

1. 서 론
2. 연구 방법
2.1 Transformer
2.2 대상 유역 및 자료구축
2.3 실험설계
2.4 평가지표
3. 결 과
3.1 유입량 예측에 대한 학습 및 검증 오차 비교
3.2 유입량 예측 시 훈련방법에 따른 성능 비교
3.3 다목적댐별 유입량 예측성능 비교
3.4 임베딩 레이어 활성화 비교 및 수문학적 유사성 분석 결과
4. 결 론
1. 서 론
수문학의 주요 목표 중 하나는 다양한 수문학적 환경에서 적용 가능한 수문 모형을 개발하는 것이다. 따라서, 다수의 연구들은 단일유역이 아닌 다양한 유역을 대상으로 군집화 및 유사성 분석을 중점적으로 수행하고 있다(Gupta et al., 2014). 최근 많은 연구들은 다수의 유역을 대상으로 다양한 유역 특성을 충분히 고려함으로써 수문학적 이해와 모형의 예측성능 개선에 기여한다고 주장하였다(Beck et al., 2017; Brunner et al., 2021; Nearing et al., 2021; Kratzert et al., 2023). 딥러닝은 방대한 데이터로부터 일반화된 지식을 학습할 수 있고, 입력 자료의 양이 증가할수록 모형의 성능이 향상된다는 장점이 있어 다수의 유역을 대상으로 할 때 성능이 개선될 수 있다 (Schmidhuber, 2015; LeCun et al., 2015; Shen et al., 2018). 이러한 접근법을 활용한 딥러닝 기반 강우-유출 모형 구축은 기존의 학습된 유역의 정보를 미계측 유역에 전달하여 데이터 불균형 문제를 해소하고, 예측성능을 높일 수 있어 주목받고 있다.
데이터 불균형 문제를 해결하기 위해 계측된 유역 특성이나 보정된 수문 매개변수를 활용하는 지역화 기법은 현재까지 연구되고 있다(Blöschl and Sivapalan, 1995; Razavi and Coulibaly, 2013). 반면에, 보편적으로 수문 모형 기반 매개변수의 지역화 방법은 등가성(equifinality), 전달 함수(transfer function)의 한계, 모형 구조의 불확실성, 입력 자료 부족과 같은 문제로 인해 높은 수준의 예측성능을 기대하기 어렵다(Sivapalan et al., 2003; Oudin et al., 2008). 반면에, 딥러닝 모형은 관측 자료로부터 직접 입출력 관계를 학습하기 때문에 비선형관계를 효과적으로 표현할 수 있고, 복잡한 수문 매개변수를 다루지 않아 적용이 용이하다(Ding et al., 2020; Chen et al., 2021). 또한, 수문 현상의 단순화로 인해 발생할 수 있는 불확실성을 줄일 수 있으며, 방대한 입력 자료를 효율적으로 처리하여 입력 자료로부터 일반화된 지식을 학습할 수 있다. 따라서, 딥러닝은 다수유역의 정보를 토대로 딥러닝 기반 수문 모형을 개발할 때 기존에 개발된 모형보다 성능의 개선은 여전히 지속 가능하다(Shen et al., 2018; Kratzert et al., 2019; Fang et al., 2022).
Long Short-Term Memory (LSTM)은 기존 순환신경망(RNN)의 기울기 소실(vanishing gradient)에 대한 문제를 극복하기 위해 등장하였으며 게이팅 메커니즘(gating mechanism)과 셀 구조를 통해 장기 의존성을 잘 포착할 수 있어 시계열 데이터 처리에 적합하여 수문 모형을 개발하는 데 사용되고 있다(Hochreiter and Schmidhuber, 1997; Zhang et al., 2018; Jeong and Park, 2019). 최근 LSTM을 개선한 모형들이 출현하여 모형의 예측성능을 개선하고 있다. Kao et al. (2020)은 LSTM-MSV-S2S의 인코더-디코더 구조를 통해 다단계 예측성능을 향상시켰으며, Gao et al. (2022)는 LSTM에 어텐션 메커니즘을 결합한 모형을 제안하여 유출량 예측 정확도를 높였다. 이러한 관점에서 수정된 LSTM 모형은 입력 자료의 은닉 상태를 효과적으로 활용할 수 있으며 중단기 예측에도 좋은 성능을 보여주었다.
자연어 처리와 이미지 처리 분야에서 주목받는 Transformer는 셀프 어텐션 메커니즘(self-attention mechanism)을 통해 시퀀스 데이터의 장기 의존성을 효과적으로 학습할 수 있다. 특히 병렬 연산을 기반하여 큰 규모의 데이터를 학습할 수 있기 때문에 높은 일반화 성능을 달성하는데 있어 적합하고 사전학습과 전이학습의 적용에 있어 접근이 용이하다(Vaswani et al., 2017; Zhou et al., 2021). 이러한 장점들로 인해 최근 빅데이터를 활용한 딥러닝 모형들은 Transformer 구조를 기반으로 개발되고 있으며, 자연어 처리, 이미지 처리 분야에 적극 도입되어 높은 수준의 성능 개선을 이룩하였다(Devlin et al., 2018; Brown et al., 2020; Dosovitskiy et al., 2020; Liu et al., 2021). 또한, 셀프 어텐션 메커니즘을 활용해 시계열 데이터의 특성을 고려할 수 있는 모형들이 설계되었으며, 시계열 예측, 이상치 탐지(Anomaly detection), 시계열 분류와 같은 시계열 기반 모형 개발에 성공적으로 적용된 바 있다(Wen et al., 2021; Wu et al., 2021; Yang et al., 2021; Zhou et al., 2021; Xu et al., 2021; Tuli et al., 2022). 따라서, Transformer 특유의 셀프 어텐션 알고리즘과 병렬 연산으로 인해 LSH (Large-sample hydrology)에 기반한 연구에 적합한 모형의 여부를 판단하는 것은 중요하다.
최근 수문학 분야에서도 LSH 접근법을 기반으로 LSTM과 Transformer를 활용한 연구가 시도되고 있다. Kratzert et al. (2018)은 Catchment Attributes and Meteorology for Large-sample Studies (CAMELS)(Newman et al., 2015; Addor et al., 2017)를 활용하여 241개 유역으로 학습한 단일 LSTM 모형을 구축하였고 각각의 유역에 대해 보정된 SAC-SMA 모형보다 우수한 예측성능을 보여주었다. Kratzert et al. (2019)은 EA-LSTM 모형을 통해 531개 유역으로 학습한 단일 모형을 구축하고 LSTM 모형이 유역 간 유사성과 차이점을 학습할 수 있음을 입증하였다. Yin et al. (2022)와 Yin et al. (2023)은 유역정보를 입력받아 예측에 활용할 수 있는 Transformer 기반 강우-유출 모형을 개발하여 다수유역에 훈련을 수행하였을 때 단일 모형으로 구축된 LSTM보다 높은 성능을 달성할 수 있음을 보였다. 또한, Xu et al. (2023)은 사전 학습된 Transformer를 통해 데이터가 부족한 유역에서도 전이학습을 활용하여 유출량 예측이 가능함을 입증하였다.
국내에서는 주로 순환신경망 구조를 기반으로 한 수위 및 유량 예측 연구가 활발히 진행되고 있다. Jun and Lee (2013)는 홍수예경보를 위해 DRNNM (Discrete Recurrent Neural Network Model)을 적용한 단기 수위예측기법을 개발하여 남강댐 상류유역에 적용하였다. Jung et al. (2018)은 금강 유역 내 대청댐 상류부의 옥천 관측소 지점에서 다중선형회귀모형과 LSTM 모형을 비교하였고, Mok et al. (2020)은 용담댐의 유입량 예측을 위해 LSTM 모형을 구축하여 단일 및 다중 입력 자료에 따른 예측 성능을 분석하였다. Jung et al. (2021)이 섬진강 구례교 지점의 수위를 예측하여 높은 정확도를 보였다. 그러나 기존의 국내 연구들은 주로 단일 유역을 대상으로 하여, 딥러닝의 장점인 대규모 데이터 학습을 통한 성능 향상을 충분히 활용하지 못하는 한계가 있다.
본 연구에서는 유역정보를 활용하여 다수의 유역을 하나의 모형에 학습하여 성능향상을 보인 해외의 연구 사례를 바탕으로 Transformer와 LSTM-MSV-S2S 모형을 이용하여 국내 10개 다목적댐 유역의 유입량 예측을 수행하고 비교하였으며 대용량 데이터를 학습시키기에 적합한 모형을 선정하였다. 이를 위해 단일유역과 다수유역 학습에 따른 예측성능 변화를 비교하고 유역별 최적 모형과 적합한 학습 방법을 선정하였다. 또한, 임베딩 레이어(embedding layer)의 활성화 벡터와 유역정보 군집화 및 유사성 분석을 통해 딥러닝 모형의 유역정보 활용 양상을 분석하였다. 본 연구의 결과를 토대로 국내 유역에 적합한 딥러닝 기반 강우-유출 예측 모형을 새롭게 제안하고, 유역정보를 활용할 수 있는 접근법의 적용 가능성을 확인하는데 충분한 정보를 제공한다.
2. 연구 방법
2.1 Transformer
본 연구는 10개 다목적댐의 유입량을 예측하기 위해 Transformer를 선정하였다(Vaswani et al., 2017). Transformer는 인코더-디코더(Encoder-Decoder) 구조를 기반으로 셀프 어텐션 메커니즘(self-attention mechanism)을 통해 입력 자료 내 각 위치 간의 관계를 효과적으로 계산할 수 있어 시계열 자료의 특징 추출이 뛰어나고 병렬 계산이 가능하여 대용량 데이터 학습에 적합하다. 본 연구는 일 단위 유입량 데이터, 기상 자료, 유역정보를 사용하여 학습을 수행하였으며, 이를 토대로 7일간의 댐 유입량을 예측하였다. 훈련 기간은 2003년부터 2015년으로 설정하였으며 2016년부터 2022년의 일 단위 댐 유입량 예측성능을 평가하였다. 10개 다목적댐의 동시 학습을 위해 기상 자료와 유역정보를 결합하여 인코더의 입력 자료로 사용하였으며, 일 단위 과거 댐 유입량을 디코더의 입력 자료로 활용하였다.
인코더의 입력자료는 임베딩 레이어를 거친 후 위치 인코딩(positional encoding)을 통해 위치 정보를 추가하며 Eqs. (1a) and (1b)와 같이 계산한다.
여기서 는 임베딩 벡터 내 차원의 인덱스, pos는 임베딩 벡터의 위치, 은 임베딩 벡터의 차원을 나타낸다. 그 후, 멀티 헤드 어텐션(multi-head attention)을 통해 병렬 연산을 수행하여 다양한 관점에서 시계열 간의 관계를 파악한다. 각 어텐션 헤드(attention head)는 서로 다른 가중치 행렬을 사용하여 어텐션 스코어(attention score)를 Eqs. (2a), (2b), (2c)와 같이 계산한다.
여기서 Q, K, V는 각각 쿼리(Query), 키(Key), 값(Value)을 나타내며, , , 는 각각 쿼리, 키, 값의 가중치 행렬을 나타낸다. 는 K 벡터의 차원, 는 각 어텐션 헤드를 나타내며 는 어텐션 헤드의 지수이다. 이어서 FFN (Feed-Forward Network) 레이어를 거쳐 출력을 생성하고 입력과 더한 후 정규화하는 과정을 반복하여 인코더의 최종 은닉 상태를 출력한다. 디코더는 인코더와 유사한 구조이며, 마스크드 셀프 어텐션(masked self-attention)을 추가로 수행하여 예측 시점 이후의 정보를 참조하지 않도록 한다. 디코더는 인코더의 출력값과 함께 연산되어 최종적으로 선형 레이어(linear layer)를 통해 예측 결과를 생성한다.
Transformer와의 유입량 예측성능을 비교를 위해 인코더-디코더 구조를 가진 LSTM-based multi-state-vector 기반 seq2seq (LSTM-MSV-S2S)(Yin et al., 2021)를 선정하였다. LSTM-MSV-S2S는 두 개의 인코더와 하나의 디코더로 구성되어 있으며 인코더는 일 단위 기상정보, 유역정보, 과거 유입량 정보를 입력받아 은닉 상태를 출력한다.
2.2 대상 유역 및 자료구축
본 연구에서 선택된 대상 유역은 과거 기간의 자료가 충분하고 결측값이 비교적 적은 국내 10개소 다목적댐을 대상으로 하였다. 각 댐 유역 및 기상 관측소의 위치는 Fig. 1과 같으며 다목적댐별 입력자료로 활용된 기상 관측소, 입력 자료구축에 사용된 댐 명과 코드는 Table 1과 같으며 2003년부터 2022년까지의 일단위 데이터를 사용하였다. 본 연구에서는 각 다목적댐 유역의 10가지 유역정보, 종관기상관측소(ASOS)의 3개(일 단위 강수량, 최저기온, 최고기온) 기상 자료를 결합하여 입력자료로 사용하였다. 유역정보는 Addor et al. (2017)의 CAMELS 데이터세트의 형식을 선택하였으며, 선행된 Kratzert et al. (2019)의 연구를 바탕으로 다수의 유역으로 학습 시 중요도가 높다고 생각되는 10개 유역정보를 선택하였다(Table 2). 지형과 관련된 인자는 국가수자원관리종합정보시스템(WAMIS)을 이용하여 구축하였고, 기상과 관련된 인자는 기상관측데이터를 기반으로 계산하였다. 각 유역의 산림 비율(Forest fraction)은 2022년 환경공간정보서비스에 제공된 내 중분류 토지피복지도를 사용하였다(Table 3).
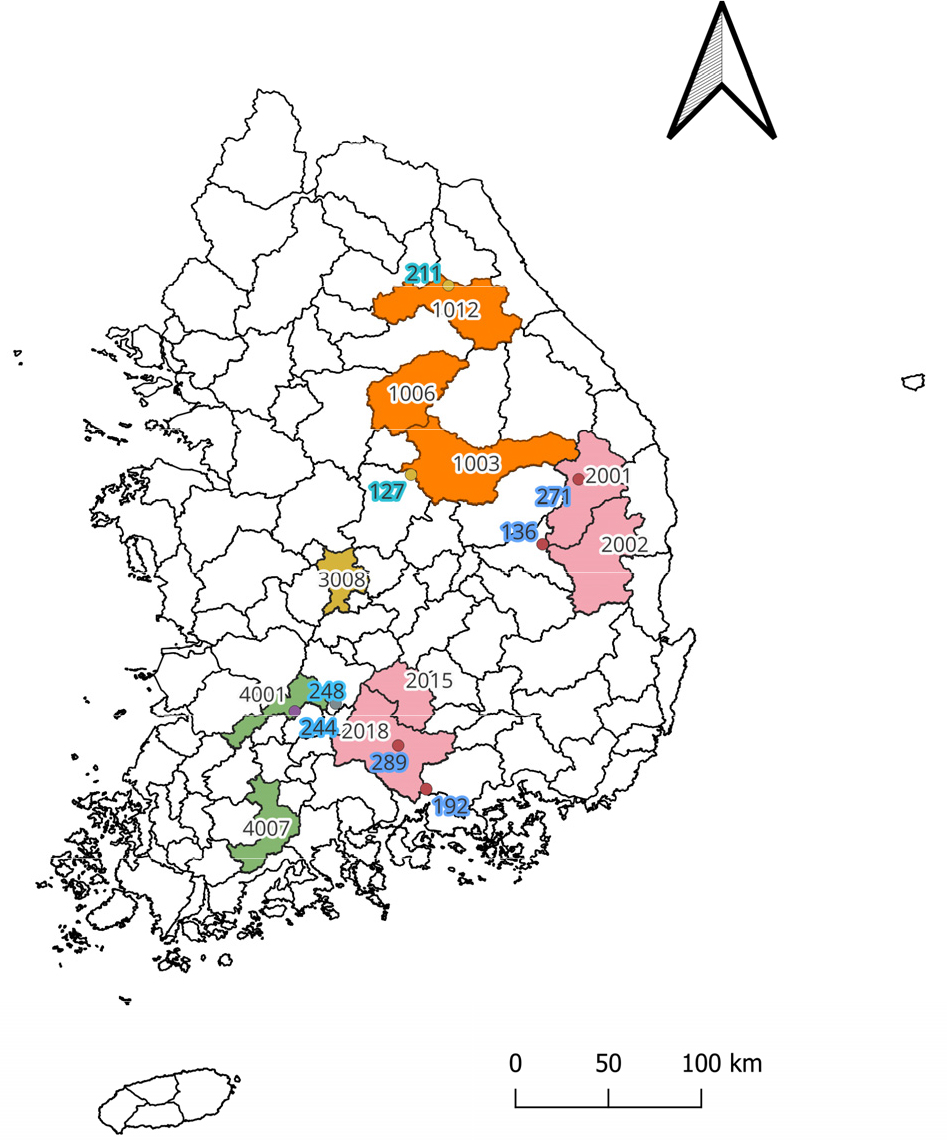
Table 1.
Multipurpose dams and weather stations used in this study
Table 2.
Catchment attributes description (Addor et al., 2017)
Table 3.
Data sources
모든 입력자료는 Z-점수 정규화(Z-score Normalization)을 거쳐 전처리 하였으며 Eq. (3)와 같이 계산한다.
여기서 는 시계열 입력자료를 나타내며, 𝜇는 입력자료의 평균, 𝜎는 표준편차를 나타낸다.
기상관측소의 결측값은 3차 다항보간법(Third-order polynomial interpolation)을 적용하여 보정하였으며 Eq. (4)과 같이 계산한다.
여기서 관측된 시점 , , 에서의 값 , , 를 만족하는 계수 , , 를 구한 후, 원하는 시간 에서의 결측값을 추정할 수 있다.
2.3 실험설계
본 연구에서 댐의 일 단위 유입량을 예측하기 위해 구성한 실험 설계는 ST (Single-Basin Training, 단일유역-단일훈련), PT (Pretraining, 다수유역-단일훈련), PT-FT (Pretraining-Finetuning, 사전훈련-파인튜닝)의 세 가지 훈련 방법을 사용하였다. 실험의 설계 과정은 Fig. 2와 같으며 훈련 방법에 따라 입력 자료 구축 및 모형 구현을 다른 방식으로 적용하였다.
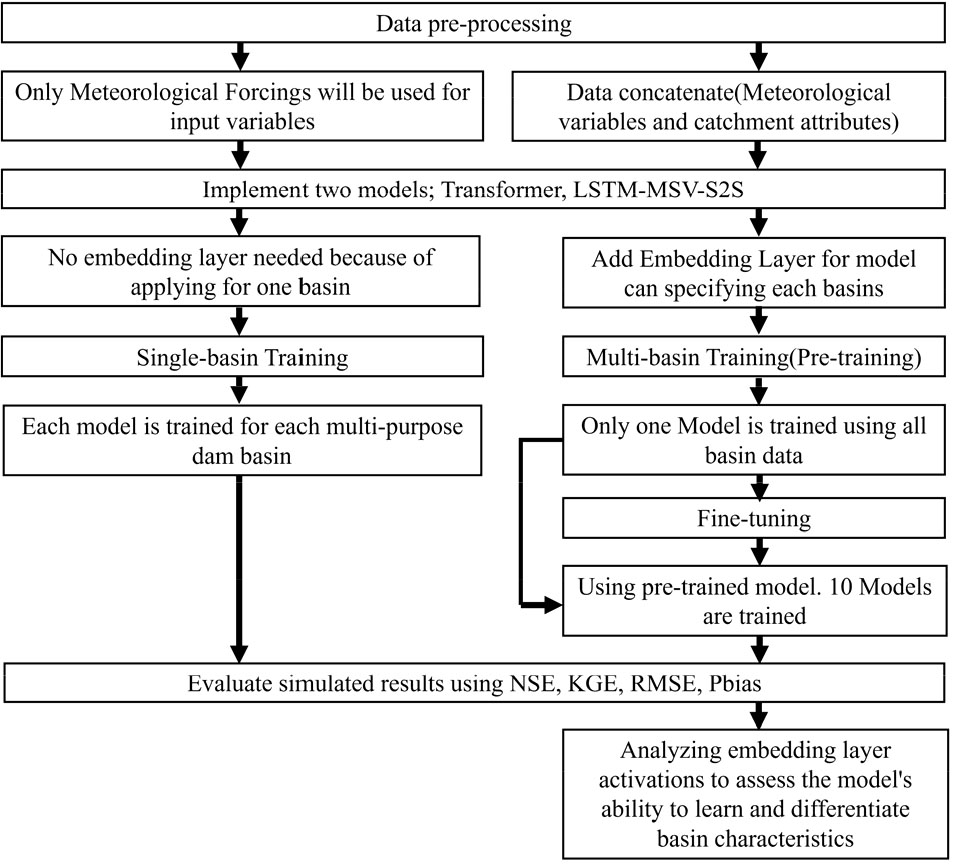
ST은 각 유역별로 독립적인 모형을 훈련하는 방법으로, 기상변수만을 입력으로 사용하며 앞서 구축한 유역정보를 활용하지 않는다. PT는 여러 유역의 정보를 동시에 학습하는 방법으로, 앞서 구축했던 10가지 유역정보를 추가 입력으로 사용하여 유역 간 유사성과 차이점을 학습에 활용한다. PT-FT는 PT에서 훈련된 모형을 사용하여 단일유역에 대해 파인튜닝하는 방법이다. LSTM-MSV-S2S와 Transformer 모형이 유역 간 유사성과 차이점을 학습하는지 확인하기 위해 유역정보 입력에 대한 임베딩 레이어를 추가하였다. 훈련 이후, 각 모형의 임베딩 레이어에서 활성화 벡터(activation vector)를 추출하여 K-Means 군집화, 실루엣 분석(silhouette analysis), 코사인 유사도(cosine similarity)를 통해 유사성 및 차이의 정도를 분석하였으며, 실제 유역정보와 활성화 값을 군집화하여 비교하였다.
각 모형의 최적 하이퍼파라미터는 PT를 기준으로 그리드 서치(Grid search) 방법으로 선정하였으며, 세 가지 훈련 방법에 동일한 하이퍼파라미터를 적용하였다. 오차함수는 MSE(Mean squared error), 최적화 알고리즘은 Adam을 사용하였다. Table 4는 각 모형에 최종적으로 적용된 하이퍼 파라미터 결과 및 그리드 서치 방법에 사용된 조합이다. ST와 PT의 훈련 에포크(epoch)는 200으로, PT-FT의 경우 Transformer는 50, LSTM-MSV-S2S는 100으로 설정하였다. 각 모형은 에포크 마다 상태를 저장하였으며, 훈련 중 가장 높은 KGE를 보인 모형을 해당 훈련 방법의 최종 모형으로 선택하였다.
Table 4.
Model hyperparameters
2.4 평가지표
본 연구는 Transformer와 LSTM-MSV-S2S의 예측성능을 종합적으로 평가하기 위해 NSE (Nash-Sutcliffe Efficiency)(Nash and Sutcliffe, 1970), KGE (Kling-Gupta Efficiency)(Gupta et al., 2009), RMSE (Root Mean Square Error), PBias(Percent Bias)를 사용하였으며 각 평가지표는 Eqs. (5), (6), (7), (8)과 같이 계산한다.
여기서 는 번째 시점의 관측 유량, 는 번째 시점의 모의 유량, 는 관측 유량의 평균을 나타낸다. Eq. (5)의 은 모의 유량과 관측 유량 간의 상관계수, β는 모의 유량의 평균과 관측 유량의 평균 비율, 𝛼는 모의 유량의 변동성과 관측 유량의 변동성 비율을 나타낸다.
3. 결 과
3.1 유입량 예측에 대한 학습 및 검증 오차 비교
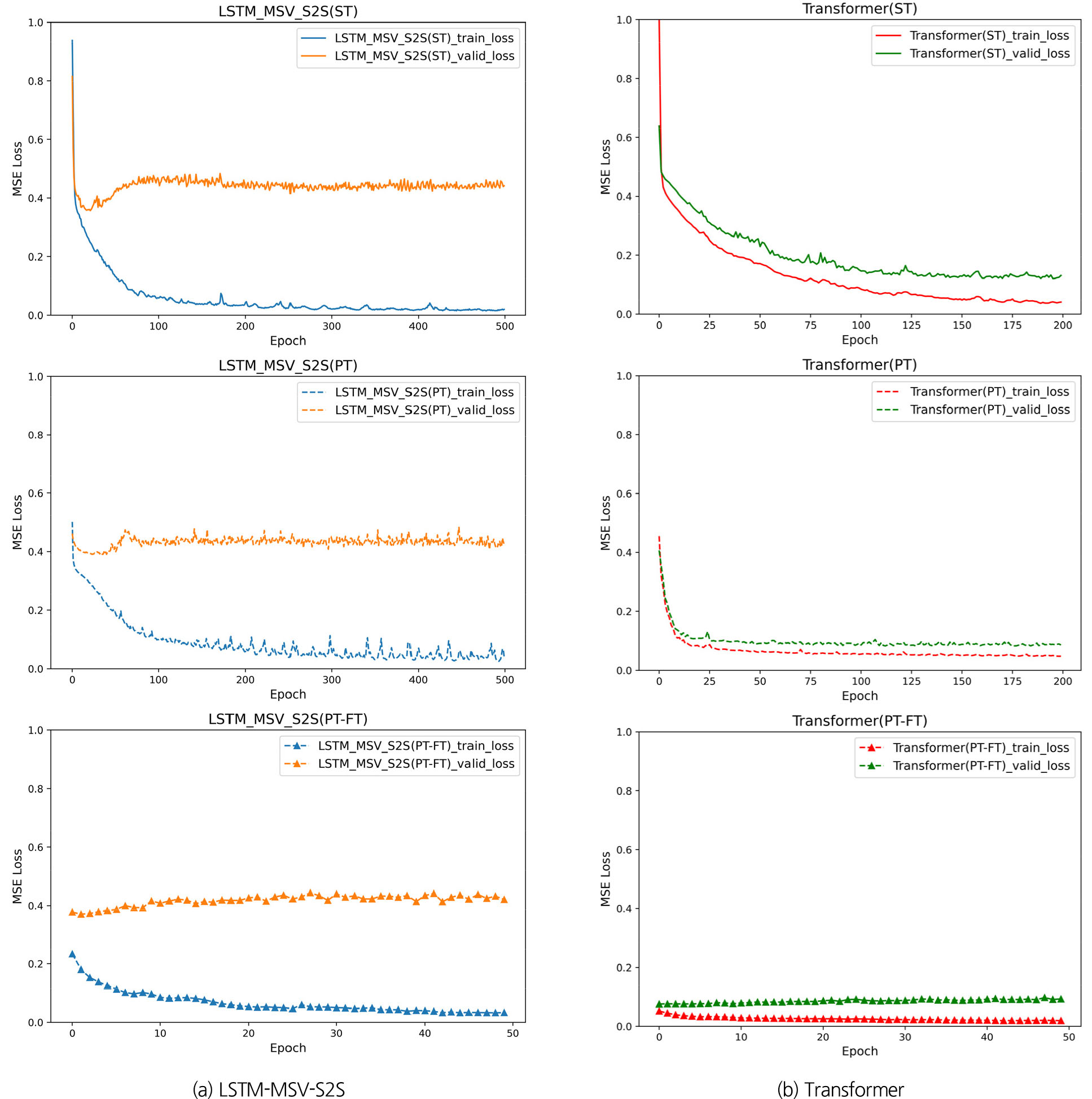
본 연구에서는 LSTM-MSV-S2S와 Transformer 모형의 훈련 방법(ST, PT, PT-FT)에 따른 학습 및 검증 오차를 비교하였으며 그 결과는 Fig. 3와 같다. ST와 PT-FT의 경우 10개 모델의 평균 오차를, PT는 10개 댐 유입량 예측값의 평균 오차를 사용하였다. LSTM-MSV-S2S의 ST는 PT보다 낮은 오차를 보였으며, 50 epoch 이내에 조기 종료되어 빠른 수렴 속도를 나타냈다. 반면, Transformer는 세 가지 훈련 방법 모두 LSTM-MSV-S2S보다 수렴 속도가 느렸으나, 학습 진행에 따라 오차가 점진적으로 감소하였다. 사전학습된 매개변수를 활용한 PT-FT의 경우, 두 모형 모두 학습 초기에 낮은 오차를 보였다. 그러나 LSTM-MSV-S2S의 PT-FT는 과적합 현상이 나타난 반면, Transformer의 PT-FT는 PT보다 낮은 검증 오차를 보이며 5 epoch 이내에 조기 종료되었다.
3.2 유입량 예측 시 훈련방법에 따른 성능 비교
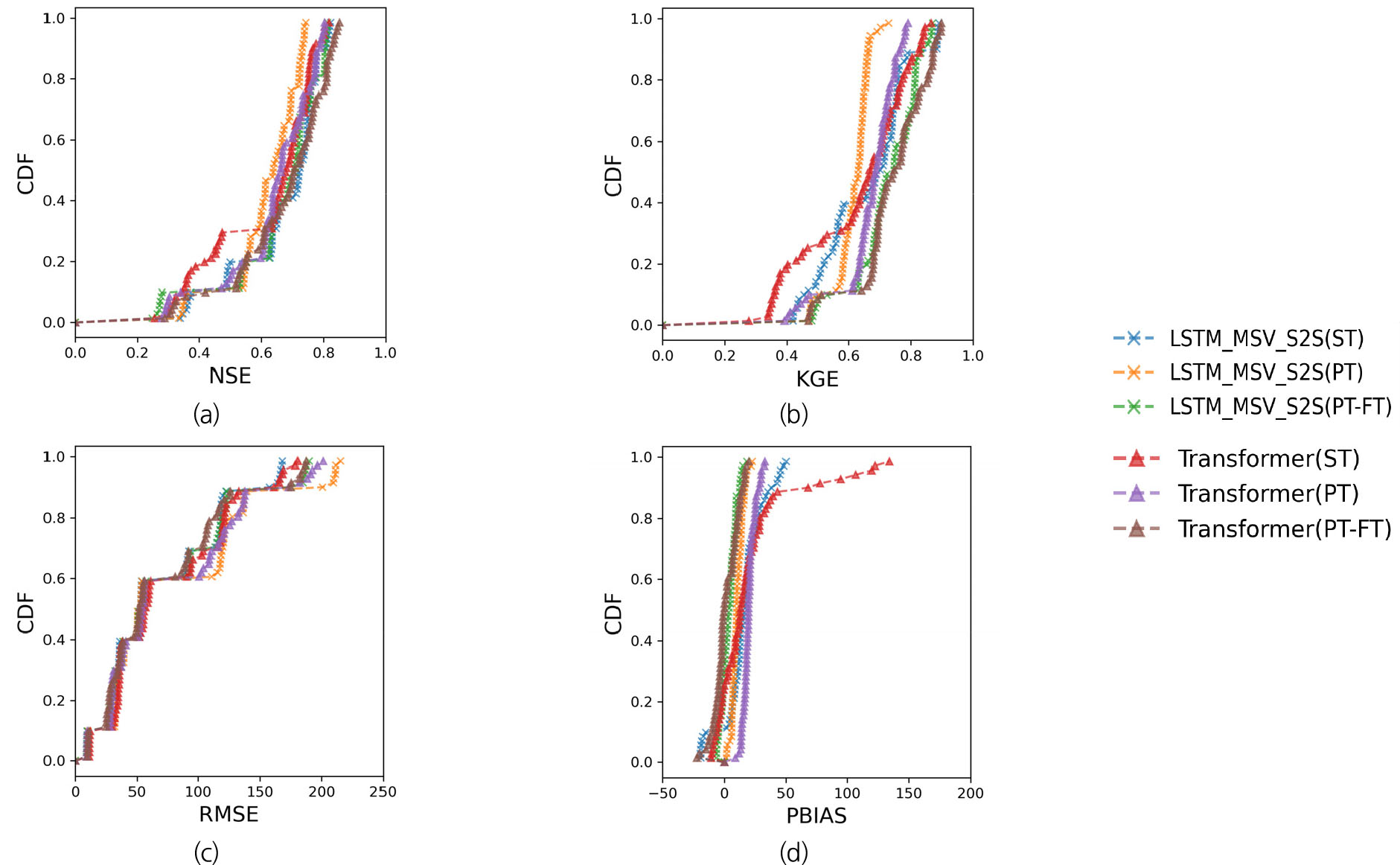
본 연구는 훈련방법에 따라 각 모형의 일 단위 댐 유입량 예측성능을 4가지 평가지표(NSE, KGE, RMSE, Pbias)를 통해 비교하였다. Fig 4.는 10개 다목적댐의 7일간의 유입량 예측 결과를 훈련 방법별로 평가한 결과이다. Transformer의 단일 유역 훈련(ST)은 평균 NSE가 가장 낮았고, 사분위수 범위(IQR)가 0.29로 가장 크게 나타나 예측 성능이 불안정하였다. 반면, LSTM-MSV-S2S의 사전훈련(PT)은 단일 유역 훈련(ST)에 비해 예측 성능이 낮았으며, NSE와 KGE 평균값이 각각 7.9%(-0.053), 7.43%(-0.049) 감소하였다. Pbias 값은 15.87%에서 4.45%로 감소하여 과대 추정 경향이 완화되었다. Transformer의 사전훈련(PT)은 ST에 비해 NSE와 KGE 평균값이 각각 4.1%(+0.025), 7.03%(+0.044) 증가하여 훈련 대상 유역 증가에 따른 성능 향상을 나타냈다. Transformer의 PT-FT는 PT보다 평균 NSE와 KGE가 각각 4.7%(+0.03), 10.3%(+0.07) 증가하여 가장 높은 성능을 보였다. LSTM-MSV-S2S의 PT-FT는 PT보다 NSE와 KGE 평균값이 각각 5.35%(+0.033), 18.7%(+0.114) 증가하였고, ST보다 KGE 평균값이 6.5%(+0.1) 증가하였다. 전반적으로 LSTM-MSV-S2S 모형은 ST 방법이 가장 효과적이며 높은 예측 성능을 나타냈으나(NSE: 0.67) 낮은 KGE값을 보였다(KGE: 0.66). 반면, Transformer 모형은 PT-FT (NSE: 0.67, KGE: 0.74), PT (NSE: 0.64, KGE: 0.67), ST (NSE: 0.615, KGE: 0.626) 순으로 성능이 우수하였다. Transformer 모형은 사전훈련과 파인튜닝을 통해 예측 성능이 크게 향상될 수 있음을 확인하였으며 유역정보를 추가로 입력하여 모형을 훈련할 시 LSTM 기반 모형에 비해 더 높은 성능을 보였다.
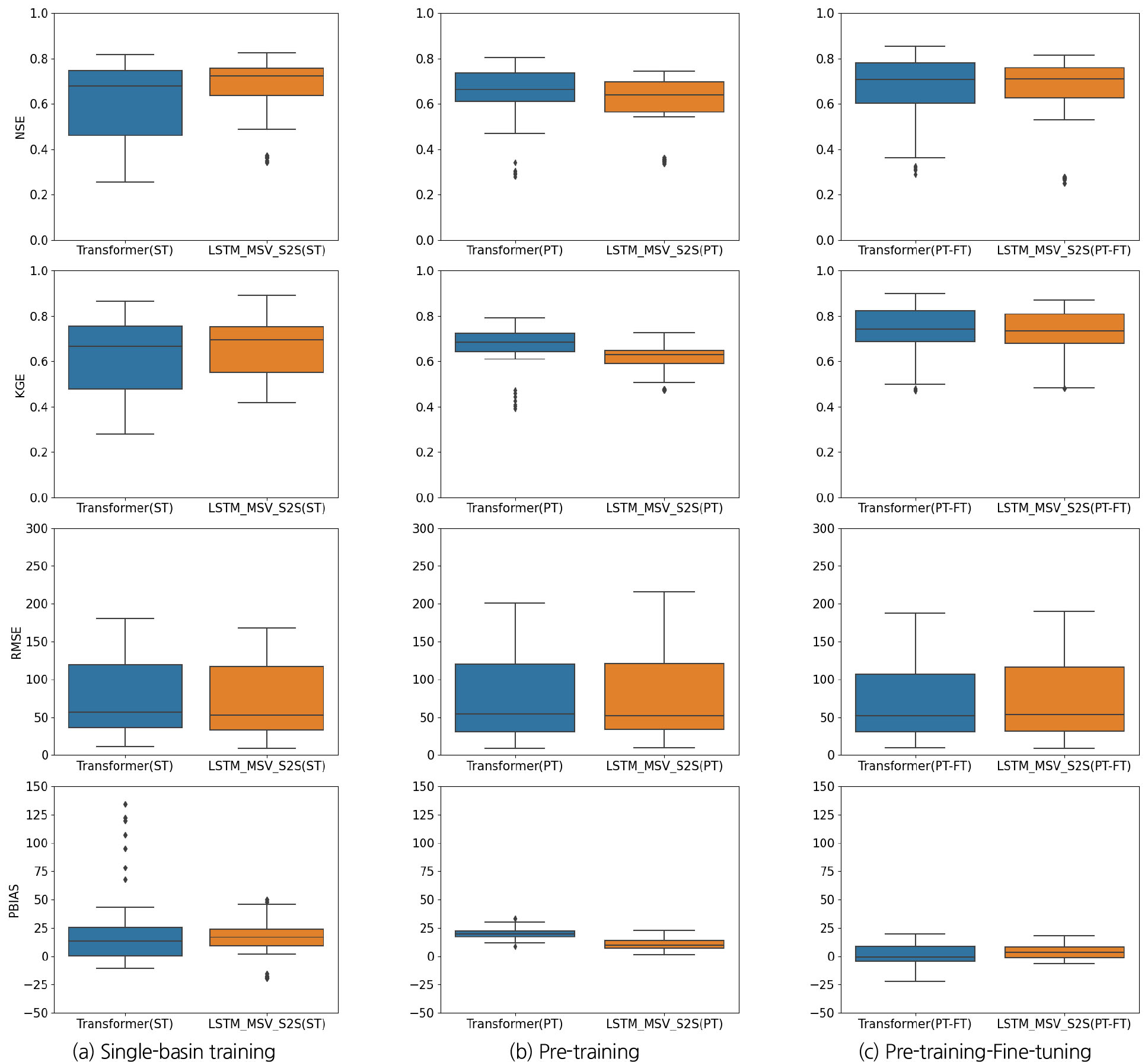
Fig. 5은 각 훈련 방법과 모델에 대한 다목적댐 및 예측 일수별 평가지표를 오름차순으로 정리한 결과이다. Fig. 5(a)는 훈련 방법별 각 모형의 NSE 지표를 오름차순 하였으며 10개 다목적댐에 대한 7일간의 예측을 수행했으므로 70개의 평가지표가 생성된다. Figs. 5(b)~5(d)은 Fig. 5(a)와 같은 방식으로 각 평가지표를 오름차순 하여 나타냈다. NSE 하위 25개 결과의 경우, Transformer의 ST에서 예측성능이 가장 낮았으며, LSTM-MSV-S2S 모형이 전반적으로 우수하였다. 반면에, Transformer의 PT-FT와 LSTM-MSV-S2S의 ST는 상위 30개 NSE 결과에서 성능이 높았으며, LSTM-MSV-S2S의 PT-FT는 NSE 0.7 이상 구간에서 앞선 PT-FT 및 ST와 유사하였다. KGE의 경우, Transformer의 PT-FT에서 NSE와 유사하게 산정되었으나, LSTM-MSV-S2S의 ST는 KGE값이 NSE값에 비해 감소하였다. 또한, LSTM-MSV-S2S의 ST는 저유량 구간을 모의할 때 성능이 낮았다. Pbias의 경우, 파인튜닝을 적용한 Transformer와 LSTM-MSV-S2S는 Pbias 값이 0에 가장 가까웠으며, 유량의 변동 추세를 비교적 잘 모의하였다.
3.3 다목적댐별 유입량 예측성능 비교
본 연구는 LSTM-MSV-S2S와 Transformer 모형의 훈련 방법에 따른 10개 다목적댐의 예측성능을 평가지표를 사용하여 비교하였다. Table 5는 각 다목적댐에 대한 최적 예측성능과 해당 모형을 나타낸 결과이다. NSE 지표의 경우, 소양강댐이 Transformer의 PT-FT는 훈련 방법 및 모형 중에서 0.823으로 가장 높았다. 반면, 임하댐은 모든 모형에서 NSE 값이 가장 낮았다. 다목적댐별 우수한 성능의 훈련 방법은 각각 충주댐은 Transformer의 ST이, 횡성댐과 섬진강댐은 LSTM-MSV-S2S의 PT-FT가, 안동댐과 임하댐은 LSTM-MSV-S2S의 ST가, 남강댐과 주암댐은 LSTM-MSV-S2S의 PT 모형에서 성능이 가장 높았다. KGE의 경우, 충주댐과 임하댐을 제외한 대부분의 댐에서 Transformer 모형이 우수하였다. 특히 소양강댐, 합천댐, 섬진강댐의 경우, Transformer의 PT-FT가 다른 모형들 중에서 KGE의 값이 가장 높았다. Pbias 지표를 분석한 결과, 사전학습 및 파인튜닝을 적용한 Transformer의 PT-FT와 LSTM-MSV-S2S의 PT-FT가 0에 가까웠으며, 성능이 가장 높았다. 전반적으로, 소양강댐, 섬진강댐, 합천댐은 NSE 지표에서 예측 성능이 우수하였으며, 임하댐과 주암(본)댐은 상대적으로 성능이 낮았다. KGE 결과도 NSE와 유사한 경향을 보였다. Pbias 지표에서는 안동댐에서 가장 낮은 값을 보였고, 대청댐에서는 반대의 결과가 도출되었다. Transformer의 PT-FT가 다수의 유역에서 견고한 성능을 달성하였으며 다양한 특성을 가진 유역에의 적용 가능성을 확인하였다.
Table 5.
Best predictive performance by model for each multipurpose dam and its corresponding model. TR: Transformer; LSTM: LSTM-MSV-S2S
3.4 임베딩 레이어 활성화 비교 및 수문학적 유사성 분석 결과
본 연구는 LSTM-MSV-S2S와 Transformer 모형의 입력 자료로 사용된 유역정보의 임베딩 레이어 활성화 값을 비교하였으며, 이를 통해 댐 유역 간 유사성을 모형들이 학습에 충분히 활용하였는지 분석하였다. Fig. 6는 유역정보를 모형에 입력 시 두 모형의 임베딩 레이어 활성화 값과 원본 유역정보 값이다. 임베딩 레이어 활성화 값의 경우, 두 모형의 비슷한 양상을 나타냈다. 예를 들어, 소양강댐과 합천댐 유역이 비슷한 활성화 패턴을 나타냈으며 이외에도 대청댐, 섬진강댐, 주암(본)댐, 횡성댐, 임하댐이 유사한 활성화 패턴을 보였다.
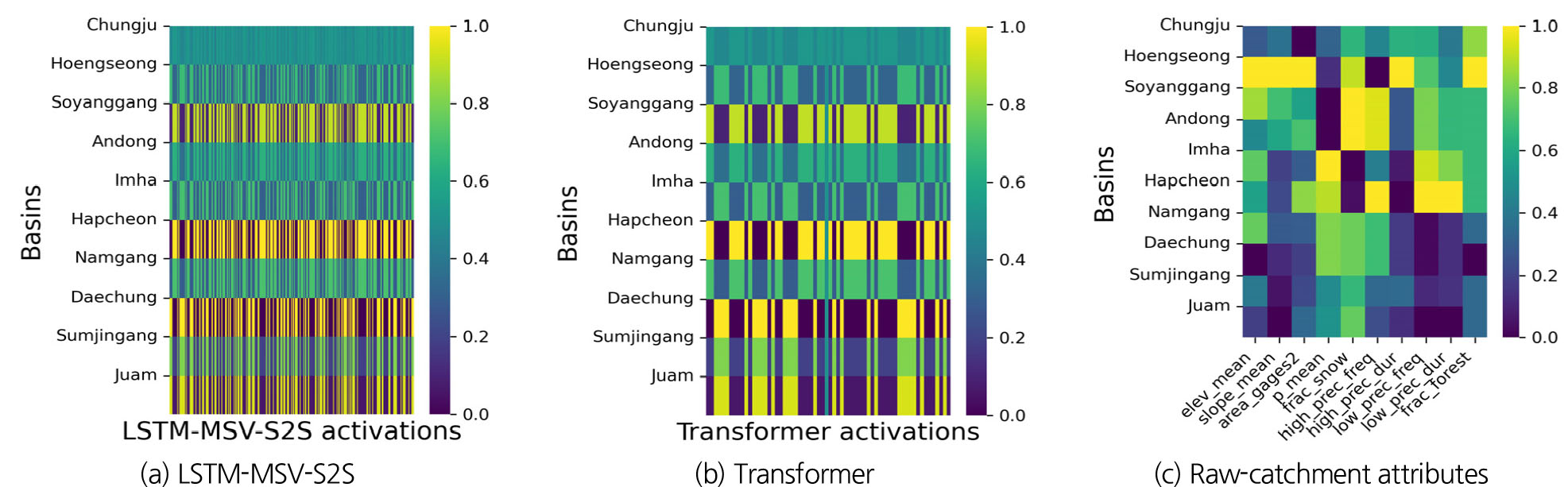
Fig. 6.
Embedding layer activations (x axis) for 10 multipurpose dams (y axis). (a) LSTM-MSV-S2S catchment attributes embbeding layer activations (hidden size = 256);(b) Transformer embbeding layer activations for catchment attributes (d_model = 64); (c) Raw catchment attributes; For ease of comparison, the activation values for each watershed are min-max normalized between [0, 1]
Fig. 7은 각 모형의 임베딩 레이어 활성화 값으로 코사인 유사도를 계산한 결과이다. 코사인 유사도 계산 결과, 두 모형 모두 유사한 양상을 보였다. 소양강댐과 합천댐 유역이 활성화 값이 유사하였으며, 이외에 대청댐, 섬진강댐, 주암(본)댐 그리고 횡성댐, 임하댐이 유사하였다. Transformer의 경우, 유역정보 입력 시 유사한 활성화 값을 보인 대청댐, 섬진강댐, 주암(본)댐에서 ST 방법보다 PT 및 PT-FT 방법이 높은 예측성능을 나타냈다.
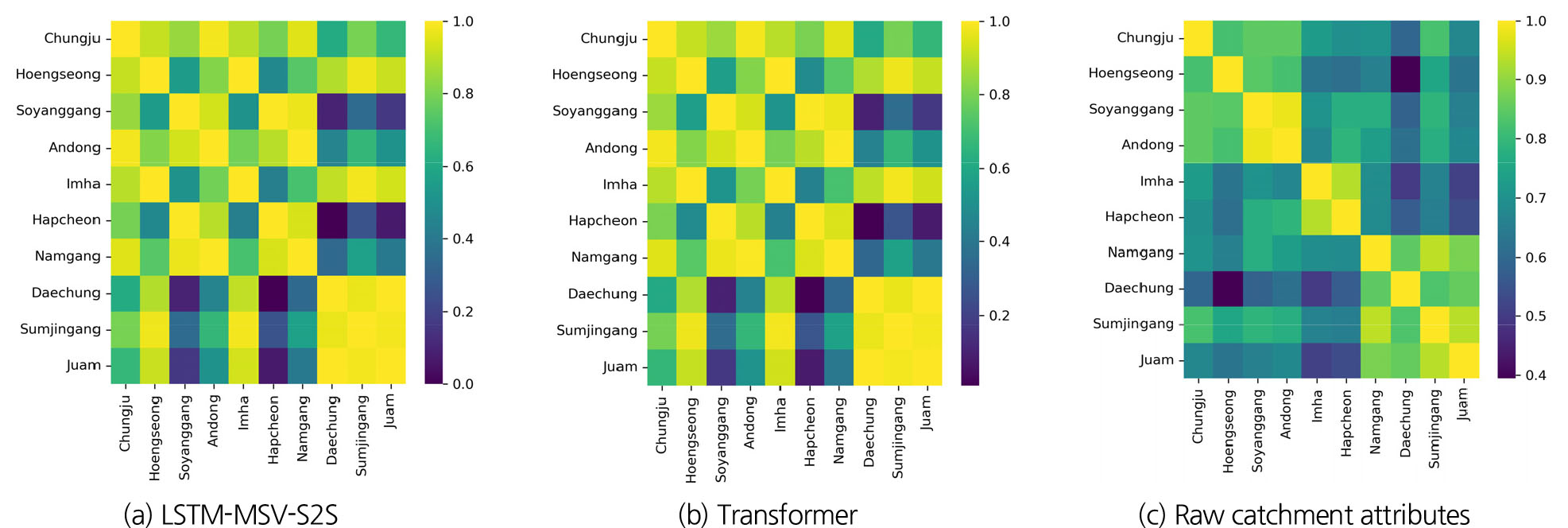
Table 6는 LSTM-MSV-S2S와 Transformer의 임베딩 레이어 활성화 값과 원본 유역정보를 사용하여 K-means 군집화한 결과를 나타낸다. K-means 군집화의 k 값은 원본 유역정보를 군집화하였을 때 실루엣 계수(silhouette score)가 높은 값인 2와 3으로 결정하였다. 군집화 결과, 두 모형의 활성화 값은 동일하게 분류되었으며, 원본의 10가지 유역정보로 분류한 결과와도 대부분 일치하였다. 특히 금강권역과 섬진강 권역의 대청댐, 섬진강댐, 주암(본)댐을 세 경우 모두 같은 군집으로 분류하였다. 이는 해당 댐들의 유역 특성이 유사하며, 모형 학습 과정에서도 유역 간의 유사성을 학습하였음을 의미한다. 한강 권역의 소양강댐과 충주댐, 낙동강 권역의 안동댐, 임하댐, 합천댐, 남강댐은 원본 유역정보로 군집화 했을 때와 임베딩 레이어 활성화 값으로 군집화 했을 때 약간의 차이가 있었다. 이는 모형이 단순히 유역의 물리적 특성뿐만 아니라 학습 과정에서 파악한 유역 간 상호작용과 강우-유출 관계의 유사성 및 차이점을 반영하여 다른 유역의 정보 또한 예측에 활용하였기 때문이다.
Table 6.
Clustering result using embbeding layer activations and raw catchment attributes for each basins. Each integer in the table indicates the cluster label assigned to each dam
4. 결 론
본 연구는 LSH (Large-sample hydrology)의 접근방식을 국내 유역에 적용하기 위해 Transformer와 LSTM-MSV-S2S 모형을 활용하여 국내 10개 다목적댐의 유입량을 예측하였다. ST (Single-basin Training, 단일유역-단일훈련), PT (Pretraining, 다수유역-단일훈련), PT-FT (Pretraining-Finetuning, 사전훈련 및 파인튜닝)의 세 가지 훈련 방법을 선정하였으며, 두 모형의 예측성능을 비교하였다.
훈련 방법에 따른 모형 성능 변화를 살펴본 결과, Transformer 모형은 PT와 PT-FT 방법에서 우수한 성능을 보인 반면, LSTM-MSV-S2S 모형은 ST 방법에서 높은 NSE값을 보였지만 KGE값은 낮았다. 대용량 데이터 활용에 Transformer가 더 적합하였고, LSTM 기반 모형은 단일유역 적용에 더 좋은 성능을 보였다. 다목적댐 유역별 최적 모형과 훈련 방법 탐색 결과, 모든 모형이 소양강댐 유입량을 잘 모의한 반면 임하댐은 낮은 성능을 보였으며, 각 댐마다 적합한 모형과 훈련 방법이 달랐다. 이는 딥러닝 기반 강우-유출 모형 개발 시 모형 특성과 입력자료의 양을 고려한 모형 선택이 중요함을 의미한다. 유역정보 활용 분석 결과, 두 모형 모두 유역 간 유사성과 차이점을 학습하였고, 군집화 결과도 원본 유역정보와 유사했다. 특히 Transformer는 유사한 활성화 값을 보인 대청댐, 섬진강댐, 주암댐 유역 간 성능이 향상되었다. 이는 다수유역 학습 시 딥러닝 모형이 유역을 구분하여 학습하고, 유역정보 및 유량 패턴을 예측에 활용할 수 있음을 보여준다.
본 연구를 통해 유역정보를 활용하여 다수의 유역을 학습시키는 접근방법이 국내 유역에도 적용 가능함을 확인하였고, 딥러닝 기반 강우-유출 모형 구축 시 대용량 데이터를 활용한 훈련 방법을 제시하였다. 추후 연구에서는 유역정보의 군집화 결과에 대한 보완 분석과 함께 미계측 유역의 유량 예측 연구를 통해 대용량 수문 데이터 기반 딥러닝 모형의 활용성을 추가로 제시할 예정이다.
