을 비교하여 그 차(Error)를 감소시키는 방향으로 연결강도를 조정해 나가는 것(Backpropagation)이 학습의 과정이다.
2.3 딥러닝
딥러닝(Deep Learning)은 머신러닝의 알고리듬 중의 하나이며, 기존 신경망 구조보다 깊게 구성한 알고리듬이다. 입력변수 간의 비선형 특성을 추정할 수 있으며, 전통적인 머신러닝 알고리듬보다 우수한 효과를 보인다. 머신러닝은 인간이 컴퓨터에 많은 정보에 대해 가르치고, 이를 컴퓨터가 예측하는 과정이라면, 딥러닝은 인간이 컴퓨터에 특정한 지도 없이도 학습하고 예측하는 특징이 있다.
인공신경망 혹은 딥러닝의 은닉층에서 사용하는 활성화 함수에는 주로 시그모이드(Sigmoid) 함수, Tanh (Hyperbolic Tangent) 함수, 렐루(Rectified Linear Unit, ReLU) 함수가 대표적이다. 시그모이드 함수는 ‘0’에서 ‘1’ 사이의 값으로 로지스틱 회귀(Logistic Regression) 함수이고, 간단한 분류 문제에 활용한다. tanh 함수는 ‘-1’에서 ‘1’ 사이의 값을 가지고, 중심값에서 멀어지면 역전파 도중에 기울기가 소실하는 문제가 발생한다. 이러한 기울기 소실 문제를 해결한 것이 렐루 함수이며, ‘0’ 이하의 값은 모두 ‘0’으로 처리하여 학습 진행을 멈춘다(Chollet, 2018). 딥러닝 모형의 종류에는 대표적으로 CNN (Convolutional Neural Network), GAN (Generative Adversarial Network), 순환신경망(Recurrent Neural Network, RNN) 등이 있으며, 본 연구에서는 시계열 데이터를 다루는 데 적합한 신경망인 RNN, LSTM, GRU을 이용하였다.
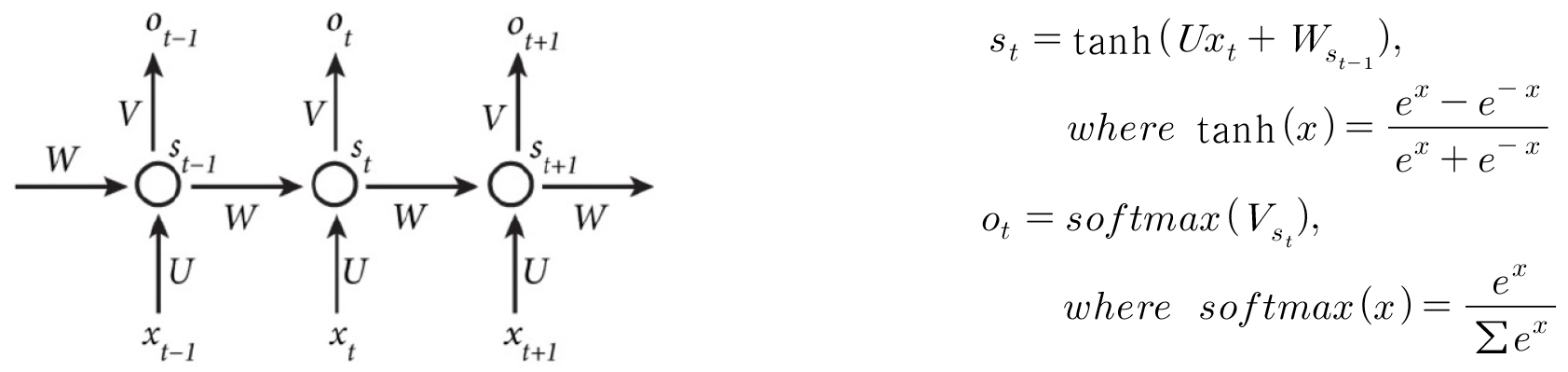
순환신경망(RNN)은 순차적인 데이터(sequential data) 학습에 특화된 인공신경망의 한 종류로써 내부의 순환구조가 들어있다는 특징을 가지고 있으며, 은닉층이 순환하는 구조를 이용하여 과거의 학습을 가중치(Weight)를 통해 현재 학습에 반영한다. Fig. 1의 순환신경망은 입력층(), 은닉층()과 출력층()으로 구성되며, 입력층과 은닉층을 연결하는 가중치 U, 은닉층과 출력층을 연결하는 가중치 V, 은닉층의 각 노드들을 연결하는 가중치 W로 구성되어 있다. 순환신경망이 기존 다층퍼셉트론 신경망과 다른 점은 이전정보에 대한 기억이 용이하도록 은닉층의 노드 간에 순차적으로 연결이 되어 있어 은닉층의 각 노드들이 네트워크 메모리 역할을 한다는 점이다. 순환신경망의 학습은 기존의 신경망과 같이 목표 값과 출력 값의 차이를 함수로 구성되는 손실함수(Loss function)를 최소화하는 확률적 경사하강법(Stochastic Gradient Descent)을 사용하여 학습을 진행한다.
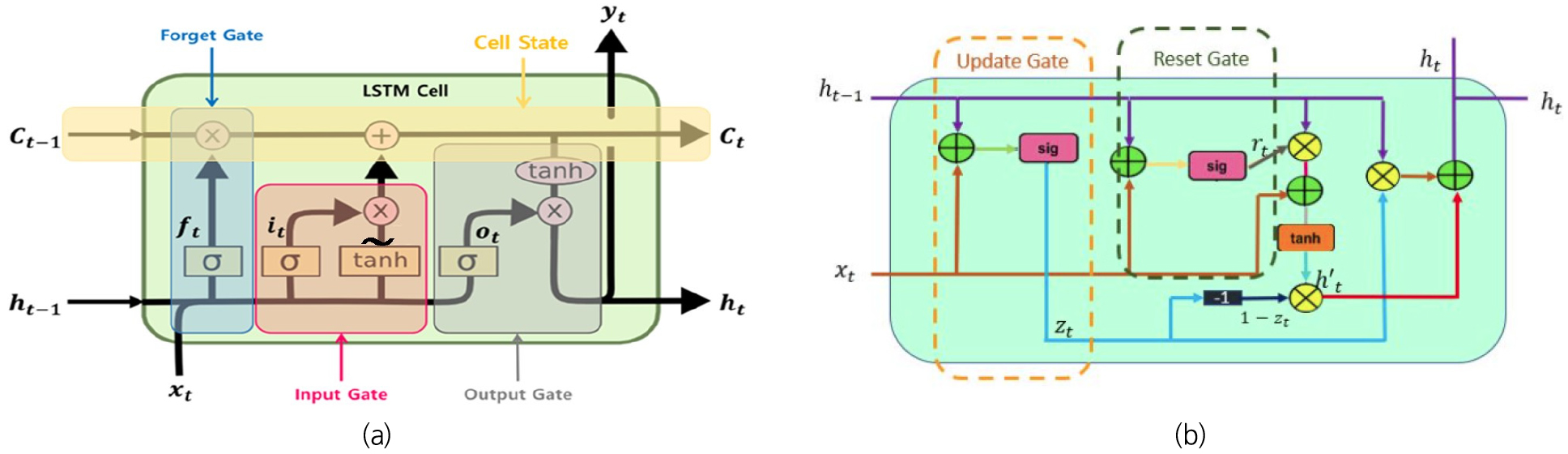
RNN은 이전 시점에서 이어받은 데이터에 반복해서 같은 가중치를 곱하기 때문에 몇 개의 층에 걸쳐 오차를 전파시키면 기울기가 소실 또는 발산하는 문제가 있다. 즉, RNN은 각 자료에 별도 가중치를 주어 중요도를 판단하여 다음 데이터를 넘기면서 기억하는 특성을 가지나, 은닉층에서 먼 과거 자료의 정보가 점차 소실하는 현상이 발생하여, 별도의 기억을 담당하는 방(Memory Cell)을 만들어 보완한 방법이 Long-Short Term Memory (LSTM)이다(Hochreiter and Schmidhuber, 1997). RNN은 하나의 Hyperbolic Tangent (tanh) layer를 반복적으로 수행하는 모듈로 구성되어 있지만, LSTM은 Fig. 2와 같이 특성 시점의 상태값(ht)을 업데이트하기 위해 장기기억메모리(ct)라는 개념을 도입하여 내부에 가지고 있는 정보를 업데이트할 것인지 아닌지를 판단한다. 구성은 망각게이트(Forget gate), 입력게이트(Input gate), 출력게이트(Output gate) 및 장기기억메모리(Cell state)로 이루어져 있으며, 망각게이트에서는 어떤 정보를 버릴지 결정하고, 입력게이트에서는 어떤 값을 업데이트할 것인지, 출력게이트에서는 출력 값을 결정한다. LSTM에서 중요한 부분인 Cell State는 컨베이어 벨트와 같은 역할로 상기 게이트를 제어하여 기울기 소실 문제를 방지하여 정보가 효과적으로 흐를 수 있게 한다.
LSTM보다 빠른 처리 속도를 위해 LSTM 구조를 개선한 방법이 GRU (Gated Recurrent Unit)이다(Chung et al., 2014). GRU는 입력게이트와 망각게이트를 합한 업데이트 게이트가 있으며, 기억셀에는 출력게이트가 없는 대신 과거에서 이어받은 기억을 선별하는 리셋 게이트가 있다. GRU층은 이러한 게이트가 동작해 LSTM처럼 장기 기억을 이어받을 수 있으며, 학습 가중치가 적어지는 장점이 있어 LSTM과 비교하면 신속한 처리 속도와 유사한 성능을 보일 수 있다.
3. 모형의 적용
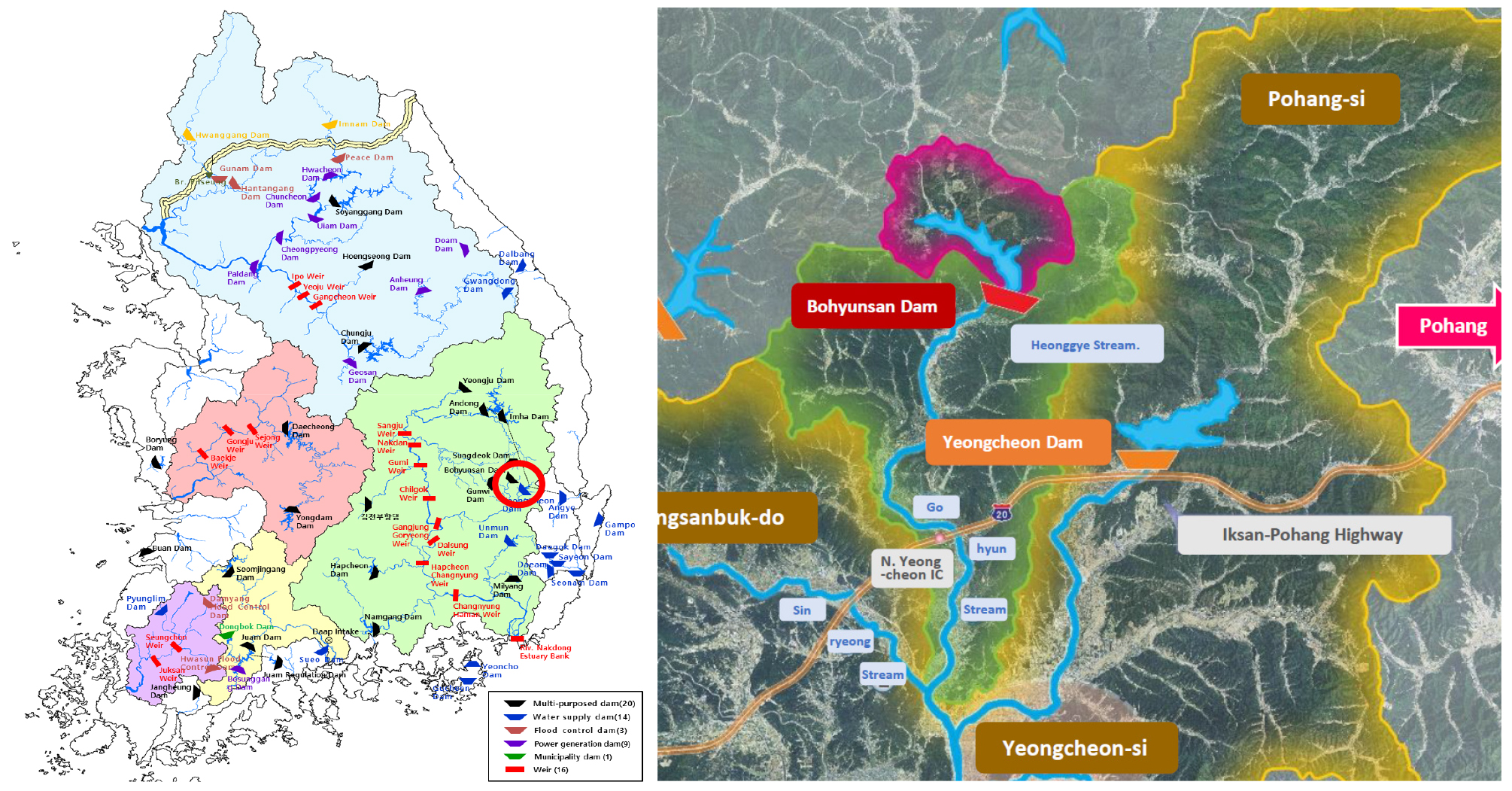
본 연구에서는 Fig. 3와 같이 경북 영천에 위치하고 있는 보현산댐과 영천댐을 대상으로 유해남조류 개체수 발생과 수질인자와의 상관관계를 결정 트리를 기반으로 하는 랜덤 포레스트 모형을 이용하여 분석하였다. 그리고, 수온을 입력인자로 ANN, RNN, LSTM, GRU와 같은 머신러닝과 딥러닝 모형을 이용하여 영천댐의 유해남조류 개체수를 예측하고 정확도를 평가하였다.
3.1 연구유역
3.1.1 보현산댐
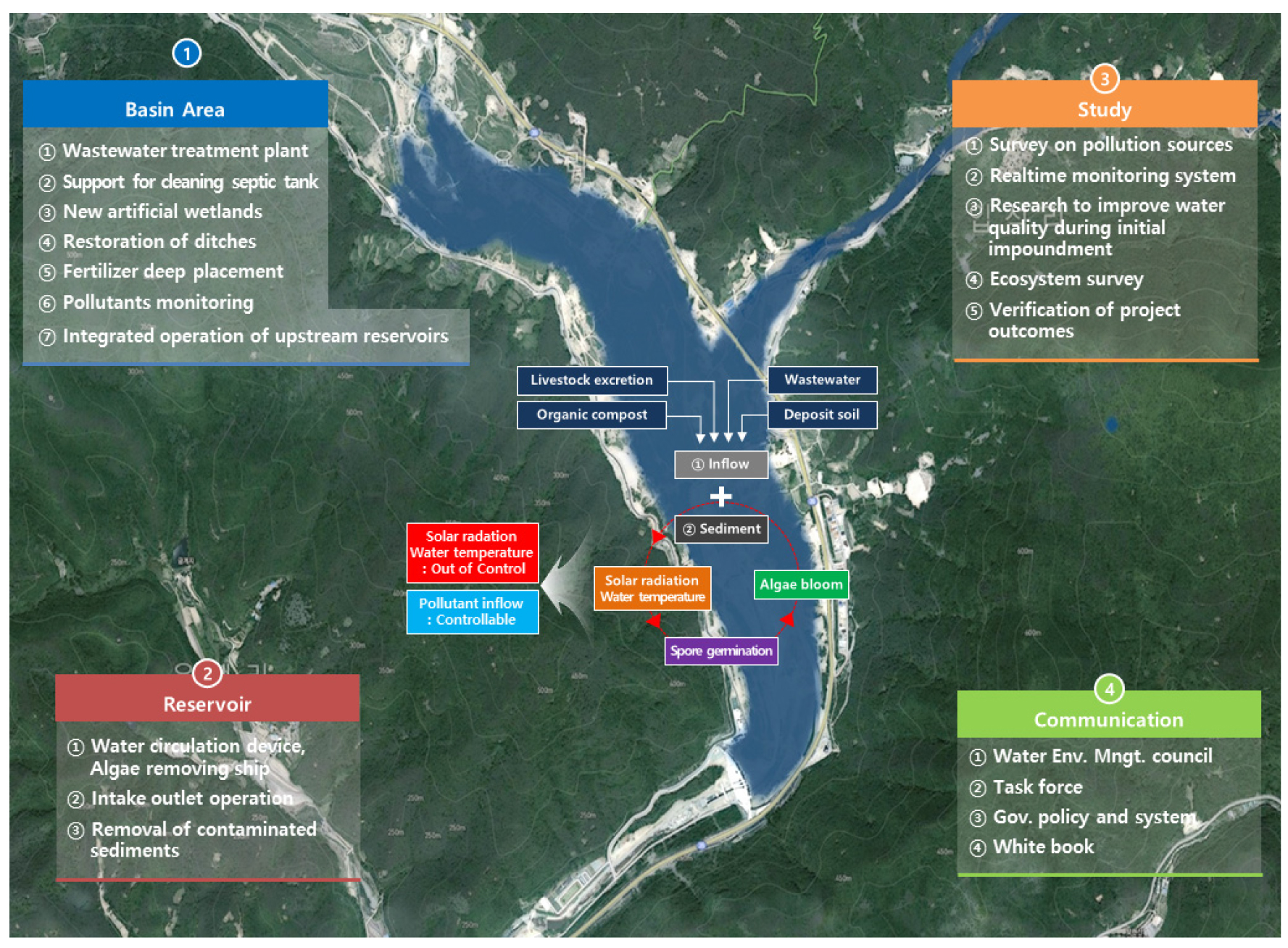
보현산댐은 경상북도 영천시 화북면(낙동강수계-금호강-고현천)에 소재하고 있고, 댐 높이는 58.5 m, 댐 길이는 250 m, 저수면적은 1.47 km2, 총저수량은 22 백만톤이다(K-water, 2010). 유역내 거주하는 총 인구는 498명이며, 하수처리율은 6.6%, 한우, 돼지 등 사육두수는 약 900여 두, 유역 전체 면적 32.2 km2 중 임야가 26.3 km2(81.7%)이고, 과수면적이 0.7 km2로 약 2.3%를 차지하고 있다(K-water, 2019). 상류유역의 낮은 하수처리율, 과수 등 농업 시비에 의한 강우유출 오염과다, 축산업 등으로 인해 녹조현상이 심하여 Fig. 4와 같이 2018년 12월에 ‘보현산댐 물환경관리 종합대책’을 수립하여 시행 중에 있다.
3.1.2 영천댐
영천댐은 보현산댐과 직선거리로 약 10 km 거리에 위치하고 있으며, 경상북도 영천시 자양면(낙동강수계-금호강-자호천)에 소재하고, 댐 높이는 42 m, 댐 길이는 300 m, 저수면적은 6.9 km2, 총저수량은 103.2 백만 톤이다. 연간 용수공급량은 107.3 백만 톤으로 이 중 생공용수로 80.3 백만 톤, 농업용수로 12.4 백만 톤, 하천유지용수로 14.6 백만 톤으로 계획되었다(WAMIS, 2021). 영천댐 도수로를 통해 임하호와 길안천의 수원으로부터 연 평균 약 40만 m3/일의 원수를 공급받고 있으며, 이 중 약 절반에 해당하는 물량을 다시 안계댐 도수로를 통해 안계호로 공급하고 있다.
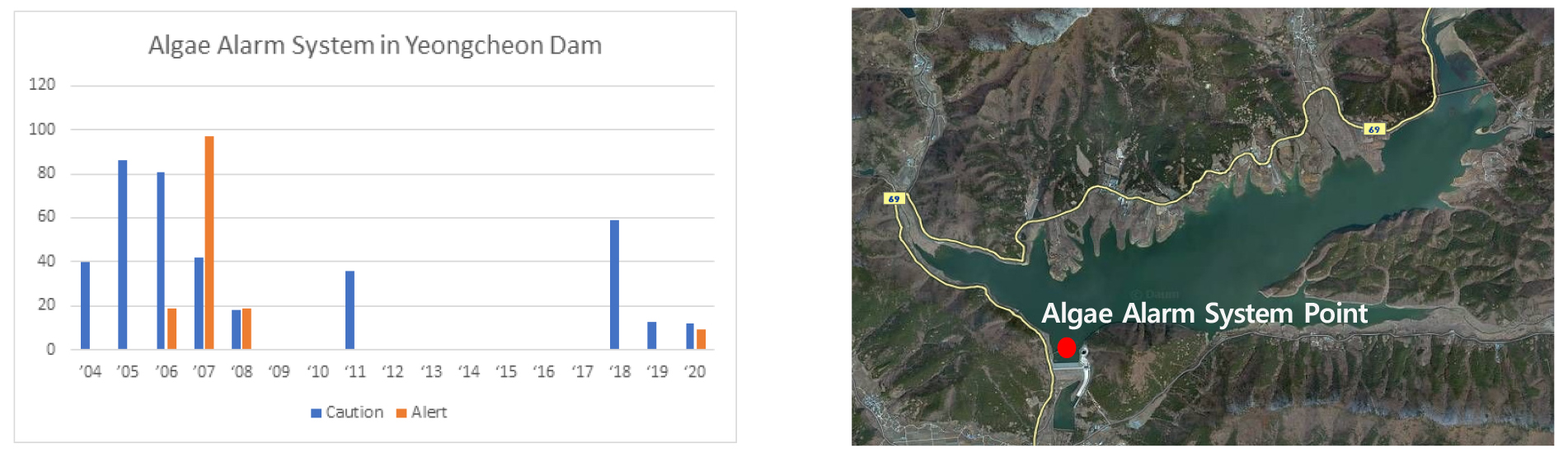
2004년부터 조류경보제 운영을 시작하였으며, 2008년까지 총 402일의 경보가 발령되었고, 2011년에 36일, 2018년에 59일 관심단계 발령, 2019년 13일 관심단계 발령, 2020년에는 관심단계 12일, 경계 9일이 발령된 사례가 있다. Fig. 5는 영천댐 조류경보제 발령기록 및 운영지점을 보여준다.
영천댐 유역의 생활계 오염원 현황은 총 인구 3,186명, 하수도 보급률은 11.5%이다. 유역 내 축산계 오염원의 경우, 한우, 젖소, 돼지, 말, 사슴, 가금 등 총 가축의 수가 1,930마리였으며, 축종별로 한우가 가장 많았다. 유역 내 토지 이용현황은 임야의 비율이 가장 많이 차지하고 있으며, 그 외 기타, 전, 답, 대지 순으로 나타났다(Lee et al., 2019).
3.2 데이터 수집 및 분석
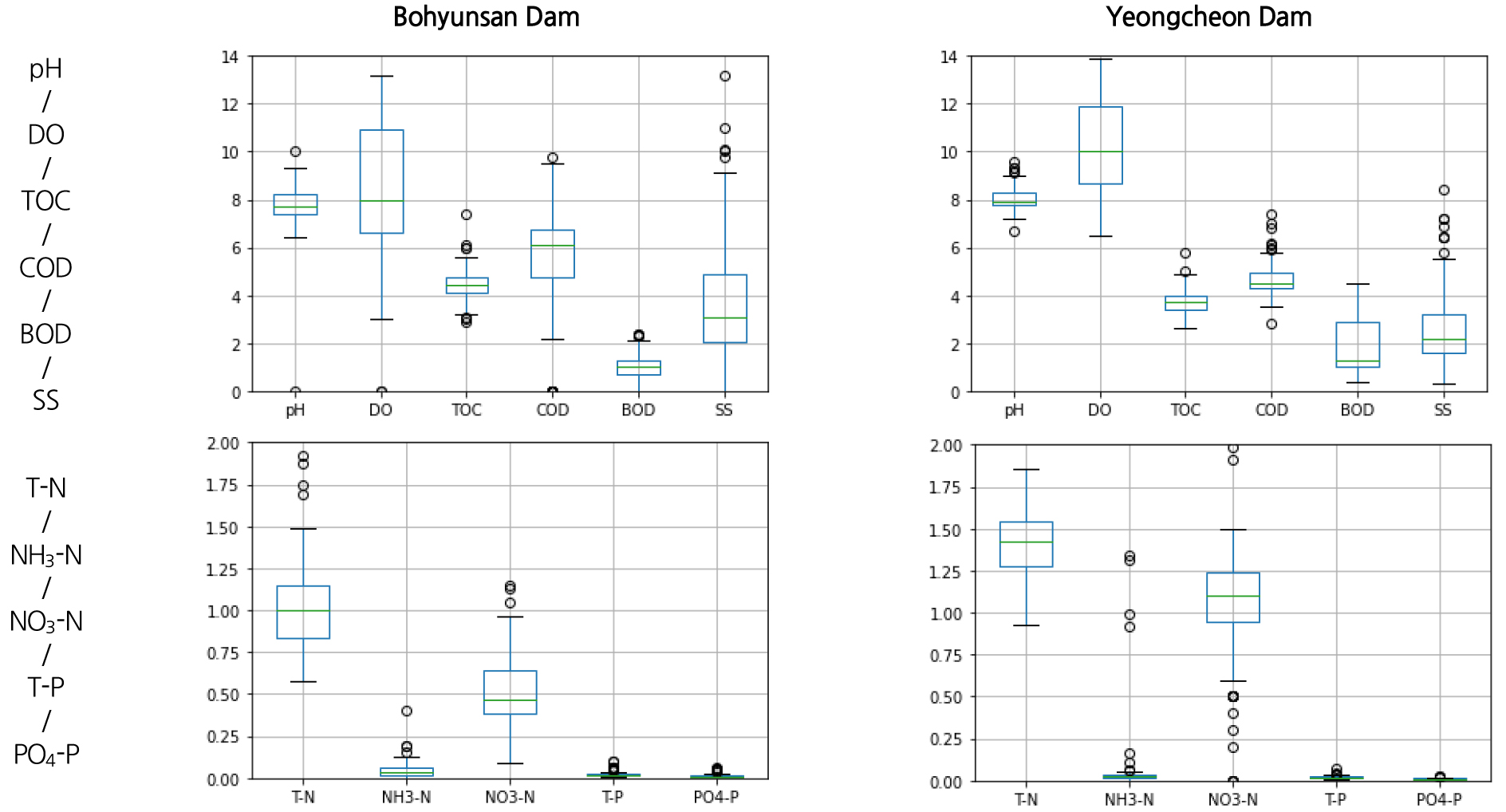
보현산댐은 2016년부터, 영천댐은 2012년부터 매월 1~2회 조사된 수질자료를 이용하였으며, 계측항목은 pH, 수온, DO, EC, BOD, COD, SS, T-N, NH3-N, NO3-N, T-P, PO4-P, TOC, Chl-a, 유해남조류 개체수 등 총 15개 항목이다. 이를 두 댐 간 비교한 결과, Fig. 6와 같이 pH, TOC, BOD, T-P, PO4-P의 경우 비슷한 값을 보였으나, 그 외의 값들은 다소 차이를 보였으며, 이는 유역 오염원, 담수 후 운영기간, 댐 방류실적 및 체류시간, 타 유역에서 유입여부 등 호소마다 특성이 다르기 때문으로 이해된다.
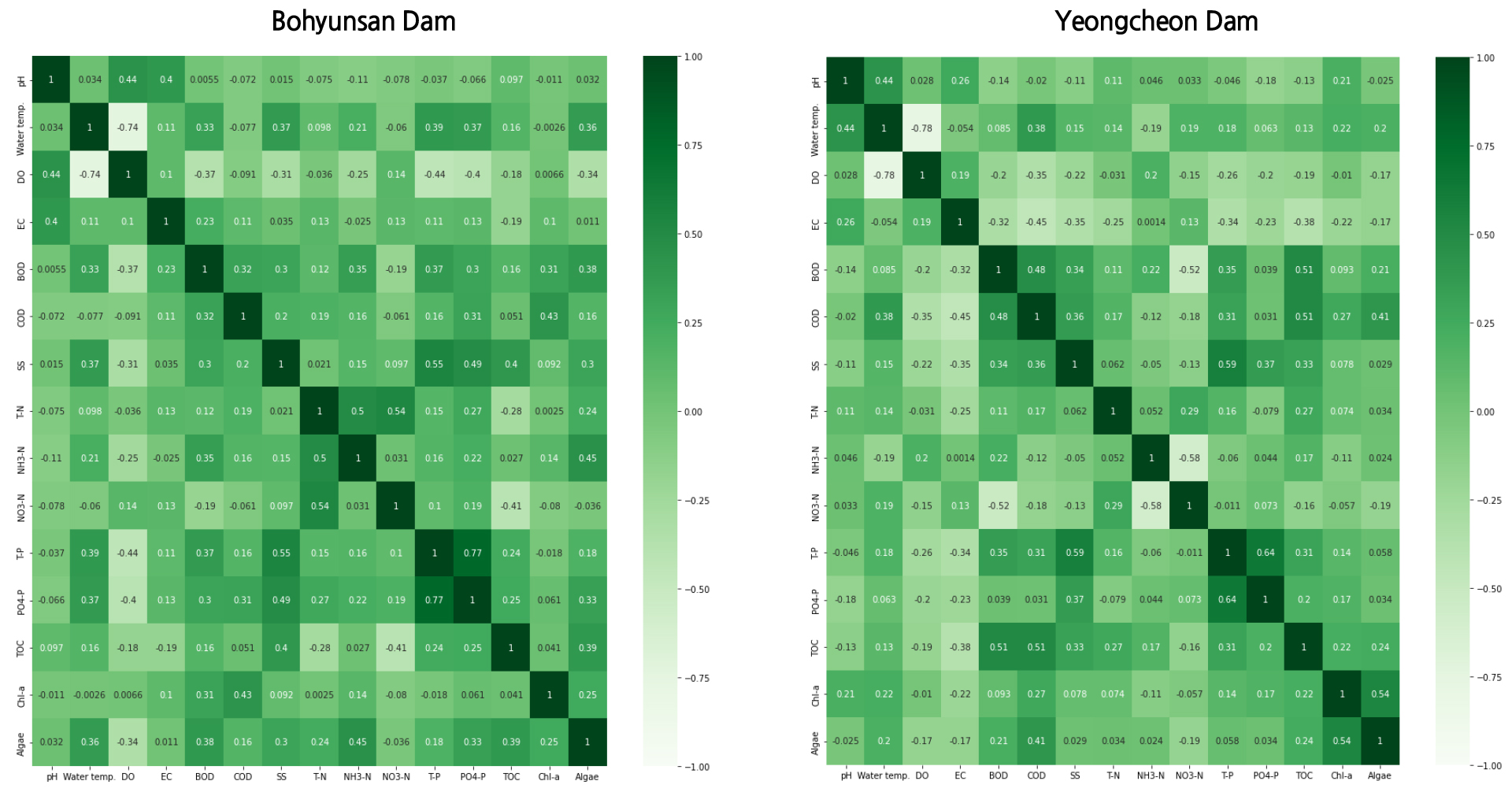
각 수질인자간 상관성을 확인하기 위해 피어슨 상관분석(Pearson Correlation Analysis)을 시행하였으며, 이를 Figs. 7 and 8과 같이 파이썬(python)의 히트맵(heatmap)과 산점도(scatter plot)를 통하여 시각화하였다. 피어슨 상관분석은 두 변수 간에 어떤 선형적 관계를 가지고 있는지를 분석하는 방법으로 보편적으로 사용되며, 상관계수 r은 -1에서 +1까지의 값을 가지며, 상관관계 분석결과 상관계수에 따른 상관관계를 표현한 Evans (1996)에 따라 보통 강도 이상의 상관관계()를 보인 수질인자를 대상으로 살펴보았다.
두 댐 모두 공통적으로 용존산소(DO)와 수온은 -0.74, -0.78로 음(-)의 강한 상관관계를 나타내었다. 이는 DO의 농도가 산소의 용해도에 영향을 미치는 수온에 의해 주로 영향을 받는 것으로 알려져 있으며(Weiss, 1970), 인공호인 영산호를 대상으로 한 연구(Song et al., 2015)에서도 수온은 다른 물리환경인자들에 비해 용존산소농도와 높은 음의 상관성(R<-0.69)를 보인다고 보고한 바 있다.
총인(T-P)와 인산염인(PO4-P)은 0.77, 0.64로 양(+)의 강한 상관관계를 나타내었다. 이는 T-P는 탁도물질에 존재하는 다양한 형태의 인을 과황산칼륨 분해로 PO4-P화 한 것과 물 속에 용존하는 PO4-P를 포함한 것이기 때문으로 보인다.
SS는 T-P와 0.55, 0.59로 양(+)의 보통 강도의 상관관계를 나타내었다. 화옹담수호로 유입되는 지천에 대해 수질현황 및 수질항목 간 상관관계에 대한 Jung et al. (2006)의 연구에서도 SS와 T-P는 0.50의 상관결정계수를 가진다고 나타내었다. 이를 통해 탁도물질의 유입에 따라 호소내 인(P) 성분이 증가하는 것을 알 수 있다. 인 성분은 점토질 입자나 토양유기물에 대한 흡착성이 크기 때문에 토양과 함께 이동하며, Australia에 있는 Herbert River의 경우 우기시 6일 동안 인 65톤과 부유물질(Suspended sediment) 10만톤이 유역으로부터 유출되었으며, 이 중 85%가 강우초기 처음 2일 동안에 일어났다고 보고한 사례가 있다(Mitchell et al., 1997).
SS와 총유기탄소(TOC)와는 0.40, 0.33로 양(+)의 보통에서 약한 상관관계를 나타내었으며, 섬진강 수계를 대상으로 수질항목별 상관분석을 실시한 Park et al. (2014)의 연구에서도 SS와 TOC의 상관계수는 0.377로 보고된 바 있다.
3.3 유해남조류와 수질인자간의 특성중요도 분석
특성 중요도(feature importance)는 트리 생성 과정에서 각 인자가 얼마나 중요하게 작용했는지를 평가한 값으로(Liaw and Wiener, 2002) 학습된 모형에서 종속 변수에 영향을 미치는 독립변수들의 영향도이다. 특성 중요도는 0과 1 사이의 사이의 수로 표현되는데, 각각의 인자들에 대해 0은 트리 생성과정에 전혀 사용되지 않은 인자임을, 1은 모델 생성에 유일하게 영향을 미치는 인자임을 의미하며, 특성 중요도의 전체 합은 1이 된다. 이를 통해 유해 남조류 발생에 영향을 미치는 중요한 인자의 특성 선택(feature selection)을 할 수 있다. 특성 선택(feature selection)은 고차원의 데이터 세트를 분석하기 위해서 반드시 필요한 과정이며 특히, 고차원의 복합 데이터를 다루는 빅데이터 분석 분야에서는 분석 과정의 효율성 및 분석결과의 정확도 등을 향상시키기 위해서 중요한 문제이다.
랜덤 포레스트를 활용하여 유해남조류와 수질인자간의 특성중요도를 Figs. 9 and 10와 같이 분석하였다. 특성 중요도는 어느 특성을 사용한 노드가 평균적으로 불순도를 얼마만큼 감소시키는지 확인하여 중요도를 계산한다. 특성 중요도를 도출하기 위한 대표적인 방법은 평균 불순물 또는 지니 중요도 감소(mean decrease impurity or Gini importance)라고 한다. DT의 특성 중요도는 노드에 사용된 특성별(현재 노드의 표본 비율 분순도)-(왼쪽 자식 노드의 표본 비율 불순도)-(오른쪽 자식 노드의 표본 비율 불순도)이다. 표본 비율은 트리 전체 샘플 수에 대한 비율이며 RF의 특성 중요도는 각 DT의 특성 중요도를 모두 계산하여 더한 후 중요도의 합이 1이 되도록 전체 합으로 나누어 정규화(normalize)한다(Dale, 2017).
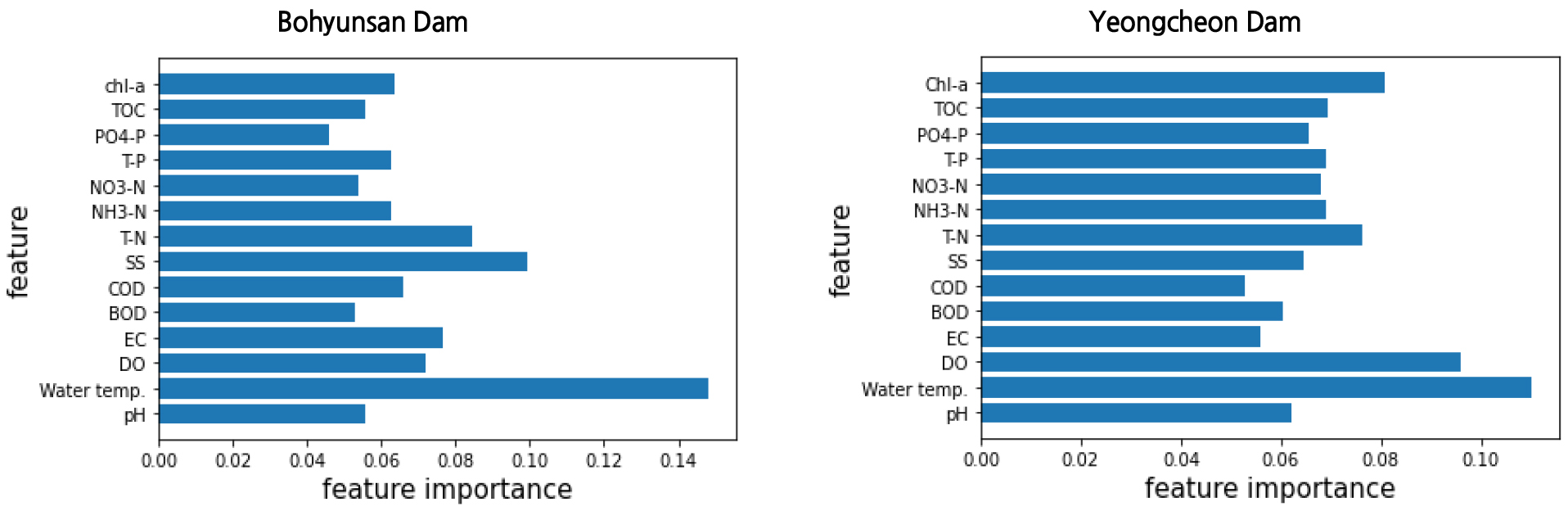
랜덤포레스트를 통한 특성중요도 분석결과, 보현산댐과 영천댐 모두 수온의 특성중요도가 가장 높았다. 그 다음으로는 보현산댐은 SS와 T-N 순이었으나, 영천댐은 DO, Chl-a과 T-N 순이었다. 이는 최근 금강수계를 중심으로 유해 남조류 개체수와 수질인자간의 상관성을 분석한 NIER (2018)에 따르면, 대청호 상류 유입지점인 추소리에 대해 다양한 통계방법(머신러닝, Spearman, 회귀분석 등)을 통한 영향인자 분석결과, 상관관계 중요도가 수온, T-N, Chl-a, 탁도, TP 순으로 나타났다고 보고하였다. 외국의 연구 사례로는 2007년 중국 Lake Taihu와 같은 초부영양호에서 녹조 발생 및 제어에 대한 집중적 연구의 결과 겨울~봄에 걸쳐 녹조 발생 초기에는 호수의 인 농도가 중요하지만, 여름~가을의 녹조 확산 시기에는 질소농도가 크게 작용하는 것으로 조사된 바 있다(Ahn et al., 2015).
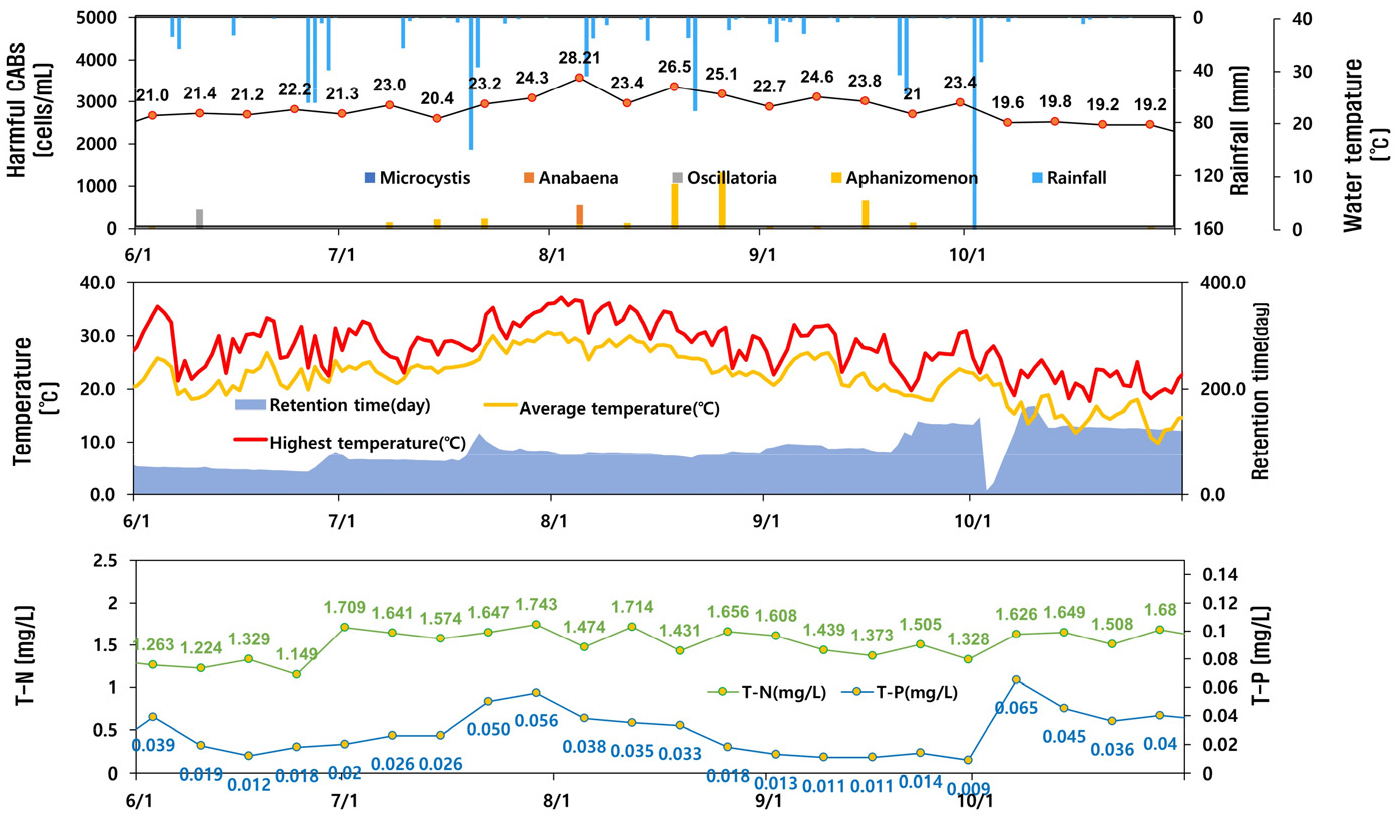
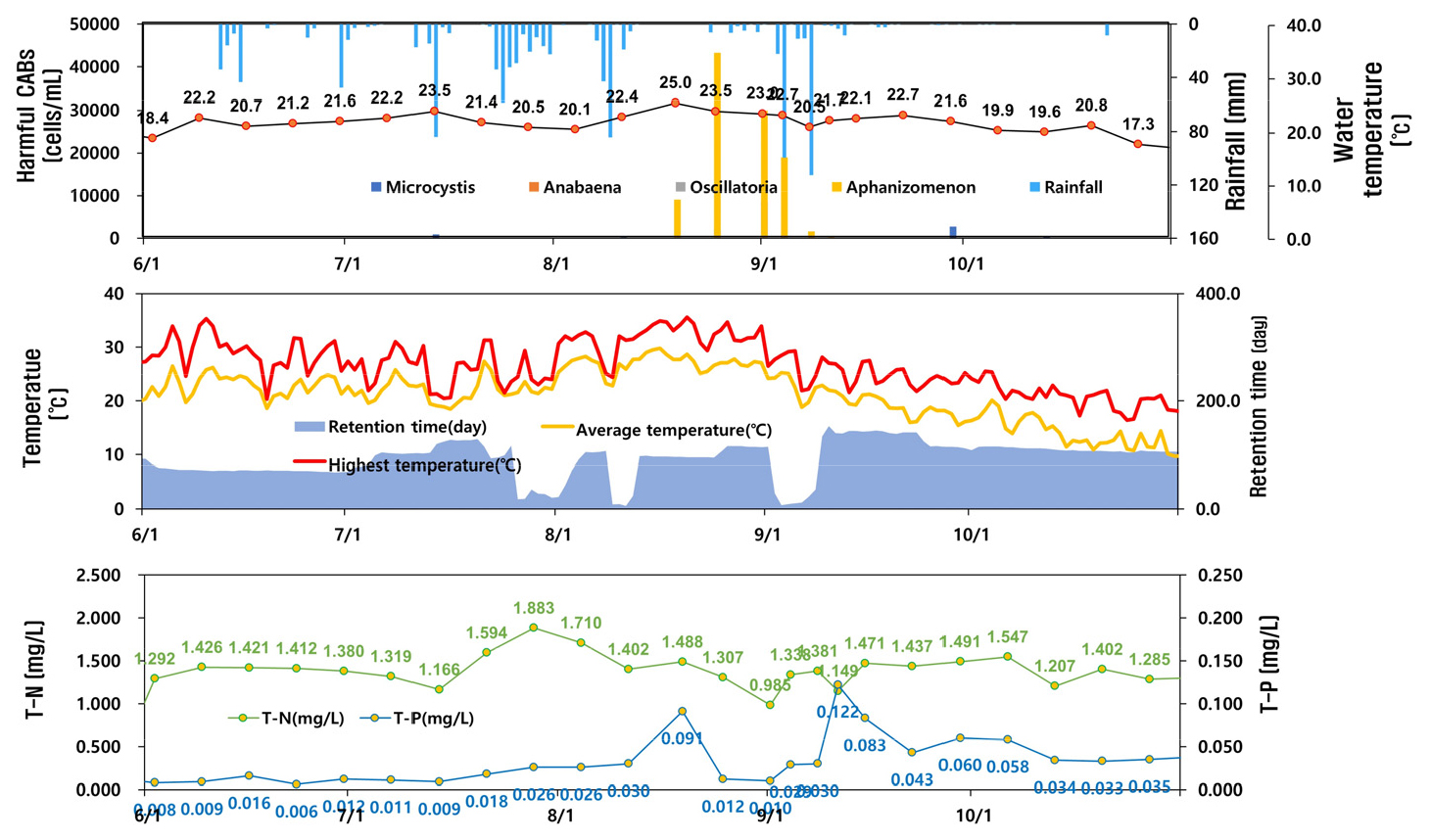
이를 2019년, 2020년 영천댐 하절기 유해 남조류 발생 현황과 대비하여 볼 때, 수온과 유해남조류 발생이 연관이 있는 것을 확인할 수 있다. 남조류는 수온이 20℃ 이상에서 대량증식한다는 연구결과가 있다(Liu et al., 2011). 영천댐의 2019년, 2020년 수온과 유해남조류 발생 등을 나타낸 Figs. 11 and 12에서도 수온이 20℃ 이상일 때부터 유해 남조류가 발생하는 것을 확인할 수 있고, 2019년 8월초 수온이 24.3℃에서 28.2℃로 급격히 상승한 시기에 유해 남조류 세포 수가 1000 cells/mL 이상으로 증가하는 경향을 보였으며, 2020년 8월 중순 수온이 25℃에 도달하였을 때에도 10,000 cells/mL 이상으로 급격히 증가하는 경향을 보이는 것을 알 수 있다.
또한, 영천호 남조류를 조사한 Lee et al. (2019)의 조사결과와 동일하게 2019년, 2020년 모두 유해 남조류 우점종은 Aphanocapsa sp.로 나타났으며, 수온이 28.2℃에 도달한 2019년 8월초에만 고수온 남조류인 Microcystis가 우점하였다.
3.4 머신러닝과 딥러닝 모형을 활용한 수온을 통한 유해 남조류 발생예측
머신러닝과 딥러닝 모형을 활용한 모형구축을 위한 자료를 분석하기 위해 인공신경망 모형과 순환신경망 모형을 동시에 구축하여 비교 분석을 통해 적합한 모형을 도출하고자 한다. 또한, 순환신경망은 RNN 모형, LSTM 모형, GRU 모형으로 세분화하여, 각 모형에 따른 성능을 비교하기 위해 선정 및 구축하였다.
모형에 입력할 시계열 자료는 영천댐의 월별 유해 남조류 개체수와 수온 자료이며, 유해남조류의 총 데이터 수는 2004년부터 2020년(17년)의 750개이다. 이 중 Fig. 13와 같이 2004년부터 2014년(11개년)까지 58%의 436개 데이터를 학습 데이터(training data)로 활용하여 모형을 학습하였고, 나머지 2015년부터 2020년(6개년)까지 42%의 314개 데이터를 테스트 데이터(test data)로 예측 모형을 검증하였다. 모형의 정확도를 평가할 지표로 결정계수(R2), 평균절대오차(Mean Absolute Error, MAE), 평균제곱근오차(Root Mean Square Error, RMSE)를 사용하였다. 또한, 시퀀스(Sequence), 배치 크기(Batch Size) 등과 같은 입력변수에 따라 예측 모형 성능이 변화하므로 비교 및 검증을 위해 모형마다 동일 노드 수와 은닉층을 3층으로 구축하고 활성화 함수는 입력변수가 0을 넘으면 그대로 출력하고, 0 이하면 0을 출력하는 ReLu 함수를 적용하였다.
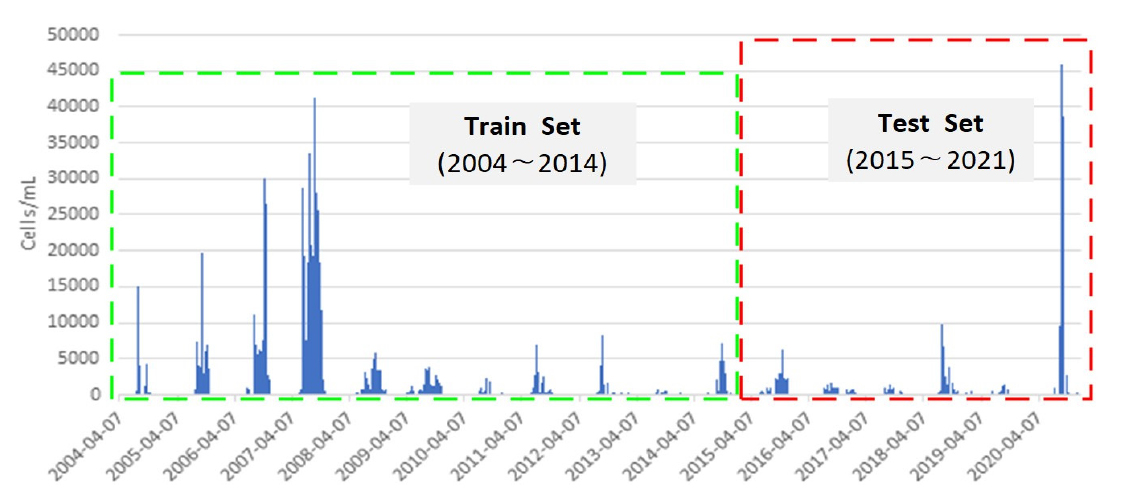
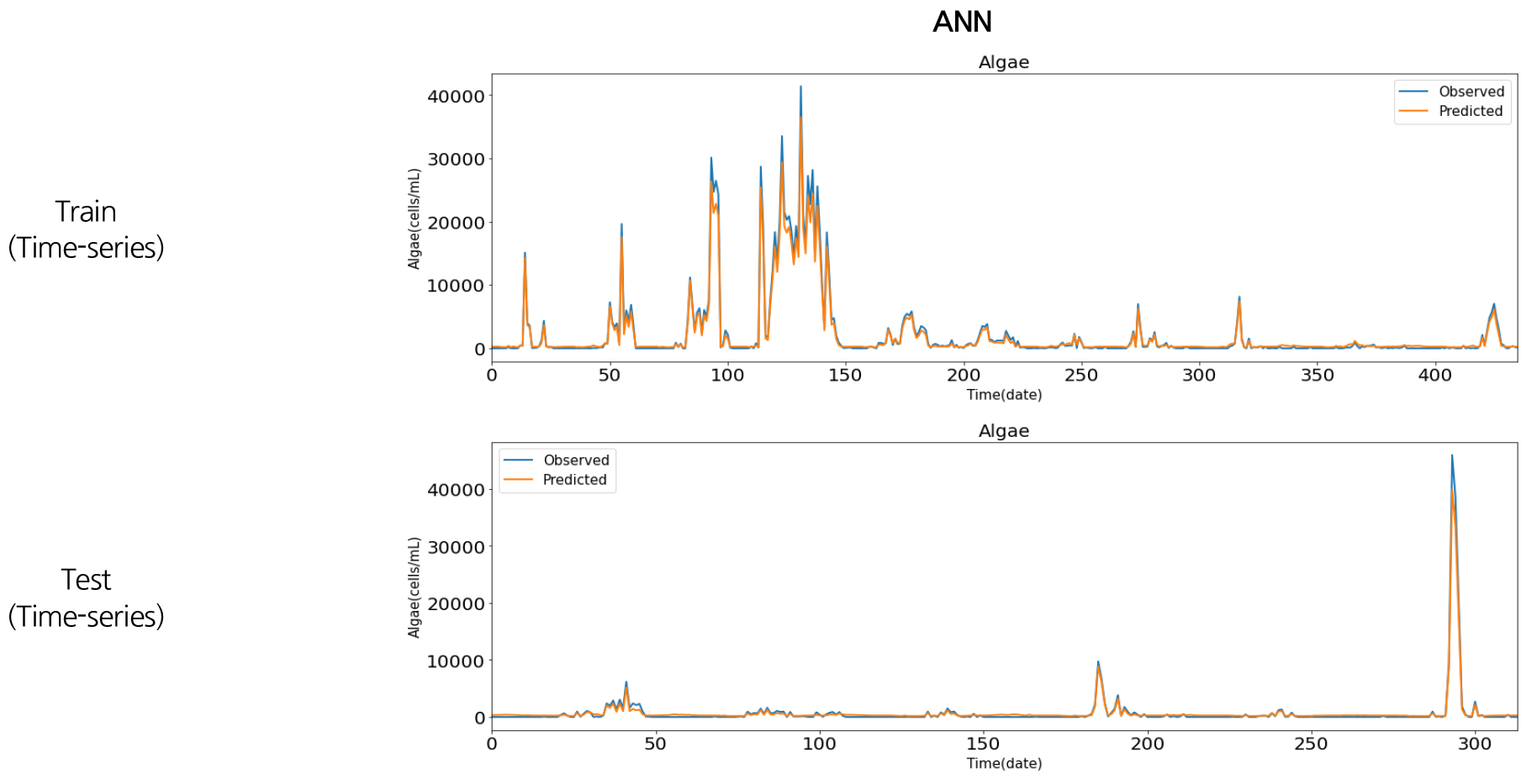
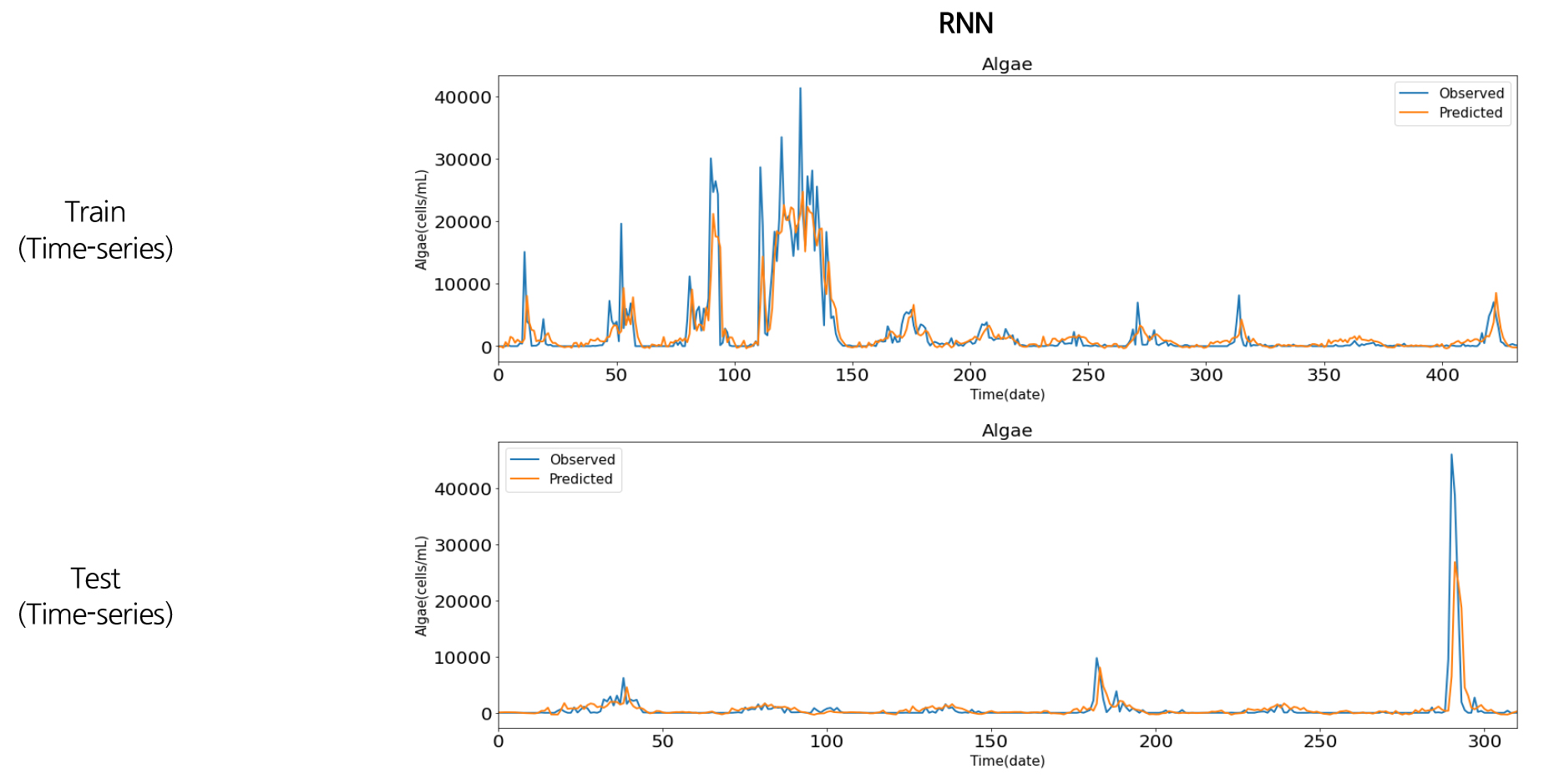
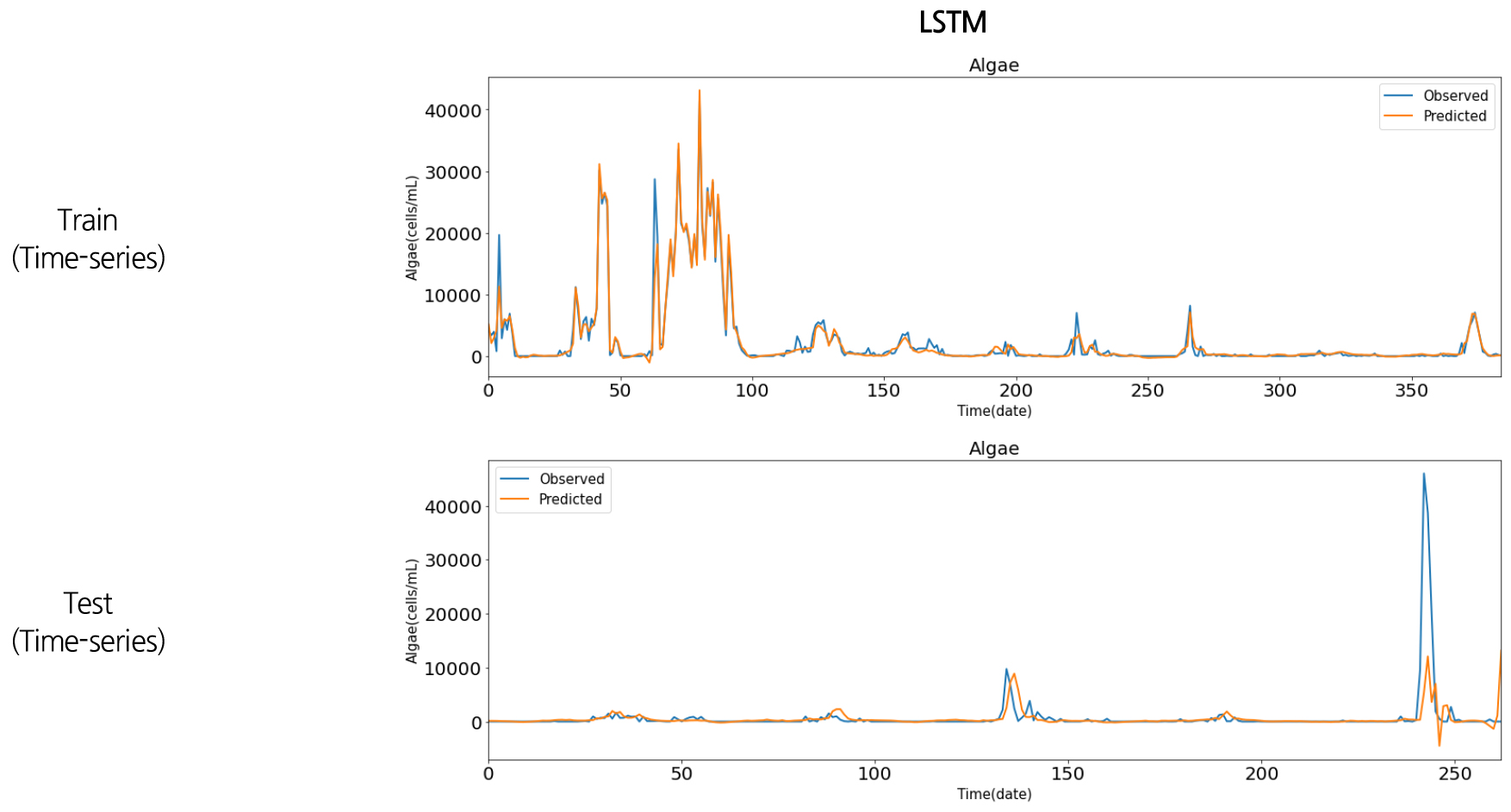
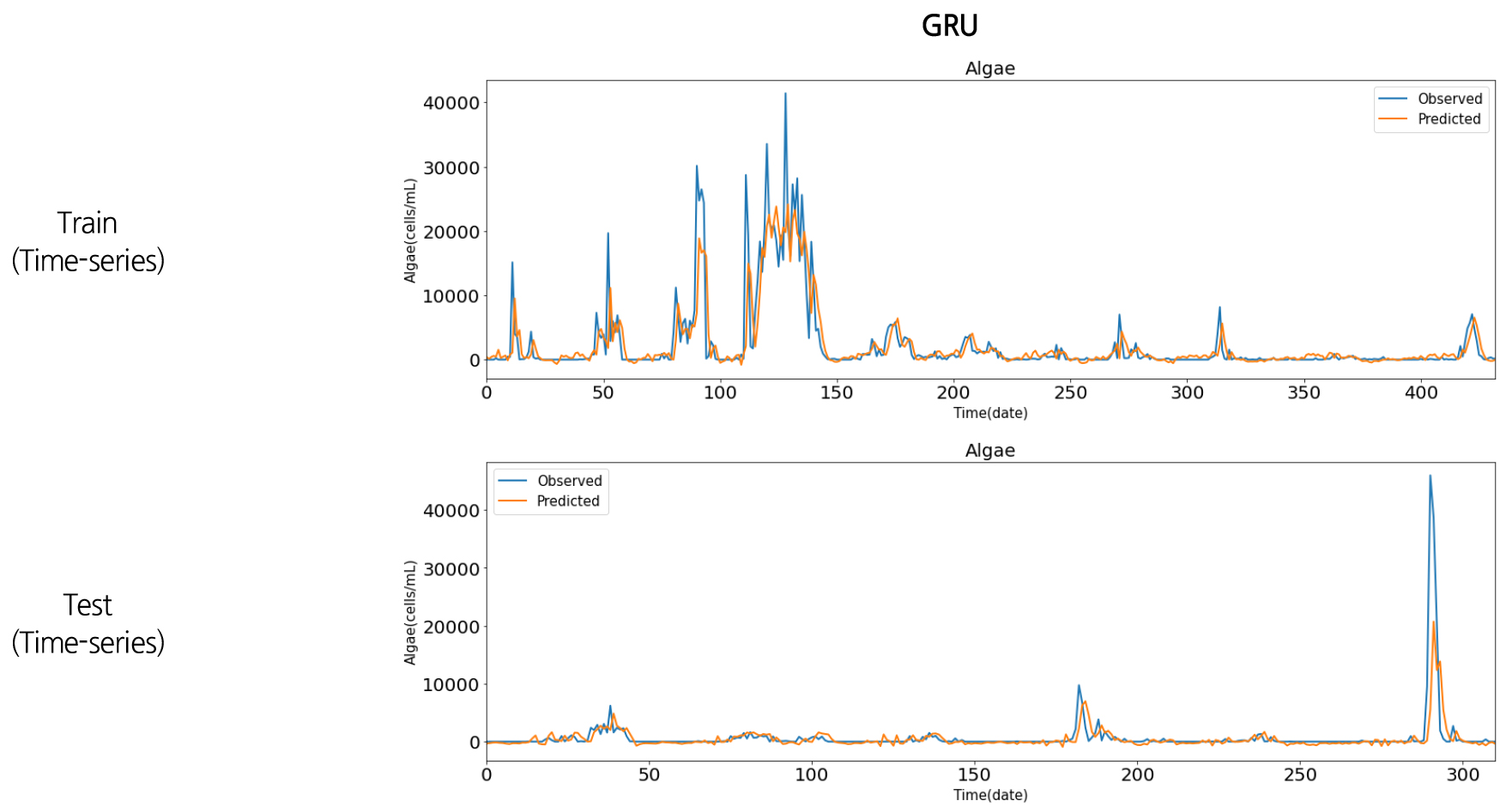
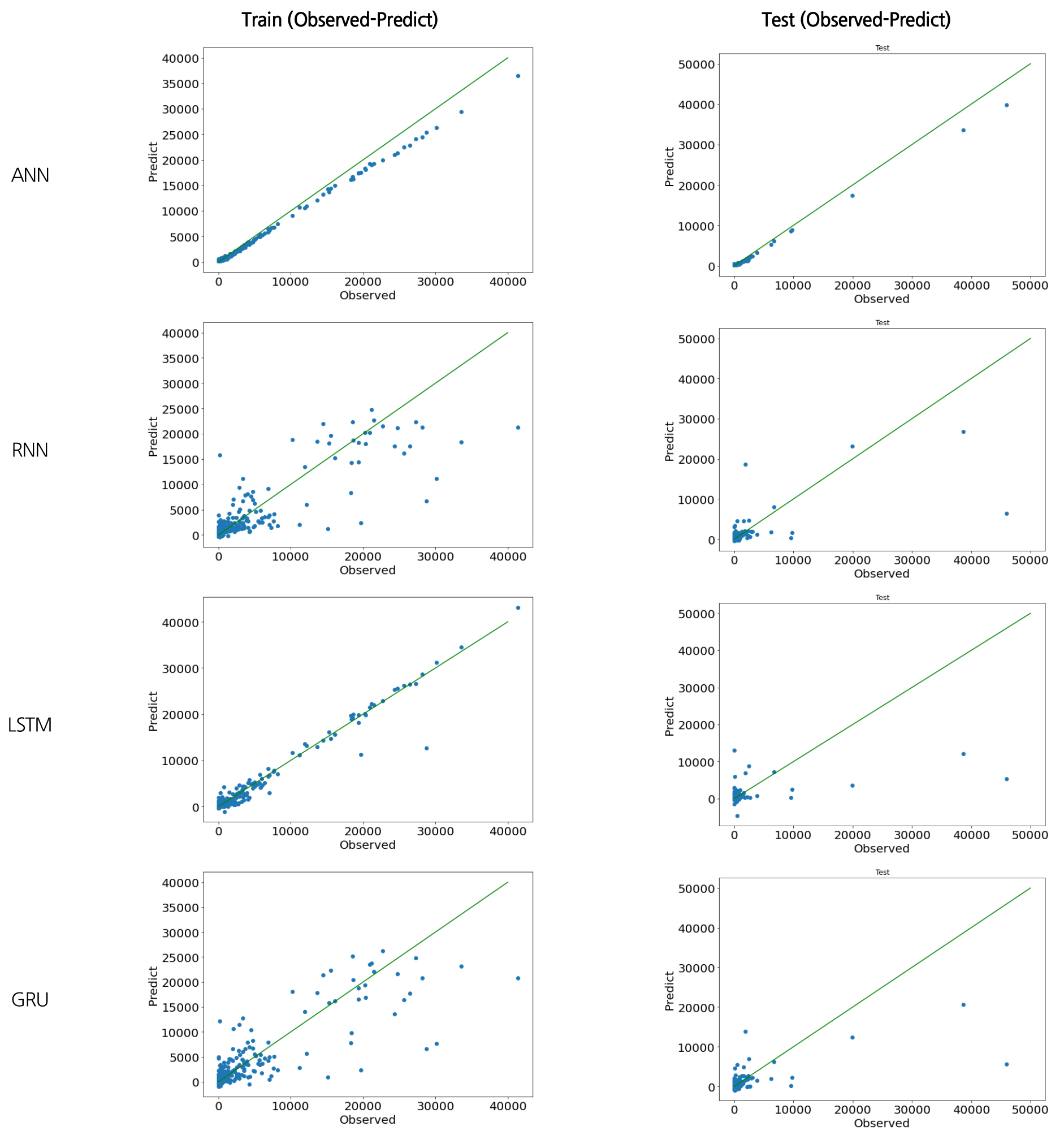
Figs. 14~17은 영천댐 유해 남조류 개체수와 수온자료의 머신러닝 예측 결과를 시계열 그림으로 나타낸 것이다. 파란색 선은 실제 유해남조류세포수 관측값이고, 빨간색 선은 본 연구에서 구축한 인공신경망과 딥러닝 예측 모형을 통해 예측을 수행한 결과이다. 전체적으로 유해남조류세포수 증감 패턴을 잘 예측하였으나, 큰 값에 대한 예측력은 다소 떨어지는 것으로 나타났다. 이는 훈련세트(2004~2014년)에서는 상대적으로 중간 또는 낮은 값의 범위(4만 cells/mL 이하)에서 학습이 진행이 되었으나, 테스트 세트(2015~2020년)에서는 학습동안 경험하지 못한 큰 값(4만 cells/mL 이상)이 존재하여 예측성능이 저하되는 것으로 판단된다. 학습 및 테스트 세트의 정확성 추세는 Fig. 18과 같이 나타났으며, 예측모형의 결정계수(R2)는 Table 1과 같이 ANN이 0.98, RNN이 0.46, LSTM이 0.38, GRU가 0.41로 나타났다.
유사한 연구사례로 미국 Erie 호수에 대해 ANN 모형을 이용하여 기온, 수온, pH, 총인(T-P), 총질소(T-N) 등 여러 입력인자로 유해남조류를 예측한 Guzel (2019)의 연구에서 최고 0.98의 결정계수(R2)를 나타내었으며, 한강을 대상으로 다양한 수질데이터를 순환신경망을 이용하여 연구한 Hong et al. (2020)의 연구에서는 상관계수(R)이 0.77~0.88으로 나타났으며, 극학습기계(Extreme Learning Machines, ELM) 모형을 이용하여 낙동강 4대강 보의 클로로필-a의 농도를 에측한 Yi et al. (2018)의 연구에서는 0.36~0.47의 결정계수(R2)를 나타내었다. 본 연구에서 LSTM의 결정계수(R2)가 0.38로 다른 모형에 비해 낮은 편인데, 이는 낙동강을 대상으로 여러 기계학습 모형으로 클로로필-a를 예측한 Shin et al. (2020)의 연구에서도 LSTM이 가장 낮은 성능을 보였으며, 이를 LSTM 구조가 좀 더 복잡하고 많은 데이터를 요구하려는 경향이 있어 이로 인한 과적합(overfitting)을 사유로 설명하였다.
4. 결 론
본 연구에서는 머신러닝 모형 중 하나인 랜덤 포레스트를 활용하여 유해 남조류 개체수에 영향을 주는 수질인자의 특성 중요치를 분석하고, 이 중 가장 밀접한 연관이 있는 수온을 입력인자로 머신러닝과 딥러닝 모형을 활용하여 유해 남조류 개체수를 예측하였다.
보현산댐과 영천댐에서 측정된 유해남조류 세포수와 나머지 14개의 수질인자의 특성중요치를 분석한 결과 공통적으로 수온이 가장 높았으며, 다음으로는 보현산댐은 SS와 T-N 순이었고, 영천댐은 DO, Chl-a과 T-N 순이었다. 최근 대청호를 대상으로 한 연구에서 T-N과의 상관관계가 높다고 보고된 바가 있으며, 중국 Lake Taihu의 연구사례에서 여름~가을의 녹조 확산 시기에는 질소농도가 크게 작용하는 것으로 조사된 바 있어, 유해 남조류 관리에 인 뿐만 아니라 질소 또한 집중적으로 관리하여야 할 필요성이 있어 보인다.
머신러닝(ANN)과 딥러닝(RNN, LSTM, GRU) 모형을 통한 수온을 입력인자로 유해남조류 세포수 예측결과, 전체적으로 증감 패턴을 잘 예측하였으나, 큰 값에 대한 예측력은 다소 떨어지는 것으로 나타났다. 이는 훈련세트(2004~2014년)에서는 상대적으로 중간 또는 낮은 값의 범위(4만 cells/mL 이하)에서 학습이 진행이 되었으나, 테스트 세트(2015~2020년)에서는 학습동안 경험하지 못한 큰 값(4만 cells/mL 이상)이 존재하여 예측성능이 저하되는 것으로 판단된다. 또한, 예측모형의 결정계수(R2)는 ANN이 0.98, RNN이 0.46, LSTM이 0.38, GRU가 0.41로 나타나, ANN이 가장 우수한 예측성능을 보여주는 것으로 나타났다.
현재 국립환경과학원에서 조류경보제 지점인 한강 낙동강, 금강 주요지점에 대해서만 유해남조류 예측결과를 예보하고 있어, 녹조관리를 위해 유해남조류 예측이 필요한 저수지의 경우 이를 활용할 수 있어 보인다. 또한, 최근 기후변화 진행 양상을 고려할 때, 지구온난화, 폭염일수 증가 등으로 평균수온 상승은 불가피해 보이며, 이를 따라 수온이 유해 남조류 발생에 미치는 영향이 더 커질 가능성이 있어 향후 추가적인 연구를 통해 보완해 나갈 필요가 있다고 생각된다.
