

1. 서 론
2. 연구지역 및 자료
2.1 연구지역
2.2 가용자료
3. 연구방법
3.1 LSTM (Long Short-Term Memory) 기법
3.2 데이터 구성
3.3 하이퍼파라미터 조정
4. 결과 및 분석
4.1 실시간 응답 모델(Real-time Response Model)
4.2 1시간 선행 예측 모델(1-hr Leading Prediction Model)
4.3 합류부 데이터 추가 모델
5. 결 론
1. 서 론
하천 수위 관측과 예측은 수자원 관리, 홍수 방지, 하천 생태계 보호를 위한 필수적인 기술로서, 기후 변화로 인한 극한 기상 현상이 빈번해짐에 따라 관측 밀도의 증대와 예측 정확도 개선의 필요성이 더욱 강조되고 있다. 그러나 기존 수위 관측은 물리적 센서와 물리 기반 모델링 기법에 크게 의존해왔다. 수위 계측을 위한 물리적 센서로 사용되는 플로트 타입, 초음파, 압력 기반 센서는 하천 및 교량에 설치되어 수위를 모니터링하는 역할을 하지만, 설치 위치의 제약과 높은 설치 및 유지보수 비용이 수반된다. 초음파 센서는 강한 소음과 온도 변화에 민감해 장기적이고 주기적인 보정이 필요하며, 압력 센서는 수온과 퇴적물의 영향을 받아 측정 오류가 발생할 가능성이 높아 고정밀 계측을 보장하기 어렵다. 또한, 레이더 센서는 교량에 현수되어 관측이 이루어지므로 광범위한 하천 구역에 대한 고밀도 모니터링에 적합하지 않고, 예측 정확도에서도 한계가 있다(Wu et al., 2023; Tawalbeh et al., 2023). 특히, 집중호우와 태풍과 같은 극단적인 기상 상황에서는 신뢰할 수 있는 데이터를 확보하는 데 제한이 있으며, 광범위한 수문학적 변동성을 실시간으로 파악하기에는 어려움이 있다.
이러한 한계를 해결하기 위해 비접촉 수위 측정 기술과 인공지능(AI) 기반 모델이 주목받고 있으며, 이는 물리적 센서의 비용 문제, 유지보수 요구 사항, 제한적인 계측 범위와 같은 단점을 완화하는 데 기여하고 있다. Depuru et al. (2023)은 IoT 기술을 활용한 스마트 수위 모니터링 시스템을 제안하여 저비용 센서 노드를 통해 실시간 데이터를 제공함으로써 수위 예측의 정확성을 높이고 유지 비용을 절감하는 방안을 제시하였다. 또한, 컴퓨터 비전과 레이더 기반 수위 측정 기술은 유지보수 효율성이 높고 다양한 지점에서 실시간 모니터링을 가능하게 하여 홍수 대응과 예측의 정확도를 향상시키는 데 효과적이다(Wu et al., 2023).
최근 LSTM과 같은 딥러닝 기술이 수위 예측에 도입되어 비선형적인 수문학적 패턴을 효과적으로 반영하는 데 활용되고 있다. 예를 들어, Lo et al. (2015)은 도심 홍수 감지를 위해 비주얼 센싱 기반의 실시간 모니터링 시스템을 도입하여 예측 정확도를 향상시켰으며, Hu et al. (2018)은 LSTM 모델이 장기 의존성을 학습하여 복잡한 수위 변화를 예측할 수 있음을 입증하였다. Li et al. (2020)은 LSTM 모델 아키텍처를 최적화하여 강우-유출 관계를 실시간으로 예측할 가능성을 제시하였고, Atashi et al. (2022)은 Red River of the North를 대상으로 다양한 기상 조건에서 시계열 딥러닝 모델을 활용하여 수위 변화를 예측하였다. Cheong et al. (2023)은 한국의 소규모 하천을 대상으로 다양한 환경 변수를 반영한 AI 기반 홍수 조기 경보 모델을 제안하여 예측 정확성을 크게 개선하였다. 이러한 연구들은 기상 패턴과 하천 환경의 복잡성을 반영함으로써 기존 물리적 센서의 한계를 보완하는 데 중요한 기여한 바 있다.
하천 관측 밀도를 획기적으로 증대하기 위해 본 연구는 LSTM 기반의 소프트웨어 가상센서를 도입하여, 초기에는 물리적 센서와 병행하여 AI 학습 및 검증을 수행한 후, 이후에는 물리적 센서 없이도 하천 수위를 예측할 수 있는 방식을 제안한다. 이러한 가상센서를 활용하면 고비용의 물리적 센서를 교량 등에 설치해야 하는 한계를 극복할 수 있으며, 장소에 구애받지 않고 효율적으로 관측 지점을 설정할 수 있어 다양한 지점에서 하천의 수문학적 특성을 반영한 정밀한 예측이 가능하다.
본 연구의 주요 기여는 다음과 같다.
첫째, LSTM 기반의 가상센서를 통해 물리적 센서가 제거된 지점에서도 하천 수위를 예측할 수 있는 모델을 구현하였다. 이는 스마트폴과 하천 관측소에서 수집된 데이터를 학습하여 물리적 센서 없이도 수위를 정밀히 추정할 수 있게 하였다.
둘째, 상류-하류 간 예측뿐만 아니라 하류-상류 간 예측과 합류 지점에서의 복잡한 수문학적 상호작용을 반영한 모델을 구축하여 다양한 지점에서의 수위 예측 성능을 평가하였다. 이러한 접근은 상류 및 지류의 영향을 반영하여 예측 정밀도를 높이는 데 기여한다.
셋째, 학습 데이터 구성과 예측 지점 설정을 다각적으로 최적화하여 실시간 응답 성능을 확보하고, 홍수 예보 및 수자원 관리에 실질적으로 적용 가능한 가상 센서 모델을 제안하였다. 특히, 최적화된 데이터 파이프라인을 설계하여 스마트폴이 제거된 이후에도 가상센서가 소프트웨어적으로 지속적인 수위 예측을 수행할 수 있도록 하였다.
이를 통해 예측이 어려운 극한 기상 상황에서도 신뢰할 수 있는 수위 예측 모델을 제시함으로써, 향후 재난 예방과 수자원 관리에 기여할 수 있을 것으로 기대된다. 또한, 예측 지점과 학습 데이터 구성의 최적화를 통해 모델의 실시간 응답 성능을 향상시켜, 계측이 어려운 지역에서도 적용 가능성을 크게 확대할 수 있을 것으로 예상된다.
2. 연구지역 및 자료
2.1 연구지역
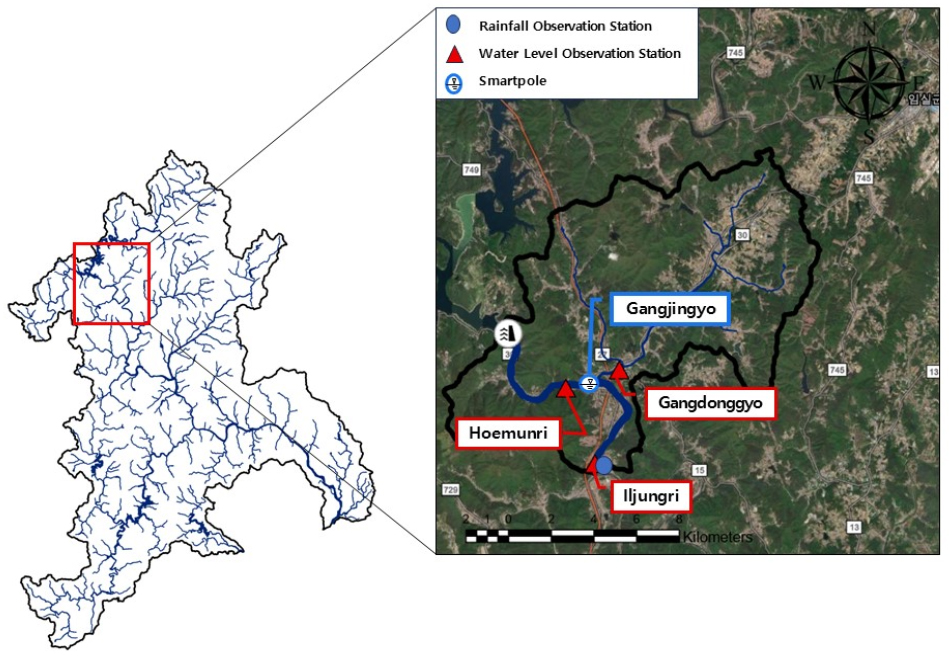
본 연구의 대상 지역은 섬진강 유역 내 단순 하도부 구간으로, 관심(예측) 지점과 그 상류 및 하류에 위치한 두 개 이상의 계측 지점을 포함한다. 단순 하도부란 하천의 유입하도나 분기부가 없거나 그 영향이 미미한 구간을 의미하며, 상대적으로 하천 흐름이 단순하여 수위 예측에 적합한 지역이다. 본 연구에 사용된 관측소는 임실군(회문리), 강진교, 임실군(강동교), 임실군(일중리)의 네 지점이다.
임실군(회문리) 관측소는 섬진강댐 하류에 위치한 관측소로, 연구 구간 중 가장 상류에 위치하며 상류 수위 변동의 기초 데이터를 제공한다. 강진교 스마트폴은 임실군(회문리) 관측소에서 약 1.09 km 하류에 위치한 스마트폴로, 상류에서의 수위 변동과 국지적 강우의 영향을 동시에 모니터링한다. 임실군(강동교) 관측소는 섬진강 본류와 지류인 갈담천이 합류하는 지점에 위치한 관측소로, 합류부에서의 수문학적 상호작용을 분석하고, 지류 유입이 본류의 흐름에 미치는 영향을 평가하는 데 기여한다. 임실군(일중리) 관측소는 연구 구간에서 가장 하류에 위치한 수위 및 강우 관측소로, 회문리에서 약 4.18 km 하류에 위치하며, 하류 구간의 종합적인 수문학적 변동을 반영한다.
각 관측소에서 수집된 데이터는 AI 기반 모델을 통해 하천의 비선형적인 수위 변동을 정밀하게 예측하는 데 활용되며, 이를 통해 관심 지점의 수위 예측 정확도를 향상시키는 데 기여한다. 관측소의 구체적인 위치와 배치는 Fig. 1에 제시되어 있다.
2.2 가용자료
본 연구에서는 섬진강 유역 내 4개의 관측소에서 수집된 수위 및 강우 데이터를 활용하였다. 관측소는 각각 상류(임실군 회문리), 중류(강진교), 하류(임실군 일중리)에 위치하며, 각 지점에서의 데이터를 기반으로 모델 학습이 수행되었다. 관측 데이터는 한국수자원공사(K-Water)와 환경부에서 제공된 공인 데이터로, 기초 데이터의 신뢰성이 보장되었다. 데이터 전처리 과정에서는 결측치와 이상값을 제거하여 학습 데이터의 품질을 개선하였다.
추가적으로, 연구 목적에 따라 임실군(회문리)와 임실군(일중리) 사이에 스마트폴을 설치하여 새로운 데이터를 수집하였다. 스마트폴은 수위 및 강우 계측 외에도 온도와 습도 등 다양한 환경 변수를 실시간으로 수집할 수 있는 다기능 센서를 탑재하고 있다. 수집된 스마트폴 데이터는 기존 관측 데이터와 통합되어 LSTM 모델 학습 및 예측 성능 평가에 활용되었다. 스마트폴을 포함한 네 개 관측소의 세부 제원은 Table 1에 제시되어 있다.
Table 1.
Specifications of water level and rainfall observatories
| Station | Managing Agency | Datum Elevation (EL.m) | Longitude | Latitude | Observation Start Date | |
| Water Level | Hoemunri | K-Water | 123.95 | 127-08-16 | 35-31-18 | 1990-12-15 |
| Iljungri | Ministry of Environment | 114.55 | 127-08-60 | 35-29-47 | 1962-06-01 | |
| Gangjingyo* | - | 120.49 | 127-08-59 | 35-31-24 | 2023-09-07 | |
| Gangdonggyo | Ministry of Environment | 125.355 | 127-06-49 | 35-32-22 | 2023-01-01 | |
| Rainfall | Iljungri | Ministry of Environment | 129.273 | 127-09-00 | 35-29-47 | 1962-06-01 |
| Gangjingyo* | - | 120.49 | 127-08-59 | 35-31-24 | 2023-09-07 |
2023년 9월부터 2024년 8월까지 스마트폴이 설치된 지점의 수위 데이터를 분석한 결과, Fig. 2의 상관지수 히트맵과 Fig. 3의 시계열 그래프에서는 임실군(회문리), 강진교, 임실군(일중리) 지점에서 유사한 수위 변동 패턴이 나타나며, 이들 지점 간 강한 수리적 연계성이 존재함을 시사한다. 특히, Fig. 2의 상관 행렬은 각 지점의 수위 자료를 기반으로 피어슨 상관계수를 계산하여 생성된 것으로, 강동교의 상관계수가 다른 지점들과 낮게 나타나는 지점(임실군(회문리) 0.36, 강진교 0.59, 임실군(일중리) 0.65)은 본류와 지류의 합류 지점으로서의 특성을 확인할 수 있다. 특히, Fig. 2의 상관 행렬은 각 지점의 수위 데이터를 기반으로 피어슨 상관계수를 계산하여 생성된 것으로, 회문리, 강진교, 일중리 등 본류 상 지점들은 상관계수가 0.92~0.98로 높게 나타난 반면, 지류(갈담천)상에 위치한 강동교 지점은 본류 지점들과의 상관계수가 0.36~0.65로 상대적으로 낮게 나타났다.
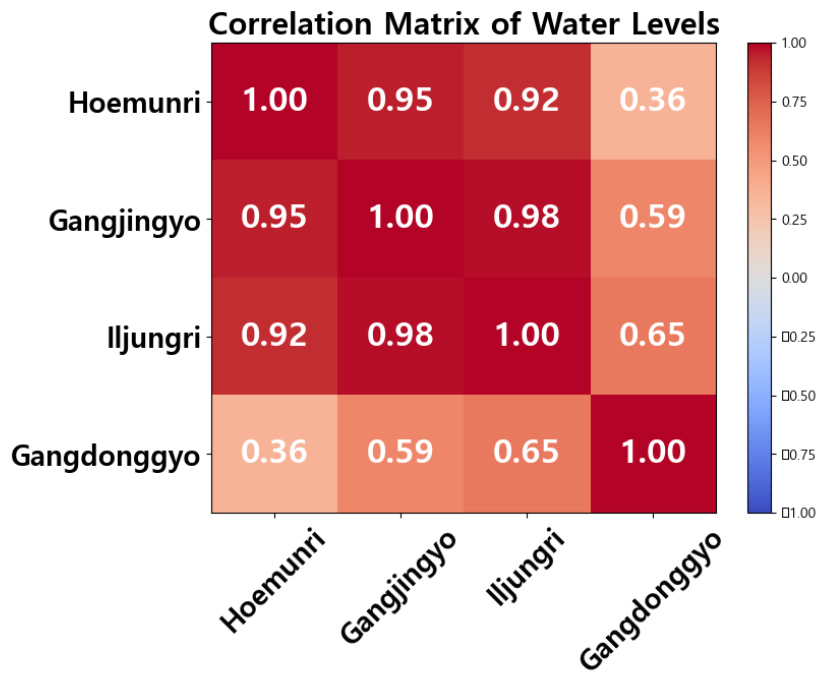
이는 동일 유역 내에서는 각 지점의 수위가 강한 상관관계를 보이는 반면, 임실군(강동교)은 섬진강 본류와 지류 갈담천이 합류하는 지점에 위치해, 다른 지점들과는 다른 수위 변동을 보인다. 지류인 갈담천의 합류부 직상류에 위치한 특성으로 인해 강동교의 수위는 다른 지점과 구별되는 수문학적 특성을 지니며, 이는 별도의 모델링 접근이 필요함을 시사한다.
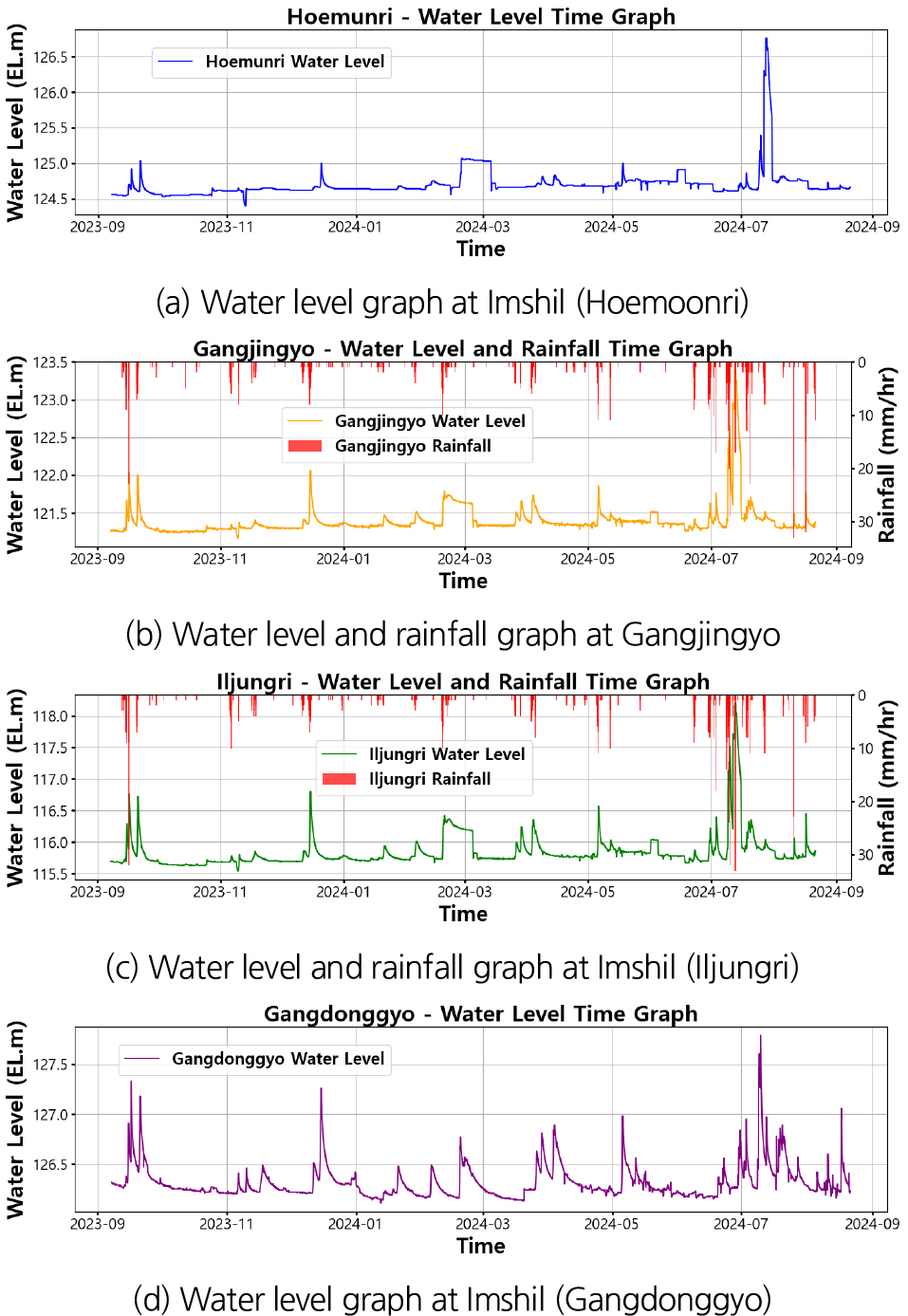
홍수 발생 시 수위 예측에 적합한 LSTM 모델의 학습 데이터 구성을 위해 고수위 기간을 설정하였다. 상류 지점인 임실군(회문리)의 평균 수위를 기준으로, 이 값을 초과하는 기간을 고수위 기간으로 정의하였다. 고수위 기간이 48시간 이상 지속되고, 직전 저수위 기간이 24시간 이내인 경우 해당 기간을 하나의 연속된 고수위 기간으로 간주하였다. 이러한 기준을 적용하여 총 7개의 주요 강우사상을 도출하였다(Table 2).
Table 2.
Major flood events during recent years (2023-2024)
3. 연구방법
3.1 LSTM (Long Short-Term Memory) 기법
Hochreiter and Schmidhuber (1997)이 제안한 Long Short- Term Memory (LSTM) 기법은 시계열 데이터 분석에 강점을 가진 순환 신경망(Recurrent Neural Network, RNN)의 일종이다. 일반적인 RNN은 시간적 의존성을 학습하는 데 적합한 구조를 갖추고 있으나, Bengio et al. (1994)에 따르면 긴 시계열 데이터를 처리할 때 기울기 소실(vanishing gradient) 문제로 인해 장기 의존성 학습에 한계가 있다. LSTM은 이러한 문제를 해결하기 위해 설계된 신경망 구조로, 셀 상태와 게이트 메커니즘을 통해 시계열 데이터의 장기 패턴을 효과적으로 학습할 수 있는 특성을 가지고 있다. LSTM의 핵심 구성 요소는 셀 상태(Cell State)와 여러 개의 게이트(Gates)로 구성된다. 셀 상태는 LSTM의 메모리 역할을 하며, 이전 시구간(Time step)에서 전달된 정보를 저장하고 유지하는 기능을 한다. 이는 모델이 시간의 흐름에 따라 중요한 정보를 잃지 않도록 돕는 역할을 한다. 입력 게이트(Input Gate)는 현재 입력 값과 이전의 은닉 상태(hidden state)를 기반으로 새로운 정보를 셀 상태에 얼마나 추가할지를 결정한다. 수학적으로는 Eq. (1)과 같이 표현된다.
여기서 는 입력 게이트의 출력, 𝜎는 시그모이드 함수, 는 가중치 행렬, 은 이전 타임스텝의 은닉 상태, 는 현재 입력, 는 편향(bias)값이다.
망각 게이트(Forget Gate)는 셀 상태에서 어떤 정보를 삭제할지를 결정하는 역할을 한다. 이 게이트는 셀 상태에서 불필요한 정보를 제거하는 데 사용되며, Eq. (2)와 같이 표현된다.
여기서 는 망각 게이트의 출력, 는 가중치 행렬, 는 편향 값이다. 셀 상태는 포겟 게이트와 입력 게이트의 출력을 기반으로 Eq. (3)과 같이 업데이트된다.
여기서 는 현재 타임스텝의 셀 상태, 는 이전 타임스텝의 셀 상태, 는 새로운 후보 셀 상태로 Eq. (4)와 같이 계산된다.
출력 게이트(Output Gate)는 셀 상태에서 어떤 정보가 출력될지를 결정하며, Eq. (5)로 표현된다.
출력 게이트의 결과와 셀 상태를 결합하여 최종 은닉 상태를 Eq. (6)과 같이 계산한다.
LSTM은 이러한 메커니즘을 통해 시계열 데이터의 특징을 효과적으로 학습할 수 있으며, 특히 긴 시계열에서 중요한 정보를 잃지 않고 예측 정확도를 높일 수 있는 강점을 가지고 있다(Hochreiter and Schmidhuber, 1997). 기존의 하도추적 모델과 물리모형은 LSTM과는 다른 방식으로 하천 유량 및 수위 예측에 활용되어 왔다. 하도추적 모델은 유량의 지체와 감쇠를 모사하는 데 강점을 가지며, 간단한 수학적 관계를 통해 계산 효율성이 높다는 장점이 있다. Muskingum-Cunge 모델은 이러한 접근법의 대표적인 예로, 유량 변화에 따른 지체와 감쇠를 정밀히 모사할 수 있다(Ponce and Yevjevich, 1978). 그러나 이 모델은 주로 선형적인 가정을 기반으로 설계되어 하천의 복잡한 비선형적 특성과 다양한 유역 조건을 충분히 반영하지 못하는 한계를 가진다. 이를 보완하기 위해 비선형 Muskingum 모델과 같은 확장된 접근법이 연구되고 있지만, 초기 조건과 상세 지형 자료의 정확성이 결과에 큰 영향을 미친다는 한계가 여전히 존재한다(Moradi et al., 2023).
물리모형은 하천의 물리적 특성을 정밀하게 모사하는 데 강점을 가지며, 장기 예측 및 상세한 하천 거동 분석에서 높은 신뢰성을 제공한다. 예를 들어, FLOW-3D와 같은 3차원 수치모형은 하천 내 유량 분포와 수위를 정밀히 모의하는 도구로 활용되고 있다. 그러나 이러한 물리모형은 높은 계산 비용과 복잡한 설정이 요구되며, 실시간 데이터 처리에는 한계가 있을 수 있다(Kim, 2019). 특히, 실시간 예측이나 빠른 의사결정이 필요한 홍수 조기 경보 시스템에는 적합하지 않은 경우가 많다.
반면, LSTM 기반 접근법은 데이터 기반으로 비선형 관계를 학습하며, 긴 시계열 데이터에서 발생하는 장기 의존성을 효과적으로 처리할 수 있는 특징을 가지고 있다. 이러한 특성은 하천의 비선형적 특성과 복잡한 상호작용을 반영하는 데 적합하며, 실시간 예측이 필요한 홍수 조기 경보 시스템이나 하천 관리 시스템에서 특히 강점을 발휘한다. 또한, LSTM은 비교적 가벼운 계산 비용으로 플랫폼 내에 코드 형태로 탑재 가능하며, 실시간 데이터 처리를 지원할 수 있다. 이는 기존 하도추적 모델이나 물리모형과 차별화되는 중요한 장점이다.
본 연구에서는 LSTM의 이러한 강점을 활용하여 가상센서를 설계하였으며, 초기에는 물리센서와 병행 운용하여 학습 및 검증을 진행하고, 이후에는 물리센서 없이도 데이터를 기반으로 지속적으로 수위 예측을 수행할 수 있는 소프트웨어적 대안을 제안하였다. 이를 통해 본 연구에서 제안한 가상센서는 하천 관측 밀도를 효율적으로 확장할 수 있는 가능성을 보여주었으며, 홍수 예측 및 실시간 대응에 있어 중요한 도구로 활용될 수 있음을 보여주고 있다.
3.2 데이터 구성
본 연구에서는 섬진강 유역 내 네 지점의 수위 자료와 두 지점의 강우 자료를 사용하여 설계된 총 16개의 LSTM 기반의 하천 수위 예측 모델을 개발하였다. 연구에서 다루는 네 지점은 상류 1지점(임실군(회문리)), 상류 2지점(강진교), 합류 지점(임실군(강동교)), 하류 지점(임실군(일중리))로 정의된다. 학습 데이터는 크게 여섯 가지로 구성되었으며, 각 구성에 따라 관심(예측) 지점과 학습 데이터를 다르게 설정하여 수위 계측 및 예측 모델을 구축하였다.
3.2.1 학습 데이터 및 관심(예측) 지점 설정
본 연구에서는 다양한 학습 데이터 구성을 통해 하천 각 지점 간 상호작용을 분석하고, 수위 예측 모델의 적용 가능성을 평가하였다. 각 데이터 구성은 상류 1지점, 상류 2지점, 합류 지점, 하류 지점의 상호작용을 반영하여 설계되었으며, 총 5가지 실험 구성을 통해 예측 모델을 개발하고 성능을 평가하였다. 주요 실험 구성은 Table 3과 같다.
Table 3.
Configuration of training data and target (Prediction) points
이와 같이 다양한 학습 데이터 구성을 통해 각 지점의 수위 계측 및 예측 모델을 개발하였으며, 이를 통해 지점 간의 데이터 상관성과 모델 성능 간의 관계를 평가하였다.
3.2.2 실시간 응답 및 1시간 선행 예측
앞선 3.2.1절에서 설명한 바와 같이, 본 연구에서는 학습 데이터 구성 및 관심(예측) 지점 변경에 따라 구축된 모델을 바탕으로 실시간(Real-Time, RT) 응답 모델과 1시간 선행 예측(1-hour Prediction, Pred) 모델의 성능을 비교하였다. 각 모델은 이름에 포함된 'RT'와 'Pred'로 구분되며, 예측 방식과 활용 목적이 상이하다.
실시간 응답 모델(RT)은 현재 시점의 데이터를 입력으로 사용하여 동일 시간대의 하천 수위를 예측하는 방식으로, 하천 수위의 실시간 모니터링 및 즉각적인 대응이 요구되는 상황에 적합하다. 예를 들어, ‘H-RT’는 Hoemunri 관측소 데이터를 기반으로 실시간 수위를 예측하는 모델을 의미한다.
1시간 선행 예측 모델(Pred)은 현재 시점의 데이터를 입력으로 사용하여 1시간 후의 하천 수위를 예측하는 방식으로, 단기적인 수위 변동을 사전에 감지하는 데 초점을 맞추고 있다. 이 모델은 홍수 예측 및 조기 경보 시스템에서의 활용 가능성을 평가하는 데 적합하다. 예를 들어, ‘Pred_HG’는 Hoemunri와 Gangjingyo 관측소 데이터를 기반으로 1시간 후의 수위를 예측하는 모델을 나타낸다.
두 예측 모델은 상이한 시나리오에서 중요한 역할을 수행한다. 실시간 예측 모델(RT)은 현재 상황을 정확히 반영함으로써 즉각적인 의사결정과 모니터링을 가능하게 하며, 1시간 선행 예측 모델(Pred)은 미래의 수위 변동을 사전에 감지하여 조기 대응의 기반을 제공한다. 본 연구에서는 두 예측 모델의 성능을 비교함으로써 시간적 선행성이 수위 예측 정확도에 미치는 영향을 분석하고, 실시간 예측 및 단기 예측 시나리오에서 LSTM 모델의 적용 가능성을 평가하였다.
Table 4와 Table 5에 제시된 LSTM 모델 이름은 관측소 이름과 예측 유형(‘RT’, ‘Pred’)을 조합하여 구성되었으며, 이는 모델의 주요 특성을 간결하고 직관적으로 표현하기 위해 설계되었다. 이러한 이름 체계는 모델의 구성을 명확히 이해하고 비교 분석하는 데 용이하다.
Table 4.
LSTM Model structure
Table 5.
LSTM Model structure (Including confluence points)
3.3 하이퍼파라미터 조정
LSTM 모델의 성능은 하이퍼파라미터 설정에 크게 의존하므로, 본 연구에서는 Keras Tuner의 Random Search 기법을 사용하여 최적의 하이퍼파라미터 조합을 도출하였다. Random Search는 하이퍼파라미터 공간에서 무작위로 조합을 선택해 성능을 평가하는 방식으로, 전수 조사(Grid Search)보다 계산 자원을 효율적으로 사용하면서도 최적의 하이퍼파라미터를 효과적으로 탐색할 수 있는 기법이다(Bergstra and Bengio, 2012).
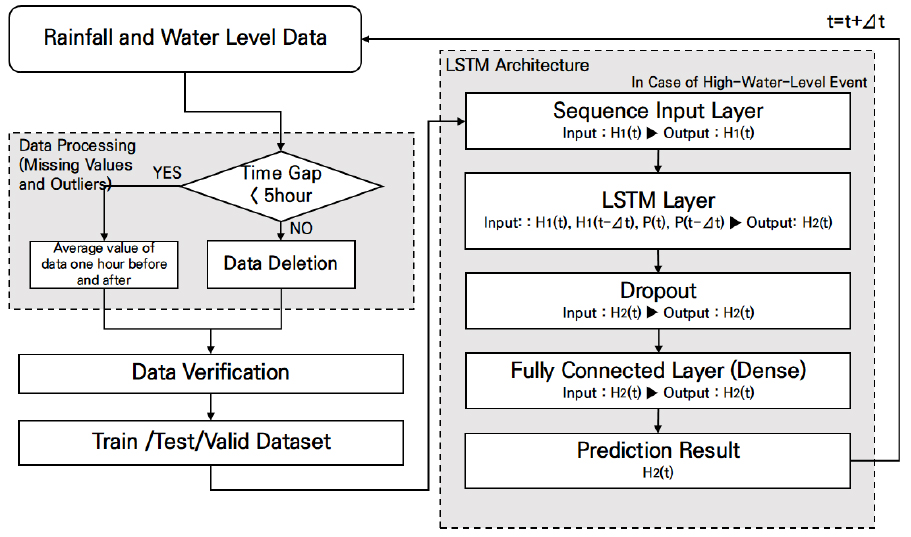
먼저, LSTM 레이어의 유닛 수는 모델의 학습 능력과 복잡도를 결정하는 핵심요소로, 유닛 수가 많을수록 복잡한 패턴을 효과적으로 학습할 수 있지만, 과도한 유닛 수는 과적합 위험을 증가시킬 수 있다. 시퀀스 길이는 입력 데이터의 길이를 의미하며, 긴 시퀀스는 모델이 더 많은 과거 정보를 학습할 수 있도록 하지만, 지나치게 길 경우 학습 난이도와 계산 비용이 증가할 수 있다. 레이어 개수는 모델의 깊이를 결정하며, 레이어 수가 증가하면 더 복잡한 패턴 학습이 가능하지만, 과도한 레이어는 과적합 위험과 학습 시간 증가를 초래할 수 있다. 배치 크기는 한 번에 학습할 데이터의 양을 결정하는 요소로, 배치 크기가 클 수록 학습 속도가 향상되지만, 세부적인 조정 능력이 감소할 수 있다. 학습률은 모델이 가중치를 업데이트하는 속도를 결정하며, 학습률이 너무 높으면 학습이 불안정해지고, 지나치게 낮으면 학습속도가 느려지거나 지역 최소값에 갇히는 문제가 발생할 수 있다. 리드 타임은 예측할 미래 시간의 간격을 의미하며, 리드 타임이 길수록 더 먼 미래를 예측할 수 있지만, 예측의 불확실성 또한 증가한다. 드롭아웃 비율은 과적합을 방지하기 위한 중요한 요소로, 드롭아웃 레이어에서 무작위로 뉴런을 비활성화함으로써 모델의 일반화 성능을 높이는 데 효과적이다(Srivastava et al., 2014). 최적화된 하이퍼파라미터 조합을 바탕으로 각 모델에서 사용된 매개변수는 Table 6과 7에 제시되어 있다. 또한, Fig. 4는 단순 하도부 구간에서 사용된 LSTM 알고리즘의 전체 구조를 시각적으로 나타낸 것이다.
Table 6.
Hyperparameters by LSTM Model
4. 결과 및 분석
본 연구에서 제안한 LSTM 기반 하천 수위 예측 모델의 성능을 평가하기 위해 NSE (Nash-Sutcliffe Efficiency), RMSE (Root Mean Square Error), MAE (Mean Absolute Error) 등의 지표를 활용하였다(Table 8). 이러한 지표들은 모델의 예측 정확도와 오차를 다양한 측면에서 평가할 수 있도록 하며, 이를 통해 각 모델의 성능을 종합적으로 분석하였다. 각 모델의 예측결과와 관측 자료를 비교하여 산정한 평가지표를 단순 계측 모델과 1시간 선행 예측 모델별로 정리하였다(Table 8).
Table 8.
Definition and Interpretation of Performance Metrics
4.1 실시간 응답 모델(Real-time Response Model)
실시간 응답 모델은 실시간으로 수집된 데이터를 바탕으로 동일 시간대의 하천 수위를 예측하는 방식이다. Table 9와 Figs. 5, 6, 7의 시뮬레이션 결과에 따르면, 이벤트에 따라 모델 성능에 차이가 발생하였다. 특히 상·하류 다중 학습데이터를 사용한 Event #3에서 RT_HG와 RT_HI모델은 각각 NSE 값 0.993과 0.980을 기록하며 우수한 성능을 보였다. 이는 상류 #1, #2 지점과 하류 지점간의 물리적 상관성을 모델이 효과적으로 학습했기 때문으로, 상류에서 발생한 수위 변동이 하류에 미치는 물리적 흐름을 성공적으로 반영하여 예측이 효과적으로 이루어졌음을 의미한다.
Table 9.
Simulation Results by LSTM model
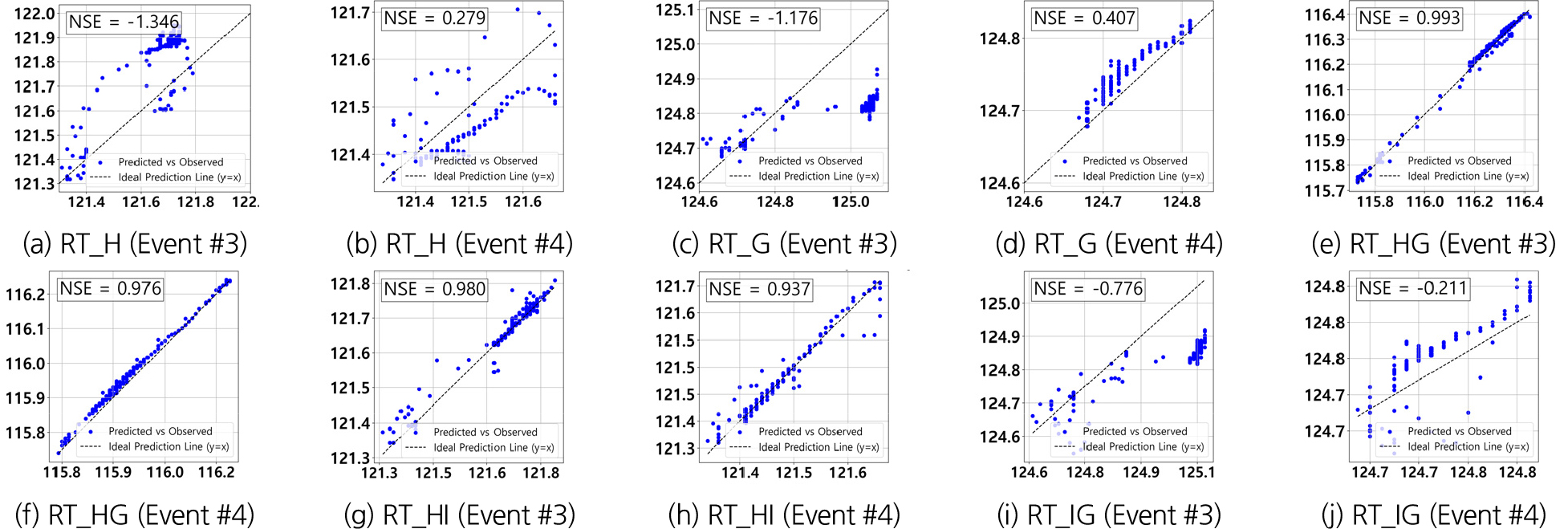
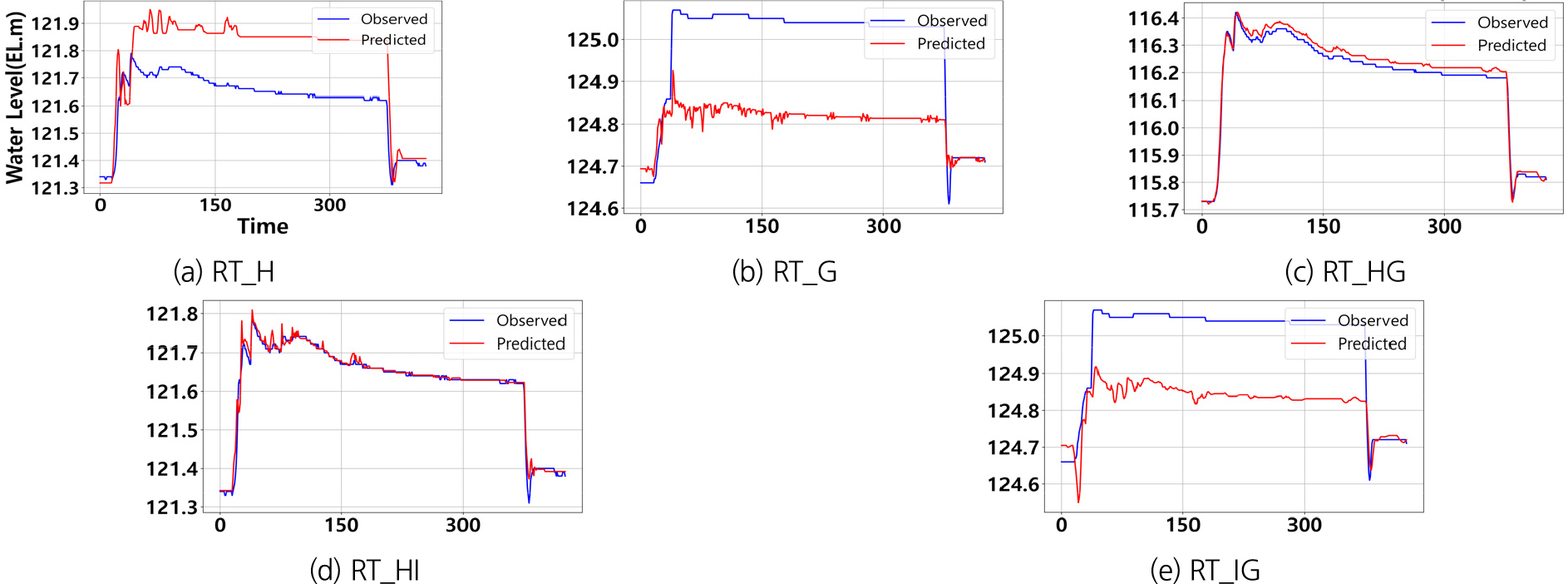
반면, 단일 학습 데이터를 사용한 RT_H과 RT_G모델은 Event #3에서 각각 NSE 값 -1.346과 -1.176으로 저조한 성능을 보였다. 이는 단일 데이터 구성이 상류와 하류 간의 복잡한 비선형 상호작용을 충분히 반영하지 못했기 때문으로, 상류-하류 간의 물리적 상관성을 고려하지 않은 경우 성능 저하가 발생할 수 있음을 보여준다.
또한 RT_IG모델은 4개의 학습 데이터를 사용했음에도 불구하고, 하류 데이터를 기반으로 상류를 예측한 경우 Event별 NSE 값이 각 -0.776, -0.211로 저조한 성능을 기록하였다. 이는 하류 데이터를 이용해 상류를 예측하는 것이 수리학으로 타당성을 결여하고 있음을 시사한다. 두 지점 간 상관계수가 높게 나타나더라도, 상류에서 하류로의 방향성을 고려하여 계측 지점과 관심 지점을 구성하는 것이 예측 신뢰도를 높이는 데 중요하다. 상류 지점의 수위는 상류 유역의 강우량과 지류 유입량 등의 영향을 받아 하류 지점의 수위 형성에 기여하므로, 상류를 계측 지점으로, 하류를 관심 지점으로 설정하는 방식이 예측 정확도를 향상시킬 수 있음을 시사한다.
현재 전국에 설치되어 있는 하천수위관측소는 대부분 교량상판에 현수된 레이더 수위계 형식이 대부분이어서 합류부나 분기부, 단면의 급변구간 등 수리학적으로 중요한 지점과 일치하지 않는 경우가 많다. 실제 현장에서 가상센서를 운용할 때, 기존 계측기가 관심 지점의 하류부 교량 지점에 설치되어 있는 경우, 하류지점의 계측을 이용하여 상류지점을 예측하는 경우 예측 성능이 기대보다 저하될 수 있다.
결론적으로, 단순 계측 모델의 예측 성능은 학습 데이터 구성의 다양성과 예측 지점 간 물리적 특성에 크게 의존한다. 상류에서 하류로의 예측은 물의 흐름이 일정한 방향으로 진행되기 때문에 비교적 예측이 용이하며, 학습 데이터의 다양성은 이러한 상관성을 더 잘 반영하여 모델 성능을 향상시킬 수 있었다. 반면, 하류에서 상류로의 예측은 비선형적 상호작용이 더 복잡하여 성능 저하가 발생하였으며, 이를 해결하기 위해서는 추가적인 데이터와 고도화된 모델링 전략이 필요하다.
4.2 1시간 선행 예측 모델(1-hr Leading Prediction Model)
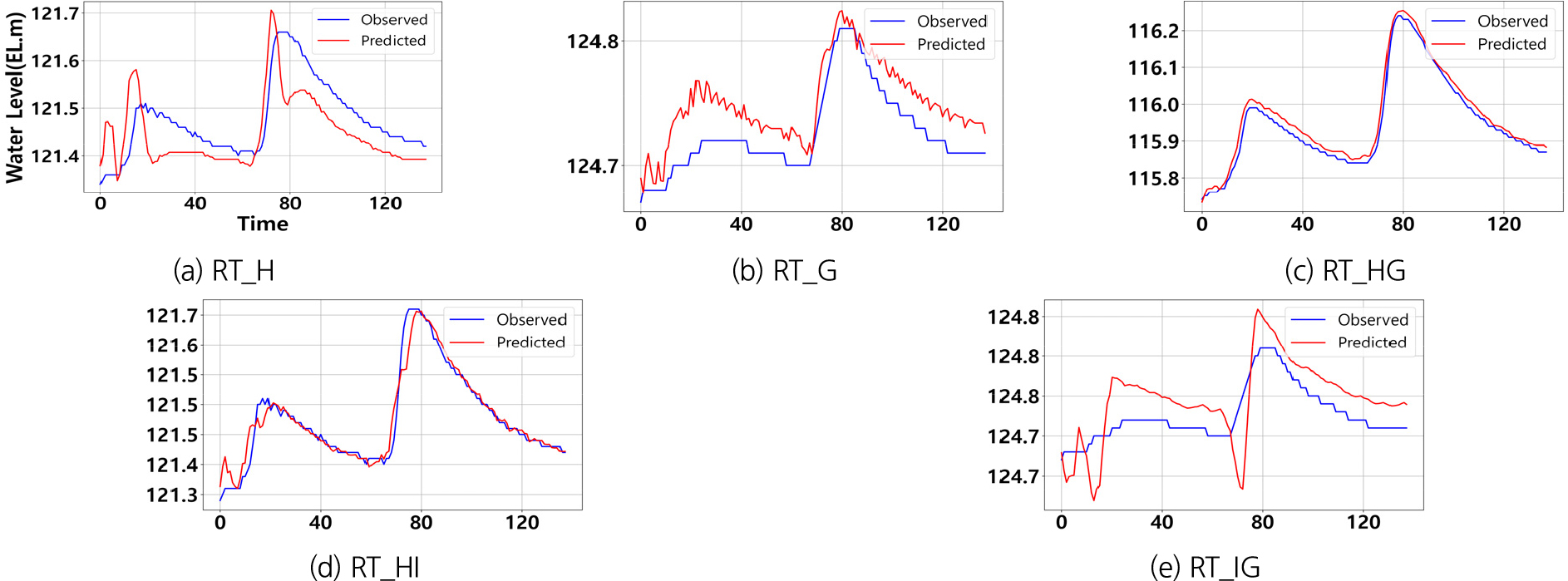
1시간 선행 예측 모델은 현재 시점의 데이터를 기반으로 1시간 후의 하천 수위를 예측하는 방식이다. Table 10와 Figs. 8, 9, 10은 이 모델의 시뮬레이션 결과를 설명하며, 다양한 시나리오에서 성능 차이를 보여준다. 특히 Event #4의 예측 정확도가 전반적으로 높게 나타났으며, 3개의 학습 데이터를 사용한 Pred_HG와 Pred_HI모델이 각각 NSE 값 0.996과 0.883을 기록하며 매우 우수한 성능을 보였다. 이는 상류(회문리, 강진교) 지점에서 발생한 수위 변동이 하류(일중리) 수위에 미치는 영향을 모델이 효과적으로 학습했음을 의미한다.
Table 10.
Simulation Results by LSTM model
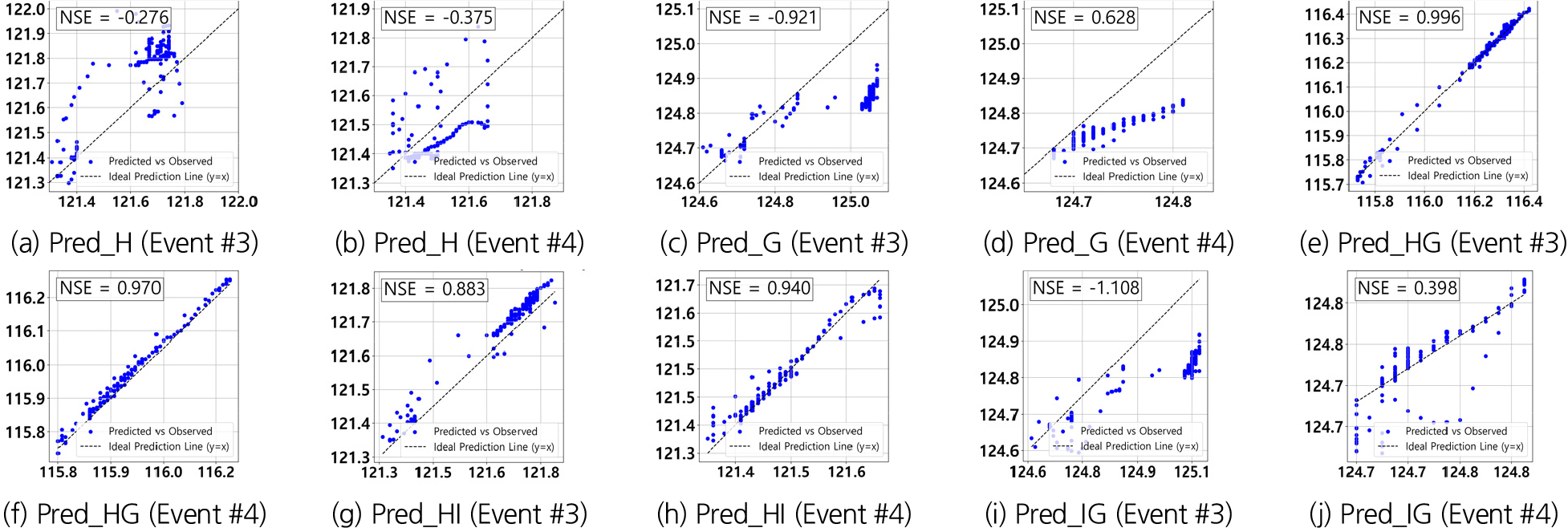
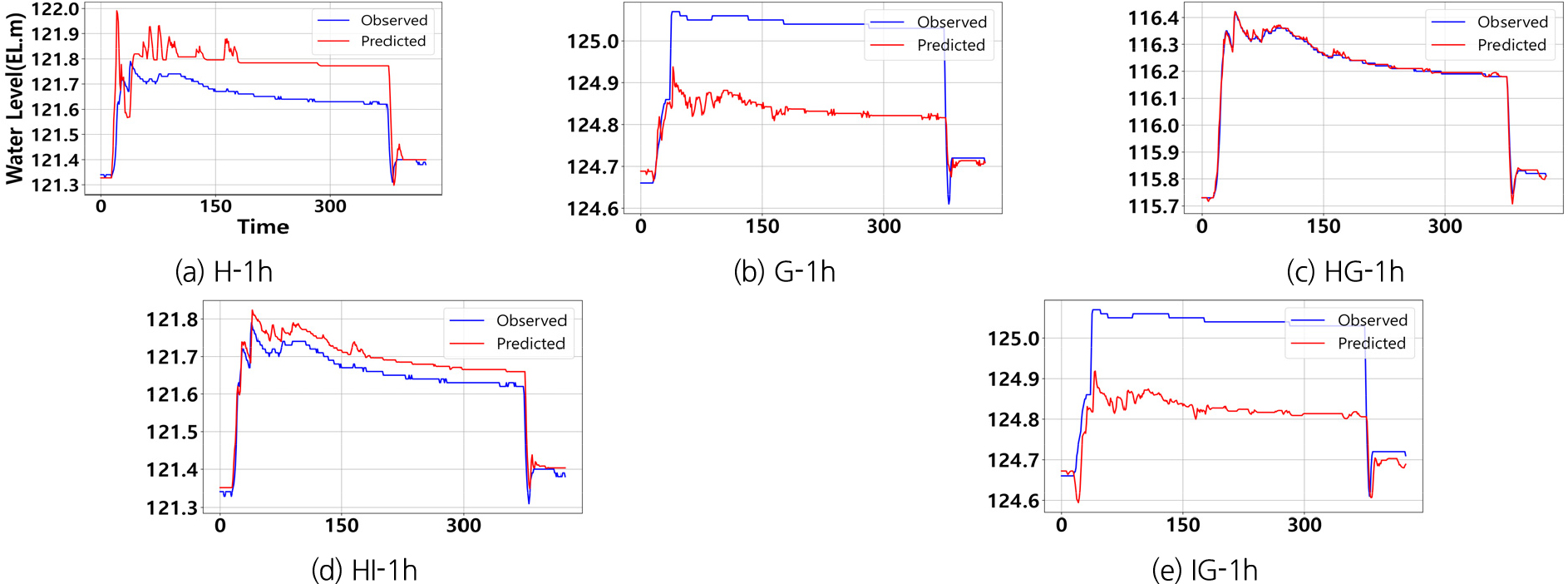
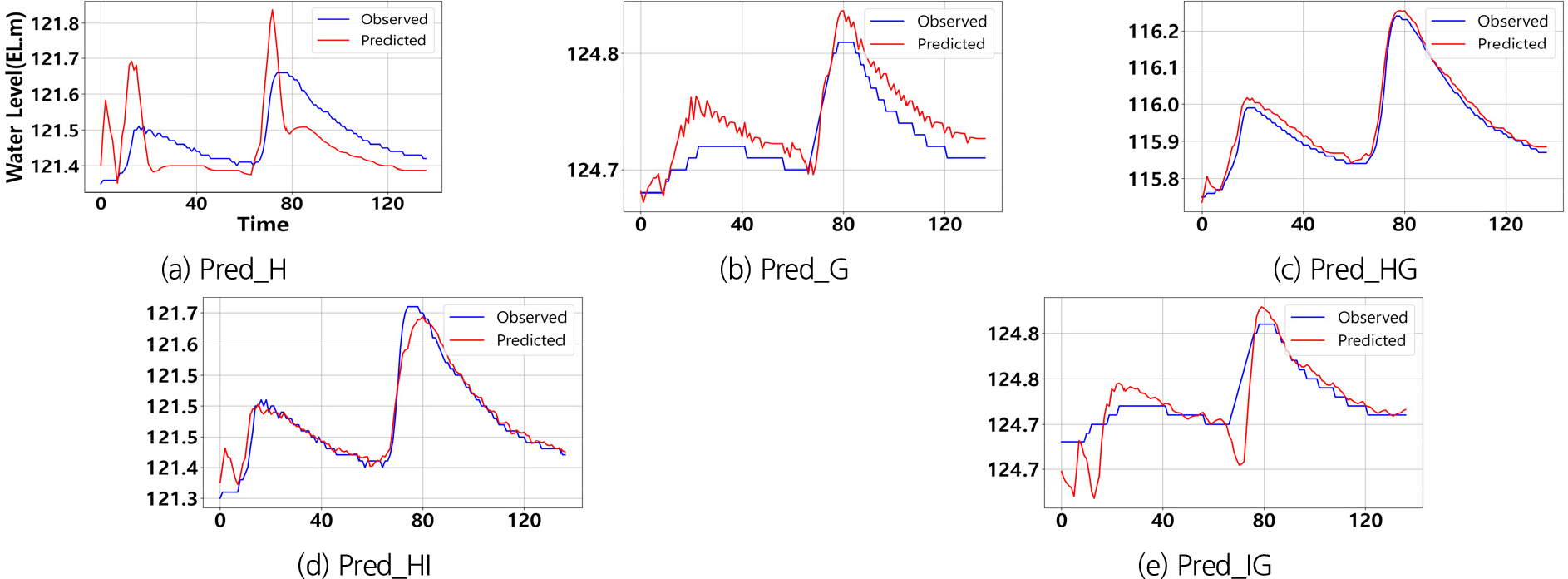
Pred_HG 모델은 Event #3과 Event #4에서 모두 뛰어난 성능을 기록하였다. Event #3에서는 NSE 값이 0.996, QER 0.072%로 매우 낮은 예측 오차를 보였으며, Event #4에서도 NSE 값 0.970, QER 0.041%로 우수한 성능을 유지하였다. 이는 상류에서 발생한 수위 변동이 1시간 후 하류에 미치는 영향을 선행 시간을 고려한 예측에서도 정확하게 반영했음을 보여준다. 학습 데이터 구성이 동일한 실시간 응답 모델인 RT_HG와 비교하였을 때, 선행시간 적용하기 전후의 성능 차이는 크지 않았다. 이는 상·하류 다중 지점 데이터를 사용할 경우, 선행시간이 예측 성능에 큰 영향을 미치지 않았음을 보여준다.
Pred_HI 모델 역시 Event #4에서 NSE값 0.940으로 우수한 성능을 기록하였으며, Event #3에서는 0.883으로 양호한 성능을 유지하였다. RT_HI 모델과 비교하였을 때, 단순 계측 모델의 성능이 상대적으로 높았으나, 선행 시간을 적용한 이후의 성능 차이는 미미한 수준임을 확인하였다.
단일지점 데이터를 사용한 Pred_H와 Pred_G모델은 Event #3에서 각각 NSE 값 -0.276과 -0.921을 기록하며 비교적 저조한 성능을 보였으나, 선행 시간을 적용한 이후 성능이 일부 개선되었다. 이는 1시간 선행 예측 모델이 상-하류 간의 데이터 상관성을 효과적으로 학습하여 미래 수위변동을 반영했기 때문으로 해석된다. 반면, 하류 데이터를 기반으로 상류 수위를 예측한 Pred_IG모델은 NSE 값이 -1.108로 매우 낮은 성능을 기록하였다. 이는 하류에서 상류로의 예측이 불안정한 성능을 보이며, 선행예측 성능에도 부정적인 영향을 미쳤음을 나타낸다.
결론적으로, 비교적 짧은 1시간 선행 예측 모델은 데이터의 불확실성과 시차에 의한 오차가 발생할 수 있으나, 전반적으로 양호한 성능을 보였다. Pred_HG와 Pred_HI모델이 특히 뛰어난 성능을 기록했으며, 이는 모델이 데이터 상관성을 효과적으로 학습하여 미래 예측에서도 성능을 유지할 수 있었음을 보여준다. 반면, Pred_H, Pred_G모델과 같은 모델들은 일부 이벤트에서 성능 저하가 발생했으며, 이는 리드타임 적용 시 발생할 수 있는 데이터 불확실성과 비선형적 상호작용의 복잡성에 기인한 것으로 판단된다.
4.3 합류부 데이터 추가 모델
본 연구에서는 합류 지점 데이터를 포함한 모델과 포함하지 않은 모델의 성능을 비교하여 평가하였다. Table 5에서 볼 수 있듯이, 합류 지점 데이터를 포함한 모델은 강동교 합류 지점의 수위 데이터를 활용하여 상류 및 하류 수위 변화를 예측하는 데 사용되었다. 강동교는 자류와 본류와의 합류점 직상류에 위치하여 본류 지점의 수위예측모델 성능에 중요한 역할을 미치는 관측지점이다.
Table 11과 Figs. 11, 12, 13에 근거하여 합류 지점 데이터를 포함한 모델의 성능을 분석한 결과, 하류 데이터를 기반으로 상류를 예측한 RT_IGG와 Pred_IGG모델의 성능이 크게 개선되었다. 특히 Pred_IGG모델은 Event #4에서 NSE 값이 0.864를 기록하며, 합류 지점 데이터를 포함함으로써 예측 성능이 향상된 것으로 나타났다. 이는 합류부에서 발생하는 수위 변동을 모델이 효과적으로 학습하여, 하류에서 상류로의 예측 시 비선형적 상호작용을 보다 정밀하게 반영할 수 있었기 때문으로 해석된다.
Table 11.
Simulation results by LSTM Model (Including confluence points)
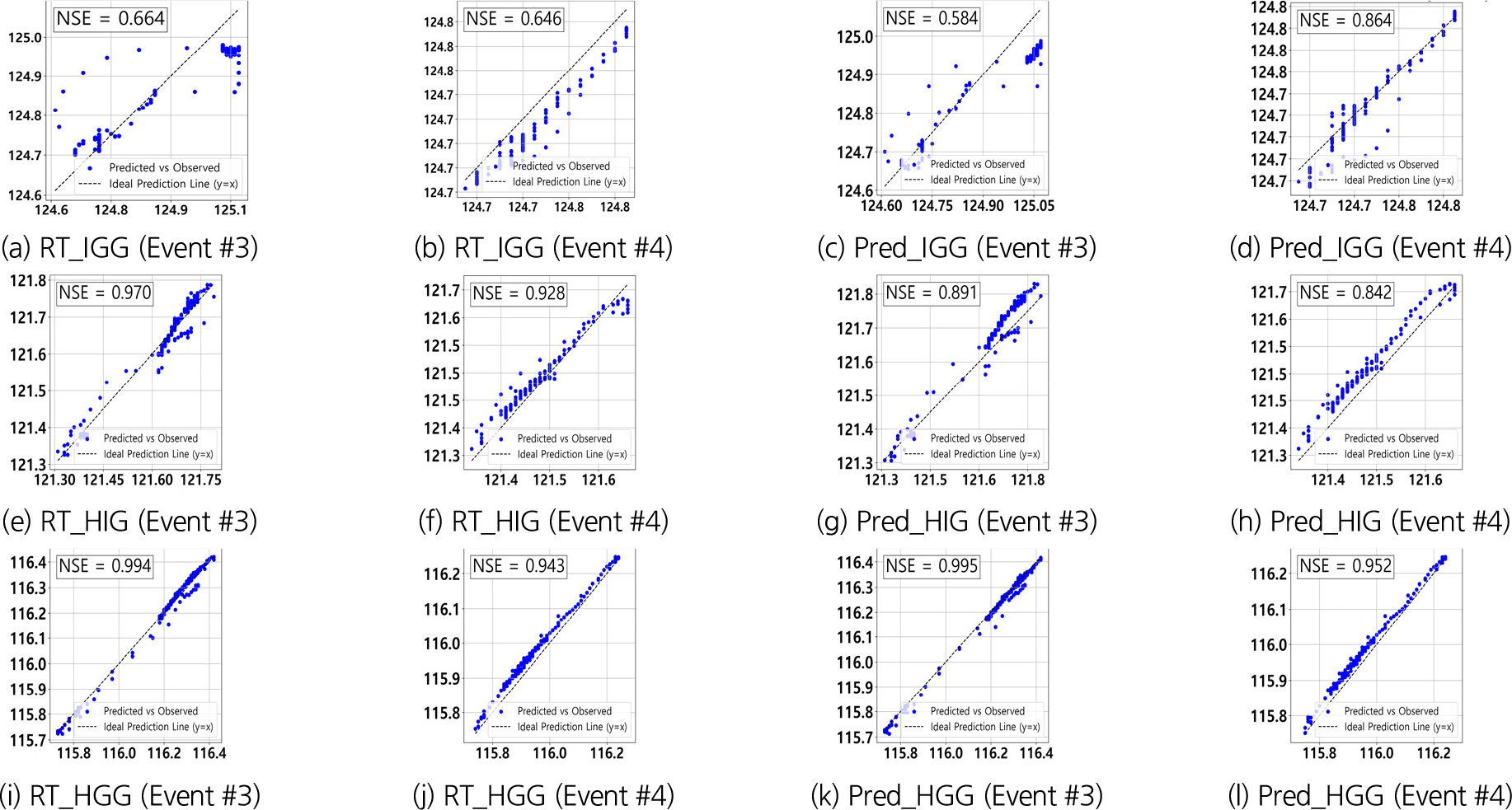
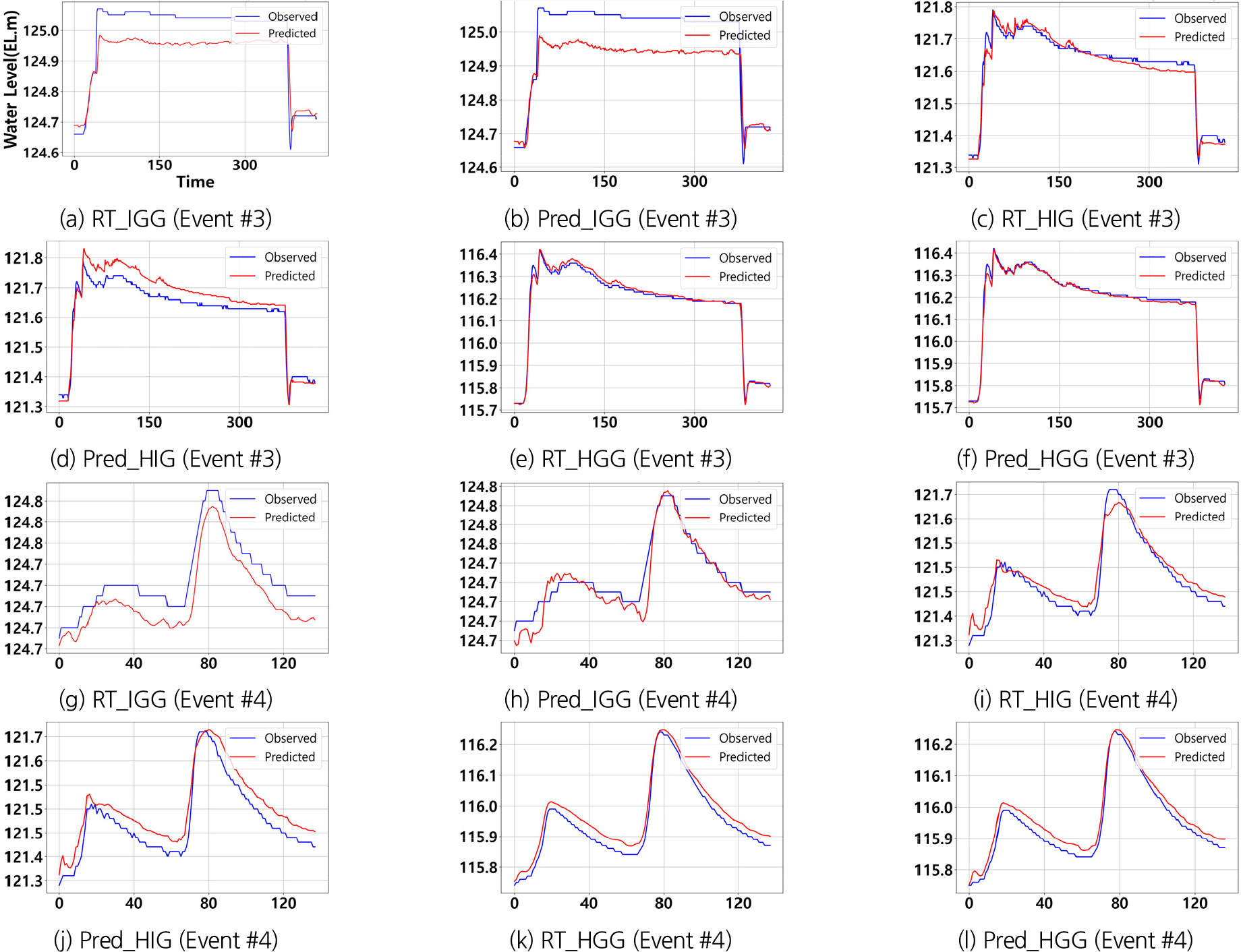
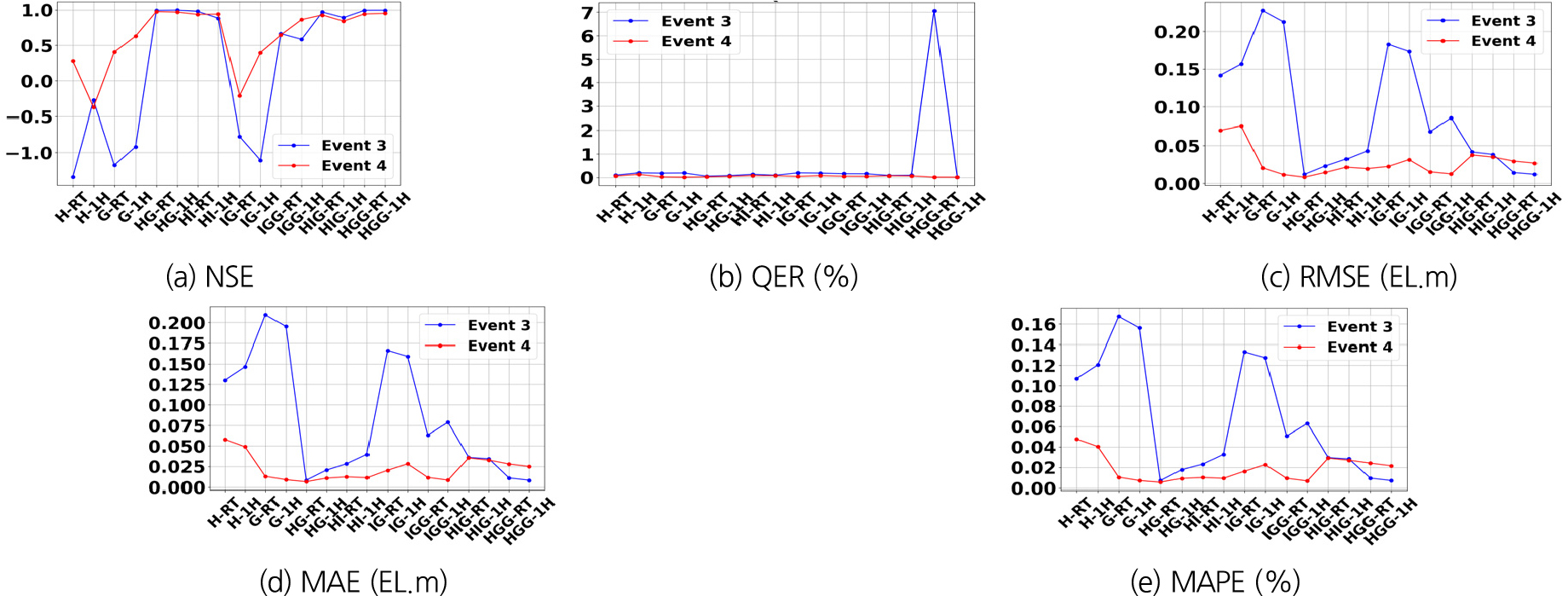
RT_HGG와 Pred_HGG 모델은 각각 NSE 값 0.994와 0.995로 매우 우수한 성능을 보였다. 특히 Pred_HGG 모델은 강동교 합류 지점 데이터를 사용하여 QER 0.0051%라는 매우 낮은 예측 오차율을 기록하며 피크 수위를 정확하게 예측하였다. 이는 모델이 강동교 합류 지점의 복잡한 유동 특성을 효과적으로 반영했음을 의미한다. 상관성 행렬분석에 따르면, 강동교는 상류 지점들과 상관성이 상대적으로 낮게 나타났지만, RT_HGG와 Pred_HGG모델은 상류 지점 데이터를 추가적으로 사용하여 합류 지점 데이터를 보완함으로써 높은 예측성능을 유지할 수 있었다. 이는 지류와 본류 간의 상호작용을 보다 정교하게 반영하는 모델링 전략이 성능향상에 기여했음을 보여준다.
결과적으로, 합류 지점 데이터를 포함한 모델은 본류 및 지류의 데이터를 종합적으로 반영하여 전반적인 예측 성능을 크게 향상시켰다. 강동교와 상류 지점 간의 상호작용을 고려한 데이터 구성이 예측 정확도를 높이는 데 중요한 역할을 하였다. 특히, 하류 데이터를 기반으로 상류를 예측할 때는 다양한 지점의 데이터를 종합적으로 활용하는 것이 성능 향상에 필수적 요소임을 확인하였다. 본 연구에서 사용된 합류 지점 데이터는 상류의 변동성을 더 정확하게 반영하여 예측 정밀도를 높이는 데 기여하였다. 반면, 상관성이 낮은 지점 간 데이터를 사용할 경우 예측 성능이 저하될 가능성이 있으며, 이러한 상호작용을 정밀하게 반영하기 위해 추가적인 데이터 수집과 개선된 모델링 전략이 필요함을 시사한다. 향후 연구를 통해 이러한 요소를 보완함으로써 더욱 신뢰성 높은 예측이 가능할 것으로 기대된다.
5. 결 론
본 연구에서는 LSTM 기반 하천 수위 예측 모델을 개발하고, 다양한 예측 지점과 학습 데이터 구성을 통해 모델 성능을 평가하였다. 또한, 실시간 응답 모델과 1시간 선행 예측 모델의 예측 결과를 비교하여 시간적 선행성과 데이터 구성의 영향을 분석하였다. 연구 결과를 바탕으로 도출된 결론은 다음과 같다.
(1) 상류 데이터를 활용한 하류 수위 예측이 가장 우수한 성능을 나타냈다. 특히, 상류 #1지점과 상류 #2지점 데이터를 함께 사용한 경우, 하류 예측의 정확도가 NSE 값 0.98~ 0.99로 크게 향상되었다. 이는 상류에서 하류로 이어지는 수문학적 흐름이 예측 정확도에 중요한 역할을 한다는 것을 보여준다. 상류 데이터를 기반으로 하류 수위를 예측할 때, 모델이 일관된 물리적 흐름을 효과적으로 반영할 수 있음을 시사한다.
(2) 하류 데이터를 기반으로 상류 수위를 예측하는 모델은 성능이 매우 저조하였다. 이는 하류에서 상류로의 역방향 예측이 강수량, 지류유입 등 다양한 상류 요인의 영향을 충분히 반영하기 어려웠기 때문으로 해석된다. 이러한 결과는 하류에서 상류로의 예측이 비가역적이고 비선형적인 유역응답을 정확히 반영하는데 한계가 있음을 시사한다.
(3) LSTM 모델의 성능은 단순히 하이퍼파라미터 최적화만으로는 충분하지 않았으며, 학습 데이터 구성에 따라 성능차이가 뚜렷하게 나타났다. 예를 들어, RT_H와 Pred_ H모델은 하이퍼파라미터를 최적화(랜덤서치)하였음에도 저조한 성능을 보였으나, 동일한 파라미터를 RT_HG와 Pred_HG모델의 데이터 구성에 적용했을 때 NSE 값이 0.96~0.99로 높은 성능을 기록하였다. 이는 모델의 성능이 단순히 하이퍼파라미터 설정에만 의존하는 것이 아니라, 학습 데이터 구성에 크게 의존한다는 점을 의미한다.
(4) 지류 유입 데이터를 반영한 모델은 본류 데이터만을 사용한 모델에 비해 전반적으로 우수한 성능을 보였다. 특히, 하류 데이터를 이용하여 상류 지점을 예측할 때, 합류 지점(지류) 데이터를 포함한 모델의 NSE 값이 크게 향상되었으며, 이는 지류와 본류 간 복합적인 상호작용이 예측 정확도에 중요한 역할을 한다는 점을 보여준다. 지류 데이터를 반영하는 것은 모델 학습과 예측 성능 향상에 중요한 요소임을 시사한다.
(5) 단순 계측 모델과 1시간 선행 예측 모델의 성능을 비교한 결과, 두 모델 간의 성능 차이는 크지 않았으나, 단순 계측 모델이 전반적으로 더 우수한 결과를 나타냈다. 이는 1시간 선행 예측 모델이 시간적 선행성을 고려하였음에도, 예측 안정성 및 신뢰성 측면에서 단순 계측 모델이 더 높은 성과를 보였음을 의미한다.
본 연구는 가상센서를 활용한 하천 수위 예측에서 의미 있는 성과를 도출하였으나, 몇 가지 한계도 존재한다. 본 연구는 특정 유역에서 수집된 데이터를 기반으로 수행되었으므로, 다른 유역으로의 확장 가능성을 검토할 필요가 있다. 이를 위해 다양한 지형 및 기후 조건을 반영한 추가적인 연구가 요구된다. 또한, 모델의 학습 방법에 대한 개선이 필요하다. 본 연구에서 사용된 LSTM 모델은 시간적 의존성을 학습하는 데 강점을 보였으나, 더 복잡한 비선형 상호작용을 반영하기 위해서는 물리적 모델과의 결합 또는 강화학습과 같은 다양한 딥러닝 기법의 도입이 유효할 수 있다.
본 연구는 다양한 지점과 합류부 데이터를 종합하여 최적의 학습 데이터 구성을 탐색함으로써, 하천 수위 예측 모델링을 위한 데이터 파이프라인 설계에 기여하였다. 상류-하류 간 물리적 상관성을 반영한 학습 데이터 구성이 하천 수위 예측 정확도를 높이는 중요한 요소임을 확인하였으며, 지류 유입 데이터를 포함하여 모델 성능을 향상시키는 최적의 데이터 입력 방식을 제시하였다. 이러한 데이터 파이프라인 최적 설계는 모델의 예측 성능을 일관되게 유지하는 데 필요한 주요 설계 요소로, 홍수 예보 및 수자원 관리와 같은 실제 응용에서 예측 신뢰성을 강화할 수 있을 것으로 기대된다.
결론적으로, 상류 데이터를 활용한 하류 수위 예측이 가장 효과적이라는 점을 확인하였으며, 학습 데이터 구성과 예측 지점 간의 물리적 특성이 모델 성능에 중요한 영향을 미친다는 사실을 밝혔다. 향후 연구에서는 다양한 유역과 기후조건에서의 모델의 확장성과 예측 성능을 검토하여, 실시간 홍수 예보와 수자원 관리에 있어서 더욱 신뢰성 있는 도구로 활용될 수 있을 것으로 기대된다.
