

1. 서 론
2. 자료 및 방법
2.1 자료
2.2 방법
3. 결과
3.1 단일 관측소 모델을 이용한 예측 결과
3.2 지역 모델을 이용한 예측 결과
3.3 관측소별 미세 조정 모델을 이용한 예측 결과
4. 토 론
5. 결 론
1. 서 론
가뭄은 장기간에 걸친 평균 이하의 강수량 또는 과도한 대기의 증발 수요로 인한 자연재해이다(Won et al., 2018). 가뭄은 농업, 경제, 환경에 중대한 영향을 미친다. 예를 들어, 1999 ~ 2000년 동안 중앙 및 남서 아시아에서 광범위한 가뭄으로 인해 6천만 명의 사람들이 피해를 보았고 추정된 경제적 손실은 약 43억 달러였으며(Agrawala and Stolte, 2001), 최근 미국 캘리포니아의 극심한 가뭄은 2014년 한 해 동안 27억 달러의 경제적 손실을 입힌 것으로 추정되었다(Howitt et al., 2014).
가뭄 예측에서 다루는 첫 번째 문제는 가뭄 식별이다. 지난 수십 년 동안 개별 또는 다중 수문 기상 변수를 기반으로 하는 가뭄지수가 제안되었다. 초기 연구에서 가뭄은 일별/월별 강수량을 기준으로 정의되었다(McGUIRE and Palmer, 1957). 이후 Palmer 가뭄 심각도 지수(Palmer, 1965), 표준 강수 지수(Standardadized Precipitation Index, SPI; McKee et al., 1993), 표준 강수 증발산 지수(Standardadized Precipitation Evapotranspiration Index, SPEI; Vicente-Serrano et al., 2010) 등과 같은 여러 가지 가뭄지수가 개발되었다. 최근에는 대기의 수분 수요의 측면을 중심으로 기준 작물 증발산량(reference crop evapotranspiration, Eo) 기반의 증발 수요 가뭄지수(Evaporative Demand Drought Index, EDDI; Hobbins et al., 2016) 및 SPI와 EDDI를 코퓰러 결합한 CJDI (Copula-based Joint Droght Index; Won et al., 2020)가 개발되었다.
가뭄 예측의 또 다른 과제는 적절한 예측 모델을 선택하고 개발하는 것이다. 이전에는 가뭄의 발생과 심각성을 예측하기 위하여 주로 ARIMA/SARIMA 모델 및 역전파 신경망 모델(Morid et al., 2007; Le et al., 2016)이 사용되었다(Mishra et al., 2007). ARIMA는 단일 도시의 가뭄을 예측하는 데 사용되는 간단하고 일반적인 방법으로, 시계열 자체의 특성만을 기반으로 하며 다른 예측 변수의 영향을 고려하지 않는다. 역전파 인공 신경망은 다양한 분야에서 예측 변수와 목표 변수 사이의 비선형 관계를 맞추는 것에 크게 이바지했다. 국내에서는 2000년대 이후 본격적으로 인공 신경망을 이용한 수문 관련 연구들이 수행되었다. 다층 퍼셉트론 신경망 모형을 이용하여 SPI에 의한 가뭄 예측을 수행하였으며(Lee et al., 2013; Jeong et al., 2016), 순환 신경망 기반의 LSTM을 이용하여 지하수위에 의한 가뭄을 예측하였다(Lim and Yang, 2020). 최근 기계학습(Machine learning) 분야의 발전으로 Random Forest (RF), Extreme Gradient Boosting (XGBoost), Light Gradient Boosting Machine (LGBM) 등과 같은 결정트리 기반의 다양한 기계학습 기법이 개발되고 있으며, 이러한 새로운 접근 방식은 일 태양 복사 예측(Fan et al., 2018), 경제 주체의 파산 여부 예측(Carmona et al., 2018), 질병 진단 및 예측(Livne et al, 2018; Taylor et al., 2018) 등과 같은 여러 분야에서 활용되고 있다. 그러나 가뭄 예측성능은 지금까지 잘 알려지지 않았다.
가뭄 예측을 위한 다양한 노력이 최근 몇 년 동안 이루어졌다. 예를 들어 지역 및 전 지구 규모에서 일관된 시간 및 공간에서의 측정이 가능한 원격 감지 제품인 정규화된 식생 지수를 가뭄 예측에 적용하고자 하였으며(Tadesse et al., 2014; Asoka and Mishra, 2015), 저수지 운영, 관개, 토지 이용 변화, 삼림 벌채 등 정량화하기 어려운 많은 인간 활동도 가뭄 예측에 통합시키려는 시도가 있었다(Yuan et al., 2017; Ma et al., 2018). 이러한 노력으로 가뭄 예측성능은 어느 정도 향상되었다. 그러나 가뭄 예측은 복잡한 기원과 다양한 시간 및 공간 규모에서 발생하기 때문에 기후학자, 수문학자, 의사 결정자 모두에게 여전히 해결해야 할 과제로 남아있다.
본 연구의 목적은 월 단위의 시간 척도에서 여러 관측소에서의 가뭄지수의 거동을 설명하는 기계학습 기법의 잠재력을 살펴보는 것이다. 덧붙여서 다수의 관측소에 대해 단일 모델을 학습함으로써 가뭄 거동을 지역화하기 위한 기계학습 기법의 가능성을 타진하고자 한다. 한반도 남동부의 부산-울산-경남(이하 부울경) 지역의 10개 기상 관측소에서 관측된 다양한 기상 자료가 사용되었다. 사용된 자료 세트는 모두 일반 대중으로 무료도 개방되어 있다. 본 연구에서는 세 개의 결정트리 기반의 앙상블 기계학습 모델(즉, RF, XGBoost, LGBM)을 이용하여 1981 ~ 2012년의 과거 EDDI 및 기상 관측자료를 기반으로 선행 시간 1개월의 시간 척도 6개월 EDDI를 예측해보고자 하였다.
2. 자료 및 방법
2.1 자료
한국 기상청 기상자료개방포털(http://data.kma.go.kr)에서 1981년부터 2020년까지 부울경 지역 10개 ASOS (Automated Synoptic Observing System) 기상 관측소(Fig. 1)로부터 평균 기압(hPa), 이슬점(℃), 강수량(mm), 상대습도(%), 평균 기온(℃), 최고 기온(℃), 최저 기온(℃), 평균 풍속(m/s)을 포함하는 일 기상 자료를 수집했으며, 이들 자료로부터 Penman-Monteith 방법(Allen et al., 1998)을 이용하여 일 Eo (mm)을 계산했다. 그런 다음 각 측정값 및 계산 값에 대한 월평균을 계산했다. 위 자료들은 모두 월별로 평균과 표준편차를 이용하여 표준화 과정을 거친 후, 모델의 입력자료로 사용되었다.
월 Eo 시계열을 이용하여 시간척도 6개월의 EDDI (즉, EDDI6)가 계산되었다. EDDI의 계산 방법은 Hobbins et al. (2016) 및 Won et al. (2018)을 참조할 수 있다. EDDI는 평균이 0이고 표준편차가 1인 표준화된 변수이다. 따라서 EDDI는 다른 시간과 공간에서 서로 비교할 수 있다. 또한 EDDI는 다른 시간척도로 계산할 수 있다. 예를 들어 현재 및 지난 2개월의 월 Eo를 사용하여 특정 월의 EDDI3을 계산할 수 있다. EDDI를 기반으로 한 가뭄의 정의 및 심각도 분류를 Table 1에 수록하였다. EDDI는 SPI 및 SPEI와는 반대로 양의 값을 가질수록 심한 가뭄을 나타낸다(Yao et al., 2018).
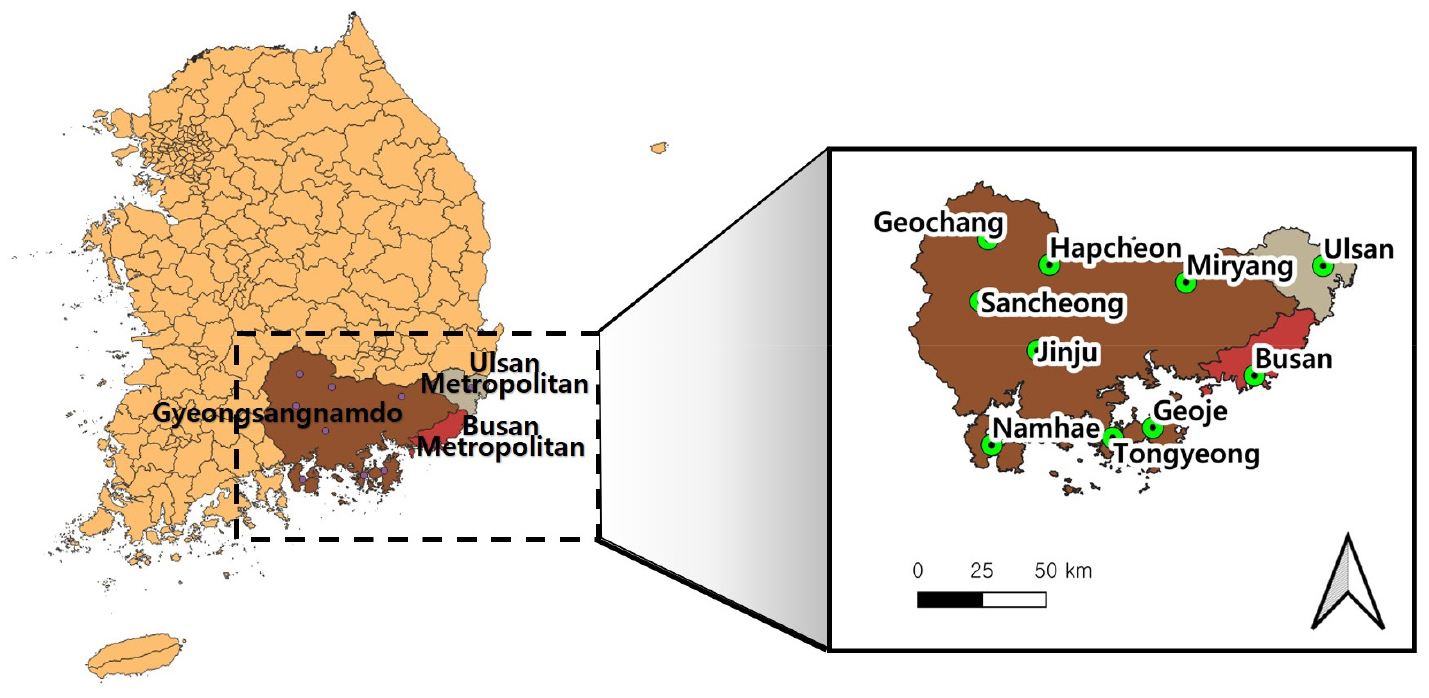
Table 1.
Categorization of dry and wet conditions for the EDDI
| Categorization | EDDI |
| Extreme dry | ≧2 |
| Severe dry | 1.50 to 1.99 |
| Moderate dry | 1.00 to 1.49 |
| Normal | -0.99 to 0.99 |
| Moderate wet | -1.49 to -1.00 |
| Severe wet | -1.99 to -1.50 |
| Extreme wet | ≦-2 |
2.2 방법
2.2.1 기계학습 기법
기계학습에서 RF는 분류 또는 회귀분석 등에 사용되는 일종의 앙상블 학습 방법이다. 학습 과정에서 구성한 다수의 결정트리(decision tree)로부터 평균 예측치를 반환한다. 현재 사용되고 있는 RF의 개념은 무작위 노드 최적화(optimization)와 배깅(bagging)을 결합한 CART (classification and regression tree)를 사용해 상관관계가 없는 트리들로 포레스트를 구성하는 방법을 제시한 Breiman (2001)의 연구에 기반을 두고 있다. RF의 성능은 일반적으로 단일 결정트리를 능가하지만, 이후 소개하는 Gradient Boosting 계열의 모델보다는 낮은 것으로 알려져 있다. 그러나 자료의 특성이 성능에 영향을 줄 수 있다(Piryonesi and El-Diraby, 2020; 2021). RF는 예측 변수(본 연구에서는 선행 EDDI6 및 선행 기상 자료)를 사용하여 목표 변수인 EDDI6를 예측한다. RF의 하이퍼 파라미터(hyper-parameter) 중 트리가 성장할 최대 깊이, 노드를 나누기 위한 최소 샘플 개수, 앙상블을 구성할 트리의 개수를 5-폴드 교차 검증을 통하여 최적화하였다. Jackknife 및 10-폴드 교차 검증과 같이 다양한 기법이 적용될 수 있을 것이나, 학습에 사용된 자료의 크기를 고려할 때 하이퍼 파라미터 튜닝 시에 5-폴드 교차 검증이면 충분할 것으로 판단하였다. 최적화 방법은 베이지안 기법을 이용하는 hyperopt를 이용하였다(Bergstra et al., 2013).
하이퍼 파라미터 공간을 탐색하는 가장 기본적인 방법으로 그리드 서치와 랜덤 서치를 비롯하여 여러 가지 기법들이 개발되어 있는데, 핵심적인 아이디어는 탐색 지역이 좋다고 판명될 때 추가적인 탐색을 수행하는 것이다. 참고로 Hyperopt는 학습률과 같은 실수와 트리가 성장할 최대 깊이 같은 이산적인 값을 포함하여 모든 종류의 복잡한 탐색 공간에 대해 최적화를 수행할 수 있는 잘 알려진 파이썬 라이브러리로서, http://github.com/hyperopt/hyperopt를 참조할 수 있다.
XGBoost는 Extreme Gradient Boosting의 약자이다. Gradient Boosting Machine (Friedman, 2001)의 효율적이고 확장 가능한 변형인 XGBoost는 편의성, 병렬성, 탁월한 예측 정확도를 기반으로 최근 몇 년 동안 여러 기계학습 대회에서 우승했다(Adam-Bourdarios et al., 2015). XGboost는 다양한 boosting 알고리즘을 지원하는데, 본 연구에서는 하이퍼 파라미터 tree_method를 ‘gpu-hist’로 지정하여 GPU 환경에서 히스토그램 기반의 Gradient Boosting 알고리즘을 사용하였다. RF와 마찬가지로 hyperopt를 이용하여 최적 하이퍼 파라미터를 탐색하였다. 탐색된 하이퍼 파라미터는 트리가 성장할 최대 깊이, 앙상블을 구성할 트리의 개수, 학습율이며, 5-폴드 교차 검증을 통하여 검증을 수행하였다.
XGBoost는 다양한 분야에서 좋은 성능을 보여주었지만, 학습 시간이 느리다는 단점이 있다. 이를 보완한 LGBM은 최근 마이크로소프트에 의해 개발된 기계학습을 위한 오픈소스 Gradient Boosting 프레임워크이다(Kopitar et al., 2020). LGBM은 의사 결정트리 알고리즘을 기반으로 순위, 분류, 기타 기계학습에 사용된다. LGBM은 고도로 최적화된 히스토그램 기반 의사 결정트리 학습 알고리즘을 구현하여 효율성과 메모리 소비 모두에서 큰 이점을 제공하는 것으로 알려져 있다. XGBoost와 마찬가지로 hyperopt를 이용하여 최적 하이퍼 파라미터를 탐색하였다. 탐색된 하이퍼 파라미터는 트리가 성장할 최대 깊이, 앙상블을 구성할 트리의 개수, 하나의 트리가 가질 수 있는 최대 리프의 개수, 학습율이며, 5-폴드 교차 검증을 통하여 검증을 수행하였다. 모델별 하이퍼 파라미터를 요약하여 Table 2에 수록하였다.
Table 2.
Hyper-parameters
| Model | Tuned hyper-parameters |
| RF | max_depth, min_samples_split, n_estimators |
| XGBoost | max_depth, n_estimators, learning_rate |
| LGBM | max_depth, n_estimators, num_leaves, learning_rate |
2.2.2 모델 구조 및 검증
본 연구의 새로운 기여는 한반도 남동부 지역의 1개월 리드 타임(lead time)에 월별 EDDI6 예측을 위한 최신의 기계학습 아키텍처(architecture)를 개발하고 그 유용성을 검증하는 것이다. 본 연구에 사용된 방법론은 Fig. 2에 나와 있다. 다양한 수문 기상 자료(평균 기압, 이슬점, 강수량, 상대습도, 평균 기온, 최고 기온, 최저 기온, 평균 풍속, Eo)와 선행 EDDI6가 적용된 세 개의 기계학습 모델의 입력자료로 사용된다. 특정 t월의 EDDI6를 예측하기 위해 요구되는 자료의 선행 기간은 12개월로 설정하였다. 즉, t-1월부터 t-12월까지의 선행 수문 기상 자료와 선행 EDDI6이 모델에 입력되면 모델은 t월의 EDDI6를 출력으로 반환한다.
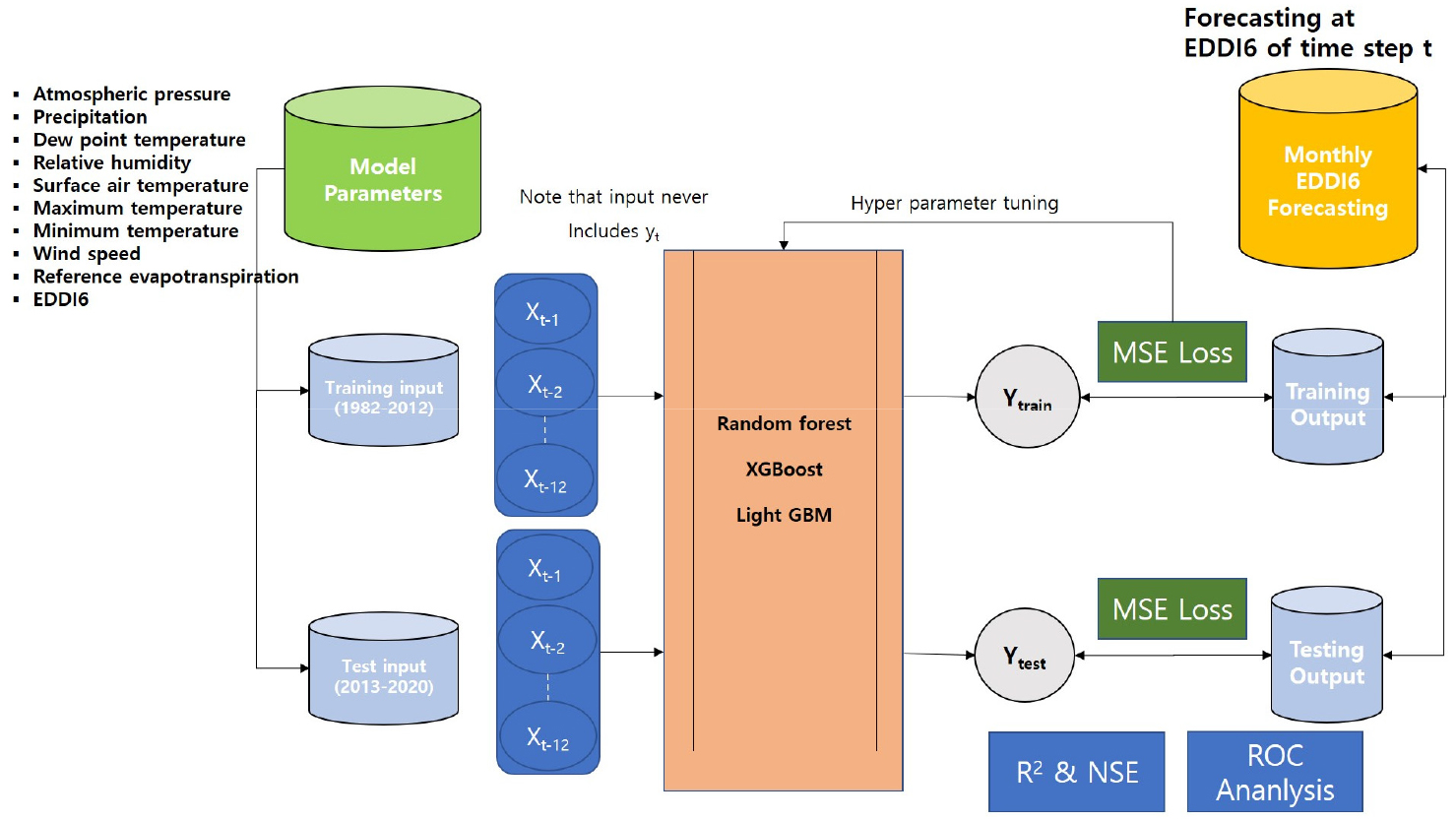
본 연구에서는 세 가지 실험이 진행되었다. 첫 번째 실험에서는 가뭄지수를 예측하는 기계학습 모델의 일반적인 기능을 살펴보았다. 실험 1은 10개의 기상 관측소 각각에 대해 하나씩, 10개의 개별적으로 훈련된 RF 모델, XGBoost 모델, LGBM 모델이 만들어진다. 두 번째 실험은 많은 학습 자료를 사용할수록 기계학습 모델의 성능이 개선될 수 있다는 사실에 착안하여 고안되었다(Schmidhuber, 2015; Hestness et al., 2017). 즉, 방대한 훈련 자료 세트를 사용하면 모델이 더 일반적이고 추상적인 패턴의 입출력 관계를 학습할 수 있다. 따라서 사용 가능한 여러 개의 기상 관측소에 대한 자료는 특정 관측소에서의 가뭄지수 예측을 위한 더 일반적인 프로세스 구현에 도움이 될 것이다. 극단적인 예로서 두 개의 유사하게 행동하는 기상 관측소에서, 그중 한 관측소는 훈련 기간에 비정상적으로 장기간 지속된 가뭄 사상이 없는 반면에 검증 기간에는 이러한 사상이 있다고 가정하고, 두 번째 관측소는 훈련 세트에서 이러한 사상을 경험했다면, 모델은 이러한 비정상적인 사상에 대한 응답 동작을 학습하고 이 지식을 첫 번째 관측소에서 사용할 수 있다. 즉, 두 번째 실험의 목표는 모델이 특정 지역 내의 모든 기상 관측소에 대해 얼마나 잘 일반화(또는 지역화)될 수 있는지를 분석하는 것이다. 실험 2는 부울경 지역에 대해 각각 1개의 RF 모델, XGBoost 모델, LGBM 모델이 만들어진다. 세 번째 실험은 지역 모델(실험 2)에 반영된 일반적인 법칙의 학습이 단일 관측소에서 모델의 성능을 향상하는 데 도움이 될 수 있는지 살펴보기 위하여 설정하였다. 기계학습 분야에서 이것은 증분 학습 또는 미세조정이라 한다(Razavian et al., 2014; Yosinski et al., 2014). 여기서 모델은 입력과 출력 사이의 일반적인 패턴을 학습하기 위해 거대한 자료 세트에서 먼저 학습된다(즉, 사전 훈련). 그런 다음 사전 훈련된 모델은 특정 관측소에 맞게 조정하기 위해 특정 관측소의 자료만으로 추가로 훈련된다. 간단히 말해서 모델은 먼저 대규모 자료 세트에서 가뭄지수 예측 프로세스의 일반적인 동작을 학습하고, 주어진 관측소의 특별한 거동을 반영하기 위해 미세 조정된다. 본 연구에서는 실험 2의 지역 모델이 사전 학습된 모델로 사용된다. 즉, 지역 모델이 특정 관측소 모델을 구성하기 위한 미세조정의 시작점으로 설정된다. 따라서 실험 3은 실험 1과 마찬가지로 10개의 관측소 각각에 대해 하나씩 10개의 서로 다른 모델이 만들어진다. 이러한 실험을 요약하여 Table 3에 정리하였다.
Table 3.
Design of model structure experiments
| Experiment ID | Description |
| Experiment 1 | one model for each site |
| Experiment 2 | one regional model for the study region |
| Experiment 3 | fine-tuning the regional model for each site |
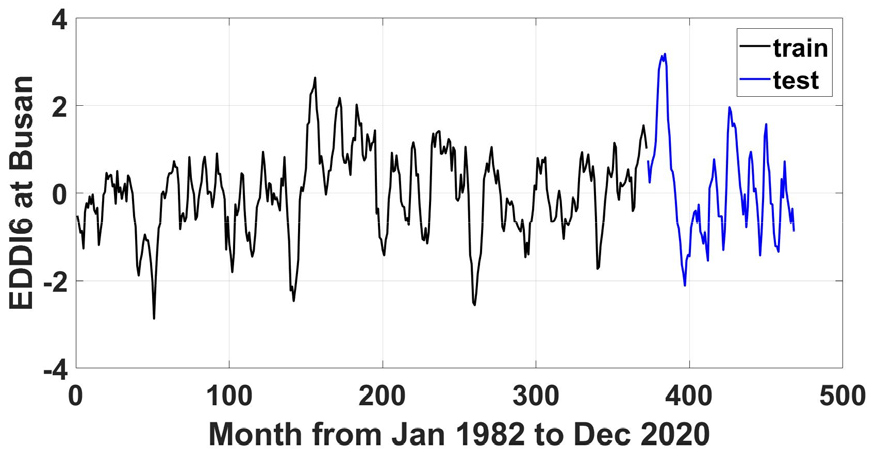
모델 학습을 위한 훈련 자료 세트는 목표 변수인 EDDI6를 기준으로 1982년부터 2012년까지 31년의 자료가 사용되었으며, 학습된 자료의 테스트 자료 세트는 2013년부터 2020년까지 8년의 자료가 사용되었다(Fig. 3). EDDI6를 예측하기 위한 모델의 유효성과 안정성을 확인하기 위해 5-폴드 교차 검증 방법을 사용했다. 즉, 훈련 자료 세트를 무작위로 다시 다섯 개의 그룹으로 나눈 후, 네 개 그룹의 자료를 이용하여 모델을 학습하고 나머지 한 개 그룹의 자료는 검증에 사용하였다. 이러한 과정을 5회 반복한 후(즉, 다섯 개 그룹 각각이 돌아가면서 한 번씩 검증자료로 사용), 각각의 검증점수(본 연구에서는 평균제곱오차)를 평균하여 최종 검증점수를 얻게 된다.
가뭄에 대한 의사 결정은 일반적으로 가뭄의 심각도에 따라 이루어지기 때문에 가뭄 범주의 예측이 실제로 더 중요할 때가 있다. 본 연구에서는 가장 간단한 형태의 범주, 즉 가뭄이냐 아니냐로 구분하여 성공적으로 예측된 가뭄 범주의 비율을 별도로 계산했다. 여기서 가뭄은 관측된 EDDI6와 예측된 EDDI6 모두 1 이상일 때를 의미한다. 모델의 가뭄 예측성능을 평가하기 위해 ROC (Receiver Operating Characteristics) 분석을 수행하였다(Fawcett, 2006). 테스트 자료 세트의 기간인 2013년 이후의 관측된 EDDI6와 1개월 선행 예측된 EDDI6를 가뭄과 비 가뭄으로 분류하여, 실제 가뭄일 때 가뭄을 예측한 경우(즉, 적중률, Hit Rate, HR)와 가뭄이 아닌데 가뭄으로 예측한 경우(즉, 오보율, False Alarm Ratio, FAR)를 모두 반영한 비율을 측정하였다. 가뭄과 관련된 ROC 분석은 Kim and Lee (2011)와 Yoo et al. (2013)을 참조할 수 있다.
2.2.3 오픈 소스 소프트웨어
본 연구는 오픈소스 소프트웨어로 수행되었다. 적용된 프로그래밍 언어는 Python 3.8이다(van Rossum, 1995). 자료 전처리 및 자료 관리에 사용된 라이브러리는 Numpy (Van Der Walt et al., 2011), Pandas (McKinney, 2010), Scikit-Learn (Pedregosa et al., 2011)이다. 사용된 머신러닝 프레임워크는 Scikit-learn, Xgboost (Chen and Guestrinm, 2016), Lightgbm (Zhang et al., 2017)이다.
3. 결 과
3.1 단일 관측소 모델을 이용한 예측 결과
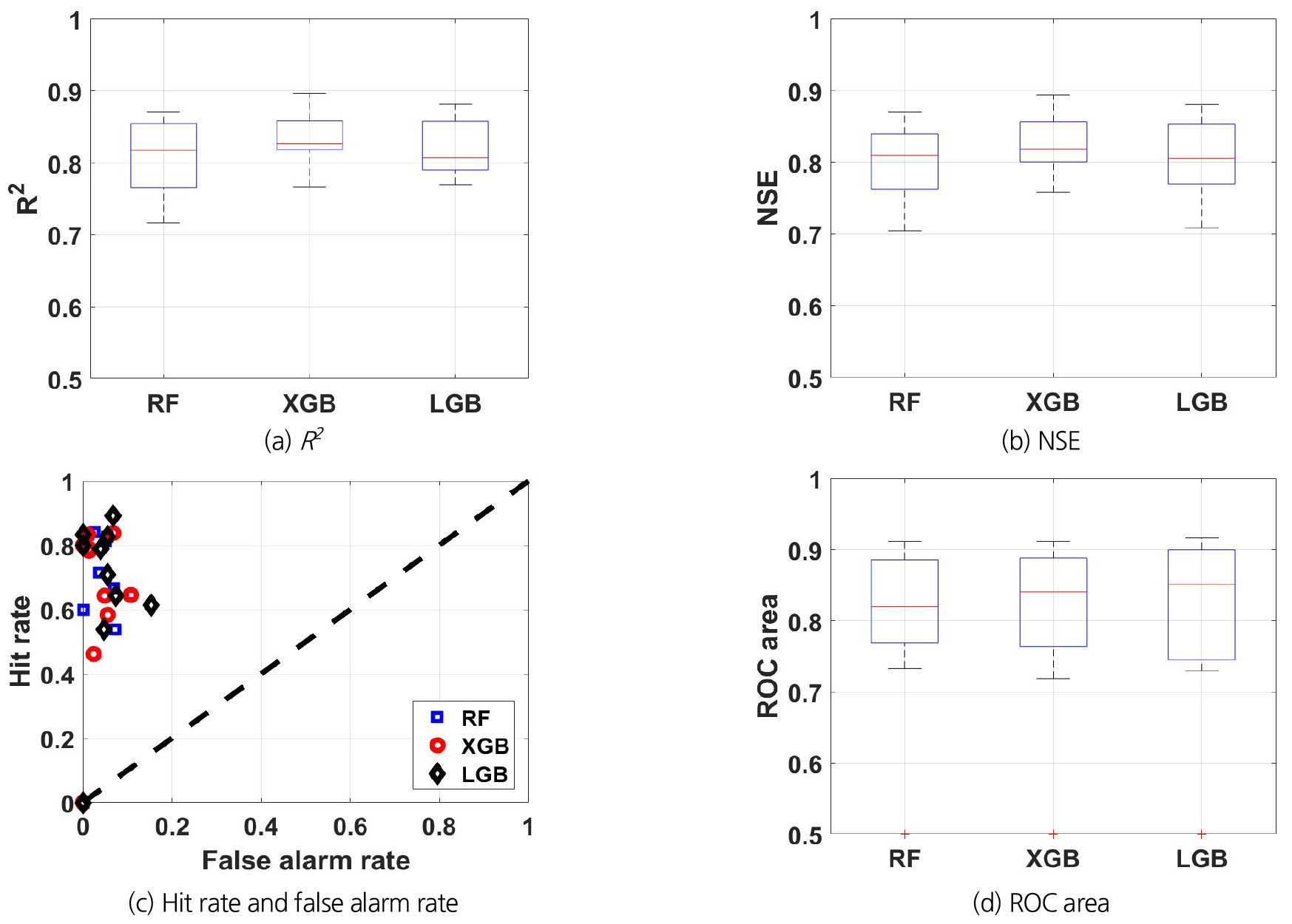
Figs. 4(a) and 4(b)는 테스트 기간(2013 ~ 2020년)에 실험 1에 대한 기계학습 모델 성능의 분포를 보여준다. 모델 성능은 결정계수(R2)와 Nash-Sutcliffe 모형효율계수(NSE; Nash and Sutcliffe, 1970)로 정량화하였다. 10개 관측소 모두에서 R2와 NSE는 0.70 이상이다. 모든 관측소에 대한 평균 NSE를 기준으로 볼 때 XGBoost 모델이 0.83으로 가장 우수하였다. 가장 낮은 성능을 보인 수치는 통영 관측소의 RF에서 나타났으며, NSE가 0.70이었다.
Figs. 4(c) and 4(d)는 테스트 기간에 실험 1에 대한 기계학습 모델 예측치의 적중률과 오보율, 그리고 그에 따른 ROC 면적을 보여준다. 참고로 ROC 면적이 1이면 적중률 100%, 오보율 0%를 의미한다. 통영 관측소의 경우에는 테스트 기간에 EDDI6가 1.0 이상인 기간이 없었기 때문에(즉, 가뭄이 없었음) 적중률과 오보율을 모두 0%로 간주하였다(따라서 ROC 면적은 0.5). 통영 관측소를 제외한 평균 적중률은 LGBM이 74%로 가장 우수하였으며, 평균 오보율은 XGBoost가 3.8%로 가장 작았다. 평균 ROC 면적은 LGBM이 0.84로 가장 넓었다. 가장 낮은 적중률은 합천 관측소의 XGBoost로 적중률이 46%이었으며, 가장 높은 오보율은 산청 관측소의 LGBM으로 15%를 기록하였다. ROC 면적은 합천 관측소의 XGBoost가 0.72로 가장 작았다.
3.2 지역 모델을 이용한 예측 결과
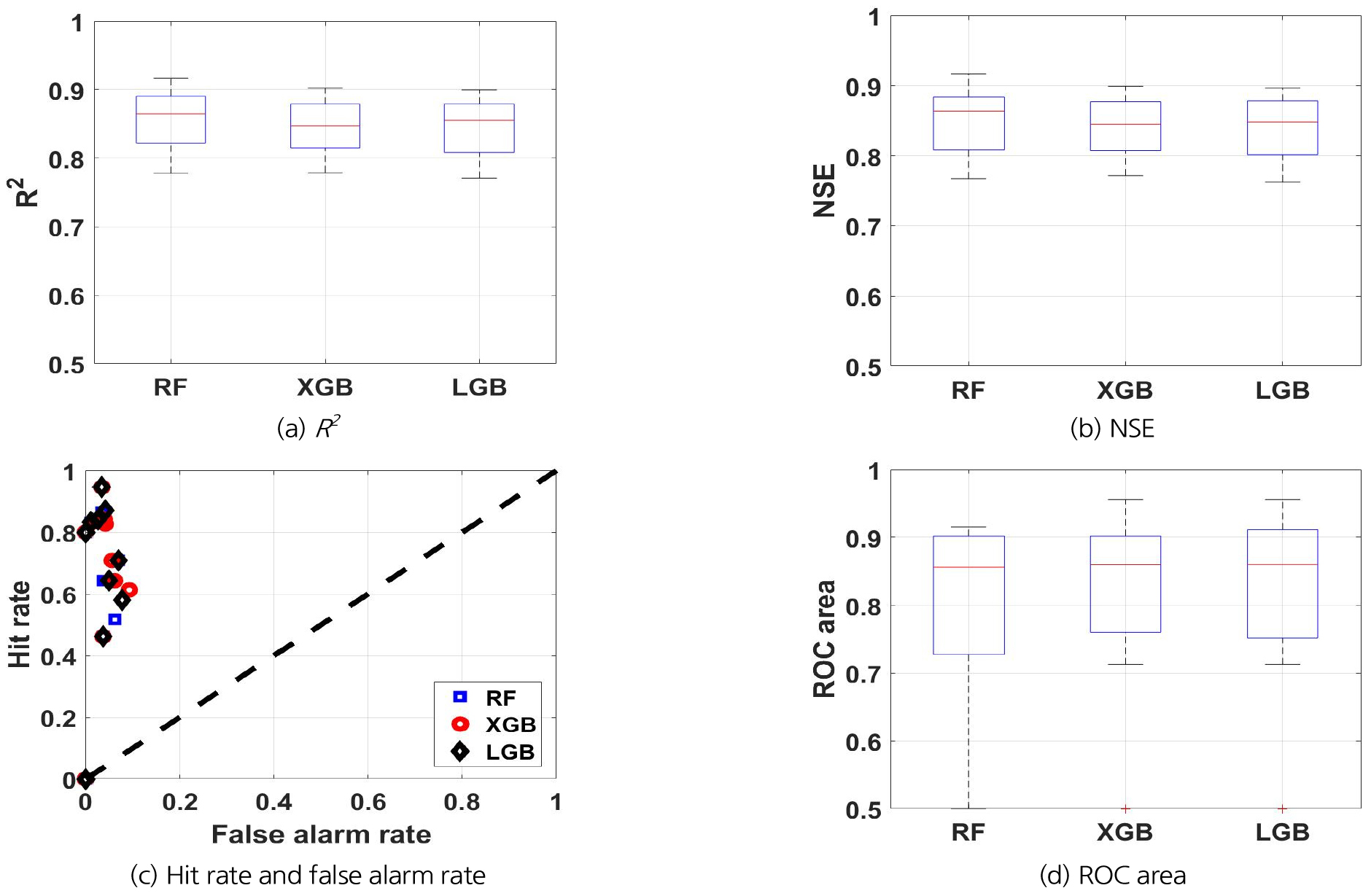
Figs. 5(a) and 5(b)는 테스트 기간(2013 ~ 2020년)에 실험 2에 대한 기계학습 모델 성능의 분포를 보여준다. 10개 관측소 모두에서 R2와 NSE는 0.76 이상이다. 모든 관측소에 대한 평균 NSE를 기준으로 볼 때 RF가 0.85로 가장 우수하였다. 가장 낮은 성능을 보인 수치는 통영 관측소의 LGBM에서 나타났으며, NSE가 0.76이었다.
Figs. 5(c) and 5(d)는 테스트 기간에 실험 2에 대한 기계학습 모델 예측치의 적중률과 오보율, 그리고 그에 따른 ROC 면적을 보여준다. 테스트 기간에 가뭄이 없었던 통영 관측소를 제외한 평균 적중률은 LGBM이 0.74로 가장 우수하였으며, 평균 오보율은 RF가 0.036으로 가장 작았다. 평균 ROC 면적은 LGBM이 0.85로 가장 넓었다. 가장 낮은 적중률은 합천 관측소에서 세 개 모델 모두 0.46이었으며, 가장 높은 오보율은 산청 관측소의 XGBoost으로 0.092를 기록하였다. ROC 면적은 합천 관측소의 세 개 모델이 모두 0.71로 가장 작았다. 전반적으로 단일 관측소 모델보다는 지역 모델의 성능이 더 우수한 것으로 나타났다.
3.3 관측소별 미세 조정 모델을 이용한 예측 결과
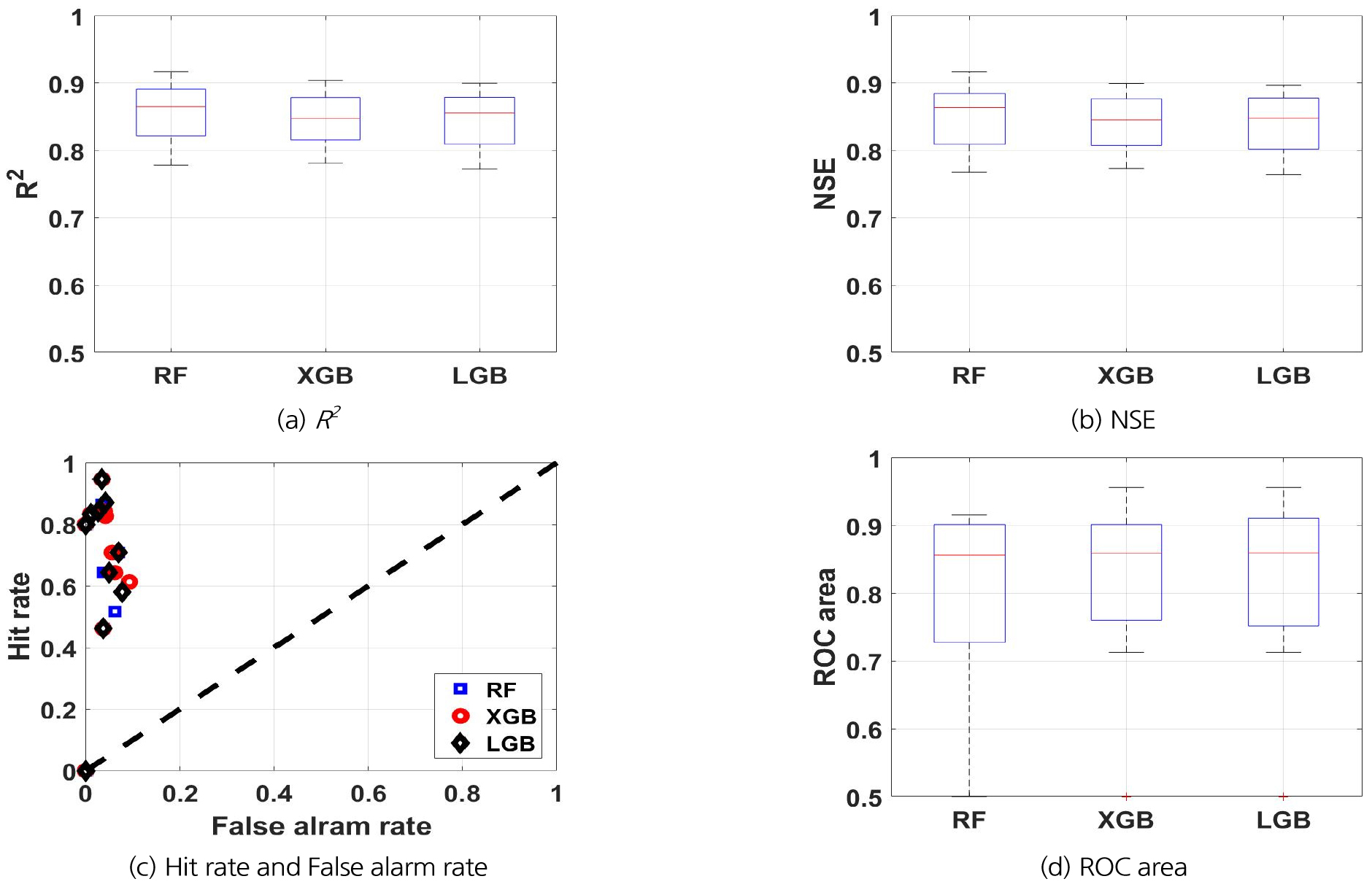
Figs. 6(a) and 6(b)는 테스트 기간(2013 ~ 2020년)에 실험 3에 대한 기계학습 모델 성능의 분포를 보여준다. 10개 관측소 모두에서 R2와 NSE는 0.76 이상이다. 모든 관측소에 대한 평균 NSE를 기준으로 볼 때 RF가 0.85로 가장 우수하였다. 가장 낮은 성능을 보인 수치는 통영 관측소의 LGBM에서 나타났으며, NSE가 0.76이었다.
Figs. 6(c) and 6(d)는 테스트 기간에 실험 3에 대한 기계학습 모델 예측치의 적중률과 오보율, 그리고 그에 따른 ROC 면적을 보여준다. 테스트 기간에 가뭄이 없었던 통영 관측소를 제외한 평균 적중률은 LGBM이 74%로 가장 우수하였으며, 평균 오보율은 RF가 3.7%로 가장 작았다. 평균 ROC 면적은 LGBM이 0.85로 가장 넓었다. 가장 낮은 적중률은 합천 관측소에서 세 개 모델 모두 46%이었으며, 가장 높은 오보율은 산청 관측소의 XGBoost으로 9.2%를 기록하였다. ROC 면적은 합천 관측소의 세 개 모델이 모두 0.71로 가장 작았다. 지역 모델의 결과와 비교해볼 때, 개별 관측소 자료에 대한 미세조정 효과는 거의 나타나지 않았음을 알 수 있다.
4. 토 론
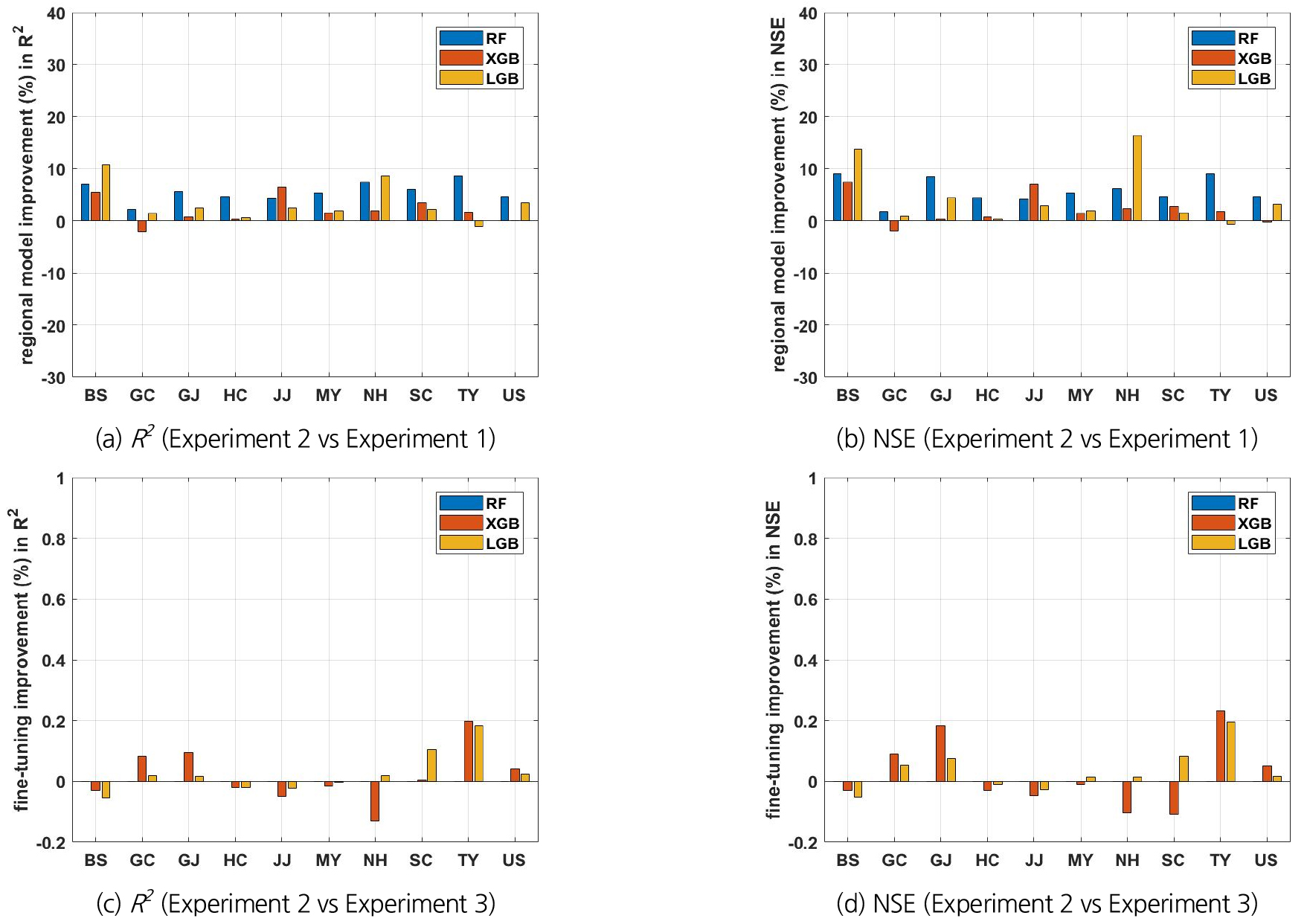
Figs. 7(a) and 7(b)는 실험 1과 2의 모델 예측치 사이의 R2와 NSE의 차이를 보여준다. Fig. 7의 관측소 영문명에 대한 지점 이름은 다음과 같다. BS-부산, GC-거창, GJ-거제, HC-합천, JJ-진주, MY-밀양, NH-남해, SC-산청, TY-통영, US-울산. 거창 관측소의 XGBoost와 통영 관측소의 LGBM을 제외한 모든 경우에서 지역 모델이 관측소별 모델보다 EDDI6 예측성능이 더 우수함을 발견할 수 있다. 거창 관측소의 XGBoost와 통영 관측소의 LGBM도 지역 모델과 관측소별 모델 사이의 예측성능 차이가 크지 않다. 즉, 대부분의 관측소에서 어떤 기계학습 모델이 적용되었는지에 상관없이 지역 모델이 단일 관측소의 자료에 대해 특별히 훈련된 모델보다 더 나은 성능을 발휘하고 있다. 이는 10개 관측소의 자료를 한 번에 모아서 기계학습 모델을 훈련하는 것이 학습 자료의 개수 확보 측면에서 유리하다는 것을 의미한다. 기계학습 모델은 결국에는 학습 자료의 확보가 관건이라는 사실을 다시 한번 확인할 수 있다. 또한 이러한 사실은 부울경 지역 정도의 공간 영역이면 한 번에 모아서 학습 자료의 크기를 확보하는 것이 개별 관측소의 고유한 다양성을 반영하는 것보다 더 중요하다는 것을 말해준다. 추후 공간적인 영역과 학습 자료의 크기 사이의 최적 접점을 찾는 문제는 기계학습 모델의 성능과 관련하여 매우 중요한 고려 사항이 될 것임을 예상할 수 있다. 참고로 가장 큰 예측성능 개선 효과를 보인 경우는 남해 관측소의 LGBM이다. 남해 관측소의 LGBM은 NSE 기준으로 지역 모델이 남해 관측소 개별 모델보다 16% 이상의 예측성능 개선 효과를 보였다.
그러나 Figs. 7(c) and 7(d)에서 알 수 있듯이 지역 모델의 결과를 기반으로 개별 관측소의 자료를 이용하여 추가 증분 훈련을 시행한 개별 관측소 모델의 예측성능 개선 효과는 크지 않았으며, 오히려 예측성능이 낮아지는 관측소(또는 모델)도 있다. 참고로 RF의 경우에는 증분 학습 기능이 제공되지 않으므로, 관측소별 미세 조정 모델을 구성할 수 없었다. RF에 기반하여 증분 학습 기능을 제공하는 별도의 기계학습 모델도 존재하지만(예를 들어, Incremental trees, https://github.com/garethjns/IncrementalTrees), XGBoost 및 LGBM의 증분 학습 효과가 크지 않기 때문에 RF에 기반한 다른 기계학습 모델을 이용한 미세 조정은 시행하지 않았다.
Figs. 8(a) and 8(b)는 실험 1과 2의 모델 예측치 사이의 HR와 ROC 면적의 차이를 보여준다. 합천 관측소, 산청 관측소, 울산 관측소의 RF 적중률은 개별 관측소 모델이 더 우수했으며, XGBoost는 산청 관측소에서 LGBM은 합천과 산청 관측소에서 개별 관측소 모델이 더 우수했다. 나머지의 경우에는 지역 모델의 적중률이 더 우수했다. ROC 면적의 경우에는 개별 관측소 모델과 지역 모델의 우열이 관측소마다 상이하게 나타났다. 한편, Figs. 8(c) and 8(d)로부터 지역 모델의 결과를 기반으로 개별 관측소의 자료를 이용하여 추가 증분 훈련을 시행한 개별 관측소 모델의 적중률 및 ROC 면적의 개선 효과는 거의 나타나지 않았음을 발견할 수 있다.
요약하자면, 가뭄지수 시계열 자체(가뭄 및 습윤 상태를 모두 포함)를 예측하는 성능은 지역 모델이 개별 관측소별 모델보다 확실하게 우위에 있다고 말할 수 있다. 하지만, 가뭄 범주 측면에서는(즉, 가뭄/비 가뭄) 지역 모델의 성능이 개별 관측소별 모델의 성능보다 확실하게 우위에 있다고 말할 수는 없었다. 이러한 사실은 기계학습 모델을 이용하여 가뭄지수를 예측하고자 할 때 목표를 어디에 두고 모델을 학습해야 할 것인가에 관한 중요한 시사점을 준다. 많지는 않지만 본 연구를 비롯하여 현재 찾아볼 수 있는 대부분의 연구(Shen et al., 2019; Zhang et al., 2019; Dikshit et al., 2021)는 가뭄지수 시계열 자체를 예측하는 성능에 초점을 맞추고 있다. 추후 가뭄 시기의 가뭄지수를 예측하는 성능에 초점을 맞춘 기계학습 아키텍처(또는 훈련 방법)의 설계가 필요할 것이다.
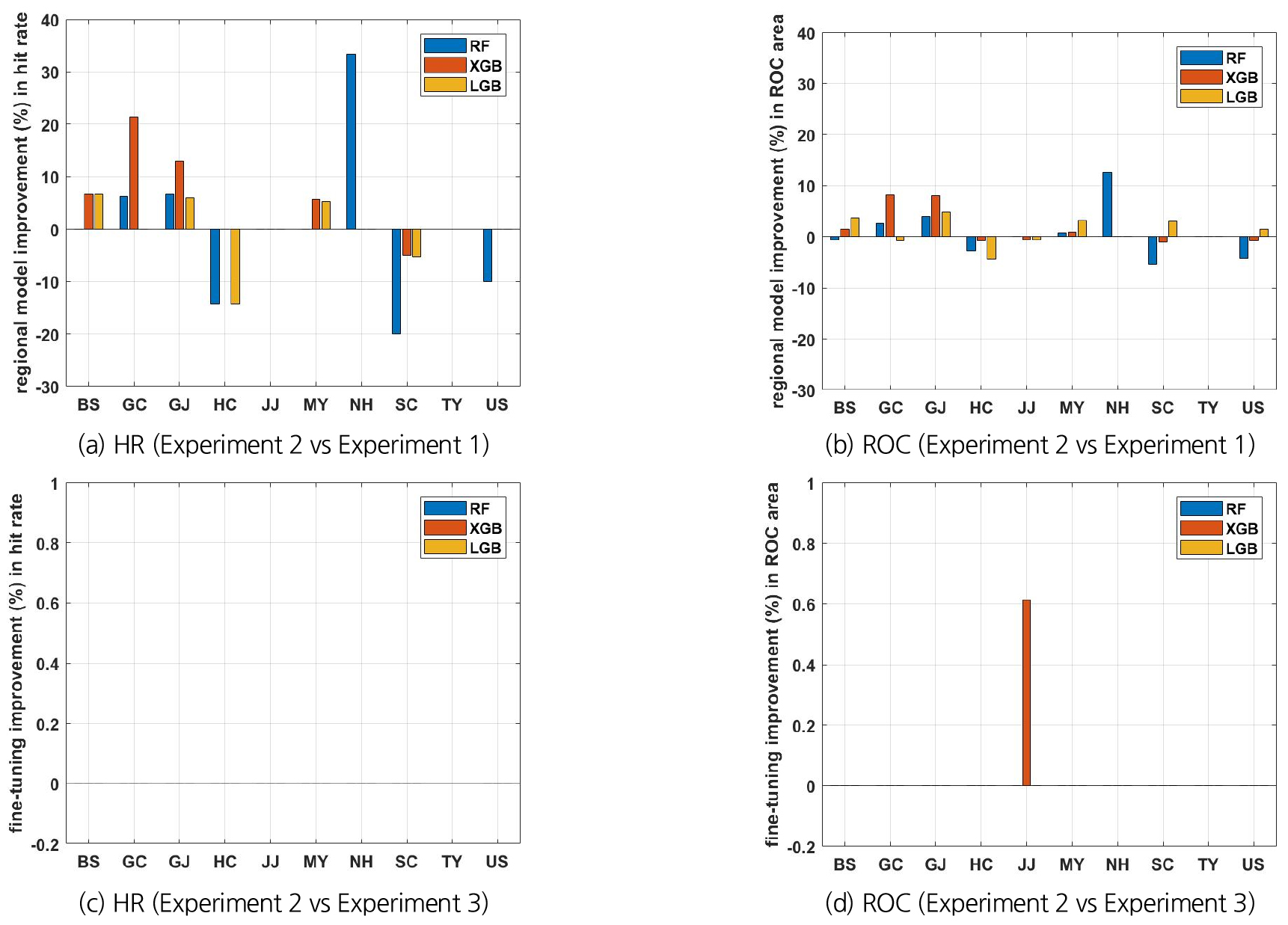
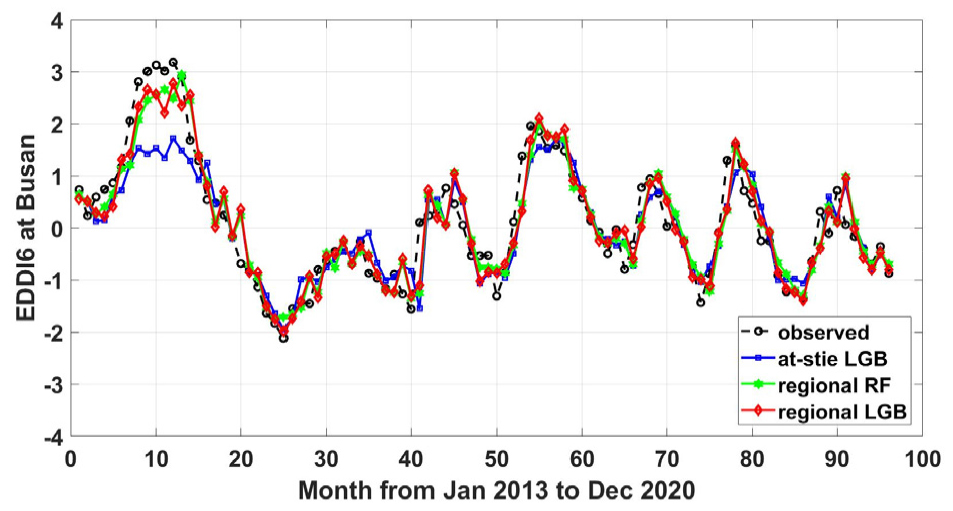
Fig. 9는 부산 관측소에서 개별 관측소 LGBM과 지역 LGBM, 지역 RF의 EDDI6 예측 결과를 보여주고 있다. 다른 관측소에서도 비슷한 결과를 볼 수 있는데, 일반적으로 기계 학습 모델 사이의 예측성능 차이는 Gradient Boosting 계열의 모델이 약간 우수하더라도 그 차이가 크지는 않다. 자료의 특성에 따라 다르겠지만 일반적으로 Gradient Boosting 계열의 모델이 RF 모델의 한계를 개선한 모델이므로, RF와 XGBoost/LGBM의 차이가 크지 않은 본 연구의 결과가 부울경 EDDI6 자료의 특성인지 아니면 일반적인 가뭄지수 자료의 특성인지는 추가적인 사례 연구를 통하여 더 살펴볼 여지가 있을 것이다. 하지만, 적용되는 공간적인 영역에 따라 차이가 있겠지만 개별 관측소 모델보다는 지역 모델의 예측성능이 우수하다는 사실은 부울경 지역의 EDDI6 예측성능에서도 어렵지 않게 확인할 수 있다.
여러 가지 한계에도 불구하고 부울경 지역의 EDDI6를 1개월 선행 예측하는 관점에서 볼 때, 기계학습 모델 측면에서는 RF, XGBoost, LGBM 사이의 예측성능 차이는 크지 않았으며, 그보다는 모델 학습 전략, 즉 개별 관측소별 모델보다는 지역 모델을 이용하여 학습된 모델이 가뭄 예측에 더 중요한 요소라고 말할 수 있을 것이다.
5. 결 론
본 연구의 공헌도는 기상 자료로부터 가뭄을 예측하기 위해 다양한 기계 학습 모델(RF, XGBoost, LGBM)을 사용하는 것에 대한 가능성을 조사했다는 것이다. 세 가지 실험을 통하여 기계학습 모델의 가능한 적용사례를 탐색하고 일정 수준 이상의 성능으로 가뭄지수를 예측할 수 있음을 보였다. 첫 번째 실험에서는 고전적인 단일 관측소 모델링을 살펴보았고, 두 번째 실험에서는 모든 관측소에 대해 하나의 모델을 학습했다. 세 번째 실험에서 사전 훈련된 모델을 사용하면 단일 관측소에서 모델 성능 향상에 이바지할 수 있을지를 살펴보았다. 이로부터 기상 관측자료로부터 가뭄을 예측할 때는 개별 관측소별 모델보다는 지역 모델 개념으로 기계학습 모델을 학습하는 것이 더 유리하다는 사실을 파악하였다. 또한 지역 모델의 개별 관측소 자료 증분 학습 효과는 거의 없었음을 확인할 수 있었다.
본 연구의 목표는 사실 기계학습 기법의 가뭄 예측에 관한 전반적인 잠재력을 탐구하는 것이지, 개별 관측소별 기계학습 모델의 가능한 최상의 성능을 구현하는 것은 아니었다. 따라서 지역 또는 개별 관측소 자료에 대한 더 철저한 하이퍼 파라미터 검색을 통해 더 나은 예측성능을 보이는 기계학습 모델을 구성할 수 있을 것이다. 그러나 비교적 간단한 베이지안 최적화를 통하여 최소한의 성능을 확보한 가뭄 예측 모델을 얻을 수 있었다.
기계학습 모델의 종류에 상관없이 학습 자료 부족 문제(예: 제한된 자료가 있는 단일 관측소 자료)는 기계학습 모델의 적용에 잠재적인 장벽이 된다. 본 연구의 실험 2에서 살펴본 것처럼 지역 모델 개념의 학습 전략이 개별 관측소에 대한 대규모 자료 요구 수준을 줄이는 유망한 방법이 될 것이다. 그러나 이 가설을 검증하기 위해서는 다양한 학습 환경에 대한 더 많은 연구가 필요할 것이다. 한편 기계학습 모델의 향후 적용을 촉진할 대형 자료 세트가 있음에 주목할 필요가 있다. 이러한 맥락에서 인공위성 원격 감지 자료 또는 전 지구 기후지수 자료 등을 기계학습 모델의 입력자료로 추가하면 가뭄 시기의 가뭄지수 예측성능 향상을 기대할 수 있을 것이다.
